



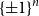

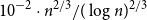
1. Introduction
There is a long line of research, spanning over three decades, on problems about covering the vertices of the
 $n$
-dimensional hypercube
$n$
-dimensional hypercube
 $\{\pm 1\}^n$
by hyperplanes (see, e.g. [Reference Alon and Füredi2, Reference Araujo, Balogh and Mattos3, Reference Clifton and Huang6, Reference Klein9, Reference Linial and Radhakrishnan10, Reference Yehuda and Yehudayoff12]). A very simple question is how many hyperplanes are needed in order to cover all vertices in
$\{\pm 1\}^n$
by hyperplanes (see, e.g. [Reference Alon and Füredi2, Reference Araujo, Balogh and Mattos3, Reference Clifton and Huang6, Reference Klein9, Reference Linial and Radhakrishnan10, Reference Yehuda and Yehudayoff12]). A very simple question is how many hyperplanes are needed in order to cover all vertices in
 $\{\pm 1\}^n$
, that is, such that every vertex is contained in at least one of these hyperplanes. This question has an equally simple answer: two hyperplanes are enough, for example, one can take the two hyperplanes given by the equations
$\{\pm 1\}^n$
, that is, such that every vertex is contained in at least one of these hyperplanes. This question has an equally simple answer: two hyperplanes are enough, for example, one can take the two hyperplanes given by the equations
 $x_1=1$
and
$x_1=1$
and
 $x_1=-1$
. However, this hyperplane cover is not truly
$x_1=-1$
. However, this hyperplane cover is not truly
 $n$
-dimensional, in the sense that the variables
$n$
-dimensional, in the sense that the variables
 $x_2,\dots, x_n$
do not appear in any of the hyperplane equations. It is therefore natural to demand in addition that each variable has a non-zero coefficient in the equation for at least one of the hyperplanes.
$x_2,\dots, x_n$
do not appear in any of the hyperplane equations. It is therefore natural to demand in addition that each variable has a non-zero coefficient in the equation for at least one of the hyperplanes.
However, this still does not lead to a very interesting problem. In addition to the hyperplanes with equations
 $x_1=1$
and
$x_1=1$
and
 $x_1=-1$
that already cover all vertices, one could add an additional hyperplane with an equation like
$x_1=-1$
that already cover all vertices, one could add an additional hyperplane with an equation like
 $x_1+x_2+\dots +x_n=0$
containing all variables with non-zero coefficients. But in some sense, this additional hyperplane is not truly part of the hyperplane cover, as it is not needed for covering all vertices (the other two hyperplanes together already cover all vertices in
$x_1+x_2+\dots +x_n=0$
containing all variables with non-zero coefficients. But in some sense, this additional hyperplane is not truly part of the hyperplane cover, as it is not needed for covering all vertices (the other two hyperplanes together already cover all vertices in
 $\{\pm 1\}^n$
).
$\{\pm 1\}^n$
).
This leads to the following notion of an essential cover of the hypercube
 $\{\pm 1\}^n$
, introduced by Linial and Radhakrishnan [Reference Linial and Radhakrishnan10] in 2005 and further studied in [Reference Araujo, Balogh and Mattos3, Reference Saxton11, Reference Yehuda and Yehudayoff12]. It describes a minimal set of hyperplanes covering all vertices in
$\{\pm 1\}^n$
, introduced by Linial and Radhakrishnan [Reference Linial and Radhakrishnan10] in 2005 and further studied in [Reference Araujo, Balogh and Mattos3, Reference Saxton11, Reference Yehuda and Yehudayoff12]. It describes a minimal set of hyperplanes covering all vertices in
 $\{\pm 1\}^n$
, which in addition has the property that each variable appears in the equation of at least one of the hyperplanes. Formally, an essential cover of the hypercube
$\{\pm 1\}^n$
, which in addition has the property that each variable appears in the equation of at least one of the hyperplanes. Formally, an essential cover of the hypercube
 $\{\pm 1\}^n$
is defined as follows.
$\{\pm 1\}^n$
is defined as follows.
Definition 1.1 (Essential cover). A collection of hyperplanes
 $h_1,\dots, h_k$
in
$h_1,\dots, h_k$
in
 $\mathbb{R}^n$
is called an essential cover of the
$\mathbb{R}^n$
is called an essential cover of the
 $n$
-dimensional hypercube
$n$
-dimensional hypercube
 $\{\pm 1\}^n$
if the following conditions are satisfied:
$\{\pm 1\}^n$
if the following conditions are satisfied:
-
(E1) For every vertex
 $x\in \{\pm 1\}^n$
, there is some
$i\in [k]$
such that
$x\in h_i$
.
$x\in \{\pm 1\}^n$
, there is some
$i\in [k]$
such that
$x\in h_i$
. -
(E2) For every
$j\in [n]$
, there is some
$i\in [k]$
such that, writing
$h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, we have
$v_{ij}\ne 0$
. -
(E3) For every
$i\in [k]$
, there is a vertex
$x\in \{\pm 1\}^n$
that is covered only by
$h_i$
and not by any of the hyperplanes
$h_1,\dots, h_{i-1},h_{i+1},\dots, h_n$
.











Condition (E1) means that every vertex in
 $\{\pm 1\}^n$
is covered by some hyperplane, and condition (E3) means that
$\{\pm 1\}^n$
is covered by some hyperplane, and condition (E3) means that
 $h_1,\dots, h_k$
is a minimal collection of hyperplanes with respect to the property of covering every vertex. Finally, condition (E2) can be restated as saying that each of the variables
$h_1,\dots, h_k$
is a minimal collection of hyperplanes with respect to the property of covering every vertex. Finally, condition (E2) can be restated as saying that each of the variables
 $x_1,\dots, x_n$
must appear with a non-zero coefficient in at least one of the hyperplane equations
$x_1,\dots, x_n$
must appear with a non-zero coefficient in at least one of the hyperplane equations
 $\langle v_i,x\rangle = \mu _i$
for
$\langle v_i,x\rangle = \mu _i$
for
 $i=1,\dots, n$
(where
$i=1,\dots, n$
(where
 $v_i=(v_{i1},\dots, v_{in})\in \mathbb{R}^n$
and
$v_i=(v_{i1},\dots, v_{in})\in \mathbb{R}^n$
and
 $\mu _i\in \mathbb{R}$
, so
$\mu _i\in \mathbb{R}$
, so
 $\langle v_i,x\rangle = \mu _i$
is a shorter form of writing the linear equation
$\langle v_i,x\rangle = \mu _i$
is a shorter form of writing the linear equation
 $v_{i1}x_1+\dots +v_{in}x_n= \mu _i$
). Note that this condition is not affected by rescaling the equations
$v_{i1}x_1+\dots +v_{in}x_n= \mu _i$
). Note that this condition is not affected by rescaling the equations
 $\langle v_i,x\rangle = \mu _i$
, so it does not depend on the parametrisation chosen for each of the hyperplanes.
$\langle v_i,x\rangle = \mu _i$
, so it does not depend on the parametrisation chosen for each of the hyperplanes.
It is now a very natural question to ask how large an essential cover of
 $\{\pm 1\}^n$
needs to be. Linial and Radhakrishnan [Reference Linial and Radhakrishnan10] showed in 2005 that any essential cover must contain at least
$\{\pm 1\}^n$
needs to be. Linial and Radhakrishnan [Reference Linial and Radhakrishnan10] showed in 2005 that any essential cover must contain at least
 $\Omega (\sqrt{n})$
hyperplanes. On the other hand, they also gave a construction of an essential cover consisting of
$\Omega (\sqrt{n})$
hyperplanes. On the other hand, they also gave a construction of an essential cover consisting of
 $\lceil n/2\rceil +1$
hyperplanes, which still remains the best known upper bound. Yehuda and Yehudayoff [Reference Yehuda and Yehudayoff12] improved the lower bound to
$\lceil n/2\rceil +1$
hyperplanes, which still remains the best known upper bound. Yehuda and Yehudayoff [Reference Yehuda and Yehudayoff12] improved the lower bound to
 $\Omega (n^{0.52})$
, and more recently Araujo, Balogh, and Mattos [Reference Araujo, Balogh and Mattos3] further improved the lower bound to
$\Omega (n^{0.52})$
, and more recently Araujo, Balogh, and Mattos [Reference Araujo, Balogh and Mattos3] further improved the lower bound to
 $\Omega (n^{5/9}/(\log n)^{4/9})$
by refining the methods in [Reference Yehuda and Yehudayoff12].
$\Omega (n^{5/9}/(\log n)^{4/9})$
by refining the methods in [Reference Yehuda and Yehudayoff12].
In this paper, we further improve the lower bound for the size of an essential cover of the hypercube.
Theorem 1.2.
For
 $n\ge 2$
, any essential cover of the
$n\ge 2$
, any essential cover of the
 $n$
-dimensional hypercube
$n$
-dimensional hypercube
 $\{\pm 1\}^n$
must consist of at least
$\{\pm 1\}^n$
must consist of at least
 $10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
hyperplanes.
$10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
hyperplanes.
The absolute constant
 $10^{-2}$
is not optimised in our proof.
$10^{-2}$
is not optimised in our proof.
We remark that our lower bound for the size of essential covers also implies new lower bounds for some problems in proof complexity, see the discussion in [Reference Yehuda and Yehudayoff12].
Linial and Radhakrishnan [Reference Linial and Radhakrishnan10], obtained their lower bound of
 $\Omega (\sqrt{n})$
for the size of essential covers of
$\Omega (\sqrt{n})$
for the size of essential covers of
 $\{\pm 1\}^n$
by showing the following. For any essential cover of
$\{\pm 1\}^n$
by showing the following. For any essential cover of
 $\{\pm 1\}^n$
consisting of
$\{\pm 1\}^n$
consisting of
 $k$
hyperplanes, each hyperplane equation contains at most
$k$
hyperplanes, each hyperplane equation contains at most
 $2k$
variables with non-zero coefficients. We also use this fact in our proof of Theorem 1.2.
$2k$
variables with non-zero coefficients. We also use this fact in our proof of Theorem 1.2.
We furthermore observed that this fact leads to an essentially tight lower bound for another well-known problem concerning hyperplane covers of
 $\{\pm 1\}^n$
, which can be stated as follows. A skew cover of the
$\{\pm 1\}^n$
, which can be stated as follows. A skew cover of the
 $n$
-dimensional hypercube
$n$
-dimensional hypercube
 $\{\pm 1\}^n$
is a collection of hyperplanes
$\{\pm 1\}^n$
is a collection of hyperplanes
 $h_1,\dots, h_k$
covering all vertices in
$h_1,\dots, h_k$
covering all vertices in
 $\{\pm 1\}^n$
such that each of the hyperplane equations contains all of the variables
$\{\pm 1\}^n$
such that each of the hyperplane equations contains all of the variables
 $x_1,\dots, x_n$
with non-zero coefficients (i.e. for
$x_1,\dots, x_n$
with non-zero coefficients (i.e. for
 $i=1,\dots, n$
, when writing
$i=1,\dots, n$
, when writing
 $h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, the vector
$h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, the vector
 $v_i$
has full support). The problem is again to determine the smallest possible size of a skew cover of
$v_i$
has full support). The problem is again to determine the smallest possible size of a skew cover of
 $\{\pm 1\}^n$
. The best lower bound for this problem that appeared explicitly in the literature was
$\{\pm 1\}^n$
. The best lower bound for this problem that appeared explicitly in the literature was
 $\Omega (n^{0.51})$
due to Yehuda–Yehudayoff [Reference Yehuda and Yehudayoff13], but a bound of
$\Omega (n^{0.51})$
due to Yehuda–Yehudayoff [Reference Yehuda and Yehudayoff13], but a bound of
 $\Omega (n^{2/3}/(\log n)^{4/3})$
follows from a recent result of Klein [Reference Klein9] via the same deduction as in [Reference Yehuda and Yehudayoff13]. From the above-mentioned fact about essential covers proved by Linial and Radhakrishnan [Reference Linial and Radhakrishnan10], one can deduce the following stronger lower bound for the size of skew covers of
$\Omega (n^{2/3}/(\log n)^{4/3})$
follows from a recent result of Klein [Reference Klein9] via the same deduction as in [Reference Yehuda and Yehudayoff13]. From the above-mentioned fact about essential covers proved by Linial and Radhakrishnan [Reference Linial and Radhakrishnan10], one can deduce the following stronger lower bound for the size of skew covers of
 $\{\pm 1\}^n$
.
$\{\pm 1\}^n$
.
Observation 1.3.
For
 $n \gt 0$
, any skew cover of the
$n \gt 0$
, any skew cover of the
 $n$
-dimensional hypercube
$n$
-dimensional hypercube
 $\{\pm 1\}^n$
must consist of at least
$\{\pm 1\}^n$
must consist of at least
 $n/2$
hyperplanes.
$n/2$
hyperplanes.
We include a proof of this observation in Section 2, since this does not seem to have been previously observed in the literature (after the preprint version of this paper appeared, this observation was also independently made in [Reference Ivanisvili, Klein and Vershynin8]). The bound in Observation 1.3 is tight up to constant factors, as it is not hard to construct a skew cover of
 $\{\pm 1\}^n$
consisting of
$\{\pm 1\}^n$
consisting of
 $n+1$
hyperplanes (by taking the hyperplanes described by the equations
$n+1$
hyperplanes (by taking the hyperplanes described by the equations
 $x_1+\dots +x_n=n-2t$
for
$x_1+\dots +x_n=n-2t$
for
 $t=0,\dots, n$
).
$t=0,\dots, n$
).
Notation. For a positive integer
 $n$
, we use
$n$
, we use
 $[n]$
to denote the set
$[n]$
to denote the set
 $\{1,\dots, n\}$
. Given sets
$\{1,\dots, n\}$
. Given sets
 $A, B, C$
, we write
$A, B, C$
, we write
 $C = A\sqcup B$
to denote a partition of the set
$C = A\sqcup B$
to denote a partition of the set
 $C$
into two disjoint subsets
$C$
into two disjoint subsets
 $A$
and
$A$
and
 $B$
. For any real
$B$
. For any real
 $x\gt 0$
, we write
$x\gt 0$
, we write
 $\log x$
for the natural logarithm of
$\log x$
for the natural logarithm of
 $x$
in base
$x$
in base
 $e$
. For two sets
$e$
. For two sets
 $A, B$
, we use
$A, B$
, we use
 $B^A$
to denote the set of maps
$B^A$
to denote the set of maps
 $A\to B$
. For
$A\to B$
. For
 $x\in B^A$
and a subset
$x\in B^A$
and a subset
 $A^{\prime}\subseteq A$
, we denote the restriction of
$A^{\prime}\subseteq A$
, we denote the restriction of
 $x$
to
$x$
to
 $A^{\prime}$
by
$A^{\prime}$
by
 $x|_{A^{\prime}}$
, as usual. Given
$x|_{A^{\prime}}$
, as usual. Given
 $x\in B^A$
, one may think of
$x\in B^A$
, one may think of
 $x$
as a vector of length
$x$
as a vector of length
 $|A|$
indexed by the elements in
$|A|$
indexed by the elements in
 $A$
with each coordinate taking values in
$A$
with each coordinate taking values in
 $B$
, and for
$B$
, and for
 $a\in A$
, we write
$a\in A$
, we write
 $x_a$
for the value
$x_a$
for the value
 $x(a)\in B$
. For convenience, given a positive integer
$x(a)\in B$
. For convenience, given a positive integer
 $n$
, we use
$n$
, we use
 $B^n$
to denote
$B^n$
to denote
 $B^{[n]}$
(of course, this is consistent with the usual definition
$B^{[n]}$
(of course, this is consistent with the usual definition
 $B^n=B\times B\times \dots \times B$
).
$B^n=B\times B\times \dots \times B$
).
For a vector
 $v = (v_1,\dots, v_n)\in{\mathbb{R}}^n$
, we use
$v = (v_1,\dots, v_n)\in{\mathbb{R}}^n$
, we use
 $\operatorname{supp}(v)$
to denote the support of
$\operatorname{supp}(v)$
to denote the support of
 $v$
, which is the set of indices
$v$
, which is the set of indices
 $i\in [n]$
where
$i\in [n]$
where
 $v_i\ne 0$
. We recall that the
$v_i\ne 0$
. We recall that the
 $\ell _1$
-norm of
$\ell _1$
-norm of
 $v$
is defined as
$v$
is defined as
 $||v||_1 = \sum _{i = 1}^n |v_i|$
, the
$||v||_1 = \sum _{i = 1}^n |v_i|$
, the
 $\ell _2$
-norm of
$\ell _2$
-norm of
 $v$
is defined as
$v$
is defined as
 $||v||_2 = \left (\sum _{i = 1}^n v_i^2\right )^{1/2}$
, and the
$||v||_2 = \left (\sum _{i = 1}^n v_i^2\right )^{1/2}$
, and the
 $\ell _\infty$
-norm of
$\ell _\infty$
-norm of
 $v$
is defined as
$v$
is defined as
 $||v||_\infty = \max _{i\in [n]}|v_i|$
. Given two vectors
$||v||_\infty = \max _{i\in [n]}|v_i|$
. Given two vectors
 $u,v\in{\mathbb{R}}^n$
, we write
$u,v\in{\mathbb{R}}^n$
, we write
 $\langle u,v\rangle = \sum _{i = 1}^n u_iv_i$
for the standard inner product on
$\langle u,v\rangle = \sum _{i = 1}^n u_iv_i$
for the standard inner product on
 ${\mathbb{R}}^n$
. For an
${\mathbb{R}}^n$
. For an
 $n\times m$
matrix
$n\times m$
matrix
 $V\in{\mathbb{R}}^{n\times m}$
and subsets
$V\in{\mathbb{R}}^{n\times m}$
and subsets
 $A\subseteq [n]$
and
$A\subseteq [n]$
and
 $ B\subseteq [m]$
, we use
$ B\subseteq [m]$
, we use
 $V[A\times B]$
to denote the
$V[A\times B]$
to denote the
 $|A|\times |B|$
submatrix of
$|A|\times |B|$
submatrix of
 $V$
consisting of the rows in
$V$
consisting of the rows in
 $A$
and the columns in
$A$
and the columns in
 $B$
.
$B$
.
2. Preliminaries
In this section, we discuss useful definitions and lemmas for our argument. We start with the following two definitions that characterise vectors with many different magnitudes.
Definition 2.1 (Magnitude). For any
 $x\in{\mathbb{R}}\setminus \{0\}$
, we say that
$x\in{\mathbb{R}}\setminus \{0\}$
, we say that
 $x$
has magnitude
$x$
has magnitude
 $j\in \mathbb{Z}$
if
$j\in \mathbb{Z}$
if
 $10^{j} \le |x| \lt 10^{j+1}$
.
$10^{j} \le |x| \lt 10^{j+1}$
.
Definition 2.2.
For a positive integer
 $S \gt 0$
, we say that a vector
$S \gt 0$
, we say that a vector
 $v$
has at least
$v$
has at least
 $S$
magnitudes if there exist
$S$
magnitudes if there exist
 $S$
non-zero entries in
$S$
non-zero entries in
 $v$
with distinct magnitudes.
$v$
with distinct magnitudes.
We remark that the notion of having many magnitudes is a simpler version of the notion of having “many scales” introduced in [Reference Yehuda and Yehudayoff13] and later used in [Reference Araujo, Balogh and Mattos3, Reference Yehuda and Yehudayoff12].
The motivation behind the above definitions is the following lemma, which states that given a vector
 $v\in{\mathbb{R}}^n$
with at least
$v\in{\mathbb{R}}^n$
with at least
 $S$
magnitudes, for a random vector
$S$
magnitudes, for a random vector
 $w\in \{\pm 1\}^n$
, the probability of the event
$w\in \{\pm 1\}^n$
, the probability of the event
 $\langle v,w\rangle = \alpha$
for any given value
$\langle v,w\rangle = \alpha$
for any given value
 $\alpha \in{\mathbb{R}}$
is exponentially small in
$\alpha \in{\mathbb{R}}$
is exponentially small in
 $S$
. For our purposes, it is convenient to state the lemma for a biased random vector
$S$
. For our purposes, it is convenient to state the lemma for a biased random vector
 $w\in \{\pm 1\}^n$
. We remark that a similar lemma also appears in [Reference Klein9].
$w\in \{\pm 1\}^n$
. We remark that a similar lemma also appears in [Reference Klein9].
Lemma 2.3.
Let
 $v\in{\mathbb{R}}^{n}$
be a vector with at least
$v\in{\mathbb{R}}^{n}$
be a vector with at least
 $S$
magnitudes. Let
$S$
magnitudes. Let
 $p\in [1/3, 2/3]^n$
and consider a random vector
$p\in [1/3, 2/3]^n$
and consider a random vector
 $w\in \{\pm 1\}^n$
with independent random entries
$w\in \{\pm 1\}^n$
with independent random entries
 $w_1,\dots, w_n\in \{\pm 1\}$
, whose distributions are given by
$w_1,\dots, w_n\in \{\pm 1\}$
, whose distributions are given by
 \begin{equation*}w_i = \begin {cases} 1 & \text {with probability } p_i \\[4pt] -1 & \text {with probability } 1-p_i \end {cases} \quad \text {for all } i\in [n].\end{equation*}
\begin{equation*}w_i = \begin {cases} 1 & \text {with probability } p_i \\[4pt] -1 & \text {with probability } 1-p_i \end {cases} \quad \text {for all } i\in [n].\end{equation*}
Then for any
 $\alpha \in{\mathbb{R}}$
, we have
$\alpha \in{\mathbb{R}}$
, we have
 \begin{equation*}{\mathbb {P}}\left[\langle v, w\rangle = \alpha \right] \le \left (\frac {2}{3}\right )^{\lceil S/2\rceil }.\end{equation*}
\begin{equation*}{\mathbb {P}}\left[\langle v, w\rangle = \alpha \right] \le \left (\frac {2}{3}\right )^{\lceil S/2\rceil }.\end{equation*}
Proof. Let
 $r = \lceil S/2\rceil$
. Among the at least
$r = \lceil S/2\rceil$
. Among the at least
 $S$
different magnitudes occurring for the entries of the vector
$S$
different magnitudes occurring for the entries of the vector
 $v$
, there are at least
$v$
, there are at least
 $r$
even numbers or at least
$r$
even numbers or at least
 $r$
odd numbers. So, upon relabelling the indices, we may assume without loss of generality that the first
$r$
odd numbers. So, upon relabelling the indices, we may assume without loss of generality that the first
 $r$
entries
$r$
entries
 $v_1,\dots, v_r$
of
$v_1,\dots, v_r$
of
 $v=(v_1,\dots, v_n)\in{\mathbb{R}}^n$
have distinct magnitudes with the same parity and are ordered in decreasing order of magnitudes. Now, for each
$v=(v_1,\dots, v_n)\in{\mathbb{R}}^n$
have distinct magnitudes with the same parity and are ordered in decreasing order of magnitudes. Now, for each
 $i\in [r-1]$
, if
$i\in [r-1]$
, if
 $m$
is the magnitude of
$m$
is the magnitude of
 $v_i$
, then
$v_i$
, then
 $v_{i+1}$
has magnitude at most
$v_{i+1}$
has magnitude at most
 $m-2$
. This means that
$m-2$
. This means that
 $|v_i|\ge 10^m$
and
$|v_i|\ge 10^m$
and
 $|v_{i+1}| \lt 10^{m-1}$
, and therefore
$|v_{i+1}| \lt 10^{m-1}$
, and therefore
 $|v_i| \ge 10 |v_{i+1}|$
for every
$|v_i| \ge 10 |v_{i+1}|$
for every
 $i\in [r-1]$
.
$i\in [r-1]$
.
This implies that for any
 $\alpha \in{\mathbb{R}}$
, there is at most one assignment for
$\alpha \in{\mathbb{R}}$
, there is at most one assignment for
 $w_1,\dots, w_r\in \{\pm 1\}$
satisfying
$w_1,\dots, w_r\in \{\pm 1\}$
satisfying
 $\sum _{i = 1}^r v_iw_i = \alpha$
. Indeed, if there were two distinct such assignments
$\sum _{i = 1}^r v_iw_i = \alpha$
. Indeed, if there were two distinct such assignments
 $(w_1,\dots, w_r),\big(w^{\prime}_1,\dots, w^{\prime}_r\big)\in \{\pm 1\}^r$
, then we would have
$(w_1,\dots, w_r),\big(w^{\prime}_1,\dots, w^{\prime}_r\big)\in \{\pm 1\}^r$
, then we would have
 $\sum _{i = 1}^r v_i\big(w_i-w^{\prime}_i\big) = \alpha -\alpha =0$
. So for the minimum index
$\sum _{i = 1}^r v_i\big(w_i-w^{\prime}_i\big) = \alpha -\alpha =0$
. So for the minimum index
 $j\in \{1,\dots, r\}$
with
$j\in \{1,\dots, r\}$
with
 $w_j\ne w^{\prime}_j$
, we would have
$w_j\ne w^{\prime}_j$
, we would have
 \begin{equation*}2|v_j|=\big|v_j\big(w_j-w^{\prime}_j\big)\big|=\left|\sum _{i = j+1}^r v_i\big(w_i-w^{\prime}_i\big)\right|\le \sum _{i = j+1}^r 2|v_i|\le \sum _{i = j+1}^r 2|v_j|/10^{j-i}\lt \frac {2}{9}\cdot |v_j|,\end{equation*}
\begin{equation*}2|v_j|=\big|v_j\big(w_j-w^{\prime}_j\big)\big|=\left|\sum _{i = j+1}^r v_i\big(w_i-w^{\prime}_i\big)\right|\le \sum _{i = j+1}^r 2|v_i|\le \sum _{i = j+1}^r 2|v_j|/10^{j-i}\lt \frac {2}{9}\cdot |v_j|,\end{equation*}
yielding a contradiction. So for any
 $\alpha \in{\mathbb{R}}$
, there can be at most one such assignment
$\alpha \in{\mathbb{R}}$
, there can be at most one such assignment
 $(w_1,\dots, w_r)\in \{\pm 1\}^r$
.
$(w_1,\dots, w_r)\in \{\pm 1\}^r$
.
Let us now condition on arbitrary outcomes of
 $w_{r+1},\dots, w_{n}\in \{\pm 1\}$
. Conditional on such fixed outcomes, it suffices to show that, for any
$w_{r+1},\dots, w_{n}\in \{\pm 1\}$
. Conditional on such fixed outcomes, it suffices to show that, for any
 $\alpha \in{\mathbb{R}}$
, we have
$\alpha \in{\mathbb{R}}$
, we have
 $\sum _{i = 1}^r v_iw_i = \alpha - \sum _{j = r+1}^n v_jw_j$
with probability at most
$\sum _{i = 1}^r v_iw_i = \alpha - \sum _{j = r+1}^n v_jw_j$
with probability at most
 $\left (\frac{2}{3}\right )^{r}$
. Recall that there is at most one assignment for
$\left (\frac{2}{3}\right )^{r}$
. Recall that there is at most one assignment for
 $w_1,\dots, w_r\in \{\pm 1\}$
satisfying this equation. Since
$w_1,\dots, w_r\in \{\pm 1\}$
satisfying this equation. Since
 $w_1,\dots, w_r$
are independent random variables with
$w_1,\dots, w_r$
are independent random variables with
 \begin{equation*}{\mathbb {P}}[w_i = 1] \le \frac {2}{3} \quad \text {and} \quad {\mathbb {P}}[w_i = -1] \le \frac {2}{3}\end{equation*}
\begin{equation*}{\mathbb {P}}[w_i = 1] \le \frac {2}{3} \quad \text {and} \quad {\mathbb {P}}[w_i = -1] \le \frac {2}{3}\end{equation*}
for every
 $i\in [r]$
, we obtain
$i\in [r]$
, we obtain
 \begin{equation*}{\mathbb {P}}\left [\sum _{i = 1}^r v_iw_i = \alpha - \sum _{j = r+1}^n v_jw_j \, \Bigg | \, w_{r+1},\dots, w_n \right ] \le \left (\frac {2}{3}\right )^r = \left (\frac {2}{3}\right )^{\lceil S/2\rceil }.\end{equation*}
\begin{equation*}{\mathbb {P}}\left [\sum _{i = 1}^r v_iw_i = \alpha - \sum _{j = r+1}^n v_jw_j \, \Bigg | \, w_{r+1},\dots, w_n \right ] \le \left (\frac {2}{3}\right )^r = \left (\frac {2}{3}\right )^{\lceil S/2\rceil }.\end{equation*}
This implies our desired statement.
The following lemma is due to Linial and Radhakrishnan [Reference Linial and Radhakrishnan10] and gives an upper bound for the number of non-zero coefficients for the hyperplane equations in an essential cover. It can be proved via the Combinatorial Nullstellensatz [Reference Alon1].
Lemma 2.4 ( [Reference Linial and Radhakrishnan10]). Let
 $h_1,\dots, h_k$
be hyperplanes in
$h_1,\dots, h_k$
be hyperplanes in
 ${\mathbb{R}}^n$
forming an essential cover of the hypercube
${\mathbb{R}}^n$
forming an essential cover of the hypercube
 $\{\pm 1\}^n$
. For each
$\{\pm 1\}^n$
. For each
 $i\in [k]$
, let
$i\in [k]$
, let
 $h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
. Then we have
$h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
. Then we have
 $|\operatorname{supp}(v_i)|\le 2k$
for all
$|\operatorname{supp}(v_i)|\le 2k$
for all
 $i\in [k]$
.
$i\in [k]$
.
We observed that Lemma 2.4 also gives a lower bound for the number of hyperplanes in any skew cover of the hypercube
 $\{\pm 1\}^n$
, as stated in Observation 1.3. Recall that the hyperplanes
$\{\pm 1\}^n$
, as stated in Observation 1.3. Recall that the hyperplanes
 $h_1,\dots, h_k$
form a skew cover of the hypercube
$h_1,\dots, h_k$
form a skew cover of the hypercube
 $\{\pm 1\}^n$
if every vertex in
$\{\pm 1\}^n$
if every vertex in
 $\{\pm 1\}^n$
is covered by at least one of the hyperplanes
$\{\pm 1\}^n$
is covered by at least one of the hyperplanes
 $h_1,\dots, h_k$
and for each
$h_1,\dots, h_k$
and for each
 $i=1,\dots, k$
, when writing
$i=1,\dots, k$
, when writing
 $h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, all coordinates of vector
$h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, all coordinates of vector
 $v_i\in{\mathbb{R}}^n$
are non-zero.
$v_i\in{\mathbb{R}}^n$
are non-zero.
Proof of Observation
1.3. Suppose
 $h_1,\dots, h_k$
are hyperplanes forming a skew cover of
$h_1,\dots, h_k$
are hyperplanes forming a skew cover of
 $\{\pm 1\}^n$
. For
$\{\pm 1\}^n$
. For
 $i=1,\dots, k$
, let us write
$i=1,\dots, k$
, let us write
 $h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
. Then for every
$h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
. Then for every
 $i\in [k]$
, all coordinates of the vector
$i\in [k]$
, all coordinates of the vector
 $v_i$
are non-zero.
$v_i$
are non-zero.
Let
 $I\subseteq [k]$
be a minimal subset with respect to the property that the hyperplanes
$I\subseteq [k]$
be a minimal subset with respect to the property that the hyperplanes
 $h_i$
for
$h_i$
for
 $i\in I$
cover all vertices in
$i\in I$
cover all vertices in
 $\{\pm 1\}^n$
(and note that
$\{\pm 1\}^n$
(and note that
 $I\ne \emptyset$
). We claim that these hyperplanes
$I\ne \emptyset$
). We claim that these hyperplanes
 $h_i$
for
$h_i$
for
 $i\in I$
form an essential cover of
$i\in I$
form an essential cover of
 $\{\pm 1\}^n$
. Indeed, conditions (E1) and (E3) in Definition 1.1 are satisfied by the choice of
$\{\pm 1\}^n$
. Indeed, conditions (E1) and (E3) in Definition 1.1 are satisfied by the choice of
 $I$
. Condition (E2) is satisfied because for every index
$I$
. Condition (E2) is satisfied because for every index
 $i\in I$
, all coordinates of
$i\in I$
, all coordinates of
 $v_i$
are non-zero (so for any
$v_i$
are non-zero (so for any
 $j\in [n]$
, one can take an arbitrary index
$j\in [n]$
, one can take an arbitrary index
 $i\in I$
in condition (E2)).
$i\in I$
in condition (E2)).
Now, taking an arbitrary index
 $i\in I$
, Lemma 2.4 implies that
$i\in I$
, Lemma 2.4 implies that
 $n=|\operatorname{supp}(v_i)|\le 2|I|\le 2k$
, so we must have
$n=|\operatorname{supp}(v_i)|\le 2|I|\le 2k$
, so we must have
 $k\ge n/2$
.
$k\ge n/2$
.
Our proof of Theorem 1.2 also relies on the following lemma, which Ball [Reference Ball4] extracted from Bang’s solution of Tarski’s plank problem [Reference Bang5] (see, e.g. [Reference Araujo, Balogh and Mattos3] for a short self-contained proof of this lemma).
Lemma 2.5 (Bang’s lemma [Reference Ball4, Reference Bang5]). Let
 $M$
be a symmetric
$M$
be a symmetric
 $\ell \times \ell$
matrix such that
$\ell \times \ell$
matrix such that
 $M_{ii} = 1$
for every
$M_{ii} = 1$
for every
 $i\in [\ell ]$
. Then for any vector
$i\in [\ell ]$
. Then for any vector
 $\mu = (\mu _1,\dots, \mu _\ell )\in{\mathbb{R}}^\ell$
and any real number
$\mu = (\mu _1,\dots, \mu _\ell )\in{\mathbb{R}}^\ell$
and any real number
 $\theta \ge 0$
, there exists
$\theta \ge 0$
, there exists
 $\varepsilon \in \{\pm 1\}^\ell$
such that
$\varepsilon \in \{\pm 1\}^\ell$
such that
 \begin{equation*}\big |(M(\theta \varepsilon ))_i - \mu _i\big |\ge \theta \quad \text {for all } i\in [\ell ].\end{equation*}
\begin{equation*}\big |(M(\theta \varepsilon ))_i - \mu _i\big |\ge \theta \quad \text {for all } i\in [\ell ].\end{equation*}
In our proof of Theorem 1.2, we apply the following corollary of Lemma 2.5 to a certain submatrix of the coefficient matrix of an essential cover. This allows us to find a point that is far from certain hyperplanes in the cover.
Corollary 2.6.
Let
 $V\in{\mathbb{R}}^{\ell \times m}$
be an
$V\in{\mathbb{R}}^{\ell \times m}$
be an
 $\ell \times m$
matrix with row vectors
$\ell \times m$
matrix with row vectors
 $v_1,\dots, v_\ell \in{\mathbb{R}}^{m}$
and column vectors
$v_1,\dots, v_\ell \in{\mathbb{R}}^{m}$
and column vectors
 $v_{*1},\dots, v_{*m}\in{\mathbb{R}}^\ell$
. Suppose that
$v_{*1},\dots, v_{*m}\in{\mathbb{R}}^\ell$
. Suppose that
 $||v_i||_2 = 1$
for all
$||v_i||_2 = 1$
for all
 $i\in [\ell ]$
, and let
$i\in [\ell ]$
, and let
 $\theta \ge 0$
be a real number satisfying
$\theta \ge 0$
be a real number satisfying
 $\theta ||v_{*j}||_1 \le 1/3$
for all
$\theta ||v_{*j}||_1 \le 1/3$
for all
 $j\in [m]$
. Then for any vector
$j\in [m]$
. Then for any vector
 $\mu = (\mu _1,\dots, \mu _\ell )\in{\mathbb{R}}^\ell$
, there exists
$\mu = (\mu _1,\dots, \mu _\ell )\in{\mathbb{R}}^\ell$
, there exists
 $y\in{\mathbb{R}}^m$
such that
$y\in{\mathbb{R}}^m$
such that
 $||y||_\infty \le 1/3$
and
$||y||_\infty \le 1/3$
and
 \begin{equation*}\big |\langle v_i, y\rangle - \mu _i\big |\ge \theta \quad \text {for all } i\in [\ell ].\end{equation*}
\begin{equation*}\big |\langle v_i, y\rangle - \mu _i\big |\ge \theta \quad \text {for all } i\in [\ell ].\end{equation*}
Proof. Apply Lemma 2.5 to the symmetric
 $\ell \times \ell$
matrix
$\ell \times \ell$
matrix
 $M:= V V^T$
and the vector
$M:= V V^T$
and the vector
 $\mu \in{\mathbb{R}}^{\ell }$
. Note that we have
$\mu \in{\mathbb{R}}^{\ell }$
. Note that we have
 $M_{ii} =1$
for all
$M_{ii} =1$
for all
 $i\in [\ell ]$
since
$i\in [\ell ]$
since
 $||v_i||_2 = 1$
for all
$||v_i||_2 = 1$
for all
 $i\in [\ell ]$
. Hence there exists a vector
$i\in [\ell ]$
. Hence there exists a vector
 $\varepsilon \in \{\pm 1\}^\ell$
such that
$\varepsilon \in \{\pm 1\}^\ell$
such that
 \begin{equation*}\big |(M(\theta \varepsilon ))_i - \mu _i\big |\ge \theta \quad \text {for all } i\in [\ell ].\end{equation*}
\begin{equation*}\big |(M(\theta \varepsilon ))_i - \mu _i\big |\ge \theta \quad \text {for all } i\in [\ell ].\end{equation*}
Setting
 $y := \theta V^T \varepsilon \in{\mathbb{R}}^m$
, for every
$y := \theta V^T \varepsilon \in{\mathbb{R}}^m$
, for every
 $i\in [\ell ]$
, we obtain
$i\in [\ell ]$
, we obtain
 \begin{equation*}\big |\langle v_i, y\rangle - \mu _i\big | =\big |(Vy)_i - \mu _i\big |=\left |(V(\theta V^T \varepsilon ))_i - \mu _i\right |=\left |(VV^T(\theta \varepsilon ))_i - \mu _i\right |=\left |(M(\theta \varepsilon ))_i - \mu _i\right |\ge \theta .\end{equation*}
\begin{equation*}\big |\langle v_i, y\rangle - \mu _i\big | =\big |(Vy)_i - \mu _i\big |=\left |(V(\theta V^T \varepsilon ))_i - \mu _i\right |=\left |(VV^T(\theta \varepsilon ))_i - \mu _i\right |=\left |(M(\theta \varepsilon ))_i - \mu _i\right |\ge \theta .\end{equation*}
Furthermore, we have
 \begin{align*} ||y||_\infty &= ||\theta V^T\varepsilon ||_\infty = \max _{j\in [m]}\left |\theta \sum _{i = 1}^\ell v_{ij}\varepsilon _i\right | \le \max _{j\in [m]}\theta \sum _{i = 1}^\ell |v_{ij}| = \max _{j\in [m]} \theta ||v_{*j}||_1 \le \frac{1}{3}, \end{align*}
\begin{align*} ||y||_\infty &= ||\theta V^T\varepsilon ||_\infty = \max _{j\in [m]}\left |\theta \sum _{i = 1}^\ell v_{ij}\varepsilon _i\right | \le \max _{j\in [m]}\theta \sum _{i = 1}^\ell |v_{ij}| = \max _{j\in [m]} \theta ||v_{*j}||_1 \le \frac{1}{3}, \end{align*}
as desired.
Finally, we will use the following well-known concentration inequality.
Lemma 2.7 (Hoeffding’s inequality [Reference Hoeffding7]). Let
 $a_1,\dots, a_\ell, b_1,\dots, b_\ell \in{\mathbb{R}}$
and let
$a_1,\dots, a_\ell, b_1,\dots, b_\ell \in{\mathbb{R}}$
and let
 $z_1,\dots, z_\ell$
be independent real random variables such that for all
$z_1,\dots, z_\ell$
be independent real random variables such that for all
 $j\in [\ell ]$
, we always have
$j\in [\ell ]$
, we always have
 $a_j\le z_j\le b_j$
. Let
$a_j\le z_j\le b_j$
. Let
 $z = \sum _{i= 1}^\ell z_i$
, then for every
$z = \sum _{i= 1}^\ell z_i$
, then for every
 $t \gt 0$
, we have
$t \gt 0$
, we have
 \begin{equation*}{\mathbb {P}}\Big [\big |z - {\mathbb {E}}[z]\big | \ge t\Big ] \le 2\cdot \exp \left ({-}\frac {2t^2}{\sum _{j = 1}^\ell (b_j - a_j)^2}\right ).\end{equation*}
\begin{equation*}{\mathbb {P}}\Big [\big |z - {\mathbb {E}}[z]\big | \ge t\Big ] \le 2\cdot \exp \left ({-}\frac {2t^2}{\sum _{j = 1}^\ell (b_j - a_j)^2}\right ).\end{equation*}
3. Outline
We employ a strategy similar to the one in [Reference Yehuda and Yehudayoff12]. Given an essential cover of the hypercube
 $\{\pm 1\}^n$
, we consider its coefficient matrix, recording the coefficients of the linear equations corresponding to the hyperplanes in the cover. More formally, if the hyperplanes are given by equations of the form
$\{\pm 1\}^n$
, we consider its coefficient matrix, recording the coefficients of the linear equations corresponding to the hyperplanes in the cover. More formally, if the hyperplanes are given by equations of the form
 $\langle v_i,x\rangle = \mu _i$
for
$\langle v_i,x\rangle = \mu _i$
for
 $i=1,\dots, k$
, then the coefficient matrix of the essential cover is the
$i=1,\dots, k$
, then the coefficient matrix of the essential cover is the
 $k\times n$
matrix with rows
$k\times n$
matrix with rows
 $v_1,\dots, v_k$
.
$v_1,\dots, v_k$
.
We first show that for any essential cover consisting of only a small number of hyperplanes, there is a decomposition of the coefficient matrix of a certain structured form. Using this decomposition, we then obtain a contradiction by probabilistically finding a vertex in
 $\{\pm 1\}^n$
that is not covered by any of the hyperplanes in the cover. Our decomposition of the coefficient matrix is given by the following proposition.
$\{\pm 1\}^n$
that is not covered by any of the hyperplanes in the cover. Our decomposition of the coefficient matrix is given by the following proposition.
Proposition 3.1 (Matrix decomposition). For
 $n\ge 2$
, let
$n\ge 2$
, let
 $h_1,\dots, h_k$
be hyperplanes in
$h_1,\dots, h_k$
be hyperplanes in
 ${\mathbb{R}}^n$
forming an essential cover of the hypercube
${\mathbb{R}}^n$
forming an essential cover of the hypercube
 $\{\pm 1\}^n$
. For each
$\{\pm 1\}^n$
. For each
 $i\in [k]$
, let
$i\in [k]$
, let
 $h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, and let
$h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, and let
 $V\in{\mathbb{R}}^{k\times n}$
be the matrix with rows
$V\in{\mathbb{R}}^{k\times n}$
be the matrix with rows
 $v_1,\dots, v_k$
. If
$v_1,\dots, v_k$
. If
 $k\le 10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
, then there exists a partition
$k\le 10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
, then there exists a partition
 $[k] = K_1\sqcup K_2\sqcup K_3$
of the row indices of
$[k] = K_1\sqcup K_2\sqcup K_3$
of the row indices of
 $V$
and a partition
$V$
and a partition
 $[n] = N_1\sqcup N_2$
of the column indices of
$[n] = N_1\sqcup N_2$
of the column indices of
 $V$
with
$V$
with
 $N_1 \ne \emptyset$
, such that the following conditions hold:
$N_1 \ne \emptyset$
, such that the following conditions hold:
-
1. Every entry in the submatrix
$V[K_1 \times N_1]$
is zero.
-
2. There exists a
$|K_2|\times |N_1|$
matrix
$V^{\prime}$
that can be obtained from
$V[K_2\times N_1]$
by rescaling the rows in some way (by some non-zero real numbers), such that every row in
$V^{\prime}$
has
$\ell _2$
-norm equal to
$1$
and every column in
$V^{\prime}$
has
$\ell _1$
-norm at most
$(60\log n)^{-1/2}$
. -
3. In the submatrix
$V[K_3\times N_1]$
, every row has at least
$\lceil 10\log n\rceil$
magnitudes.













Figure 1. The decomposition of the coefficient matrix
 $V$
of the essential cover.
$V$
of the essential cover.
Figure 1 illustrates the decomposition in Proposition 3.1. We remark that in Proposition 3.1, some of the subsets
 $K_1,K_2,K_3\subseteq [k]$
may be empty, and similarly,
$K_1,K_2,K_3\subseteq [k]$
may be empty, and similarly,
 $N_2\subseteq [n]$
may be empty.
$N_2\subseteq [n]$
may be empty.
Given an essential cover whose coefficient matrix can be decomposed as in Proposition 3.1, we show that there must exist a vertex in
 $\{\pm 1\}^n$
that is not covered by any of the hyperplanes (yielding a contradiction to condition (E1)). This is stated in the following proposition.
$\{\pm 1\}^n$
that is not covered by any of the hyperplanes (yielding a contradiction to condition (E1)). This is stated in the following proposition.
Proposition 3.2.
For
 $n\ge 2$
, let
$n\ge 2$
, let
 $h_1,\dots, h_k$
be hyperplanes in
$h_1,\dots, h_k$
be hyperplanes in
 ${\mathbb{R}}^n$
forming an essential cover of the hypercube
${\mathbb{R}}^n$
forming an essential cover of the hypercube
 $\{\pm 1\}^n$
. For each
$\{\pm 1\}^n$
. For each
 $i\in [k]$
, let
$i\in [k]$
, let
 $h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, and let
$h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, and let
 $V\in{\mathbb{R}}^{k\times n}$
be the matrix with rows
$V\in{\mathbb{R}}^{k\times n}$
be the matrix with rows
 $v_1,\dots, v_k$
. Suppose that the matrix
$v_1,\dots, v_k$
. Suppose that the matrix
 $V$
has a decomposition as in Proposition 3.1 and that
$V$
has a decomposition as in Proposition 3.1 and that
 $k\le n$
. Then there exists
$k\le n$
. Then there exists
 $w\in \{\pm 1\}^n$
such that
$w\in \{\pm 1\}^n$
such that
 $\langle v_i, w\rangle \ne \mu _i$
for all
$\langle v_i, w\rangle \ne \mu _i$
for all
 $i\in [k]$
.
$i\in [k]$
.
In other words, this proposition states that actually the coefficient matrix of an essential cover cannot have a decomposition as in Proposition 3.1. This means that we cannot have
 $k\le 10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
.
$k\le 10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
.
The proof of Proposition 3.2 employs a similar strategy to [Reference Araujo, Balogh and Mattos3, Reference Yehuda and Yehudayoff12]: we find a certain probability distribution on
 $\{\pm 1\}^n$
such that with positive probability a random vertex
$\{\pm 1\}^n$
such that with positive probability a random vertex
 $w\in \{\pm 1\}^n$
with this distribution avoids all the hyperplanes. To do so, we first fix the coordinates of
$w\in \{\pm 1\}^n$
with this distribution avoids all the hyperplanes. To do so, we first fix the coordinates of
 $w$
with indices in
$w$
with indices in
 $N_2$
deterministically using the minimality property of an essential cover (property (E3) in Definition 1.1) to always avoid all the hyperplanes
$N_2$
deterministically using the minimality property of an essential cover (property (E3) in Definition 1.1) to always avoid all the hyperplanes
 $h_i$
with
$h_i$
with
 $i\in K_1$
. Then we construct probability distributions for the coordinates of
$i\in K_1$
. Then we construct probability distributions for the coordinates of
 $w$
with indices in
$w$
with indices in
 $N_1$
such that with positive probability
$N_1$
such that with positive probability
 $w$
avoids all the hyperplanes
$w$
avoids all the hyperplanes
 $h_i$
with
$h_i$
with
 $i\in K_2\cup K_3$
. The probability distribution is constructed by applying Corollary 2.6 (a corollary of Bang’s lemma) to the matrix
$i\in K_2\cup K_3$
. The probability distribution is constructed by applying Corollary 2.6 (a corollary of Bang’s lemma) to the matrix
 $V^{\prime}$
in condition (2) in Proposition 3.1. This way, we find a point
$V^{\prime}$
in condition (2) in Proposition 3.1. This way, we find a point
 $y\in [-1/3,1/3]^{N_1}$
that is “far away” from all hyperplanes
$y\in [-1/3,1/3]^{N_1}$
that is “far away” from all hyperplanes
 $h_i$
with
$h_i$
with
 $i\in K_2$
. We then randomly round
$i\in K_2$
. We then randomly round
 $y$
to a vertex in
$y$
to a vertex in
 $\{\pm 1\}^{N_1}$
of the hypercube to define coordinates of
$\{\pm 1\}^{N_1}$
of the hypercube to define coordinates of
 $w$
with indices in
$w$
with indices in
 $N_1$
. We can show that for any
$N_1$
. We can show that for any
 $i\in K_2$
, the vertex
$i\in K_2$
, the vertex
 $w$
is unlikely to be contained in the hyperplane
$w$
is unlikely to be contained in the hyperplane
 $h_i$
because
$h_i$
because
 $y$
is “far away” from
$y$
is “far away” from
 $h_i$
. To bound the probability that
$h_i$
. To bound the probability that
 $w$
is contained in a hyperplane
$w$
is contained in a hyperplane
 $h_i$
with
$h_i$
with
 $i\in K_3$
, we use that by condition (3) in Proposition 3.1 every row of the submatrix
$i\in K_3$
, we use that by condition (3) in Proposition 3.1 every row of the submatrix
 $V[K_3\times N_1]$
has many magnitudes. So for each
$V[K_3\times N_1]$
has many magnitudes. So for each
 $i\in K_3$
, Lemma 2.3 implies an upper bound for the probability that
$i\in K_3$
, Lemma 2.3 implies an upper bound for the probability that
 $w$
is contained in
$w$
is contained in
 $h_i$
.
$h_i$
.
Despite the similarity in the overall strategy between our argument and the arguments in [Reference Araujo, Balogh and Mattos3, Reference Yehuda and Yehudayoff12], we highlight the fact that we have a simpler matrix decomposition in Proposition 3.1 and a much shorter proof for Proposition 3.2, while obtaining a better bound. The proof of Proposition 1.2 follows directly from combining Propositions 3.1 and 3.2.
Proof of Theorem
1.2. Suppose for contradiction that the hyperplanes
 $h_1,\dots, h_k$
form an essential cover of the hypercube
$h_1,\dots, h_k$
form an essential cover of the hypercube
 $\{\pm 1\}^{n}$
of size
$\{\pm 1\}^{n}$
of size
 $k \lt 10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
. For each
$k \lt 10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
. For each
 $i\in [k]$
, let
$i\in [k]$
, let
 $h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, and let
$h_i=\{x\in{\mathbb{R}}^n \mid \langle v_i,x\rangle = \mu _i\}$
, and let
 $V\in{\mathbb{R}}^{k\times n}$
be the matrix with rows
$V\in{\mathbb{R}}^{k\times n}$
be the matrix with rows
 $v_1,\dots, v_k$
. Then, we can decompose
$v_1,\dots, v_k$
. Then, we can decompose
 $V$
as in Proposition 3.1. But now by Proposition 3.2, there must be a vertex
$V$
as in Proposition 3.1. But now by Proposition 3.2, there must be a vertex
 $w\in \{\pm 1\}^n$
that is not covered by any of the hyperplanes
$w\in \{\pm 1\}^n$
that is not covered by any of the hyperplanes
 $h_1,\dots, h_k$
. This contradicts condition (E1) in the definition of an essential cover in Definition 1.1.
$h_1,\dots, h_k$
. This contradicts condition (E1) in the definition of an essential cover in Definition 1.1.
The rest of the paper is structured as follows. In section 4, we show that for an essential cover whose coefficient matrix has a decomposition as in Proposition 3.1, there must be a vertex
 $w\in \{\pm 1\}^n$
that is not covered by any of the hyperplanes; that is, we prove Proposition 3.2. Then in section 5, we prove Proposition 3.1.
$w\in \{\pm 1\}^n$
that is not covered by any of the hyperplanes; that is, we prove Proposition 3.2. Then in section 5, we prove Proposition 3.1.
4. Finding the uncovered vertex
In this section, we prove Proposition 3.2; that is, we show that given an essential cover of the hypercube
 $\{\pm 1\}^{n}$
whose the coefficient matrix
$\{\pm 1\}^{n}$
whose the coefficient matrix
 $V\in{\mathbb{R}}^{k\times n}$
can be decomposed as in Proposition 3.1, we can find a vertex
$V\in{\mathbb{R}}^{k\times n}$
can be decomposed as in Proposition 3.1, we can find a vertex
 $w\in \{\pm 1\}^n$
that is not covered by any of the hyperplanes. For partitions
$w\in \{\pm 1\}^n$
that is not covered by any of the hyperplanes. For partitions
 $[k] = K_1\sqcup K_2\sqcup K_3$
and
$[k] = K_1\sqcup K_2\sqcup K_3$
and
 $[n] = N_1\sqcup N_2$
as in Proposition 3.1, we construct
$[n] = N_1\sqcup N_2$
as in Proposition 3.1, we construct
 $w\in \{\pm 1\}^n$
by first fixing the entries
$w\in \{\pm 1\}^n$
by first fixing the entries
 $w_j$
for
$w_j$
for
 $j\in N_2$
to avoid all the hyperplanes
$j\in N_2$
to avoid all the hyperplanes
 $h_i$
with
$h_i$
with
 $i\in K_1$
deterministically and then probabilistically choosing the entries
$i\in K_1$
deterministically and then probabilistically choosing the entries
 $w_j$
for
$w_j$
for
 $j\in N_1$
, avoiding all the hyperplanes
$j\in N_1$
, avoiding all the hyperplanes
 $h_i$
with
$h_i$
with
 $i\in K_2\cup K_3$
with positive probability.
$i\in K_2\cup K_3$
with positive probability.
Proof of Proposition
3.2. Let
 $[k] = K_1\sqcup K_2\sqcup K_3$
and
$[k] = K_1\sqcup K_2\sqcup K_3$
and
 $[n] = N_1\sqcup N_2$
be partitions satisfying the conditions in Proposition 3.1. Note that these conditions are not affected by rescaling the hyperplane equations
$[n] = N_1\sqcup N_2$
be partitions satisfying the conditions in Proposition 3.1. Note that these conditions are not affected by rescaling the hyperplane equations
 $\langle v_i,x\rangle = \mu _i$
describing the hyperplanes
$\langle v_i,x\rangle = \mu _i$
describing the hyperplanes
 $h_i$
for
$h_i$
for
 $i\in K_2$
. We may therefore assume that the matrix
$i\in K_2$
. We may therefore assume that the matrix
 $V^{\prime}$
in condition (2) in Proposition 3.1 is simply
$V^{\prime}$
in condition (2) in Proposition 3.1 is simply
 $V^{\prime}=V[K_2\times N_1]$
after rescaling the equations
$V^{\prime}=V[K_2\times N_1]$
after rescaling the equations
 $\langle v_i,x\rangle = \mu _i$
for
$\langle v_i,x\rangle = \mu _i$
for
 $i\in K_2$
appropriately (note that this precisely corresponds to rescaling the rows of
$i\in K_2$
appropriately (note that this precisely corresponds to rescaling the rows of
 $V$
with indices in
$V$
with indices in
 $K_2$
). Specifically, this means that we have
$K_2$
). Specifically, this means that we have
 $||v_i|_{N_1}||_2 = 1$
for each
$||v_i|_{N_1}||_2 = 1$
for each
 $i\in K_2$
, and furthermore, for each
$i\in K_2$
, and furthermore, for each
 $j\in N_1$
, the
$j\in N_1$
, the
 $j$
-th column
$j$
-th column
 $v_{*j}$
of
$v_{*j}$
of
 $V$
satisfies
$V$
satisfies
 $||v_{*j}|_{K_2}||_1\le (60\log n)^{-1/2}$
.
$||v_{*j}|_{K_2}||_1\le (60\log n)^{-1/2}$
.
Next, we claim that
 $K_1\ne [k]$
. Indeed, condition (E2) in Definition 1.1 means that the matrix
$K_1\ne [k]$
. Indeed, condition (E2) in Definition 1.1 means that the matrix
 $V$
cannot have any column with all entries being zero. On the other hand, by condition (1) in Proposition 3.1 the submatrix
$V$
cannot have any column with all entries being zero. On the other hand, by condition (1) in Proposition 3.1 the submatrix
 $V[K_1\times N_1]$
of
$V[K_1\times N_1]$
of
 $V$
is the zero matrix. Therefore, if we had
$V$
is the zero matrix. Therefore, if we had
 $K_1= [k]$
, then for every
$K_1= [k]$
, then for every
 $j\in N_1$
the
$j\in N_1$
the
 $j$
-th column of
$j$
-th column of
 $V$
would be all-zero. This would be a contradiction, given that
$V$
would be all-zero. This would be a contradiction, given that
 $N_1\ne \emptyset$
. Thus, we indeed have
$N_1\ne \emptyset$
. Thus, we indeed have
 $K_1\ne [k]$
.
$K_1\ne [k]$
.
Now, we can fix the entries
 $w_j$
for
$w_j$
for
 $j\in N_2$
of our desired vertex
$j\in N_2$
of our desired vertex
 $w\in \{\pm 1\}^n$
using the following lemma.
$w\in \{\pm 1\}^n$
using the following lemma.
Lemma 4.1.
There exists
 $\tilde{w}\in \{\pm 1\}^{N_2}$
such that for every
$\tilde{w}\in \{\pm 1\}^{N_2}$
such that for every
 $w\in \{\pm 1\}^n$
with
$w\in \{\pm 1\}^n$
with
 $w|_{N_2} = \tilde{w}$
, we have
$w|_{N_2} = \tilde{w}$
, we have
 $\langle v_i, w\rangle \ne \mu _i$
for all
$\langle v_i, w\rangle \ne \mu _i$
for all
 $i\in K_1$
.
$i\in K_1$
.
Proof. By condition (E3) in Definition 1.1 applied to some element of
 $[k]\setminus K_1$
, there exists a vertex
$[k]\setminus K_1$
, there exists a vertex
 $x\in \{\pm 1\}^n$
such that
$x\in \{\pm 1\}^n$
such that
 $\langle v_i, x\rangle \ne \mu _i$
for all
$\langle v_i, x\rangle \ne \mu _i$
for all
 $i\in K_1$
. We set
$i\in K_1$
. We set
 $\tilde{w} := x|_{N_2}$
. By condition (1) in Proposition 3.1, for every
$\tilde{w} := x|_{N_2}$
. By condition (1) in Proposition 3.1, for every
 $i\in K_1$
, the restriction
$i\in K_1$
, the restriction
 $v_i|_{N_1}$
is the all-zero vector. Therefore, for every
$v_i|_{N_1}$
is the all-zero vector. Therefore, for every
 $w\in \{\pm 1\}^n$
with
$w\in \{\pm 1\}^n$
with
 $w|_{N_2} = \tilde{w}$
, we have
$w|_{N_2} = \tilde{w}$
, we have
 \begin{equation*}\langle v_i, w\rangle = \langle v_i|_{N_2}, \tilde {w}\rangle = \langle v_i|_{N_2}, x|_{N_2}\rangle = \langle v_i, x\rangle \ne \mu _i\end{equation*}
\begin{equation*}\langle v_i, w\rangle = \langle v_i|_{N_2}, \tilde {w}\rangle = \langle v_i|_{N_2}, x|_{N_2}\rangle = \langle v_i, x\rangle \ne \mu _i\end{equation*}
for all
 $i\in K_1$
, as desired.
$i\in K_1$
, as desired.
Let
 $\tilde{w}\in \{\pm 1\}^{N_2}$
be as in Lemma 4.1, and fix
$\tilde{w}\in \{\pm 1\}^{N_2}$
be as in Lemma 4.1, and fix
 $w_j = \tilde{w}_j$
for all
$w_j = \tilde{w}_j$
for all
 $j\in N_2$
. Next, we define a probability distribution for the entries
$j\in N_2$
. Next, we define a probability distribution for the entries
 $w_j$
for
$w_j$
for
 $j\in N_1$
. To do so, we apply Corollary 2.6 to the matrix,
$j\in N_1$
. To do so, we apply Corollary 2.6 to the matrix,
 $V[K_2\times N_1]$
with
$V[K_2\times N_1]$
with
 $\theta = (6\log n)^{1/2}$
and
$\theta = (6\log n)^{1/2}$
and
 $\mu ^{\prime}\in{\mathbb{R}}^{K_2}$
defined by
$\mu ^{\prime}\in{\mathbb{R}}^{K_2}$
defined by
 $\mu ^{\prime}_i = \mu _i - \langle v_i|_{N_2}, \tilde{w}\rangle$
for all
$\mu ^{\prime}_i = \mu _i - \langle v_i|_{N_2}, \tilde{w}\rangle$
for all
 $j\in K_2$
. We have
$j\in K_2$
. We have
 $\theta ||v_{*j}|_{K_2}||_1\le (6\log n)^{1/2}\cdot (60\log n)^{-1/2}\le 1/3$
for all
$\theta ||v_{*j}|_{K_2}||_1\le (6\log n)^{1/2}\cdot (60\log n)^{-1/2}\le 1/3$
for all
 $j\in N_1$
, as well as
$j\in N_1$
, as well as
 $||v_i|_{N_1}||_2 = 1$
for all
$||v_i|_{N_1}||_2 = 1$
for all
 $i\in K_2$
, so the conditions of Corollary 2.6 are satisfied for the matrix
$i\in K_2$
, so the conditions of Corollary 2.6 are satisfied for the matrix
 $V[K_2\times N_1]$
. So we obtain
$V[K_2\times N_1]$
. So we obtain
 $y\in{\mathbb{R}}^{N_1}$
such that
$y\in{\mathbb{R}}^{N_1}$
such that
 $||y||_\infty \le 1/3$
and
$||y||_\infty \le 1/3$
and
 $\left |\langle v_i|_{N_1}, y\rangle - \mu^{\prime}_i \right | \ge \theta$
for all
$\left |\langle v_i|_{N_1}, y\rangle - \mu^{\prime}_i \right | \ge \theta$
for all
 $i\in K_2$
. Then for every
$i\in K_2$
. Then for every
 $j\in N_1$
, let us take a random variable
$j\in N_1$
, let us take a random variable
 $w_j\in \{\pm 1\}$
with distribution
$w_j\in \{\pm 1\}$
with distribution
 \begin{equation} w_j = \begin{cases} 1 & \text{with probability } (1+y_j)/2 \\ -1 & \text{with probability } (1-y_j)/2, \end{cases} \end{equation}
\begin{equation} w_j = \begin{cases} 1 & \text{with probability } (1+y_j)/2 \\ -1 & \text{with probability } (1-y_j)/2, \end{cases} \end{equation}
such that the random variables
 $w_j$
are independent for all
$w_j$
are independent for all
 $j\in N_1$
. Note that then we have
$j\in N_1$
. Note that then we have
 ${\mathbb{E}}[w_j] = y_j$
for each
${\mathbb{E}}[w_j] = y_j$
for each
 $j\in N_1$
.
$j\in N_1$
.
Taking the entries of
 $w$
to be the random variables
$w$
to be the random variables
 $w_j$
for
$w_j$
for
 $j\in N_1$
together with the fixed values
$j\in N_1$
together with the fixed values
 $w_j=\tilde{w}_j$
for
$w_j=\tilde{w}_j$
for
 $j\in N_2$
defined above, we have now defined a random vertex
$j\in N_2$
defined above, we have now defined a random vertex
 $w\in \{\pm 1\}^n$
. Our goal is to show that with positive probability
$w\in \{\pm 1\}^n$
. Our goal is to show that with positive probability
 $w\in \{\pm 1\}^n$
satisfies
$w\in \{\pm 1\}^n$
satisfies
 $\langle v_i, w\rangle \ne \mu _i$
for all
$\langle v_i, w\rangle \ne \mu _i$
for all
 $i\in [k]$
. By the choice of
$i\in [k]$
. By the choice of
 $\tilde{w}$
in Lemma 4.1 we always have
$\tilde{w}$
in Lemma 4.1 we always have
 $\langle v_i, w\rangle \ne \mu _i$
for all
$\langle v_i, w\rangle \ne \mu _i$
for all
 $i\in K_1$
. Next, we show that for
$i\in K_1$
. Next, we show that for
 $i\in K_2$
we are unlikely to have
$i\in K_2$
we are unlikely to have
 $ \langle w, v_i\rangle = \mu _i$
.
$ \langle w, v_i\rangle = \mu _i$
.
Claim 4.2.
For every
 $i\in K_2$
, we have
$i\in K_2$
, we have
 \begin{equation*} {\mathbb {P}} \Big [\langle v_i,w\rangle = \mu _i\Big ] \le \frac {1}{2n}.\end{equation*}
\begin{equation*} {\mathbb {P}} \Big [\langle v_i,w\rangle = \mu _i\Big ] \le \frac {1}{2n}.\end{equation*}
Proof. Fix
 $i\in K_2$
. By our definition of
$i\in K_2$
. By our definition of
 $\mu ^{\prime}_i=\mu _i - \langle v_i|_{N_2}, \tilde{w}\rangle =\mu _i - \langle v_i|_{N_2}, w|_{N_2}\rangle$
, we have
$\mu ^{\prime}_i=\mu _i - \langle v_i|_{N_2}, \tilde{w}\rangle =\mu _i - \langle v_i|_{N_2}, w|_{N_2}\rangle$
, we have
 $\langle v_i,w\rangle = \mu _i$
if and only if
$\langle v_i,w\rangle = \mu _i$
if and only if
 $\langle v_i|_{N_1},w|_{N_1}\rangle = \mu^{\prime}_i$
. So it suffices to show that
$\langle v_i|_{N_1},w|_{N_1}\rangle = \mu^{\prime}_i$
. So it suffices to show that
 \begin{equation*}{\mathbb {P}} \Big [\langle v_i|_{N_1}, w|_{N_1}\rangle = \mu^{\prime}_i\Big ] \le \frac {1}{2n}.\end{equation*}
\begin{equation*}{\mathbb {P}} \Big [\langle v_i|_{N_1}, w|_{N_1}\rangle = \mu^{\prime}_i\Big ] \le \frac {1}{2n}.\end{equation*}
Since
 ${\mathbb{E}}[w_j] = y_j$
for all
${\mathbb{E}}[w_j] = y_j$
for all
 $j\in N_1$
, by linearity of expectation, we have
$j\in N_1$
, by linearity of expectation, we have
 ${\mathbb{E}}[\langle v_i|_{N_1},w|_{N_1}\rangle ] = \langle v_i|_{N_1},y\rangle$
. In addition, recall that we have
${\mathbb{E}}[\langle v_i|_{N_1},w|_{N_1}\rangle ] = \langle v_i|_{N_1},y\rangle$
. In addition, recall that we have
 $\left |\langle v_i|_{N_1},y\rangle - \mu^{\prime}_i\right |\ge \theta$
, so we obtain
$\left |\langle v_i|_{N_1},y\rangle - \mu^{\prime}_i\right |\ge \theta$
, so we obtain
 \begin{align*}{\mathbb{P}}\Big [\langle v_i|_{N_1},w|_{N_1}\rangle = \mu^{\prime}_i\Big ] &\le{\mathbb{P}}\Big [\big |\langle v_i|_{N_1},w|_{N_1}\rangle - \langle v_i|_{N_1},y\rangle \big |\ge \theta \Big ]\\[4pt]& ={\mathbb{P}}\Big [\big |\langle v_i|_{N_1},w|_{N_1}\rangle -{\mathbb{E}}[\langle v_i|_{N_1},w|_{N_1}\rangle ]\big |\ge \theta \Big ]. \end{align*}
\begin{align*}{\mathbb{P}}\Big [\langle v_i|_{N_1},w|_{N_1}\rangle = \mu^{\prime}_i\Big ] &\le{\mathbb{P}}\Big [\big |\langle v_i|_{N_1},w|_{N_1}\rangle - \langle v_i|_{N_1},y\rangle \big |\ge \theta \Big ]\\[4pt]& ={\mathbb{P}}\Big [\big |\langle v_i|_{N_1},w|_{N_1}\rangle -{\mathbb{E}}[\langle v_i|_{N_1},w|_{N_1}\rangle ]\big |\ge \theta \Big ]. \end{align*}
Now, we can apply Hoeffding’s inequality (Lemma 2.7) to the random variables
 $v_{ij}w_j$
for
$v_{ij}w_j$
for
 $j\in N_1$
, whose sum is
$j\in N_1$
, whose sum is
 $\sum _{j\in N_1}v_{ij}w_j=\langle v_i|_{N_1},w|_{N_1}\rangle$
. Note that the random variables
$\sum _{j\in N_1}v_{ij}w_j=\langle v_i|_{N_1},w|_{N_1}\rangle$
. Note that the random variables
 $v_{ij}w_j$
are independent and bounded by
$v_{ij}w_j$
are independent and bounded by
 $-|v_{ij}|\le v_{ij}w_j\le |v_{ij}|$
for each
$-|v_{ij}|\le v_{ij}w_j\le |v_{ij}|$
for each
 $j\in N_1$
. Since we have
$j\in N_1$
. Since we have
 $||v_i|_{N_1}||_2 = 1$
, we obtain
$||v_i|_{N_1}||_2 = 1$
, we obtain
 \begin{align*}{\mathbb{P}}\Big [\big |\langle v_i|_{N_1},w|_{N_1}\rangle -{\mathbb{E}}[\langle v_i|_{N_1},w|_{N_1}\rangle ]\big |\ge \theta \Big ] & \le 2\cdot \exp \left ({-}\frac{2\theta ^2}{\sum _{j\in N_1} (2v_{ij})^2}\right )\\ & = 2\cdot \exp \left ({-}\frac{2\theta ^2}{4 ||v_i|_{N_1}||_2^2}\right )\\ &=2\cdot \exp \left ({-}\frac{\theta ^2}{2}\right ). \end{align*}
\begin{align*}{\mathbb{P}}\Big [\big |\langle v_i|_{N_1},w|_{N_1}\rangle -{\mathbb{E}}[\langle v_i|_{N_1},w|_{N_1}\rangle ]\big |\ge \theta \Big ] & \le 2\cdot \exp \left ({-}\frac{2\theta ^2}{\sum _{j\in N_1} (2v_{ij})^2}\right )\\ & = 2\cdot \exp \left ({-}\frac{2\theta ^2}{4 ||v_i|_{N_1}||_2^2}\right )\\ &=2\cdot \exp \left ({-}\frac{\theta ^2}{2}\right ). \end{align*}
Substituting in our choice of
 $\theta = (6\log n)^{1/2}$
, we can deduce (recalling
$\theta = (6\log n)^{1/2}$
, we can deduce (recalling
 $n\ge 2$
)
$n\ge 2$
)
 \begin{equation*}{\mathbb {P}} \Big [\langle v_i|_{N_1},w|_{N_1}\rangle = \mu^{\prime}_i\Big ] \le 2\exp ({-}3\log n) = \frac {2}{n^3} \le \frac {1}{2n}.\end{equation*}
\begin{equation*}{\mathbb {P}} \Big [\langle v_i|_{N_1},w|_{N_1}\rangle = \mu^{\prime}_i\Big ] \le 2\exp ({-}3\log n) = \frac {2}{n^3} \le \frac {1}{2n}.\end{equation*}
On the other hand, by condition (3) in Proposition 3.1, for every
 $i\in K_3$
, the vector
$i\in K_3$
, the vector
 $v_i|_{N_1}$
has at least
$v_i|_{N_1}$
has at least
 $\lceil 10\log n\rceil$
magnitudes. Thus, by Lemma 2.3 applied to
$\lceil 10\log n\rceil$
magnitudes. Thus, by Lemma 2.3 applied to
 $p\in [1/3,2/3]^{N_1}$
given by
$p\in [1/3,2/3]^{N_1}$
given by
 $p_j=(1+y_j)/2$
for all
$p_j=(1+y_j)/2$
for all
 $j\in N_1$
, we have
$j\in N_1$
, we have
 \begin{equation*}{\mathbb {P}}\Big [\langle v_i,w\rangle = \mu _i \Big ] ={\mathbb {P}}\Big [ \langle v_i|_{N_1},w|_{N_1}\rangle = \mu _i -\langle v_i|_{N_2},\tilde {w}\rangle \Big ]\le \left (\frac {2}{3}\right )^{\lceil 10\log n /2\rceil }\le \left (\frac {2}{3}\right )^{5\log n}\le \frac {1}{n^2}\le \frac {1}{2n}\end{equation*}
\begin{equation*}{\mathbb {P}}\Big [\langle v_i,w\rangle = \mu _i \Big ] ={\mathbb {P}}\Big [ \langle v_i|_{N_1},w|_{N_1}\rangle = \mu _i -\langle v_i|_{N_2},\tilde {w}\rangle \Big ]\le \left (\frac {2}{3}\right )^{\lceil 10\log n /2\rceil }\le \left (\frac {2}{3}\right )^{5\log n}\le \frac {1}{n^2}\le \frac {1}{2n}\end{equation*}
for every
 $i\in K_3$
. Together with Claim 4.2, we can take a union bound over all
$i\in K_3$
. Together with Claim 4.2, we can take a union bound over all
 $i\in K_2\cup K_3$
and obtain
$i\in K_2\cup K_3$
and obtain
 \begin{equation*}{\mathbb {P}}\Big [\langle v_i,w\rangle = \mu _i \text { for some }i\in K_2\cup K_3\Big ]\le \sum _{i\in K_2\cup K_3}{\mathbb {P}}\Big [ \langle v_i,w\rangle = \mu _i \Big ]\le k\cdot \frac {1}{2n}\le n\cdot \frac {1}{2n} = \frac {1}{2},\end{equation*}
\begin{equation*}{\mathbb {P}}\Big [\langle v_i,w\rangle = \mu _i \text { for some }i\in K_2\cup K_3\Big ]\le \sum _{i\in K_2\cup K_3}{\mathbb {P}}\Big [ \langle v_i,w\rangle = \mu _i \Big ]\le k\cdot \frac {1}{2n}\le n\cdot \frac {1}{2n} = \frac {1}{2},\end{equation*}
recalling that
 $k\le n$
.
$k\le n$
.
Thus, with probability at least
 $1/2$
, our random vertex
$1/2$
, our random vertex
 $w\in \{\pm 1\}^n$
satisfies
$w\in \{\pm 1\}^n$
satisfies
 $\langle v_i, w\rangle \ne \mu _i$
for all
$\langle v_i, w\rangle \ne \mu _i$
for all
 $i\in K_2\cup K_3$
. Recalling that we always have
$i\in K_2\cup K_3$
. Recalling that we always have
 $\langle v_i, w\rangle \ne \mu _i$
for all
$\langle v_i, w\rangle \ne \mu _i$
for all
 $i\in K_1$
, this means that with probability at least
$i\in K_1$
, this means that with probability at least
 $1/2$
, we have
$1/2$
, we have
 $\langle v_i, w\rangle \ne \mu _i$
for all
$\langle v_i, w\rangle \ne \mu _i$
for all
 $i\in [k]$
. Hence, there exists a vertex in
$i\in [k]$
. Hence, there exists a vertex in
 $w\in \{\pm 1\}^n$
such that
$w\in \{\pm 1\}^n$
such that
 $\langle v_i, w\rangle \ne \mu _i$
for all
$\langle v_i, w\rangle \ne \mu _i$
for all
 $i\in [k]$
.
$i\in [k]$
.
5. Decomposing the matrix
Finally, we prove Proposition 3.1.
Proof of Proposition
3.1. We decompose the matrix
 $V$
using the following algorithm that starts with all the column indices in
$V$
using the following algorithm that starts with all the column indices in
 $N_1$
. At any iteration of the algorithm, we have a partition
$N_1$
. At any iteration of the algorithm, we have a partition
 $[n] = N_1\sqcup N_2$
of the column indices, and furthermore, the row indices
$[n] = N_1\sqcup N_2$
of the column indices, and furthermore, the row indices
 $i\in [k]$
are partitioned into three types: being in
$i\in [k]$
are partitioned into three types: being in
 $K_1$
, active, and inactive (defined later). Throughout the algorithm, we move certain columns from
$K_1$
, active, and inactive (defined later). Throughout the algorithm, we move certain columns from
 $N_1$
to
$N_1$
to
 $N_2$
. When the algorithm terminates, the desired partitions of the row and column indices of the matrix will be formed by taking the sets
$N_2$
. When the algorithm terminates, the desired partitions of the row and column indices of the matrix will be formed by taking the sets
 $K_1$
,
$K_1$
,
 $N_1$
, and
$N_1$
, and
 $N_2$
at the end of the algorithm, as well as taking
$N_2$
at the end of the algorithm, as well as taking
 $K_2$
to be the active row indices and
$K_2$
to be the active row indices and
 $K_3$
to be the inactive row indices at the end of the algorithm.
$K_3$
to be the inactive row indices at the end of the algorithm.
-
1. Initialise
$N_1 = [n],\, N_2= \emptyset$
and
$K_1= \emptyset$
. -
2. For each
$i\in [k]\setminus K_1$
such that
$v_i|_{N_1}$
is the all-zero vector, we move
$i$
into
$K_1$
. -
3. For each
$i\in [k]\setminus K_1$
, we say that
$i$
is inactive if the vector
$v_i|_{N_1}$
has at least
$\lceil 10\log n\rceil$
magnitudes; otherwise, we say that
$i$
is active. -
4. For each active
$i\in [k]\setminus K_1$
and each
$j\in N_1$
, we assign a weight
$w_{ij}$
to the entry
$v_{ij}$
of
$V$
as follows: if
$v_{ij}=0$
, define
$w_{ij}=0$
. If
$v_{ij}\ne 0$
, let
$m$
be the magnitude of
$v_{ij}$
, and let
$N_m(i)$
be the number of entries of
$v_i|_{N_1}$
with magnitude
$m$
, and define
$w_{ij}=10/\sqrt{N_m(i)}$
. -
5. For every
$j\in N_1$
, calculate the total weight
$\sum _i w_{ij}$
in column
$j$
, where the sum is taken over all active
$i\in [k]\setminus K_1$
. If there exists some
$j\in N_1$
where this total weight is larger than
$(60\log n)^{-1/2}$
, then move this index
$j$
from
$N_1$
to
$N_2$
and remove all weights in column
$j$
(if there exist multiple such
$j$
, choose one arbitrarily), and go to back to Step 2. If there is no such index
$j\in N_1$
, go to Step 6. -
6. Terminate and output the current sets
$N_1, N_2, K_1$
, output the current set of active row indices as
$K_2$
, and output the current set of inactive row indices as
$K_3$
.








































It is clear that this algorithm must eventually terminate since in every iteration, a column index is moved from
 $N_1$
to
$N_1$
to
 $N_2$
(so the set
$N_2$
(so the set
 $N_1$
is getting strictly smaller with every iteration). It is also clear that the algorithm produces a partition
$N_1$
is getting strictly smaller with every iteration). It is also clear that the algorithm produces a partition
 $[k] = K_1\sqcup K_2\sqcup K_3$
of the row indices of
$[k] = K_1\sqcup K_2\sqcup K_3$
of the row indices of
 $V$
and a partition
$V$
and a partition
 $[n] = N_1\sqcup N_2$
of the column indices. Furthermore, it is not hard to see that these partitions satisfy conditions (1) and (3) in Proposition 3.1. Indeed, condition (1) is satisfied by the rule of moving row indices into
$[n] = N_1\sqcup N_2$
of the column indices. Furthermore, it is not hard to see that these partitions satisfy conditions (1) and (3) in Proposition 3.1. Indeed, condition (1) is satisfied by the rule of moving row indices into
 $K_1$
in Step 2 of the algorithm, and condition (3) is satisfied by the definition of inactive rows in Step 3.
$K_1$
in Step 2 of the algorithm, and condition (3) is satisfied by the definition of inactive rows in Step 3.
To show condition (2) in Proposition 3.1, consider the
 $|K_2|\times |N_1|$
matrix
$|K_2|\times |N_1|$
matrix
 $V^{\prime}$
obtained from
$V^{\prime}$
obtained from
 $V[K_2\times N_1]$
by normalising every row to have
$V[K_2\times N_1]$
by normalising every row to have
 $\ell _2$
-norm equal to
$\ell _2$
-norm equal to
 $1$
(note that by the condition in Step 2, all the rows of
$1$
(note that by the condition in Step 2, all the rows of
 $V[K_2\times N_1]$
are non-zero). Let us write
$V[K_2\times N_1]$
are non-zero). Let us write
 $v^{\prime}_i=(1/||v_i|_{N_1}||_2)v_i|_{N_1}$
for
$v^{\prime}_i=(1/||v_i|_{N_1}||_2)v_i|_{N_1}$
for
 $i\in K_2$
for the rows of
$i\in K_2$
for the rows of
 $V^{\prime}$
. Now, for every entry
$V^{\prime}$
. Now, for every entry
 $v_{ij}\ne 0$
of
$v_{ij}\ne 0$
of
 $V[K_2\times N_1]$
with some magnitude
$V[K_2\times N_1]$
with some magnitude
 $m$
, we have
$m$
, we have
 $10^{m}\le |v_{ij}| \lt 10^{m+1}$
, and for each
$10^{m}\le |v_{ij}| \lt 10^{m+1}$
, and for each
 $i\in K_2$
, there are
$i\in K_2$
, there are
 $N_m(i)$
such entries in
$N_m(i)$
such entries in
 $v_i|_{N_1}$
. Thus,
$v_i|_{N_1}$
. Thus,
 $||v_i|_{N_1}||_2\ge \sqrt{N_m(i)}\cdot 10^{m}$
for every magnitude
$||v_i|_{N_1}||_2\ge \sqrt{N_m(i)}\cdot 10^{m}$
for every magnitude
 $m$
appearing among the entries of
$m$
appearing among the entries of
 $v_i|_{N_1}$
, and we can conclude that
$v_i|_{N_1}$
, and we can conclude that
 \begin{equation*}|v^{\prime}_{ij}|=\frac {|v_{ij}|}{||v_i|_{N_1}||_2}\lt \frac {10^{m+1}}{\sqrt {N_m(i)}\cdot 10^{m}} = \frac {10}{\sqrt {N_m(i)}} = w_{ij}\end{equation*}
\begin{equation*}|v^{\prime}_{ij}|=\frac {|v_{ij}|}{||v_i|_{N_1}||_2}\lt \frac {10^{m+1}}{\sqrt {N_m(i)}\cdot 10^{m}} = \frac {10}{\sqrt {N_m(i)}} = w_{ij}\end{equation*}
for every entry
 $v_{ij}\ne 0$
of
$v_{ij}\ne 0$
of
 $V[K_2\times N_1]$
with magnitude
$V[K_2\times N_1]$
with magnitude
 $m$
. This shows that
$m$
. This shows that
 $|v^{\prime}_{ij}| \le w_{ij}$
for all
$|v^{\prime}_{ij}| \le w_{ij}$
for all
 $i\in K_2$
and
$i\in K_2$
and
 $j\in N_1$
(note that in the case
$j\in N_1$
(note that in the case
 $v_{ij}= 0$
, we trivially have
$v_{ij}= 0$
, we trivially have
 $|v^{\prime}_{ij}|=0 = w_{ij}$
).
$|v^{\prime}_{ij}|=0 = w_{ij}$
).
Now, to check condition (2), observe that for every
 $j\in N_1$
, we have
$j\in N_1$
, we have
 $\sum _{i\in K_2} w_{ij}\le (60\log n)^{-1/2}$
since otherwise the algorithm would not have terminated. Consequently, for every
$\sum _{i\in K_2} w_{ij}\le (60\log n)^{-1/2}$
since otherwise the algorithm would not have terminated. Consequently, for every
 $j\in N_1$
, we have
$j\in N_1$
, we have
 $\sum _{i\in K_2} |v^{\prime}_{ij}|\le \sum _{i\in K_2} w_{ij}\le (60\log n)^{-1/2}$
, meaning that the
$\sum _{i\in K_2} |v^{\prime}_{ij}|\le \sum _{i\in K_2} w_{ij}\le (60\log n)^{-1/2}$
, meaning that the
 $\ell _1$
-norm of every column in
$\ell _1$
-norm of every column in
 $V^{\prime}$
is at most
$V^{\prime}$
is at most
 $(60\log n)^{-1/2}$
.
$(60\log n)^{-1/2}$
.
It remains to show
 $N_1\ne \emptyset$
. Recall that at the start, we have
$N_1\ne \emptyset$
. Recall that at the start, we have
 $N_1=[n]$
, and in every iteration of the algorithm, we move one index from
$N_1=[n]$
, and in every iteration of the algorithm, we move one index from
 $N_1$
into
$N_1$
into
 $N_2$
. So we need to show that the number of column indices moved into
$N_2$
. So we need to show that the number of column indices moved into
 $N_2$
throughout the algorithm is less than
$N_2$
throughout the algorithm is less than
 $n$
. At every step, we consider the total weight in the matrix. Whenever we move a column index from
$n$
. At every step, we consider the total weight in the matrix. Whenever we move a column index from
 $N_1$
into
$N_1$
into
 $N_2$
, this total weight decreases by at least
$N_2$
, this total weight decreases by at least
 $(60\log n)^{-1/2}$
(by the condition on the column weight in Step 5 of the algorithm).
$(60\log n)^{-1/2}$
(by the condition on the column weight in Step 5 of the algorithm).
However, note after moving a column from
 $N_1$
to
$N_1$
to
 $N_2$
, when reassigning the weights in Step 3 in the next iteration, some of the weights in the remaining columns with indices in
$N_2$
, when reassigning the weights in Step 3 in the next iteration, some of the weights in the remaining columns with indices in
 $N_1$
may increase (indeed, the numbers
$N_1$
may increase (indeed, the numbers
 $N_m(i)$
may decrease by removing a column from
$N_m(i)$
may decrease by removing a column from
 $N_1$
). Furthermore, new row indices may become active as the set
$N_1$
). Furthermore, new row indices may become active as the set
 $N_1$
gets smaller throughout the algorithm (but note that once a row index becomes active, it cannot become inactive anymore afterwards).
$N_1$
gets smaller throughout the algorithm (but note that once a row index becomes active, it cannot become inactive anymore afterwards).
For every row index
 $i\in [k]$
that becomes active at some point during the algorithm, and every magnitude occurring among the entries of
$i\in [k]$
that becomes active at some point during the algorithm, and every magnitude occurring among the entries of
 $v_i|_{N_1}$
at the moment when the index
$v_i|_{N_1}$
at the moment when the index
 $i$
first becomes active, let
$i$
first becomes active, let
 $N^*_m(i)$
denote the number of entries of
$N^*_m(i)$
denote the number of entries of
 $v_i|_{N_1}$
with magnitude
$v_i|_{N_1}$
with magnitude
 $m$
when the row index
$m$
when the row index
 $i$
first becomes active. At that iteration of the algorithm, each of these
$i$
first becomes active. At that iteration of the algorithm, each of these
 $N^*_m(i)$
entries is assigned weight
$N^*_m(i)$
entries is assigned weight
 $10/\sqrt{N^*_m(i)}$
. When a column index of some entry of
$10/\sqrt{N^*_m(i)}$
. When a column index of some entry of
 $v_i|_{N_1}$
with magnitude
$v_i|_{N_1}$
with magnitude
 $m$
gets moved into
$m$
gets moved into
 $N_2$
later in the algorithm, the quantity
$N_2$
later in the algorithm, the quantity
 $N_m(i)$
decreases, and so the weights of the remaining entries of
$N_m(i)$
decreases, and so the weights of the remaining entries of
 $v_i|_{N_1}$
with magnitude
$v_i|_{N_1}$
with magnitude
 $m$
increase. More precisely, when this happens for the
$m$
increase. More precisely, when this happens for the
 $t$
-th time (for
$t$
-th time (for
 $t\in \{1,\dots, N^*_m(i)-1\}$
), the weight of the
$t\in \{1,\dots, N^*_m(i)-1\}$
), the weight of the
 $N^*_m(i)-t$
remaining entries of
$N^*_m(i)-t$
remaining entries of
 $v_i|_{N_1}$
with magnitude
$v_i|_{N_1}$
with magnitude
 $m$
is increased from
$m$
is increased from
 $10/\sqrt{N^*_m(i)-t+1}$
to
$10/\sqrt{N^*_m(i)-t+1}$
to
 $10/\sqrt{N^*_m(i)-t}$
. Thus, the total weight that is added to the entries with magnitude
$10/\sqrt{N^*_m(i)-t}$
. Thus, the total weight that is added to the entries with magnitude
 $m$
in row
$m$
in row
 $i$
throughout the algorithm (both when row
$i$
throughout the algorithm (both when row
 $i$
first becomes active and as the weights get re-assigned) is at most
$i$
first becomes active and as the weights get re-assigned) is at most
 \begin{align*} & N^*_m(i)\cdot \frac{10}{\sqrt{N^*_m(i)}} + \sum _{t = 1}^{N^*_m(i)-1} \left (N^*_m(i) - t\right ) \left (\frac{10}{\sqrt{N^*_m(i) - t}} - \frac{10}{\sqrt{N^*_m(i) - t + 1}}\right )\\ &= 10\sqrt{N^*_m(i)} + 10\sum _{t = 1}^{N^*_m(i) - 1} t \left (\frac{1}{\sqrt{t}} - \frac{1}{\sqrt{t+1}}\right ) = 10\sqrt{N^*_m(i)} + 10\sum _{t = 1}^{N^*_m(i) - 1} t \cdot \frac{\sqrt{t+1} - \sqrt{t}}{\sqrt{t(t+1)}} \\ &\le 10\sqrt{N^*_m(i)} + 10\sum _{t = 1}^{N^*_m(i) - 1} \left (\sqrt{t+1} - \sqrt{t}\right ) \le 10\sqrt{N^*_m(i)} + 10\sqrt{N^*_m(i)} = 20\sqrt{N^*_m(i)} \end{align*}
\begin{align*} & N^*_m(i)\cdot \frac{10}{\sqrt{N^*_m(i)}} + \sum _{t = 1}^{N^*_m(i)-1} \left (N^*_m(i) - t\right ) \left (\frac{10}{\sqrt{N^*_m(i) - t}} - \frac{10}{\sqrt{N^*_m(i) - t + 1}}\right )\\ &= 10\sqrt{N^*_m(i)} + 10\sum _{t = 1}^{N^*_m(i) - 1} t \left (\frac{1}{\sqrt{t}} - \frac{1}{\sqrt{t+1}}\right ) = 10\sqrt{N^*_m(i)} + 10\sum _{t = 1}^{N^*_m(i) - 1} t \cdot \frac{\sqrt{t+1} - \sqrt{t}}{\sqrt{t(t+1)}} \\ &\le 10\sqrt{N^*_m(i)} + 10\sum _{t = 1}^{N^*_m(i) - 1} \left (\sqrt{t+1} - \sqrt{t}\right ) \le 10\sqrt{N^*_m(i)} + 10\sqrt{N^*_m(i)} = 20\sqrt{N^*_m(i)} \end{align*}
for any row index
 $i$
becoming active at some point during the algorithm and any
$i$
becoming active at some point during the algorithm and any
 $m$
appearing as magnitude among the entries of
$m$
appearing as magnitude among the entries of
 $v_i|_{N_1}$
at the moment when the index
$v_i|_{N_1}$
at the moment when the index
 $i$
first becomes active.
$i$
first becomes active.
For notational convenience, let
 $S = \lceil 10\log n\rceil -1$
. Recall that when the row index
$S = \lceil 10\log n\rceil -1$
. Recall that when the row index
 $i$
becomes active, there are strictly less than
$i$
becomes active, there are strictly less than
 $\lceil 10\log n\rceil$
(i.e., at most
$\lceil 10\log n\rceil$
(i.e., at most
 $S$
) magnitudes appearing among the entries of
$S$
) magnitudes appearing among the entries of
 $v_i|_{N_1}$
. For these at most
$v_i|_{N_1}$
. For these at most
 $S$
different magnitudes
$S$
different magnitudes
 $m$
, the numbers
$m$
, the numbers
 $N^*_m(i)$
defined above (counting the entries of
$N^*_m(i)$
defined above (counting the entries of
 $v_i|_{N_1}$
of magnitude
$v_i|_{N_1}$
of magnitude
 $m$
when the row index
$m$
when the row index
 $i$
first becomes active) satisfy
$i$
first becomes active) satisfy
 \begin{equation*}\sum _m N^*_m(i) = |\operatorname {supp}(v_i|_{N_1})|\le |\operatorname {supp}(v_i)|\le 2k,\end{equation*}
\begin{equation*}\sum _m N^*_m(i) = |\operatorname {supp}(v_i|_{N_1})|\le |\operatorname {supp}(v_i)|\le 2k,\end{equation*}
where the last inequality holds by Lemma 2.4. Hence
 \begin{equation*}\sum _m 20 \sqrt {N_m(i)}= 20\sum _m \sqrt {N_m(i)}\le 20 \cdot \sqrt {S} \cdot \sqrt {\sum _m N^*_m(i)}\le 20 \cdot \sqrt {S} \cdot \sqrt {2k} \le 30 \sqrt {kS}\end{equation*}
\begin{equation*}\sum _m 20 \sqrt {N_m(i)}= 20\sum _m \sqrt {N_m(i)}\le 20 \cdot \sqrt {S} \cdot \sqrt {\sum _m N^*_m(i)}\le 20 \cdot \sqrt {S} \cdot \sqrt {2k} \le 30 \sqrt {kS}\end{equation*}
by the Cauchy–Schwarz inequality, so for every row, the total weight added to the entries throughout the algorithm is at most
 $30 \sqrt{kS}$
. Thus, the total weight increase for the entire
$30 \sqrt{kS}$
. Thus, the total weight increase for the entire
 $k\times n$
matrix
$k\times n$
matrix
 $V$
throughout the algorithm is at most
$V$
throughout the algorithm is at most
 \begin{equation*}k\cdot 30 \sqrt {kS}=30k^{3/2}\sqrt {S}\le 30k^{3/2}\cdot (10\log n)^{1/2}.\end{equation*}
\begin{equation*}k\cdot 30 \sqrt {kS}=30k^{3/2}\sqrt {S}\le 30k^{3/2}\cdot (10\log n)^{1/2}.\end{equation*}
Recall that whenever we move a column index from
 $N_1$
into
$N_1$
into
 $N_2$
, the weight in the matrix
$N_2$
, the weight in the matrix
 $V$
decreases by at least
$V$
decreases by at least
 $(60\log n)^{-1/2}$
. Therefore, at most
$(60\log n)^{-1/2}$
. Therefore, at most
 \begin{equation*}\frac {30k^{3/2}\cdot (10\log n)^{1/2}}{(60\log n)^{-1/2}}\le 750k^{3/2}\cdot \log n\end{equation*}
\begin{equation*}\frac {30k^{3/2}\cdot (10\log n)^{1/2}}{(60\log n)^{-1/2}}\le 750k^{3/2}\cdot \log n\end{equation*}
column indices can be moved from
 $N_1$
into
$N_1$
into
 $N_2$
. By our assumption
$N_2$
. By our assumption
 $k \le 10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
, this number of column indices moved from
$k \le 10^{-2}\cdot n^{2/3}/(\log n)^{2/3}$
, this number of column indices moved from
 $N_1$
into
$N_1$
into
 $N_2$
is at most
$N_2$
is at most
 \begin{equation*}750k^{3/2}\cdot \log n\le 750\cdot 10^{-3}\cdot \frac {n}{\log n}\cdot \log n \lt n.\end{equation*}
\begin{equation*}750k^{3/2}\cdot \log n\le 750\cdot 10^{-3}\cdot \frac {n}{\log n}\cdot \log n \lt n.\end{equation*}
Thus, we have
 $N_1\ne \emptyset$
at the end of the algorithm, as desired.
$N_1\ne \emptyset$
at the end of the algorithm, as desired.


