



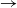
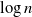
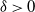
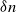
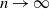
1. Introduction
A key component of any epidemic model is the assumption made concerning transmission of infection between individuals. In almost all epidemic models it is assumed that infection spreads via interactions of pairs of individuals, one of whom is infective and the other susceptible. In some epidemic models, such as network models (e.g. Newman [Reference Newman15]), this assumption is explicit, whereas in others, such as the so-called general stochastic epidemic (e.g. Bailey [Reference Bailey1, Chapter 6]) and many deterministic models, it is implicit. In the general stochastic epidemic, the process of the numbers of susceptible and infective individuals,
 $\{(S(t), I(t))\,:\,t \ge 0\}$
, is modelled as a continuous-time Markov chain with infinitesimal transition probabilities
$\{(S(t), I(t))\,:\,t \ge 0\}$
, is modelled as a continuous-time Markov chain with infinitesimal transition probabilities
 \begin{align*}{\mathbb{P}}((S(t+\Delta t), I(t+\Delta t))=(s-1,i+1)|(S(t),I(t))=(s,i))&= \beta si \Delta t+o(\Delta t),\\{\mathbb{P}}((S(t+\Delta t), I(t+\Delta t))=(s,i-1)|(S(t),I(t))=(s,i))&= \gamma i \Delta t+o(\Delta t),\end{align*}
\begin{align*}{\mathbb{P}}((S(t+\Delta t), I(t+\Delta t))=(s-1,i+1)|(S(t),I(t))=(s,i))&= \beta si \Delta t+o(\Delta t),\\{\mathbb{P}}((S(t+\Delta t), I(t+\Delta t))=(s,i-1)|(S(t),I(t))=(s,i))&= \gamma i \Delta t+o(\Delta t),\end{align*}
and with all other transitions having probability
 $o(\Delta t)$
. Here,
$o(\Delta t)$
. Here,
 $\beta$
is the individual-to-individual infection rate and
$\beta$
is the individual-to-individual infection rate and
 $\gamma$
is the recovery rate. However, it is probabilistically equivalent to a model in which the infectious periods of infectives follow independent exponential random variables having mean
$\gamma$
is the recovery rate. However, it is probabilistically equivalent to a model in which the infectious periods of infectives follow independent exponential random variables having mean
 $\gamma^{-1}$
and contacts between distinct pairs of individuals occur at the points of independent Poisson processes, each having rate
$\gamma^{-1}$
and contacts between distinct pairs of individuals occur at the points of independent Poisson processes, each having rate
 $\beta$
.
$\beta$
.
In real-life epidemics, people often meet in groups of size larger than two; in many countries, one of the most significant control measures in the COVID-19 pandemic was to impose limits on the size of gatherings outside of the home. In Cortez [Reference Cortez8] and Ball and Neal [Reference Ball and Neal5], the authors independently introduced a new class of SIR (susceptible
 $\to$
infective
$\to$
infective
 $\to$
recovered) epidemic model, in which mixing events occur at the points of a Poisson process, with the sizes of successive mixing events being independently distributed according to a random variable having support contained in
$\to$
recovered) epidemic model, in which mixing events occur at the points of a Poisson process, with the sizes of successive mixing events being independently distributed according to a random variable having support contained in
 $\{2,3,\dots, n\}$
, where n is the population size. Mixing events are instantaneous, and at a mixing event of size c, each infective present contacts each susceptible present independently with probability
$\{2,3,\dots, n\}$
, where n is the population size. Mixing events are instantaneous, and at a mixing event of size c, each infective present contacts each susceptible present independently with probability
 $\pi_c$
; a susceptible becomes infected if they are contacted by at least one infective. Such an infected susceptible immediately becomes infective, although they cannot infect other susceptibles at the same mixing event, and remains so for a time that follows an exponential distribution with mean
$\pi_c$
; a susceptible becomes infected if they are contacted by at least one infective. Such an infected susceptible immediately becomes infective, although they cannot infect other susceptibles at the same mixing event, and remains so for a time that follows an exponential distribution with mean
 $\gamma^{-1}$
. In Cortez [Reference Cortez8] and Ball and Neal [Reference Ball and Neal5], the temporal behaviour of epidemics with many initial infectives is studied, with [Reference Cortez8] considering the mean-field limit of the stochastic epidemic process. In Ball and Neal [Reference Ball and Neal5], the focus is on a functional central limit theorem for the temporal behaviour of epidemics with many initial infectives and on central limit theorems for the final size of (i) an epidemic with many initial infectives and (ii) an epidemic with few initial infectives that becomes established and leads to a major outbreak. A branching process which approximates the early stages of an epidemic with few initial infectives is described in [Reference Ball and Neal5], though no rigorous justification is provided. A key result required in the proof of the central limit theorem for the final size in Case (ii) above is that there exists
$\gamma^{-1}$
. In Cortez [Reference Cortez8] and Ball and Neal [Reference Ball and Neal5], the temporal behaviour of epidemics with many initial infectives is studied, with [Reference Cortez8] considering the mean-field limit of the stochastic epidemic process. In Ball and Neal [Reference Ball and Neal5], the focus is on a functional central limit theorem for the temporal behaviour of epidemics with many initial infectives and on central limit theorems for the final size of (i) an epidemic with many initial infectives and (ii) an epidemic with few initial infectives that becomes established and leads to a major outbreak. A branching process which approximates the early stages of an epidemic with few initial infectives is described in [Reference Ball and Neal5], though no rigorous justification is provided. A key result required in the proof of the central limit theorem for the final size in Case (ii) above is that there exists
 $\delta\gt 0$
(which depends on model parameters) such that the probability that an epidemic infects at least a fraction
$\delta\gt 0$
(which depends on model parameters) such that the probability that an epidemic infects at least a fraction
 $\delta$
of the population, given that it infects at least
$\delta$
of the population, given that it infects at least
 $\log n$
individuals, converges to one as the population size
$\log n$
individuals, converges to one as the population size
 $n \to \infty$
. This result is simply stated without a proof in [Reference Ball and Neal5]. The aim of the present paper is to fill these gaps for a model that allows more general transmission of infection at mixing events than that considered in [Reference Ball and Neal5].
$n \to \infty$
. This result is simply stated without a proof in [Reference Ball and Neal5]. The aim of the present paper is to fill these gaps for a model that allows more general transmission of infection at mixing events than that considered in [Reference Ball and Neal5].
Approximation of the process of infectives in an epidemic model by a branching process has a long history that goes back to the pioneering work of Bartlett [Reference Bartlett7, pp. 147–148] and Kendall [Reference Kendall12], who considered approximation of the number of infectives in the general stochastic epidemic by a linear birth-and-death process, with birth rate
 $\beta N$
and death rate
$\beta N$
and death rate
 $\gamma$
, where N is the initial number of susceptibles. This leads to the celebrated threshold theorem (Whittle [Reference Whittle17] and Williams [Reference Williams18]), arguably the most important result in mathematical epidemic theory. The approximation was made fully rigorous by Ball [Reference Ball2] (cf. Metz [Reference Metz13]), who defined realisations of the general stochastic epidemic, indexed by N, with the Nth epidemic having infection rate
$\gamma$
, where N is the initial number of susceptibles. This leads to the celebrated threshold theorem (Whittle [Reference Whittle17] and Williams [Reference Williams18]), arguably the most important result in mathematical epidemic theory. The approximation was made fully rigorous by Ball [Reference Ball2] (cf. Metz [Reference Metz13]), who defined realisations of the general stochastic epidemic, indexed by N, with the Nth epidemic having infection rate
 $\beta N^{-1}$
and recovery rate
$\beta N^{-1}$
and recovery rate
 $\gamma$
, and the limiting birth-and-death process on a common probability space and used a coupling argument to prove almost sure convergence, as
$\gamma$
, and the limiting birth-and-death process on a common probability space and used a coupling argument to prove almost sure convergence, as
 $N \to \infty$
, of the epidemic process to the limiting branching process over any finite time interval [0, t]. The method was extended by Ball and Donnelly [Reference Ball and Donnelly3] to show almost sure convergence over suitable intervals
$N \to \infty$
, of the epidemic process to the limiting branching process over any finite time interval [0, t]. The method was extended by Ball and Donnelly [Reference Ball and Donnelly3] to show almost sure convergence over suitable intervals
 $[0, t_N]$
, where
$[0, t_N]$
, where
 $t_N \to \infty$
as
$t_N \to \infty$
as
 $N \to \infty$
.
$N \to \infty$
.
The key idea of Ball [Reference Ball2] is to construct a realisation of the epidemic process for each N from the same realisation of the limiting branching process. Moreover, this coupling is done on an individual basis, in that the behaviour of an infective in the Nth epidemic model is derived from the behaviour of a corresponding individual in the branching process. The method is very powerful and applicable to a broad range of epidemic models. However, it cannot be easily applied to epidemics with mixing groups, because the mixing groups induce dependencies between different infectives. Thus instead, we generalise the method of Ball and O’Neill [Reference Ball and O’Neill6], which involves constructing sample paths of the epidemic process, indexed by the population size n, and the limiting branching process (more precisely, the numbers of infectives in the epidemic processes and the number of individuals in the branching process) via a sequence of independent and identically distributed (i.i.d.) random vectors. The generalisation is far from straightforward, since Ball and O’Neill [Reference Ball and O’Neill6] consider only epidemics in which the number of infectives changes in steps of size 1, as in the general stochastic epidemic, whereas in the model with mixing events, although the number of infectives can only decrease in steps of size 1, it can increase in steps of any size not greater than the population size n. We improve on the coupling given in [Reference Ball and O’Neill6] by coupling the time of events in the limiting branching process and epidemic processes, so that the event times agree with high probability, tending to 1 as the population size
 $n \to \infty$
, rather than having the event times in the epidemic processes converge in the limit, as the population size
$n \to \infty$
, rather than having the event times in the epidemic processes converge in the limit, as the population size
 $n \to \infty$
, to the event times of the branching process. Finally, we use the coupling to prove the above-mentioned result concerning epidemics of size at least
$n \to \infty$
, to the event times of the branching process. Finally, we use the coupling to prove the above-mentioned result concerning epidemics of size at least
 $\log n$
, which was not addressed in [Reference Ball and O’Neill6].
$\log n$
, which was not addressed in [Reference Ball and O’Neill6].
The remainder of the paper is structured as follows. The model with mixing groups
 $\mathcal{E}^{(n)}$
is defined in Section 2. The approximating branching process
$\mathcal{E}^{(n)}$
is defined in Section 2. The approximating branching process
 $\mathcal{B}$
and the main results of the paper are given in Section 3. The branching process
$\mathcal{B}$
and the main results of the paper are given in Section 3. The branching process
 $\mathcal{B}$
is described in Section 3.1, where some of its basic properties are presented. The offspring mean of
$\mathcal{B}$
is described in Section 3.1, where some of its basic properties are presented. The offspring mean of
 $\mathcal{B}$
yields the basic reproduction number
$\mathcal{B}$
yields the basic reproduction number
 $R_0$
of the epidemic
$R_0$
of the epidemic
 $\mathcal{E}^{(n)}$
. The extinction probability and Malthusian parameter of
$\mathcal{E}^{(n)}$
. The extinction probability and Malthusian parameter of
 $\mathcal{B}$
are derived. The main results of the paper are collected together in Section 3.2. Theorem 3.1 shows that the number of infectives in the epidemic process
$\mathcal{B}$
are derived. The main results of the paper are collected together in Section 3.2. Theorem 3.1 shows that the number of infectives in the epidemic process
 $\mathcal{E}^{(n)}$
converges almost surely to the number of individuals alive in the branching process
$\mathcal{E}^{(n)}$
converges almost surely to the number of individuals alive in the branching process
 $\mathcal{B}$
on
$\mathcal{B}$
on
 $[0,t_n)$
as
$[0,t_n)$
as
 $n \to \infty$
, where
$n \to \infty$
, where
 $t_n = \infty$
in the case the branching process goes extinct and
$t_n = \infty$
in the case the branching process goes extinct and
 $t_n = \rho \log n$
for some
$t_n = \rho \log n$
for some
 $\rho\gt 0$
otherwise. A major outbreak is defined as one that infects at least
$\rho\gt 0$
otherwise. A major outbreak is defined as one that infects at least
 $\log n$
individuals. Theorem 3.2(a) shows that the probability of a major outbreak converges to the survival probability of
$\log n$
individuals. Theorem 3.2(a) shows that the probability of a major outbreak converges to the survival probability of
 $\mathcal{B}$
as
$\mathcal{B}$
as
 $n \to \infty$
. Theorem 3.2(b) shows that if
$n \to \infty$
. Theorem 3.2(b) shows that if
 $R_0\gt 1$
, so a major outbreak occurs with non-zero probability in the limit
$R_0\gt 1$
, so a major outbreak occurs with non-zero probability in the limit
 $n \to \infty$
, then there exists
$n \to \infty$
, then there exists
 $\delta\gt 0$
such that the probability that a major outbreak infects at least a fraction
$\delta\gt 0$
such that the probability that a major outbreak infects at least a fraction
 $\delta$
of the population tends to one as
$\delta$
of the population tends to one as
 $n \to \infty$
. Moreover, we show that there exists
$n \to \infty$
. Moreover, we show that there exists
 $\delta^\prime \gt 0$
such that the fraction of the population infectious at the peak of the epidemic exceeds
$\delta^\prime \gt 0$
such that the fraction of the population infectious at the peak of the epidemic exceeds
 $\delta^\prime$
with probability tending to one as
$\delta^\prime$
with probability tending to one as
 $n \to \infty$
. The proofs of Theorems 3.1 and 3.2 are given in Sections 4 and 5, respectively. Brief concluding comments are given in Section 6.
$n \to \infty$
. The proofs of Theorems 3.1 and 3.2 are given in Sections 4 and 5, respectively. Brief concluding comments are given in Section 6.
2. Model
We consider the spread of an SIR epidemic in a closed population of n individuals, with infection spread via mixing events which occur at the points of a homogeneous Poisson process having rate
 $n\lambda$
. The sizes of mixing events are i.i.d. according to a random variable
$n\lambda$
. The sizes of mixing events are i.i.d. according to a random variable
 $C^{(n)}$
having support
$C^{(n)}$
having support
 $\{2,3,\dots,n\}$
. If a mixing event has size c then it is formed by choosing c individuals uniformly at random from the population without replacement. Suppose that a mixing event of size c involves i susceptible and j infective individuals, and hence
$\{2,3,\dots,n\}$
. If a mixing event has size c then it is formed by choosing c individuals uniformly at random from the population without replacement. Suppose that a mixing event of size c involves i susceptible and j infective individuals, and hence
 $c-i-j$
recovered individuals. Then the probability that w new infectives are created at the event is
$c-i-j$
recovered individuals. Then the probability that w new infectives are created at the event is
 $\pi_c(w;\,i,j)$
. The only restrictions we impose on
$\pi_c(w;\,i,j)$
. The only restrictions we impose on
 $\pi_c (w;\,i,j) $
are the natural ones that, for
$\pi_c (w;\,i,j) $
are the natural ones that, for
 $w \gt 0$
,
$w \gt 0$
,
 $\pi_c (w;\,i,0) =0$
; infections can only occur at a mixing event if there is at least one infective present; and for
$\pi_c (w;\,i,0) =0$
; infections can only occur at a mixing event if there is at least one infective present; and for
 $w \gt i$
,
$w \gt i$
,
 $\pi_c (w;\,i,j) =0$
: the maximum number of new infectives created at a mixing event is the number of susceptibles involved in the event. Mixing events are assumed to be instantaneous. The infectious periods of infectives follow independent
$\pi_c (w;\,i,j) =0$
: the maximum number of new infectives created at a mixing event is the number of susceptibles involved in the event. Mixing events are assumed to be instantaneous. The infectious periods of infectives follow independent
 ${\rm Exp}(\gamma)$
random variables, i.e. exponential random variables having rate
${\rm Exp}(\gamma)$
random variables, i.e. exponential random variables having rate
 $\gamma$
and hence mean
$\gamma$
and hence mean
 $\gamma^{-1}$
. There is no latency period, so newly infected individuals are immediately able to infect other individuals. (The possibility of their being able to infect other susceptibles during the mixing event at which they were infected can be incorporated into the
$\gamma^{-1}$
. There is no latency period, so newly infected individuals are immediately able to infect other individuals. (The possibility of their being able to infect other susceptibles during the mixing event at which they were infected can be incorporated into the
 $\pi_c(w;\,i,j)$
.) All processes and random variables in the above model are mutually independent. The epidemic starts at time
$\pi_c(w;\,i,j)$
.) All processes and random variables in the above model are mutually independent. The epidemic starts at time
 $t=0$
with
$t=0$
with
 $m_n$
infective and
$m_n$
infective and
 $n-m_n$
susceptible individuals, and terminates when there is no infective left in the population. Denote this epidemic model by
$n-m_n$
susceptible individuals, and terminates when there is no infective left in the population. Denote this epidemic model by
 $\mathcal{E}^{(n)}$
.
$\mathcal{E}^{(n)}$
.
2.1. Special cases
2.1.1. General stochastic epidemic
If all mixing groups have size 2, i.e.
 ${\mathbb{P}}(C^{(n)}=2)=1$
, and
${\mathbb{P}}(C^{(n)}=2)=1$
, and
 $\pi_c (0;\,1,1)=\pi_c (1;\,1,1)=\frac{1}{2}$
, then the model reduces to the general stochastic epidemic, with individual-to-individual infection rate
$\pi_c (0;\,1,1)=\pi_c (1;\,1,1)=\frac{1}{2}$
, then the model reduces to the general stochastic epidemic, with individual-to-individual infection rate
 $\beta=\frac{\lambda}{n-1}$
and recovery rate
$\beta=\frac{\lambda}{n-1}$
and recovery rate
 $\gamma$
.
$\gamma$
.
2.1.2. Binomial sampling
The models studied in Cortez [Reference Cortez8] and Ball and Neal [Reference Ball and Neal5] make the Reed–Frost-type assumption that at a mixing event of size c, each infective present has probability
 $\pi_c$
of making an infectious contact with any given susceptible present, with all such contacts being independent. This corresponds to
$\pi_c$
of making an infectious contact with any given susceptible present, with all such contacts being independent. This corresponds to
 \[\pi_c(w;\,i,j)=\binom{i}{w}\left(1-(1-\pi_c)\,^j\right)^w (1-\pi_c)\,^{j(i-w)} \qquad (w=0,1,\dots,i).\]
\[\pi_c(w;\,i,j)=\binom{i}{w}\left(1-(1-\pi_c)\,^j\right)^w (1-\pi_c)\,^{j(i-w)} \qquad (w=0,1,\dots,i).\]
3. Approximating branching process and main results
3.1. Approximating branching process
We approximate the process of infectives in the early stages of the epidemic
 $\mathcal{E}^{(n)}$
by a branching process
$\mathcal{E}^{(n)}$
by a branching process
 $\mathcal{B}$
, which assumes that every mixing event which includes at least one infective consists of a single infective in an otherwise susceptible group. In the epidemic
$\mathcal{B}$
, which assumes that every mixing event which includes at least one infective consists of a single infective in an otherwise susceptible group. In the epidemic
 $\mathcal{E}^{(n)}$
, the probability that a given mixing event of size c involves a specified individual,
$\mathcal{E}^{(n)}$
, the probability that a given mixing event of size c involves a specified individual,
 $i_*$
say, is
$i_*$
say, is
 $\frac{c}{n}$
, so mixing events that include
$\frac{c}{n}$
, so mixing events that include
 $i_*$
occur at rate
$i_*$
occur at rate
 \begin{equation}\lambda n \sum_{c=2}^n p^{(n)}_C(c)\frac{c}{n}=\lambda \mu^{(n)}_C,\end{equation}
\begin{equation}\lambda n \sum_{c=2}^n p^{(n)}_C(c)\frac{c}{n}=\lambda \mu^{(n)}_C,\end{equation}
where
 $p^{(n)}_C(c) = {\mathbb{P}} \big(C^{(n)} =c\big)$
$p^{(n)}_C(c) = {\mathbb{P}} \big(C^{(n)} =c\big)$
 $(c=2,3,\ldots, n)$
and
$(c=2,3,\ldots, n)$
and
 $\mu^{(n)}_C={\mathbb{E}}[C^{(n)}]$
. Furthermore, the probability that a given mixing event is of size c given that it includes
$\mu^{(n)}_C={\mathbb{E}}[C^{(n)}]$
. Furthermore, the probability that a given mixing event is of size c given that it includes
 $i_*$
is
$i_*$
is
 \[\frac{p^{(n)}_C(c)\frac{c}{n}}{\sum_{c^{\prime}=2}^n p^{(n)}_C(c^{\prime})\frac{c^{\prime}}{n}} = \frac{c p^{(n)}_C(c)}{\mu^{(n)}_C}\qquad(c=2,3,\dots,n).\]
\[\frac{p^{(n)}_C(c)\frac{c}{n}}{\sum_{c^{\prime}=2}^n p^{(n)}_C(c^{\prime})\frac{c^{\prime}}{n}} = \frac{c p^{(n)}_C(c)}{\mu^{(n)}_C}\qquad(c=2,3,\dots,n).\]
Suppose that
 $C^{(n)} \stackrel{{\rm D}}{\longrightarrow} C$
as
$C^{(n)} \stackrel{{\rm D}}{\longrightarrow} C$
as
 $n \to \infty$
(where
$n \to \infty$
(where
 $\stackrel{{\rm D}}{\longrightarrow}$
denotes convergence in distribution),
$\stackrel{{\rm D}}{\longrightarrow}$
denotes convergence in distribution),
 $p_C(c)={\mathbb{P}}(C=c)$
$p_C(c)={\mathbb{P}}(C=c)$
 $(c=2,3,\dots)$
, and
$(c=2,3,\dots)$
, and
 $\mu^{(n)}_C \to \mu_C=\sum_{c=2}^{\infty} cp_C(c)$
, which we assume to be finite. Thus in the limit as
$\mu^{(n)}_C \to \mu_C=\sum_{c=2}^{\infty} cp_C(c)$
, which we assume to be finite. Thus in the limit as
 $n \to \infty$
, mixing events involving
$n \to \infty$
, mixing events involving
 $i_*$
occur at rate
$i_*$
occur at rate
 $\lambda \mu_C$
, and the size of such a mixing event is distributed according to
$\lambda \mu_C$
, and the size of such a mixing event is distributed according to
 $\tilde{C}$
, the size-biased version of C, having probability mass function
$\tilde{C}$
, the size-biased version of C, having probability mass function
 \begin{equation}p_{\tilde{C}}(c)={\mathbb{P}}(\tilde{C}=c)=\frac{cp_C(c)}{\mu_C} \qquad (c=2,3,\dots).\end{equation}
\begin{equation}p_{\tilde{C}}(c)={\mathbb{P}}(\tilde{C}=c)=\frac{cp_C(c)}{\mu_C} \qquad (c=2,3,\dots).\end{equation}
We assume that the initial number of infectives
 $m_n=m$
for all sufficiently large n, so the branching process
$m_n=m$
for all sufficiently large n, so the branching process
 $\mathcal{B}$
has m ancestors.
$\mathcal{B}$
has m ancestors.
In
 $\mathcal{B}$
, a typical individual,
$\mathcal{B}$
, a typical individual,
 $i_*$
say, has lifetime
$i_*$
say, has lifetime
 $L \sim {\rm Exp}(\gamma)$
, during which they have birth events at rate
$L \sim {\rm Exp}(\gamma)$
, during which they have birth events at rate
 $\lambda \mu_C$
. Let
$\lambda \mu_C$
. Let
 $\tilde{Z}_1, \tilde{Z}_2, \dots$
denote the number of offspring
$\tilde{Z}_1, \tilde{Z}_2, \dots$
denote the number of offspring
 $i_*$
has at successive birth events. A birth event corresponds to a mixing event involving a single infective in an otherwise susceptible group in the epidemic. Thus,
$i_*$
has at successive birth events. A birth event corresponds to a mixing event involving a single infective in an otherwise susceptible group in the epidemic. Thus,
 $\tilde{Z}_1, \tilde{Z}_2, \dots$
are i.i.d. copies of a random variable
$\tilde{Z}_1, \tilde{Z}_2, \dots$
are i.i.d. copies of a random variable
 $\tilde{Z}$
, with
$\tilde{Z}$
, with
 ${\mathbb{P}}(\tilde{Z}=w)=\varphi_w$
${\mathbb{P}}(\tilde{Z}=w)=\varphi_w$
 $(w=0,1,\dots)$
, where
$(w=0,1,\dots)$
, where
 \begin{equation}\varphi_w=\sum_{c=w+1}^{\infty} p_{\tilde{C}}(c) \pi_c(w;\,c-1,1)=\frac{1}{\mu_C}\sum_{c=w+1}^{\infty} c p_C(c)\pi_c(w;\,c-1,1),\end{equation}
\begin{equation}\varphi_w=\sum_{c=w+1}^{\infty} p_{\tilde{C}}(c) \pi_c(w;\,c-1,1)=\frac{1}{\mu_C}\sum_{c=w+1}^{\infty} c p_C(c)\pi_c(w;\,c-1,1),\end{equation}
using (3.2). Note that an individual may produce no offspring at a birth event. The number of birth events a typical individual has during their lifetime, G say, has the geometric distribution
 \begin{equation}{\mathbb{P}}(G=k)=\frac{\gamma}{\gamma+\lambda \mu_C}\left(\frac{\lambda \mu_C}{\gamma+\lambda \mu_C}\right)^k \qquad (k=0,1,\dots).\end{equation}
\begin{equation}{\mathbb{P}}(G=k)=\frac{\gamma}{\gamma+\lambda \mu_C}\left(\frac{\lambda \mu_C}{\gamma+\lambda \mu_C}\right)^k \qquad (k=0,1,\dots).\end{equation}
Let R be the total number of offspring a typical individual has during their lifetime. Then
 \begin{equation}R=\sum_{i=1}^G \tilde{Z}_i,\end{equation}
\begin{equation}R=\sum_{i=1}^G \tilde{Z}_i,\end{equation}
where
 $G, \tilde{Z}_1, \tilde{Z}_2, \dots$
are independent and the sum is zero if
$G, \tilde{Z}_1, \tilde{Z}_2, \dots$
are independent and the sum is zero if
 $G=0$
.
$G=0$
.
The basic reproduction number
 $R_0={\mathbb{E}}[R]$
. Hence, using (3.5) and (3.4),
$R_0={\mathbb{E}}[R]$
. Hence, using (3.5) and (3.4),
 \begin{align}R_0={\mathbb{E}}[G]{\mathbb{E}}[\tilde{Z}]&=\frac{\lambda \mu_C}{\gamma}\sum_{w=1}^{\infty}\frac{w}{\mu_C}\sum_{c=w+1}^\infty c p_{C} (c)\pi_c (w;\, c-1,1)\nonumber \\&=\frac{\lambda}{\gamma} \sum_{c=2}^\infty c p_{C} (c)\sum_{w=1}^{c-1} w \pi_c (w;\, c-1,1)\nonumber\\&=\frac{\lambda}{\gamma} {\mathbb{E}}[C \nu (C)],\end{align}
\begin{align}R_0={\mathbb{E}}[G]{\mathbb{E}}[\tilde{Z}]&=\frac{\lambda \mu_C}{\gamma}\sum_{w=1}^{\infty}\frac{w}{\mu_C}\sum_{c=w+1}^\infty c p_{C} (c)\pi_c (w;\, c-1,1)\nonumber \\&=\frac{\lambda}{\gamma} \sum_{c=2}^\infty c p_{C} (c)\sum_{w=1}^{c-1} w \pi_c (w;\, c-1,1)\nonumber\\&=\frac{\lambda}{\gamma} {\mathbb{E}}[C \nu (C)],\end{align}
where
 \begin{equation}\nu(c)=\sum_{w=1}^{c-1} w \pi_c (w;\, c-1,1)\end{equation}
\begin{equation}\nu(c)=\sum_{w=1}^{c-1} w \pi_c (w;\, c-1,1)\end{equation}
is the mean number of new infectives generated in a mixing event of size c with one infective and
 $c-1$
susceptibles. Again using (3.5) and (3.4), the offspring probability generating function for the branching process
$c-1$
susceptibles. Again using (3.5) and (3.4), the offspring probability generating function for the branching process
 $\mathcal{B}$
is
$\mathcal{B}$
is
 \[f_R(s)={\mathbb{E}}[s^R]=\frac{\gamma}{\gamma+\lambda \mu_C\left(1-f_{\tilde{Z}}(s)\right)},\]
\[f_R(s)={\mathbb{E}}[s^R]=\frac{\gamma}{\gamma+\lambda \mu_C\left(1-f_{\tilde{Z}}(s)\right)},\]
where
 $f_{\tilde{Z}}(s)=\sum_{w=0}^{\infty} \varphi_w s^w$
. By standard branching process theory, the extinction probability z of
$f_{\tilde{Z}}(s)=\sum_{w=0}^{\infty} \varphi_w s^w$
. By standard branching process theory, the extinction probability z of
 $\mathcal{B}$
, given that initially there is one individual, is given by the smallest solution in [0, 1] of
$\mathcal{B}$
, given that initially there is one individual, is given by the smallest solution in [0, 1] of
 $f_R(s)=s$
. Furthermore,
$f_R(s)=s$
. Furthermore,
 $z\lt 1$
if and only if
$z\lt 1$
if and only if
 $R_0\gt 1$
.
$R_0\gt 1$
.
Let r denote the Malthusian parameter of
 $\mathcal{B}$
; see Jagers [Reference Jagers11, p. 10] for details. The mean rate at which an individual produces offspring t time units after their birth is
$\mathcal{B}$
; see Jagers [Reference Jagers11, p. 10] for details. The mean rate at which an individual produces offspring t time units after their birth is
 ${\mathbb{P}}(L\gt t) \lambda \mu_C {\mathbb{E}}[\tilde{Z}_1]=\gamma {\rm e}^{-\gamma t} R_0$
${\mathbb{P}}(L\gt t) \lambda \mu_C {\mathbb{E}}[\tilde{Z}_1]=\gamma {\rm e}^{-\gamma t} R_0$
 $(t \gt 0)$
, so r is the unique solution in
$(t \gt 0)$
, so r is the unique solution in
 $(0, \infty)$
of
$(0, \infty)$
of
 \[\int_0^{\infty}{\rm e}^{-rt} \gamma {\rm e}^{-\gamma t} R_0 \,{\rm d}t=1,\]
\[\int_0^{\infty}{\rm e}^{-rt} \gamma {\rm e}^{-\gamma t} R_0 \,{\rm d}t=1,\]
whence
 \begin{equation}r=\gamma(R_0-1). \end{equation}
\begin{equation}r=\gamma(R_0-1). \end{equation}
Note that r depends on the parameters of the epidemic model only through
 $(R_0, \gamma)$
. Thus, if
$(R_0, \gamma)$
. Thus, if
 $R_0$
and
$R_0$
and
 $\gamma$
are held fixed, then the Malthusian parameter is the same for all corresponding choices of the distribution of C and
$\gamma$
are held fixed, then the Malthusian parameter is the same for all corresponding choices of the distribution of C and
 $\{\pi_c(w;\,i,j)\}$
. In particular, under these conditions, the early exponential growth of an epidemic that takes off is the same as that of the general stochastic epidemic.
$\{\pi_c(w;\,i,j)\}$
. In particular, under these conditions, the early exponential growth of an epidemic that takes off is the same as that of the general stochastic epidemic.
3.2. Strong convergence of epidemic processes
In this section we consider a sequence of epidemics
 $(\mathcal{E}^{(n)})$
, in which
$(\mathcal{E}^{(n)})$
, in which
 $m_n=m$
for all sufficiently large n, and state results concerned with convergence of the process of infectives in the epidemic process
$m_n=m$
for all sufficiently large n, and state results concerned with convergence of the process of infectives in the epidemic process
 $\mathcal{E}^{(n)}$
to the branching process
$\mathcal{E}^{(n)}$
to the branching process
 $\mathcal{B}$
as
$\mathcal{B}$
as
 $n \to \infty$
that are proved in Section 4. The usual approach to proving such results is based upon that of Ball [Reference Ball2] and Ball and Donnelly [Reference Ball and Donnelly3], in which the sample paths of the epidemic process for each n are constructed from those of the limiting branching process,
$n \to \infty$
that are proved in Section 4. The usual approach to proving such results is based upon that of Ball [Reference Ball2] and Ball and Donnelly [Reference Ball and Donnelly3], in which the sample paths of the epidemic process for each n are constructed from those of the limiting branching process,
 $\mathcal{B}$
. As noted in the introduction, that approach is not easily implemented in the present setting, because the mixing groups induce dependencies between different infectives. We therefore generalise the method in Ball and O’Neill [Reference Ball and O’Neill6] and construct sample paths of the epidemic processes and the limiting branching process,
$\mathcal{B}$
. As noted in the introduction, that approach is not easily implemented in the present setting, because the mixing groups induce dependencies between different infectives. We therefore generalise the method in Ball and O’Neill [Reference Ball and O’Neill6] and construct sample paths of the epidemic processes and the limiting branching process,
 $\mathcal{B}$
, from a sequence of i.i.d. random vectors defined on an underlying probability space
$\mathcal{B}$
, from a sequence of i.i.d. random vectors defined on an underlying probability space
 $(\Omega, \mathcal{F}, {\mathbb{P}})$
. The construction is described in Section 4.
$(\Omega, \mathcal{F}, {\mathbb{P}})$
. The construction is described in Section 4.
For
 $t \ge 0$
, let
$t \ge 0$
, let
 $S^{(n)}(t)$
and
$S^{(n)}(t)$
and
 $I^{(n)}(t)$
be the numbers of susceptibles and infectives, respectively, at time t in
$I^{(n)}(t)$
be the numbers of susceptibles and infectives, respectively, at time t in
 $\mathcal{E}^{(n)}$
. Let
$\mathcal{E}^{(n)}$
. Let
 $T^{(n)}=n-S^{(n)}(\infty)$
be the total size of the epidemic
$T^{(n)}=n-S^{(n)}(\infty)$
be the total size of the epidemic
 $\mathcal{E}^{(n)}$
, i.e. the total number of individuals infected during its course, including the initial infectives. For
$\mathcal{E}^{(n)}$
, i.e. the total number of individuals infected during its course, including the initial infectives. For
 $t \geq 0$
, let I(t) be the number of individuals alive at time t in
$t \geq 0$
, let I(t) be the number of individuals alive at time t in
 $\mathcal{B}$
, and let T be the total size of the branching process
$\mathcal{B}$
, and let T be the total size of the branching process
 $\mathcal{B}$
, including the m ancestors. Note that whereas
$\mathcal{B}$
, including the m ancestors. Note that whereas
 $T^{(n)}(\omega)\lt\infty$
for all
$T^{(n)}(\omega)\lt\infty$
for all
 $\omega \in \Omega$
,
$\omega \in \Omega$
,
 $T(\omega)=\infty$
if the branching process
$T(\omega)=\infty$
if the branching process
 $\mathcal{B}(\omega)$
does not go extinct.
$\mathcal{B}(\omega)$
does not go extinct.
Throughout the remainder of the paper we assume that
 $m_n =m$
and
$m_n =m$
and
 $\mu^{(n)}_C \leq \mu_C$
for all sufficiently large n. The assumption
$\mu^{(n)}_C \leq \mu_C$
for all sufficiently large n. The assumption
 $\mu^{(n)}_C \leq \mu_C$
simplifies the presentation of certain results, in particular, Lemma 4.2, and holds in the most common cases: (i) C has finite support
$\mu^{(n)}_C \leq \mu_C$
simplifies the presentation of certain results, in particular, Lemma 4.2, and holds in the most common cases: (i) C has finite support
 $\{2,3,\ldots, n_0\}$
, and for
$\{2,3,\ldots, n_0\}$
, and for
 $n \geq n_0$
,
$n \geq n_0$
,
 $C^{(n)} = C$
; (ii)
$C^{(n)} = C$
; (ii)
 $C^{(n)} = \min \{ C, n \}$
; and (iii)
$C^{(n)} = \min \{ C, n \}$
; and (iii)
 $C^{(n)} \stackrel{D}{=} C | C\leq n$
. We also assume throughout that
$C^{(n)} \stackrel{D}{=} C | C\leq n$
. We also assume throughout that
 $C^{(n)} \stackrel{{\rm D}}{\longrightarrow} C$
and
$C^{(n)} \stackrel{{\rm D}}{\longrightarrow} C$
and
 ${\mathbb{E}}[(C^{(n)})^2] \to {\mathbb{E}}[C^2] \lt\infty$
as
${\mathbb{E}}[(C^{(n)})^2] \to {\mathbb{E}}[C^2] \lt\infty$
as
 $n \to \infty$
. For Theorem 3.1(b) and Theorem 3.2, we require additional conditions on
$n \to \infty$
. For Theorem 3.1(b) and Theorem 3.2, we require additional conditions on
 $C^{(n)}$
and C, namely that
$C^{(n)}$
and C, namely that
 \begin{eqnarray}\lim_{n \to \infty} {\mathbb{E}}\big[C^{(n)} \big(C^{(n)} -1\big) \nu \big(C^{(n)}\big)\big] = {\mathbb{E}}[C (C -1) \nu (C)] \lt \infty, \end{eqnarray}
\begin{eqnarray}\lim_{n \to \infty} {\mathbb{E}}\big[C^{(n)} \big(C^{(n)} -1\big) \nu \big(C^{(n)}\big)\big] = {\mathbb{E}}[C (C -1) \nu (C)] \lt \infty, \end{eqnarray}
and that there exists
 $\theta_0 \gt 0$
such that
$\theta_0 \gt 0$
such that
 \begin{eqnarray}\lim_{n \to \infty} n^{\theta_0} \sum_{c=2}^\infty c \left\vert p_C^{(n)} (c) - p_C (c) \right\vert =0. \end{eqnarray}
\begin{eqnarray}\lim_{n \to \infty} n^{\theta_0} \sum_{c=2}^\infty c \left\vert p_C^{(n)} (c) - p_C (c) \right\vert =0. \end{eqnarray}
Note that
 ${\mathbb{E}}[\big(C^{(n)}\big)^3] \to {\mathbb{E}}[C^3] \lt\infty$
as
${\mathbb{E}}[\big(C^{(n)}\big)^3] \to {\mathbb{E}}[C^3] \lt\infty$
as
 $n \to \infty$
is a sufficient condition for (3.9) to hold. Also, in the three common cases listed above for constructing
$n \to \infty$
is a sufficient condition for (3.9) to hold. Also, in the three common cases listed above for constructing
 $C^{(n)}$
from C, (3.10) holds for any
$C^{(n)}$
from C, (3.10) holds for any
 $0 \lt \theta_0 \lt \alpha$
, for which
$0 \lt \theta_0 \lt \alpha$
, for which
 ${\mathbb{E}} [C^{1 + \alpha}] \lt \infty$
. (For Case (i), this is immediate. For Cases (ii) and (iii), the proof is similar to that of (A1) in the Supplementary Information of Ball and Neal [Reference Ball and Neal5].)
${\mathbb{E}} [C^{1 + \alpha}] \lt \infty$
. (For Case (i), this is immediate. For Cases (ii) and (iii), the proof is similar to that of (A1) in the Supplementary Information of Ball and Neal [Reference Ball and Neal5].)
Theorem 3.1.
Under the stated conditions on
 $C^{(n)}$
, there exists a probability space
$C^{(n)}$
, there exists a probability space
 $(\Omega, \mathcal{F}, {\mathbb{P}})$
on which are defined a sequence of epidemic models,
$(\Omega, \mathcal{F}, {\mathbb{P}})$
on which are defined a sequence of epidemic models,
 $\mathcal{E}^{(n)}$
, indexed by n, and the approximating branching process,
$\mathcal{E}^{(n)}$
, indexed by n, and the approximating branching process,
 $\mathcal{B}$
, with the following properties.
$\mathcal{B}$
, with the following properties.
Denote by
 $A_{ext}$
the set on which the branching process
$A_{ext}$
the set on which the branching process
 $\mathcal{B}$
becomes extinct:
$\mathcal{B}$
becomes extinct:
 \begin{eqnarray}A_{ext} = \left\{ \omega \in \Omega \,:\, T(\omega) \lt \infty \right\}. \nonumber\end{eqnarray}
\begin{eqnarray}A_{ext} = \left\{ \omega \in \Omega \,:\, T(\omega) \lt \infty \right\}. \nonumber\end{eqnarray}
-
(a) Then, as
 $n \rightarrow \infty$
, for
\begin{eqnarray}\sup_{0 \leq t \lt \infty} \big| I^{(n)} (t) - I (t) \big| \rightarrow 0 \nonumber\end{eqnarray}
${\mathbb{P}}$
-almost all
$\omega \in A_{ext}$
.
$n \rightarrow \infty$
, for
\begin{eqnarray}\sup_{0 \leq t \lt \infty} \big| I^{(n)} (t) - I (t) \big| \rightarrow 0 \nonumber\end{eqnarray}
${\mathbb{P}}$
-almost all
$\omega \in A_{ext}$
.
-
(b) Suppose that (3.9) holds and (3.10) holds for some
$\theta_0 \gt 0$
. Then, if there exists
$\alpha \geq 1$
such that
${\mathbb{E}} [C^{\alpha +1}] \lt \infty$
, we have for (3.11)as
\begin{eqnarray} 0 \lt \rho \lt \frac{1}{r} \min \left\{ \frac{\alpha \theta_0}{2 (1+\alpha)}, \frac{\alpha}{2 + 4 \alpha} \right\},\end{eqnarray}
$n \rightarrow \infty$
, (3.12)for
\begin{eqnarray} \sup_{0 \leq t \leq \rho \log n} \big| I^{(n)} (t) - I (t) \big| \rightarrow 0\end{eqnarray}
${\mathbb{P}}$
-almost all
$\omega \in A_{ext}^c$
.












The proof of Theorem 3.1 is presented in Section 4.
Note that
 $\rho$
given in (3.11) satisfies
$\rho$
given in (3.11) satisfies
 $\rho \lt (4r)^{-1}$
, and thus Theorem 3.1(b) is weaker than [Reference Ball and Donnelly3, Theorem 2.1, (2.2)], where (3.12) is shown to hold for
$\rho \lt (4r)^{-1}$
, and thus Theorem 3.1(b) is weaker than [Reference Ball and Donnelly3, Theorem 2.1, (2.2)], where (3.12) is shown to hold for
 $\rho \lt (2r)^{-1}$
in the standard pairwise mixing epidemic model. The following corollary of Theorem 3.1 concerns the final size of the epidemic.
$\rho \lt (2r)^{-1}$
in the standard pairwise mixing epidemic model. The following corollary of Theorem 3.1 concerns the final size of the epidemic.
Corollary 3.1.
For
 $(\Omega, \mathcal{F}, {\mathbb{P}})$
defined in Theorem 3.1
, we have, for
$(\Omega, \mathcal{F}, {\mathbb{P}})$
defined in Theorem 3.1
, we have, for
 ${\mathbb{P}}$
-almost all
${\mathbb{P}}$
-almost all
 $\omega \in \Omega$
,
$\omega \in \Omega$
,
 \[\lim_{n \to \infty} T^{(n)}(\omega)=T(\omega).\]
\[\lim_{n \to \infty} T^{(n)}(\omega)=T(\omega).\]
Corollary 3.1 shows that for large n, the final size of the epidemic
 $\mathcal{E}^{(n)}$
can be approximated by the total size of
$\mathcal{E}^{(n)}$
can be approximated by the total size of
 $\mathcal{B}$
. This leads to a threshold theorem for the epidemic process
$\mathcal{B}$
. This leads to a threshold theorem for the epidemic process
 $\mathcal{E}^{(n)}$
by associating survival (i.e. non-extinction) of the branching process
$\mathcal{E}^{(n)}$
by associating survival (i.e. non-extinction) of the branching process
 $\mathcal{B}$
with a major outbreak in the epidemic process
$\mathcal{B}$
with a major outbreak in the epidemic process
 $\mathcal{E}^{(n)}$
(cf. Ball [Reference Ball2, Theorem 6], and Ball and Donnelly [Reference Ball and Donnelly3, Corollary 3.4]). It then follows that a major outbreak occurs with non-zero probability if and only if
$\mathcal{E}^{(n)}$
(cf. Ball [Reference Ball2, Theorem 6], and Ball and Donnelly [Reference Ball and Donnelly3, Corollary 3.4]). It then follows that a major outbreak occurs with non-zero probability if and only if
 $R_0\gt 1$
, and the probability of a major outbreak is
$R_0\gt 1$
, and the probability of a major outbreak is
 $1-z^m$
. However, for practical applications it is useful to have a definition of a major outbreak that depends on n. We say that a major outbreak occurs if and only if
$1-z^m$
. However, for practical applications it is useful to have a definition of a major outbreak that depends on n. We say that a major outbreak occurs if and only if
 $T^{(n)} \ge \log n$
.
$T^{(n)} \ge \log n$
.
Theorem 3.2.
Suppose that (3.9) holds and (3.10) holds for some
 $\theta_0 \gt 0$
.
$\theta_0 \gt 0$
.
-
(a) Then
(3.13)
\begin{equation}{\mathbb{P}}\big(T^{(n)} \ge \log n\big) \to 1-z^m \quad\textit{as } n \to \infty.\end{equation}
-
(b) If also
$R_0\gt 1$
and there exists
$\alpha \gt 1$
such that
${\mathbb{E}} [C^{1 + \alpha}]\lt\infty$
, then there exists
$\delta\gt 0$
such that (3.14)
\begin{equation}{\mathbb{P}}\big(T^{(n)} \ge \delta n \vert T^{(n)} \ge \log n\big) \to 1 \quad\textit{as } n \to \infty.\end{equation}






The proof of Theorem 3.2 is presented in Section 5.
Theorem 3.2(b) implies that a major outbreak infects at least a fraction
 $\delta$
of the population with probability tending to one as
$\delta$
of the population with probability tending to one as
 $n \to \infty$
. However,
$n \to \infty$
. However,
 $\delta$
depends on the parameters of the epidemic
$\delta$
depends on the parameters of the epidemic
 $\mathcal{E}^{(n)}$
and can be arbitrarily close to 0. An immediate consequence of the proof of Theorem 3.2(b) is Corollary 3.2, which states that, in the limit as
$\mathcal{E}^{(n)}$
and can be arbitrarily close to 0. An immediate consequence of the proof of Theorem 3.2(b) is Corollary 3.2, which states that, in the limit as
 $n \to \infty$
, there exists
$n \to \infty$
, there exists
 $\delta^\prime \gt 0$
such that in the event of a major epidemic outbreak the proportion of the population infectious at the peak of the epidemic exceeds
$\delta^\prime \gt 0$
such that in the event of a major epidemic outbreak the proportion of the population infectious at the peak of the epidemic exceeds
 $\delta^\prime$
.
$\delta^\prime$
.
Corollary 3.2.
Under the conditions of Theorem 3.2(b), there exists
 $\delta^\prime \gt 0$
such that
$\delta^\prime \gt 0$
such that
 \begin{equation}{\mathbb{P}}\left( \left. \sup_{t \geq 0} \left\vert \frac{I^{(n)} (t)}{n} \right\vert \ge \delta^\prime \right\vert T^{(n)} \ge \log n \right) \to 1 \quad\textit{as } n \to \infty. \end{equation}
\begin{equation}{\mathbb{P}}\left( \left. \sup_{t \geq 0} \left\vert \frac{I^{(n)} (t)}{n} \right\vert \ge \delta^\prime \right\vert T^{(n)} \ge \log n \right) \to 1 \quad\textit{as } n \to \infty. \end{equation}
A central limit theorem for the total size
 $T^{(n)}$
in the event of a major outbreak is given in Ball and Neal [Reference Ball and Neal5], for the special case of binomial sampling (Section 2.1.2), by using the theory of (asymptotically) density-dependent population processes (Ethier and Kurtz [Reference Ethier and Kurtz10, Chapter 11] and Pollett [Reference Pollett16]) to obtain a functional central limit theorem for a random time-scale transformation of
$T^{(n)}$
in the event of a major outbreak is given in Ball and Neal [Reference Ball and Neal5], for the special case of binomial sampling (Section 2.1.2), by using the theory of (asymptotically) density-dependent population processes (Ethier and Kurtz [Reference Ethier and Kurtz10, Chapter 11] and Pollett [Reference Pollett16]) to obtain a functional central limit theorem for a random time-scale transformation of
 $\{(S^{(n)}(t), I^{(n)}(t)):t \ge 0\}$
and hence a central limit theorem for the number of susceptibles when the number of infectives reaches zero, via a boundary-crossing problem. As noted in the introduction, Theorem 3.2(b) is a key step in the proof of the above central limit theorem, though the result was only stated in [Reference Ball and Neal5]. A similar central limit theorem for
$\{(S^{(n)}(t), I^{(n)}(t)):t \ge 0\}$
and hence a central limit theorem for the number of susceptibles when the number of infectives reaches zero, via a boundary-crossing problem. As noted in the introduction, Theorem 3.2(b) is a key step in the proof of the above central limit theorem, though the result was only stated in [Reference Ball and Neal5]. A similar central limit theorem for
 $T^{(n)}$
is likely to hold for our more general model, although details will be messy unless
$T^{(n)}$
is likely to hold for our more general model, although details will be messy unless
 $\pi_c(w;\,i,j)$
takes a convenient form.
$\pi_c(w;\,i,j)$
takes a convenient form.
4. Proof of Theorem 3.2
4.1. Overview
We present an overview of the steps to prove Theorem 3.1. We construct on a common probability space the Markovian branching process
 $\mathcal{B}$
and the sequence of epidemic processes
$\mathcal{B}$
and the sequence of epidemic processes
 $( \mathcal{E}^{(n)} )$
, in which we equate infection and removal events in the epidemic process,
$( \mathcal{E}^{(n)} )$
, in which we equate infection and removal events in the epidemic process,
 $\mathcal{E}^{(n)}$
, with birth and death events, respectively, in the branching process,
$\mathcal{E}^{(n)}$
, with birth and death events, respectively, in the branching process,
 $\mathcal{B}$
. Given that at time
$\mathcal{B}$
. Given that at time
 $t \geq 0$
there are the same number of infectious individuals in the epidemic process
$t \geq 0$
there are the same number of infectious individuals in the epidemic process
 $\mathcal{E}^{(n)}$
as there are individuals alive in the branching process
$\mathcal{E}^{(n)}$
as there are individuals alive in the branching process
 $\mathcal{B}$
, the removal rate in
$\mathcal{B}$
, the removal rate in
 $\mathcal{E}^{(n)}$
is equal to the death rate in
$\mathcal{E}^{(n)}$
is equal to the death rate in
 $\mathcal{B}$
. For
$\mathcal{B}$
. For
 $k=0,1,\ldots$
, the rate at which an infection event occurs which generates k new infections in
$k=0,1,\ldots$
, the rate at which an infection event occurs which generates k new infections in
 $\mathcal{E}^{(n)}$
will depend upon the state of the population (number of susceptibles and infectives), and during the early stages of the epidemic this rate will be close to, but typically not equal to, the rate at which a birth event resulting in k new individuals occurs in
$\mathcal{E}^{(n)}$
will depend upon the state of the population (number of susceptibles and infectives), and during the early stages of the epidemic this rate will be close to, but typically not equal to, the rate at which a birth event resulting in k new individuals occurs in
 $\mathcal{B}$
. Therefore, we look to bound the difference between the infection rate in
$\mathcal{B}$
. Therefore, we look to bound the difference between the infection rate in
 $\mathcal{E}^{(n)}$
and the birth rate in
$\mathcal{E}^{(n)}$
and the birth rate in
 $\mathcal{B}$
in order to establish a coupling between the two processes.
$\mathcal{B}$
in order to establish a coupling between the two processes.
A useful observation is that in the epidemic processes
 $\mathcal{E}^{(n)}$
(the branching process
$\mathcal{E}^{(n)}$
(the branching process
 $\mathcal{B}$
) the number of infectives and susceptibles (the number of individuals alive) is piecewise constant between events, where an event is either a mixing event or a recovery. Therefore, in Section 4.2, we define embedded discrete-time jump processes for
$\mathcal{B}$
) the number of infectives and susceptibles (the number of individuals alive) is piecewise constant between events, where an event is either a mixing event or a recovery. Therefore, in Section 4.2, we define embedded discrete-time jump processes for
 $\mathcal{E}^{(n)}$
and
$\mathcal{E}^{(n)}$
and
 $\mathcal{B}$
, for the number of infectives (and susceptibles) and the number of individuals alive after each event. In the case of
$\mathcal{B}$
, for the number of infectives (and susceptibles) and the number of individuals alive after each event. In the case of
 $\mathcal{B}$
the embedded discrete-time jump process is a random walk. Then, in Section 4.3, we provide a bound on the rate of convergence to 0 of the difference between the infection rate in
$\mathcal{B}$
the embedded discrete-time jump process is a random walk. Then, in Section 4.3, we provide a bound on the rate of convergence to 0 of the difference between the infection rate in
 $\mathcal{E}^{(n)}$
and the birth rate in
$\mathcal{E}^{(n)}$
and the birth rate in
 $\mathcal{B}$
in Lemma 4.1, which is applicable during the early stages of the epidemic when only a few individuals have been infected. Lemma 4.1 enables us to construct the embedded discrete-time jump processes defined in Section 4.2 on a common probability space (Section 4.4) and provide an almost sure coupling between the discrete-time processes during the initial stages of the epidemic (Section 4.5). That is, we couple the outcomes of the kth
$\mathcal{B}$
in Lemma 4.1, which is applicable during the early stages of the epidemic when only a few individuals have been infected. Lemma 4.1 enables us to construct the embedded discrete-time jump processes defined in Section 4.2 on a common probability space (Section 4.4) and provide an almost sure coupling between the discrete-time processes during the initial stages of the epidemic (Section 4.5). That is, we couple the outcomes of the kth
 $(k=1, 2, \ldots)$
events in
$(k=1, 2, \ldots)$
events in
 $\mathcal{E}^{(n)}$
and
$\mathcal{E}^{(n)}$
and
 $\mathcal{B}$
so that the types of event—birth (infection) and death (removal)—match, and in the case of birth/infection, the same numbers of births and infections occur. Once we have established an almost sure agreement between the types of events that have occurred in the epidemic and branching processes, it is straightforward to provide an almost sure coupling of the timing of the events. The key couplings are drawn together in Lemma 4.2, from which Theorem 3.1 follows almost immediately. Finally, we consider the total sizes of the epidemic processes
$\mathcal{B}$
so that the types of event—birth (infection) and death (removal)—match, and in the case of birth/infection, the same numbers of births and infections occur. Once we have established an almost sure agreement between the types of events that have occurred in the epidemic and branching processes, it is straightforward to provide an almost sure coupling of the timing of the events. The key couplings are drawn together in Lemma 4.2, from which Theorem 3.1 follows almost immediately. Finally, we consider the total sizes of the epidemic processes
 $\mathcal{E}^{(n)}$
and the branching process
$\mathcal{E}^{(n)}$
and the branching process
 $\mathcal{B}$
and provide a proof of Corollary 3.1.
$\mathcal{B}$
and provide a proof of Corollary 3.1.
4.2. Embedded random walk
Let the random walk
 $\mathcal{R}$
be defined as follows. Let
$\mathcal{R}$
be defined as follows. Let
 $Y_k$
denote the position of the random walk after k steps, with
$Y_k$
denote the position of the random walk after k steps, with
 $Y_0 = m \gt 0$
. For
$Y_0 = m \gt 0$
. For
 $k=1,2,\ldots$
, let
$k=1,2,\ldots$
, let
 $Y_k = Y_{k-1} + Z_k$
, where
$Y_k = Y_{k-1} + Z_k$
, where
 $Z_1, Z_2, \ldots$
are i.i.d. with probability mass function
$Z_1, Z_2, \ldots$
are i.i.d. with probability mass function
 \begin{align} {\mathbb{P}} \left( Z_k=w \right) = \left\{ \begin{array}{l@{\quad}l} \dfrac{\beta \varphi_w}{\gamma + \beta}, & w=0,1,\ldots, \\[9pt]\dfrac{\gamma}{\gamma + \beta}, & w=-1,\\[7pt] 0 & \mbox{otherwise,} \end{array} \right. \end{align}
\begin{align} {\mathbb{P}} \left( Z_k=w \right) = \left\{ \begin{array}{l@{\quad}l} \dfrac{\beta \varphi_w}{\gamma + \beta}, & w=0,1,\ldots, \\[9pt]\dfrac{\gamma}{\gamma + \beta}, & w=-1,\\[7pt] 0 & \mbox{otherwise,} \end{array} \right. \end{align}
where
 $\beta=\lambda \mu_C$
and
$\beta=\lambda \mu_C$
and
 $\varphi_w$
is defined as in (3.3). Thus, upward (downward) steps in
$\varphi_w$
is defined as in (3.3). Thus, upward (downward) steps in
 $\mathcal{R}$
correspond to birth (death) events in
$\mathcal{R}$
correspond to birth (death) events in
 $\mathcal{B}$
. Note that
$\mathcal{B}$
. Note that
 $Z_k =0$
is possible, corresponding to a step with no change in the random walk (a birth event with no births in
$Z_k =0$
is possible, corresponding to a step with no change in the random walk (a birth event with no births in
 $\mathcal{B}$
). For
$\mathcal{B}$
). For
 $k=1,2,\ldots$
, let
$k=1,2,\ldots$
, let
 $\eta_k$
denote the time of the kth event in
$\eta_k$
denote the time of the kth event in
 $\mathcal{B}$
with
$\mathcal{B}$
with
 $\eta_0 =0$
; then we can construct
$\eta_0 =0$
; then we can construct
 $\mathcal{R}$
from
$\mathcal{R}$
from
 $\mathcal{B}$
by setting
$\mathcal{B}$
by setting
 $Y_k = I (\eta_k)$
, where I(t)
$Y_k = I (\eta_k)$
, where I(t)
 $(t \geq 0)$
is the size of the population of
$(t \geq 0)$
is the size of the population of
 $\mathcal{B}$
at time t. Note that if
$\mathcal{B}$
at time t. Note that if
 $I (\eta_k) =0$
, then the branching process has gone extinct and
$I (\eta_k) =0$
, then the branching process has gone extinct and
 $Y_k=0$
, i.e. the random walk has hit 0. We can continue the construction of the random walk after the branching process has gone extinct using
$Y_k=0$
, i.e. the random walk has hit 0. We can continue the construction of the random walk after the branching process has gone extinct using
 $Y_k = Y_{k-1} + Z_k$
, but our primary interest is in the case where the two processes are positive. Conversely, we can construct
$Y_k = Y_{k-1} + Z_k$
, but our primary interest is in the case where the two processes are positive. Conversely, we can construct
 $\mathcal{B}$
from
$\mathcal{B}$
from
 $\mathcal{R}$
by using, in addition to
$\mathcal{R}$
by using, in addition to
 $\{Y_k\}=\{Y_k:k=0,1,\dots\}$
, a sequence of i.i.d. random variables
$\{Y_k\}=\{Y_k:k=0,1,\dots\}$
, a sequence of i.i.d. random variables
 $V_1, V_2, \ldots$
, where
$V_1, V_2, \ldots$
, where
 $V_k \sim {\rm Exp} (1)$
. (Throughout the paper, discrete-time processes are assumed to have index set
$V_k \sim {\rm Exp} (1)$
. (Throughout the paper, discrete-time processes are assumed to have index set
 $\mathbb{Z}_+$
unless indicated otherwise.) For
$\mathbb{Z}_+$
unless indicated otherwise.) For
 $k=1,2, \ldots$
,
$k=1,2, \ldots$
,
 \begin{eqnarray} \eta_k = \eta_{k-1} + \frac{V_k}{ (\gamma + \beta) Y_{k-1}}, \nonumber\end{eqnarray}
\begin{eqnarray} \eta_k = \eta_{k-1} + \frac{V_k}{ (\gamma + \beta) Y_{k-1}}, \nonumber\end{eqnarray}
and for any
 $\eta_k \leq t \lt \eta_{k+1}$
, we set
$\eta_k \leq t \lt \eta_{k+1}$
, we set
 $I (t) = Y_k$
. Note that
$I (t) = Y_k$
. Note that
 $\eta_k = \infty$
if
$\eta_k = \infty$
if
 $Y_{k-1} =0$
, corresponding to the branching process going extinct with
$Y_{k-1} =0$
, corresponding to the branching process going extinct with
 $I(t) =0$
for all
$I(t) =0$
for all
 $t \geq \eta_{k-1}$
. Finally, note that
$t \geq \eta_{k-1}$
. Finally, note that
 ${\mathbb{E}} [Z_1] \lt 0$
,
${\mathbb{E}} [Z_1] \lt 0$
,
 $=0$
, or
$=0$
, or
 $\gt 0$
if and only if
$\gt 0$
if and only if
 $R_0 \lt 1$
,
$R_0 \lt 1$
,
 $=1$
, or
$=1$
, or
 $\gt 1$
, respectively.
$\gt 1$
, respectively.
We turn to the sequence of epidemic processes,
 $(\mathcal{E}^{(n)})$
, and for each
$(\mathcal{E}^{(n)})$
, and for each
 $\mathcal{E}^{(n)}$
, an associated discrete-time epidemic jump process
$\mathcal{E}^{(n)}$
, an associated discrete-time epidemic jump process
 $\mathcal{S}^{(n)}$
. Let
$\mathcal{S}^{(n)}$
. Let
 $Q^{(n)}_c (i,j\vert x,y)$
denote the probability that a mixing event of size c in a population of size n with x susceptibles and y infectives (and hence
$Q^{(n)}_c (i,j\vert x,y)$
denote the probability that a mixing event of size c in a population of size n with x susceptibles and y infectives (and hence
 $n-x-y$
recovered individuals) involves i susceptibles and j infectives (and hence
$n-x-y$
recovered individuals) involves i susceptibles and j infectives (and hence
 $c-i-j$
recovered individuals). Note that
$c-i-j$
recovered individuals). Note that
 \begin{eqnarray}Q^{(n)}_c (i,j\vert x,y) = \frac{\binom{x}{i} \times \binom{y}{j}\times \binom{n-x-y}{c-i-j}}{\binom{n}{c}}.\end{eqnarray}
\begin{eqnarray}Q^{(n)}_c (i,j\vert x,y) = \frac{\binom{x}{i} \times \binom{y}{j}\times \binom{n-x-y}{c-i-j}}{\binom{n}{c}}.\end{eqnarray}
For
 $w=0,1,\ldots$
, let
$w=0,1,\ldots$
, let
 $q^{(n)} (x,y,w)$
be such that
$q^{(n)} (x,y,w)$
be such that
 \begin{align}q^{(n)} (x,y,w) y &= n \lambda \sum_{c=w+1}^n p^{(n)}_C (c) \sum_{j=1}^{c-w} \sum_{l=0}^{c-w-j} \left\{ Q^{(n)}_c (c-j-l,j\vert x,y) \pi_c (w;\,c-j-l,j) \right\}, \nonumber \\\end{align}
\begin{align}q^{(n)} (x,y,w) y &= n \lambda \sum_{c=w+1}^n p^{(n)}_C (c) \sum_{j=1}^{c-w} \sum_{l=0}^{c-w-j} \left\{ Q^{(n)}_c (c-j-l,j\vert x,y) \pi_c (w;\,c-j-l,j) \right\}, \nonumber \\\end{align}
where the indices j and l refer to the numbers of infectives and recovered individuals, respectively, involved in the mixing event. Thus, for
 $w=1,2,\ldots,x$
,
$w=1,2,\ldots,x$
,
 $q^{(n)}(x,y,w) y$
denotes the rate of occurrence of mixing events that create w new infectives within a population of size n having x susceptibles and y infectives. Hence,
$q^{(n)}(x,y,w) y$
denotes the rate of occurrence of mixing events that create w new infectives within a population of size n having x susceptibles and y infectives. Hence,
 $q^{(n)} (x,y,w)$
can be viewed as the rate at which an infectious individual in a population of size n containing x susceptibles and y infectives generates w new infectives. Note that
$q^{(n)} (x,y,w)$
can be viewed as the rate at which an infectious individual in a population of size n containing x susceptibles and y infectives generates w new infectives. Note that
 $q^{(n)}(x,y,0) y$
is the rate of occurrence of mixing events which involve at least one infective and create no new infectives, in a population with x susceptibles and
$q^{(n)}(x,y,0) y$
is the rate of occurrence of mixing events which involve at least one infective and create no new infectives, in a population with x susceptibles and
 $y\gt 0$
infectives.
$y\gt 0$
infectives.
Recall that, for
 $t \geq 0$
,
$t \geq 0$
,
 $S^{(n)} (t)$
and
$S^{(n)} (t)$
and
 $I^{(n)}(t)$
denote respectively the numbers of susceptibles and infectives at time t in
$I^{(n)}(t)$
denote respectively the numbers of susceptibles and infectives at time t in
 $\mathcal{E}^{(n)}$
. Since the population is closed, for all
$\mathcal{E}^{(n)}$
. Since the population is closed, for all
 $t \geq 0$
,
$t \geq 0$
,
 $n - S^{(n)} (t)- I^{(n)}(t)$
denotes the number of recovered individuals, and we can describe the epidemic
$n - S^{(n)} (t)- I^{(n)}(t)$
denotes the number of recovered individuals, and we can describe the epidemic
 $\mathcal{E}^{(n)}$
in terms of
$\mathcal{E}^{(n)}$
in terms of
 $\big\{(S^{(n)}(t), I^{(n)}(t))\,:\, t \geq 0\big\}$
, which is a continuous-time Markov chain on the state space
$\big\{(S^{(n)}(t), I^{(n)}(t))\,:\, t \geq 0\big\}$
, which is a continuous-time Markov chain on the state space
 $E^{(n)}=\big\{ (x,y) \in \mathbb{Z}^2\,:\, x+y \leq n, 0 \leq x \leq n-m_n, y \geq 0 \big\}$
with transition probabilities
$E^{(n)}=\big\{ (x,y) \in \mathbb{Z}^2\,:\, x+y \leq n, 0 \leq x \leq n-m_n, y \geq 0 \big\}$
with transition probabilities
 \begin{align}&{\mathbb{P}} \left( (S^{(n)}(t + \Delta t), I^{(n)}(t + \Delta t)) = (x-w,y+w) \right\vert \left. (S^{(n)}(t), I^{(n)}(t)) = (x,y) \right)\nonumber \\ &\qquad\qquad\qquad= q^{(n)} (x,y,w) y \Delta t + o (\Delta t) \qquad (w=0,1,\dots,x), \end{align}
\begin{align}&{\mathbb{P}} \left( (S^{(n)}(t + \Delta t), I^{(n)}(t + \Delta t)) = (x-w,y+w) \right\vert \left. (S^{(n)}(t), I^{(n)}(t)) = (x,y) \right)\nonumber \\ &\qquad\qquad\qquad= q^{(n)} (x,y,w) y \Delta t + o (\Delta t) \qquad (w=0,1,\dots,x), \end{align}
 \begin{align}&{\mathbb{P}} \left((S^{(n)}(t + \Delta t), I^{(n)}(t + \Delta t)) = (x,y-1) \right\vert \left. (S^{(n)}(t), I^{(n)}(t)) = (x,y) \right)\nonumber\\&\qquad\qquad\qquad = \gamma y \Delta t + o (\Delta t), \end{align}
\begin{align}&{\mathbb{P}} \left((S^{(n)}(t + \Delta t), I^{(n)}(t + \Delta t)) = (x,y-1) \right\vert \left. (S^{(n)}(t), I^{(n)}(t)) = (x,y) \right)\nonumber\\&\qquad\qquad\qquad = \gamma y \Delta t + o (\Delta t), \end{align}
and with all other transitions having probability
 $o (\Delta t)$
. The events (4.4) and (4.5) correspond to infection of w individuals and recovery of an individual, respectively. The function
$o (\Delta t)$
. The events (4.4) and (4.5) correspond to infection of w individuals and recovery of an individual, respectively. The function
 $q^{(n)}$
is real-valued with domain a subset of
$q^{(n)}$
is real-valued with domain a subset of
 $\mathbb{Z}_+ \times \mathbb{Z}_+ \times \mathbb{N}$
. We note that the epidemic process is invariant to the choice of
$\mathbb{Z}_+ \times \mathbb{Z}_+ \times \mathbb{N}$
. We note that the epidemic process is invariant to the choice of
 $q^{(n)} (x,y,0) \geq 0$
, so we can define
$q^{(n)} (x,y,0) \geq 0$
, so we can define
 $q^{(n)} (x,y,0)$
to satisfy (4.3) with
$q^{(n)} (x,y,0)$
to satisfy (4.3) with
 $w=0$
. Similarly, the epidemic process is invariant to the choice of
$w=0$
. Similarly, the epidemic process is invariant to the choice of
 $q^{(n)} (x,0,w)$
, as no infections can occur if
$q^{(n)} (x,0,w)$
, as no infections can occur if
 $y=0$
, but for coupling purposes it is useful to define
$y=0$
, but for coupling purposes it is useful to define
 $q^{(n)} (x,y,w) = \beta \varphi_w$
for
$q^{(n)} (x,y,w) = \beta \varphi_w$
for
 $y=0,-1,-2,\ldots$
. Finally, as noted in Section 4.1, we observe that the recovery rate (4.5) coincides with the death rate of the branching process
$y=0,-1,-2,\ldots$
. Finally, as noted in Section 4.1, we observe that the recovery rate (4.5) coincides with the death rate of the branching process
 $\mathcal{B}$
, so to couple the number of infectives in the epidemic process
$\mathcal{B}$
, so to couple the number of infectives in the epidemic process
 $\mathcal{E}^{(n)}$
to the number of individuals in the branching process
$\mathcal{E}^{(n)}$
to the number of individuals in the branching process
 $\mathcal{B}$
, we require that
$\mathcal{B}$
, we require that
 $q^{(n)} (x,y,w) \approx \beta \varphi_w$
and
$q^{(n)} (x,y,w) \approx \beta \varphi_w$
and
 $q^{(n)} (x,y) = \sum_{w=0}^{n-1} q^{(n)} (x,y,w) = \sum_{w=0}^{\infty} q^{(n)} (x,y,w) \approx \beta$
as n becomes large.
$q^{(n)} (x,y) = \sum_{w=0}^{n-1} q^{(n)} (x,y,w) = \sum_{w=0}^{\infty} q^{(n)} (x,y,w) \approx \beta$
as n becomes large.
 $\Big($
Note that for
$\Big($
Note that for
 $w \gt n-1$
,
$w \gt n-1$
,
 $q^{(n)} (x,y,w) =0.\Big)$
We proceed by making this precise after first describing the discrete-time epidemic jump process
$q^{(n)} (x,y,w) =0.\Big)$
We proceed by making this precise after first describing the discrete-time epidemic jump process
 $\mathcal{S}^{(n)}$
.
$\mathcal{S}^{(n)}$
.
For
 $n=1,2,\ldots$
and
$n=1,2,\ldots$
and
 $k=0,1,\ldots$
, let
$k=0,1,\ldots$
, let
 $\Big(X_k^{(n)}, Y_k^{(n)}\Big)$
denote the state of the jump process
$\Big(X_k^{(n)}, Y_k^{(n)}\Big)$
denote the state of the jump process
 $\mathcal{S}^{(n)}$
after the kth event with
$\mathcal{S}^{(n)}$
after the kth event with
 $\Big(X_0^{(n)}, Y_0^{(n)}\Big) = (n-m_n, m_n)$
. For
$\Big(X_0^{(n)}, Y_0^{(n)}\Big) = (n-m_n, m_n)$
. For
 $k=1,2,\ldots$
,
$k=1,2,\ldots$
,
 $(x,y) \in E^{(n)}$
, and
$(x,y) \in E^{(n)}$
, and
 $w=0,1,\ldots,x$
, let
$w=0,1,\ldots,x$
, let
 \begin{eqnarray} {\mathbb{P}} \left( \left. \Big(X_{k+1}^{(n)},Y_{k+1}^{(n)}\Big)= (x-w,y+w) \right\vert \Big(X_k^{(n)},Y_k^{(n)}\Big)= (x,y) \right) &=& \frac{q^{(n)} (x,y,w)}{\gamma + q^{(n)} (x,y)}, \nonumber \\{\mathbb{P}} \left( \left. \Big(X_{k+1}^{(n)},Y_{k+1}^{(n)}\Big)= (x,y-1) \right\vert \Big(X_k^{(n)},Y_k^{(n)}\Big)= (x,y) \right) &=& \frac{\gamma}{\gamma + q^{(n)} (x,y)}, \nonumber\end{eqnarray}
\begin{eqnarray} {\mathbb{P}} \left( \left. \Big(X_{k+1}^{(n)},Y_{k+1}^{(n)}\Big)= (x-w,y+w) \right\vert \Big(X_k^{(n)},Y_k^{(n)}\Big)= (x,y) \right) &=& \frac{q^{(n)} (x,y,w)}{\gamma + q^{(n)} (x,y)}, \nonumber \\{\mathbb{P}} \left( \left. \Big(X_{k+1}^{(n)},Y_{k+1}^{(n)}\Big)= (x,y-1) \right\vert \Big(X_k^{(n)},Y_k^{(n)}\Big)= (x,y) \right) &=& \frac{\gamma}{\gamma + q^{(n)} (x,y)}, \nonumber\end{eqnarray}
with all other transitions having probability 0 of occurring. Letting
 $\eta_k^{(n)}$
denote the time of the kth event in
$\eta_k^{(n)}$
denote the time of the kth event in
 $\mathcal{E}^{(n)}$
, with
$\mathcal{E}^{(n)}$
, with
 $\eta_0^{(n)} =0$
, we can construct
$\eta_0^{(n)} =0$
, we can construct
 $\mathcal{S}^{(n)}$
from
$\mathcal{S}^{(n)}$
from
 $\mathcal{E}^{(n)}$
by setting
$\mathcal{E}^{(n)}$
by setting
 $\Big(X_k^{(n)}, Y_k^{(n)}\Big) = \Big(S^{(n)}\big(\eta_k^{(n)}\big), I^{(n)}\big(\eta_k^{(n)}\big)\Big)$
. As with the construction of
$\Big(X_k^{(n)}, Y_k^{(n)}\Big) = \Big(S^{(n)}\big(\eta_k^{(n)}\big), I^{(n)}\big(\eta_k^{(n)}\big)\Big)$
. As with the construction of
 $\mathcal{R}$
, we can continue the construction of
$\mathcal{R}$
, we can continue the construction of
 $\mathcal{S}^{(n)}$
after the kth event with
$\mathcal{S}^{(n)}$
after the kth event with
 $Y_k^{(n)}=0$
, using
$Y_k^{(n)}=0$
, using
 $q^{(n)} (x,y,w) = \beta \varphi_w$
for
$q^{(n)} (x,y,w) = \beta \varphi_w$
for
 $y=0,-1,-2,\ldots$
. Conversely, we can construct
$y=0,-1,-2,\ldots$
. Conversely, we can construct
 $\mathcal{E}^{(n)}$
from
$\mathcal{E}^{(n)}$
from
 $\mathcal{S}^{(n)}$
by in addition using the sequence of i.i.d. random variables
$\mathcal{S}^{(n)}$
by in addition using the sequence of i.i.d. random variables
 $V_1^{(n)}, V_2^{(n)}, \ldots$
, where
$V_1^{(n)}, V_2^{(n)}, \ldots$
, where
 $V_i^{(n)} \sim {\rm Exp} (1)$
. For
$V_i^{(n)} \sim {\rm Exp} (1)$
. For
 $k=1,2, \ldots$
, set
$k=1,2, \ldots$
, set
 \begin{eqnarray} \eta_k^{(n)} = \eta_{k-1}^{(n)} + \frac{ V_k^{(n)}}{\left[ \gamma + q^{(n)} \Big(X_{k-1}^{(n)},Y_{k-1}^{(n)}\Big) \right] Y_{k-1}^{(n)}}, \end{eqnarray}
\begin{eqnarray} \eta_k^{(n)} = \eta_{k-1}^{(n)} + \frac{ V_k^{(n)}}{\left[ \gamma + q^{(n)} \Big(X_{k-1}^{(n)},Y_{k-1}^{(n)}\Big) \right] Y_{k-1}^{(n)}}, \end{eqnarray}
then for any
 $\eta_k^{(n)} \leq t \lt \eta_{k+1}^{(n)}$
, set
$\eta_k^{(n)} \leq t \lt \eta_{k+1}^{(n)}$
, set
 $\big(S^{(n)} (t),I^{(n)} (t)\big) = \Big(X_k^{(n)}, Y_k^{(n)}\Big)$
. Note that if
$\big(S^{(n)} (t),I^{(n)} (t)\big) = \Big(X_k^{(n)}, Y_k^{(n)}\Big)$
. Note that if
 $Y_{k-1}^n =0$
,
$Y_{k-1}^n =0$
,
 $\eta_k^{(n)} = \infty$
and for all
$\eta_k^{(n)} = \infty$
and for all
 $t \geq \eta_{k-1}^{(n)}$
, the epidemic has died out with
$t \geq \eta_{k-1}^{(n)}$
, the epidemic has died out with
 $\big(S^{(n)} (t),I^{(n)} (t)\big) = \Big(X_{k-1}^{(n)}, 0\Big)$
.
$\big(S^{(n)} (t),I^{(n)} (t)\big) = \Big(X_{k-1}^{(n)}, 0\Big)$
.
We briefly discuss the choice of
 $V^{(n)}_k$
. A simple coupling with the branching process
$V^{(n)}_k$
. A simple coupling with the branching process
 $\mathcal{B}$
would be to set
$\mathcal{B}$
would be to set
 $V^{(n)}_k =V_k$
, which results in
$V^{(n)}_k =V_k$
, which results in
 $\eta_k^{(n)} \approx \eta_k$
if
$\eta_k^{(n)} \approx \eta_k$
if
 $\eta_{k-1}^{(n)} \approx \eta_{k-1}$
and
$\eta_{k-1}^{(n)} \approx \eta_{k-1}$
and
 $ Y_{k-1}^{(n)} \Big[\gamma + q^{(n)} \big(X_{k-1}^{(n)},Y_{k-1}^{(n)}\big) \Big] \approx Y_{k-1} [\gamma + \beta]$
. This is the approach taken in [Reference Ball and O’Neill6] and leads to a slight mismatch between the event times in
$ Y_{k-1}^{(n)} \Big[\gamma + q^{(n)} \big(X_{k-1}^{(n)},Y_{k-1}^{(n)}\big) \Big] \approx Y_{k-1} [\gamma + \beta]$
. This is the approach taken in [Reference Ball and O’Neill6] and leads to a slight mismatch between the event times in
 $\mathcal{E}^{(n)}$
and
$\mathcal{E}^{(n)}$
and
 $\mathcal{B}$
, with the mismatch converging to 0 as
$\mathcal{B}$
, with the mismatch converging to 0 as
 $n \rightarrow \infty$
. Therefore we take an alternative approach which results in there being high probability of
$n \rightarrow \infty$
. Therefore we take an alternative approach which results in there being high probability of
 $\eta_k^{(n)} =\eta_k$
, if
$\eta_k^{(n)} =\eta_k$
, if
 $\eta_{k-1}^{(n)} = \eta_{k-1}$
and
$\eta_{k-1}^{(n)} = \eta_{k-1}$
and
 $Y_{k-1}^{(n)} = Y_{k-1}$
, with the details provided in Section 4.4.
$Y_{k-1}^{(n)} = Y_{k-1}$
, with the details provided in Section 4.4.
4.3. Matching infection rate to birth rate
In this section, we provide bounds on the differences between the rate,
 $q^{(n)}\big(x^{(n)}, y^{(n)}, w\big)$
, at which events creating w (
$q^{(n)}\big(x^{(n)}, y^{(n)}, w\big)$
, at which events creating w (
 $w=0,1, \ldots$
) new infectives occur in
$w=0,1, \ldots$
) new infectives occur in
 $\mathcal{E}^{(n)}$
with
$\mathcal{E}^{(n)}$
with
 $x^{(n)}$
susceptibles and
$x^{(n)}$
susceptibles and
 $y^{(n)}$
infectives present in the population, and the rate,
$y^{(n)}$
infectives present in the population, and the rate,
 $\beta \varphi_w$
, at which birth events creating w new individuals occur in
$\beta \varphi_w$
, at which birth events creating w new individuals occur in
 $\mathcal{B}$
. The bounds on the difference in rates are appropriate during the early stages of the epidemic process where
$\mathcal{B}$
. The bounds on the difference in rates are appropriate during the early stages of the epidemic process where
 $n - r_n \leq x \leq n - m_n$
(i.e. whilst fewer than
$n - r_n \leq x \leq n - m_n$
(i.e. whilst fewer than
 $r_n$
individuals have ever been in the infectious state), for a sequence
$r_n$
individuals have ever been in the infectious state), for a sequence
 $(r_n)$
satisfying
$(r_n)$
satisfying
 $r_n \rightarrow \infty$
and
$r_n \rightarrow \infty$
and
 $r_n/ \sqrt{n} \rightarrow 0$
as
$r_n/ \sqrt{n} \rightarrow 0$
as
 $n \rightarrow \infty$
.
$n \rightarrow \infty$
.
In the early stages of the epidemic, when
 $x \ge n - r_n$
, it is unlikely that a mixing event will involve more than one non-susceptible individual. Thus we split the double sum over j and l in (4.3) into the case
$x \ge n - r_n$
, it is unlikely that a mixing event will involve more than one non-susceptible individual. Thus we split the double sum over j and l in (4.3) into the case
 $j=1$
and
$j=1$
and
 $l=0$
, a single infective in an otherwise susceptible group of size c, and the case
$l=0$
, a single infective in an otherwise susceptible group of size c, and the case
 $j+l \geq 2$
, where there is more than one non-susceptible individual in a mixing event. This gives, for
$j+l \geq 2$
, where there is more than one non-susceptible individual in a mixing event. This gives, for
 $y\gt 0$
,
$y\gt 0$
,
 \begin{align}q^{(n)} (x,y,w) &= \frac{n \lambda}{y} \sum_{c=w+1}^n p^{(n)}_C (c) Q^{(n)}_c (c-1,1\vert x,y) \pi_c (w;\,c-1,1)\nonumber \\ & \quad + \frac{n \lambda}{y} \sum_{c=w+1}^n p^{(n)}_C (c) \sum_{j+l\geq 2} \left\{ Q^{(n)}_c (c-j-l,j\vert x,y) \pi_c (w;\,c-j-l,j) \right\}\nonumber \\&= q^{(n)}_1 (x,y,w) + q^{(n)}_2 (x,y,w), \quad \mbox{say}.\end{align}
\begin{align}q^{(n)} (x,y,w) &= \frac{n \lambda}{y} \sum_{c=w+1}^n p^{(n)}_C (c) Q^{(n)}_c (c-1,1\vert x,y) \pi_c (w;\,c-1,1)\nonumber \\ & \quad + \frac{n \lambda}{y} \sum_{c=w+1}^n p^{(n)}_C (c) \sum_{j+l\geq 2} \left\{ Q^{(n)}_c (c-j-l,j\vert x,y) \pi_c (w;\,c-j-l,j) \right\}\nonumber \\&= q^{(n)}_1 (x,y,w) + q^{(n)}_2 (x,y,w), \quad \mbox{say}.\end{align}
We consider the two terms on the right-hand side of (4.7). Note that for
 $y \leq0$
, we set
$y \leq0$
, we set
 $q^{(n)}_1 (x,y,w) = \beta \varphi_w$
and
$q^{(n)}_1 (x,y,w) = \beta \varphi_w$
and
 $q^{(n)}_2 (x,y,w) = 0$
, which is consistent with
$q^{(n)}_2 (x,y,w) = 0$
, which is consistent with
 $q^{(n)} (x,y,w) =\beta \varphi_w$
$q^{(n)} (x,y,w) =\beta \varphi_w$
 $(y=0,-1,\ldots)$
. Also, for
$(y=0,-1,\ldots)$
. Also, for
 $w=n, n+1, \ldots$
,
$w=n, n+1, \ldots$
,
 $q^{(n)} (x,y,w) =0$
, which implies
$q^{(n)} (x,y,w) =0$
, which implies
 $q^{(n)}_h (x,y,w) = 0$
$q^{(n)}_h (x,y,w) = 0$
 $(h=1,2)$
. For
$(h=1,2)$
. For
 $h=1,2$
, let
$h=1,2$
, let
 $q^{(n)}_h (x,y) = \sum_{w=0}^{n-1} q^{(n)}_h (x,y,w) = \sum_{w=0}^{\infty} q^{(n)}_h (x,y,w)$
, the sums over w of the two components of
$q^{(n)}_h (x,y) = \sum_{w=0}^{n-1} q^{(n)}_h (x,y,w) = \sum_{w=0}^{\infty} q^{(n)}_h (x,y,w)$
, the sums over w of the two components of
 $q^{(n)} (x,y,w)$
in (4.7). Hence
$q^{(n)} (x,y,w)$
in (4.7). Hence
 $q^{(n)} (x,y) = q^{(n)}_1 (x,y) + q^{(n)}_2 (x,y)$
.
$q^{(n)} (x,y) = q^{(n)}_1 (x,y) + q^{(n)}_2 (x,y)$
.
Lemma 4.1 provides bounds on the rate of convergence to 0, as
 $n \to \infty$
, of the difference between the infection rate in the epidemic process and the birth rate in the branching process, in terms of the number of non-susceptibles in the population (
$n \to \infty$
, of the difference between the infection rate in the epidemic process and the birth rate in the branching process, in terms of the number of non-susceptibles in the population (
 $r_n$
) and the rate of convergence of
$r_n$
) and the rate of convergence of
 $C^{(n)}$
to C. Remember that throughout we assume that
$C^{(n)}$
to C. Remember that throughout we assume that
 $C^{(n)} \stackrel{{\rm D}}{\longrightarrow} C$
and
$C^{(n)} \stackrel{{\rm D}}{\longrightarrow} C$
and
 ${\mathbb{E}} [(C^{(n)})^2] \rightarrow {\mathbb{E}} [C^2]$
as
${\mathbb{E}} [(C^{(n)})^2] \rightarrow {\mathbb{E}} [C^2]$
as
 $n \rightarrow \infty$
, with
$n \rightarrow \infty$
, with
 ${\mathbb{E}} [C^2] \lt \infty$
; see the conditions stated before Theorem 3.1 in Section 3.2.
${\mathbb{E}} [C^2] \lt \infty$
; see the conditions stated before Theorem 3.1 in Section 3.2.
Lemma 4.1.
Let
 $(r_n)$
be a sequence of positive real numbers such that
$(r_n)$
be a sequence of positive real numbers such that
 $r_n \rightarrow \infty$
and
$r_n \rightarrow \infty$
and
 $r_n/\sqrt{n} \rightarrow 0$
as
$r_n/\sqrt{n} \rightarrow 0$
as
 $n \rightarrow \infty$
.
$n \rightarrow \infty$
.
Let
 $(s_n)$
be a sequence of positive real numbers such that
$(s_n)$
be a sequence of positive real numbers such that
 $s_n r_n^2/n \rightarrow 0$
and
$s_n r_n^2/n \rightarrow 0$
and
 \begin{eqnarray}s_n \sum_{c=2}^n c \left\vert p_C^{(n)} (c) - p_C (c) \right\vert \rightarrow 0 \quad \textit{ as } n \rightarrow \infty.\end{eqnarray}
\begin{eqnarray}s_n \sum_{c=2}^n c \left\vert p_C^{(n)} (c) - p_C (c) \right\vert \rightarrow 0 \quad \textit{ as } n \rightarrow \infty.\end{eqnarray}
Suppose that
 $(x^{(n)})$
and
$(x^{(n)})$
and
 $(y^{(n)})$
are two sequences such that
$(y^{(n)})$
are two sequences such that
 $n - r_n \leq x^{(n)} \leq n - m_n$
and
$n - r_n \leq x^{(n)} \leq n - m_n$
and
 $0 \lt y^{(n)} \leq r_n$
for all sufficiently large n. Then
$0 \lt y^{(n)} \leq r_n$
for all sufficiently large n. Then
 \begin{equation}s_n \sum_{w=0}^{\infty} \left\vert q^{(n)}_1 (x^{(n)} , y^{(n)} ,w) - \beta \varphi_w \right\vert \to 0 \quad \textit{ as } n \rightarrow \infty\end{equation}
\begin{equation}s_n \sum_{w=0}^{\infty} \left\vert q^{(n)}_1 (x^{(n)} , y^{(n)} ,w) - \beta \varphi_w \right\vert \to 0 \quad \textit{ as } n \rightarrow \infty\end{equation}
and
 \begin{equation} \sum_{w=0}^\infty s_n \left\vert q^{(n)}_2 \big(x^{(n)}, y^{(n)},w\big)\right\vert = s_n \sum_{w=0}^{n-1} \left\vert q^{(n)}_2 (x^{(n)} , y^{(n)} ,w) \right\vert \to 0 \quad \textit{ as } n \rightarrow \infty.\end{equation}
\begin{equation} \sum_{w=0}^\infty s_n \left\vert q^{(n)}_2 \big(x^{(n)}, y^{(n)},w\big)\right\vert = s_n \sum_{w=0}^{n-1} \left\vert q^{(n)}_2 (x^{(n)} , y^{(n)} ,w) \right\vert \to 0 \quad \textit{ as } n \rightarrow \infty.\end{equation}
Consequently, if
 $s_n r_n^2/n \rightarrow 0$
as
$s_n r_n^2/n \rightarrow 0$
as
 $n \rightarrow \infty$
, then
$n \rightarrow \infty$
, then
 \begin{eqnarray} s_n \left\vert q^{(n)} (x^{(n)} , y^{(n)} ) - \beta \right\vert = s_n \left\vert \sum_{w=0}^{\infty} \left\{q^{(n)} (x^{(n)} , y^{(n)} ,w) - \beta \varphi_w\right\}\right\vert &\rightarrow& 0 \quad \textit{ as } n \rightarrow \infty. \nonumber \\\end{eqnarray}
\begin{eqnarray} s_n \left\vert q^{(n)} (x^{(n)} , y^{(n)} ) - \beta \right\vert = s_n \left\vert \sum_{w=0}^{\infty} \left\{q^{(n)} (x^{(n)} , y^{(n)} ,w) - \beta \varphi_w\right\}\right\vert &\rightarrow& 0 \quad \textit{ as } n \rightarrow \infty. \nonumber \\\end{eqnarray}
Proof. First note that, for
 $Q^{(n)}_c \big(c-1,1\vert x^{(n)} ,y^{(n)} \big)$
defined in (4.2) and any
$Q^{(n)}_c \big(c-1,1\vert x^{(n)} ,y^{(n)} \big)$
defined in (4.2) and any
 $c=2,3, \ldots$
,
$c=2,3, \ldots$
,
 \begin{align} Q^{(n)}_c \big(c-1,1\vert x^{(n)} ,y^{(n)} \big) &= c \frac{y^{(n)} }{n} \prod_{j=0}^{c-2} \frac{x^{(n)} -j}{n-1-j} \nonumber \\&= c \frac{y^{(n)} }{n} + y^{(n)} \epsilon^{(n)}_c \big(x^{(n)} \big),\end{align}
\begin{align} Q^{(n)}_c \big(c-1,1\vert x^{(n)} ,y^{(n)} \big) &= c \frac{y^{(n)} }{n} \prod_{j=0}^{c-2} \frac{x^{(n)} -j}{n-1-j} \nonumber \\&= c \frac{y^{(n)} }{n} + y^{(n)} \epsilon^{(n)}_c \big(x^{(n)} \big),\end{align}
where
 \[ \epsilon^{(n)}_c \big(x^{(n)} \big) = \frac{c}{n} \left\{\left[ \prod_{j=0}^{c-2} \frac{x^{(n)} -j}{n-1-j}\right] - 1 \right\}. \]
\[ \epsilon^{(n)}_c \big(x^{(n)} \big) = \frac{c}{n} \left\{\left[ \prod_{j=0}^{c-2} \frac{x^{(n)} -j}{n-1-j}\right] - 1 \right\}. \]
For
 $x^{(n)} \geq n - r_n$
and
$x^{(n)} \geq n - r_n$
and
 $c \leq n/2$
, we have that
$c \leq n/2$
, we have that
 \begin{align*}1 \geq \prod_{j=0}^{c-2} \frac{x^{(n)} -j}{n-1-j} &= \prod_{j=0}^{c-2} \left( 1 - \frac{n-1-x^{(n)}}{n-1-j} \right) \\& \geq 1 - [n-1 - x^{(n)}] \left\{ \frac{1}{n-1} + \frac{1}{n-2} + \ldots + \frac{1}{n-c+1} \right\} \\& \geq 1 - [r_n -1] \left\{ \frac{1}{n-1} + \frac{1}{n-2} + \ldots + \frac{1}{n-c+1} \right\} \\& \geq 1 - [r_n -1] \frac{c-1}{n-c+1} \geq 1 - \frac{2r_n (c-1)}{n}.\end{align*}
\begin{align*}1 \geq \prod_{j=0}^{c-2} \frac{x^{(n)} -j}{n-1-j} &= \prod_{j=0}^{c-2} \left( 1 - \frac{n-1-x^{(n)}}{n-1-j} \right) \\& \geq 1 - [n-1 - x^{(n)}] \left\{ \frac{1}{n-1} + \frac{1}{n-2} + \ldots + \frac{1}{n-c+1} \right\} \\& \geq 1 - [r_n -1] \left\{ \frac{1}{n-1} + \frac{1}{n-2} + \ldots + \frac{1}{n-c+1} \right\} \\& \geq 1 - [r_n -1] \frac{c-1}{n-c+1} \geq 1 - \frac{2r_n (c-1)}{n}.\end{align*}
Therefore, for
 $x^{(n)} \geq n - r_n$
and
$x^{(n)} \geq n - r_n$
and
 $c \leq n/2$
,
$c \leq n/2$
,
 \begin{align} - \frac{c}{n} \times \frac{2r_n (c-1)}{n} \leq \epsilon^{(n)}_c (x^{(n)} ) \leq 0.\end{align}
\begin{align} - \frac{c}{n} \times \frac{2r_n (c-1)}{n} \leq \epsilon^{(n)}_c (x^{(n)} ) \leq 0.\end{align}
Note that
 $p_C^{(n)} (c)=0$
for
$p_C^{(n)} (c)=0$
for
 $c\gt n$
. Also, using (3.3) and recalling that
$c\gt n$
. Also, using (3.3) and recalling that
 $\beta = \lambda \mu_C$
, we have
$\beta = \lambda \mu_C$
, we have
 \[ \lambda \sum_{c=w+1}^\infty c p_C (c) \pi_c (w;\,c-1,1) = \lambda \mu_C \varphi_w = \beta \varphi_w \qquad (w=0,1,\ldots). \]
\[ \lambda \sum_{c=w+1}^\infty c p_C (c) \pi_c (w;\,c-1,1) = \lambda \mu_C \varphi_w = \beta \varphi_w \qquad (w=0,1,\ldots). \]
Hence, for
 $w=0,1,\ldots$
,
$w=0,1,\ldots$
,
 \begin{align*}q^{(n)}_1 \big(x^{(n)},y^{(n)},w\big)&= \frac{n \lambda}{y^{(n)}} \sum_{c=w+1}^n p_C^{(n)} (c) Q^{(n)}_c \big(c-1,1\vert x^{(n)} ,y^{(n)} \big) \pi_c (w;\, c-1,1) \\&= \frac{n \lambda}{y^{(n)}} \sum_{c=w+1}^n p_C^{(n)} (c) \left\{ \frac{c y^{(n)}}{n} + y^{(n)} \epsilon^{(n)}_c (x^{(n)} ) \right\} \pi_c (w;\, c-1,1) \\&= \lambda \sum_{c=w+1}^n c p_C^{(n)} (c) \pi_c (w;\, c-1,1)\\& \quad + \lambda \sum_{c=w+1}^n p_C^{(n)} (c) n \epsilon^{(n)}_c (x^{(n)} ) \pi_c (w;\, c-1,1) \\&= \lambda \sum_{c=w+1}^\infty c p_C (c) \pi_c (w;\,c-1,1)\\& \quad + \lambda \sum_{c=w+1}^{\infty} c \big[p^{(n)}_C (c)-p_C (c)\big] \pi_c (w;\,c-1,1) \\& \quad + \lambda \sum_{c=w+1}^n p^{(n)}_C (c) n \epsilon^{(n)}_c (x^{(n)} ) \pi_c (w;\,c-1,1) \\&= \beta \varphi_w + \lambda \sum_{c=w+1}^{\infty} c \big[p^{(n)}_C (c)-p_C (c)\big] \pi_c (w;\,c-1,1) \\& \quad + \lambda \sum_{c=w+1}^n p^{(n)}_C (c) n \epsilon^{(n)}_c (x^{(n)} ) \pi_c (w;\,c-1,1).\end{align*}
\begin{align*}q^{(n)}_1 \big(x^{(n)},y^{(n)},w\big)&= \frac{n \lambda}{y^{(n)}} \sum_{c=w+1}^n p_C^{(n)} (c) Q^{(n)}_c \big(c-1,1\vert x^{(n)} ,y^{(n)} \big) \pi_c (w;\, c-1,1) \\&= \frac{n \lambda}{y^{(n)}} \sum_{c=w+1}^n p_C^{(n)} (c) \left\{ \frac{c y^{(n)}}{n} + y^{(n)} \epsilon^{(n)}_c (x^{(n)} ) \right\} \pi_c (w;\, c-1,1) \\&= \lambda \sum_{c=w+1}^n c p_C^{(n)} (c) \pi_c (w;\, c-1,1)\\& \quad + \lambda \sum_{c=w+1}^n p_C^{(n)} (c) n \epsilon^{(n)}_c (x^{(n)} ) \pi_c (w;\, c-1,1) \\&= \lambda \sum_{c=w+1}^\infty c p_C (c) \pi_c (w;\,c-1,1)\\& \quad + \lambda \sum_{c=w+1}^{\infty} c \big[p^{(n)}_C (c)-p_C (c)\big] \pi_c (w;\,c-1,1) \\& \quad + \lambda \sum_{c=w+1}^n p^{(n)}_C (c) n \epsilon^{(n)}_c (x^{(n)} ) \pi_c (w;\,c-1,1) \\&= \beta \varphi_w + \lambda \sum_{c=w+1}^{\infty} c \big[p^{(n)}_C (c)-p_C (c)\big] \pi_c (w;\,c-1,1) \\& \quad + \lambda \sum_{c=w+1}^n p^{(n)}_C (c) n \epsilon^{(n)}_c (x^{(n)} ) \pi_c (w;\,c-1,1).\end{align*}
It follows that
 \begin{align} &\sum_{w=0}^\infty s_n \left\vert q^{(n)}_1 \big(x^{(n)}, y^{(n)},w\big)- \beta \varphi_w \right\vert \nonumber \\& \quad \leq s_n \sum_{w=0}^\infty \left\vert \lambda \sum_{c=w+1}^\infty c \big[p^{(n)}_C (c)-p_C (c)\big] \pi_c (w;\,c-1,1) \right\vert \nonumber \\& \qquad + s_n \sum_{w=0}^\infty \left\vert \lambda \sum_{c=w+1}^n p^{(n)}_C (c) n \epsilon^{(n)}_c (x^{(n)} ) \pi_c (w;\,c-1,1) \right\vert \nonumber \\& \quad \leq \lambda s_n \sum_{w=0}^\infty \sum_{c=w+1}^\infty c \big\vert p^{(n)}_C (c)-p_C (c)\big\vert \pi_c (w;\,c-1,1) \nonumber \\& \qquad + \lambda s_n \sum_{w=0}^\infty \sum_{c=w+1}^n p^{(n)}_C (c) \left\vert n \epsilon^{(n)}_c (x^{(n)} ) \right\vert \pi_c (w;\,c-1,1) \nonumber \\& \quad = \lambda s_n \sum_{c=2}^\infty c \big\vert p^{(n)}_C (c)-p_C (c)\big\vert \sum_{w=0}^{c-1} \pi_c (w;\,c-1,1) \nonumber \\& \qquad + \lambda s_n \sum_{c=2}^n p^{(n)}_C (c) \left\vert n \epsilon^{(n)}_c (x^{(n)} ) \right\vert \sum_{w=0}^{c-1} \pi_c (w;\,c-1,1) \nonumber \\ & \quad = \lambda s_n \sum_{c=2}^\infty c \big\vert p^{(n)}_C (c)-p_C (c)\big\vert +\lambda s_n \sum_{c=2}^n p^{(n)}_C (c) \left\vert n \epsilon^{(n)}_c (x^{(n)} ) \right\vert . \end{align}
\begin{align} &\sum_{w=0}^\infty s_n \left\vert q^{(n)}_1 \big(x^{(n)}, y^{(n)},w\big)- \beta \varphi_w \right\vert \nonumber \\& \quad \leq s_n \sum_{w=0}^\infty \left\vert \lambda \sum_{c=w+1}^\infty c \big[p^{(n)}_C (c)-p_C (c)\big] \pi_c (w;\,c-1,1) \right\vert \nonumber \\& \qquad + s_n \sum_{w=0}^\infty \left\vert \lambda \sum_{c=w+1}^n p^{(n)}_C (c) n \epsilon^{(n)}_c (x^{(n)} ) \pi_c (w;\,c-1,1) \right\vert \nonumber \\& \quad \leq \lambda s_n \sum_{w=0}^\infty \sum_{c=w+1}^\infty c \big\vert p^{(n)}_C (c)-p_C (c)\big\vert \pi_c (w;\,c-1,1) \nonumber \\& \qquad + \lambda s_n \sum_{w=0}^\infty \sum_{c=w+1}^n p^{(n)}_C (c) \left\vert n \epsilon^{(n)}_c (x^{(n)} ) \right\vert \pi_c (w;\,c-1,1) \nonumber \\& \quad = \lambda s_n \sum_{c=2}^\infty c \big\vert p^{(n)}_C (c)-p_C (c)\big\vert \sum_{w=0}^{c-1} \pi_c (w;\,c-1,1) \nonumber \\& \qquad + \lambda s_n \sum_{c=2}^n p^{(n)}_C (c) \left\vert n \epsilon^{(n)}_c (x^{(n)} ) \right\vert \sum_{w=0}^{c-1} \pi_c (w;\,c-1,1) \nonumber \\ & \quad = \lambda s_n \sum_{c=2}^\infty c \big\vert p^{(n)}_C (c)-p_C (c)\big\vert +\lambda s_n \sum_{c=2}^n p^{(n)}_C (c) \left\vert n \epsilon^{(n)}_c (x^{(n)} ) \right\vert . \end{align}
The first term on the right-hand side of (4.14) converges to 0 by (4.8). Using (4.13) and Markov’s inequality, the second term on the right-hand side of (4.14) satisfies
 \begin{align*}&\lambda s_n \sum_{c=2}^n p^{(n)}_C (c) \left\vert n \epsilon^{(n)}_c (x^{(n)} ) \right\vert \\&\qquad\qquad\leq \lambda \left\{ \sum_{c=2}^{\lfloor n/2 \rfloor} s_n p^{(n)}_C (c) \left( \frac{2 c (c-1) r_n}{n} \right) +\sum_{c=\lfloor n/2 \rfloor+1}^n s_n p^{(n)}_C (c) c\right\} \\& \qquad\qquad \leq \lambda \left\{ 2 \frac{s_n r_n}{n} {\mathbb{E}} \left[C^{(n)} (C^{(n)}-1) \right] + s_n n {\mathbb{P}} \left(C^{(n)} \gt \lfloor n/2 \rfloor +1 \right) \right\} \\& \qquad\qquad \leq \lambda \left\{2 \frac{s_n r_n}{n} {\mathbb{E}} \left[C^{(n)} (C^{(n)}-1) \right] + s_n n \times \frac{4}{n^2} {\mathbb{E}} \left[ \big(C^{(n)}\big)^2 \right] \right\} \\ &\qquad\qquad\rightarrow 0 \quad \mbox{as } n \rightarrow \infty.\end{align*}
\begin{align*}&\lambda s_n \sum_{c=2}^n p^{(n)}_C (c) \left\vert n \epsilon^{(n)}_c (x^{(n)} ) \right\vert \\&\qquad\qquad\leq \lambda \left\{ \sum_{c=2}^{\lfloor n/2 \rfloor} s_n p^{(n)}_C (c) \left( \frac{2 c (c-1) r_n}{n} \right) +\sum_{c=\lfloor n/2 \rfloor+1}^n s_n p^{(n)}_C (c) c\right\} \\& \qquad\qquad \leq \lambda \left\{ 2 \frac{s_n r_n}{n} {\mathbb{E}} \left[C^{(n)} (C^{(n)}-1) \right] + s_n n {\mathbb{P}} \left(C^{(n)} \gt \lfloor n/2 \rfloor +1 \right) \right\} \\& \qquad\qquad \leq \lambda \left\{2 \frac{s_n r_n}{n} {\mathbb{E}} \left[C^{(n)} (C^{(n)}-1) \right] + s_n n \times \frac{4}{n^2} {\mathbb{E}} \left[ \big(C^{(n)}\big)^2 \right] \right\} \\ &\qquad\qquad\rightarrow 0 \quad \mbox{as } n \rightarrow \infty.\end{align*}
Hence (4.9) is proved.
The probability that a pair of individuals, chosen uniformly at random, are both non-susceptible is
 $(n-x^{(n)})(n-x^{(n)}-1)/[n(n-1)]$
. In a group of c individuals there are
$(n-x^{(n)})(n-x^{(n)}-1)/[n(n-1)]$
. In a group of c individuals there are
 $c(c-1)/2$
pairs, so
$c(c-1)/2$
pairs, so
 \begin{eqnarray} \sum_{j+l \geq 2} Q^{(n)}_c \big(c-j-l,j\vert x^{(n)},y^{(n)}\big) \leq \frac{c (c-1)}{2} \times \frac{(n-x^{(n)})(n-x^{(n)}-1)}{n(n-1)}.\end{eqnarray}
\begin{eqnarray} \sum_{j+l \geq 2} Q^{(n)}_c \big(c-j-l,j\vert x^{(n)},y^{(n)}\big) \leq \frac{c (c-1)}{2} \times \frac{(n-x^{(n)})(n-x^{(n)}-1)}{n(n-1)}.\end{eqnarray}
For
 $x^{(n)} \geq n - r_n$
, the right-hand side of (4.15) is bounded above by
$x^{(n)} \geq n - r_n$
, the right-hand side of (4.15) is bounded above by
 $[ c(c-1)/2] \times [r_n/n ]^2$
.
$[ c(c-1)/2] \times [r_n/n ]^2$
.
Therefore, since
 $ q^{(n)}_2 \big(x^{(n)}, y^{(n)},w\big) =0$
for
$ q^{(n)}_2 \big(x^{(n)}, y^{(n)},w\big) =0$
for
 $w =n, n+1, \ldots$
, we have that
$w =n, n+1, \ldots$
, we have that
 \begin{align*} &\sum_{w=0}^\infty s_n \left\vert q^{(n)}_2 \big(x^{(n)}, y^{(n)},w\big)\right\vert = \sum_{w=0}^{n-1} s_n \left\vert q^{(n)}_2 \big(x^{(n)}, y^{(n)},w\big)\right\vert \\&\qquad = \frac{s_n n}{y^{(n)}} \lambda \sum_{w=0}^{n-1} \sum_{c=w+1}^n p^{(n)}_C (c) \sum_{j+l \geq 2} \left\{ Q^{(n)}_c \big(c-j-l,j\vert x^{(n)},y^{(n)}\big) \pi_c (w;\,c-j-l,j) \right\} \\&\qquad = \frac{s_n n}{y^{(n)}} \lambda \sum_{c=2}^n p^{(n)}_C (c) \sum_{j+l \geq 2} \left\{ Q^{(n)}_c \big(c-j-l,j\vert x^{(n)},y^{(n)}\big) \sum_{w=0}^{c-j-l} \pi_c (w;c-j-l,l,j) \right\} \\&\qquad \leq \lambda \frac{s_n r_n^2}{n} \sum_{c=2}^n p^{(n)}_C (c) \frac{c(c-1)}{2} \\&\qquad = \lambda \frac{s_n r_n^2}{2n} {\mathbb{E}} \left[C^{(n)} (C^{(n)}-1) \right] \rightarrow 0 \quad \mbox{as } n \rightarrow \infty,\end{align*}
\begin{align*} &\sum_{w=0}^\infty s_n \left\vert q^{(n)}_2 \big(x^{(n)}, y^{(n)},w\big)\right\vert = \sum_{w=0}^{n-1} s_n \left\vert q^{(n)}_2 \big(x^{(n)}, y^{(n)},w\big)\right\vert \\&\qquad = \frac{s_n n}{y^{(n)}} \lambda \sum_{w=0}^{n-1} \sum_{c=w+1}^n p^{(n)}_C (c) \sum_{j+l \geq 2} \left\{ Q^{(n)}_c \big(c-j-l,j\vert x^{(n)},y^{(n)}\big) \pi_c (w;\,c-j-l,j) \right\} \\&\qquad = \frac{s_n n}{y^{(n)}} \lambda \sum_{c=2}^n p^{(n)}_C (c) \sum_{j+l \geq 2} \left\{ Q^{(n)}_c \big(c-j-l,j\vert x^{(n)},y^{(n)}\big) \sum_{w=0}^{c-j-l} \pi_c (w;c-j-l,l,j) \right\} \\&\qquad \leq \lambda \frac{s_n r_n^2}{n} \sum_{c=2}^n p^{(n)}_C (c) \frac{c(c-1)}{2} \\&\qquad = \lambda \frac{s_n r_n^2}{2n} {\mathbb{E}} \left[C^{(n)} (C^{(n)}-1) \right] \rightarrow 0 \quad \mbox{as } n \rightarrow \infty,\end{align*}
and (4.10) is proved.
Finally, (4.11) follows from (4.9) and (4.10) by the triangle inequality.
Note that if C has finite support
 $\{2, 3, \ldots, n_0 \}$
, then for all
$\{2, 3, \ldots, n_0 \}$
, then for all
 $n \geq n_0$
,
$n \geq n_0$
,
 $C^{(n)} \equiv C$
, and (4.8) holds for any sequence
$C^{(n)} \equiv C$
, and (4.8) holds for any sequence
 $\{s_n \}$
.
$\{s_n \}$
.
4.4. Construction of the event processes
Lemma 4.1 implies that the difference between the transition probabilities of
 $\mathcal{R}$
and
$\mathcal{R}$
and
 $\mathcal{S}^{(n)}$
tends to 0 as
$\mathcal{S}^{(n)}$
tends to 0 as
 $n \to \infty$
, provided the number of non-susceptible individuals remains sufficiently small. We proceed by constructing
$n \to \infty$
, provided the number of non-susceptible individuals remains sufficiently small. We proceed by constructing
 $\mathcal{R}$
and
$\mathcal{R}$
and
 $\mathcal{S}^{(n)}$
on a common probability space
$\mathcal{S}^{(n)}$
on a common probability space
 $(\Omega, \mathcal{F}, {\mathbb{P}})$
, with
$(\Omega, \mathcal{F}, {\mathbb{P}})$
, with
 $Y_0 = m$
and, for all sufficiently large n,
$Y_0 = m$
and, for all sufficiently large n,
 $\Big(X_0^{(n)}, Y_0^{(n)}\Big) = (n-m_n ,m_n) = (n-m,m)$
. For
$\Big(X_0^{(n)}, Y_0^{(n)}\Big) = (n-m_n ,m_n) = (n-m,m)$
. For
 $k=1,2,\ldots$
, let
$k=1,2,\ldots$
, let
 $\textbf{U}_k = (U_{k,1}, U_{k,2}, U_{k,3})$
be i.i.d. random vectors defined on
$\textbf{U}_k = (U_{k,1}, U_{k,2}, U_{k,3})$
be i.i.d. random vectors defined on
 $(\Omega, \mathcal{F}, {\mathbb{P}})$
, with
$(\Omega, \mathcal{F}, {\mathbb{P}})$
, with
 $U_{k,i} \sim {\rm U}(0,1)$
$U_{k,i} \sim {\rm U}(0,1)$
 $(i=1,2,3)$
being independent, where
$(i=1,2,3)$
being independent, where
 ${\rm U}(0,1)$
denotes a random variable that is uniformly distributed on [0, 1].
${\rm U}(0,1)$
denotes a random variable that is uniformly distributed on [0, 1].
We construct
 $\mathcal{R}$
as follows. Suppose that for some
$\mathcal{R}$
as follows. Suppose that for some
 $k=1,2,\ldots$
,
$k=1,2,\ldots$
,
 $Y_{k-1} =y$
. The kth step in
$Y_{k-1} =y$
. The kth step in
 $\mathcal{R}$
is a downward step (of size 1) with
$\mathcal{R}$
is a downward step (of size 1) with
 $Y_k = y-1$
if
$Y_k = y-1$
if
 $U_{k,1} \leq \gamma/(\gamma + \beta)$
. Otherwise the random walk has an ‘upward’ step of size
$U_{k,1} \leq \gamma/(\gamma + \beta)$
. Otherwise the random walk has an ‘upward’ step of size
 $a_k$
with
$a_k$
with
 $Y_k = y+a_k$
, where
$Y_k = y+a_k$
, where
 $a_k$
satisfies
$a_k$
satisfies
 \begin{eqnarray*}\sum_{l=0}^{a_k -1} \varphi_l \lt U_{k,2} \leq \sum_{l=0}^{a_k} \varphi_l.\end{eqnarray*}
\begin{eqnarray*}\sum_{l=0}^{a_k -1} \varphi_l \lt U_{k,2} \leq \sum_{l=0}^{a_k} \varphi_l.\end{eqnarray*}
Note that all sums are equal to 0, if vacuous;
 $a_k=0$
is possible and the probability that
$a_k=0$
is possible and the probability that
 $a_k =i$
is
$a_k =i$
is
 $\varphi_i$
.
$\varphi_i$
.
Similarly, we construct
 $\mathcal{S}^{(n)}$
as follows. Suppose that for some
$\mathcal{S}^{(n)}$
as follows. Suppose that for some
 $k=1,2,\ldots$
,
$k=1,2,\ldots$
,
 $\Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) =\Big(x_k^{(n)},y_k^{(n)}\Big)$
. The kth event in
$\Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) =\Big(x_k^{(n)},y_k^{(n)}\Big)$
. The kth event in
 $\mathcal{S}^{(n)}$
is a recovery with
$\mathcal{S}^{(n)}$
is a recovery with
 $\Big(X_k^{(n)}, Y_k^{(n)}\Big) =\Big(x_k^{(n)},y_k^{(n)}-1\Big)$
if
$\Big(X_k^{(n)}, Y_k^{(n)}\Big) =\Big(x_k^{(n)},y_k^{(n)}-1\Big)$
if
 $U_{k,1} \leq \gamma/\Big[\gamma + q^{(n)} \Big(x_k^{(n)},y_k^{(n)}\Big)\Big]$
. Otherwise the kth event in
$U_{k,1} \leq \gamma/\Big[\gamma + q^{(n)} \Big(x_k^{(n)},y_k^{(n)}\Big)\Big]$
. Otherwise the kth event in
 $\mathcal{S}^{(n)}$
is an infection event of size
$\mathcal{S}^{(n)}$
is an infection event of size
 $a_k^{(n)}$
with
$a_k^{(n)}$
with
 $\Big(X_k^{(n)}, Y_k^{(n)}\Big) =\Big(x_k^{(n)}-a_k^{(n)},y_k^{(n)}+a_k^{(n)}\Big)$
, where
$\Big(X_k^{(n)}, Y_k^{(n)}\Big) =\Big(x_k^{(n)}-a_k^{(n)},y_k^{(n)}+a_k^{(n)}\Big)$
, where
 $a_k^{(n)}$
satisfies
$a_k^{(n)}$
satisfies
 \begin{eqnarray*}{\mathbb{P}} \big(a_k^{(n)} =i\big) = \frac{q^{(n)} \Big(x_k^{(n)}, y_k^{(n)},i\Big)}{q^{(n)}\Big(x_k^{(n)}, y_k^{(n)}\Big)} = \varphi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big), \quad \mbox{say}.\end{eqnarray*}
\begin{eqnarray*}{\mathbb{P}} \big(a_k^{(n)} =i\big) = \frac{q^{(n)} \Big(x_k^{(n)}, y_k^{(n)},i\Big)}{q^{(n)}\Big(x_k^{(n)}, y_k^{(n)}\Big)} = \varphi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big), \quad \mbox{say}.\end{eqnarray*}
To enable an effective coupling between
 $\mathcal{R}$
and
$\mathcal{R}$
and
 $\mathcal{S}^{(n)}$
, we obtain
$\mathcal{S}^{(n)}$
, we obtain
 $a_k^{(n)}$
as follows. For
$a_k^{(n)}$
as follows. For
 $i=0,1,\ldots$
, let
$i=0,1,\ldots$
, let
 $\varpi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big) = \min \left\{ \varphi_i, \varphi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big) \right\}$
and let
$\varpi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big) = \min \left\{ \varphi_i, \varphi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big) \right\}$
and let
 \begin{eqnarray} D^{(n)}_2 \Big(x^{(n)}_k, y^{(n)}_k\Big) = \bigcup_{w=0}^\infty \left(\sum_{l=0}^{w-1} \varphi_l + \varpi_w^{(n)} \Big(x^{(n)}_k, y^{(n)}_k\Big), \sum_{l=0}^{w} \varphi_l \right], \end{eqnarray}
\begin{eqnarray} D^{(n)}_2 \Big(x^{(n)}_k, y^{(n)}_k\Big) = \bigcup_{w=0}^\infty \left(\sum_{l=0}^{w-1} \varphi_l + \varpi_w^{(n)} \Big(x^{(n)}_k, y^{(n)}_k\Big), \sum_{l=0}^{w} \varphi_l \right], \end{eqnarray}
where (a, b] is the empty set if
 $a=b$
. If
$a=b$
. If
 $U_{k,2} \not\in D^{(n)}_2 \big(x^{(n)}_k, y^{(n)}_k\big) $
, then there exists
$U_{k,2} \not\in D^{(n)}_2 \big(x^{(n)}_k, y^{(n)}_k\big) $
, then there exists
 $i \in \mathbb{Z}_+$
such that
$i \in \mathbb{Z}_+$
such that
 \begin{eqnarray} \sum_{l=0}^{i -1} \varphi_l \lt U_{k,2} \leq \sum_{l=0}^{i -1} \varphi_l + \varpi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big),\end{eqnarray}
\begin{eqnarray} \sum_{l=0}^{i -1} \varphi_l \lt U_{k,2} \leq \sum_{l=0}^{i -1} \varphi_l + \varpi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big),\end{eqnarray}
and we set
 $a_k^{(n)} = i$
. Therefore, if
$a_k^{(n)} = i$
. Therefore, if
 $U_{k,2} \not\in D^{(n)}_2 \big(x^{(n)}_k, y^{(n)}_k\big) $
, we have that
$U_{k,2} \not\in D^{(n)}_2 \big(x^{(n)}_k, y^{(n)}_k\big) $
, we have that
 $a_k^{(n)} = a_k$
. Let
$a_k^{(n)} = a_k$
. Let
 \[ d^{(n)}_k \Big(x_k^{(n)}, y_k^{(n)}\Big) = {\mathbb{P}} \left( U_{k,2} \in D^{(n)}_2 \big(x^{(n)}_k, y^{(n)}_k\big) \right) = 1 - \sum_{v=0}^\infty \varpi^{(n)}_v \Big(x_k^{(n)}, y_k^{(n)}\Big), \]
\[ d^{(n)}_k \Big(x_k^{(n)}, y_k^{(n)}\Big) = {\mathbb{P}} \left( U_{k,2} \in D^{(n)}_2 \big(x^{(n)}_k, y^{(n)}_k\big) \right) = 1 - \sum_{v=0}^\infty \varpi^{(n)}_v \Big(x_k^{(n)}, y_k^{(n)}\Big), \]
the total variation distance between
 $(\varphi_0, \varphi_1, \ldots)$
and
$(\varphi_0, \varphi_1, \ldots)$
and
 $\Big(\varphi_0^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big), \varphi_1^{(n)}\Big(x_k^{(n)}, y_k^{(n)}\Big), \ldots\Big)$
. If
$\Big(\varphi_0^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big), \varphi_1^{(n)}\Big(x_k^{(n)}, y_k^{(n)}\Big), \ldots\Big)$
. If
 $U_{k,2} \in D^{(n)}_2 \big(x^{(n)}_k, y^{(n)}_k\big) $
, we set
$U_{k,2} \in D^{(n)}_2 \big(x^{(n)}_k, y^{(n)}_k\big) $
, we set
 $a_k^{(n)} =i$
with probability
$a_k^{(n)} =i$
with probability
 \begin{eqnarray*}\frac{\varphi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big) - \varpi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big)}{d^{(n)}_k \Big(x_k^{(n)}, y_k^{(n)}\Big)},\end{eqnarray*}
\begin{eqnarray*}\frac{\varphi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big) - \varpi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big)}{d^{(n)}_k \Big(x_k^{(n)}, y_k^{(n)}\Big)},\end{eqnarray*}
which ensures that overall the probability that
 $a_k^{(n)} = i$
is
$a_k^{(n)} = i$
is
 $ \varphi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big)$
. We do not need to be more explicit about the choice
$ \varphi_i^{(n)} \Big(x_k^{(n)}, y_k^{(n)}\Big)$
. We do not need to be more explicit about the choice
 $a_k^{(n)}$
when
$a_k^{(n)}$
when
 $a_k^{(n)} \neq a_k$
.
$a_k^{(n)} \neq a_k$
.
Given
 $V_1, V_2, \ldots$
, i.i.d. according to
$V_1, V_2, \ldots$
, i.i.d. according to
 ${\rm Exp} (1)$
, we can construct
${\rm Exp} (1)$
, we can construct
 $\mathcal{B}$
from
$\mathcal{B}$
from
 $\mathcal{R}$
as outlined in Section 4.2. We conclude this section with a description of the construction of
$\mathcal{R}$
as outlined in Section 4.2. We conclude this section with a description of the construction of
 $\mathcal{E}^{(n)}$
from
$\mathcal{E}^{(n)}$
from
 $\mathcal{S}^{(n)}$
, in order to couple the time of events in
$\mathcal{S}^{(n)}$
, in order to couple the time of events in
 $\mathcal{E}^{(n)}$
to the event times in
$\mathcal{E}^{(n)}$
to the event times in
 $\mathcal{B}$
. Given that there are
$\mathcal{B}$
. Given that there are
 $y^{(n)}$
infectives in the population, the probability that an individual chosen uniformly at random is infectious is
$y^{(n)}$
infectives in the population, the probability that an individual chosen uniformly at random is infectious is
 $y^{(n)}/n$
, so the probability that a mixing event of size c involves at least one infective is bounded above by
$y^{(n)}/n$
, so the probability that a mixing event of size c involves at least one infective is bounded above by
 $c y^{(n)}/n$
. Therefore
$c y^{(n)}/n$
. Therefore
 \begin{align} q^{(n)} \big(x^{(n)},y^{(n)}\big) =\sum_{w=0}^{n-1} q^{(n)} \big(x^{(n)},y^{(n)},w\big) & \leq \frac{1}{y^{(n)}} n \lambda \sum_{c=2}^n \frac{c y^{(n)}}{n} \times p_C^{(n)} (c) \nonumber \\&= \lambda \mu_C^{(n)}. \end{align}
\begin{align} q^{(n)} \big(x^{(n)},y^{(n)}\big) =\sum_{w=0}^{n-1} q^{(n)} \big(x^{(n)},y^{(n)},w\big) & \leq \frac{1}{y^{(n)}} n \lambda \sum_{c=2}^n \frac{c y^{(n)}}{n} \times p_C^{(n)} (c) \nonumber \\&= \lambda \mu_C^{(n)}. \end{align}
Hence, under the assumption
 $\mu_C^{(n)} \leq \mu_C$
, we have that
$\mu_C^{(n)} \leq \mu_C$
, we have that
 $q^{(n)} \big(x^{(n)},y^{(n)}\big) \leq \beta (= \lambda \mu_C)$
. Therefore, letting
$q^{(n)} \big(x^{(n)},y^{(n)}\big) \leq \beta (= \lambda \mu_C)$
. Therefore, letting
 \begin{eqnarray} \tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) = \frac{ \beta - q^{(n)} \big(x^{(n)}, y^{(n)}\big)}{\gamma + \beta} \geq 0, \end{eqnarray}
\begin{eqnarray} \tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) = \frac{ \beta - q^{(n)} \big(x^{(n)}, y^{(n)}\big)}{\gamma + \beta} \geq 0, \end{eqnarray}
we have, if
 $\Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) = \big(x^{(n)},y^{(n)}\big)$
, that
$\Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) = \big(x^{(n)},y^{(n)}\big)$
, that
 \begin{eqnarray*}\frac{\gamma + \beta}{\gamma + q^{(n)} \Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) } V_k \sim {\rm Exp} \left( 1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \right) = \tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big), \mbox{ say}.\end{eqnarray*}
\begin{eqnarray*}\frac{\gamma + \beta}{\gamma + q^{(n)} \Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) } V_k \sim {\rm Exp} \left( 1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \right) = \tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big), \mbox{ say}.\end{eqnarray*}
For
 $z \geq 0$
, let
$z \geq 0$
, let
 \begin{eqnarray} \tilde{f}_V \big(z;\, x^{(n)}, y^{(n)} \big)= \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\} \exp \left( - z \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\} \right)\end{eqnarray}
\begin{eqnarray} \tilde{f}_V \big(z;\, x^{(n)}, y^{(n)} \big)= \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\} \exp \left( - z \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\} \right)\end{eqnarray}
denote the probability density function of
 $\tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big)$
. Similarly, let
$\tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big)$
. Similarly, let
 $f_V (z) = \exp(\!-\!z)$
$f_V (z) = \exp(\!-\!z)$
 $(z\geq 0)$
denote the probability density function of
$(z\geq 0)$
denote the probability density function of
 $V_1$
. It follows from (4.20), for all
$V_1$
. It follows from (4.20), for all
 $z \geq 0$
, that
$z \geq 0$
, that
 \begin{align} \tilde{f}_V \big(z;\, x^{(n)}, y^{(n)} \big) & \geq \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\} \exp \left( - z \right) \nonumber \\ &= \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\}\, f_V (z). \nonumber\end{align}
\begin{align} \tilde{f}_V \big(z;\, x^{(n)}, y^{(n)} \big) & \geq \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\} \exp \left( - z \right) \nonumber \\ &= \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\}\, f_V (z). \nonumber\end{align}
Therefore, we can construct a realisation of
 $\tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big)$
by setting
$\tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big)$
by setting
 $\tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big) = V_k$
if
$\tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big) = V_k$
if
 $U_{k,3} \leq 1 - \tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big)$
, and if
$U_{k,3} \leq 1 - \tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big)$
, and if
 $U_{k,3} \gt 1 - \tilde{d}^{(n)}\big(x^{(n)}, y^{(n)}\big)$
, we draw
$U_{k,3} \gt 1 - \tilde{d}^{(n)}\big(x^{(n)}, y^{(n)}\big)$
, we draw
 $\tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big)$
from a random variable with, for
$\tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big)$
from a random variable with, for
 $z \geq 0$
, probability density function
$z \geq 0$
, probability density function
 \begin{eqnarray} f^\ast \big(z;\, x^{(n)}, y^{(n)} \big)= \frac{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) }{\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big)} \left[ \exp \left( - z \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\} \right) - \exp (\!-\!z) \right]. \nonumber \\\end{eqnarray}
\begin{eqnarray} f^\ast \big(z;\, x^{(n)}, y^{(n)} \big)= \frac{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) }{\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big)} \left[ \exp \left( - z \big\{1 -\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) \big\} \right) - \exp (\!-\!z) \right]. \nonumber \\\end{eqnarray}
Finally, we set
 \begin{eqnarray} V_k^{(n)} = \tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big) \frac{\gamma +q^{(n)} \big(x^{(n)},y^{(n)}\big)}{\gamma + \beta},\end{eqnarray}
\begin{eqnarray} V_k^{(n)} = \tilde{V}_k^{(n)} \big(x^{(n)}, y^{(n)}\big) \frac{\gamma +q^{(n)} \big(x^{(n)},y^{(n)}\big)}{\gamma + \beta},\end{eqnarray}
which ensures that
 $V_k^{(n)} \sim {\rm Exp} (1)$
. Also, if
$V_k^{(n)} \sim {\rm Exp} (1)$
. Also, if
 $\eta_{k-1}^{(n)} = \eta_{k-1}$
,
$\eta_{k-1}^{(n)} = \eta_{k-1}$
,
 $Y_{k-1}^{(n)} = Y_{k-1}$
, and
$Y_{k-1}^{(n)} = Y_{k-1}$
, and
 $U_{k,3} \leq 1 - \tilde{d}^{(n)} \Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big)$
, then
$U_{k,3} \leq 1 - \tilde{d}^{(n)} \Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big)$
, then
 $\tilde{V}_k^{(n)} \Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) = V_k$
, and substituting
$\tilde{V}_k^{(n)} \Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) = V_k$
, and substituting
 $V_k^{(n)}$
into (4.6) and using (4.22) gives
$V_k^{(n)}$
into (4.6) and using (4.22) gives
 \begin{align} \eta_k^{(n)} &= \eta_{k-1}^{(n)} + \frac{ V_k^{(n)}}{Y_{k-1}^{(n)} \left[\gamma + q^{(n)} \Big( X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) \right]} \nonumber \\&= \eta_{k-1} + \frac{1}{Y_{k-1} \left[\gamma + q^{(n)} \Big( X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) \right]} \times \frac{\gamma + q^{(n)} \Big( X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big)}{\gamma + \beta} \tilde{V}_k^{(n)} \Big( X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) \nonumber \\&= \eta_{k-1} + \frac{V_k}{Y_{k-1} (\gamma + \beta)} = \eta_k.\end{align}
\begin{align} \eta_k^{(n)} &= \eta_{k-1}^{(n)} + \frac{ V_k^{(n)}}{Y_{k-1}^{(n)} \left[\gamma + q^{(n)} \Big( X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) \right]} \nonumber \\&= \eta_{k-1} + \frac{1}{Y_{k-1} \left[\gamma + q^{(n)} \Big( X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) \right]} \times \frac{\gamma + q^{(n)} \Big( X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big)}{\gamma + \beta} \tilde{V}_k^{(n)} \Big( X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) \nonumber \\&= \eta_{k-1} + \frac{V_k}{Y_{k-1} (\gamma + \beta)} = \eta_k.\end{align}
4.5. Coupling of the epidemic and branching processes
A mismatch occurs at event k whenever the kth events in the epidemic process,
 $\mathcal{E}^{(n)}$
(discrete epidemic jump process
$\mathcal{E}^{(n)}$
(discrete epidemic jump process
 $\mathcal{S}^{(n)}$
), and branching process,
$\mathcal{S}^{(n)}$
), and branching process,
 $\mathcal{B}$
(random walk
$\mathcal{B}$
(random walk
 $\mathcal{R}$
), are either a removal (
$\mathcal{R}$
), are either a removal (
 $\mathcal{E}^{(n)}$
) and a birth (
$\mathcal{E}^{(n)}$
) and a birth (
 $\mathcal{B}$
), or an infection (
$\mathcal{B}$
), or an infection (
 $\mathcal{E}^{(n)}$
) and a birth
$\mathcal{E}^{(n)}$
) and a birth
 $(\mathcal{B})$
where the number of new infections (
$(\mathcal{B})$
where the number of new infections (
 $\mathcal{E}^{(n)}$
) and the number of births
$\mathcal{E}^{(n)}$
) and the number of births
 $(\mathcal{B})$
differ. The first type of mismatch occurs in Ball and O’Neill [Reference Ball and O’Neill6], where also mismatches of the type with an infection (
$(\mathcal{B})$
differ. The first type of mismatch occurs in Ball and O’Neill [Reference Ball and O’Neill6], where also mismatches of the type with an infection (
 $\mathcal{E}^{(n)}$
) and a death (
$\mathcal{E}^{(n)}$
) and a death (
 $\mathcal{B}$
) are permissible. Owing to (4.18) and the assumption that
$\mathcal{B}$
) are permissible. Owing to (4.18) and the assumption that
 $\mu_C^{(n)} \leq \mu_C$
for all sufficiently large n, an infection in (
$\mu_C^{(n)} \leq \mu_C$
for all sufficiently large n, an infection in (
 $\mathcal{E}^{(n)}$
) and a death (
$\mathcal{E}^{(n)}$
) and a death (
 $\mathcal{B}$
) is not possible for such n in the current setup, but the arguments can easily be modified to allow for this situation. The second type of mismatch comes from allowing multiple infections/births.
$\mathcal{B}$
) is not possible for such n in the current setup, but the arguments can easily be modified to allow for this situation. The second type of mismatch comes from allowing multiple infections/births.
Since
 $q^{(n)} \big(x^{(n)},y^{(n)}\big) \leq \beta$
, a type-1 mismatch occurs at event k, where after event
$q^{(n)} \big(x^{(n)},y^{(n)}\big) \leq \beta$
, a type-1 mismatch occurs at event k, where after event
 $k-1$
there are
$k-1$
there are
 $x^{(n)}$
susceptibles and
$x^{(n)}$
susceptibles and
 $y^{(n)}$
infectives, if and only if
$y^{(n)}$
infectives, if and only if
 \begin{eqnarray} U_{k,1} \in D^{(n)}_1 \big(x^{(n)}, y^{(n)}\big) \equiv \left( \frac{\gamma}{ \beta + \gamma}, \frac{\gamma}{q^{(n)} \big(x^{(n)},y^{(n)}\big)+ \gamma} \right],\end{eqnarray}
\begin{eqnarray} U_{k,1} \in D^{(n)}_1 \big(x^{(n)}, y^{(n)}\big) \equiv \left( \frac{\gamma}{ \beta + \gamma}, \frac{\gamma}{q^{(n)} \big(x^{(n)},y^{(n)}\big)+ \gamma} \right],\end{eqnarray}
with
 \begin{eqnarray} {\mathbb{P}} \left(U_{k,1} \in D^{(n)}_1 \big(x^{(n)}, y^{(n)}\big) \right)= \frac{\gamma \big[\beta - q^{(n)} \big(x^{(n)},y^{(n)}\big)\big] }{\big[\gamma + q^{(n)} \big(x^{(n)},y^{(n)}\big)\big][\gamma + \beta]}.\end{eqnarray}
\begin{eqnarray} {\mathbb{P}} \left(U_{k,1} \in D^{(n)}_1 \big(x^{(n)}, y^{(n)}\big) \right)= \frac{\gamma \big[\beta - q^{(n)} \big(x^{(n)},y^{(n)}\big)\big] }{\big[\gamma + q^{(n)} \big(x^{(n)},y^{(n)}\big)\big][\gamma + \beta]}.\end{eqnarray}
Let
 $\tilde{Z}_1, \tilde{Z}_2, \ldots$
be i.i.d. according to
$\tilde{Z}_1, \tilde{Z}_2, \ldots$
be i.i.d. according to
 $\tilde{Z}$
with probability mass function
$\tilde{Z}$
with probability mass function
 ${\mathbb{P}} (\tilde{Z} = i) = \varphi_i$
${\mathbb{P}} (\tilde{Z} = i) = \varphi_i$
 $(i=0,1,\ldots)$
. We construct
$(i=0,1,\ldots)$
. We construct
 $\tilde{Z}_1, \tilde{Z}_2, \ldots$
from
$\tilde{Z}_1, \tilde{Z}_2, \ldots$
from
 $U_{1,2}, U_{2,2}, \ldots$
by setting
$U_{1,2}, U_{2,2}, \ldots$
by setting
 $\tilde{Z}_k$
to satisfy
$\tilde{Z}_k$
to satisfy
 \begin{eqnarray}\sum_{i=0}^{\tilde{Z}_k -1} \varphi_i \lt U_{k,2} \leq \sum_{i=0}^{\tilde{Z}_k} \varphi_i.\end{eqnarray}
\begin{eqnarray}\sum_{i=0}^{\tilde{Z}_k -1} \varphi_i \lt U_{k,2} \leq \sum_{i=0}^{\tilde{Z}_k} \varphi_i.\end{eqnarray}
Thus
 $\tilde{Z}_k$
is the number of births (size of the ‘upward step’) occurring in
$\tilde{Z}_k$
is the number of births (size of the ‘upward step’) occurring in
 $\mathcal{B}$
(
$\mathcal{B}$
(
 $\mathcal{R}$
) if the kth event is a birth event.
$\mathcal{R}$
) if the kth event is a birth event.
A third type of mismatch occurs in coupling the event times in
 $\mathcal{E}^{(n)}$
and
$\mathcal{E}^{(n)}$
and
 $\mathcal{B}$
. Conditionally upon there being no mismatches of the first two types in the first k events and
$\mathcal{B}$
. Conditionally upon there being no mismatches of the first two types in the first k events and
 $\eta_{k-1}^{(n)} = \eta_{k-1}$
, we have by (4.23) that a mismatch occurs and
$\eta_{k-1}^{(n)} = \eta_{k-1}$
, we have by (4.23) that a mismatch occurs and
 $\eta_k^{(n)} \neq \eta_k$
only if
$\eta_k^{(n)} \neq \eta_k$
only if
 $U_{k,3} \gt 1 - \tilde{d}^{(n)} \Big(X^{(n)}_{k-1}, Y^{(n)}_{k-1}\Big)$
.
$U_{k,3} \gt 1 - \tilde{d}^{(n)} \Big(X^{(n)}_{k-1}, Y^{(n)}_{k-1}\Big)$
.
The following lemma gives conditions under which the processes
 $\mathcal{B}$
$\mathcal{B}$
 $(\mathcal{R})$
and
$(\mathcal{R})$
and
 $\mathcal{E}^{(n)}$
$\mathcal{E}^{(n)}$
 $(\mathcal{S}^{(n)})$
can be constructed on a common probability space
$(\mathcal{S}^{(n)})$
can be constructed on a common probability space
 $(\Omega, \mathcal{F}, {\mathbb{P}})$
, so that for
$(\Omega, \mathcal{F}, {\mathbb{P}})$
, so that for
 ${\mathbb{P}}$
-almost all
${\mathbb{P}}$
-almost all
 $\omega \in \Omega$
they coincide over the first
$\omega \in \Omega$
they coincide over the first
 $u_n$
events for all sufficiently large n, where
$u_n$
events for all sufficiently large n, where
 $u_n \rightarrow \infty$
as
$u_n \rightarrow \infty$
as
 $n \rightarrow \infty$
.
$n \rightarrow \infty$
.
Lemma 4.2.
Suppose that (3.9) holds and (3.10) holds for some
 $\theta_0 \gt 0$
. Suppose that there exists
$\theta_0 \gt 0$
. Suppose that there exists
 $\alpha \geq 1$
such that
$\alpha \geq 1$
such that
 ${\mathbb{E}} [C^{\alpha +1}] \lt \infty$
, which in turn implies that
${\mathbb{E}} [C^{\alpha +1}] \lt \infty$
, which in turn implies that
 ${\mathbb{E}} [\tilde{Z}^\alpha] \lt \infty$
.
${\mathbb{E}} [\tilde{Z}^\alpha] \lt \infty$
.
Let
 $(u_n)$
be any non-decreasing sequence of integers such that there exists
$(u_n)$
be any non-decreasing sequence of integers such that there exists
 \begin{eqnarray} 0 \lt\zeta \lt \min \left\{ \frac{\alpha \theta_0}{2 (1 + \alpha)}, \frac{\alpha}{ 2+ 4 \alpha} \right\}, \end{eqnarray}
\begin{eqnarray} 0 \lt\zeta \lt \min \left\{ \frac{\alpha \theta_0}{2 (1 + \alpha)}, \frac{\alpha}{ 2+ 4 \alpha} \right\}, \end{eqnarray}
so that for all sufficiently large n,
 $u_n \leq \lfloor K n^\zeta \rfloor$
for some
$u_n \leq \lfloor K n^\zeta \rfloor$
for some
 $K \in \mathbb{R}^+$
.
$K \in \mathbb{R}^+$
.
Then there exists a probability space
 $(\Omega, \mathcal{F}, {\mathbb{P}})$
, on which are defined the branching process,
$(\Omega, \mathcal{F}, {\mathbb{P}})$
, on which are defined the branching process,
 $\mathcal{B}$
, the random walk,
$\mathcal{B}$
, the random walk,
 $\mathcal{R}$
, and the sequence of epidemic processes and discrete epidemic processes,
$\mathcal{R}$
, and the sequence of epidemic processes and discrete epidemic processes,
 $\left(\mathcal{E}_n, \mathcal{S}_n\right)$
, such that for
$\left(\mathcal{E}_n, \mathcal{S}_n\right)$
, such that for
 ${\mathbb{P}}$
-almost all
${\mathbb{P}}$
-almost all
 $\omega \in \Omega$
,
$\omega \in \Omega$
,
 \begin{eqnarray} \Big(Y_1^{(n)} (\omega), Y_2^{(n)} (\omega), \ldots, Y_{u_n}^{(n)} (\omega)\Big) = (Y_1 (\omega), Y_2 (\omega), \ldots, Y_{u_n} (\omega))\end{eqnarray}
\begin{eqnarray} \Big(Y_1^{(n)} (\omega), Y_2^{(n)} (\omega), \ldots, Y_{u_n}^{(n)} (\omega)\Big) = (Y_1 (\omega), Y_2 (\omega), \ldots, Y_{u_n} (\omega))\end{eqnarray}
and
 \begin{eqnarray} \Big(\eta_1^{(n)} (\omega), \eta_2^{(n)} (\omega), \ldots, \eta_{u_n}^{(n)} (\omega)\Big) = \big(\eta_1 (\omega), \eta_2 (\omega), \ldots, \eta_{u_n} (\omega)\big)\end{eqnarray}
\begin{eqnarray} \Big(\eta_1^{(n)} (\omega), \eta_2^{(n)} (\omega), \ldots, \eta_{u_n}^{(n)} (\omega)\Big) = \big(\eta_1 (\omega), \eta_2 (\omega), \ldots, \eta_{u_n} (\omega)\big)\end{eqnarray}
for all sufficiently large n.
Proof. Without loss of generality, we prove the lemma by taking
 $u_n = \lfloor K n^\zeta \rfloor$
for some
$u_n = \lfloor K n^\zeta \rfloor$
for some
 $K \in (0, \infty)$
and
$K \in (0, \infty)$
and
 $\zeta$
satisfying (4.27). It follows from (4.27) that
$\zeta$
satisfying (4.27). It follows from (4.27) that
 $\theta$
and
$\theta$
and
 $\delta$
can be chosen so that
$\delta$
can be chosen so that
 $\theta, \delta \gt 0$
,
$\theta, \delta \gt 0$
,
 $\frac{2 (1 + \alpha)}{\alpha} \zeta \lt \theta \leq \theta_0$
, and
$\frac{2 (1 + \alpha)}{\alpha} \zeta \lt \theta \leq \theta_0$
, and
 $\theta + 2 \zeta + 2 \delta \lt 1$
. (Note that (4.27) implies
$\theta + 2 \zeta + 2 \delta \lt 1$
. (Note that (4.27) implies
 $2 \zeta (1+\alpha)/\alpha \lt \theta_0$
. Furthermore,
$2 \zeta (1+\alpha)/\alpha \lt \theta_0$
. Furthermore,
 \[ \inf_{\theta \gt 2(1+ \alpha) \zeta/\alpha} \{ \theta + 2 \zeta\} = \frac{2 + 4 \alpha}{\alpha} \zeta \lt 1, \]
\[ \inf_{\theta \gt 2(1+ \alpha) \zeta/\alpha} \{ \theta + 2 \zeta\} = \frac{2 + 4 \alpha}{\alpha} \zeta \lt 1, \]
by (4.27).) Set
 $s_n = n^{\theta}$
,
$s_n = n^{\theta}$
,
 $r_n = K n^{ \zeta + \delta}$
,
$r_n = K n^{ \zeta + \delta}$
,
 $a_n = \lfloor n^{\theta/(\alpha+1)} \rfloor$
, and, for convenience,
$a_n = \lfloor n^{\theta/(\alpha+1)} \rfloor$
, and, for convenience,
 $\epsilon_n =1/s_n$
. Note that
$\epsilon_n =1/s_n$
. Note that
 $s_nr_n^2/n \rightarrow 0$
as
$s_nr_n^2/n \rightarrow 0$
as
 $n \to \infty$
, satisfying the conditions of Lemma 4.1.
$n \to \infty$
, satisfying the conditions of Lemma 4.1.
For
 $h,n=1,2,\ldots$
, let
$h,n=1,2,\ldots$
, let
 $\textbf{x}_h^{(n)}= \Big(x_0^{(n)}, x_1^{(n)}, \ldots, x_h^{(n)}\Big)$
and define
$\textbf{x}_h^{(n)}= \Big(x_0^{(n)}, x_1^{(n)}, \ldots, x_h^{(n)}\Big)$
and define
 $\textbf{y}_h^{(n)}$
similarly. Let
$\textbf{y}_h^{(n)}$
similarly. Let
 \[\tilde{A}_{n,0} = \left\{ \big(\textbf{x}^{(n)}_{u_n},\textbf{y}^{(n)}_{u_n}\big): \min_{\{1 \leq h \leq u_n\}} x^{(n)}_h =x^{(n)}_{u_n} \geq n - r_n, \max_{\{1 \leq h \leq u_n\}} y^{(n)}_h \leq r_n \right\} \]
\[\tilde{A}_{n,0} = \left\{ \big(\textbf{x}^{(n)}_{u_n},\textbf{y}^{(n)}_{u_n}\big): \min_{\{1 \leq h \leq u_n\}} x^{(n)}_h =x^{(n)}_{u_n} \geq n - r_n, \max_{\{1 \leq h \leq u_n\}} y^{(n)}_h \leq r_n \right\} \]
and
 $A_{n,0}=\Big\{\omega \in \Omega: \Big(\textbf{X}^{(n)}_{u_n} (\omega),\textbf{Y}^{(n)}_{u_n} (\omega)\Big) \in \tilde{A}_{n,0}\Big\}$
. Note that if
$A_{n,0}=\Big\{\omega \in \Omega: \Big(\textbf{X}^{(n)}_{u_n} (\omega),\textbf{Y}^{(n)}_{u_n} (\omega)\Big) \in \tilde{A}_{n,0}\Big\}$
. Note that if
 $\omega \in A_{n,0}$
for all sufficiently large n, then
$\omega \in A_{n,0}$
for all sufficiently large n, then
 $\Big\{\Big(X^{(n)}_k(\omega), Y^{(n)}_k(\omega)\Big)\Big\}$
satisfies the conditions of Lemma 4.1.
$\Big\{\Big(X^{(n)}_k(\omega), Y^{(n)}_k(\omega)\Big)\Big\}$
satisfies the conditions of Lemma 4.1.
Let
 $H_n$
denote the event at which the first mismatch occurs between
$H_n$
denote the event at which the first mismatch occurs between
 $\mathcal{S}_n$
and
$\mathcal{S}_n$
and
 $\mathcal{R}$
. Then, for
$\mathcal{R}$
. Then, for
 $\omega \in \Omega$
, (4.28) holds if and only if
$\omega \in \Omega$
, (4.28) holds if and only if
 $H_n (\omega) \gt u_n$
. Note that the first mismatch occurs at event k with
$H_n (\omega) \gt u_n$
. Note that the first mismatch occurs at event k with
 $\Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) = \Big(x^{(n)}_{k-1}, y_{k-1}^{(n)}\Big)$
, if
$\Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) = \Big(x^{(n)}_{k-1}, y_{k-1}^{(n)}\Big)$
, if
 \[ U_{h,1} \in D^{(n)}_1 \Big(x^{(n)}_{k-1}, y^{(n)}_{k-1}\Big) \quad \mbox{or} \quad U_{h,2} \in D^{(n)}_2 \Big(x^{(n)}_{k-1}, y^{(n)}_{k-1}\Big), \]
\[ U_{h,1} \in D^{(n)}_1 \Big(x^{(n)}_{k-1}, y^{(n)}_{k-1}\Big) \quad \mbox{or} \quad U_{h,2} \in D^{(n)}_2 \Big(x^{(n)}_{k-1}, y^{(n)}_{k-1}\Big), \]
where
 $D^{(n)}_1 \big(x^{(n)}, y^{(n)}\big)$
and
$D^{(n)}_1 \big(x^{(n)}, y^{(n)}\big)$
and
 $D^{(n)}_2 \big(x^{(n)}, y^{(n)}\big)$
are defined in (4.24) and (4.16), respectively.
$D^{(n)}_2 \big(x^{(n)}, y^{(n)}\big)$
are defined in (4.24) and (4.16), respectively.
Similarly, let
 $\tilde{H}_n$
denote the event at which the first mismatch occurs between the times of corresponding events in
$\tilde{H}_n$
denote the event at which the first mismatch occurs between the times of corresponding events in
 $\mathcal{E}_n$
and
$\mathcal{E}_n$
and
 $\mathcal{B}$
. Then (4.29) holds if and only if
$\mathcal{B}$
. Then (4.29) holds if and only if
 $\tilde{H}_n (\omega) \gt u_n$
. Note that if
$\tilde{H}_n (\omega) \gt u_n$
. Note that if
 $H_n (\omega ) \gt u_n$
then the first mismatch in the time of events occurs at event k with
$H_n (\omega ) \gt u_n$
then the first mismatch in the time of events occurs at event k with
 $\Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) = \Big(x^{(n)}_{k-1}, y_{k-1}^{(n)}\Big)$
, if
$\Big(X_{k-1}^{(n)}, Y_{k-1}^{(n)}\Big) = \Big(x^{(n)}_{k-1}, y_{k-1}^{(n)}\Big)$
, if
 \[ U_{h,3} \in D^{(n)}_3 \Big(x^{(n)}_{k-1}, y^{(n)}_{k-1}\Big) \equiv \left( 1- \tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) ,1\right], \]
\[ U_{h,3} \in D^{(n)}_3 \Big(x^{(n)}_{k-1}, y^{(n)}_{k-1}\Big) \equiv \left( 1- \tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big) ,1\right], \]
where
 $\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big)$
is defined in (4.19).
$\tilde{d}^{(n)} \big(x^{(n)}, y^{(n)}\big)$
is defined in (4.19).
By Lemma 4.1, we have for any
 $\ell \gt 0$
, for all sufficiently large n and
$\ell \gt 0$
, for all sufficiently large n and
 $\Big(\textbf{x}^{(n)}_{u_n}, \textbf{y}^{(n)}_{u_n}\Big) \in \tilde{A}_{n,0}$
, that
$\Big(\textbf{x}^{(n)}_{u_n}, \textbf{y}^{(n)}_{u_n}\Big) \in \tilde{A}_{n,0}$
, that
 $\sum_{w=0}^\infty \big\vert q^{(n)} \big(x^{(n)}, y^{(n)},w\big) - \beta \varphi_w \big\vert \lt \ell \epsilon_n$
and
$\sum_{w=0}^\infty \big\vert q^{(n)} \big(x^{(n)}, y^{(n)},w\big) - \beta \varphi_w \big\vert \lt \ell \epsilon_n$
and
 $\big\vert q^{(n)} \big(x^{(n)},y^{(n)}\big) - \beta\big\vert \lt \ell \epsilon_n$
. The first inequality implies that for all
$\big\vert q^{(n)} \big(x^{(n)},y^{(n)}\big) - \beta\big\vert \lt \ell \epsilon_n$
. The first inequality implies that for all
 $w \in \mathbb{Z}_+$
,
$w \in \mathbb{Z}_+$
,
 \[ \Big\vert q^{(n)} \big(x^{(n)}, y^{(n)},w\big) - \beta \varphi_w \Big\vert \lt \ell \epsilon_n. \]
\[ \Big\vert q^{(n)} \big(x^{(n)}, y^{(n)},w\big) - \beta \varphi_w \Big\vert \lt \ell \epsilon_n. \]
Therefore, since
 $q^{(n)} \big(x^{(n)}, y^{(n)}\big) \gt \beta/2$
for all sufficiently large n, we have by the triangle inequality that
$q^{(n)} \big(x^{(n)}, y^{(n)}\big) \gt \beta/2$
for all sufficiently large n, we have by the triangle inequality that
 \begin{eqnarray*} \left\vert \varpi_w^{(n)} \big(x^{(n)}, y^{(n)}\big) - \varphi_w \right\vert & = & \left\vert \frac{q^{(n)} \big(x^{(n)}, y^{(n)},w\big)}{q^{(n)} \big(x^{(n)}, y^{(n)}\big)} - \frac{\beta \varphi_w}{\beta} \right\vert\\& \leq & \frac{1}{q^{(n)} \big(x^{(n)}, y^{(n)}\big)} \left\vert q^{(n)} \big(x^{(n)}, y^{(n)},w\big) - \beta \varphi_w \right\vert\\& \qquad &+\ \beta \varphi_w \left\vert \frac{1}{q^{(n)} \big(x^{(n)}, y^{(n)}\big)} - \frac{1}{\beta} \right\vert \nonumber \\& \leq& \frac{2}{\beta} \left\vert q^{(n)} \big(x^{(n)}, y^{(n)},w\big) - \beta \varphi_w \right\vert + \frac{2 \varphi_w}{\beta} \left\vert q^{(n)} \big(x^{(n)}, y^{(n)}\big) - \beta \right\vert \nonumber \\& \leq & \frac{4}{\beta} \ell \epsilon_n.\end{eqnarray*}
\begin{eqnarray*} \left\vert \varpi_w^{(n)} \big(x^{(n)}, y^{(n)}\big) - \varphi_w \right\vert & = & \left\vert \frac{q^{(n)} \big(x^{(n)}, y^{(n)},w\big)}{q^{(n)} \big(x^{(n)}, y^{(n)}\big)} - \frac{\beta \varphi_w}{\beta} \right\vert\\& \leq & \frac{1}{q^{(n)} \big(x^{(n)}, y^{(n)}\big)} \left\vert q^{(n)} \big(x^{(n)}, y^{(n)},w\big) - \beta \varphi_w \right\vert\\& \qquad &+\ \beta \varphi_w \left\vert \frac{1}{q^{(n)} \big(x^{(n)}, y^{(n)}\big)} - \frac{1}{\beta} \right\vert \nonumber \\& \leq& \frac{2}{\beta} \left\vert q^{(n)} \big(x^{(n)}, y^{(n)},w\big) - \beta \varphi_w \right\vert + \frac{2 \varphi_w}{\beta} \left\vert q^{(n)} \big(x^{(n)}, y^{(n)}\big) - \beta \right\vert \nonumber \\& \leq & \frac{4}{\beta} \ell \epsilon_n.\end{eqnarray*}
Setting
 $\ell=\frac{\beta}{5}$
, we have that for all sufficiently large n,
$\ell=\frac{\beta}{5}$
, we have that for all sufficiently large n,
 $\left\vert \varpi_w^{(n)} \big(x^{(n)}, y^{(n)}\big) - \varphi_w \right\vert \le \epsilon_n$
$\left\vert \varpi_w^{(n)} \big(x^{(n)}, y^{(n)}\big) - \varphi_w \right\vert \le \epsilon_n$
 $(w=0,1,\ldots)$
.
$(w=0,1,\ldots)$
.
Thus we can define sets
 $\tilde{D}^{(n)}_i$
$\tilde{D}^{(n)}_i$
 $(i=1,2,3)$
such that for all sufficiently large n, if
$(i=1,2,3)$
such that for all sufficiently large n, if
 $\big(x^{(n)}, y^{(n)}\big) \in \tilde{A}_n$
, then
$\big(x^{(n)}, y^{(n)}\big) \in \tilde{A}_n$
, then
 $D^{(n)}_i \big(x^{(n)}, y^{(n)}\big) \subseteq \tilde{D}_i^{(n)}$
$D^{(n)}_i \big(x^{(n)}, y^{(n)}\big) \subseteq \tilde{D}_i^{(n)}$
 $(i=1,2,3)$
, where
$(i=1,2,3)$
, where
 \begin{eqnarray*}\tilde{D}^{(n)}_1 &=& \left(\frac{\gamma}{\beta + \gamma}, \frac{\gamma}{\beta - \epsilon_n + \gamma} \right], \\ \tilde{D}_2^{(n)} &=& \bigcup_{w=0}^{a_n} \left(\sum_{l=0}^w \varphi_l -\min \{ \varphi_w, \epsilon_n\}, \sum_{l=0}^w \varphi_l \right] \cup \left( \sum_{l=0}^{a_n} \varphi_l,1\right], \end{eqnarray*}
\begin{eqnarray*}\tilde{D}^{(n)}_1 &=& \left(\frac{\gamma}{\beta + \gamma}, \frac{\gamma}{\beta - \epsilon_n + \gamma} \right], \\ \tilde{D}_2^{(n)} &=& \bigcup_{w=0}^{a_n} \left(\sum_{l=0}^w \varphi_l -\min \{ \varphi_w, \epsilon_n\}, \sum_{l=0}^w \varphi_l \right] \cup \left( \sum_{l=0}^{a_n} \varphi_l,1\right], \end{eqnarray*}
and
 \[ \tilde{D}_3^{(n)} =\left(1-\epsilon_n, 1\right].\]
\[ \tilde{D}_3^{(n)} =\left(1-\epsilon_n, 1\right].\]
Since
 $\epsilon_n$
is decreasing in n, we have that for all n,
$\epsilon_n$
is decreasing in n, we have that for all n,
 $\tilde{D}_i^{(n+1)} \subseteq \tilde{D}_i^{(n)}$
$\tilde{D}_i^{(n+1)} \subseteq \tilde{D}_i^{(n)}$
 $(i=1,2,3)$
.
$(i=1,2,3)$
.
For
 $i=1,2,3$
, let
$i=1,2,3$
, let
 \[ A_{n,i} = \bigcap_{h=1}^{u_n} \left\{ U_{h,i} \not\in \tilde{D}_i^{(n)} \right\}.\]
\[ A_{n,i} = \bigcap_{h=1}^{u_n} \left\{ U_{h,i} \not\in \tilde{D}_i^{(n)} \right\}.\]
We observe that if
 $u_{n+1} = u_n$
, then
$u_{n+1} = u_n$
, then
 $A_{n,i} \subseteq A_{n+1,i}$
$A_{n,i} \subseteq A_{n+1,i}$
 $(i=0,1,2,3)$
. Therefore, following Ball and O’Neill [Reference Ball and O’Neill6, Lemma 2.11], we define
$(i=0,1,2,3)$
. Therefore, following Ball and O’Neill [Reference Ball and O’Neill6, Lemma 2.11], we define
 $\mathcal{Q} = \{ n \in \mathbb{N}: \lfloor K n^\zeta \rfloor \neq \lfloor K (n-1)^\zeta \rfloor\}$
and note that, for
$\mathcal{Q} = \{ n \in \mathbb{N}: \lfloor K n^\zeta \rfloor \neq \lfloor K (n-1)^\zeta \rfloor\}$
and note that, for
 $i=0,1,2,3$
, to show that
$i=0,1,2,3$
, to show that
 \[ {\mathbb{P}} \big( A_{n,i}^c \mbox{ occurs for infinitely many } n\big) = 0, \]
\[ {\mathbb{P}} \big( A_{n,i}^c \mbox{ occurs for infinitely many } n\big) = 0, \]
it is sufficient to show that
 \begin{eqnarray} {\mathbb{P}} \big( A_{n,i}^c \mbox{ occurs for infinitely many } n \in \mathcal{Q}\big) = 0. \end{eqnarray}
\begin{eqnarray} {\mathbb{P}} \big( A_{n,i}^c \mbox{ occurs for infinitely many } n \in \mathcal{Q}\big) = 0. \end{eqnarray}
Given that (4.30) holds for
 $i=0,1,2,3$
, we have that there exists
$i=0,1,2,3$
, we have that there exists
 $\tilde{\Omega} \subseteq \Omega$
such that
$\tilde{\Omega} \subseteq \Omega$
such that
 ${\mathbb{P}} (\tilde{\Omega}) =1$
and for every
${\mathbb{P}} (\tilde{\Omega}) =1$
and for every
 $\omega \in \tilde{\Omega}$
, there exists
$\omega \in \tilde{\Omega}$
, there exists
 $n(\omega) \in \mathbb{N}$
such that for all
$n(\omega) \in \mathbb{N}$
such that for all
 $n \geq n (\omega)$
,
$n \geq n (\omega)$
,
 $H_n (\omega) \gt u_n$
and
$H_n (\omega) \gt u_n$
and
 $\tilde{H}_n (\omega) \gt u_n$
. Thus (4.28) and (4.29) hold, and the lemma follows.
$\tilde{H}_n (\omega) \gt u_n$
. Thus (4.28) and (4.29) hold, and the lemma follows.
We complete the proof of the lemma by proving (4.30) for
 $i=0,1,2,3$
. Suppose that, for
$i=0,1,2,3$
. Suppose that, for
 $i=0,1,2,3$
, there exist
$i=0,1,2,3$
, there exist
 $L_i \lt \infty$
and
$L_i \lt \infty$
and
 $\chi_i \gt 1$
such that, for all sufficiently large n,
$\chi_i \gt 1$
such that, for all sufficiently large n,
 \begin{eqnarray} {\mathbb{P}} \big(A_{n,i}^c\big) \leq L_i n^{-\zeta \chi_i}.\end{eqnarray}
\begin{eqnarray} {\mathbb{P}} \big(A_{n,i}^c\big) \leq L_i n^{-\zeta \chi_i}.\end{eqnarray}
Following the proof of Ball and O’Neill [Reference Ball and O’Neill6, Lemma 2.10], we have that
 \[\sum_{n \in \mathcal{Q}} {\mathbb{P}} \big(A_{n,i}^c\big) \leq \sum_{n \in \mathcal{Q}} L_i n^{-\zeta \chi_i} \lt \infty,\]
\[\sum_{n \in \mathcal{Q}} {\mathbb{P}} \big(A_{n,i}^c\big) \leq \sum_{n \in \mathcal{Q}} L_i n^{-\zeta \chi_i} \lt \infty,\]
so by the first Borel–Cantelli lemma, (4.30) holds.
Let us prove (4.31). Recall that
 $\mu_C = {\mathbb{E}}[C]$
,
$\mu_C = {\mathbb{E}}[C]$
,
 ${\mathbb{E}} [\tilde{Z}] = {\mathbb{E}} [C \nu (C)]/\mu_C$
, and
${\mathbb{E}} [\tilde{Z}] = {\mathbb{E}} [C \nu (C)]/\mu_C$
, and
 ${\mathbb{E}} [C (C-1) \nu (C)] \lt \infty$
, where
${\mathbb{E}} [C (C-1) \nu (C)] \lt \infty$
, where
 $\nu (c)$
, defined at (3.7), is the mean number of new infectives created in a mixing event of size c with 1 infective and
$\nu (c)$
, defined at (3.7), is the mean number of new infectives created in a mixing event of size c with 1 infective and
 $c-1$
susceptibles. Since
$c-1$
susceptibles. Since
 $u_n \leq \lfloor K n^\zeta \rfloor$
and
$u_n \leq \lfloor K n^\zeta \rfloor$
and
 $r_n =K n^{\zeta +\delta}$
, by Chebyshev’s inequality, we have that, for all sufficiently large n,
$r_n =K n^{\zeta +\delta}$
, by Chebyshev’s inequality, we have that, for all sufficiently large n,
 \begin{align}{\mathbb{P}} \big(A_{n,0}^c\big) &= {\mathbb{P}} \left( \sum_{j=1}^{u_n} \tilde{Z}_j \gt r_n -m \right) \nonumber \\& \leq {\mathbb{P}} \left( \left\vert \sum_{j=1}^{u_n} \tilde{Z}_j - u_n {\mathbb{E}} [\tilde{Z}] \right\vert \gt \frac{r_n}{2} \right) \nonumber \\& \leq \frac{4}{r_n^2} {\rm Var} \left( \sum_{j=1}^{u_n} \tilde{Z}_j \right) \leq \frac{4 u_n}{r_n^2} {\mathbb{E}} [\tilde{Z}_1^2] \nonumber \\&= \frac{4u_n}{r_n^2} \sum_{w=0}^\infty w^2 \frac{1}{\mu_C} \sum_{c=w+1}^\infty c p_C (c) \pi_c (w;\, c-1,1) \nonumber \\& = \frac{4u_n}{r_n^2} \times \frac{1}{\mu_C} \sum_{c=2}^\infty c p_C (c) \sum_{w=0}^{c-1} w^2 \pi_c (w;\, c-1,1) \nonumber\\& \leq \frac{4u_n}{r_n^2} \times \frac{1}{\mu_C} \sum_{c=2}^\infty c (c-1) p_C (c) \sum_{w=0}^{c-1} w \pi_c (w;\, c-1,1) \nonumber \\& \leq \frac{4u_n}{r_n^2} \times \frac{{\mathbb{E}} [C (C-1) \nu (C)]}{\mu_C} \leq \frac{4 {\mathbb{E}} [C (C-1) \nu (C)]}{K \mu_C} n^{-\zeta (1+ 2 \delta/\zeta)}.\end{align}
\begin{align}{\mathbb{P}} \big(A_{n,0}^c\big) &= {\mathbb{P}} \left( \sum_{j=1}^{u_n} \tilde{Z}_j \gt r_n -m \right) \nonumber \\& \leq {\mathbb{P}} \left( \left\vert \sum_{j=1}^{u_n} \tilde{Z}_j - u_n {\mathbb{E}} [\tilde{Z}] \right\vert \gt \frac{r_n}{2} \right) \nonumber \\& \leq \frac{4}{r_n^2} {\rm Var} \left( \sum_{j=1}^{u_n} \tilde{Z}_j \right) \leq \frac{4 u_n}{r_n^2} {\mathbb{E}} [\tilde{Z}_1^2] \nonumber \\&= \frac{4u_n}{r_n^2} \sum_{w=0}^\infty w^2 \frac{1}{\mu_C} \sum_{c=w+1}^\infty c p_C (c) \pi_c (w;\, c-1,1) \nonumber \\& = \frac{4u_n}{r_n^2} \times \frac{1}{\mu_C} \sum_{c=2}^\infty c p_C (c) \sum_{w=0}^{c-1} w^2 \pi_c (w;\, c-1,1) \nonumber\\& \leq \frac{4u_n}{r_n^2} \times \frac{1}{\mu_C} \sum_{c=2}^\infty c (c-1) p_C (c) \sum_{w=0}^{c-1} w \pi_c (w;\, c-1,1) \nonumber \\& \leq \frac{4u_n}{r_n^2} \times \frac{{\mathbb{E}} [C (C-1) \nu (C)]}{\mu_C} \leq \frac{4 {\mathbb{E}} [C (C-1) \nu (C)]}{K \mu_C} n^{-\zeta (1+ 2 \delta/\zeta)}.\end{align}
Hence (4.31) holds for
 $i=0$
.
$i=0$
.
Since
 $\theta - 2 (1 + \alpha) \zeta/\alpha \gt 0$
, we have that for all sufficiently large n,
$\theta - 2 (1 + \alpha) \zeta/\alpha \gt 0$
, we have that for all sufficiently large n,
 \begin{align}{\mathbb{P}} \big(A_{n,1}^c\big) &= {\mathbb{P}} \left( \bigcup_{h=1}^{u_n} \left\{ U_{h,1} \in \tilde{D}^{(n)}_1 \right\} \right) \nonumber \\& \leq \left(\frac{2 \gamma}{(\beta + \gamma)^2} \right) u_n \epsilon_n \nonumber \\& \leq \left(\frac{2 \gamma}{(\beta + \gamma)^2} \right) K n^{\zeta} n^{-\theta} \nonumber \\&\leq \left(\frac{2 \gamma}{(\beta + \gamma)^2} \right) K n^{-\zeta (1 + 2/\alpha)}.\end{align}
\begin{align}{\mathbb{P}} \big(A_{n,1}^c\big) &= {\mathbb{P}} \left( \bigcup_{h=1}^{u_n} \left\{ U_{h,1} \in \tilde{D}^{(n)}_1 \right\} \right) \nonumber \\& \leq \left(\frac{2 \gamma}{(\beta + \gamma)^2} \right) u_n \epsilon_n \nonumber \\& \leq \left(\frac{2 \gamma}{(\beta + \gamma)^2} \right) K n^{\zeta} n^{-\theta} \nonumber \\&\leq \left(\frac{2 \gamma}{(\beta + \gamma)^2} \right) K n^{-\zeta (1 + 2/\alpha)}.\end{align}
Hence (4.31) holds for
 $i=1$
.
$i=1$
.
Similarly, since
 ${\mathbb{P}} (A_{n,3}^c) \leq u_n \epsilon_n$
, we have that (4.31) holds for
${\mathbb{P}} (A_{n,3}^c) \leq u_n \epsilon_n$
, we have that (4.31) holds for
 $i=3$
.
$i=3$
.
Finally, let
 $\delta_1 = \frac{\alpha}{\zeta(1+ \alpha)} \theta - 2 \gt 0$
. For all sufficiently large n, we have that
$\delta_1 = \frac{\alpha}{\zeta(1+ \alpha)} \theta - 2 \gt 0$
. For all sufficiently large n, we have that
 $a_n^{\alpha} , s_n/a_n \geq \frac{1}{2} n^{\theta \alpha/(1+\alpha)}$
. Thus, recalling that
$a_n^{\alpha} , s_n/a_n \geq \frac{1}{2} n^{\theta \alpha/(1+\alpha)}$
. Thus, recalling that
 $\epsilon_n=1/s_n$
, we have that for all sufficiently large n,
$\epsilon_n=1/s_n$
, we have that for all sufficiently large n,
 \begin{align} {\mathbb{P}} \big(A_{n,2}^c\big) &= {\mathbb{P}} \left( \bigcup_{h=1}^{u_n} \left\{ U_{h,2} \in \tilde{D}^{(n)}_2 \right\} \right) \nonumber \\& \leq u_n \left\{ a_n \epsilon_n + {\mathbb{P}} (\tilde{Z} \gt a_n )\right\} \nonumber \\& \leq u_n \left\{ \frac{a_n}{s_n} + \frac{ {\mathbb{E}} [\tilde{Z}^\alpha]}{a_n^{\alpha}} \right\} \nonumber \\& \leq 2 (1 + {\mathbb{E}} [\tilde{Z}^\alpha]) K n^{\zeta} n^{-\theta \alpha/(1+\alpha)} \nonumber \\& = 2 (1 + {\mathbb{E}} [\tilde{Z}^\alpha]) n^{-\zeta (1+ \delta_1)}.\end{align}
\begin{align} {\mathbb{P}} \big(A_{n,2}^c\big) &= {\mathbb{P}} \left( \bigcup_{h=1}^{u_n} \left\{ U_{h,2} \in \tilde{D}^{(n)}_2 \right\} \right) \nonumber \\& \leq u_n \left\{ a_n \epsilon_n + {\mathbb{P}} (\tilde{Z} \gt a_n )\right\} \nonumber \\& \leq u_n \left\{ \frac{a_n}{s_n} + \frac{ {\mathbb{E}} [\tilde{Z}^\alpha]}{a_n^{\alpha}} \right\} \nonumber \\& \leq 2 (1 + {\mathbb{E}} [\tilde{Z}^\alpha]) K n^{\zeta} n^{-\theta \alpha/(1+\alpha)} \nonumber \\& = 2 (1 + {\mathbb{E}} [\tilde{Z}^\alpha]) n^{-\zeta (1+ \delta_1)}.\end{align}
Hence (4.31) holds for
 $i=2$
. Thus (4.30) holds for
$i=2$
. Thus (4.30) holds for
 $i=0,1,2,3$
and the lemma is proved.
$i=0,1,2,3$
and the lemma is proved.
Lemma 4.2 ensures that the the processes
 $\mathcal{E}^{(n)}$
(
$\mathcal{E}^{(n)}$
(
 $\mathcal{S}^{(n)}$
) and
$\mathcal{S}^{(n)}$
) and
 $\mathcal{B}$
(
$\mathcal{B}$
(
 $\mathcal{R}$
) coincide for an increasing number of events as n increases. For Theorem 3.1(a) we do not require as strong a result as Lemma 4.2, and the following corollary, which can be proved in a similar fashion to Lemma 4.2, suffices.
$\mathcal{R}$
) coincide for an increasing number of events as n increases. For Theorem 3.1(a) we do not require as strong a result as Lemma 4.2, and the following corollary, which can be proved in a similar fashion to Lemma 4.2, suffices.
Corollary 4.1.
For any
 $K \in \mathbb{N}$
, we have, for
$K \in \mathbb{N}$
, we have, for
 $(\Omega, \mathcal{F}, {\mathbb{P}})$
defined in Lemma 4.2, that for
$(\Omega, \mathcal{F}, {\mathbb{P}})$
defined in Lemma 4.2, that for
 ${\mathbb{P}}$
-almost all
${\mathbb{P}}$
-almost all
 $\omega \in \Omega$
,
$\omega \in \Omega$
,
 \[ \Big(Y_1^{(n)} (\omega), Y_2^{(n)} (\omega), \ldots, Y_K^{(n)} (\omega)\Big) = (Y_1 (\omega), Y_2 (\omega), \ldots, Y_K (\omega)) \]
\[ \Big(Y_1^{(n)} (\omega), Y_2^{(n)} (\omega), \ldots, Y_K^{(n)} (\omega)\Big) = (Y_1 (\omega), Y_2 (\omega), \ldots, Y_K (\omega)) \]
and
 \[ \Big(\eta_1^{(n)} (\omega), \eta_2^{(n)} (\omega), \ldots, \eta_K^{(n)} (\omega)\Big) = (\eta_1 (\omega), \eta_2 (\omega), \ldots, \eta_K (\omega)), \]
\[ \Big(\eta_1^{(n)} (\omega), \eta_2^{(n)} (\omega), \ldots, \eta_K^{(n)} (\omega)\Big) = (\eta_1 (\omega), \eta_2 (\omega), \ldots, \eta_K (\omega)), \]
for all sufficiently large n.
The coupling in Lemma 4.2 includes birth events where no births occur, that is,
 $Z_1 =0$
. Given that
$Z_1 =0$
. Given that
 $\lambda \lt \infty$
$\lambda \lt \infty$
 $(\beta = \lambda \mu_C\lt\infty)$
and
$(\beta = \lambda \mu_C\lt\infty)$
and
 $\gamma \gt 0$
, it follows that
$\gamma \gt 0$
, it follows that
 ${\mathbb{P}} (Z_1 \neq 0) \gt 0$
. Since
${\mathbb{P}} (Z_1 \neq 0) \gt 0$
. Since
 $Z_1, Z_2, \ldots$
are i.i.d., the strong law of large numbers yields
$Z_1, Z_2, \ldots$
are i.i.d., the strong law of large numbers yields
 \begin{equation}\frac{1}{p}\sum_{i=1}^p 1_{\{Z_i \neq 0\}} \stackrel{{\rm a.s.}}{\longrightarrow} {\mathbb{P}}(Z_1 \neq 0) \qquad \text{as } p \to \infty,\end{equation}
\begin{equation}\frac{1}{p}\sum_{i=1}^p 1_{\{Z_i \neq 0\}} \stackrel{{\rm a.s.}}{\longrightarrow} {\mathbb{P}}(Z_1 \neq 0) \qquad \text{as } p \to \infty,\end{equation}
where
 $\stackrel{{\rm a.s.}}{\longrightarrow}$
denotes convergence almost surely. For
$\stackrel{{\rm a.s.}}{\longrightarrow}$
denotes convergence almost surely. For
 $k=1,2,\ldots$
, let
$k=1,2,\ldots$
, let
 \begin{equation} M_k=\min\Bigg\{p:\sum_{i=1}^p 1_{\{Z_i \neq 0\}}=k\Bigg\}.\end{equation}
\begin{equation} M_k=\min\Bigg\{p:\sum_{i=1}^p 1_{\{Z_i \neq 0\}}=k\Bigg\}.\end{equation}
Thus
 $M_k$
is the kth event in
$M_k$
is the kth event in
 $\mathcal{B}$
for which
$\mathcal{B}$
for which
 $Z_i \neq 0$
. (If
$Z_i \neq 0$
. (If
 $\mathcal{B}$
goes extinct then
$\mathcal{B}$
goes extinct then
 $M_k$
has this interpretation for only finitely many k.) Theorem 3.1 now follows straightforwardly from Lemma 4.2.
$M_k$
has this interpretation for only finitely many k.) Theorem 3.1 now follows straightforwardly from Lemma 4.2.
Proof of Theorem 3.1. (a) Recall that T is the total size of the branching process
 $\mathcal{B}$
and
$\mathcal{B}$
and
 $A_{ext} = \{ \omega \in \Omega\,:\, T (\omega) \lt \infty \}$
.
$A_{ext} = \{ \omega \in \Omega\,:\, T (\omega) \lt \infty \}$
.
Fix
 $\omega \in A_{ext}$
and suppose that
$\omega \in A_{ext}$
and suppose that
 $T(\omega) =k \lt\infty$
. Then there exists
$T(\omega) =k \lt\infty$
. Then there exists
 $h = h (\omega) \leq 2 k -m$
such that
$h = h (\omega) \leq 2 k -m$
such that
 $Y_{M_h} (\omega) =0$
. That is, there are at most
$Y_{M_h} (\omega) =0$
. That is, there are at most
 $k-m$
birth events (with a strictly positive number of births) and k death events in the branching process. By Corollary 4.1 there exists
$k-m$
birth events (with a strictly positive number of births) and k death events in the branching process. By Corollary 4.1 there exists
 $n_2 (\omega) \in \mathbb{N}$
such that for all
$n_2 (\omega) \in \mathbb{N}$
such that for all
 $n \geq n_2 (\omega)$
and
$n \geq n_2 (\omega)$
and
 $l=1,2,\ldots, M_h (\omega)$
,
$l=1,2,\ldots, M_h (\omega)$
,
 $Y_l^{(n)} (\omega) = Y_l(\omega)$
and
$Y_l^{(n)} (\omega) = Y_l(\omega)$
and
 $\eta_l^{(n)} (\omega) = \eta_l (\omega) $
, and hence, for all
$\eta_l^{(n)} (\omega) = \eta_l (\omega) $
, and hence, for all
 $t \geq 0$
,
$t \geq 0$
,
 $I_n (t,\omega) = I (t, \omega)$
.
$I_n (t,\omega) = I (t, \omega)$
.
(b) Let
 $\rho$
satisfy (3.11) and
$\rho$
satisfy (3.11) and
 $t_n = \rho \log n$
. Remembering from (3.8) that
$t_n = \rho \log n$
. Remembering from (3.8) that
 $r = \gamma (R_0 -1)$
is the Malthusian parameter (growth rate) of the branching process, we take
$r = \gamma (R_0 -1)$
is the Malthusian parameter (growth rate) of the branching process, we take
 $\zeta$
such that
$\zeta$
such that
 \[ \rho r \lt \zeta \lt \min \left\{ \frac{\alpha \theta_0}{2 (1 + \alpha)}, \frac{\alpha}{ 2+ 4 \alpha} \right\}, \]
\[ \rho r \lt \zeta \lt \min \left\{ \frac{\alpha \theta_0}{2 (1 + \alpha)}, \frac{\alpha}{ 2+ 4 \alpha} \right\}, \]
so that
 $\zeta$
satisfies (4.27) in the statement of Lemma 4.2.
$\zeta$
satisfies (4.27) in the statement of Lemma 4.2.
For
 $t \geq 0$
, let N(t) denote the total number of (birth and death) events in the branching process
$t \geq 0$
, let N(t) denote the total number of (birth and death) events in the branching process
 $\mathcal{B}$
up to and including time t. Then, if
$\mathcal{B}$
up to and including time t. Then, if
 $N(t_n, \omega) \leq u_n = \lfloor n^\zeta \rfloor$
and
$N(t_n, \omega) \leq u_n = \lfloor n^\zeta \rfloor$
and
 $\big(Y^{(n)}_h (\omega) , \eta^{(n)}_h (\omega)\big)= (Y_h (\omega) , \eta_h (\omega))$
$\big(Y^{(n)}_h (\omega) , \eta^{(n)}_h (\omega)\big)= (Y_h (\omega) , \eta_h (\omega))$
 $(h=1,2,\ldots, u_n)$
, we have from Lemma 4.2 that
$(h=1,2,\ldots, u_n)$
, we have from Lemma 4.2 that
 \[ \sup_{0 \leq t \leq t_n} \big\vert I^{(n)} (t) - I(t) \big\vert =0. \]
\[ \sup_{0 \leq t \leq t_n} \big\vert I^{(n)} (t) - I(t) \big\vert =0. \]
Give the initial ancestors the labels
 $-(m -1), -(m-2), \ldots, 0$
, and label the individuals born in the branching process sequentially
$-(m -1), -(m-2), \ldots, 0$
, and label the individuals born in the branching process sequentially
 $1,2,\ldots$
. For
$1,2,\ldots$
. For
 $i=1,2,\ldots$
, let
$i=1,2,\ldots$
, let
 $\tau_i$
denote the time of the birth of the ith individual, with the conventions that
$\tau_i$
denote the time of the birth of the ith individual, with the conventions that
 $\tau_i =\infty$
if fewer than i births occur, and
$\tau_i =\infty$
if fewer than i births occur, and
 $\tau_i=0$
for
$\tau_i=0$
for
 $i=-(m-1), -(m-2), \ldots, 0$
. For
$i=-(m-1), -(m-2), \ldots, 0$
. For
 $i=-(m-1),-(m-2), \ldots$
, let
$i=-(m-1),-(m-2), \ldots$
, let
 $\tilde{G}_i (s)$
denote the number of birth and death events involving individual i in the first s time units after their birth, if
$\tilde{G}_i (s)$
denote the number of birth and death events involving individual i in the first s time units after their birth, if
 $s \ge 0$
, and let
$s \ge 0$
, and let
 $\tilde{G}_i (s)=0$
if
$\tilde{G}_i (s)=0$
if
 $s\lt 0$
. Note that
$s\lt 0$
. Note that
 $\tilde{G}_i (s)$
is non-decreasing in s and
$\tilde{G}_i (s)$
is non-decreasing in s and
 $\tilde{G}_i (\infty) \stackrel{D}{=} G +1$
, where G is the number of birth events involving an individual and is a geometric random variable given by (3.4). Therefore, for all
$\tilde{G}_i (\infty) \stackrel{D}{=} G +1$
, where G is the number of birth events involving an individual and is a geometric random variable given by (3.4). Therefore, for all
 $t \geq 0$
,
$t \geq 0$
,
 \begin{eqnarray} N(t) = \sum_{i=-(m-1)}^\infty \tilde{G}_i (t - \tau_i). \end{eqnarray}
\begin{eqnarray} N(t) = \sum_{i=-(m-1)}^\infty \tilde{G}_i (t - \tau_i). \end{eqnarray}
Note that N(t) satisfies the form of Nerman [Reference Nerman14, (1.11)]. It is straightforward to show that the conditions of Theorem 5.4 in Nerman [Reference Nerman14] hold, since
 ${\mathbb{E}} [\tilde{G} (\infty)] =(\gamma + \lambda \mu_C)/\gamma$
. Therefore, by that theorem, there exists a positive, almost surely finite random variable W such that
${\mathbb{E}} [\tilde{G} (\infty)] =(\gamma + \lambda \mu_C)/\gamma$
. Therefore, by that theorem, there exists a positive, almost surely finite random variable W such that
 \[ \lim_{t \to \infty} \exp(\!-\! r t) N (t, \omega) = W(\omega) \gt 0 \]
\[ \lim_{t \to \infty} \exp(\!-\! r t) N (t, \omega) = W(\omega) \gt 0 \]
for
 ${\mathbb{P}}$
-almost all
${\mathbb{P}}$
-almost all
 $\omega \in A_{\rm ext}^c$
. It is then straightforward to show, following the proof of Ball and O’Neill [Reference Ball and O’Neill6, Lemma 2.9], that there exists some
$\omega \in A_{\rm ext}^c$
. It is then straightforward to show, following the proof of Ball and O’Neill [Reference Ball and O’Neill6, Lemma 2.9], that there exists some
 ${\mathbb{P}}$
-measurable set
${\mathbb{P}}$
-measurable set
 $B_1 \subseteq A_{\rm ext}^c$
such that
$B_1 \subseteq A_{\rm ext}^c$
such that
 ${\mathbb{P}} (B_1) = {\mathbb{P}} (A_{\rm ext}^c)$
and for all
${\mathbb{P}} (B_1) = {\mathbb{P}} (A_{\rm ext}^c)$
and for all
 $\omega \in B_1$
,
$\omega \in B_1$
,
 \[ \lim_{t \to \infty} n^{-c r} N (t_n, \omega) = W(\omega). \]
\[ \lim_{t \to \infty} n^{-c r} N (t_n, \omega) = W(\omega). \]
Hence, for all sufficiently large n,
 $N(t_n, \omega ) \leq 2 W (\omega) n^{\rho r} \leq u_n$
. Finally, by Lemma 4.2, for
$N(t_n, \omega ) \leq 2 W (\omega) n^{\rho r} \leq u_n$
. Finally, by Lemma 4.2, for
 ${\mathbb{P}}$
-almost all
${\mathbb{P}}$
-almost all
 $\omega \in B_1$
, (4.28) and (4.29) hold, so (3.12) follows.
$\omega \in B_1$
, (4.28) and (4.29) hold, so (3.12) follows.
Finally, we consider the total size of the epidemic processes and branching processes, with Corollary 3.1 following straightforwardly from Corollary 4.1.
Proof of Corollary 3.1. Let
 $\hat{\Omega} \subseteq \Omega$
be the set on which the convergence underlying (4.35) holds, so
$\hat{\Omega} \subseteq \Omega$
be the set on which the convergence underlying (4.35) holds, so
 ${\mathbb{P}}(\hat{\Omega})=1$
, and fix
${\mathbb{P}}(\hat{\Omega})=1$
, and fix
 $\omega \in\tilde{\Omega} \cap \hat{\Omega}$
. Suppose that
$\omega \in\tilde{\Omega} \cap \hat{\Omega}$
. Suppose that
 $T(\omega)=k\lt\infty$
. Then there exists
$T(\omega)=k\lt\infty$
. Then there exists
 $h=h(\omega) \leq 2k-m$
such that
$h=h(\omega) \leq 2k-m$
such that
 $Y_{M_h}(\omega)=0$
. By Corollary 4.1, there exists
$Y_{M_h}(\omega)=0$
. By Corollary 4.1, there exists
 $\tilde{n} (\omega) \in \mathbb{N}$
such that for all
$\tilde{n} (\omega) \in \mathbb{N}$
such that for all
 $n \geq \tilde{n} (\omega)$
,
$n \geq \tilde{n} (\omega)$
,
 $Y_i^{(n)} (\omega)=Y_i (\omega)$
$Y_i^{(n)} (\omega)=Y_i (\omega)$
 $(i=1,2,\dots, M_h (\omega))$
. Thus,
$(i=1,2,\dots, M_h (\omega))$
. Thus,
 $T^{(n)} (\omega) = T (\omega)$
for all
$T^{(n)} (\omega) = T (\omega)$
for all
 $n \geq \tilde{n} (\omega)$
.
$n \geq \tilde{n} (\omega)$
.
Suppose instead that
 $T(\omega)=\infty$
. Choose any
$T(\omega)=\infty$
. Choose any
 $k_1 \in \mathbb{N}$
and let
$k_1 \in \mathbb{N}$
and let
 $n_E(k_1, \omega)$
be the number of events in
$n_E(k_1, \omega)$
be the number of events in
 $\mathcal{B}$
when the total size of
$\mathcal{B}$
when the total size of
 $\mathcal{B}$
first reaches at least
$\mathcal{B}$
first reaches at least
 $k_1$
. Then arguing as above, with k replaced by
$k_1$
. Then arguing as above, with k replaced by
 $k_1$
and h replaced by
$k_1$
and h replaced by
 $n_E(k_1, \omega)$
, shows that
$n_E(k_1, \omega)$
, shows that
 $T^{(n)} (\omega) \ge k_1$
for all sufficiently large n. This holds for all
$T^{(n)} (\omega) \ge k_1$
for all sufficiently large n. This holds for all
 $k_1 \in \mathbb{N}$
, so
$k_1 \in \mathbb{N}$
, so
 $T^{(n)}(\omega) \to \infty$
as
$T^{(n)}(\omega) \to \infty$
as
 $n \rightarrow \infty$
.
$n \rightarrow \infty$
.
5. Proof of Theorem 3.2
5.1. Overview
We present an overview of the steps to prove Theorem 3.2. In Section 5.2, we prove Theorem 3.2(a), which states that as
 $n \to \infty$
, the probability of a major epidemic outbreak in
$n \to \infty$
, the probability of a major epidemic outbreak in
 $\mathcal{E}^{(n)}$
(the epidemic infects at least
$\mathcal{E}^{(n)}$
(the epidemic infects at least
 $\log n$
individuals) tends to the probability that the branching process,
$\log n$
individuals) tends to the probability that the branching process,
 $\mathcal{B}$
, does not go extinct. In Section 5.3, we introduce a sequence of lower-bound random walks,
$\mathcal{B}$
, does not go extinct. In Section 5.3, we introduce a sequence of lower-bound random walks,
 $(\mathcal{L}^{(n)})$
, which is a key component in showing that a major epidemic in the discrete epidemic jump process,
$(\mathcal{L}^{(n)})$
, which is a key component in showing that a major epidemic in the discrete epidemic jump process,
 $\mathcal{S}^{(n)}$
, and hence in the epidemic process
$\mathcal{S}^{(n)}$
, and hence in the epidemic process
 $\mathcal{E}^{(n)}$
infects at least
$\mathcal{E}^{(n)}$
infects at least
 $\delta^\ast n$
individuals with probability tending to 1 as
$\delta^\ast n$
individuals with probability tending to 1 as
 $n \to \infty$
. We provide an outline of the coupling of
$n \to \infty$
. We provide an outline of the coupling of
 $\mathcal{S}^{(n)}$
and
$\mathcal{S}^{(n)}$
and
 $\mathcal{L}^{(n)}$
, via an intermediary process
$\mathcal{L}^{(n)}$
, via an intermediary process
 $\mathcal{G}^{(n)}$
, and in (5.5) we identify the relationship between the three processes with
$\mathcal{G}^{(n)}$
, and in (5.5) we identify the relationship between the three processes with
 $\mathcal{L}^{(n)}$
as a lower bound in terms of the number of infectives in the epidemic, to establish Theorem 3.2(b). The details of
$\mathcal{L}^{(n)}$
as a lower bound in terms of the number of infectives in the epidemic, to establish Theorem 3.2(b). The details of
 $\mathcal{L}^{(n)}$
are provided in Section 5.4, along with Lemmas 5.1 and 5.2, which provide the main steps in establishing (5.5). Finally, Section 5.4 concludes with the proof of Theorem 3.2(b), from which Corollary 3.2 follows immediately.
$\mathcal{L}^{(n)}$
are provided in Section 5.4, along with Lemmas 5.1 and 5.2, which provide the main steps in establishing (5.5). Finally, Section 5.4 concludes with the proof of Theorem 3.2(b), from which Corollary 3.2 follows immediately.
5.2. Probability of a major epidemic
Under the conditions of Theorem 3.2, the conditions of Lemma 4.2 are satisfied with
 $\alpha =1$
since
$\alpha =1$
since
 ${\mathbb{E}}[C^2] \lt \infty$
. The proof of Theorem 3.2(a) then follows almost immediately from the proof of Theorem 3.1 by considering the embedded random walk and discrete-time epidemic jump process. From Lemma 4.2, (4.28), we have that
${\mathbb{E}}[C^2] \lt \infty$
. The proof of Theorem 3.2(a) then follows almost immediately from the proof of Theorem 3.1 by considering the embedded random walk and discrete-time epidemic jump process. From Lemma 4.2, (4.28), we have that
 $\textbf{Y}_{u_n} = (Y_1, Y_2, \ldots, Y_{u_n})$
and
$\textbf{Y}_{u_n} = (Y_1, Y_2, \ldots, Y_{u_n})$
and
 $\textbf{Y}_{u_n}^{(n)} = \big(Y_1^{(n)}, Y_2^{(n)}, \ldots, Y_{u_n}^{(n)}\big)$
can be constructed so that
$\textbf{Y}_{u_n}^{(n)} = \big(Y_1^{(n)}, Y_2^{(n)}, \ldots, Y_{u_n}^{(n)}\big)$
can be constructed so that
 \begin{eqnarray} {\mathbb{P}} \big( \textbf{Y}_{u_n}^{(n)} = \textbf{Y}_{u_n} \big) \rightarrow 1 \quad \mbox{as } n \to \infty,\end{eqnarray}
\begin{eqnarray} {\mathbb{P}} \big( \textbf{Y}_{u_n}^{(n)} = \textbf{Y}_{u_n} \big) \rightarrow 1 \quad \mbox{as } n \to \infty,\end{eqnarray}
for
 $u_n = \lfloor n^\zeta \rfloor$
and
$u_n = \lfloor n^\zeta \rfloor$
and
 $\zeta \gt 0$
satisfying (4.27) with
$\zeta \gt 0$
satisfying (4.27) with
 $\alpha =1$
. Hence we can couple the process
$\alpha =1$
. Hence we can couple the process
 $\mathcal{S}^{(n)}$
to
$\mathcal{S}^{(n)}$
to
 $\mathcal{R}$
over the first
$\mathcal{R}$
over the first
 $u_n$
steps, and Theorem 3.2(a) follows, as we now show.
$u_n$
steps, and Theorem 3.2(a) follows, as we now show.
Proof of Theorem 3.2 (a). Since T is the total size of a branching process with m initial ancestors, it follows that
 \begin{eqnarray} {\mathbb{P}}(T \ge \log n) \to 1-z^m \quad\mbox{as } n \to \infty.\end{eqnarray}
\begin{eqnarray} {\mathbb{P}}(T \ge \log n) \to 1-z^m \quad\mbox{as } n \to \infty.\end{eqnarray}
Following the proof of Corollary 3.1,
 $T \lt \log n$
if there exists
$T \lt \log n$
if there exists
 $h_n \leq 2 \log n -m$
such that
$h_n \leq 2 \log n -m$
such that
 $Y_{M_{h_n}}=0$
. Let
$Y_{M_{h_n}}=0$
. Let
 $\tilde{\Omega}$
and
$\tilde{\Omega}$
and
 $\hat{\Omega}$
be as in the proofs of Lemma 4.2 and Corollary 3.1, respectively, and note that
$\hat{\Omega}$
be as in the proofs of Lemma 4.2 and Corollary 3.1, respectively, and note that
 ${\mathbb{P}} (\tilde{\Omega} \cap \hat{\Omega}) =1$
. Fix
${\mathbb{P}} (\tilde{\Omega} \cap \hat{\Omega}) =1$
. Fix
 $\omega \in \tilde{\Omega} \cap \hat{\Omega} $
. Then
$\omega \in \tilde{\Omega} \cap \hat{\Omega} $
. Then
 \begin{eqnarray*} M_{\lfloor 2\log n \rfloor} (\omega) \le \frac{3}{{\mathbb{P}}(Z_1 \neq 0)} \log n \leq u_n\end{eqnarray*}
\begin{eqnarray*} M_{\lfloor 2\log n \rfloor} (\omega) \le \frac{3}{{\mathbb{P}}(Z_1 \neq 0)} \log n \leq u_n\end{eqnarray*}
for all sufficiently large n, where
 $M_k$
is given in (4.36) and
$M_k$
is given in (4.36) and
 $\tilde{\Omega}$
and
$\tilde{\Omega}$
and
 $\hat{\Omega}$
are defined in Lemma 4.2 and Corollary 3.1, respectively, with
$\hat{\Omega}$
are defined in Lemma 4.2 and Corollary 3.1, respectively, with
 ${\mathbb{P}} (\tilde{\Omega} \cap \hat{\Omega}) =1$
. It follows using Lemma 4.2 that
${\mathbb{P}} (\tilde{\Omega} \cap \hat{\Omega}) =1$
. It follows using Lemma 4.2 that
 $1_{\{T(\omega)\lt\log n\}}=1_{\{T^{(n)}(\omega)\lt\log n\}}$
for all sufficiently large n. Thus,
$1_{\{T(\omega)\lt\log n\}}=1_{\{T^{(n)}(\omega)\lt\log n\}}$
for all sufficiently large n. Thus,
 $1_{\{T\lt \log n\}}-1_{\{T^{(n)}\lt\log n\}}$
converges almost surely (and hence in probability) to 0 as
$1_{\{T\lt \log n\}}-1_{\{T^{(n)}\lt\log n\}}$
converges almost surely (and hence in probability) to 0 as
 $n \to \infty$
. Therefore,
$n \to \infty$
. Therefore,
 \[\big\vert {\mathbb{P}}\big(T^{(n)} \ge \log n\big) - {\mathbb{P}}(T \ge \log n) \big\vert = \big\vert {\mathbb{P}} \big(T^{(n)} \lt \log n\big) - {\mathbb{P}} (T \lt \log n) \big\vert \to 0 \quad\mbox{as } n \to \infty,\]
\[\big\vert {\mathbb{P}}\big(T^{(n)} \ge \log n\big) - {\mathbb{P}}(T \ge \log n) \big\vert = \big\vert {\mathbb{P}} \big(T^{(n)} \lt \log n\big) - {\mathbb{P}} (T \lt \log n) \big\vert \to 0 \quad\mbox{as } n \to \infty,\]
5.3. Coupling of the lower-bound random walk to the epidemic
We turn to the proof of Theorem 3.2(b) and note that we now need to consider the epidemic process and any approximation over
 $\lfloor \delta_1 n \rfloor$
events for some
$\lfloor \delta_1 n \rfloor$
events for some
 $\delta_1 \gt 0$
. The couplings utilised thus far do not extend to
$\delta_1 \gt 0$
. The couplings utilised thus far do not extend to
 $\lfloor \delta_1 n \rfloor$
events in the limit as
$\lfloor \delta_1 n \rfloor$
events in the limit as
 $n \rightarrow \infty$
. However, we can still utilise the couplings over the first
$n \rightarrow \infty$
. However, we can still utilise the couplings over the first
 $u_n = \lfloor n^\zeta \rfloor$
events. Hence, given that the embedded discrete epidemic jump process
$u_n = \lfloor n^\zeta \rfloor$
events. Hence, given that the embedded discrete epidemic jump process
 $\mathcal{S}^{(n)}$
reaches
$\mathcal{S}^{(n)}$
reaches
 $u_n$
events without hitting 0 (the epidemic process
$u_n$
events without hitting 0 (the epidemic process
 $\mathcal{E}^{(n)}$
does not go extinct), we can show, following the proof of Theorem 3.2(a), that, with probability tending to 1 as
$\mathcal{E}^{(n)}$
does not go extinct), we can show, following the proof of Theorem 3.2(a), that, with probability tending to 1 as
 $n \rightarrow \infty$
,
$n \rightarrow \infty$
,
 $T^{(n)} \geq v_n$
, where
$T^{(n)} \geq v_n$
, where
 $v_n = {\mathbb{P}} (Z_1 \neq 0) u_n/3$
. It immediately follows using the coupling in Lemma 4.2 (see (5.1)) that
$v_n = {\mathbb{P}} (Z_1 \neq 0) u_n/3$
. It immediately follows using the coupling in Lemma 4.2 (see (5.1)) that
 ${\mathbb{P}} \big(T \geq v_n \vert T^{(n)} \geq v_n\big) \rightarrow 1$
as
${\mathbb{P}} \big(T \geq v_n \vert T^{(n)} \geq v_n\big) \rightarrow 1$
as
 $n \rightarrow \infty$
. We have that if
$n \rightarrow \infty$
. We have that if
 $T \geq v_n$
, then
$T \geq v_n$
, then
 $\min_{k \leq v_n} \{ Y_k \} \gt 0$
, and by the weak law of large numbers,
$\min_{k \leq v_n} \{ Y_k \} \gt 0$
, and by the weak law of large numbers,
 \[ \left\vert \frac{1}{v_n} \sum_{k=1}^{v_n} Z_k - {\mathbb{E}} [Z] \right\vert \stackrel{{\rm p}}{\longrightarrow} 0 \quad \mbox{as } n \rightarrow \infty. \]
\[ \left\vert \frac{1}{v_n} \sum_{k=1}^{v_n} Z_k - {\mathbb{E}} [Z] \right\vert \stackrel{{\rm p}}{\longrightarrow} 0 \quad \mbox{as } n \rightarrow \infty. \]
Hence, under the assumption
 $R_0 \gt 1$
, which is required for Theorem 3.2(b), we have that
$R_0 \gt 1$
, which is required for Theorem 3.2(b), we have that
 ${\mathbb{E}} [Z] \gt 0$
and, since
${\mathbb{E}} [Z] \gt 0$
and, since
 $Y_{v_n} = m + \sum_{k=1}^{v_n} Z_k$
, that
$Y_{v_n} = m + \sum_{k=1}^{v_n} Z_k$
, that
 \begin{equation} {\mathbb{P}} \left( \left. Y_{v_n}\gt \frac{v_n {\mathbb{E}} [Z]}{2}, \min_{k \leq v_n} \{ Y_k \} \gt 0 \right\vert T \geq v_n \right) \to 1 \quad \mbox{as } n \rightarrow \infty.\end{equation}
\begin{equation} {\mathbb{P}} \left( \left. Y_{v_n}\gt \frac{v_n {\mathbb{E}} [Z]}{2}, \min_{k \leq v_n} \{ Y_k \} \gt 0 \right\vert T \geq v_n \right) \to 1 \quad \mbox{as } n \rightarrow \infty.\end{equation}
Now (5.3) implies that if the branching process
 $\mathcal{B}$
has at least
$\mathcal{B}$
has at least
 $v_n$
individuals ever alive, then the number of individuals alive in
$v_n$
individuals ever alive, then the number of individuals alive in
 $\mathcal{B}$
(the position of the random walk
$\mathcal{B}$
(the position of the random walk
 $\mathcal{R}$
) after
$\mathcal{R}$
) after
 $v_n$
events exceeds
$v_n$
events exceeds
 $v_n {\mathbb{E}}[Z]/2$
with probability tending to 1 as
$v_n {\mathbb{E}}[Z]/2$
with probability tending to 1 as
 $n \to \infty$
. Combined with (5.1) the same holds true for
$n \to \infty$
. Combined with (5.1) the same holds true for
 $Y^{(n)}_{v_n}$
in
$Y^{(n)}_{v_n}$
in
 $\mathcal{E}^{(n)}$
and
$\mathcal{E}^{(n)}$
and
 $\mathcal{S}^{(n)}$
.
$\mathcal{S}^{(n)}$
.
The next step is to show that, given that the epidemic
 $\mathcal{E}^{(n)}$
(
$\mathcal{E}^{(n)}$
(
 $\mathcal{S}^{(n)}$
) has not gone extinct in
$\mathcal{S}^{(n)}$
) has not gone extinct in
 $v_n$
events, there exists
$v_n$
events, there exists
 $\delta^\ast\gt 0$
such that, with probability tending to 1 as
$\delta^\ast\gt 0$
such that, with probability tending to 1 as
 $n \rightarrow \infty$
, at least
$n \rightarrow \infty$
, at least
 $\lfloor \delta^\ast n \rfloor$
events occur in
$\lfloor \delta^\ast n \rfloor$
events occur in
 $\mathcal{S}^{(n)}$
. In order to do this, we introduce a lower-bound random walk
$\mathcal{S}^{(n)}$
. In order to do this, we introduce a lower-bound random walk
 $\mathcal{L}^{(n)}$
indexed by the population size n. Lower-bound branching processes (random walks) for epidemic processes go back to [Reference Whittle17], and the main idea is along similar lines to [Reference Whittle17], in that we set up the lower-bound random walk so that the number of infectives in the discrete epidemic jump process
$\mathcal{L}^{(n)}$
indexed by the population size n. Lower-bound branching processes (random walks) for epidemic processes go back to [Reference Whittle17], and the main idea is along similar lines to [Reference Whittle17], in that we set up the lower-bound random walk so that the number of infectives in the discrete epidemic jump process
 $\mathcal{S}^{(n)}$
is at least the number of individuals alive in the branching process with embedded random walk
$\mathcal{S}^{(n)}$
is at least the number of individuals alive in the branching process with embedded random walk
 $\mathcal{L}^{(n)}$
for the initial stages of the epidemic process.
$\mathcal{L}^{(n)}$
for the initial stages of the epidemic process.
The key features in setting up
 $\mathcal{L}^{(n)}$
are as follows. Let
$\mathcal{L}^{(n)}$
are as follows. Let
 $L^{(n)}_k$
denote the position of the random walk
$L^{(n)}_k$
denote the position of the random walk
 $\mathcal{L}^{(n)}$
after k steps. The random walk
$\mathcal{L}^{(n)}$
after k steps. The random walk
 $\mathcal{L}^{(n)}$
is set identical to the random walk
$\mathcal{L}^{(n)}$
is set identical to the random walk
 $\mathcal{R}$
for the first
$\mathcal{R}$
for the first
 $v_n$
steps; that is, the distribution of steps is according to Z given in (4.1). Hence
$v_n$
steps; that is, the distribution of steps is according to Z given in (4.1). Hence
 $L_0^{(n)} = m$
, and for
$L_0^{(n)} = m$
, and for
 $k=1,2,\ldots,v_n$
,
$k=1,2,\ldots,v_n$
,
 $L_k^{(n)} = Y_k$
. For
$L_k^{(n)} = Y_k$
. For
 $k=v_n + 1, v_n +2, \ldots$
, the steps in
$k=v_n + 1, v_n +2, \ldots$
, the steps in
 $\mathcal{L}^{(n)}$
are i.i.d. according to
$\mathcal{L}^{(n)}$
are i.i.d. according to
 $\hat{Z}^{(n)}$
defined below in (5.9), with
$\hat{Z}^{(n)}$
defined below in (5.9), with
 ${\mathbb{E}} [ \hat{Z}^{(n)}] \gt 0$
so that the lower-bound random walk has positive drift. Therefore we can show that, as
${\mathbb{E}} [ \hat{Z}^{(n)}] \gt 0$
so that the lower-bound random walk has positive drift. Therefore we can show that, as
 $n \rightarrow \infty$
, if
$n \rightarrow \infty$
, if
 $\mathcal{L}^{(n)}$
has not hit 0 in the first
$\mathcal{L}^{(n)}$
has not hit 0 in the first
 $v_n$
steps when it is coupled to
$v_n$
steps when it is coupled to
 $\mathcal{R}$
, and hence reached
$\mathcal{R}$
, and hence reached
 $L_{v_n}^{(n)} = Y_{v_n} \geq v_n {\mathbb{E}} [Z]/2$
(cf. (5.3)), with probability tending to 1 it will not hit 0 in the first
$L_{v_n}^{(n)} = Y_{v_n} \geq v_n {\mathbb{E}} [Z]/2$
(cf. (5.3)), with probability tending to 1 it will not hit 0 in the first
 $\lfloor \delta_1 n \rfloor$
steps for
$\lfloor \delta_1 n \rfloor$
steps for
 $\delta_1 \gt 0$
.
$\delta_1 \gt 0$
.
It is difficult to directly couple
 $\mathcal{S}^{(n)}$
and
$\mathcal{S}^{(n)}$
and
 $\mathcal{L}^{(n)}$
, owing to differences in the distribution of steps caused by the changing rate of events in
$\mathcal{L}^{(n)}$
, owing to differences in the distribution of steps caused by the changing rate of events in
 $\mathcal{E}^{(n)}$
and hence the probability of events occurring in
$\mathcal{E}^{(n)}$
and hence the probability of events occurring in
 $\mathcal{S}^{(n)}$
. Therefore we introduce an intermediary process
$\mathcal{S}^{(n)}$
. Therefore we introduce an intermediary process
 $\mathcal{G}^{(n)}$
. The intermediary process
$\mathcal{G}^{(n)}$
. The intermediary process
 $\mathcal{G}^{(n)}$
is a bivariate (epidemic) process, indexed by the population size n, whose steps are state-dependent, with the dependence corresponding to the number of susceptibles and infectives in the population. For
$\mathcal{G}^{(n)}$
is a bivariate (epidemic) process, indexed by the population size n, whose steps are state-dependent, with the dependence corresponding to the number of susceptibles and infectives in the population. For
 $k=1,2,\ldots$
, let
$k=1,2,\ldots$
, let
 $\big(A_k^{(n)}, G_k^{(n)}\big)$
denote the state of
$\big(A_k^{(n)}, G_k^{(n)}\big)$
denote the state of
 $\mathcal{G}^{(n)}$
after k steps (events), with
$\mathcal{G}^{(n)}$
after k steps (events), with
 $A_k^{(n)}$
and
$A_k^{(n)}$
and
 $G_k^{(n)}$
denoting the numbers of susceptibles and infectives, respectively. For the first
$G_k^{(n)}$
denoting the numbers of susceptibles and infectives, respectively. For the first
 $v_n$
steps,
$v_n$
steps,
 $\mathcal{G}^{(n)}$
is set identical to
$\mathcal{G}^{(n)}$
is set identical to
 $\mathcal{S}^{(n)}$
, so that for
$\mathcal{S}^{(n)}$
, so that for
 $k=1,2,\ldots, v_n$
,
$k=1,2,\ldots, v_n$
,
 $\big(A_k^{(n)}, G_k^{(n)}\big) = \big(X_k^{(n)},Y_k^{(n)}\big)$
. After
$\big(A_k^{(n)}, G_k^{(n)}\big) = \big(X_k^{(n)},Y_k^{(n)}\big)$
. After
 $v_n$
steps have occurred in both
$v_n$
steps have occurred in both
 $\mathcal{G}^{(n)}$
and
$\mathcal{G}^{(n)}$
and
 $\mathcal{S}^{(n)}$
, we allow the two processes to differ as follows. The process
$\mathcal{S}^{(n)}$
, we allow the two processes to differ as follows. The process
 $\mathcal{G}^{(n)}$
is associated with an epidemic-type process,
$\mathcal{G}^{(n)}$
is associated with an epidemic-type process,
 $\mathcal{E}^{(n)}_G$
, which has a higher rate of events than the epidemic process
$\mathcal{E}^{(n)}_G$
, which has a higher rate of events than the epidemic process
 $\mathcal{E}^{(n)}$
, but in such a way that the additional events in
$\mathcal{E}^{(n)}$
, but in such a way that the additional events in
 $\mathcal{E}^{(n)}_G$
, which do not occur in
$\mathcal{E}^{(n)}_G$
, which do not occur in
 $\mathcal{E}^{(n)}$
, are infection events where no infections occur. In this way we can construct
$\mathcal{E}^{(n)}$
, are infection events where no infections occur. In this way we can construct
 $\mathcal{E}^{(n)}_G$
from
$\mathcal{E}^{(n)}_G$
from
 $\mathcal{E}^{(n)}$
so that all events in
$\mathcal{E}^{(n)}$
so that all events in
 $\mathcal{E}^{(n)}$
occur in
$\mathcal{E}^{(n)}$
occur in
 $\mathcal{E}^{(n)}_G$
, but there are additional ghost events which occur in
$\mathcal{E}^{(n)}_G$
, but there are additional ghost events which occur in
 $\mathcal{E}^{(n)}_G$
where there is no change in state (no infection or removal occurs); the only change is to increment the counter of the number of events. Similarly, we can reverse this process and generate
$\mathcal{E}^{(n)}_G$
where there is no change in state (no infection or removal occurs); the only change is to increment the counter of the number of events. Similarly, we can reverse this process and generate
 $\mathcal{E}^{(n)}$
from
$\mathcal{E}^{(n)}$
from
 $\mathcal{E}^{(n)}_G$
by eliminating, with an appropriate probability, some of the events where no change in state occurs. Therefore, for
$\mathcal{E}^{(n)}_G$
by eliminating, with an appropriate probability, some of the events where no change in state occurs. Therefore, for
 $k=1,2,\ldots$
, there exists
$k=1,2,\ldots$
, there exists
 $\kappa_n (k) \leq k$
such that
$\kappa_n (k) \leq k$
such that
 \begin{equation}\left(X_{\kappa_n (k)}^{(n)}, Y_{\kappa_n (k)}^{(n)}\right) = \left(A_k^{(n)}, G_k^{(n)}\right).\end{equation}
\begin{equation}\left(X_{\kappa_n (k)}^{(n)}, Y_{\kappa_n (k)}^{(n)}\right) = \left(A_k^{(n)}, G_k^{(n)}\right).\end{equation}
Note that for
 $k=1,2,\ldots,v_n$
,
$k=1,2,\ldots,v_n$
,
 $\kappa_n (k) = k$
.
$\kappa_n (k) = k$
.
We couple
 $\mathcal{G}^{(n)}$
and
$\mathcal{G}^{(n)}$
and
 $\mathcal{L}^{(n)}$
so that, with probability tending to 1 as
$\mathcal{L}^{(n)}$
so that, with probability tending to 1 as
 $n \to \infty$
, we have
$n \to \infty$
, we have
 $G_k^{(n)} \geq L_k^{(n)}$
for
$G_k^{(n)} \geq L_k^{(n)}$
for
 $k=1,2,\ldots,\lfloor \delta_1 n \rfloor$
, where
$k=1,2,\ldots,\lfloor \delta_1 n \rfloor$
, where
 $\delta_1 \gt 0$
is given in (5.7). That is, for the first
$\delta_1 \gt 0$
is given in (5.7). That is, for the first
 $\lfloor \delta_1 n \rfloor$
events, the number of infectives in the process
$\lfloor \delta_1 n \rfloor$
events, the number of infectives in the process
 $\mathcal{G}^{(n)}$
is at least the number of individuals alive in the random walk
$\mathcal{G}^{(n)}$
is at least the number of individuals alive in the random walk
 $\mathcal{L}^{(n)}$
. It then follows that, for
$\mathcal{L}^{(n)}$
. It then follows that, for
 $k=1,2,\ldots, \lfloor \delta_1n \rfloor$
, we have
$k=1,2,\ldots, \lfloor \delta_1n \rfloor$
, we have
 \begin{eqnarray} Y_{\kappa_n (k)}^{(n)} = G_k^{n} \geq L_k^{(n)}\end{eqnarray}
\begin{eqnarray} Y_{\kappa_n (k)}^{(n)} = G_k^{n} \geq L_k^{(n)}\end{eqnarray}
with probability tending to 1 as
 $n \rightarrow \infty$
. The proof of Theorem 3.2(b) follows almost immediately after we have established (5.5).
$n \rightarrow \infty$
. The proof of Theorem 3.2(b) follows almost immediately after we have established (5.5).
5.4. Lower bound for the size of a major epidemic outbreak
In this section we formally define the lower-bound random walk
 $\mathcal{L}^{(n)}$
. Then, in Lemma 5.1, we show that
$\mathcal{L}^{(n)}$
. Then, in Lemma 5.1, we show that
 $\mathcal{L}^{(n)}$
has positive drift, so that after
$\mathcal{L}^{(n)}$
has positive drift, so that after
 $\lfloor \delta_1 n \rfloor$
steps we have, for some
$\lfloor \delta_1 n \rfloor$
steps we have, for some
 $\delta \gt 0$
(defined in (5.10)), that
$\delta \gt 0$
(defined in (5.10)), that
 $L_{\lfloor \delta_1 n \rfloor}^{(n)} \geq \delta n$
with probability tending to 1 as
$L_{\lfloor \delta_1 n \rfloor}^{(n)} \geq \delta n$
with probability tending to 1 as
 $n \rightarrow \infty$
. This is followed by the construction of
$n \rightarrow \infty$
. This is followed by the construction of
 $\mathcal{G}^{(n)}$
. We show that whilst fewer than
$\mathcal{G}^{(n)}$
. We show that whilst fewer than
 $\lfloor \delta_1 n \rfloor$
events have occurred, the number of susceptibles (with high probability) remains above
$\lfloor \delta_1 n \rfloor$
events have occurred, the number of susceptibles (with high probability) remains above
 $(1- \epsilon_1) n$
, where
$(1- \epsilon_1) n$
, where
 $\epsilon_1 \gt 0$
is given in (5.7), which enables us to show, in Lemma 5.2, that the inequality in (5.5) holds with probability tending to 1 as
$\epsilon_1 \gt 0$
is given in (5.7), which enables us to show, in Lemma 5.2, that the inequality in (5.5) holds with probability tending to 1 as
 $n \rightarrow \infty$
. We then establish the equality in (5.5) through the coupling of
$n \rightarrow \infty$
. We then establish the equality in (5.5) through the coupling of
 $\mathcal{S}^{(n)}$
and
$\mathcal{S}^{(n)}$
and
 $\mathcal{G}^{(n)}$
, with the proof of Theorem 3.2(b) following.
$\mathcal{G}^{(n)}$
, with the proof of Theorem 3.2(b) following.
By (4.18), we have, for all
 $\big(x^{(n)}, y^{(n)}\big)$
, that
$\big(x^{(n)}, y^{(n)}\big)$
, that
 $q^{(n)} \big(x^{(n)}, y^{(n)} \big) \leq \lambda \mu_C^{(n)} = \beta^{(n)}$
, say. Since
$q^{(n)} \big(x^{(n)}, y^{(n)} \big) \leq \lambda \mu_C^{(n)} = \beta^{(n)}$
, say. Since
 $R_0 \gt 1 $
, and by (3.9),
$R_0 \gt 1 $
, and by (3.9),
 $ {\mathbb{E}} [ C (C -1) \nu (C)] \lt \infty$
, we can define
$ {\mathbb{E}} [ C (C -1) \nu (C)] \lt \infty$
, we can define
 \begin{eqnarray}\epsilon = \frac{ (R_0-1) \gamma}{2 \lambda {\mathbb{E}} [ C (C -1) \nu (C)] } \gt 0.\end{eqnarray}
\begin{eqnarray}\epsilon = \frac{ (R_0-1) \gamma}{2 \lambda {\mathbb{E}} [ C (C -1) \nu (C)] } \gt 0.\end{eqnarray}
We can then fix
 $\delta_1$
and
$\delta_1$
and
 $\epsilon_1 \lt \epsilon$
such that
$\epsilon_1 \lt \epsilon$
such that
 \begin{eqnarray}0 \lt \delta_1 \lt \epsilon_1 \frac{\mu_C}{{\mathbb{E}} [C^2]}. \end{eqnarray}
\begin{eqnarray}0 \lt \delta_1 \lt \epsilon_1 \frac{\mu_C}{{\mathbb{E}} [C^2]}. \end{eqnarray}
Throughout the remainder of the section we assume that
 $\delta_1$
and
$\delta_1$
and
 $\epsilon_1$
satisfy (5.7). For
$\epsilon_1$
satisfy (5.7). For
 $n=1,2,\ldots$
and
$n=1,2,\ldots$
and
 $w=1,2,\ldots,n-1$
, let
$w=1,2,\ldots,n-1$
, let
 \begin{eqnarray}\psi_w^{(n)} = \max \left\{ \frac{\lambda}{\beta^{(n)}} \sum_{c=w+1}^n c p_C^{(n)} (c) \pi_c (w;\,c-1,1) [ 1 - 2 \epsilon_1 (c-1)] ,0\right\}\end{eqnarray}
\begin{eqnarray}\psi_w^{(n)} = \max \left\{ \frac{\lambda}{\beta^{(n)}} \sum_{c=w+1}^n c p_C^{(n)} (c) \pi_c (w;\,c-1,1) [ 1 - 2 \epsilon_1 (c-1)] ,0\right\}\end{eqnarray}
and
 $\psi_0^{(n)} = 1- \sum_{v=1}^{n-1} \psi_v^{(n)}$
. Note that there exists
$\psi_0^{(n)} = 1- \sum_{v=1}^{n-1} \psi_v^{(n)}$
. Note that there exists
 $n_0 \in \mathbb{N}$
such that for all
$n_0 \in \mathbb{N}$
such that for all
 $n \geq n_0$
,
$n \geq n_0$
,
 $2 \epsilon_1 \lfloor n/2 \rfloor \gt 1$
, and hence
$2 \epsilon_1 \lfloor n/2 \rfloor \gt 1$
, and hence
 $\psi_w^{(n)} =0$
for all
$\psi_w^{(n)} =0$
for all
 $w \gt \lfloor n/2 \rfloor$
. We define
$w \gt \lfloor n/2 \rfloor$
. We define
 \begin{eqnarray} {\mathbb{P}}(\hat{Z}^{(n)} = w) = \left\{ \begin{array}{ll} \dfrac{\beta^{(n)} \psi_w^{(n)}}{\gamma + \beta^{(n)}}, &\quad w=1,2,\ldots, n-1, \\[10pt]\dfrac{\beta^{(n)} }{\gamma + \beta^{(n)}} \left( 1 - \sum_{i=1}^{n-1} \psi_i^{(n)} \right), &\quad w=0, \\[9pt] \dfrac{\gamma}{\gamma + \beta^{(n)}}, &\quad w=-1, \\[8pt]0 &\quad \mbox{otherwise.} \end{array} \right.\end{eqnarray}
\begin{eqnarray} {\mathbb{P}}(\hat{Z}^{(n)} = w) = \left\{ \begin{array}{ll} \dfrac{\beta^{(n)} \psi_w^{(n)}}{\gamma + \beta^{(n)}}, &\quad w=1,2,\ldots, n-1, \\[10pt]\dfrac{\beta^{(n)} }{\gamma + \beta^{(n)}} \left( 1 - \sum_{i=1}^{n-1} \psi_i^{(n)} \right), &\quad w=0, \\[9pt] \dfrac{\gamma}{\gamma + \beta^{(n)}}, &\quad w=-1, \\[8pt]0 &\quad \mbox{otherwise.} \end{array} \right.\end{eqnarray}
Let
 $\hat{Z}^{(n)}_{v_n +1}, \hat{Z}^{(n)}_{v_n +2}, \ldots$
, be i.i.d. according to
$\hat{Z}^{(n)}_{v_n +1}, \hat{Z}^{(n)}_{v_n +2}, \ldots$
, be i.i.d. according to
 $\hat{Z}^{(n)}$
given in (5.9). Then, given
$\hat{Z}^{(n)}$
given in (5.9). Then, given
 $L_{v_n}^{(n)} = Y_{v_n}$
, for
$L_{v_n}^{(n)} = Y_{v_n}$
, for
 $v_n +1 \leq k \leq \lfloor \delta_1 n \rfloor$
we set
$v_n +1 \leq k \leq \lfloor \delta_1 n \rfloor$
we set
 \begin{eqnarray*} L_k^{(n)} = L_{k-1}^{(n)} + \hat{Z}_k^{(n)}.\end{eqnarray*}
\begin{eqnarray*} L_k^{(n)} = L_{k-1}^{(n)} + \hat{Z}_k^{(n)}.\end{eqnarray*}
Lemma 5.1.
Let
 $b_n$
be any sequence of positive integers such that
$b_n$
be any sequence of positive integers such that
 $b_n \to \infty$
as
$b_n \to \infty$
as
 $n \to \infty$
. Let
$n \to \infty$
. Let
 $\delta_1$
satisfy (5.7), and let
$\delta_1$
satisfy (5.7), and let
 $\delta$
satisfy
$\delta$
satisfy
 \begin{eqnarray} 0 \lt \delta \lt \delta_1 \frac{(R_0 -1) \gamma - 2 \epsilon_1 \lambda {\mathbb{E}} [C (C-1) \nu (C)]}{\gamma + \lambda \mu_C},\end{eqnarray}
\begin{eqnarray} 0 \lt \delta \lt \delta_1 \frac{(R_0 -1) \gamma - 2 \epsilon_1 \lambda {\mathbb{E}} [C (C-1) \nu (C)]}{\gamma + \lambda \mu_C},\end{eqnarray}
where
 $\epsilon_1 \lt \epsilon$
ensures that the right-hand side of (5.10) is positive. Then
$\epsilon_1 \lt \epsilon$
ensures that the right-hand side of (5.10) is positive. Then
 \begin{eqnarray} {\mathbb{P}} \left( L^{(n)}_{\lfloor \delta_1 n \rfloor} \geq \lfloor \delta n \rfloor, \min_{k \gt v_n} \left\{ L_k^{(n)} \gt 0 \right\} \left| L_{v_n}^{(n)} \geq b_n\right. \right) \rightarrow 1 \quad \mbox{as } n \to \infty,\end{eqnarray}
\begin{eqnarray} {\mathbb{P}} \left( L^{(n)}_{\lfloor \delta_1 n \rfloor} \geq \lfloor \delta n \rfloor, \min_{k \gt v_n} \left\{ L_k^{(n)} \gt 0 \right\} \left| L_{v_n}^{(n)} \geq b_n\right. \right) \rightarrow 1 \quad \mbox{as } n \to \infty,\end{eqnarray}
where
 $v_n = {\mathbb{P}}(Z_1 \neq 0) u_n/3$
.
$v_n = {\mathbb{P}}(Z_1 \neq 0) u_n/3$
.
 \begin{align*}{\mathbb{E}} [\hat{Z}^{(n)} ] &= - \frac{\gamma}{\gamma + \beta^{(n)}} + \sum_{w=1}^{n-1} w \frac{\beta^{(n)} \psi_w^n}{\gamma + \beta^{(n)}} \\& \geq \frac{1}{\gamma + \beta^{(n)}} \left\{ - \gamma + \sum_{w=1}^{n-1} w \left[\lambda \sum_{c=w+1}^{n} c p_C^{(n)} (c) \pi_c (w;\, c-1,1) \left[ 1 - 2 \epsilon_1 (c-1) \right] \right] \right\} \\& = \frac{1}{\gamma + \beta^{(n)}}\left\{ - \gamma + \lambda \sum_{c=2}^n c p_C^{(n)} (c) \sum_{w=1}^{c-1} w \pi_c (w;\,c-1,1) \right.\\&\left.\qquad\qquad\qquad\qquad- 2\epsilon_1 \lambda \sum_{c=2}^n c(c-1) p_C^{(n)} \sum_{w=1}^{c-1} w \pi_c (w;\, c-1,1) \right\} \\&= \frac{1}{\gamma + \beta^{(n)}}\left\{ - \gamma + \lambda {\mathbb{E}} \big[C^{(n)} \nu \big(C^{(n)}\big)\big] - 2\epsilon_1 \lambda{\mathbb{E}} \big[C^{(n)} \big(C^{(n)} -1\big) \nu \big(C^{(n)}\big)\big] \right\}.\end{align*}
\begin{align*}{\mathbb{E}} [\hat{Z}^{(n)} ] &= - \frac{\gamma}{\gamma + \beta^{(n)}} + \sum_{w=1}^{n-1} w \frac{\beta^{(n)} \psi_w^n}{\gamma + \beta^{(n)}} \\& \geq \frac{1}{\gamma + \beta^{(n)}} \left\{ - \gamma + \sum_{w=1}^{n-1} w \left[\lambda \sum_{c=w+1}^{n} c p_C^{(n)} (c) \pi_c (w;\, c-1,1) \left[ 1 - 2 \epsilon_1 (c-1) \right] \right] \right\} \\& = \frac{1}{\gamma + \beta^{(n)}}\left\{ - \gamma + \lambda \sum_{c=2}^n c p_C^{(n)} (c) \sum_{w=1}^{c-1} w \pi_c (w;\,c-1,1) \right.\\&\left.\qquad\qquad\qquad\qquad- 2\epsilon_1 \lambda \sum_{c=2}^n c(c-1) p_C^{(n)} \sum_{w=1}^{c-1} w \pi_c (w;\, c-1,1) \right\} \\&= \frac{1}{\gamma + \beta^{(n)}}\left\{ - \gamma + \lambda {\mathbb{E}} \big[C^{(n)} \nu \big(C^{(n)}\big)\big] - 2\epsilon_1 \lambda{\mathbb{E}} \big[C^{(n)} \big(C^{(n)} -1\big) \nu \big(C^{(n)}\big)\big] \right\}.\end{align*}
Recall the expression (3.6) for
 $R_0$
and the fact that by (3.9),
$R_0$
and the fact that by (3.9),
 ${\mathbb{E}}[C(C-1) \nu (C)] \lt\infty$
. Since
${\mathbb{E}}[C(C-1) \nu (C)] \lt\infty$
. Since
 $ \lambda {\mathbb{E}} [C^{(n)}\nu \big(C^{(n)}\big)] \rightarrow R_0 \gamma$
and
$ \lambda {\mathbb{E}} [C^{(n)}\nu \big(C^{(n)}\big)] \rightarrow R_0 \gamma$
and
 $\beta^{(n)} \to \beta = \lambda \mu_C$
as
$\beta^{(n)} \to \beta = \lambda \mu_C$
as
 $n \rightarrow \infty$
, we have that
$n \rightarrow \infty$
, we have that
 \begin{eqnarray*} \liminf_{n \rightarrow \infty} {\mathbb{E}} [\hat{Z}^{(n)} ] \geq \frac{(R_0 -1) \gamma - 2 \epsilon_1 \lambda {\mathbb{E}} [C(C-1) \nu (C)] }{\gamma + \lambda \mu_C} \gt 0,\end{eqnarray*}
\begin{eqnarray*} \liminf_{n \rightarrow \infty} {\mathbb{E}} [\hat{Z}^{(n)} ] \geq \frac{(R_0 -1) \gamma - 2 \epsilon_1 \lambda {\mathbb{E}} [C(C-1) \nu (C)] }{\gamma + \lambda \mu_C} \gt 0,\end{eqnarray*}
where the final inequality follows from (5.10). It also follows from (5.8) that
 $\beta^{(n)} \psi_w^{(n)} \leq \lambda \sum_{c=w+1}^n c p_C^{(n)} (c) \pi_c (w;\, c-1,1)$
, for all
$\beta^{(n)} \psi_w^{(n)} \leq \lambda \sum_{c=w+1}^n c p_C^{(n)} (c) \pi_c (w;\, c-1,1)$
, for all
 $w=1,2,\ldots, n-1$
, so
$w=1,2,\ldots, n-1$
, so
 \begin{align} {\mathbb{E}} [(\hat{Z}^{(n)})^2 ] &\leq \frac{\gamma}{\gamma + \beta^{(n)}} + \frac{1}{\gamma + \beta^{(n)}} \sum_{w=1}^{n-1} w^2 \lambda \sum_{c=w+1}^n c p_C^{(n)} (c) \pi_c (w;\, c-1,1) \nonumber \\& = \frac{1}{\gamma + \lambda {\mathbb{E}} [C^{(n)}] } \left\{ \gamma + \lambda \sum_{c=2}^n c p_C^{(n)} (c) \sum_{w=1}^{c-1} w^2 \pi_c (w;\, c-1,1) \right\} \nonumber \\& \leq \frac{1}{\gamma + \lambda {\mathbb{E}} [C^{(n)}] } \left\{ \gamma + \lambda \sum_{c=2}^n c(c-1) p_C^{(n)} (c) \sum_{w=1}^{c-1} w\pi_c (w;\, c-1,1) \right\} \nonumber \\& = \frac{1}{\gamma + \lambda {\mathbb{E}} [C^{(n)}] } \left\{ \gamma + \lambda {\mathbb{E}} \big[C^{(n)} \big(C^{(n)} -1\big) \nu \big(C^{(n)}\big)\big] \right\} \nonumber \\&\rightarrow \frac{\gamma + \lambda {\mathbb{E}} [ C (C-1) \nu (C)]}{\gamma + \lambda \mu_C} \qquad \text{as } n \to \infty,\end{align}
\begin{align} {\mathbb{E}} [(\hat{Z}^{(n)})^2 ] &\leq \frac{\gamma}{\gamma + \beta^{(n)}} + \frac{1}{\gamma + \beta^{(n)}} \sum_{w=1}^{n-1} w^2 \lambda \sum_{c=w+1}^n c p_C^{(n)} (c) \pi_c (w;\, c-1,1) \nonumber \\& = \frac{1}{\gamma + \lambda {\mathbb{E}} [C^{(n)}] } \left\{ \gamma + \lambda \sum_{c=2}^n c p_C^{(n)} (c) \sum_{w=1}^{c-1} w^2 \pi_c (w;\, c-1,1) \right\} \nonumber \\& \leq \frac{1}{\gamma + \lambda {\mathbb{E}} [C^{(n)}] } \left\{ \gamma + \lambda \sum_{c=2}^n c(c-1) p_C^{(n)} (c) \sum_{w=1}^{c-1} w\pi_c (w;\, c-1,1) \right\} \nonumber \\& = \frac{1}{\gamma + \lambda {\mathbb{E}} [C^{(n)}] } \left\{ \gamma + \lambda {\mathbb{E}} \big[C^{(n)} \big(C^{(n)} -1\big) \nu \big(C^{(n)}\big)\big] \right\} \nonumber \\&\rightarrow \frac{\gamma + \lambda {\mathbb{E}} [ C (C-1) \nu (C)]}{\gamma + \lambda \mu_C} \qquad \text{as } n \to \infty,\end{align}
where
 ${\mathbb{E}} [ C (C-1) \nu (C)]\lt\infty$
ensures that the right-hand side of (5.12) is finite.
${\mathbb{E}} [ C (C-1) \nu (C)]\lt\infty$
ensures that the right-hand side of (5.12) is finite.
Let
 $z_n$
be the probability that the random walk
$z_n$
be the probability that the random walk
 $\mathcal{L}^{(n)}$
ever hits 0 given
$\mathcal{L}^{(n)}$
ever hits 0 given
 $L^{(n)}_{v_n} =1$
. Since
$L^{(n)}_{v_n} =1$
. Since
 $\liminf_{n \to \infty}{\mathbb{E}} [\hat{Z}^{(n)} ] \gt 0$
and
$\liminf_{n \to \infty}{\mathbb{E}} [\hat{Z}^{(n)} ] \gt 0$
and
 $\sup_n {\mathbb{E}} [(\hat{Z}^{(n)})^2 ] \lt \infty $
, it follows from Ball and Neal [Reference Ball and Neal4, Lemma A.3] that
$\sup_n {\mathbb{E}} [(\hat{Z}^{(n)})^2 ] \lt \infty $
, it follows from Ball and Neal [Reference Ball and Neal4, Lemma A.3] that
 $\limsup_{n \to \infty} z_n \lt 1$
. Therefore, for any
$\limsup_{n \to \infty} z_n \lt 1$
. Therefore, for any
 $b_n \to \infty$
as
$b_n \to \infty$
as
 $n \rightarrow \infty$
, we have that
$n \rightarrow \infty$
, we have that
 $z_n^{b_n} \to 0$
as
$z_n^{b_n} \to 0$
as
 $n \rightarrow \infty$
. Moreover, for
$n \rightarrow \infty$
. Moreover, for
 $\sup_n {\mathbb{E}} [(\hat{Z}^{(n)})^2 ] \lt \infty $
, it follows by the weak law of large numbers for triangular arrays (e.g. Durrett [Reference Durrett9, Theorem 2.2.4]) that
$\sup_n {\mathbb{E}} [(\hat{Z}^{(n)})^2 ] \lt \infty $
, it follows by the weak law of large numbers for triangular arrays (e.g. Durrett [Reference Durrett9, Theorem 2.2.4]) that
 \begin{eqnarray*} \left\vert \frac{1}{\lfloor \delta_1 n \rfloor - v_n} \sum_{l=v_n+1}^{\lfloor \delta_1 n \rfloor} \hat{Z}_l^n - {\mathbb{E}} [\hat{Z}^n] \right\vert \stackrel{{\rm p}}{\longrightarrow} 0 \quad \mbox{as } n \rightarrow \infty. \end{eqnarray*}
\begin{eqnarray*} \left\vert \frac{1}{\lfloor \delta_1 n \rfloor - v_n} \sum_{l=v_n+1}^{\lfloor \delta_1 n \rfloor} \hat{Z}_l^n - {\mathbb{E}} [\hat{Z}^n] \right\vert \stackrel{{\rm p}}{\longrightarrow} 0 \quad \mbox{as } n \rightarrow \infty. \end{eqnarray*}
Hence, for any
 $b_n \to \infty$
and
$b_n \to \infty$
and
 $\delta$
satisfying (5.10), we have that (5.11) holds.
$\delta$
satisfying (5.10), we have that (5.11) holds.
Turning to the intermediary (ghost) process
 $\mathcal{G}^{(n)}$
, we define independent random variables
$\mathcal{G}^{(n)}$
, we define independent random variables
 $W^{(n)}_k \big(x^{(n)}, y^{(n)}\big)$
$W^{(n)}_k \big(x^{(n)}, y^{(n)}\big)$
 $(k=v_n +1, v_n + 2, \ldots)$
to define the transitions given the current state
$(k=v_n +1, v_n + 2, \ldots)$
to define the transitions given the current state
 $(A^{(n)}, G^{(n)}) = \big(x^{(n)}, y^{(n)}\big)$
after event
$(A^{(n)}, G^{(n)}) = \big(x^{(n)}, y^{(n)}\big)$
after event
 $v_n$
. For
$v_n$
. For
 $k=v_n + 1,v_n +2,\ldots$
, let
$k=v_n + 1,v_n +2,\ldots$
, let
 $W_k^{(n)} \big(x^{(n)}, y^{(n)}\big)$
satisfy
$W_k^{(n)} \big(x^{(n)}, y^{(n)}\big)$
satisfy
 \begin{eqnarray} {\mathbb{P}}\big(W_k^{(n)} \big(x^{(n)}, y^{(n)}\big)= w\big) = \left\{ \begin{array}{ll} \dfrac{q^{(n)} (x^{(n)}, y^{(n)}, w)}{\gamma + \beta^{(n)}}, &\quad w=1,2,\ldots, n-1, \\[9pt] \dfrac{ \beta^{(n)} - \sum_{v=1}^{n-1} q^{(n)} (x^{(n)}, y^{(n)}, v)}{\gamma + \beta^{(n)}}, &\quad w=0, \\[9pt] \dfrac{\gamma}{\gamma + \beta^{(n)}}, &\quad w=-1, \\[9pt] 0 & \quad \mbox{otherwise.} \end{array} \right.\end{eqnarray}
\begin{eqnarray} {\mathbb{P}}\big(W_k^{(n)} \big(x^{(n)}, y^{(n)}\big)= w\big) = \left\{ \begin{array}{ll} \dfrac{q^{(n)} (x^{(n)}, y^{(n)}, w)}{\gamma + \beta^{(n)}}, &\quad w=1,2,\ldots, n-1, \\[9pt] \dfrac{ \beta^{(n)} - \sum_{v=1}^{n-1} q^{(n)} (x^{(n)}, y^{(n)}, v)}{\gamma + \beta^{(n)}}, &\quad w=0, \\[9pt] \dfrac{\gamma}{\gamma + \beta^{(n)}}, &\quad w=-1, \\[9pt] 0 & \quad \mbox{otherwise.} \end{array} \right.\end{eqnarray}
Then for
 $\Big(A^{(n)}_{k-1}, G_{k-1}^{(n)}\Big) = \big(x^{(n)}, y^{(n)}\big)$
, we set
$\Big(A^{(n)}_{k-1}, G_{k-1}^{(n)}\Big) = \big(x^{(n)}, y^{(n)}\big)$
, we set
 \begin{eqnarray} \nonumber \Big((A^{(n)}_k, G_k^{(n)}\Big) = \Bigg(x^{(n)} - W^{(n)}_k \big(x^{(n)}, y^{(n)}\big) 1_{\big\{W^{(n)}_k (x^{(n)}, y^{(n)}) \geq 0 \big\}}, y^{(n)} +W^{(n)}_k \big(x^{(n)}, y^{(n)}\big) \Bigg).\end{eqnarray}
\begin{eqnarray} \nonumber \Big((A^{(n)}_k, G_k^{(n)}\Big) = \Bigg(x^{(n)} - W^{(n)}_k \big(x^{(n)}, y^{(n)}\big) 1_{\big\{W^{(n)}_k (x^{(n)}, y^{(n)}) \geq 0 \big\}}, y^{(n)} +W^{(n)}_k \big(x^{(n)}, y^{(n)}\big) \Bigg).\end{eqnarray}
The continuous-time epidemic-type process
 $\mathcal{E}_G^{(n)}$
is constructed from
$\mathcal{E}_G^{(n)}$
is constructed from
 $\mathcal{G}^{(n)}$
as follows. If
$\mathcal{G}^{(n)}$
as follows. If
 $G_k^{(n)} = y^{(n)}$
, then the time from the kth to the
$G_k^{(n)} = y^{(n)}$
, then the time from the kth to the
 $(k+1)$
th event is drawn from
$(k+1)$
th event is drawn from
 ${\rm Exp} \big((\gamma + \beta^{(n)}) y^{(n)}\big)$
, regardless of
${\rm Exp} \big((\gamma + \beta^{(n)}) y^{(n)}\big)$
, regardless of
 $A^{(n)}$
, the number of susceptibles. Therefore, if there are
$A^{(n)}$
, the number of susceptibles. Therefore, if there are
 $y^{(n)}$
infectives in the population, mixing events occur at rate
$y^{(n)}$
infectives in the population, mixing events occur at rate
 $\beta^{(n)} y^{(n)}$
, with the number of individuals infected in such a mixing event depending on the number of susceptibles,
$\beta^{(n)} y^{(n)}$
, with the number of individuals infected in such a mixing event depending on the number of susceptibles,
 $A^{(n)}$
.
$A^{(n)}$
.
We consider the coupling of
 $\mathcal{G}^{(n)}$
and
$\mathcal{G}^{(n)}$
and
 $\mathcal{L}^{(n)}$
in Lemma 5.2 before finalising the coupling between
$\mathcal{L}^{(n)}$
in Lemma 5.2 before finalising the coupling between
 $\mathcal{G}^{(n)}$
and
$\mathcal{G}^{(n)}$
and
 $\mathcal{S}^{(n)}$
.
$\mathcal{S}^{(n)}$
.
Lemma 5.2.
There exists a coupling of
 $\mathcal{G}^{(n)}$
and
$\mathcal{G}^{(n)}$
and
 $\mathcal{L}^{(n)}$
such that, for any
$\mathcal{L}^{(n)}$
such that, for any
 $\delta_1$
satisfying (5.7),
$\delta_1$
satisfying (5.7),
 \begin{eqnarray} {\mathbb{P}} \left( \bigcap_{k=1}^{\lfloor \delta_1 n \rfloor} \left\{ G_k^{(n)} \geq L_k^{(n)} \right\} \right) \rightarrow 1 \quad \mbox{as } n \to \infty.\end{eqnarray}
\begin{eqnarray} {\mathbb{P}} \left( \bigcap_{k=1}^{\lfloor \delta_1 n \rfloor} \left\{ G_k^{(n)} \geq L_k^{(n)} \right\} \right) \rightarrow 1 \quad \mbox{as } n \to \infty.\end{eqnarray}
Proof. By the construction of
 $\mathcal{G}^{(n)}$
and
$\mathcal{G}^{(n)}$
and
 $\mathcal{L}^{(n)}$
and Lemma 4.2, (4.28), we have that with probability tending to 1,
$\mathcal{L}^{(n)}$
and Lemma 4.2, (4.28), we have that with probability tending to 1,
 $G_{k}^{(n)} = Y_{k} = L_{k}^{(n)}$
$G_{k}^{(n)} = Y_{k} = L_{k}^{(n)}$
 $(k=1,2,\ldots,v_n)$
.
$(k=1,2,\ldots,v_n)$
.
The first step is to show that
 ${\mathbb{P}} \Big(A_{\lfloor \delta_1 n \rfloor}^{(n)} \geq (1-\epsilon_1) n\Big) \to 1$
as
${\mathbb{P}} \Big(A_{\lfloor \delta_1 n \rfloor}^{(n)} \geq (1-\epsilon_1) n\Big) \to 1$
as
 $n \to \infty$
, which, since
$n \to \infty$
, which, since
 $A_k^{(n)}$
is non-increasing in k, implies that, for all
$A_k^{(n)}$
is non-increasing in k, implies that, for all
 $k=1,2,\ldots,\lfloor \delta_1 n \rfloor$
,
$k=1,2,\ldots,\lfloor \delta_1 n \rfloor$
,
 $A_k^{(n)} \geq (1-\epsilon_1) n$
with probability tending to 1 as
$A_k^{(n)} \geq (1-\epsilon_1) n$
with probability tending to 1 as
 $n \to \infty$
.
$n \to \infty$
.
It is straightforward to show, for all
 $\big(x^{(n)}, y^{(n)}\big)$
, that
$\big(x^{(n)}, y^{(n)}\big)$
, that
 $W^{(n)} \big(x^{(n)}, y^{(n)}\big)$
is stochastically smaller than (
$W^{(n)} \big(x^{(n)}, y^{(n)}\big)$
is stochastically smaller than (
 $ \stackrel{st}{\le}$
) a random variable
$ \stackrel{st}{\le}$
) a random variable
 $\tilde{W}^{(n)}$
, where
$\tilde{W}^{(n)}$
, where
 ${\mathbb{P}} (\tilde{W}^{(n)} = -1) = \gamma/\big(\gamma + \beta^{(n)}\big)$
and for
${\mathbb{P}} (\tilde{W}^{(n)} = -1) = \gamma/\big(\gamma + \beta^{(n)}\big)$
and for
 $k=1,2,\ldots$
,
$k=1,2,\ldots$
,
 ${\mathbb{P}} (\tilde{W}^{(n)} = k) = \beta^{(n)} {\mathbb{P}} (\tilde{C}^{(n)} = k+1) /\big(\gamma + \beta^{(n)}\big)$
, with
${\mathbb{P}} (\tilde{W}^{(n)} = k) = \beta^{(n)} {\mathbb{P}} (\tilde{C}^{(n)} = k+1) /\big(\gamma + \beta^{(n)}\big)$
, with
 \begin{eqnarray*} {\mathbb{P}} (\tilde{C}^{(n)} = c) = \left\{ \begin{array}{ll} \dfrac{c p_C^{(n)} (c)}{ \mu_C^{(n)}}, &\quad c=2,3,\ldots, \\[8pt] 0 & \quad \mbox{otherwise}. \end{array} \right.\end{eqnarray*}
\begin{eqnarray*} {\mathbb{P}} (\tilde{C}^{(n)} = c) = \left\{ \begin{array}{ll} \dfrac{c p_C^{(n)} (c)}{ \mu_C^{(n)}}, &\quad c=2,3,\ldots, \\[8pt] 0 & \quad \mbox{otherwise}. \end{array} \right.\end{eqnarray*}
Note that
 $\tilde{C}^{(n)}$
is the size-biased distribution of mixing group sizes, and for
$\tilde{C}^{(n)}$
is the size-biased distribution of mixing group sizes, and for
 $c \geq 2$
,
$c \geq 2$
,
 ${\mathbb{P}} (\tilde{W}^{(n)}=c-1)$
is the probability that an event is a mixing event multiplied by the probability that a mixing event involving a given infective is of size c. It is then assumed that a mixing group of size c involving an infective produces
${\mathbb{P}} (\tilde{W}^{(n)}=c-1)$
is the probability that an event is a mixing event multiplied by the probability that a mixing event involving a given infective is of size c. It is then assumed that a mixing group of size c involving an infective produces
 $c-1$
new infections, the maximum number of new infections that can be produced from a mixing group of size c.
$c-1$
new infections, the maximum number of new infections that can be produced from a mixing group of size c.
The proof that
 $W^{(n)} \big(x^{(n)}, y^{(n)}\big) \stackrel{st}{\le} \tilde{W}^{(n)}$
is as follows. Remember that
$W^{(n)} \big(x^{(n)}, y^{(n)}\big) \stackrel{st}{\le} \tilde{W}^{(n)}$
is as follows. Remember that
 $Q_c^{(n)} \big(l,i|x^{(n)}, y^{(n)}\big) $
, defined in (4.2), is the probability that a mixing group of size c in a population of size n containing
$Q_c^{(n)} \big(l,i|x^{(n)}, y^{(n)}\big) $
, defined in (4.2), is the probability that a mixing group of size c in a population of size n containing
 $x^{(n)}$
susceptibles and
$x^{(n)}$
susceptibles and
 $y^{(n)}$
infectives contains l susceptibles and i infectives. Note that for
$y^{(n)}$
infectives contains l susceptibles and i infectives. Note that for
 $v\gt 0$
, the probability that such a mixing group results in v new infectives,
$v\gt 0$
, the probability that such a mixing group results in v new infectives,
 $\pi_c (v;\, l,i)$
, is not equal to 0 only if
$\pi_c (v;\, l,i)$
, is not equal to 0 only if
 $i \gt 0$
and
$i \gt 0$
and
 $v \leq l$
. Given that there are
$v \leq l$
. Given that there are
 $y^{(n)}$
infectives in the population, the probability that a mixing group of size c includes at least one infective is at most
$y^{(n)}$
infectives in the population, the probability that a mixing group of size c includes at least one infective is at most
 $c y^{(n)}/n$
, and therefore, for
$c y^{(n)}/n$
, and therefore, for
 $w=0,1,\ldots$
,
$w=0,1,\ldots$
,
 \begin{eqnarray*} && {\mathbb{P}} \left(W^{(n)} \big(x^{(n)}, y^{(n)}\big) \geq w\right) \nonumber \\ & & \quad = \frac{1}{\gamma + \beta^{(n)}} \sum_{v=w}^{n-1} q^{(n)} \big(x^{(n)}, y^{(n)},v\big) \nonumber \\& & \quad= \frac{1}{\gamma + \beta^{(n)}} \sum_{v=w}^{n-1} \frac{n \lambda}{y^{(n)}} \sum_{c=v+1}^n p_C^{(n)} (c) \sum_{i,j} Q_c^{(n)} \big(c-i-j,i|x^{(n)}, y^{(n)}\big) \pi_c (v;\, c-i-j,i) \nonumber \\& & \quad= \frac{1}{\gamma + \beta^{(n)}} \sum_{c=w+1}^n p_C^{(n)} (c) \frac{n \lambda}{y^{(n)}} \sum_{i,j} Q_c^{(n)} \big(c-i-j,i|x^{(n)}, y^{(n)}\big) \left\{ \sum_{v=w}^{c-1} \pi_c (v;\, c-i-j,i) \right\} \nonumber \\& & \quad \leq \frac{1}{\gamma + \beta^{(n)}} \sum_{c=w+1}^n p_C^{(n)} (c) \frac{n \lambda}{y^{(n)}} \times \frac{c y^{(n)}}{n} \nonumber \\& & \quad= \frac{\lambda}{\gamma + \beta^{(n)}} \sum_{c=w+1}^n c p_C^{(n)} (c) \nonumber \\& & \quad= \frac{\lambda \mu_C^{(n)} }{\gamma + \beta^{(n)}} \sum_{c=w+1}^n {\mathbb{P}} (\tilde{C}^{(n)} =c) = {\mathbb{P}} \left(\tilde{W}^{(n)} \geq w\right),\end{eqnarray*}
\begin{eqnarray*} && {\mathbb{P}} \left(W^{(n)} \big(x^{(n)}, y^{(n)}\big) \geq w\right) \nonumber \\ & & \quad = \frac{1}{\gamma + \beta^{(n)}} \sum_{v=w}^{n-1} q^{(n)} \big(x^{(n)}, y^{(n)},v\big) \nonumber \\& & \quad= \frac{1}{\gamma + \beta^{(n)}} \sum_{v=w}^{n-1} \frac{n \lambda}{y^{(n)}} \sum_{c=v+1}^n p_C^{(n)} (c) \sum_{i,j} Q_c^{(n)} \big(c-i-j,i|x^{(n)}, y^{(n)}\big) \pi_c (v;\, c-i-j,i) \nonumber \\& & \quad= \frac{1}{\gamma + \beta^{(n)}} \sum_{c=w+1}^n p_C^{(n)} (c) \frac{n \lambda}{y^{(n)}} \sum_{i,j} Q_c^{(n)} \big(c-i-j,i|x^{(n)}, y^{(n)}\big) \left\{ \sum_{v=w}^{c-1} \pi_c (v;\, c-i-j,i) \right\} \nonumber \\& & \quad \leq \frac{1}{\gamma + \beta^{(n)}} \sum_{c=w+1}^n p_C^{(n)} (c) \frac{n \lambda}{y^{(n)}} \times \frac{c y^{(n)}}{n} \nonumber \\& & \quad= \frac{\lambda}{\gamma + \beta^{(n)}} \sum_{c=w+1}^n c p_C^{(n)} (c) \nonumber \\& & \quad= \frac{\lambda \mu_C^{(n)} }{\gamma + \beta^{(n)}} \sum_{c=w+1}^n {\mathbb{P}} (\tilde{C}^{(n)} =c) = {\mathbb{P}} \left(\tilde{W}^{(n)} \geq w\right),\end{eqnarray*}
as required.
Hence we can couple
 $\Big\{W^{(n)}_k \Big(A^{(n)}_{k-1}, G^{(n)}_{k-1}\Big) \Big\}$
and
$\Big\{W^{(n)}_k \Big(A^{(n)}_{k-1}, G^{(n)}_{k-1}\Big) \Big\}$
and
 $\big\{\tilde{W}^{(n)}_k \big\} $
so that, for all
$\big\{\tilde{W}^{(n)}_k \big\} $
so that, for all
 $k=v_n + 1,v_n+ 2,\ldots$
,
$k=v_n + 1,v_n+ 2,\ldots$
,
 \begin{eqnarray*} W^{(n)}_k \Big(A^{(n)}_{k-1}, G^{(n)}_{k-1}\Big) \leq \tilde{W}^{(n)}_k.\end{eqnarray*}
\begin{eqnarray*} W^{(n)}_k \Big(A^{(n)}_{k-1}, G^{(n)}_{k-1}\Big) \leq \tilde{W}^{(n)}_k.\end{eqnarray*}
Recall that
 ${\mathbb{E}} [(C^{(n)})^2] \to {\mathbb{E}} [C^2]$
as
${\mathbb{E}} [(C^{(n)})^2] \to {\mathbb{E}} [C^2]$
as
 $n \to \infty$
, where
$n \to \infty$
, where
 ${\mathbb{E}} [C^2] \lt \infty$
. By the weak law of large numbers for triangular arrays, we have that
${\mathbb{E}} [C^2] \lt \infty$
. By the weak law of large numbers for triangular arrays, we have that
 \begin{eqnarray} \frac{1}{\lfloor \delta_1 n \rfloor -v_n} \sum_{k=v_n +1}^{\lfloor \delta_1 n \rfloor} |\tilde{W}_k^{(n)}| \stackrel{{\rm p}}{\longrightarrow} \frac{\gamma}{\gamma + \beta} + \frac{\beta}{\gamma + \beta} \frac{{\mathbb{E}}[C^2]}{\mu_C} \quad \mbox{as } n \rightarrow \infty, \end{eqnarray}
\begin{eqnarray} \frac{1}{\lfloor \delta_1 n \rfloor -v_n} \sum_{k=v_n +1}^{\lfloor \delta_1 n \rfloor} |\tilde{W}_k^{(n)}| \stackrel{{\rm p}}{\longrightarrow} \frac{\gamma}{\gamma + \beta} + \frac{\beta}{\gamma + \beta} \frac{{\mathbb{E}}[C^2]}{\mu_C} \quad \mbox{as } n \rightarrow \infty, \end{eqnarray}
where the right-hand side of (5.15) is less than
 ${\mathbb{E}}[C^2]/\mu_C$
. As noted at the start of the proof,
${\mathbb{E}}[C^2]/\mu_C$
. As noted at the start of the proof,
 $G_{k}^{(n)} = Y_{k} = L_{k}^{(n)}$
$G_{k}^{(n)} = Y_{k} = L_{k}^{(n)}$
 $(k=1,2,\ldots,v_n)$
with probability tending to 1 as
$(k=1,2,\ldots,v_n)$
with probability tending to 1 as
 $n \to \infty$
, where
$n \to \infty$
, where
 $Y_k = m + \sum_{j=1}^k \tilde{Z}_j$
. Therefore, for any
$Y_k = m + \sum_{j=1}^k \tilde{Z}_j$
. Therefore, for any
 $\epsilon_2$
satisfying
$\epsilon_2$
satisfying
 $\delta_1 {\mathbb{E}}[C^2]/\mu_C \lt \epsilon_2 \lt \epsilon_1$
, we have that
$\delta_1 {\mathbb{E}}[C^2]/\mu_C \lt \epsilon_2 \lt \epsilon_1$
, we have that
 \begin{eqnarray*} {\mathbb{P}} \left( A_{\lfloor \delta_1 n \rfloor}^{(n)} \gt (1 - \epsilon_1)n \right) &\geq& {\mathbb{P}} \left(\left\{ m + \sum_{j=1}^{v_n} |\tilde{Z}_j|\leq (\epsilon_1 -\epsilon_2) n \right\} \cap \bigcap_{k=1}^{v_n} \left\{ G_{k}^{(n)} = Y_{k} = L_{k}^{(n)} \right\} \right) \\ && \quad \times{\mathbb{P}} \left( \sum_{k=v_n + 1}^{\lfloor \delta_1 n \rfloor} |\tilde{W}_k^{(n)}| \leq \epsilon_2 n \right) \rightarrow 1 \quad \mbox{ as } n \to \infty.\end{eqnarray*}
\begin{eqnarray*} {\mathbb{P}} \left( A_{\lfloor \delta_1 n \rfloor}^{(n)} \gt (1 - \epsilon_1)n \right) &\geq& {\mathbb{P}} \left(\left\{ m + \sum_{j=1}^{v_n} |\tilde{Z}_j|\leq (\epsilon_1 -\epsilon_2) n \right\} \cap \bigcap_{k=1}^{v_n} \left\{ G_{k}^{(n)} = Y_{k} = L_{k}^{(n)} \right\} \right) \\ && \quad \times{\mathbb{P}} \left( \sum_{k=v_n + 1}^{\lfloor \delta_1 n \rfloor} |\tilde{W}_k^{(n)}| \leq \epsilon_2 n \right) \rightarrow 1 \quad \mbox{ as } n \to \infty.\end{eqnarray*}
In Section 4.3, we showed that, during the early stages of the epidemic, the contribution to the spread of the disease from mixing events containing more than one non-susceptible individual is negligible, and whilst the number of susceptibles remains above
 $(1-\epsilon_1) n$
we can similarly bound the contribution from mixing events with multiple non-susceptible individuals. Following the proof of Lemma 4.1, we have for
$(1-\epsilon_1) n$
we can similarly bound the contribution from mixing events with multiple non-susceptible individuals. Following the proof of Lemma 4.1, we have for
 $w=1,2,\ldots, [n/2]$
that
$w=1,2,\ldots, [n/2]$
that
 $q^{(n)} \big(x^{(n)},y^{(n)},w\big) \geq q^{(n)}_1 \big(x^{(n)},y^{(n)},w\big) $
, and using (4.12) and (4.13), for
$q^{(n)} \big(x^{(n)},y^{(n)},w\big) \geq q^{(n)}_1 \big(x^{(n)},y^{(n)},w\big) $
, and using (4.12) and (4.13), for
 $x^{(n)} \geq (1- \epsilon_1) n$
, we have that
$x^{(n)} \geq (1- \epsilon_1) n$
, we have that
 \begin{align*}q^{(n)}_1 \big(x^{(n)},y^{(n)},w\big) &\geq \frac{n \lambda}{y^{(n)}} \sum_{c=w+1}^{\lfloor n/2 \rfloor} p_C^{(n)} (c) \frac{c y^{(n)}}{n} \left[ 1 - \frac{2 (c-1) \epsilon_1 n}{n} \right] \pi_c (w;\, c-1,1) \nonumber \\&= \lambda \sum_{c=w+1}^{\lfloor n/2 \rfloor} c p_C^{(n)} (c) \left[ 1 - 2 (c-1) \epsilon_1 \right] \pi_c (w;\, c-1,1) \nonumber \\& \geq \beta^{(n)} \psi_w^{(n)}\end{align*}
\begin{align*}q^{(n)}_1 \big(x^{(n)},y^{(n)},w\big) &\geq \frac{n \lambda}{y^{(n)}} \sum_{c=w+1}^{\lfloor n/2 \rfloor} p_C^{(n)} (c) \frac{c y^{(n)}}{n} \left[ 1 - \frac{2 (c-1) \epsilon_1 n}{n} \right] \pi_c (w;\, c-1,1) \nonumber \\&= \lambda \sum_{c=w+1}^{\lfloor n/2 \rfloor} c p_C^{(n)} (c) \left[ 1 - 2 (c-1) \epsilon_1 \right] \pi_c (w;\, c-1,1) \nonumber \\& \geq \beta^{(n)} \psi_w^{(n)}\end{align*}
for all sufficiently large n, as, for such n,
 $\psi_w^{(n)} = 0$
for all
$\psi_w^{(n)} = 0$
for all
 $w \gt \lfloor n/2 \rfloor$
. Hence, for
$w \gt \lfloor n/2 \rfloor$
. Hence, for
 $k=v_n +1, v_n +2, \ldots, \lfloor \delta_1 n \rfloor$
, provided that
$k=v_n +1, v_n +2, \ldots, \lfloor \delta_1 n \rfloor$
, provided that
 $A_{k-1}^{(n)} \geq (1-\epsilon_1)n$
, we can couple
$A_{k-1}^{(n)} \geq (1-\epsilon_1)n$
, we can couple
 $W^{(n)}_k \Big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\Big)$
and
$W^{(n)}_k \Big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\Big)$
and
 $\hat{Z}^{(n)}_k$
, defined in (5.13) and (5.9) respectively, so that
$\hat{Z}^{(n)}_k$
, defined in (5.13) and (5.9) respectively, so that
 \begin{eqnarray*}\hat{Z}^{(n)}_k \leq W^{(n)}_k \Big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\Big)\end{eqnarray*}
\begin{eqnarray*}\hat{Z}^{(n)}_k \leq W^{(n)}_k \Big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\Big)\end{eqnarray*}
for all sufficiently large n. Specifically, we couple deaths (downward steps) in
 $\mathcal{L}^{(n)}$
with removals in
$\mathcal{L}^{(n)}$
with removals in
 $\mathcal{G}^{(n)}$
, so
$\mathcal{G}^{(n)}$
, so
 $W^{(n)}_k \big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\big) =-1$
if and only if
$W^{(n)}_k \big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\big) =-1$
if and only if
 $\hat{Z}^{(n)}_k =-1$
. For
$\hat{Z}^{(n)}_k =-1$
. For
 $w =1,2,\ldots$
, if
$w =1,2,\ldots$
, if
 $W^{(n)}_k \big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\big) = w$
then we set
$W^{(n)}_k \big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\big) = w$
then we set
 $\hat{Z}^{(n)}_k =w$
with probability
$\hat{Z}^{(n)}_k =w$
with probability
 $\psi_w^{(n)}/q^{(n)} \big(x^{(n)}, y^{(n)},w\big)$
and set
$\psi_w^{(n)}/q^{(n)} \big(x^{(n)}, y^{(n)},w\big)$
and set
 $\hat{Z}^{(n)}_k =0$
otherwise. Provided that
$\hat{Z}^{(n)}_k =0$
otherwise. Provided that
 $A_{\lfloor \delta_1 n \rfloor}^{(n)} \geq (1-\epsilon_1) n$
, it then immediately follows by induction that for
$A_{\lfloor \delta_1 n \rfloor}^{(n)} \geq (1-\epsilon_1) n$
, it then immediately follows by induction that for
 $k=v_n +1, v_n +2, \ldots, \lfloor \delta_1 n \rfloor$
,
$k=v_n +1, v_n +2, \ldots, \lfloor \delta_1 n \rfloor$
,
 \begin{eqnarray*}G_k^{(n)} = G_{k-1}^{(n)} + W^{(n)}_k \big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\big) \geq L_{k-1}^{(n)} + \hat{Z}^{(n)}_k = L_k^{(n)},\end{eqnarray*}
\begin{eqnarray*}G_k^{(n)} = G_{k-1}^{(n)} + W^{(n)}_k \big(A_{k-1}^{(n)}, G_{k-1}^{(n)}\big) \geq L_{k-1}^{(n)} + \hat{Z}^{(n)}_k = L_k^{(n)},\end{eqnarray*}
and (5.14) holds.
The final step is to couple
 $\mathcal{S}^{(n)}$
to
$\mathcal{S}^{(n)}$
to
 $\mathcal{G}^{(n)}$
. By definition, the processes
$\mathcal{G}^{(n)}$
. By definition, the processes
 $\mathcal{S}^{(n)}$
and
$\mathcal{S}^{(n)}$
and
 $\mathcal{G}^{(n)}$
coincide for the first
$\mathcal{G}^{(n)}$
coincide for the first
 $v_n$
events, so
$v_n$
events, so
 $\big(X_{v_n}^{(n)}, Y_{v_n}^{(n)}\big) = \big(A_{v_n}^{(n)}, G_{v_n}^{(n)}\big)$
. Remember, for
$\big(X_{v_n}^{(n)}, Y_{v_n}^{(n)}\big) = \big(A_{v_n}^{(n)}, G_{v_n}^{(n)}\big)$
. Remember, for
 $k=v_n +1, v_n +2, \ldots, \lfloor \delta_1 n \rfloor$
, that
$k=v_n +1, v_n +2, \ldots, \lfloor \delta_1 n \rfloor$
, that
 $\kappa_n (k)$
, defined in (5.4), denotes the number of events that have occurred in
$\kappa_n (k)$
, defined in (5.4), denotes the number of events that have occurred in
 $\mathcal{S}^{(n)}$
up to and including the kth event in
$\mathcal{S}^{(n)}$
up to and including the kth event in
 $\mathcal{G}^{(n)}$
, with
$\mathcal{G}^{(n)}$
, with
 $\kappa_n (v_n) = v_n$
by definition. It is helpful to consider the epidemic processes
$\kappa_n (v_n) = v_n$
by definition. It is helpful to consider the epidemic processes
 $\mathcal{E}^{(n)}$
$\mathcal{E}^{(n)}$
 $(\mathcal{S}^{(n)})$
and
$(\mathcal{S}^{(n)})$
and
 $\mathcal{E}_G^{(n)}$
$\mathcal{E}_G^{(n)}$
 $(\mathcal{G}^{(n)})$
and to note that the rates at which events occur are
$(\mathcal{G}^{(n)})$
and to note that the rates at which events occur are
 $\Big\{\gamma + \sum_{v=0}^{n-1} q^{(n)} (x^{(n)},y^{(n)},v)\Big\} y^{(n)}$
and
$\Big\{\gamma + \sum_{v=0}^{n-1} q^{(n)} (x^{(n)},y^{(n)},v)\Big\} y^{(n)}$
and
 $\big\{\gamma + \beta^{(n)}\big\} y^{(n)}$
, respectively. Therefore, the rate of occurrence of an event which results in
$\big\{\gamma + \beta^{(n)}\big\} y^{(n)}$
, respectively. Therefore, the rate of occurrence of an event which results in
 $w =1,2,\ldots, n-1$
infections, when the population is in state
$w =1,2,\ldots, n-1$
infections, when the population is in state
 $\big(x^{(n)}, y^{(n)}\big)$
, is
$\big(x^{(n)}, y^{(n)}\big)$
, is
 $q^{(n)} \big(x^{(n)},y^{(n)},w\big) y^{(n)}$
in both
$q^{(n)} \big(x^{(n)},y^{(n)},w\big) y^{(n)}$
in both
 $\mathcal{E}^{(n)}$
and
$\mathcal{E}^{(n)}$
and
 $\mathcal{E}_G^{(n)}$
. Similarly, the rate at which a removal occurs in state
$\mathcal{E}_G^{(n)}$
. Similarly, the rate at which a removal occurs in state
 $\big(x^{(n)}, y^{(n)}\big)$
is
$\big(x^{(n)}, y^{(n)}\big)$
is
 $\gamma y^{(n)}$
. Thus, the only difference in event rates is for infection events which produce no infections where the rates are
$\gamma y^{(n)}$
. Thus, the only difference in event rates is for infection events which produce no infections where the rates are
 $q^{(n)} \big(x^{(n)},y^{(n)},0\big)$
and
$q^{(n)} \big(x^{(n)},y^{(n)},0\big)$
and
 $\beta^{(n)} - \sum_{v=1}^{n-1} q^{(n)} \big(x^{(n)},y^{(n)},v\big)$
in
$\beta^{(n)} - \sum_{v=1}^{n-1} q^{(n)} \big(x^{(n)},y^{(n)},v\big)$
in
 $\mathcal{E}^{(n)}$
and
$\mathcal{E}^{(n)}$
and
 $\mathcal{E}_G^{(n)}$
, respectively. Hence, if
$\mathcal{E}_G^{(n)}$
, respectively. Hence, if
 $W_k^{(n)} \Big(A_{k-1}^{(n)},G_{k-1}^{(n)}\Big) \neq 0$
, we set
$W_k^{(n)} \Big(A_{k-1}^{(n)},G_{k-1}^{(n)}\Big) \neq 0$
, we set
 $\kappa_n (k) = \kappa_n (k-1) +1$
, and
$\kappa_n (k) = \kappa_n (k-1) +1$
, and
 \begin{align} \begin{array}{rll} X_{\kappa_n (k) }^{(n)} &= X_{\kappa_n (k-1) }^{(n)} - W_k^{(n)} \Big(A_{k-1}^{(n)},G_{k-1}^{(n)}\Big) 1_{\big\{W_k^{(n)} (A_{k-1}^{(n)},G_{k-1}^{(n)}) \big\}}, \\Y_{\kappa_n (k) }^{(n)} &= Y_{\kappa_n (k-1) }^{(n)} + W_k^{(n)} \Big(A_{k-1}^{(n)},G_{k-1}^{(n)}\Big). \end{array}\end{align}
\begin{align} \begin{array}{rll} X_{\kappa_n (k) }^{(n)} &= X_{\kappa_n (k-1) }^{(n)} - W_k^{(n)} \Big(A_{k-1}^{(n)},G_{k-1}^{(n)}\Big) 1_{\big\{W_k^{(n)} (A_{k-1}^{(n)},G_{k-1}^{(n)}) \big\}}, \\Y_{\kappa_n (k) }^{(n)} &= Y_{\kappa_n (k-1) }^{(n)} + W_k^{(n)} \Big(A_{k-1}^{(n)},G_{k-1}^{(n)}\Big). \end{array}\end{align}
That is, each event which leads to a change in the state of the population in
 $\mathcal{E}^{(n)}_G$
$\mathcal{E}^{(n)}_G$
 $(\mathcal{G}^{(n)})$
has a corresponding event in
$(\mathcal{G}^{(n)})$
has a corresponding event in
 $\mathcal{E}^{(n)}$
$\mathcal{E}^{(n)}$
 $(\mathcal{S}^{(n)})$
. Similarly, if
$(\mathcal{S}^{(n)})$
. Similarly, if
 $W_k^{(n)} \Big(A_{k-1}^{(n)},G_{k-1}^{(n)}\Big) = 0$
, we set
$W_k^{(n)} \Big(A_{k-1}^{(n)},G_{k-1}^{(n)}\Big) = 0$
, we set
 $\kappa_n (k) = \kappa_n (k-1) +1$
with probability
$\kappa_n (k) = \kappa_n (k-1) +1$
with probability
 $q^{(n)} \big(x^{(n)},y^{(n)},0\big)/ \Big\{\beta^{(n)} - \sum_{v=1}^{n-1} q^{(n)} (x^{(n)},y^{(n)},v)\Big\}$
and (5.16) holds with
$q^{(n)} \big(x^{(n)},y^{(n)},0\big)/ \Big\{\beta^{(n)} - \sum_{v=1}^{n-1} q^{(n)} (x^{(n)},y^{(n)},v)\Big\}$
and (5.16) holds with
 $\Big(X_{\kappa_n (k) }^{(n)}, Y_{\kappa_n (k) }\Big) = \Big(X_{\kappa_n (k-1) }^{(n)}, Y_{\kappa_n (k-1) }^{(n)}\Big)$
; otherwise we set
$\Big(X_{\kappa_n (k) }^{(n)}, Y_{\kappa_n (k) }\Big) = \Big(X_{\kappa_n (k-1) }^{(n)}, Y_{\kappa_n (k-1) }^{(n)}\Big)$
; otherwise we set
 $\kappa_n (k) = \kappa_n (k-1) $
, corresponding to no event in
$\kappa_n (k) = \kappa_n (k-1) $
, corresponding to no event in
 $\mathcal{E}^{(n)}$
$\mathcal{E}^{(n)}$
 $(\mathcal{S}^{(n)})$
and a ghost event in
$(\mathcal{S}^{(n)})$
and a ghost event in
 $\mathcal{E}_G^{(n)}$
$\mathcal{E}_G^{(n)}$
 $(\mathcal{G}^{(n)})$
. Thus there exists
$(\mathcal{G}^{(n)})$
. Thus there exists
 $\kappa_n (\lfloor \delta_1 n \rfloor) \leq \lfloor \delta_1 n \rfloor$
such that
$\kappa_n (\lfloor \delta_1 n \rfloor) \leq \lfloor \delta_1 n \rfloor$
such that
 \begin{eqnarray} Y_{\kappa_n (\lfloor \delta_1 n \rfloor)}^{(n)} = G_{\lfloor \delta_1 n \rfloor}^{(n)}.\end{eqnarray}
\begin{eqnarray} Y_{\kappa_n (\lfloor \delta_1 n \rfloor)}^{(n)} = G_{\lfloor \delta_1 n \rfloor}^{(n)}.\end{eqnarray}
Proof of Theorem 3.2
(b). Let
 $v_n = \lfloor \log n \rfloor$
and
$v_n = \lfloor \log n \rfloor$
and
 $u_n = \lfloor 3 v_n /{\mathbb{P}} (Z_1 \neq 0) \rfloor$
, so
$u_n = \lfloor 3 v_n /{\mathbb{P}} (Z_1 \neq 0) \rfloor$
, so
 $(u_n)$
satisfies the conditions stated in Lemma 4.2. Let
$(u_n)$
satisfies the conditions stated in Lemma 4.2. Let
 $\epsilon$
satisfy (5.6), and fix
$\epsilon$
satisfy (5.6), and fix
 $\delta_1$
and
$\delta_1$
and
 $\epsilon_1 \lt \epsilon$
such that
$\epsilon_1 \lt \epsilon$
such that
 $0 \lt \delta_1 \lt \epsilon_1 \mu_C/{\mathbb{E}}[C^2]$
(i.e. satisfying (5.7)). It follows from (5.3) that, for
$0 \lt \delta_1 \lt \epsilon_1 \mu_C/{\mathbb{E}}[C^2]$
(i.e. satisfying (5.7)). It follows from (5.3) that, for
 $R_0\gt 1$
,
$R_0\gt 1$
,
 ${\mathbb{E}} [Z]\gt 0$
and for
${\mathbb{E}} [Z]\gt 0$
and for
 $T^{(n)} \geq v_n$
with probability tending to 1 as
$T^{(n)} \geq v_n$
with probability tending to 1 as
 $n \rightarrow \infty$
,
$n \rightarrow \infty$
,
 $Y_{v_n}\gt v_n {\mathbb{E}} [Z]/2$
.
$Y_{v_n}\gt v_n {\mathbb{E}} [Z]/2$
.
Given
 $\delta \gt 0$
satisfying (5.10), it follows from (5.17) and Lemma 5.2 that, with probability tending to 1 as
$\delta \gt 0$
satisfying (5.10), it follows from (5.17) and Lemma 5.2 that, with probability tending to 1 as
 $n \to \infty$
, for all
$n \to \infty$
, for all
 $k = v_n +1, v_n +2, \ldots, \lfloor \delta_1 n \rfloor$
,
$k = v_n +1, v_n +2, \ldots, \lfloor \delta_1 n \rfloor$
,
 \begin{eqnarray*} Y_{\kappa_n (k)}^{(n)} = G_k^{(n)} \geq L_{k}^{(n)}.\end{eqnarray*}
\begin{eqnarray*} Y_{\kappa_n (k)}^{(n)} = G_k^{(n)} \geq L_{k}^{(n)}.\end{eqnarray*}
By setting
 $b_n = v_n {\mathbb{E}} [Z]/2$
in Lemma 5.1, we have that, as
$b_n = v_n {\mathbb{E}} [Z]/2$
in Lemma 5.1, we have that, as
 $n \to \infty$
,
$n \to \infty$
,
 \begin{eqnarray} {\mathbb{P}} \left( \left. Y_{\kappa_n (\lfloor \delta_1 n \rfloor) }^{(n)} \geq \lfloor \delta n \rfloor, \min_{v_n \leq k \lt \kappa_n (\lfloor \delta_1 n \rfloor) } \left\{Y^{(n)}_k \right\} \gt 0 \right|T^{(n)} \geq v_n \right) \rightarrow 1. \end{eqnarray}
\begin{eqnarray} {\mathbb{P}} \left( \left. Y_{\kappa_n (\lfloor \delta_1 n \rfloor) }^{(n)} \geq \lfloor \delta n \rfloor, \min_{v_n \leq k \lt \kappa_n (\lfloor \delta_1 n \rfloor) } \left\{Y^{(n)}_k \right\} \gt 0 \right|T^{(n)} \geq v_n \right) \rightarrow 1. \end{eqnarray}
Given that
 $T^{(n)} \geq Y_{\kappa_n (\lfloor \delta_1 n \rfloor) }$
, (3.14) follows immediately.
$T^{(n)} \geq Y_{\kappa_n (\lfloor \delta_1 n \rfloor) }$
, (3.14) follows immediately.
Finally, note that Corollary 3.2 follows immediately from (5.18) as
 $\sup_{t \geq 0} I^{(n)} (t) \geq Y_{\kappa_n (\lfloor \delta_1 n \rfloor) }$
.
$\sup_{t \geq 0} I^{(n)} (t) \geq Y_{\kappa_n (\lfloor \delta_1 n \rfloor) }$
.
6. Concluding comments
As noted in the introduction, the aims of this paper are to provide a rigorous justification for the approximating branching process introduced in Ball and Neal [Reference Ball and Neal5] and a proof of a key result (Theorem 3.2 of this paper) required for a central limit theorem in [Reference Ball and Neal5] for the size of a major outbreak for epidemics with few initial infectives. The latter clearly requires a limit theorem. A limit theorem is also a common approach to rigorously justifying a branching process, but for practical purposes it is often useful to have information concerning the accuracy of the approximation for finite population size n, as given for example by a bound on the total variation distance between the epidemic
 $\mathcal{E}^{(n)}$
in a population of size n and the limiting branching process
$\mathcal{E}^{(n)}$
in a population of size n and the limiting branching process
 $\mathcal{B}$
. A detailed analysis of such accuracy of approximation is beyond the scope of the paper, so here we make a few very brief comments.
$\mathcal{B}$
. A detailed analysis of such accuracy of approximation is beyond the scope of the paper, so here we make a few very brief comments.
Recall from Section 4.5 that
 $H_n$
denotes the first event at which a mismatch occurs between the embedded discrete jump processes of
$H_n$
denotes the first event at which a mismatch occurs between the embedded discrete jump processes of
 $\mathcal{E}^{(n)}$
and
$\mathcal{E}^{(n)}$
and
 $\mathcal{B}$
. It follows immediately from results in the proof of Lemma 4.2, using the notation in that lemma and its proof, that
$\mathcal{B}$
. It follows immediately from results in the proof of Lemma 4.2, using the notation in that lemma and its proof, that
 \begin{equation}{\mathbb{P}}(H_n \le u_n)\le {\mathbb{P}}\big(A_{n,0}^c\big)+{\mathbb{P}}\big(A_{n,1}^c\big)+{\mathbb{P}}\big(A_{n,2}^c\big),\end{equation}
\begin{equation}{\mathbb{P}}(H_n \le u_n)\le {\mathbb{P}}\big(A_{n,0}^c\big)+{\mathbb{P}}\big(A_{n,1}^c\big)+{\mathbb{P}}\big(A_{n,2}^c\big),\end{equation}
thus yielding a bound on the total variation distance between
 $\mathcal{E}^{(n)}$
and
$\mathcal{E}^{(n)}$
and
 $\mathcal{B}$
over the first
$\mathcal{B}$
over the first
 $u_n$
events for quantities that do not depend on the times of those events. The latter can be included by adding
$u_n$
events for quantities that do not depend on the times of those events. The latter can be included by adding
 ${\mathbb{P}}\big(A_{n,3}^c\big)$
to the right-hand side of (6.1). Bounds for
${\mathbb{P}}\big(A_{n,3}^c\big)$
to the right-hand side of (6.1). Bounds for
 ${\mathbb{P}}(A_{n,i}^c)$
(
${\mathbb{P}}(A_{n,i}^c)$
(
 $i=0,1,2,3$
) can be obtained using results given in the proof of Lemma 4.2. For approximation purposes a source of inaccuracy can be removed by using a branching process defined analogously to
$i=0,1,2,3$
) can be obtained using results given in the proof of Lemma 4.2. For approximation purposes a source of inaccuracy can be removed by using a branching process defined analogously to
 $\mathcal{B}$
but with C replaced by
$\mathcal{B}$
but with C replaced by
 $C^{(n)}$
.
$C^{(n)}$
.
Acknowledgement
We would like to thank two anonymous reviewers for their helpful comments, which have significantly improved the presentation. In particular, comments by one reviewer motivating the exact coupling of event times between the epidemic and branching processes.
Funding information
There are no funding bodies to thank in relation to the creation of this article.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.
