
4 results
7 - Machine Learning for Big Data
- from Part III - Machine Learning for Big Data
-
- Book:
- Large-Scale Data Analytics with Python and Spark
- Published online:
- 15 December 2023
- Print publication:
- 23 November 2023, pp 212-253
-
- Chapter
- Export citation
TRUTH AND FEASIBLE REDUCIBILITY
-
- Journal:
- The Journal of Symbolic Logic / Volume 85 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 20 September 2019, pp. 367-421
- Print publication:
- March 2020
-
- Article
- Export citation
-
Let
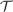 ${\cal T}$ be any of the three canonical truth theories CT− (compositional truth without extra induction), FS− (Friedman–Sheard truth without extra induction), or KF− (Kripke–Feferman truth without extra induction), where the base theory of
${\cal T}$ be any of the three canonical truth theories CT− (compositional truth without extra induction), FS− (Friedman–Sheard truth without extra induction), or KF− (Kripke–Feferman truth without extra induction), where the base theory of 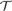 ${\cal T}$ is PA (Peano arithmetic). We establish the following theorem, which implies that
${\cal T}$ is PA (Peano arithmetic). We establish the following theorem, which implies that 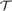 ${\cal T}$ has no more than polynomial speed-up over PA.
${\cal T}$ has no more than polynomial speed-up over PA.Theorem.
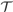 ${\cal T}$is feasibly reducible to PA, in the sense that there is a polynomial time computable function f such that for every
${\cal T}$is feasibly reducible to PA, in the sense that there is a polynomial time computable function f such that for every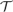 ${\cal T}$-proof π of an arithmetical sentence ϕ, f (π) is a PA-proof of ϕ.
${\cal T}$-proof π of an arithmetical sentence ϕ, f (π) is a PA-proof of ϕ.
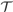
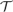
MODELS OF POSITIVE TRUTH
-
- Journal:
- The Review of Symbolic Logic / Volume 12 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 26 December 2018, pp. 144-172
- Print publication:
- March 2019
-
- Article
- Export citation
-
This paper is a follow-up to [4], in which a mistake in [6] (which spread also to [9]) was corrected. We give a strenghtening of the main result on the semantical nonconservativity of the theory of PT− with internal induction for total formulae
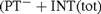 ${(\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}\left( {{\rm{tot}}} \right)$, denoted by PT− in [9]). We show that if to PT− the axiom of internal induction for all arithmetical formulae is added (giving
${(\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}\left( {{\rm{tot}}} \right)$, denoted by PT− in [9]). We show that if to PT− the axiom of internal induction for all arithmetical formulae is added (giving 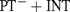 ${\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}$), then this theory is semantically stronger than
${\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}$), then this theory is semantically stronger than 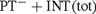 ${\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}\left( {{\rm{tot}}} \right)$. In particular the latter is not relatively truth definable (in the sense of [11]) in the former. Last but not least, we provide an axiomatic theory of truth which meets the requirements put forward by Fischer and Horsten in [9]. The truth theory we define is based on Weak Kleene Logic instead of the Strong one.
${\rm{P}}{{\rm{T}}^ - } + {\rm{INT}}\left( {{\rm{tot}}} \right)$. In particular the latter is not relatively truth definable (in the sense of [11]) in the former. Last but not least, we provide an axiomatic theory of truth which meets the requirements put forward by Fischer and Horsten in [9]. The truth theory we define is based on Weak Kleene Logic instead of the Strong one.
Splitting theorems for speed-up related to order of enumeration1
-
- Journal:
- The Journal of Symbolic Logic / Volume 47 / Issue 1 / March 1982
- Published online by Cambridge University Press:
- 12 March 2014, pp. 1-7
- Print publication:
- March 1982
-
- Article
- Export citation
