


Introduction
Fall-related injury represents a major social issue. Fall frequency drastically increases among elderly: the 28–35% of people over 65 fall each year (World Health Organization, Ageing and Life Course Unit, 2008). This percentage reaches the 32–42% for people over 70. As a consequence, automatic fall detection is becoming a crucial task to increase safety of elderly people, especially when they live alone.
According to (Mubashir, Shao, & Seed, Reference Mubashir, Shao and Seed2013), fall detection approaches are based on: wearable, ambience and vision devices (Mehmood, Nadeem, Ashraf, Alghamdi, & Siddiqui, Reference Mehmood, Nadeem, Ashraf, Alghamdi and Siddiqui2019; Liciotti, Bernardini, Romeo, & Frontoni, Reference Liciotti, Bernardini, Romeo and Frontoniin press; Shojaei-Hashemi, Nasiopolous, Little, & Pourazad, Reference Shojaei-Hashemi, Nasiopolous, Little and Pourazad2018; Wang, Chen, Zhou, Sun, & Dong, Reference Wang, Chen, Zhou, Sun and Dong2016). Regarding wearable devices, elderly often forget or refuse to wear them (Mubashir et al., Reference Mubashir, Shao and Seed2013) and approaches that use ambient devices suffer from high sensitivity to noise (Delahoz & Labrador, Reference Delahoz and Labrador2014). A possible solution would be to monitor, through RGB camera, home environment and develop a fall-detection algorithm that could alert caregivers once falls occur.
Objective
The goal of this work is to develop an automatic solution to perform fall detection from RGB video sequences (the code is available on request on GitHubFootnote 1). The proposed approach exploits VGG16 (Simonyan & Zisserman, Reference Simonyan and Zisserman2014), a convolutional neural network (CNN), as feature extractor and a Bidirectional Long Short Term Memory (Graves & Schmidhuber, Reference Graves and Schmidhuber2005) (Bi-LSTM), a recurrent neural network (RNN), as feature classifier. Due to the lack of large and annotated publicly available datasets in the field, we used VGG16 pretrained on the ImageNet dataset and Bi-LSTM pretrained on the UCF-101 action recognition dataset.Footnote 2 We then fine-tuned the Bi-LSTM for the fall-detection task on a custom-built dataset (the fall dataset) publicly available for the scientific community.Footnote 3 Figure 1 shows an overview of the workflow of the proposed method.
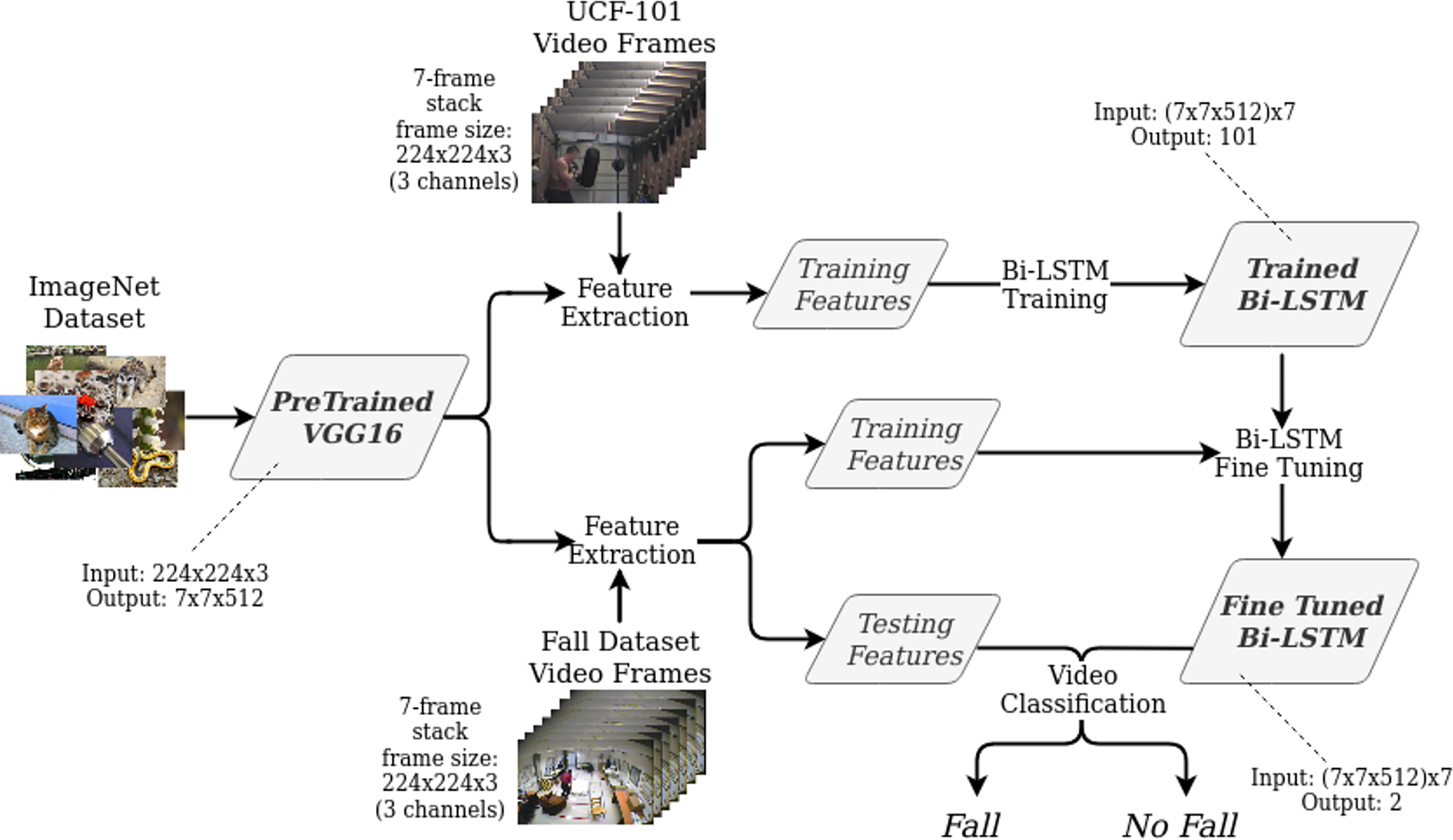
Figure. 1. Workflow of the proposed approach for fall detection from RGB video sequences.
Methods
To exploit temporal information, we processed stacks of 7 consecutive frames (inter-frame distance was 1 s). To extract features from UCF-101 videos, we used two pretrained VGG16 configurations: with (Top) and without (No Top) fully connected layers, resulting in a vector of 4096 × 7 and 25088 × 7 features, respectively. These features were used to train two Bi-LSTMs (one per VGG16 configuration). VGG16 was used as feature extractor since, unlike other deeper networks (e.g., ResNet50), with its few layers it can extract more general features from images improving the generalization power of the Bi-LSTM classifiers.
We selected the configuration giving the highest macro recall (Rec) on UCF-101, and fine tuned it on the fall dataset (without freezing any layers (No Freeze) and freezing the first layer (Freeze)) to perform fall detection. To fine tune the selected configuration we added two dense layers (32 and 2 neurons, respectively) on top of the original Bi-LSTM architecture. We initialized these last two layers with the standard Glorot initialization, while the other layers with the weights resulting from the training on UCF-101. The fall dataset is composed of 216 videos (108 falls and 108 activities of daily living) collected from different sources. From each video, the first 7 frames were extracted (inter-frame distance = 225 ms). The Bi-LSTM was fine tuned for 150 epochs using Adam to minimize the categorical cross entropy. The best Bi-LSTM model was retrieved as the one that maximised Rec on the validation set.
Results
Figure 2 shows the descriptive statistics for Rec for the two Bi-LSTM tested on UCF-101 using the (left) Top and (right) No Top configuration.The best result was achieved by the No Top configuration (mean Rec = 0.836).
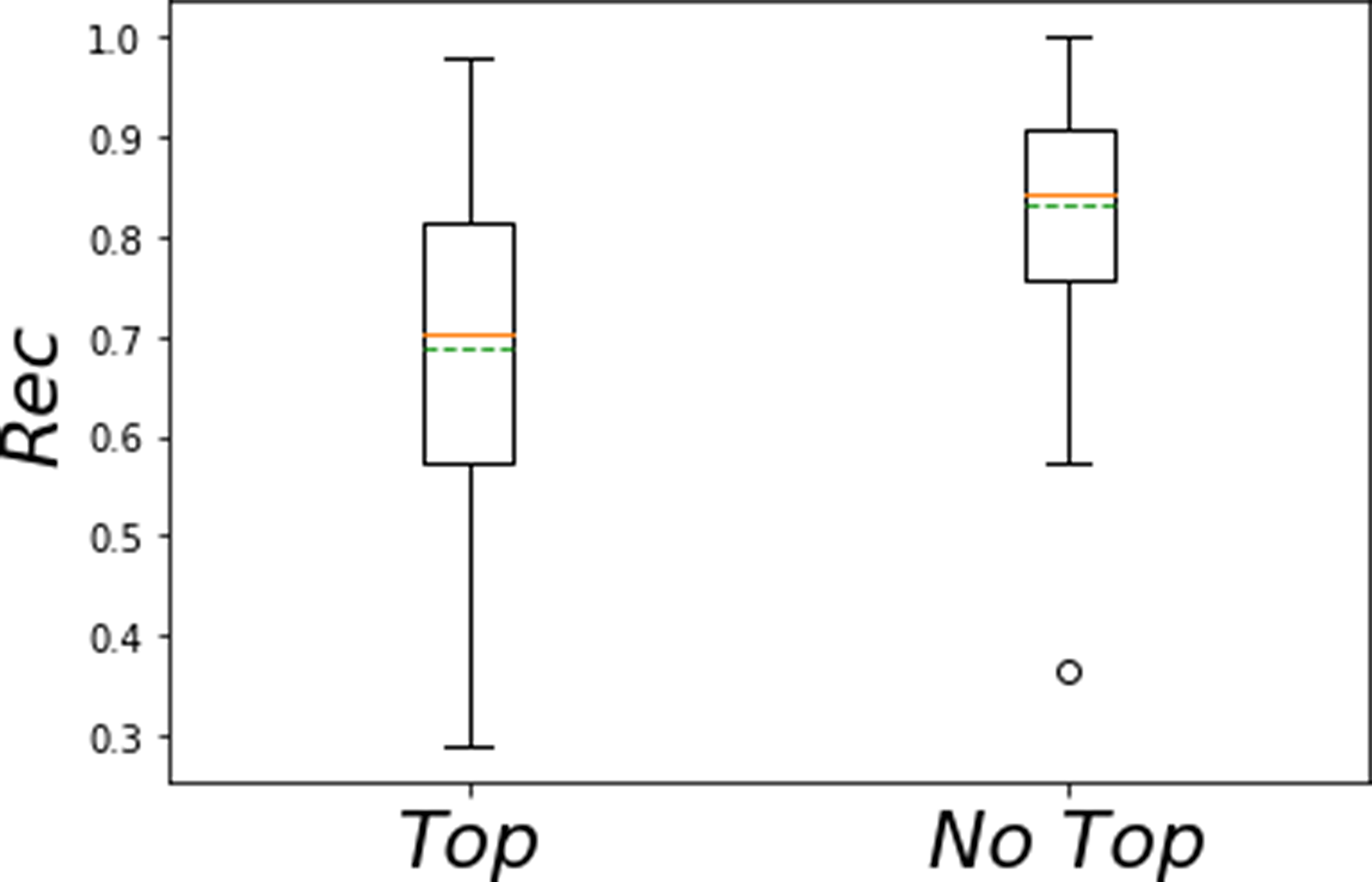
Figure 2. Boxplots of the Rec for classification on UCF-101 achieved with the Top and the No Top configurations. Mean (green) and Median (orange) of the Rec are showed too.
For robust result evaluation, performance on the fall dataset was assessed with 5-fold cross validation. For each fold, the 30% of the training set was used as validation. Results were evaluated with the area under the ROC curves (AUC) and the confusion matrices (one per fold). Figure 3 shows the ROC curves for the (left) No Freeze and (right) Freeze configuration. The best result was achieved with No Freeze (AUC = 0.93 ± 0.04).
Figure 3. ROC curves for the five folds of the No Freeze (up) and the Freeze (down) approaches. Mean AUC (± standard deviation) is reported, too.
Figure 4 shows the confusion matrices for the five folds, achieved on fine tuned Bi-LSTM without freezing any layers. The mean Rec for all the folds was 0.916 and 0.860 for the fall and no fall class, respectively.
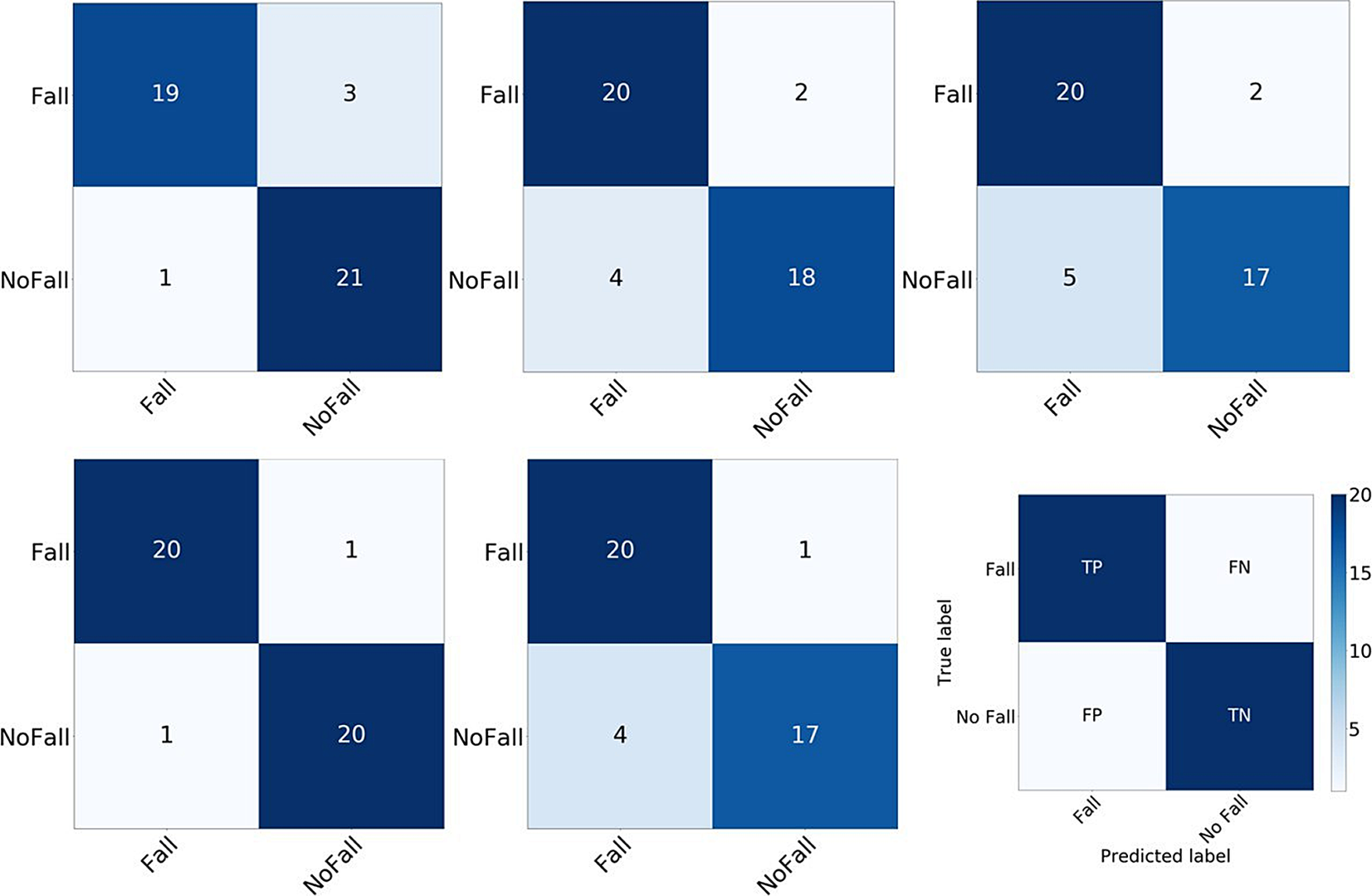
Figure 4. Confusion matrices for 5-fold cross-validation with the No Freeze configuration. The colorbar indicates the number of test samples.
Discussions
The proposed approach implemented fine tuning to overcome challenges related to the small size of the fall dataset. The No Top approach achieved higher macro Rec (Fig. 2:). Indeed, the Bi-LSTM is fed with features from the last VGG16 convolutional layer, which are less specific than those from the fully connected one (used in the Top configuration).
Figure 3 shows that the No Freeze approach achieved the highest performance, which may be attributed to the considerable difference between videos in UCF-101 and in fall dataset. Confusion matrices in Fig. 4 show comparable values among the two classes, pointing out the stability on the proposed approach.
Conclusions
In this paper, we proposed a deep-learning method for automatic fall detection from RGB videos. The proposed method showed promising results (mean Rec = 0.916 for the fall class), which could be eventually enhanced by enlarging the training dataset and testing more advanced architectures based on spatio-temporal features (Colleoni, Moccia, Du, De Momi, & Stoyanov, Reference Colleoni, Moccia, Du, De Momi and Stoyanov2019). As future work we will investigate longer frame sequences to exploit the full potential of Bi-LSTM. Moreover, we plan to implement a CNN with 3D convolutions (able to process features both in space and time) to accomplish fall-detection task. This model could be used for comparison against the approach proposed in this contribution.
To account for privacy issues, future work could also deal with depth-video processing, which has already shown promising results for movement analysis (Moccia, Migliorelli, Pietrini, & Frontoni, Reference Moccia, Migliorelli, Pietrini and Frontoni2019). This work, in integration with an alert system, could have a positive impact on elderly people safety and quality of life by ensuring prompt implementation of first aid.
Acknowledgements
We thank our colleagues from Department of Information Engineering, Università Politecnica delle Marche, who provided insight and expertise that greatly assisted the research.
Author Contributions
Daniele Berardini, Sara Moccia and Emanuele Frontoni conceived and designed the study and the methodology. Iacopo Pacifici and Paolo di Massimo conducted data gathering. Daniele Berardini and Sara Moccia performed statistical analyses. Daniele Berardini, Sara Moccia and Lucia Migliorelli wrote the article. Marina Paolanti reviewed and corrected the article.
Funding Information
This research received no specific grant from any funding agency, commercial or not-for-profit sectors.
Conflict of Interest
Author Daniele Berardini, author Sara Moccia, author Lucia Migliorelli, author Iacopo Pacifici, author Paolo di Massimo, author Marina Paolanti and author Emanuele Frontoni declare none.
Data availability
The dataset that support the findings of this study is available from the author D. Berardini at http://192.168.2.30/owncloud/index.php/s/1FmsIiKWrO9APVw upon reasonable request.
The code necessary to reproduce the work is available on GitHub using the following bash command: “git clone https://github.com/daniebera/deep-learning-fall-detection.git”, from the corresponding author, D. Berardini, upon reasonable request.





 Open access
Open access
Comments
Comments to the Author: This paper is based on a research regarding use of deep learning for automatic fall detection of elderly-peope. In detail, the detection is done over videos and the paper considers the obtained findings as well as the development flow in this manner. From a general perspective, the paper has an interesting, important topic and comes with a pure, technically-enough content. So, it seems acceptable. I only suggest a few minor revisions as final touches:
1- Please support the first paragraph of the Introduction section, with one or two more references. That will make more sense in terms of starting point of the research.
2- After starting to the 2nd paragraph of the Introduction section with “According to [2]…”, the sentence should be ended as “…devices [3-5].” by taking citations at the end of the sentence.
3- In Fig. 3, please provide the graphics in bigger sizes, (from up to down) in order to improve readability.
4- Is there any future work(s) planned? That should be indicated at the last section briefly. Thanks the author(s) for their valuable efforts to form this paper-research.