



Introduction
One of the most intriguing questions posed in linguistic research over the past 40 years has been whether the human brain implements abstractions in the form of symbolic rules in the acquisition and processing of language. Although this question inspired a considerable amount of research on the nature of linguistic representations, whether linguistic productivity – in particular, at the level of inflection – involves rules that operate over variables or can be accounted for without recourse to explicit rules, solely by analogy, is yet to be resolved.
Linguistic research owes a great deal to the presence of irregularity in inflectional morphology in accounting for whether a rule-based or a rule-free, but analogy-based path is followed in the representation of linguistic knowledge. Irregularities in morphology embody a number of interesting properties that shed important light on the development of linguistic representations. At various stages of acquisition children are known to overregularize or irregularize grammatical morphemes, yielding grammatical errors. The path children follow in learning the morphemes and the errors they make have put them in the center of some heated debates about the neurocognitive reality of rules in acquisition. Of central concern in these debates is whether regular and irregular forms are a product of a single, analogy-based mechanism or are products of a dual mechanism where irregulars are analogy-based but regulars are rule-based. Formulated mostly to account for the acquisition and processing of the English past tense, two theoretical positions and various gradient offshoots of these positions that differ from each other in respect of how much they incorporate analogy and frequency to the model they advocate, stand out on the issue. According to the rule-based position, past tense inflection is a dual-route process involving a rule for regulars and an analogy-based mechanism for irregulars. In the earlier versions of the rule-based accounts, such as the Dual-route Model (Pinker & Prince, Reference Pinker and Prince1988; Marcus et al., Reference Marcus, Pinker, Ullman, Hollander, Rosen and Xu1992; Marcus, Reference Marcus1995, Reference Marcus1998, Reference Marcus2001; Prasada & Pinker, Reference Ramscar and Yarlett1993; Pinker, Reference Pinker1999, Reference Pinker and Dupoux2001; Pinker & Ullman, Reference Pinker and Ullman2002), regulars are viewed as products of a context-free deterministic rule that is insensitive to phonology and frequency effects; whereas irregulars are viewed as products of an associative process where phonology and frequency play key roles.
Countering the rule-based approach, the analogy-based approach advocates a model that accounts for the behavior of both regulars and irregulars by a single associative mechanism. In this model, morphology learning/ processing is explained not by instantiating deterministic rules but by means of probabilistic schemas that implicitly encode phonological similarities and effects of frequency (e.g., Schema-based model of Bybee & Slobin, Reference Bybee and Slobin1982; Bybee & Moder, Reference Bybee and Moder1983; Connectionist/Single-Route Models of Rumelhart & McClelland, Reference Sak, Güngör and Saraçlar1986; Alegre & Gordon, Reference Alegre and Gordon1999; Hahn & Chater, Reference Hahn and Chater1998; Hare, Elman & Daugherty, Reference Hare, Elman and Daugherty1995; McClelland & Patterson, Reference McClelland and Patterson2002; Meunier & Marslen-Wilson, Reference Meunier and Marslen-Wilson2004; Mirković, Seidenberg & Joanisse, Reference Mirković, Seidenberg and Joanisse2011; Nakisa, Plunkett & Hahn, Reference Nakisa, Plunkett, Hahn, Broeder and Murre2000; Plunkett & Marchman, Reference Prasada and Pinker1993).
Challenging these two positions, Albright and Hayes (Reference Albright and Hayes2003) propose a third approach which employs multiple rules and no analogy. By testing adult English speakers on novel stems Albright and Hayes contrast the predictions of a purely analogical-model against those of a model that employs rules; and finds out that a rule-based model always outperforms an analogical-model. More precisely, the results show that speakers do not rely on a single general rule for regulars, and instead use a mechanism that is sensitive to phonological contexts for both regulars and irregulars. The underperformance of the analogical-model is attributed to its reliance on a variegated notion of similarity according to which the model searches for stem-internal similarities between novel verbs and the analogous forms in the lexicon, in determining the past forms. A variegated notion of similarity, however, is observed to lead to poor results in predicting the allomorphic distribution. In the light of these considerations, Albright and Hayes advocate the Multiple-Rules Model, which, unlike the strict rule-based accounts, holds that rule application is not independent of the phonological properties of verbs and type frequency. These two crucial assumptions thus render the proposed model sensitive to both phonology and frequency.
The validity of the rule-based and analogy-based models has been checked against acquisition and adult processing data from various languages. The vast amount of cross-linguistic research conducted so far is far from converging to consensus. For example, because regulars generalize beyond similarity and exhibit a rule-driven generalization, some research advocates a rule-based approach: for example, on adults’ processing of English past tense (Marslen-Wilson, Hare & Older, Reference Marslen-Wilson, Hare and Older1995; Pinker, Reference Pinker1991, Reference Pinker1995); German plural (Marcus, Reference Marcus1995; Clahsen, Reference Clahsen1999); Portuguese verbs (Veríssimo & Clahsen, Reference Veríssimo and Clahsen2014), Hungarian plurals and past tense (Nemeth et al., Reference Nemeth, Janacsek, Turi, Lukacs, Peckham, Szanka, Gazso, Lovassy and Ullman2015); and acquisition of Spanish verbal inflection (Clahsen, Fraibet & Roca, Reference Clahsen, Fraibet and Roca2002).
Studies conducted in various other languages, however, support an analogy-based approach: such as in adults’ processing of Dutch plural (Keuleers et al., Reference Keuleers, Sandra, Daelemans, Gillis, Durieux and Martens2007); German plural (Hahn & Nakisa, Reference Hahn and Nakisa2000; Szagun, Reference Veríssimo and Clahsen2011; Penke & Krause, Reference Penke and Krause2002) – challenging the earlier rule-based analyses of Marcus (Reference Marcus1995) and Clahsen (Reference Clahsen1999) for German; Italian verbs (Orsolini & Marslen-Wilson, Reference Orsolini and Marslen-Wilson1997); French verbs (Meunier & Marslen-Wilson, Reference Meunier and Marslen-Wilson2004); Polish case-inflections (Dąbrowska, Reference Dąbrowska2008); and Serbian nominal inflections (Mirković et al., Reference Mirković, Seidenberg and Joanisse2011). Likewise, findings obtained in some recent studies lend support to analogy-driven generalizations in acquisition: such as production of novel verbs in English past tense (Blything, Ambridge & Lieven, Reference Blything, Ambridge and Lieven2018; Ambridge, Reference Ambridge2010); Finnish verbal inflections (Kirjavainen, Nikolaev & Kidd, Reference Kirjavainen, Nikolaev and Kidd2012; Räsänen, Ambridge & Pine, Reference Rumelhart, McClelland, McClelland and Rumelhart2016); and Estonian, Finnish, and Polish nominal inflections (Granlund et al., Reference Granlund, Kolak, Vihman, Engelmann, Lieven, Pine, Theakston and Ambridge2019).
Given the current state of affairs, whether acquisition and processing of inflectional morphology can be attributed to analogical mechanisms or to rules continues to be a matter of heated debate. In the present study we bring in acquisition data from an irregular pattern in Turkish. By testing 140 children from a wide age range (29 to 97 months) on an elicitation task, we show that in tackling the allomorphic distribution of the Turkish aorist, children employ an inductive learning mechanism. We further advocate that a proper account of the Turkish findings is possible only by combining various key aspects of the analogy-based and rule-based models. Let us begin by introducing the irregularity in the Turkish aorist.
The Turkish aorist
Turkish being an agglutinative language exhibits a rich array of inflectional morphemes that can be affixed to the verbs. In affirmative contexts a Turkish verb stem is immediately followed by a tense/ aspect/ modality (TAM) marker as in the so-called aorist in (1).Footnote 2

The morphological richness of Turkish coupled with the challenge imposed by vowel- harmony – for example in (1) the affix vowel has to agree with the immediately preceding vowel in frontness – can at first be deemed to give rise to an insurmountable acquisition effort. Yet, Turkish-speaking children appear to master the system early on with remarkable success (Aksu-Koç & Slobin, Reference Aksu-Koç, Slobin and Slobin1985). What appears to lie behind this early mastery of Turkish is a regular and rule-governed morpheme manifestation for most inflectional morphemes. There are, however, a few contexts where regularity is disrupted and this paper brings in evidence from one of them: namely, the aorist.
In Turkish, affixes fall into two types with respect to the vowels they contain: high-vowel affixes, i.e., those that contain /i/, /ı/, /u/, /ü/ ; and non-high-vowel affixes, i.e., those that contain /a/, /e/. The Turkish aorist behaves idiosyncratically in allowing both a high-vowel affix, i.e., -Ir (ir, ır, ür, ur) and a non-high-vowel affix, i.e., -Ar (ar, er), the former being used with consonant-final multisyllabic verbs and the latter with most monosyllabic verbs. Hence, multisyllabic verbs ending in consonants take one of the variants of -Ir, as in (2). For example, if the last vowel of the stem is front /e/ as in diren- ‘resist’, the aorist surfaces with a high, front, unrounded vowel – hence, –ir; if it is back and rounded as in /u/ in otur- ‘sit’, the suffix manifests itself as -ur – hence, with a back and rounded vowel.

The majority of consonant-ending monosyllabic verbs select one of the -Ar variants as determined by the non-high vowel-harmony rule. As shown in example (3), the non-back/back vowels of the stems necessitate the suffix to surface with a front vowel, -er or a back vowel -ar, respectively.

Finally, any vowel-ending verb, regardless of the number of its syllables, selects –r, as in (4).

This rule-governed distribution where vowel-final multisyllabics occur with the suffix –r, consonant-final multisyllabics with the suffix –Ir, and monosyllabics with -Ar, however, is obscured by the presence of 13 monosyllabic verbs that behave in a peculiar way. In contrast to the majority, the 13 verbs listed in (5), take -Ir rather than -Ar.

One property that these verbs have in common is that they all end in sonorants – in particular, the liquids /l, r/ and the nasal /n/. Though at first blush, this pattern appears to serve as a cue that one can rely on in predicting the form of the aorist allomorph, the presence of 47 other sonorant-ending monosyllabic verbs that require -Ar in Turkish excludes this hypothesis. Some examples of sonorant-ending -Ar-taking verbs are given in (6):

This peculiarity of the Turkish aorist presents an interesting problem from an acquisition perspective. In a nutshell, the child, when learning the aorist, has to tackle why some monosyllabic verbs that share the same phonological rhyme as in the examples in (7) surface with -Ir and -Ar.
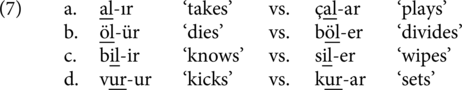
Given the nature of the question this paper aims to address, before turning to our study, it is important to complement the above illustration of the allomorphic distribution of the aorist with frequency information. The type and token counts of the aorist in the largest available online Turkish corpus, the BOUN Corpus (Sak, Güngör & Saraçlar, 2008) show that, overall, in Turkish -Ar has a higher type (218) and token frequency (975,005) with monosyllabic roots. -Ir is more prevalent both in type (9420) and in token (2,607,320) with multisyllabic verbs (Michon, Reference Michon2017). In particular, of the 231 monosyllabic verbs, 13 are -Ir types, where all the roots are sonorant-ending; 218 are -Ar types, where only 47 are sonorant-ending (see Appendix A for frequency counts of monosyllabic and multisyllabic verbs in Turkish).
The present study
Given the allomorphic distribution of the Turkish aorist, it is quite unlikely that children would experience an error-free acquisition path. We conjecture that the learnability puzzle the aorist presents can be tackled if the child’s learning experience is viewed as entertaining specific hypotheses within a space of possibilities determined by the structural properties the aorist brings about, such as the syllable count, the sonority of the final consonant, and frequency counts of the allomorphs.
As the distribution of the aorist reveals, to master the form the child has to observe that monosyllabic and multisyllabic verbs exhibit different behaviors; in particular, consonant-final multisyllabic verbs irrespective of the phonological properties of the final consonant take -Ir. In doing so, the child will initially be able to constrain the space of hypotheses that she entertains with monosyllabic verbs. During acquisition, a number of further assumptions are called for to learn the aorist. In particular, the child has to question what gives rise to the distributional asymmetry within monosyllabic verb: that is, s/he must puzzle over why some monosyllabic verbs take -Ir, while the majority of monosyllabic verbs take -Ar, – let us refer to the latter as the regular suffix just on the basis of type count.
A hastily drawn conclusion that the problem resides in the sonorant-ending verbs can mislead the child into thinking that s/he should narrow the problem space down to all sonorant-ending monosyllabic verbs. As not all sonorant-ending monosyllabic verbs exhibit irregularity and take -Ir, such a conclusion will be false and yield errors with sonorant-ending regularly behaving verbs. Subsequently, the child has to figure out that the idiosyncratic behavior of the 13 verbs does not owe to the sonority of the final consonant and cannot be accounted for plausibly in phonological terms.
Armed with these insights, we attempt to unpack the nature of the constraints under which a Turkish-speaking child would operate in order to acquire the aorist. The inferences that the child has to make allow us to formulate the specific hypotheses below about the acquisition path the child may follow:
-
i. If children are sensitive to phonology they would pay attention to the syllable count and dissociate between monosyllabic and multisyllabic verbs. Such a dissociation would lead to fewer errors on multisyllabic verbs as opposed to monosyllabics, as multisyllabic verbs do not exhibit any irregularity. That said, children may still experience difficulty in zeroing in on the affix that attaches to multisyllabic verbs and produce errors like *tırman-ar for tırman-ır ‘climbs’.
-
ii. Sensitivity to phonology would further assist children in dissociating among verbs with respect to whether they are sonorant- or non-sonorant-ending: thus, if children pay attention to the sonority of the stem-final consonant one would expect them to err more on sonorant-ending verbs as irregular verbs are all sonorant-final.
-
iii. As only 13 out of 231 monosyllabic verbs exhibit irregularity and take -Ir in Turkish, it is highly probable that, during acquisition, irregular verbs are produced as regular ones, thereby giving rise to overregularization errors, (i.e., -Ir > *-Ar), such as *al-ar for al-ır ‘takes’ and *öl-er for öl-ür ‘dies’.
-
iv. As irregular verbs are sonorant-ending, children may hypothesize that all sonorant-ending monosyllabic verbs would exhibit irregularity. Such a prediction, however, would be misleading, as there are 47 other sonorant-ending monosyllabic verbs that take the regular -Ar form. We, therefore predict that children may irregularize the sonorant-ending regularly behaving verbs, and produce irregularization errors (i.e., -Ar > *-Ir) such as *dal-ır for dal-ar ‘dives’, *gül-ür for gül-er ‘laughs’.
-
v. Children may also hypothesize that all monosyllabic verbs, regardless of whether they end in sonorants or not, occur with -Ir on the basis of the overall type and token count of -Ir in Turkish and produce irregularization errors on non-sonorant-ending regular monosyllabics (i.e., -Ar > *-Ir) such as *at-ır for at-ar ‘throws’, *tut-ur for tut-ar ‘holds’.
In learning the aorist if children employ inductive generalizations on the basis of the phonological features of the data that would suggest that children are sensitive to phonology and use structural features to tackle the allomorphs. Phonological contexts relevant to the distribution of the allomorphs can be located by carrying out similarity comparisons between stored exemplars. Thus adherence to structure has to be driven by analogy at the outset. Any overregularizations on -Ir-taking verbs or irregularizations on -Ar-taking verbs, if proven to be based on the type-frequency of the respective morphemes, would be evidence for a rule-driven generalization. To the contrary, any finding that suggests that errors can be unambiguously associated with stored analogous exemplars in Turkish would lend support to an analogy-driven generalization. With these predictions in place, we proceed to illustrate the method we implemented in testing the Turkish-speaking children on the use of aorist.
Method
Participants
142 children (67 girls and 75 boys) ranging in age from 29 to 97 months (M = 64.1, SD = 18.8) participated in the study. The children were recruited and tested at four day-care centers and one elementary school in İstanbul, Turkey. All children were monolingual Turkish speakers and came from upper middle-class families.
Materials and procedure
In order to elicit an aorist attached verb, we used a picture description and an elicited production task. An experimenter tested the children individually and the sessions were audio-recorded. Informed consent was obtained from the parents of all the children (ID 5075). The stimuli used in the picture description task consisted of 25 hand-drawn and colored pictures that depicted characters engaged in activities such as playing an instrument, swinging, etc., and were presented to the children in a random order. The participants were expected to use the verb that the description of a particular activity required. In the elicited production task, the children were given scenarios, where they were asked to either make a specific request (e.g., by saying, ‘Your friend is very loud, ask her to be quieter’ to elicit the irregular ol- ‘be’), or comment on the outcome of a particular event (e.g., by asking ‘What happens if you do not water a plant?’ to elicit the irregular verb öl- ‘die’ and the regular sol- ‘fade’). Five monolingual adult controls were tested on the stimuli before the tasks were administered to children. Adult controls had a success rate of 100% illustrating that the test items were successful in eliciting the aorist attached forms.
Before the experiment was administered, the children completed a warm-up trial where they were required to use the appropriate tense marker. The present study attempted to elicit
-
a. 9 Ir-taking monosyllabic verbs ending in the sonorants /l, r/;
-
b. 9 Ar-taking monosyllabic verbs ending in the sonorants /l, n, r/;
-
c. 7 Ar-taking monosyllabic verbs ending in non-sonorants;
-
d. 7 Ir-taking multisyllabic verbs.
As is apparent, of the 13 irregular verbs, nine were included in the stimuli set. The irregular verbs bil ‘know’ and gel ‘come’ were excluded as they were difficult to elicit in a context that required an aorist; var ‘arrive’ was excluded as it is a low frequency verb and unlikely to be elicited from the children and san ‘think’ was excluded as it is a mental-state verb that children start using late in acquisition. The warm-up trial, test stimuli, a sample protocol and sample test items are provided in Appendix B.
Transcription and coding
Three linguistics graduate students who were also the experimenters transcribed children’s responses. The authors of the study later coded the transcribed data. The responses the children gave were coded as correct if the child produced
-
i. -Ar for -Ar-taking (regular) monosyllabic verbs;
-
ii. -Ir for -Ir-taking (irregular) monosyllabic verbs;
-
iii. -Ir for multisyllabic verbs.
The responses were coded as incorrect if the child produced
-
i. -Ar for -Ir-taking monosyllabic verbs (overregularization errors);
-
ii. -Ir for -Ar-taking monosyllabic verbs (irregularization errors);
-
iii. -Ar for multisyllabic verbs.
If children failed to respond to a question, or if the targeted verb was replaced by another verb (e.g., yat ‘lie down’ was replaced by uyu ‘sleep’) or a tense marker (e.g., use of progressive aspect instead of aorist) in children’s productions, the responses were coded as unscorable. A sizable percentage of unscorable responses were produced by three- and four-year-olds.
Data analysis
To test our hypotheses, we conducted mixed effects analyses since mixed effects models enable the inclusion of subject- and item-related factors that may affect the outcomes (Baayen, Reference Baayen2008). Mixed effects logistic regression models were built with the lme4 package (Bates et al., Reference Bates, Maechler, Bolker and Walker2015) in R (R Core Team, 2013). As a continuous predictor, age (in months) was scaled to avoid model convergence problems (Brown, Reference Brown2021). For each outcome variable, multiple models were built that include a different combination of fixed and random effects. The best fitted model was selected based on likelihood ratio test comparisons. In these comparisons, we first compared models having the same fixed effect but different random effect structures. The model that provided the best fit was then compared to another model that further included an interaction between the fixed effects. Based on these comparisons, the model that provided the best fit for the data was selected. For the selected models, significance values of categorical predictors were obtained with the simr package (Green & MacLeod, Reference Green and MacLeod2016). To explore the interactions between categorical and continuous predictors, the interactions package was used (Long, Reference Long2019). Finally, the emmeans package was used to run post-hoc pairwise comparisons for categorical variables (Lenth, Reference Lenth2020). The data of two children (aged 2;5 and 5;4) were not entered into the analyses since these children were outliers in terms of their correct response rates (i.e., lower than mean-3*SD of the whole group). For the remaining children, a total of 869 multisyllabic verbs out of 980 test items and 3102 monosyllabic verbs out of 3500 items were elicited. A total of 111 responses (11%) in multisyllabic verbs and 398 (11%) in monosyllabic verbs were unscorable. Since such unscorable responses were not errors, they were treated as missing data and were not entered into the analyses. Finally, to explore whether errors were analogy-driven or not we looked into the type/token count of the stored -Ar exemplars, -Ir exemplars and analogous n-grams that overlap with the erroneous generalizations. The data file and the analysis script can be found at https://osf.io/4cnsk/.
Results and discussion
Turkish is widely known to display an almost error-free acquisition path (Aksu-Koç & Slobin, Reference Aksu-Koç, Slobin and Slobin1985). Our findings, however, show that what at first sight appears to be a minor irregularity, affecting only a small set of verbs, gives rise to a sizable number of errors. The overall results indicate that Turkish-speaking children show a non-adult-like performance with respect to the use of the aorist until the age of 8. In what follows, we will first look into the children’s performance on multisyllabic verbs as opposed to monosyllabic verbs, then we will examine monosyllabic verbs – in particular, how children performed on sonorant-ending monosyllabic verbs as opposed to non-sonorant-ending ones. Finally, we will turn to a discussion of the overregularization and irregularization errors children produced with sonorant-ending monosyllabic verbs by examining to what extent neighboring -Ir/-Ar types for each verb, and n-grams that overlap with the syllable rhymes and -Ir/-Ar types serve as platforms for analogization.
Multisyllabic verbs vs. monosyllabic verbs
According to our first hypothesis, we expected children to produce more erroneous responses on monosyllabic compared to multisyllabic verbs since multisyllabic verbs do not exhibit any irregularity. Supporting our hypothesis, children’s error rate on multisyllabic verbs was 4.8% (827 correct and 42 incorrect responses), while their error rate on monosyllabic verbs was 18.8% (2518 correct and 584 incorrect responses).
To analyze whether the error rate differed with respect to the verb being monosyllabic or multisyllabic and children’s age, we constructed mixed effects logistic regression models with the response being correct or incorrect as the outcome variable. Four children were excluded for being outliers on monosyllabic or multisyllabic verbs (i.e., correct response rate < mean - 3*SD). In the first step, we compared regression models that had verb type (i.e., monosyllabic/multisyllabic) and age as fixed effects, and different random effect structures. Table 1 provides information about the models. The best fitted model (Model 1b) had by-item random intercepts, and by-participants random slopes for verb type. Adding the verb type*age interaction to this model (AIC = 2666, BIC = 2716) did not lead to a significant improvement in model fit, χ2(1) = 0.12, p = .73. In line with our hypothesis, in Model 1b, children provided more correct responses on multisyllabic compared to monosyllabic verbs (estimate = -7.48, SE = 1.06, p < .001). Children also provided more correct responses with increasing age (estimate = 0.55, SE = 0.07, p < .001).
Table 1. Model Comparisons between Mixed Effects Regression Models with Different Predictors.

Note. * denotes the model that is selected for interpretation based on model comparisons with likelihood ratio tests. AIC = Akaike information criterion, BIC = Bayesian information criterion.
Low error rates on multisyllabic verbs compared to significantly higher rates of errors on monosyllabic verbs suggest that children reduce the search space for irregularity to monosyllabic verbs from early on. In what follows, we turn to an in-depth analysis of children’s performance with monosyllabic verbs.
Monosyllabic verbs
From an acquisition perspective, the crux of the problem appears to be the monosyllabic verbs: in particular, the sonorant-ending monosyllabic roots. We expected children to produce more errors on sonorant-ending compared to non-sonorant-ending monosyllabic verbs. In line with this prediction, we observed an error rate of 5% on non-sonorant-ending monosyllabic verbs (788 correct and 41 incorrect responses) and an error rate of 23.9% (1730 correct and 543 incorrect responses) on sonorant-ending monosyllabic verbs. We followed up on this difference by conducting mixed effects analysis. For this analysis, three children were excluded based on their low (i.e., lower than mean-3*SD) correct response rates on non-sonorant monosyllabic verbs. The best fitted model (Model 2c) to explain the differences in responses in sonorant versus non-sonorant-ending monosyllabic verbs included both the verb type (i.e., sonorant vs. non-sonorant-ending) and age as fixed effects, by-participant random intercepts, and by-item random slopes for age. The model that further included verb type*age interaction did not lead to a significant improvement in model fit, χ2(1) = 0.29, p = .59: thus Model 2c was preferred. According to this model, children gave more incorrect responses on sonorant- compared to non-sonorant-ending verbs (estimate = -2.02, SE = 0.41, p < .001). As expected, children’s correct responses increased with age (estimate = 0.68, SE = 0.10, p < .001). This difference in error rates suggests that the final consonant of the root is a phonological cue that children rely on in dissociating between regulars and irregulars.
So far, the results show that in learning the aorist, Turkish-speaking children make significantly more errors on monosyllabic verbs as opposed to multisyllabic verbs and that within monosyllabic verbs they make more errors with sonorant-ending monosyllabics as opposed to non-sonorant-ending ones (see Figure 1).

Figure 1. The distribution of errors on multisyllabic, non-sonorant- and sonorant-ending monosyllabic verbs with respect to age. Error bars denote standard error.
The distribution of errors clearly suggests that the domain of hypotheses children entertain is narrowed down over time initially by dissociating between multisyllabic and monosyllabic verbs and perhaps simultaneously, between non-sonorant-ending and sonorant-ending monosyllabic verbs. The path children follow in learning the aorist clearly suggests that they are sensitive to the syllable count and the sonority of the root-final consonant, and adhere to featural properties that they can only tap into by making similarity comparisons between analogous exemplars. In addressing the question of how similarity comparisons are made and what comparisons between aorist attached forms may involve, we will adopt the key assumptions of the theory of structural alignment which is invoked to explain similarity in various cognitive domains (Gentner, Reference Gentner1983; Markman & Gentner, Reference Markman and Gentner1993, Reference Markman and Gentner2000; Gentner & Hoyos, Reference Gentner and Hoyos2017; Krawczyk, Holyoak & Hummel, Reference Krawczyk, Holyoak and Hummel2005) and, in particular, word similarity (Goldstone, Reference Goldstone1994a, Reference Goldstone1994b; Hahn & Bailey, Reference Hahn and Bailey2005 among others). According to this view, comparisons between mental representations involve an alignment process where corresponding components are identified based on their featural and structural properties. In the case of the aorist-bearing monosyllabic verbs, the featural property the Turkish-speaking children adhere to in delineating the corresponding components is the (non-)sonority of the root-final consonant and the structural/hierarchical property is the rhyme, i.e., the nucleus and the coda of the monosyllabic verb. When a child is engaged in similarity comparisons for monosyllabics, as similarity between words depends on comparisons between aligned parts, the rhyme stands out as the aligned part for the monosyllabics. The aligned part for al (‘take’) and çal (‘play’), for example, directs the child’s attention to the variation in the aorist attached forms i.e., -Ir vs. -Ar in al-ır and çal-ar. However, when the root-final consonant is non-sonorant, as in the monosyllabic at ‘throw’, it is the absence of the sequence (x)at-ır as an aorist attached form in the input that assists the child in rapidly extracting the licit -Ar type for the non-sonorant-ending monosyllabic verbs. As a result, the child infers that only in the environment of monosyllabics with root-final sonorants, the aorist morpheme exhibits variation. Furthermore, the sequence (x)at-ır partially overlapping with multisyllabic verbs e.g., anlat-ır ‘tells’, yarat-ır ‘creates’ can provide grounds for a similarity comparison between the monosyllabic at-ar ‘throws’ and the multisyllabics anlat-ır, yarat-ır and serve as a cue the child uses to dissociate between these verbs and to conclude that a multisyllabic is always affixed an -Ir and a non-sonorant-ending monosyllabic, an -Ar. We conjecture that it is through such similarity comparisons the child draws on patterns relevant for the distribution of monosyllabic verbs, i.e., (non)-sonority of the root-final consonant; and for multisyllabic verbs, i.e., syllable count of the root and learns to preserve the relevant information. Thereafter, the child’s cognitive system must be maintaining this salient frequency distribution (i.e., -Ir for multisyllabics, -Ar for non-sonorant-ending monosyllabics). Furthermore, similarity comparisons and sensitivity to phonology suggest that the developing morphological system is driven by analogy at the outset.
The asymmetry in the acquisition of sonorant- vs. non-sonorant-ending monosyllabic verbs further reveals that children attend to type frequency to untangle the behavior of regulars, (i.e., non-sonorant-ending verbs are always regular and take -Ar – hence, the fewer errors); and that they have an implicit knowledge of where the problem resides with respect to the irregularity in the aorist. In other words, to tackle the allomorphic distribution, children appear to have learned that sonority of the final consonant is what they have to attend to. Zeroing in on the sonorant-ending monosyllabic verbs, however, proves to be a double-edged sword; while it assists children in cracking the code for the 13 irregularly behaving verbs, it misleads the children into thinking that all sonorant-ending verbs have to be affixed -Ir – hence, yielding irregularization errors. In what follows, we turn to an in-depth analysis of this emerging developmental system by focusing on the overregularization and irregularization errors.
Overregularization vs. irregularization errors
According to our third and fourth hypotheses, we expected children to produce overregularization and irregularization errors on sonorant-ending monosyllabic verbs. While the overall rate of overregularization errors (Ir > *Ar) was 18.4% (955 correct and 215 incorrect responses), that of irregularization errors (Ar > *Ir) was 29.7% (775 correct and 328 incorrect responses). We conducted mixed effects analyses to investigate whether children were significantly more likely to err on sonorant-ending -Ir-taking monosyllabic verbs compared to sonorant-ending -Ar-taking monosyllabic verbs. A second aim was to examine the change in overregularization and irregularization errors with age.
First, we compared the models having verb type (i.e., Ar-taking/Ir-taking) and age as fixed effects and different random effect structures. Model 3b that had by-participants random slopes for verb type and by-item random intercepts provided the best fit, and thus was compared to Model 3e that further included the verb type*age interaction. According to a likelihood ratio test comparison, Model 3e (AIC = 1893, BIC = 1938) provided a better fit to the data (AIC = 1896, BIC = 1935), χ2(1) = 5.0, p = .025. In this model, the interaction between age and verb type was significant (estimate = 0.59, SE = 0.26, p = .026). Follow-up analyses showed a steeper slope for Ir-taking verbs (estimate = 0.96, SE = 0.18, p < .001) compared to Ar-taking verbs (estimate = 0.38, SE = 0.14, p = .01). Figure 2 depicts this difference and shows that although with age the predicted probabilities of giving a correct response increased for both Ir-taking and Ar-taking verbs, the slope was steeper for Ir-taking verbs indicating that with increasing age the correct response rate on irregular verbs increased more rapidly than regular verbs. This finding thus demonstrates a marked contrast in terms of the developmental path the children follow in learning the sonorant-ending regular and irregular monosyllabic verbs. More precisely, children retreat from overregularization errors rapidly with age but cannot resolve irregularization errors for an extended period of time.

Figure 2. Predicted probabilities of giving a correct response on Ir-taking and Ar-taking verbs with respect to age according to Model 3e listed in Table 1. Shaded regions represent 95% confidence intervals.
Errors yield important insights into the generalization mechanism underlying Turkish-speaking children’s productivity with the aorist. The high rates of overregularization and irregularization errors, in other words, the evaluation of the competing patterns the children appear to have extracted for sonorant-ending monosyllabics presents a unique opportunity to adjudicate between an analogy-based and a rule-based model. In what follows, we will examine the errors in detail in order to see whether they reflect an analogy-driven or a rule-driven generalization.
Overregularization errors: analogy vs. rule
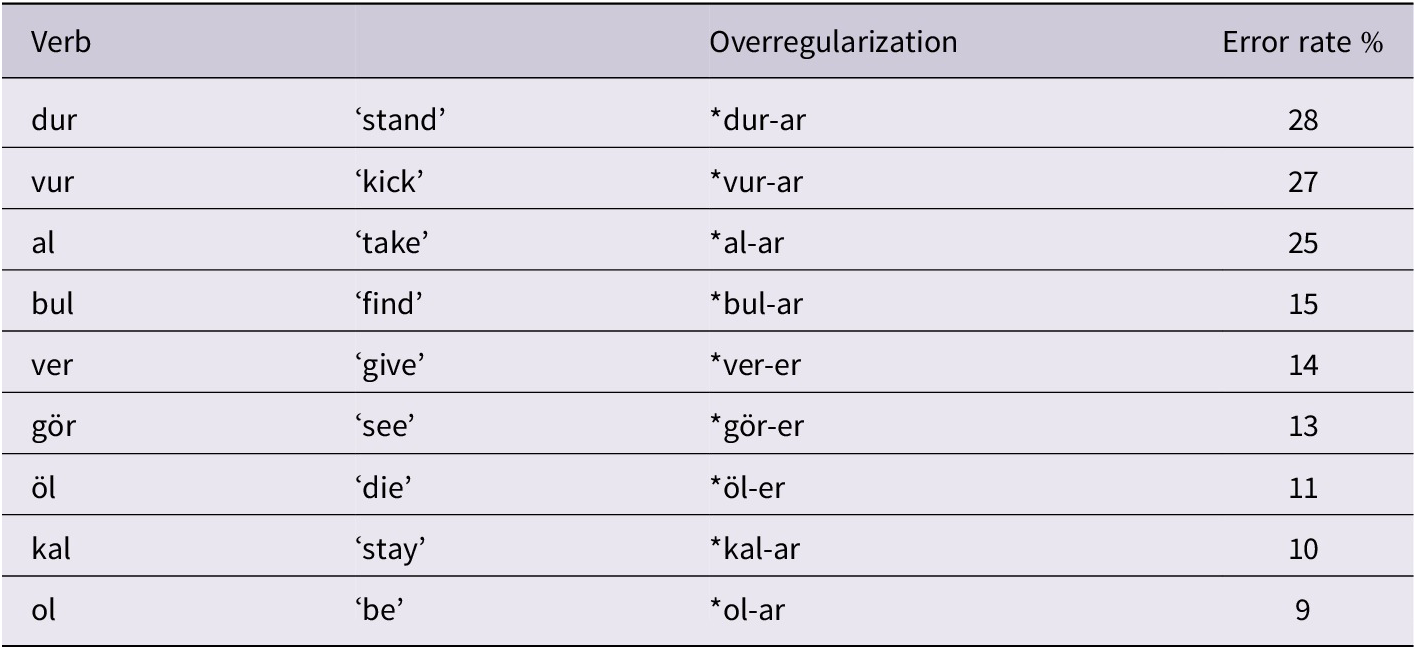
Children produced overregularization errors with every sonorant-ending Ir-taking monosyllabic verb we tested. The verbs differed, however, in terms of the erroneous use they yielded. Table 2 below illustrates the overall error rates each verb triggered. A quick scan of the errors immediately reveals that among the irregular verbs, dur ‘stand’, vur ‘kick’, both ending in the rhyme [ur], and al ‘take’ have yielded considerably more errors.
Table 2. Overregularization errors on sonorant-ending irregular verbs
The overregularization errors suggest that there is a generalization mechanism underlying children’s productivity and in principle, the mechanism can be rule-driven or analogy-driven. In what follows, we will attempt to uncover to what extent children’s errors reflect analogy across stored exemplars or use of a morphological rule (for example, add -Ar for monosyllabics). For the purposes of this paper, in unmasking the role of analogy we will limit ourselves to an analysis of whether within the monosyllabic verbs, the potential of a syllable rhyme to exhibit overregularization or irregularization is correlated with the presence of neighboring -Ar and -Ir types in the aorist. This is an analogy process that operates solely across aorist bearing morpheme boundaries. Implementing a novel similarity measure, we further seek to show that existing trigram and quadrigram sequences (henceforth n-grams) in Turkish that overlap with the syllable rhymes and -Ar/-Ir types both within words and across morpheme boundaries may serve as a platform for analogization. We conjecture that n-gram counts in an agglutinative language like Turkish, which also exhibits vowel-harmony, can potentially capture similarity effects beyond the reach of phonological properties.
Teasing apart the role of analogy is not an easy task due to the complex nature of variables that may play a role in analogization. In seeking to delineate the role of analogy we will not employ a general variegated notion of similarity as implemented in Albright and Hayes (Reference Albright and Hayes2003). In other words, the measure we employ does not check the ways in which an existing verb overlaps with stored analogous forms in respect of whether they share the same onset, nucleus or onset+coda etc. where a stem may resemble existing stems in variegated ways.Footnote 3 We will just explore the role of stored analogous n-grams coinciding with the rhymes of monosyllabics that are overregularized or irregularized the most, thereby we will specifically tap into the stored analogous existing sequences in Turkish.
To illustrate what we will look into for exploring the role of analogy, let us start out with an analysis of the rhyme [ur] in the verbs vur and dur which led to a total of 37% of the overregularization errors (79/215). As laid out in Table 3(i), [ur] has two -Ar neighbors (kur-ar ‘sets’; bur-ar ‘twists’) and two -Ir neighbors (dur-ur ‘stands’; vur-ur ‘kicks’). So, while typewise the distribution is equal, tokenwise -Ir wins out as 74% of the tokens with the rhyme [ur] in Turkish display -Ir (11398 out of 15447 tokens). Examples of n-grams as they pertain to -Ir and -Ar forms with the rhyme [ur] in Turkish are sequences [uru]/ [urur] overlapping with the correct irregulars durur and vurur and sequences [ura]/ [urar] overlapping with the overregularization errors *durar and *vurar. Analysis of n-grams for [ur] shows that [uru]/ [urur] are more frequent in type and token than [ura]/ [urar] (see Table 3(ii)).
Table 3. Type/Token counts of Ir/Ar neighbors and n-grams for the rhyme [ur] (taken from Michon, Reference Michon2017)
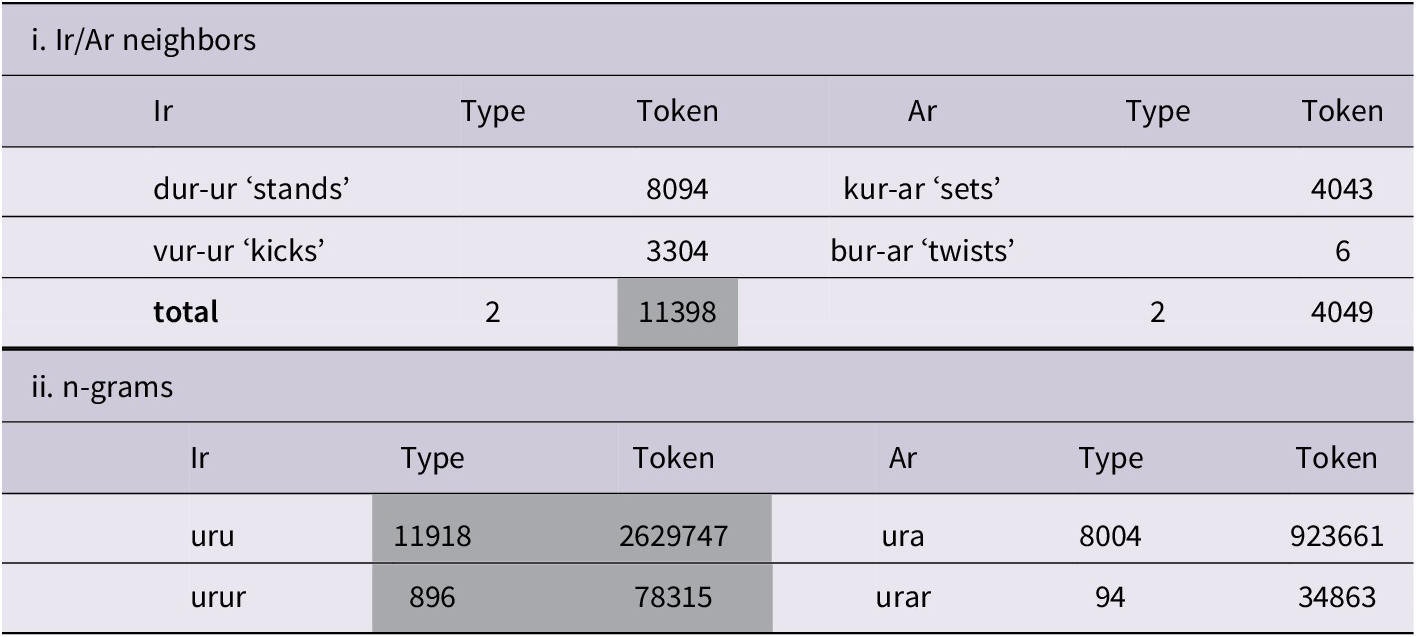
Note. Shaded areas indicate more frequent types/tokens and n-grams.
Frequency counts thus show that the existing -Ir types are higher in token and the -Ir n-grams are higher both in type and token for the rhyme [ur]. This finding suggests that the Turkish-speaking child is potentially exposed to more [uru/urur] sequences than to [ura/urar] sequences in learning the language.
On the basis of these observations, we tentatively conclude that the high rate of overregularizations (i.e., *vur-ar/ *dur-ar) cannot be viewed as the outcome of analogy acting over stored exemplars as there are neither frequent -Ar tokens nor -Ar n-grams that would render analogizing possible for the rhyme [ur]. To the contrary, it appears to be the high type frequency of -Ar with monosyllabic verbs that provides the generalization mechanism with the information it needs to abstract the regular pattern – hence, the formulation of the rule – add -Ar.
The overregularization errors provide evidence bearing on the important question of whether morphological learning proceeds on the basis of types or tokens. If Turkish-speaking children were to proceed untangling the distribution of the aorist on the basis of tokens, they would not have produced overregularization errors with the rhyme [ur] in the presence of massively frequent -Ir tokens and -Ir n-grams.
In Table 4 below, we list the remaining overregularized verbs (except for al which we will discuss later) with respect to their -Ir/ -Ar neighbors and the frequent n-grams overlapping with -Ir/ -Ar, to see whether overregularizations are correlated with stored exemplars.
Table 4. Analysis of overregularization errors wrt neighboring Ir/Ar types and frequent n-grams

The first three verbs bul, ver and gör are overregularized in similar rates. Whereas the root bul yielded overregularization errors in the absence of -Ar neighbors, the root ver ‘give’ with four -Ar neighbors (er-er ‘rises’, ger-er ‘stretches’, ser-er ‘spreads’, yer-er ‘criticizes’) and gör with one (ör-er ‘knits’) were overregularized almost as much as bul ‘find’. Furthermore, whereas the frequent -Ar n-gram in the case of bul may have provided grounds for analogization with similar forms thus triggering overregularization errors, the frequent -Ir n-grams in the case of ver and gör may have blocked further overregularizations. Thus, teasing apart the influence of similar forms is not easy for these verbs – however, we maintain that one cannot unambiguously argue that overregularization errors are analogy-driven in the case of bul, ver and gör. Turning now to the last 2 verbs that are overregularized the least by children, we see that they exhibit single -Ir types, i.e., öl-ür ‘dies’/ ol-ur ‘is’ and a handful of neighboring -Ar types with very low token frequency. The irregular verbs öl ‘die’ and ol ‘be’, despite the frequent overlapping -Ir n-grams that support the sequence [ölür] and the frequent -Ar n-grams, supporting the sequence [olar] are overregularized in similar rates. In the case of [ol], the massively high token frequency of ol-ur ‘is’ may be preventing more intrusion of -Ar n-grams – hence, the relatively low rate of overregularization errors with ol ‘be’. Nonetheless in neither case can we conclusively pin down what has triggered or blocked overregularization errors.
In closing this section, we argue that an analysis of the neighboring -Ar/ -Ir types and n-grams as they pertain to overregularization errors proves to be fruitful in showing that errors on dur and vur, the verbs that are overregularized the most, are not analogy-driven. Furthermore, the behavior of verbs that are overregularized in much lower rates cannot be unambiguously interpreted as reflecting the influence of stored exemplars. Rather overregularization errors reveal children’s tendency to default to -Ar – hence, implicate formulation of an abstraction based on the high type frequency of -Ar with monosyllabic verbs. Given this, the findings of the present study are consistent with the observations in Plunkett and Marchman (Reference Prasada and Pinker1993), Bybee (Reference Bybee1995, Reference Bybee2001), Albright and Hayes (Reference Albright and Hayes2003), Dąbrowska and Szcerbinski (Reference Dąbrowska and Szcerbinski2006) that morphological patterns are extended on the basis of type frequency. We maintain that it is the application of the rule (i.e., add -Ar) that yields overregularization errors with irregularly behaving monosyllabics.
Irregularization errors: analogy vs. rule
Just as in the case of overregularization errors, every sonorant-ending regular verb tested has yielded irregularization errors in varying proportions (see Table 5).
Table 5. Irregularization errors on sonorant-ending regular verbs

In what follows, we analyze the first three verbs that yielded the most irregularization errors with respect to the neighboring -Ir/-Ar types and the overlapping n-grams. As will be apparent momentarily, the behavior of these verbs suggests that the trajectory of irregularization errors appears to be shaped by various measures of similarity. Among the nine verbs we tested, quite interestingly, the first two verbs sür ‘drive’ and kır ‘break’ and four more do not have any -Ir neighbors in the aorist. Thus what triggers irregularizations in the absence of irregular neighbors gets doubly intriguing, especially from an analogy-based perspective.
As presented in Table 6(i), the rhyme [ür] in the verb sür has two -Ar neighbors (sür-er ‘drives’/dür-er ‘folds’) and no -Ir neighbors. With respect to n-grams, [üre] is higher in token, [ürü] is higher in type, and [ürür] is higher both in type and token. This indicates that the overall irregularization rate of almost 50% with the verb sür may be correlated with the type frequency of the trigram [ürü] and the type and token frequency of the quadrigram [ürür] in Turkish.
Table 6. Type/ Token counts of Ir/Ar neighbors and n-grams for the rhyme [ür]

Note. Shaded areas indicate more frequent types/tokens and n-grams.
The second most irregularized verb kır ‘break’ has one -Ar type but no -Ir type. The n-gram counts show that [ırı]/ [ırır] are more frequent both in type and token (see Table 7).
Table 7. Type/ Token counts of Ir/Ar neighbors and n-grams for the rhyme [ır]

Note. Shaded areas indicate more frequent types/tokens and n-grams.
As there are no existing -Ir types in the language, n-grams may be providing platforms for analogization for the verbs sür and kır and the resulting errors *sürür and *kırır. The third verb with which children produced the most irregularization errors was sol ‘fade’ and it shares the rhyme [ol] with the irregular verb ol ‘be’. This is a rhyme instance that has given rise to both irregularizations and overregularizations. Table 8 illustrates the breakdown of the -Ir/-Ar types and the n-grams with the rhyme [ol].
Table 8. Type/ Token counts of Ir/Ar neighbors and n-grams for the rhyme [ol]

Note. Shaded areas indicate more frequent types/tokens and n-grams.
There are three very low frequency -Ar types (sol-ar ‘fades’/ yol-ar ‘plucks’/ dol-ar ‘fills’) and a single very high frequency -Ir type in the case of the rhyme [ol]. Unlike what we have observed in the first two verbs, in [ol] one would expect the frequent -Ar n-gram [ola/olar] to render less irregularization. Yet the irregularization rate with sol is 38%. In this instance, what gives rise to the *sol-ur error could be the high token frequency (239904) of the irregular verb ol-ur ‘is’. That is, the stored analogous exemplar ol-ur ‘is’ may be intruding in the production of sol ‘fade’ yielding the erroneous *sol-ur. Finally, let us look into one other rhyme instance that has given rise to both overregularization and irregularization errors. The rhyme [al] had given rise to overregularizations *al-ar (25%) and *kal-ar (10%) and irregularizations *dal-ır (32%) and *çal-ır (26%).
While the rhyme [al] has three -Ar (i.e., dal-ar ‘dives’/ sal-ar ‘emits’/ çal-ar ‘plays’) and two -Ir types (al-ır ‘takes’/ kal-ır ‘stays’), of the 72000 total tokens 97% are -Ir forms, again suggesting that the child would be exposed to -Ir types more than -Ar types (see Table 9). This can potentially explain the high rate of irregularizations. However, when we look at the n-gram counts (Table 9ii) we see that -Ar n-grams are more frequent, which in principle would increase the likelihood of overregularization errors while blocking the irregularization errors. Though we cannot unambiguously argue that the errors on the rhyme [al] are analogy-driven, it is clear that the competing -Ir and -Ar forms appear to invite the intrusion of analogous exemplars.
Table 9. Type/ Token counts of Ir/Ar neighbors and n-grams for the rhyme [al]

Summing up, the top four irregularization errors could be analogy-driven – more precisely, *sür-ür could be produced by the influence of the frequent ürü/ ürür n-grams, *kır-ır by that of ırı/ ırır n-grams and *sol-ur and *dal-ır by the influence of the analogous stored exemplars olur ‘is’ and alır ‘takes’.
To round out this section, analysis of overregularization errors suggests that non-sonority presents a morphophonological space for -Ar to yield abstraction. The child observes that non-sonorant-ending monosyllabics are exclusively affixed with -Ar – hence, s/he defaults to -Ar rapidly. Sonority, however, does not present a morphophonological space for -Ir to yield abstraction as there are sonorant-ending monosyllabics that do not take -Ir; it rather misleads the child into drawing an erroneous micro-generalization i.e., add -Ir to all sonorant-ending, regular monosyllabics – hence, the irregularization errors. That said, whether irregularization errors are analogy-driven or rule-driven is more difficult to disentangle. We doubt that we can unambiguously claim that irregularization errors can solely be interpreted as children’s attempts to default to -Ir for sonorant-ending monosyllabic verbs. It could be that -Ir types and -Ir n-grams in general confound the picture and lead the analogous exemplars to influence the outcome.
General discussion
Irregular patterns within morphological systems provide a golden opportunity to explore how the brain learns language and serve as a unique platform for a discussion of whether morphology learning employs rule-based or analogy-based procedures. The findings of the present study strongly suggest a model of morphological learning that is driven by similarity comparisons – hence, analogy at the outset – and that invokes rule-induction in later stages.
Crucially, the findings reveal that Turkish-speaking children employ an inductive learning mechanism to unravel the puzzle the aorist presents. Results show that to tackle the allomorphs of the aorist, children initially engage in similarity comparisons between stored analogous forms. In line with the theory of structural alignment (Markman & Gentner, Reference Markman and Gentner1993, Reference Markman and Gentner2000) invoked to explain similarity in human cognition, we conjecture that the comparison process is driven by a search for corresponding structures and operates to align them. Comparisons between the aligned parts of the aorist-bearing forms thus assist the child in locating phonological contexts for the distribution of the allomorphs. The child finds out that multisyllabicity serves as a reliable phonological context for -Ir use and monosyllabicity for -Ar use unless the verb is sonorant-final. Low error rates with multisyllabics and non-sonorant-ending monosyllabics even at 29 months of age suggest that the Turkish-speaking child has already drawn a generalization for multisyllabics which is induced by the massive -Ir type; and for non-sonorant-ending monosyllabics, by the high -Ar type. Sonorant-final monosyllabics, however, puzzle the child well into the primary school years. Overall low error rates on multisyllabic (4.8%) and non-sonorant-ending monosyllabic verbs (5%) as opposed to sonorant-ending monosyllabics (24%) clearly suggest that the Turkish-speaking child is sensitive to the phonological properties of the verbs.
In learning the aorist, the behavior of sonorant-ending monosyllabics proves to be stubbornly puzzling and, in attempts to untangle it, the child is misled into formulating conflicting generalizations. The child’s attempts in adjudicating between these conflicting generalizations give rise to overregularization (i.e., use of -Ar for irregulars) and irregularization errors (use of -Ir for regulars). The trajectories of errors further offer crucial insights into the nature of the generalization mechanism underlying children’s productivity with aorist forms and open an exciting avenue for a discussion of the nature of the unfolding linguistic representations.
Overregularization errors suggest that the statistical regularities in the input must be pushing the child to draw a generalization on the basis of the high type-count of -Ar for monosyllabics. In the adult end-state, there are 231 monosyllabic types and of these verbs, 218 i.e., 94% are -Ar type. Of course, what is equally relevant is the type and token frequency of the aorist forms in the developing child lexicon. It turns out that while monosyllabic verb stems constitute about 2.2% of the adult verb lexicon (Nakipoğlu & Üntak, Reference Nakipoğlu and Üntak2008), they constitute approximately 52% of the early verb lexicon of Turkish-speaking children (Aksu-Koç Corpora at CHILDES). Thus due to the presence of relatively more monosyllabic verbs in the early verb vocabulary, and even higher frequency of aorist verbs taking -Ar as opposed to -Ir (70% of the aorist verb tokens carry -Ar in child-directed speech (Aksu-Koç Corpora at CHILDES, children up to 3 years)) the child encounters more -Ar exemplars which could result in a rapid abstraction to -Ar rendering overregularizations inevitable.
The findings thus show that as the morphophonological space non-sonority presents for Ar-taking monosyllabics is exceptionless, the child defaults to -Ar and this gives rise to overregularizations on irregularly behaving monosyllabics. The trajectory of overregularization errors further reveals that with age children retreat from overregularizations by restricting the hypothesis domain for the irregulars with sonorant-ending monosyllabics. However, as the morphophological space the 13 irregularly behaving verbs present cannot exclude -Ar taking sonorant-ending verbs, the child is misled into thinking that all sonorant-ending monosyllabics require the affix -Ir. The erroneous micro-generalization that the child draws yields irregularization errors that pervade for extended periods of acquisition. The intriguing question that calls for an answer is why children cannot recover from the irregularization errors well into the primary school years.
Long periods of irregularization errors appear to be potentially correlated with three factors: (1) analogous -Ir n-grams intruding in the learning system; (2) expanding verb vocabulary with age – when the proportion of monosyllabic verbs (231 types) to multisyllabic verbs (4700+ types) in the entire verb lexicon (Nakipoğlu & Üntak, Reference Nakipoğlu and Üntak2008) is considered, the expansion of verb vocabulary naturally suggests more multisyllabic verbs, i.e., more -Ir exemplars entering the child’s lexicon; (3) developing mastery in the use of more complex grammatical operations which for an agglutinative language like Turkish means more multisyllabic exemplars. For example, valency-changing operations like causativization, passivization render a monosyllabic, multisyllabic in Turkish (e.g., at-ar ‘throws’ when causativized is at-tır-ır ‘makes someone throw’; when passivized is at-ıl-ır ‘is thrown’) giving rise to even more -Ir exemplars when the aorist is attached. As a result, constant exposure to -Ir forms would make it more demanding to retreat from the irregularization errors.
The results we report here show that aorist findings are in no way consistent with the assumptions of a strong rule-based account which rules out any sensitivity to phonology or frequency. Quite the contrary, the results strongly suggest that in extracting the grammatical (ir)regularities through similarity comparisons, the Turkish-speaking child relies on phonology and type frequency. After all, in learning the aorist, the child has to convert what s/he hears into structured linguistic representations and it appears that syllable count and (non)-sonority of the final consonant – hence, phonological cues, assist children early on in composing a space of hypotheses so that they can arrive at generalizations. Furthermore, high overregularization and irregularization errors the aorist findings reveal run contrary to the predictions of strong rule-based accounts. Rule-based accounts like the Dual-route model predict low error rates and assume that overregularization errors would cease immediately as a result of the competing irregular forms blocking the default rule. The aorist findings, however, are incompatible with this prediction. Rather the results strongly suggest a competition between correct, overregularized and irregularized forms in the developing representational system of the child for extended periods of time. In a developing memory system, as claimed in Ramscar and Yarlett (Reference Ramscar, Dye and McCauley2007), Ramscar, Dye and McCauley (Reference Räsänen, Ambridge and Pine2013), correct forms can co-exist with overregularized forms and the repeated rehearsal of the correct form (i.e., what the child extracts from the input) would strengthen memory traces both for the regulars and the irregulars. Thus, relatively quick recovery from the overregularization errors must also be closely tied to a developing memory system.
The findings of the present study are not consistent with the assumptions of a purely analogy-based account, either. Though in early acquisition children by engaging in similarity comparisons learn to attend to the sonority of the root-final consonant and the syllable count of the verb, constant search for similarity in the input and comparison of analogous forms would be futile. Thus, the Turkish findings are not consistent with analogy-based accounts that attempt to attribute all inflectional morphology to analogy-driven generalizations and that hold that inflection does not rely on symbolic operations at all. In fact, a learning mechanism has to be parsimonious and we postulate that parsimony can be attained by abstracting across the input.
The aorist results however support any model of morphology learning which posits an inductive learning algorithm to discover the relevant morphological generalizations like the Multiple Rules Model of Albright and Hayes (Reference Albright and Hayes2003). The findings clearly show how rules are discovered by induction, i.e., how macro-generalizations (i.e., -Ir use for multisyllabics and -Ar use for non-sonorant-ending monosyllabics are type-based) are rapidly expressed via rules. The irregulars might as well be deemed as products of a minor -Ir rule that applies to the 13 irregularly behaving verbs.
The present study with its ambitious scope in terms of the number of children tested unpacks the entire developmental trajectory of the Turkish aorist. Testing a sizable number of children from a wide age range on a production task has equipped us with the opportunity of seeing through how a particular representation develops over time and how it intersects with other representations that develop over the same period. We hope to have shown that children’s adherence to phonology is similarity-driven at the outset, and in a developing learning system comparison of analogous forms is indispensable in the earlier stages of acquisition. Unending search for similarity, however, cannot be advantageous to any learning system. We advance the idea that through developing insensitivity to phonology and adherence to type-frequency, the learning system must be starting to abstract across the input. Overregularization errors unquestionably reveal how the morphophonological space the non-sonority presents, coupled with the predominance of -Ar types both in early child-directed speech and in adult grammar, moves the system to abstraction – hence, the rule for regularly behaving monosyllabic verbs. The ambiguous morphophonological space sonority presents for -Ir-taking monosyllabic verbs, inviting intrusion of analogous -Ir forms, however, presents a long lasting chaos for children as evidenced by the proportion of irregularization errors and children’s inability to recover from them up until the age of 8.
So far, we have argued that an account of a developing morphological system must incorporate the role of analogy and the assumptions that the language learner computes phonological analyses and is sensitive to frequency. That being said, the urge to seek analogous forms as they pertain to linguistic representations appears to be in our lives not only in childhood but, though to a limited extent, in adulthood as well. In a recent study on adults’ processing of the Turkish aorist, Michon (Reference Michon2017), implementing an elicited production task, tested 90 Turkish adults on 168 sonorant-ending monosyllabic novel stems to see whether adult speakers of Turkish would default to -Ar based on type frequency; or opt for the use of -Ir, suggesting the intrusion of analogy. The results were unsurprising in that Turkish adults have opted for the use of -Ar with a rate of 86%. The role of analogy – hence, the use of –Ir – was evident only in 14% of the overall use. Though minuscule in size, analogous exemplars have intruded in the system even at the adult level. Thus there is no escape from analogy even at the adult stage.
Armed with the fresh insights the aorist findings provide, rather than adjudicating between an analogy-based and a rule-based account, we maintain that a proper account of the learning of the Turkish aorist and, perhaps, of any morphological system is possible only by combining various key aspects of both models. We thus advance the idea that an integrated model of analogy and rules should invoke manipulation of analogy through similarity comparisons in the earlier stages of acquisition so that the system moves beyond rote-learning and that it should invoke rule-induction on the basis of type-frequency in later stages. Through similarity comparisons the child draws on patterns relevant for the distribution of the affixes and taps into the phonological and structural properties of the data to untangle the distribution of both the regular and irregular affixes. Therefore, similarity comparisons – hence, analogy – must be at work not only for pinning down the irregular but the regular distribution as well.
Our findings strongly suggest that in learning the aorist the Turkish-speaking child draws inductive generalizations within a hypothesis domain. The generalizations that are compatible with the input rapidly lead to abstraction across the input. The conflicting generalizations yield both overregularization and irregularization errors. Overgeneralizations are clear attempts to default to the regular affix. Perhaps the most telling evidence for the inductive mechanism that the child brain is implementing comes from the irregularization errors. The massive rates of irregularizations the children produced suggest both an attempt to default to the irregular affix and also the intrusion of analogous exemplars. In the light of these findings, we argue that children gradually discover the rules that pertain to the distribution of aorist by an inductive learning mechanism.
Acknowledgments
Thanks to the children at Koza Preschool, Sevgi Preschool, Şişli Terakki Preschool and Primary School, Boğaziçi University Preschool for their participation in the experiment. We would like to thank João Veríssimo for very helpful comments and suggestions during the review process. Very special and warm thanks go to the University of Oslo and Dr. Emel Türker for hosting Mine Nakipoğlu in 2019 (September-December) as a Visiting Scholar, which enabled her to write the manuscript. Part of the present study was presented at BUCLD 30 and published in the Proceedings. This study was supported by Boğaziçi University Research grant (5075) awarded to the first author.
Supplementary Materials
To view supplementary material for this article, please visit http://doi.org/10.1017/S0305000921000921.















 Open access
Open access