



It is hard to imagine cognitive psychology and neuroscience without computational models – they are invaluable tools to study, analyze, and understand the human mind. Traditionally, such computational models have been hand-designed by expert researchers. In a cognitive architecture, for instance, researchers provide a fixed set of structures and a definition of how these structures interact with each other (Anderson, Reference Anderson2013b). In a Bayesian model of cognition, researchers instead specify a prior and a likelihood function that – in combination with Bayes' rule – fully determine the model's behavior (Griffiths, Kemp, & Tenenbaum, Reference Griffiths, Kemp, Tenenbaum and Sun2008). To provide one concrete example, consider the Bayesian model of function learning proposed by Lucas, Griffiths, Williams, and Kalish (Reference Lucas, Griffiths, Williams and Kalish2015). The goal of this model is to capture human learning in a setting that requires mapping input features to a numerical target value. When constructing their model, the authors had to hand-design a prior over functions that people expect to encounter. In this particular case, it was assumed that people prioritize linear functions over quadratic and other nonlinear functions.
The framework of meta-learning (Bengio, Bengio, & Cloutier, Reference Bengio, Bengio and Cloutier1991; Schmidhuber, Reference Schmidhuber1987; Thrun & Pratt, Reference Thrun, Pratt, Thrun and Pratt1998) offers a radically different approach for constructing computational models by learning them through repeated interactions with an environment instead of requiring a priori specifications from a researcher. This process enables such models to acquire their inductive biases from experience, thereby departing from the traditional paradigm of hand-crafted models. For the function learning example mentioned above, this means that we do not need to specify which functions people expect to encounter in advance. Instead, during meta-learning a model would be exposed to many realistic function learning problems on which it then can figure out which functions are likely and which are not.
Recently, psychologists have started to apply meta-learning to the study of human learning (Griffiths et al., Reference Griffiths, Callaway, Chang, Grant, Krueger and Lieder2019). It has been shown that meta-learned models can capture a wide range of empirically observed phenomena that could not be explained otherwise. They, among others, reproduce human biases in probabilistic reasoning (Dasgupta, Schulz, Tenenbaum, & Gershman, Reference Dasgupta, Schulz, Tenenbaum and Gershman2020), discover heuristic decision-making strategies used by people (Binz, Gershman, Schulz, & Endres, Reference Binz, Gershman, Schulz and Endres2022), and generalize compositionally on complex language tasks in a human-like manner (Lake & Baroni, Reference Lake and Baroni2023). The goal of the present article is to develop a research program around meta-learned models of cognition and, in doing so, offer a synthesis of previous work and outline new research directions.
To establish such a research program, we will make use of a recent result from the machine learning community showing that meta-learning can be used to construct Bayes-optimal learning algorithms (Mikulik et al., Reference Mikulik, Delétang, McGrath, Genewein, Martic, Legg, Ortega, Larochelle, Ranzato, Hadsell, Balcan and Lin2020; Ortega et al., Reference Ortega, Wang, Rowland, Genewein, Kurth-Nelson, Pascanu and Legg2019; Rabinowitz, Reference Rabinowitz2019). This correspondence is interesting from a psychological perspective because it allows us to connect meta-learning to another already well-established framework: the rational analysis of cognition (Anderson, Reference Anderson2013a; Chater & Oaksford, Reference Chater and Oaksford1999). In a rational analysis, one first has to specify the goal of an agent along with a description of the environment the agent interacts with. The Bayes-optimal solution for the task at hand is then derived based on these assumptions and tested against empirical data. If needed, assumptions are modified and the whole process is repeated. This approach for constructing cognitive models has had a tremendous impact on psychology because it explains “why cognition works, by viewing it as an approximation to ideal statistical inference given the structure of natural tasks and environments” (Tenenbaum, 2021). The observation that meta-learned models can implement Bayesian inference implies that a meta-learned model can be used as a replacement for the corresponding Bayesian model in a rational analysis and thus suggests that any behavioral phenomenon that can be captured by a Bayesian model can also be captured by a meta-learned model.
We start our article by presenting a simplified version of an argument originally formulated by Ortega et al. (Reference Ortega, Wang, Rowland, Genewein, Kurth-Nelson, Pascanu and Legg2019) and thereby make their result accessible to a broader audience. Having established that meta-learning produces models that can simulate Bayesian inference, we go on to discuss what additional explanatory power the meta-learning framework offers. After all, why should one not just stick to the tried-and-tested Bayesian approach? We answer this question by providing four original arguments in favor of the meta-learning framework (see Fig. 1 for a visual synopsis):
• Meta-learning can produce approximately optimal learning algorithms even if exact Bayesian inference is computationally intractable.
• Meta-learning can produce approximately optimal learning algorithms even if it is not possible to phrase the corresponding inference problem in the first place.
• Meta-learning makes it easy to manipulate a learning algorithm's complexity and can therefore be used to construct resource-rational models of learning.
• Meta-learning allows us to integrate neuroscientific insights into the rational analysis of cognition by incorporating these insights into model architectures.

Figure 1. Visual synopsis of the four different arguments for meta-learning over Bayesian inference put forward in this article.
The first two points highlight situations in which meta-learned models can be used for rational analysis but traditional Bayesian models cannot. The latter two points provide examples of how meta-learning enables us to make rational models of cognition more realistic, either by incorporating limited computational resources or neuroscientific insights. Taken together, these arguments showcase that meta-learning considerably extends the scope of rational analysis and thereby of cognitive theories more generally.
We will discuss each of these four points in detail and provide illustrations to highlight their relevance. We then reexamine prior studies from psychology and neuroscience that have applied meta-learning and put them into the context of our newly acquired insights. For each of the reviewed studies, we highlight how it relates to the four presented arguments, and discuss why its findings could not have been obtained using a classical Bayesian model. Following that, we describe under which conditions traditional models are preferable to those obtained by meta-learning. We finish our article by speculating what the future holds for meta-learning. Therein, we focus on how meta-learning could be the key to building a domain-general model of human cognition.
1. Meta-learned rationality
The prefix meta- is generally used in a self-referential sense: A meta-rule is a rule about rules, a meta-discussion is a discussion about discussions, and so forth. Meta-learning, consequently, refers to learning about learning. We, therefore, need to first establish a common definition of learning before covering meta-learning in more detail. For the present article, we adopt the following definition from Mitchell (Reference Mitchell1997):
Definition: Learning
For a given task, training experience, and performance measure, an algorithm is said to learn if its performance at the task improves with experience.
To illustrate this definition, consider the following example which we will return to throughout the text: You are a biologist who has just discovered a new insect species and now set yourself the task of predicting how large members of this species are. You have already observed three exemplars in the wild with lengths of 16, 12, and 15 cm, respectively. These data amount to your training experience. Ideally, you can use this experience to make better predictions about the length of the next individual you encounter. You are said to have learned something if your performance is better after seeing the data than it was before. Typical performance measures for this example problem include the mean-squared error or the (negative) log-likelihood.
1.1 Bayesian inference for rational analyses
In a rational analysis of cognition, researchers are trying to compare human behavior to that of an optimal learning algorithm. However, it turns out that no learning algorithm is better than another when averaged over all possible problems (Wolpert, Reference Wolpert1996; Wolpert & Macready, Reference Wolpert and Macready1997), which means that we first have to make additional assumptions about the to-be-solved problem to obtain a well-defined notion of optimality. For our running example, one may make the following – somewhat unrealistic – assumptions:
(1) Each observed insect length x k is sampled from a normal distribution with mean μ and standard deviation σ.
(2) An insect species' mean length μ cannot be observed directly, but the standard deviation σ is known to be 2 cm.
(3) Mean lengths across all insect species are distributed according to a normal distribution with a mean of 10 cm and a standard deviation of 3 cm.
An optimal way of making predictions about new observations under such assumptions is specified by Bayesian inference. Bayesian inference requires access to a prior distribution p(μ) that defines an agent's initial beliefs about possible parameter values before observing any data and a likelihood p(x 1:t|μ) that captures the agent's knowledge about how data are generated for a given set of parameters. In our running example, the prior and the likelihood can be identified as follows:


where x 1:t = x 1, x 2, …, x t denote a sequence of observed insect lengths and the product in Equation (2) arises because of the additional assumption that observations are independent given the parameters.
The outcome of Bayesian inference is a posterior predictive distribution p(x t+1|x 1: t), which the agent can use to make probabilistic predictions about a hypothetical future observation. To obtain this posterior predictive distribution, the agent first combines prior and likelihood into a posterior distribution over parameters by applying Bayes' theorem:

In a subsequent step, the agent then averages over all possible parameter values weighted by their posterior probability to get the posterior predictive distribution:

Multiple arguments justify Bayesian inference as a normative procedure, and thereby its use for rational analyses (Corner & Hahn, Reference Corner and Hahn2013). This includes Dutch book arguments (Lewis, Reference Lewis and Lewis1999; Rescorla, Reference Rescorla2020), free-energy minimization (Friston, Reference Friston2010; Hinton & Van Camp, Reference Hinton and Van Camp1993), and performance-based justifications (Aitchison, Reference Aitchison1975; Rosenkrantz, Reference Rosenkrantz1992). For this article, we are mainly interested in the latter class of performance-based justifications because these can be used – as we will demonstrate later on – to derive meta-learning algorithms that learn approximations to Bayesian inference.
Performance-based justifications are based on the notion of frequentist statistics. They assert that no learning algorithm can be better than Bayesian inference on a certain performance measure. Particularly relevant for this article is a theorem first proved by Aitchison (Reference Aitchison1975). It states that the posterior predictive distribution is the distribution from the set of all possible distributions Q that maximizes the log-likelihood of hypothetical future observations when averaged over the data-generating distribution p (μ, x 1:t+1) = p(μ)p(x 1:t+1|μ):

Equation (5) implies that if an agent wants to make a prediction about the length of a still unobserved exemplar from a particular insect species and measures its performance using the log-likelihood, then – averaged across all possible species that can be encountered – there is no better way of doing it than using the posterior predictive distribution. We decided to include a short proof of this theorem within Box 1 for the curious reader as it does not appear in popular textbooks on probabilistic machine learning (Bishop, Reference Bishop2006; Murphy, Reference Murphy2012) nor in survey articles on Bayesian models of cognition. Note that, although the theorem itself is central to our later argument, working through its proof is not required to follow the remainder of this article.
Box 1 Proof: meta-learning maximizes log-likelihoods of future observations
We proof that the posterior predictive distribution p(x t+1|x 1:t) maximizes the log-likelihood of future observations averaged over the data-generating distribution:

The essence of this proof is to show that the posterior predictive distribution is superior to any other reference distribution r(x t+1|x 1:t) in terms of log-likelihood:

or equivalently that:

Proofing this conjecture is straight-forward (Aitchison, Reference Aitchison1975):

Note that although we used sums in our proof, thereby assuming that relevant quantities take discrete values, the same ideas can be readily applied to continuous-valued quantities by replacing sums with integrals.
1.2 Meta-learning
Having summarized the general concepts behind Bayes-optimal learning, we can now start to describe meta-learning in more detail. Formally speaking, a meta-learning algorithm is defined as any algorithm that “uses its experience to change certain aspects of a learning algorithm, or the learning method itself, such that the modified learner is better than the original learner at learning from additional experience” (Schaul & Schmidhuber, Reference Schaul and Schmidhuber2010).
To accomplish this, one first decides on an inner-loop (or base) learning algorithm and determines which of its aspects can be modified. We also refer to these modifiable aspects as meta-parameters (i.e., meta-parameters are simply parameters of a system that are adapted during meta-learning). In an outer-loop (or meta-learning) process, the system is then trained on a series of learning problems such that the inner-loop learning algorithm gets better at solving the problems that it encounters. We provide a high-level overview of this framework in Figure 2.
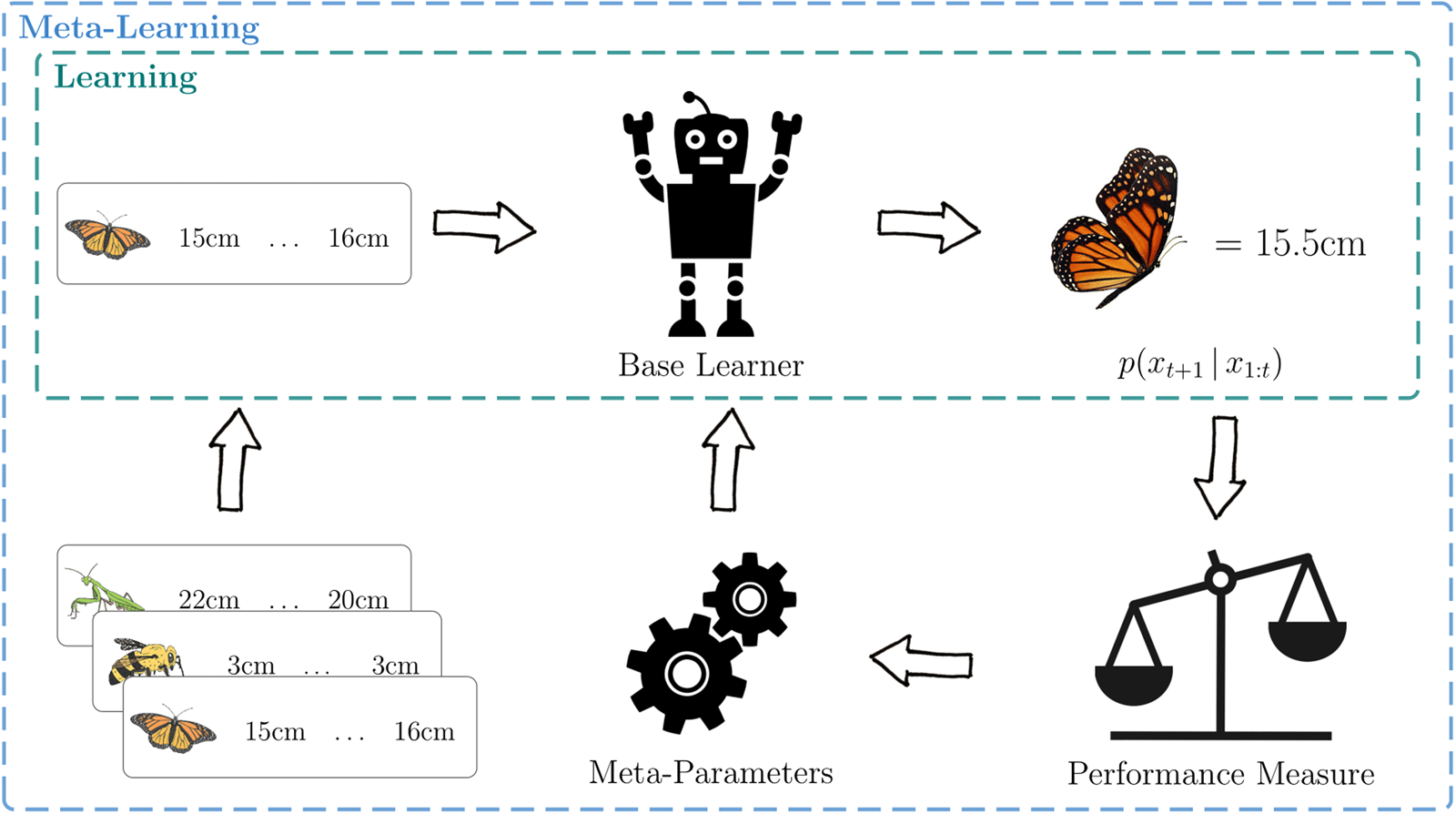
Figure 2. High-level overview of the meta-learning process. A base learner (green rectangle) receives data and performs some internal computations that improve its predictions on future data-points. A meta-learner (blue rectangle) encompasses a set of meta-parameters that can be adapted to create an improved learner. This is accomplished by training the learner on a distribution of related learning problems.
The previous definition is quite broad and includes a variety of methods. It is, for example, possible to meta-learn:
• Hyperparameters for a base learning algorithm, such as learning rates, batch sizes, or the number of training epochs (Doya, Reference Doya2002; Feurer & Hutter, Reference Feurer, Hutter, Hutter, Kotthoff and Vanschoren2019; Li, Zhou, Chen, & Li, Reference Li, Zhou, Chen and Li2017).
• Initial parameters of a neural network that is trained via stochastic gradient descent (Finn, Abbeel, & Levine, Reference Finn, Abbeel and Levine2017; Nichol, Achiam, & Schulman, Reference Nichol, Achiam and Schulman2018).
• Prior distributions in a probabilistic graphical model (Baxter, Reference Baxter, Thrun and Pratt1998; Grant, Finn, Levine, Darrell, & Griffiths, Reference Grant, Finn, Levine, Darrell and Griffiths2018).
• Entire learning algorithms (Hochreiter, Younger, & Conwell, Reference Hochreiter, Younger and Conwell2001; Santoro, Bartunov, Botvinick, Wierstra, & Lillicrap, Reference Santoro, Bartunov, Botvinick, Wierstra and Lillicrap2016).
Although all these methods have their own merits, we will be primarily concerned with the latter approach. Learning entire learning algorithms from scratch is arguably the most general and ambitious type of meta-learning, and it is the focus of this article because it is the only one among the aforementioned approaches leading to Bayes-optimal learning algorithms that can be used for rational analyses.
1.3 Meta-learned inference
It may seem like a daunting goal to learn an entire learning algorithm from scratch, but the core idea behind the approach we discuss in the following is surprisingly simple: Instead of using Bayesian inference to obtain the posterior predictive distribution, we teach a general-purpose function approximator to do this inference. Previous work has mostly focused on using recurrent neural networks as function approximators in this setting and thus we will – without loss of generality – focus our upcoming exposition on this class of models.
Like the posterior predictive distribution, the recurrent neural network processes a sequence of observed length from a particular insect species and produces a predictive distribution over the lengths of potential future observations from the same species. More concretely, the meta-learned predictive distribution takes a predetermined functional form whose parameters are given by the network outputs. If we had, for example, decided to use a normal distribution as the functional form of the meta-learned predictive distribution, outputs of the network would correspond to an expected length m t+1 and its standard deviation s t+1. Figure 3a illustrates this setup graphically.

Figure 3. Meta-learning illustration. (a) A recurrent neural network processes a sequence of observations and produces a predictive distribution at the final time-step. (b) Pseudocode for a simple meta-learning algorithm. (c) Loss during meta-learning with shaded contours corresponding to the standard deviation across 30 runs. (d) Posterior and meta-learned predictive distributions for an example sequence at beginning and end of meta-learning. The dotted gray line denotes the (unobserved) mean length.
Initially, the recurrent neural network implements a randomly initialized learning algorithm.Footnote 1 The goal of the meta-learning process is then to turn this system into an improved learning algorithm. The final result is a learning algorithm that is learned or trained rather than specified by a practitioner. To create a learning signal to do this training, we need a performance measure that can be used to optimize the network. Equation (5) suggests a straightforward strategy for designing such a measure by replacing the maximization over all possible distributions with a maximization over meta-parameters Θ (in our case, the weights of the recurrent neural network):

To turn this expression into a practical meta-learning algorithm, we will – as common practice when training deep neural networks – maximize a sample-based version using stochastic gradient ascent:

Figure 3b presents pseudocode for a simple gradient-based procedure that maximizes Equation (7). The entire meta-learning algorithm can be implemented in just around 30 lines of self-contained PyTorch code (Paszke et al., Reference Paszke, Gross, Massa, Lerer, Bradbury, Chanan, Chintala, Wallach, Larochelle, Beygelzimer, d'Alché-Buc, Fox and Garnett2019). We provide an annotated reference implementation on this article's accompanying Github repository.Footnote 2
1.4 How good is a meta-learned algorithm?
We have previously shown that the global optimum of Equation (7) is achieved by the posterior predictive distribution. Thus, by maximizing this performance measure, the network is actively encouraged to implement an approximation to exact Bayesian inference. Importantly, after meta-learning is completed, producing an approximation to the posterior predictive distribution does not require any further updates to the network weights. To perform an inference (i.e., the learn), we simply have to query the network's outputs after providing it with a particular sequence of observations. Learning at this stage is then realized by updating the hidden activations of the recurrent neural network as opposed to its weights. The characteristics of this new activation-based learning algorithm can be potentially vastly different from the weight-based learning algorithm used for meta-learning.
If we want to use the fully optimized network for rational analyses, we have to ask ourselves: How well does the resulting model approximate Bayesian inference? Two aspects have to be considered when answering this question. First, the network has to be sufficiently expressive to produce the exact posterior predictive distribution for all input sequences. Neural networks of sufficient width are universal function approximators (Hornik, Stinchcombe, & White, Reference Hornik, Stinchcombe and White1989), meaning that they can approximate any continuous function to arbitrary precision. Therefore, this aspect is not too problematic for the optimality argument. The second aspect is a bit more intricate: Assuming that the network is powerful enough to represent the global optimum of Equation (7), the employed optimization procedure also has to find it. Although we are not aware of any theorem that could provide such a guarantee, in practice, it has been observed that meta-learning procedures similar to the one discussed here often lead to networks that closely approximate Bayesian inference (Mikulik et al., Reference Mikulik, Delétang, McGrath, Genewein, Martic, Legg, Ortega, Larochelle, Ranzato, Hadsell, Balcan and Lin2020; Rabinowitz, Reference Rabinowitz2019). We provide a visualization demonstrating that the predictions of a meta-learned model closely resemble those of exact Bayesian inference for our insect length example in Figures 3c and 3d.
Although our exposition in this section focused on the supervised learning case, the same ideas can also be readily extended to the reinforcement learning setting (Duan et al., Reference Duan, Schulman, Chen, Bartlett, Sutskever and Abbeel2016; Wang et al., Reference Wang, Kurth-Nelson, Tirumala, Soyer, Leibo, Munos and Botvinick2016). Box 2 outlines the general ideas behind the meta-reinforcement learning framework.
Box 2 Meta-reinforcement learning
The main text has focused on tasks in which an agent receives direct feedback about which response would have been correct. In the real world, however, people do not always receive such explicit feedback. They, instead, often have to deal with partial information – taking the form of rewards, utilities, or costs – that merely informs them about the quality of their response.
Problems that fall into this category are often modeled as Markov decision processes (MDPs). In an MDP, an agent repeatedly interacts with an environment. In each time-step, it observes the state of the environment s t and can take an action a t that leads to a reward signal r t sampled from a reward distribution p(r t|s t, a t, μ r). Executing an action furthermore influences the environment state at the next time-step according to a transition distribution p(s t+1|s t, a t, μ s).
The goal of a Bayes-optimal reinforcement learning agent is to find a policy, which is a mapping from a history of observations h t = s 1, a 1, r 1, …, s t−1, a t−1, r t−1, s t to a probability distribution over actions $\pi ^{\rm \ast }( {a_t{\rm \vert }h_t} )$ , that maximizes the total amount of obtained rewards across a finite horizon H averaged over all problems that may be encountered:
, that maximizes the total amount of obtained rewards across a finite horizon H averaged over all problems that may be encountered:

MDPs with unknown reward and transition distributions are substantially more challenging to solve optimally compared to supervised problems as there is no teacher informing the agent about which actions are right or wrong. Instead, the agent has to figure out the most rewarding course of action solely through trial and error. Finding an analytical solution to Equation (9) is extremely challenging and indeed only possible for a few special cases (Duff, Reference Duff2003; Gittins, Reference Gittins1979), which made it historically near impossible to investigate such problems within the framework of rational analysis.
Even though finding an analytical expression of the Bayes-optimal policy is often impossible, it is straightforward to meta-learn an approximation to it (Duan et al., Reference Duan, Schulman, Chen, Bartlett, Sutskever and Abbeel2016; Wang et al., Reference Wang, Kurth-Nelson, Tirumala, Soyer, Leibo, Munos and Botvinick2016). The general concept is almost identical to the supervised learning case: Parameterize the to-be-learned policy with a recurrent neural network and replace the maximization over the set of all possible policies from Equation (9) with a sample-based approximation that maximizes over neural network parameters. The resulting problem can then be solved using any standard deep reinforcement learning algorithm.
Like in the supervised learning case, the resulting recurrent neural network implements a free-standing reinforcement learning algorithm after meta-learning is completed. Learning is once again implemented via a simple forward pass through the network, i.e., by conditioning the model on an additional data-point. The meta-learned reinforcement learning algorithm approximates the Bayes-optimal policy under the same conditions as in the supervised learning case: A sufficiently expressive model and an optimization procedure that is able to find the global optimum.
1.5 Tool or theory?
It is often not so trivial to separate meta-learning from normal learning. We believe that part of this confusion arises from an underspecification regarding what is being studied. In particular, the meta-learning framework provides opportunities to address two distinct research questions:
(1) It can be used to study how people improve their learning abilities over time.
(2) It can be used as a methodological tool to construct learning algorithms with the properties of interest (and thereafter compare the emerging learning algorithms to human behavior).
Historically, behavioral psychologists have been mainly interested in the former aspect (Doya, Reference Doya2002; Harlow, Reference Harlow1949). In the 1940s, for example, Harlow (Reference Harlow1949) already studied how learning in monkeys improves over time. He found that they adapted their learning strategies after sufficiently many interactions with tasks that shared a common structure, thereby showing a learning-to-learn effect. By now, examples of this phenomenon have been found in many different species – including humans – across nature (Wang, Reference Wang2021).
More recently, psychologists have started to view meta-learning as a methodological tool to construct approximations to Bayes-optimal learning algorithms (Binz et al., Reference Binz, Gershman, Schulz and Endres2022; Kumar, Dasgupta, Cohen, Daw, & Griffiths, Reference Kumar, Dasgupta, Cohen, Daw and Griffiths2020a), and subsequently use the resulting algorithms to study human cognition. The key difference from the former approach is that, in this setting, one abstracts away from the process of meta-learning and instead focuses on its outcome. From this perspective, only the fully converged model is of interest. Importantly, this approach allows us to investigate human learning from a rational perspective because we have demonstrated that meta-learning can be used to construct approximations to Bayes-optimal learning.
We place an emphasis on the second aspect in the present article and advocate for using fully converged meta-learned algorithms – as replacements for the corresponding Bayesian models – for rational analyses of cognition.Footnote 3 In the next section, we will outline several arguments that support this approach. However, it is important to mention that we believe that meta-learning can also be a valuable tool to understand the process of learning-to-learn itself. In this context, several intriguing questions arise: At what timescale does meta-learning take place in humans? How much of it is because of task-specific adaptations? How much of it is based on evolutionary or developmental processes? Although we agree that these are important questions, they are not the focus of this article.
2. Why not Bayesian inference?
We have just argued that it is possible to meta-learn Bayes-optimal learning algorithms. What are the implications of this result? If one has access to two different theories that make identical predictions, which of them should be preferred? Bayesian inference has already established itself as a valuable tool for building cognitive models in the recent decades. Thus, the burden of proof is arguably on the meta-learning framework. In this section, we provide four different arguments that highlight the advantages of meta-learning for building models of cognition. Many of these arguments are novel and have not been put forward explicitly in previous literature. The first two arguments highlight situations in which meta-learned models can be used for rational analysis but traditional Bayesian models cannot. The latter two provide examples of how meta-learning enables us to make rational models of cognition more realistic, either by incorporating limited computational resources or neuroscientific insights.
2.1 Intractable inference
Argument 1
Meta-learning can produce approximately optimal learning algorithms even if exact Bayesian inference is computationally intractable.
Bayesian inference becomes intractable very quickly because the complexity of computing the normalization constant that appears in the denominator grows exponentially with the number of unobserved parameters. In addition, it is only possible to find a closed-form expression of the posterior distribution for certain combinations of prior and likelihood. In our running example, we assumed that both prior and likelihood follow a normal distribution, which, in turn, leads to a normally distributed posterior. However, if one would instead assume that the prior over mean length follows an exponential distribution – which is arguably a more sensible assumption as it enforces lengths to be positive – it becomes already impossible to find an analytical expression for the posterior distribution.
Researchers across disciplines have recognized these challenges and have, in turn, developed approaches that can approximate Bayesian inference without running into computational difficulties. Prime examples of this are variational inference (Jordan, Ghahramani, Jaakkola, & Saul, Reference Jordan, Ghahramani, Jaakkola and Saul1999) and Markov chain Monte-Carlo (MCMC) methods (Geman & Geman, Reference Geman and Geman1984). In variational inference, one phrases inference as an optimization problem by positing a variational approximation whose parameters are fitted to minimize a divergence measure to the true posterior distribution. MCMC methods, on the other hand, draw samples from a Markov chain that has the posterior distribution as its equilibrium distribution. Previous research in cognitive science indicates that human learning shows characteristics of such approximations (Courville & Daw, Reference Courville, Daw, Platt, Koller, Singer and Roweis2008; Dasgupta, Schulz, & Gershman, Reference Dasgupta, Schulz and Gershman2017; Daw, Courville, & Dayan, Reference Daw, Courville, Dayan, Chater and Oaksford2008; Sanborn, Griffiths, & Navarro, Reference Sanborn, Griffiths and Navarro2010; Sanborn & Silva, Reference Sanborn and Silva2013).
Meta-learned inference also never requires an explicit calculation of the exact posterior or posterior predictive distribution. Instead, it performs approximately optimal inference via a single forward pass through the network. Inference, in this case, is approximate because we had to determine a functional form for the predictive distribution. The chosen form may deviate from the true form of the posterior predictive distribution, which, in turn, leads to approximation errors.Footnote 4 In some sense, this type of approximation is similar to variational inference: Both approaches involve optimization and require one to define a functional form of the respective distribution. However, the optimization process in both approaches uses a different loss function and happens at different timescales. Although variational inference employs the negative evidence lower bound as its loss function, meta-learning directly maximizes for models that can be expected to generalize well to unseen observations (using the performance-based measure from Equation (5)). Furthermore, meta-learned inference only involves optimization during the outer-loop meta-learning process but not during the actual learning itself. To update how a meta-learned model makes predictions in the light of new data, we only have to perform a simple forward pass through the network. In contrast to this, standard variational inference requires us to rerun the whole optimization process from scratch every time a new data-point is observed.Footnote 5
In summary, it is possible to meta-learn an approximately Bayes-optimal learning algorithm. If exact Bayesian inference is not tractable, such models are our best option for performing rational analyses. Yet, many other methods for approximate inference, such as variational inference and MCMC methods, also share this feature, and it will thus ultimately be an empirical question which of these approximations provides a better description of human learning.
2.2 Unspecified problems
Argument 2
Meta-learning can produce optimal learning algorithms even if it is not possible to phrase the corresponding inference problem in the first place.
Bayesian inference is hard, but posing the correct inference problem can be even harder. What exactly do we mean by that? To perform Bayesian inference, we need to specify a prior and a likelihood. Together, these two objects fully specify the assumed data-generating distribution, and thus the inference problem. Ideally, the specified data-generating distribution should match how the environment actually generates its data. It is fairly straightforward to fulfill this requirement in artificial scenarios, but for many real-world problems, it is not. Take for instance our running example: Does the prior over mean length really follow a normal distribution? If yes, what are the mean and variance of this distribution? Are the underlying parameters actually time-invariant or do they, for example, change based on seasons? None of these questions can be answered with certainty.
In his seminal work on Bayesian decision theory, Savage (Reference Savage1972) made the distinction between small- and large-world problems. A small-world problem is one “in which all relevant alternatives, their consequences, and probabilities are known” (Gigerenzer & Gaissmaier, Reference Gigerenzer and Gaissmaier2011). A large-world problem, on the other hand, is one in which the prior, the likelihood, or both cannot be identified. Savage's distinction between small and large worlds is relevant for the rational analysis of human cognition as its critics have pointed out that Bayesian inference only provides a justification for optimal reasoning in small-world problems (Binmore, Reference Binmore2007) and that “very few problems of interest to the cognitive, behavioral, and social sciences can be said to satisfy [this] condition” (Brighton & Gigerenzer, Reference Brighton, Gigerenzer, Okasha and Binmore2012).
Identifying the correct set of assumptions becomes especially challenging once we deal with more complex problems. To illustrate this, consider a study conducted by Lucas et al. (Reference Lucas, Griffiths, Williams and Kalish2015) who attempted to construct a Bayesian model of human function learning. Doing so required them to specify a prior over functions that people expect to encounter. Without direct access to such a distribution, they instead opted for a heuristic solution: 98.8% of functions are expected to be linear, 1.1% are expected to be quadratic, and 0.1% are expected to be nonlinear. Empirically, this choice led to good results, but it is hard to justify from a rational perspective. We simply do not know the frequency with which these functions appear in the real world, nor whether the given selection fully covers the set of functions expected by participants.
There are also inference problems in which it is not possible to specify or compute the likelihood function. These problems have been studied extensively in the machine learning community under the names of simulation-based or likelihood-free inference (Cranmer, Brehmer, & Louppe, Reference Cranmer, Brehmer and Louppe2020; Lueckmann, Boelts, Greenberg, Goncalves, & Macke, Reference Lueckmann, Boelts, Greenberg, Goncalves and Macke2021). In this setting, it is typically assumed that we can sample data from the likelihood for a given parameter setting but that computing the corresponding likelihood is impossible. Take, for instance, our insect length example. It should be clear that an insect's length does not only depend on its species' mean but also on many other factors such as climate, genetics, and the individual's age. Even if all these factors were known, mapping them to a likelihood function does seem close to impossible.Footnote 6 But, we can generate samples easily by observing insects in the wild. If we had access to large database of insect length measurements for different species, this could be directly used to meta-learn an approximately Bayes-optimal learning algorithm for predicting their length, while circumventing an explicit definition of a likelihood function.
In cases where we do not have access to a prior or a likelihood, we can neither apply exact Bayesian inference nor approximate inference schemes such as variational inference or MCMC methods. In contrast to this, meta-learned inference does not require us to define the prior or the likelihood explicitly. It only demands samples from the data-generating distribution to meta-learn an approximately Bayes-optimal learning algorithm – a much weaker requirement (Müller, Hollmann, Arango, Grabocka, & Hutter, Reference Müller, Hollmann, Arango, Grabocka and Hutter2021). The ability to construct Bayes-optimal learning algorithms for large-world problems is a unique feature of the meta-learning framework, and we believe that it could open up totally new avenues for constructing rational models of human cognition. To highlight one concrete example, it would be possible to take a collection of real-world decision-making tasks – such as the ones presented by Czerlinski et al. (Reference Czerlinski, Gigerenzer, Goldstein, Gigerenzer and Todd1999) – and use them to obtain a meta-learned agent that is adapted to the decision-making problems that people actually encounter in their everyday lives. This algorithm could then serve as a normative standard against which we can compare human decision making.
2.3 Resource rationality
Argument 3
Meta-learning makes it easy to manipulate a learning algorithm's complexity and can therefore be used to construct resource-rational models of learning.
Bayesian inference has been successfully applied to model human behavior across a number of domains, including perception (Knill & Richards, Reference Knill and Richards1996), motor control (Körding & Wolpert, Reference Körding and Wolpert2004), everyday judgments (Griffiths & Tenenbaum, Reference Griffiths and Tenenbaum2006), and logical reasoning (Oaksford et al., Reference Oaksford and Chater2007). Notwithstanding these success stories, there are also well-documented deviations from the notion of optimality prescribed by Bayesian inference. People, for example, underreact to prior information (Kahneman & Tversky, Reference Kahneman and Tversky1973), ignore evidence (Benjamin, Reference Benjamin, Bernheim, DellaVigna and Laibson2019), and rely on heuristic decision-making strategies (Gigerenzer & Gaissmaier, Reference Gigerenzer and Gaissmaier2011).
The intractability of Bayesian inference – together with empirically observed deviations from it – has led researchers to conjecture that people only attempt to approximate Bayesian inference. Many different notions of what constitutes a computational resource have been suggested, such as memory (Dasgupta & Gershman, Reference Dasgupta and Gershman2021), thinking time (Ratcliff & McKoon, Reference Ratcliff and McKoon2008), or physical effort (Hoppe & Rothkopf, Reference Hoppe and Rothkopf2016).
Cover (Reference Cover1999) relies on a dichotomy that will be useful for our following discussion. He refers to the algorithmic complexity of an algorithm as the number of bits needed to implement it. In contrast, he refers to the computational complexity of an algorithm as the space, time, or effort required to execute it. It is possible to cast many approximate inference schemes as resource-rational algorithms (Sanborn, Reference Sanborn2017). The resulting models typically consider some form of computational complexity. In MCMC methods, computational complexity can be measured in terms of the number of drawn samples: Drawing fewer samples leads to faster inference at the cost of introducing a bias (Courville & Daw, Reference Courville, Daw, Platt, Koller, Singer and Roweis2008; Sanborn et al., Reference Sanborn, Griffiths and Navarro2010). In variational inference, on the other hand, it is possible to introduce an additional parameter that allows to trade-off performance against the computational complexity of transforming the prior into the posterior distribution (Binz & Schulz, Reference Binz and Schulz2022b; Ortega, Braun, Dyer, Kim, & Tishby, Reference Ortega, Braun, Dyer, Kim and Tishby2015). Likewise, other frameworks for building resource-rational models, such as rational meta-reasoning (Lieder & Griffiths, Reference Lieder and Griffiths2017), also only target computational complexity.
The prevalence of resource-rational models based on computational complexity is likely because of the fact that building similar models based on algorithmic complexity is much harder. Measuring algorithmic complexity historically relies on the notion of Kolmogorov complexity, which is the size of the shortest computer program that produces a particular data sequence (Chaitin, Reference Chaitin1969; Kolmogorov, Reference Kolmogorov1965; Solomonoff, Reference Solomonoff1964). Kolmogorov complexity is in general noncomputable, and, therefore, of limited practical interest.Footnote 7
Meta-learning provides us with a straightforward way to manipulate both algorithmic and computational complexity in a common framework by adapting the size of the underlying neural network model. Limiting the complexity of network weights places a constraint on algorithmic complexity (as reducing the number of weights decreases the number of bits needed to store them, and hence also the number of bits needed to store the learning algorithm). Limiting the complexity of activations, on the other hand, places a constraint on computational complexity (reducing the number of hidden units, e.g., decreases the memory needed for executing the meta-learned model). This connection can be made more formal in an information-theoretic framework (Hinton & Van Camp, Reference Hinton and Van Camp1993; Hinton & Zemel, Reference Hinton and Zemel1993). For applications of this idea in the context of human cognition, see, for instance, Binz et al. (Reference Binz, Gershman, Schulz and Endres2022) or Bates and Jacobs (Reference Bates and Jacobs2020).
Previously, both forms of complexity constraints have been realized in meta-learned models. Dasgupta et al. (Reference Dasgupta, Schulz, Tenenbaum and Gershman2020) decreased the number of hidden units of a meta-learned inference algorithm, effectively reducing its computational complexity. In contrast, Binz et al. (Reference Binz, Gershman, Schulz and Endres2022) placed a constraint on the description length of neural network weights (i.e., the number of bits required to store them), which implements a form of algorithmic complexity. To the best of our knowledge, no other class of resource-rational models exists that allows us to take both algorithmic and computational complexity into account, making this ability a unique feature of the meta-learning framework.
2.4 Neuroscience
Argument 4
Meta-learning allows us to integrate neuroscientific insights into the rational analysis of cognition by incorporating these insights into model architectures.
In addition to providing a framework for understanding many aspects of behavior, meta-learning offers a powerful lens through which to view brain structure and function. For instance, Wang et al. (Reference Wang, Kurth-Nelson, Kumaran, Tirumala, Soyer, Leibo and Botvinick2018) presented observations supporting the hypothesis that prefrontal circuits may constitute a meta-reinforcement learning system. From a computational perspective, meta-learning strives to learn a faster inner-loop learning algorithm via an adjustment of neural network weights in a slower outer-loop learning process. Within the brain, an analogous process plausibly occurs when slow, dopamine-driven synaptic change gives rise to reinforcement learning processes that occur within the activity dynamics of the prefrontal network, allowing for adaptation on much faster timescales. This perspective recontextualized the role of dopamine function in reward-based learning and was able to account for a range of previously puzzling neuroscientific findings. To highlight one example, Bromberg-Martin, Matsumoto, Hong, and Hikosaka (Reference Bromberg-Martin, Matsumoto, Hong and Hikosaka2010) found that dopamine signaling reflected updates in not only experienced but also inferred values of targets. Notably, a meta-reinforcement learning agent trained on the same task also recovered this pattern. Having a mapping of meta-reinforcement learning components onto existing brain regions furthermore allows us to apply experimental manipulations that directly perturb neural activity, for example by using optogenetic techniques. Wang et al. (Reference Wang, Kurth-Nelson, Kumaran, Tirumala, Soyer, Leibo and Botvinick2018) used this idea to modify their original meta-reinforcement learning architecture to mimic the blocking or enhancement of dopaminergic reward prediction error signals, in direct analogy with optogenetic stimulation delivered to rats performing a two-armed bandit task (Stopper, Maric, Montes, Wiedman, & Floresco, Reference Stopper, Maric, Montes, Wiedman and Floresco2014).
Importantly, the direction of exchange can also work in the other direction, with neuroscientific findings constraining and inspiring new forms of meta-learning architectures. Bellec, Salaj, Subramoney, Legenstein, and Maass (Reference Bellec, Salaj, Subramoney, Legenstein and Maass2018), for example, showed that recurrent networks of spiking neurons are able to display convincing learning-to-learn behavior, including in the realm of reinforcement learning. Episodic meta-reinforcement learning (Ritter et al., Reference Ritter, Wang, Kurth-Nelson, Jayakumar, Blundell, Pascanu and Botvinick2018) architectures are also heavily inspired by neuroscientific accounts of complementary learning systems in the brain (McClelland, McNaughton, & O'Reilly, Reference McClelland, McNaughton and O'Reilly1995). Both of these examples demonstrate that meta-learning can be used to build more biologically plausible learning algorithms, and thereby highlight that it can act as a bridge between Marr's computational and implementational levels (Marr, Reference Marr2010).
Finally, the meta-learning perspective not only allows us to connect machine learning and neuroscience via architectural design choices but also via the kinds of tasks that are of interest. Dobs, Martinez, Kell, and Kanwisher (Reference Dobs, Martinez, Kell and Kanwisher2022), for instance, suggested that functional specialization in neural circuits, which has been widely observed in biological brains, arises as a consequence of task demands. In particular, they found that convolutional neural networks “optimized for both tasks spontaneously segregate themselves into separate systems for faces and objects.” Likewise, Yang, Joglekar, Song, Newsome, and Wang (Reference Yang, Joglekar, Song, Newsome and Wang2019) found that training a single recurrent neural network to perform a wide range of cognitive tasks yielded units that were clustered along different functional cognitive processes. Put another way, it seems plausible that functional specialization emerges by training neural networks on multiple tasks. Although this has not been tested so far, we speculate that this also holds in the meta-learning setting, as it involves training on multiple tasks by design. If this were true, we could look at the emerging areas inside a meta-learned model, and use the resulting insights to generate novel predictions about the processes happening in individual brain areas (Kanwisher, Khosla, & Dobs, Reference Kanwisher, Khosla and Dobs2023).
3. Previous research
Meta-learned models are already starting to transform the cognitive sciences today. They allow us to model things that are hard to capture with traditional models such as compositional generalization, language understanding, and model-based reasoning. In this section, we provide an overview of what has been achieved with the help of meta-learning in previous work. We arranged this review into various thematic subcategories. For each of them, we summarize which key findings have been obtained by meta-learning and discuss why these results would have been difficult to obtain using traditional models of learning by appealing to the insights from the previous section.
3.1 Heuristics and cognitive biases
Meta-learning has been previously used to discover algorithms with a limited computational budget that show human-like cognitive biases as we have already alluded to earlier. Dasgupta et al. (Reference Dasgupta, Schulz, Tenenbaum and Gershman2020) trained a neural network on a distribution of probabilistic inference problems while controlling for the number of its hidden units. They found that their model – when restricted to just a single hidden unit – captured many biases in human reasoning, including a conservatism bias and base rate neglect. Likewise, Binz et al. (Reference Binz, Gershman, Schulz and Endres2022) trained a neural network on a distribution of decision-making problems while controlling for the number of bits needed to represent the network. Their model discovered two previously suggested heuristics in specific environments and made precise prognoses about when these heuristics should be applied. In particular, knowing the correct ranking of features led to one reason decision making, knowing the directions of features led to an equal weighting heuristic, and not knowing about either of them led to strategies that use weighted combinations of features (also see Figs. 4a and 4b).

Figure 4. Example results obtained using meta-learned models. (a) In a paired comparison task, a meta-learned model identified a single-cue heuristic as the resource-rational solution when information about the feature ranking was available. Follow-up experiments revealed that people indeed apply this heuristic under the given circumstances. (b) If information about feature directions was available, the same meta-learned model identified an equal weighting heuristic as the resource-rational solution. People also applied this heuristic in the given context (Binz et al., Reference Binz, Gershman, Schulz and Endres2022). (c) Wang et al. (Reference Wang, Kurth-Nelson, Tirumala, Soyer, Leibo, Munos and Botvinick2016) showed that meta-learned models can exhibit model-based learning characteristics in the two-step task (Daw et al., Reference Daw, Gershman, Seymour, Dayan and Dolan2011) even when they were purely trained through model-free approaches. The plots on the right illustrate the probability of repeating the previous action for different agents (model-free, model-based, meta-learned) after a common or uncommon transition and after a received or omitted reward.
In both of these studies, meta-learned models offered a novel perspective on results that were previously viewed as contradictory. This was in part possible because meta-learning enabled us to easily manipulate the complexity of the underlying learning algorithm. Although doing so is, at least in theory, also possible within the Bayesian framework, no Bayesian model that captures the full set of findings from Dasgupta et al. (Reference Dasgupta, Schulz, Tenenbaum and Gershman2020) and Binz et al. (Reference Binz, Gershman, Schulz and Endres2022) has been discovered so far. We hypothesize that this could be because traditional rational process models struggle to capture that human strategy selection is context-dependent even before receiving any direct feedback signal (Mercier & Sperber, Reference Mercier and Sperber2017). The meta-learned models of Dasgupta et al. (Reference Dasgupta, Schulz, Tenenbaum and Gershman2020) and Binz et al. (Reference Binz, Gershman, Schulz and Endres2022), on the other hand, were able to readily show context-specific biases when trained on an appropriate task distribution.
3.2 Language understanding
Meta-learning may also help us to answer questions regarding how people process, understand, and produce language. Whether the inductive biases needed to acquire a language are learned from experience or are inherited is one of these questions (Yang & Piantadosi, Reference Yang and Piantadosi2022). McCoy, Grant, Smolensky, Griffiths, and Linzen (Reference McCoy, Grant, Smolensky, Griffiths and Linzen2020) investigated how to equip a model with a set of linguistic inductive biases that are relevant to human cognition. Their solution to this problem builds upon the idea of model-agnostic meta-learning (Finn et al., Reference Finn, Abbeel and Levine2017). In particular, they meta-learned the initial weights of a neural network such that the network can adapt itself quickly to new languages using standard gradient-based learning. When being trained on a distribution over languages, these initial weights can be interpreted as universal factors that are shared across all languages. They showed that this approach identifies inductive biases (e.g., a bias for treating certain phonemes as vowels) that are useful for acquiring a language's syllable structure. Although their current work makes limited claims about human language acquisition, their approach be used in future studies to disentangle which inductive biases are learned from experience and which ones are inherited. They additionally argued that a Bayesian modeling approach would only be able to consider a restrictive set of inductive biases as it needs to commit to a particular representation and inference algorithm. In contrast, the meta-learning framework made it easy to implement the intended inductive biases by simply manipulating the distribution of encountered languages.
The ability to compose simple elements into complex entities is at the heart of human language. The property of languages to “make infinite use of finite means” (Chomsky, Reference Chomsky2014) is what allows us to make strong generalizations from limited data. For example, people readily understand what it means to “dax twice” or to “dax slowly” after learning about the meaning of the verb “dax.” How to build models with a similar proficiency, however, remains an open research question. Lake (Reference Lake2019) showed that a transformer-like neural network can be trained to make such compositional generalizations through meta-learning. Importantly, during meta-learning, his models were adapted to problems that required compositional generalization, and could thereby acquire the skills needed to solve entirely new problems.
Although Lake (Reference Lake2019) argued that meta-learning “has implications for understanding how people generalize compositionally,” he did not conduct a direct comparison to human behavior. In a follow-up study, Lake and Baroni (Reference Lake and Baroni2023) addressed this shortcoming and found that meta-learned models “mimic human systematic generalization in a head-to-head comparison.” These results are further corroborated by a recent paper of Jagadish, Binz, Saanum, Wang, and Schulz (Reference Jagadish, Binz, Saanum, Wang and Schulz2023) which demonstrated that meta-learned models capture human zero-shot compositional inferences in a reinforcement learning setting. However, there also remain open challenges in this context. For example, meta-learned models do not always generalize systematically to longer sequences than those in the training data (Lake, Reference Lake2019; Lake & Baroni, Reference Lake and Baroni2023). How to resolve this issue will be an important challenge for future work.
3.3 Inductive biases
Human cognition comes with many useful inductive biases beyond the ability to reason compositionally. The preference for simplicity is one of these biases (Chater & Vitányi, Reference Chater and Vitányi2003; Feldman, Reference Feldman2016). We readily extract abstract low-dimensional rules that allow us to generalize entirely new situations. Meta-learning is an ideal tool to build models with similar preferences because we can easily generate tasks based on simple rules and use them for meta-learning, thereby enabling an agent to acquire the desired inductive bias from data.
Toward this end, Kumar, Dasgupta, Cohen, Daw, and Griffiths (Reference Kumar, Dasgupta, Cohen, Daw and Griffiths2020b) tested humans and meta-reinforcement agents on a grid-based task. People, as well as agents, encountered a series of 7 × 7 grids. Initially, all tiles were white, but clicking on them revealed their identity as either red or blue. The goal was to reveal all the red tiles while revealing as few blue tiles as possible. There was an underlying pattern that determined how the red tiles were placed, which was either specified by a structured grammar or by a nonstructured process with matched statistics. Humans found it easier to learn in structured tasks, confirming that they have strong priors toward simple abstract rules (Schulz, Tenenbaum, Duvenaud, Speekenbrink, & Gershman, Reference Schulz, Tenenbaum, Duvenaud, Speekenbrink and Gershman2017). However, their analysis also indicated that meta-learning is easier on nonstructured tasks than on structured tasks. In follow-up work, they found that this result also holds for agents that were trained purely on the structured version of their task but evaluated on both versions (Kumar et al., Reference Kumar, Correa, Dasgupta, Marjieh, Hu, Hawkins, Griffiths, Oh, Agarwal, Belgrave and Cho2022a) – a quite astonishing finding considering that one would expect an agent to perform better on the task distribution it was trained on. The authors addressed this mismatch between humans and meta-learned agents by guiding agents during training to reproduce natural language descriptions that people provided to describe a given task. They found that grounding meta-learned agents in natural language descriptions not only improved their performance but also led to more human-like inductive biases, demonstrating that natural language can serve as a source for abstractions within human cognition.
Their line of work uses another interesting technique for training meta-learning agents (Kumar et al., Reference Kumar, Correa, Dasgupta, Marjieh, Hu, Hawkins, Griffiths, Oh, Agarwal, Belgrave and Cho2022a, Reference Kumar, Dasgupta, Marjieh, Daw, Cohen and Griffiths2022b). It does not rely on a hand-designed task distribution but instead involves sampling tasks from the prior distribution of human participants using a technique known as Gibbs sampling with people (Harrison et al., Reference Harrison, Marjieh, Adolfi, van Rijn, Anglada-Tort, Tchernichovski and Jacoby2020; Sanborn & Griffiths, Reference Sanborn and Griffiths2007). Although doing so provides them with a data-set of tasks, no expression of the corresponding prior distribution over them is accessible and, hence, it is nontrivial to define a Bayesian model for the given setting. A meta-learned agent, on the other hand, was readily obtained by training on the collected samples.
3.4 Model-based reasoning
Many realistic scenarios afford two distinct types of learning: model-free and model-based. Model-free learning algorithms directly adjust their strategies using observed outcomes. Model-based learning algorithms, on the other hand, learn about the transition and reward probabilities of an environment, which are then used for downstream reasoning tasks. People are generally thought to be able to perform model-based learning, at least to some extent, and assuming that the problem at hand calls for it (Daw, Gershman, Seymour, Dayan, & Dolan, Reference Daw, Gershman, Seymour, Dayan and Dolan2011; Kool, Cushman, & Gershman, Reference Kool, Cushman and Gershman2016). Wang et al. (Reference Wang, Kurth-Nelson, Tirumala, Soyer, Leibo, Munos and Botvinick2016) showed that a meta-learned algorithm can display model-based behavior, even if it was trained through a pure model-free reinforcement learning algorithm (see Fig. 4c).
Having a model of the world also acts as the basis for causal reasoning. Traditionally, making causal inferences relies on the notion of Pearl's do-calculus (Pearl, Reference Pearl2009). Dasgupta et al. (Reference Dasgupta, Wang, Chiappa, Mitrovic, Ortega, Raposo and Kurth-Nelson2019), however, showed that meta-learning can be used to create models that draw causal inferences from observational data, select informative interventions, and make counterfactual predictions. Although they have not related their model to human data directly, it could in future work serve as the basis to study how people make causal judgments in complex domains and explain why and when they deviate from normative causal theories (Bramley, Dayan, Griffiths, & Lagnado, Reference Bramley, Dayan, Griffiths and Lagnado2017; Gerstenberg, Goodman, Lagnado, & Tenenbaum, Reference Gerstenberg, Goodman, Lagnado and Tenenbaum2021).
Together, these two examples highlight that model-based reasoning capabilities can emerge internally in a meta-learned model if they are beneficial for solving the encountered problem. Although there are already many traditional models that can perform such tasks, these models are often slow at run-time as they typically involve Bayesian inference, planning, or both. Meta-learning, on the other hand, “shifts most of the compute burden from inference time to training time [which] is advantageous when training time is ample but fast answers are needed at run-time” (Dasgupta et al., Reference Dasgupta, Wang, Chiappa, Mitrovic, Ortega, Raposo and Kurth-Nelson2019), and may therefore explain how people can perform such intricate computations within a reasonable time frame.
Although model-based reasoning is an emerging property of meta-learned models, it may also be integrated explicitly into such models should it be desired. Jensen, Hennequin, and Mattar (Reference Jensen, Hennequin and Mattar2023) have taken this route, and augmented a standard meta-reinforcement learning agent with the ability to perform temporally extended planning using imagined rollouts. In each time-step, their agent can decide to perform a planning operation instead of directly interacting with the environment (in this case, a spatial navigation task). Their meta-learned agents opted to perform this planning operation consistently after training. Importantly, the model showed striking similarities to patterns of human deliberation by performing more planning early on and with an increased distance to the goal. Furthermore, they found that patterns of hippocampal replays resembled the rollouts of their model.
3.5 Exploration
People do not only have to integrate observed information into their existing knowledge, but they also have to actively determine what information to sample. They constantly face situations that require them to decide whether they should explore something new or whether they should rather exploit what they already know. Previous research suggests that people solve this exploration–exploitation dilemma using a combination of directed and random exploration strategies (Gershman, Reference Gershman2018; Schulz & Gershman, Reference Schulz and Gershman2019; Wilson, Geana, White, Ludvig, & Cohen, Reference Wilson, Geana, White, Ludvig and Cohen2014; Wu, Schulz, Speekenbrink, Nelson, & Meder, Reference Wu, Schulz, Speekenbrink, Nelson and Meder2018). Why do people use these particular strategies and not others? Binz and Schulz (Reference Binz, Schulz, Oh, Agarwal, Belgrave and Cho2022a) hypothesized that they do so because human exploration follows resource-rational principles. To test this claim, they devised a family of resource-rational reinforcement learning algorithms by combining ideas from meta-learning and information theory. Their meta-learned model discovered a diverse set of exploration strategies, including random and directed exploration, that captured human exploration better than alternative approaches. In this domain, meta-learning offered a direct path toward investigating the hypothesis that people try to explore optimally but are subject to limited computational resources, whereas designing hand-crafted models for studying the same question would have been more intricate.
It is not only important to decide how to explore, but also to decide whether exploration is worthwhile in the first place. Lange and Sprekeler (Reference Lange and Sprekeler2020) studied this question using the meta-learning framework. Their meta-learned agents are able to flexibly interpolate between implementing exploratory learning behaviors and hard-coded, nonlearning strategies. Importantly, which behavior was realized crucially depended on environmental properties, such as the diversity of the task distribution, the task complexity, and the agent's lifetime. They showed, for instance, that agents with a short lifetime should opt for small rewards that are easy to find, whereas agents with an extended lifetime should spend their time exploring the environment. The study of Lange and Sprekeler (Reference Lange and Sprekeler2020) clearly demonstrates that meta-learning makes it conceptually easy to iterate over different environmental assumptions inside a rational analysis of cognition. They only had to modify the environment as desired, followed by rerunning their meta-learning procedure. In contrast, traditional modeling approaches would require hand-designing a new optimal agent each time an environmental change occurs.
3.6 Cognitive control
Humans are remarkable at adapting to task-specific demands. The processes behind this ability are collectively referred to as cognitive control (Botvinick, Braver, Barch, Carter, & Cohen, Reference Botvinick, Braver, Barch, Carter and Cohen2001). Cohen (Reference Cohen and Egner2017) even argues that “the capacity for cognitive control is perhaps the most distinguishing characteristic of human behavior.” It should therefore come as no surprise that cognitive control has received a significant amount of attention from a computational perspective (Botvinick & Cohen, Reference Botvinick and Cohen2014; Collins & Frank, Reference Collins and Frank2013). Recently, some of these computational investigations have been extended to the meta-learning framework.
The ability to adjust computational resources as needed is one hallmark of cognitive control. Moskovitz, Miller, Sahani, and Botvinick (Reference Moskovitz, Miller, Sahani and Botvinick2022) proposed a meta-learned model with such characteristics. Their model learns a simple default policy – similar to the model of Binz and Schulz (Reference Binz, Schulz, Oh, Agarwal, Belgrave and Cho2022a) – that can be overwritten by a more complex one if necessary. They demonstrate that this model is not only able to capture behavioral phenomena from the cognitive control literature but also known effects in decision-making and reinforcement learning tasks, thereby linking the three domains. Importantly, their study highlights that the meta-learning framework offers the means to account for multiple computational costs instead of just a single one – in this case, a cost for implementing the default policy and one for deviating from it.
Taking contextual cues into consideration is another vital aspect of cognitive control. Dubey, Grant, Luo, Narasimhan, and Griffiths (Reference Dubey, Grant, Luo, Narasimhan and Griffiths2020) implemented this idea in the meta-learning framework. In their model, contextual cues determine the initialization of a task-specific neural network that is then trained using model-agnostic meta-learning. They showed that such a model captures “the context-sensitivity of human behavior in a simple but well-studied cognitive control task.” Furthermore, they demonstrated that it scales well to more complex domains (including tasks from the MuJoCo [Todorov, Erez, & Tassa, Reference Todorov, Erez and Tassa2012], CelebA [Liu, Luo, Wang, & Tang, Reference Liu, Luo, Wang and Tang2015], and MetaWorld [Yu et al., Reference Yu, Quillen, He, Julian, Hausman, Finn and Levine2020] benchmarks), thereby opening up new opportunities for modeling human behavior in naturalistic scenarios.
4. Why is not everything meta-learned?
We have laid out different arguments that make meta-learning a useful tool for constructing cognitive models, but it is important to note that we do not claim that meta-learning is the ultimate solution to every modeling problem. Instead, it is essential to understand when meta-learning is the right tool for the job and when not.
4.1 Lack of interpretability
Perhaps its most significant detriment is that meta-learning never provides us with analytical solutions that we can inspect, analyze, and reason about. In contrast to this, some Bayesian models have analytical solutions. Take as an example the data-generating distribution that we encountered earlier (Equations (1)–(2)). For these assumptions, a closed-form expression of the posterior predictive distribution is available. By looking at this closed-form expression, researchers have generated new predictions and subsequently tested them empirically (Daw et al., Reference Daw, Courville, Dayan, Chater and Oaksford2008; Dayan & Kakade, Reference Dayan and Kakade2000; Gershman, Reference Gershman2015). Performing the same kind of analysis with a meta-learned model is not as straightforward. We do not have access to an underlying mathematical expression, which makes a structured exploration of theories much harder.
That being said, there are still ways to analyze a meta-learned model's behavior. For one, it is possible to use model architectures that facilitate interpretability. Binz et al. (Reference Binz, Gershman, Schulz and Endres2022) relied on this approach and designed a neural network architecture that produced weights of a probit regression model that were then used to cluster applied strategies into different categories. Doing so enabled them to identify which strategy was used by their meta-learned model in a particular situation.
Recently, researchers have also started to use tools from cognitive psychology to analyze the behavior of black-box models (Bowers et al., Reference Bowers, Malhotra, Dujmović, Montero, Tsvetkov, Biscione and Blything2022; Rich & Gureckis, Reference Rich and Gureckis2019; Ritter, Barrett, Santoro, & Botvinick, Reference Ritter, Barrett, Santoro and Botvinick2017; Schulz & Dayan, Reference Schulz and Dayan2020). For example, it is possible to treat such models just like participants in a psychological experiment and use the collected data to analyze their behavior similar to how psychologists would analyze human behavior (Binz & Schulz, Reference Binz and Schulz2023; Dasgupta et al., Reference Dasgupta, Lampinen, Chan, Creswell, Kumaran, McClelland and Hill2022; Rahwan et al., Reference Rahwan, Cebrian, Obradovich, Bongard, Bonnefon, Breazeal and Wellman2019; Schramowski, Turan, Andersen, Rothkopf, & Kersting, Reference Schramowski, Turan, Andersen, Rothkopf and Kersting2022). We believe that this approach has great potential for analyzing increasingly capable and opaque artificial agents, including those obtained via meta-learning.
4.2 Intricate training processes
When using the meta-learning framework, one also has to deal with the fact that training neural networks is complex and takes time. Neural network models contain many moving parts, like weight initializations or the used optimizer, that have to be chosen appropriately such that training can take off in the first place, and training itself may take hours or days until it is finished. When we want to modify assumptions in the data-generating distribution, we have to retrain the whole system from scratch altogether. Thus, although the process of iterating over different environmental assumptions is conceptually straightforward in the meta-learning framework, it may be time consuming. Bayesian models can, in comparison, sometimes be more quickly adapted to changes in environmental assumptions. To illustrate this, let us assume that you wanted to explain human behavior through a meta-learned model that was trained on the data-generating distribution from Equations (1)–(2), but found that the resulting model does not fit the observed data well. Next, you want to consider the alternative hypothesis that people assume a nonstationary environment. Although this modification could be done quickly in the corresponding Bayesian model, the meta-learning framework requires retraining on newly generated data.
There is, furthermore, no guarantee that a fully converged meta-learned model implements a Bayes-optimal learning algorithm. Indeed, there are reported cases in which meta-learning failed to find the Bayes-optimal solution (Wang et al., Reference Wang, King, Porcel, Kurth-Nelson, Zhu, Deck and Botvinick2021). In simple scenarios, like our insect length example, we can resolve this issue by comparing to analytical solutions. This kind of reasoning applies to some of the settings in which meta-learning has been used to study human behavior. For example, for the exploration studies discussed in the previous section, it has been shown that meta-learned models closely approximate the (tractable but computationally expensive) Bayes-optimal algorithm (Duan et al., Reference Duan, Schulman, Chen, Bartlett, Sutskever and Abbeel2016; Wang et al., Reference Wang, Kurth-Nelson, Tirumala, Soyer, Leibo, Munos and Botvinick2016). However, in more complex scenarios, it is impossible to verify that a meta-learned algorithm is optimal. We believe that this issue can be somewhat mitigated by validating meta-learned models in various ways. For example, we may get an intuition for the correspondence between a meta-learned model and an intractable Bayes-optimal algorithm by comparing to other approximate inference techniques (as done in Binz et al., Reference Binz, Gershman, Schulz and Endres2022) or to symbolic models (as done in Lake & Baroni, Reference Lake and Baroni2023). In the end, however, we believe that this issue is still an open problem and that future work needs to come up with novel techniques to verify meta-learned models. Nevertheless, this is already a step forward as verifying solutions is often easier than generating them.
4.3 Meta-learned or Bayesian inference?
In summary, both frameworks – meta-learning and Bayesian inference – have their unique strengths and weaknesses. The meta-learning framework does and will not replace Bayesian inference but complement it. It broadens our available toolkit and enables researchers to study questions that were previously out of reach. However, there are certainly situations in which traditional Bayesian inference is a more appropriate modeling choice as we have outlined in this section.
5. The role of neural networks
Most of the points we have discussed so far are agnostic regarding the function approximator implementing the meta-learned algorithm. However, at the same time, we have appealed to neural networks at various points throughout the text. When one looks at prior work, it can also be observed that neural networks are the predominant model class in the meta-learning setting. Why is that the case? In addition to their universality, neural networks offer one big opportunity: They provide a flexible framework for engineering different types of inductive biases into a computational model (Goyal & Bengio, Reference Goyal and Bengio2022). In the following section, we will highlight three examples of how previous work has accomplished this. For each of these examples, we take a concept from psychology, and show how it can be readily accommodated in a meta-learned model.
Perhaps one of the most persuasive ideas in cognitive modeling is that of gradient-based learning. It is not only at the heart of one of the most influential models – the Rescorla–Wagner model (Gershman, Reference Gershman2015; Rescorla, Reference Rescorla, Black and Prokasy1972) – but also features prominently in many other theories of human learning, such as connectionist models (Rumelhart et al., Reference Rumelhart, McClelland and PDP Research Group1988). Even though the earlier outlined meta-learning procedure relies on gradient-based learning in the outer-loop, the resulting inner-loop dynamics must bear no resemblance to gradient descent. However, it is possible to construct meta-learned models whose inner-loop updates rely on gradient-based learning. Finn et al. (Reference Finn, Abbeel and Levine2017) proposed a meta-learning technique known as model-agnostic meta-learning that finds optimal initial parameters of a feedforward neural network that is subsequently trained via gradient descent. The idea is that these optimal initial parameters allow the feedforward network to generalize to multiple tasks in a minimal number of gradient steps. Although their general setup is similar to the one we discussed, it leads to models that learn via gradient descent instead of models that implement a learning algorithm inside the dynamics of a recurrent neural network. Kirsch and Schmidhuber (Reference Kirsch and Schmidhuber2021) recently brought these two approaches together into a single model. Their proposed architecture consists of multiple recurrent neural networks that interact with each other. Importantly, they showed that one particular configuration of these networks could implement backpropagation in the forward pass, thereby being able to perform gradient-based learning in a memory-based system.
Exemplar-based models – like the generalized category model (Nosofsky, Reference Nosofsky, Pothos and Wills2011) – are one of the most prominent approaches for modeling how people categorize items into different classes (Kruschke, Reference Kruschke1990; Shepard, Reference Shepard1987). They categorize a new instance based on the estimated similarity between that instance and previously seen examples. Recently, meta-learned models with exemplar-based reasoning abilities have been proposed for the task of few-shot classification, in which a classifier must generalize based on a training set containing only a few examples. Matching networks (Vinyals et al., Reference Vinyals, Blundell, Lillicrap and Wierstra2016) accomplish this by classifying a new data-point using a similarity-weighted combination of categories in the training set. Importantly, similarity is computed over a learned embedding space, thereby ensuring that the model can scale to high-dimensional stimuli. Follow-up work has taken inspiration from another hugely influential model of human category learning and replaced the exemplar-based mechanism used in matching networks with one based on category prototypes (Snell, Swersky, & Zemel, Reference Snell, Swersky and Zemel2017).
Finally, making inferences using similarities to previous experiences is not only useful for supervised learning but also in the reinforcement learning setting. In the reinforcement learning literature, the ability to store and recollect states or trajectories for later use is studied under the name of episodic memory (Lengyel & Dayan, Reference Lengyel and Dayan2007). It has been argued that episodic memory could be the key to explaining human performance in naturalistic environments (Gershman & Daw, Reference Gershman and Daw2017). Episodic memory also plays a crucial role in neuroscience, with studies showing that highly rewarding instances are stored in the hippocampus and made available for recall as and when required (Blundell et al., Reference Blundell, Uria, Pritzel, Li, Ruderman, Leibo and Hassabis2016). Ritter et al. (Reference Ritter, Wang, Kurth-Nelson, Jayakumar, Blundell, Pascanu and Botvinick2018) build upon the neural episodic control idea from Pritzel et al. (Reference Pritzel, Uria, Srinivasan, Badia, Vinyals, Hassabis and Blundell2017) and use a differential neural dictionary for episodic recall in the context of meta-learning. Their dictionary stores encodings from previously experienced tasks, which can then be later queried as needed. With this addition, their meta-learned model is able to recall previously discovered policies, retrieve memories using category examples, handle compositional tasks, re-instate memories while traversing the environment, and recover a learning strategy people use in a neuroscience-inspired task.
In summary, human cognition comes with a variety of inductive biases and neural networks provide flexible ways to easily incorporate them into meta-learned models of cognition. We have outlined three such examples in the section, demonstrating how to integrate gradient-based learning, exemplar- and prototype-based reasoning, and episodic memory into a meta-learned model. There are, furthermore, many other inductive biases for neural network architectures that could be used in the context of meta-learning but have not been yet. Examples include networks that perform differentiable planning (Farquhar, Rocktäschel, Igl, & Whiteson, Reference Farquhar, Rocktäschel, Igl and Whiteson2017; Tamar, Wu, Thomas, Levine, & Abbeel, Reference Tamar, Wu, Thomas, Levine and Abbeel2016), extract object-based representations (Piloto, Weinstein, Battaglia, & Botvinick, Reference Piloto, Weinstein, Battaglia and Botvinick2022; Sancaktar, Blaes, & Martius, Reference Sancaktar, Blaes, Martius, Oh, Agarwal, Belgrave and Cho2022), or modify their own connections through synaptic plasticity (Miconi, Rawal, Clune, & Stanley, Reference Miconi, Rawal, Clune and Stanley2020; Schlag, Irie, & Schmidhuber, Reference Schlag, Irie and Schmidhuber2021).
6. Toward a domain-general model of human learning
What does the future hold for meta-learning? The current generation of meta-learned models of cognition is almost exclusively trained on the data-generating distribution of a specific problem family. Although this training process enables them to generalize to new tasks inside this problem family, they are unlikely to generalize to completely different domains. We would, for example, not expect a meta-learned algorithm to perform a challenging maze navigation task if it was only trained to predict the lengths of insect species.
Although domain-specific models have (and will continue to) provide answers to important research questions, we agree with Newell (Reference Newell1992) that “unified theories of cognition are the only way to bring this wonderful, increasing fund of knowledge under intellectual control.” Ideally, such a unified theory should manifest itself in a domain-general cognitive model that cannot only solve prediction tasks but is also capable of human-like decision making (Gigerenzer & Gaissmaier, Reference Gigerenzer and Gaissmaier2011), category learning (Ashby et al., Reference Ashby and Maddox2005), navigation (Montello, Reference Montello2005), problem-solving (Newell et al., Reference Newell and Simon1972), and so forth. We consider the meta-learning framework the ideal tool for accomplishing this goal as it allows us to compile arbitrary assumptions about an agent's beliefs of the world (arguments 1 and 2) and its computational architecture (arguments 3 and 4) into a cognitive model.
To obtain such a domain-general cognitive model via meta-learning, however, a few challenges need to be tackled. First of all, there is the looming question of how a data-generating distribution that contains many different problems should be constructed. Here, we may take inspiration from the machine learning community, where researchers have devised generalist agents by training neural networks on a large set of problems (Reed et al., Reference Reed, Zolna, Parisotto, Colmenarejo, Novikov, Barth-Maron and de Freitas2022). Team et al. (Reference Team, Bauer, Baumli, Baveja, Behbahani, Bhoopchand and Zhang2023) have recently shown that this is a promising path for scaling up meta-learning models. They trained a meta-reinforcement learning agent on a vast open-ended world with over 1040 possible tasks. The resulting agent can adapt to held-out problems as quickly as humans, and “displays on-the-fly hypothesis-driven exploration, efficient exploitation of acquired knowledge, and can successfully be prompted with first-person demonstrations.” In the same vein, we may come up with a large collection of tasks that are more commonly used to study human behavior (Miconi, Reference Miconi2023; Molano-Mazon et al., Reference Molano-Mazon, Barbosa, Pastor-Ciurana, Fradera, Zhang, Forest and Yang2022; Yang et al., Reference Yang, Joglekar, Song, Newsome and Wang2019), and use them to train a meta-learned model of cognition.
Language will likely play an important role in future meta-learning systems. We do not want a system that learns every task from scratch via trial and error but one that can be provided with a set of instructions similar to how a human subject would be instructed in a psychological experiment. Having agents capable of language will not only enable them to understand new tasks in a zero-shot manner but may also facilitate their cognitive abilities. It, for example, allows them to decompose tasks into subtasks, learn from other agents, or generate explanations (Colas, Karch, Moulin-Frier, & Oudeyer, Reference Colas, Karch, Moulin-Frier and Oudeyer2022). Fortunately, our current best language models (Brown et al., Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal and Amodei2020; Chowdhery et al., Reference Chowdhery, Narang, Devlin, Bosma, Mishra, Roberts and Fiedel2022) and meta-learning systems are both based on neural networks. Thus, integrating language capabilities into a meta-learned model of cognition should – at least conceptually – be fairly straightforward. Doing so would furthermore enable such models to harvest the compositional nature of language to make strong generalizations to tasks outside of the meta-learning distribution. The potential for this was highlighted in a recent study (Riveland & Pouget, Reference Riveland and Pouget2022) which found that language-conditioned recurrent neural network models can perform entirely novel psychophysical tasks with high accuracy.
Moreover, a sufficiently general model of human cognition must not only be able to select among several given options, like in a decision-making or category learning setting, but it also needs to maneuver within a complex world. For this, it needs to perceive and process high-dimensional visual stimuli, it needs to control a body with many degrees of freedom, and it needs to actively engage with other agents. Many of these problems have been at the heart of the deep learning community (Hill et al., Reference Hill, Lampinen, Schneider, Clark, Botvinick, McClelland and Santoro2020; McClelland, Hill, Rudolph, Baldridge, & Schütze, Reference McClelland, Hill, Rudolph, Baldridge and Schütze2020; Strouse, McKee, Botvinick, Hughes, & Everett, Reference Strouse, McKee, Botvinick, Hughes and Everett2021; Team et al., Reference Team, Stooke, Mahajan, Barros, Deck, Bauer and Czarnecki2021), and it will be interesting to see whether the solutions developed there can be integrated into a meta-learned model of cognition.
Finally, there are also some challenges on the algorithmic side that need to be taken into account. In particular, it is unclear how far currently used model architectures and outer-loop learning algorithms scale. Although contemporary meta-learning algorithms are able to find approximately Bayes-optimal solutions to simple problems, they sometimes struggle to do so on more complex ones (e.g., as in the earlier discussed work of Wang et al., Reference Wang, King, Porcel, Kurth-Nelson, Zhu, Deck and Botvinick2021). Therefore, it seems likely that simply increasing the complexity of the meta-learning distribution will not be sufficient – we will also need model architectures and outer-loop learning algorithms that can handle increasingly complex data-generating distributions. The transformer architecture (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez and Polosukhin2017), which has been very successful at training large language models (Brown et al., Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal and Amodei2020; Chowdhery et al., Reference Chowdhery, Narang, Devlin, Bosma, Mishra, Roberts and Fiedel2022), provides one promising candidate, but there could be countless other (so far undiscovered) alternatives.
Thus, taken together, there are still substantial challenges involved in creating a domain-general meta-learned model of cognition. In particular, we have argued in this section that we need to (1) meta-learn on more diverse task distributions, (2) develop agents that can parse instructions in the form of natural language, (3) embody these agents in realistic problem settings, and (4) find model architectures that scale to these complex problems. Figure 5 summarizes these points graphically.
Figure 5. Illustration of how a domain-general meta-learned model of cognition could look like. Modifications include training on more diverse task distributions, providing natural language instructions as additional inputs, and relying on scalable model architectures.
7. Conclusion
Most computational models of human learning are hand-designed, meaning that at some point a researcher sat down and defined how they behave. Meta-learning starts with an entirely different premise. Instead of designing learning algorithms by hand, one trains a system to achieve its goals by repeatedly letting it interact with an environment. Although this seems quite different from traditional models of learning on the surface, we have highlighted that the meta-learning framework actually has a deep connection to the idea of Bayesian inference, and thereby to the rational analysis of cognition. Using this connection as a starting point, we have highlighted several advantages of the meta-learning framework for constructing rational models of cognition. Together, our arguments demonstrate that meta-learning cannot only be applied in situations where Bayesian inference is impossible but also facilitates the inclusion of computational constraints and neuroscientific insights into rational models of human cognition. Earlier criticisms of the rational analysis of cognition have repeatedly pointed out that “rational Bayesian models are significantly unconstrained” and that they should be “developed in conjunction with mechanistic considerations to offer substantive explanations of cognition” (Jones & Love, Reference Jones and Love2011). Likewise, Bowers and Davis (Reference Bowers and Davis2012) argued that to understand human cognition “important constraints [must] come from biological, evolutionary, and processing (algorithmic) considerations.” We believe that the meta-learning framework provides the ideal opportunity to address these criticisms as it allows for a painless integration of flexible algorithmic (often biologically inspired) mechanisms.
It is worth pointing out that meta-learning can be also motivated by taking neural networks as a starting point. From this perspective, it bridges two of the most popular theories of cognition – Bayesian models and connectionism – by bringing the scalability of neural network models into the rational analysis of cognition. The blending of Bayesian models and neural networks situates the meta-learning framework at the heart of the debate on whether cognition is best explained by emergentist or structured probabilistic approaches (Griffiths, Chater, Kemp, Perfors, & Tenenbaum, Reference Griffiths, Chater, Kemp, Perfors and Tenenbaum2010; McClelland et al., Reference McClelland, Botvinick, Noelle, Plaut, Rogers, Seidenberg and Smith2010). Like traditional connectionist approaches, meta-learning provides a means to explain how cognition could emerge as a system repeatedly interacts with an environment. Whether the current techniques used for meta-learning mirror the emergence of cognitive processes in people however remains an open question. Personally, we believe that this is unlikely and that there are more elaborate processes in play during human meta-learning than the gradient descent-based algorithms that are commonly used for training neural networks (Schulze Buschoff, Schulz, & Binz, Reference Schulze Buschoff, Schulz and Binz2023). To study this question systemically, we would need to look at human behavior across much longer timescales (e.g., developmental or evolutionary). Yet, at the same time, meta-learning does not limit itself to a purely emergentist perspective. The modern neural network toolbox allows researchers to flexibly integrate additional structure and inductive biases into a model by adjusting the underlying network architecture – as we have argued in Section 5 – thereby preserving a key advantage of structured probabilistic approaches. How much hand-crafting within the network architecture is needed ultimately depends on the designer's goals. The meta-learning framework is agnostic to this and allows it to range from almost nothing to a substantial amount.
We believe that meta-learning provides a powerful tool to scale up psychological theories to more complex settings. However, at the same time, meta-learning has not delivered on this promise yet. Existing meta-learned models of cognition are typically applied to classical scenarios where established models already exist. Thus, we have to ask: What prevents the application to more complex and general paradigms? First, such paradigms themselves have to be developed. Fortunately, there is currently a trend toward measuring human behavior on more naturalistic tasks (Brändle, Binz, & Schulz, Reference Brändle, Binz, Schulz, Cogliati Dezza, Schulz and Wu2022a; Brändle, Stocks, Tenenbaum, Gershman, & Schulz, Reference Brändle, Stocks, Tenenbaum, Gershman and Schulz2022b; Schulz et al., Reference Schulz, Bhui, Love, Brier, Todd and Gershman2019), and it will be interesting to see what role meta-learning will play in modeling behavior in such settings. Furthermore, meta-learning can be intricate and time consuming. We hope that the present article – together with the accompanying code examples – makes this technique less opaque and more accessible to a wider audience. Future advances in hardware will likely make the meta-learning process quicker and we are therefore hopeful that meta-learning can ultimately fulfill its promise of identifying plausible models of human cognition in situations that are out of reach for hand-designed algorithms.
Acknowledgments
The authors thank Sreejan Kumar, Tobias Ludwig, Dominik Endres, and Adam Santoro for their valuable feedback on an earlier draft.
Financial support
This work was funded by the Max Planck Society, the Volkswagen Foundation, as well as the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy EXC2064/1-390727645.
Competing interest
None.






Target article
Meta-learned models of cognition
Related commentaries (22)
Bayes beyond the predictive distribution
Challenges of meta-learning and rational analysis in large worlds
Combining meta-learned models with process models of cognition
Integrative learning in the lens of meta-learned models of cognition: Impacts on animal and human learning outcomes
Is human compositionality meta-learned?
Learning and memory are inextricable
Linking meta-learning to meta-structure
Meta-learned models as tools to test theories of cognitive development
Meta-learned models beyond and beneath the cognitive
Meta-learning and the evolution of cognition
Meta-learning as a bridge between neural networks and symbolic Bayesian models
Meta-learning goes hand-in-hand with metacognition
Meta-learning in active inference
Meta-learning modeling and the role of affective-homeostatic states in human cognition
Meta-learning: Bayesian or quantum?
Probabilistic programming versus meta-learning as models of cognition
Quantum Markov blankets for meta-learned classical inferential paradoxes with suboptimal free energy
Quo vadis, planning?
The added value of affective processes for models of human cognition and learning
The hard problem of meta-learning is what-to-learn
The meta-learning toolkit needs stronger constraints
The reinforcement metalearner as a biologically plausible meta-learning framework
Author response
Meta-learning: Data, architecture, and both