



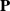
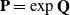
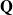
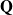
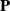
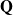
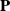
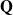
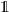
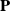
1. Introduction
The embedding problem of Markov chains is a long-standing challenge. It involves investigating whether a given stochastic matrix
 $ \mathbf{P}$
can be considered as the matrix of transition probabilities from time 0 to time 1 of a continuous-time Markov chain. The problem was first proposed by Elfving [Reference Elfving12] with a first in-depth study by Kingman [Reference Kingman24]. If the Markov chain is homogeneous, this problem boils down to checking whether
$ \mathbf{P}$
can be considered as the matrix of transition probabilities from time 0 to time 1 of a continuous-time Markov chain. The problem was first proposed by Elfving [Reference Elfving12] with a first in-depth study by Kingman [Reference Kingman24]. If the Markov chain is homogeneous, this problem boils down to checking whether
 $ \mathbf{P}$
is the exponential of some matrix
$ \mathbf{P}$
is the exponential of some matrix
 $ \mathbf{Q}$
having all non-negative off-diagonal entries and zero row-sums, called a rate matrix. This matrix
$ \mathbf{Q}$
having all non-negative off-diagonal entries and zero row-sums, called a rate matrix. This matrix
 $ \mathbf{Q}$
then represents the transition rates of the underlying continuous-time homogeneous Markov chain (CTHMC). If
$ \mathbf{Q}$
then represents the transition rates of the underlying continuous-time homogeneous Markov chain (CTHMC). If
 $ \exp{\mathbf{Q}} = \mathbf{P}$
for some rate matrix
$ \exp{\mathbf{Q}} = \mathbf{P}$
for some rate matrix
 $ \mathbf{Q}$
, it is said that
$ \mathbf{Q}$
, it is said that
 $ \mathbf{P}$
is embeddable and that
$ \mathbf{P}$
is embeddable and that
 $ \mathbf{Q}$
is a Markov generator of
$ \mathbf{Q}$
is a Markov generator of
 $ \mathbf{P}$
. For the non-homogeneous case, it has been proved that if
$ \mathbf{P}$
. For the non-homogeneous case, it has been proved that if
 $ \mathbf{P}$
belongs to the interior of the set of embeddable matrices, then
$ \mathbf{P}$
belongs to the interior of the set of embeddable matrices, then
 $ \mathbf{P}$
is equal to a finite product of exponentials of extreme rate matrices, i.e. rate matrices with only one off-diagonal element strictly positive; see [Reference Johansen20]. This characterization is known as a Bang-Bang representation.
$ \mathbf{P}$
is equal to a finite product of exponentials of extreme rate matrices, i.e. rate matrices with only one off-diagonal element strictly positive; see [Reference Johansen20]. This characterization is known as a Bang-Bang representation.
The characterizations described above are general and theoretically significant, yet they are difficult to verify practically. As of now, a complete solution to the embedding problem in terms of the matrix elements remains to be found. Currently, embeddability criteria have been established in the homogeneous case for chains up to four states; see [Reference Baake and Sumner4], [Reference Carette5], [Reference Casanellas, Fernández-Sánchez and Roca-Lacostena7], and [Reference Johansen21]. In the non-homogeneous case, research has focused on the Bang-Bang representation of embeddable stochastic matrices, leading to more concrete results for the
 $ 3\times 3$
case; see [Reference Frydman13] and [Reference Johansen and Ramsey22]. In this paper we focus on the homogeneous embedding problem and will therefore omit the word ‘homogeneous’.
$ 3\times 3$
case; see [Reference Frydman13] and [Reference Johansen and Ramsey22]. In this paper we focus on the homogeneous embedding problem and will therefore omit the word ‘homogeneous’.
The issue of embeddability presents significant challenges in various aspects. Even if
 $ \mathbf{P}$
is confirmed as embeddable, there could be more than one Markov generator associated with it. Using a CTHMC as a foundational model necessitates decisions on handling non-embeddable transition matrices or multiple Markov generators. In the case of non-embeddability, a regularization algorithm is proposed to obtain a rate matrix
$ \mathbf{P}$
is confirmed as embeddable, there could be more than one Markov generator associated with it. Using a CTHMC as a foundational model necessitates decisions on handling non-embeddable transition matrices or multiple Markov generators. In the case of non-embeddability, a regularization algorithm is proposed to obtain a rate matrix
 $ \mathbf{Q}$
that minimizes
$ \mathbf{Q}$
that minimizes
 $ \|\mathbf{P} - \exp{\mathbf{Q}}\|$
; see [Reference Davies10], [Reference Israel, Rosenthal and Wei17], and [Reference Kreinin and Sidelnikova25]. When there are multiple Markov generators, the practitioner can try to identify and select the rate matrix reflecting the nature of the system under study; see [Reference Singer and Spilerman28].
$ \|\mathbf{P} - \exp{\mathbf{Q}}\|$
; see [Reference Davies10], [Reference Israel, Rosenthal and Wei17], and [Reference Kreinin and Sidelnikova25]. When there are multiple Markov generators, the practitioner can try to identify and select the rate matrix reflecting the nature of the system under study; see [Reference Singer and Spilerman28].
Rather than accounting for the system’s nature when determining an appropriate Markov generator for
 $ \mathbf{P}$
, model-specific embedding problems have recently been considered for certain classes of stochastic matrices, leading to further results. For example, the elements of the transition matrix can be limited to certain values reflecting the characteristics of the system under study; see [Reference Ardiyansyah, Kosta and Kubjas1], [Reference Baake and Sumner2], [Reference Baake and Sumner3], [Reference Jia19], and [Reference Roca-Lacostena and Fernández-Sánchez27].
$ \mathbf{P}$
, model-specific embedding problems have recently been considered for certain classes of stochastic matrices, leading to further results. For example, the elements of the transition matrix can be limited to certain values reflecting the characteristics of the system under study; see [Reference Ardiyansyah, Kosta and Kubjas1], [Reference Baake and Sumner2], [Reference Baake and Sumner3], [Reference Jia19], and [Reference Roca-Lacostena and Fernández-Sánchez27].
An alternative train of thought is to derive a rate matrix from the empirical transition matrix based on the assumption that there is a maximum of one transition per unit of time. Considering that a discrete-time Markov chain allows only one transition or jump per time step, it seems reasonable to view the underlying continuous-time process through a similar perspective. Furthermore, this one-jump hypothesis has not only theoretical but also practical grounds. In financial risk management, credit rating migration models evaluate how borrowers move between credit rating categories over time. These changes in credit ratings usually occur gradually and infrequently. Similarly, in healthcare, transitions between health states occur slowly over extended periods, resulting in infrequent state changes within short time intervals. In their study of credit risk migration, Jarrow, Lando, and Turnbull (JLT) assume that each firm has made zero or one transition per year; see [Reference Jarrow, Lando and Turnbull18]. Fundamentally, their approach designates the empirical transition probability
 $ p_{ij}$
to represent the probability of jumping from state i to state j by or before
$ p_{ij}$
to represent the probability of jumping from state i to state j by or before
 $ t=1$
. This facilitates the formulation of an approximate Markov generator for the empirical transition matrix in closed form.
$ t=1$
. This facilitates the formulation of an approximate Markov generator for the empirical transition matrix in closed form.
In this study, we explore the one-jump hypothesis through a data-centric approach. Our only assumption is that the sampled entities or individuals adhere to the one-jump hypothesis; we do not presume any specific number of jumps for the entire population under study. Considering that a CTHMC model allows for several jumps in any given period, this approach appears to be more fitting if the goal is to employ the CTHMC to explore population dynamics. Hence we study a conditional version of the embedding problem by aligning the empirical transition matrix with the conditional transition matrix over a single unit of time of the CTHMC given the event that at most one jump has occurred during a unit length time interval. The main result of this paper is that, regardless of the number of states, precisely one rate matrix solves our conditional embedding problem in the case where the empirical transition matrix has non-zero diagonal elements; see Theorem 3.2. We also describe how to obtain this rate matrix from the empirical transition matrix. In summary, the conditional embedding problem, when considered in a one-jump context, yields a solution that avoids the regularization and identification challenges associated with the original embedding problem.
Our paper is structured as follows. In Section 2 we formalize and define the notion of a conditional one-step probability matrix given an event of interest. We derive an explicit expression for the conditional transition probabilities for the event that the number of jumps between t and
 $ t+1$
is zero or one. In Section 3 we dive into the conditional one-jump version of the embedding problem, introducing and focusing on the concepts of
$ t+1$
is zero or one. In Section 3 we dive into the conditional one-jump version of the embedding problem, introducing and focusing on the concepts of
 ${\unicode{x1D7D9}}$
-embeddability and
${\unicode{x1D7D9}}$
-embeddability and
 ${\unicode{x1D7D9}}$
-generator. Our key finding in this section asserts that any stochastic matrix of order n with non-zero diagonal elements is
${\unicode{x1D7D9}}$
-generator. Our key finding in this section asserts that any stochastic matrix of order n with non-zero diagonal elements is
 ${\unicode{x1D7D9}}$
-embeddable and possesses a unique
${\unicode{x1D7D9}}$
-embeddable and possesses a unique
 ${\unicode{x1D7D9}}$
-generator. Section 4 highlights the difference in one-jump setting approaches leading to the
${\unicode{x1D7D9}}$
-generator. Section 4 highlights the difference in one-jump setting approaches leading to the
 ${\unicode{x1D7D9}}$
-generator and the rate matrix
${\unicode{x1D7D9}}$
-generator and the rate matrix
 $ \mathbf{Q}_{\text{JLT}}$
derived by Jarrow et al. [Reference Jarrow, Lando and Turnbull18]. We also show which of these two matrices serves as a better approximate Markov generator of the empirical transition matrix for a number of specific cases. We conclude with a discussion in Section 5. The supporting lemmas and their proofs are gathered in the Appendix.
$ \mathbf{Q}_{\text{JLT}}$
derived by Jarrow et al. [Reference Jarrow, Lando and Turnbull18]. We also show which of these two matrices serves as a better approximate Markov generator of the empirical transition matrix for a number of specific cases. We conclude with a discussion in Section 5. The supporting lemmas and their proofs are gathered in the Appendix.
2. Conditional transition probabilities
To state the conditional embedding problem, we first introduce the concept of conditional transition probability.
Consider a continuous-time homogeneous Markov chain (‘CTHMC’)
 $ (X_t)_{t\geq 0}$
on a probability triple
$ (X_t)_{t\geq 0}$
on a probability triple
 $ (\Omega,\mathscr{F},\mathbb{P})$
with state space
$ (\Omega,\mathscr{F},\mathbb{P})$
with state space
 $ \mathcal{S}=\{1,2,\ldots,n\}$
.
$ \mathcal{S}=\{1,2,\ldots,n\}$
.
Definition 2.1. Let
 $ t\geq 0$
and
$ t\geq 0$
and
 $ \mathcal{E}_t\in\mathscr{F}$
. We call the matrix
$ \mathcal{E}_t\in\mathscr{F}$
. We call the matrix
 $ \mathbf{P}^{\mathcal{E}_t}(t)$
with elements
$ \mathbf{P}^{\mathcal{E}_t}(t)$
with elements
 \[ p^{\mathcal{E}_t}_{ij}(t)=\mathbb{P}(X_{t+1}=j \mid X_{t}=i ,\,\mathcal{E}_t),\quad i,j\in\mathcal{S},\]
\[ p^{\mathcal{E}_t}_{ij}(t)=\mathbb{P}(X_{t+1}=j \mid X_{t}=i ,\,\mathcal{E}_t),\quad i,j\in\mathcal{S},\]
the conditional transition probability matrix from time t to time
 $ t+1$
given the event
$ t+1$
given the event
 $ \mathcal{E}_t$
of the CTHMC.
$ \mathcal{E}_t$
of the CTHMC.
Remark 2.1. The (classical) transition probabilities
 $ p_{ij}(t)=\mathbb{P}(X_{t+1}=j \mid X_t=i)$
can be obtained using
$ p_{ij}(t)=\mathbb{P}(X_{t+1}=j \mid X_t=i)$
can be obtained using
 $ \mathcal{E}_t \,:\!=\, \Omega$
, i.e.
$ \mathcal{E}_t \,:\!=\, \Omega$
, i.e.
 $ p_{ij}(t)=p^{\Omega}_{ij}(t)$
.
$ p_{ij}(t)=p^{\Omega}_{ij}(t)$
.
In this paper, for given t, the event of interest is the occurrence of at most one jump of the CTHMC in the interval
 $ (t,t+1]$
, i.e.
$ (t,t+1]$
, i.e.
 $ \mathcal{E}_t=\{N_{t+1}-N_{t}\leq 1\}$
, where
$ \mathcal{E}_t=\{N_{t+1}-N_{t}\leq 1\}$
, where
 $ N_s$
represents the number of state changes (‘jumps’) of the CTHMC up to and including time
$ N_s$
represents the number of state changes (‘jumps’) of the CTHMC up to and including time
 $ s\geq 0$
. For simplicity, we denote
$ s\geq 0$
. For simplicity, we denote
 $ \mathbf{P}^{\unicode{x1D7D9}}(t)\,:\!=\, \mathbf{P}^{\mathcal{E}_t}(t)$
.
$ \mathbf{P}^{\unicode{x1D7D9}}(t)\,:\!=\, \mathbf{P}^{\mathcal{E}_t}(t)$
.
For a CTHMC with rate matrix
 $ \mathbf{Q}$
, the connection between
$ \mathbf{Q}$
, the connection between
 $ \mathbf{P}^{\unicode{x1D7D9}}(t)=({p}^{\unicode{x1D7D9}}_{ij}(t))$
and
$ \mathbf{P}^{\unicode{x1D7D9}}(t)=({p}^{\unicode{x1D7D9}}_{ij}(t))$
and
 $ \mathbf{Q}$
is established by the following proposition.
$ \mathbf{Q}$
is established by the following proposition.
Proposition 2.1.
For a CTHMC with rate matrix
 $ \mathbf{Q}=(q_{ij})$
, it holds that
$ \mathbf{Q}=(q_{ij})$
, it holds that
 \[ {p}^{\unicode{x1D7D9}}_{ij}(t) = \dfrac{p_{ij}^{*}}{\sum_{k\in\mathcal{S}} p_{ik}^{*}}\quad for\ all\ i,j\ \in \mathcal{S}\ and\ t \geq 0, \]
\[ {p}^{\unicode{x1D7D9}}_{ij}(t) = \dfrac{p_{ij}^{*}}{\sum_{k\in\mathcal{S}} p_{ik}^{*}}\quad for\ all\ i,j\ \in \mathcal{S}\ and\ t \geq 0, \]
where
 \begin{align} p_{ij}^{*} = \begin{cases}q_{ij}\,\tau(q_{ii},q_{jj}) & if\ i\neq j,\\[3pt] \tau(q_{ii},q_{ii}) & if\ i=j,\end{cases} \end{align}
\begin{align} p_{ij}^{*} = \begin{cases}q_{ij}\,\tau(q_{ii},q_{jj}) & if\ i\neq j,\\[3pt] \tau(q_{ii},q_{ii}) & if\ i=j,\end{cases} \end{align}
and where the function
 $ \tau \colon \mathbb{R}^2\to\mathbb{R}$
is defined as
$ \tau \colon \mathbb{R}^2\to\mathbb{R}$
is defined as
 \begin{align}\tau(x,y)=\int_{0}^{1} \mathrm{e}^{ux+(1-u)y}\,\mathrm{d}{u}=\begin{cases}\dfrac{\mathrm{e}^{x}-\mathrm{e}^{y}}{x-y} & if\ x\neq y,\\[3pt]\mathrm{e}^{x} & if\ x=y.\end{cases}\end{align}
\begin{align}\tau(x,y)=\int_{0}^{1} \mathrm{e}^{ux+(1-u)y}\,\mathrm{d}{u}=\begin{cases}\dfrac{\mathrm{e}^{x}-\mathrm{e}^{y}}{x-y} & if\ x\neq y,\\[3pt]\mathrm{e}^{x} & if\ x=y.\end{cases}\end{align}
Proof. Using the definition of conditional probability, we have
 \[\mathbb{P}(A \mid B\cap C)=\dfrac{\mathbb{P}(A\cap B \mid C)}{\mathbb{P}(B \mid C)},\quad\text{if}\ \mathbb{P}(B \mid C) \gt 0, \]
\[\mathbb{P}(A \mid B\cap C)=\dfrac{\mathbb{P}(A\cap B \mid C)}{\mathbb{P}(B \mid C)},\quad\text{if}\ \mathbb{P}(B \mid C) \gt 0, \]
whence
 \begin{equation*}{p}^{\unicode{x1D7D9}}_{ij}(t) = \mathbb{P}(X_{t+1}=j \mid X_{t}=i,\,\mathcal{E}_t)=\dfrac{\mathbb{P}(X_{t+1}=j,\,\mathcal{E}_t \mid X_{t}=i)}{\mathbb{P}(\mathcal{E}_t \mid X_{t}=i)}.\end{equation*}
\begin{equation*}{p}^{\unicode{x1D7D9}}_{ij}(t) = \mathbb{P}(X_{t+1}=j \mid X_{t}=i,\,\mathcal{E}_t)=\dfrac{\mathbb{P}(X_{t+1}=j,\,\mathcal{E}_t \mid X_{t}=i)}{\mathbb{P}(\mathcal{E}_t \mid X_{t}=i)}.\end{equation*}
Let us denote
 \begin{align} p^{*}_{ij}(t)\,:\!=\, \mathbb{P}(X_{t+1}=j,\,\mathcal{E}_t \mid X_{t}=i).\end{align}
\begin{align} p^{*}_{ij}(t)\,:\!=\, \mathbb{P}(X_{t+1}=j,\,\mathcal{E}_t \mid X_{t}=i).\end{align}
By the sum rule for disjoint events, we have
 \[{p}^{\unicode{x1D7D9}}_{ij}(t)=\dfrac{p_{ij}^{*}(t)}{\sum_{k \in \mathcal{S}} p_{ik}^{*}(t)},\]
\[{p}^{\unicode{x1D7D9}}_{ij}(t)=\dfrac{p_{ij}^{*}(t)}{\sum_{k \in \mathcal{S}} p_{ik}^{*}(t)},\]
so it remains to be shown that
 $ p_{ij}^{*}(t)=p^{*}_{ij}$
for all
$ p_{ij}^{*}(t)=p^{*}_{ij}$
for all
 $ i,j\in\mathcal{S}$
, where
$ i,j\in\mathcal{S}$
, where
 $ p^{*}_{ij}$
is given by (2.1).
$ p^{*}_{ij}$
is given by (2.1).
Denote
 $ \mathcal{S}$
as the disjoint union of
$ \mathcal{S}$
as the disjoint union of
 $ \mathcal{S}^{\text{T}}\,:\!=\, \{i\in\mathcal{S} \colon q_{ii} \lt 0\}$
(the subset of transient states) and
$ \mathcal{S}^{\text{T}}\,:\!=\, \{i\in\mathcal{S} \colon q_{ii} \lt 0\}$
(the subset of transient states) and
 $ \mathcal{S}^{\text{A}}\,:\!=\, \{i\in\mathcal{S} \colon q_{ii}=0\}$
(the subset of absorbing states). Let
$ \mathcal{S}^{\text{A}}\,:\!=\, \{i\in\mathcal{S} \colon q_{ii}=0\}$
(the subset of absorbing states). Let
 $ Y_t\,:\!=\, \inf\{s \gt 0 \colon X_{t+s}\neq X_t\}$
be the residual time in state
$ Y_t\,:\!=\, \inf\{s \gt 0 \colon X_{t+s}\neq X_t\}$
be the residual time in state
 $ X_t$
until the first jump after t. In a CTHMC, the holding times are memoryless, hence the conditional distribution of
$ X_t$
until the first jump after t. In a CTHMC, the holding times are memoryless, hence the conditional distribution of
 $ Y_t$
, given state
$ Y_t$
, given state
 $ X_t$
, does not depend on time t. For
$ X_t$
, does not depend on time t. For
 $ k\in\mathcal{S}^{\text{T}}$
, let
$ k\in\mathcal{S}^{\text{T}}$
, let
 $ f_k$
denote the conditional probability density function of
$ f_k$
denote the conditional probability density function of
 $ Y_t$
given
$ Y_t$
given
 $ X_t=k$
and
$ X_t=k$
and
 $ F_k$
its associated cumulative distribution function. Lastly, we shall write
$ F_k$
its associated cumulative distribution function. Lastly, we shall write
 $ s_{ij}$
to denote the transition probability from state i to state j conditional on transitioning out of state i.
$ s_{ij}$
to denote the transition probability from state i to state j conditional on transitioning out of state i.
We start with the case
 $ i,j\in\mathcal{S}^{\text{T}}$
,
$ i,j\in\mathcal{S}^{\text{T}}$
,
 $ i\neq j$
. Then (2.3) entails
$ i\neq j$
. Then (2.3) entails
 \[p^{*}_{ij}(t)=\mathbb{P}(Y_t\leq 1,X_{t+Y_t}=j,Y_{t+Y_t} \gt 1-Y_t \mid X_t=i),\]
\[p^{*}_{ij}(t)=\mathbb{P}(Y_t\leq 1,X_{t+Y_t}=j,Y_{t+Y_t} \gt 1-Y_t \mid X_t=i),\]
and hence, by marginalizing on
 $ Y_t$
, we obtain
$ Y_t$
, we obtain
 \begin{align*}p^{*}_{ij}(t)&=\int_{0}^{1}\mathbb{P}(X_{t+u}=j,Y_{t+u} \gt 1-u \mid Y_t=u,X_t=i)f_i(u)\,\mathrm{d}{u} \\[3pt]&=\int_{0}^{1}\mathbb{P}(Y_{t+u} \gt 1-u \mid X_{t+u}=j,Y_t=u,X_t=i)\, \mathbb{P}(X_{t+u}=j \mid Y_t=u,X_t=i)f_i(u)\,\mathrm{d}{u} \\[3pt]&=\int_{0}^{1}(1-F_j(1-u))\,s_{ij}\,f_i(u)\,\mathrm{d}{u}.\end{align*}
\begin{align*}p^{*}_{ij}(t)&=\int_{0}^{1}\mathbb{P}(X_{t+u}=j,Y_{t+u} \gt 1-u \mid Y_t=u,X_t=i)f_i(u)\,\mathrm{d}{u} \\[3pt]&=\int_{0}^{1}\mathbb{P}(Y_{t+u} \gt 1-u \mid X_{t+u}=j,Y_t=u,X_t=i)\, \mathbb{P}(X_{t+u}=j \mid Y_t=u,X_t=i)f_i(u)\,\mathrm{d}{u} \\[3pt]&=\int_{0}^{1}(1-F_j(1-u))\,s_{ij}\,f_i(u)\,\mathrm{d}{u}.\end{align*}
Since both residual and holding times in a transient state k have an exponential distribution with rate parameter
 $ -q_{kk}$
and since
$ -q_{kk}$
and since
 $ s_{ij}={{q_{ij}}/{-q_{ii}}}$
, we arrive at
$ s_{ij}={{q_{ij}}/{-q_{ii}}}$
, we arrive at
 \[p^{*}_{ij}(t)=\int_{0}^{1} \mathrm{e}^{q_{jj}(1-u)} \,\dfrac{q_{ij}}{-q_{ii}}\,({-}q_{ii})\mathrm{e}^{q_{ii}u}\,\mathrm{d}{u}= q_{ij}\int_{0}^{1}\mathrm{e}^{q_{ii}u+q_{jj}(1-u)}\,\mathrm{d}{u}=q_{ij}\,\tau(q_{ii},q_{jj})=p^\ast_{ij},\]
\[p^{*}_{ij}(t)=\int_{0}^{1} \mathrm{e}^{q_{jj}(1-u)} \,\dfrac{q_{ij}}{-q_{ii}}\,({-}q_{ii})\mathrm{e}^{q_{ii}u}\,\mathrm{d}{u}= q_{ij}\int_{0}^{1}\mathrm{e}^{q_{ii}u+q_{jj}(1-u)}\,\mathrm{d}{u}=q_{ij}\,\tau(q_{ii},q_{jj})=p^\ast_{ij},\]
where
 $ p^\ast_{ij}$
and
$ p^\ast_{ij}$
and
 $ \tau$
are given by (2.1) and (2.2).
$ \tau$
are given by (2.1) and (2.2).
We now turn to the case
 $ i\in\mathcal{S}^{\text{T}}$
and
$ i\in\mathcal{S}^{\text{T}}$
and
 $ j\in\mathcal{S}^{\text{A}}$
. Then, using (2.3) and marginalizing on
$ j\in\mathcal{S}^{\text{A}}$
. Then, using (2.3) and marginalizing on
 $ Y_t$
, we get
$ Y_t$
, we get
 \begin{align*}p^{*}_{ij}(t)&=\mathbb{P}(Y_t\leq 1,X_{t+Y_t}=j \mid X_t=i)\\[3pt]&=\int_{0}^{1}\mathbb{P}(X_{t+u}=j \mid Y_t=u,X_t=i)f_i(u)\,\mathrm{d}{u} \\[3pt]&=\int_{0}^{1}s_{ij}\,f_i(u)\,\mathrm{d}{u}\\[3pt]&=\int_{0}^{1} \dfrac{q_{ij}}{-q_{ii}}\,({-}q_{ii})\mathrm{e}^{q_{ii}u}\,\mathrm{d}{u}\\[3pt]&=q_{ij}\int_{0}^{1} \mathrm{e}^{q_{ii}u}\,\mathrm{d}{u}=q_{ij}\tau(q_{ii},0).\end{align*}
\begin{align*}p^{*}_{ij}(t)&=\mathbb{P}(Y_t\leq 1,X_{t+Y_t}=j \mid X_t=i)\\[3pt]&=\int_{0}^{1}\mathbb{P}(X_{t+u}=j \mid Y_t=u,X_t=i)f_i(u)\,\mathrm{d}{u} \\[3pt]&=\int_{0}^{1}s_{ij}\,f_i(u)\,\mathrm{d}{u}\\[3pt]&=\int_{0}^{1} \dfrac{q_{ij}}{-q_{ii}}\,({-}q_{ii})\mathrm{e}^{q_{ii}u}\,\mathrm{d}{u}\\[3pt]&=q_{ij}\int_{0}^{1} \mathrm{e}^{q_{ii}u}\,\mathrm{d}{u}=q_{ij}\tau(q_{ii},0).\end{align*}
Consequently,
 $ p^\ast_{ij}(t)=q_{ij}\tau(q_{ii},q_{jj})=p^\ast_{ij}$
, as
$ p^\ast_{ij}(t)=q_{ij}\tau(q_{ii},q_{jj})=p^\ast_{ij}$
, as
 $ q_{jj}=0$
.
$ q_{jj}=0$
.
When
 $ i\in\mathcal{S}^{\text{A}}$
and
$ i\in\mathcal{S}^{\text{A}}$
and
 $ j\in\mathcal{S}$
,
$ j\in\mathcal{S}$
,
 $ j\neq i$
, we obviously have
$ j\neq i$
, we obviously have
 $ p^\ast_{ij}(t)=0$
. Hence
$ p^\ast_{ij}(t)=0$
. Hence
 \[p^\ast_{ij}(t)=q_{ij}\tau(q_{ii},q_{jj})=p^\ast_{ij},\]
\[p^\ast_{ij}(t)=q_{ij}\tau(q_{ii},q_{jj})=p^\ast_{ij},\]
as
 $ q_{ij}=0$
under these conditions.
$ q_{ij}=0$
under these conditions.
Finally, if
 $ i\in\mathcal{S}^{\text{T}}$
, (2.3) yields
$ i\in\mathcal{S}^{\text{T}}$
, (2.3) yields
 \[p^{*}_{ii}(t)=\mathbb{P}(Y_t \gt 1 \mid X_t=i)=1-F_i(1)=\mathrm{e}^{q_{ii}}=\tau(q_{ii},q_{ii})=p^\ast_{ii} ,\]
\[p^{*}_{ii}(t)=\mathbb{P}(Y_t \gt 1 \mid X_t=i)=1-F_i(1)=\mathrm{e}^{q_{ii}}=\tau(q_{ii},q_{ii})=p^\ast_{ii} ,\]
and if
 $ i\in\mathcal{S}^{\text{A}}$
, then
$ i\in\mathcal{S}^{\text{A}}$
, then
 \begin{equation*}p^{*}_{ii}(t)=1=\tau(0,0)=\tau(q_{ii},q_{ii})=p^\ast_{ii}. \end{equation*}
\begin{equation*}p^{*}_{ii}(t)=1=\tau(0,0)=\tau(q_{ii},q_{ii})=p^\ast_{ii}. \end{equation*}
We note that Minin and Suchard [Reference Minin and Suchard26] arrive at the same formula for
 $ p^\ast_{ij}$
, using a matrix differential equation involving the matrix with elements
$ p^\ast_{ij}$
, using a matrix differential equation involving the matrix with elements
 $ q_{ij}(k,t)$
representing the joint probability of transitioning in k jumps from state i to state j within a time-interval of length t.
$ q_{ij}(k,t)$
representing the joint probability of transitioning in k jumps from state i to state j within a time-interval of length t.
According to Proposition 2.1, the matrix
 $ \mathbf{P}^{\unicode{x1D7D9}}(t)$
does not depend on t. We will therefore write
$ \mathbf{P}^{\unicode{x1D7D9}}(t)$
does not depend on t. We will therefore write
 $ \mathbf{P}^{\unicode{x1D7D9}}\,:\!=\, \mathbf{P}^{\unicode{x1D7D9}}(t)$
and refer to it as a conditional one-jump transition matrix.
$ \mathbf{P}^{\unicode{x1D7D9}}\,:\!=\, \mathbf{P}^{\unicode{x1D7D9}}(t)$
and refer to it as a conditional one-jump transition matrix.
Corollary 2.1.
For all
 $ i\in\mathcal{S}$
, we have
$ i\in\mathcal{S}$
, we have
 $ {p}^{\unicode{x1D7D9}}_{ii} \gt 0$
.
$ {p}^{\unicode{x1D7D9}}_{ii} \gt 0$
.
Proof. This follows from the fact that
 $ p^{*}_{ii}=\tau(q_{ii},q_{ii})=\mathrm{e}^{q_{ii}} \gt 0$
.
$ p^{*}_{ii}=\tau(q_{ii},q_{ii})=\mathrm{e}^{q_{ii}} \gt 0$
.
Remark 2.2. Corollary 2.1 can also be justified as follows. The only way to go from state i at time t to state i at time
 $ t+1$
, given the event
$ t+1$
, given the event
 $ \{N_{t+1}-N_t\leq 1\}$
, is to stay in that state for the entire time interval. The probability of this event is non-zero due to the exponential distribution governing the holding time in a state.
$ \{N_{t+1}-N_t\leq 1\}$
, is to stay in that state for the entire time interval. The probability of this event is non-zero due to the exponential distribution governing the holding time in a state.
According to Proposition 2.1, the conditional one-jump transition matrix
 $ \mathbf{P}^{\unicode{x1D7D9}}$
is fully specified by the rate matrix
$ \mathbf{P}^{\unicode{x1D7D9}}$
is fully specified by the rate matrix
 $ \mathbf{Q}$
of the CTHMC. In what follows, and when needed, we explicitly indicate this dependence using the notation
$ \mathbf{Q}$
of the CTHMC. In what follows, and when needed, we explicitly indicate this dependence using the notation
 $ \mathbf{P}^{\unicode{x1D7D9}}(\mathbf{Q})$
.
$ \mathbf{P}^{\unicode{x1D7D9}}(\mathbf{Q})$
.
3. Conditional embedding problem
The following question then naturally arises. Given a stochastic matrix
 $ \mathbf{P}$
, is there a rate matrix
$ \mathbf{P}$
, is there a rate matrix
 $ \mathbf{Q}$
such that
$ \mathbf{Q}$
such that
 $ \mathbf{P}^{\unicode{x1D7D9}}(\mathbf{Q})=\mathbf{P}$
? And if so, is this rate matrix
$ \mathbf{P}^{\unicode{x1D7D9}}(\mathbf{Q})=\mathbf{P}$
? And if so, is this rate matrix
 $ \mathbf{Q}$
unique?
$ \mathbf{Q}$
unique?
It will be helpful to introduce some terminology before proceeding.
Definition 3.1. A stochastic matrix
 $ \mathbf{P}$
is called
$ \mathbf{P}$
is called
 ${\unicode{x1D7D9}}$
-embeddable if and only if there exists a CTHMC with rate matrix
${\unicode{x1D7D9}}$
-embeddable if and only if there exists a CTHMC with rate matrix
 $ \mathbf{Q}$
satisfying
$ \mathbf{Q}$
satisfying
 $ \mathbf{P}=\mathbf{P}^{\unicode{x1D7D9}}(\mathbf{Q})$
. This rate matrix is called a
$ \mathbf{P}=\mathbf{P}^{\unicode{x1D7D9}}(\mathbf{Q})$
. This rate matrix is called a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
.
$ \mathbf{P}$
.
For a transition matrix
 $ \mathbf{P}$
that is not embeddable, a
$ \mathbf{P}$
that is not embeddable, a
 ${\unicode{x1D7D9}}$
-generator can be seen as a solution to a conditional version of the embedding problem where the rate matrix
${\unicode{x1D7D9}}$
-generator can be seen as a solution to a conditional version of the embedding problem where the rate matrix
 $ \mathbf{Q}$
satisfies
$ \mathbf{Q}$
satisfies
 $ \mathbf{P}^{\unicode{x1D7D9}}(\mathbf{Q})=\mathbf{P}$
. Corollary 2.1 establishes that a
$ \mathbf{P}^{\unicode{x1D7D9}}(\mathbf{Q})=\mathbf{P}$
. Corollary 2.1 establishes that a
 ${\unicode{x1D7D9}}$
-embeddable stochastic matrix must not contain a zero on its main diagonal. Consequently, our subsequent analysis will focus on stochastic matrices
${\unicode{x1D7D9}}$
-embeddable stochastic matrix must not contain a zero on its main diagonal. Consequently, our subsequent analysis will focus on stochastic matrices
 $ \mathbf{P}=(p_{ij})$
where
$ \mathbf{P}=(p_{ij})$
where
 $ p_{ii} \gt 0$
for all i. Note that this necessary condition for
$ p_{ii} \gt 0$
for all i. Note that this necessary condition for
 ${\unicode{x1D7D9}}$
-embeddability is not more restrictive than the necessary embedding condition
${\unicode{x1D7D9}}$
-embeddability is not more restrictive than the necessary embedding condition
 $ \prod_{i=1}^{n} p_{ii} \geq \det{P} \gt 0$
as formulated by Goodman in [Reference Goodman16].
$ \prod_{i=1}^{n} p_{ii} \geq \det{P} \gt 0$
as formulated by Goodman in [Reference Goodman16].
Interestingly, the off-diagonal elements of a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
are uniquely defined by its diagonal elements and the elements of
$ \mathbf{P}$
are uniquely defined by its diagonal elements and the elements of
 $ \mathbf{P}$
. To express this relationship, we introduce the function
$ \mathbf{P}$
. To express this relationship, we introduce the function
 $ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
, defined as follows:
$ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
, defined as follows:
 \begin{align} \rho(x,y)=\dfrac{\mathrm{e}}{\tau(1-\ln{x},1-\ln{y})} =\begin{cases} xy\dfrac{\ln{x}-\ln{y}}{x-y} & \text{if}\ x\neq y,\\[3pt] x & \text{if}\ x=y. \end{cases}\end{align}
\begin{align} \rho(x,y)=\dfrac{\mathrm{e}}{\tau(1-\ln{x},1-\ln{y})} =\begin{cases} xy\dfrac{\ln{x}-\ln{y}}{x-y} & \text{if}\ x\neq y,\\[3pt] x & \text{if}\ x=y. \end{cases}\end{align}
Proposition 3.1.
Suppose
 $ \mathbf{P}=(p_{ij})$
is an
$ \mathbf{P}=(p_{ij})$
is an
 $ n\times n$
stochastic matrix that satisfies
$ n\times n$
stochastic matrix that satisfies
 $ p_{ii} \gt 0$
for all i. If
$ p_{ii} \gt 0$
for all i. If
 $ \mathbf{Q}=(q_{ij})$
is a
$ \mathbf{Q}=(q_{ij})$
is a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
, then
$ \mathbf{P}$
, then
 \begin{equation*} q_{ij}= \dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_ip_{ii}} \quad for\ all\ i \neq j, \end{equation*}
\begin{equation*} q_{ij}= \dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_ip_{ii}} \quad for\ all\ i \neq j, \end{equation*}
where
 $ \theta_i=\mathrm{e}^{1-q_{ii}}$
for all i and the function
$ \theta_i=\mathrm{e}^{1-q_{ii}}$
for all i and the function
 $ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
is given by (3.1).
$ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
is given by (3.1).
Proof. Suppose
 $ \mathbf{Q}$
is a
$ \mathbf{Q}$
is a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}=(p_{ij})$
and let
$ \mathbf{P}=(p_{ij})$
and let
 $ i\neq j$
. Then, according to Proposition 2.1, we have
$ i\neq j$
. Then, according to Proposition 2.1, we have
 \[ \dfrac{p_{ij}}{p_{ii}}=\dfrac{{p}^{\unicode{x1D7D9}}_{ij}}{{p}^{\unicode{x1D7D9}}_{ii}}=\dfrac{p^*_{ij}}{p^*_{ii}}=\dfrac{q_{ij}\tau(q_{ii},q_{jj})}{\tau(q_{ii},q_{ii})}. \]
\[ \dfrac{p_{ij}}{p_{ii}}=\dfrac{{p}^{\unicode{x1D7D9}}_{ij}}{{p}^{\unicode{x1D7D9}}_{ii}}=\dfrac{p^*_{ij}}{p^*_{ii}}=\dfrac{q_{ij}\tau(q_{ii},q_{jj})}{\tau(q_{ii},q_{ii})}. \]
Consequently, since
 $ \tau(q_{ii},q_{ii})=\mathrm{e}^{q_{ii}}=\mathrm{e}/\theta_i$
and
$ \tau(q_{ii},q_{ii})=\mathrm{e}^{q_{ii}}=\mathrm{e}/\theta_i$
and
 $ \tau(q_{ii},q_{jj})=\tau(1-\ln{\theta_i},1-\ln{\theta_j})=\mathrm{e}/\rho(\theta_i,\theta_j)$
, we get
$ \tau(q_{ii},q_{jj})=\tau(1-\ln{\theta_i},1-\ln{\theta_j})=\mathrm{e}/\rho(\theta_i,\theta_j)$
, we get
 \begin{equation*} q_{ij}=\dfrac{\tau(q_{ii},q_{ii})p_{ij}}{\tau(q_{ii},q_{jj})p_{ii}}=\dfrac{(\mathrm{e}/\theta_i)p_{ij}}{(\mathrm{e}/\rho(\theta_i,\theta_j))p_{ii}}=\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}}\quad \text{for all } i \neq {j.} \end{equation*}
\begin{equation*} q_{ij}=\dfrac{\tau(q_{ii},q_{ii})p_{ij}}{\tau(q_{ii},q_{jj})p_{ii}}=\dfrac{(\mathrm{e}/\theta_i)p_{ij}}{(\mathrm{e}/\rho(\theta_i,\theta_j))p_{ii}}=\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}}\quad \text{for all } i \neq {j.} \end{equation*}
The outcome of Proposition 3.2 provides a requirement concerning the diagonal elements of any
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
.
$ \mathbf{P}$
.
Proposition 3.2.
Let
 $ \mathbf{P}=(p_{ij})$
be an
$ \mathbf{P}=(p_{ij})$
be an
 $ n\times n$
stochastic matrix that satisfies
$ n\times n$
stochastic matrix that satisfies
 $ p_{ii} \gt 0$
for all i. If
$ p_{ii} \gt 0$
for all i. If
 $ \mathbf{Q}=(q_{ij})$
is a
$ \mathbf{Q}=(q_{ij})$
is a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
, then the n-tuple
$ \mathbf{P}$
, then the n-tuple
 $ (\mathrm{e}^{1-q_{11}},\ldots,\mathrm{e}^{1-q_{nn}})$
is a fixed point of the vector function
$ (\mathrm{e}^{1-q_{11}},\ldots,\mathrm{e}^{1-q_{nn}})$
is a fixed point of the vector function
 $ \mathbf{T}=(T_1,\ldots,T_n) \colon \mathbb{R}_+^{n}\to\mathbb{R}_+^{n}$
, which is defined as
$ \mathbf{T}=(T_1,\ldots,T_n) \colon \mathbb{R}_+^{n}\to\mathbb{R}_+^{n}$
, which is defined as
 \begin{align} T_i(x_1,\ldots,x_n)=\exp{W_0\Biggl(\dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(x_i,x_j)\Biggr)}\quad for\ all\ i \in\mathcal{S}, \end{align}
\begin{align} T_i(x_1,\ldots,x_n)=\exp{W_0\Biggl(\dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(x_i,x_j)\Biggr)}\quad for\ all\ i \in\mathcal{S}, \end{align}
where
 $ W_0$
represents the principal branch of the Lambert W function, and where the function
$ W_0$
represents the principal branch of the Lambert W function, and where the function
 $ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
is defined as in (3.1).
$ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
is defined as in (3.1).
Proof. Denote
 $ \theta_i=\mathrm{e}^{1-q_{ii}}$
for all
$ \theta_i=\mathrm{e}^{1-q_{ii}}$
for all
 $ i\in\mathcal{S}$
. Then
$ i\in\mathcal{S}$
. Then
 $ \theta_i \gt 0$
and
$ \theta_i \gt 0$
and
 $ q_{ii}=1-\ln{\theta_i}$
for all i. Using Proposition 3.1 and the fact that
$ q_{ii}=1-\ln{\theta_i}$
for all i. Using Proposition 3.1 and the fact that
 $ \mathbf{Q}$
is a rate matrix, we then have
$ \mathbf{Q}$
is a rate matrix, we then have
 \[ -1+\ln{\theta_i}=-q_{ii}=\sum_{j\in\mathcal{S}\setminus\{i\}}q_{ij}=\sum_{j\in\mathcal{S}\setminus\{i\}}\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}}\quad\text{for all } i \in\mathcal{S}, \]
\[ -1+\ln{\theta_i}=-q_{ii}=\sum_{j\in\mathcal{S}\setminus\{i\}}q_{ij}=\sum_{j\in\mathcal{S}\setminus\{i\}}\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}}\quad\text{for all } i \in\mathcal{S}, \]
which can be rewritten, using the fact that
 $ \rho(\theta_i,\theta_i)=\theta_i$
, as
$ \rho(\theta_i,\theta_i)=\theta_i$
, as
 \begin{align} \theta_i\ln{\theta_i}=\dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j)\quad\text{for all } i\in\mathcal{S}. \end{align}
\begin{align} \theta_i\ln{\theta_i}=\dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j)\quad\text{for all } i\in\mathcal{S}. \end{align}
Using the principal branch
 $ W_0$
of the Lambert W function (which is the multi-valued inverse of the function
$ W_0$
of the Lambert W function (which is the multi-valued inverse of the function
 $ w\mapsto w\mathrm{e}^{w}$
(
$ w\mapsto w\mathrm{e}^{w}$
(
 $ w\in\mathbb{C}$
); see [Reference Corless, Gonnet, Hare, Jeffrey and Knuth9]), we find that
$ w\in\mathbb{C}$
); see [Reference Corless, Gonnet, Hare, Jeffrey and Knuth9]), we find that
 \[ \ln{\theta_i}=W_0\Biggl(\dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j)\Biggr)\quad\text{for all } i\in\mathcal{S}, \]
\[ \ln{\theta_i}=W_0\Biggl(\dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j)\Biggr)\quad\text{for all } i\in\mathcal{S}, \]
which proves the result.
Propositions 3.1 and 3.2 imply that a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
defines a fixed point of the vector function
$ \mathbf{P}$
defines a fixed point of the vector function
 $ \mathbf{T}$
. The reverse is also true, as stated in the following proposition.
$ \mathbf{T}$
. The reverse is also true, as stated in the following proposition.
Proposition 3.3.
Suppose
 $ \mathbf{P}=(p_{ij})$
is a stochastic matrix that satisfies
$ \mathbf{P}=(p_{ij})$
is a stochastic matrix that satisfies
 $ p_{ii} \gt 0$
for all
$ p_{ii} \gt 0$
for all
 $ i\in\mathcal{S}$
. Let
$ i\in\mathcal{S}$
. Let
 $ \boldsymbol{\theta}=(\theta_1,\ldots,\theta_n)$
be a fixed point of the vector function
$ \boldsymbol{\theta}=(\theta_1,\ldots,\theta_n)$
be a fixed point of the vector function
 $ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
, defined in (3.2). Then the matrix
$ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
, defined in (3.2). Then the matrix
 $ \mathbf{Q}=(q_{ij})$
with elements
$ \mathbf{Q}=(q_{ij})$
with elements
 \begin{align} q_{ii}= 1-\ln{\theta_i},\quad q_{ij}=\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}},\quad i\neq j, \end{align}
\begin{align} q_{ii}= 1-\ln{\theta_i},\quad q_{ij}=\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}},\quad i\neq j, \end{align}
where
 $ \rho$
is defined by (3.1), is a
$ \rho$
is defined by (3.1), is a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
.
$ \mathbf{P}$
.
Proof. Let
 $ \boldsymbol{\theta}=(\theta_1,\theta_2,\ldots,\theta_n)\in\mathbb{R}_+^n$
be a fixed point of
$ \boldsymbol{\theta}=(\theta_1,\theta_2,\ldots,\theta_n)\in\mathbb{R}_+^n$
be a fixed point of
 $ \mathbf{T}$
and let the matrix
$ \mathbf{T}$
and let the matrix
 $ \mathbf{Q}$
be defined by (3.4). We first show that
$ \mathbf{Q}$
be defined by (3.4). We first show that
 $ \mathbf{Q}$
is a rate matrix. By (3.4), all off-diagonal elements of
$ \mathbf{Q}$
is a rate matrix. By (3.4), all off-diagonal elements of
 $ \mathbf{Q}$
are non-negative. Since
$ \mathbf{Q}$
are non-negative. Since
 $ T_i(\boldsymbol{\theta})=\theta_i$
, we have
$ T_i(\boldsymbol{\theta})=\theta_i$
, we have
 \[ \ln{\theta_i}=W_0\Biggl(\frac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j)\Biggr), \]
\[ \ln{\theta_i}=W_0\Biggl(\frac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j)\Biggr), \]
yielding
 \[ \theta_i\ln{\theta_i}=\frac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j), \]
\[ \theta_i\ln{\theta_i}=\frac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j), \]
by definition of the Lambert
 $ W_0$
function. Using (3.4) and since
$ W_0$
function. Using (3.4) and since
 $ \rho(\theta_i,\theta_i)=\theta_i$
, we can rewrite this equation as
$ \rho(\theta_i,\theta_i)=\theta_i$
, we can rewrite this equation as
 \[ \theta_i(1-q_{ii})=\theta_i+\frac{1}{p_{ii}}\sum_{j\in\mathcal{S}\setminus\{i\}}q_{ij}\theta_ip_{ii}. \]
\[ \theta_i(1-q_{ii})=\theta_i+\frac{1}{p_{ii}}\sum_{j\in\mathcal{S}\setminus\{i\}}q_{ij}\theta_ip_{ii}. \]
After simplification, we get
 $ q_{ii}=-\sum_{j\in\mathcal{S}\setminus\{i\}}q_{ij}$
. Thus
$ q_{ii}=-\sum_{j\in\mathcal{S}\setminus\{i\}}q_{ij}$
. Thus
 $ \mathbf{Q}$
has zero row sums. Consequently,
$ \mathbf{Q}$
has zero row sums. Consequently,
 $ \mathbf{Q}$
is a rate matrix.
$ \mathbf{Q}$
is a rate matrix.
It remains to be proved that
 $ {p}^{\unicode{x1D7D9}}_{ij}(\mathbf{Q})=p_{ij}$
for all i and j. Let
$ {p}^{\unicode{x1D7D9}}_{ij}(\mathbf{Q})=p_{ij}$
for all i and j. Let
 $ p^\ast_{ij}$
be defined by (2.1) and (2.2). Using (3.4) and (3.1), we have
$ p^\ast_{ij}$
be defined by (2.1) and (2.2). Using (3.4) and (3.1), we have
 \[ p^*_{ij}=q_{ij}\tau(q_{ii},q_{jj})=\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}}\tau(1-\ln{\theta_i},1-\ln{\theta_j})=\dfrac{\mathrm{e}\, p_{ij}}{\theta_ip_{ii}}, \quad\text{if }i\neq {j,} \]
\[ p^*_{ij}=q_{ij}\tau(q_{ii},q_{jj})=\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}}\tau(1-\ln{\theta_i},1-\ln{\theta_j})=\dfrac{\mathrm{e}\, p_{ij}}{\theta_ip_{ii}}, \quad\text{if }i\neq {j,} \]
and
 \[ p^*_{ii}=\tau(q_{ii},q_{ii})=\mathrm{e}^{q_{ii}}=\mathrm{e}^{1-\ln{\theta_i}}=\dfrac{\mathrm{e}}{\theta_i}\quad \text{for all} \, \textit{i}, \]
\[ p^*_{ii}=\tau(q_{ii},q_{ii})=\mathrm{e}^{q_{ii}}=\mathrm{e}^{1-\ln{\theta_i}}=\dfrac{\mathrm{e}}{\theta_i}\quad \text{for all} \, \textit{i}, \]
hence
 \[ p^*_{ij}=\frac{\mathrm{e}\, p_{ij}}{\theta_ip_{ii}} \quad\text{for all} \, \textit{i} \, and \, \textit{j}. \]
\[ p^*_{ij}=\frac{\mathrm{e}\, p_{ij}}{\theta_ip_{ii}} \quad\text{for all} \, \textit{i} \, and \, \textit{j}. \]
Consequently, by Proposition 2.1 and since
 $ \mathbf{P}$
is a stochastic matrix, we now have
$ \mathbf{P}$
is a stochastic matrix, we now have
 \[ {p}^{\unicode{x1D7D9}}_{ij}(\mathbf{Q})=\dfrac{p^*_{ij}}{\sum_{k\in\mathcal{S}} p^*_{ik}}=\dfrac{\mathrm{e}\,p_{ij}}{\theta_ip_{ii}}\biggm/ \dfrac{\mathrm{e}}{\theta_ip_{ii}}=p_{ij}, \]
\[ {p}^{\unicode{x1D7D9}}_{ij}(\mathbf{Q})=\dfrac{p^*_{ij}}{\sum_{k\in\mathcal{S}} p^*_{ik}}=\dfrac{\mathrm{e}\,p_{ij}}{\theta_ip_{ii}}\biggm/ \dfrac{\mathrm{e}}{\theta_ip_{ii}}=p_{ij}, \]
which concludes the proof.
By combining Propositions 3.1, 3.2, and 3.3, we establish a one-to-one relationship between the
 ${\unicode{x1D7D9}}$
-generators of
${\unicode{x1D7D9}}$
-generators of
 $ \mathbf{P}$
and the fixed points of the vector function
$ \mathbf{P}$
and the fixed points of the vector function
 $ \mathbf{T}$
. The subsequent lemma describes the properties of the vector function
$ \mathbf{T}$
. The subsequent lemma describes the properties of the vector function
 $ \mathbf{T}$
, which are crucial to determining its number of fixed points.
$ \mathbf{T}$
, which are crucial to determining its number of fixed points.
Lemma 3.1.
Let
 $ \mathbf{P}=(p_{ij})$
be an
$ \mathbf{P}=(p_{ij})$
be an
 $ n\times n$
stochastic matrix. Let
$ n\times n$
stochastic matrix. Let
 $ \delta=\min\{p_{ii},\,i\in\mathcal{S}\}$
and
$ \delta=\min\{p_{ii},\,i\in\mathcal{S}\}$
and
 $ \Delta=\max\{p_{ii},\,i\in\mathcal{S}\}$
. Suppose
$ \Delta=\max\{p_{ii},\,i\in\mathcal{S}\}$
. Suppose
 $ p_{ii} \gt 0$
for all i. Consider the vector function
$ p_{ii} \gt 0$
for all i. Consider the vector function
 $ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
, defined as in (3.2), and the set
$ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
, defined as in (3.2), and the set
 \begin{align} \mathcal{X}=\{(x_1,\ldots,x_n)\in\mathbb{R}^n \colon \mathrm{e}^{1/\Delta}\leq x_i \leq \mathrm{e}^{1/\delta}\; \forall i\}. \end{align}
\begin{align} \mathcal{X}=\{(x_1,\ldots,x_n)\in\mathbb{R}^n \colon \mathrm{e}^{1/\Delta}\leq x_i \leq \mathrm{e}^{1/\delta}\; \forall i\}. \end{align}
Then
(i) every fixed point of
 $ \mathbf{T}$
belongs to
$ \mathbf{T}$
belongs to
 $ \mathcal{X}$
.
$ \mathcal{X}$
.
(ii)
 $ \mathbf{T}$
maps
$ \mathbf{T}$
maps
 $ \mathcal{X}$
into
$ \mathcal{X}$
into
 $ \mathcal{X}$
.
$ \mathcal{X}$
.
Proof. (i) Let
 $ \boldsymbol{\theta}=(\theta_1,\ldots,\theta_n)\in\mathbb{R}_+^n$
be a fixed point of
$ \boldsymbol{\theta}=(\theta_1,\ldots,\theta_n)\in\mathbb{R}_+^n$
be a fixed point of
 $ \mathbf{T}$
. Let
$ \mathbf{T}$
. Let
 $ m=\min\{\theta_1,\ldots,\theta_n\}$
and
$ m=\min\{\theta_1,\ldots,\theta_n\}$
and
 $ M=\max\{\theta_1,\ldots,\theta_n\}$
. We shall prove that
$ M=\max\{\theta_1,\ldots,\theta_n\}$
. We shall prove that
 $ m\geq\mathrm{e}^{1/\Delta}$
and that
$ m\geq\mathrm{e}^{1/\Delta}$
and that
 $ M\leq\mathrm{e}^{1/\delta}$
.
$ M\leq\mathrm{e}^{1/\delta}$
.
Let r be an index such that
 $ \theta_r=m$
. Then, by Lemma A.2(iv), we have
$ \theta_r=m$
. Then, by Lemma A.2(iv), we have
 $ \rho(\theta_r,\theta_j)\geq m$
for all j. Since
$ \rho(\theta_r,\theta_j)\geq m$
for all j. Since
 $ T_r(\boldsymbol{\theta})=\theta_r$
, we have
$ T_r(\boldsymbol{\theta})=\theta_r$
, we have
 \[ \ln{\theta_r}=W_0\Biggl(\frac{1}{p_{rr}}\sum_{j\in\mathcal{S}}p_{rj}\rho(\theta_r,\theta_j)\Biggr), \]
\[ \ln{\theta_r}=W_0\Biggl(\frac{1}{p_{rr}}\sum_{j\in\mathcal{S}}p_{rj}\rho(\theta_r,\theta_j)\Biggr), \]
yielding
 \[ \theta_r\ln{\theta_r}=\frac{1}{p_{rr}}\sum_{j\in\mathcal{S}}p_{rj}\rho(\theta_r,\theta_j) \]
\[ \theta_r\ln{\theta_r}=\frac{1}{p_{rr}}\sum_{j\in\mathcal{S}}p_{rj}\rho(\theta_r,\theta_j) \]
by definition of the Lambert
 $ W_0$
function. Using the fact that
$ W_0$
function. Using the fact that
 $ \sum_{j\in\mathcal{S}} p_{rj}=1$
, we then obtain
$ \sum_{j\in\mathcal{S}} p_{rj}=1$
, we then obtain
 \[ m\ln{m}=\theta_r\ln{\theta_r}=\dfrac{1}{p_{rr}}\sum_{j\in\mathcal{S}}p_{rj}\rho(\theta_r,\theta_j)\geq \dfrac{m}{p_{rr}}\geq\dfrac{m}{\Delta}, \]
\[ m\ln{m}=\theta_r\ln{\theta_r}=\dfrac{1}{p_{rr}}\sum_{j\in\mathcal{S}}p_{rj}\rho(\theta_r,\theta_j)\geq \dfrac{m}{p_{rr}}\geq\dfrac{m}{\Delta}, \]
which implies
 $ \ln{m}\geq{{1}/{\Delta}}$
and thus
$ \ln{m}\geq{{1}/{\Delta}}$
and thus
 $ m\geq \mathrm{e}^{1/\Delta}$
. To prove the second inequality, let s be an index such that
$ m\geq \mathrm{e}^{1/\Delta}$
. To prove the second inequality, let s be an index such that
 $ \theta_s=M$
. Then, by Lemma A.2(iv), we have
$ \theta_s=M$
. Then, by Lemma A.2(iv), we have
 $ \rho(\theta_s,\theta_j)\leq M$
for all j. Hence, by
$ \rho(\theta_s,\theta_j)\leq M$
for all j. Hence, by
 $ T_s(\theta)=\theta_s$
and the unit row sum property of
$ T_s(\theta)=\theta_s$
and the unit row sum property of
 $ \mathbf{P}$
,
$ \mathbf{P}$
,
 \[ M\ln{M}=\theta_s\ln{\theta_s}=\dfrac{1}{p_{ss}}\sum_{j\in\mathcal{S}}p_{sj}\rho(\theta_s,\theta_j)\leq \dfrac{M}{p_{ss}} \leq\dfrac{M}{\delta}, \]
\[ M\ln{M}=\theta_s\ln{\theta_s}=\dfrac{1}{p_{ss}}\sum_{j\in\mathcal{S}}p_{sj}\rho(\theta_s,\theta_j)\leq \dfrac{M}{p_{ss}} \leq\dfrac{M}{\delta}, \]
which yields
 $ \ln{M}\leq {{1}/{\delta}}$
and thus
$ \ln{M}\leq {{1}/{\delta}}$
and thus
 $ M\leq\mathrm{e}^{1/\delta}$
.
$ M\leq\mathrm{e}^{1/\delta}$
.
(ii) Let
 $ (x_1,\ldots,x_n)\in \mathcal{X}$
. By Lemma A.2(iv),
$ (x_1,\ldots,x_n)\in \mathcal{X}$
. By Lemma A.2(iv),
 \begin{equation*} \mathrm{e}^{1/\Delta}\leq\min\{x_i,x_j\}\leq\rho(x_i,x_j)\leq\max\{x_i,x_j\}\leq \mathrm{e}^{1/\delta}\quad\text{for all} \textit{i} \, and \textit{j}. \end{equation*}
\begin{equation*} \mathrm{e}^{1/\Delta}\leq\min\{x_i,x_j\}\leq\rho(x_i,x_j)\leq\max\{x_i,x_j\}\leq \mathrm{e}^{1/\delta}\quad\text{for all} \textit{i} \, and \textit{j}. \end{equation*}
Then, since
 $ \mathbf{P}$
has unit row sums, we have for all i
$ \mathbf{P}$
has unit row sums, we have for all i
 \begin{equation*} \dfrac{\mathrm{e}^{1/\Delta}}{\Delta}\leq\dfrac{\mathrm{e}^{1/\Delta}}{p_{ii}}\leq \dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(x_i,x_j)\leq \dfrac{\mathrm{e}^{1/\delta}}{p_{ii}}\leq\dfrac{\mathrm{e}^{1/\delta}}{\delta}. \end{equation*}
\begin{equation*} \dfrac{\mathrm{e}^{1/\Delta}}{\Delta}\leq\dfrac{\mathrm{e}^{1/\Delta}}{p_{ii}}\leq \dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(x_i,x_j)\leq \dfrac{\mathrm{e}^{1/\delta}}{p_{ii}}\leq\dfrac{\mathrm{e}^{1/\delta}}{\delta}. \end{equation*}
Now,
 $ W_0$
and
$ W_0$
and
 $ \exp$
are increasing functions, and therefore
$ \exp$
are increasing functions, and therefore
 \[ \exp{W_0\biggl(\frac{1}{\Delta}\mathrm{e}^{1/\Delta}\biggr)} \leq T_i(x_1,\ldots,x_n) \leq\exp{W_0\biggl(\frac{1}{\delta}\mathrm{e}^{1/\delta}\biggr)}\quad\text{for all} \, \textit{i}. \]
\[ \exp{W_0\biggl(\frac{1}{\Delta}\mathrm{e}^{1/\Delta}\biggr)} \leq T_i(x_1,\ldots,x_n) \leq\exp{W_0\biggl(\frac{1}{\delta}\mathrm{e}^{1/\delta}\biggr)}\quad\text{for all} \, \textit{i}. \]
The result now follows by applying the property
 $ W_0(x\mathrm{e}^x)=x$
for
$ W_0(x\mathrm{e}^x)=x$
for
 $ x \gt 0$
.
$ x \gt 0$
.
Lemma 3.1 implies that the maximal and minimal diagonal elements of
 $ \mathbf{P}$
impose a lower and upper bound on the diagonal elements of the
$ \mathbf{P}$
impose a lower and upper bound on the diagonal elements of the
 ${\unicode{x1D7D9}}$
-generators of
${\unicode{x1D7D9}}$
-generators of
 $ \mathbf{P}$
.
$ \mathbf{P}$
.
Proposition 3.4.
Let
 $ \mathbf{P}=(p_{ij})$
be an
$ \mathbf{P}=(p_{ij})$
be an
 $ n\times n$
stochastic matrix. Let
$ n\times n$
stochastic matrix. Let
 $ \Delta=\max\{p_{ii},\,i\in\mathcal{S}\}$
and
$ \Delta=\max\{p_{ii},\,i\in\mathcal{S}\}$
and
 $ \delta=\min\{p_{ii},\,i\in\mathcal{S}\}$
. Suppose
$ \delta=\min\{p_{ii},\,i\in\mathcal{S}\}$
. Suppose
 $ p_{ii} \gt 0$
for all i. Then, if
$ p_{ii} \gt 0$
for all i. Then, if
 $ \mathbf{Q}=(q_{ij})$
is a
$ \mathbf{Q}=(q_{ij})$
is a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
, we have
$ \mathbf{P}$
, we have
 \[ 1-\dfrac{1}{\delta}\leq q_{ii}\leq 1-\dfrac{1}{\Delta}\quad\textit{for all i.} \]
\[ 1-\dfrac{1}{\delta}\leq q_{ii}\leq 1-\dfrac{1}{\Delta}\quad\textit{for all i.} \]
Proof. If
 $ \mathbf{Q}=(q_{ij})$
is a
$ \mathbf{Q}=(q_{ij})$
is a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
, we have by Proposition 3.2 that the vector
$ \mathbf{P}$
, we have by Proposition 3.2 that the vector
 $ (\theta_1,\ldots,\theta_n)$
, where
$ (\theta_1,\ldots,\theta_n)$
, where
 $ \theta_i=\mathrm{e}^{1-q_{ii}}$
for all i, is a fixed point of
$ \theta_i=\mathrm{e}^{1-q_{ii}}$
for all i, is a fixed point of
 $ \mathbf{T}$
. Applying Lemma 3.1(i), we have
$ \mathbf{T}$
. Applying Lemma 3.1(i), we have
 $ \mathrm{e}^{1/\Delta}\leq\theta_i\leq\mathrm{e}^{1/\delta}$
for all i, from which the result now follows.
$ \mathrm{e}^{1/\Delta}\leq\theta_i\leq\mathrm{e}^{1/\delta}$
for all i, from which the result now follows.
With regard to the number of fixed points of
 $ \mathbf{T}$
, we now prove the following important result.
$ \mathbf{T}$
, we now prove the following important result.
Theorem 3.1.
Suppose
 $ \mathbf{P}=(p_{ij})$
is an
$ \mathbf{P}=(p_{ij})$
is an
 $ n\times n$
stochastic matrix that satisfies
$ n\times n$
stochastic matrix that satisfies
 $ p_{ii} \gt 0$
for all i. Then the vector function
$ p_{ii} \gt 0$
for all i. Then the vector function
 $ \mathbf{T} \colon \mathbb{R}_+^n\to \mathbb{R}_+^n$
, defined as in (3.2), has a unique fixed point.
$ \mathbf{T} \colon \mathbb{R}_+^n\to \mathbb{R}_+^n$
, defined as in (3.2), has a unique fixed point.
Proof. According to Lemma 3.1(ii),
 $ \mathbf{T}$
maps the compact convex set
$ \mathbf{T}$
maps the compact convex set
 $ \mathcal{X}\subset\mathbb{R}_+^n$
, defined by (3.5), into itself. In addition,
$ \mathcal{X}\subset\mathbb{R}_+^n$
, defined by (3.5), into itself. In addition,
 $ \mathbf{T}$
is continuous as the function
$ \mathbf{T}$
is continuous as the function
 $ \rho$
, defined by (3.1), is continuous (Lemma A.2(ii)) and continuity is preserved by linear combination and composition of continuous functions. Hence, according to the Brouwer fixed point theorem,
$ \rho$
, defined by (3.1), is continuous (Lemma A.2(ii)) and continuity is preserved by linear combination and composition of continuous functions. Hence, according to the Brouwer fixed point theorem,
 $ \mathbf{T}$
has a fixed point. By the definition of
$ \mathbf{T}$
has a fixed point. By the definition of
 $ \mathbf{T}$
, this fixed point must have all positive components. We now show that the function
$ \mathbf{T}$
, this fixed point must have all positive components. We now show that the function
 $ \mathbf{g} \colon \mathbb{R}_+^n\to\mathbb{R}^n$
defined as
$ \mathbf{g} \colon \mathbb{R}_+^n\to\mathbb{R}^n$
defined as
 $ \mathbf{g}=\mathbf{T}-\mathbf{Id}$
, where
$ \mathbf{g}=\mathbf{T}-\mathbf{Id}$
, where
 $ \mathbf{Id} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
is the identity mapping, satisfies all conditions of Theorem 3.1 in [Reference Kennan23]. This theorem presents sufficient conditions for the function
$ \mathbf{Id} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
is the identity mapping, satisfies all conditions of Theorem 3.1 in [Reference Kennan23]. This theorem presents sufficient conditions for the function
 $ \mathbf{g}$
to have at most one vector
$ \mathbf{g}$
to have at most one vector
 $ \mathbf{x}\in\mathbb{R}_+^n$
with
$ \mathbf{x}\in\mathbb{R}_+^n$
with
 $ \mathbf{g}(\mathbf{x})=(0,\ldots,0)$
. These conditions are that (a)
$ \mathbf{g}(\mathbf{x})=(0,\ldots,0)$
. These conditions are that (a)
 $ \mathbf{g}$
is quasi-increasing and (b)
$ \mathbf{g}$
is quasi-increasing and (b)
 $ \mathbf{g}$
is strictly R-concave. Both (a) and (b) are proved in the Appendix; see Lemma A.4. So, we have established that
$ \mathbf{g}$
is strictly R-concave. Both (a) and (b) are proved in the Appendix; see Lemma A.4. So, we have established that
 $ \mathbf{T}$
has precisely one fixed point.
$ \mathbf{T}$
has precisely one fixed point.
We are now ready to state and prove our main result in the following theorem.
Theorem 3.2.
Suppose
 $ \mathbf{P}=(p_{ij})$
is an
$ \mathbf{P}=(p_{ij})$
is an
 $ n\times n$
stochastic matrix that satisfies
$ n\times n$
stochastic matrix that satisfies
 $ p_{ii} \gt 0$
for all i. Then
$ p_{ii} \gt 0$
for all i. Then
 $ \mathbf{P}$
has precisely one
$ \mathbf{P}$
has precisely one
 ${\unicode{x1D7D9}}$
-generator. Moreover, this
${\unicode{x1D7D9}}$
-generator. Moreover, this
 ${\unicode{x1D7D9}}$
-generator
${\unicode{x1D7D9}}$
-generator
 $ \mathbf{Q}=(q_{ij})$
is given by
$ \mathbf{Q}=(q_{ij})$
is given by
 \begin{align} q_{ii}= 1-\ln{\theta_i},\quad q_{ij}=\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}},\quad i\neq j, \end{align}
\begin{align} q_{ii}= 1-\ln{\theta_i},\quad q_{ij}=\dfrac{\rho(\theta_i,\theta_j)p_{ij}}{\theta_i p_{ii}},\quad i\neq j, \end{align}
where the scalar function
 $ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
is defined by (3.1), and
$ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
is defined by (3.1), and
 $ (\theta_1,\ldots,\theta_n)$
is the unique fixed point of the vector function
$ (\theta_1,\ldots,\theta_n)$
is the unique fixed point of the vector function
 $ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
defined by (3.2).
$ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
defined by (3.2).
Proof. We first prove that
 $ \mathbf{P}$
has a
$ \mathbf{P}$
has a
 ${\unicode{x1D7D9}}$
-generator. By Theorem 3.1, the vector function
${\unicode{x1D7D9}}$
-generator. By Theorem 3.1, the vector function
 $ \mathbf{T}$
has a unique fixed point
$ \mathbf{T}$
has a unique fixed point
 $ \boldsymbol{\theta}=(\theta_1,\theta_2,\ldots,\theta_n)\in\mathbb{R}_+^n$
. Starting from
$ \boldsymbol{\theta}=(\theta_1,\theta_2,\ldots,\theta_n)\in\mathbb{R}_+^n$
. Starting from
 $ \boldsymbol{\theta}$
, construct the matrix
$ \boldsymbol{\theta}$
, construct the matrix
 $ \mathbf{Q}=(q_{ij})$
according to (3.6). Then
$ \mathbf{Q}=(q_{ij})$
according to (3.6). Then
 $ \mathbf{Q}$
is a
$ \mathbf{Q}$
is a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
, by Proposition 3.3.
$ \mathbf{P}$
, by Proposition 3.3.
To prove the uniqueness of the
 ${\unicode{x1D7D9}}$
-generator, suppose that
${\unicode{x1D7D9}}$
-generator, suppose that
 $ \mathbf{P}$
has
$ \mathbf{P}$
has
 ${\unicode{x1D7D9}}$
-generators
${\unicode{x1D7D9}}$
-generators
 $ \mathbf{R}=(r_{ij})$
and
$ \mathbf{R}=(r_{ij})$
and
 $ \mathbf{S}=(s_{ij})$
. Then, by Proposition 3.2, the vectors
$ \mathbf{S}=(s_{ij})$
. Then, by Proposition 3.2, the vectors
 $ {\theta}_{\mathbf{R}}=(\mathrm{e}^{1-r_{11}},\ldots,\mathrm{e}^{1-r_{nn}})$
and
$ {\theta}_{\mathbf{R}}=(\mathrm{e}^{1-r_{11}},\ldots,\mathrm{e}^{1-r_{nn}})$
and
 $ {\theta}_{\mathbf{S}} = ({\mathrm{e}}^{1-s_{11}},\ldots,{\mathrm{e}}^{1-s_{nn}})$
are fixed points of the vector function
$ {\theta}_{\mathbf{S}} = ({\mathrm{e}}^{1-s_{11}},\ldots,{\mathrm{e}}^{1-s_{nn}})$
are fixed points of the vector function
 $ \mathbf{T}$
. By Theorem 3.1,
$ \mathbf{T}$
. By Theorem 3.1,
 $ {\theta}_{\mathbf{R}}={\theta}_{\mathbf{S}}$
. Hence, by Proposition 3.1, we must have
$ {\theta}_{\mathbf{R}}={\theta}_{\mathbf{S}}$
. Hence, by Proposition 3.1, we must have
 $ \mathbf{R}=\mathbf{S}$
.
$ \mathbf{R}=\mathbf{S}$
.
Finally, the requirement that the elements of a
 ${\unicode{x1D7D9}}$
-generator comply with (3.6) is inferred from Propositions 3.1 and 3.2. The proof is now complete.
${\unicode{x1D7D9}}$
-generator comply with (3.6) is inferred from Propositions 3.1 and 3.2. The proof is now complete.
Since
 $ p_{ii} \gt 0$
for all i is a necessary condition for embeddability (see [Reference Goodman16]), Theorem 3.2 immediately establishes a link between embeddability and
$ p_{ii} \gt 0$
for all i is a necessary condition for embeddability (see [Reference Goodman16]), Theorem 3.2 immediately establishes a link between embeddability and
 ${\unicode{x1D7D9}}$
-embeddability.
${\unicode{x1D7D9}}$
-embeddability.
Corollary 3.1.
An embeddable stochastic matrix is
 ${\unicode{x1D7D9}}$
-embeddable.
${\unicode{x1D7D9}}$
-embeddable.
According to Theorem 3.2, the unique
 ${\unicode{x1D7D9}}$
-generator is entirely characterized by the fixed point of the function
${\unicode{x1D7D9}}$
-generator is entirely characterized by the fixed point of the function
 $ \mathbf{T} \colon \mathcal{X}\to\mathcal{X}$
. When
$ \mathbf{T} \colon \mathcal{X}\to\mathcal{X}$
. When
 $ \mathbf{T}$
acts as a contraction on
$ \mathbf{T}$
acts as a contraction on
 $ \mathcal{X}$
, the Banach fixed point theorem ensures the convergence of the fixed point iteration method, which can then be used to estimate
$ \mathcal{X}$
, the Banach fixed point theorem ensures the convergence of the fixed point iteration method, which can then be used to estimate
 $ (\theta_1,\ldots,\theta_n)$
. In the case when not all diagonal elements of
$ (\theta_1,\ldots,\theta_n)$
. In the case when not all diagonal elements of
 $ \mathbf{P}$
are equal, Proposition 3.5 produces a necessary condition for
$ \mathbf{P}$
are equal, Proposition 3.5 produces a necessary condition for
 $ \mathbf{T}$
to behave as a contraction under the infinity vector norm. This condition is based on the largest and smallest diagonal elements of the matrix
$ \mathbf{T}$
to behave as a contraction under the infinity vector norm. This condition is based on the largest and smallest diagonal elements of the matrix
 $ \mathbf{P}$
.
$ \mathbf{P}$
.
Proposition 3.5.
Let
 $ \mathbf{P}=(p_{ij})$
be an
$ \mathbf{P}=(p_{ij})$
be an
 $ n\times n$
stochastic matrix such that
$ n\times n$
stochastic matrix such that
 $ 0 \lt \delta \lt \Delta$
, where
$ 0 \lt \delta \lt \Delta$
, where
 $ \delta=\min\{p_{ii},\,i\in\mathcal{S}\}$
and
$ \delta=\min\{p_{ii},\,i\in\mathcal{S}\}$
and
 $ \Delta=\max\{p_{ii},\,i\in\mathcal{S}\}$
. Let the set
$ \Delta=\max\{p_{ii},\,i\in\mathcal{S}\}$
. Let the set
 $ \mathcal{X}$
be defined by (3.5) and the function
$ \mathcal{X}$
be defined by (3.5) and the function
 $ \mathbf{T}$
as in (3.2). Then, with respect to the infinity norm, the function
$ \mathbf{T}$
as in (3.2). Then, with respect to the infinity norm, the function
 $ \mathbf{T}$
is Lipschitz-continuous on
$ \mathbf{T}$
is Lipschitz-continuous on
 $ \mathcal{X}$
with Lipschitz constant
$ \mathcal{X}$
with Lipschitz constant
 \[ K=\frac{1+({{1}/{\delta}}-1)C(\alpha)}{1+{{1}/{\Delta}}}, \]
\[ K=\frac{1+({{1}/{\delta}}-1)C(\alpha)}{1+{{1}/{\Delta}}}, \]
where
 \[ C(\alpha)=-1+\frac{\alpha+1}{\alpha-1}\ln{\alpha}\quad \textit{and} \quad\alpha=\mathrm{e}^{{{1}/{\delta}}-{{1}/{\Delta}}}. \]
\[ C(\alpha)=-1+\frac{\alpha+1}{\alpha-1}\ln{\alpha}\quad \textit{and} \quad\alpha=\mathrm{e}^{{{1}/{\delta}}-{{1}/{\Delta}}}. \]
Proof. Using Lemmas A.6 and A.7, we can prove that
 \[ |T_{i}(\mathbf{x})-T_{i}(\mathbf{y})|\leq K\|\mathbf{x}-\mathbf{y}\|_{\infty}\quad\text{for all}\ \mathbf{x},\mathbf{y}\in \mathcal{X}\ \text{and for all} \, \textit{i}, \]
\[ |T_{i}(\mathbf{x})-T_{i}(\mathbf{y})|\leq K\|\mathbf{x}-\mathbf{y}\|_{\infty}\quad\text{for all}\ \mathbf{x},\mathbf{y}\in \mathcal{X}\ \text{and for all} \, \textit{i}, \]
where
 \[ K=\dfrac{1+({{1}/{\delta}}-1)C(\alpha)}{1+{{1}/{\Delta}}},\quad C(\alpha)=-1+\dfrac{\alpha+1}{\alpha-1}\ln{\alpha}\quad\text{and}\quad \alpha=\mathrm{e}^{{{1}/{\delta}}-{{1}/{\Delta}}}. \]
\[ K=\dfrac{1+({{1}/{\delta}}-1)C(\alpha)}{1+{{1}/{\Delta}}},\quad C(\alpha)=-1+\dfrac{\alpha+1}{\alpha-1}\ln{\alpha}\quad\text{and}\quad \alpha=\mathrm{e}^{{{1}/{\delta}}-{{1}/{\Delta}}}. \]
For more details we refer the reader to the Appendix.
If all diagonal elements of
 $ \mathbf{P}$
are identical, there is a closed-form expression for the unique
$ \mathbf{P}$
are identical, there is a closed-form expression for the unique
 ${\unicode{x1D7D9}}$
-generator, which is detailed in the following proposition. Such matrices occur as substitution matrices in Markov models for DNA evolution, among others. See [Reference Casanellas, Fernández-Sánchez and Roca-Lacostena6] for a discussion of the embeddability of such matrices in the context of the so-called JC69, K80, and K81 models.
${\unicode{x1D7D9}}$
-generator, which is detailed in the following proposition. Such matrices occur as substitution matrices in Markov models for DNA evolution, among others. See [Reference Casanellas, Fernández-Sánchez and Roca-Lacostena6] for a discussion of the embeddability of such matrices in the context of the so-called JC69, K80, and K81 models.
Proposition 3.6.
Suppose
 $ \mathbf{P}=(p_{ij})$
is an
$ \mathbf{P}=(p_{ij})$
is an
 $ n\times n$
stochastic matrix satisfying
$ n\times n$
stochastic matrix satisfying
 $ p_{ii}=p \gt 0$
for all i. Then its unique
$ p_{ii}=p \gt 0$
for all i. Then its unique
 ${\unicode{x1D7D9}}$
-generator
${\unicode{x1D7D9}}$
-generator
 $ \mathbf{Q}$
is given by
$ \mathbf{Q}$
is given by
 $ \mathbf{Q}=\tfrac{1}{p}(\mathbf{P}-\mathbf{I})$
, where
$ \mathbf{Q}=\tfrac{1}{p}(\mathbf{P}-\mathbf{I})$
, where
 $ \mathbf{I}$
is the
$ \mathbf{I}$
is the
 $ n\times n$
identity matrix.
$ n\times n$
identity matrix.
Proof. Let
 $ \mathbf{Q}=(q_{ij})$
be a
$ \mathbf{Q}=(q_{ij})$
be a
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
. It follows from Proposition 3.4 that
$ \mathbf{P}$
. It follows from Proposition 3.4 that
 $ q_{ii}=1-1/p$
for all i. Moreover, if
$ q_{ii}=1-1/p$
for all i. Moreover, if
 $ i\neq j$
, Theorem 3.2 and equation (3.1) imply that
$ i\neq j$
, Theorem 3.2 and equation (3.1) imply that
 \[ q_{ij}=\dfrac{\rho(\mathrm{e}^{1-q_{ii}},\mathrm{e}^{1-q_{jj}})p_{ij}}{\mathrm{e}^{1-q_{ii}}p_{ii}}=\dfrac{\rho(\mathrm{e}^{1/p},\mathrm{e}^{1/p})p_{ij}}{\mathrm{e}^{1/p}p}=\dfrac{p_{ij}}{p}. \]
\[ q_{ij}=\dfrac{\rho(\mathrm{e}^{1-q_{ii}},\mathrm{e}^{1-q_{jj}})p_{ij}}{\mathrm{e}^{1-q_{ii}}p_{ii}}=\dfrac{\rho(\mathrm{e}^{1/p},\mathrm{e}^{1/p})p_{ij}}{\mathrm{e}^{1/p}p}=\dfrac{p_{ij}}{p}. \]
In summary, we have
 \[ q_{ii}=1-\frac{1}{p}=\frac{1}{p}(p_{ii}-1),\quad q_{ij}=\frac{1}{p}p_{ij},\quad i\neq j, \]
\[ q_{ii}=1-\frac{1}{p}=\frac{1}{p}(p_{ii}-1),\quad q_{ij}=\frac{1}{p}p_{ij},\quad i\neq j, \]
concluding the proof.
4. Comparison of alternative one-jump approaches and illustrations
Consider a continuous-time Markov chain that is discretely observed at times
 $ t=0, 1, 2, \ldots , T$
(
$ t=0, 1, 2, \ldots , T$
(
 $ T\geq 2$
). Let
$ T\geq 2$
). Let
 $ \mathbf{P}$
be the empirical transition matrix estimated from these observations. If
$ \mathbf{P}$
be the empirical transition matrix estimated from these observations. If
 $ \mathbf{P}$
is not embeddable, there is no Markov generator of
$ \mathbf{P}$
is not embeddable, there is no Markov generator of
 $ \mathbf{P}$
, making it a challenge to find an approximate generator. However, if one assumes that the likelihood of more than one transition occurring between two consecutive observations is very low – a scenario referred to as a one-jump setting – it is possible to find a unique rate matrix serving as an approximate generator of
$ \mathbf{P}$
, making it a challenge to find an approximate generator. However, if one assumes that the likelihood of more than one transition occurring between two consecutive observations is very low – a scenario referred to as a one-jump setting – it is possible to find a unique rate matrix serving as an approximate generator of
 $ \mathbf{P}$
.
$ \mathbf{P}$
.
Let us adopt the notation
 $ \mathbf{Q}^{\text{JLT}}$
, employed in [Reference Israel, Rosenthal and Wei17], to denote the one-jump rate matrix of Jarrow et al. [Reference Jarrow, Lando and Turnbull18]. Furthermore, we denote
$ \mathbf{Q}^{\text{JLT}}$
, employed in [Reference Israel, Rosenthal and Wei17], to denote the one-jump rate matrix of Jarrow et al. [Reference Jarrow, Lando and Turnbull18]. Furthermore, we denote
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
for the
$ \mathbf{Q}^{\unicode{x1D7D9}}$
for the
 ${\unicode{x1D7D9}}$
-generator of
${\unicode{x1D7D9}}$
-generator of
 $ \mathbf{P}$
. In this section we discuss the specifics of both approaches and compare the resulting rate matrices
$ \mathbf{P}$
. In this section we discuss the specifics of both approaches and compare the resulting rate matrices
 $ \mathbf{Q}^{\text{JLT}}$
and
$ \mathbf{Q}^{\text{JLT}}$
and
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
as approximate generators of
$ \mathbf{Q}^{\unicode{x1D7D9}}$
as approximate generators of
 $ \mathbf{P}$
. To effectively represent the distinction between the two approaches, we use the recursively defined jump times
$ \mathbf{P}$
. To effectively represent the distinction between the two approaches, we use the recursively defined jump times
 $ \tau_0\,:\!=\, 0$
and
$ \tau_0\,:\!=\, 0$
and
 $ \tau_k=\inf\{t\geq \tau_{k-1} \colon X_t\neq X_{\tau_{k-1}}\}$
(
$ \tau_k=\inf\{t\geq \tau_{k-1} \colon X_t\neq X_{\tau_{k-1}}\}$
(
 $ k=1,2,\ldots$
) of the associated CTHMC
$ k=1,2,\ldots$
) of the associated CTHMC
 $ (X_t)_{t\geq 0}$
.
$ (X_t)_{t\geq 0}$
.
In their interpretation of the one-jump scenario, Jarrow et al. [Reference Jarrow, Lando and Turnbull18] deduce the rate matrix
 $ \mathbf{Q}^{\text{JLT}}=(q_{ij}^{\text{JLT}})$
directly from
$ \mathbf{Q}^{\text{JLT}}=(q_{ij}^{\text{JLT}})$
directly from
 $ \mathbf{P}=(p_{ij})$
through
$ \mathbf{P}=(p_{ij})$
through
 \begin{align} q^{\text{JLT}}_{ii}=\ln{p_{ii}} ,\quad q^{\text{JLT}}_{ij} = \begin{cases} \dfrac{p_{ij} \ln{p_{ii}}}{p_{ii} - 1} & \text{if}\ 0 \lt p_{ii} \lt 1, \\[7pt]0 & \text{if}\ p_{ii}=1,\end{cases} \quad i \neq j,\end{align}
\begin{align} q^{\text{JLT}}_{ii}=\ln{p_{ii}} ,\quad q^{\text{JLT}}_{ij} = \begin{cases} \dfrac{p_{ij} \ln{p_{ii}}}{p_{ii} - 1} & \text{if}\ 0 \lt p_{ii} \lt 1, \\[7pt]0 & \text{if}\ p_{ii}=1,\end{cases} \quad i \neq j,\end{align}
assuming
 $ 0 \lt p_{ii}$
for all i. From a probabilistic perspective considering jump times, the elements
$ 0 \lt p_{ii}$
for all i. From a probabilistic perspective considering jump times, the elements
 $ q_{ij}^{\text{JLT}}$
are defined as the solutions to the equations
$ q_{ij}^{\text{JLT}}$
are defined as the solutions to the equations
 \begin{align} \mathbb{P}(\tau_1 \gt 1 \mid X_0=i)=p_{ii},\quad \mathbb{P}(\tau_1\leq 1, X_{\tau_1}=j \mid X_0=i)= p_{ij},\quad i \neq j.\end{align}
\begin{align} \mathbb{P}(\tau_1 \gt 1 \mid X_0=i)=p_{ii},\quad \mathbb{P}(\tau_1\leq 1, X_{\tau_1}=j \mid X_0=i)= p_{ij},\quad i \neq j.\end{align}
Essentially, their one-jump approach designates
 $ p_{ij}$
to represent the probability of jumping from state i to state j at or before time
$ p_{ij}$
to represent the probability of jumping from state i to state j at or before time
 $ t=1$
.
$ t=1$
.
In this paper we derive the
 ${\unicode{x1D7D9}}$
-generator via an alternative approach, as expressed by
${\unicode{x1D7D9}}$
-generator via an alternative approach, as expressed by
 \begin{align} \mathbb{P}(X_1=j \mid X_0=i,\tau_2 \gt 1)=p_{ij}\quad \text{for all \textit{i} and \textit{j},}\end{align}
\begin{align} \mathbb{P}(X_1=j \mid X_0=i,\tau_2 \gt 1)=p_{ij}\quad \text{for all \textit{i} and \textit{j},}\end{align}
which implies that
 $ p_{ij}$
represents the likelihood of going from state i at
$ p_{ij}$
represents the likelihood of going from state i at
 $ t=0$
to state j at
$ t=0$
to state j at
 $ t=1$
via at most one jump before or at
$ t=1$
via at most one jump before or at
 $ t=1$
. Hence the difference between the methods (4.2) and (4.3) depends on how the empirical transition probability matrix
$ t=1$
. Hence the difference between the methods (4.2) and (4.3) depends on how the empirical transition probability matrix
 $ \mathbf{P}$
is viewed in the scenario of a single jump. Both approaches have the merit of bypassing the identification and regularization stages (see [Reference Davies10], [Reference Israel, Rosenthal and Wei17], and [Reference Kreinin and Sidelnikova25]) associated with the embedding problem.
$ \mathbf{P}$
is viewed in the scenario of a single jump. Both approaches have the merit of bypassing the identification and regularization stages (see [Reference Davies10], [Reference Israel, Rosenthal and Wei17], and [Reference Kreinin and Sidelnikova25]) associated with the embedding problem.
In regularization problems where the transition matrix
 $ \mathbf{P}$
is not embeddable, the goal is to find an approximate Markov generator
$ \mathbf{P}$
is not embeddable, the goal is to find an approximate Markov generator
 $ \mathbf{Q}$
for
$ \mathbf{Q}$
for
 $ \mathbf{P}$
by minimizing the discrepancy between
$ \mathbf{P}$
by minimizing the discrepancy between
 $ \exp{\mathbf{Q}}$
and
$ \exp{\mathbf{Q}}$
and
 $ \mathbf{P}$
. The magnitude of this difference
$ \mathbf{P}$
. The magnitude of this difference
 $ \|\mathbf{P} - \exp{\mathbf{Q}}\|$
depends on the norm used. Davies [Reference Davies10] explored the use of the infinity norm in addressing the regularization problem. For an
$ \|\mathbf{P} - \exp{\mathbf{Q}}\|$
depends on the norm used. Davies [Reference Davies10] explored the use of the infinity norm in addressing the regularization problem. For an
 $ n\times n$
matrix
$ n\times n$
matrix
 $ \mathbf{M}=(m_{ij})$
, the infinity norm is given by
$ \mathbf{M}=(m_{ij})$
, the infinity norm is given by
 $ \|\mathbf{M}\|_{\infty} = \max_{1 \leq i \leq n} \sum_{j=1}^{n} |m_{ij}|$
. This norm proves useful in comparing transition matrices, since both
$ \|\mathbf{M}\|_{\infty} = \max_{1 \leq i \leq n} \sum_{j=1}^{n} |m_{ij}|$
. This norm proves useful in comparing transition matrices, since both
 $ \mathbf{P}$
and
$ \mathbf{P}$
and
 $ \exp{\mathbf{Q}}$
consist of rows that are stochastic vectors. The Manhattan or Taxicab distance between the corresponding rows, the ith rows in particular, i.e.
$ \exp{\mathbf{Q}}$
consist of rows that are stochastic vectors. The Manhattan or Taxicab distance between the corresponding rows, the ith rows in particular, i.e.
 $ \sum_{j=1}^{n} |\mathbf{P}_{ij} - (\exp{\mathbf{Q}})_{ij}|$
, is a simple indicator of the discrepancy between the transition probability distributions from state i. Consequently, the maximum absolute row sum of
$ \sum_{j=1}^{n} |\mathbf{P}_{ij} - (\exp{\mathbf{Q}})_{ij}|$
, is a simple indicator of the discrepancy between the transition probability distributions from state i. Consequently, the maximum absolute row sum of
 $ \mathbf{P} - \exp{\mathbf{Q}}$
offers a distinct measure to evaluate the difference between
$ \mathbf{P} - \exp{\mathbf{Q}}$
offers a distinct measure to evaluate the difference between
 $ \mathbf{P}$
and
$ \mathbf{P}$
and
 $ \exp{\mathbf{Q}}$
. The infinity norm will be used consistently in the remainder of this paper.
$ \exp{\mathbf{Q}}$
. The infinity norm will be used consistently in the remainder of this paper.
An interesting question arises as to whether systematically
 $ \exp{\mathbf{Q}}^{\text{JLT}}$
or
$ \exp{\mathbf{Q}}^{\text{JLT}}$
or
 $ \exp{\mathbf{Q}}^{\unicode{x1D7D9}}$
is the best approximation to
$ \exp{\mathbf{Q}}^{\unicode{x1D7D9}}$
is the best approximation to
 $ \mathbf{P}$
, or whether this answer depends on the transition matrix
$ \mathbf{P}$
, or whether this answer depends on the transition matrix
 $ \mathbf{P}$
. In the following sections, we analyse the discrepancies
$ \mathbf{P}$
. In the following sections, we analyse the discrepancies
 $ \|\mathbf{P} - \exp{\mathbf{Q}}^{\text{JLT}}\|_{\infty}$
and
$ \|\mathbf{P} - \exp{\mathbf{Q}}^{\text{JLT}}\|_{\infty}$
and
 $ \|\mathbf{P} - \exp{\mathbf{Q}}^{\unicode{x1D7D9}}\|_{\infty}$
for specific categories of the transition matrix
$ \|\mathbf{P} - \exp{\mathbf{Q}}^{\unicode{x1D7D9}}\|_{\infty}$
for specific categories of the transition matrix
 $ \mathbf{P}$
.
$ \mathbf{P}$
.
4.1. Credit rating transition matrix
Consider the empirical transition matrix
 \[\renewcommand{\arraystretch}{.8}\mathbf{P}=\left[ \begin{array}{r@{\quad}r@{\quad}r@{\quad}r@{\quad}r@{\quad}r@{\quad}r@{\quad}r} 0.8910 & 0.0963 & 0.0078 & 0.0019 & 0.0030 & 0.0000 & 0.0000 & 0.0000 \\[3pt] 0.0086 & 0.9010 & 0.0747 & 0.0099 & 0.0029 & 0.0029 & 0.0000 & 0.0000 \\[3pt] 0.0009 & 0.0291 & 0.8896 & 0.0649 & 0.0101 & 0.0045 & 0.0000 & 0.0009 \\[3pt] 0.0006 & 0.0043 & 0.0656 & 0.8428 & 0.0644 & 0.0160 & 0.0018 & 0.0045 \\[3pt] 0.0004 & 0.0022 & 0.0079 & 0.0719 & 0.7765 & 0.1043 & 0.0127 & 0.0241 \\[3pt] 0.0000 & 0.0019 & 0.0031 & 0.0066 & 0.0517 & 0.8247 & 0.0435 & 0.0685 \\[3pt] 0.0000 & 0.0000 & 0.0116 & 0.0116 & 0.0203 & 0.0754 & 0.6492 & 0.2319 \\[3pt] 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 1.0000 \\[3pt] \end{array} \right]\! ,\]
\[\renewcommand{\arraystretch}{.8}\mathbf{P}=\left[ \begin{array}{r@{\quad}r@{\quad}r@{\quad}r@{\quad}r@{\quad}r@{\quad}r@{\quad}r} 0.8910 & 0.0963 & 0.0078 & 0.0019 & 0.0030 & 0.0000 & 0.0000 & 0.0000 \\[3pt] 0.0086 & 0.9010 & 0.0747 & 0.0099 & 0.0029 & 0.0029 & 0.0000 & 0.0000 \\[3pt] 0.0009 & 0.0291 & 0.8896 & 0.0649 & 0.0101 & 0.0045 & 0.0000 & 0.0009 \\[3pt] 0.0006 & 0.0043 & 0.0656 & 0.8428 & 0.0644 & 0.0160 & 0.0018 & 0.0045 \\[3pt] 0.0004 & 0.0022 & 0.0079 & 0.0719 & 0.7765 & 0.1043 & 0.0127 & 0.0241 \\[3pt] 0.0000 & 0.0019 & 0.0031 & 0.0066 & 0.0517 & 0.8247 & 0.0435 & 0.0685 \\[3pt] 0.0000 & 0.0000 & 0.0116 & 0.0116 & 0.0203 & 0.0754 & 0.6492 & 0.2319 \\[3pt] 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 1.0000 \\[3pt] \end{array} \right]\! ,\]
which is derived from Table 3 in Jarrow et al. [Reference Jarrow, Lando and Turnbull18, p. 506]. We have made minor adjustments to five entries on the main diagonal to ensure that all row sums are equal to one, as some rows in Table 3 did not add up to one because of rounding. For this matrix, the vector function
 $ \mathbf{T} \colon \mathcal{X}\to\mathcal{X}$
, defined by (3.2), is a contraction mapping with Lipschitz constant
$ \mathbf{T} \colon \mathcal{X}\to\mathcal{X}$
, defined by (3.2), is a contraction mapping with Lipschitz constant
 $ K \lt 1$
(
$ K \lt 1$
(
 $ K\approx 0.7833$
); see Proposition 3.5. Using fixed-point iteration and (3.6), we find that the unique
$ K\approx 0.7833$
); see Proposition 3.5. Using fixed-point iteration and (3.6), we find that the unique
 ${\unicode{x1D7D9}}$
-generator, truncated to four decimal places, is given by
${\unicode{x1D7D9}}$
-generator, truncated to four decimal places, is given by
 \[\renewcommand{\arraystretch}{.8}\mathbf{Q}^{\unicode{x1D7D9}}=\left[ \begin{array}{r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\quad}r} -0.1221 & 0.1075 & 0.0088 & 0.0022 & 0.0036 & 0.0000 & 0.0000 & 0.0000 \\[3pt] 0.0096 & -0.1114 & 0.0836 & 0.0114 & 0.0035 & 0.0034 & 0.0000 & 0.0000 \\[3pt] 0.0010 & 0.0325 & -0.1271 & 0.0752 & 0.0122 & 0.0053 & 0.0000 & 0.0009 \\[3pt] 0.0007 & 0.0049 & 0.0755 & -0.1874 & 0.0798 & 0.0192 & 0.0024 & 0.0049 \\[3pt] 0.0005 & 0.0026 & 0.0094 & 0.0886 & -0.2759 & 0.1301 & 0.0178 & 0.0270 \\[3pt] 0.0000 & 0.0022 & 0.0036 & 0.0079 & 0.0647 & -0.2121 & 0.0592 & 0.0746 \\[3pt] 0.0000 & 0.0000 & 0.0152 & 0.0157 & 0.0287 & 0.1031 & -0.4460 & 0.2834 \\[3pt] 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 \\[3pt] \end{array} \right]\! .\]
\[\renewcommand{\arraystretch}{.8}\mathbf{Q}^{\unicode{x1D7D9}}=\left[ \begin{array}{r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\quad}r} -0.1221 & 0.1075 & 0.0088 & 0.0022 & 0.0036 & 0.0000 & 0.0000 & 0.0000 \\[3pt] 0.0096 & -0.1114 & 0.0836 & 0.0114 & 0.0035 & 0.0034 & 0.0000 & 0.0000 \\[3pt] 0.0010 & 0.0325 & -0.1271 & 0.0752 & 0.0122 & 0.0053 & 0.0000 & 0.0009 \\[3pt] 0.0007 & 0.0049 & 0.0755 & -0.1874 & 0.0798 & 0.0192 & 0.0024 & 0.0049 \\[3pt] 0.0005 & 0.0026 & 0.0094 & 0.0886 & -0.2759 & 0.1301 & 0.0178 & 0.0270 \\[3pt] 0.0000 & 0.0022 & 0.0036 & 0.0079 & 0.0647 & -0.2121 & 0.0592 & 0.0746 \\[3pt] 0.0000 & 0.0000 & 0.0152 & 0.0157 & 0.0287 & 0.1031 & -0.4460 & 0.2834 \\[3pt] 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 \\[3pt] \end{array} \right]\! .\]
In contrast, the rate matrix
 $ \mathbf{Q}^{\text{JLT}}$
, published in Jarrow et al. [Reference Jarrow, Lando and Turnbull18] and defined by equation (4.1), is
$ \mathbf{Q}^{\text{JLT}}$
, published in Jarrow et al. [Reference Jarrow, Lando and Turnbull18] and defined by equation (4.1), is
 \[\renewcommand{\arraystretch}{.8}\mathbf{Q}^{\text{JLT}}=\left[\begin{array}{r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\quad}r} -0.1154 & 0.1020 & 0.0083 & 0.0020 & 0.0032 & 0.0000 & 0.0000 & 0.0000 \\[3pt] 0.0091 & -0.1043 & 0.0787 & 0.0104 & 0.0031 & 0.0031 & 0.0000 & 0.0000 \\[3pt] 0.0010 & 0.0308 & -0.1170 & 0.0688 & 0.0107 & 0.0048 & 0.0000 & 0.0010 \\[3pt] 0.0007 & 0.0047 & 0.0714 & -0.1710 & 0.0701 & 0.0174 & 0.0020 & 0.0049 \\[3pt] 0.0005 & 0.0025 & 0.0089 & 0.0814 & -0.2530 & 0.1180 & 0.0144 & 0.0273 \\[3pt] 0.0000 & 0.0021 & 0.0034 & 0.0073 & 0.0568 & -0.1927 & 0.0478 & 0.0753 \\[3pt] 0.0000 & 0.0000 & 0.0143 & 0.0143 & 0.0250 & 0.0929 & -0.4320 & 0.2856 \\[3pt] 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 \\[3pt] \end{array} \right]\! .\]
\[\renewcommand{\arraystretch}{.8}\mathbf{Q}^{\text{JLT}}=\left[\begin{array}{r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\,\,\,}r@{\quad}r} -0.1154 & 0.1020 & 0.0083 & 0.0020 & 0.0032 & 0.0000 & 0.0000 & 0.0000 \\[3pt] 0.0091 & -0.1043 & 0.0787 & 0.0104 & 0.0031 & 0.0031 & 0.0000 & 0.0000 \\[3pt] 0.0010 & 0.0308 & -0.1170 & 0.0688 & 0.0107 & 0.0048 & 0.0000 & 0.0010 \\[3pt] 0.0007 & 0.0047 & 0.0714 & -0.1710 & 0.0701 & 0.0174 & 0.0020 & 0.0049 \\[3pt] 0.0005 & 0.0025 & 0.0089 & 0.0814 & -0.2530 & 0.1180 & 0.0144 & 0.0273 \\[3pt] 0.0000 & 0.0021 & 0.0034 & 0.0073 & 0.0568 & -0.1927 & 0.0478 & 0.0753 \\[3pt] 0.0000 & 0.0000 & 0.0143 & 0.0143 & 0.0250 & 0.0929 & -0.4320 & 0.2856 \\[3pt] 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 & 0.0000 \\[3pt] \end{array} \right]\! .\]
We find
 $ \|\mathbf{P}-\exp{\mathbf{Q}}^{\unicode{x1D7D9}}\|_{\infty}\approx 0.0247$
and
$ \|\mathbf{P}-\exp{\mathbf{Q}}^{\unicode{x1D7D9}}\|_{\infty}\approx 0.0247$
and
 $ \|\mathbf{P}-\exp{\mathbf{Q}}^{\text{JLT}}\|_{\infty}\approx 0.0277$
(accurate to four decimal places). Hence it appears that
$ \|\mathbf{P}-\exp{\mathbf{Q}}^{\text{JLT}}\|_{\infty}\approx 0.0277$
(accurate to four decimal places). Hence it appears that
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
is a better approximate generator of
$ \mathbf{Q}^{\unicode{x1D7D9}}$
is a better approximate generator of
 $ \mathbf{P}$
than
$ \mathbf{P}$
than
 $ \mathbf{Q}^{\text{JLT}}$
, when using the infinity norm.
$ \mathbf{Q}^{\text{JLT}}$
, when using the infinity norm.
Observe that the magnitudes of the diagonal entries in
 $ \mathbf{Q}^{\text{JLT}}$
are smaller compared to those in the
$ \mathbf{Q}^{\text{JLT}}$
are smaller compared to those in the
 ${\unicode{x1D7D9}}$
-generator. This observation persists across all matrices
${\unicode{x1D7D9}}$
-generator. This observation persists across all matrices
 $ \mathbf{P}$
with non-zero diagonal entries, as demonstrated by the following proposition.
$ \mathbf{P}$
with non-zero diagonal entries, as demonstrated by the following proposition.
Proposition 4.1.
Suppose
 $ \mathbf{P}=(p_{ij})$
is an
$ \mathbf{P}=(p_{ij})$
is an
 $ n\times n$
stochastic matrix that satisfies
$ n\times n$
stochastic matrix that satisfies
 $ p_{ii} \gt 0$
for all i. Then
$ p_{ii} \gt 0$
for all i. Then
 $ q_{ii}^{\unicode{x1D7D9}}\leq q_{ii}^{\mathrm{JLT}}$
for all i.
$ q_{ii}^{\unicode{x1D7D9}}\leq q_{ii}^{\mathrm{JLT}}$
for all i.
Proof. By Theorem 3.2,
 $ q_{ii}^{\unicode{x1D7D9}}=1-\ln{\theta_i}$
for all i, where
$ q_{ii}^{\unicode{x1D7D9}}=1-\ln{\theta_i}$
for all i, where
 $ \theta=(\theta_1,\ldots,\theta_n)$
is the unique fixed point of the vector function
$ \theta=(\theta_1,\ldots,\theta_n)$
is the unique fixed point of the vector function
 $ \mathbf{T}=(T_1,\ldots,T_n)$
, defined by (3.2). For
$ \mathbf{T}=(T_1,\ldots,T_n)$
, defined by (3.2). For
 $ i\in\mathcal{S}$
, we have by (3.3) that
$ i\in\mathcal{S}$
, we have by (3.3) that
 \[ \theta_i\ln{\theta_i}=\dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j). \]
\[ \theta_i\ln{\theta_i}=\dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}}p_{ij}\rho(\theta_i,\theta_j). \]
Using the definition of the function
 $ \rho$
in (3.1), the above equation can be rewritten as
$ \rho$
in (3.1), the above equation can be rewritten as
 \begin{align} \biggl(\dfrac{\theta_i}{\mathrm{e}}-1\biggr)\rho(\theta_i,\mathrm{e})=\theta_i\ln{\theta_i}-\theta_i= \dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}\setminus\{i\}}p_{ij}\rho(\theta_i,\theta_j). \end{align}
\begin{align} \biggl(\dfrac{\theta_i}{\mathrm{e}}-1\biggr)\rho(\theta_i,\mathrm{e})=\theta_i\ln{\theta_i}-\theta_i= \dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}\setminus\{i\}}p_{ij}\rho(\theta_i,\theta_j). \end{align}
Now, since
 $ 1-\ln{\theta_j}=q_{jj}^{\unicode{x1D7D9}}\leq 0$
, we have
$ 1-\ln{\theta_j}=q_{jj}^{\unicode{x1D7D9}}\leq 0$
, we have
 $ \theta_j\geq\mathrm{e}$
for all j. By Lemma A.2(iii),
$ \theta_j\geq\mathrm{e}$
for all j. By Lemma A.2(iii),
 $ \rho(\theta_i,\theta_j)\geq \rho(\theta_i,\mathrm{e})$
for all j. Hence, from (4.4), it follows that
$ \rho(\theta_i,\theta_j)\geq \rho(\theta_i,\mathrm{e})$
for all j. Hence, from (4.4), it follows that
 \[ \biggl(\dfrac{\theta_i}{\mathrm{e}}-1\biggr)\rho(\theta_i,\mathrm{e})\geq \dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}\setminus\{i\}}p_{ij}\rho(\theta_i,\mathrm{e})=\biggl(\dfrac{1}{p_{ii}}-1\biggr)\rho(\theta_i,\mathrm{e}), \]
\[ \biggl(\dfrac{\theta_i}{\mathrm{e}}-1\biggr)\rho(\theta_i,\mathrm{e})\geq \dfrac{1}{p_{ii}}\sum_{j\in\mathcal{S}\setminus\{i\}}p_{ij}\rho(\theta_i,\mathrm{e})=\biggl(\dfrac{1}{p_{ii}}-1\biggr)\rho(\theta_i,\mathrm{e}), \]
which simplifies to
 $ \theta_i\geq \mathrm{e}/p_{ii}$
. Taking logarithms from both sides of this inequality and using
$ \theta_i\geq \mathrm{e}/p_{ii}$
. Taking logarithms from both sides of this inequality and using
 $ q_{ii}^{\unicode{x1D7D9}}=1-\ln{\theta_i}$
, we arrive at
$ q_{ii}^{\unicode{x1D7D9}}=1-\ln{\theta_i}$
, we arrive at
 $ q_{ii}^{\unicode{x1D7D9}}\leq\ln{p_{ii}}=q_{ii}^{\mathrm{JLT}}$
.
$ q_{ii}^{\unicode{x1D7D9}}\leq\ln{p_{ii}}=q_{ii}^{\mathrm{JLT}}$
.
4.2. Transition matrices with identical diagonal entries
When the stochastic matrix
 $ \mathbf{P}$
has identical diagonal entries
$ \mathbf{P}$
has identical diagonal entries
 $ p_{ii}=p \gt 0$
, for all i, Proposition 3.6 indicates that the
$ p_{ii}=p \gt 0$
, for all i, Proposition 3.6 indicates that the
 ${\unicode{x1D7D9}}$
-generator can be explicitly represented as
${\unicode{x1D7D9}}$
-generator can be explicitly represented as
 \[\mathbf{Q}^{\unicode{x1D7D9}}=\frac{1}{p}(\mathbf{P}-\mathbf{I}),\]
\[\mathbf{Q}^{\unicode{x1D7D9}}=\frac{1}{p}(\mathbf{P}-\mathbf{I}),\]
with
 $ \mathbf{I}$
denoting the
$ \mathbf{I}$
denoting the
 $ n\times n$
identity matrix. Furthermore, by (4.1), we have
$ n\times n$
identity matrix. Furthermore, by (4.1), we have
 \[ \mathbf{Q}^{\text{JLT}} = \frac{\ln{p}}{p-1}(\mathbf{P}-\mathbf{I}).\]
\[ \mathbf{Q}^{\text{JLT}} = \frac{\ln{p}}{p-1}(\mathbf{P}-\mathbf{I}).\]
Both
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
and
$ \mathbf{Q}^{\unicode{x1D7D9}}$
and
 $ \mathbf{Q}^{\text{JLT}}$
share a similar structure; indeed, they can be expressed as
$ \mathbf{Q}^{\text{JLT}}$
share a similar structure; indeed, they can be expressed as
 \[\mathbf{Q}^{\unicode{x1D7D9}}=\mathbf{Q}\biggl(\frac{1}{p}\biggr)\quad\text{and}\quad\mathbf{Q}^{\text{JLT}}=\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr),\]
\[\mathbf{Q}^{\unicode{x1D7D9}}=\mathbf{Q}\biggl(\frac{1}{p}\biggr)\quad\text{and}\quad\mathbf{Q}^{\text{JLT}}=\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr),\]
where
 \begin{align}\mathbf{Q}(k)=k(\mathbf{P}-\mathbf{I}), \quad k\geq 0.\end{align}
\begin{align}\mathbf{Q}(k)=k(\mathbf{P}-\mathbf{I}), \quad k\geq 0.\end{align}
In this section, we explore which matrix, either
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
or
$ \mathbf{Q}^{\unicode{x1D7D9}}$
or
 $ \mathbf{Q}^{\text{JLT}}$
, is the better approximate generator of
$ \mathbf{Q}^{\text{JLT}}$
, is the better approximate generator of
 $ \mathbf{P}$
according to the infinity norm.
$ \mathbf{P}$
according to the infinity norm.
For the
 $ 2 \times 2$
case,
$ 2 \times 2$
case,
 \begin{equation*}\mathbf{P}= \left[\begin{array} {c@{\quad}c} p & 1-p \\[3pt] 1-p & p \end{array} \right]\!, \quad 0 \lt p \lt 1,\end{equation*}
\begin{equation*}\mathbf{P}= \left[\begin{array} {c@{\quad}c} p & 1-p \\[3pt] 1-p & p \end{array} \right]\!, \quad 0 \lt p \lt 1,\end{equation*}
it is known from [Reference Kingman24] that
 $ \mathbf{P}$
is embeddable if and only if its trace exceeds 1, i.e.
$ \mathbf{P}$
is embeddable if and only if its trace exceeds 1, i.e.
 $ p \gt \tfrac{1}{2}$
. The unique Markov generator of
$ p \gt \tfrac{1}{2}$
. The unique Markov generator of
 $ \mathbf{P}$
is then given by
$ \mathbf{P}$
is then given by
 \[\mathbf{Q}\biggl(\frac{\ln{(2p-1)}}{2(p-1)}\biggr);\]
\[\mathbf{Q}\biggl(\frac{\ln{(2p-1)}}{2(p-1)}\biggr);\]
see [Reference Singer and Spilerman28, p. 392]. If
 $ \mathbf{P}$
is not embeddable (
$ \mathbf{P}$
is not embeddable (
 $ p \leq \tfrac{1}{2}$
), it turns out that
$ p \leq \tfrac{1}{2}$
), it turns out that
 $ \|\mathbf{P}-\exp{\mathbf{Q}^{\unicode{x1D7D9}}}\|_{\infty} \lt \|\mathbf{P}-\exp{\mathbf{Q}^{\text{JLT}}}\|_{\infty}$
, an inequality that even holds for all
$ \|\mathbf{P}-\exp{\mathbf{Q}^{\unicode{x1D7D9}}}\|_{\infty} \lt \|\mathbf{P}-\exp{\mathbf{Q}^{\text{JLT}}}\|_{\infty}$
, an inequality that even holds for all
 $ p\in(0,1)$
. This is proved in Lemma A.8 in the Appendix.
$ p\in(0,1)$
. This is proved in Lemma A.8 in the Appendix.
For the
 $ n \times n$
case where
$ n \times n$
case where
 $ n\geq 3$
, the answer to our question seems no longer clear-cut. For instance, if
$ n\geq 3$
, the answer to our question seems no longer clear-cut. For instance, if
 \begin{align} \mathbf{P} = \left[\begin{array} {c@{\quad}c@{\quad}c} p & 1-p & 0 \\[3pt] \tfrac{1}{2}(1-p) & p & \tfrac{1}{2}(1-p) \\[3pt] 0 & 1-p & p \\[3pt] \end{array} \right]\!,\quad 0 \lt p \lt 1,\end{align}
\begin{align} \mathbf{P} = \left[\begin{array} {c@{\quad}c@{\quad}c} p & 1-p & 0 \\[3pt] \tfrac{1}{2}(1-p) & p & \tfrac{1}{2}(1-p) \\[3pt] 0 & 1-p & p \\[3pt] \end{array} \right]\!,\quad 0 \lt p \lt 1,\end{align}
we have
 $ \|\mathbf{P}-\exp{\mathbf{Q}^{\unicode{x1D7D9}}}\|_{\infty} \lt \|\mathbf{P}-\exp{\mathbf{Q}^{\text{JLT}}}\|_{\infty}$
; see Lemma A.9. However, if
$ \|\mathbf{P}-\exp{\mathbf{Q}^{\unicode{x1D7D9}}}\|_{\infty} \lt \|\mathbf{P}-\exp{\mathbf{Q}^{\text{JLT}}}\|_{\infty}$
; see Lemma A.9. However, if
 \begin{align} \mathbf{P} = \left[\begin{array} {c@{\quad}c@{\quad}c} p & 0 & 1-p \\[3pt] 0 & p & 1-p \\[3pt] 0 & 1-p & p \\[3pt]\end{array} \right]\!, \quad 0 \lt p \lt 1,\end{align}
\begin{align} \mathbf{P} = \left[\begin{array} {c@{\quad}c@{\quad}c} p & 0 & 1-p \\[3pt] 0 & p & 1-p \\[3pt] 0 & 1-p & p \\[3pt]\end{array} \right]\!, \quad 0 \lt p \lt 1,\end{align}
we have the reversed inequality, i.e.
 $ \|\mathbf{P}-\exp{\mathbf{Q}^{\unicode{x1D7D9}}}\|_{\infty} \gt \|\mathbf{P}-\exp{\mathbf{Q}^{\text{JLT}}}\|_{\infty}$
; see Lemma A.10. We note that the transition matrices of (4.6) and (4.7) are not embeddable, since for some
$ \|\mathbf{P}-\exp{\mathbf{Q}^{\unicode{x1D7D9}}}\|_{\infty} \gt \|\mathbf{P}-\exp{\mathbf{Q}^{\text{JLT}}}\|_{\infty}$
; see Lemma A.10. We note that the transition matrices of (4.6) and (4.7) are not embeddable, since for some
 $ i\neq j$
we have
$ i\neq j$
we have
 $ \mathbf{P}_{ij}=0$
but
$ \mathbf{P}_{ij}=0$
but
 $ (\mathbf{P}^2)_{ij} \gt 0$
; see [Reference Chung8, Theorem 5, p. 126], highlighting the importance of investigating
$ (\mathbf{P}^2)_{ij} \gt 0$
; see [Reference Chung8, Theorem 5, p. 126], highlighting the importance of investigating
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
and
$ \mathbf{Q}^{\unicode{x1D7D9}}$
and
 $ \mathbf{Q}^{\text{JLT}}$
as approximate Markov generators.
$ \mathbf{Q}^{\text{JLT}}$
as approximate Markov generators.
5. Discussion and future research avenues
From a one-jump perspective, we obtain a modified version of the Markov embedding problem, producing for each
 $ n\times n$
transition matrix
$ n\times n$
transition matrix
 $ \mathbf{P}$
having non-zero diagonal elements a unique rate matrix
$ \mathbf{P}$
having non-zero diagonal elements a unique rate matrix
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
. If
$ \mathbf{Q}^{\unicode{x1D7D9}}$
. If
 $ \mathbf{P}$
is embeddable, its Markov generator does not necessarily equal
$ \mathbf{P}$
is embeddable, its Markov generator does not necessarily equal
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
. However, if the one-jump assumption is acceptable, we might expect the Markov generator to be close to
$ \mathbf{Q}^{\unicode{x1D7D9}}$
. However, if the one-jump assumption is acceptable, we might expect the Markov generator to be close to
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
in some sense.
$ \mathbf{Q}^{\unicode{x1D7D9}}$
in some sense.
The existence and uniqueness of a
 ${\unicode{x1D7D9}}$
-generator is an advantage of our conditional embedding approach because neither regularization nor identification is needed. For some types of transition matrix (as in Proposition 3.6) there exists a closed form for the
${\unicode{x1D7D9}}$
-generator is an advantage of our conditional embedding approach because neither regularization nor identification is needed. For some types of transition matrix (as in Proposition 3.6) there exists a closed form for the
 ${\unicode{x1D7D9}}$
-generator; in other situations the
${\unicode{x1D7D9}}$
-generator; in other situations the
 ${\unicode{x1D7D9}}$
-generator can be determined based on Theorem 3.2.
${\unicode{x1D7D9}}$
-generator can be determined based on Theorem 3.2.
Comparing our conditional one-jump approach with that of Jarrow et al. in [Reference Jarrow, Lando and Turnbull18], we observe reduced discrepancies
 $ \|\mathbf{P}-\exp{\mathbf{Q}}\|_{\infty}$
for certain transition matrices
$ \|\mathbf{P}-\exp{\mathbf{Q}}\|_{\infty}$
for certain transition matrices
 $ \mathbf{P}$
when using
$ \mathbf{P}$
when using
 $ \mathbf{Q}=\mathbf{Q}^{\unicode{x1D7D9}}$
over
$ \mathbf{Q}=\mathbf{Q}^{\unicode{x1D7D9}}$
over
 $ \mathbf{Q}=\mathbf{Q}^{\text{JLT}}$
. Future research could focus on quantifying the improvements achieved by using
$ \mathbf{Q}=\mathbf{Q}^{\text{JLT}}$
. Future research could focus on quantifying the improvements achieved by using
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
over
$ \mathbf{Q}^{\unicode{x1D7D9}}$
over
 $ \mathbf{Q}^{\text{JLT}}$
. It would also be valuable to determine which transition matrices
$ \mathbf{Q}^{\text{JLT}}$
. It would also be valuable to determine which transition matrices
 $ \mathbf{P}$
are better approximately generated by
$ \mathbf{P}$
are better approximately generated by
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
compared to
$ \mathbf{Q}^{\unicode{x1D7D9}}$
compared to
 $ \mathbf{Q}^{\text{JLT}}$
. Furthermore, exploring how the deviations of
$ \mathbf{Q}^{\text{JLT}}$
. Furthermore, exploring how the deviations of
 $ \exp(\mathbf{Q}^{\unicode{x1D7D9}})$
and
$ \exp(\mathbf{Q}^{\unicode{x1D7D9}})$
and
 $ \exp(\mathbf{Q}^{\text{JLT}})$
from
$ \exp(\mathbf{Q}^{\text{JLT}})$
from
 $ \mathbf{P}$
vary with different matrix norms beyond the infinity norm used in this study could provide deeper insights. In addition to the comparison based on the discrepancies
$ \mathbf{P}$
vary with different matrix norms beyond the infinity norm used in this study could provide deeper insights. In addition to the comparison based on the discrepancies
 $ \|\mathbf{P}-\exp{\mathbf{Q}}\|_{\infty}$
, it would also be interesting to consider other criteria, such as the extent to which
$ \|\mathbf{P}-\exp{\mathbf{Q}}\|_{\infty}$
, it would also be interesting to consider other criteria, such as the extent to which
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
and
$ \mathbf{Q}^{\unicode{x1D7D9}}$
and
 $ \mathbf{Q}^{\text{JLT}}$
are in line with the specificity of the model. Moreover, for an embeddable transition matrix
$ \mathbf{Q}^{\text{JLT}}$
are in line with the specificity of the model. Moreover, for an embeddable transition matrix
 $ \mathbf{P}$
, a comparison of
$ \mathbf{P}$
, a comparison of
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
and
$ \mathbf{Q}^{\unicode{x1D7D9}}$
and
 $ \mathbf{Q}^{\text{JLT}}$
with the Markov generators of
$ \mathbf{Q}^{\text{JLT}}$
with the Markov generators of
 $ \mathbf{P}$
could be of interest.
$ \mathbf{P}$
could be of interest.
To study the dynamics of CTHMCs with Markov generators
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
and
$ \mathbf{Q}^{\unicode{x1D7D9}}$
and
 $ \mathbf{Q}^{\text{JLT}}$
, we can evaluate the mobility index
$ \mathbf{Q}^{\text{JLT}}$
, we can evaluate the mobility index
 $ M(\mathbf{Q}) = -\tfrac{1}{n}\mathrm{Tr}{\mathbf{Q}}$
(see [Reference Geweke, Marshall and Zarkin15]), where
$ M(\mathbf{Q}) = -\tfrac{1}{n}\mathrm{Tr}{\mathbf{Q}}$
(see [Reference Geweke, Marshall and Zarkin15]), where
 $ \mathbf{Q}$
is an
$ \mathbf{Q}$
is an
 $ n\times n$
rate matrix and
$ n\times n$
rate matrix and
 $ \mathrm{Tr}\mathbf{Q}$
its trace. Proposition 4.1 indicates
$ \mathrm{Tr}\mathbf{Q}$
its trace. Proposition 4.1 indicates
 $ M(\mathbf{Q}^{\unicode{x1D7D9}}) \gt M(\mathbf{Q}^{\text{JLT}})$
, suggesting more dynamic transitions in the CTHMC governed by
$ M(\mathbf{Q}^{\unicode{x1D7D9}}) \gt M(\mathbf{Q}^{\text{JLT}})$
, suggesting more dynamic transitions in the CTHMC governed by
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
. More comparative research on
$ \mathbf{Q}^{\unicode{x1D7D9}}$
. More comparative research on
 $ \mathbf{Q}^{\unicode{x1D7D9}}$
and
$ \mathbf{Q}^{\unicode{x1D7D9}}$
and
 $ \mathbf{Q}^{\text{JLT}}$
using other mobility indices would be valuable.
$ \mathbf{Q}^{\text{JLT}}$
using other mobility indices would be valuable.
Appendix. Lemmas and proofs
Lemma A.1.
The function f with
 $ f(t)=\mathrm{e}^{W_0(t)}$
,
$ f(t)=\mathrm{e}^{W_0(t)}$
,
 $ t\geq0$
, is strictly concave.
$ t\geq0$
, is strictly concave.
Proof. By taking second-order derivatives and since
 \[ W_0^{\prime}(t)=\frac{W_0(t)}{t(1+W_0(t))}\quad\text{and}\quad W_0^{\prime\prime}(t)=\frac{-2W_0(t)^2-W_0(t)^3}{t^2(1+W_0(t))^3} \]
\[ W_0^{\prime}(t)=\frac{W_0(t)}{t(1+W_0(t))}\quad\text{and}\quad W_0^{\prime\prime}(t)=\frac{-2W_0(t)^2-W_0(t)^3}{t^2(1+W_0(t))^3} \]
(see e.g. [Reference Dence11]), we find
 \[f^{\prime\prime}(t)=f(t)\bigl(W_0^{\prime}(t)^2+W_0^{\prime\prime}(t)\bigr)=f(t)\dfrac{-W_0(t)^2}{t^2(1+W_0(t))^3}, \]
\[f^{\prime\prime}(t)=f(t)\bigl(W_0^{\prime}(t)^2+W_0^{\prime\prime}(t)\bigr)=f(t)\dfrac{-W_0(t)^2}{t^2(1+W_0(t))^3}, \]
which is negative for all
 $ t \gt 0$
since
$ t \gt 0$
since
 $ W_0(t) \gt 0$
if
$ W_0(t) \gt 0$
if
 $ t \gt 0$
.
$ t \gt 0$
.
Let
 $ \mathbf{o}=(0,\ldots,0)\in\mathbb{R}^n$
. In what follows, we consider the partial ordering of
$ \mathbf{o}=(0,\ldots,0)\in\mathbb{R}^n$
. In what follows, we consider the partial ordering of
 $ \mathbb{R}^n$
induced by componentwise ordering. That is, if
$ \mathbb{R}^n$
induced by componentwise ordering. That is, if
 $ \mathbf{x}=(x_1,\ldots,x_n)\in\mathbb{R}^n,$
and
$ \mathbf{x}=(x_1,\ldots,x_n)\in\mathbb{R}^n,$
and
 $ \mathbf{y}=(y_1,\ldots,y_n)\in\mathbb{R}^n$
, we write
$ \mathbf{y}=(y_1,\ldots,y_n)\in\mathbb{R}^n$
, we write
 $ \mathbf{x}\preceq\mathbf{y}$
if and only if
$ \mathbf{x}\preceq\mathbf{y}$
if and only if
 $ x_i\leq y_i$
for all i. Likewise, we write
$ x_i\leq y_i$
for all i. Likewise, we write
 $ \mathbf{x}\succ\mathbf{o}$
if and only if
$ \mathbf{x}\succ\mathbf{o}$
if and only if
 $ x_i \gt 0$
for all i.
$ x_i \gt 0$
for all i.
Lemma A.2. The function
 $ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
, defined as in (3.1), satisfies the following properties:
$ \rho \colon \mathbb{R}_+^2\to\mathbb{R}_+$
, defined as in (3.1), satisfies the following properties:
-
(i)
 $ \rho$
is linearly homogeneous, i.e.
$ \rho(\lambda\mathbf{x})=\lambda\rho(\mathbf{x})$
for all
$ \mathbf{x}\in\mathbb{R}_+^2$
and
$ \lambda \gt 0$
,
$ \rho$
is linearly homogeneous, i.e.
$ \rho(\lambda\mathbf{x})=\lambda\rho(\mathbf{x})$
for all
$ \mathbf{x}\in\mathbb{R}_+^2$
and
$ \lambda \gt 0$
, -
(ii)
$ \rho$
is continuous on
$ \mathbb{R}_+^2$
, -
(iii)
$ \rho$
is increasing, i.e.
$ \rho(\mathbf{x})\leq\rho(\mathbf{y})$
for all
$ \mathbf{x},\mathbf{y}\in\mathbb{R}_+^2$
with
$ \mathbf{x}\preceq\mathbf{y}$
, -
(iv)
$ \min\{x,y\}\leq \rho(x,y)\leq\max\{x,y\}$
for all
$ (x,y)\in\mathbb{R}_+^2$
, -
(v)
$ \rho$
is concave.













Proof. Let
 $ \mathbf{u}=(u_1,u_2)\in\mathbb{R}_+^2$
. It is easy to see that
$ \mathbf{u}=(u_1,u_2)\in\mathbb{R}_+^2$
. It is easy to see that
 $ \rho(\mathbf{u})=u_2f(u_1/u_2)=u_1f(u_2/u_1)$
, where f is the continuous function defined by
$ \rho(\mathbf{u})=u_2f(u_1/u_2)=u_1f(u_2/u_1)$
, where f is the continuous function defined by
 \[ f(t)=\begin{cases} \dfrac{t\ln{t}}{t-1} & \text{if}\ t \gt 0\ \text{and}\ t \neq 1, \\[7pt] 1 & \text{if}\ t=1. \end{cases} \]
\[ f(t)=\begin{cases} \dfrac{t\ln{t}}{t-1} & \text{if}\ t \gt 0\ \text{and}\ t \neq 1, \\[7pt] 1 & \text{if}\ t=1. \end{cases} \]
Property (i) follows directly from the above. Property (ii) is a direct consequence of the above. For property (iii), by standard calculus, we have
 \[ f^{\prime}(t) = \begin{cases} \dfrac{t-1- \ln{t}}{(t-1)^2} & \text{if}\ t \gt 0\ \text{and}\ t \neq 1, \\[7pt] 1/2 & \text{if}\ t=1, \end{cases} \]
\[ f^{\prime}(t) = \begin{cases} \dfrac{t-1- \ln{t}}{(t-1)^2} & \text{if}\ t \gt 0\ \text{and}\ t \neq 1, \\[7pt] 1/2 & \text{if}\ t=1, \end{cases} \]
hence f is (strictly) increasing on the positive real half-line since
 $ \ln{t} \lt t-1$
for all
$ \ln{t} \lt t-1$
for all
 $ t \gt 0$
with
$ t \gt 0$
with
 $ t\neq 1$
. Now, take
$ t\neq 1$
. Now, take
 $ \mathbf{x}=(x_1,x_2)$
and
$ \mathbf{x}=(x_1,x_2)$
and
 $ \mathbf{y}=(y_1,y_2)$
, so that
$ \mathbf{y}=(y_1,y_2)$
, so that
 $ \mathbf{o}\prec\mathbf{x}\preceq\mathbf{y}$
. Then, as f is increasing,
$ \mathbf{o}\prec\mathbf{x}\preceq\mathbf{y}$
. Then, as f is increasing,
 $ \rho(\mathbf{x})=x_2f(x_1/x_2)\leq x_2f(y_1/x_2)=y_1f(x_2/y_1)\leq y_1f(y_2/y_1)=\rho(\mathbf{y})$
.
$ \rho(\mathbf{x})=x_2f(x_1/x_2)\leq x_2f(y_1/x_2)=y_1f(x_2/y_1)\leq y_1f(y_2/y_1)=\rho(\mathbf{y})$
.
(iv) Consider the case
 $ 0 \lt x\leq y$
. Since f is increasing on
$ 0 \lt x\leq y$
. Since f is increasing on
 $ \mathbb{R}_+$
, we have
$ \mathbb{R}_+$
, we have
 \[ x=xf(1)\leq xf(y/x)=\rho(x,y)=yf(x/y)\leq yf(1)=y. \]
\[ x=xf(1)\leq xf(y/x)=\rho(x,y)=yf(x/y)\leq yf(1)=y. \]
The result for the case
 $ 0 \lt y\leq x$
is proved analogously.
$ 0 \lt y\leq x$
is proved analogously.
(v) Since
 $ \rho(x,y)=x\rho(1,y/x)$
by the homogeneity property (i) from Lemma A.2,
$ \rho(x,y)=x\rho(1,y/x)$
by the homogeneity property (i) from Lemma A.2,
 $ \rho$
is the perspective of the continuous function
$ \rho$
is the perspective of the continuous function
 $ t\mapsto f(t)=\rho(1,t)$
. A straightforward computation reveals
$ t\mapsto f(t)=\rho(1,t)$
. A straightforward computation reveals
 \[ f^{\prime\prime}(t) = \frac{g(t)}{(t-1)^3}, \]
\[ f^{\prime\prime}(t) = \frac{g(t)}{(t-1)^3}, \]
where
 $ g(t) = {{1}/{t}}-t+2 \ln t$
. Since
$ g(t) = {{1}/{t}}-t+2 \ln t$
. Since
 \[ g^{\prime}(t) = -\frac{(t-1)^2}{t^2} \lt 0\quad\text{for all}\ t \gt 0, \]
\[ g^{\prime}(t) = -\frac{(t-1)^2}{t^2} \lt 0\quad\text{for all}\ t \gt 0, \]
we have
 $ g(t) \gt g(1) = 0$
for all
$ g(t) \gt g(1) = 0$
for all
 $ 0 \lt t \lt 1$
and
$ 0 \lt t \lt 1$
and
 $ g(t) \lt g(1)=0$
for all
$ g(t) \lt g(1)=0$
for all
 $ t \gt 1$
. Hence
$ t \gt 1$
. Hence
 $ f^{\prime\prime}(t) \lt 0$
for all
$ f^{\prime\prime}(t) \lt 0$
for all
 $ t \gt 0$
,
$ t \gt 0$
,
 $ t\neq 1$
. Therefore f is concave, so
$ t\neq 1$
. Therefore f is concave, so
 $ \rho$
is concave as the perspective of a concave function.
$ \rho$
is concave as the perspective of a concave function.
Lemma A.3.
The vector function
 $ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
from Proposition 3.2 is increasing, i.e.
$ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
from Proposition 3.2 is increasing, i.e.
 $ \mathbf{T}(\mathbf{x})\preceq\mathbf{T}(\mathbf{y})$
for all
$ \mathbf{T}(\mathbf{x})\preceq\mathbf{T}(\mathbf{y})$
for all
 $ \mathbf{x},\mathbf{y}\in\mathbb{R}_+^n$
with
$ \mathbf{x},\mathbf{y}\in\mathbb{R}_+^n$
with
 $ \mathbf{x}\preceq\mathbf{y}$
.
$ \mathbf{x}\preceq\mathbf{y}$
.
Proof. Let
 $ i\in\{1,\ldots,n\}$
and take
$ i\in\{1,\ldots,n\}$
and take
 $ \mathbf{x},\mathbf{y}\in\mathbb{R}_+^n$
so that
$ \mathbf{x},\mathbf{y}\in\mathbb{R}_+^n$
so that
 $ \mathbf{x}\preceq\mathbf{y}$
. Denote
$ \mathbf{x}\preceq\mathbf{y}$
. Denote
 \[ F_i(\mathbf{u})=\dfrac{1}{p_{ii}}\Biggl(\sum_{j=1}^{n} p_{ij}\rho(u_i,u_j)\Biggr) \quad \text{for}\ \mathbf{u}=(u_1,\ldots,u_n) . \]
\[ F_i(\mathbf{u})=\dfrac{1}{p_{ii}}\Biggl(\sum_{j=1}^{n} p_{ij}\rho(u_i,u_j)\Biggr) \quad \text{for}\ \mathbf{u}=(u_1,\ldots,u_n) . \]
By Lemma A.2(iii) we have
 $ F_i(\mathbf{x})\leq F_i(\mathbf{y})$
, which yields
$ F_i(\mathbf{x})\leq F_i(\mathbf{y})$
, which yields
 $ T_i(\mathbf{x})=\mathrm{e}^{W_0(F_i(\mathbf{x}))}\leq \mathrm{e}^{W_0(F_i(\mathbf{y}))}=T_i(\mathbf{y})$
since the principal branch
$ T_i(\mathbf{x})=\mathrm{e}^{W_0(F_i(\mathbf{x}))}\leq \mathrm{e}^{W_0(F_i(\mathbf{y}))}=T_i(\mathbf{y})$
since the principal branch
 $ W_0$
of the Lambert W function is increasing (see e.g. [Reference Corless, Gonnet, Hare, Jeffrey and Knuth9]).
$ W_0$
of the Lambert W function is increasing (see e.g. [Reference Corless, Gonnet, Hare, Jeffrey and Knuth9]).
Lemma A.4.
Let the vector function
 $ \mathbf{g} \colon \mathbb{R}_+^n\to\mathbb{R}^n$
given by
$ \mathbf{g} \colon \mathbb{R}_+^n\to\mathbb{R}^n$
given by
 $ \mathbf{g}(\mathbf{x})=\mathbf{T}(\mathbf{x})-\mathbf{x}$
for all
$ \mathbf{g}(\mathbf{x})=\mathbf{T}(\mathbf{x})-\mathbf{x}$
for all
 $ \mathbf{x}\succ\mathbf{o}$
, where the vector function
$ \mathbf{x}\succ\mathbf{o}$
, where the vector function
 $ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
is defined as in (3.2). Then
$ \mathbf{T} \colon \mathbb{R}_+^n\to\mathbb{R}_+^n$
is defined as in (3.2). Then
 $ \mathbf{g}=(g_1,\ldots,g_n)$
is
$ \mathbf{g}=(g_1,\ldots,g_n)$
is
-
(i) quasi-increasing, i.e. for all i it holds that
$ \mathbf{o}\prec\mathbf{x}\preceq\mathbf{y}$
and
$ x_i=y_i$
imply
$ g_i(\mathbf{x})\leq g_i(\mathbf{y})$
, -
(ii) strictly R-concave, i.e. if
$ \mathbf{x}\succ\mathbf{o}$
,
$ \mathbf{g}(\mathbf{x})=\mathbf{o}$
and
$ 0 \lt \lambda \lt 1$
, then
$ \mathbf{g}(\lambda\mathbf{x})\succ\mathbf{o}$
.







Proof. (i) Take
 $ i\in\{1,\ldots,n\}$
and suppose that
$ i\in\{1,\ldots,n\}$
and suppose that
 $ \mathbf{o}\prec\mathbf{x}\preceq\mathbf{y}$
with
$ \mathbf{o}\prec\mathbf{x}\preceq\mathbf{y}$
with
 $ x_i=y_i$
. Then
$ x_i=y_i$
. Then
 $ g_i(\mathbf{x})\leq g_i(\mathbf{y})$
, since
$ g_i(\mathbf{x})\leq g_i(\mathbf{y})$
, since
 $ x_i=y_i$
and
$ x_i=y_i$
and
 $ T_i(\mathbf{x})\leq T_i(\mathbf{y})$
(Lemma A.3).
$ T_i(\mathbf{x})\leq T_i(\mathbf{y})$
(Lemma A.3).
(ii) Let
 $ \mathbf{x}=(x_1,\ldots,x_n)\succ\mathbf{o}$
be such that
$ \mathbf{x}=(x_1,\ldots,x_n)\succ\mathbf{o}$
be such that
 $ \mathbf{g}(\mathbf{x})=\mathbf{o}$
. Let
$ \mathbf{g}(\mathbf{x})=\mathbf{o}$
. Let
 $ 0 \lt \lambda \lt 1$
and take
$ 0 \lt \lambda \lt 1$
and take
 $ i\in\{1,\ldots,n\}$
. Denote
$ i\in\{1,\ldots,n\}$
. Denote
 \[ F_i(\mathbf{x})=\frac{1}{p_{ii}}\Biggl(\sum_{j=1}^n p_{ij}\rho(x_i,x_j)\Biggr). \]
\[ F_i(\mathbf{x})=\frac{1}{p_{ii}}\Biggl(\sum_{j=1}^n p_{ij}\rho(x_i,x_j)\Biggr). \]
By Lemma A.2(i),
 $ F_i(\lambda\mathbf{x})=\lambda F_i(\mathbf{x})$
. Hence
$ F_i(\lambda\mathbf{x})=\lambda F_i(\mathbf{x})$
. Hence
 \[ T_i(\lambda\mathbf{x})=\mathrm{e}^{W_0(F_i(\lambda\mathbf{x}))}=\mathrm{e}^{W_0(\lambda F_i(\mathbf{x}))} \gt \lambda\mathrm{e}^{W_0(F_i(\mathbf{x}))}=\lambda T_i(\mathbf{x}), \]
\[ T_i(\lambda\mathbf{x})=\mathrm{e}^{W_0(F_i(\lambda\mathbf{x}))}=\mathrm{e}^{W_0(\lambda F_i(\mathbf{x}))} \gt \lambda\mathrm{e}^{W_0(F_i(\mathbf{x}))}=\lambda T_i(\mathbf{x}), \]
where the inequality follows from the fact that the function
 $ t\mapsto\mathrm{e}^{W_0(t)}$
is strictly concave (Lemma A.1) and
$ t\mapsto\mathrm{e}^{W_0(t)}$
is strictly concave (Lemma A.1) and
 $ W_0(0)=0$
. Consequently, for all i,
$ W_0(0)=0$
. Consequently, for all i,
 \[ g_i(\lambda\mathbf{x})=T_i(\lambda\mathbf{x})-\lambda x_i \gt \lambda(T_i(\mathbf{x})-x_i)=\lambda g_i(\mathbf{x})=0, \]
\[ g_i(\lambda\mathbf{x})=T_i(\lambda\mathbf{x})-\lambda x_i \gt \lambda(T_i(\mathbf{x})-x_i)=\lambda g_i(\mathbf{x})=0, \]
i.e.
 $ \mathbf{g}(\lambda\mathbf{x})\succ\mathbf{o}$
.
$ \mathbf{g}(\lambda\mathbf{x})\succ\mathbf{o}$
.
Lemma A.5.
For all
 $ 0 \lt p \lt 1$
, it holds that
$ 0 \lt p \lt 1$
, it holds that
-
(i)
$ 1+\mathrm{e}^{2-2/p}-2p \gt 0$
, -
(ii)
$ 1-\mathrm{e}^{1-1/p} \lt \tfrac{4}{3}(1-p)$
.


Proof. (i) Let
 $ f(t)=1+\mathrm{e}^{2-2/t}-2t$
, which is continuous on the half-open interval (0, 1]. A straightforward calculation reveals
$ f(t)=1+\mathrm{e}^{2-2/t}-2t$
, which is continuous on the half-open interval (0, 1]. A straightforward calculation reveals
 $ f^{\prime}(t)=2t^{-2}(\mathrm{e}^{2-2/t}-t^2)$
and
$ f^{\prime}(t)=2t^{-2}(\mathrm{e}^{2-2/t}-t^2)$
and
 $ f^{\prime\prime}(t)=4t^{-4}(1-t)\mathrm{e}^{2-2/t}$
. So,
$ f^{\prime\prime}(t)=4t^{-4}(1-t)\mathrm{e}^{2-2/t}$
. So,
 $ f^{\prime\prime}(t) \gt 0$
for all
$ f^{\prime\prime}(t) \gt 0$
for all
 $ t\in(0,1)$
. Consequently,
$ t\in(0,1)$
. Consequently,
 $ f^{\prime}(t) \lt 0$
for all
$ f^{\prime}(t) \lt 0$
for all
 $ t\in(0,1)$
because
$ t\in(0,1)$
because
 $ f^{\prime}$
increases monotonically on (0,1) and
$ f^{\prime}$
increases monotonically on (0,1) and
 $ f^{\prime}(1)=0$
. Hence f is monotonically decreasing on (0,1). The result now follows from the fact that
$ f^{\prime}(1)=0$
. Hence f is monotonically decreasing on (0,1). The result now follows from the fact that
 $ f(1)=0$
.
$ f(1)=0$
.
(ii) Consider the function
 $ f(t)=\tfrac{4}{3}(1-t)-1+\mathrm{e}^{1-1/t}$
which is differentiable on
$ f(t)=\tfrac{4}{3}(1-t)-1+\mathrm{e}^{1-1/t}$
which is differentiable on
 $ \mathbb{R}_+\setminus\{0\}$
. Let
$ \mathbb{R}_+\setminus\{0\}$
. Let
 $ p_0$
be a critical point of f, then
$ p_0$
be a critical point of f, then
 $ f^{\prime}(p_0)=-\tfrac{4}{3}+\mathrm{e}^{1-1/p_0}p_0^{-2}=0$
, yielding
$ f^{\prime}(p_0)=-\tfrac{4}{3}+\mathrm{e}^{1-1/p_0}p_0^{-2}=0$
, yielding
 $ \mathrm{e}^{1-1/p_0}=\tfrac{4}{3}p_0^2$
. Clearly
$ \mathrm{e}^{1-1/p_0}=\tfrac{4}{3}p_0^2$
. Clearly
 $ p_0\neq\tfrac{1}{2}$
, and hence
$ p_0\neq\tfrac{1}{2}$
, and hence
 \[ f(p_0)=\frac{4}{3}(1-p_0)-1+\frac{4}{3}p_0^2=\frac{4}{3}\biggl(\frac{1}{4}-p_0+p_0^2\biggr)=\frac{4}{3}\biggl(\frac{1}{2}-p_0\biggr)^2 \gt 0. \]
\[ f(p_0)=\frac{4}{3}(1-p_0)-1+\frac{4}{3}p_0^2=\frac{4}{3}\biggl(\frac{1}{4}-p_0+p_0^2\biggr)=\frac{4}{3}\biggl(\frac{1}{2}-p_0\biggr)^2 \gt 0. \]
So, all critical points of f have positive function values. In addition, we have
 $ f(1)=0$
and
$ f(1)=0$
and
 $ \lim_{t\to0^+}f(t)=1/3 \gt 0$
. Therefore
$ \lim_{t\to0^+}f(t)=1/3 \gt 0$
. Therefore
 $ f(t) \gt 0$
for all
$ f(t) \gt 0$
for all
 $ t\in(0,1)$
.
$ t\in(0,1)$
.
Lemma A.6.
For all
 $ x,y\geq 0$
,
$ x,y\geq 0$
,
 $ x\neq y$
, it holds that
$ x\neq y$
, it holds that
 \[ |\mathrm{e}^{W_0(x)}-\mathrm{e}^{W_0(y)}|\lt \frac{|x-y|}{1+\min\{W_0(x),W_0(y)\}}. \]
\[ |\mathrm{e}^{W_0(x)}-\mathrm{e}^{W_0(y)}|\lt \frac{|x-y|}{1+\min\{W_0(x),W_0(y)\}}. \]
Proof. Assume
 $ x, y \geq 0$
and
$ x, y \geq 0$
and
 $ x \neq y$
. To simplify, consider the function
$ x \neq y$
. To simplify, consider the function
 $ f(t) = {\mathrm{e}}^{W_0(t)}$
where
$ f(t) = {\mathrm{e}}^{W_0(t)}$
where
 $ t \geq 0$
. Given that
$ t \geq 0$
. Given that
 $ W_0$
is a monotonically increasing function, it follows that f is also increasing. Hence, according to the mean value theorem, there is a value c in the interval between x and y such that
$ W_0$
is a monotonically increasing function, it follows that f is also increasing. Hence, according to the mean value theorem, there is a value c in the interval between x and y such that
 \[ |f(x)-f(y)|=f^{\prime}(c)\cdot|x-y|. \]
\[ |f(x)-f(y)|=f^{\prime}(c)\cdot|x-y|. \]
It remains to be proved that
 \[ f^{\prime}(c)\lt \frac{1}{1+W_0(\min\{x,y\})}. \]
\[ f^{\prime}(c)\lt \frac{1}{1+W_0(\min\{x,y\})}. \]
Since
 \[ W_0^{\prime}(t)=\frac{W_0(t)}{t(1+W_0(t))} \]
\[ W_0^{\prime}(t)=\frac{W_0(t)}{t(1+W_0(t))} \]
(see [Reference Corless, Gonnet, Hare, Jeffrey and Knuth9]), we have
 \[ f^{\prime}(t)=\mathrm{e}^{W_0(t)}\dfrac{W_0(t)}{t(1+W_0(t))}=\dfrac{1}{1+W_0(t)}, \]
\[ f^{\prime}(t)=\mathrm{e}^{W_0(t)}\dfrac{W_0(t)}{t(1+W_0(t))}=\dfrac{1}{1+W_0(t)}, \]
where the last equality follows from the identity
 $ W_0(t)\mathrm{e}^{W_0(t)}=t$
. Hence, because
$ W_0(t)\mathrm{e}^{W_0(t)}=t$
. Hence, because
 $ W_0$
is an increasing function, we have
$ W_0$
is an increasing function, we have
 \begin{equation*} f^{\prime}(c)=\dfrac{1}{1+W_0(c)} \lt \dfrac{1}{1+W_0(\min\{x,y\})}=\dfrac{1}{1+\min\{W_0(x),W_0(y)\}}. \end{equation*}
\begin{equation*} f^{\prime}(c)=\dfrac{1}{1+W_0(c)} \lt \dfrac{1}{1+W_0(\min\{x,y\})}=\dfrac{1}{1+\min\{W_0(x),W_0(y)\}}. \end{equation*}
Lemma A.7.
Let
 $ \mathbf{P}=(p_{ij})$
be an
$ \mathbf{P}=(p_{ij})$
be an
 $ n\times n$
stochastic matrix such that
$ n\times n$
stochastic matrix such that
 $ p_{ii} \gt 0$
for all i. Let
$ p_{ii} \gt 0$
for all i. Let
 $ \delta=\min\{p_{ii},\,i\in\mathcal{S}\}$
. For all i and
$ \delta=\min\{p_{ii},\,i\in\mathcal{S}\}$
. For all i and
 $ \mathbf{x}=(x_1,\ldots,x_n)\in\mathbb{R}_+^n$
, denote
$ \mathbf{x}=(x_1,\ldots,x_n)\in\mathbb{R}_+^n$
, denote
 \begin{align} F_{i}(\mathbf{x})=\frac{1}{p_{ii}}\sum_{j=1}^{n}p_{ij}\rho(x_i,x_j) . \end{align}
\begin{align} F_{i}(\mathbf{x})=\frac{1}{p_{ii}}\sum_{j=1}^{n}p_{ij}\rho(x_i,x_j) . \end{align}
For
 $ m \gt 0$
and
$ m \gt 0$
and
 $ \alpha \gt 1$
, define the set
$ \alpha \gt 1$
, define the set
 \begin{align} \mathcal{X}_{m,\alpha}=\{(x_1,\ldots,x_n)\in\mathbb{R}^n \colon m\leq x_i \leq m\alpha\;\forall i\}. \end{align}
\begin{align} \mathcal{X}_{m,\alpha}=\{(x_1,\ldots,x_n)\in\mathbb{R}^n \colon m\leq x_i \leq m\alpha\;\forall i\}. \end{align}
Then
 \[ |F_{i}(\mathbf{x})-F_{i}(\mathbf{y})|\leq K\|\mathbf{x}-\mathbf{y}\|_{\infty}\quad for\ all\ \mathbf{x},\mathbf{y}\in \mathcal{X}_{m,\alpha}\ and\ for\ all\ \textit{i}, \]
\[ |F_{i}(\mathbf{x})-F_{i}(\mathbf{y})|\leq K\|\mathbf{x}-\mathbf{y}\|_{\infty}\quad for\ all\ \mathbf{x},\mathbf{y}\in \mathcal{X}_{m,\alpha}\ and\ for\ all\ \textit{i}, \]
where
 \[ K=1+\biggl(\frac{1}{\delta}-1\biggr)C(\alpha)\quad\textit{and}\quad C(\alpha)=-1+\frac{\alpha+1}{\alpha-1}\ln{\alpha}. \]
\[ K=1+\biggl(\frac{1}{\delta}-1\biggr)C(\alpha)\quad\textit{and}\quad C(\alpha)=-1+\frac{\alpha+1}{\alpha-1}\ln{\alpha}. \]
Proof. Take
 $ \mathbf{x},\mathbf{y}\in \mathcal{X}_{m,\alpha}$
and take
$ \mathbf{x},\mathbf{y}\in \mathcal{X}_{m,\alpha}$
and take
 $ i,j\in\{1,\ldots,n\}$
. If
$ i,j\in\{1,\ldots,n\}$
. If
 $ \rho(x_i,x_j)\leq \rho(y_i,y_j)$
, then, by concavity of the function
$ \rho(x_i,x_j)\leq \rho(y_i,y_j)$
, then, by concavity of the function
 $ \rho(x,y)$
and the fact that its partial derivatives are non-negative (as stated in Lemma A.2, items (v) and (iii)), it follows that
$ \rho(x,y)$
and the fact that its partial derivatives are non-negative (as stated in Lemma A.2, items (v) and (iii)), it follows that
 \begin{align*} |\rho(x_i,x_j)-\rho(y_i,y_j)|&=\rho(y_i,y_j)-\rho(x_i,x_j)\\[3pt] &\leq \frac{\partial \rho}{\partial x}(x_i,x_j)(y_i-x_i)+\frac{\partial \rho}{\partial y}(x_i,x_j)(y_j-x_j) \\[3pt] &\leq C\|\mathbf{x}-\mathbf{y}\|_{\infty} , \end{align*}
\begin{align*} |\rho(x_i,x_j)-\rho(y_i,y_j)|&=\rho(y_i,y_j)-\rho(x_i,x_j)\\[3pt] &\leq \frac{\partial \rho}{\partial x}(x_i,x_j)(y_i-x_i)+\frac{\partial \rho}{\partial y}(x_i,x_j)(y_j-x_j) \\[3pt] &\leq C\|\mathbf{x}-\mathbf{y}\|_{\infty} , \end{align*}
where
 \begin{align} C=\max\biggl\{\frac{\partial \rho}{\partial x}(u,v)+\frac{\partial \rho}{\partial y}(u,v) \colon m\leq u,v\leq m\alpha\biggr\}. \end{align}
\begin{align} C=\max\biggl\{\frac{\partial \rho}{\partial x}(u,v)+\frac{\partial \rho}{\partial y}(u,v) \colon m\leq u,v\leq m\alpha\biggr\}. \end{align}
Similarly, if
 $ \rho(x_i,x_j) \gt \rho(y_i,y_j)$
, the concave nature of the function
$ \rho(x_i,x_j) \gt \rho(y_i,y_j)$
, the concave nature of the function
 $ \rho$
along with the non-negativity of its partial derivatives imply
$ \rho$
along with the non-negativity of its partial derivatives imply
 \begin{align*} |\rho(x_i,x_j)-\rho(y_i,y_j)|&=\rho(x_i,x_j)-\rho(y_i,y_j)\\[3pt] &\leq \frac{\partial \rho}{\partial x}(y_i,y_j)(x_i-y_i)+\frac{\partial \rho}{\partial y}(y_i,y_j)(x_j-y_j) \\[3pt] &\leq C\|\mathbf{x}-\mathbf{y}\|_{\infty}. \end{align*}
\begin{align*} |\rho(x_i,x_j)-\rho(y_i,y_j)|&=\rho(x_i,x_j)-\rho(y_i,y_j)\\[3pt] &\leq \frac{\partial \rho}{\partial x}(y_i,y_j)(x_i-y_i)+\frac{\partial \rho}{\partial y}(y_i,y_j)(x_j-y_j) \\[3pt] &\leq C\|\mathbf{x}-\mathbf{y}\|_{\infty}. \end{align*}
Hence, since
 $ \mathbf{P}$
is a stochastic matrix,
$ \mathbf{P}$
is a stochastic matrix,
 \begin{align*} |F_i(\mathbf{x})-F_i(\mathbf{y})|&\leq\frac{1}{p_{ii}}\sum_{j=1}^{n}p_{ij}|\rho(x_i,x_j)-\rho(y_i,y_j)| \\[3pt] &\leq \frac{1}{p_{ii}} \Biggl(p_{ii}|x_i-y_i|+\sum_{j=1,j\neq i}^{n}p_{ij}|\rho(x_i,x_j)-\rho(y_i,y_j)|\Biggr)\\[3pt] &\leq \|\mathbf{x}-\mathbf{y}\|_{\infty} + \frac{1-p_{ii}}{p_{ii}}C\|\mathbf{x}-\mathbf{y}\|_{\infty}\\[3pt] &= \biggl(1+\biggl(\frac{1}{p_{ii}}-1\biggr)C\biggr)\|\mathbf{x}-\mathbf{y}\|_{\infty} \\[3pt] &\leq \biggl(1+\biggl(\frac{1}{\delta}-1\biggr)C\biggr)\|\mathbf{x}-\mathbf{y}\|_{\infty}. \end{align*}
\begin{align*} |F_i(\mathbf{x})-F_i(\mathbf{y})|&\leq\frac{1}{p_{ii}}\sum_{j=1}^{n}p_{ij}|\rho(x_i,x_j)-\rho(y_i,y_j)| \\[3pt] &\leq \frac{1}{p_{ii}} \Biggl(p_{ii}|x_i-y_i|+\sum_{j=1,j\neq i}^{n}p_{ij}|\rho(x_i,x_j)-\rho(y_i,y_j)|\Biggr)\\[3pt] &\leq \|\mathbf{x}-\mathbf{y}\|_{\infty} + \frac{1-p_{ii}}{p_{ii}}C\|\mathbf{x}-\mathbf{y}\|_{\infty}\\[3pt] &= \biggl(1+\biggl(\frac{1}{p_{ii}}-1\biggr)C\biggr)\|\mathbf{x}-\mathbf{y}\|_{\infty} \\[3pt] &\leq \biggl(1+\biggl(\frac{1}{\delta}-1\biggr)C\biggr)\|\mathbf{x}-\mathbf{y}\|_{\infty}. \end{align*}
It remains to be shown that
 \[C=C(\alpha)=-1+\frac{\alpha+1}{\alpha-1}\ln{\alpha}.\]
\[C=C(\alpha)=-1+\frac{\alpha+1}{\alpha-1}\ln{\alpha}.\]
For
 $ u \gt 0$
and
$ u \gt 0$
and
 $ v \gt 0$
, the homogeneity of the function
$ v \gt 0$
, the homogeneity of the function
 $ \rho$
(see Lemma A.2(i)) and a simple calculation of its partial derivatives entail
$ \rho$
(see Lemma A.2(i)) and a simple calculation of its partial derivatives entail
 \[ \frac{\partial \rho}{\partial x}(u,v)+\frac{\partial \rho}{\partial y}(u,v) = -1 + \frac{u+v}{uv}\rho(u,v) = -1 + \biggl(1+\frac{v}{u}\biggr)\rho\biggl(\frac{u}{v},1\biggr). \]
\[ \frac{\partial \rho}{\partial x}(u,v)+\frac{\partial \rho}{\partial y}(u,v) = -1 + \frac{u+v}{uv}\rho(u,v) = -1 + \biggl(1+\frac{v}{u}\biggr)\rho\biggl(\frac{u}{v},1\biggr). \]
Denoting
 $ t={{u}/{v}}$
and
$ t={{u}/{v}}$
and
 $ f(t)=(1+\tfrac{1}{t})\rho(t,1)$
, it then follows from (A.3) that
$ f(t)=(1+\tfrac{1}{t})\rho(t,1)$
, it then follows from (A.3) that
 \[ C=-1 + \max\biggl\{f(t) \colon \frac{1}{\alpha}\leq t \leq \alpha\biggr\} \]
\[ C=-1 + \max\biggl\{f(t) \colon \frac{1}{\alpha}\leq t \leq \alpha\biggr\} \]
Using (3.1), we obtain
 \[ f(t)=\begin{cases} \dfrac{t+1}{t-1}\ln{t} & \text{if } t \neq 1, \\[7pt] 2 & \text{if } t=1, \end{cases} \]
\[ f(t)=\begin{cases} \dfrac{t+1}{t-1}\ln{t} & \text{if } t \neq 1, \\[7pt] 2 & \text{if } t=1, \end{cases} \]
and by standard calculus, we find that
 $ \max\{f(t) \colon {{1}/{\alpha}}\leq t \leq \alpha\}=f(\alpha)$
. The proof is complete.
$ \max\{f(t) \colon {{1}/{\alpha}}\leq t \leq \alpha\}=f(\alpha)$
. The proof is complete.
Proof of Proposition 3.5. Let
 $ i\in\{1,\ldots,n\}$
and
$ i\in\{1,\ldots,n\}$
and
 $ \mathbf{x},\mathbf{y}\in \mathcal{X}$
. Using (3.2) and (A.1), we have
$ \mathbf{x},\mathbf{y}\in \mathcal{X}$
. Using (3.2) and (A.1), we have
 $ T_i(\mathbf{u})=\exp{W_0(F_i(\mathbf{u}))}$
for all
$ T_i(\mathbf{u})=\exp{W_0(F_i(\mathbf{u}))}$
for all
 $ \mathbf{u}\in\mathbb{R}_+^n$
. Since
$ \mathbf{u}\in\mathbb{R}_+^n$
. Since
 $ \mathbf{T}$
maps
$ \mathbf{T}$
maps
 $ \mathcal{X}$
into itself (see Lemma 3.1(ii)), we have
$ \mathcal{X}$
into itself (see Lemma 3.1(ii)), we have
 $ \min\{T_i(\mathbf{x}),T_i(\mathbf{y})\}\geq \mathrm{e}^{1/\Delta}$
, hence
$ \min\{T_i(\mathbf{x}),T_i(\mathbf{y})\}\geq \mathrm{e}^{1/\Delta}$
, hence
 $ \min\{W_0(F_i(\mathbf{x})),W_0(F_i(\mathbf{y}))\}\geq {{1}/{\Delta}}$
. Therefore, by Lemma A.6,
$ \min\{W_0(F_i(\mathbf{x})),W_0(F_i(\mathbf{y}))\}\geq {{1}/{\Delta}}$
. Therefore, by Lemma A.6,
 \[ |T_i(\mathbf{x})-T_i(\mathbf{y})|\leq \dfrac{|F_i(\mathbf{x})-F_i(\mathbf{y})|}{1+\min\{W_0(F_i(\mathbf{x})),W_0(F_i(\mathbf{y}))\}} \leq \dfrac{|F_i(\mathbf{x})-F_i(\mathbf{y})|}{1+{{1}/{\Delta}}} . \]
\[ |T_i(\mathbf{x})-T_i(\mathbf{y})|\leq \dfrac{|F_i(\mathbf{x})-F_i(\mathbf{y})|}{1+\min\{W_0(F_i(\mathbf{x})),W_0(F_i(\mathbf{y}))\}} \leq \dfrac{|F_i(\mathbf{x})-F_i(\mathbf{y})|}{1+{{1}/{\Delta}}} . \]
Denote
 $ m=\mathrm{e}^{1/\Delta}$
and
$ m=\mathrm{e}^{1/\Delta}$
and
 $ \alpha=\mathrm{e}^{{{1}/{\delta}}-{{1}/{\Delta}}}$
, then by (A.2),
$ \alpha=\mathrm{e}^{{{1}/{\delta}}-{{1}/{\Delta}}}$
, then by (A.2),
 $ \mathcal{X}=\mathcal{X}_{m,\alpha}$
. The proposition now follows from Lemma A.7.
$ \mathcal{X}=\mathcal{X}_{m,\alpha}$
. The proposition now follows from Lemma A.7.
Lemma A.8. Let
 \[ \mathbf{P} = \left[\begin{array}{c@{\quad}c} p & 1-p \\[3pt] 1-p & p \end{array}\right] \!,\quad 0 \lt p \lt 1, \]
\[ \mathbf{P} = \left[\begin{array}{c@{\quad}c} p & 1-p \\[3pt] 1-p & p \end{array}\right] \!,\quad 0 \lt p \lt 1, \]
and let
 $ \mathbf{Q}(k)$
be defined as in (4.5). Then
$ \mathbf{Q}(k)$
be defined as in (4.5). Then
 \[ \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty} \lt \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}. \]
\[ \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty} \lt \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}. \]
Proof. It can be shown (e.g. by using Lagrange–Sylvester interpolation to compute functions of matrices; see [Reference Gantmacher14]), that
 \[ \mathbf{P}-\exp{\mathbf{Q}(k)}= \biggl(\dfrac{1}{2}+\dfrac{{\mathrm{e}}^{2 k (p-1)}}{2}-p\biggr) \left[\begin{array}{c@{\quad}c} -1 & 1 \\[3pt]1 & -1\end{array}\right]\!, \]
\[ \mathbf{P}-\exp{\mathbf{Q}(k)}= \biggl(\dfrac{1}{2}+\dfrac{{\mathrm{e}}^{2 k (p-1)}}{2}-p\biggr) \left[\begin{array}{c@{\quad}c} -1 & 1 \\[3pt]1 & -1\end{array}\right]\!, \]
so that
 \[ \|\mathbf{P}-\exp{\mathbf{Q}(k)}\|_{\infty}=|f(k)|, \]
\[ \|\mathbf{P}-\exp{\mathbf{Q}(k)}\|_{\infty}=|f(k)|, \]
where
 $ f(k)=1+\mathrm{e}^{2k(p-1)}-2p$
. Since
$ f(k)=1+\mathrm{e}^{2k(p-1)}-2p$
. Since
 $ p \lt 1$
, the function f is strictly decreasing, hence
$ p \lt 1$
, the function f is strictly decreasing, hence
 \[ f\biggl(\frac{\ln{p}}{p-1}\biggr) \gt f\biggl(\frac{1}{p}\biggr). \]
\[ f\biggl(\frac{\ln{p}}{p-1}\biggr) \gt f\biggl(\frac{1}{p}\biggr). \]
Furthermore,
 $ f({{1}/{p}}) \gt 0$
by Lemma A.5(i). Consequently,
$ f({{1}/{p}}) \gt 0$
by Lemma A.5(i). Consequently,
 \begin{equation*} \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty}=f\biggl(\frac{1}{p}\biggr) \lt f\biggl(\frac{\ln{p}}{p-1}\biggr)=\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}. \end{equation*}
\begin{equation*} \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty}=f\biggl(\frac{1}{p}\biggr) \lt f\biggl(\frac{\ln{p}}{p-1}\biggr)=\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}. \end{equation*}
Lemma A.9. For
 \[ \mathbf{P} = \left[\begin{array}{c@{\quad}c@{\quad}c} p & 1-p & 0 \\[3pt] \tfrac{1}{2}(1-p) & p & \tfrac{1}{2}(1-p) \\[3pt] 0 & 1-p & p \\[3pt]\end{array}\right]\!,\quad 0 \lt p \lt 1,\]
\[ \mathbf{P} = \left[\begin{array}{c@{\quad}c@{\quad}c} p & 1-p & 0 \\[3pt] \tfrac{1}{2}(1-p) & p & \tfrac{1}{2}(1-p) \\[3pt] 0 & 1-p & p \\[3pt]\end{array}\right]\!,\quad 0 \lt p \lt 1,\]
and
 $ \mathbf{Q}(k)$
defined as in (4.5), it holds that
$ \mathbf{Q}(k)$
defined as in (4.5), it holds that
 \[ \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty} \lt \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}. \]
\[ \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty} \lt \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}. \]
Proof. It can be shown (e.g. by applying Sylvester’s theorem for computing functions of a matrix) that
 \[\mathbf{P}-\exp{\mathbf{Q}}(k) = \left[\begin{array}{c@{\quad}c@{\quad}c} -\alpha(k) & \beta(k) & \alpha(k)-\beta(k) \\[3pt] \frac{1}{2}\beta(k) & -\beta(k) & \frac{1}{2}\beta(k) \\[3pt] \alpha(k)-\beta(k) & \beta(k) & -\alpha(k)\end{array}\right]\!,\]
\[\mathbf{P}-\exp{\mathbf{Q}}(k) = \left[\begin{array}{c@{\quad}c@{\quad}c} -\alpha(k) & \beta(k) & \alpha(k)-\beta(k) \\[3pt] \frac{1}{2}\beta(k) & -\beta(k) & \frac{1}{2}\beta(k) \\[3pt] \alpha(k)-\beta(k) & \beta(k) & -\alpha(k)\end{array}\right]\!,\]
where
 \begin{align} \alpha(k)=\frac{1}{4}\,\gamma(k)^2+\frac{1}{2}\,\gamma(k)+\frac{1}{4}-p,\quad \beta(k)=\frac{1}{2}\,\gamma(k)^2+\frac{1}{2}-p ,\quad \gamma(k)=\mathrm{e}^{k(p-1)}.\end{align}
\begin{align} \alpha(k)=\frac{1}{4}\,\gamma(k)^2+\frac{1}{2}\,\gamma(k)+\frac{1}{4}-p,\quad \beta(k)=\frac{1}{2}\,\gamma(k)^2+\frac{1}{2}-p ,\quad \gamma(k)=\mathrm{e}^{k(p-1)}.\end{align}
A simple calculation reveals
 \begin{align} \alpha(k)-\beta(k)=-\frac{1}{4}(1-\gamma(k)^2),\end{align}
\begin{align} \alpha(k)-\beta(k)=-\frac{1}{4}(1-\gamma(k)^2),\end{align}
hence
 $ \alpha(k)-\beta(k)\leq 0$
. Therefore, by the triangle inequality,
$ \alpha(k)-\beta(k)\leq 0$
. Therefore, by the triangle inequality,
 \begin{align} \|\mathbf{P}-\exp{\mathbf{Q}(k)}\|_{\infty} =|\alpha(k)|+|\beta(k)|+\beta(k)-\alpha(k).\end{align}
\begin{align} \|\mathbf{P}-\exp{\mathbf{Q}(k)}\|_{\infty} =|\alpha(k)|+|\beta(k)|+\beta(k)-\alpha(k).\end{align}
Since
 \[\gamma\biggl(\frac{\ln{p}}{p-1}\biggr)=p,\]
\[\gamma\biggl(\frac{\ln{p}}{p-1}\biggr)=p,\]
we have
 \[\alpha\biggl(\frac{\ln{p}}{p-1}\biggr) \gt 0\quad\text{and}\quad\beta\biggl(\frac{\ln{p}}{p-1}\biggr) \gt 0,\]
\[\alpha\biggl(\frac{\ln{p}}{p-1}\biggr) \gt 0\quad\text{and}\quad\beta\biggl(\frac{\ln{p}}{p-1}\biggr) \gt 0,\]
so that (A.6) leads to
 \begin{align}\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}=2\beta\biggl(\frac{\ln{p}}{p-1}\biggr)=(1-p)^2.\end{align}
\begin{align}\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}=2\beta\biggl(\frac{\ln{p}}{p-1}\biggr)=(1-p)^2.\end{align}
Furthermore, Lemma A.5(i) entails that
 $ \beta({{1}/{p}}) \gt 0$
. We now need to consider two cases related to
$ \beta({{1}/{p}}) \gt 0$
. We now need to consider two cases related to
 $ \alpha({{1}/{p}})$
. If
$ \alpha({{1}/{p}})$
. If
 $ \alpha({{1}/{p}})\geq 0$
, we have by (A.6), (A.7) and the fact that
$ \alpha({{1}/{p}})\geq 0$
, we have by (A.6), (A.7) and the fact that
 $ \beta$
is strictly decreasing (because
$ \beta$
is strictly decreasing (because
 $ p \lt 1$
) that
$ p \lt 1$
) that
 \[\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty}=2\beta\biggl(\frac{1}{p}\biggr) \lt 2\beta\biggl(\frac{\ln{p}}{p-1}\biggr)=\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}.\]
\[\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty}=2\beta\biggl(\frac{1}{p}\biggr) \lt 2\beta\biggl(\frac{\ln{p}}{p-1}\biggr)=\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}.\]
When
 $ \alpha({{1}/{p}}) \lt 0$
, we have by (A.6) and (A.5)
$ \alpha({{1}/{p}}) \lt 0$
, we have by (A.6) and (A.5)
 \begin{equation*}\biggl\|\mathbf{P}-\exp{\mathbf{Q}}\biggl(\frac{1}{p}\biggr)\biggr\|_{\infty}=2\beta\biggl(\frac{1}{p}\biggr)-2\alpha\biggl(\frac{1}{p}\biggr)= \frac{1}{2}\biggl(1-\gamma\biggl(\frac{1}{p}\biggr)\biggr)^2.\end{equation*}
\begin{equation*}\biggl\|\mathbf{P}-\exp{\mathbf{Q}}\biggl(\frac{1}{p}\biggr)\biggr\|_{\infty}=2\beta\biggl(\frac{1}{p}\biggr)-2\alpha\biggl(\frac{1}{p}\biggr)= \frac{1}{2}\biggl(1-\gamma\biggl(\frac{1}{p}\biggr)\biggr)^2.\end{equation*}
By Lemma A.5(ii) and the assumption
 $ 0 \lt p \lt 1$
, we have
$ 0 \lt p \lt 1$
, we have
 $ 0 \lt 1-\gamma({{1}/{p}}) \lt \tfrac{4}{3}(1-p)$
. Hence
$ 0 \lt 1-\gamma({{1}/{p}}) \lt \tfrac{4}{3}(1-p)$
. Hence
 \[\biggl\|\mathbf{P}-\exp{\mathbf{Q}}\biggl(\frac{1}{p}\biggr)\biggr\|_{\infty} \lt \frac{8}{9}(1-p)^2 \lt (1-p)^2=\biggl\|\mathbf{P}-\exp{\mathbf{Q}}\biggl(\frac{\ln{p}}{p-1}\biggr)\biggr\|_{\infty}.\]
\[\biggl\|\mathbf{P}-\exp{\mathbf{Q}}\biggl(\frac{1}{p}\biggr)\biggr\|_{\infty} \lt \frac{8}{9}(1-p)^2 \lt (1-p)^2=\biggl\|\mathbf{P}-\exp{\mathbf{Q}}\biggl(\frac{\ln{p}}{p-1}\biggr)\biggr\|_{\infty}.\]
In either case, we have proved the result.
Lemma A.10. For
 \[ \mathbf{P} = \left[\begin{array}{c@{\quad}c@{\quad}c} p & 0 & 1-p \\[3pt] 0 & p & 1-p \\[3pt] 0 & 1-p & p \\[3pt]\end{array}\right]\!,\quad 0 \lt p \lt 1,\]
\[ \mathbf{P} = \left[\begin{array}{c@{\quad}c@{\quad}c} p & 0 & 1-p \\[3pt] 0 & p & 1-p \\[3pt] 0 & 1-p & p \\[3pt]\end{array}\right]\!,\quad 0 \lt p \lt 1,\]
and
 $ \mathbf{Q}(k)$
defined as in (4.5), it holds that
$ \mathbf{Q}(k)$
defined as in (4.5), it holds that
 \[ \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty} \gt \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}. \]
\[ \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty} \gt \biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}. \]
Proof. It can be shown (e.g. by applying Sylvester’s theorem for computing functions of a matrix) that
 \[\mathbf{P}-\exp{\mathbf{Q}}(k) = \left[\begin{array}{c@{\quad}c@{\quad}c} p-\gamma(k) & \gamma(k)-p-\beta(k) & \beta(k) \\[3pt] 0 & -\beta(k) & \beta(k) \\[3pt] 0 & \beta(k) & -\beta(k)\end{array}\right]\!,\]
\[\mathbf{P}-\exp{\mathbf{Q}}(k) = \left[\begin{array}{c@{\quad}c@{\quad}c} p-\gamma(k) & \gamma(k)-p-\beta(k) & \beta(k) \\[3pt] 0 & -\beta(k) & \beta(k) \\[3pt] 0 & \beta(k) & -\beta(k)\end{array}\right]\!,\]
where
 $ \beta(k)=\tfrac{1}{2}\,\gamma(k)^2+\tfrac{1}{2}-p$
and
$ \beta(k)=\tfrac{1}{2}\,\gamma(k)^2+\tfrac{1}{2}-p$
and
 $ \gamma(k)=\mathrm{e}^{k(p-1)}$
. Therefore, by the triangle inequality,
$ \gamma(k)=\mathrm{e}^{k(p-1)}$
. Therefore, by the triangle inequality,
 \begin{align} \|\mathbf{P}-\exp{\mathbf{Q}(k)}\|_{\infty} =|p-\gamma(k)|+|p-\gamma(k)+\beta(k)|+|\beta(k)|.\end{align}
\begin{align} \|\mathbf{P}-\exp{\mathbf{Q}(k)}\|_{\infty} =|p-\gamma(k)|+|p-\gamma(k)+\beta(k)|+|\beta(k)|.\end{align}
Let
 $ \delta(k)=(\gamma(k)-1)^2$
. Since
$ \delta(k)=(\gamma(k)-1)^2$
. Since
 \[\gamma\biggl(\frac{\ln{p}}{p-1}\biggr)=p,\]
\[\gamma\biggl(\frac{\ln{p}}{p-1}\biggr)=p,\]
we have
 \[\beta\biggl(\frac{\ln{p}}{p-1}\biggr)=\frac{1}{2}(p-1)^2 \gt 0,\]
\[\beta\biggl(\frac{\ln{p}}{p-1}\biggr)=\frac{1}{2}(p-1)^2 \gt 0,\]
so that (A.8) leads to
 \begin{align}\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}=2\beta\biggl(\frac{\ln{p}}{p-1}\biggr)=(p-1)^2=\delta\biggl(\frac{\ln{p}}{p-1}\biggr).\end{align}
\begin{align}\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{\ln{p}}{p-1}\biggr)}\biggr\|_{\infty}=2\beta\biggl(\frac{\ln{p}}{p-1}\biggr)=(p-1)^2=\delta\biggl(\frac{\ln{p}}{p-1}\biggr).\end{align}
Moreover, Lemma A.5(i) shows that
 $ \beta({{1}/{p}}) \gt 0$
. Also,
$ \beta({{1}/{p}}) \gt 0$
. Also,
 \[\gamma\biggl(\frac{1}{p}\biggr) \lt \gamma\biggl(\frac{\ln{p}}{p-1}\biggr)=p,\]
\[\gamma\biggl(\frac{1}{p}\biggr) \lt \gamma\biggl(\frac{\ln{p}}{p-1}\biggr)=p,\]
because
 $ \gamma$
is a strictly decreasing function of k. Thus it follows from (A.8) that
$ \gamma$
is a strictly decreasing function of k. Thus it follows from (A.8) that
 \[\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty}=2\biggl(p-\gamma\biggl(\frac{1}{p}\biggr)+\beta\biggl(\frac{1}{p}\biggr)\biggr)=\delta\biggl(\frac{1}{p}\biggr).\]
\[\biggl\|\mathbf{P}-\exp{\mathbf{Q}\biggl(\frac{1}{p}\biggr)}\biggr\|_{\infty}=2\biggl(p-\gamma\biggl(\frac{1}{p}\biggr)+\beta\biggl(\frac{1}{p}\biggr)\biggr)=\delta\biggl(\frac{1}{p}\biggr).\]
The proof is now complete because
 $ \delta$
is a strictly increasing function of k, leading to
$ \delta$
is a strictly increasing function of k, leading to
 \begin{equation*} \delta\biggl(\frac{\ln{p}}{p-1}\biggr) \lt \delta\biggl(\frac{1}{p}\biggr). \end{equation*}
\begin{equation*} \delta\biggl(\frac{\ln{p}}{p-1}\biggr) \lt \delta\biggl(\frac{1}{p}\biggr). \end{equation*}
Funding information
There are no funding bodies to thank relating to the creation of this article.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.






 Open access
Open access