
861 results
5 - Data and Methods for Modeling Climate-Related Migration
-
- Book:
- Migration and Displacement in a Changing Climate
- Published online:
- 10 April 2025
- Print publication:
- 17 April 2025, pp 162-188
-
- Chapter
- Export citation
Leveraging initial conditions memory for modelling Rayleigh–Taylor turbulence
-
- Journal:
- Journal of Fluid Mechanics / Volume 1009 / 25 April 2025
- Published online by Cambridge University Press:
- 14 April 2025, A17
-
- Article
- Export citation
Predicting experiences of paranoia and auditory verbal hallucinations in daily life with ambulatory sensor data – A feasibility study
-
- Journal:
- Psychological Medicine / Volume 55 / 2025
- Published online by Cambridge University Press:
- 11 April 2025, e114
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Validity and accuracy of artificial intelligence-based dietary intake assessment methods: a systematic review
-
- Journal:
- British Journal of Nutrition , First View
- Published online by Cambridge University Press:
- 10 April 2025, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data publishing in mechanics and dynamics: challenges, guidelines, and examples from engineering design
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 08 April 2025, e23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
5 - Anti-discrimination
- from Part II - Legal Controls
-
- Book:
- Combatting the Code
- Published online:
- 26 March 2025
- Print publication:
- 03 April 2025, pp 74-95
-
- Chapter
- Export citation
Capitalizing on natural language processing (NLP) to automate the evaluation of coach implementation fidelity in guided digital cognitive-behavioral therapy (GdCBT)
-
- Journal:
- Psychological Medicine / Volume 55 / 2025
- Published online by Cambridge University Press:
- 02 April 2025, e106
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NLP verification: towards a general methodology for certifying robustness
-
- Journal:
- European Journal of Applied Mathematics , First View
- Published online by Cambridge University Press:
- 02 April 2025, pp. 1-58
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Machine-learning-based pressure reconstruction with moving boundaries
-
- Journal:
- Journal of Fluid Mechanics / Volume 1008 / 10 April 2025
- Published online by Cambridge University Press:
- 02 April 2025, A21
-
- Article
- Export citation
Using machine learning to identify features associated with different types of self-injurious behaviors in autistic youth
-
- Journal:
- Psychological Medicine / Volume 55 / 2025
- Published online by Cambridge University Press:
- 31 March 2025, e98
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How to beat a Bayesian adversary
- Part of
-
- Journal:
- European Journal of Applied Mathematics , First View
- Published online by Cambridge University Press:
- 28 March 2025, pp. 1-23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
News Cycles and Satisfaction With Democracy: How the Pandemic Short-Circuited Media Polarization
-
- Journal:
- British Journal of Political Science / Volume 55 / 2025
- Published online by Cambridge University Press:
- 26 March 2025, e49
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Validation of large language models (Llama 3 and ChatGPT-4o mini) for title and abstract screening in biomedical systematic reviews
-
- Journal:
- Research Synthesis Methods ,
- Published online by Cambridge University Press:
- 24 March 2025, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring the Impact of China’s Retaliatory Tariffs on US Soybean Exports with Machine Learning Techniques
-
- Journal:
- Journal of Agricultural and Applied Economics , FirstView
- Published online by Cambridge University Press:
- 24 March 2025, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Factors associated with carditis adverse events following SARS-COV-2-19 vaccination
-
- Journal:
- Epidemiology & Infection / Volume 153 / 2025
- Published online by Cambridge University Press:
- 19 March 2025, e51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using machine learning for communication classification
-
- Journal:
- Experimental Economics / Volume 22 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 14 March 2025, pp. 1002-1029
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Elastoinertial turbulence: data-driven reduced-order model based on manifold dynamics
-
- Journal:
- Journal of Fluid Mechanics / Volume 1007 / 25 March 2025
- Published online by Cambridge University Press:
- 13 March 2025, R1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Elastoinertial turbulence (EIT) is a chaotic state that emerges in the flows of dilute polymer solutions. Direct numerical simulation (DNS) of EIT is highly computationally expensive due to the need to resolve the multiscale nature of the system. While DNS of two-dimensional (2-D) EIT typically requires
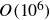 $O(10^6)$ degrees of freedom, we demonstrate here that a data-driven modelling framework allows for the construction of an accurate model with 50 degrees of freedom. We achieve a low-dimensional representation of the full state by first applying a viscoelastic variant of proper orthogonal decomposition to DNS results, and then using an autoencoder. The dynamics of this low-dimensional representation is learned using the neural ordinary differential equation (NODE) method, which approximates the vector field for the reduced dynamics as a neural network. The resulting low-dimensional data-driven model effectively captures short-time dynamics over the span of one correlation time, as well as long-time dynamics, particularly the self-similar, nested travelling wave structure of 2-D EIT in the parameter range considered.
$O(10^6)$ degrees of freedom, we demonstrate here that a data-driven modelling framework allows for the construction of an accurate model with 50 degrees of freedom. We achieve a low-dimensional representation of the full state by first applying a viscoelastic variant of proper orthogonal decomposition to DNS results, and then using an autoencoder. The dynamics of this low-dimensional representation is learned using the neural ordinary differential equation (NODE) method, which approximates the vector field for the reduced dynamics as a neural network. The resulting low-dimensional data-driven model effectively captures short-time dynamics over the span of one correlation time, as well as long-time dynamics, particularly the self-similar, nested travelling wave structure of 2-D EIT in the parameter range considered.
Decoding development: the AI frontier in policy crafting: A systematic review
-
- Journal:
- Data & Policy / Volume 7 / 2025
- Published online by Cambridge University Press:
- 11 March 2025, e31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Advances in methods for characterising dietary patterns: a scoping review
-
- Journal:
- British Journal of Nutrition , First View
- Published online by Cambridge University Press:
- 10 March 2025, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Can machine learning help accelerate article screening for systematic reviews? Yes, when article separability in embedding space is high
-
- Journal:
- Research Synthesis Methods / Volume 16 / Issue 1 / January 2025
- Published online by Cambridge University Press:
- 10 March 2025, pp. 194-210
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
