



1. Introduction
Simultaneous localisation and mapping (SLAM) has seen widespread application across numerous domains, including intelligent substations [Reference Lu, Zhang and Su1] and exoskeleton robots [Reference Li, Li, Su and Xu2, Reference Li, Li, Wu, Kan, Su and Liu3], to facilitate safe and stable navigation for mobile and manipulative robots undertaking varied tasks. The unstructured nature of substations necessitates that the SLAM technology employed by robots exhibits robust generalisation capabilities to accommodate fluctuations in the environment [Reference Li, Cong, Liu and Du4]. Robots designed for intelligent substations are instrumental in executing a myriad of tasks, leveraging functionalities such as map construction [Reference Wang, Zhang, Song, Pang and Zhang5], autonomous positioning, path planning [Reference Cai, Yan, Shi, Zhang and Guo6], and the identification and retrieval of equipment.
Laser-based SLAM predominantly relies on lasers to reconstruct environments for positioning and mapping purposes. Nonetheless, 2D laser systems offer insufficient data, while 3D laser systems are prohibitively expensive. In contrast, visual sensors employed in Visual SLAM (vSLAM) have witnessed significant advancements owing to their cost-effectiveness and the rich semantic information they provide. However, the efficacy of most vSLAM systems is predicated on the assumption of static environments [Reference Hao, Chengju and Qijun7], which restricts their overall robustness.
The concept of keyframe-based vSLAM has rapidly evolved, attributed to its minimal computational demand and high precision [Reference Naudet-Collette, Melbouci, Gay-Bellile, Ait-Aider and Dhome8]. This approach focuses on pose optimisation and map creation through the establishment of feature points and keyframes. ORB-SLAM3 [Reference Campos, Elvira, Rodríguez, Montiel and Tardós9] exemplifies this, achieving enhanced speed and accuracy in computation by linking keyframes with active maps. In static settings, the correlation between feature points typically exhibits strong geometric consistency. Conversely, in dynamic environments, the clarity of these geometric correlations can diminish. Techniques such as local bundle adjustment (BA) and loop closure detection are employed to reduce the adverse effects of dynamic objects on cross-frame pose estimation. Despite these advancements, the challenge posed by dynamic objects remains, affecting the stability of sophisticated vSLAM systems. The utility of neural networks in improving robotic perception is increasingly recognised as a solution to the challenges presented by dynamic environments [Reference Fei, Wang, Tedeschi and Kennedy10].
In recent years, the integration of deep learning with simultaneous localisation and mapping has witnessed rapid advancements. Detect-SLAM [Reference Zhong, Wang, Zhang, Chen and Wang11] employs object detection to enhance robustness in dynamic environments, albeit at the cost of reducing the number of available static feature points. Previous literature [Reference Ul Islam, Ibrahim, Chin, Lim and Abdullah12] has demonstrated that instance segmentation can effectively eliminate dynamic feature points, yet this approach significantly compromises real-time performance. Further studies [Reference Liu and Miura13–Reference Kenye and Kala16] have explored the amalgamation of deep learning and clustering techniques to efficaciously remove feature points, although the definition of clustering hyperparameters presents challenges and necessitates reliance on more precise depth maps. Moreover, the integration of multi-view geometry with deep learning, as discussed in refs. [Reference Yu, Liu, Liu, Xie, Yang, Wei and Fei17, Reference Henein, Zhang, Mahony and Ila18], overlooks the semantic information pertinent to feature points.
This work introduces novel approaches for the detection of dynamic feature points and the fusion of multiple modules. Initially, an enhanced lightweight neural network is employed to identify dynamic objects through detection frames and segmentation results, subsequently using these results alongside the positional relationships of feature points to generate a mask for dynamic feature points. Tailored improvements, predicated on the characteristics of vSLAM, are implemented within the network to facilitate increased speed and accuracy. Furthermore, a dynamic threshold method is introduced to ascertain the maximal number of features that can be feasibly removed, offering superior adaptability to environmental variations in comparison to the deterministic threshold and movement capability approaches referenced in ref. [Reference Zhong, Wang, Zhang, Chen and Wang11]. Lastly, within the multi-module fusion process, the object detection framework is integrated into the backend local map to validate and adaptively determine the operation of the instance segmentation modules. This method, in contrast to the deterministic operating modes discussed in refs. [Reference Liu and Miura13, Reference Ji, Wang and Xie14], effectively consolidates individual modules, curtailing overall running time and bolstering stability.
The main contributions of this paper include:
-
The development of a lightweight neural network tailored for multimodal semantic vSLAM, featuring a rapid and efficient backbone network structure alongside decoupled headers for enhanced parameter sharing.
-
The proposition of a novel framework that adeptly merges deep learning with vSLAM, wherein the concurrent detection and segmentation technique substantially improves both the speed and accuracy of dynamic feature point detection within vSLAM.
-
The introduction of a lightweight semantic vSLAM framework capable of automatic environmental adaptation, with experiments on datasets and in real-world scenarios demonstrating its superiority over existing vSLAM methodologies in terms of speed and accuracy.
2. Related work
In scenarios characteristic of substations, the requirement for humans and machines to collaborate necessitates an environment that is frequently dynamic rather than static. Robots are thus required to possess the capability to comprehend complex scenarios and task processes [Reference Li, Cong, Liu and Du19, Reference Miao, Jia and Sun20]. This necessitates the deployment of vSLAM technologies capable of managing feature points on dynamic objects while simultaneously balancing performance with efficiency.
Multi-view geometric verification methods utilise reprojection errors between successive frames to identify dynamic objects. Zhang et al. [Reference Zhang, Zhang, Li, Nakamura and Zhang21] employ the residuals of relative positions derived from dense optical flow between consecutive frames for dynamic object segmentation. Dai et al. [Reference Dai, Zhang, Li, Fang and Scherer22] leverage the relative positional invariance of map points to distinguish moving objects across successive frames. The principal advantage of geometric methods lies in their capacity to deduce the mobility of objects within the environment through the analysis of image relations across different frames, without the need for extensive prior information. However, these methods do not adequately consider the overall semantic relationships between feature points.
Object detection methods differentiate between dynamic and static feature points through the extent of the detection bounding box. MOD-SLAM [Reference Hu, Fang, Yang and Zha23] integrates an object detection module that utilises the results from detection boxes to eliminate dynamic features. Bao et al. [Reference Bao, Komatsu, Miyagusuku, Chino, Yamashita and Asama24] introduced a method that initially applies detection results obtained from the detection module, subsequently determining whether to proceed with semantic segmentation based on the quantity of static feature points. Such targeted detection algorithms enhance the robustness of vSLAM in dynamic environments with minimal impact on real-time performance. Nonetheless, the discrepancy between the size of the detection frame and the actual contours of objects constrains the effectiveness of object detection within vSLAM systems.
Semantic segmentation-based approaches remove dynamic feature points based on segmentation results. DynaSLAM [Reference Bescos, Fácil, Civera and Neira25] combines Mask R-CNN [Reference He, Gkioxari, Dollár and Girshick26] with multi-view geometry to exclude dynamic feature points, albeit at the expense of significantly affecting the real-time performance of vSLAM. DS-SLAM [Reference Yu, Liu, Liu, Xie, Yang, Wei and Fei17] suggests executing geometry checks and Segnet [Reference Badrinarayanan, Kendall and Cipolla27] in parallel threads to accurately identify dynamic object masks, though improvements in speed are not markedly evident. Ji et al. [Reference Ji, Wang and Xie14] proposed a combined approach of semantic segmentation and clustering, wherein dynamic object masks are acquired through segmentation of keyframes using Segnet and clustering on the depth graph with Kmeans [Reference Wong28], achieving notable speed and segmentation accuracy. However, this approach is contingent upon the sensor’s ability to accurately gauge depth, and its effectiveness is notably influenced by the settings of hyperparameters.
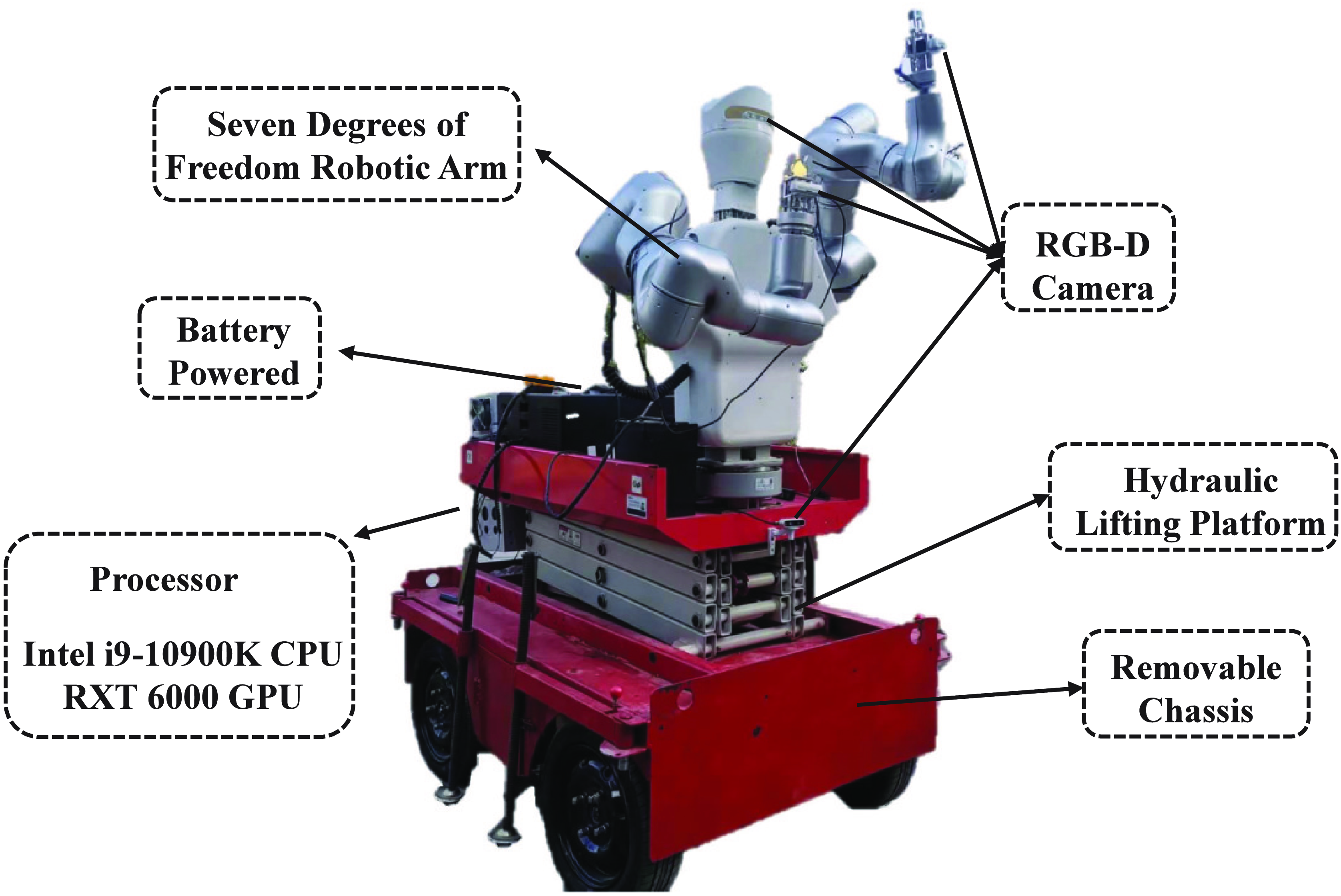
Figure 1. An overview of the smart substation robot platform.
3. System description
Experimental validation was conducted using the developed substation robotic equipment, as depicted in Fig. 1. This apparatus encompasses a mobile chassis, a hydraulic lifting platform, a robotic arm, several RGB-D cameras, and a central processing unit equipped with an Intel i9-10900X CPU and an NVIDIA Quadro RTX 6000 GPU. The hardware components and their respective functionalities are outlined as follows:
-
The mobile chassis affords the substation robot mobility and directional steering capabilities. Equipped with four-wheel steering, the chassis is designed to minimise the turning radius, thereby enhancing manoeuvrability in confined spaces. Furthermore, its dual-drive architecture at the front and rear facilitates navigation over complex terrains.
-
The hydraulic lifting platform primarily serves to extend the vertical operational range of the robotic arm, allowing it to reach varying heights across different scenarios. This design feature effectively addresses the constraints associated with working within a singular vertical space.
-
The robotic arm, featuring seven degrees of freedom, enables precise grasping and manipulation within intricate environments. Additionally, it is outfitted with a terminal rotation motor at its front end, facilitating tasks such as tightening and disassembling components.
-
Multiple RGB-D cameras are strategically positioned on various parts of the substation robot to cater to the demands of diverse tasks. The camera located on the robot’s head offers a comprehensive view and depth perception for the robotic arm’s operational area. The camera attached to the extremity of the arm delivers finer resolution images and depth detail for precise manipulation tasks. Meanwhile, the camera mounted on the mobile chassis provides consistent height and positional imagery for accurate positioning and navigation, ensuring the stability of the external parameter matrix between the chassis and its environment.
-
The central processor, boasting significant computational power, orchestrates the substation robot’s perception, control, planning, and locomotion. It assimilates and processes data from the robotic arm, the RGB-D cameras, and the chassis, integrating this information to furnish real-time feedback and control over the robot’s operations.
4. Method
The methodology proposed herein amalgamates object detection and instance segmentation techniques to eliminate dynamic objects from scenes. Leveraging the profound capability of neural networks to decipher semantic information, this approach efficiently removes a majority of the dynamic feature points. The integration of object detection and instance segmentation methodologies is designed to address the limitations inherent in each individual module. As illustrated in Fig. 2, feature extraction is conducted via the backbone network, with object detection and instance segmentation modules appended to each frame to identify dynamic entities. Within the vSLAM tracking thread, the results from instance segmentation are employed to enhance the precision of pose optimisation. Concurrently, in the local mapping thread, the outcomes of object detection and instance segmentation are amalgamated to refine the delineation of dynamic objects.
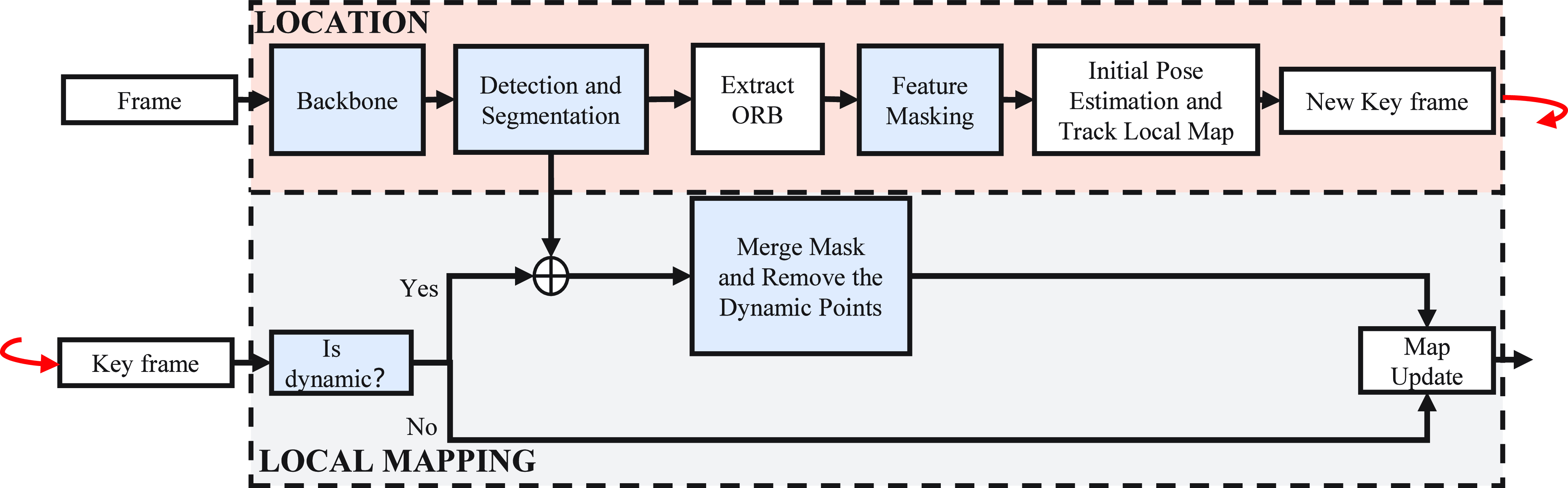
Figure 2. The overall flow chart of the system. The blue blocks are modules we added in ORB-SLAM3.
4.1. Location
Neural networks have been incorporated within the tracking thread to detect and segment dynamic objects. In selecting an appropriate network, both the performance and efficiency of the algorithm were considered, leading to the adoption of YOLOv8 [Reference Dumitriu, Tatui, Miron, Ionescu and Timofte29] as the primary network. YOLOv8 is capable of conducting both object detection and instance segmentation concurrently, offering improvements in speed and accuracy over previously suggested methods. However, the exigencies of vSLAM in dynamic settings necessitate even faster neural network performance. The original pretraining weights, optimised for the eighty categories of the COCO dataset, include several categories irrelevant to dynamic vSLAM scenarios. Consequently, a subset of 20 pertinent dynamic and static object categories from COCO was chosen for detection. The YOLOv8s-seg model was selected as the foundational model, with proposed enhancements aimed at rendering it more lightweight without compromising algorithmic performance.
4.1.1. Network improvements
The performance of the target detection and instance segmentation network is significantly influenced by its ’Neck’ component. Models constructed using an abundance of depthwise separable convolutional layers fail to achieve the desired level of accuracy. This paper proposes the incorporation of GSConv [Reference Li, Li, Wei, Liu, Zhan and Ren30] into the ’Neck’ of the YOLOv8s-seg network to diminish model complexity while preserving accuracy. Specifically, GSConv is integrated with the VoVGSCSP module, wherein the VoVGSCSP module supersedes the C2f module in the original YOLOv8 architecture. This modification results in a more efficient ’Slim-Neck’, thereby enhancing the network’s computational cost-effectiveness. The GSConv and VoVGSCSP modules are depicted in Fig. 3.
GSConv aims to minimise the loss of semantic information during the process of channel expansion and feature map reduction. However, its implementation within the backbone network incurs significant computational overhead. The adjustment of channel numbers and feature map dimensions in the ’Neck’ section, conversely, is more judicious, thus not excessively augmenting inference time consumption. Given the necessity to fuse feature maps across varying channels, an attention mechanism is requisite. Hence, informed by the findings of [Reference Li, Li, Wei, Liu, Zhan and Ren30], GSConv has been integrated into the ’Neck’ section of the YOLOv8 architecture, culminating in the formation of the YOLOv8s-seg-Slim-Neck structure. This adaptation not only curtails computational demands but also augments the network’s efficacy in both detection and segmentation tasks. Detailed experimental comparisons are provided in the subsequent experimental section.
YoloV8 utilises a decoupled head design, segregating the predictions of classification and bounding boxes into distinct branches. It has been observed that the decoupled head of YoloV8 harbours a relatively large parameter count, which, for network deployment, could potentially impair real-time performance. To mitigate this, parameters of certain layers within the decoupled head are shared, and a convolutional module endowed with a re-parameterization mechanism (RepConv) [Reference Soudy, Afify and Badr31] is introduced to offset the performance decrement occasioned by the reduction of parameters, as illustrated in Fig. 4.
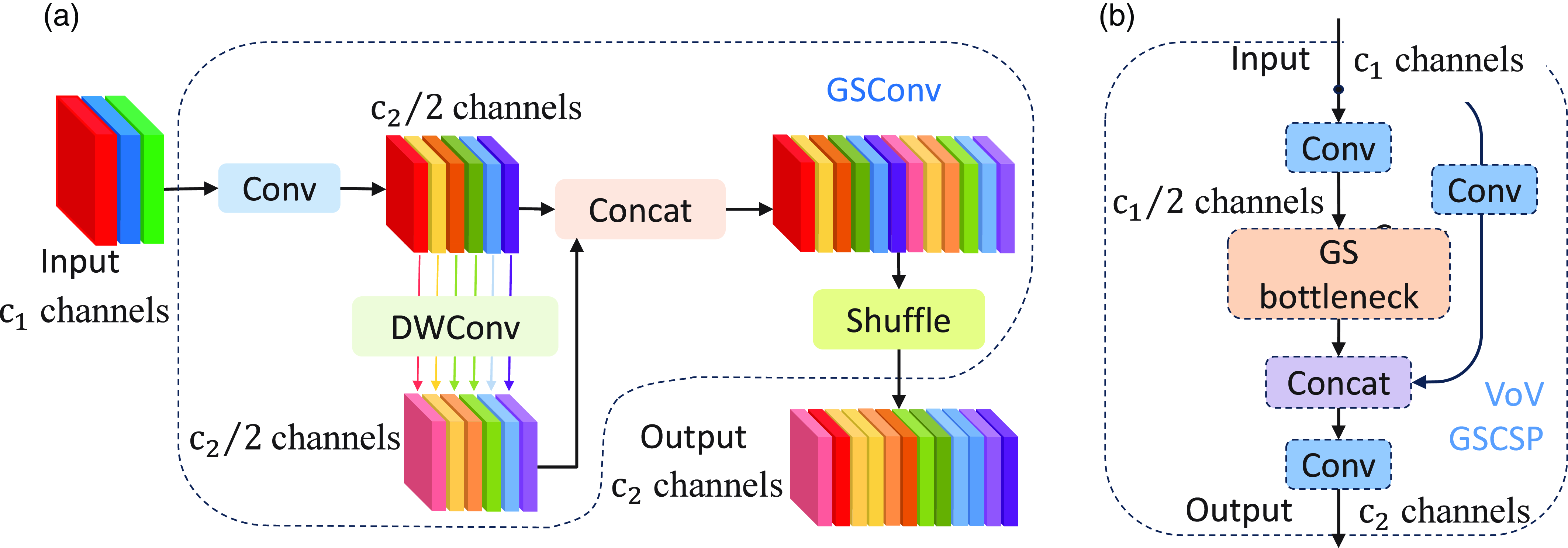
Figure 3. (a) The composition of the GSConv module. (b) The VoVGSCSP module is composed of GSConv.
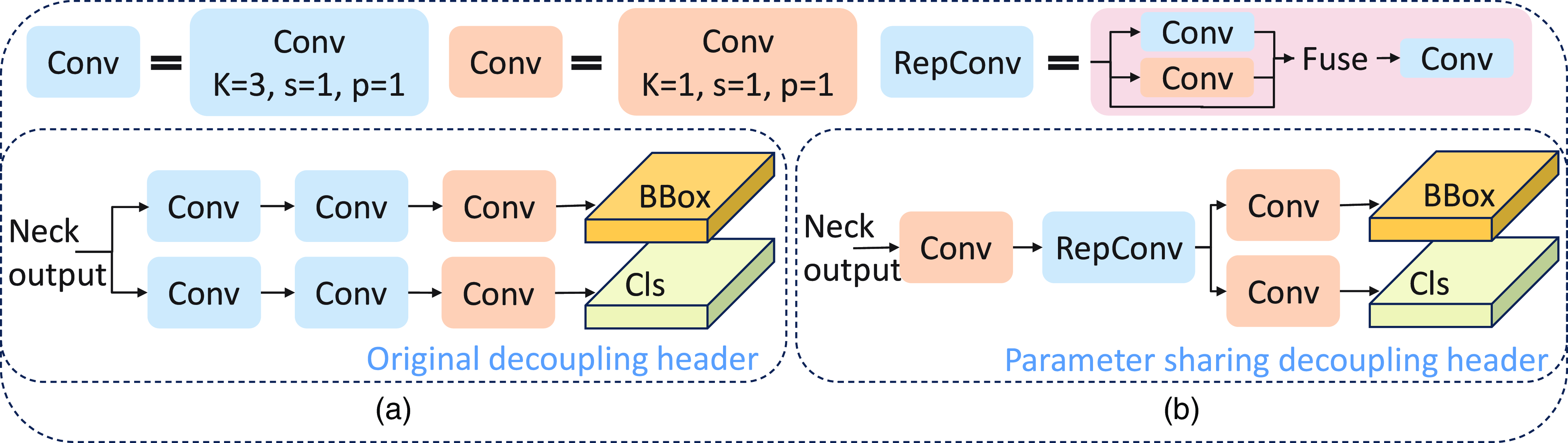
Figure 4. (a) Original decoupling header in yolov8. (b) A decoupling header for parameter sharing has been added to yolov8.
RepConv represents a convolutional module that reallocates the parameters of its internal convolution through computational fusion. This design is more conducive to hardware compatibility, yet a straightforward network architecture might diminish the network’s feature extraction capability and the path of gradient flow. Consequently, during training, RepConv incorporates multiple branches within the module to enhance the network’s feature extraction capacity. Nevertheless, in the inference phase, these multiple computational modules are consolidated into a single entity to enhance both the efficiency and performance of the model.
For instance segmentation, the network’s output header adopts a simplistic structure. Reductions in convolution layers and channels confer marginal improvements in speed, yet precipitate a considerable diminution in network precision.
Both the slim-neck structural refinement and the implementation of a parameter-sharing decoupled head through RepConv facilitate a substantial reduction in parameters, enhancing the inference speed of YoloV8 without compromising its performance. These enhancements have been amalgamated to formulate the final YOLOv8s-seg-gs-rep network architecture. To further augment network velocity, the TensorRT inference framework is employed during network deployment, thereby expediting the integration of the network with vSLAM. The efficacy of these improvement techniques has been empirically validated within the ablation study section, elucidating the influence of each enhancement on both speed and accuracy.
4.1.2. Posture optimisation
In the context of front-end pose optimisation within vSLAM, the outcomes of instance segmentation are utilised to obscure dynamic feature points. The processed image, courtesy of the refined YOLOv8s-seg network, facilitates the acquisition of segmentation results for currently active objects. These results are subsequently amalgamated into a comprehensive mask map, excluding dynamic feature points from the pose optimisation process.
The segmentation of dynamic objects necessitates the predefinition of such entities based on artificial priors. Nonetheless, the inherent mobility of an object is not a definitive attribute; hence, variable segmented mobility values are ascribed to distinct objects.
The methodology for allocating mobility segments is delineated in Fig. 5. Three intervals are equidistantly distributed between 0 and 1, with the quartile thresholds representing varying probabilities of movement. For instance, a value of 1 denotes a human, indicative of a high probability of dynamic movement; 0.75 pertains to a sports ball, signifying a moderate probability of motion; and 0.25 is attributed to a keyboard, suggesting a minimal likelihood of movement, thereby classifying it as a static object with low confidence.

Figure 5. Movement confidence thresholds for different objects.
The presence of dynamic points within an image can significantly consume spatial resources. Utilising a fixed threshold method or a binary mobility capability assignment could result in the failure of optimisation efforts. To circumvent this, four methods of mobility capability assignment alongside dynamic threshold techniques are employed to bolster the algorithm’s robustness. The dynamic threshold approach operates as follows:
 \begin{equation} d_{Point} = \begin{cases} static, & \mbox{if } m \leq m_{th} \\ dynamic, & \mbox{otherwise} \end{cases}, \end{equation}
\begin{equation} d_{Point} = \begin{cases} static, & \mbox{if } m \leq m_{th} \\ dynamic, & \mbox{otherwise} \end{cases}, \end{equation}
where
 $d_{Point}$
is a flag of whether the feature points are dynamic.
$d_{Point}$
is a flag of whether the feature points are dynamic.
 $m$
means the mobility of the category to which the current feature point belongs.
$m$
means the mobility of the category to which the current feature point belongs.
 $m_{th}$
represents the threshold for judging the dynamics of feature points, which is 0.25 at the beginning. The formula only calculates the dynamics of feature points within the segmentation mask, and those not within the segmentation mask are considered static. If the number of static points does not meet the set minimum number,
$m_{th}$
represents the threshold for judging the dynamics of feature points, which is 0.25 at the beginning. The formula only calculates the dynamics of feature points within the segmentation mask, and those not within the segmentation mask are considered static. If the number of static points does not meet the set minimum number,
 $m_{th}$
needs to be adaptively increased by 0.1 until it reaches the maximum of 1. If it is not satisfied when
$m_{th}$
needs to be adaptively increased by 0.1 until it reaches the maximum of 1. If it is not satisfied when
 $m_{th}$
is 1, dynamic objects may fill the entire picture, and we would give up this dynamic object optimisation.
$m_{th}$
is 1, dynamic objects may fill the entire picture, and we would give up this dynamic object optimisation.
When the remaining static points meet the needs of attitude estimation, the camera poses
 $T_{wc} \in SE(3)$
would be estimated and optimised using BA. The camera poses
$T_{wc} \in SE(3)$
would be estimated and optimised using BA. The camera poses
 $T_{wc}$
, which comprises the camera’s rotation
$T_{wc}$
, which comprises the camera’s rotation
 $R$
and position
$R$
and position
 $t$
. The set of static feature points on the current image is
$t$
. The set of static feature points on the current image is
 $p_c$
. The coordinate set of the points in the three-dimensional world matched by
$p_c$
. The coordinate set of the points in the three-dimensional world matched by
 $p_c$
is
$p_c$
is
 $P$
. The optimisation equation is as follows:
$P$
. The optimisation equation is as follows:
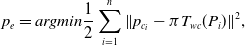 \begin{equation} p_{e} = argmin \frac{1}{2} \sum _{i=1}^{n}\| p_{c_i} - \pi T_{wc}(P_i) \|^2, \end{equation}
\begin{equation} p_{e} = argmin \frac{1}{2} \sum _{i=1}^{n}\| p_{c_i} - \pi T_{wc}(P_i) \|^2, \end{equation}
where
 $p_{e}$
is the camera pose iterative optimisation error,
$p_{e}$
is the camera pose iterative optimisation error,
 $\pi$
is the inherent parameter of the camera, which is the reprojection model from the three-dimensional coordinates to the camera coordinate system, and
$\pi$
is the inherent parameter of the camera, which is the reprojection model from the three-dimensional coordinates to the camera coordinate system, and
 $n$
is the number of matching feature points between the three-dimensional space and the two-dimensional space. A more accurate camera pose
$n$
is the number of matching feature points between the three-dimensional space and the two-dimensional space. A more accurate camera pose
 $T_{wc}$
can be obtained by continuously iterating to reduce the reprojection error.
$T_{wc}$
can be obtained by continuously iterating to reduce the reprojection error.
4.2. Local mapping
Enhancing the efficiency and reducing the complexity of neural networks may compromise their performance. To mitigate this issue within the backend of vSLAM, we employ a technique that combines detection bounding boxes and strengthens segmentation outcomes. However, this adjustment need not be applied to every backend keyframe but rather to those keyframes exhibiting significant dynamic characteristics. Consequently, we utilise the outcomes from the front-end detection of dynamic feature point numbers and employ formula 3 to assess the dynamism of the current frame.
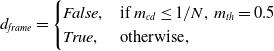 \begin{equation} d_{frame} = \begin{cases} False, & \mbox{if } m_{cd} \leq 1/ N, \, m_{th} = 0.5 \\ True, & \mbox{otherwise}, \end{cases} \end{equation}
\begin{equation} d_{frame} = \begin{cases} False, & \mbox{if } m_{cd} \leq 1/ N, \, m_{th} = 0.5 \\ True, & \mbox{otherwise}, \end{cases} \end{equation}
where
 $m_{cd}$
represents the number of dynamic feature points in the front-end under the threshold
$m_{cd}$
represents the number of dynamic feature points in the front-end under the threshold
 $m_{th} = 0.5$
,
$m_{th} = 0.5$
,
 $N$
represents the total number of feature points in the current image, and
$N$
represents the total number of feature points in the current image, and
 $d_{frame}$
is a flag of whether the frame is dynamic. Only dynamic keyframes perform joint optimisation of object detection and instance segmentation.
$d_{frame}$
is a flag of whether the frame is dynamic. Only dynamic keyframes perform joint optimisation of object detection and instance segmentation.
Given the compact nature of the base network model, instance segmentation may yield inaccurate results or fail altogether. To address this challenge, we introduce a strategy whereby the detection and segmentation heads operate in a complementary fashion. Specifically, we juxtapose the outcomes of object detection bounding boxes with those of instance segmentation. Should the ratio
 $s_o$
, representing the quotient of the instance segmentation area to the object detection bounding box area, fall below a minimal threshold
$s_o$
, representing the quotient of the instance segmentation area to the object detection bounding box area, fall below a minimal threshold
 $t_o$
, the instance segmentation result for the current object is deemed unsuccessful, and the bounding box mask is adopted as the definitive mask. This comparative analysis of object detection and instance segmentation results facilitates the calculation of the overlap area, utilising the indices provided by the model’s object detection and instance segmentation heads. The mask calculation formula of the jointly optimised dynamic object is as follows:
$t_o$
, the instance segmentation result for the current object is deemed unsuccessful, and the bounding box mask is adopted as the definitive mask. This comparative analysis of object detection and instance segmentation results facilitates the calculation of the overlap area, utilising the indices provided by the model’s object detection and instance segmentation heads. The mask calculation formula of the jointly optimised dynamic object is as follows:
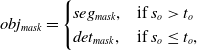 \begin{equation} obj_{mask} = \begin{cases} seg_{mask}, & \mbox{if } s_o \gt t_o \\ det_{mask}, & \mbox{if } s_o \leq t_o, \end{cases} \end{equation}
\begin{equation} obj_{mask} = \begin{cases} seg_{mask}, & \mbox{if } s_o \gt t_o \\ det_{mask}, & \mbox{if } s_o \leq t_o, \end{cases} \end{equation}
where
 $seg_{mask}$
is the mask obtained from instance segmentation, and
$seg_{mask}$
is the mask obtained from instance segmentation, and
 $det_{mask}$
is the mask obtained from object detection.
$det_{mask}$
is the mask obtained from object detection.
 $t_o$
is selected as 0.25.
$t_o$
is selected as 0.25.
The outcome post-fusion serves as the definitive mask, enabling the removal of dynamic points during the back-projection and optimisation processes. This approach ensures the precise exclusion of keyframes and dynamic points from the map. Whether in map matching or keyframe matching, the influence of dynamic objects is markedly diminished. The algorithm proposed herein adeptly balances speed and performance, demonstrating versatility across varied environments.
5. Experiments and results
5.1. Ablation experiment
In the realm of network lightening, it is imperative to minimise any reduction in model accuracy. Should a module manage to decrease the number of parameters without compromising, or indeed enhancing, the model’s accuracy, it would thereby elevate the cost-efficiency of the optimisation process. The selection of network modules must also take into account the compatibility of the network structure with the hardware platform. The GSConv module redefines convolution operations, enriching the network with enhanced gradient flow and informational exchange. The RepConv module, during training, leverages multiple convolution combinations and, throughout inference, employs convolution merging to optimise the utilisation of convolution modules. Furthermore, RepConv exhibits considerable compatibility with hardware. Both modules contribute to rendering the network more efficient and faster. However, considering the YOLOv8-seg model necessitates attention to both detection and segmentation heads, prompting thorough comparative experimentation. Experiments were conducted on 20 specifically chosen categories, as delineated in Table I, to ascertain the efficacy of the proposed module amalgamation.
A suite of evaluative metrics was employed in comparative analyses between the refined and original networks. The dataset for comparison was compiled by extracting relevant data from the original COCO dataset, as per the categories listed in Table I, with the original COCO test set serving as the evaluation benchmark. The comparative outcomes are presented in Table II.
Table I. Twenty categories selected from COCO.

Table II. Comparison of combined experiments between different modules.

The evaluation criteria used in Table II are as follows:
 $size\_{pixels}$
represents the size of the image input by the network, mAP represents the average accuracy of each detection category under a fixed IOU threshold,
$size\_{pixels}$
represents the size of the image input by the network, mAP represents the average accuracy of each detection category under a fixed IOU threshold,
 $mAP_{0.5:0.95}$
represents the average of all mAP with IOU thresholds from 0.5 to 0.95, which can represent generalisation performance of the network.
$mAP_{0.5:0.95}$
represents the average of all mAP with IOU thresholds from 0.5 to 0.95, which can represent generalisation performance of the network.
 $Box \ mAP_{0.5:0.95}$
represents the generalisation performance of the detection box,
$Box \ mAP_{0.5:0.95}$
represents the generalisation performance of the detection box,
 $seg \ mAP_{0.5:0.95}$
represents the generalisation performance of segmentation, and
$seg \ mAP_{0.5:0.95}$
represents the generalisation performance of segmentation, and
 $FLOPs$
represents the network required floating point operations are in giga.
$FLOPs$
represents the network required floating point operations are in giga.
 $Gradients(M)$
represents the number of gradients in millions when the network is backpropagated.
$Gradients(M)$
represents the number of gradients in millions when the network is backpropagated.
 $Params(M)$
represents the total number of parameters owned by the network in millions, and epoch represents the number of iterations of the data by the training network.
$Params(M)$
represents the total number of parameters owned by the network in millions, and epoch represents the number of iterations of the data by the training network.
We found that using GSConv in the neck part to form a slim-neck structure and using the RepConv structure in the parameter sharing decoupling header can achieve higher inference speed and lower parameter amount. At the same time, the network’s performance is also optimal compared to other structures.
5.2. Simulation experiment
5.2.1 TUM and EUROC dataset
The EUROC dataset [Reference Burri, Nikolic, Gohl, Schneider, Rehder, Omari, Achtelik and Siegwart32] and the TUM RGB-D dataset [Reference Sturm, Burgard and Cremers33] serve as benchmarks for evaluating the performance of vSLAM across various scenarios. These datasets facilitate a comprehensive assessment of the method proposed herein. Predicated upon the foundational ORB-SLAM3, the proposed algorithm demonstrates comparable performance on datasets characterised by lower levels of mobility. Nevertheless, it substantially surpasses the original ORB-SLAM3 in sequences featuring significant object movement. The focus of our experiments is on sequences with high dynamics, specifically
 $fr3/walking\_*$
, with outcomes juxtaposed against those obtained with the original ORB-SLAM3 and other contemporary state-of-the-art methodologies.
$fr3/walking\_*$
, with outcomes juxtaposed against those obtained with the original ORB-SLAM3 and other contemporary state-of-the-art methodologies.
5.2.2 Evaluation metrics
The evaluation of vSLAM principally involves measuring the discrepancy between the trajectory delineated by the algorithm and the actual trajectory. Absolute trajectory error (ATE) and relative pose error (RPE) are commonly employed as evaluative metrics, with their root mean square error typically utilised to gauge accuracy. ATE quantifies the absolute discrepancy (in metres) between the actual and estimated positions across all frames, whereas RPE assesses the error in relative pose estimation (in radians). The standard deviation (std) is employed to quantify the dispersion of values within a dataset, signifying the mean distance between data points and the dataset’s average. A larger standard deviation indicates a more dispersed distribution, directly reflecting the global trajectory algorithm’s precision. RPE measures the variance in positional changes at identical timestamps, encompassing translation error (in metres per second) and rotation error (in degrees per second). The final error metric is derived by averaging the outcomes of multiple experiments conducted on the same dataset.
5.2.3 Implementation configuration
The neural network model is seamlessly integrated within the vSLAM framework. Utilising TensorRT, the neural network is converted into a TRT (fp16) model, with both the pre-processing and post-processing stages of the network parallelised and executed on the GPU. The entire algorithmic suite is developed in C++. This approach optimises the network’s speed while maintaining accuracy.
In operational scenarios within substations, enhancing the algorithm’s performance is paramount, with a particular emphasis on accelerating its execution speed. Hence, in comparison to our prior work [Reference Li, Gu and Feng34], the methodology we propose achieves a two- to three-fold increase in speed, simultaneously ensuring enhanced precision and greater stability.
The proposed algorithm necessitates the input of an RGB image, functioning effectively provided the selected hardware is capable of supplying RGB images. For instance, when employing stereo vision, the left-eye image is utilised as input.
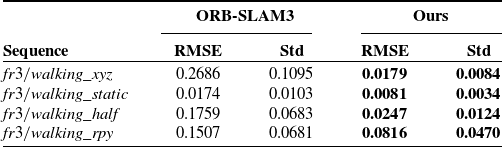
Table III. Comparison with ORB-SLAM3 using ATE as evaluation metric [m]. Highlight the best results in bold.
5.3. Experimental comparison
5.3.1 Comparison with ORB-SLAM3
To ascertain the efficacy of the proposed method, we undertook experimental evaluations across various datasets. Ensuring the reliability of our findings, we performed tests on our apparatus using both the original ORB-SLAM3 and our proposed method, facilitating a direct comparison of outcomes. For a more intuitive analysis of the experimental data, we intend to produce a comparative chart of the trajectories. The sequences
 $fr3/walking\_xyz$
,
$fr3/walking\_xyz$
,
 $fr3/walking\_static$
,
$fr3/walking\_static$
,
 $fr3/walking\_half$
, and
$fr3/walking\_half$
, and
 $fr3/walking\_rpy$
from the TUM dataset, each exhibiting varying levels of dynamic activity, were selected for this comparative analysis. The outcomes of this comparison are delineated in Table III and illustrated in Fig. 6.
$fr3/walking\_rpy$
from the TUM dataset, each exhibiting varying levels of dynamic activity, were selected for this comparative analysis. The outcomes of this comparison are delineated in Table III and illustrated in Fig. 6.
The experimental outcomes indicate that the proposed methodology yields results comparable to those of ORB-SLAM3 under static conditions. In scenarios marked by minimal object movement, the outlier optimisation mechanism utilised by ORB-SLAM3 proves effective in discarding dynamic points, with outcomes closely mirroring those of our proposed approach. However, in environments characterised by considerable object movement, ORB-SLAM3’s optimisation methods and mechanisms encounter difficulties in adequately addressing the influence of dynamic objects. This challenge becomes increasingly evident as the frequency of object movement escalates or in consistently high-motion scenes, leading to a notable decline in ORB-SLAM3’s performance. Conversely, our optimised method maintains commendable performance under these conditions. Throughout the experimentation phase, we garnered specific insights, illustrated in Fig. 7, which portrays the precision in eliminating dynamic objects.
Table IV. The absolute trajectory error (ATE) is used as the standard for comparison. [m].


Figure 6. Comparison of trajectory estimation accuracy of the proposed method with ORB-SLAM3. (a) The EUROC datasets V101 were generated in a static environment. (b), (c) and (d) The TUM dataset includes
 $fr3/walking\_rpy$
,
$fr3/walking\_rpy$
,
 $fr3/walking\_xyz$
and
$fr3/walking\_xyz$
and
 $fr3/walking\_half$
, which were collected in a high-motion environment.
$fr3/walking\_half$
, which were collected in a high-motion environment.

Figure 7. Interception of experimental results. (a). Results under static scenes. (b), (c) and (d). Experimental screenshots under different dynamic scenarios.
5.3.2 Comparison with other vSLAM
Furthermore, the integration of deep learning into vSLAM is gaining traction, prompting a comparison of our method with several leading-edge vSLAM technologies, including Detect-SLAM [Reference Zhong, Wang, Zhang, Chen and Wang11], KMOPvSLAM [Reference Liu and Miura13], Rts-SLAM [Reference Ji, Wang and Xie14], RGBD-SLAM [Reference Xie, Liu and Zheng15], DS-SLAM [Reference Yu, Liu, Liu, Xie, Yang, Wei and Fei17], DynaSLAM [Reference Bescos, Fácil, Civera and Neira25], and RGB-D SLAM [Reference Dai, Zhang, Li, Fang and Scherer22]. The comparative analysis focuses on both accuracy and speed. While some dynamic SLAM systems exhibit rapid processing speeds, their accuracy leaves much to be desired. Others, such as DynaSLAM [Reference Bescos, Fácil, Civera and Neira25], demonstrate superior performance in dynamic environments but are constrained to offline execution, thus precluding real-time operation. The comparative outcomes, employing ATE as a metric, are presented in Table IV. Additionally, the results for RPE, encompassing both translation and rotation, are summarised in Tables V, underscoring the advanced nature of the proposed method.
Table V. Comparison of root mean square error (RMSE) for translational drift in meters per second
 $(m/s)$
and RMSE for rotational drift in degrees per second
$(m/s)$
and RMSE for rotational drift in degrees per second
 $(^\circ/s).$
$(^\circ/s).$

5.4. Real-world experiment
Real-world experiments were carried out using robotic equipment within substations, where substation robots are primarily deployed to support staff in routine maintenance and inspection tasks, operating amidst complex scenes populated with dynamic objects.
Initially, the efficacy of the proposed vSLAM method was assessed through the odometry technique. The integration of multi-sensor odometry fusion methods has gained widespread acceptance for enhancing mobile robot localisation and navigation due to its straightforward application, acceptable error margin, and cost-effectiveness [Reference Li, Zhang, Ye, Lin, Yu and Meng35, Reference Girbés-Juan, Armesto, Hernández-Ferrándiz, Dols and Sala36, Reference Zhang, Mononen, Mattila and Aref37]. In the context of substations, where privacy concerns preclude the use of GPS, our experiments relied on the fusion of IMU and encoder-based odometry as the benchmark for validating the proposed vSLAM method’s effectiveness. Encoders fitted on both the front and rear steering mechanisms, coupled with IMU data from the bio-camera, ensure precise odometry. Moreover, the odometry fusion method delineated in prior research [Reference Girbés-Juan, Armesto, Hernández-Ferrándiz, Dols and Sala36] was employed.
The field experiment within the substation is depicted in Fig. 8a, where the algorithm’s capacity to identify dynamic objects and its efficacy in eliminating such objects were tested by an experimenter swiftly moving in front of the substation robot. Figure 8b illustrates the trajectory of the substation robot as it advances in the real-world scenario, with the procedural outcomes presented in Fig. 8c. As demonstrated in Fig. 8d, the generated map remains unimpacted by dynamic entities, underscoring the superiority of the proposed algorithm in practical applications.

Figure 8. Experiments in different real-world scenarios. (a). Experimental environments with fast moving objects. (b). Realistic route of substation robot movement. (c). Screenshots of the experimental process. (d). Trajectory maps generated in mobile environments.
Time efficiency serves as a critical metric for evaluating an algorithm’s performance. To ascertain the temporal demands of each module within the proposed method, experiments were conducted to record the operational duration of each component under dynamic and static conditions. Table VI enumerates the average running times. In dynamic keyframe scenarios, the algorithm necessitates the amalgamation of detection and segmentation results.
Table VI. Time consumption of each part [ms]. The RMSE comparison uses the results of ORB-SLAM3 as the relative benchmark.

Within static keyframes, the algorithm obviates the need for fusion, thereby not incurring additional time expenditure. This observation underscores that the proposed method operates efficiently without compromising real-time performance. To further substantiate the algorithm’s real-time capabilities, experiments were executed on the NVidia Jetson AGX Xavier, equipped with a 512-core Volta GPU, an 8-core ARM 64-bit CPU, and 16 GB of RAM. The results of these comparative studies on the temporal demands of various algorithms are presented in Table VII.
Table VII. Comparison of computation time [ms].

6. Conclusion and discussion
This study introduces a lightweight, multi-modal semantic SLAM framework designed to enhance mapping accuracy while diminishing the computational demands of the fusion process. Utilising an instance segmentation model, the framework adeptly identifies and eliminates dynamic objects within each frame, thereby ensuring the integrity of map generation. The foundation of this framework is the incorporation of state-of-the-art detection models and a segmentation head, predicated on the understanding that the amalgamation of neural networks with SLAM requires not the utmost segmentation precision but a balanced approach. Moreover, the adoption of lightweight strategies aims to reduce computational burdens while maintaining the efficacy of the neural network model employed. This approach further amalgamates the detection bounding boxes with instance segmentation outcomes, mitigating potential discrepancies in instance segmentation accuracy. The proposed method has demonstrated enhancements in both positional accuracy and operational speed across a variety of scenarios, affirming its innovative contributions.
Nonetheless, the proposed method is not without limitations. Currently, ORB feature points are delineated manually, bypassing the neural network’s capability to extract and fortify feature points’ robustness. Future endeavours will explore the substitution of the entire front-end process with neural network operations, leveraging the network’s potential for feature point extraction. Additionally, efforts will be directed towards integrating the removal of dynamic feature points within the neural network’s feature point extraction process, utilising initial semantic insights to dispense with dynamic feature points, thereby cultivating robustness in diverse and intricate environments.
Author contributions
Zhijun Li and Shaohu Li conceived the method, built the framework, designed the experiments, and conducted the theoretical analysis. Shaohu Li, Shaofeng Li, and Bixiang Guo designed and performed the experiments. Shaohu Li processed the data and performed analysis. Jason Gu carried out the discussion and refinement of the paper. Shangbing Gao and Feng Zhao performed the experiments. Yuwei Yang and Guoxin Li assisted in revising the paper. Lanfang Dong gave expertise on multi-modal fusion.
Financial support
This work was supported by the National Key Research and Development Program of China (Grant No. 2020YFB1313602) and the Anhui Provincial Natural Science Foundation, Anhui Energy-Internet Joint Program (No. 2008085UD01).
Competing interests
The authors declare no competing interests exist.
Ethical approval
None.




















