
63 results
GenFormer: a deep-learning-based approach for generating multivariate stochastic processes
-
- Journal:
- Data-Centric Engineering / Volume 6 / 2025
- Published online by Cambridge University Press:
- 27 February 2025, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The number of overlapping customers in Erlang-A queues: an asymptotic approach
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 21 February 2025, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The impact of pinning points on memorylessness in Lévy random bridges
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 15 October 2024, pp. 172-187
- Print publication:
- March 2025
-
- Article
-
- You have access
- HTML
- Export citation
8 - Hydrothermal planning
-
- Book:
- Optimization Models in Electricity Markets
- Published online:
- 09 January 2025
- Print publication:
- 13 June 2024, pp 179-206
-
- Chapter
- Export citation
On a variant of the product replacement algorithm
- Part of
-
- Journal:
- Glasgow Mathematical Journal / Volume 66 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 09 January 2024, pp. 221-228
- Print publication:
- January 2024
-
- Article
-
- You have access
- HTML
- Export citation

Data Modeling for the Sciences
- Applications, Basics, Computations
-
- Published online:
- 17 August 2023
- Print publication:
- 31 August 2023
Intraindividual phenotyping of depression in high-risk youth: An application of a multilevel hidden Markov model
-
- Journal:
- Development and Psychopathology / Volume 36 / Issue 3 / August 2024
- Published online by Cambridge University Press:
- 23 May 2023, pp. 1262-1271
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Behavioural equivalences for continuous-time Markov processes
-
- Journal:
- Mathematical Structures in Computer Science / Volume 33 / Issue 4-5 / April 2023
- Published online by Cambridge University Press:
- 30 March 2023, pp. 222-258
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Matrix calculations for moments of Markov processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 02 September 2022, pp. 126-150
- Print publication:
- March 2023
-
- Article
- Export citation
Appendix K - Stochastic Processes
-
- Book:
- Liquid Crystals and their Computer Simulations
- Published online:
- 21 July 2022
- Print publication:
- 28 July 2022, pp 602-603
-
- Chapter
- Export citation
Unified signature cumulants and generalized Magnus expansions
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 09 June 2022, e42
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Orthogonal Polynomials in the Spectral Analysis of Markov Processes
- Birth-Death Models and Diffusion
-
- Published online:
- 08 October 2021
- Print publication:
- 21 October 2021
Pull out all the stops: Textual analysis via punctuation sequences
-
- Journal:
- European Journal of Applied Mathematics / Volume 32 / Issue 6 / December 2021
- Published online by Cambridge University Press:
- 21 September 2020, pp. 1069-1105
-
- Article
- Export citation
Optimal stopping for measure-valued piecewise deterministic Markov processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 57 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 16 July 2020, pp. 497-512
- Print publication:
- June 2020
-
- Article
- Export citation
A Note on Rényi's ‘Record’ Problem and Engel's Series
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society / Volume 61 / Issue 2 / May 2018
- Published online by Cambridge University Press:
- 15 February 2018, pp. 363-369
-
- Article
- Export citation
A Markov model for Selmer ranks in families of twists
- Part of
-
- Journal:
- Compositio Mathematica / Volume 150 / Issue 7 / July 2014
- Published online by Cambridge University Press:
- 30 June 2014, pp. 1077-1106
- Print publication:
- July 2014
-
- Article
- Export citation
-
We study the distribution of 2-Selmer ranks in the family of quadratic twists of an elliptic curve
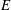 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}E$ over an arbitrary number field
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}E$ over an arbitrary number field 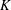 $K$. Under the assumption that
$K$. Under the assumption that 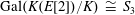 ${\rm Gal}(K(E[2])/K) \ {\cong }\ S_3$, we show that the density (counted in a nonstandard way) of twists with Selmer rank
${\rm Gal}(K(E[2])/K) \ {\cong }\ S_3$, we show that the density (counted in a nonstandard way) of twists with Selmer rank  $r$ exists for all positive integers
$r$ exists for all positive integers  $r$, and is given via an equilibrium distribution, depending only on a single parameter (the ‘disparity’), of a certain Markov process that is itself independent of
$r$, and is given via an equilibrium distribution, depending only on a single parameter (the ‘disparity’), of a certain Markov process that is itself independent of 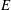 $E$ and
$E$ and 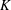 $K$. More generally, our results also apply to
$K$. More generally, our results also apply to 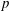 $p$-Selmer ranks of twists of two-dimensional self-dual
$p$-Selmer ranks of twists of two-dimensional self-dual 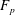 ${\bf F}_p$-representations of the absolute Galois group of
${\bf F}_p$-representations of the absolute Galois group of 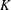 $K$ by characters of order
$K$ by characters of order 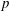 $p$.
$p$.
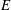
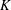
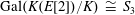


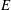
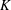
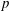
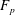
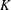
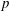
Robust guaranteed cost control for descriptor systems with Markov jumping parameters and state delays
-
- Journal:
- The ANZIAM Journal / Volume 47 / Issue 4 / April 2006
- Published online by Cambridge University Press:
- 17 February 2009, pp. 569-580
-
- Article
-
- You have access
- Export citation
Potentials of a Markov process are expected suprema
-
- Journal:
- ESAIM: Probability and Statistics / Volume 11 / June 2007
- Published online by Cambridge University Press:
- 01 March 2007, pp. 89-101
- Print publication:
- June 2007
-
- Article
- Export citation
A discrete-time approximation technique for the time-cost trade-off in PERT networks
-
- Journal:
- RAIRO - Operations Research / Volume 41 / Issue 1 / January 2007
- Published online by Cambridge University Press:
- 15 June 2007, pp. 61-81
- Print publication:
- January 2007
-
- Article
- Export citation
Binomial-Poisson entropic inequalities and the M/M/∞ queue
-
- Journal:
- ESAIM: Probability and Statistics / Volume 10 / February 2006
- Published online by Cambridge University Press:
- 08 September 2006, pp. 317-339
- Print publication:
- February 2006
-
- Article
- Export citation
