



Acoustic Analysis, Assessing Voice Fundamental Frequency
The voice’s fundamental frequency (F0) is physically linked to the vibration frequency of the vocal folds. Loudness and pitch constitute fundamental auditory sensations (Oxenham, Reference Oxenham2012). Pitch represents the perceptual counterpart of a soundwave’s resonant frequency, known as its fundamental frequency (F0), which corresponds to the wave’s periodicity or repetition rate. At the same time, loudness is the perceptual counterpart of intensity. From a production-oriented perspective, the voice’s frequency is considered the acoustic counterpart of the vibration frequency of the vocal folds (Imamura et al., Reference Imamura, Tsuji and Sennes2003). The factors underlying its determination have been extensively decomposed and explored by the classical myoelastic-aerodynamic theory of voice production (van den Berg, Reference van den Berg1958). The F0 of the voice depends on five interdependent factors related to the vibrating portion of the vocal folds, namely its effective mass, effective tension, the effective area of the glottis during the cycle, subglottal pressure, and damping (van den Berg, Reference van den Berg1958). It represents the lowest frequency in a periodic waveform and plays a pivotal role in determining a voice’s pitch. Pitch, conversely, represents the perceptual counterpart of F0. This perception is also influenced by how the listener’s auditory system interprets these sounds, allowing us to distinguish between high and low tones and discern a low pitch from a high-pitched voice (Titze, Reference Titze2000).
The existing literature on voice has predominantly centered on interindividual variations in centrality metrics, which describe the position of F0 along the spectral dimension while ignoring deviations from its average values. To highlight the significance of other aspects of F0 in speech, prosody in conversation fluctuates in response to alterations in frequency contour (Dombrowski & Niebuhr, Reference Dombrowski and Niebuhr2005; Xu, Reference Xu and Romero-Trillo2012), reflecting abrupt changes in emotional states (da Silva & Barbosa, Reference da Silva and Barbosa2017; Han et al., Reference Han, Munson and Schlauch2021) and conveying diverse prosodic and linguistic information. This fluctuation in F0, known as intonation, is crucial for effective communication (Hirst & Di Cristo, Reference Hirst and Di Cristo1998), directly influencing F0 variability and its standard deviation (F0sd), which is statistical indicators together with variation quotients of speech ‘liveliness’ (Hincks, 2014; Traunmüller & Eriksson, Reference Traunmüller and Eriksson1994).
Moreover, F0 can be characterized by a baseline value, termed F0 baseline (F0base), representing a neutral mode of vibration to which the vocal folds revert after a prosodic shift and reflecting habitual pitch (Lindh & Eriksson, Reference Lindh and Eriksson2007). Additionally, F0 variations span the lowest and highest points during the speech, referred to as F0 minima (F0min) and maxima (F0max) respectively, constituting the F0 dynamic range (Titze, Reference Titze2006). Furthermore, the pleasantness or tension in voice correlates with the F0 interquartile semi-amplitude (F0SAQ), a measure of dispersion (dos Reis, Reference dos Reis2017); individuals with tense voices exhibit elevated F0 measures and increased variability, reflected by higher F0SAQ values (dos Reis, Reference dos Reis2017). Conversely, calmness in speakers is linked to decreased F0med and F0SAQ (da Silva & Barbosa, Reference da Silva and Barbosa2017).
The intrinsic geometry of the vocal folds, including factors such as length, depth and thickness, is associated with vibration frequency and F0 variations in response to physiological conditions, age and gender, with children typically exhibiting higher F0 compared to adults, and females generally higher than males (Zhang, Reference Zhang2016). These factors, in turn, are influenced by both intrinsic and extrinsic modifiers, indicating a significant genetic organic impact on an individual’s F0, as evidenced by acoustic-phonetic genetic-related speaker studies.
Twin Studies
The association of genetic differences and the proportion of phenotypic variance can be assessed by statistical estimation of heritability measures. The twin approach enables investigation of genetic and environmental influences on human traits, presenting an overall heritability estimate of h 2 = 0.49 (Polderman et al., Reference Polderman, Benyamin, De Leeuw, Sullivan, Van Bochoven, Visscher and Posthuma2015). Among acoustic-phonetic approaches, F0 emerges as one of the most commonly studied parameters in speech and voice analysis, with numerous studies consistently showing a strong correlation between monozygotic (MZ) twins regarding speaking style (Arantes & Eriksson, Reference Arantes and Eriksson2019; Signorello et al., Reference Signorello, Demolin, Henrich Bernardoni, Gerratt, Zhang and Kreiman2020), speaking condition (de Jong et al., Reference de Jong, Hudson, Nolan and McDougall2011), emotional state (Higuchi et al., Reference Higuchi, Hirai, Sagisaka, Santen, Olive, Sproat and Hirschberg1997), and sociocultural factors (Rilliard et al., Reference Rilliard, de Moraes, Erickson and Shochi2013) on their F0. However, many studies have predominantly focused on a limited set of F0 statistical descriptors, such as mean and standard deviation values, neglecting the genetic impact on other dimensions of the parameter.
For instance, comprehensive research examining the voice quality characteristics of MZ twins across a wide age range (8 to 61 years old) found no influence of sex and age on vocal similarities, with high correlation scores observed for their F0 estimates, supported by auditory perceptual evaluations (van Lierde et al., Reference van Lierde, Vinck, De Ley, Clement and Van Cauwenberge2005). Similarly, a case study of a pair of male MZ twins and their age- and sex-matched sibling revealed striking similarities in speech characteristics, particularly in pitch mean, suggesting a degree of family resemblance (Whiteside & Rixon, Reference Whiteside and Rixon2013). F0’s potential as a phenotype was examined in twin speakers of American English, revealing an association with age and weight (Przybyla et al., Reference Przybyla, Horii and Crawford1992). No disparities were found between MZ and dizygotic (DZ) twins in F0mean and F0sd, although DZ twins exhibited greater variation in F0 measures (in Hz; Przybyla et al., Reference Przybyla, Horii and Crawford1992). Despite these findings, F0 measures may be influenced by factors beyond genetic constitution alone, such as spontaneous and nonspontaneous speech, even among twins.
Examining F0 and its intra-speaker variability during a reading task in adult Dutch speakers, highly similar results were observed between MZ and DZ twins, while no correlation was observed among unrelated peers, indicating that an individual’s voice is influenced by factors beyond genetic constitution alone (Debruyne et al., Reference Debruyne, Decoster, Van Gijsel and Vercammen2002). Similarly, an analysis of long-term F0 in twin speakers of Australian English revealed that twins tend to exhibit more similar mean long-term F0 values than unrelated pairs, though not always presenting the closest mean F0 values within twin pairs (Loakes, Reference Loakes2006).
Despite the significant contributions of twin studies, they are vastly represented by WEIRD (Western, Educated, Industrialized, Rich and Democratic) societies, particularly by seven countries: the United States, the United Kingdom, Australia, the Netherlands, Sweden, Denmark and Finland (Fernandes et al., Reference Fernandes, Ferreira, de Felipe, Segal and Otta2024). This is evident in the review of human trait heritability in 50 years of twin studies (Polderman et al., Reference Polderman, Benyamin, De Leeuw, Sullivan, Van Bochoven, Visscher and Posthuma2015), in which they represent more than 90% of the studies. This WEIRD sampling problem involves similar countries in cultural history, social values and standard of living (Uchiyama et al, Reference Uchiyama, Spicer and Muthukrishna2022).
A further issue arises from the disproportionate representativeness of the WEIRD twins, which is identified as a challenge within the portability problem discussed by Matthews and Turkheimer (Reference Matthews and Turkheimer2022), given that WEIRD societies represent only 2% of humanity. It is thus imperative to acknowledge and evaluate the contributions of twin studies conducted in non-WEIRD populations (Hagenbeek et al., Reference Hagenbeek, van Dongen, Pool, Boomsma, Tarnoki, Tarnoki, Harris and Segal2022). It is noteworthy that Brazilian twin research remains underrepresented internationally (Fernandes et al., Reference Fernandes, Ferreira, de Felipe, Segal and Otta2024) and, to the best of our knowledge, there are few studies that have specifically examined the F0 speech parameters in twins.
For example, one study focused on the speaker-discriminatory potential of F0 estimates in comparisons between intra-identical twin pairs and across all speakers in Brazilian Portuguese (Cavalcanti et al., Reference Cavalcanti, Eriksson and Barbosa2021a). In another study, the acoustic analyses of connected speech samples and lengthened vowels of adult male twins revealed that F0base, central tendency, and extreme values were mostly discriminatory in both intra-twin pair and cross-pair comparisons, suggesting the influence of speaking style and dialect on dynamic F0 patterns (Cavalcanti et al., Reference Cavalcanti, Eriksson and Barbosa2021b).
In this present study, we aim to assess whether zygosity influences F0 from connected speech using twin intra-sibling similarity by examining statistical descriptors of the parameter in both MZ and DZ twins. Our research focuses on adult Brazilian Portuguese speakers and extends beyond central tendency measures of F0, allowing for a comprehensive analysis of how these variables contribute to differences in F0 across speakers.
Materials and Methods
Participants
The recruitment of twins was conducted online, with each pair receiving a telephone invitation to personally visit the laboratory of the Institute of Psychology at the University of São Paulo (USP) to participate in the research. Peripheral blood samples were collected from each individual’s arm for DNA testing to determine zygosity. These samples were sent to a laboratory for genotyping procedures, based on 22 autosomal STR loci, along with amelogenin and DYS391 (cf. Varella et al., Reference Varella, Fernandes, Fridman, Lucci, Defelipe, Fernandes, Antonio, Segal and Ottain press). The study covered recordings of sentences spoken by 88 Brazilian twin pairs, consisting of 72 MZ and 15 DZ pairs, ranging in age from 18 to 66 years (mean age 31.7 ± 11.6 years), who volunteered for the study. Only same-sex twin dyads were included. After addressing all recording issues, such as noise or missing data from one twin within each pair, we analyzed a total of 79 pairs, consisting of 21 male pairs and 58 female pairs, with only one pair residing outside the state of São Paulo.
Recording Procedure
Participants were instructed to utter the greeting phrase in Brazilian Portuguese, ‘Hi, my name is Pedro’ (for male speakers) and ‘Hi, my name is Ana’ (for female speakers;‘Oi, meu nome é Pedro/Ana’), as well as the spoken version of the Brazilian Portuguese version of ‘Happy Birthday to You’ song. Recordings were conducted in a soundproof room at the Psychology Institute of the USP using a Zoom H1 Handy Recorder paired with a studio microphone BM8000 positioned approximately 15 cm away from the participant’s mouth. Recordings were made in stereo mode at 24-Bit/96kHz resolution and saved in an uncompressed ‘.wav’ format.
Acoustic Analysis
Each recorded voice was segmented into six chunks: the greeting segment ‘Hi, my name is Ana/Pedro’ comprised two chunks, and the ‘Parabéns a você’, ‘nesta data querida’, ‘muitas felicidades’, ‘muitos anos de vida’ song was divided into four chunks. From each chunk we extracted various acoustic measures, including mean F0 (F0mean), median F0 (F0med), F0 interquartile semi-amplitude (F0SAQ), F0 baseline (F0base), F0 standard deviation (F0sd), minimum F0 (F0min), and maximum F0 (F0max), expressed in both scales, semitones (st) and Hertz (Hz). Table 1 delineates these measures and their relevance to voice perception. All analyses were conducted using the free software Praat 6.1.32 (Boersma & Weenink, Reference Boersma and Weenink2020) with the ‘Prosody Descriptor Extractor’ script (Barbosa, Reference Barbosa2021). The F0 floor and ceiling for parameter extraction were set at 60 Hz and 300 Hz respectively, and both Hertz and semitones scales were utilized, with a reference of 1 Hz for the latter.
Table 1. Fundamental frequency (F0) descriptors and their physical or perceptual correlates
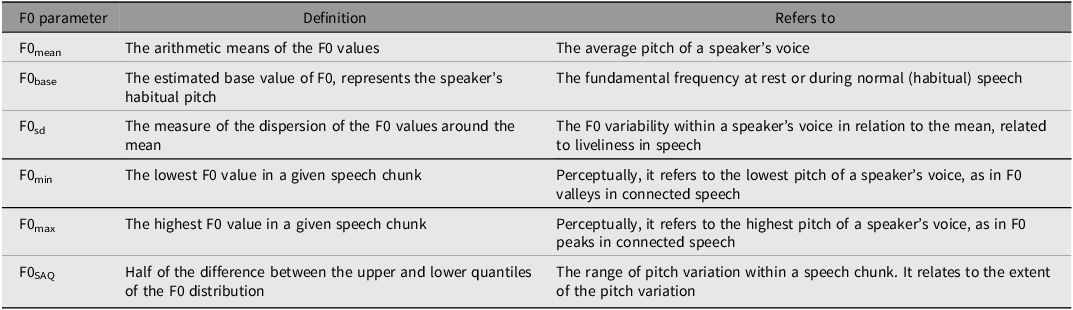
Note: base, baseline; sd, standard deviation; min, minima; max, maxima; SAQ, interquartile semi-amplitude.
We employed the Hz scale to represent fundamental frequencies and incorporated a semitone (nonlinear) representation of the same F0 parameters. Production and perceptual differences in human speech that convey emotion can be detected on a logarithmic scale, even without conscious attention (see Bjørkljnd, Reference Bjørkljnd2005; McDermott et al., Reference McDermott, Keebler, Micheyl and Oxenham2010). By considering the impact of F0 variations on communication, we offer valuable insights for future research into auditory perception of similar voices.
Studies suggest that listeners may discern two tones as distinct if their fundamental frequencies (F0) differ by 3 to 4 semitones (Assmann, Reference Assmann1999; Consoni et al., Reference Consoni, Peres, Lassak, Rosa and Ferreira Netto2009). Therefore, it is crucial to report intra-twin pair differences surpassing this threshold, as such distinctions could significantly affect future studies on voice perception. By including the semitone scale (st), we aimed to assess differences between twin siblings potentially perceivable by the auditory system (Vargas et al., Reference Vargas, Costa and Hanayama2005) and gender-based disparities, unattainable using the Hz scale and irrespective of individual voice frequency (Costa et al., Reference Costa, Gama, Oliveira and de Rezende Neto2008). Apart from examining variations in acoustic parameters among subjects, we sought to explore the communication implications of such differences, offering insights for future perceptual studies.
Figure 1 represents an illustration of the Praat window and transcription. The upper segment shows the audio signal used for extracting F0 descriptors. The grayscale spectrogram of the Brazilian Portuguese speech segment ‘Hi, my name is Ana’ is displayed, with F0 and intensity curves overlaid in blue and yellow lines respectively (note the two scales on the spectrogram’s vertical axis; yellow and blue lines correspond to values on the right side from 75 to 169.3 Hz). The first tier presents the orthographic transcription of the phrases, while the second tier exhibits the vowel-to-vowel transcription. In our study, F0 parameters were extracted from tier 1, specifically at the phrase level.
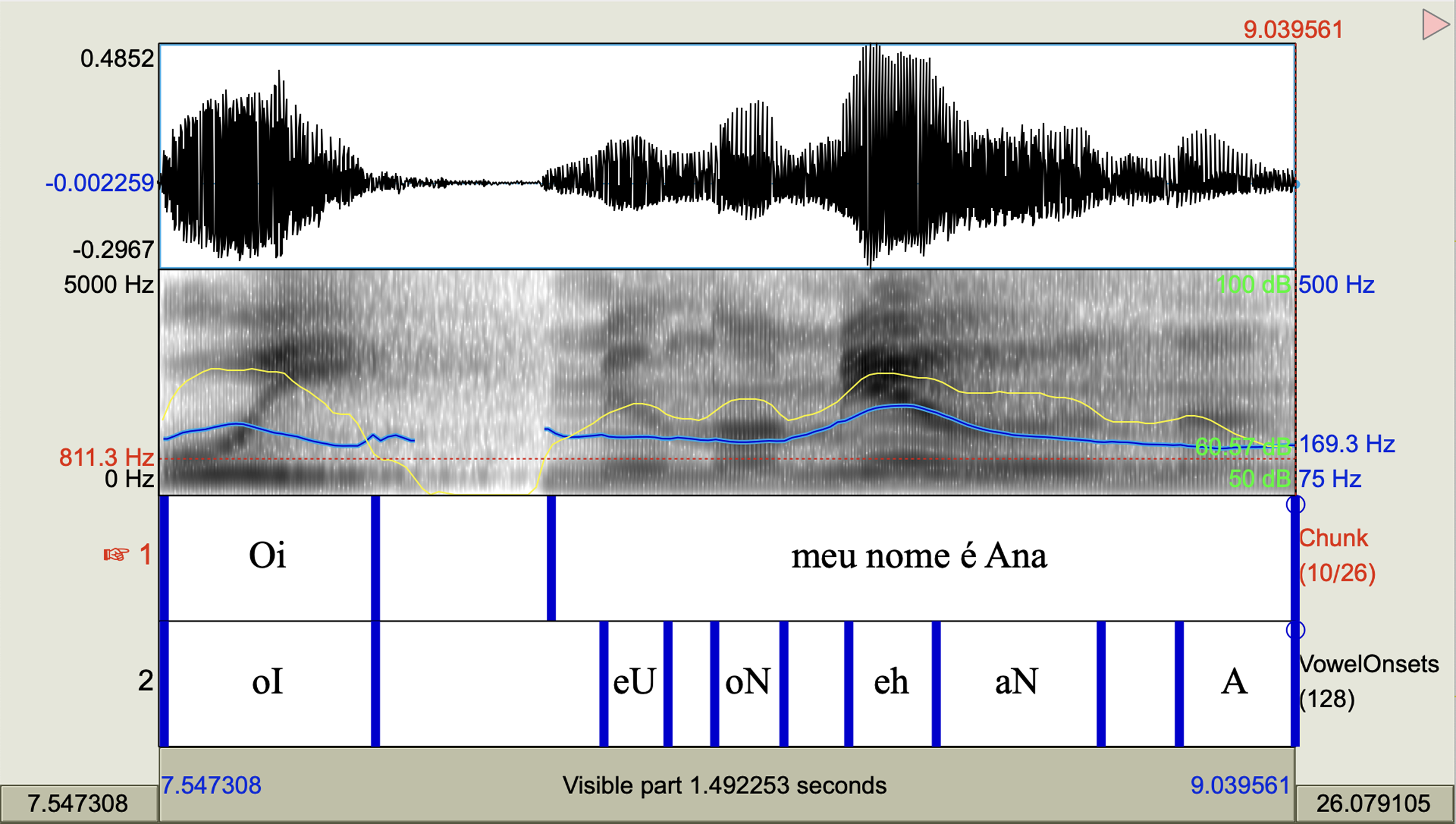
Figure 1. Praat window and transcription of the speech segment ‘Hi, my name is Ana’ in Brazilian Portuguese.
Statistical Analysis
We estimated the mean and range values for all F0 parameters in both semitones and Hertz. To compare MZ and DZ dyads, we employed an independent sample Mann-Whitney U test. Covariation among siblings from both MZ and DZ groups was determined using a Wald chi-square mixed model. Sex was included as a factor in the model, with age serving as a covariate variable. Intra-sibling covariance in F0 parameters was applied to estimate heritability (h 2) based on the ACE additive model. This model assumes that all genetic influence arises from additive effects (A), while excluding dominant (D) and epistasis (I) genetic effects. Consequently, the model encompasses total genetic effects (A) along with shared (C) and nonshared (E) environmental influences (Zyphur et al., Reference Zyphur, Zhang, Barsky and Li2013). Random intercepts and slopes were incorporated into the model, with slopes varying according to zygosity. Heritability was calculated as twice the difference between MZ and DZ covariances. Analyses were conducted using Stata v. 16.0, with the significance level set at p = .05.
Results
Given the normal distribution of our data and the similarity between F0med and F0mean values, we opted to use F0mean due to its lesser susceptibility to data distribution effects. We first provide a summarizing overview of the parameters, followed by the outcomes of Hz modeling. Subsequently, we emphasize the distinctions observed when utilizing st for ACE model covariances and effects among twin pairs.
Regarding sex, male MZ and DZ twins exhibited comparable F0 dimensions (Table 2). Five out of six parameters showed differences between male MZ and DZ twins, except for F0SAQ, U = 1.270, df = 1, p = .26, with no disparities found between MZ and DZ females. Besides zygosity, F0mean ranged from 93−158 Hz in males and 130−270 Hz in females, with F0sd varying from 1 to 68 Hz among them and 2−31 Hz in males (F0mean male MZ 120.47 ± 13.46; DZ 129.50 ± 10.60; female MZ 199.20 ± 25.96; DZ 200.43 ± 26.13).
Table 2. Male and female fundamental frequency (F0) descriptors from 79 pairs of Brazilian twins’ speech in hertz (Hz)
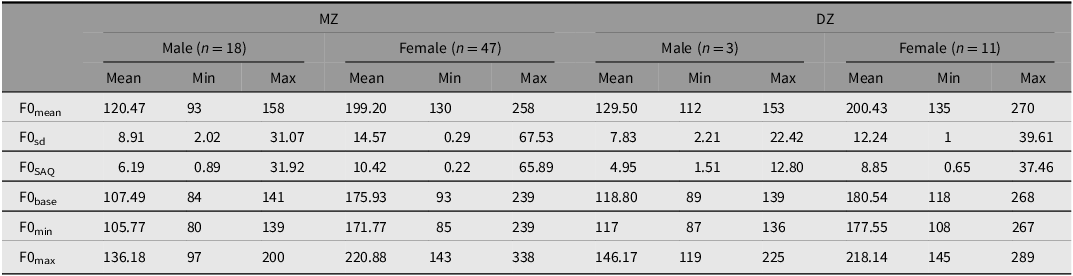
Note: sd, standard deviation; SAQ, interquartile semi-amplitude; base, baseline; min, minima; max, maxima.
Considering the semitones scale, F0mean ranged from 76 to 88 st in males and 80 to 98 st in females, with higher F0sd observed in females compared to males (Table 3). In general, intrasexual variation was lower than zygosity, except for F0SAQ, which exhibited the most variation both intra-sexual and between MZ and DZ. Analyzing intra-twin differences between MZ and DZ siblings in terms of F0 average parameters, we found a difference only in F0base, U = 411.5, df = 1, p = .011.
Table 3. Male and female fundamental frequency (F0) descriptors from 79 pairs of Brazilian twins’ speech in semitones (st)
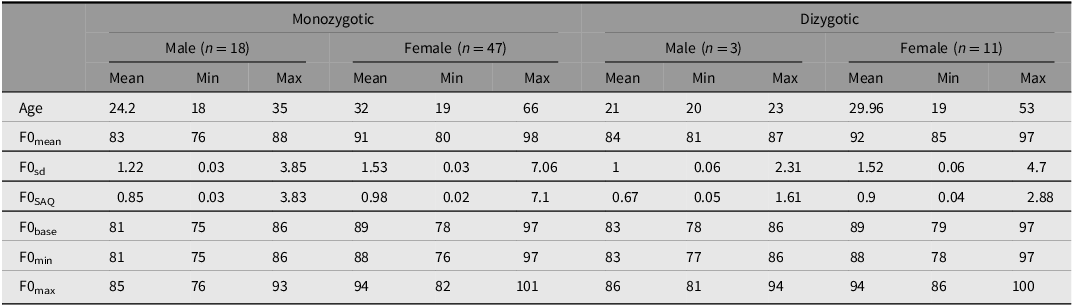
Note: sd, standard deviation; SAQ, interquartile semi-amplitude; base, baseline; min, minima; max, maxima.
For visual representation, the violin plots in Figure 2 show the distribution of specific F0 descriptors among MZ and DZ twins, highlighting differences in F0 distribution across these groups. Outliers were removed based on the interquartile range method. While median values for F0mean and F0base are somewhat similar between MZ and DZ twins (Table 3 and Figure 2), the distributions skew more towards lower values in MZ. This skewness towards lower values in MZ twins suggests a propensity for certain voices to cluster around specific values more frequently than in DZ twins. Notably, the plots reveal two distinct clusters for MZ twins, one in higher and another in lower F0 regions.
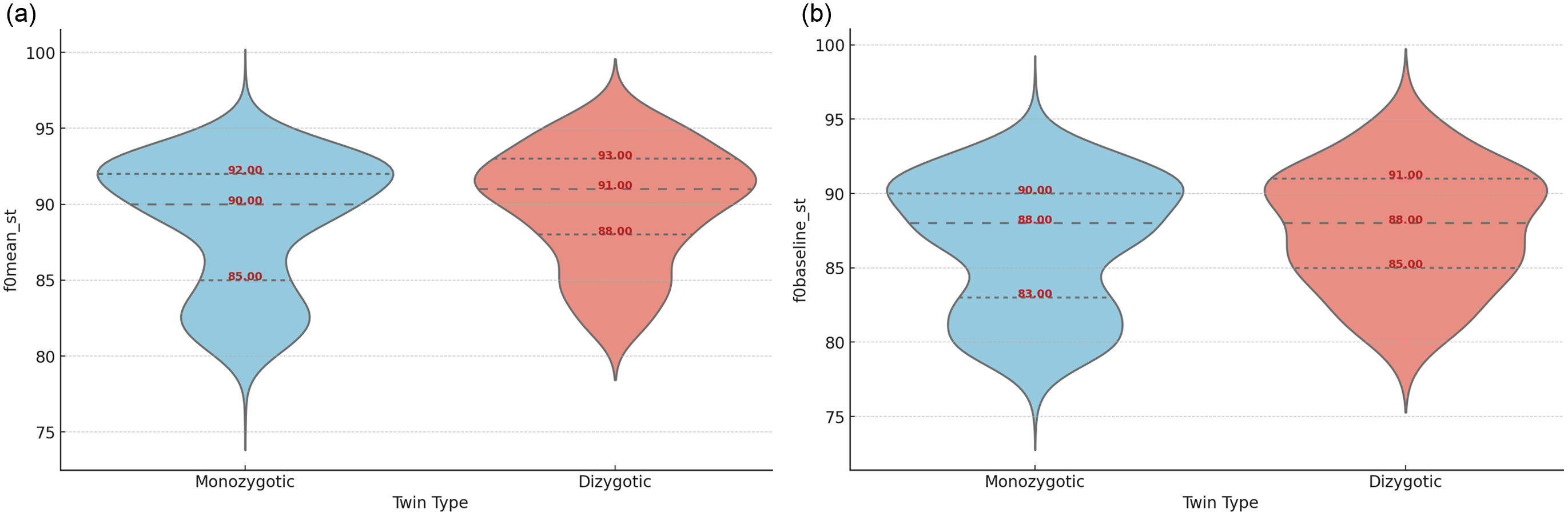
Figure 2. Distribution of mean values of F0mean (a) and F0base (b) within speech chunks between monozygotic and dizygotic twins.
Note: base, baseline.
Given the uneven distribution of twin pairs in each group, with higher numbers of MZ than DZ pairs (72 vs. 15), we anticipated a broader range of F0 values for MZ twins in descriptors such as F0mean and F0base, as evidenced by the range (from minimum to maximum values) in the plots (Figure 3). Despite this discrepancy in the number of observations between the twin groups, the distribution for dispersion measures like F0sd and F0SAQ appeared relatively uniform between MZ and DZ.
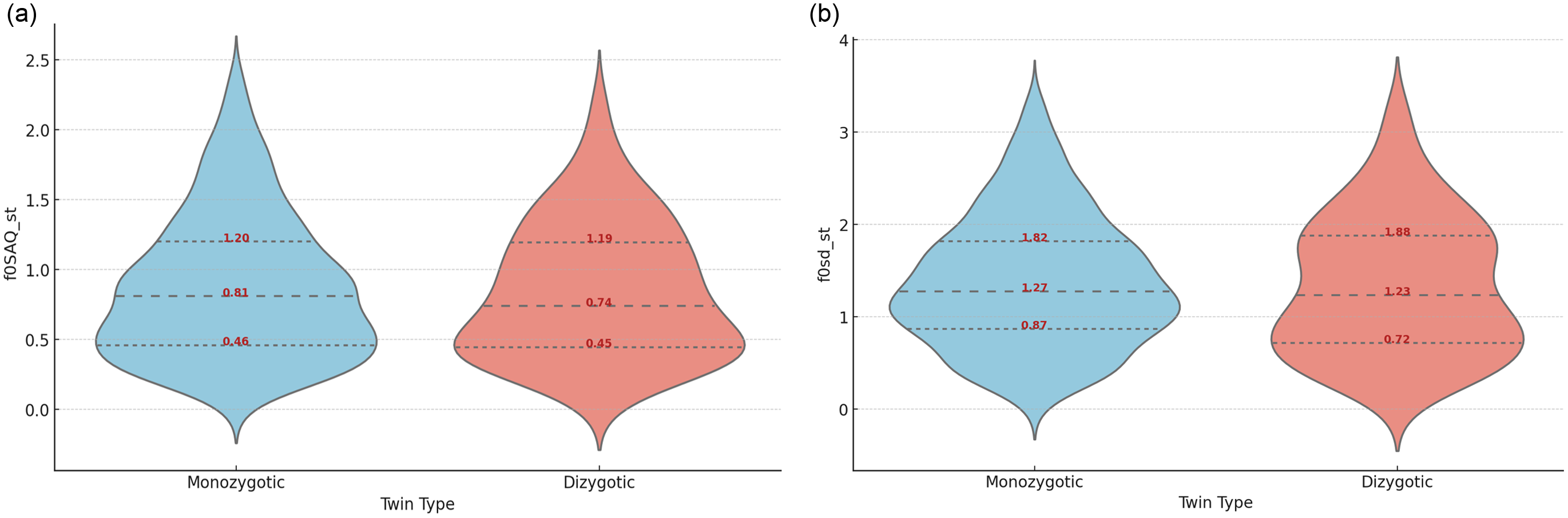
Figure 3. Distribution of mean values of F0SAQ (a) and F0sd (b) within speech chunks between monozygotic and dizygotic twins.
Note: SAQ, interquartile semi-amplitude; sd, standard deviation.
Intra-Twin Covariation
Twinship exerts an influence on speech parameters, with MZ twins accounting for at least 10% of the variance in all six parameters. A minor effect was observed solely in F0SAQ (<10%). Although we did not conduct statistical analysis, all intra-siblings’ variations showed disparities of 2% to 6% (F0mean, F0sd, F0base, and F0max) when comparing values from Hz and st scales (Tables 4 and 5). The environmental component in the ACE model is referred to as the twinning effect.
Table 4. Estimated heritability in F0 parameters in hertz considering the effects of twinning (sibling) monozygosity (MZ), sex, and age on intra-siblings’ covariance calculated by the ACE model
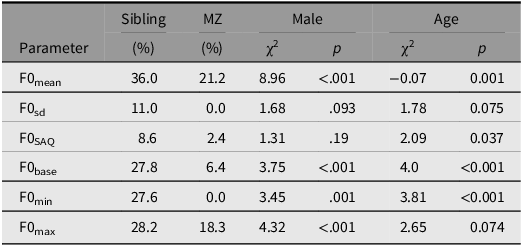
Note: ACE: total genetic effects, A; shared environmental influences, C; nonshared environmental influences, E. sd, standard deviation; SAQ, interquartile semi-amplitude; base, baseline; min, minima; max, maxima.
Table 5. Estimated heritability in F0 parameters in semitones considering the effects of twinning (sibling) monozygosity (MZ), sex, and age on intra-siblings’ covariance calculated by the ACE model
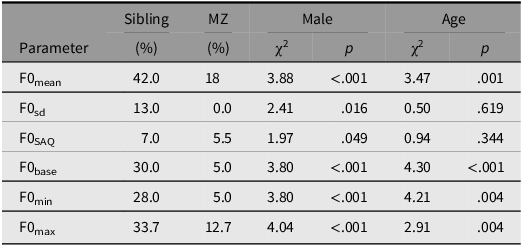
Note: ACE: total genetic effects, A; shared environmental influences, C; nonshared environmental influences, E. sd, standard deviation; SAQ, interquartile semi-amplitude; base, baseline; min, minima; max, maxima.
Intra-twin covariation in hertz. Table 4 illustrates the covariance between twin siblings across all F0 parameters. Our findings indicate a significant heritability effect on voice, with twinship accounting for 36% of the variance, and monozygosity adding 21.2%, resulting in 57.2% explained variance in F0mean. Similarly, monozygosity contributed with more 18.3% to intra-sibling variance explaining 46.5% of their similarity in F0base. However, monozygosity did not show an additive effect on F0sd and F0min, with shared environmental factors explaining 11% and 27.6% of the variance, respectively. Sex did not affect two F0 parameters (F0sd, χ2 = 1.68, p = .093 and F0SAQ, χ2 = 1.31, p = .19), while age influenced four out of six parameters, except F0sd, χ2 = 1.78, p = .075, and F0max, χ2 = 2.65, p = .074.
Intra-twin covariation in semitones. When analyzed in st, we observed slight differences compared to hertz (Table 5). The twinning effect alone explained 42% of the covariance in F0mean and 33.7% in F0max. The additional effect of monozygosity explained 60% of the variance in F0mean and 46.4% in F0max. The genetic similarity negligibly increased 5% the effect on F0SAQ (increased to 12.5%) and F0base (increased to 35%).
In contrast to what was observed when measured in HZ scale (no additive effect, Table 4), F0min, monozygosity added 5% to the twinning effect (28%) totaling 33% of the explained variance between twins. On the other hand, sharing practically the same DNA did not affect the covariance between siblings, when measured in st, with the shared environment alone explaining 13% of the variance in F0sd.
Sex influenced the covariance between twin siblings in all F0 parameters in semitones. Although F0SAQ was just below the significance level threshold, χ2 = 1.97, p = .049, there was no effect of age on two out of six parameters: F0sd, χ2 = 0.5, p = .619 and F0SAQ, χ2 = 0.94, p = .344 (Table 5).
Regarding statistical comparisons intra-twin, only two parameters showed differences exceeding 3 semitones: F0mean and F0base. Specifically, six pairs — five female and one male — exhibited these differences in F0mean, including four pairs with one male MZ twin. For F0base, seven pairs showed differences, comprised of six female pairs (three of whom were MZ) and one male MZ pair. Among female twins, there was an equal split between MZ and DZ twins.
Comparisons between scales: semitones and hertz. Upon comparing the outcomes in hertz and semitones, we observed that monozygosity contributed to explaining variance across more parameters in semitones, including an additive effect on F0min, which was absent in hertz measurements (Tables 4 and 5). Additionally, sex exerted influence on all parameters, including F0SAQ. However, it is noteworthy that monozygosity did not have an additive effect on F0SAQ in either scale, with the twinning effect remaining the sole relevant factor in this case.
Discussion
In this study, we aimed to assess whether zygosity influences F0 dimensions based on intra-sibling similarity, considering both linear (Hz) and nonlinear (semitones [st]) scales. However, for clarity purposes in our discussion, we will focus solely on st. As anticipated, MZ twins exhibited greater resemblance to each other compared to DZ twins.
Zygosity accounted for variance in five out of six F0 parameters, contributing 18% to F0mean and 12.7% to F0max, with approximately 5% in F0SAQ, F0base, and F0min. The likeness in F0 parameters among MZ siblings is closely tied to similarities in vocal fold geometry and anatomical properties, such as mass, tension area and pressure measures (Zhang, Reference Zhang2016). Our findings reaffirmed expectations that male twins with larger vocal folds would produce lower vibration frequencies (presenting lower F0).
While MZ twins share identical genetic makeup, variations in their environment and experiences can lead to differences in anatomical and physiological characteristics. It is regularly assumed that these differences may become more pronounced as twins age and encounter diverse environments and lifestyles, possibly due to epigenetic changes (Fraga et al., Reference Fraga, Ballestar, Paz, Ropero, Setien, Ballestar, Heine-Suñer, Cigudosa, Urioste, Benitez, Boix-Chornet, Sanchez-Aguilera, Ling, Carlsson, Poulsen, Vaag, Stephan, Spector, Wu and Esteller2005). However, in our sample, we did not observe an age-related effect on intra-twin pairs’ F0 variation in a cross-sectional analysis.
The voice variation during speech or ‘liveliness’ (F0sd) averaged around 1 st in male siblings and 1.5 st in females. In our study, F0sd was not influenced by monozygosity, suggesting that environmental and linguistic factors may play a more significant role in explaining individual variations in this parameter, such as speech flow (Traunmüller & Eriksson, Reference Traunmüller and Eriksson1994) and variation and modulation estimates, particularly in spontaneous dialogues (Cavalcanti, Reference Cavalcanti, Eriksson and Barbosa2021a, Hincks, Reference Hincks2005).
In addition to assessing differences in acoustic parameters across subjects, we aimed to explore the potential implications of such differences on the communication process, offering insights for future perception studies. Listeners may distinguish two tones if their F0 differences range between 3 st to 4 st (Assmann, Reference Assmann1999; Consoni et al., Reference Consoni, Peres, Lassak, Rosa and Ferreira Netto2009). Even though we found intra-twin differences in F0Mean and F0base in only six pairs (five females and one male) and F0base in seven pairs, such findings are valuable for understanding how twin voices are perceived, suggesting that twins may differ in the way their pitch is perceived. Other studies exploring different dimensions, such as temporal and spectral characteristics, illustrate how twins can align or diverge in their speech production behavior (cf. Cavalcanti et al., Reference Cavalcanti, Eriksson and Barbosa2021a, Reference Cavalcanti, Eriksson and Barbosa2021b). In other words, different parameters play a role in determining how their voice qualities are perceived as similar or different.
Previous evidence suggests that vocal F0 alone is insufficient to determine zygosity in same-sex twin pairs; instead, a combination of 14 acoustic parameters is required, including F0mean, F0sd, and formant frequencies, among others (Forrai & Gordos, Reference Forrai and Gordos1983). In our study, we observed no additive effect of zygosity only in F0sd, with F0mean emerging as the vocal parameter most significantly influenced by monozygosity.
While certain F0 parameters are more influenced by genetic factors (Debruyne et al., Reference Debruyne, Decoster, Van Gijsel and Vercammen2002; Sataloff, Reference Sataloff1995, Reference Sataloff1997), temporal patterns (van Lierde et al., Reference van Lierde, Vinck, De Ley, Clement and Van Cauwenberge2005) and changes within speech utterances are likely shaped by environmental factors such as accent, dialect, coarticulation pattern and speaking style (Whiteside & Rixon, Reference Whiteside and Rixon2003, Reference Whiteside and Rixon2013) filled with culturally specific codes in prosody (Rilliard et al., Reference Rilliard, de Moraes, Erickson and Shochi2013). It was expected that MZ twins would exhibit greater similarity in temporal and spectral characteristics compared to DZ twins. However, F0sd demonstrated the least variance explained by monozygosity, suggesting a lesser genetic influence on this parameter, possibly due to environmental factors that shape ‘pitch variation and intonation’ and thereby neutralizing any genetic effects on this parameter (Debruyne et al., Reference Debruyne, Decoster, Van Gijsel and Vercammen2002).
Sex exerted influence on all voice parameters in st over the explained variance among MZ and DZ twins, indicating potential differences in genetic and environmental contributions between sexes. However, the imbalance between the MZ and DZ samples must be highlighted. Since zygosity was not known until after data collection, we could not balance the two groups, and statistical tools were used to account for these differences in modeling. In addition, given the limited participation of male pairs in our sample (25% male pairs), caution is warranted in generalizing these findings. The statistical power and possible generalizations are limited by men’s reluctance to participate in research (e.g., friendship — Butera, Reference Butera2006; or health — Glass et al., Reference Glass, Kelsall, Slegers, Forbes, Loff, Zion and Fritschi2015).
Future studies should explore correlations and interactions among F0 descriptors and include other acoustic parameters (such as formant frequencies, voice quality metrics and temporal aspects of speech) to provide a more comprehensive understanding of the acoustic phenotype. Also, for clinical applications, other instrumental assessments could be considered to analyze anatomical variables contributing to prosody, which was beyond our study goals. Investigating these parameters together would enable researchers to assess the multivariate effects of genetics, environment and life history on voice characteristics, offering deeper insights into the complex interplay of factors influencing vocal traits in MZ and DZ twins.
In summary, our findings highlight the influence of zygosity and environmental factors on voice, with variations observed between measurement scales (Hz and st). This study offers insights into the intricate determinants of vocal traits, underscoring the nuanced contributions of genetic and environmental factors and the importance of scale selection in investigating hypotheses related to the human voice.
Data availability statement
Due to the nature of the research and ethical restrictions, supporting data is not available.
Acknowledgments
The authors thank the twins who participated in the study, who without their contribution this article would not exist. We are also grateful to the University of Sao Paulo Twin Panel (Painel USP de Gêmeos) colleagues and collaborators who helped the authors during data collection and analysis, especially Bruna Campos Paula, who trained LCL to use the software.
Author contribution
PFM, EO designed the study; EO Funding acquisition; Project administration; TKL recruitment, data acquisition; LCL Investigation, data preparation and segmentation; LCL, JCC,VFD data analysis; LCL Original Draft manuscript; PFM, TKL, JCC, VFD, EO manuscript review.
Financial support
This work was supported by the Fundação de Amparo à Pesquisa do Estado de São Paulo, FAPESP (E.O. grant number 2014/50282-5), (L.C.L grant numbers 2020/14250-2, 2022/08063-0), (J.C.C. grant number 2023/11070-1) and by Coordenação de Aperfeiçoamento de Pessoal de Nível Superior, CAPES (funding code 001).
Competing interests
None.
Ethical standards
The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008.








