



1. Introduction
The study of stochastic matching models is currently a very active line of research in applied probability. It has been demonstrated in various contexts that these stochastic models are suitable for capturing the dynamics of a wide range of real-time random systems, in which items enter the system at (possibly) random times, with a view to finding a match, which is identified as such in accordance with specified compatibility rules, given by a compatibility graph between classes of items. Matched couples leave the system right away, as soon as a match has been found. This is the case in various applications, such as peer-to-peer applications, job searches, public housing or college allocations, organ transplants, blood banks, car sharing, assemble-to-order systems, and so on. These models have been introduced in [15] for bipartite graphs (which are suitable for supply/demand-type applications) and arrivals by couples, as a variant of the seminal works [Reference Adan and Weiss3, Reference Caldentey, Kaplan and Weiss16]. To account for a wider range of applications (e.g., dating websites, crossed kidney transplants, assemble-to-order systems, or car-sharing), they have been generalized to general graphs (with simple arrivals) in [Reference Mairesse and Moyal32], and then to hypergraphs in [Reference Nazari and Stolyar40, Reference Rahme and Moyal42] and graphs with self-loops, in [Reference Begeot, Marcovici, Moyal and Rahme8].
Applications such as organ transplants are subject to very strong timing constraints: the patients waiting for a transplant have a finite lifetime in the system, and similarly, available organs are highly perishable and must be transplanted very quickly—hence the need to incorporate an impatience (or reneging) parameter into the system. More precisely, in this paper we address a general stochastic matching model, as defined in [Reference Mairesse and Moyal32], in which the items have a finite (and possibly random) patience upon arrival, before the end of which they must find a match. Otherwise, they renege and leave the system forever. Matching models with impatience have recently been addressed for a bipartite model and the ‘N’ graph in [Reference Castro, Nazerzadeh and Yan17] for a matching policy of the first-come-first-matched (fcfm) type, and from the point of view of stochastic optimization, for partially static policies, in [Reference Aveklouris, DeValve, Ward and Wu5]. On another hand, in [Reference Jonckheere, Moyal, Ramrez and Soprano-Loto26], stability conditions, together with moment bounds at equilibrium, have been given for models in which some, but not all, classes of items are impatient, and the matching policy is of the max-weight class.
However, it is important to observe, first, that the exact computation of the stability regions of matching models is difficult for general graphs, and heavily depends on the matching policy; see e.g. [Reference Mairesse and Moyal32, Reference Moyal and Perry38]. Second, the stationary distributions of the models at hand are in general unknown, and little is known about the characteristics of the steady state. In the existing literature, the models implementing the fcfm policy constitute the only exception, in which the stationary distribution is known explicitly. It can often be characterized in a product form, as is shown using dynamic reversibility arguments (see, for the various models, [Reference Adan, Bušić, Mairesse and Weiss1, Reference Adan, Kleiner, Righter and Weiss2, Reference Begeot, Marcovici, Moyal and Rahme8, Reference Comte18, Reference Moyal37]), for models without reneging. Let us also observe the recent advances in [Reference Begeot, Marcovici and Moyal7, Reference Comte and Mathieu19] concerning the invariance of stationary matching rates on the matching policy for various graphs—which shows that all matching policies have the same matching rates as fcfm.
However, in the cases of models with reneging, aside from the particular graph geometries addressed in [Reference Castro, Nazerzadeh and Yan17], no exact results are known. Moreover, fcfm policies are clearly not always the best option in a real-time context: coming back to the case of organ transplants, other criteria must be taken into account, such as the level of emergency, equity, ages of the patient and donor, various levels of compatibility, and so on. Mimicking the various existing results in queueing theory, implementing policies of the match-the-longest-queue (ML) or earliest-deadline-first (EDF) type may be profitable to minimize loss, and it is significant that EDF does not amount to fcfm if the patience times are random.
Our aim is to analyze matching models with reneging in steady state, for general matching policies. In view of the above discussion, we thus need to assess the stationary distribution of the matching model at hand, without knowledge of this distribution in closed form. As is well known, this task can be handled through perfect simulation of this steady state.
Perfect simulation has been a constantly active line of research in the analysis of stochastic systems, since the pioneering works of Propp and Wilson [Reference Propp and Wilson41] and Borovkov and Foss [Reference Borovkov and Foss11, Reference Borovkov and Foss12]. The underlying idea is now well known: consider a discrete-event stochastic system whose stationary distribution is intractable mathematically. Then we can study the system in steady state by precisely simulating samples of the stationary distribution, even though the latter is not known in closed form, instead of approximating it by long-run trajectories. Then various average performance parameters at equilibrium can be assessed by Monte Carlo techniques.
The celebrated algorithm of Propp and Wilson [Reference Propp and Wilson41] is based on coupling from the past (CFTP); namely, all trajectories of the considered Markov chain coalesce before time 0, whenever these trajectories are initiated from all possible states of the chain, far away enough in the past. This phenomenon is closely related to the concept of strong backwards coupling (see e.g. [Reference Borovkov13] and Chapter 2.5 of [Reference Baccelli and Brémaud6]), and the connections between the two notions are investigated for various cases of stochastic recursions in [Reference Foss and Tweedie22]. Strong backwards coupling is the pillar of the construction of the stationary state under general non-Markov assumptions, via the use of renovating events; see e.g. [Reference Borovkov and Foss11, Reference Borovkov and Foss12]. It is also a tool for constructing stationary states on enriched probability spaces via skew-product constructions; see [Reference Anantharam and Konstantopoulos4, Reference Lisek31, Reference Moyal36].
As they rely on the exact coalescence of a family of Markov chains, CFTP algorithms are typically adapted to finite state spaces and to monotonic dynamics, using envelope techniques. Various authors have extended these settings: generalizing the ideas in [Reference Foss and Tweedie22], it is proven in [Reference Kendall28] that geometrically ergodic Markov chains admit a CFTP algorithm of the envelope type, even if they are not monotonic, a result that was then generalized to a wider class of ergodic Markov chains in [Reference Connor and Kendall20]. Various related approaches have since been proposed, all of which rely on the intuitive idea of simulating from the past a ‘simpler’ recursion, then deducing the stationary state of the recursion of interest by comparison. This is the core idea of dominated coupling from the past (DCFTP), introduced in [Reference Kendall29, Reference Kendall and Moller30] and then [Reference Kendall28]; of the bounding chains of Huber [Reference Huber24, Reference Huber25], which are particularly adapted to mechanical-statistical contexts; and of various envelope techniques for queueing systems (see e.g. [14]). More recently, DCFTP-related methods have been implemented, together with saturation techniques, to perfectly simulate non-Markov queueing systems; see [Reference Blanchet and Dong9] for infinite-server and loss queues, and [Reference Blanchet, Dong and Pei10] for multiple-server queues.
This paper is a first contribution on the perfect sampling of stochastic matching models. We introduce two perfect sampling algorithms, Algorithms 2 and 3 below, that produce samples of the stationary distribution of stochastic matching models with reneging, in the case where arrival times are discrete. The first algorithm simply relies on the control of the model at hand by an infinite-server queue, an algorithm that would clearly not be optimal in a context with heavy traffic. Indeed, as was observed in [Reference Blanchet and Dong9], as it relies on the depletion of a corresponding infinite-server model, the coalescence time for Algorithm 2 grows exponentially as a function of the arrival rates; see [Reference Kelly27]. Our second algorithm, Algorithm 3, is peculiar to the case where patience times are deterministic (and so the matching policies fcfm and edf are equivalent). In that case, we propose an ad-hoc control of the system simulated backwards in time by the input of the system. Then the algorithm substantially reduces the number of operations compared to the primitive CFTP. In particular, if latency is allowed, we show that Algorithm 3 also outperforms the algorithm based on control by the infinite-server queue, Algorithm 2. In fact, both Algorithms 2 and 3 can be seen as particular cases of a more general perfect sampling algorithm for bounded Markov chains, namely Algorithm 1 below, which we call perfect sampling by control, a condition that is closely related to those under which a DCFTP-type algorithm can be implemented.
This paper is organized as follows. After some preliminaries in Section 2, we introduce our general algorithm for perfect sampling by control in Section 3. In Section 4 we introduce the general stochastic matching model with reneging, and we introduce the two corresponding perfect sampling algorithms in Subsections 4.2 and 4.3.3. The performance of the latter algorithm is investigated in Subsection 4.3.4. We compare the performance of Algorithm 3 to that of the primitive CFTP algorithm in Subsection 4.5, and to that of Algorithm 2 in Subsection 4.4, for a model with reneging and latency. In Subsection 4.5 we provide a first application to the comparison of the steady-state performances of two matching policies (here, edf—or, in other words, fcfm—and ml).
2. Preliminaries
In what follows,
 $\mathbb{R}$
,
$\mathbb{R}$
,
 $\mathbb{N}$
,
$\mathbb{N}$
,
 $\mathbb{N}^*$
, and
$\mathbb{N}^*$
, and
 $\mathbb{Z}$
denote the sets of real numbers, non-negative integers, strictly positive integers, and integers, respectively. For any two elements
$\mathbb{Z}$
denote the sets of real numbers, non-negative integers, strictly positive integers, and integers, respectively. For any two elements
 $a,b\in \mathbb{Z}$
, let
$a,b\in \mathbb{Z}$
, let
 $[\![ a,b ]\!]$
denote the integer interval
$[\![ a,b ]\!]$
denote the integer interval
 $[a,b]\cap \mathbb{Z}$
.
$[a,b]\cap \mathbb{Z}$
.
Any (simple, finite, and undirected) graph G is denoted by
 $G=(\mathbb {V},E)$
, where
$G=(\mathbb {V},E)$
, where
 $\mathbb {V}$
is the set of nodes and E is the set of edges for a node
$\mathbb {V}$
is the set of nodes and E is the set of edges for a node
 $i\in \mathbb {V}$
. For
$i\in \mathbb {V}$
. For
 $n\in\mathbb{N}^*$
, we say that G is of size n if the cardinality
$n\in\mathbb{N}^*$
, we say that G is of size n if the cardinality
 $|\mathbb {V}|$
of
$|\mathbb {V}|$
of
 $\mathbb {V}$
is n. For any nodes
$\mathbb {V}$
is n. For any nodes
 $i,j\in \mathbb {V}$
, we write
$i,j\in \mathbb {V}$
, we write
 $i - j$
if i and j share an edge in G, that is,
$i - j$
if i and j share an edge in G, that is,
 $\{i,j\}\in E$
. Otherwise, we write
$\{i,j\}\in E$
. Otherwise, we write
 $i -\!\!\!\!/\;\; j$
. For any set
$i -\!\!\!\!/\;\; j$
. For any set
 $U\subset \mathbb {V}$
, we denote by E(U) the neighborhood of U, namely,
$U\subset \mathbb {V}$
, we denote by E(U) the neighborhood of U, namely,
 \[E(U)=\left\{j\in \mathbb {V}\,:\, i - j \mbox{ for some }i \in U\right\}.\]
\[E(U)=\left\{j\in \mathbb {V}\,:\, i - j \mbox{ for some }i \in U\right\}.\]
For simplicity, for all
 $i\in \mathbb {V}$
we set
$i\in \mathbb {V}$
we set
 $E(i)\;:\!=\;E(\{i\})$
, the set of neighbors of node i in
$E(i)\;:\!=\;E(\{i\})$
, the set of neighbors of node i in
 $\mathbb {V}$
.
$\mathbb {V}$
.
Throughout the paper, all the random variables we consider are defined on a common probability space
 $(\Omega,\mathcal F,\mathbb P)$
.
$(\Omega,\mathcal F,\mathbb P)$
.
Definition 1. Let
 $\mathbb{X}$
and
$\mathbb{X}$
and
 $\mathbb{V}$
be two separable metric spaces. Let
$\mathbb{V}$
be two separable metric spaces. Let
 $k\in\mathbb{Z}$
and
$k\in\mathbb{Z}$
and
 $x\in \mathbb{X}$
. Let f be a measurable mapping from
$x\in \mathbb{X}$
. Let f be a measurable mapping from
 $\,\mathbb{X} \times \mathbb{V}$
to
$\,\mathbb{X} \times \mathbb{V}$
to
 $\mathbb{X}$
, and let
$\mathbb{X}$
, and let
 $\left(v_n\right)_{n\in\mathbb{Z}}$
be an identically distributed sequence of
$\left(v_n\right)_{n\in\mathbb{Z}}$
be an identically distributed sequence of
 $\mathbb{V}$
-valued random variables. We denote by
$\mathbb{V}$
-valued random variables. We denote by
 $\left(X_n^{k}(x)\right)_{n\ge k}$
the stochastic recursive sequence (SRS) driven by
$\left(X_n^{k}(x)\right)_{n\ge k}$
the stochastic recursive sequence (SRS) driven by
 $\left(f,\left(v_n\right)_{n\in\mathbb{Z}}\right)$
, with initial value x at time k. Namely,
$\left(f,\left(v_n\right)_{n\in\mathbb{Z}}\right)$
, with initial value x at time k. Namely,
 $\left(X_n^{k}(x)\right)_{n\ge k}$
is fully determined by the recurrence equation
$\left(X_n^{k}(x)\right)_{n\ge k}$
is fully determined by the recurrence equation
 \[\begin{cases}X^k_k(x) &=x\,,\\[5pt] X^k_{n+1}(x) &= f (X^k_n(x),v_n) \,\quad \mbox{a.s. for all }n\ge k.\end{cases}\]
\[\begin{cases}X^k_k(x) &=x\,,\\[5pt] X^k_{n+1}(x) &= f (X^k_n(x),v_n) \,\quad \mbox{a.s. for all }n\ge k.\end{cases}\]
It is immediate that
 $\left(X_n^{k}(x)\right)_{n\in\mathbb{Z}}$
is an
$\left(X_n^{k}(x)\right)_{n\in\mathbb{Z}}$
is an
 $\mathbb{X}$
-valued Markov chain whenever the sequence
$\mathbb{X}$
-valued Markov chain whenever the sequence
 $\left(v_n\right)_{n\in\mathbb{Z}}$
is independent and identically distributed (i.i.d.). Conversely, any
$\left(v_n\right)_{n\in\mathbb{Z}}$
is independent and identically distributed (i.i.d.). Conversely, any
 $\mathbb{X}$
-valued Markov chain
$\mathbb{X}$
-valued Markov chain
 $\left(Z_n\right)_{n\in\mathbb{N}}$
of fixed starting time k and initial value x, and with transition matrix Q over
$\left(Z_n\right)_{n\in\mathbb{N}}$
of fixed starting time k and initial value x, and with transition matrix Q over
 $\mathbb{X}$
, can be represented by the SRS driven by
$\mathbb{X}$
, can be represented by the SRS driven by
 $\left(f,\left(v_n\right)_{n\in\mathbb{Z}}\right)$
, where
$\left(f,\left(v_n\right)_{n\in\mathbb{Z}}\right)$
, where
 $\left(v_n\right)_{n\in\mathbb{Z}}$
is an i.i.d. sequence of uniformly distributed random variables on [0, 1], and f is piecewise constant and satisfies, for all
$\left(v_n\right)_{n\in\mathbb{Z}}$
is an i.i.d. sequence of uniformly distributed random variables on [0, 1], and f is piecewise constant and satisfies, for all
 $x_1,x_2\in \mathbb{X}$
,
$x_1,x_2\in \mathbb{X}$
,
 \begin{align*} \lambda\left(\lbrace x\,:\,,f(x_1,x) = x_2 \rbrace\right) = Q(x_1,x_2),\end{align*}
\begin{align*} \lambda\left(\lbrace x\,:\,,f(x_1,x) = x_2 \rbrace\right) = Q(x_1,x_2),\end{align*}
for
 $\lambda$
the Lebesgue measure; see e.g. Section 2.5.3 of [Reference Baccelli and Brémaud6].
$\lambda$
the Lebesgue measure; see e.g. Section 2.5.3 of [Reference Baccelli and Brémaud6].
Fix an SRS
 $X\;:\!=\;\left(X_n^{k}(x)\right)_{n\ge k}$
. Then for all
$X\;:\!=\;\left(X_n^{k}(x)\right)_{n\ge k}$
. Then for all
 $e\in \mathbb{X}$
, we set
$e\in \mathbb{X}$
, we set
 \[\tau^{X,k}_e(x) =\inf\left\{n\ge k\,:\, X_n^{k}(x)=e\right\},\]
\[\tau^{X,k}_e(x) =\inf\left\{n\ge k\,:\, X_n^{k}(x)=e\right\},\]
the hitting time of the value e by
 $\left(X_n^{k}(x)\right)_{n\ge k}$
. If
$\left(X_n^{k}(x)\right)_{n\ge k}$
. If
 $\left(v_n\right)_{n\in\mathbb{Z}}$
is i.i.d., then
$\left(v_n\right)_{n\in\mathbb{Z}}$
is i.i.d., then
 $\left(X_n^{k}(x)\right)_{n\ge k}$
is a Markov chain, and the distribution of
$\left(X_n^{k}(x)\right)_{n\ge k}$
is a Markov chain, and the distribution of
 $\tau^{X,k}_e(x) - k$
is independent of k. In that case, we then denote by
$\tau^{X,k}_e(x) - k$
is independent of k. In that case, we then denote by
 $\tau^{X}_e(x)$
a generic random variable that is so distributed.
$\tau^{X}_e(x)$
a generic random variable that is so distributed.
3. A perfect sampling algorithm by control
In this section we present a perfect simulation algorithm, Algorithm 3, for processes that are bounded, in a sense that we will make precise hereafter.
Algorithm 1: Simulation of the stationary probability of X.

Our procedure is closely related to that of the DCFTP algorithm introduced by Kendall and Moller in [Reference Kendall29, Reference Kendall and Moller30]. Algorithm 1 proceeds roughly as follows: we simulate from the past an auxiliary chain Y, until it has reached one of the endpoints, at which time we start simulating a trajectory of the CTMC X, up to time 0. As will be shown hereafter, under certain conditions the output of Algorithm 1 is sampled exactly from the stationary distribution of X.
Until the end of this section, we fix three separable metric spaces
 $\mathbb{X}$
,
$\mathbb{X}$
,
 $\mathbb {Y}$
, and
$\mathbb {Y}$
, and
 $\mathbb{V}$
, and two mappings
$\mathbb{V}$
, and two mappings
 $f\;:\;\mathbb{X} \times \mathbb{V}\to \mathbb{X}$
and
$f\;:\;\mathbb{X} \times \mathbb{V}\to \mathbb{X}$
and
 $g\;:\;\mathbb {Y} \times \mathbb{V}\to \mathbb {Y}$
.
$g\;:\;\mathbb {Y} \times \mathbb{V}\to \mathbb {Y}$
.
3.1. A control condition
The control of an SRS of interest by an auxiliary one is the key to our perfect simulation algorithm. It is defined below.
Definition 2. Let
 $\left(X_n\right)_{n\in\mathbb{Z}}$
and
$\left(X_n\right)_{n\in\mathbb{Z}}$
and
 $\left(Y_n\right)_{n\in\mathbb{Z}}$
be two SRSs, respectively valued in
$\left(Y_n\right)_{n\in\mathbb{Z}}$
be two SRSs, respectively valued in
 $\mathbb{X}$
and
$\mathbb{X}$
and
 $\mathbb {Y}$
, and let
$\mathbb {Y}$
, and let
 $r \in \mathbb{N}^*$
. We say that
$r \in \mathbb{N}^*$
. We say that
 $\left(Y_n\right)_{n\in\mathbb{Z}}$
r-controls
$\left(Y_n\right)_{n\in\mathbb{Z}}$
r-controls
 $\left(X_n\right)_{n\in\mathbb{Z}}$
if there exist
$\left(X_n\right)_{n\in\mathbb{Z}}$
if there exist
 $b_1,\ldots,b_r,y \in \mathbb {Y}$
and
$b_1,\ldots,b_r,y \in \mathbb {Y}$
and
 $a_1,\ldots,a_r \in \mathbb{X}$
such that the following holds:
$a_1,\ldots,a_r \in \mathbb{X}$
such that the following holds:
 \begin{equation}\mbox{For all } i \in [\![ 1, r ]\!],\ k \in \mathbb{Z},\ \mbox{and } n \ge k,\quad \left[ Y^{k}_n(y)=b_i \right] \Longrightarrow \left[\forall x \in \mathbb{X},\, X^k_n(x)=a_i \right].\end{equation}
\begin{equation}\mbox{For all } i \in [\![ 1, r ]\!],\ k \in \mathbb{Z},\ \mbox{and } n \ge k,\quad \left[ Y^{k}_n(y)=b_i \right] \Longrightarrow \left[\forall x \in \mathbb{X},\, X^k_n(x)=a_i \right].\end{equation}
The points
 $b_1,\ldots,b_r$
are called the endpoints of Y. If
$b_1,\ldots,b_r$
are called the endpoints of Y. If
 $r = 1$
, we simply say that Y controls X.
$r = 1$
, we simply say that Y controls X.
The following result establishes that under certain conditions including the control of
 $\left(X_n\right)_{n\in\mathbb{Z}}$
and
$\left(X_n\right)_{n\in\mathbb{Z}}$
and
 $\left(Y_n\right)_{n\in\mathbb{Z}}$
, Algorithm 1 terminates almost surely, and the output is a sample of the stationary distribution of the SRS
$\left(Y_n\right)_{n\in\mathbb{Z}}$
, Algorithm 1 terminates almost surely, and the output is a sample of the stationary distribution of the SRS
 $\left(X_n\right)_{n\in\mathbb{Z}}$
.
$\left(X_n\right)_{n\in\mathbb{Z}}$
.
Theorem 1. Suppose that the sequence
 $\left(v_n\right)_{n\in\mathbb{Z}}$
is i.i.d., and let X and Y be two SRSs respectively driven by
$\left(v_n\right)_{n\in\mathbb{Z}}$
is i.i.d., and let X and Y be two SRSs respectively driven by
 $\left(f,\left(v_n\right)_{n\in\mathbb{Z}}\right)$
and
$\left(f,\left(v_n\right)_{n\in\mathbb{Z}}\right)$
and
 $\left(g,\left(v_n\right)_{n\in\mathbb{Z}}\right)$
. Suppose that X is r-controlled by Y for
$\left(g,\left(v_n\right)_{n\in\mathbb{Z}}\right)$
. Suppose that X is r-controlled by Y for
 $b_1,\ldots,b_r,y$
and
$b_1,\ldots,b_r,y$
and
 $a_1,\ldots,a_r$
, and that it holds that
$a_1,\ldots,a_r$
, and that it holds that
 \begin{equation}{\mathbb P}\left[\tau^Y_{b_i}(y) <\infty\right] =1, \quad i \in [\![ 1, r ]\!].\end{equation}
\begin{equation}{\mathbb P}\left[\tau^Y_{b_i}(y) <\infty\right] =1, \quad i \in [\![ 1, r ]\!].\end{equation}
Then Algorithm 1 terminates almost surely, and its output is sampled from the unique stationary distribution of X.
Proof. We first show that Algorithm 1 terminates almost surely. To see this, observe that for any
 $i \in [\![ 1, r ]\!]$
and any
$i \in [\![ 1, r ]\!]$
and any
 $N \in \mathbb{N}$
,
$N \in \mathbb{N}$
,
 \begin{align*}\mathbb{P}\left(\bigcup\limits_{n\in \mathbb{N} } \left\lbrace \tau^{Y,-2^n}_{b_i}(y)\leq 0\right\rbrace \right)&=\mathbb{P}\left(\bigcup\limits_{n\in \mathbb{N} } \left\lbrace \tau^{Y,-2^n}_{b_i}(y)+2^n\leq 2^{n} \right\rbrace \right)\\[5pt] &\geq \mathbb{P}\left(\left\lbrace \tau^{Y,-2^N}_{b_i}(y)+2^N\leq 2^{N} \right\rbrace\right) = \mathbb{P}\left( \left\lbrace \tau^{Y}_{b_i}(y) \leq 2^{N} \right\rbrace\right),\end{align*}
\begin{align*}\mathbb{P}\left(\bigcup\limits_{n\in \mathbb{N} } \left\lbrace \tau^{Y,-2^n}_{b_i}(y)\leq 0\right\rbrace \right)&=\mathbb{P}\left(\bigcup\limits_{n\in \mathbb{N} } \left\lbrace \tau^{Y,-2^n}_{b_i}(y)+2^n\leq 2^{n} \right\rbrace \right)\\[5pt] &\geq \mathbb{P}\left(\left\lbrace \tau^{Y,-2^N}_{b_i}(y)+2^N\leq 2^{N} \right\rbrace\right) = \mathbb{P}\left( \left\lbrace \tau^{Y}_{b_i}(y) \leq 2^{N} \right\rbrace\right),\end{align*}
in view of the stationarity of the input. So we obtain that
 \begin{align*} \mathbb{P}\left(\bigcup\limits_{n\in \mathbb{N} } \left\lbrace \tau^{Y,-2^n}_{b_i}(y)\leq 0\right\rbrace \right) &\geq \lim_{N \rightarrow +\infty} \ \mathbb{P}\left( \left\lbrace \tau^{Y}_{b_i}(y) \leq 2^{N} \right\rbrace\right)\\[5pt] &= \mathbb{P}( \lbrace \tau^{Y}_{b_i}(y) < +\infty \rbrace) = 1,\end{align*}
\begin{align*} \mathbb{P}\left(\bigcup\limits_{n\in \mathbb{N} } \left\lbrace \tau^{Y,-2^n}_{b_i}(y)\leq 0\right\rbrace \right) &\geq \lim_{N \rightarrow +\infty} \ \mathbb{P}\left( \left\lbrace \tau^{Y}_{b_i}(y) \leq 2^{N} \right\rbrace\right)\\[5pt] &= \mathbb{P}( \lbrace \tau^{Y}_{b_i}(y) < +\infty \rbrace) = 1,\end{align*}
showing that Algorithm 1 terminates almost surely.
Now, let N be the backwards coalescence time of the chain X, that is, the smallest starting time for which the CFTP algorithm terminates for X; in other words,
 \begin{equation}N=\min\left\{n\ge 0\,:\,X^{-n}_0(x)=X^{-n}_0(x')\mbox{ for all }x\ne x' \in \mathbb{X}\right\}.\end{equation}
\begin{equation}N=\min\left\{n\ge 0\,:\,X^{-n}_0(x)=X^{-n}_0(x')\mbox{ for all }x\ne x' \in \mathbb{X}\right\}.\end{equation}
Let R be the smallest termination time of Algorithm 1. Then, by the very definition of Algorithm 1 and (1), there exist
 $ i \in [\![ 1, q ]\!]$
and a time
$ i \in [\![ 1, q ]\!]$
and a time
 $n_0>0$
such that
$n_0>0$
such that
 $-R<-n_0$
, and such that
$-R<-n_0$
, and such that
 $X^{-R}_{-n_0}(x)=X^{-R}_{-n_0}(x')=a_i$
for all
$X^{-R}_{-n_0}(x)=X^{-R}_{-n_0}(x')=a_i$
for all
 $x,x'\in \mathbb{X}$
,
$x,x'\in \mathbb{X}$
,
 $x\ne x'$
, so that
$x\ne x'$
, so that
 \begin{equation}X^{-R}_0(x)=X^{-R}_0(x')=X^{-n_0}_0(a_i),\mbox{ for all $x,x'\in \mathbb{X}$, $x\ne x'$. }\end{equation}
\begin{equation}X^{-R}_0(x)=X^{-R}_0(x')=X^{-n_0}_0(a_i),\mbox{ for all $x,x'\in \mathbb{X}$, $x\ne x'$. }\end{equation}
In particular, it naturally follows from (3) that we necessarily have
 $R\ge N$
; otherwise all versions of the chain X starting from a time posterior to
$R\ge N$
; otherwise all versions of the chain X starting from a time posterior to
 $-N$
would have coalesced before 0, an absurdity. In particular, N is almost surely finite. In the terms of [Reference Foss and Tweedie22], the vertical backwards coalescence time of X is successful, and so it follows from Theorem 4.1 in [Reference Foss and Tweedie22], first, that there exists a unique invariant probability
$-N$
would have coalesced before 0, an absurdity. In particular, N is almost surely finite. In the terms of [Reference Foss and Tweedie22], the vertical backwards coalescence time of X is successful, and so it follows from Theorem 4.1 in [Reference Foss and Tweedie22], first, that there exists a unique invariant probability
 $\pi$
for the chain X, and second, that the output
$\pi$
for the chain X, and second, that the output
 $X^{-N}_0(x)$
of the CFTP algorithm when started from any
$X^{-N}_0(x)$
of the CFTP algorithm when started from any
 $x\in\mathbb{X}$
is sampled from
$x\in\mathbb{X}$
is sampled from
 $\pi$
. But it also follows from (4) that
$\pi$
. But it also follows from (4) that
 \begin{align*}X^{-R}_0(x)=X^{-N}_0(x)=X^{-n_0}_0(a_i),\quad \mbox{ for all }x\in \mathbb{X}.\end{align*}
\begin{align*}X^{-R}_0(x)=X^{-N}_0(x)=X^{-n_0}_0(a_i),\quad \mbox{ for all }x\in \mathbb{X}.\end{align*}
So Algorithm 1 and the CFTP algorithm produce the same output, which completes the proof.
Remark 1. The assumptions of Theorem 1 are satisfied in particular if Y is positive recurrent and irreducible on the discrete state space
 $\mathbb {Y}$
, or if the distribution of Y has atoms at points
$\mathbb {Y}$
, or if the distribution of Y has atoms at points
 $b_1,\ldots,b_r$
with finite hitting times from y.
$b_1,\ldots,b_r$
with finite hitting times from y.
Remark 2. It follows from the equivalence shown in Theorem 4.2 of [Reference Foss and Tweedie22] that under the assumptions of Theorem 1, the Markov chain X is uniformly ergodic, since the vertical coalescence time for X is successful.
3.2. Renovating events and small sets
Assumption (1) is key to our analysis. Under this control condition, the value of the SRS Y forces that of X at time n, whatever the value of X at time N. This is reminiscent of the concept of a renovating event, as introduced by Borovkov and Foss; see [Reference Borovkov and Foss11, Reference Borovkov and Foss12].
Definition 3. Let us recall the following. Let X be an SRS driven by f and
 $\left(v_n\right)_{n\in\mathbb{Z}}$
, and let
$\left(v_n\right)_{n\in\mathbb{Z}}$
, and let
 $\left(A_n\right)_{n\in\mathbb{N}}$
be a sequence of events. We say that
$\left(A_n\right)_{n\in\mathbb{N}}$
be a sequence of events. We say that
 $\left(A_n\right)_{n\in\mathbb{N}}$
is a sequence of renovating events of length m and associated mapping
$\left(A_n\right)_{n\in\mathbb{N}}$
is a sequence of renovating events of length m and associated mapping
 $h\;:\; \mathbb{V}^m\rightarrow \mathbb{X}$
for the chain X if for any
$h\;:\; \mathbb{V}^m\rightarrow \mathbb{X}$
for the chain X if for any
 $n \in \mathbb{Z}$
, on
$n \in \mathbb{Z}$
, on
 $A_n$
we have
$A_n$
we have
 \begin{align*}X_{n+m} = h(v_n,\ldots,v_{n+m-1}).\end{align*}
\begin{align*}X_{n+m} = h(v_n,\ldots,v_{n+m-1}).\end{align*}
Now suppose that (1) holds for
 $a_1,\ldots,a_r,b_1,\ldots,b_r$
and y. Then it is easily seen that for all
$a_1,\ldots,a_r,b_1,\ldots,b_r$
and y. Then it is easily seen that for all
 $k\in\mathbb{Z}$
,
$k\in\mathbb{Z}$
,
 $ i \in [\![ 1, r ]\!]$
, and
$ i \in [\![ 1, r ]\!]$
, and
 $x\in\mathbb{X}$
,
$x\in\mathbb{X}$
,
 $\left(\{Y^{k}_n(y)=b_i\}\right)_{n\ge k}$
is a sequence of renovating events of length 1 for the sequence
$\left(\{Y^{k}_n(y)=b_i\}\right)_{n\ge k}$
is a sequence of renovating events of length 1 for the sequence
 $\left(X^k_n(x)\right)_{n\ge k}$
. Indeed, for all
$\left(X^k_n(x)\right)_{n\ge k}$
. Indeed, for all
 $n\ge k$
, on
$n\ge k$
, on
 $\{Y^{k}_n(y)=b_i\}$
we get that
$\{Y^{k}_n(y)=b_i\}$
we get that
 $X^k_n(x)=a_i$
, and therefore
$X^k_n(x)=a_i$
, and therefore
 \begin{align*}X^k_{n+1}(x)=f(a_i,v_n)\;=\!:\;h(v_n).\end{align*}
\begin{align*}X^k_{n+1}(x)=f(a_i,v_n)\;=\!:\;h(v_n).\end{align*}
One can then give various conditions on the events
 $\left(\{Y^{k}_n(y)=b_i\}\right)_{n\ge k}$
which imply that there exists a stationary version of the chain
$\left(\{Y^{k}_n(y)=b_i\}\right)_{n\ge k}$
which imply that there exists a stationary version of the chain
 $\left(X_n\right)_{n\in\mathbb{N}}$
; see e.g. Theorem 2.5.3 and Property 2.5.5 in [Reference Baccelli and Brémaud6].
$\left(X_n\right)_{n\in\mathbb{N}}$
; see e.g. Theorem 2.5.3 and Property 2.5.5 in [Reference Baccelli and Brémaud6].
There is also an insightful connection between the control condition of Definition 2 and the concept of a small set, which is recalled below as formulated in Chapter 5 of [Reference Meyn and Tweedie33].
Definition 4. For a positive integer m, we say that the subset
 $A\subset \mathbb{X}$
is m- small for the Markov chain
$A\subset \mathbb{X}$
is m- small for the Markov chain
 $\left(X_n\right)_{n\in\mathbb{N}}$
on
$\left(X_n\right)_{n\in\mathbb{N}}$
on
 $\mathbb{X}$
if there exist
$\mathbb{X}$
if there exist
 $\eta_m>0$
and a non-null Borel measure
$\eta_m>0$
and a non-null Borel measure
 $\mu_m$
on
$\mu_m$
on
 $\mathbb{X}$
such that
$\mathbb{X}$
such that
 \[\forall x \in A,\forall B\in \mathcal B(\mathbb{X}),\quad {\mathbb P}\left[X_m \in B \,|\, X_0 = x\right] \ge \eta_m\mu_m(B).\]
\[\forall x \in A,\forall B\in \mathcal B(\mathbb{X}),\quad {\mathbb P}\left[X_m \in B \,|\, X_0 = x\right] \ge \eta_m\mu_m(B).\]
Thus, starting from such a set, the chain (partially) regenerates in a finite horizon of size m, since after that, the transitions of the chain do not depend on the starting point x with strictly positive probability. The existence of small sets is of crucial use in the construction of uniformly ergodic Markov chains; see [Reference Connor and Kendall20, Reference Foss and Tweedie22, Reference Kendall28].
It is significant that under the control condition of Definition 2 and (2), the whole set
 $\mathbb{X}$
is small. To see this, observe that for any
$\mathbb{X}$
is small. To see this, observe that for any
 $i\in[\![ 1,r ]\!]$
, for any
$i\in[\![ 1,r ]\!]$
, for any
 $m\in\mathbb{N}$
such that
$m\in\mathbb{N}$
such that
 ${\mathbb P}\left[\tau^Y_{b_i}(y)=m-1\right]>0$
, in view of the Markov property, for all
${\mathbb P}\left[\tau^Y_{b_i}(y)=m-1\right]>0$
, in view of the Markov property, for all
 $x\in \mathbb{X}$
and all Borel subsets
$x\in \mathbb{X}$
and all Borel subsets
 $B\subset \mathbb{X}$
we have
$B\subset \mathbb{X}$
we have
 \begin{align*}{\mathbb P}\left[X_m \in B \,|\, X_0 = x\right]&\ge {\mathbb P}\left[\{X_m \in B\}\cap\{X_{m-1}=a_i\}\,|\, X_0 = x\right]\\[5pt] &={\mathbb P}\left[X_{m-1}=a_i\,|\,X_0 = x\right]{\mathbb P}\left[X_m \in B\,|\,\{X_{m-1}=a_i\} \cap\{X_0 = x\}\right]\\[5pt] &\ge {\mathbb P}\left[\tau^Y_{b_i}(y)=m-1\right]{\mathbb P}\left[X_1 \in B\,|\,X_{0} = a_i\right]\\[5pt] &\;=\!:\; \delta^i_m \mu^i_m(B). \end{align*}
\begin{align*}{\mathbb P}\left[X_m \in B \,|\, X_0 = x\right]&\ge {\mathbb P}\left[\{X_m \in B\}\cap\{X_{m-1}=a_i\}\,|\, X_0 = x\right]\\[5pt] &={\mathbb P}\left[X_{m-1}=a_i\,|\,X_0 = x\right]{\mathbb P}\left[X_m \in B\,|\,\{X_{m-1}=a_i\} \cap\{X_0 = x\}\right]\\[5pt] &\ge {\mathbb P}\left[\tau^Y_{b_i}(y)=m-1\right]{\mathbb P}\left[X_1 \in B\,|\,X_{0} = a_i\right]\\[5pt] &\;=\!:\; \delta^i_m \mu^i_m(B). \end{align*}
Hence
 $\mathbb{X}$
is m-small.
$\mathbb{X}$
is m-small.
3.3. The ordered case
A typical context in which the control of the SRS X by the SRS Y occurs is when the two sequences are constructed on the same input, and their driving maps satisfy some monotonicity properties, which we detail below. Throughout this section,
 $(\mathbb U,\prec)$
denotes a partially ordered space, and we define two mappings
$(\mathbb U,\prec)$
denotes a partially ordered space, and we define two mappings
 $\varphi\;:\;\mathbb{X} \longmapsto \mathbb U$
and
$\varphi\;:\;\mathbb{X} \longmapsto \mathbb U$
and
 $\psi\;:\;\mathbb {Y} \longmapsto \mathbb U$
.
$\psi\;:\;\mathbb {Y} \longmapsto \mathbb U$
.
Definition 5. We say that the mapping
 $f\;:\; \mathbb{X} \to \mathbb{X}$
is dominated (for
$f\;:\; \mathbb{X} \to \mathbb{X}$
is dominated (for
 $\mathbb U$
,
$\mathbb U$
,
 $\varphi$
, and
$\varphi$
, and
 $\psi$
) by the mapping
$\psi$
) by the mapping
 $g \;:\;\mathbb {Y} \to \mathbb {Y} $
, and write
$g \;:\;\mathbb {Y} \to \mathbb {Y} $
, and write
 $f \prec^{\mathbb U,\varphi,\psi} g$
, if
$f \prec^{\mathbb U,\varphi,\psi} g$
, if
 \begin{equation*}\forall x \in \mathbb{X},\,y\in\mathbb {Y}, \quad \left[\varphi(x)\prec \psi(y)\right] \Longrightarrow \,\left[\varphi\circ f(x) \prec \psi\circ g(y)\right].\end{equation*}
\begin{equation*}\forall x \in \mathbb{X},\,y\in\mathbb {Y}, \quad \left[\varphi(x)\prec \psi(y)\right] \Longrightarrow \,\left[\varphi\circ f(x) \prec \psi\circ g(y)\right].\end{equation*}
In the definition above,
 $\mathbb U$
is an auxiliary partially ordered set that is used for comparing f to g via the projections
$\mathbb U$
is an auxiliary partially ordered set that is used for comparing f to g via the projections
 $\varphi$
and
$\varphi$
and
 $\psi$
. Observe the following simple special case.
$\psi$
. Observe the following simple special case.
Proposition 1. In the case where
 $\mathbb{X}=\mathbb {Y}=\mathbb U$
,
$\mathbb{X}=\mathbb {Y}=\mathbb U$
,
 $\mathbb{X}$
is partially ordered by
$\mathbb{X}$
is partially ordered by
 $\prec$
, and
$\prec$
, and
 $\varphi=\psi=\mbox{i}$
is the identity function, we have
$\varphi=\psi=\mbox{i}$
is the identity function, we have
 $f\prec^{\mathbb{X},\mbox{i},\mbox{i}} g$
under either one of the conditions below:
$f\prec^{\mathbb{X},\mbox{i},\mbox{i}} g$
under either one of the conditions below:
-
(i) g is
 $\prec$
-non-decreasing and pointwise lower-bounded by f;
$\prec$
-non-decreasing and pointwise lower-bounded by f; -
(ii) f is
$\prec$
-non-decreasing and pointwise upper-bounded by g.


Proof. Plainly, for all
 $x,y \in \mathbb{X}$
such that
$x,y \in \mathbb{X}$
such that
 $x\prec y$
, if we assume that (i) holds, then we get
$x\prec y$
, if we assume that (i) holds, then we get
 $f(x)\prec g(x)\prec g(y),$
whereas if (ii) holds we obtain that
$f(x)\prec g(x)\prec g(y),$
whereas if (ii) holds we obtain that
 $f(x) \prec f(y)\prec g(y).$
$f(x) \prec f(y)\prec g(y).$
Proposition 2. Let X and Y be two SRSs respectively driven by
 $(f,\left(v_n\right)_{n\in\mathbb{Z}})$
and
$(f,\left(v_n\right)_{n\in\mathbb{Z}})$
and
 $(g,\left(v_n\right)_{n\in\mathbb{Z}})$
, where the input
$(g,\left(v_n\right)_{n\in\mathbb{Z}})$
, where the input
 $\left(v_n\right)_{n\in\mathbb{Z}}$
is i.i.d. on
$\left(v_n\right)_{n\in\mathbb{Z}}$
is i.i.d. on
 $\mathbb{V}$
. Suppose that
$\mathbb{V}$
. Suppose that
 $f(.,v)\prec^{\mathbb U,\varphi,\psi} g(.,v)$
for all
$f(.,v)\prec^{\mathbb U,\varphi,\psi} g(.,v)$
for all
 $v\in \mathbb{V}$
, where
$v\in \mathbb{V}$
, where
 $\mathbb U$
admits the
$\mathbb U$
admits the
 $\prec$
-minimal point o. Suppose also that
$\prec$
-minimal point o. Suppose also that
 $\varphi^{-1}(o) =\{a\}$
, that there exists
$\varphi^{-1}(o) =\{a\}$
, that there exists
 $y\in\mathbb {Y}$
such that
$y\in\mathbb {Y}$
such that
 \begin{equation}\forall x\in \mathbb{X},\,\,\varphi(x) \prec \psi(y),\end{equation}
\begin{equation}\forall x\in \mathbb{X},\,\,\varphi(x) \prec \psi(y),\end{equation}
and that
 $\tau^Y_b(y)$
is almost surely finite for some
$\tau^Y_b(y)$
is almost surely finite for some
 $b\in \psi^{-1}(o)$
. Then Algorithm 1 for y, a, and b terminates almost surely and produces a sample of the unique stationary distribution of X.
$b\in \psi^{-1}(o)$
. Then Algorithm 1 for y, a, and b terminates almost surely and produces a sample of the unique stationary distribution of X.
Proof. We aim to show that Y controls X for b, y, a. Let
 $k,n\in\mathbb{Z}$
be such that
$k,n\in\mathbb{Z}$
be such that
 $n>k$
and
$n>k$
and
 $Y^{k}_n(y) = b$
. Let
$Y^{k}_n(y) = b$
. Let
 $ x \in \mathbb{X} $
. We show by induction on
$ x \in \mathbb{X} $
. We show by induction on
 $\ell$
that for all
$\ell$
that for all
 $\ell\in[\![ k,n ]\!]$
,
$\ell\in[\![ k,n ]\!]$
,
 \begin{equation}\varphi(X^k_{\ell}(x)) \prec \psi(Y^k_{\ell}(y)).\end{equation}
\begin{equation}\varphi(X^k_{\ell}(x)) \prec \psi(Y^k_{\ell}(y)).\end{equation}
First, from (5) we get that
 $ \varphi(X^{k}_k(x))= \varphi (x) \prec \psi(y) = \psi(Y^{k}_k(y)),$
so (6) holds for
$ \varphi(X^{k}_k(x))= \varphi (x) \prec \psi(y) = \psi(Y^{k}_k(y)),$
so (6) holds for
 $\ell=k$
. Suppose that it is true at rank
$\ell=k$
. Suppose that it is true at rank
 $\ell \in [\![ k,n-1 ]\!]$
, i.e., that
$\ell \in [\![ k,n-1 ]\!]$
, i.e., that
 $\varphi(X^k_{\ell}(x)) \prec \psi(Y^k_{\ell}(y))$
. Then, from the assumption that g dominates f, we obtain that
$\varphi(X^k_{\ell}(x)) \prec \psi(Y^k_{\ell}(y))$
. Then, from the assumption that g dominates f, we obtain that
 \begin{align*}\varphi(X^k_{\ell+1}(x)) = \varphi(f(X^k_{\ell}(x),v_{\ell})) \prec \psi(g(Y^k_{\ell}(y),v_{\ell})) = \psi(Y^k_{\ell+1}(y)),\end{align*}
\begin{align*}\varphi(X^k_{\ell+1}(x)) = \varphi(f(X^k_{\ell}(x),v_{\ell})) \prec \psi(g(Y^k_{\ell}(y),v_{\ell})) = \psi(Y^k_{\ell+1}(y)),\end{align*}
so (6) holds at rank
 $\ell+1$
. It is therefore true for all
$\ell+1$
. It is therefore true for all
 $\ell\in[\![ k,n ]\!]$
. In particular, we have that
$\ell\in[\![ k,n ]\!]$
. In particular, we have that
 \begin{align*}\varphi(X^{k}_n(x))\prec \psi(Y^{k}_n(y)) = \psi(b) =o,\end{align*}
\begin{align*}\varphi(X^{k}_n(x))\prec \psi(Y^{k}_n(y)) = \psi(b) =o,\end{align*}
implying that
 $X^{k}_n(x) = a $
. Thus Y controls X, and we conclude using Theorem 1.
$X^{k}_n(x) = a $
. Thus Y controls X, and we conclude using Theorem 1.
As a conclusion, provided that
 $f\prec^{\mathbb U,\varphi,\psi} g$
, Algorithm 1 provides a perfect sampling algorithm for the SRS X. In fact, in this ordered case, Algorithm 1 is closely related to the DCFTP algorithms of Kendall; see [Reference Connor and Kendall20, Reference Kendall28]. Specifically, as in [Reference Connor and Kendall20], thanks to (5) we have an upper-bound process Y that we can simulate backwards in time. We also have a lower-bound process, namely the constant process equal to b. Similarly to the sandwiching method in [Reference Propp and Wilson41], we only have to simulate the process Y starting at state y. When that process meets the lower bound backwards in time, it means that coalescence has been detected. Then, as in [Reference Connor and Kendall20, Reference Kendall28], we simulate X starting from a single state until time 0. Notice that the DCFTP algorithms introduced in [Reference Connor and Kendall20, Reference Kendall28] use geometric ergodicity and are based on the construction of small sets. As we observed above (Section 3.2), the control condition implies the smallness of
$f\prec^{\mathbb U,\varphi,\psi} g$
, Algorithm 1 provides a perfect sampling algorithm for the SRS X. In fact, in this ordered case, Algorithm 1 is closely related to the DCFTP algorithms of Kendall; see [Reference Connor and Kendall20, Reference Kendall28]. Specifically, as in [Reference Connor and Kendall20], thanks to (5) we have an upper-bound process Y that we can simulate backwards in time. We also have a lower-bound process, namely the constant process equal to b. Similarly to the sandwiching method in [Reference Propp and Wilson41], we only have to simulate the process Y starting at state y. When that process meets the lower bound backwards in time, it means that coalescence has been detected. Then, as in [Reference Connor and Kendall20, Reference Kendall28], we simulate X starting from a single state until time 0. Notice that the DCFTP algorithms introduced in [Reference Connor and Kendall20, Reference Kendall28] use geometric ergodicity and are based on the construction of small sets. As we observed above (Section 3.2), the control condition implies the smallness of
 $\mathbb{X}$
, so our approach is reminiscent of this idea.
$\mathbb{X}$
, so our approach is reminiscent of this idea.
Observe that similar approaches are used for the perfect sampling of loss queueing systems in [Reference Blanchet and Dong9], which uses the domination of the system by an infinite-server queue in some sense (an idea that we also use in the construction of Section 4.2 below), and likewise for the perfect sampling of multiple-server queues in [Reference Blanchet, Dong and Pei10].
Remark 3. The above DCFTP conditions are in fact reminiscent of stochastic domination conditions for the construction of stationary SRSs in the general stationary ergodic context. For instance, for
 $\mathbb{X}=E$
a lattice space, Condition (i) in Proposition 1 above amounts to Condition (H1) in [Reference Moyal36] for any SRSs X and Y that are respectively driven by f and g, and a common input
$\mathbb{X}=E$
a lattice space, Condition (i) in Proposition 1 above amounts to Condition (H1) in [Reference Moyal36] for any SRSs X and Y that are respectively driven by f and g, and a common input
 $\left(v_n\right)_{n\in\mathbb{Z}}$
. This latter condition guarantees, under general stationary ergodic assumptions, the existence of a stationary version of the SRS X, at least on an extended probability space, provided that a stationary version of the SRS Y exists on the original one. See [Reference Lisek31] and Theorem 3 in [Reference Moyal36].
$\left(v_n\right)_{n\in\mathbb{Z}}$
. This latter condition guarantees, under general stationary ergodic assumptions, the existence of a stationary version of the SRS X, at least on an extended probability space, provided that a stationary version of the SRS Y exists on the original one. See [Reference Lisek31] and Theorem 3 in [Reference Moyal36].
4. A stochastic matching model with impatience
In this section we address the perfect sampling of the stationary state of a class of models, which we refer to as ‘general stochastic matching models with impatience’.
4.1. The model
We consider a general stochastic matching model (GM), as defined in [Reference Mairesse and Moyal32]: items enter a system one by one, and each of them belongs to a determinate class. The set of classes is denoted by
 $\mathbb{V}$
and is identified with
$\mathbb{V}$
and is identified with
 $[\![ 1,|\mathbb{V}|]\!]$
. We fix a simple, connected graph
$[\![ 1,|\mathbb{V}|]\!]$
. We fix a simple, connected graph
 $G = (\mathbb{V}, E)$
having set of nodes
$G = (\mathbb{V}, E)$
having set of nodes
 $\mathbb{V}$
, termed a compatibility graph. Upon the arrival of an incoming item of class, say,
$\mathbb{V}$
, termed a compatibility graph. Upon the arrival of an incoming item of class, say,
 $i \in \mathbb{V}$
, either it is matched with an item present in the buffer, of a class j such that i shares an edge with j in G, if any, or if no such item is available, it is stored in the buffer to wait for a match. Whenever several possible matches are possible for an incoming item i, a matching policy determines what the match of i is, without ambiguity. Each matched pair departs the system right away.
$i \in \mathbb{V}$
, either it is matched with an item present in the buffer, of a class j such that i shares an edge with j in G, if any, or if no such item is available, it is stored in the buffer to wait for a match. Whenever several possible matches are possible for an incoming item i, a matching policy determines what the match of i is, without ambiguity. Each matched pair departs the system right away.
A GM model with impatience is a GM model in which each item entering the system is assigned a patience time upon arrival. If the item under consideration has not been matched at the end of its patience time, then it leaves the system forever. To formalize this, after fixing the compatibility graph
 $G=(\mathbb{V},E)$
and the matching policy
$G=(\mathbb{V},E)$
and the matching policy
 $\Phi$
, we assume that arrivals occur at integer times, i.e., we suppose that the generic inter-arrival time
$\Phi$
, we assume that arrivals occur at integer times, i.e., we suppose that the generic inter-arrival time
 $\xi$
is constant equal to one, and fix two i.i.d. sequences
$\xi$
is constant equal to one, and fix two i.i.d. sequences
 $\left(V_n\right)_{n\in\mathbb{Z}}$
and
$\left(V_n\right)_{n\in\mathbb{Z}}$
and
 $\left(P_n\right)_{n\in\mathbb{Z}}$
, where for all
$\left(P_n\right)_{n\in\mathbb{Z}}$
, where for all
 $n\in\mathbb{Z}$
,
$n\in\mathbb{Z}$
,
 $P_n\in\mathbb{R}_+$
and
$P_n\in\mathbb{R}_+$
and
 $V_n\in \mathbb{V}$
respectively represent the patience time and the class of the nth item entering the system. By V and P we denote generic random variables distributed like
$V_n\in \mathbb{V}$
respectively represent the patience time and the class of the nth item entering the system. By V and P we denote generic random variables distributed like
 $\left(V_n\right)_{n\in\mathbb{Z}}$
and
$\left(V_n\right)_{n\in\mathbb{Z}}$
and
 $\left(P_n\right)_{n\in\mathbb{Z}}$
, respectively, and we assume throughout that the random variable P is integrable. The two sequences
$\left(P_n\right)_{n\in\mathbb{Z}}$
, respectively, and we assume throughout that the random variable P is integrable. The two sequences
 $\left(V_n\right)_{n\in\mathbb{Z}}$
and
$\left(V_n\right)_{n\in\mathbb{Z}}$
and
 $\left(P_n\right)_{n\in\mathbb{Z}}$
are not necessarily independent. In particular, it can be the case that the patience time
$\left(P_n\right)_{n\in\mathbb{Z}}$
are not necessarily independent. In particular, it can be the case that the patience time
 $P_n$
of the nth item depends on its class
$P_n$
of the nth item depends on its class
 $V_n$
. In what follows, we denote by
$V_n$
. In what follows, we denote by
 $\mu$
the law of V on
$\mu$
the law of V on
 $\mathbb {V}$
.
$\mathbb {V}$
.
The class of models defined in Section 4.1 admits the following Markov representation. Define the set
 \[{\mathbb X}\;:\!=\;\{\emptyset\}\cup \bigcup_{q=1}^{\infty} \left(\mathbb{R}^*_+\times \mathbb{V}\right)^q.\]
\[{\mathbb X}\;:\!=\;\{\emptyset\}\cup \bigcup_{q=1}^{\infty} \left(\mathbb{R}^*_+\times \mathbb{V}\right)^q.\]
For all
 $t \ge 0$
, let Q(t) be the number of customers in the system at time t, and let us define the profile of the system at t as the following element of
$t \ge 0$
, let Q(t) be the number of customers in the system at time t, and let us define the profile of the system at t as the following element of
 ${\mathbb X}$
:
${\mathbb X}$
:
 \begin{equation} X(t) = \begin{cases} \left( \left({R}^1(t),V^1(t)\right),\cdots, \left({R}^{{Q}(t)}(t),V^{Q(t)}(t)\right)\right)&\mbox{ if }{Q}(t)\ge 1,\\[5pt] \emptyset &\mbox{ otherwise,} \end{cases}\end{equation}
\begin{equation} X(t) = \begin{cases} \left( \left({R}^1(t),V^1(t)\right),\cdots, \left({R}^{{Q}(t)}(t),V^{Q(t)}(t)\right)\right)&\mbox{ if }{Q}(t)\ge 1,\\[5pt] \emptyset &\mbox{ otherwise,} \end{cases}\end{equation}
where for all
 $i\in [\![ 1,Q(t) ]\!]$
, we denote by
$i\in [\![ 1,Q(t) ]\!]$
, we denote by
 $R^i(t)$
(resp.,
$R^i(t)$
(resp.,
 $\mathbb{V}^i(t)$
) the remaining patience (resp., the class) at time t of the ith item in line at time t, in the order of arrival. If the system is empty at t, we again set
$\mathbb{V}^i(t)$
) the remaining patience (resp., the class) at time t of the ith item in line at time t, in the order of arrival. If the system is empty at t, we again set
 $ X(t)=\emptyset$
.
$ X(t)=\emptyset$
.
Definition 6. We say that the matching policy
 $\Phi$
is admissible if, upon each arrival, the choice of the match amongst compatible items in line at t, if any, is made solely according to the knowledge of X(t), and possibly of a draw that is independent of everything else.
$\Phi$
is admissible if, upon each arrival, the choice of the match amongst compatible items in line at t, if any, is made solely according to the knowledge of X(t), and possibly of a draw that is independent of everything else.
Remark 4. It is easily seen that matching policies that depend only on the arrival times (first-come-first-matched (fcfm) or last-come-first-matched (lcfm)), remaining patience times (earliest-deadline-first, latest-deadline-first), matching policies that depend on the queue sizes of the various nodes (match-the-longest, match-the-shortest, max-weight), and priority policies are all admissible. See e.g. [Reference Jonckheere, Moyal, Ramrez and Soprano-Loto26, Reference Mairesse and Moyal32, Reference Moyal37] for a detailed presentation of admissible policies for classical matching models.
Set
 $\left(T_n\right)_{n\in\mathbb{Z}}=\left(n\right)_{n\in\mathbb{Z}}$
, the arrival times to the system, and for all
$\left(T_n\right)_{n\in\mathbb{Z}}=\left(n\right)_{n\in\mathbb{Z}}$
, the arrival times to the system, and for all
 $n\in\mathbb{Z}$
, denote by
$n\in\mathbb{Z}$
, denote by
 $X_n= X(T_n^-)=X(n^-)$
the state of the system seen by the customer entering at time n. Then we obtain the following result.
$X_n= X(T_n^-)=X(n^-)$
the state of the system seen by the customer entering at time n. Then we obtain the following result.
Proposition 3. For any admissible matching policy
 $\Phi$
, the profile sequence
$\Phi$
, the profile sequence
 $\left( X_n\right)_{n\in\mathbb{Z}}$
is stochastic recursive, driven by the sequence of pairs
$\left( X_n\right)_{n\in\mathbb{Z}}$
is stochastic recursive, driven by the sequence of pairs
 $\left((V_n,P_n)\right)_{n\in\mathbb{Z}}$
and a mapping
$\left((V_n,P_n)\right)_{n\in\mathbb{Z}}$
and a mapping
 $ f^\Phi\;:\;\mathbb{X}\times (\mathbb{R}_+\times \mathbb{V}) \longmapsto \mathbb{X}$
that depends on
$ f^\Phi\;:\;\mathbb{X}\times (\mathbb{R}_+\times \mathbb{V}) \longmapsto \mathbb{X}$
that depends on
 $\Phi$
and possibly on a random draw independent of everything else. In other words, we get that
$\Phi$
and possibly on a random draw independent of everything else. In other words, we get that
 \[ X_{n+1}= f^\Phi\left( X_n,(P_n,V_n)\right),\quad n\in\mathbb{Z}.\]
\[ X_{n+1}= f^\Phi\left( X_n,(P_n,V_n)\right),\quad n\in\mathbb{Z}.\]
Proof. The construction of
 $f^\Phi$
is immediate: if the incoming item at n is matched upon arrival, the pair corresponding to this match, determined by
$f^\Phi$
is immediate: if the incoming item at n is matched upon arrival, the pair corresponding to this match, determined by
 $\Phi$
, is erased from the vector
$\Phi$
, is erased from the vector
 $X_n$
; otherwise, the pair
$X_n$
; otherwise, the pair
 $(V_n,P_n)$
is added at the end of the vector
$(V_n,P_n)$
is added at the end of the vector
 $X_n$
. Lastly, the pairs (possibly including the incoming pair
$X_n$
. Lastly, the pairs (possibly including the incoming pair
 $(V_n,P_n)$
) whose second coordinate is strictly less than 1 at n are erased from the vector
$(V_n,P_n)$
) whose second coordinate is strictly less than 1 at n are erased from the vector
 $X_n$
(because they will have reneged by time
$X_n$
(because they will have reneged by time
 $n+1$
), and the second coordinates of all other pairs in
$n+1$
), and the second coordinates of all other pairs in
 $X_n$
, if any, decrease by 1.
$X_n$
, if any, decrease by 1.
4.2. A first perfect sampling algorithm
We can now design a first perfect sampling algorithm for matching models with impatience, which is simply based on control (in the sense of Section 3) by an infinite-server system. In this context, we let
 $ Y\;:\!=\;\left(Y_n\right)_{n\in\mathbb{Z}}$
be an
$ Y\;:\!=\;\left(Y_n\right)_{n\in\mathbb{Z}}$
be an
 $\mathbb{R}_+$
-valued SRS defined by the recursion
$\mathbb{R}_+$
-valued SRS defined by the recursion
 \begin{equation}Y_{n+1}=\left[\max(Y_n,P_n)-1\right]^+\;=\!:\; g\left(Y_n,P_n\right),\quad n \in \mathbb{Z}.\end{equation}
\begin{equation}Y_{n+1}=\left[\max(Y_n,P_n)-1\right]^+\;=\!:\; g\left(Y_n,P_n\right),\quad n \in \mathbb{Z}.\end{equation}
Then, for all n,
 $Y_n$
can be interpreted as the largest remaining service time of a D/GI/
$Y_n$
can be interpreted as the largest remaining service time of a D/GI/
 $\infty$
queue of service times
$\infty$
queue of service times
 $\left(P_n\right)_{n\in\mathbb{Z}}$
, upon the arrival of the nth customer. As the generic random variable P is assumed integrable, it is well known that whenever
$\left(P_n\right)_{n\in\mathbb{Z}}$
, upon the arrival of the nth customer. As the generic random variable P is assumed integrable, it is well known that whenever
 \begin{equation}\mathbb{P}(P \le \xi) = \mathbb{P}(P \le 1) >0,\end{equation}
\begin{equation}\mathbb{P}(P \le \xi) = \mathbb{P}(P \le 1) >0,\end{equation}
the Markov chain
 $\left(Y_n\right)_{n\in\mathbb{Z}}$
is positive recurrent; see e.g. Corollary 4.32 in [Reference Decreusefond and Moyal21, Reference Thorisson43], and the generalization to the case where
$\left(Y_n\right)_{n\in\mathbb{Z}}$
is positive recurrent; see e.g. Corollary 4.32 in [Reference Decreusefond and Moyal21, Reference Thorisson43], and the generalization to the case where
 $\left(P_n\right)_{n\in\mathbb{Z}}$
is stationary ergodic, combining Lemma 5 of [Reference Moyal34] with Corollary 2 in [Reference Moyal35]. Consider Algorithm 2, which is a declination of Algorithm 1 started with
$\left(P_n\right)_{n\in\mathbb{Z}}$
is stationary ergodic, combining Lemma 5 of [Reference Moyal34] with Corollary 2 in [Reference Moyal35]. Consider Algorithm 2, which is a declination of Algorithm 1 started with
 $y=m$
for m defined below, for Y the recursion defined by (8),
$y=m$
for m defined below, for Y the recursion defined by (8),
 $q=1$
,
$q=1$
,
 $a_1=\emptyset$
, and
$a_1=\emptyset$
, and
 $b_1=0$
.
$b_1=0$
.
Algorithm 2: Simulation of the stationary probability of X - Matching model with impatience.

Theorem 2. Under Condition (9), the profile Markov chain
 $\left( X_n\right)_{n\in\mathbb{Z}}$
admits a unique stationary distribution. If moreover there exists
$\left( X_n\right)_{n\in\mathbb{Z}}$
admits a unique stationary distribution. If moreover there exists
 $m>0$
such that
$m>0$
such that
 $\mathbb{P}(P\leq m)=1$
, then Algorithm 2 terminates almost surely, and its output is sampled from the stationary distribution of
$\mathbb{P}(P\leq m)=1$
, then Algorithm 2 terminates almost surely, and its output is sampled from the stationary distribution of
 $\left( X_n\right)_{n\in\mathbb{Z}}$
.
$\left( X_n\right)_{n\in\mathbb{Z}}$
.
Proof. We apply Proposition 2, by setting in this case
 \begin{eqnarray}\varphi: & \mathbb{X} &\longrightarrow \mathbb{R}_+\\[5pt] & x=\left((r_1,v_1),\cdots,(r_q,v_q)\right)\ne \emptyset\quad &\longmapsto \max\left\{r_i:\,i\in[\![ 1,q ]\!]\right\}\notag\\[5pt] &\emptyset &\longmapsto 0.\notag \end{eqnarray}
\begin{eqnarray}\varphi: & \mathbb{X} &\longrightarrow \mathbb{R}_+\\[5pt] & x=\left((r_1,v_1),\cdots,(r_q,v_q)\right)\ne \emptyset\quad &\longmapsto \max\left\{r_i:\,i\in[\![ 1,q ]\!]\right\}\notag\\[5pt] &\emptyset &\longmapsto 0.\notag \end{eqnarray}
As the time spent in the system by any item is less than or equal to its patience time, for any
 $n\in\mathbb{Z}$
,
$n\in\mathbb{Z}$
,
 $\varphi( X_n)$
corresponds to the largest remaining maximal sojourn time in the system of an item in the system just before time
$\varphi( X_n)$
corresponds to the largest remaining maximal sojourn time in the system of an item in the system just before time
 $T_n$
. Consequently, for any
$T_n$
. Consequently, for any
 $(p,v) \in \mathbb{R}_+\times \mathbb{V}$
, for all
$(p,v) \in \mathbb{R}_+\times \mathbb{V}$
, for all
 $ x\in \mathbb{X}$
we obtain that
$ x\in \mathbb{X}$
we obtain that
 \begin{equation}\varphi\left( f^\Phi\left( x,(p,v)\right)\right) \le \left[\max\left(\varphi\left( x\right),p\right) - 1\right]^+= g\left(\varphi\left( x\right),p\right).\end{equation}
\begin{equation}\varphi\left( f^\Phi\left( x,(p,v)\right)\right) \le \left[\max\left(\varphi\left( x\right),p\right) - 1\right]^+= g\left(\varphi\left( x\right),p\right).\end{equation}
Therefore, for any
 $ x\in\mathbb{X}$
and
$ x\in\mathbb{X}$
and
 $y\in\mathbb{R}_+$
such that
$y\in\mathbb{R}_+$
such that
 $\varphi( x) \le y$
, for any (p, v), as
$\varphi( x) \le y$
, for any (p, v), as
 $ g(.,p)$
is non-decreasing on
$ g(.,p)$
is non-decreasing on
 $\mathbb{R}_+$
we get that
$\mathbb{R}_+$
we get that
 \[\varphi\left( f^\Phi\left( x,(p,v)\right)\right) \le g\left(y,p\right).\]
\[\varphi\left( f^\Phi\left( x,(p,v)\right)\right) \le g\left(y,p\right).\]
Proposition 2 completes the proof.
4.3. Deterministic patience times
Whenever Condition (9) does not hold, the existence and uniqueness of a stationary distribution for the Markov chain
 $\left(X_n\right)_{n\in\mathbb{N}}$
are not granted. One then has to resort to ad-hoc techniques to show stability and to sample the stationary state.
$\left(X_n\right)_{n\in\mathbb{N}}$
are not granted. One then has to resort to ad-hoc techniques to show stability and to sample the stationary state.
In this section, we consider the particular case of the previous model, in which patience times are deterministic. Specifically, we suppose that
 $P\equiv p+\varepsilon$
, for some
$P\equiv p+\varepsilon$
, for some
 $p\in\mathbb{N}^*$
and
$p\in\mathbb{N}^*$
and
 $0<\varepsilon<1$
. Assuming that patience times are not integers, while arrivals occur at integer times, allows us to avoid the ambiguous situation in which an item enters the system and finds an item with remaining patience time zero. In practice, any incoming item can be matched either upon arrival, or with one of the p items that enter subsequently. If not, the item is lost before the arrival of the
$0<\varepsilon<1$
. Assuming that patience times are not integers, while arrivals occur at integer times, allows us to avoid the ambiguous situation in which an item enters the system and finds an item with remaining patience time zero. In practice, any incoming item can be matched either upon arrival, or with one of the p items that enter subsequently. If not, the item is lost before the arrival of the
 $(p+1)$
th item after it, because its remaining time then equals
$(p+1)$
th item after it, because its remaining time then equals
 $\varepsilon-1<0$
. For short, we denote such a matching model by
$\varepsilon-1<0$
. For short, we denote such a matching model by
 $(G,\Phi,\mu,p)$
.
$(G,\Phi,\mu,p)$
.
Clearly, in this context, (9) fails. (Notice that taking
 $p=0$
in the present construction would lead to a system in which no item could ever be matched.) In this section, we show that such systems are nevertheless positive recurrent, and construct an alternative perfect sampling algorithm that is another declination of Algorithm 3, and is again based on the control condition defined in Section 3.
$p=0$
in the present construction would lead to a system in which no item could ever be matched.) In this section, we show that such systems are nevertheless positive recurrent, and construct an alternative perfect sampling algorithm that is another declination of Algorithm 3, and is again based on the control condition defined in Section 3.
4.3.1. Alternative Markov representation
In this particular case, the profile Markov chain can be simplified so as to yield the following alternative, simpler Markov representation of the system state.
Definition 7. For all
 $n\in\mathbb{Z}$
, the word-profile of the system just before time n is defined by the word
$n\in\mathbb{Z}$
, the word-profile of the system just before time n is defined by the word
 \begin{align*}\tilde X_n = w_1\cdots w_p \in (\mathbb{V}\cup\{0\})^p,\end{align*}
\begin{align*}\tilde X_n = w_1\cdots w_p \in (\mathbb{V}\cup\{0\})^p,\end{align*}
where for all
 $i \in [\![ 1,p ]\!]$
,
$i \in [\![ 1,p ]\!]$
,
 \[w_ i = \begin{cases} V_{n-p+i-1} & \mbox{if the item entered at }n-p+i-1\mbox{ was not matched before }\small{n},\\[5pt] 0 &\mbox{otherwise}. \end{cases}.\]
\[w_ i = \begin{cases} V_{n-p+i-1} & \mbox{if the item entered at }n-p+i-1\mbox{ was not matched before }\small{n},\\[5pt] 0 &\mbox{otherwise}. \end{cases}.\]
In particular, if the item that entered at time
 $n-p$
is still in the system at time n (its class thus appearing as the first letter of the word
$n-p$
is still in the system at time n (its class thus appearing as the first letter of the word
 $\tilde X_n$
), it is either matched with the incoming item at time n, or considered lost.
$\tilde X_n$
), it is either matched with the incoming item at time n, or considered lost.
We call
 $\tilde{\mathbb {X}} \subset (\mathbb{V}\cup\{0\})^p$
the (finite) state space of
$\tilde{\mathbb {X}} \subset (\mathbb{V}\cup\{0\})^p$
the (finite) state space of
 $\tilde X$
. Similarly to Proposition 3, it is immediate that for any admissible policy
$\tilde X$
. Similarly to Proposition 3, it is immediate that for any admissible policy
 $\Phi$
, the sequence
$\Phi$
, the sequence
 $\left(\tilde X_n\right)_{n\in\mathbb{Z}}$
is a Markov chain, and we denote by
$\left(\tilde X_n\right)_{n\in\mathbb{Z}}$
is a Markov chain, and we denote by
 $\tilde f^{\Phi}$
the (deterministic, up to a possible draw that is independent of everything else) map
$\tilde f^{\Phi}$
the (deterministic, up to a possible draw that is independent of everything else) map
 $\tilde f^\Phi: \tilde{\mathbb {X}}\times \mathbb{V} \to \tilde{\mathbb {X}}$
such that
$\tilde f^\Phi: \tilde{\mathbb {X}}\times \mathbb{V} \to \tilde{\mathbb {X}}$
such that
 \[\tilde X_{n+1}=\tilde f^\Phi\left(\tilde X_n,V_n\right),\quad n\in\mathbb{Z}.\]
\[\tilde X_{n+1}=\tilde f^\Phi\left(\tilde X_n,V_n\right),\quad n\in\mathbb{Z}.\]
4.3.2. Synchronizing words
For a fixed model
 $(G,\Phi,\mu,p)$
, with
$(G,\Phi,\mu,p)$
, with
 $G = (V,E)$
, let
$G = (V,E)$
, let
 $\mathbb{V}^*$
be the set of words on
$\mathbb{V}^*$
be the set of words on
 $\mathbb{V}$
. For any word
$\mathbb{V}$
. For any word
 $v = v_1\cdots v_l$
in
$v = v_1\cdots v_l$
in
 $\mathbb{V}^*$
and any
$\mathbb{V}^*$
and any
 $\tilde X\in \tilde{\mathbb {X}}$
, let us denote by
$\tilde X\in \tilde{\mathbb {X}}$
, let us denote by
 $W^\Phi(\tilde X,v)\in\tilde{\mathbb {X}}$
the state of a system started at
$W^\Phi(\tilde X,v)\in\tilde{\mathbb {X}}$
the state of a system started at
 $\tilde X$
and receiving the arrivals
$\tilde X$
and receiving the arrivals
 $v_1,\ldots,v_l$
in that order.
$v_1,\ldots,v_l$
in that order.
Definition 8. Fix a model
 $(G,\Phi,\mu,p)$
. A word
$(G,\Phi,\mu,p)$
. A word
 $w = w_1\,\cdots\, w_q \in \mathbb{V}^*$
is said to be synchronizing if
$w = w_1\,\cdots\, w_q \in \mathbb{V}^*$
is said to be synchronizing if
 \begin{align*}\exists z(w) \in \tilde{\mathbb {X}}\;:\; \forall \tilde x \in \tilde{\mathbb {X}},\,W^\Phi(\tilde x,w) = z(w).\end{align*}
\begin{align*}\exists z(w) \in \tilde{\mathbb {X}}\;:\; \forall \tilde x \in \tilde{\mathbb {X}},\,W^\Phi(\tilde x,w) = z(w).\end{align*}
In other words, w is a synchronizing word if all buffers synchronize to some value z(w) whenever they are fed by a common arrival scenario w, whatever the initial state. It is obvious how synchronizing words can be used for perfect simulation. Indeed, if we start the Markov chain at a time
 $-M$
from all possible states, observing a synchronizing word of length
$-M$
from all possible states, observing a synchronizing word of length
 $q<M$
amongst the arrivals (in the sense that the classes of q consecutive incoming items are given by the letters of w, in that order) clearly guarantees that all chains have coalesced by time 0. In fact, recalling Definition 4, it is immediate that whenever there exists a synchronizing word w, the whole set
$q<M$
amongst the arrivals (in the sense that the classes of q consecutive incoming items are given by the letters of w, in that order) clearly guarantees that all chains have coalesced by time 0. In fact, recalling Definition 4, it is immediate that whenever there exists a synchronizing word w, the whole set
 $\tilde{\mathbb {X}}$
is
$\tilde{\mathbb {X}}$
is
 $(q+1)$
-small for the chain
$(q+1)$
-small for the chain
 $\left(\tilde X_n\right)_{n\in\mathbb{Z}}$
. Indeed, for all
$\left(\tilde X_n\right)_{n\in\mathbb{Z}}$
. Indeed, for all
 $\tilde x\in\tilde{\mathbb {X}}$
and
$\tilde x\in\tilde{\mathbb {X}}$
and
 $B\subset \tilde{\mathbb {X}}$
,
$B\subset \tilde{\mathbb {X}}$
,
 \begin{align*}{\mathbb P}\left[\tilde X_{q+1} \in B \,|\, \tilde X_0 = \tilde x\right]&\ge {\mathbb P}\left[\{\tilde X_{q+1} \in B\}\cap\{V_0V_1\,\cdots\, V_{q-1}=w\}\,|\, \tilde X_0 = \tilde x\right]\\[5pt] &={\mathbb P}\left[V_0V_1\,\,\cdots\,\, V_{q-1}=w\right]{\mathbb P}\left[\tilde X_{q+1} \in B\,|\,\{V_0V_1\,\cdots\, V_{q-1}=w\}\cap\{\tilde X_0 = \tilde x\}\right]\\[5pt] &= \prod_{i=0}^{q-1}\mu(w_i) {\mathbb P}\left[\tilde X_{q+1} \in B\,|\,\tilde X_{q} = z\right]. \end{align*}
\begin{align*}{\mathbb P}\left[\tilde X_{q+1} \in B \,|\, \tilde X_0 = \tilde x\right]&\ge {\mathbb P}\left[\{\tilde X_{q+1} \in B\}\cap\{V_0V_1\,\cdots\, V_{q-1}=w\}\,|\, \tilde X_0 = \tilde x\right]\\[5pt] &={\mathbb P}\left[V_0V_1\,\,\cdots\,\, V_{q-1}=w\right]{\mathbb P}\left[\tilde X_{q+1} \in B\,|\,\{V_0V_1\,\cdots\, V_{q-1}=w\}\cap\{\tilde X_0 = \tilde x\}\right]\\[5pt] &= \prod_{i=0}^{q-1}\mu(w_i) {\mathbb P}\left[\tilde X_{q+1} \in B\,|\,\tilde X_{q} = z\right]. \end{align*}
In fact, our approach hereafter for perfect simulation is reminiscent of the small-set techniques for exact sampling in [Reference Green and Murdoch23, Reference Murdoch and Green39, Reference Wilson44]. Specifically, we will use the arrivals of synchronizing words as a control to ensure the coalescence of all versions of the Markov chains.
We first provide a sufficient condition for the existence of synchronizing words, for any discrete matching system. Hereafter, for any
 $k,\ell \in V$
we write
$k,\ell \in V$
we write
 $k \hbox{--} \ell$
if
$k \hbox{--} \ell$
if
 $(k,\ell) \in E$
, that is, if the nodes k and
$(k,\ell) \in E$
, that is, if the nodes k and
 $\ell$
share an edge in G. Otherwise, we write
$\ell$
share an edge in G. Otherwise, we write
 $k-\!\!\!\!/\;\; \ell$
.
$k-\!\!\!\!/\;\; \ell$
.
Definition 9. Let
 $w\in \mathbb{V}^*$
. We say that the word of length 2p given by
$w\in \mathbb{V}^*$
. We say that the word of length 2p given by
 $w=w_1\,\cdots\, w_{2p}\in \mathbb{V}^*$
is strongly synchronizing if
$w=w_1\,\cdots\, w_{2p}\in \mathbb{V}^*$
is strongly synchronizing if
 \begin{align*}\forall i \in [\![ 1,p ]\!],\,\forall j \in [\![ p+1, p+i ]\!],\, w_i -\!\!\!\!/\;\; w_j.\end{align*}
\begin{align*}\forall i \in [\![ 1,p ]\!],\,\forall j \in [\![ p+1, p+i ]\!],\, w_i -\!\!\!\!/\;\; w_j.\end{align*}
The term ‘strongly synchronizing’ is justified by the following result.
Theorem 3. In a discrete matching model with impatience
 $(G,\Phi,\mu,p)$
, any strongly synchronizing word is a synchronizing word.
$(G,\Phi,\mu,p)$
, any strongly synchronizing word is a synchronizing word.
Proof. Let
 $w=w_1 \,\cdots\, w_{2p}$
be a strongly synchronizing word, and let
$w=w_1 \,\cdots\, w_{2p}$
be a strongly synchronizing word, and let
 $u = w_1\,\cdots\, w_p$
and
$u = w_1\,\cdots\, w_p$
and
 $v = w_{p+1}\,\cdots\, w_{2p}$
. Let
$v = w_{p+1}\,\cdots\, w_{2p}$
. Let
 $\tilde x \in \tilde{\mathbb {X}}$
, and let
$\tilde x \in \tilde{\mathbb {X}}$
, and let
 $\mathbf 0_p = \underbrace{0\,\cdots\, 0}_{p}$
be the empty state. As u is of length p, any item present in the buffer represented by
$\mathbf 0_p = \underbrace{0\,\cdots\, 0}_{p}$
be the empty state. As u is of length p, any item present in the buffer represented by
 $\tilde x$
is no longer in there after the arrivals represented by u (it is either matched or discarded, possibly just after the arrival of the last item of class
$\tilde x$
is no longer in there after the arrivals represented by u (it is either matched or discarded, possibly just after the arrival of the last item of class
 $w_p$
). Therefore
$w_p$
). Therefore
 $W^\Phi(\tilde x,u)= u'= w'_{\!\!1},\ldots,w'_{\!\!p}$
where for all
$W^\Phi(\tilde x,u)= u'= w'_{\!\!1},\ldots,w'_{\!\!p}$
where for all
 $i \in [\![ 1, p ]\!]$
,
$i \in [\![ 1, p ]\!]$
,
 $w'_{\!\!i}= w_i$
if the corresponding item is still in the buffer after these arrivals, and
$w'_{\!\!i}= w_i$
if the corresponding item is still in the buffer after these arrivals, and
 $w'_{\!\!i}=0$
otherwise. As w is strongly synchronizing, for any
$w'_{\!\!i}=0$
otherwise. As w is strongly synchronizing, for any
 $i \in [\![ 1, p ]\!]$
such that
$i \in [\![ 1, p ]\!]$
such that
 $w'_{\!\!i} \ne 0$
and any
$w'_{\!\!i} \ne 0$
and any
 $j \in [\![ p+1;\; p+i ]\!]$
, we have that
$j \in [\![ p+1;\; p+i ]\!]$
, we have that
 $w'_{\!\!i} -\!\!\!\!/\;\; w_j$
. All items corresponding to non-zero letters of u
′ are not matched, because their patience necessarily expires before the arrival of a compatible item, and no letters from v can be matched to a letter in u
′. Therefore, if
$w'_{\!\!i} -\!\!\!\!/\;\; w_j$
. All items corresponding to non-zero letters of u
′ are not matched, because their patience necessarily expires before the arrival of a compatible item, and no letters from v can be matched to a letter in u
′. Therefore, if
 $j,h \in [\![ p+1, 2p ]\!]$
are such that the item corresponding to
$j,h \in [\![ p+1, 2p ]\!]$
are such that the item corresponding to
 $w_j$
is matched to that corresponding to
$w_j$
is matched to that corresponding to
 $w_h$
if we add v to the empty buffer
$w_h$
if we add v to the empty buffer
 $\mathbf 0_p$
, then this is also the case if we add v to the buffer u
′. In other words, we get that
$\mathbf 0_p$
, then this is also the case if we add v to the buffer u
′. In other words, we get that
 \begin{align*}W^{\Phi}(\tilde x,w) = W^\Phi(W^\Phi(\tilde x,u),v) = W^\Phi(u',v)=W^\Phi(\mathbf 0_p,v).\end{align*}
\begin{align*}W^{\Phi}(\tilde x,w) = W^\Phi(W^\Phi(\tilde x,u),v) = W^\Phi(u',v)=W^\Phi(\mathbf 0_p,v).\end{align*}
As this is true for any
 $\tilde x\in\tilde{\mathbb {X}}$
, w is a synchronizing word for
$\tilde x\in\tilde{\mathbb {X}}$
, w is a synchronizing word for
 $z(w)\;:\!=\;W^\Phi(\mathbf 0_p,v).$
$z(w)\;:\!=\;W^\Phi(\mathbf 0_p,v).$
We proceed with two technical lemmas. In what follows, for all
 $a\in \mathbb{V}\cup \{0\}$
and all
$a\in \mathbb{V}\cup \{0\}$
and all
 $k \in [\![ 0 , p ]\!]$
, we define the following word of length p:
$k \in [\![ 0 , p ]\!]$
, we define the following word of length p:
 \[x^a(k)=\underbrace{0\cdots 0}_k\underbrace{a\cdots a}_{p-k}.\]
\[x^a(k)=\underbrace{0\cdots 0}_k\underbrace{a\cdots a}_{p-k}.\]
First observe the following.
Lemma 1. Consider a matching model with impatience
 $(G,{\rm{\small{FCFM}}},\mu,p)$
, with matching policy fcfm. Let
$(G,{\rm{\small{FCFM}}},\mu,p)$
, with matching policy fcfm. Let
 $a \in \mathbb{V}$
. Then, for all
$a \in \mathbb{V}$
. Then, for all
 $k \in [\![ 0 , p-1 ]\!]$
, for all words w of length p,
$k \in [\![ 0 , p-1 ]\!]$
, for all words w of length p,
 $W^\Phi(x^a(k),w)$
and
$W^\Phi(x^a(k),w)$
and
 $W^\Phi(x^a(k+1),w)$
differ at most by one letter in some position i (substituting 0 to the ith letter).
$W^\Phi(x^a(k+1),w)$
differ at most by one letter in some position i (substituting 0 to the ith letter).
Proof. Let
 $k \in [\![ 0 , p-1 ]\!]$
, and write
$k \in [\![ 0 , p-1 ]\!]$
, and write
 $w=w_1\,\cdots \,w_p$
. With some abuse of notation, in the proof below, the matching procedure of the initial state
$w=w_1\,\cdots \,w_p$
. With some abuse of notation, in the proof below, the matching procedure of the initial state
 $x^a(k)$
(or
$x^a(k)$
(or
 $x^a(k+1)$
) with the arrival represented by w is itself called
$x^a(k+1)$
) with the arrival represented by w is itself called
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
(or
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
(or
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
).
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
).
If
 $w_i -\!\!\!\!/\;\; a$
for all
$w_i -\!\!\!\!/\;\; a$
for all
 $i\in[\![ 1,p ]\!]$
, then we trivially get that
$i\in[\![ 1,p ]\!]$
, then we trivially get that
 \begin{align*}W^{\rm{\small{FCFM}}}(x^a(k),w)=W^{\rm{\small{FCFM}}}(x^a(k+1),w).\end{align*}
\begin{align*}W^{\rm{\small{FCFM}}}(x^a(k),w)=W^{\rm{\small{FCFM}}}(x^a(k+1),w).\end{align*}
Otherwise, let
 $i_1,\ldots,i_l$
be the indices, in increasing order, of the letters of w matched with letters of
$i_1,\ldots,i_l$
be the indices, in increasing order, of the letters of w matched with letters of
 $x^a(k+1)$
in
$x^a(k+1)$
in
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
. There are three possibilities for the indices (in increasing order) of the letters of w that are matched with letters of
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
. There are three possibilities for the indices (in increasing order) of the letters of w that are matched with letters of
 $x^a(k)$
in
$x^a(k)$
in
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
(which we call for short ‘the indices’ in the discussion hereafter):
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
(which we call for short ‘the indices’ in the discussion hereafter):
-
1. The first a of
$x^a(k)$
is matched in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
with a letter of w of index
$i_0<i_1$
. Then all the remaining a’s in
$x^a(k)$
are matched in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
exactly like the a’s in
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
, and so the indices are precisely
$i_0,i_1,\ldots,i_l$
. -
2. The first a of
$x^a(k)$
is not matched in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
. Then all the remaining a’s of
$x^a(k)$
are matched in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
exactly like the a’s in
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
, and the indices are again
$i_1,\ldots,i_l$
. -
3. The first matched a of
$x^a(k)$
in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
is matched with the letter of index
$i_1$
in w. Then, in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
, either the indices of the matched letters of w are the same as in
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
(and then the last a in
$x^a(k)$
remains unmatched), or the first
$p-k-1$
a’s of
$x^a(k)$
are matched with letters of w at indices
$i_1,\ldots,i_l$
, and the last a is matched with a letter of w of index
$i_{l+1}$
, with
$i_l<i_{l+1}$
, in which case the indices are
$i_1,\ldots,i_{l+1}$
.

























If the indices are
 $i_1,\ldots,i_l$
, then
$i_1,\ldots,i_l$
, then
 $W^{\rm{\small{FCFM}}}(x^a(k),w)=W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
. If the indices are
$W^{\rm{\small{FCFM}}}(x^a(k),w)=W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
. If the indices are
 $i_0,i_1,\ldots,i_l$
or
$i_0,i_1,\ldots,i_l$
or
 $i_1,\ldots,i_{l+1}$
, then there is a letter b of w that is not matched with an a of
$i_1,\ldots,i_{l+1}$
, then there is a letter b of w that is not matched with an a of
 $x^a(k+1)$
in
$x^a(k+1)$
in
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
, but is matched with an a of
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
, but is matched with an a of
 $x^a(k)$
in
$x^a(k)$
in
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
. Then, either that letter b remains unmatched in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
. Then, either that letter b remains unmatched in
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
, in which case
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
, in which case
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
and
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
and
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
differ only at the index
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
differ only at the index
 $i_0$
(or
$i_0$
(or
 $i_{l+1}$
), where there is a b in
$i_{l+1}$
), where there is a b in
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
and 0 in
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
and 0 in
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
; or b is matched with a letter c of w in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
; or b is matched with a letter c of w in
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
. Then, either the letter c remains unmatched in
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
. Then, either the letter c remains unmatched in
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
, in which case
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
, in which case
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
and
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
and
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
differ only at the index of that letter c in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
differ only at the index of that letter c in
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
, where there is a 0 in
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
, where there is a 0 in
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
; or c is matched with another letter b
′ in
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
; or c is matched with another letter b
′ in
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
, in which case we can repeat the same procedure for b
′ instead of b. As we have a finite number of letters in w, we eventually stop with a letter being present in a buffer and 0 in the other. In all cases, the buffers
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
, in which case we can repeat the same procedure for b
′ instead of b. As we have a finite number of letters in w, we eventually stop with a letter being present in a buffer and 0 in the other. In all cases, the buffers
 $W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
and
$W^{\rm{\small{FCFM}}}(x^a(k+1),w)$
and
 $W^{\rm{\small{FCFM}}}(x^a(k),w)$
differ only by one letter.
$W^{\rm{\small{FCFM}}}(x^a(k),w)$
differ only by one letter.
For all
 $\tilde x\in\tilde{\mathbb {X}}$
, let us define
$\tilde x\in\tilde{\mathbb {X}}$
, let us define
 \begin{align*}T(\tilde x,a) = \mbox{Card}\left\{ \mbox{letters }\tilde x_i \mbox{ of } \tilde x\,:\, \tilde x_i - a \right\}.\end{align*}
\begin{align*}T(\tilde x,a) = \mbox{Card}\left\{ \mbox{letters }\tilde x_i \mbox{ of } \tilde x\,:\, \tilde x_i - a \right\}.\end{align*}
The above leads to the following result.
Corollary 1. Let w be a word of length 2p such that for some
 $i \in [\![ 1;\;p ]\!]$
and
$i \in [\![ 1;\;p ]\!]$
and
 $j \in [\![ p+1;\; p+i ]\!],$
we have
$j \in [\![ p+1;\; p+i ]\!],$
we have
 $w_i - w_j$
. For such a pair
$w_i - w_j$
. For such a pair
 $\{i,j\}$
, and
$\{i,j\}$
, and
 $k\in [\![ 0 , 2p ]\!]$
, let
$k\in [\![ 0 , 2p ]\!]$
, let
 \[x^{i,j}(k)= \begin{cases}x^{w_i}(k) &\mbox{ if }k \in [\![ 0,p-1 ]\!],\\[5pt] \mathbf 0_{2p}&\mbox{ if }k =p,\\[5pt] x^{w_j}(2p-k)&\mbox{ if }k \in [\![ p+1,2p ]\!].\end{cases}\]
\[x^{i,j}(k)= \begin{cases}x^{w_i}(k) &\mbox{ if }k \in [\![ 0,p-1 ]\!],\\[5pt] \mathbf 0_{2p}&\mbox{ if }k =p,\\[5pt] x^{w_j}(2p-k)&\mbox{ if }k \in [\![ p+1,2p ]\!].\end{cases}\]
Also let
 $u(k) = W^{\rm{\small{FCFM}}}(x^{i,j}(k),w_1\,\cdots\, w_p),$
for all
$u(k) = W^{\rm{\small{FCFM}}}(x^{i,j}(k),w_1\,\cdots\, w_p),$
for all
 $k \in [\![ 0 , 2p ]\!] $
. Then there exists an integer k in
$k \in [\![ 0 , 2p ]\!] $
. Then there exists an integer k in
 $[\![ 0 , 2p-1 ]\!]$
such that
$[\![ 0 , 2p-1 ]\!]$
such that
 $u(k) = z_1\,\cdots\, z_p$
differs from
$u(k) = z_1\,\cdots\, z_p$
differs from
 $u(k+1) = z'_{\!\!1}\,\cdots\, z'_{\!\!p}$
by only one letter in some position l, where
$u(k+1) = z'_{\!\!1}\,\cdots\, z'_{\!\!p}$
by only one letter in some position l, where
 $z_l - w_{j}$
,
$z_l - w_{j}$
,
 $z'_{\!\!l} = 0$
, and for all
$z'_{\!\!l} = 0$
, and for all
 $h \in [\![ 1 , p ]\!]$
,
$h \in [\![ 1 , p ]\!]$
,
 $z'_{\!\!h}= w_h$
or
$z'_{\!\!h}= w_h$
or
 $z'_{\!\!h} = 0$
. Moreover we have that
$z'_{\!\!h} = 0$
. Moreover we have that
 $T(u(k),w_{j}) = 1$
and
$T(u(k),w_{j}) = 1$
and
 $T(u(k+1),w_{j}) = 0$
.
$T(u(k+1),w_{j}) = 0$
.
Proof. By Lemma 1, for all
 $k \in [\![ 0 , 2p-1 ]\!]$
, u(k) and
$k \in [\![ 0 , 2p-1 ]\!]$
, u(k) and
 $u(k+1)$
differ at most by one letter in some position i (one being
$u(k+1)$
differ at most by one letter in some position i (one being
 $w_i$
, the other being a 0). Therefore, for all
$w_i$
, the other being a 0). Therefore, for all
 $k \in [\![ 0 , 2p-1 ]\!]$
,
$k \in [\![ 0 , 2p-1 ]\!]$
,
 $\vert T(u(k),w_{j})- T(u(k+1),w_{j}) \vert \leq 1$
. Now notice that
$\vert T(u(k),w_{j})- T(u(k+1),w_{j}) \vert \leq 1$
. Now notice that
 $2 \leq T(u(0),w_{j})$
, because gathering the words
$2 \leq T(u(0),w_{j})$
, because gathering the words
 $x^{i,j}(0)$
and w would lead to at least
$x^{i,j}(0)$
and w would lead to at least
 $p+1$
$p+1$
 $w_i$
’s out of 2p letters—so at least two
$w_i$
’s out of 2p letters—so at least two
 $w_i$
’s must remain in u(0). On the other hand, we also have that
$w_i$
’s must remain in u(0). On the other hand, we also have that
 $ T(u(2p),w_{j}) =0 $
, because any letter of
$ T(u(2p),w_{j}) =0 $
, because any letter of
 $w_1\,\cdots\, w_p$
that can be matched with
$w_1\,\cdots\, w_p$
that can be matched with
 $w_{j}$
gets matched in u(2p) with the letters of
$w_{j}$
gets matched in u(2p) with the letters of
 $x^{i,j}(2p)$
. As a consequence, there exists a rank
$x^{i,j}(2p)$
. As a consequence, there exists a rank
 $k \in [\![ 0 , 2p-1 ]\!] $
such that
$k \in [\![ 0 , 2p-1 ]\!] $
such that
 $T(u(k),w_j) =1$
and
$T(u(k),w_j) =1$
and
 $T(u(k+1),w_j) =0$
. The remaining statements follow readily from Lemma 1.
$T(u(k+1),w_j) =0$
. The remaining statements follow readily from Lemma 1.
Theorem 4. Consider a matching model with impatience
 $(G,{\rm{\small{FCFM}}},\mu,p)$
. Let w be a word of length 2p of
$(G,{\rm{\small{FCFM}}},\mu,p)$
. Let w be a word of length 2p of
 $\mathbb{V}^*$
. Then the following conditions are equivalent:
$\mathbb{V}^*$
. Then the following conditions are equivalent:
-
(i) w is a strongly synchronizing word;
-
(ii) w is a synchronizing word.
Proof. In view of Theorem 3, only the implication (ii)
 $\Rightarrow$
(i) remains to be proven. For this, we reason by contraposition. So let w be a word of length 2p such that
$\Rightarrow$
(i) remains to be proven. For this, we reason by contraposition. So let w be a word of length 2p such that
 $w_i - w_j$
for some
$w_i - w_j$
for some
 $i \in [\![ 1;\; p ]\!]$
and
$i \in [\![ 1;\; p ]\!]$
and
 $j \in [\![ p+1;\; p+i ]\!]$
. Let
$j \in [\![ p+1;\; p+i ]\!]$
. Let
 $i^* \in [\![ 1;\; p ]\!]$
and
$i^* \in [\![ 1;\; p ]\!]$
and
 $j^* \in [\![ p+1;\; p+i^* ]\!]$
be such that
$j^* \in [\![ p+1;\; p+i^* ]\!]$
be such that
 $w_{i^*} - w_{j^*}$
and
$w_{i^*} - w_{j^*}$
and
 $j^* = \inf \lbrace j \in [\![ p+1;\; 2p ]\!]$
,
$j^* = \inf \lbrace j \in [\![ p+1;\; 2p ]\!]$
,
 $ \exists i \in [\![ 2p -j; p ]\!]$
$ \exists i \in [\![ 2p -j; p ]\!]$
 $ w_i-w_j \rbrace$
. We let
$ w_i-w_j \rbrace$
. We let
 $u = w_1\cdots w_p$
and
$u = w_1\cdots w_p$
and
 $v = w_{p+1}\cdots w_{2p}$
. Let
$v = w_{p+1}\cdots w_{2p}$
. Let
 $k^*$
be the integer obtained in Corollary 1 for
$k^*$
be the integer obtained in Corollary 1 for
 $i\equiv i^*$
and
$i\equiv i^*$
and
 $j\equiv j^*$
. Then we get
$j\equiv j^*$
. Then we get
 $u(k^*) = d_1\cdots d_p$
and
$u(k^*) = d_1\cdots d_p$
and
 $u(k^*+1) = e_1\cdots e_p$
, where
$u(k^*+1) = e_1\cdots e_p$
, where
 $u(.)$
is defined in Corollary 1. We will prove that
$u(.)$
is defined in Corollary 1. We will prove that
 $W^{\rm{\small{FCFM}}}(u(k^*),v) \neq W^{\rm{\small{FCFM}}}(u(k^*+1),v)$
, which will show in turn that w is not a synchronizing word.
$W^{\rm{\small{FCFM}}}(u(k^*),v) \neq W^{\rm{\small{FCFM}}}(u(k^*+1),v)$
, which will show in turn that w is not a synchronizing word.
Let
 $i_1,\ldots,i_l$
be the indices (in increasing order) of letters of v that are matched with letters of
$i_1,\ldots,i_l$
be the indices (in increasing order) of letters of v that are matched with letters of
 $u(k^*)$
in
$u(k^*)$
in
 $W^{\rm{\small{FCFM}}}(u(k^*),v)$
, and let
$W^{\rm{\small{FCFM}}}(u(k^*),v)$
, and let
 $i'_{\!\!1},\ldots,i'_{\!\!h}$
be the indices (in increasing order) of letters of v that are matched with letters of
$i'_{\!\!1},\ldots,i'_{\!\!h}$
be the indices (in increasing order) of letters of v that are matched with letters of
 $u(k^*+1)$
in
$u(k^*+1)$
in
 $W^{\rm{\small{FCFM}}}(u(k^*+1),v)$
. Now let us define the following sets:
$W^{\rm{\small{FCFM}}}(u(k^*+1),v)$
. Now let us define the following sets:
 \[\begin{cases}I_0 &=\emptyset,\\[5pt] I_{m+1} &= I_m \cup \left\{ \inf \left\{ j \in [\![ p+1, p+m+1 ]\!] \setminus I_m\,:\, w_j - d_{m+1} \right\} \right\},\,m\in [\![ 0,p-1 ]\!]. \end{cases}\]
\[\begin{cases}I_0 &=\emptyset,\\[5pt] I_{m+1} &= I_m \cup \left\{ \inf \left\{ j \in [\![ p+1, p+m+1 ]\!] \setminus I_m\,:\, w_j - d_{m+1} \right\} \right\},\,m\in [\![ 0,p-1 ]\!]. \end{cases}\]
At each step of this construction we add to the set
 $I_m$
the index of the letter that is matched with
$I_m$
the index of the letter that is matched with
 $d_{m+1}$
in
$d_{m+1}$
in
 $W^{\rm{\small{FCFM}}}(u(k^*),v)$
, if any, as in fcfm,
$W^{\rm{\small{FCFM}}}(u(k^*),v)$
, if any, as in fcfm,
 $d_{m+1}$
is matched with the first compatible letter that has not been matched to a previous letter of
$d_{m+1}$
is matched with the first compatible letter that has not been matched to a previous letter of
 $u_k^*$
. In particular, we finally obtain that
$u_k^*$
. In particular, we finally obtain that
 $I_p = \lbrace i_1,\ldots,i_l \rbrace$
. In the same way, we define the sets
$I_p = \lbrace i_1,\ldots,i_l \rbrace$
. In the same way, we define the sets
 \[\begin{cases}I'_{\!\!0} &=\emptyset,\\[5pt] I'_{\!\!m+1} &= I'_{\!\!m} \cup \left\{ \inf \left\{ j \in [\![ p+1, p+m+1 ]\!] \setminus I'_{\!\!m}\,:\, w_j - e_{m+1} \right\} \right\},\,m\in [\![ 0,p-1 ]\!], \end{cases}\]
\[\begin{cases}I'_{\!\!0} &=\emptyset,\\[5pt] I'_{\!\!m+1} &= I'_{\!\!m} \cup \left\{ \inf \left\{ j \in [\![ p+1, p+m+1 ]\!] \setminus I'_{\!\!m}\,:\, w_j - e_{m+1} \right\} \right\},\,m\in [\![ 0,p-1 ]\!], \end{cases}\]
and the same argument leads to
 $I'_{\!\!p} = \lbrace i'_{\!\!1},\ldots,i'_{\!\!h} \rbrace$
.
$I'_{\!\!p} = \lbrace i'_{\!\!1},\ldots,i'_{\!\!h} \rbrace$
.
If, in Corollary 1, the letter a that can be matched with
 $w_{j^*}$
in
$w_{j^*}$
in
 $u(k^*)$
(and be replaced by a 0 in
$u(k^*)$
(and be replaced by a 0 in
 $u(k^*+1)$
) is at position m, then by construction of
$u(k^*+1)$
) is at position m, then by construction of
 $j^*$
,
$j^*$
,
 $u(k^*)$
, and
$u(k^*)$
, and
 $u(k^*+1)$
, a will indeed be matched with
$u(k^*+1)$
, a will indeed be matched with
 $w_{j^*}$
in
$w_{j^*}$
in
 $u(k^*)$
. So the mth step is different for
$u(k^*)$
. So the mth step is different for
 $W^{\rm{\small{FCFM}}}(u(k^*),v)$
and
$W^{\rm{\small{FCFM}}}(u(k^*),v)$
and
 $W^{\rm{\small{FCFM}}}(u(k^*+1),v)$
. For every other step m’, as
$W^{\rm{\small{FCFM}}}(u(k^*+1),v)$
. For every other step m’, as
 $d_{m'} -\!\!\!\!/\;\; w_{j^*}$
and
$d_{m'} -\!\!\!\!/\;\; w_{j^*}$
and
 $e^{m'}-\!\!\!\!/\;\; w_{j^*}$
, we add the same letter, if any, to
$e^{m'}-\!\!\!\!/\;\; w_{j^*}$
, we add the same letter, if any, to
 $I_{m'-1}$
and
$I_{m'-1}$
and
 $I'_{\!\!m'-1}$
. So we have
$I'_{\!\!m'-1}$
. So we have
 $I_p = I'_{\!\!p} \cup \lbrace j^* \rbrace$
. Let
$I_p = I'_{\!\!p} \cup \lbrace j^* \rbrace$
. Let
 $n_1$
(resp.,
$n_1$
(resp.,
 $n_2$
) be the total number of letters from v that are matched in
$n_2$
) be the total number of letters from v that are matched in
 $W^{\rm{\small{FCFM}}}(u(k^*),v)$
(resp.,
$W^{\rm{\small{FCFM}}}(u(k^*),v)$
(resp.,
 $W^{\rm{\small{FCFM}}}(u(k^*+1),v)$
). As the total numbers of matched letters are even, both
$W^{\rm{\small{FCFM}}}(u(k^*+1),v)$
). As the total numbers of matched letters are even, both
 $n_1 + \vert I_p \vert$
and
$n_1 + \vert I_p \vert$
and
 $n_2 + \vert I'_{\!\!p} \vert$
are even. But as
$n_2 + \vert I'_{\!\!p} \vert$
are even. But as
 $\vert I_p \vert$
and
$\vert I_p \vert$
and
 $ \vert I'_{\!\!p} \vert $
are of different parity, so are
$ \vert I'_{\!\!p} \vert $
are of different parity, so are
 $n_1$
and
$n_1$
and
 $n_2$
. Thus,
$n_2$
. Thus,
 \begin{align*}W^{\rm{\small{FCFM}}}(x^{i^*,j^*}(k^*),w) = W^{\rm{\small{FCFM}}}(u(k^*),v)&\neq W^{\rm{\small{FCFM}}}(u(k^*+1),v)\\[5pt] &= W^{\rm{\small{FCFM}}}(x^{i^*,j^*}(k^*+1),w),\end{align*}
\begin{align*}W^{\rm{\small{FCFM}}}(x^{i^*,j^*}(k^*),w) = W^{\rm{\small{FCFM}}}(u(k^*),v)&\neq W^{\rm{\small{FCFM}}}(u(k^*+1),v)\\[5pt] &= W^{\rm{\small{FCFM}}}(x^{i^*,j^*}(k^*+1),w),\end{align*}
and w is not a synchronizing word.
We have proven that being strongly synchronizing is a necessary and sufficient condition for being a synchronizing word of length 2p in the case where the matching policy is fcfm. This is not the case for all matching policies. For example, for the last-come-first-matched policy (lcfm), it can be proven that there exist synchronizing words of length
 $\lfloor\frac{3p}{2}\rfloor$
, so that any suffix of those words that does not satisfy the p-condition would still be a synchronizing word. However, as we prove below, checking that a word is strongly synchronizing is a simple criterion that can be used to construct an efficient perfect sampling algorithm.
$\lfloor\frac{3p}{2}\rfloor$
, so that any suffix of those words that does not satisfy the p-condition would still be a synchronizing word. However, as we prove below, checking that a word is strongly synchronizing is a simple criterion that can be used to construct an efficient perfect sampling algorithm.
4.3.3. A second perfect sampling algorithm
We are now in position to introduce a perfect sampling algorithm for the state of a matching model with deterministic patience.
Definition 10. Consider a model
 $(G,\Phi,\mu,p)$
, and for all
$(G,\Phi,\mu,p)$
, and for all
 $k\in\mathbb{Z}$
, define the SRS
$k\in\mathbb{Z}$
, define the SRS
 $\tilde Y\;:\!=\;\left(\tilde Y^k_n\right)_{n\ge k}$
on the set
$\tilde Y\;:\!=\;\left(\tilde Y^k_n\right)_{n\ge k}$
on the set
 $\tilde {\mathbb Y} = \lbrace\emptyset \rbrace \cup \bigcup_{j=1}^{2p} \mathbb{V}^{j}$
by
$\tilde {\mathbb Y} = \lbrace\emptyset \rbrace \cup \bigcup_{j=1}^{2p} \mathbb{V}^{j}$
by
 \[\begin{cases}\tilde Y^k_k &=\emptyset,\\[5pt] \tilde Y^k_{n+1} &=\tilde g(\tilde Y^k_{n},V_{n+1})\\[5pt] &\;:\!=\;\begin{cases}v_1\cdots v_iV_{n+1},\mbox{ if $\tilde Y^k_n=v_1\cdots v_i \in \mathbb{V}^i$ with $i<2p$}\\[5pt] v_2\cdots v_{2p}V_{n+1},\mbox{ if $\tilde Y^k_n=v_1\cdots v_{2p} \in \mathbb{V}^{2p}$}\end{cases},\,n\ge k,\end{cases}\]
\[\begin{cases}\tilde Y^k_k &=\emptyset,\\[5pt] \tilde Y^k_{n+1} &=\tilde g(\tilde Y^k_{n},V_{n+1})\\[5pt] &\;:\!=\;\begin{cases}v_1\cdots v_iV_{n+1},\mbox{ if $\tilde Y^k_n=v_1\cdots v_i \in \mathbb{V}^i$ with $i<2p$}\\[5pt] v_2\cdots v_{2p}V_{n+1},\mbox{ if $\tilde Y^k_n=v_1\cdots v_{2p} \in \mathbb{V}^{2p}$}\end{cases},\,n\ge k,\end{cases}\]
in such a way that for all k and all
 $n\ge k+2p$
,
$n\ge k+2p$
,
 $\tilde Y^k_n$
represents the last 2p arrivals to the system at time n.
$\tilde Y^k_n$
represents the last 2p arrivals to the system at time n.
Consider Algorithm 3. It consists of another declination of Algorithm 1, started with
 $\tilde Y = \emptyset$
, for
$\tilde Y = \emptyset$
, for
 $\tilde Y$
being the recursion of Definition 10,
$\tilde Y$
being the recursion of Definition 10,
 $b_1,\ldots,b_q$
the strongly synchronizing words of the model, and
$b_1,\ldots,b_q$
the strongly synchronizing words of the model, and
 $a_1,\ldots,a_q$
the states of
$a_1,\ldots,a_q$
the states of
 $\tilde X$
after the arrival of
$\tilde X$
after the arrival of
 $b_1$
,…,
$b_1$
,…,
 $b_q$
, respectively.
$b_q$
, respectively.
Algorithm 3: Simulation of the stationary probability of X̃ - Matching model with deterministic patience.

We have the following result.
Proposition 4.
 $\tilde X$
is positive recurrent. Moreover, Algorithm 3 terminates almost surely, and its output is sampled from the stationary distribution of
$\tilde X$
is positive recurrent. Moreover, Algorithm 3 terminates almost surely, and its output is sampled from the stationary distribution of
 $\tilde X$
.
$\tilde X$
.
Proof. We can easily show that
 $\tilde Y$
r-controls
$\tilde Y$
r-controls
 $\tilde X$
, with q the number of strongly synchronizing words. Let w be a strongly synchronizing word. By Theorem 3, w is a synchronizing word. Thus for all
$\tilde X$
, with q the number of strongly synchronizing words. Let w be a strongly synchronizing word. By Theorem 3, w is a synchronizing word. Thus for all
 $k\in\mathbb{Z}$
and
$k\in\mathbb{Z}$
and
 $n\ge k$
, we get in particular that
$n\ge k$
, we get in particular that
 \begin{equation}\left[ \tilde Y^{k}_n(\emptyset)= w \right] \Longrightarrow \left[\forall \tilde x \in \tilde{\mathbb {X}},\, \tilde X^{k}_n(\tilde x)= W^{\Phi}(\emptyset,w) \right],\end{equation}
\begin{equation}\left[ \tilde Y^{k}_n(\emptyset)= w \right] \Longrightarrow \left[\forall \tilde x \in \tilde{\mathbb {X}},\, \tilde X^{k}_n(\tilde x)= W^{\Phi}(\emptyset,w) \right],\end{equation}
which implies that
 $\tilde Y$
controls
$\tilde Y$
controls
 $\tilde X$
over all strongly synchronizing words. We conclude using Theorem 1.
$\tilde X$
over all strongly synchronizing words. We conclude using Theorem 1.
Remark 5. Observe that
 $\tilde Y$
is not irreducible; however, it reaches its recurrent class in 2p iterations. So for all strongly synchronizing words w, we still have that
$\tilde Y$
is not irreducible; however, it reaches its recurrent class in 2p iterations. So for all strongly synchronizing words w, we still have that
 \begin{align*}\mathbb{P}(\tau_\emptyset^{\tilde Y}(w) < \infty) = 1.\end{align*}
\begin{align*}\mathbb{P}(\tau_\emptyset^{\tilde Y}(w) < \infty) = 1.\end{align*}
4.3.4. Efficiency of Algorithm 3
In this section we analyze the coalescence time of Algorithm 3. For this, one needs to assess the probability that a given input word of length 2p is strongly synchronizing. This is, in turn, a function of
 $\mu$
and of the number of admissible arrival words of length 2p that are strongly synchronizing. The latter number is, clearly, highly dependent on the geometry of the compatibility graph at hand.
$\mu$
and of the number of admissible arrival words of length 2p that are strongly synchronizing. The latter number is, clearly, highly dependent on the geometry of the compatibility graph at hand.
Let us first bound the average number of iterations of the algorithm to see the coalescence time, and then for the corresponding horizon in the past, as a function of the number of strongly synchronizing words. We have the following.
Proposition 5. Let I be the number of iterations of Algorithm 1 to detect coalescence, and let
 $T=-p2^I$
be the corresponding starting time. Then we have that
$T=-p2^I$
be the corresponding starting time. Then we have that
 \begin{align*}{\mathbb E}\left[-T\right] \le \frac{2p}{\mathbb P^{p,\mu}}\,,\end{align*}
\begin{align*}{\mathbb E}\left[-T\right] \le \frac{2p}{\mathbb P^{p,\mu}}\,,\end{align*}
where
 \[\mathbb P^{p,\mu}={\mathbb P}\left[V_1\cdots V_{2p}\mbox{ is strongly synchronizing}\right].\]
\[\mathbb P^{p,\mu}={\mathbb P}\left[V_1\cdots V_{2p}\mbox{ is strongly synchronizing}\right].\]
Proof. For any integer
 $n\ge 1$
, for all
$n\ge 1$
, for all
 $i\in\mathbb{N}^*$
, we let
$i\in\mathbb{N}^*$
, we let
 $z^n_i $
be the word of length 2p representing the arrivals into the system between time
$z^n_i $
be the word of length 2p representing the arrivals into the system between time
 $-p2^n+(i-1)2p$
and time
$-p2^n+(i-1)2p$
and time
 $-p2^n+i2p-1$
, inclusive, in order of arrival. We also let
$-p2^n+i2p-1$
, inclusive, in order of arrival. We also let
 \[K^n=\inf\left\{i \in \mathbb{N}^*\,:\,z^n_i\mbox{ is strongly synchronizing}\right\}.\]
\[K^n=\inf\left\{i \in \mathbb{N}^*\,:\,z^n_i\mbox{ is strongly synchronizing}\right\}.\]
The independence of arrivals implies that the random variables
 $K^n,$
$K^n,$
 $n\in\mathbb{N}^*$
, are identically distributed (but not independent), with geometric distribution of parameter
$n\in\mathbb{N}^*$
, are identically distributed (but not independent), with geometric distribution of parameter
 $\mathbb P^{p,\mu}.$
$\mathbb P^{p,\mu}.$
Now, it readily follows from Theorem 3 that for all
 $n\in\mathbb{N}^*$
,
$n\in\mathbb{N}^*$
,
 $I \le n$
in particular if there has been a strongly synchronizing arrival array between times
$I \le n$
in particular if there has been a strongly synchronizing arrival array between times
 $-p2^{n}$
and
$-p2^{n}$
and
 $-1$
inclusive, that is, if
$-1$
inclusive, that is, if
 $2pK^n \le p2^n$
. Consequently, for all
$2pK^n \le p2^n$
. Consequently, for all
 $n\in\mathbb{N}^*$
we get that
$n\in\mathbb{N}^*$
we get that
 \begin{equation*}{\mathbb P}\left[-T > p2^n\right] = {\mathbb P}\left[I >n\right] \le {\mathbb P}\left[2pK^n > p2^n\right]={\mathbb P}\left[2p K^1 > p2^n\right].\end{equation*}
\begin{equation*}{\mathbb P}\left[-T > p2^n\right] = {\mathbb P}\left[I >n\right] \le {\mathbb P}\left[2pK^n > p2^n\right]={\mathbb P}\left[2p K^1 > p2^n\right].\end{equation*}
This readily implies that
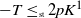 $-T \le_{\tiny{\mbox{st}}} 2p K^1$
, where
$-T \le_{\tiny{\mbox{st}}} 2p K^1$
, where
 $\le_{\tiny{\mbox{st}}}$
denotes the strong stochastic ordering. We deduce that
$\le_{\tiny{\mbox{st}}}$
denotes the strong stochastic ordering. We deduce that
 \begin{align*}{\mathbb E}\left[-T\right] \le 2p{\mathbb E}\left[K^1\right]=\frac{2p}{\mathbb P^{p,\mu}}.\end{align*}
\begin{align*}{\mathbb E}\left[-T\right] \le 2p{\mathbb E}\left[K^1\right]=\frac{2p}{\mathbb P^{p,\mu}}.\end{align*}
Whenever the arrival measure
 $\mu$
is uniform over
$\mu$
is uniform over
 $\mathbb{V}$
, the latter result specializes as follows.
$\mathbb{V}$
, the latter result specializes as follows.
Corollary 2. If the graph
 $G=(\mathbb{V},E)$
is of size n and
$G=(\mathbb{V},E)$
is of size n and
 $\mu$
is uniform over
$\mu$
is uniform over
 $\mathbb{V}$
, we get the bounds
$\mathbb{V}$
, we get the bounds
where N(G,p) is the number of strongly synchronizing words of
 $\mathbb{V}^*$
.
$\mathbb{V}^*$
.
Proof. The results readily follow from Proposition 5, observing that in this case
 \begin{align*}\mathbb P^{p,\mu}=\frac{N(G,p)}{n^{2p}}\cdot\end{align*}
\begin{align*}\mathbb P^{p,\mu}=\frac{N(G,p)}{n^{2p}}\cdot\end{align*}
For a given G and a given p, computing the number N(G, p) of strongly synchronizing words is of crucial interest for assessing the efficiency of Algorithm 3. As Corollary 2 demonstrates, a function of the latter quantity provides bounds for the expected values of
 $|T|$
and I. We now turn to a specific evaluation of N(G, p), and for this, we first need the following definitions.
$|T|$
and I. We now turn to a specific evaluation of N(G, p), and for this, we first need the following definitions.
Definition 11. Let
 $(G = (\mathbb{V},E),\Phi,\mu,p)$
be a discrete matching model with impatience. For any strongly synchronizing word
$(G = (\mathbb{V},E),\Phi,\mu,p)$
be a discrete matching model with impatience. For any strongly synchronizing word
 $w=w_1\cdots w_{2p}$
, the trace of w is defined as the word
$w=w_1\cdots w_{2p}$
, the trace of w is defined as the word
 $Z^w$
gathering, in order of their appearance, all distinct letters of the second half of w. In other words, we set
$Z^w$
gathering, in order of their appearance, all distinct letters of the second half of w. In other words, we set
-
(1)
$Z^w_1 = w_{p+1}$
; -
(2) for all
$i \in [\![ 1,p-1]\!]$
,and
\[Z^w_{i+1} = \begin{cases}Z^w_i &\,\mbox{ if }w_{p+i+1} \in Z^w_i,\\[5pt] Z^w_i \ w_{p+i+1} &\,\mbox{ if }w_{p+i+1}\notin Z^w_i,\end{cases}\]
$Z^w \equiv Z^w_p$
.




In what follows, for any word
 $z=z_1\,\cdots\, z_l$
, we denote by
$z=z_1\,\cdots\, z_l$
, we denote by
 $\beta(z)$
the cardinality of the set of nodes that are incompatible with all letters of z; that is,
$\beta(z)$
the cardinality of the set of nodes that are incompatible with all letters of z; that is,
 \begin{align*}\beta(z) = \mbox{Card} \Bigl\{ v \in \mathbb{V}\,:\, \forall i \in [\![ 1,l ]\!], v -\!\!\!\!/\;\; z_i \Bigl\}.\end{align*}
\begin{align*}\beta(z) = \mbox{Card} \Bigl\{ v \in \mathbb{V}\,:\, \forall i \in [\![ 1,l ]\!], v -\!\!\!\!/\;\; z_i \Bigl\}.\end{align*}
We have the following.
Proposition 6. Let
 $(G = (\mathbb{V},E),\Phi,\mu,p)$
be a discrete matching model with impatience, and let
$(G = (\mathbb{V},E),\Phi,\mu,p)$
be a discrete matching model with impatience, and let
 $\mathscr T(G)$
be the set of words having distinct letters, that form a permutation of the elements of a set
$\mathscr T(G)$
be the set of words having distinct letters, that form a permutation of the elements of a set
 $U\subset \mathbb{V}$
such that
$U\subset \mathbb{V}$
such that
 $E(U) \ne \mathbb{V}$
. Then the number N(G,p) of strongly synchronizing words is given by
$E(U) \ne \mathbb{V}$
. Then the number N(G,p) of strongly synchronizing words is given by
 \begin{equation*}N(G,p)= \sum\limits_{z= z_1\cdots z_l \in \mathscr T(G)} \sum\limits_{\lbrace 1=k_1<k_2<\cdots <k_{l}< k_{l+1}= p+1 \rbrace} \prod_{i=1}^{l} i^{k_{i+1}-k_{i}-1}\beta(z_1 z_2\cdots z_i)^{k_{i+1}-k_{i}}.\end{equation*}
\begin{equation*}N(G,p)= \sum\limits_{z= z_1\cdots z_l \in \mathscr T(G)} \sum\limits_{\lbrace 1=k_1<k_2<\cdots <k_{l}< k_{l+1}= p+1 \rbrace} \prod_{i=1}^{l} i^{k_{i+1}-k_{i}-1}\beta(z_1 z_2\cdots z_i)^{k_{i+1}-k_{i}}.\end{equation*}
Proof. Let
 $z=z_1\,\cdots \,z_l\in \mathbb{V}^*$
be a word having l distinct letters. For any word
$z=z_1\,\cdots \,z_l\in \mathbb{V}^*$
be a word having l distinct letters. For any word
 $w = w_1\,\cdots \,w_{2p}$
of trace z, let us denote by
$w = w_1\,\cdots \,w_{2p}$
of trace z, let us denote by
 \[k^w_i = \inf \Bigl\lbrace j \in [\![ 1, p]\!],\,w_{p+j} = z_{i} \Bigl\},\quad i \in [\![ 1, l ]\!],\]
\[k^w_i = \inf \Bigl\lbrace j \in [\![ 1, p]\!],\,w_{p+j} = z_{i} \Bigl\},\quad i \in [\![ 1, l ]\!],\]
the consecutive indices, in the second half suffix of w, corresponding to the first occurrences of the successive letters of z.
Let
 $1=k_1<k_2<\cdots <k_{l} <k_{l+1}=p+1$
be a fixed family of integers, and let w be a word of length 2p. We first show the equivalence between the following two assertions:
$1=k_1<k_2<\cdots <k_{l} <k_{l+1}=p+1$
be a fixed family of integers, and let w be a word of length 2p. We first show the equivalence between the following two assertions:
-
(i) w is strongly synchronizing, has trace
$z = z_1 \cdots z_l$
, and satisfies
\begin{align*}(k^w_1,k^w_2,\ldots,k^w_l) =(k_1,k_2,\ldots,k_{l});\end{align*}
-
(ii) for all
$i \in [\![ 1 , l ]\!]$
, -
(iia)
$w_{p+k_i} = z_{i}$
; -
(iib) for all
$j \in [\![ k_{i},k_{i+1} -1 ]\!],\, w_{p+j} \in \lbrace z_1 , \cdots, z_i \rbrace$
and
$w_{j} \in E\left(\{z_1,\,\cdots\,,z_i\}\right)^c.$






Indeed, if (i) holds true, then (ii) also holds by induction on i: first, (iia)–(iib) hold true for
 $i=1$
. Indeed, for all
$i=1$
. Indeed, for all
 $j \in [\![ k_{1},k_{2} -1 ]\!]$
we have that
$j \in [\![ k_{1},k_{2} -1 ]\!]$
we have that
 $w_{p+j} =z_1$
by definition of
$w_{p+j} =z_1$
by definition of
 $k_1$
and
$k_1$
and
 $k_2$
, and thus, by definition of a strongly synchronizing word, that
$k_2$
, and thus, by definition of a strongly synchronizing word, that
 $w_{j} -\!\!\!\!/\;\; w_{p+k_1}=z_{1}$
. Now suppose that (iia)–(iib) hold true for some
$w_{j} -\!\!\!\!/\;\; w_{p+k_1}=z_{1}$
. Now suppose that (iia)–(iib) hold true for some
 $i-1\in[\![ 1,p-1 ]\!]$
. Then (iia) holds for i by definition of the trace and of
$i-1\in[\![ 1,p-1 ]\!]$
. Then (iia) holds for i by definition of the trace and of
 $k_i$
. The statement (iib) also holds true by induction on j over
$k_i$
. The statement (iib) also holds true by induction on j over
 $[\![ k_{i},k_{i+1} -1]\!]$
: first, we have
$[\![ k_{i},k_{i+1} -1]\!]$
: first, we have
 $w_{p+k_i} = z_{i}$
by (iia), implying, by definition of a strongly synchronizing word and in view of the induction assumption, that
$w_{p+k_i} = z_{i}$
by (iia), implying, by definition of a strongly synchronizing word and in view of the induction assumption, that
 \begin{align*}w_{k_i} &\in E\left(\left\{w_\ell\,:\,\ell \in [\![ p+1,p+k_i ]\!]\right\}\right)^c\\[5pt] &= E\left(\left\{w_\ell\,:\,\ell \in [\![ p+1,p+k_i-1 ]\!]\right\}\cup\{w_{p+k_i}\}\right)^c\\[5pt] &=E\left(\left\{z_1,\cdots,z_i-1\right\}\cup\{z_i\}\right)^c=E\left(\left\{z_1,\cdots,z_i\right\}\right)^c,\end{align*}
\begin{align*}w_{k_i} &\in E\left(\left\{w_\ell\,:\,\ell \in [\![ p+1,p+k_i ]\!]\right\}\right)^c\\[5pt] &= E\left(\left\{w_\ell\,:\,\ell \in [\![ p+1,p+k_i-1 ]\!]\right\}\cup\{w_{p+k_i}\}\right)^c\\[5pt] &=E\left(\left\{z_1,\cdots,z_i-1\right\}\cup\{z_i\}\right)^c=E\left(\left\{z_1,\cdots,z_i\right\}\right)^c,\end{align*}
so the properties in (iib) hold for
 $j=k_i$
. Now suppose that they hold true for some
$j=k_i$
. Now suppose that they hold true for some
 $j-1\in [\![ k_{i},k_{i+1} -2]\!]$
. Then
$j-1\in [\![ k_{i},k_{i+1} -2]\!]$
. Then
 $w_{p+j} \in \{z_1,\cdots,z_i\}$
by the very definition of
$w_{p+j} \in \{z_1,\cdots,z_i\}$
by the very definition of
 $k_i$
. Thus, as w is strongly synchronizing, we have that
$k_i$
. Thus, as w is strongly synchronizing, we have that
 \begin{align*}w_{j} &\in E\left(\left\{w_\ell\,:\,\ell \in [\![ p+1,p+j ]\!]\right\}\right)^c\\[5pt] &=E\left(\left\{w_\ell\,:\,\ell \in [\![ p+1,p+j-1 ]\!]\right\}\cup \{w_{p+j}\}\right)^c\\[5pt] &=E\left(\left\{z_1,\cdots,z_i\right\}\cup \{w_{p+j}\}\right)^c=E\left(\left\{z_1,\cdots,z_i\right\}\right)^c.\end{align*}
\begin{align*}w_{j} &\in E\left(\left\{w_\ell\,:\,\ell \in [\![ p+1,p+j ]\!]\right\}\right)^c\\[5pt] &=E\left(\left\{w_\ell\,:\,\ell \in [\![ p+1,p+j-1 ]\!]\right\}\cup \{w_{p+j}\}\right)^c\\[5pt] &=E\left(\left\{z_1,\cdots,z_i\right\}\cup \{w_{p+j}\}\right)^c=E\left(\left\{z_1,\cdots,z_i\right\}\right)^c.\end{align*}
Thus (iib) holds true at index i, which completes the proof of (ii).
Now suppose that (ii) holds. Then it follows from (iia) and the first property in (iib) that
 $k^w_i=k_i$
for all
$k^w_i=k_i$
for all
 $i\in[\![ 1,l ]\!]$
. Now fix
$i\in[\![ 1,l ]\!]$
. Now fix
 $j\in[\![ 1,p ]\!]$
, and let i be the index in
$j\in[\![ 1,p ]\!]$
, and let i be the index in
 $[\![ 1,l ]\!]$
such that
$[\![ 1,l ]\!]$
such that
 $j\in [\![ k_i,k_{i+1}-1 ]\!]$
. Then, in view of (iia)–(iib), we get that
$j\in [\![ k_i,k_{i+1}-1 ]\!]$
. Then, in view of (iia)–(iib), we get that
 \[w_{j} \in E\left(\{z_1,\,\cdots\,,z_i\}\right)^c=E\left(\{w_{p+1},\,\cdots\,,z_{p+j}\}\right)^c,\]
\[w_{j} \in E\left(\{z_1,\,\cdots\,,z_i\}\right)^c=E\left(\{w_{p+1},\,\cdots\,,z_{p+j}\}\right)^c,\]
so w is indeed strongly synchronizing. From (ii), w also clearly has trace z, so (i) holds, which concludes the proof of (i)
 $\Leftrightarrow$
(ii).
$\Leftrightarrow$
(ii).
Now, for a fixed trace z, to count the strongly synchronizing words having trace z, it thus suffices to count, for all families of integers
 $1=k_1<k_2<\cdots<k_l<k_{l+1}=p+1$
, all the words w satisfying (ii). First, the letters at indices
$1=k_1<k_2<\cdots<k_l<k_{l+1}=p+1$
, all the words w satisfying (ii). First, the letters at indices
 $k_1$
,…,
$k_1$
,…,
 $k_{l}$
are fixed, and for all
$k_{l}$
are fixed, and for all
 $i \in [\![ 1, l ]\!]$
we have i possibilities for each letter between indices
$i \in [\![ 1, l ]\!]$
we have i possibilities for each letter between indices
 $k_i+1$
and
$k_i+1$
and
 $k_{i+1}-1$
, and
$k_{i+1}-1$
, and
 $\beta(z_1\cdots z_i)$
possibilities for each letter between indices
$\beta(z_1\cdots z_i)$
possibilities for each letter between indices
 $k_{i}-p$
and
$k_{i}-p$
and
 $k_{i+1}-1-p$
. Therefore, the number of strongly synchronizing words having trace z is given by
$k_{i+1}-1-p$
. Therefore, the number of strongly synchronizing words having trace z is given by
 \begin{equation}N_z\;:\!=\;\sum\limits_{\lbrace 1=k_1<k_2<\cdots <k_{l}< k_{l+1}= p+1 \rbrace} \prod_{i=1}^{l} i^{k_{i+1}-k_{i}-1}\beta(z_1 z_2\cdots z_i)^{k_{i+1}-k_{i}}.\end{equation}
\begin{equation}N_z\;:\!=\;\sum\limits_{\lbrace 1=k_1<k_2<\cdots <k_{l}< k_{l+1}= p+1 \rbrace} \prod_{i=1}^{l} i^{k_{i+1}-k_{i}-1}\beta(z_1 z_2\cdots z_i)^{k_{i+1}-k_{i}}.\end{equation}
Lastly, to get N(G, p) we must sum the above quantity over all possible traces of strongly synchronizing words. To characterize this set, observe that any trace z necessarily has distinct letters, forming a permutation of a set
 $U_z\subset \mathbb{V}$
. If
$U_z\subset \mathbb{V}$
. If
 $E(U_z) \ne \mathbb{V}$
, then there exists a letter
$E(U_z) \ne \mathbb{V}$
, then there exists a letter
 $i \in \mathbb{V}\setminus E(U_z)$
, and z clearly is the trace of any word w whose prefix of size p is
$i \in \mathbb{V}\setminus E(U_z)$
, and z clearly is the trace of any word w whose prefix of size p is
 $ii\,\cdots \,i$
, and whose suffix of size p is a permutation of the elements of U. Now, if
$ii\,\cdots \,i$
, and whose suffix of size p is a permutation of the elements of U. Now, if
 $E(U_z) =\mathbb{V}$
, for any strongly synchronizing word w having trace z we must have that
$E(U_z) =\mathbb{V}$
, for any strongly synchronizing word w having trace z we must have that
 $w_p \not\in E(U_z)$
, leading to an immediate contradiction. Thus, for z to be a trace, it is necessary and sufficient that
$w_p \not\in E(U_z)$
, leading to an immediate contradiction. Thus, for z to be a trace, it is necessary and sufficient that
 $E(U_z) \ne \mathbb{V}$
, which concludes the proof.
$E(U_z) \ne \mathbb{V}$
, which concludes the proof.
4.3.5. Example
To illustrate the efficiency of Algorithm 3 in the case of deterministic patience times, we consider the simple non-trivial example of the so-called paw graph G of Figure 1.

Figure 1. The paw graph.
As the above results demonstrate, for any p, to compute the number N(G, p) of strongly synchronizing words, we first need to determine the set of all possible traces
 $\mathscr T(G)$
of G. In the present case we readily obtain that
$\mathscr T(G)$
of G. In the present case we readily obtain that
 \[\mathscr T(G)=\{1,2,3,4,13,14,31,34,41,43,134,143,314,341,413,431\}.\]
\[\mathscr T(G)=\{1,2,3,4,13,14,31,34,41,43,134,143,314,341,413,431\}.\]
Indeed, any trace containing a 2 can only contain 2, since adding another class will result in having compatible classes, which cannot be the case for a trace. Conversely, any other word containing only 1 or 3 or 4 is possible as a trace, since not having 2 in the word means that the letters of the word are still compatible with the class 1. It is then immediate to compute
 $\beta(z)$
for all
$\beta(z)$
for all
 $z\in\mathscr T(G)$
using (13). We obtain
$z\in\mathscr T(G)$
using (13). We obtain
 \begin{equation}\begin{cases}N_{1}=3^p,\,N_2=1,\,N_3=2^p,\,N_4=2^p,N_{13} =\frac{3}{2} 4^p - 2.3^p,\,N_{14}=\frac{3}{2} 4^p - 2.3^p,\\[5pt] N_{31}=\frac{1}{2}4^p - 2^p,\,N_{34}=(p-1) 2^{p-1},\,N_{41}=\frac{1}{2}4^{p} - 2^p,\,N_{43}= (p-1) 2^{p-1},\\[5pt] N_{134}= 3.2^{2p-1} - (2p+4)3^{p-1},\,N_{143} = 3.2^{2p-1} - (2p+4)3^{p-1},\\[5pt] N_{314}= 2^{2p-1} - 4.3^{p-1}+2^{p},\,N_{341}= 2.3^{p-1} -(p+1) 2^{p-1},\\[5pt] N_{413}= 2^{2p-1} - 4.3^{p-1}+2^{p},\,N_{431} = 2.3^{p-1} -(p+1) 2^{p-1}.\end{cases}\end{equation}
\begin{equation}\begin{cases}N_{1}=3^p,\,N_2=1,\,N_3=2^p,\,N_4=2^p,N_{13} =\frac{3}{2} 4^p - 2.3^p,\,N_{14}=\frac{3}{2} 4^p - 2.3^p,\\[5pt] N_{31}=\frac{1}{2}4^p - 2^p,\,N_{34}=(p-1) 2^{p-1},\,N_{41}=\frac{1}{2}4^{p} - 2^p,\,N_{43}= (p-1) 2^{p-1},\\[5pt] N_{134}= 3.2^{2p-1} - (2p+4)3^{p-1},\,N_{143} = 3.2^{2p-1} - (2p+4)3^{p-1},\\[5pt] N_{314}= 2^{2p-1} - 4.3^{p-1}+2^{p},\,N_{341}= 2.3^{p-1} -(p+1) 2^{p-1},\\[5pt] N_{413}= 2^{2p-1} - 4.3^{p-1}+2^{p},\,N_{431} = 2.3^{p-1} -(p+1) 2^{p-1}.\end{cases}\end{equation}
For clarity, let us detail one of the above computations, for
 $z = 13$
. We then have
$z = 13$
. We then have
 $\beta(1) = \vert \lbrace 1,3,4 \rbrace \vert = 3$
and
$\beta(1) = \vert \lbrace 1,3,4 \rbrace \vert = 3$
and
 $\beta(13) = \vert \lbrace 1,3 \rbrace\vert = 2$
. Therefore, using (13) we have
$\beta(13) = \vert \lbrace 1,3 \rbrace\vert = 2$
. Therefore, using (13) we have
 \begin{align*}N_{13} &= \sum_{k_2=2}^{p} 1^{k_2-1-1}\beta(1)^{k_2-1} 2^{p+1-k_2-1}\beta(13) ^{p+1-k_2}\\[5pt] &= \sum_{k_2=2}^{p} 3^{k_2-1} 2^{p-k_2} 2^{p+1-k_2}\\[5pt] &= \frac{2\times 4^p}{3} \sum_{k_2=2}^{p} \left(\frac{3}{4}\right)^{k_2}= \frac{3}{2} 4^p - 2.3^p.\end{align*}
\begin{align*}N_{13} &= \sum_{k_2=2}^{p} 1^{k_2-1-1}\beta(1)^{k_2-1} 2^{p+1-k_2-1}\beta(13) ^{p+1-k_2}\\[5pt] &= \sum_{k_2=2}^{p} 3^{k_2-1} 2^{p-k_2} 2^{p+1-k_2}\\[5pt] &= \frac{2\times 4^p}{3} \sum_{k_2=2}^{p} \left(\frac{3}{4}\right)^{k_2}= \frac{3}{2} 4^p - 2.3^p.\end{align*}
Summing all elements of (14) and rearranging, we obtain that
 \begin{equation*}N(G,p) = 1 +2^{2p+3} - 3^{p+1} -4(p+3)3^{p-1}.\end{equation*}
\begin{equation*}N(G,p) = 1 +2^{2p+3} - 3^{p+1} -4(p+3)3^{p-1}.\end{equation*}
Then, applying Corollary 2 and Jensen’s inequality, for the average number of iterations needed by Algorithm 1 to detect coalescence, we obtain the bound

and the average starting time T to detect coalescence is bounded by
 $-p2^{B_I}$
. In Table 1, we specify the number of strongly synchronizing words, together with the corresponding bounds for
$-p2^{B_I}$
. In Table 1, we specify the number of strongly synchronizing words, together with the corresponding bounds for
 ${\mathbb E}\left[I\right]$
and
${\mathbb E}\left[I\right]$
and
 ${\mathbb E}\left[-T\right]$
, for various values of p.
${\mathbb E}\left[-T\right]$
, for various values of p.
Table 1. Efficiency of Algorithm 1.

4.3.6. Complexity comparison
Having provided a bound for the average coalescence time for Algorithm 3, we now compare the number of operations necessary to complete Algorithm 3 to the number of operations necessary to complete the primitive CFTP algorithm, which consists of running chains started from all possible states in parallel. To compare these two algorithms, we need to specify what we mean by operations: we say that an algorithm does one operation if it compares two letters of
 $\mathbb{V}$
to determine whether they are equal or not, or whether the two letters are connected in G. It is intuitively clear that each of the two algorithms can basically be decomposed into a sequence of such operations:
$\mathbb{V}$
to determine whether they are equal or not, or whether the two letters are connected in G. It is intuitively clear that each of the two algorithms can basically be decomposed into a sequence of such operations:
-
In the CFTP algorithm, the matching of the incoming individuals amounts to an investigation of the set of stored compatible items in a determinate order, and thus to a sequence of such operations. Second, so does the test of equality of the current states of all Markov chains, at any given time.
-
In Algorithm 3, testing the ‘strongly synchronizing’ property at all times is again a sequence of operations, and so is the construction of the dynamics of the recursion, from the coalescence time onward.
To estimate the number of operations in the two algorithms, for two values of p (3 and 6), we first drew realizations of Erdös–Rényi graphs G of parameters
 $(n,\alpha)$
, which are conditioned to be connected, for various values of the size n and of the connectivity parameter
$(n,\alpha)$
, which are conditioned to be connected, for various values of the size n and of the connectivity parameter
 $\alpha$
. We then tracked the average number of operations for 10 realizations of both algorithms, on the same graph each time.
$\alpha$
. We then tracked the average number of operations for 10 realizations of both algorithms, on the same graph each time.
The results, presented in Tables 2–5, tend to indicate that Algorithm 3 is much more efficient than primitive CFTP, and that the performance gap is particular important for sparse graphs. This last fact is an intuitively clear consequence of the fact that the proportion of strongly synchronizing words is decreasing in the number of edges. For
 $\alpha \geq \frac{3}{4}$
, however, we observe cases where Algorithm 3 does not terminate in a reasonable amount of time.
$\alpha \geq \frac{3}{4}$
, however, we observe cases where Algorithm 3 does not terminate in a reasonable amount of time.
Table 2. Average number of operations of the algorithms for 10 repetitions with
 $p=3$
and multiple values of
$p=3$
and multiple values of
 $(n,\alpha)$
.
$(n,\alpha)$
.

Table 3. Average CPU time of the algorithms on a standard computer for 10 repetitions with
 $p=3$
and multiple values of
$p=3$
and multiple values of
 $(n,\alpha)$
.
$(n,\alpha)$
.

Table 4. Average number of operations of the algorithms for 10 repetitions with
 $p=6$
and multiple values of
$p=6$
and multiple values of
 $(n,\alpha)$
.
$(n,\alpha)$
.

Table 5. Average CPU time of the algorithms on a standard computer for 10 repetitions with
 $p=6$
and multiple values of
$p=6$
and multiple values of
 $(n,\alpha)$
.
$(n,\alpha)$
.

4.4. Deterministic matching model with latency
It is well known that the primitive CFTP algorithm is in general not a good benchmark in terms of complexity, as it requires the coalescence of a large number of versions of the Markov chain considered—which makes its use impractical for a large state space. On the other hand, as previously mentioned, non-trivial deterministic matching models do not satisfy Condition (9). This means that the SRS defined by the recursion (2) cannot hit 0, and so we cannot use Algorithm 2 for deterministic matching models.
In this section we introduce the following variant of the model of Section 4.3: we suppose that latency is allowed; that is, at each instant we suppose that, with a positive probability
 $\gamma$
, no item enters the system. In other words, the generic inter-arrival time
$\gamma$
, no item enters the system. In other words, the generic inter-arrival time
 $\xi$
follows a geometric law of parameter
$\xi$
follows a geometric law of parameter
 $1-\gamma$
. The sequences
$1-\gamma$
. The sequences
 $\left(\widehat V_n\right)_{n\in\mathbb{Z}}$
and
$\left(\widehat V_n\right)_{n\in\mathbb{Z}}$
and
 $\left(\widehat P_n\right)_{n\in\mathbb{Z}}$
are then defined as follows:
$\left(\widehat P_n\right)_{n\in\mathbb{Z}}$
are then defined as follows:
-
If a n item enters the system at time n, then
$\widehat V_n$
is the class of the item entering the system, and
$\widehat P_n = p+\varepsilon$
is the patience of the item entering the system. -
Otherwise, we set
$\widehat V_n = -1$
and
$\widehat P_n = 0$
.




We denote such a deterministic model with latency by
 $(G,\Phi,\mu,p,\gamma).$
Similarly as in Section 4.3, we then easily obtain a simplified representation of the system state.
$(G,\Phi,\mu,p,\gamma).$
Similarly as in Section 4.3, we then easily obtain a simplified representation of the system state.
Definition 12. For all
 $n\in\mathbb{Z}$
, the word-profile of the system just before time n is defined by the word
$n\in\mathbb{Z}$
, the word-profile of the system just before time n is defined by the word
 \begin{align*} \widehat X_n = w_1\cdots w_p \in (\mathbb{V}\cup\{0\}\cup\{-1\})^p,\end{align*}
\begin{align*} \widehat X_n = w_1\cdots w_p \in (\mathbb{V}\cup\{0\}\cup\{-1\})^p,\end{align*}
where for all
 $i \in [\![ 1,p ]\!]$
,
$i \in [\![ 1,p ]\!]$
,

We can therefore view the latency at a certain time n as the arrival of an item labeled
 $-1$
that cannot be matched with any other item. We then denote by
$-1$
that cannot be matched with any other item. We then denote by
 \[\widehat{\mathbb{X}} = (\mathbb{V}\cup\{0\}\cup\{-1\})^p \]
\[\widehat{\mathbb{X}} = (\mathbb{V}\cup\{0\}\cup\{-1\})^p \]
the (finite) state space space of
 $\widehat{X}$
. In contrast to the model of Section 4.3 (which can be seen as a particular of the present one for
$\widehat{X}$
. In contrast to the model of Section 4.3 (which can be seen as a particular of the present one for
 $\gamma=0$
), (9) is satisfied here, since the geometric random variable
$\gamma=0$
), (9) is satisfied here, since the geometric random variable
 $\xi$
can be arbitrarily large. Therefore, Algorithm 2 can be used to design a perfect sampling algorithm in this case. Let
$\xi$
can be arbitrarily large. Therefore, Algorithm 2 can be used to design a perfect sampling algorithm in this case. Let
 $ \widehat{Y}\;:\!=\;\left(\widehat{Y}_n\right)_{n\in\mathbb{Z}}$
be the SRS defined by the recursive equation
$ \widehat{Y}\;:\!=\;\left(\widehat{Y}_n\right)_{n\in\mathbb{Z}}$
be the SRS defined by the recursive equation
 \begin{equation}\widehat{Y}_{n+1}=\left[\max(\widehat{Y}_n,\widehat{P}_n)-1\right]^+= g\left(\widehat{Y}_n,\widehat{P}_n\right),\quad n \in \mathbb{Z}.\end{equation}
\begin{equation}\widehat{Y}_{n+1}=\left[\max(\widehat{Y}_n,\widehat{P}_n)-1\right]^+= g\left(\widehat{Y}_n,\widehat{P}_n\right),\quad n \in \mathbb{Z}.\end{equation}
Proposition 7. For any
 $n \in \mathbb{Z}$
, the following statements are equivalent:
$n \in \mathbb{Z}$
, the following statements are equivalent:
-
(i)
$\widehat{Y}_n = 0$
. -
(ii) For all
$k\in [\![ 1, p]\!],\widehat{V}_{n-k} = -1$
(and equivalently
$\widehat{P}_{n-k} = 0$
).



Proof. Fix
 $n\in\mathbb{Z}$
. Regarding the implication (ii)
$n\in\mathbb{Z}$
. Regarding the implication (ii)
 $\Rightarrow$
(i), by the construction of
$\Rightarrow$
(i), by the construction of
 $\widehat{P}$
and
$\widehat{P}$
and
 $\widehat{Y}$
we have that
$\widehat{Y}$
we have that
 \begin{equation*}\widehat{Y}_{n-p} \leq p+\varepsilon-1.\end{equation*}
\begin{equation*}\widehat{Y}_{n-p} \leq p+\varepsilon-1.\end{equation*}
Moreover, for all
 $k \in [\![ 1 , p]\!]$
,
$k \in [\![ 1 , p]\!]$
,
 \begin{equation*}\widehat{Y}_{n-k+1} = \left[\max(\widehat{Y}_{n-k},{\widehat{P}_{n-k}})-1\right]^+ = \left[\max(\widehat{Y}_{n-k},0)-1\right]^+ = \left[\widehat{Y}_{n-k}-1\right]^+,\end{equation*}
\begin{equation*}\widehat{Y}_{n-k+1} = \left[\max(\widehat{Y}_{n-k},{\widehat{P}_{n-k}})-1\right]^+ = \left[\max(\widehat{Y}_{n-k},0)-1\right]^+ = \left[\widehat{Y}_{n-k}-1\right]^+,\end{equation*}
so by induction we obtain that
 \begin{equation*}\widehat{Y}_n \leq \max(\widehat{Y}_{n-p}-p,0) \leq \max(p{+\varepsilon}-1-p,0) = 0.\end{equation*}
\begin{equation*}\widehat{Y}_n \leq \max(\widehat{Y}_{n-p}-p,0) \leq \max(p{+\varepsilon}-1-p,0) = 0.\end{equation*}
We now turn to the converse implication (i)
 $\Rightarrow$
(ii). Suppose to the contrary that for some
$\Rightarrow$
(ii). Suppose to the contrary that for some
 $k \in [\![ 1 , p ]\!]$
we have
$k \in [\![ 1 , p ]\!]$
we have
 $\widehat{P}_{n-k} \neq 0$
, which, by the very definition of
$\widehat{P}_{n-k} \neq 0$
, which, by the very definition of
 $\widehat{P}$
, means that
$\widehat{P}$
, means that
 $\widehat{P}_{n-k} = p+\varepsilon$
. Then, as
$\widehat{P}_{n-k} = p+\varepsilon$
. Then, as
 $\widehat{Y}_{n-k} \leq p+\varepsilon-1$
, we have that
$\widehat{Y}_{n-k} \leq p+\varepsilon-1$
, we have that
 \begin{equation*}\widehat{Y}_{n-k+1} = \left[\max(\widehat{Y}_{n-k},\widehat{P}_{n-k})-1\right]^+ = \widehat{P}_{n-k} -1 =p+\varepsilon - 1.\end{equation*}
\begin{equation*}\widehat{Y}_{n-k+1} = \left[\max(\widehat{Y}_{n-k},\widehat{P}_{n-k})-1\right]^+ = \widehat{P}_{n-k} -1 =p+\varepsilon - 1.\end{equation*}
But for all
 $l \in [\![ 1,k-1 ]\!] $
we have that
$l \in [\![ 1,k-1 ]\!] $
we have that
 $\widehat{Y}_{n-l+1} \geq \widehat{Y}_{n-l}-1$
, so that by an immediate induction,
$\widehat{Y}_{n-l+1} \geq \widehat{Y}_{n-l}-1$
, so that by an immediate induction,
 \begin{equation*}\widehat{Y}_n\geq p+\varepsilon -1 -(k-1) \geq \varepsilon >0.\end{equation*}
\begin{equation*}\widehat{Y}_n\geq p+\varepsilon -1 -(k-1) \geq \varepsilon >0.\end{equation*}
As a consequence of Proposition 7, determining when
 $\widehat{Y} = 0$
in Algorithm 2 amounts to checking that the last p arrivals are all
$\widehat{Y} = 0$
in Algorithm 2 amounts to checking that the last p arrivals are all
 $-1$
’s, meaning that no item has entered the system in the last p instants. In fact, as (ii) above has a positive probability, we immediately see that in the present context, Algorithm 2 terminates almost surely.
$-1$
’s, meaning that no item has entered the system in the last p instants. In fact, as (ii) above has a positive probability, we immediately see that in the present context, Algorithm 2 terminates almost surely.
For any
 $x = x_1 \,\cdots\, x_p \in \widehat{\mathbb{X}}$
, denote by
$x = x_1 \,\cdots\, x_p \in \widehat{\mathbb{X}}$
, denote by
 $\overset{\circ}{x}$
the word
$\overset{\circ}{x}$
the word
 $\overset{\circ}{x}_1\,\cdots\, \overset{\circ}{x}_p$
, where for all
$\overset{\circ}{x}_1\,\cdots\, \overset{\circ}{x}_p$
, where for all
 $i \in [\![ 1 , p ]\!],$
$i \in [\![ 1 , p ]\!],$
 $\overset{\circ}{x}_i=x_i\mathbf 1_{x_i \ne -1}$
. The notions of synchronizing and strongly synchronizing words are then extended as follows.
$\overset{\circ}{x}_i=x_i\mathbf 1_{x_i \ne -1}$
. The notions of synchronizing and strongly synchronizing words are then extended as follows.
Definition 13. A word
 $w\in (\mathbb{V}\cup {-1})^*$
is said to be synchronizing for the deterministic matching model with latency
$w\in (\mathbb{V}\cup {-1})^*$
is said to be synchronizing for the deterministic matching model with latency
 $(G,\Phi,\mu,p,\gamma)$
if
$(G,\Phi,\mu,p,\gamma)$
if
 \begin{equation}\exists z \in \widehat{\mathbb{X}},\, \forall x \in \widehat{\mathbb{X}},\,W^\Phi(x,w) = w_x \mbox{ is such that } \overset{\circ}{w_x} = z.\end{equation}
\begin{equation}\exists z \in \widehat{\mathbb{X}},\, \forall x \in \widehat{\mathbb{X}},\,W^\Phi(x,w) = w_x \mbox{ is such that } \overset{\circ}{w_x} = z.\end{equation}
We say that a word
 $w=w_1\cdots w_{2p}\in (\mathbb{V}\cup {-1})^*$
is strongly synchronizing if
$w=w_1\cdots w_{2p}\in (\mathbb{V}\cup {-1})^*$
is strongly synchronizing if
 \[\forall i \in [\![ 1,p ]\!],\,\forall j \in [\![ p+1, p+i ]\!],\, w_i -\!\!\!\!/\;\; w_j,\]
\[\forall i \in [\![ 1,p ]\!],\,\forall j \in [\![ p+1, p+i ]\!],\, w_i -\!\!\!\!/\;\; w_j,\]
where, by convention, for all
 $v \in \mathbb {V}$
,
$v \in \mathbb {V}$
,
 $v -\!\!\!\!/\;\; -1$
.
$v -\!\!\!\!/\;\; -1$
.
We can then apply the exact same arguments as for Theorems 3 and 4 to show the following.
Proposition 8. Any strongly synchronizing word
 $w \in (\mathbb {V} \cup -1)^*$
is also a synchronizing word for the deterministic matching model with latency
$w \in (\mathbb {V} \cup -1)^*$
is also a synchronizing word for the deterministic matching model with latency
 $(G,\Phi,\mu,p,\gamma)$
. Conversely, if the matching policy
$(G,\Phi,\mu,p,\gamma)$
. Conversely, if the matching policy
 $\Phi$
is fcfm, then any synchronizing word of length 2p is strongly synchronizing.
$\Phi$
is fcfm, then any synchronizing word of length 2p is strongly synchronizing.
The previous result implies that Algorithm 3 (by taking strongly synchronizing words in this new sense) terminates almost surely, and also produces a sample of the stationary distribution of the model with latency.
In conclusion, for a model with latency, both Algorithm 2 and Algorithm 3 are valid perfect sampling algorithms that terminate almost surely, and we can now compare their performance. For this, first notice that Algorithm 3 is obviously faster than Algorithm 2, since the arrival of p consecutive
 $-1$
’s also creates a strongly synchronizing word, as any word of length 2p in which the first or last p letters are all
$-1$
’s also creates a strongly synchronizing word, as any word of length 2p in which the first or last p letters are all
 $-1$
is strongly synchronizing. In Tables 6–9, we quantify the gain from applying Algorithm 3 rather than Algorithm 2 in terms of CPU time, for various parameters.
$-1$
is strongly synchronizing. In Tables 6–9, we quantify the gain from applying Algorithm 3 rather than Algorithm 2 in terms of CPU time, for various parameters.
Table 6. Average CPU time of the algorithms on a standard computer for 100 repetitions with
 $p=3$
,
$p=3$
,
 $\gamma = 0.2$
, and multiple values of
$\gamma = 0.2$
, and multiple values of
 $(n,\alpha)$
.
$(n,\alpha)$
.

Table 7. Average CPU time of the algorithms on a standard computer for
 $10^4$
repetitions with
$10^4$
repetitions with
 $p=3$
,
$p=3$
,
 $\gamma =0.5$
, and multiple values of
$\gamma =0.5$
, and multiple values of
 $(n,\alpha)$
.
$(n,\alpha)$
.

Table 8. Average CPU time of the algorithms for 100 repetitions with
 $p=6$
,
$p=6$
,
 $\gamma = 0.2$
, and multiple values of
$\gamma = 0.2$
, and multiple values of
 $(n,\alpha)$
.
$(n,\alpha)$
.

Table 9. Average CPU time of the algorithms on a standard computer for
 $10^4$
repetitions with
$10^4$
repetitions with
 $p=6$
,
$p=6$
,
 $\gamma = 0.5$
, and multiple values of
$\gamma = 0.5$
, and multiple values of
 $(n,\alpha)$
.
$(n,\alpha)$
.

4.5. Estimating of the loss probability for ml and fcfm
Algorithm 3 returns a random variable that is distributed from the stationary distribution of the system. This result can be of critical use in comparing the performance of systems for which no exact characterization of the steady state is known. As an example, we are able to assess the asymptotic loss rate of items of every class. We use this to compare two matching policies in steady state: match-the-longest (ML) and first-come-first-matched (FCFM).
Let
 $(G = (\mathbb{V},E),\Phi,\mu,p)$
be a discrete matching model with deterministic impati ence, and let
$(G = (\mathbb{V},E),\Phi,\mu,p)$
be a discrete matching model with deterministic impati ence, and let
 $\tilde X= \left(\tilde X_n\right)_{n\in\mathbb{Z}}$
be the Markov chain of the system. Let
$\tilde X= \left(\tilde X_n\right)_{n\in\mathbb{Z}}$
be the Markov chain of the system. Let
 $\pi$
be the stationary distribution for X, and for all
$\pi$
be the stationary distribution for X, and for all
 $(i,j) \in \mathbb{V}^2$
such that
$(i,j) \in \mathbb{V}^2$
such that
 $(i,j)\not\in E$
, let
$(i,j)\not\in E$
, let
 \begin{align*}A_{i,j} = \lbrace x=x_1\cdots x_j \in \mathbb{X}, \,x_1 = i \text{ and the arrival is of class } j\mbox{ in a buffer }x\rbrace.\end{align*}
\begin{align*}A_{i,j} = \lbrace x=x_1\cdots x_j \in \mathbb{X}, \,x_1 = i \text{ and the arrival is of class } j\mbox{ in a buffer }x\rbrace.\end{align*}
The asymptotic loss rate of items of class i is denoted by

where for all n,
 \begin{align*}A^i_n = \lbrace \text{an item of class } i \text{ is lost at time } n \rbrace.\end{align*}
\begin{align*}A^i_n = \lbrace \text{an item of class } i \text{ is lost at time } n \rbrace.\end{align*}
An immediate first-step analysis implies that
 \begin{equation}\rho(i) = \sum \limits_{j \in \mathbb{V}} \pi(A_{i,j}) \mu(j),\end{equation}
\begin{equation}\rho(i) = \sum \limits_{j \in \mathbb{V}} \pi(A_{i,j}) \mu(j),\end{equation}
so
 $\rho(i)$
can also be interpreted as the probability of losing an item of class i in the system at a given instant, in steady state. Reasoning similarly, we have that
$\rho(i)$
can also be interpreted as the probability of losing an item of class i in the system at a given instant, in steady state. Reasoning similarly, we have that
 \begin{align*}\rho = \sum\limits_{i \in \mathbb{V}} \rho(i)\end{align*}
\begin{align*}\rho = \sum\limits_{i \in \mathbb{V}} \rho(i)\end{align*}
is the asymptotic loss rate of items (of any class) in the system, and can also be seen as the probability of losing an item (of any class) at a given time, in steady state. Using Equation 18, we can then estimate these asymptotic loss rates by running our perfect simulation Algorithm 3, and then estimating
 $\pi(A_{i,j})$
for all
$\pi(A_{i,j})$
for all
 $i,j \in \mathbb{V}$
using a Monte Carlo estimate.
$i,j \in \mathbb{V}$
using a Monte Carlo estimate.
Table 10 presents the results over
 $10^4$
simulations, for G a random Erdös–Rényi graph of parameters
$10^4$
simulations, for G a random Erdös–Rényi graph of parameters
 $n = 5$
,
$n = 5$
,
 $\alpha = 0.6$
, conditioned on being connected, for
$\alpha = 0.6$
, conditioned on being connected, for
 $p = 5$
, and for
$p = 5$
, and for
 $\mu$
the uniform distribution. Both matching policies fcfm and ml are implemented on the same samples each time. We observe that the overall asymptotic loss rate is slightly, but consistently, lower under fcfm than under ml, although nominal loss rates of given nodes can be higher under fcfm.
$\mu$
the uniform distribution. Both matching policies fcfm and ml are implemented on the same samples each time. We observe that the overall asymptotic loss rate is slightly, but consistently, lower under fcfm than under ml, although nominal loss rates of given nodes can be higher under fcfm.
Table 10. Monte Carlo estimates for the asymptotic loss rates for
 $10^4$
repetitions of Algorithm 3 for a random Erdös–Rényi graph of parameters
$10^4$
repetitions of Algorithm 3 for a random Erdös–Rényi graph of parameters
 $n = 5$
,
$n = 5$
,
 $\alpha = 0.6 $
, for
$\alpha = 0.6 $
, for
 $p = 5$
and
$p = 5$
and
 $\mu$
the uniform distribution.
$\mu$
the uniform distribution.

Funding information
This research was funded by the research grant ANR-18-CE40-0019-01, ‘MATCHES’, and by a Région Grand Est PhD grant.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.









































