



1. Introduction
Nuclear fusion is among the largest research and development (R&D) projects. ITER, the first-of-a-kind experimental fusion reactor, currently under construction in the south of France, is one of the most complex machines in the world. We are concerned with the structural complexity of this machine, which relates to the amount, diversity and entanglement of technologies that need to be developed and integrated (Federici et al. Reference Federici, Bachmann, Biel, Boccaccini, Cismondi, Ciattaglia, Coleman, Day, Diegele, Franke, Grattarola, Hurzlmeier, Ibarra, Loving, Maviglia, Meszaros, Morlock, Rieth, Shannon, Taylor, Tran, You, Wenninger and Zani2016). Cost and duration of such R&D projects depend highly on these aspects. It is in the designers’ best interest to manage structural complexity. But this requires the answer to a fundamental question: How does this kind of complexity manifest itself during the design process? Structural complexity – hereafter simply referred to as complexity – is the main focus of this paper.
Uncertainty related to technical performance might be an important driver of complexity. In early development stages, designers have to make conceptual design decisions with only preliminary knowledge about their future implications (Simpson et al. Reference Simpson, Rosen, Allen and Mistree1998; Tan, Otto, & Wood Reference Tan, Otto and Wood2017). Committing to decisions is necessary, however, to advance the engineering project. In the 18s-year-long conceptual design stage of ITER, the project had generated around 4,000 scientific publications. This number had reached 25,000 only 15 years after the conceptual design review. It seems that knowledge output sharply increases toward late design stages.
Unfortunately, a solution trajectory that is promising in early stages may give rise to new problems in later development. Such problems could have been avoided if the right knowledge was available at the time. However, instead of revising an earlier decision, designers have a tendency to solve such problems by adding more design elements (Adams et al. Reference Adams, Converse, Hales and Klotz2021). Those elements will contribute to complexity, further increasing the likelihood of problem propagation (Eckert, Clarkson, & Zanker Reference Eckert, Clarkson and Zanker2004; Watson et al. Reference Watson, Anway, McKinney, Rosser and MacCarthy2019).
Mirror technology is a characteristic example of the exploratory nature of R&D. Modern fusion devices are equipped with many optical measurement systems that feature metallic mirrors in close proximity to the fusion plasma (Costley et al. Reference Costley, Sugie, Vayakis and Walker2005). The hostile environment causes multiple problems that have led to the addition of novel solutions: Extreme temperatures are managed through cooling systems (Salewski et al. Reference Salewski, Meo, Bindslev, Furtula, Korsholm, Lauritzen, Leipold, Michelsen, Nielsen and Nonbøl2008), while newly developed cleaning systems remove any optical contamination (Leipold et al. Reference Leipold, Reichle, Vorpahl, Mukhin, Dmitriev, Razdobarin, Samsonov, Marot, Moser, Steiner and Meyer2016; Ushakov et al. Reference Ushakov, Verlaan, Stephan, Steinke, de Bock, Maniscalco and Verhoeff2020; Stephan et al. Reference Stephan, Steinke, Ushakov, Verlaan, de Bock, Moser, Maniscalco, van Beekum and Verhoeff2021). But analysis shows that together, these cooling and cleaning systems will lead to an electrical grounding problem. This problem can be resolved by adding yet another element: a notch filter (Dmitriev et al. Reference Dmitriev, Babinov, Bazhenov, Bukreev, Elets, Filimonov, Koval, Kueskiev, Litvinov, Mikhin, Razdobarin, Samsonov, Senitchenkov, Solovei, Terechenko, Tolstyakov, Varshavchik, Chernakov, Chernakov, Chernakov, Tugarionov, Shigin, Leipold, Reichle, Walsh and Pflug2019). The complexity of the system, in terms of number of components and interactions, has grown significantly in this design trajectory.
We need a deeper understanding of how we can effectively solve unexpected problems. Even under extreme uncertainty, it is good practice to solve the right problem with a minimal amount of complexity. Our aim is to support designers in making complexity-conscious design decisions, by studying the following questions:
-
• Which prior design decisions have led to the manifestation of a particular design problem?
-
• Can we observe and control the complexity of an engineered system over time?
-
• How has each design decision contributed to complexity?
We seek to answer these questions via a newly proposed theoretical basis for the manifestation of design problems. The theory revolves around a model of the designed system that is subject to a series of design decisions. Each design decision adds new elements, thus expanding the model. We mathematically formulate two metrics that capture each decision’s contribution to complexity. The theory is then specialized with the Function-Behavior-Structure (FBS) ontology, to create a systematic problem-solving method. We demonstrate this method for a nuclear fusion optical measurement system, illustrating system-level decision-making and complexity management.
We start this paper with a literature background on design problems and solutions, how to represent products and systems, techniques to manage complexity, definitions of complexity, dependency structure matrices and relevant applications of systems engineering in nuclear fusion. We then define the core ideas of this work by presenting our general theory of manifesting problems and complexity. In the following section, we frame the theory in the FBS ontology. The final section of this work comprises the demonstrations.
2. Background
Summers & Shah (Reference Summers and Shah2010) distinguish three aspects of design: the design problem, the design process and the design product. We refer to the latter as the design solution. It is this solution that seems to exhibit an ever-increasing complexity, and somehow new design problems seem to manifest themselves in it.
The design problem is a statement of needs, requirements and objectives, which in practice is often ambiguous and ill-structured (Jonassen, Strobel, & Lee Reference Jonassen, Strobel and Lee2006). It is therefore commonplace for designers themselves to interpret and formulate design problems (Daly et al. Reference Daly, McKilligan, Studer, Murray and Seifert2018). Problem exploration is an important aspect of the design process (Martinec et al. Reference Martinec, Škec, Lukačević and Štorga2021; Obieke, Milisavljevic-Syed, & Han Reference Obieke, Milisavljevic-Syed and Han2021) and even requires the generation of potential solutions (Zhang & Ma Reference Zhang and Ma2021). Indeed, it seems natural that problems and solutions coevolve over time (Dorst Reference Dorst2019). However, we have not seen systematic methods that trace arising problems during the design process.
There are varying ideas about what happens in the design process, but most of them have converged into three simple, yet powerful, notions: Function, Behavior and Structure (FBS) (Gero Reference Gero1990; Umeda et al. Reference Umeda, Takeda, Tomiyama and Yoshikawa1990). Function is what the product is used for, structure is what it is, and behavior is what it does (Gero & Kannengiesser Reference Gero and Kannengiesser2004). The FBS ontology has been at the basis of modern systematic engineering design approaches (Pahl et al. Reference Pahl, Beitz, Feldhusen and Grote2007), helping engineers to define essential design steps. One example is synthesis, the transition from function to a structure that is recurring throughout literature (Brunetti & Golob Reference Brunetti and Golob2000; Mathias et al. Reference Mathias, Eifler, Engelhardt, Kloberdanz and Bohn2011; Drave et al. Reference Drave, Rumpe, Wortmann, Berroth, Hoepfner, Jacobs, Spuetz, Zerwas, Guist and Kohl2020; Ramsaier et al. Reference Ramsaier, Stetter, Till and Rudolph2020).
Most current-day solutions are too complex to be viewed as a product of a single function, a single behavior and a single structure. They are better represented as systems, i.e., arrangements of interdependent products with multiple functions, behaviors and structures. The widely accepted V-model specifically defines decomposition and integration activities to manage the holistic systems engineering process (Forsberg & Mooz Reference Forsberg and Mooz1991).
A system’s complexity is dependent in part on its architecture: a mapping between functions and physical components (Ulrich Reference Ulrich1995). Designing an architecture is often framed as a single-level decision problem, for example, by function-means analysis (Johannesson & Claesson Reference Johannesson and Claesson2005), and can therefore only explore a limited solution space. Recent developments have moved to architecture design as a multilevel decision problem (Bussemaker, Ciampa, & Nagel Reference Bussemaker, Ciampa and Nagel2020; Panarotto et al. Reference Panarotto, Kipouros, Brahma, Isaksson, Strandh Tholin and Clarkson2022). These methods systematically generate diverse system architectures that can be further analyzed and optimized. However, these works neither quantify complexity nor analyze the contribution of each decision to the properties of an architecture.
In practice, large-scale engineering projects have to deal with more terms than just function, behavior and structure. Complexity in such projects is also a product of stakeholders, requirements and many nontechnical factors (Watson et al. Reference Watson, Anway, McKinney, Rosser and MacCarthy2019; Yang et al. Reference Yang, Yang, Browning, Jiang and Yao2019). Particularly in R&D of complex physical systems, budget and schedule are dominated by modeling, prototyping and verification procedures.
A modern way to deal with such heterogeneous complexity is Model-Based Systems Engineering (MBSE). MBSE envelopes techniques that apply models as central, ‘single source of truth’ artifacts that formalize heterogeneous and multidisciplinary design information. The model can be inspected through viewpoints that provide relevant information to stakeholders, whether they are in physics, engineering, construction or procurement. When we speak of a model
 $ M $
, we mean the most abstract representation of a design that includes, but is not limited to, a system architecture. We refer to Estefan (Reference Estefan2007) and Dickerson & Mavris (Reference Dickerson and Mavris2013) for a complete overview of MBSE development, and to Madni & Sievers (Reference Madni and Sievers2018) for a recent status quo of the field.
$ M $
, we mean the most abstract representation of a design that includes, but is not limited to, a system architecture. We refer to Estefan (Reference Estefan2007) and Dickerson & Mavris (Reference Dickerson and Mavris2013) for a complete overview of MBSE development, and to Madni & Sievers (Reference Madni and Sievers2018) for a recent status quo of the field.
Systems theory is at the basis of MBSE. It models a system as
 $ M=\left(E,R\right) $
, with
$ M=\left(E,R\right) $
, with
 $ E $
a set of entities and
$ E $
a set of entities and
 $ R $
a collection of relations on
$ R $
a collection of relations on
 $ E $
(Lin Reference Lin1999). We refer to
$ E $
(Lin Reference Lin1999). We refer to
 $ E $
and
$ E $
and
 $ R $
as design elements. Depending on the modeling paradigm, elements may represent components, requirements, use cases, functions, variables, etc. The model
$ R $
as design elements. Depending on the modeling paradigm, elements may represent components, requirements, use cases, functions, variables, etc. The model
 $ M=\left(E,R\right) $
connects systems engineering to network theory, by interpreting a system as a network with nodes
$ M=\left(E,R\right) $
connects systems engineering to network theory, by interpreting a system as a network with nodes
 $ E $
and edges
$ E $
and edges
 $ R $
. This representation has enabled Sinha & de Weck (Reference Sinha and de Weck2013) to implement network metrics in a mathematical definition of structural complexity:
$ R $
. This representation has enabled Sinha & de Weck (Reference Sinha and de Weck2013) to implement network metrics in a mathematical definition of structural complexity:
 $$ \xi (M)=\sum \limits_{i=1}^N{\alpha}_i+\left(\sum \limits_{i=1}^N\sum \limits_{j=1}^N{\beta}_{ij}{A}_{ij}\right)\frac{\varepsilon (A)}{N}, $$
$$ \xi (M)=\sum \limits_{i=1}^N{\alpha}_i+\left(\sum \limits_{i=1}^N\sum \limits_{j=1}^N{\beta}_{ij}{A}_{ij}\right)\frac{\varepsilon (A)}{N}, $$
where
 $ N=\mid E\mid $
is the number of nodes in the network,
$ N=\mid E\mid $
is the number of nodes in the network,
 $ {\alpha}_i $
is the scalar internal complexity of node
$ {\alpha}_i $
is the scalar internal complexity of node
 $ {e}_i\in E $
,
$ {e}_i\in E $
,
 $ {\beta}_{ij} $
is the scalar complexity of edge
$ {\beta}_{ij} $
is the scalar complexity of edge
 $ \left({e}_i,{e}_j\right)\in R $
,
$ \left({e}_i,{e}_j\right)\in R $
,
 $ A $
is the binary adjacency matrix of the network and
$ A $
is the binary adjacency matrix of the network and
 $ \varepsilon (A) $
is the matrix energy. If node
$ \varepsilon (A) $
is the matrix energy. If node
 $ {e}_i $
represents a subsystem, its internal complexity
$ {e}_i $
represents a subsystem, its internal complexity
 $ {\alpha}_i $
may be acquired by applying Equation (1) recursively. Otherwise, the complexity
$ {\alpha}_i $
may be acquired by applying Equation (1) recursively. Otherwise, the complexity
 $ {\alpha}_i $
could be assessed via Technology Readiness Levels (TRLs) (Sinha & de Weck Reference Sinha and de Weck2013). The matrix energy represents the ‘intricateness’ of the network structure and can be obtained through singular value decomposition (Klema & Laub Reference Klema and Laub1980). So in Equation (1), complexity is determined by the number and internal complexity of the individual nodes and edges, and the structure of the network. Determining values for
$ {\alpha}_i $
could be assessed via Technology Readiness Levels (TRLs) (Sinha & de Weck Reference Sinha and de Weck2013). The matrix energy represents the ‘intricateness’ of the network structure and can be obtained through singular value decomposition (Klema & Laub Reference Klema and Laub1980). So in Equation (1), complexity is determined by the number and internal complexity of the individual nodes and edges, and the structure of the network. Determining values for
 $ \alpha $
and
$ \alpha $
and
 $ \beta $
is out of the scope of this work, so we assume 1 where possible.
$ \beta $
is out of the scope of this work, so we assume 1 where possible.
Potts, Johnson, & Bullock (Reference Potts, Johnson and Bullock2020) argue that, while Equation (1) ‘is certainly a useful representation of an engineered system for systems engineers, the complexity of this representation is not necessarily the complexity of the system itself’. Indeed, complexity can have many attributes, many of which are qualitative and intangible (Watson et al. Reference Watson, Anway, McKinney, Rosser and MacCarthy2019). Even experienced systems engineers find it hard to agree on the definition and importance of complexity (Potts et al. Reference Potts, Sartor, Johnson and Bullock2020).
Notwithstanding, Equation (1) has found some useful applications. Albeit in very limited samples, Sinha & de Weck (Reference Sinha and de Weck2013) have observed that development costs increase super-linearly with
 $ \xi $
. Raja, Kokkolaras, & Isaksson (Reference Raja, Kokkolaras and Isaksson2019) have used this metric for analysis of integrated load-carrying structures in an aerospace application. For a recent overview of other commonly used patterns and metrics in network-based analysis of engineered systems, we refer to Paparistodimou et al. (Reference Paparistodimou, Duffy, Whitfield, Knight and Robb2020).
$ \xi $
. Raja, Kokkolaras, & Isaksson (Reference Raja, Kokkolaras and Isaksson2019) have used this metric for analysis of integrated load-carrying structures in an aerospace application. For a recent overview of other commonly used patterns and metrics in network-based analysis of engineered systems, we refer to Paparistodimou et al. (Reference Paparistodimou, Duffy, Whitfield, Knight and Robb2020).
Finally, it is worth highlighting advances in Dependency Structure Matrix (DSM) modeling techniques to manage complexity. A DSM is a matrix representation of a network model that can be analyzed, organized and annotated to reveal critical aspects of complex problems (Eppinger & Browning Reference Eppinger and Browning2012) and has been an important tool in the study of complex architectures (Browning Reference Browning2016; Wilschut et al. Reference Wilschut, Etman, Rooda and Vogel2018). Hamraz et al. (Reference Hamraz, Caldwell, Wynn and Clarkson2013) have combined DSMs and the FBS ontology into a tool for multi-domain change management.
How are the above systems engineering methods represented in nuclear fusion development? Most attention seems to be on requirements engineering (Cinque et al. Reference Cinque, De Tommasi, De Vries, Fucci, Zabeo, Ambrosino, Bremond, Gomez, Karkinsky, Mattei, Nouailletas, Pironti, Rimini, Snipes, Treutterer and Walker2020), and axiomatic design, a systematic design method (Suh Reference Suh1990; Di Gironimo et al. Reference Di Gironimo, Lanzotti, Marzullo, Esposito, Carfora and Siuko2015; Marzullo et al. Reference Marzullo, Bachmann, Coccorese, Di Gironimo, Mazzone and You2017; Lanzotti et al. Reference Lanzotti, Marzullo, Imbriani, Mazzone, You, Di Gironimo, Gerbino, Lanzotti, Martorelli, Buil, Rizzi and Roucoules2023).
We find only little work on system architectures: Grossetti et al. (Reference Grossetti, Brown, Franke, Gafert, Galliara, Jenkins, Mantel, Strauß, Tran and Wenninger2018) use MBSE to define the architecture of heating and current drives; Moscato et al. (Reference Moscato, Barucca, Bubelis, Caruso, Ciattaglia, Ciurluini, Del Nevo, Di Maio, Giannetti, Hering, Lorusso, Martelli, Narcisi, Norrman, Pinna, Perez-Martin, Quartararo, Szogradi, Tarallo and Vallone2022) evaluate the functional performance of various conceptual tokamak cooling systems; Dongiovanni et al. (Reference Dongiovanni, Esposito, Marocco and Marzullo2018) have documented the systematic architectural design of a neutron diagnostic subsystem, explicitly accounting for complexity; and Beernaert et al. (Reference Beernaert, Etman, De Bock, De Baar and Classen2022) have used a system architecture as a framework to organize multiparty engineering collaborations. All are affected by complexity, although none of these works actively reduce it.
We identify a gap at the intersection of various fields. Problems and solutions seem to coevolve during the design process, but there is no method to formalize the dynamics of problem causality. Techniques proposed by Bussemaker et al. (Reference Bussemaker, Ciampa and Nagel2020) and Panarotto et al. (Reference Panarotto, Kipouros, Brahma, Isaksson, Strandh Tholin and Clarkson2022) can generate diverse system architectures from a multistage decision framework. However, they are unable to define the contribution of each decision to an architecture and do not include the evolution of problems, solutions and complexity in time.
The question of complexity remains at the heart of nuclear fusion development. Applications of system architecture techniques in nuclear fusion are sparse, but there seems to be a growing awareness of their benefits (Wolff et al. Reference Wolff, Brown, Curson, Ellis, Galliara and Harris2018). Being able to trace complexity as the design process unfolds will benefit the nuclear fusion project on all levels.
We have begun to address these gaps in previous work, by proposing a method to formalize problem manifestation and their impacts on engineering models (Beernaert et al. Reference Beernaert, Etman, De Bock, Classen and De Baar2021). We continue this research by including the FBS ontology in our method. This leads to a more practical, systematic design method that we demonstrate for a nuclear fusion application.
3. Theory of problem-solving
This section constitutes the main contribution of this paper, introducing a novel theory of the relation between complexity and a problem-solving design process.
First, we must define the dynamics of a model-based design trajectory. Let
 $ {M}_t $
be a system design model, and observe its expansion over discrete time steps
$ {M}_t $
be a system design model, and observe its expansion over discrete time steps
 $ t $
. Refer to Figure 1. In this sequence of model instances, every transition from
$ t $
. Refer to Figure 1. In this sequence of model instances, every transition from
 $ {M}_t $
to
$ {M}_t $
to
 $ {M}_{t+1} $
represents a problem-solving design process that addresses a problem
$ {M}_{t+1} $
represents a problem-solving design process that addresses a problem
 $ p $
and adds elements as a solution
$ p $
and adds elements as a solution
 $ s $
. The collection of problems and solutions encountered in this sequence are denoted as
$ s $
. The collection of problems and solutions encountered in this sequence are denoted as
 $ P $
and
$ P $
and
 $ S $
, respectively. Model
$ S $
, respectively. Model
 $ {M}_0 $
represents the context of the system to be designed and defines the root design problem.
$ {M}_0 $
represents the context of the system to be designed and defines the root design problem.

Figure 1. A model expands over three subsequent design processes. Model
 $ {M}_t $
is a subset of any subsequent models
$ {M}_t $
is a subset of any subsequent models
 $ {M}_{>t} $
.
$ {M}_{>t} $
.
We define each of these design processes
 $ d\in D $
by a tuple
$ d\in D $
by a tuple
 $ d=\left(p,s,t\right) $
. We refer to
$ d=\left(p,s,t\right) $
. We refer to
 $ p $
as a local design problem and to
$ p $
as a local design problem and to
 $ s $
as a local design solution. Both
$ s $
as a local design solution. Both
 $ p $
and
$ p $
and
 $ s $
are sets of design elements, i.e., subsets of
$ s $
are sets of design elements, i.e., subsets of
 $ M $
. The time at which
$ M $
. The time at which
 $ d $
is implemented is
$ d $
is implemented is
 $ t $
. We assume an incremental design sequence, i.e., only a single
$ t $
. We assume an incremental design sequence, i.e., only a single
 $ d $
can be implemented at
$ d $
can be implemented at
 $ t $
. Design process
$ t $
. Design process
 $ d $
implies a mapping from problem to solution:
$ d $
implies a mapping from problem to solution:
 $$ d:p\to s. $$
$$ d:p\to s. $$
We assume that both problem and solution can be defined in terms of design elements, such as requirements, components and parameters. The problem elements
 $ p $
are already present in the model before the design process, so
$ p $
are already present in the model before the design process, so
 $ p\subseteq {M}_t $
. The solution, however, is described in newly generated elements. The model is expanded to cover these solution elements:
$ p\subseteq {M}_t $
. The solution, however, is described in newly generated elements. The model is expanded to cover these solution elements:
 $ {M}_{t+1}={M}_t\hskip0.5em \cup \hskip0.5em s $
. We can also write
$ {M}_{t+1}={M}_t\hskip0.5em \cup \hskip0.5em s $
. We can also write
 $ {M}_t $
as the union of an initial model
$ {M}_t $
as the union of an initial model
 $ {M}_0 $
and the outcome of all design processes that have been implemented until time
$ {M}_0 $
and the outcome of all design processes that have been implemented until time
 $ t $
:
$ t $
:
 $$ {M}_t={M}_0\hskip0.5em \cup \hskip0.5em \left\{s\hskip0.5em |\hskip0.5em \left(p,s,{t}_d\right)\in D\hskip0.5em \mathrm{and}\hskip0.5em {t}_d\le t\right\}. $$
$$ {M}_t={M}_0\hskip0.5em \cup \hskip0.5em \left\{s\hskip0.5em |\hskip0.5em \left(p,s,{t}_d\right)\in D\hskip0.5em \mathrm{and}\hskip0.5em {t}_d\le t\right\}. $$
Note that
 $ {M}_0 $
and
$ {M}_0 $
and
 $ s $
are sets of design elements, such that
$ s $
are sets of design elements, such that
 $ {M}_t $
becomes the union of design elements:
$ {M}_t $
becomes the union of design elements:
 $ {M}_t={M}_0\hskip0.5em \cup \hskip0.5em {s}_1\hskip0.5em \cup \hskip0.5em {s}_2\hskip0.5em \cup \hskip0.5em \dots \hskip0.5em \cup \hskip0.5em {s}_t $
.
$ {M}_t={M}_0\hskip0.5em \cup \hskip0.5em {s}_1\hskip0.5em \cup \hskip0.5em {s}_2\hskip0.5em \cup \hskip0.5em \dots \hskip0.5em \cup \hskip0.5em {s}_t $
.
A key assumption in our theory is the neutrality of design elements: An element does not in itself imply a design problem or a design solution. In fact, we build this theory on the presumption that a single element can be both a problem and a solution at the same time.
What is a solution for one process may well become a problem for another. Consider the chain of processes depicted in Figure 2. An initial model
 $ {M}_0 $
exhibits some design problem that is the input of a problem-solving process
$ {M}_0 $
exhibits some design problem that is the input of a problem-solving process
 $ {d}_1=\left({p}_1,{s}_1,{t}_1\right) $
. The outcome of that process adds new elements to the model, expanding it to
$ {d}_1=\left({p}_1,{s}_1,{t}_1\right) $
. The outcome of that process adds new elements to the model, expanding it to
 $ {M}_1={M}_0\hskip0.5em \cup \hskip0.5em {s}_1 $
. However, in a subsequent stage, those added elements pose a new problem
$ {M}_1={M}_0\hskip0.5em \cup \hskip0.5em {s}_1 $
. However, in a subsequent stage, those added elements pose a new problem
 $ {p}_2 $
that should be solved by
$ {p}_2 $
that should be solved by
 $ {d}_2 $
. But even
$ {d}_2 $
. But even
 $ {M}_2 $
is not free of problems, and the design process has to continue.
$ {M}_2 $
is not free of problems, and the design process has to continue.

Figure 2. Design as a sequence of problem-solving processes. Each arrow represents one process as the mapping from a problem to a solution, both in terms of design elements of a model
 $ M $
. Each process contains the manifestation of a design problem, and the expansion of the design model with the design elements from a newly generated solution. It can happen that a new problem manifests itself due to those elements, which extends the sequence.
$ M $
. Each process contains the manifestation of a design problem, and the expansion of the design model with the design elements from a newly generated solution. It can happen that a new problem manifests itself due to those elements, which extends the sequence.
We adopt the following vocabulary, so that these dynamics can be properly framed. All problems, except initial problems, manifest themselves as a result of a design decision. We distinguish defined and discovered problems, depending on the conditions for their manifestation. If the designer anticipated the problem manifestation when making the decision, and made the decision in awareness of that manifestation, we say that the problem has been defined by the designer. Conversely, if the designer did not anticipate the problem, we say that the problem has been discovered. Defined problems manifest themselves relatively soon after a design decision – or simultaneously – while discovered problems manifest themselves at a later stage. Defined problems are not necessarily bad, as they can help designers in decomposing and tracing the design process. We presume, however, that discovered problems usually impact the design negatively, since by definition they were not accounted for in decision-making. This does not mean, however, that a discovered problem can always be avoided.
When discovering a problem, we can do either of two things. We can solve the problem by introducing new elements, continuing the chain and increasing the design complexity. The other option – which may be more elegant – is to avoid the problem by reconsidering an earlier design step. If we repeat process
 $ {d}_1 $
and consider a different outcome (i.e.,
$ {d}_1 $
and consider a different outcome (i.e.,
 $ {s}_1^{\prime } $
instead of
$ {s}_1^{\prime } $
instead of
 $ {s}_1 $
), we are on a different design trajectory where problems
$ {s}_1 $
), we are on a different design trajectory where problems
 $ {p}_2 $
and
$ {p}_2 $
and
 $ {p}_3 $
are potentially avoided. This is visualized by design process
$ {p}_3 $
are potentially avoided. This is visualized by design process
 $ {d}_1^{\prime }=\left({p}_1,{s}_1^{\prime}\right) $
at some time increment when a different trajectory is adopted. Note that in Figure 2, the time
$ {d}_1^{\prime }=\left({p}_1,{s}_1^{\prime}\right) $
at some time increment when a different trajectory is adopted. Note that in Figure 2, the time
 $ t $
of design process
$ t $
of design process
 $ d $
is omitted.
$ d $
is omitted.
Our modeling method is developed to identify and analyze cause–effect relations between problem-solving processes. The input data that are required from designers include the problems that were encountered, in terms of design elements; the solutions that were designed, also in terms of design elements; and the intended mappings between them, which solution solves which problem.
3.1. Problem causality
We define that problem
 $ p $
is caused by solution
$ p $
is caused by solution
 $ s $
if solution
$ s $
if solution
 $ s $
has introduced any element that is describing problem
$ s $
has introduced any element that is describing problem
 $ p $
. This is easily identified as a non-empty intersection of those sets. We use the arrow notation to signify that
$ p $
. This is easily identified as a non-empty intersection of those sets. We use the arrow notation to signify that
 $ p $
manifests itself due to
$ p $
manifests itself due to
 $ s $
. The manifestation relations from solutions and the problem are collected in the set
$ s $
. The manifestation relations from solutions and the problem are collected in the set
 $ Q $
, where each
$ Q $
, where each
 $ q\in Q $
is a tuple
$ q\in Q $
is a tuple
 $ \left(s,p\right) $
and:
$ \left(s,p\right) $
and:
 $$ q:s\to p\hskip1em \iff \hskip0.5em s\hskip0.5em \cap \hskip0.5em p\ne \varnothing . $$
$$ q:s\to p\hskip1em \iff \hskip0.5em s\hskip0.5em \cap \hskip0.5em p\ne \varnothing . $$
Figure 3 introduces the problem hierarchy, the causal structure of the design process that represents both design decisions and problem manifestations. This kind of graph, a directed acyclic graph, is necessary to study cause–effect relations (Rötzer et al. Reference Rötzer, Schweigert-Recksiek, Thoma and Zimmermann2022).

Figure 3. Two similar problem hierarchies represent how alternative decision-making leads to different design trajectories. Hierarchy B shows that
 $ {p}_5 $
is avoided by selecting an alternative solution to
$ {p}_5 $
is avoided by selecting an alternative solution to
 $ {p}_3 $
, at the cost of a new manifesting problem
$ {p}_3 $
, at the cost of a new manifesting problem
 $ {p}_6 $
. The resulting design models are derived from Equation (3):
$ {p}_6 $
. The resulting design models are derived from Equation (3):
 $ {M}_A=\cup \left\{{M}_0,{s}_1,{s}_2,{s}_{3A},{s}_4,{s}_{5A}\right\} $
and
$ {M}_A=\cup \left\{{M}_0,{s}_1,{s}_2,{s}_{3A},{s}_4,{s}_{5A}\right\} $
and
 $ {M}_B=\cup \left\{{M}_0,{s}_1,{s}_2,{s}_{3B},{s}_4,{s}_{6B}\right\} $
.
$ {M}_B=\cup \left\{{M}_0,{s}_1,{s}_2,{s}_{3B},{s}_4,{s}_{6B}\right\} $
.
The problem hierarchy
 $ H=\left({E}_H,{R}_H\right) $
is a tuple of nodes
$ H=\left({E}_H,{R}_H\right) $
is a tuple of nodes
 $ {E}_H $
and relations
$ {E}_H $
and relations
 $ {R}_H $
. Problems and solutions form the nodes of the graph:
$ {R}_H $
. Problems and solutions form the nodes of the graph:
 $ {E}_H=P\hskip0.5em \cup \hskip0.5em S $
. They are visualized as triangles pointing upward and downward, respectively. The relations are design processes and manifestations:
$ {E}_H=P\hskip0.5em \cup \hskip0.5em S $
. They are visualized as triangles pointing upward and downward, respectively. The relations are design processes and manifestations:
 $ {R}_H=D\hskip0.5em \cup \hskip0.5em Q $
. A solid arrow from a problem to a solution signifies a design process, see Equation (2). As Figure 3 indicates, a single solution can cause multiple problems. A dashed arrow from a solution to a problem signifies manifestation, see Equation (4).
$ {R}_H=D\hskip0.5em \cup \hskip0.5em Q $
. A solid arrow from a problem to a solution signifies a design process, see Equation (2). As Figure 3 indicates, a single solution can cause multiple problems. A dashed arrow from a solution to a problem signifies manifestation, see Equation (4).
A node’s vertical position in the hierarchy represents its rank that can be obtained through partial ordering (Wallis Reference Wallis2012). Problems that do not manifest themselves due to any design decision have rank 1 and are called root problems. These are visualized at the top of the hierarchy. Problems that occur downstream, i.e., manifest themselves due to a series of decisions, have a high rank and are placed at the bottom of the hierarchy.
The problem hierarchy will be a helpful tool in design space exploration. It compactly visualizes the design reasoning steps that have led designers to a particular solution set. Critical decisions, those that lead to many problems, stand out at the top of the hierarchy.
Problem hierarchy A in Figure 3 could be a formalization of the mirror technology design process, given as an example in the introduction to this paper, if we interpret that:
-
•
 $ {p}_1 $
is the need to route light in proximity to the fusion plasma;
$ {p}_1 $
is the need to route light in proximity to the fusion plasma; -
•
$ {s}_1 $
is the use of a metallic mirror, a response to
$ {p}_1 $
; -
•
$ {p}_2 $
is the risk of an overheating mirror, a direct consequence of
$ {s}_1 $
; -
•
$ {p}_3 $
is the problem of mirror surface contamination, also a consequence of
$ {s}_1 $
; -
•
$ {s}_2 $
represents a liquid cooling system, addressing
$ {p}_2 $
; -
•
$ {s}_3 $
represents a cleaning system, addressing
$ {p}_3 $
; -
•
$ {p}_4 $
is a problem only related to the cooling system, e.g., water leaks; -
•
$ {s}_4 $
addresses the water leak problem through the use of dedicated seals; -
•
$ {p}_5 $
is the electrical grounding issue that arises from the combination of the cooling system
$ {s}_2 $
and the cleaning system
$ {s}_3 $
; and -
•
$ {s}_5 $
is the notch filter that is proposed to resolve
$ {p}_5 $
.


















This visual representation emphasizes the far-reaching, and potentially underestimated, consequences of the decision to use metallic mirrors.
The formal description of the problem hierarchy
 $ H=\left({E}_H,{R}_H\right) $
allows us to define various sets that will support subsequent analyses. For any node
$ H=\left({E}_H,{R}_H\right) $
allows us to define various sets that will support subsequent analyses. For any node
 $ h\in {E}_H $
, we can collect all adjacent input and output nodes in sets
$ h\in {E}_H $
, we can collect all adjacent input and output nodes in sets
 $ \mathcal{X}(h) $
and
$ \mathcal{X}(h) $
and
 $ \mathcal{Y}(h) $
, respectively:
$ \mathcal{Y}(h) $
, respectively:
 $$ \mathcal{X}(h)=\left\{{h}^{\prime}\in {E}_H\hskip0.5em |\hskip0.5em \left({h}^{\prime}\to h\right)\in {R}_H\right\} $$
$$ \mathcal{X}(h)=\left\{{h}^{\prime}\in {E}_H\hskip0.5em |\hskip0.5em \left({h}^{\prime}\to h\right)\in {R}_H\right\} $$
and
 $$ \mathcal{Y}(h)=\left\{{h}^{\prime}\in {E}_H\hskip0.5em |\hskip0.5em \left(h\to {h}^{\prime}\right)\in {R}_H\right\}. $$
$$ \mathcal{Y}(h)=\left\{{h}^{\prime}\in {E}_H\hskip0.5em |\hskip0.5em \left(h\to {h}^{\prime}\right)\in {R}_H\right\}. $$
For example, node
 $ {s}_2 $
in hierarchy A of Figure 3 has a single input node and two output nodes:
$ {s}_2 $
in hierarchy A of Figure 3 has a single input node and two output nodes:
 $ \mathcal{X}\left({s}_2\right)=\left\{{p}_2\right\} $
and
$ \mathcal{X}\left({s}_2\right)=\left\{{p}_2\right\} $
and
 $ \mathcal{Y}\left({s}_2\right)=\left\{{p}_4,{p}_5\right\} $
. We furthermore define the recursive sets
$ \mathcal{Y}\left({s}_2\right)=\left\{{p}_4,{p}_5\right\} $
. We furthermore define the recursive sets
 $ {\mathcal{X}}^{\infty }(h) $
as the nodes that can reach
$ {\mathcal{X}}^{\infty }(h) $
as the nodes that can reach
 $ h $
, and
$ h $
, and
 $ {\mathcal{Y}}^{\infty }(h) $
as the nodes that can be reached from
$ {\mathcal{Y}}^{\infty }(h) $
as the nodes that can be reached from
 $ h $
:
$ h $
:
 $$ {\mathcal{X}}^{\infty }(h)=\underset{h^{\prime}\in \mathcal{X}(h)}{\cup}\left(\left\{{h}^{\prime}\right\}\cup {\mathcal{X}}^{\infty}\left({h}^{\prime}\right)\right) $$
$$ {\mathcal{X}}^{\infty }(h)=\underset{h^{\prime}\in \mathcal{X}(h)}{\cup}\left(\left\{{h}^{\prime}\right\}\cup {\mathcal{X}}^{\infty}\left({h}^{\prime}\right)\right) $$
and
 $$ {\mathcal{Y}}^{\infty }(h)=\underset{h^{\prime}\in \mathcal{Y}(h)}{\cup}\left(\left\{{h}^{\prime}\right\}\hskip0.5em \cup \hskip0.5em {\mathcal{Y}}^{\infty}\left({h}^{\prime}\right)\right). $$
$$ {\mathcal{Y}}^{\infty }(h)=\underset{h^{\prime}\in \mathcal{Y}(h)}{\cup}\left(\left\{{h}^{\prime}\right\}\hskip0.5em \cup \hskip0.5em {\mathcal{Y}}^{\infty}\left({h}^{\prime}\right)\right). $$
For example, that same node
 $ {s}_2 $
can be reached from the three nodes
$ {s}_2 $
can be reached from the three nodes
 $ {\mathcal{X}}^{\infty}\left({s}_2\right)=\left\{{p}_1,{s}_1,{p}_2\right\} $
and can reach the four nodes
$ {\mathcal{X}}^{\infty}\left({s}_2\right)=\left\{{p}_1,{s}_1,{p}_2\right\} $
and can reach the four nodes
 $ {\mathcal{Y}}^{\infty }=\left\{{p}_4,{s}_4,{p}_5,{s}_{5A}\right\} $
$ {\mathcal{Y}}^{\infty }=\left\{{p}_4,{s}_4,{p}_5,{s}_{5A}\right\} $
The sets
 $ {\mathcal{X}}^{\infty } $
and
$ {\mathcal{X}}^{\infty } $
and
 $ {\mathcal{Y}}^{\infty } $
are essential to understand the precedents and consequences of the way designers solve problems. Now that we have formalized the dynamics of problem-solving, we can investigate its relation to the complexity of the design model.
$ {\mathcal{Y}}^{\infty } $
are essential to understand the precedents and consequences of the way designers solve problems. Now that we have formalized the dynamics of problem-solving, we can investigate its relation to the complexity of the design model.
3.2. Complexity
We can use Equation (1) to calculate the complexity of the model as the design process unfolds. If the complexity of any network model
 $ M $
can be written as
$ M $
can be written as
 $ \xi (M) $
, then we can substitute Equation (3) to define complexity as a function of time:
$ \xi (M) $
, then we can substitute Equation (3) to define complexity as a function of time:
 $$ \xi \left({M}_t\right)=\xi \left({M}_0\hskip0.5em \cup \hskip0.5em \left\{s\hskip0.5em |\hskip0.5em \left(p,s,{t}_d\right)\in D\hskip0.5em \mathrm{and}\hskip0.5em {t}_d\le t\right\}\right). $$
$$ \xi \left({M}_t\right)=\xi \left({M}_0\hskip0.5em \cup \hskip0.5em \left\{s\hskip0.5em |\hskip0.5em \left(p,s,{t}_d\right)\in D\hskip0.5em \mathrm{and}\hskip0.5em {t}_d\le t\right\}\right). $$
Note that solutions
 $ s $
are sets of model elements.
$ s $
are sets of model elements.
Equation (9) can be used to plot the whole system’s complexity development over a sequence of design iterations. But what can this tell us about the contribution of each individual design process
 $ d $
?
$ d $
?
It is helpful to introduce three sections of the model
 $ M $
, as a function of design process
$ M $
, as a function of design process
 $ d=\left({p}_d,{s}_d,{t}_d\right) $
. First, there is
$ d=\left({p}_d,{s}_d,{t}_d\right) $
. First, there is
 $ {M}^{-}(d) $
, the subset of design elements that has led to the problem
$ {M}^{-}(d) $
, the subset of design elements that has led to the problem
 $ {p}_d $
. The elements in
$ {p}_d $
. The elements in
 $ {M}^{-}(d) $
are added by the solutions in
$ {M}^{-}(d) $
are added by the solutions in
 $ {\mathcal{X}}^{\infty}\left({p}_d\right) $
, i.e., those solutions that have led up to
$ {\mathcal{X}}^{\infty}\left({p}_d\right) $
, i.e., those solutions that have led up to
 $ {p}_d $
:
$ {p}_d $
:
 $$ {M}^{-}(d)={M}_0\hskip0.5em \cup \hskip0.5em {\mathcal{X}}^{\infty}\left({p}_d\right). $$
$$ {M}^{-}(d)={M}_0\hskip0.5em \cup \hskip0.5em {\mathcal{X}}^{\infty}\left({p}_d\right). $$
Second, there is
 $ {M}^{+}(d) $
, which adds the design elements that are generated by process
$ {M}^{+}(d) $
, which adds the design elements that are generated by process
 $ d $
:
$ d $
:
 $$ {M}^{+}(d)={M}^{-}(d)\hskip0.5em \cup \hskip0.5em {s}_d. $$
$$ {M}^{+}(d)={M}^{-}(d)\hskip0.5em \cup \hskip0.5em {s}_d. $$
Finally, we can add the design elements that are generated by follow-up processes, for which process
 $ d $
is partly responsible. These are the processes that deal with the problems that manifest themselves due to
$ d $
is partly responsible. These are the processes that deal with the problems that manifest themselves due to
 $ {s}_d $
:
$ {s}_d $
:
 $$ {M}^{++}(d)={M}^{+}(d)\hskip0.5em \cup \hskip0.5em {\mathcal{Y}}^{\infty}\left({s}_d\right). $$
$$ {M}^{++}(d)={M}^{+}(d)\hskip0.5em \cup \hskip0.5em {\mathcal{Y}}^{\infty}\left({s}_d\right). $$
We use the collections
 $ {M}^{-}(d) $
,
$ {M}^{-}(d) $
,
 $ {M}^{+}(d) $
and
$ {M}^{+}(d) $
and
 $ {M}^{++}(d) $
to characterize the evolution of the complexity as a function of the design choices. We define two impact factors as
$ {M}^{++}(d) $
to characterize the evolution of the complexity as a function of the design choices. We define two impact factors as
 $$ {I}_L(d)=\xi \left({M}^{+}(d)\right)-\xi \left({M}^{-}(d)\right) $$
$$ {I}_L(d)=\xi \left({M}^{+}(d)\right)-\xi \left({M}^{-}(d)\right) $$
and
 $$ {I}_G(d)=\xi \left({M}^{++}(d)\right)-\xi \left({M}^{-}(d)\right). $$
$$ {I}_G(d)=\xi \left({M}^{++}(d)\right)-\xi \left({M}^{-}(d)\right). $$
The local complexity impact
 $ {I}_L $
is the difference in system complexity before and after
$ {I}_L $
is the difference in system complexity before and after
 $ d $
and therefore reflects the direct contribution of solution
$ d $
and therefore reflects the direct contribution of solution
 $ {s}_d $
. But what about knock-on effects? If
$ {s}_d $
. But what about knock-on effects? If
 $ {s}_d $
is a ‘bad’ design that leads to many problems, and solving those problems would lead to more complexity, we would like to retrace those effects to
$ {s}_d $
is a ‘bad’ design that leads to many problems, and solving those problems would lead to more complexity, we would like to retrace those effects to
 $ d $
. The global complexity impact
$ d $
. The global complexity impact
 $ {I}_G $
does this, by adding the complexity that was added due to manifested problems.
$ {I}_G $
does this, by adding the complexity that was added due to manifested problems.
In practice, designers do not know beforehand whether a particular design decision will lead to undesired problems. Such effects are easily underestimated. Only in later stages will the true gravity of early-stage decisions appear (Tan et al. Reference Tan, Otto and Wood2017). This is nicely captured in
 $ {I}_G $
, since this metric depends on
$ {I}_G $
, since this metric depends on
 $ {\mathcal{Y}}^{\infty }(d) $
. This set increases as more and more downstream problems are solved. Therefore,
$ {\mathcal{Y}}^{\infty }(d) $
. This set increases as more and more downstream problems are solved. Therefore,
 $ {I}_G $
will increase over time. An illustration is provided in the demonstration section.
$ {I}_G $
will increase over time. An illustration is provided in the demonstration section.
If we view complexity
 $ \xi $
as just another attribute that depends on the design, the theory becomes more widely applicable. We can replace complexity
$ \xi $
as just another attribute that depends on the design, the theory becomes more widely applicable. We can replace complexity
 $ \xi $
by any attribute
$ \xi $
by any attribute
 $ X $
that depends on the design model, and Equations (9)–(14) can still be applied. Considering, for example, the various Design-for-X studies, the theory presented above allows traceability of any performance indicator over time and can distill desired and undesired contributions of individual design decisions.
$ X $
that depends on the design model, and Equations (9)–(14) can still be applied. Considering, for example, the various Design-for-X studies, the theory presented above allows traceability of any performance indicator over time and can distill desired and undesired contributions of individual design decisions.
We have introduced a theory of how design models develop through a series of problem-solving processes. Problems that manifest themselves due to a prior decision can be easily identified by overlapping design elements. This dynamic defines how the model
 $ M $
develops over time and for different solution alternatives. Additions to the model cause its complexity to increase, as is captured in two derived network metrics.
$ M $
develops over time and for different solution alternatives. Additions to the model cause its complexity to increase, as is captured in two derived network metrics.
3.3. Algorithmic approach
We summarize the theory presented into an algorithmic problem-solving method. The following steps include problem identification, causal analysis, complexity assessments and design revisions. They are intended to guide designers through the various decision branches in the design process.
-
1. Initialize design model and problem hierarchy. Initialize the problem hierarchy
$ H=\left({E}_H,{R}_H\right) $
. The nodes of
$ H $
are
$ {E}_H=P\hskip0.5em \cup \hskip0.5em S $
, with problems
$ P=\varnothing $
and solutions
$ S=\varnothing $
. The relations of
$ H $
are
$ {R}_H=D\hskip0.5em \cup \hskip0.5em Q $
, with design processes
$ D=\varnothing $
and manifestations
$ Q=\varnothing $
. -
2. Discover a design problem. Analyze the design model
$ M $
. Can a design problem be discovered in
$ M $
?Yes → Describe the discovered problem
$ p $
in terms of design elements of
$ M $
and add it to the set of design problems:
$ p\subseteq M $
and
$ P=P\hskip0.5em \cup \hskip0.5em \left\{p\right\} $
. Continue with Step 3.















No → The design is finished.
-
3. Trace problem causality. The elements in
$ p $
might have been introduced by earlier solutions. The causal relations between earlier solutions and the problem
$ p $
can be identified mathematically and added to
$ Q $
:



 $$ Q=Q\hskip0.5em \cup \hskip0.5em \left\{\left(s,p\right)\hskip0.5em |\hskip0.5em s\in S\hskip0.5em \mathrm{and}\hskip0.5em s\hskip0.5em \cap \hskip0.5em p\ne \varnothing \right\}. $$
$$ Q=Q\hskip0.5em \cup \hskip0.5em \left\{\left(s,p\right)\hskip0.5em |\hskip0.5em s\in S\hskip0.5em \mathrm{and}\hskip0.5em s\hskip0.5em \cap \hskip0.5em p\ne \varnothing \right\}. $$
-
4. Avoid the problem. Investigate whether revising an earlier decision could circumvent
$ p $
. First, collect the root problems
$ {P}_r $
that have led to the manifestation of
$ p $
. This collection is
$ {P}_r=P\hskip0.5em \cap \hskip0.5em {\mathcal{X}}^{\infty }(p) $
. The problems
$ {P}_r $
were addressed in an earlier design stage with limited knowledge about their consequences, namely, in design processes
$ {D}_r=\left\{\left({p}^{\prime },{s}^{\prime },{t}^{\prime}\right)\in D\hskip0.5em |\hskip0.5em {p}^{\prime}\in {P}_r\right\} $
. Given the current knowledge, is there a good alternative to the outcome of any
$ {d}_r\in {D}_r $
that could avoid
$ p $
?Yes → Retrace the design trajectory to
$ {d}_r $
by executing Step *. Then, shift from
$ p $
to
$ {p}^{\prime } $
and continue with Step 5.











No → Continue with Step 5.
-
5. Add a solution. Generate a set of solution candidates, express them in terms of design elements and make a selection. Formalize a new design process
$ d=\left(p,s,t\right) $
for the selected candidate
$ s $
at current time
$ t $
. Add the solution
$ s $
to the model and to the problem hierarchy. If
$ s $
implies follow-up problems that must be managed, add these defined problems
$ {P}_d $
to the set
$ P $
. Update the sets as follows:







 $$ {\displaystyle \begin{array}{l}M=M\hskip0.5em \cup \hskip0.5em s,\\ {}S=S\hskip0.5em \cup \hskip0.5em \left\{s\right\},\\ {}D=D\hskip0.5em \cup \hskip0.5em \left\{d\right\}\hskip0.5em \mathrm{and}\\ {}P=P\hskip0.5em \cup \hskip0.5em \left\{{p}_d\in {P}_d\hskip0.5em |\hskip0.5em {p}_d\hskip0.5em \subseteq \hskip0.5em M\right\}.\end{array}} $$
$$ {\displaystyle \begin{array}{l}M=M\hskip0.5em \cup \hskip0.5em s,\\ {}S=S\hskip0.5em \cup \hskip0.5em \left\{s\right\},\\ {}D=D\hskip0.5em \cup \hskip0.5em \left\{d\right\}\hskip0.5em \mathrm{and}\\ {}P=P\hskip0.5em \cup \hskip0.5em \left\{{p}_d\in {P}_d\hskip0.5em |\hskip0.5em {p}_d\hskip0.5em \subseteq \hskip0.5em M\right\}.\end{array}} $$
-
6. Evaluate earlier decisions. The addition of
$ s $
and the corresponding increase in complexity are a consequence of earlier decisions. It is likely that the complexity was not accounted for when those decisions were made. Therefore, we recommend to evaluate the complexity contribution of prior design processes in the problem hierarchy. The design processes that have indirectly caused the complexity in
$ s $
are given by
$ {D}_r=\left\{\left({p}^{\prime },{s}^{\prime },{t}^{\prime}\right)\in D\hskip0.5em |\hskip0.5em {s}^{\prime}\in {\mathcal{X}}^{\infty }(s)\right\} $
. For each process
$ {d}_r\in {D}_r $
, compute complexity metrics
$ {I}_L\left({d}_r\right) $
and
$ {I}_G\left({d}_r\right) $
. The local
$ {I}_L\left({d}_r\right) $
is the complexity impact that was expected at time
$ {t}^{\prime } $
, while the global
$ {I}_G\left({d}_r\right) $
represents the actual impact at this moment. Therefore, a process that underestimated future complexity impact at time
$ {t}^{\prime } $
is indicated by
$ {I}_G\left({d}_r\right)\gg {I}_L\left({d}_r\right) $
. Given the current complexity impact of decision
$ {d}_r $
, could you revise that decision?Yes → Retrace the design trajectory to
$ {d}_r $
by executing Step *. Then, shift from
$ p $
to
$ {p}^{\prime } $
and continue with Step 5.















No → Continue with Step 7.
-
7. Address open problems. The problems
$ {P}_d $
that were defined in Step 5 need to be addressed. Defined but unaddressed problems are given by
$ {P}_o=\left\{p\in P\hskip0.5em |\hskip0.5em \mathcal{Y}(p)=\varnothing \right\} $
. Are there any open problems, i.e., is
$ {P}_o $
non-empty?Yes → Shift to an open problem
$ {p}_o\in {P}_o $
and continue with Step 3.




No → Continue with Step 2.
-
* Retrace design trajectory. Steps 4 and 6 can remove some processes from the design trajectory. Any design elements in
$ M $
associated with those processes need to be removed, and the problem hierarchy needs to be updated. To retrace the trajectory to design process
$ d=\left(p,s,t\right) $
, update the sets:


 $$ {\displaystyle \begin{array}{c}M=M\backslash \hskip0.5em \cup \hskip0.5em \left(S\hskip0.5em \cap \hskip0.5em {\mathcal{Y}}^{\infty }(s)\right),\\ {}S=S\backslash {\mathcal{Y}}^{\infty }(s),\\ {}P=P\backslash {\mathcal{Y}}^{\infty }(s),\\ {}D=\left\{\left({p}^{\prime },{s}^{\prime },{t}^{\prime}\right)\in D\hskip0.5em |\hskip0.5em {s}^{\prime}\in S\right\}\mathrm{and}\\ {}Q=\left\{\left({s}^{\prime },{p}^{\prime}\right)\in Q\hskip0.5em |\hskip0.5em {p}^{\prime}\in P\right\}.\end{array}} $$
$$ {\displaystyle \begin{array}{c}M=M\backslash \hskip0.5em \cup \hskip0.5em \left(S\hskip0.5em \cap \hskip0.5em {\mathcal{Y}}^{\infty }(s)\right),\\ {}S=S\backslash {\mathcal{Y}}^{\infty }(s),\\ {}P=P\backslash {\mathcal{Y}}^{\infty }(s),\\ {}D=\left\{\left({p}^{\prime },{s}^{\prime },{t}^{\prime}\right)\in D\hskip0.5em |\hskip0.5em {s}^{\prime}\in S\right\}\mathrm{and}\\ {}Q=\left\{\left({s}^{\prime },{p}^{\prime}\right)\in Q\hskip0.5em |\hskip0.5em {p}^{\prime}\in P\right\}.\end{array}} $$
where the backslash symbol
 $ \left(\backslash \right) $
is the set difference operator, i.e.,
$ \left(\backslash \right) $
is the set difference operator, i.e.,
 $ A\backslash B=\left\{a\in A\hskip0.5em |\hskip0.5em a\notin B\right\} $
. Return to the respective step.
$ A\backslash B=\left\{a\in A\hskip0.5em |\hskip0.5em a\notin B\right\} $
. Return to the respective step.
4. Function-behavior-structure
The above theory can in principle use any network model
 $ M $
. We will now frame the theory in a specific modeling paradigm, popularized in design science: FBS. So far we have been using the terms problem, solution, design element and design process in a rather general sense. In this section, we will make these terms specific for the FBS paradigm.
$ M $
. We will now frame the theory in a specific modeling paradigm, popularized in design science: FBS. So far we have been using the terms problem, solution, design element and design process in a rather general sense. In this section, we will make these terms specific for the FBS paradigm.
Our ideas are based on the situated FBS framework by Gero & Kannengiesser (Reference Gero and Kannengiesser2004). This framework contains ten specific classes of design elements and twenty design processes between those elements. While this level of detail provides an insightful contribution to design science, a simplified interpretation will be sufficient for the scope of our work. The original situated FBS framework is visualized in Figure 4.

Figure 4. The situated FBS framework classifies design elements as requirements, functions, structures and behaviors. Subsets of these elements play a particular role in different contexts: the external world, the interpreted world and the expected world. Arrows between elements represent twenty classes of a design process (Gero & Kannengiesser Reference Gero and Kannengiesser2004).
Our simplified interpretation disregards the requirements as separate design elements. Furthermore, we combine the design elements from different contexts into functions (Fe, Fi, Fei), structures (Se, Si, Sei) and behaviors (Be, Bi, Bei). This leads us to a simpler model of design, where there are only three possible processes: formulation is the transition from behavior to function, process 16 in Figure 4; synthesis is the transition from function to structure, processes 10 and 11 in Figure 4; and analysis is the transition from structure to behavior, process 14 in Figure 4.
Our theory frames each of these processes as a mapping from problem to solution. Most designers start with formulating an intent to influence the behavior of a given system. The formulation process
 $ {d}_f $
therefore takes a behavioral problem
$ {d}_f $
therefore takes a behavioral problem
 $ {p}_f $
as an input and provides a functional solution
$ {p}_f $
as an input and provides a functional solution
 $ {s}_f $
as an output. Once a functional specification is established, designers generate the components that will perform functionality. This synthesis process
$ {s}_f $
as an output. Once a functional specification is established, designers generate the components that will perform functionality. This synthesis process
 $ {d}_s $
takes a functional problem
$ {d}_s $
takes a functional problem
 $ {p}_s $
as an input and provides a structural solution
$ {p}_s $
as an input and provides a structural solution
 $ {s}_s $
as an output. Finally, designers analyze the generated parts to determine their behavior in the working environment. The analysis process
$ {s}_s $
as an output. Finally, designers analyze the generated parts to determine their behavior in the working environment. The analysis process
 $ {d}_a $
therefore takes a structural problem
$ {d}_a $
therefore takes a structural problem
 $ {p}_a $
as an input and provides a behavioral solution
$ {p}_a $
as an input and provides a behavioral solution
 $ {s}_a $
as an output. Our framing of the situated FBS framework has led to a cycle of problem-solving, visualized in Figure 5. In the upcoming demonstration section, we will use the colors blue to indicate function, orange to indicate structure and green to indicate behavior.
$ {s}_a $
as an output. Our framing of the situated FBS framework has led to a cycle of problem-solving, visualized in Figure 5. In the upcoming demonstration section, we will use the colors blue to indicate function, orange to indicate structure and green to indicate behavior.

Figure 5. Three FBS problem-solving processes form an iterative design cycle. The overlapping input and output of two processes signifies a causal problem manifestation.
Problems cannot and should not always be avoided: The outcome of a formulation will always need to be synthesized, and the outcome of a synthesis will always need to be analyzed. Hence, we would classify synthesis and analysis problems as defined problems. However, the problems we would want to avoid are those that manifest when an analysis discovers undesired behavior. Those discovered problems would need to be addressed in another formulation-synthesis-analysis cycle. This cycle only ends after an analysis shows no new design problems.
In the remainder of this section, we will introduce a network representation of FBS design elements, i.e., nodes and edges of
 $ M $
. Then we propose which of these elements we use to describe which class of problem and solution. Finally, we explain how to visualize an FBS network in a product DSM.
$ M $
. Then we propose which of these elements we use to describe which class of problem and solution. Finally, we explain how to visualize an FBS network in a product DSM.
4.1. Network representation
We derive from the situated FBS framework a network model with three classes of nodes and six classes of edges. Figure 6 shows these design elements. We will refer to sets of nodes by single letters and to sets of edges by double letters.

Figure 6. An FBS network model contains three classes of nodes and six classes of edges.
Nodes in our FBS model represent functions
 $ F $
, structures
$ F $
, structures
 $ C $
and behaviors
$ C $
and behaviors
 $ B $
. We use the letter
$ B $
. We use the letter
 $ C $
for structures, in order to avoid confusion with the set of solutions
$ C $
for structures, in order to avoid confusion with the set of solutions
 $ S $
. Functions are the tasks that the design should perform, structures are its physical components and behaviors are the physical phenomena it exhibits. In the words of Gero & Kannengiesser (Reference Gero and Kannengiesser2004): Function describes what a design is for, structure describes what it is and behavior describes what it does.
$ S $
. Functions are the tasks that the design should perform, structures are its physical components and behaviors are the physical phenomena it exhibits. In the words of Gero & Kannengiesser (Reference Gero and Kannengiesser2004): Function describes what a design is for, structure describes what it is and behavior describes what it does.
Edges between nodes of the same class are either functional
 $ FF $
, structural
$ FF $
, structural
 $ CC $
or behavioral
$ CC $
or behavioral
 $ BB $
dependencies. A functional dependency is directed, specifying that one function requires another function; a structural dependency specifies the common geometrical features of two objects; and a behavioral dependency specifies the coupling between physical phenomena. Structural and behavioral dependencies are often modeled as undirected edges.
$ BB $
dependencies. A functional dependency is directed, specifying that one function requires another function; a structural dependency specifies the common geometrical features of two objects; and a behavioral dependency specifies the coupling between physical phenomena. Structural and behavioral dependencies are often modeled as undirected edges.
This leaves us with three mappings between nodes of different classes. The mappings
 $ FC $
define which function is performed by which structure, and the mappings
$ FC $
define which function is performed by which structure, and the mappings
 $ CB $
define which structure exhibits which behavior. Finally, the mappings
$ CB $
define which structure exhibits which behavior. Finally, the mappings
 $ FB $
define which function is intended to influence which behavior. We consider the latter as a functional dependency between the behavior of an existing component and the function of a to-be-designed component. For example, the function of a new cooling system (e.g., ‘extract heat’) is to influence the behavior of an existing camera (e.g., ‘thermodynamics’).
$ FB $
define which function is intended to influence which behavior. We consider the latter as a functional dependency between the behavior of an existing component and the function of a to-be-designed component. For example, the function of a new cooling system (e.g., ‘extract heat’) is to influence the behavior of an existing camera (e.g., ‘thermodynamics’).
As such, design model
 $ M $
is the union of the sets:
$ M $
is the union of the sets:
 $$ M=\hskip0.5em \cup \hskip0.5em \left\{F,B,C, FF, BB, CC, FB, FC, CB\right\}. $$
$$ M=\hskip0.5em \cup \hskip0.5em \left\{F,B,C, FF, BB, CC, FB, FC, CB\right\}. $$
Each node is a description of function, behavior or structure that can in itself contain various design statements on what is desired or what is expected. As such, functional, behavioral or structural requirements can be part of any of these respective nodes.
4.2. Problems and solutions
We can now allocate the nodes and edges of our network model to the problems and solutions of our problem-solving cycle:
-
• The formulation problem
$ {p}_f $
is about expressing the behavior
$ B $
of a contextual system that needs to be changed or improved. The undesired behavior may also arise from interactions between behaviors,
$ BB $
. -
• The formulation solution
$ {s}_f $
is defined in terms of new functions
$ F $
that need to be introduced, the functional dependencies
$ FF $
and
$ FB $
indicating which behavior of the contextual system is to be changed by the new functions. -
• The synthesis problem
$ {p}_s $
is expressed in exactly the terms of a formulation solution: the desired new functionalities
$ F $
and dependencies
$ FF $
and
$ FB $
. These three sets of design elements need to be implemented by structural features. -
• The synthesis solution
$ {s}_s $
consists of the newly generated components
$ C $
, the newly introduced structural dependencies
$ CC $
and the mapping between functions and components
$ FC $
. -
• The analysis problem
$ {p}_a $
is to derive the behavior of a set of components
$ C $
and component dependencies
$ CC $
. -
• The analysis solution
$ {s}_a $
consists of the discovered behavior
$ B $
and behavioral dependencies
$ BB $
of the system in design, as well as the attribution of behavior to components
$ CB $
.






















Table 1 summarizes the analogy between the situated FBS framework and our interpretation in problem-solving.
Table 1. Employing the situated FBS framework (Gero & Kannengiesser Reference Gero and Kannengiesser2004) in our problem-solving theory has led to a network model with nodes
 $ F $
,
$ F $
,
 $ B $
and
$ B $
and
 $ C $
, and edges
$ C $
, and edges
 $ FF $
,
$ FF $
,
 $ BB $
,
$ BB $
,
 $ CC $
,
$ CC $
,
 $ FB $
,
$ FB $
,
 $ FC $
and
$ FC $
and
 $ BC $
. Design processes 10, 11, 14 and 16 are interpreted as three problem-solving processes and defined in terms of the network model
$ BC $
. Design processes 10, 11, 14 and 16 are interpreted as three problem-solving processes and defined in terms of the network model

4.3. Visualization
We have already introduced the general problem hierarchy in Figure 3 to support designers in their decision-making process. In the case of FBS modeling, the problems and solutions of the hierarchy will represent either formulation, synthesis or analysis.
Additionally, designers need to inspect their FBS model at different times and for alternative decisions. There are many possibilities to visualize such a model, but we propose to use a product DSM (Eppinger & Browning Reference Eppinger and Browning2012).
The product DSM represents a system as the arrangement of components and their interfaces. We project functional, structural and behavioral dependencies from our FBS model onto this DSM. The leading elements on the axes of the DSM are structural elements
 $ C $
. Structural interfaces
$ C $
. Structural interfaces
 $ CC $
connect two structural elements and therefore appear as symmetric off-diagonal entries in the DSM.
$ CC $
connect two structural elements and therefore appear as symmetric off-diagonal entries in the DSM.
Functional and behavioral dependencies
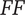 $ FF $
,
$ FF $
,
 $ FB $
and
$ FB $
and
 $ BB $
do not directly connect to structural elements. They do, however, connect indirectly.
$ BB $
do not directly connect to structural elements. They do, however, connect indirectly.
If two components (
 $ {c}_1 $
and
$ {c}_1 $
and
 $ {c}_2 $
) are each related to a function (
$ {c}_2 $
) are each related to a function (
 $ {c}_1\to {f}_1 $
and
$ {c}_1\to {f}_1 $
and
 $ {c}_2\to {f}_2 $
), and those functions have a mutual dependency (
$ {c}_2\to {f}_2 $
), and those functions have a mutual dependency (
 $ {f}_1\to {f}_2 $
), then we can presume that there is a functional dependency between the two components (
$ {f}_1\to {f}_2 $
), then we can presume that there is a functional dependency between the two components (
 $ {c}_1\to {c}_2 $
). The presumed directed dependency can then be visualized in the product DSM. Behavioral dependencies are derived in the same way but yield an undirected dependency in the DSM. Figure 7 visualizes this process.
$ {c}_1\to {c}_2 $
). The presumed directed dependency can then be visualized in the product DSM. Behavioral dependencies are derived in the same way but yield an undirected dependency in the DSM. Figure 7 visualizes this process.

Figure 7. Left: Behavioral and functional dependencies are projected to their respective structures. Right: Proposed DSM to visualize the functional, behavioral and structural interfaces between structures. The DSM visualizes that A is a highly integrative component and that B and C form a cohesive module.
What practical advice would our method give to designers that use the FBS paradigm? The problem hierarchy will show a recurring sequence of formulation, synthesis and analysis problems. This should motivate designers to avoid downstream problems. Revising a synthesis process could lead to geometrical reshaping or even the use of another technology. Reanalyzing a structural system could lead to a more accurate understanding of a behavioral problem. Finally, reformulating function to change a problem-solving intent might allow other solution architectures.
In this section, we have specialized our general theory for the FBS modeling paradigm. Next we demonstrate how the proposed method can be used in a fusion diagnostics-related design problem.
5. Demonstration
The Visible Spectroscopy Reference System (VSRS) is one of the diagnostic subsystems to be integrated in ITER. The VSRS is an optical diagnostic system that has the role of collecting light emitted by the high-temperature plasma where the fusion process occurs and conducting real-time spectroscopic measurements. These measurements then provide data on the state of the plasma that can be used for machine protection and plasma control. Such functionalities are indispensable for operating ITER.
The VSRS generally consists of three kinds of components that implement a range of technologies: optical elements, such as mirrors, fibers and windows; measurement devices including a polychromator and multiple spectrometers; and electronic devices comprising data processors, analog and digital controllers and network equipment. Figure 8 gives a simple sketch of the VSRS.

Figure 8. The Visible Spectroscopy Reference System (VSRS) is an optical measurement system in ITER. From left to right: The toroidal fusion chamber emits a pink light. That light is relayed through a sequence of eight mirrors. An optical fiber bundle transports the light to a separate building with normal environmental conditions. The light is analyzed by a polychromator and multiple spectrometers and processed by electronic equipment. The remaining components fulfill auxiliary functionalities, such as controlling a shutter, cleaning the mirrors in-vacuum and aligning and calibrating optics.
In the following sections, we treat two problems. First, with a rather minimal view of the VSRS we show how alternative decisions lead to alternative problems and alternative design models. Second, we increase the granularity of the models. This allows us to focus on the development of the system over time, and we can identify those decisions that have most contributed to its complexity.
5.1. A simple model
This simple model of the VSRS design captures a very typical problem in low-maturity systems development. It revolves around a single critical synthesis decision: whether to use a glass fiber or a metallic mirror to transport light. At this point in time, the designer lacks detailed knowledge about any downstream issues that may occur but has to make a preliminary decision nevertheless. If in the future a problem is discovered, the designer quickly needs to assess the impact of revising the earlier decision. How can our method help the designer?
Let us first define an initial model
 $ {M}_0 $
from which to explore our alternative design trajectories. Suppose that the designer has selected the metallic mirror: case A. We break down the development process into the six subsequent formulation, synthesis and analysis processes
$ {M}_0 $
from which to explore our alternative design trajectories. Suppose that the designer has selected the metallic mirror: case A. We break down the development process into the six subsequent formulation, synthesis and analysis processes
 $$ {D}_A=\left\{\begin{array}{ll}{d}_f\left({p}_1,{s}_1,1\right)& {d}_f\left({p}_4,{s}_4,4\right)\\ {}{d}_s\left({p}_2,{s}_2,2\right)& {d}_s\left({p}_5,{s}_5,5\right)\\ {}{d}_a\left({p}_3,{s}_3,3\right)& {d}_a\left({p}_6,{s}_6,6\right)\end{array}\right\} $$
$$ {D}_A=\left\{\begin{array}{ll}{d}_f\left({p}_1,{s}_1,1\right)& {d}_f\left({p}_4,{s}_4,4\right)\\ {}{d}_s\left({p}_2,{s}_2,2\right)& {d}_s\left({p}_5,{s}_5,5\right)\\ {}{d}_a\left({p}_3,{s}_3,3\right)& {d}_a\left({p}_6,{s}_6,6\right)\end{array}\right\} $$
where
 $ d\left(p,s,t\right) $
defines process
$ d\left(p,s,t\right) $
defines process
 $ d $
in terms of a design problem
$ d $
in terms of a design problem
 $ p $
, a design solution
$ p $
, a design solution
 $ s $
and the time
$ s $
and the time
 $ t $
when the process occurred. The elements of
$ t $
when the process occurred. The elements of
 $ {M}_0 $
and the processes and solutions in
$ {M}_0 $
and the processes and solutions in
 $ {D}_A $
are visualized in Figure 9.
$ {D}_A $
are visualized in Figure 9.

Figure 9. Six problem-solving processes have led to the nominal VSRS design. We discover five causality relations that indicate a linear decision-making sequence.
These processes represent two FBS cycles, as shown in Figure 5. We can use Equation (4) to derive problem causality. This reveals a linear problem hierarchy without branches. We refer to this problem hierarchy as the nominal solution path, shown in Figure 10.

Figure 10. The problem hierarchy shows relations between functional (blue), behavioral (green) and structural (orange) problems and solutions. After a nominal development path, a shorter solution path is discovered by reconsidering the solution to
 $ {p}_2 $
: to use a fiber bundle instead of a metallic mirror.
$ {p}_2 $
: to use a fiber bundle instead of a metallic mirror.
After this series of decisions, Equation (3) dictates that the FBS model is the union of all the nodes and edges shown in Figure 9. Equation (9) quantifies the complexity of the system as
 $ \xi =277 $
. At this point, the designer is discontent, particularly because of the burden of developing an auxiliary cooling system. This was not anticipated.
$ \xi =277 $
. At this point, the designer is discontent, particularly because of the burden of developing an auxiliary cooling system. This was not anticipated.
Seeing the importance of their earlier decisions, the designer is triggered to think of an alternative solution. A glass fiber bundle is a working principle that can transport light and could therefore be used instead of a metallic mirror. This decision is part of the synthesis process
 $ {p}_2\to {s}_2 $
. An alternative path opens up at
$ {p}_2\to {s}_2 $
. An alternative path opens up at
 $ {p}_2 $
: case B. The designer explores this path through the processes
$ {p}_2 $
: case B. The designer explores this path through the processes
 $$ {D}_B=\left\{\begin{array}{l}{d}_f\left({p}_1,{s}_1,1\right)\\ {}{d}_s\left({p}_2,{s}_2^{\prime },2\right)\\ {}{d}_a\left({p}_3^{\prime },{s}_3^{\prime },3\right)\end{array}\right\}. $$
$$ {D}_B=\left\{\begin{array}{l}{d}_f\left({p}_1,{s}_1,1\right)\\ {}{d}_s\left({p}_2,{s}_2^{\prime },2\right)\\ {}{d}_a\left({p}_3^{\prime },{s}_3^{\prime },3\right)\end{array}\right\}. $$
Figure 11 defines the model elements of this alternative solution path.

Figure 11. The problem-solving processes of an alternative development path. Using a fiber bundle instead of a metallic mirror leads to a shorter development and a simpler architecture.
The new mapping
 $ {p}_2\to {s}_2^{\prime } $
reflects the decision to implement a fiber bundle instead of a mirror to transport light. Analyzing that system (
$ {p}_2\to {s}_2^{\prime } $
reflects the decision to implement a fiber bundle instead of a mirror to transport light. Analyzing that system (
 $ {p}_3^{\prime}\to {s}_3^{\prime } $
) shows new behavior regarding optical transmission and darkening. In contrast to the mirror, the fiber bundle is not sensitive to thermal displacements that affect its optical behavior. However, glass fibers tend to darken over time when placed in a radioactive environment. This may pose a problem in the future. This example clearly demonstrates how the follow-up complexity of a cooling system can be limited by avoiding an identified problem.
$ {p}_3^{\prime}\to {s}_3^{\prime } $
) shows new behavior regarding optical transmission and darkening. In contrast to the mirror, the fiber bundle is not sensitive to thermal displacements that affect its optical behavior. However, glass fibers tend to darken over time when placed in a radioactive environment. This may pose a problem in the future. This example clearly demonstrates how the follow-up complexity of a cooling system can be limited by avoiding an identified problem.
The problem hierarchy is now significantly shorter, see Figure 10. The DSM representation of both alternative solution paths in Figure 12 shows that the cooling system is not anymore in the design. Also, the complexity of this design is considerably less than before:
 $ \xi =127 $
.
$ \xi =127 $
.

Figure 12. Two DSMs represent the outcome of two solution paths with architectural design alternatives: one using a mirror (left) and one using a fiber bundle (right).
There may still be unidentified problems ahead, but for now the designer has more confidence in the fiber bundle solution
 $ {s}_2^{\prime } $
. The rejected mirror solution
$ {s}_2^{\prime } $
. The rejected mirror solution
 $ {s}_2 $
can still play an important role in design justification. In large development projects, multiple alternative solutions are actually explored in parallel. Our approach can play a supporting role in such efforts.
$ {s}_2 $
can still play an important role in design justification. In large development projects, multiple alternative solutions are actually explored in parallel. Our approach can play a supporting role in such efforts.
We have visualized the chain of decisions that has led to the current design, realized the potential of revising an early decision, systematically explored an alternative solution and automatically generated its corresponding design model. Now let’s focus on the development of complexity over time.
5.2. A larger model
This demonstration revolves around a much larger FBS model, comprising 71 nodes (20 functional, 18 structural and 33 behavioral) and 134 edges. The model was set up after the conceptual design phase through informal interviews with a system expert. We framed the major design decisions up to that point in terms of formulation, synthesis and analysis processes.
Table A.2 in the Appendix shows the 21 processes that were established, ranked in order of occurrence in the development process. Thus each
 $ t=1,2,\dots $
represents a time step when both a problem was identified and a solution was generated. Going through each individual process, the expert explained in detail the objectives and risks of the problem that was identified, and the contents of the solution that was provided. We then defined each problem and solution in FBS design elements. The problems are defined in the Appendix, in Table A.3, and the solutions in Table A.4. The initial model is given in Table A.1, and Table A.5 lists all the nodes in the model by name.
$ t=1,2,\dots $
represents a time step when both a problem was identified and a solution was generated. Going through each individual process, the expert explained in detail the objectives and risks of the problem that was identified, and the contents of the solution that was provided. We then defined each problem and solution in FBS design elements. The problems are defined in the Appendix, in Table A.3, and the solutions in Table A.4. The initial model is given in Table A.1, and Table A.5 lists all the nodes in the model by name.
In the following sections, we present the results obtained by our method. First, we show the identified problem hierarchy, then we discuss the time-evolution of complexity and we finish this section by generating intermediate design models.
5.2.1. Problem hierarchy
The nodes of the problem hierarchy are given by problems
 $ P $
and solutions
$ P $
and solutions
 $ S $
, both of which are specified in Tables A.3 and A.4. The edges of the problem hierarchy consist of problem-solving dependencies
$ S $
, both of which are specified in Tables A.3 and A.4. The edges of the problem hierarchy consist of problem-solving dependencies
 $ P\to S $
and causal dependencies
$ P\to S $
and causal dependencies
 $ S\to P $
. Problem-solving dependencies are also specified by the designer (Table A.2), so we only need to derive the set of causal dependencies
$ S\to P $
. Problem-solving dependencies are also specified by the designer (Table A.2), so we only need to derive the set of causal dependencies
 $ S\to P $
to finalize the problem hierarchy. Equation (4) identifies 20 of these dependencies. Figure 12 shows the resulting hierarchy.
$ S\to P $
to finalize the problem hierarchy. Equation (4) identifies 20 of these dependencies. Figure 12 shows the resulting hierarchy.
The hierarchy ranks design decisions from essential (top) to supportive (bottom). It shows us three levels of FBS processes, i.e., subsequent formulation, synthesis and analysis. The level 1 design process brings us from
 $ {p}_1 $
to
$ {p}_1 $
to
 $ {s}_3 $
and captures the basic design decisions to solve the root problem. The level 2 processes go from
$ {s}_3 $
and captures the basic design decisions to solve the root problem. The level 2 processes go from
 $ {p}_4 $
,
$ {p}_4 $
,
 $ {p}_7 $
and
$ {p}_7 $
and
 $ {p}_{10} $
to
$ {p}_{10} $
to
 $ {s}_6 $
,
$ {s}_6 $
,
 $ {s}_9 $
,
$ {s}_9 $
,
 $ {s}_{12} $
and
$ {s}_{12} $
and
 $ {s}_{15} $
, dealing with the consequences of our initial design. Finally, level 3 processes deal with leftover problems
$ {s}_{15} $
, dealing with the consequences of our initial design. Finally, level 3 processes deal with leftover problems
 $ {p}_{15} $
and
$ {p}_{15} $
and
 $ {p}_{18} $
. The visualization will support designers in identifying high-level opportunities for low-level problem avoidance.
$ {p}_{18} $
. The visualization will support designers in identifying high-level opportunities for low-level problem avoidance.
5.2.2. Complexity
One of our primary objectives was to monitor the evolution of complexity during the VSRS development process. Refer to Figure 13. We do this by evaluating Equation (9) for every
 $ t $
in Table A.2. At every time step, there is a new solution that increases the complexity (see also Figure 2). The left plot of Figure 14 shows the resulting development of complexity over time. We see a steady increase in complexity as more and more design decisions are made.
$ t $
in Table A.2. At every time step, there is a new solution that increases the complexity (see also Figure 2). The left plot of Figure 14 shows the resulting development of complexity over time. We see a steady increase in complexity as more and more design decisions are made.

Figure 13. Problem hierarchy of the VSRS design process. Green, blue and orange nodes, respectively, represent behavioral, functional and structural problems and solutions. The problems and solutions are numbered in order of appearance in the design process, as listed in Table A.2. In the following section, the three highlighted solutions will be analyzed in greater depth.

Figure 14. Left: Growth of system complexity over the development process, as computed from Equation (9). Right: Contribution of three characteristic processes, evaluated over time by the global complexity impact (Equation 14). The close similarity between the black line in the left plot and the blue line in the right plot indicates that solution 1 has been highly influential in the evolution of complexity. The difference between these lines is the complexity that can be attributed to the initial model
 $ {M}_0 $
.
$ {M}_0 $
.
A secondary objective is to identify the contribution of individual processes to complexity. In the right plot of Figure 14, we present the development of the global complexity impact
 $ {I}_G $
(Equation 14) of three solutions:
$ {I}_G $
(Equation 14) of three solutions:
 $ {s}_1 $
,
$ {s}_1 $
,
 $ {s}_7 $
and
$ {s}_7 $
and
 $ {s}_{10} $
. You will find that these processes are in characteristic places of the problem hierarchy, Figure 13. The lines represent how the
$ {s}_{10} $
. You will find that these processes are in characteristic places of the problem hierarchy, Figure 13. The lines represent how the
 $ {I}_G $
of each process was evaluated at different points in time.
$ {I}_G $
of each process was evaluated at different points in time.
The evolution of the global complexity impact
 $ {I}_G $
of solution
$ {I}_G $
of solution
 $ {s}_1 $
is represented by the blue line. Solution
$ {s}_1 $
is represented by the blue line. Solution
 $ {s}_1 $
is the outcome of the first design process and therefore appears at the top of the problem hierarchy. The hierarchy shows that all subsequent problems (in)directly manifest themselves from this outcome. The complexity of every other solution is accounted for in the
$ {s}_1 $
is the outcome of the first design process and therefore appears at the top of the problem hierarchy. The hierarchy shows that all subsequent problems (in)directly manifest themselves from this outcome. The complexity of every other solution is accounted for in the
 $ {I}_G $
of solution
$ {I}_G $
of solution
 $ {s}_1 $
, which is why the curve closely follows the trend of the overall complexity. As these solutions are added to the model, the plot shows that solution
$ {s}_1 $
, which is why the curve closely follows the trend of the overall complexity. As these solutions are added to the model, the plot shows that solution
 $ {s}_1 $
has a bigger and bigger contribution to complexity.
$ {s}_1 $
has a bigger and bigger contribution to complexity.
The global complexity impact of solution
 $ {s}_{10} $
as a function of time is represented by the red line. We see that this solution added some elements at
$ {s}_{10} $
as a function of time is represented by the red line. We see that this solution added some elements at
 $ t=10 $
but caused only a single problem. Because solution
$ t=10 $
but caused only a single problem. Because solution
 $ {s}_{10} $
is not responsible for any of the complexity added at
$ {s}_{10} $
is not responsible for any of the complexity added at
 $ t>12 $
, the line flattens. Note that this can be verified by the position in the problem hierarchy.
$ t>12 $
, the line flattens. Note that this can be verified by the position in the problem hierarchy.
Finally, the
 $ {I}_G $
of solution
$ {I}_G $
of solution
 $ {s}_7 $
is represented by the green line. This solution follows a similar trend to solution
$ {s}_7 $
is represented by the green line. This solution follows a similar trend to solution
 $ {s}_{10} $
: The curve flattens after some initial complexity, indicating closure of one branch of development. But then, unexpectedly, problem
$ {s}_{10} $
: The curve flattens after some initial complexity, indicating closure of one branch of development. But then, unexpectedly, problem
 $ {p}_{14} $
was identified. A second increase in
$ {p}_{14} $
was identified. A second increase in
 $ {I}_G $
shows that the decisions made in solution
$ {I}_G $
shows that the decisions made in solution
 $ {s}_7 $
lead to more complexity than initially thought.
$ {s}_7 $
lead to more complexity than initially thought.
We conclude from these graphs that it is solution
 $ {s}_1 $
, obviously, that has the highest impact on the system. This is in line with claims that costs, schedule and technical performance of engineering projects are mostly determined by early-stage decision-making. The course of solution
$ {s}_1 $
, obviously, that has the highest impact on the system. This is in line with claims that costs, schedule and technical performance of engineering projects are mostly determined by early-stage decision-making. The course of solution
 $ {s}_{10} $
is an indication of good decisions that do not impact complexity in later stages. However, the second increase in
$ {s}_{10} $
is an indication of good decisions that do not impact complexity in later stages. However, the second increase in
 $ {I}_G $
of solution
$ {I}_G $
of solution
 $ {s}_7 $
should serve as a warning: This process has caused an unforeseen problem.
$ {s}_7 $
should serve as a warning: This process has caused an unforeseen problem.
5.2.3. Model expansion
We know now how the complexity of the VSRS has developed over time. Inspecting the design model at different stages will give us complementary insight into how its architecture grows. We have made three product DSM snapshots at the beginning, middle and end of the development process. Figure 15 compares these DSMs.

Figure 15. Product DSMs representing the VSRS at the beginning (
 $ t=0 $
), middle (
$ t=0 $
), middle (
 $ t=11 $
) and end (
$ t=11 $
) and end (
 $ t=21 $
) of the development process.
$ t=21 $
) of the development process.
We see that the initial DSM contains no functional interfaces. It represents the initial design problem as a behavioral one, before any design intent is formulated. Over time, more components and interfaces contribute to complexity.
The DSMs also show that the modularity of the design changes over time. Consider the differences between the matrix in the middle and the one on the right. The computer
 $ {c}_6 $
was initially placed in a module with five other components. However, at a later stage the computer became more centrally connected and was therefore moved to the bus. This meant that the heating beam
$ {c}_6 $
was initially placed in a module with five other components. However, at a later stage the computer became more centrally connected and was therefore moved to the bus. This meant that the heating beam
 $ {c}_1 $
, the spectrometers
$ {c}_1 $
, the spectrometers
 $ {c}_5 $
and the light source
$ {c}_5 $
and the light source
 $ {c}_{12} $
could be removed from the module as well and are now more independent. Finally, the rightmost matrix introduces more components that form new modules.
$ {c}_{12} $
could be removed from the module as well and are now more independent. Finally, the rightmost matrix introduces more components that form new modules.
Architectural changes in the technical system often have a large impact on the developing organization and its strategies. Analyzing architectural patterns through time provides a systematic means to adapt, for example, by redistributing responsibilities and redefining organizational structures.
6. Closing remarks
Designers can only solve problems effectively if provided with the right tools and techniques. In this paper, we took aim at the case of arising problems. These often unexpected problems appear in late design stages of solution search as a consequence of earlier decisions. We observe that solving such problems can lead to undesired system complexity and, unfortunately, more problems. Our objective is to show designers the cause–effect relations in their decision-making process. This will motivate them to try to avoid problems and complexity by reconsidering a prior design decision.
We have presented a theoretical basis for the interplay between problems and solutions. We consider both problems and solutions as elements of a design model, and formalize two causal relations: First, as a conscious design process, a solution adds elements to the model in order to solve a problem. Second, a problem manifests itself due to a solution if that solution has added an element that also represents a problem. We visualize these relations in a problem hierarchy. We furthermore introduce two impact factors that quantify the contribution of each decision to the complexity of the design.
Our theory of problem-solving is then merged with the FBS paradigm. The result is a systematic problem-solving method that specializes design processes and problem causality: formulation, synthesis and analysis are the specific design processes that connect functional, behavioral and structural problems and solutions. These elements are visualized in a product DSM. Instances of this DSM can be automatically generated to explore the time-evolution of alternative solution paths.
We have illustrated our design method in two cases of the VSRS, an optical measurement system for nuclear fusion reactors. A simple example with six design steps shows how two alternative solution paths lead to different manifesting problems and different system complexity. The following demonstration contains 21 design steps and focuses on the evolution of the system through time. We are able to monitor the growing complexity throughout the design process and can assess the impact of each individual decision on the overall complexity.
Nuclear fusion reactors are already complex enough, while the search for a viable implementation of this technology is still ongoing. Similar complexity cascades arise also in many other first-of-a-kind development projects in big science and engineering. Let us try to avoid unnecessary problems and manage their complexity.
Acknowledgements
We express our sincere gratitude to the ITER Port Plugs and Diagnostics Department, for providing access to the Interface Database. We would also like to thank the anonymous reviewers of this journal for their constructive feedback, which has led to significant improvements to this paper.
Nomenclature
-
$ M $
-
Design model consisting of design elements
-
$ E $
-
Entities of a design model
-
$ R $
-
Relations of a design model
-
$ \xi $
-
Structural complexity, a scalar attribute of a design model
-
$ D $
-
Set of design processes, each process mapping a problem into a solution
-
$ P $
-
Set of design problems
-
$ S $
-
Set of design solutions
-
$ H $
-
Problem hierarchy, representing the causal structure of the design process by problems and solutions
-
$ \mathcal{X}(h) $
-
Set of input nodes to node
$ h\in H $
-
$ {\mathcal{X}}^{\infty }(h) $
-
Set of nodes from which through hierarchy
$ H $
node
$ h\in H $
can be reached -
$ \mathcal{Y}(h) $
-
Set of output nodes from node
$ h\in H $
-
$ {\mathcal{Y}}^{\infty }(h) $
-
Set of nodes that can be reached through hierarchy
$ H $
departing from node
$ h\in H $
-
$ {I}_L(d) $
-
Local complexity impact due to design process
$ d\in D $
-
$ {I}_G(d) $
-
Global complexity impact due to design process
$ d\in D $
-
$ F $
-
Functions of a system
-
$ B $
-
Behaviors of a system
-
$ C $
-
Structural components of a system

























Disclaimer
The views and opinions expressed herein do not necessarily reflect those of the ITER Organization.
Appendix
This appendix contains the information of the detailed VSRS demonstration. The design process departs from the initial model in Table A.1. Table A.2 defines the subsequent design steps as mappings between a problem and a solution. Tables A.3 and A.4 define those problems and solutions, respectively, in terms of FBS nodes and edges. Table A.5 lists these functional, structural and behavioral nodes by name.
Table A.1. The initial model of the VSRS consists only of structural and behavioral elements
 $ C $
and
$ C $
and
 $ B $
$ B $

Table A.2. Problem-solving processes in the development of the VSRS

Table A.3. Definition of all design problems in the development of the VSRS

Table A.4. Definition of all design solutions in the development of the VSRS

Table A.5. Functions
 $ f $
, structures
$ f $
, structures
 $ c $
and behaviors
$ c $
and behaviors
 $ b $
of the VSRS
$ b $
of the VSRS


















































 Open access
Open access