



No CrossRef data available.
Article contents
Multivariate analysis from SSR and morphological data in chickpea (Cicer arietinum L.) for breeding purposes
Published online by Cambridge University Press: 07 March 2023
Abstract
In order to enhance genetic potential of chickpea materials from the National University of Córdoba Breeding Programme and Germplasm collection (Argentina), a study for a comprehensive understanding of the amount and pattern of genetic variation within and between genotypes was carried out by applying a multivariate analysis form single simple repeats (SSR) and morphological data. Molecular data were also used to determine the discriminating power for genotype identification, and to find the optimal primer combination to ensure unambiguous identification. With the analysis of 15 SSR markers on 53 genotypes, a total of 58 alleles were detected with individual values ranging from one to nine alleles per locus. High values of discriminating power (Dj ⩾ 0.7, PIC ⩾ 0.7), and low values of confusion probability (Cj ⩽ 0.23) were obtained for at least four evaluated markers. The combination of TA113 + TA114 + H1B09 + TA106 primers was effective for discriminating the 53 chickpea genotypes with a cumulative confusion probability value (Ck) of 9.60 × 10−4. Except for some exceptions, individual chickpea genotypes within a cluster in the consensus tree were definitely more closely related with each other by the origin or pedigree. The results confirmed that both multivariate data analysis methods, ordination and clustering, were complementary. In most genotypes, discriminant principal component analysis classification was consistent with the original clusters defined by molecular data. Differences in results from molecular and morphological data indicate that they provide complementary and relevant information for establishing genetic relationships among chickpea materials and a better description and interpretation of the available variability in the germplasm collection.
- Type
- Research Article
- Information
- Copyright
- Copyright © The Author(s), 2023. Published by Cambridge University Press on behalf of NIAB
References
Abbo, S, Berger, J and Turner, NC (2003) Viewpoint: evolution of cultivated chickpea: four bottlenecks limit diversity and constrain adaptation. Functional Plant Biology 30, 1081–1087.CrossRefGoogle ScholarPubMed
Balzarini, M, Arroyo, A, Bruno, C and Di Rienzo, J (2006) Análisis de datos de marcadores con Info-Gen. XXXV Congreso Argentino de Genética, San Luis. Argentina.Google Scholar
Belaj, A, Satovic, Z, Rallo, L and Trujillo, I (2004) Optimal use of RAPD markers for identifying varieties in olive (Olea europaea L.) germplasm collections. Journal of the American Society for Horticultural Science 107, 266–270.CrossRefGoogle Scholar
Bellemou, D, Millàn, T, Gil, J, Abdelguerfi, A and Laouar, M (2020) Genetic diversity and population structure of Algerian chickpea (Cicer arietinum) genotypes: use of agro-morphological traits and molecular markers linked or not linked to the gene or QTL of interest. Crop & Pasture Science 71, 155–170.CrossRefGoogle Scholar
Berger, JD, Abbo, S and Turner, NC (2003) Ecogeography of annual wild Cicer species: the poor state of the world collection. Crop Science 43, 1076–1090.CrossRefGoogle Scholar
Botstein, D, White, RL, Skolnick, M and Davis, RW (1980) Construction of a genetic linkage map in man using restriction fragment length polymorphisms. American Journal of Human Genetics 32, 314–331.Google ScholarPubMed
Carreras, J, Allende, MJ, Rojas, E and Bologna, S (2016) Programa de mejoramiento del garbanzo (Cicer arietinum L.). labor interinstitucional e interdisciplinaria. In Carreras, J, Mazzuferi, V and Karlin, M (eds) El Cultivo de Garbanzo en Argentina. Córdoba: Universidad Nacional de Córdoba, p. 567.Google Scholar
Castro, P, Millán, T, Gil, J, Mérida, J, García, ML, Rubio, J and Fernández, MD (2010) Identification of chickpea cultivars by microsatellite markers. Journal of Agricultural Science 149, 1–10.Google Scholar
Cevik, S, Unyayar, S and Ergul, A (2015) Genetic relationships between cultivars of Cicer arietinum and its progenitor grown in Turkey determined by using the SSR markers. Turkish Journal of Field Crops 20, 109–114.CrossRefGoogle Scholar
Choudhary, P, Khanna, SM, Jain, PK, Bharadwaj, C, Kumar, J, Lakhera, PC and Srinivasan, R (2012) Genetic structure and diversity analysis of the primary gene pool of chickpea using SSR markers. Genetics and Molecular Research 11, 891–905.CrossRefGoogle ScholarPubMed
Clera (2019) Available at https://pulsepod.globalpulses.com/pod-feed/post/update-on-argentina-2019-chickpea-planting.Google Scholar
Creste, S, Tulmann Neto, A and Figueira, A (2001) Detection of single sequence repeat polymorphisms in denaturing polyacrylamide sequencing. Sugarcane microsatellites for the assessment of genetic diversity in sugarcane germplasm. Plant Science 155, 161–168.Google Scholar
Di Rienzo, JA, Casanoves, F, Balzarini, MG, Gonzalez, L, Tablada, M and Robledo, CW (2013) InfoStat versión 2013. Grupo InfoStat, FCA, Universidad Nacional de Córdoba, Argentina. Available at http://www.infostat.com.ar.Google Scholar
Getahun, T, Tesfaye, K, Fikre, A, Haileslassie, T, Chitikineni, A, Thudi, M and Varshney, R (2021) Molecular genetic diversity and population structure in Ethiopian chickpea germplasm accessions. Diversity 13, 247–262.CrossRefGoogle Scholar
Ghaffari, P, Talebi, R and Keshavarz, F (2014) Genetic diversity and geographical differentiation of Iranian landrace, cultivars and exotic chickpea lines as revealed by morphological and microsatellite markers. Physiology and Molecular Biology of Plants 20, 225–233.CrossRefGoogle ScholarPubMed
Hajibarat, Z, Saidi, A, Hajibarat, Z and Talebi, R (2015) Characterization of genetic diversity in chickpea using SSR markers, start codon targeted polymorphism (SCoT) and conserved DNA-derived polymorphism (CDDP). Physiology and Molecular Biology of Plants 21, 365–373.CrossRefGoogle ScholarPubMed
Jomova, K, Benkova, M, Zakova, M, Gregova, E and Kraic, J (2005) Clustering of chickpea (Cicer arietinum L.) accessions Genetic. Resources and Crop Evolution 52, 1039–1048.CrossRefGoogle Scholar
Kumar, J and Abbo, S (2001) Genetics of flowering time in chickpea and its bearing on productivity in semiarid environments. In Spaks, DL (ed.), Advances in Agronomy. New York: Academic Press, pp. 122–124.Google Scholar
Lichtenzveig, J, Scheuring, C, Dodge, J, Abbo, S and Zhang, HB (2005) Construction of BAC and BIBAC libraries and their applications for generation of SSR markers for genome analysis of chickpea, Cicer arietinum L. Theoretical and Applied Genetics 110, 492–510.CrossRefGoogle ScholarPubMed
Millan, T, Winter, P, Jungling, R, Gil, J, Rubio, J, Cho, S, Cobos, MJ, Iruela, M, Rajesh, PM, Tekeoglu, M, Kahl, G and Muehlbauer, FJ (2010) A consensus genetic map of chickpea (Cicer arietinum L.) based on 10 mapping populations. Euphytica 175, 175–189.CrossRefGoogle Scholar
Rojas, W (2003) Análisis multivariado en estudios de variabilidad genética. In Franco, TL and Hidalgo, R (eds), Análisis Estadístico de Datos de Caracterización Morfológica de Recursos Fitogenéticos. Cali, Colombia: Instituto Internacional de Recursos Fitogenéticos (IPGRI), pp. 32–39.Google Scholar
Sachdeva, S, Bharadwaj, C, Sharma, V, Patil, BS, Soren, KR, Roorkiwal, M, Varshney, V and Bhat, KV (2018) Molecular and phenotypic diversity among chickpea (Cicer arietinum) genotypes as a function of drought tolerance. Crop and Pasture Science 69, 142–153.CrossRefGoogle Scholar
Saeed, A, Hovsepyan, H, Darvishzadeh, R, Imtiaz, M, Panguluri, SK and Nazaryan, R (2011) Genetic diversity of Iranian accessions, improved lines of chickpea (Cicer arietinum L.) and their wild relatives by using simple sequence repeats. Plant Molecular Biology Reporter 29, 848–858.CrossRefGoogle Scholar
Semagn, K (2002) Genetic relationships among ten endod types as revealed by a combination of morphological, RAPD and AFLP markers. Hereditas 137, 149–156.CrossRefGoogle ScholarPubMed
Sethy, NK, Shokeen, B, Edwards, KJ and Bhatia, S (2006) Development of microsatellite markers and analysis of intraspecific genetic variability in chickpea (Cicer arietinum L.). Theoretical and Applied Genetics 112, 1416–1428.CrossRefGoogle ScholarPubMed
Seyedimoradi, H, Talebi, R, Kanouni, H, Naji, AM and Karami, E (2019) Agro-morphological description, genetic diversity and population structure of chickpea using genomic-SSR and ESR-SSR molecular markers. Journal of Plant Biochemistry and Biotechnology 28, 483–495.CrossRefGoogle Scholar
Singh, S, Singh, I, Kapoor, K, Gaur, PM, Chaturvedi, SK, Singh, NP and Sandhu, JS (2014) Chickpea. In Singh, M, Bisht, IS and Dutta, M (eds), Broadening the Genetic Base of Grain Legumes. India: Springer, pp. 51–73.CrossRefGoogle Scholar
Singh, MO, Bhardwaj, C, Singh, S, Panatu, S, Chaturved, SK, Rana, JC, Rizvi, AH, Kumar, N and Sarker, A (2016) Chickpea genetic resources and its utilization in India: current status and future prospects. Indian Journal of Genetics and Plant Breeding 76, 515–529.CrossRefGoogle Scholar
Suzuki, R and Shimodaira, H (2006) 1. Pvclust: an R package for assessing the uncertainty in hierarchical clustering. Bioinformatics Applications Note 22, 1540–1542.Google Scholar
Tayyar, R, Federici, CV and Waines, GJ (1996) Natural outcrossing in chickpea (Cicer arietinum L.). Crop Science 36, 203–205.CrossRefGoogle Scholar
Tessier, C, David, J and This, P (1999) Optimization of the choice of molecular markers for varietal identification in Vitis vinifera L. Theoretical and Applied Genetics 98, 171–177.CrossRefGoogle Scholar
Torutaeva, E, Asanaliev, A, Prieto-Linde, ML, Zborowska, A, Ortiz, R, Bryngelsson, T and Garkava-Gustavsson, L (2014) Evaluation of microsatellite-based genetic diversity, protein and mineral content in chickpea accessions grown in Kyrgyzstan. Hereditas 151, 81–90.CrossRefGoogle ScholarPubMed
Upadhyaya, H, Thudi, M, Dronavalli, N, Gujaria, N, Singh, S, Sharma, S and Varshney, R (2011) Genomic tools and germplasm diversity for chickpea improvement. Plant Genetic Resources 9, 45–58.CrossRefGoogle Scholar
Valadez-Moctezuma, E, Cabrera-Hidalgo, AJ and Arreguin-Espinosa, R (2019) Genetic variability and population structure of Mexican chickpea (Cicer arietinum L.) germplasm accessions revealed by microsatellite markers. Journal of Plant Biochemistry and Biotechnology 29, 357–367. https://doi.org/10.1007/s13562-019-00532-0.CrossRefGoogle Scholar
Winter, P, Pfaff, T, Udupa, SM, Hüttel, B, Sharma, PC, Sahi, S, Arreguin-Espinoza, R, Weigand, F, Muehlbauer, FJ and Kahl, G (1999) Characterization and mapping of sequence-tagged microsatellite sites in the chickpea (Cicer arietinum L.) genome. Molecular Genetics 262, 90–101.Google ScholarPubMed
Yuvaraj, M, Pandiyan, M and Gayathri, P (2020) Role of legumes in improving soil fertility status. doi: 10.5772/intechopen.93247CrossRefGoogle Scholar

Mariana et al. supplementary material
Mariana et al. supplementary material 1
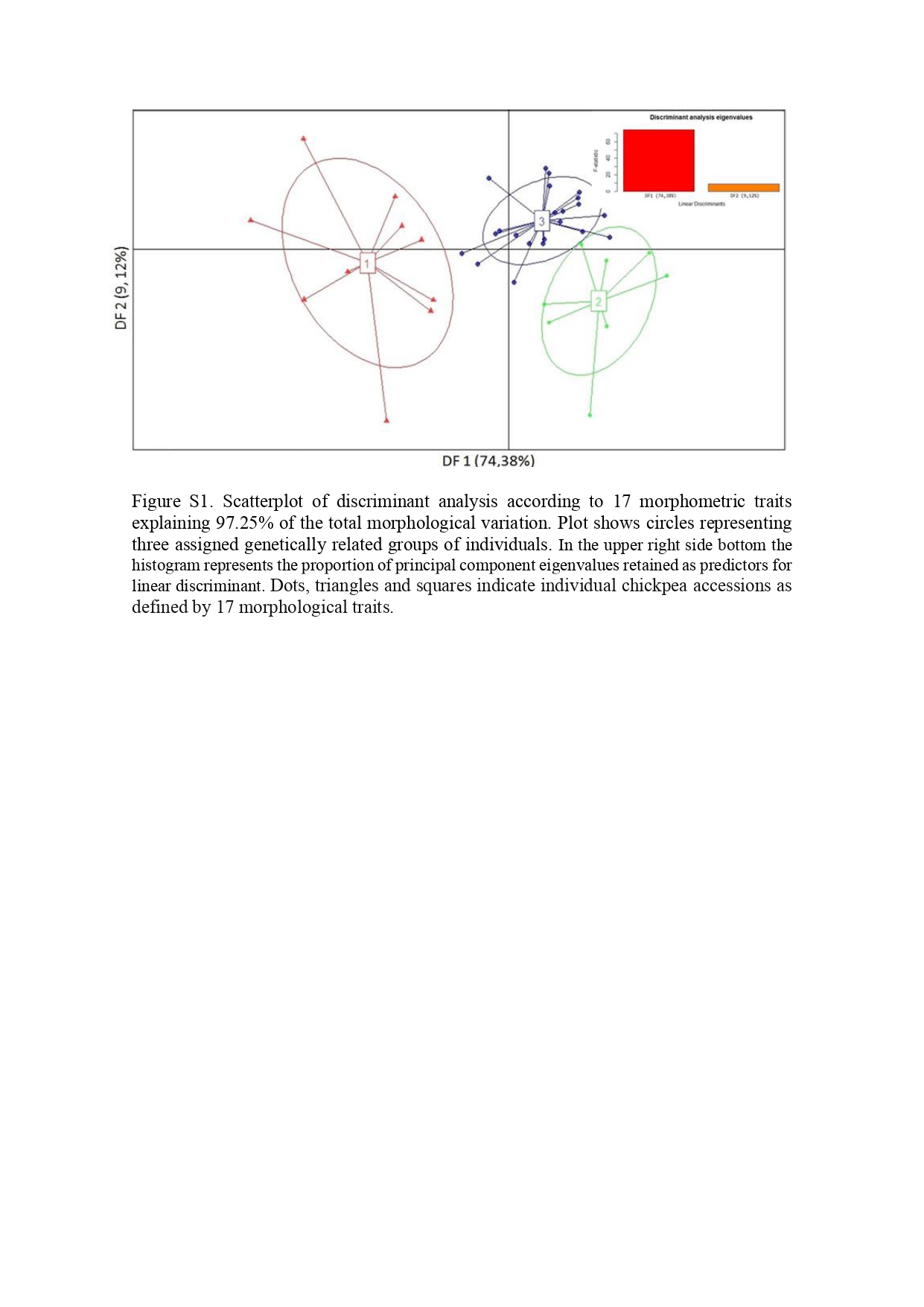
Image
277.5 KB
Mariana et al. supplementary material
Mariana et al. supplementary material 2

Image
197.4 KB