

Contents
EDITORIAL
GUEST EDITORS' EDITORIAL: RECENT DEVELOPMENTS IN MODEL SELECTION AND RELATED AREAS
-
- Published online by Cambridge University Press:
- 30 November 2007, pp. 319-322
-
- Article
-
- You have access
- HTML
- Export citation
Research Article
SHRINKAGE ESTIMATION FOR NEARLY SINGULAR DESIGNS
-
- Published online by Cambridge University Press:
- 30 November 2007, pp. 323-337
-
- Article
- Export citation
CAN ONE ESTIMATE THE UNCONDITIONAL DISTRIBUTION OF POST-MODEL-SELECTION ESTIMATORS?
-
- Published online by Cambridge University Press:
- 30 November 2007, pp. 338-376
-
- Article
- Export citation
AN IN-DEPTH LOOK AT HIGHEST POSTERIOR MODEL SELECTION
-
- Published online by Cambridge University Press:
- 30 November 2007, pp. 377-403
-
- Article
- Export citation
FORMALIZED DATA SNOOPING BASED ON GENERALIZED ERROR RATES
-
- Published online by Cambridge University Press:
- 30 November 2007, pp. 404-447
-
- Article
- Export citation
ADAPTIVE ESTIMATORS OF A MEAN MATRIX: TOTAL LEAST SQUARES VERSUS TOTAL SHRINKAGE
-
- Published online by Cambridge University Press:
- 15 January 2008, pp. 448-471
-
- Article
- Export citation
LOCALIZED MODEL SELECTION FOR REGRESSION
-
- Published online by Cambridge University Press:
- 15 January 2008, pp. 472-492
-
- Article
- Export citation
MINIMIZING AVERAGE RISK IN REGRESSION MODELS
-
- Published online by Cambridge University Press:
- 15 January 2008, pp. 493-527
-
- Article
- Export citation
PREDICTIVE DENSITY ESTIMATION FOR MULTIPLE REGRESSION
-
- Published online by Cambridge University Press:
- 15 January 2008, pp. 528-544
-
- Article
- Export citation
-
Suppose we observe X ∼ Nm(Aβ,σ2I) and would like to estimate the predictive density p(y|β) of a future Y ∼ Nn(Bβ,σ2I). Evaluating predictive estimates
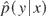 by Kullback–Leibler loss, we develop and evaluate Bayes procedures for this problem. We obtain general sufficient conditions for minimaxity and dominance of the “noninformative” uniform prior Bayes procedure. We extend these results to situations where only a subset of the predictors in A is thought to be potentially irrelevant. We then consider the more realistic situation where there is model uncertainty and this subset is unknown. For this situation we develop multiple shrinkage predictive estimators and obtain general minimaxity and dominance conditions. Finally, we provide an explicit example of a minimax multiple shrinkage predictive estimator based on scaled harmonic priors.
by Kullback–Leibler loss, we develop and evaluate Bayes procedures for this problem. We obtain general sufficient conditions for minimaxity and dominance of the “noninformative” uniform prior Bayes procedure. We extend these results to situations where only a subset of the predictors in A is thought to be potentially irrelevant. We then consider the more realistic situation where there is model uncertainty and this subset is unknown. For this situation we develop multiple shrinkage predictive estimators and obtain general minimaxity and dominance conditions. Finally, we provide an explicit example of a minimax multiple shrinkage predictive estimator based on scaled harmonic priors.We acknowledge Larry Brown, Feng Liang, Linda Zhao, and three referees for their helpful suggestions. This work was supported by various NSF grants, DMS-0605102 the most recent.
FAST RATES FOR ESTIMATION ERROR AND ORACLE INEQUALITIES FOR MODEL SELECTION
-
- Published online by Cambridge University Press:
- 15 January 2008, pp. 545-552
-
- Article
- Export citation
USING MACRO DATA TO OBTAIN BETTER MICRO FORECASTS
-
- Published online by Cambridge University Press:
- 21 January 2008, pp. 553-579
-
- Article
- Export citation
CORRIGENDUM
CORRIGENDUM: Correction to “Performance Limits for Estimators of the Risk or Distribution of Shrinkage-Type Estimators, and Some General Lower Risk-Bound Results”
-
- Published online by Cambridge University Press:
- 18 February 2008, pp. 581-583
-
- Article
- Export citation