
135 results
8 - Special Matrices, Markov Chains, and PageRank
-
- Book:
- Linear Algebra for Data Science, Machine Learning, and Signal Processing
- Published online:
- 01 November 2024
- Print publication:
- 16 May 2024, pp 283-334
-
- Chapter
- Export citation

Economic Networks
- Theory and Computation
-
- Published online:
- 11 April 2024
- Print publication:
- 25 April 2024
Topological reconstruction of compact supports of dependent stationary random variables
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 02 April 2024, pp. 1339-1369
- Print publication:
- December 2024
-
- Article
-
- You have access
- HTML
- Export citation
-
In this paper we extend results on reconstruction of probabilistic supports of independent and identically distributed random variables to supports of dependent stationary
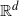 ${\mathbb R}^d$-valued random variables. All supports are assumed to be compact of positive reach in Euclidean space. Our main results involve the study of the convergence in the Hausdorff sense of a cloud of stationary dependent random vectors to their common support. A novel topological reconstruction result is stated, and a number of illustrative examples are presented. The example of the Möbius Markov chain on the circle is treated at the end with simulations.
${\mathbb R}^d$-valued random variables. All supports are assumed to be compact of positive reach in Euclidean space. Our main results involve the study of the convergence in the Hausdorff sense of a cloud of stationary dependent random vectors to their common support. A novel topological reconstruction result is stated, and a number of illustrative examples are presented. The example of the Möbius Markov chain on the circle is treated at the end with simulations.
Perfect sampling of stochastic matching models with reneging
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 4 / December 2024
- Published online by Cambridge University Press:
- 04 March 2024, pp. 1307-1339
- Print publication:
- December 2024
-
- Article
-
- You have access
- HTML
- Export citation
An inaccuracy measure between non-explosive point processes with applications to Markov chains
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 25 October 2023, pp. 735-756
- Print publication:
- June 2024
-
- Article
-
- You have access
- HTML
- Export citation
MECHANISTIC MARKOV MODELS FOR THE EVOLUTION OF GENE FAMILIES
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 108 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 10 August 2023, pp. 513-515
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
On Markov chain approximations for computing boundary crossing probabilities of diffusion processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 11 May 2023, pp. 1386-1415
- Print publication:
- December 2023
-
- Article
- Export citation
-
We propose a discrete-time discrete-space Markov chain approximation with a Brownian bridge correction for computing curvilinear boundary crossing probabilities of a general diffusion process on a finite time interval. For broad classes of curvilinear boundaries and diffusion processes, we prove the convergence of the constructed approximations in the form of products of the respective substochastic matrices to the boundary crossing probabilities for the process as the time grid used to construct the Markov chains is getting finer. Numerical results indicate that the convergence rate for the proposed approximation with the Brownian bridge correction is
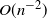 $O(n^{-2})$ in the case of
$O(n^{-2})$ in the case of 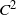 $C^2$ boundaries and a uniform time grid with n steps.
$C^2$ boundaries and a uniform time grid with n steps.
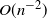
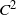
Mixing time bounds for edge flipping on regular graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 26 April 2023, pp. 1317-1332
- Print publication:
- December 2023
-
- Article
- Export citation
-
An edge flipping is a non-reversible Markov chain on a given connected graph, as defined in Chung and Graham (2012). In the same paper, edge flipping eigenvalues and stationary distributions for some classes of graphs were identified. We further study edge flipping spectral properties to show a lower bound for the rate of convergence in the case of regular graphs. Moreover, we show by a coupling argument that a cutoff occurs at
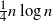 $\frac{1}{4} n \log n$ for the edge flipping on the complete graph.
$\frac{1}{4} n \log n$ for the edge flipping on the complete graph.
Multiple random walks on graphs: mixing few to cover many
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 15 February 2023, pp. 594-637
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Random walks on graphs are an essential primitive for many randomised algorithms and stochastic processes. It is natural to ask how much can be gained by running
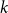 $k$
multiple random walks independently and in parallel. Although the cover time of multiple walks has been investigated for many natural networks, the problem of finding a general characterisation of multiple cover times for worst-case start vertices (posed by Alon, Avin, Koucký, Kozma, Lotker and Tuttle in 2008) remains an open problem. First, we improve and tighten various bounds on the stationary cover time when
$k$
multiple random walks independently and in parallel. Although the cover time of multiple walks has been investigated for many natural networks, the problem of finding a general characterisation of multiple cover times for worst-case start vertices (posed by Alon, Avin, Koucký, Kozma, Lotker and Tuttle in 2008) remains an open problem. First, we improve and tighten various bounds on the stationary cover time when
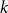 $k$
random walks start from vertices sampled from the stationary distribution. For example, we prove an unconditional lower bound of
$k$
random walks start from vertices sampled from the stationary distribution. For example, we prove an unconditional lower bound of
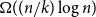 $\Omega ((n/k) \log n)$
on the stationary cover time, holding for any
$\Omega ((n/k) \log n)$
on the stationary cover time, holding for any
 $n$
-vertex graph
$n$
-vertex graph
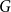 $G$
and any
$G$
and any
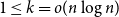 $1 \leq k =o(n\log n )$
. Secondly, we establish the stationary cover times of multiple walks on several fundamental networks up to constant factors. Thirdly, we present a framework characterising worst-case cover times in terms of stationary cover times and a novel, relaxed notion of mixing time for multiple walks called the partial mixing time. Roughly speaking, the partial mixing time only requires a specific portion of all random walks to be mixed. Using these new concepts, we can establish (or recover) the worst-case cover times for many networks including expanders, preferential attachment graphs, grids, binary trees and hypercubes.
$1 \leq k =o(n\log n )$
. Secondly, we establish the stationary cover times of multiple walks on several fundamental networks up to constant factors. Thirdly, we present a framework characterising worst-case cover times in terms of stationary cover times and a novel, relaxed notion of mixing time for multiple walks called the partial mixing time. Roughly speaking, the partial mixing time only requires a specific portion of all random walks to be mixed. Using these new concepts, we can establish (or recover) the worst-case cover times for many networks including expanders, preferential attachment graphs, grids, binary trees and hypercubes.

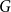
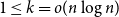
9 - The Things that Bug Us*
-
- Book:
- Dicing with Death
- Published online:
- 18 November 2022
- Print publication:
- 08 December 2022, pp 178-205
-
- Chapter
- Export citation
1 - Introduction
-
- Book:
- Large Deviations for Markov Chains
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022, pp 1-13
-
- Chapter
- Export citation
Fast mixing of a randomized shift-register Markov chain
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 02 September 2022, pp. 253-266
- Print publication:
- March 2023
-
- Article
- Export citation
-
We present a Markov chain on the n-dimensional hypercube
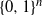 $\{0,1\}^n$
which satisfies
$\{0,1\}^n$
which satisfies
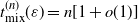 $t_{{\rm mix}}^{(n)}(\varepsilon) = n[1 + o(1)]$
. This Markov chain alternates between random and deterministic moves, and we prove that the chain has a cutoff with a window of size at most
$t_{{\rm mix}}^{(n)}(\varepsilon) = n[1 + o(1)]$
. This Markov chain alternates between random and deterministic moves, and we prove that the chain has a cutoff with a window of size at most
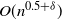 $O(n^{0.5+\delta})$
, where
$O(n^{0.5+\delta})$
, where
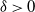 $\delta>0$
. The deterministic moves correspond to a linear shift register.
$\delta>0$
. The deterministic moves correspond to a linear shift register.
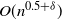
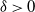

Large Deviations for Markov Chains
-
- Published online:
- 03 August 2022
- Print publication:
- 27 October 2022
Syllable Structure Spatially Distributed: Patterns of Monosyllables in German Dialects
-
- Journal:
- Journal of Germanic Linguistics / Volume 34 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 01 August 2022, pp. 241-287
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Normal Approximation for Functions of Hidden Markov Models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 06 June 2022, pp. 536-569
- Print publication:
- June 2022
-
- Article
- Export citation
4 - Static Systems: Probabilistic Structural Uncertainty
-
- Book:
- Large-Scale System Analysis Under Uncertainty
- Published online:
- 17 January 2022
- Print publication:
- 17 February 2022, pp 91-129
-
- Chapter
- Export citation
On the forward algorithm for stopping problems on continuous-time Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 22 November 2021, pp. 1043-1063
- Print publication:
- December 2021
-
- Article
- Export citation
On the mixing time of coordinate Hit-and-Run
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 2 / March 2022
- Published online by Cambridge University Press:
- 25 August 2021, pp. 320-332
-
- Article
- Export citation
-
We obtain a polynomial upper bound on the mixing time
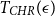 $T_{CHR}(\epsilon)$
of the coordinate Hit-and-Run (CHR) random walk on an
$T_{CHR}(\epsilon)$
of the coordinate Hit-and-Run (CHR) random walk on an 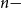 $n-$
dimensional convex body, where
$n-$
dimensional convex body, where 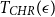 $T_{CHR}(\epsilon)$
is the number of steps needed to reach within
$T_{CHR}(\epsilon)$
is the number of steps needed to reach within  $\epsilon$
of the uniform distribution with respect to the total variation distance, starting from a warm start (i.e., a distribution which has a density with respect to the uniform distribution on the convex body that is bounded above by a constant). Our upper bound is polynomial in n, R and
$\epsilon$
of the uniform distribution with respect to the total variation distance, starting from a warm start (i.e., a distribution which has a density with respect to the uniform distribution on the convex body that is bounded above by a constant). Our upper bound is polynomial in n, R and 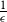 $\frac{1}{\epsilon}$
, where we assume that the convex body contains the unit
$\frac{1}{\epsilon}$
, where we assume that the convex body contains the unit 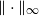 $\Vert\cdot\Vert_\infty$
-unit ball
$\Vert\cdot\Vert_\infty$
-unit ball 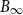 $B_\infty$
and is contained in its R-dilation
$B_\infty$
and is contained in its R-dilation 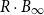 $R\cdot B_\infty$
. Whether CHR has a polynomial mixing time has been an open question.
$R\cdot B_\infty$
. Whether CHR has a polynomial mixing time has been an open question.
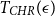
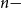
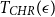

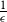
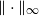
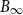
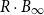
A product form for the general stochastic matching model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 449-468
- Print publication:
- June 2021
-
- Article
- Export citation
Entropy of killed-resurrected stationary Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 25 February 2021, pp. 177-196
- Print publication:
- March 2021
-
- Article
- Export citation
