



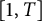
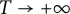
1 General introduction
The first attempts to study number-theoretic problems by means of probabilistic methods date back to the 19th century and involve mainly two mathematicians: first Gauss, who was interested in the number of products of exactly k distinct primes below a certain threshold (and the solution of this problem for
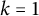 $k=1$
is the famous prime number theorem, proved by Hadamard and de la Vallée Poussin, building on the ideas of Riemann, only in 1896; see [Reference Davenport7, Chapter 8]) and then Cesàro, who showed in 1881 that the probability that two randomly chosen integers are coprime is
$k=1$
is the famous prime number theorem, proved by Hadamard and de la Vallée Poussin, building on the ideas of Riemann, only in 1896; see [Reference Davenport7, Chapter 8]) and then Cesàro, who showed in 1881 that the probability that two randomly chosen integers are coprime is
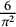 $\frac {6}{\pi ^2}$
. In 1885, he then published a book [Reference Cesàro3] collecting some interesting problems from some articles he published in Annali di matematica pura ed applicata: the article we are interested in is Eventualités de la division arithmétique, which originally appeared as [Reference Cesàro2]. There he states that, dividing two random integers, the probability that the ith digit after the decimal point is r is given by
$\frac {6}{\pi ^2}$
. In 1885, he then published a book [Reference Cesàro3] collecting some interesting problems from some articles he published in Annali di matematica pura ed applicata: the article we are interested in is Eventualités de la division arithmétique, which originally appeared as [Reference Cesàro2]. There he states that, dividing two random integers, the probability that the ith digit after the decimal point is r is given by
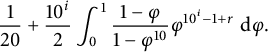 $$ \begin{align} \frac{1}{20}+\frac{10^i}{2}\int_0^1\frac{1-\varphi}{1-\varphi^{10}}\varphi^{10^i-1+r}\,\,\mathrm{d}\varphi. \end{align} $$
$$ \begin{align} \frac{1}{20}+\frac{10^i}{2}\int_0^1\frac{1-\varphi}{1-\varphi^{10}}\varphi^{10^i-1+r}\,\,\mathrm{d}\varphi. \end{align} $$
As a consequence, we have the somewhat surprising discovery that if one takes two “random” positive integers n and m and considers the distribution of the first decimal digit of their ratio
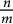 $\frac {n}{m}$
, it is slightly more likely that this turns out to be
$\frac {n}{m}$
, it is slightly more likely that this turns out to be
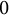 $0$
rather than, say,
$0$
rather than, say,
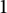 $1$
.
$1$
.
Taking as a starting point, this result and the Benford law [Reference Benford1], which has a similar behavior with regard to the frequency distribution of the main digit in many real-life numerical datasets, Gambini, Mingari Scarpello, and Ritelli [Reference Gambini, Scarpello and Ritelli8] studied the problem in more detail, and recognized that the integral can be expressed in terms of the digamma function
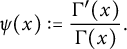 $$ \begin{align*} \psi(x) := \frac{\Gamma'(x)}{\Gamma(x)}. \end{align*} $$
$$ \begin{align*} \psi(x) := \frac{\Gamma'(x)}{\Gamma(x)}. \end{align*} $$
The representation
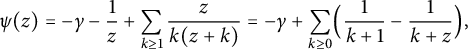 $$ \begin{align*} \psi(z) = - \gamma - \frac1z + \sum_{k \ge 1} \frac z{k (z + k)} = - \gamma + \sum_{k \ge 0} \Bigl( \frac1{k + 1} - \frac1{k + z} \Bigr), \end{align*} $$
$$ \begin{align*} \psi(z) = - \gamma - \frac1z + \sum_{k \ge 1} \frac z{k (z + k)} = - \gamma + \sum_{k \ge 0} \Bigl( \frac1{k + 1} - \frac1{k + z} \Bigr), \end{align*} $$
which is (5.7.6) of [Reference Olver, Lozier, Boisvert and Clark10], led the authors to a different form for the integral in (1.1), which made them suspect that an elementary proof of the result was possible. Indeed, they were able to find it, and this is the starting point for our study.
In order to be more precise, we start giving some definitions. We consider a number base
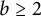 $b \ge 2$
and the corresponding set of digits
$b \ge 2$
and the corresponding set of digits
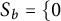 $S_b = \{ 0$
, …,
$S_b = \{ 0$
, …,
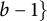 $b - 1 \}$
. Given a positive real number x and a positive integer i, we are concerned with the ith digit to the right of the point in the representation in base b of x: we will call it
$b - 1 \}$
. Given a positive real number x and a positive integer i, we are concerned with the ith digit to the right of the point in the representation in base b of x: we will call it
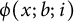 $\phi (x; b; i)$
. We remark that
$\phi (x; b; i)$
. We remark that
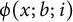 $\phi (x; b; i)$
can be computed by means of
$\phi (x; b; i)$
can be computed by means of
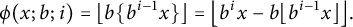 $$ \begin{align*} \phi(x; b; i) = \lfloor b \{ b^{i - 1} x \} \rfloor = \bigl\lfloor b^i x - b \lfloor b^{i - 1} x \rfloor \bigr\rfloor. \end{align*} $$
$$ \begin{align*} \phi(x; b; i) = \lfloor b \{ b^{i - 1} x \} \rfloor = \bigl\lfloor b^i x - b \lfloor b^{i - 1} x \rfloor \bigr\rfloor. \end{align*} $$
In fact, this formula is correct for any
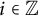 $i \in \mathbb {Z}$
, with the obvious interpretation if
$i \in \mathbb {Z}$
, with the obvious interpretation if
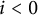 $i < 0$
. We recall that
$i < 0$
. We recall that
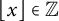 $\lfloor x \rfloor \in \mathbb {Z}$
and
$\lfloor x \rfloor \in \mathbb {Z}$
and
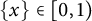 $\{ x \} \in [0, 1)$
denote the integer and the fractional part of the real number x, respectively, so that
$\{ x \} \in [0, 1)$
denote the integer and the fractional part of the real number x, respectively, so that
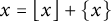 $x = \lfloor x \rfloor + \{ x \}$
.
$x = \lfloor x \rfloor + \{ x \}$
.
With b and i as above and a digit
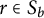 $r \in S_b$
, we also define
$r \in S_b$
, we also define
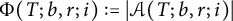 $\Phi (T; b, r; i):= \vert \mathcal {A}(T; b, r; i) \vert $
, where
$\Phi (T; b, r; i):= \vert \mathcal {A}(T; b, r; i) \vert $
, where
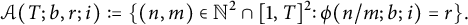 $$ \begin{align*} \mathcal{A}(T; b, r; i) := \{ (n, m) \in \mathbb{N}^2 \cap [1, T]^2 \colon \phi(n / m; b; i) = r \}. \end{align*} $$
$$ \begin{align*} \mathcal{A}(T; b, r; i) := \{ (n, m) \in \mathbb{N}^2 \cap [1, T]^2 \colon \phi(n / m; b; i) = r \}. \end{align*} $$
Throughout the paper, for brevity, we often drop the dependency on b, r, and i of our functions, whenever there is no possibility of misunderstanding. We recall that Gambini et al. [Reference Gambini, Scarpello and Ritelli8] implicitly obtained the asymptotic formula
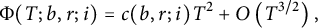 $$ \begin{align*} \Phi(T; b, r; i) = c(b, r; i) T^2 + O\left(T^{3 / 2}\right), \end{align*} $$
$$ \begin{align*} \Phi(T; b, r; i) = c(b, r; i) T^2 + O\left(T^{3 / 2}\right), \end{align*} $$
as
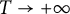 $T \to +\infty $
, where b, r, and i are fixed. The authors considered couples of real numbers, both taken from
$T \to +\infty $
, where b, r, and i are fixed. The authors considered couples of real numbers, both taken from
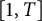 $[1,T]$
, whereas we are only interested in points with integral coordinates. The constant
$[1,T]$
, whereas we are only interested in points with integral coordinates. The constant
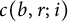 $c(b, r; i)$
is defined as an infinite series and can be expressed by means of the digamma function, as follows:
$c(b, r; i)$
is defined as an infinite series and can be expressed by means of the digamma function, as follows:
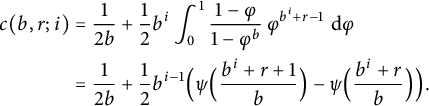 $$ \begin{align} c(b, r; i) &= \frac1{2 b} + \frac12 b^i \int_0^1 \frac{1 - \varphi}{1 - \varphi^b} \, \varphi^{b^i + r - 1} \, \,\mathrm{d} \varphi \nonumber\\ &= \frac1{2 b} + \frac12 b^{i - 1} \Bigl( \psi \Bigl( \frac{b^i + r + 1}b \Bigr) - \psi \Bigl( \frac{b^i + r}b \Bigr) \Bigr). \end{align} $$
$$ \begin{align} c(b, r; i) &= \frac1{2 b} + \frac12 b^i \int_0^1 \frac{1 - \varphi}{1 - \varphi^b} \, \varphi^{b^i + r - 1} \, \,\mathrm{d} \varphi \nonumber\\ &= \frac1{2 b} + \frac12 b^{i - 1} \Bigl( \psi \Bigl( \frac{b^i + r + 1}b \Bigr) - \psi \Bigl( \frac{b^i + r}b \Bigr) \Bigr). \end{align} $$
This agrees with (1.1) by (5.9.16) of [Reference Olver, Lozier, Boisvert and Clark10]. We remark here that this problem is appropriately situated among the classical problems of counting lattice points that belong to some region of the plane. One of the most famous of these results is Minkowski’s theorem, which states that every closed convex set in
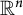 $\mathbb {R}^n$
that is symmetric with respect to the origin and with volume greater than
$\mathbb {R}^n$
that is symmetric with respect to the origin and with volume greater than
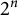 $2^n$
contains at least one point with integer coordinates distinct from the origin. This theorem, proved in 1889, gave birth to a new branch of number theory: the Geometry of Numbers. Another famous result in this direction is Pick’s theorem; proved in 1899 (see [Reference Pick11]), it relates the area of a simple polygon with integer coordinates with the number of lattice points in its interior and the number of lattice points on its boundary. Finally, it is mandatory to refer to two of the most famous problems in analytic number theory, which are related to ours: Gauss’ circle problem and Dirichlet’s divisor problem (see [Reference Hardy and Wright9, Chapter 18]). Both of them deal with counting points with integer coordinates belonging to some region delimited by conics: a circle and a hyperbola. The two mathematicians were able to provide a formula with the area of the region as a main term plus some error due to the integer points near the boundary. For example, Gauss proved that in the circle of radius r, there are
$2^n$
contains at least one point with integer coordinates distinct from the origin. This theorem, proved in 1889, gave birth to a new branch of number theory: the Geometry of Numbers. Another famous result in this direction is Pick’s theorem; proved in 1899 (see [Reference Pick11]), it relates the area of a simple polygon with integer coordinates with the number of lattice points in its interior and the number of lattice points on its boundary. Finally, it is mandatory to refer to two of the most famous problems in analytic number theory, which are related to ours: Gauss’ circle problem and Dirichlet’s divisor problem (see [Reference Hardy and Wright9, Chapter 18]). Both of them deal with counting points with integer coordinates belonging to some region delimited by conics: a circle and a hyperbola. The two mathematicians were able to provide a formula with the area of the region as a main term plus some error due to the integer points near the boundary. For example, Gauss proved that in the circle of radius r, there are
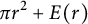 $$ \begin{align*} \pi r^2 + E(r) \end{align*} $$
$$ \begin{align*} \pi r^2 + E(r) \end{align*} $$
points with integer coordinates, where
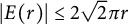 $\left \vert E(r)\right \vert \le 2\sqrt {2}\pi r$
. By this simple formulation, one could think that guessing the right order of magnitude of the error term should not be a hard problem; actually, although many (slow) improvements have been done, both problems remain open.
$\left \vert E(r)\right \vert \le 2\sqrt {2}\pi r$
. By this simple formulation, one could think that guessing the right order of magnitude of the error term should not be a hard problem; actually, although many (slow) improvements have been done, both problems remain open.
The interest in the random integer quotients also embraces other fields in analytic number theory. Recently, there have been several papers dealing with the cardinalities of
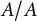 $A/A$
for subsets A of the set of the first n positive integers getting general lower and upper bounds (see Cilleruelo and Guijarro-Ordóñez [Reference Cilleruelo and Guijarro-Ordóñez4] and Cilleruelo, Ramana, and Ramaré [Reference Cilleruelo, Ramana and Ramaré5, Reference Cilleruelo, Ramana and Ramaré6]). Another line of research has to do with the search for prime numbers with a positive proportion of preassigned digits in base b and the estimation of the number of these prime numbers (see Swaenepoel [Reference Swaenepoel12]).
$A/A$
for subsets A of the set of the first n positive integers getting general lower and upper bounds (see Cilleruelo and Guijarro-Ordóñez [Reference Cilleruelo and Guijarro-Ordóñez4] and Cilleruelo, Ramana, and Ramaré [Reference Cilleruelo, Ramana and Ramaré5, Reference Cilleruelo, Ramana and Ramaré6]). Another line of research has to do with the search for prime numbers with a positive proportion of preassigned digits in base b and the estimation of the number of these prime numbers (see Swaenepoel [Reference Swaenepoel12]).
2 Results
After this excursus, which gives some motivation to our research for a better error term, we turn to our results. In this paper, we introduce some number-theoretic devices which allow us to improve upon the result by Gambini et al., and specifically to obtain a better error term. In all statements, we consider b, r, and i fixed, so that, here and throughout the paper, implicit constants may depend on them. We also recall that
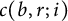 $c(b, r; i)$
is the constant defined in (1.2).
$c(b, r; i)$
is the constant defined in (1.2).
Theorem 2.1 As
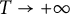 $T \to +\infty $
, we have
$T \to +\infty $
, we have
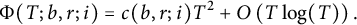 $$ \begin{align*} \Phi(T; b, r; i) = c(b, r; i) T^2 + O\left(T \log(T)\right). \end{align*} $$
$$ \begin{align*} \Phi(T; b, r; i) = c(b, r; i) T^2 + O\left(T \log(T)\right). \end{align*} $$
Our improvement stems largely from the fact that we evaluate more carefully the error terms arising from computing ratios of integers with the desired digit and that we introduce a variable threshold, to be chosen at the end of the proof, which allows us to ignore some points in
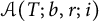 $\mathcal {A}(T; b, r; i)$
.
$\mathcal {A}(T; b, r; i)$
.
In the second part of the paper, we deal with a variation of the same problem: we consider the case of primes. We let
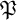 $\mathfrak {P}$
denote the set of positive prime integers. For the sake of clarity, for
$\mathfrak {P}$
denote the set of positive prime integers. For the sake of clarity, for
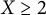 $X \ge 2$
, we let
$X \ge 2$
, we let
 $$ \begin{align} \mathcal{E}(X) := \mathop{\mathrm{sup}}\limits_{2 \le x \le X} \bigl\vert \pi(x) - \operatorname{\mathrm{li}}(x) \bigr\vert, \end{align} $$
$$ \begin{align} \mathcal{E}(X) := \mathop{\mathrm{sup}}\limits_{2 \le x \le X} \bigl\vert \pi(x) - \operatorname{\mathrm{li}}(x) \bigr\vert, \end{align} $$
so that
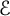 $\mathcal {E}$
is nonnegative and increasing, and can be bounded by means of the Prime Number Theorem, which is Lemma 5.1 below.
$\mathcal {E}$
is nonnegative and increasing, and can be bounded by means of the Prime Number Theorem, which is Lemma 5.1 below.
Theorem 2.2 In the case of primes, as
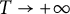 $T \to +\infty $
, we have
$T \to +\infty $
, we have
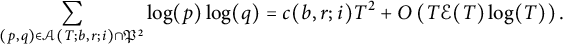 $$ \begin{align*} \sum_{(p, q) \in \mathcal{A}(T; b, r; i) \cap \mathfrak{P}^2} \log(p) \log(q) = c(b, r; i) T^2 + O\left( T \mathcal{E}(T) \log(T)\right). \end{align*} $$
$$ \begin{align*} \sum_{(p, q) \in \mathcal{A}(T; b, r; i) \cap \mathfrak{P}^2} \log(p) \log(q) = c(b, r; i) T^2 + O\left( T \mathcal{E}(T) \log(T)\right). \end{align*} $$
It is also possible to study the corresponding problem where only the numerator or the denominator is restricted to being a prime, and the result is similar. See Section 5 for some comments and details on the error term in Theorem 2.2.
We also tackle another variant of this problem where we consider only points that are visible from the origin, casting out multiplicities. We obtain our last result as a corollary of Theorem 2.1, via Möbius inversion.
Theorem 2.3 As
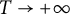 $T \to +\infty $
, we have
$T \to +\infty $
, we have
 $$ \begin{align*} \sum_{\substack{(n, m) \in \mathcal{A}(T; b, r; i) \\ (n, m) = 1}} 1 = \frac{c(b, r; i)}{\zeta(2)} T^2 + O\left(T \log^2(T)\right), \end{align*} $$
$$ \begin{align*} \sum_{\substack{(n, m) \in \mathcal{A}(T; b, r; i) \\ (n, m) = 1}} 1 = \frac{c(b, r; i)}{\zeta(2)} T^2 + O\left(T \log^2(T)\right), \end{align*} $$
where
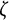 $\zeta $
denotes the Riemann
$\zeta $
denotes the Riemann
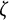 $\zeta $
-function.
$\zeta $
-function.
3 Basic strategy of the proofs
We follow [Reference Gambini, Scarpello and Ritelli8] quite closely. The proofs share some common features, and it is probably clearer if we deal with them at the outset. We remark that we may assume that T is an integer, because the total error involved in changing T by a bounded amount is small: see the end of this section. We first decompose the set
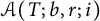 $\mathcal {A}(T; b, r; i)$
as an appropriate union of sets. For
$\mathcal {A}(T; b, r; i)$
as an appropriate union of sets. For
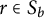 $r \in S_b$
, we define
$r \in S_b$
, we define
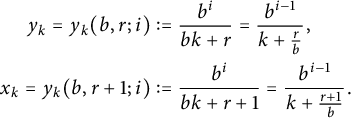 $$ \begin{align*} y_k = y_k(b, r; i) &:= \frac{b^i}{b k + r} = \frac{b^{i - 1}}{k+\frac{r}{b}}, \\ x_k = y_k(b, r+1;i) &:= \frac{b^i}{b k + r+1} =\frac{b^{i - 1}}{k+\frac{r+1}{b}}. \end{align*} $$
$$ \begin{align*} y_k = y_k(b, r; i) &:= \frac{b^i}{b k + r} = \frac{b^{i - 1}}{k+\frac{r}{b}}, \\ x_k = y_k(b, r+1;i) &:= \frac{b^i}{b k + r+1} =\frac{b^{i - 1}}{k+\frac{r+1}{b}}. \end{align*} $$
With these definitions and Figure 1 in mind, we write
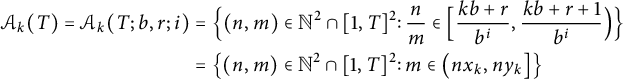 $$ \begin{align} \notag \mathcal{A}_k(T) = \mathcal{A}_k(T; b, r; i) &= \Bigl\{ (n, m) \in \mathbb{N}^2 \cap [1, T]^2 \colon \frac nm \in \Bigl[ \frac{k b + r}{b^i}, \frac{k b + r + 1}{b^i}\Bigr) \Bigr\} \\ &= \bigl\{ (n, m) \in \mathbb{N}^2 \cap [1, T]^2 \colon m \in \bigl( n x_k, n y_k \bigr] \bigr\} \end{align} $$
$$ \begin{align} \notag \mathcal{A}_k(T) = \mathcal{A}_k(T; b, r; i) &= \Bigl\{ (n, m) \in \mathbb{N}^2 \cap [1, T]^2 \colon \frac nm \in \Bigl[ \frac{k b + r}{b^i}, \frac{k b + r + 1}{b^i}\Bigr) \Bigr\} \\ &= \bigl\{ (n, m) \in \mathbb{N}^2 \cap [1, T]^2 \colon m \in \bigl( n x_k, n y_k \bigr] \bigr\} \end{align} $$
 $$ \begin{align} & \qquad\qquad\,\,\,\,\qquad = \bigl\{ (n, m) \in \mathbb{N}^2 \cap [1, T]^2 \colon n \in \bigl[ m / y_k, m / x_k \bigr) \bigr\}, \end{align} $$
$$ \begin{align} & \qquad\qquad\,\,\,\,\qquad = \bigl\{ (n, m) \in \mathbb{N}^2 \cap [1, T]^2 \colon n \in \bigl[ m / y_k, m / x_k \bigr) \bigr\}, \end{align} $$
so that
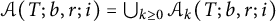 $\mathcal {A}(T; b, r; i) = \bigcup _{k \ge 0} \mathcal {A}_k(T; b, r; i)$
. This is easily checked using the definition of
$\mathcal {A}(T; b, r; i) = \bigcup _{k \ge 0} \mathcal {A}_k(T; b, r; i)$
. This is easily checked using the definition of
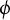 $\phi $
. The sets
$\phi $
. The sets
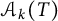 $\mathcal {A}_k(T)$
are pairwise disjoint and correspond to the lattice points contained in triangles with a vertex at the origin and the other vertices either on the segment
$\mathcal {A}_k(T)$
are pairwise disjoint and correspond to the lattice points contained in triangles with a vertex at the origin and the other vertices either on the segment
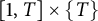 $[1, T] \times \{ T \}$
, when
$[1, T] \times \{ T \}$
, when
 $0 \le k < b^{i - 1}$
(i.e.,
$0 \le k < b^{i - 1}$
(i.e.,
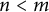 $n<m$
), or on
$n<m$
), or on
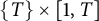 $\{ T \} \times [1, T]$
, when
$\{ T \} \times [1, T]$
, when
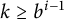 $k \ge b^{i - 1}$
(i.e.,
$k \ge b^{i - 1}$
(i.e.,
 $n\ge m$
), provided that k satisfies (3.3) below. Therefore, we split the infinite union above accordingly as
$n\ge m$
), provided that k satisfies (3.3) below. Therefore, we split the infinite union above accordingly as
 $$ \begin{align*} \mathcal{U}(T; b, r; i) := \bigcup_{k = 0}^{b^{i - 1} - 1} \mathcal{A}_k(T; b, r; i) \quad\text{and}\quad \mathcal{L}(T; b, r; i) := \bigcup_{k \ge b^{i - 1}} \mathcal{A}_k(T; b, r; i). \end{align*} $$
$$ \begin{align*} \mathcal{U}(T; b, r; i) := \bigcup_{k = 0}^{b^{i - 1} - 1} \mathcal{A}_k(T; b, r; i) \quad\text{and}\quad \mathcal{L}(T; b, r; i) := \bigcup_{k \ge b^{i - 1}} \mathcal{A}_k(T; b, r; i). \end{align*} $$
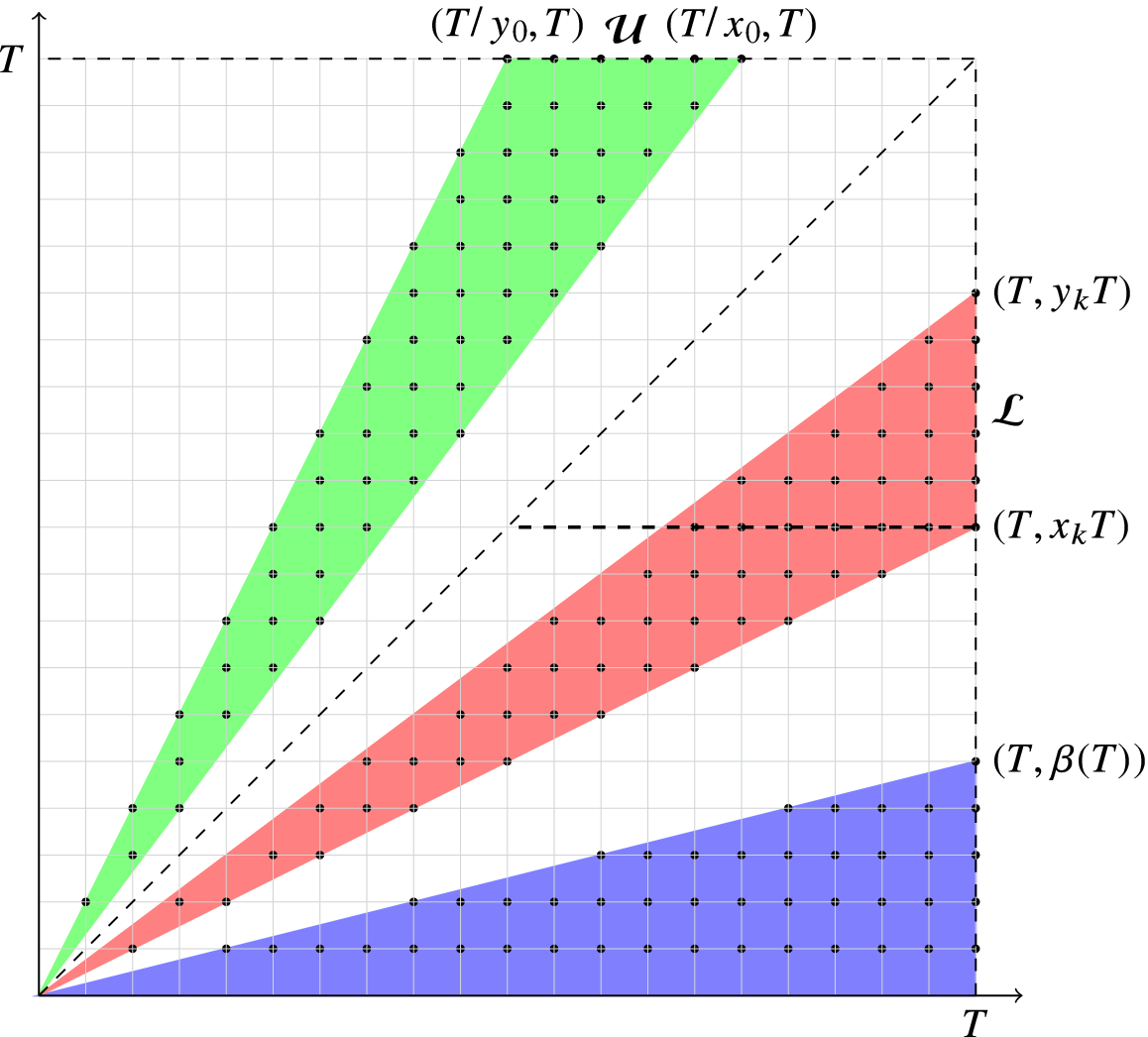
Figure 1 How to split the sets: here, we illustrate the case
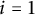 $i = 1$
. The set
$i = 1$
. The set
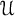 $\mathcal {U}$
is a triangle. The set
$\mathcal {U}$
is a triangle. The set
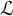 $\mathcal {L}$
is an infinite union of triangles; we estimate trivially the contribution from triangles in the shaded region at the bottom. In the paper, we consistently use n for the abscissa and m for the ordinate of the points.
$\mathcal {L}$
is an infinite union of triangles; we estimate trivially the contribution from triangles in the shaded region at the bottom. In the paper, we consistently use n for the abscissa and m for the ordinate of the points.
At this point, it is worth looking back at the definition of
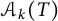 $\mathcal {A}_k(T)$
. When k is such that
$\mathcal {A}_k(T)$
. When k is such that
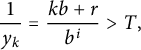 $$ \begin{align*} \frac1{y_k} = \frac{k b + r}{b^i}> T, \end{align*} $$
$$ \begin{align*} \frac1{y_k} = \frac{k b + r}{b^i}> T, \end{align*} $$
the set
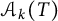 $\mathcal {A}_k(T)$
is empty. This means that we can bound the range for k, taking
$\mathcal {A}_k(T)$
is empty. This means that we can bound the range for k, taking
 $$ \begin{align} k\le b^{i-1}T - \frac rb \le b^{i-1}T. \end{align} $$
$$ \begin{align} k\le b^{i-1}T - \frac rb \le b^{i-1}T. \end{align} $$
Hence, we have that
 $$ \begin{align*} \mathcal{L}(T; b, r; i) = \bigcup_{b^{i - 1} \le k \le b^{i-1}T} \mathcal{A}_k(T; b, r; i). \end{align*} $$
$$ \begin{align*} \mathcal{L}(T; b, r; i) = \bigcup_{b^{i - 1} \le k \le b^{i-1}T} \mathcal{A}_k(T; b, r; i). \end{align*} $$
For k, above a certain threshold depending on T, it is difficult to evaluate the cardinality of
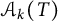 $\mathcal {A}_k(T)$
exactly: this will be the source of our first error term.
$\mathcal {A}_k(T)$
exactly: this will be the source of our first error term.
We notice here, even though we will need this later, that for
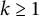 $k\ge 1$
and
$k\ge 1$
and
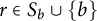 $r \in S_b \cup \{ b \}$
, we have
$r \in S_b \cup \{ b \}$
, we have
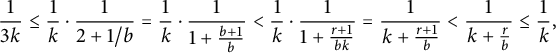 $$ \begin{align*} \frac{1}{3k} \le \frac{1}{k}\cdot\frac{1}{2+1/b} = \frac{1}{k}\cdot\frac{1}{1+\frac{b+1}{b}} < \frac{1}{k}\cdot\frac{1}{1+\frac{r+1}{bk}} = \frac{1}{k+\frac{r+1}{b}} < \frac{1}{k+\frac{r}{b}} \le\frac{1}{k}, \end{align*} $$
$$ \begin{align*} \frac{1}{3k} \le \frac{1}{k}\cdot\frac{1}{2+1/b} = \frac{1}{k}\cdot\frac{1}{1+\frac{b+1}{b}} < \frac{1}{k}\cdot\frac{1}{1+\frac{r+1}{bk}} = \frac{1}{k+\frac{r+1}{b}} < \frac{1}{k+\frac{r}{b}} \le\frac{1}{k}, \end{align*} $$
so that
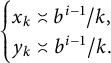 $$ \begin{align*} \begin{cases} x_k\asymp {b^{i-1}}/k, \\ y_k\asymp {b^{i-1}}/k. \end{cases} \end{align*} $$
$$ \begin{align*} \begin{cases} x_k\asymp {b^{i-1}}/k, \\ y_k\asymp {b^{i-1}}/k. \end{cases} \end{align*} $$
3.1 Weights
In order to treat our problems in a unified fashion, we introduce weights associated to points with integral coordinates in
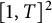 $[1, T]^2$
. We will eventually choose the following weights:
$[1, T]^2$
. We will eventually choose the following weights:
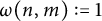 $\omega (n, m) := 1$
for all n and m in the problem with all integers;
$\omega (n, m) := 1$
for all n and m in the problem with all integers;
 $$ \begin{align*} \omega(n, m) := \begin{cases} \log(n) \log(m) &\text{if }n \text{ and } m \text{ are both prime numbers,} \\ 0 &\text{otherwise}, \end{cases} \end{align*} $$
$$ \begin{align*} \omega(n, m) := \begin{cases} \log(n) \log(m) &\text{if }n \text{ and } m \text{ are both prime numbers,} \\ 0 &\text{otherwise}, \end{cases} \end{align*} $$
in the problem with primes; and
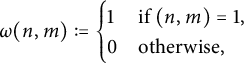 $$ \begin{align*} \omega(n, m) := \begin{cases} 1 &\text{if }(n, m) = 1, \\ 0 &\text{otherwise}, \end{cases} \end{align*} $$
$$ \begin{align*} \omega(n, m) := \begin{cases} 1 &\text{if }(n, m) = 1, \\ 0 &\text{otherwise}, \end{cases} \end{align*} $$
in the problems with “reduced” couples. We have to evaluate
 $$ \begin{align*} \sum_{(n, m) \in \mathcal{U}(T; b, r; i)} \omega(n, m) \qquad\text{and}\qquad \sum_{(n, m) \in \mathcal{L}(T; b, r; i)} \omega(n, m). \end{align*} $$
$$ \begin{align*} \sum_{(n, m) \in \mathcal{U}(T; b, r; i)} \omega(n, m) \qquad\text{and}\qquad \sum_{(n, m) \in \mathcal{L}(T; b, r; i)} \omega(n, m). \end{align*} $$
With this choice of weights, we see that the error involved in changing T to the nearest integer is
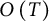 $O\left (T\right )$
in the case of integers and
$O\left (T\right )$
in the case of integers and
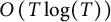 $O\left (T \log (T)\right )$
in the case of primes.
$O\left (T \log (T)\right )$
in the case of primes.
3.2 The contribution from the set
 $\mathcal {U}(T; b, r; i)$
$\mathcal {U}(T; b, r; i)$
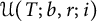
We refer to Figure 1, and remark that
 $$\begin{align*} \sum_{(n, m) \in \mathcal{U}(T; b, r, i)} \omega(n, m) &= \sum_{k = 0}^{b^{i - 1} - 1} \sum_{(n, m) \in \mathcal{A}_k(T; b, r; i)} \omega(n, m) \end{align*}$$
$$\begin{align*} \sum_{(n, m) \in \mathcal{U}(T; b, r, i)} \omega(n, m) &= \sum_{k = 0}^{b^{i - 1} - 1} \sum_{(n, m) \in \mathcal{A}_k(T; b, r; i)} \omega(n, m) \end{align*}$$
 $$ \begin{align} &\qquad\qquad\qquad\qquad\qquad\quad\kern-1pt= \sum_{k = 0}^{b^{i - 1} - 1} \sum_{m \in [1, T]} \sum_{n \in [m / y_k, m / x_k)} \omega(n, m). \end{align} $$
$$ \begin{align} &\qquad\qquad\qquad\qquad\qquad\quad\kern-1pt= \sum_{k = 0}^{b^{i - 1} - 1} \sum_{m \in [1, T]} \sum_{n \in [m / y_k, m / x_k)} \omega(n, m). \end{align} $$
3.3 The contribution from the set
$\mathcal {L}(T; b, r; i)$
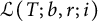
To a first approximation,
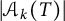 $\vert \mathcal {A}_k(T) \vert $
is the area of the corresponding triangle, with an error proportional to the perimeter, that is
$\vert \mathcal {A}_k(T) \vert $
is the area of the corresponding triangle, with an error proportional to the perimeter, that is
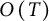 $O\left (T\right )$
. However, as
$O\left (T\right )$
. However, as
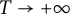 $T\to +\infty $
, the number of such triangles tends to infinity as well, and their area may be small, and we have to be much more careful than this. We choose an appropriate function
$T\to +\infty $
, the number of such triangles tends to infinity as well, and their area may be small, and we have to be much more careful than this. We choose an appropriate function
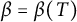 $\beta = \beta (T)$
and estimate trivially the contribution from k satisfying (3.3) with
$\beta = \beta (T)$
and estimate trivially the contribution from k satisfying (3.3) with
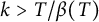 $k> T / \beta (T)$
. It is
$k> T / \beta (T)$
. It is
 $$ \begin{align} \ll \sum_{n \le T} \sum_{m \le n \beta(T) / T} \omega(n, m) \le T \beta(T) \max_{n \le T} \max_{m \le n \beta(T) / T} \omega(n, m). \end{align} $$
$$ \begin{align} \ll \sum_{n \le T} \sum_{m \le n \beta(T) / T} \omega(n, m) \le T \beta(T) \max_{n \le T} \max_{m \le n \beta(T) / T} \omega(n, m). \end{align} $$
Recalling (3.1), we see that the contribution from
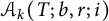 $\mathcal {A}_k(T; b, r; i)$
is
$\mathcal {A}_k(T; b, r; i)$
is
 $$ \begin{align} &\sum_{m \le x_k T} \sum_{n \in [m / y_k, m / x_k)} \omega(n, m) + \sum_{x_k T < m \le y_k T} \sum_{n \in [m / y_k, T]} \omega(n, m) \nonumber \\ &\qquad = \sum_{m \le x_k T} \sum_{n \in [m / y_k, m / x_k)} \omega(n, m) + \sum_{x_k T / y_k \le n \le T} \sum_{m \in [x_k T, n y_k]} \omega(n, m). \end{align} $$
$$ \begin{align} &\sum_{m \le x_k T} \sum_{n \in [m / y_k, m / x_k)} \omega(n, m) + \sum_{x_k T < m \le y_k T} \sum_{n \in [m / y_k, T]} \omega(n, m) \nonumber \\ &\qquad = \sum_{m \le x_k T} \sum_{n \in [m / y_k, m / x_k)} \omega(n, m) + \sum_{x_k T / y_k \le n \le T} \sum_{m \in [x_k T, n y_k]} \omega(n, m). \end{align} $$
We find it convenient to write these quantities as above in order to keep error terms under control.
3.4 The value of the constants
$c(b,r;i)$
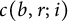
The following lemma will take care of the constant appearing in the main terms.
Lemma 3.1 For
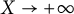 $X \to +\infty $
, we have
$X \to +\infty $
, we have
 $$ \begin{align*} \sum_{b^{i-1} \le k \le X} (y_k - x_k) = \sum_{k \ge b^{i - 1}} \frac{b^i}{(b k + r) (b k + r + 1)} + O\left(X^{-1}\right). \end{align*} $$
$$ \begin{align*} \sum_{b^{i-1} \le k \le X} (y_k - x_k) = \sum_{k \ge b^{i - 1}} \frac{b^i}{(b k + r) (b k + r + 1)} + O\left(X^{-1}\right). \end{align*} $$
Furthermore,
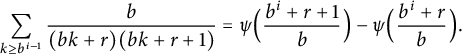 $$ \begin{align} \sum_{k \ge b^{i - 1}} \frac{b}{(b k + r) (b k + r + 1)} = \psi\Bigl( \frac{b^i + r + 1}b \Bigr) - \psi\Bigl( \frac{b^i + r}b \Bigr). \end{align} $$
$$ \begin{align} \sum_{k \ge b^{i - 1}} \frac{b}{(b k + r) (b k + r + 1)} = \psi\Bigl( \frac{b^i + r + 1}b \Bigr) - \psi\Bigl( \frac{b^i + r}b \Bigr). \end{align} $$
Proof. Because
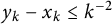 $y_k - x_k \le k^{-2}$
, the error term arising from extending the sum over k to all positive integers is
$y_k - x_k \le k^{-2}$
, the error term arising from extending the sum over k to all positive integers is
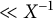 $\ll X^{-1}$
. The results follow from the same property of the digamma function quoted above: see [Reference Olver, Lozier, Boisvert and Clark10, equation (5.7.6)].▪
$\ll X^{-1}$
. The results follow from the same property of the digamma function quoted above: see [Reference Olver, Lozier, Boisvert and Clark10, equation (5.7.6)].▪
4 The proof of Theorem 2.1 for integers
Our improvement over the previous results depends on the fact that we manage to choose a specific threshold for k: above it, but below (3.3), we will estimate
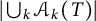 $\vert \bigcup _k \mathcal {A}_k(T) \vert $
trivially, while for k less than it, we will evaluate
$\vert \bigcup _k \mathcal {A}_k(T) \vert $
trivially, while for k less than it, we will evaluate
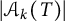 $\vert \mathcal {A}_k(T) \vert $
more precisely.
$\vert \mathcal {A}_k(T) \vert $
more precisely.
4.1 Estimate of
$\mathcal {U}(T)$
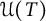
Now, let us consider
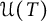 $\mathcal {U}(T)$
. By (3.4), we have
$\mathcal {U}(T)$
. By (3.4), we have
 $$ \begin{align*} \vert \mathcal{U}(T; b, r; i) \vert &= \sum_{k = 0}^{b^{i - 1} - 1} \vert \mathcal{A}_k(T; b, r; i) \vert = \sum_{k = 0}^{b^{i - 1} - 1} \sum_{m \in [1, T]} \Bigl( \frac{m}{x_k} - \frac{m}{y_k} + O\left(1\right) \Bigr) \\ &= b^{i - 1} \sum_{m \in [1, T]} \frac{m}{b^i} + O\left(T\right). \end{align*} $$
$$ \begin{align*} \vert \mathcal{U}(T; b, r; i) \vert &= \sum_{k = 0}^{b^{i - 1} - 1} \vert \mathcal{A}_k(T; b, r; i) \vert = \sum_{k = 0}^{b^{i - 1} - 1} \sum_{m \in [1, T]} \Bigl( \frac{m}{x_k} - \frac{m}{y_k} + O\left(1\right) \Bigr) \\ &= b^{i - 1} \sum_{m \in [1, T]} \frac{m}{b^i} + O\left(T\right). \end{align*} $$
If
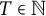 $T \in \mathbb {N}$
, we have
$T \in \mathbb {N}$
, we have
 $$ \begin{align} \vert \mathcal{U}(T; b, r; i) \vert = \frac{T (T + 1)}{2b} + O\left(T\right) = \frac{T^2}{2b} + O\left(T\right). \end{align} $$
$$ \begin{align} \vert \mathcal{U}(T; b, r; i) \vert = \frac{T (T + 1)}{2b} + O\left(T\right) = \frac{T^2}{2b} + O\left(T\right). \end{align} $$
4.2 Estimate of
$\mathcal {L}(T)$

Using (3.6), we see that the number of lattice points in
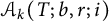 $\mathcal {A}_k(T; b, r; i)$
is
$\mathcal {A}_k(T; b, r; i)$
is
 $$ \begin{align} = \sum_{n \le x_k T} \Bigl( \Bigl[ \frac n{x_k} \Bigr] - \Bigl[ \frac n{y_k} \Bigr] \Bigr) + \sum_{x_k T / y_k \le n \le T} \bigl( [n y_k] - [x_k T] \bigr). \end{align} $$
$$ \begin{align} = \sum_{n \le x_k T} \Bigl( \Bigl[ \frac n{x_k} \Bigr] - \Bigl[ \frac n{y_k} \Bigr] \Bigr) + \sum_{x_k T / y_k \le n \le T} \bigl( [n y_k] - [x_k T] \bigr). \end{align} $$
The first term in (4.2) is
 $$ \begin{align} \notag = \sum_{n \le x_k T} \Bigl( \frac n{x_k} - \frac n{y_k} \Bigr) + O\left(x_k T\right) &= \Bigl( \frac 1{x_k} - \frac1{y_k} \Bigr) \sum_{n \le x_k T} n + O\left(\frac Tk\right) \\ &= \frac{y_k - x_k}{x_k y_k} \sum_{n \le x_k T} n + O\left(\frac Tk\right) \\ \notag &= \frac{y_k - x_k}{2 x_k y_k} \Bigl( (x_k T)^2 + O\left(x_k T\right) \Bigr) + O\left(\frac Tk\right) \end{align} $$
$$ \begin{align} \notag = \sum_{n \le x_k T} \Bigl( \frac n{x_k} - \frac n{y_k} \Bigr) + O\left(x_k T\right) &= \Bigl( \frac 1{x_k} - \frac1{y_k} \Bigr) \sum_{n \le x_k T} n + O\left(\frac Tk\right) \\ &= \frac{y_k - x_k}{x_k y_k} \sum_{n \le x_k T} n + O\left(\frac Tk\right) \\ \notag &= \frac{y_k - x_k}{2 x_k y_k} \Bigl( (x_k T)^2 + O\left(x_k T\right) \Bigr) + O\left(\frac Tk\right) \end{align} $$
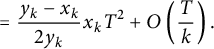 $$ \begin{align} &\qquad\qquad\qquad\kern-1pt= \frac{y_k - x_k}{2 y_k} x_k T^2 + O\left(\frac Tk\right). \end{align} $$
$$ \begin{align} &\qquad\qquad\qquad\kern-1pt= \frac{y_k - x_k}{2 y_k} x_k T^2 + O\left(\frac Tk\right). \end{align} $$
We further rewrite the last summand in (4.2) as
 $$ \begin{align*} \sum_{x_k T / y_k \le n \le T} \bigl( [n y_k] - [x_k T] \bigr) &= \sum_{x_k T / y_k \le n \le T} \bigl( n y_k - \{ n y_k \} \bigr) - [x_k T] \Bigl( T - \Bigl[ \frac{x_k T}{y_k} \Bigr] \Bigr) \\ &= I_1 - I_2, \end{align*} $$
$$ \begin{align*} \sum_{x_k T / y_k \le n \le T} \bigl( [n y_k] - [x_k T] \bigr) &= \sum_{x_k T / y_k \le n \le T} \bigl( n y_k - \{ n y_k \} \bigr) - [x_k T] \Bigl( T - \Bigl[ \frac{x_k T}{y_k} \Bigr] \Bigr) \\ &= I_1 - I_2, \end{align*} $$
say. We have
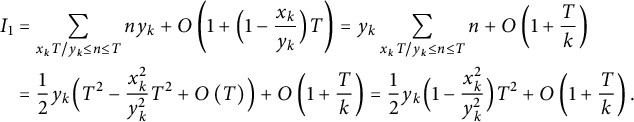 $$ \begin{align} \notag I_1 &= \sum_{x_k T / y_k \le n \le T} n y_k + O\left(1 + \Bigl( 1 - \frac{x_k}{y_k} \Bigr) T\right) = y_k \sum_{x_k T / y_k \le n \le T} n + O\left(1 + \frac Tk\right) \\ &= \frac12 y_k \Bigl( T^2 - \frac{x_k^2}{y_k^2} T^2 + O\left(T\right) \Bigr) + O\left(1 + \frac Tk\right) = \frac12 y_k \Bigl( 1 - \frac{x_k^2}{y_k^2} \Bigr) T^2 + O\left(1 + \frac Tk\right). \end{align} $$
$$ \begin{align} \notag I_1 &= \sum_{x_k T / y_k \le n \le T} n y_k + O\left(1 + \Bigl( 1 - \frac{x_k}{y_k} \Bigr) T\right) = y_k \sum_{x_k T / y_k \le n \le T} n + O\left(1 + \frac Tk\right) \\ &= \frac12 y_k \Bigl( T^2 - \frac{x_k^2}{y_k^2} T^2 + O\left(T\right) \Bigr) + O\left(1 + \frac Tk\right) = \frac12 y_k \Bigl( 1 - \frac{x_k^2}{y_k^2} \Bigr) T^2 + O\left(1 + \frac Tk\right). \end{align} $$
We also have
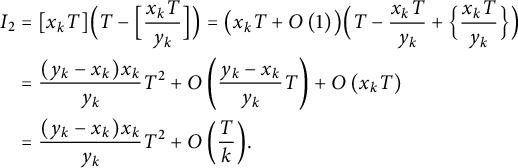 $$ \begin{align} \notag I_2 &= [x_k T] \Bigl( T - \Bigl[ \frac{x_k T}{y_k} \Bigr] \Bigr) = \bigl( x_k T + O\left(1\right) \bigr) \Bigl( T - \frac{x_k T}{y_k} + \Bigl\{ \frac{x_k T}{y_k} \Bigr\} \Bigr) \\ \notag &= \frac{(y_k - x_k) x_k}{y_k} T^2 + O\left(\frac{y_k - x_k}{y_k} T\right) + O\left(x_k T\right) \\ &= \frac{(y_k - x_k) x_k}{y_k} T^2 + O\left(\frac Tk\right)\!. \end{align} $$
$$ \begin{align} \notag I_2 &= [x_k T] \Bigl( T - \Bigl[ \frac{x_k T}{y_k} \Bigr] \Bigr) = \bigl( x_k T + O\left(1\right) \bigr) \Bigl( T - \frac{x_k T}{y_k} + \Bigl\{ \frac{x_k T}{y_k} \Bigr\} \Bigr) \\ \notag &= \frac{(y_k - x_k) x_k}{y_k} T^2 + O\left(\frac{y_k - x_k}{y_k} T\right) + O\left(x_k T\right) \\ &= \frac{(y_k - x_k) x_k}{y_k} T^2 + O\left(\frac Tk\right)\!. \end{align} $$
Summing up (4.2) and (4.4)-(4.6), we have
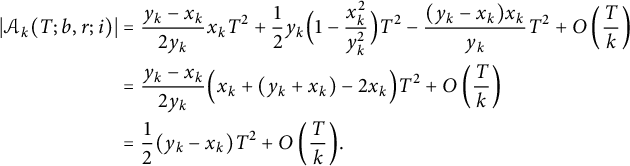 $$ \begin{align} \notag \vert \mathcal{A}_k(T; b, r; i) \vert &= \frac{y_k - x_k}{2 y_k} x_k T^2 + \frac12 y_k \Bigl( 1 - \frac{x_k^2}{y_k^2} \Bigr) T^2 - \frac{(y_k - x_k) x_k}{y_k} T^2 + O\left(\frac Tk\right) \\ \notag &= \frac{y_k - x_k}{2 y_k} \Bigl( x_k + (y_k + x_k) - 2 x_k \Bigr) T^2 + O\left(\frac Tk\right) \\ &= \frac12 (y_k - x_k) T^2 + O\left(\frac Tk\right)\!. \end{align} $$
$$ \begin{align} \notag \vert \mathcal{A}_k(T; b, r; i) \vert &= \frac{y_k - x_k}{2 y_k} x_k T^2 + \frac12 y_k \Bigl( 1 - \frac{x_k^2}{y_k^2} \Bigr) T^2 - \frac{(y_k - x_k) x_k}{y_k} T^2 + O\left(\frac Tk\right) \\ \notag &= \frac{y_k - x_k}{2 y_k} \Bigl( x_k + (y_k + x_k) - 2 x_k \Bigr) T^2 + O\left(\frac Tk\right) \\ &= \frac12 (y_k - x_k) T^2 + O\left(\frac Tk\right)\!. \end{align} $$
We finally sum (4.7) over
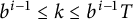 $b^{i - 1} \le k \le b^{i - 1}T $
, obtaining
$b^{i - 1} \le k \le b^{i - 1}T $
, obtaining
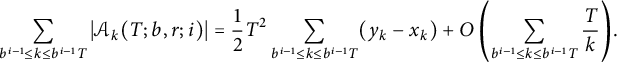 $$ \begin{align*} \sum_{b^{i - 1} \le k \le b^{i - 1}T} \vert \mathcal{A}_k(T; b, r; i) \vert = \frac12 T^2 \sum_{b^{i - 1} \le k \le b^{i - 1}T} (y_k - x_k) + O\left(\sum_{b^{i - 1} \le k \le b^{i - 1}T} \frac Tk\right)\!. \end{align*} $$
$$ \begin{align*} \sum_{b^{i - 1} \le k \le b^{i - 1}T} \vert \mathcal{A}_k(T; b, r; i) \vert = \frac12 T^2 \sum_{b^{i - 1} \le k \le b^{i - 1}T} (y_k - x_k) + O\left(\sum_{b^{i - 1} \le k \le b^{i - 1}T} \frac Tk\right)\!. \end{align*} $$
Using Lemma 3.1 with
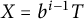 $X = b^{i - 1}T$
, we see that the error term arising from the completion of the series is
$X = b^{i - 1}T$
, we see that the error term arising from the completion of the series is
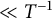 $\ll T^{-1}$
. The other error term contributes
$\ll T^{-1}$
. The other error term contributes
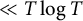 $\ll T \log T$
. Hence,
$\ll T \log T$
. Hence,
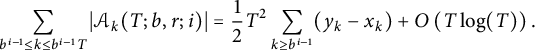 $$ \begin{align*} \sum_{b^{i - 1} \le k \le b^{i - 1}T} \vert \mathcal{A}_k(T; b, r; i) \vert = \frac12 T^2 \sum_{k \ge b^{i - 1}} (y_k - x_k) + O\left(T \log(T)\right). \end{align*} $$
$$ \begin{align*} \sum_{b^{i - 1} \le k \le b^{i - 1}T} \vert \mathcal{A}_k(T; b, r; i) \vert = \frac12 T^2 \sum_{k \ge b^{i - 1}} (y_k - x_k) + O\left(T \log(T)\right). \end{align*} $$
5 Primes with weights: approach via
$\theta $
In this section, we prove Theorem 2.2. With notation as in Section 3 and splitting the sets in the same way, we set
 $$ \begin{align*} N_k(T) := \sum_{(p, q) \in \mathcal{A}_k(T)} (\log p)(\log q). \end{align*} $$
$$ \begin{align*} N_k(T) := \sum_{(p, q) \in \mathcal{A}_k(T)} (\log p)(\log q). \end{align*} $$
We write
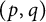 $(p, q)$
for prime numbers in place of
$(p, q)$
for prime numbers in place of
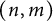 $(n, m)$
and use logarithmic weights in order to exploit the linearity of the main term of the Chebyshev
$(n, m)$
and use logarithmic weights in order to exploit the linearity of the main term of the Chebyshev
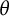 $\theta $
-function. This is critical in order to avoid the introduction of special functions whose behavior is hard to estimate carefully over the range of values of k that we need. We give more details at the end of this section.
$\theta $
-function. This is critical in order to avoid the introduction of special functions whose behavior is hard to estimate carefully over the range of values of k that we need. We give more details at the end of this section.
Lemma 5.1 (Prime Number Theorem)
There exists a positive constant c such that
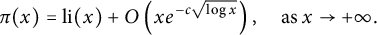 $$ \begin{align*} \pi(x) = \operatorname{\mathrm{li}}(x) + O\left(x e^{-c\sqrt{\log x}}\right), \quad \text{as }x\to +\infty. \end{align*} $$
$$ \begin{align*} \pi(x) = \operatorname{\mathrm{li}}(x) + O\left(x e^{-c\sqrt{\log x}}\right), \quad \text{as }x\to +\infty. \end{align*} $$
If the Riemann Hypothesis is true, then the error term on the right-hand side may be replaced by
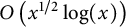 $O\left (x^{1/2} \log (x)\right )$
.
$O\left (x^{1/2} \log (x)\right )$
.
We will need repeatedly the following simple lemma, whose proof by partial summation is straightforward.
Lemma 5.2 Let
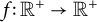 $f \colon \mathbb {R}^+ \to \mathbb {R}^+$
be a smooth increasing function, and let
$f \colon \mathbb {R}^+ \to \mathbb {R}^+$
be a smooth increasing function, and let
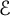 $\mathcal {E}$
be defined by (2.1). Then,
$\mathcal {E}$
be defined by (2.1). Then,
 $$ \begin{align*} \sum_{p \le X} f(p) = \int_2^X \frac{f(t)}{\log(t)} \, \,\mathrm{d} t + O\left(f(X) \mathcal{E}(X)\right), \qquad\text{as }X \to +\infty. \end{align*} $$
$$ \begin{align*} \sum_{p \le X} f(p) = \int_2^X \frac{f(t)}{\log(t)} \, \,\mathrm{d} t + O\left(f(X) \mathcal{E}(X)\right), \qquad\text{as }X \to +\infty. \end{align*} $$
5.1 The contribution from the set
$\mathcal {U}(T)$

Using Lemma 5.2 with
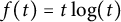 $f(t) = t \log (t)$
and recalling (3.2) and (3.4), for
$f(t) = t \log (t)$
and recalling (3.2) and (3.4), for
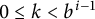 $0 \le k < b^{i-1}$
, we have to evaluate
$0 \le k < b^{i-1}$
, we have to evaluate
 $$ \begin{align*} \notag \sum_{q \le T} \Bigl( \theta \Bigl( \frac q{x_k} \Bigr) - \theta \Bigl( \frac q{y_k} \Bigr) \Bigr) \log(q) &= \frac1{b^i} \sum_{q \le T} q \log(q) + \sum_{p \le T} O\left(\mathcal{E}(p) \log(p)\right) \\ \notag &= \frac1{b^i} \int_2^T t \, \,\mathrm{d} t + O\left(T \mathcal{E}(T) \log(T)\right) + O\left(\theta(T) \mathcal{E}(T)\right) \\ &= \frac1{2 b^i} T^2 + O\left(T \mathcal{E}(T) \log(T)\right). \end{align*} $$
$$ \begin{align*} \notag \sum_{q \le T} \Bigl( \theta \Bigl( \frac q{x_k} \Bigr) - \theta \Bigl( \frac q{y_k} \Bigr) \Bigr) \log(q) &= \frac1{b^i} \sum_{q \le T} q \log(q) + \sum_{p \le T} O\left(\mathcal{E}(p) \log(p)\right) \\ \notag &= \frac1{b^i} \int_2^T t \, \,\mathrm{d} t + O\left(T \mathcal{E}(T) \log(T)\right) + O\left(\theta(T) \mathcal{E}(T)\right) \\ &= \frac1{2 b^i} T^2 + O\left(T \mathcal{E}(T) \log(T)\right). \end{align*} $$
Summing over the values of k mentioned above, we find that the total contribution from the set
 $\mathcal {U}(T)$
is
$\mathcal {U}(T)$
is
 $$ \begin{align} \frac1{2 b} T^2 + O\left(T \mathcal{E}(T) \log(T)\right). \end{align} $$
$$ \begin{align} \frac1{2 b} T^2 + O\left(T \mathcal{E}(T) \log(T)\right). \end{align} $$
5.2 The contribution from the set
$\mathcal {L}(T)$
Using (3.6), we see that we have to evaluate
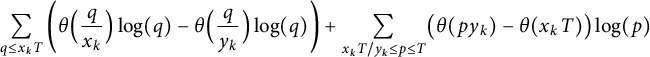 $$ \begin{align*} \sum_{q \le x_k T} \left( \theta \Bigl(\frac q{x_k} \Bigr) \log(q) - \theta \Bigl(\frac q{y_k} \Bigr) \log(q) \right) + \sum_{x_k T / y_k \le p \le T} \bigl( \theta(p y_k) - \theta(x_k T) \bigr) \log(p) \end{align*} $$
$$ \begin{align*} \sum_{q \le x_k T} \left( \theta \Bigl(\frac q{x_k} \Bigr) \log(q) - \theta \Bigl(\frac q{y_k} \Bigr) \log(q) \right) + \sum_{x_k T / y_k \le p \le T} \bigl( \theta(p y_k) - \theta(x_k T) \bigr) \log(p) \end{align*} $$
for
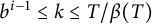 $b^{i-1} \le k \le T / \beta (T)$
. Using Lemma 5.2 with
$b^{i-1} \le k \le T / \beta (T)$
. Using Lemma 5.2 with
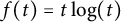 $f(t) = t \log (t)$
, we deduce that the first summand is
$f(t) = t \log (t)$
, we deduce that the first summand is
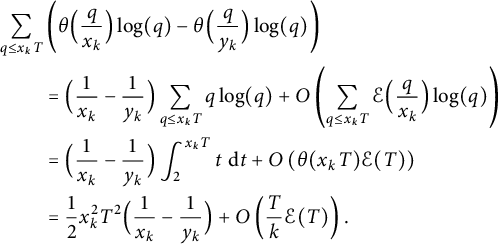 $$ \begin{align*} \sum_{q \le x_k T} &\left( \theta \Bigl(\frac q{x_k} \Bigr) \log(q) - \theta \Bigl(\frac q{y_k} \Bigr) \log(q) \right) \\ &= \Bigl( \frac1{x_k} - \frac1{y_k} \Bigr) \sum_{q \le x_k T} q \log(q) + O\left(\sum_{q \le x_k T} \mathcal{E}\Bigl(\frac q{x_k} \Bigr) \log(q)\right) \\ &= \Bigl( \frac1{x_k} - \frac1{y_k} \Bigr) \int_2^{x_k T} t \, \,\mathrm{d} t + O\left(\theta(x_k T) \mathcal{E}(T)\right) \\ &= \frac12 x_k^2 T^2 \Bigl( \frac1{x_k} - \frac1{y_k} \Bigr) + O\left(\frac Tk \mathcal{E}(T)\right). \end{align*} $$
$$ \begin{align*} \sum_{q \le x_k T} &\left( \theta \Bigl(\frac q{x_k} \Bigr) \log(q) - \theta \Bigl(\frac q{y_k} \Bigr) \log(q) \right) \\ &= \Bigl( \frac1{x_k} - \frac1{y_k} \Bigr) \sum_{q \le x_k T} q \log(q) + O\left(\sum_{q \le x_k T} \mathcal{E}\Bigl(\frac q{x_k} \Bigr) \log(q)\right) \\ &= \Bigl( \frac1{x_k} - \frac1{y_k} \Bigr) \int_2^{x_k T} t \, \,\mathrm{d} t + O\left(\theta(x_k T) \mathcal{E}(T)\right) \\ &= \frac12 x_k^2 T^2 \Bigl( \frac1{x_k} - \frac1{y_k} \Bigr) + O\left(\frac Tk \mathcal{E}(T)\right). \end{align*} $$
The second summand is
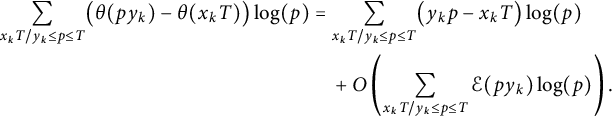 $$ \begin{align*} \sum_{x_k T / y_k \le p \le T} \bigl( \theta(p y_k) - \theta(x_k T) \bigr) \log(p) &= \sum_{x_k T / y_k \le p \le T} \bigl(y_k p - x_k T \bigr) \log(p) \\ &\quad+ O\left(\sum_{x_k T / y_k \le p \le T} \mathcal{E}(p y_k) \log(p)\right). \end{align*} $$
$$ \begin{align*} \sum_{x_k T / y_k \le p \le T} \bigl( \theta(p y_k) - \theta(x_k T) \bigr) \log(p) &= \sum_{x_k T / y_k \le p \le T} \bigl(y_k p - x_k T \bigr) \log(p) \\ &\quad+ O\left(\sum_{x_k T / y_k \le p \le T} \mathcal{E}(p y_k) \log(p)\right). \end{align*} $$
Using again Lemma 5.2, we see that the main term is
 $$ \begin{align*} y_k \int_{x_k T / y_k}^T t \, \,\mathrm{d} t - x_k T \int_{x_k T / y_k}^T \,\mathrm{d} t + O\left(y_k T \mathcal{E}(T)\right) = \frac12 y_k \Bigl( 1 - \frac{x_k}{y_k} \Bigr)^2 T^2 + O\left(\frac Tk \mathcal{E}(T)\right). \end{align*} $$
$$ \begin{align*} y_k \int_{x_k T / y_k}^T t \, \,\mathrm{d} t - x_k T \int_{x_k T / y_k}^T \,\mathrm{d} t + O\left(y_k T \mathcal{E}(T)\right) = \frac12 y_k \Bigl( 1 - \frac{x_k}{y_k} \Bigr)^2 T^2 + O\left(\frac Tk \mathcal{E}(T)\right). \end{align*} $$
The error term is
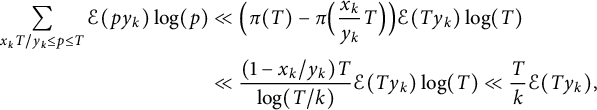 $$ \begin{align*} \sum_{x_k T / y_k \le p \le T} \mathcal{E}(p y_k) \log(p) &\ll \Bigl( \pi(T) - \pi\Bigl( \frac{x_k}{y_k} T \Bigr) \Bigr) \mathcal{E}(T y_k) \log(T) \\ &\ll \frac{(1 - x_k / y_k) T}{\log(T / k)} \mathcal{E}(T y_k) \log(T) \ll \frac Tk \mathcal{E}(T y_k), \end{align*} $$
$$ \begin{align*} \sum_{x_k T / y_k \le p \le T} \mathcal{E}(p y_k) \log(p) &\ll \Bigl( \pi(T) - \pi\Bigl( \frac{x_k}{y_k} T \Bigr) \Bigr) \mathcal{E}(T y_k) \log(T) \\ &\ll \frac{(1 - x_k / y_k) T}{\log(T / k)} \mathcal{E}(T y_k) \log(T) \ll \frac Tk \mathcal{E}(T y_k), \end{align*} $$
by the Brun–Titchmarsh inequality.
Summing up, the total contribution of the main terms is
 $$ \begin{align} \notag \frac12 T^2 \sum_{b^{i - 1} \le k \le T / \beta(T)} &\Bigl( x_k^2 \Bigl( \frac1{x_k} - \frac1{y_k} \Bigr) + y_k \Bigl( 1 - \frac{x_k}{y_k} \Bigr)^2 \Bigr) \\ \notag &= \frac12 T^2 \sum_{b^{i - 1} \le k \le T / \beta(T)} (y_k - x_k) \\ &= \frac{b^{i-1}}2 T^2 \Bigl( \psi \Bigl( \frac{b^i + r + 1}b \Bigr) - \psi \Bigl( \frac{b^i + r}b \Bigr) \Bigr) + O\left(T \beta(T)\right), \end{align} $$
$$ \begin{align} \notag \frac12 T^2 \sum_{b^{i - 1} \le k \le T / \beta(T)} &\Bigl( x_k^2 \Bigl( \frac1{x_k} - \frac1{y_k} \Bigr) + y_k \Bigl( 1 - \frac{x_k}{y_k} \Bigr)^2 \Bigr) \\ \notag &= \frac12 T^2 \sum_{b^{i - 1} \le k \le T / \beta(T)} (y_k - x_k) \\ &= \frac{b^{i-1}}2 T^2 \Bigl( \psi \Bigl( \frac{b^i + r + 1}b \Bigr) - \psi \Bigl( \frac{b^i + r}b \Bigr) \Bigr) + O\left(T \beta(T)\right), \end{align} $$
by Lemma 3.1. The total error term is
 $$ \begin{align} \ll T \mathcal{E}(T) \sum_{b^{i - 1} \le k \le T / \beta(T)} \frac 1k \ll T \mathcal{E}(T) \log(T). \end{align} $$
$$ \begin{align} \ll T \mathcal{E}(T) \sum_{b^{i - 1} \le k \le T / \beta(T)} \frac 1k \ll T \mathcal{E}(T) \log(T). \end{align} $$
In order to complete the proof, we just collect (5.1)-(5.3) and choose
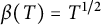 $\beta (T) = T^{1 / 2}$
.
$\beta (T) = T^{1 / 2}$
.
5.3 Comments on the choice of weights
We remark that using the characteristic function of the primes as the choice of weight in this problem leads to a number of technical complications. If we insist on counting couples of primes without weights, we would find a much weaker result, with the error term smaller than the main term just by a factor
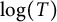 $\log (T)$
.
$\log (T)$
.
6 On points which are visible from the origin
We now deal with a similar problem, where we only count points that are visible from the origin, that is, couples
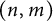 $(n, m)$
with
$(n, m)$
with
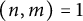 $(n, m) = 1$
. We could use the familiar device of writing the characteristic function of such couples by means of the Möbius function
$(n, m) = 1$
. We could use the familiar device of writing the characteristic function of such couples by means of the Möbius function
 $\mu $
. As we said in Section 3, we could write,
$\mu $
. As we said in Section 3, we could write,
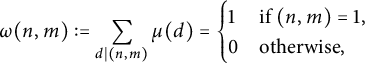 $$ \begin{align*} \omega(n, m) := \sum_{d \mid (n, m)} \mu(d) = \begin{cases} 1 &\text{if }(n, m) = 1, \\ 0 &\text{otherwise,} \end{cases} \end{align*} $$
$$ \begin{align*} \omega(n, m) := \sum_{d \mid (n, m)} \mu(d) = \begin{cases} 1 &\text{if }(n, m) = 1, \\ 0 &\text{otherwise,} \end{cases} \end{align*} $$
and then proceed along the same lines as in Section 3. This approach does not lead to any particular improvement, because the extra sum on d generates an additional logarithm in the error term. Nevertheless, numerical data suggest a slight regularization in this case (see Section 7).
6.1 Deduction of Theorem 2.3 from Theorem 2.1
We notice that
 $$ \begin{align*} \vert\{ (n, m) \in [1, T]^2 &\colon \phi(n / m) = r \}\vert \\ &= \sum_{d \le T} \vert\{ (n, m) \in [1, T]^2 \colon (n, m) = d \land \phi(n / m) = r \}\vert \\ &= \sum_{d \le T} \vert\{ (n, m) \in [1, T / d]^2 \colon (n, m) = 1 \land \phi(n / m) = r \}\vert. \end{align*} $$
$$ \begin{align*} \vert\{ (n, m) \in [1, T]^2 &\colon \phi(n / m) = r \}\vert \\ &= \sum_{d \le T} \vert\{ (n, m) \in [1, T]^2 \colon (n, m) = d \land \phi(n / m) = r \}\vert \\ &= \sum_{d \le T} \vert\{ (n, m) \in [1, T / d]^2 \colon (n, m) = 1 \land \phi(n / m) = r \}\vert. \end{align*} $$
Hence, by the Möbius inversion formula, we have
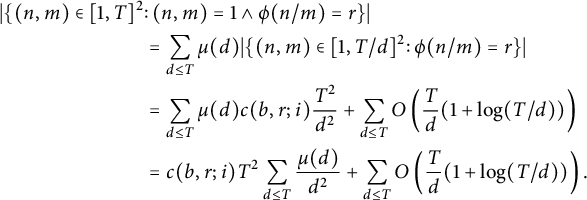 $$ \begin{align*} \vert\{ (n, m) \in [1, T]^2 &\colon (n, m) = 1 \land \phi(n / m) = r \}\vert \\ &= \sum_{d \le T} \mu(d) \vert\{ (n, m) \in [1, T / d]^2 \colon \phi(n / m) = r \}\vert \\ &= \sum_{d \le T} \mu(d) c(b, r; i) \frac{T^2}{d^2} + \sum_{d \le T} O\left(\frac Td (1 + \log(T / d))\right) \\ &= c(b, r; i) T^2 \sum_{d \le T} \frac{\mu(d)}{d^2} + \sum_{d \le T} O\left(\frac Td (1 + \log(T / d))\right). \end{align*} $$
$$ \begin{align*} \vert\{ (n, m) \in [1, T]^2 &\colon (n, m) = 1 \land \phi(n / m) = r \}\vert \\ &= \sum_{d \le T} \mu(d) \vert\{ (n, m) \in [1, T / d]^2 \colon \phi(n / m) = r \}\vert \\ &= \sum_{d \le T} \mu(d) c(b, r; i) \frac{T^2}{d^2} + \sum_{d \le T} O\left(\frac Td (1 + \log(T / d))\right) \\ &= c(b, r; i) T^2 \sum_{d \le T} \frac{\mu(d)}{d^2} + \sum_{d \le T} O\left(\frac Td (1 + \log(T / d))\right). \end{align*} $$
The leading term is
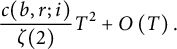 $$ \begin{align*} \frac{c(b, r; i)}{\zeta(2)} T^2 + O\left(T\right). \end{align*} $$
$$ \begin{align*} \frac{c(b, r; i)}{\zeta(2)} T^2 + O\left(T\right). \end{align*} $$
The first error term contributes
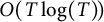 $O\!\left (T \log (T)\!\right )$
. The second error term is
$O\!\left (T \log (T)\!\right )$
. The second error term is
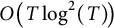 $O\!\left (T \log ^2(T)\!\right )$
.
$O\!\left (T \log ^2(T)\!\right )$
.
7 Remarks and numerical data
7.1 The limit of the method
Given an integer
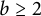 $b \ge 2$
, pick a digit
$b \ge 2$
, pick a digit
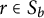 $r \in S_b$
. We choose
$r \in S_b$
. We choose
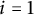 $i = 1$
for simplicity. We want to count the number of lattice points lying on the boundary of the region
$i = 1$
for simplicity. We want to count the number of lattice points lying on the boundary of the region
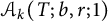 $\mathcal {A}_k(T; b, r; 1)$
. We start with estimating
$\mathcal {A}_k(T; b, r; 1)$
. We start with estimating
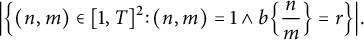 $$ \begin{align} \Bigl\vert\Bigl\{ (n, m) \in [1, T]^2 \colon (n, m) = 1 \land b \Bigl\{ \frac nm \Bigr\} = r \Bigr\}\Bigr\vert. \end{align} $$
$$ \begin{align} \Bigl\vert\Bigl\{ (n, m) \in [1, T]^2 \colon (n, m) = 1 \land b \Bigl\{ \frac nm \Bigr\} = r \Bigr\}\Bigr\vert. \end{align} $$
We obviously have
 $$ \begin{align*} b \Bigl\{ \frac nm \Bigr\} = r \qquad\Longleftrightarrow\qquad \Bigl\{ \frac nm \Bigr\} = \frac rb = \frac{r / (b, r)}{b / (b, r)}. \end{align*} $$
$$ \begin{align*} b \Bigl\{ \frac nm \Bigr\} = r \qquad\Longleftrightarrow\qquad \Bigl\{ \frac nm \Bigr\} = \frac rb = \frac{r / (b, r)}{b / (b, r)}. \end{align*} $$
The fractions at far left and far right are reduced, and this forces
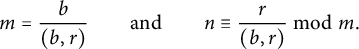 $$ \begin{align*} m = \frac b{(b, r)} \qquad\text{and}\qquad n \equiv \frac r{(b, r)}\mod m. \end{align*} $$
$$ \begin{align*} m = \frac b{(b, r)} \qquad\text{and}\qquad n \equiv \frac r{(b, r)}\mod m. \end{align*} $$
Let
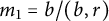 $m_1 = b / (b, r)$
. Hence, the cardinality of the set in (7.1) is
$m_1 = b / (b, r)$
. Hence, the cardinality of the set in (7.1) is
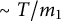 $\sim T / m_1$
. A similar argument shows that
$\sim T / m_1$
. A similar argument shows that
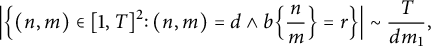 $$ \begin{align*} \Bigl\vert\Bigl\{ (n, m) \in [1, T]^2 \colon (n, m) = d \land b \Bigl\{ \frac nm \Bigr\} = r \Bigr\}\Bigr\vert \sim \frac T{d m_1}, \end{align*} $$
$$ \begin{align*} \Bigl\vert\Bigl\{ (n, m) \in [1, T]^2 \colon (n, m) = d \land b \Bigl\{ \frac nm \Bigr\} = r \Bigr\}\Bigr\vert \sim \frac T{d m_1}, \end{align*} $$
for
 $d \le T / m_1$
. Hence, the total number of lattice points on the boundary of the set
$d \le T / m_1$
. Hence, the total number of lattice points on the boundary of the set
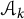 $\mathcal {A}_k$
is
$\mathcal {A}_k$
is
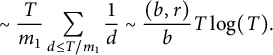 $$ \begin{align} \sim \frac T{m_1} \sum_{d \le T / m_1} \frac1d \sim \frac {(b, r)}b T \log(T). \end{align} $$
$$ \begin{align} \sim \frac T{m_1} \sum_{d \le T / m_1} \frac1d \sim \frac {(b, r)}b T \log(T). \end{align} $$
This seems to be the limit of our method for the proof of Theorem 2.1.
In the next paragraph, we will show that for “small”
 $ T$
, actually there seems to be a bit of difference in the convergence rate and this is evident with peaks when
$ T$
, actually there seems to be a bit of difference in the convergence rate and this is evident with peaks when
 $\frac {(b, r)}b$
is large.
$\frac {(b, r)}b$
is large.
7.2 Numerical data
We collect here some histograms, created using Wolfram Mathematica, obtained with the numerical computations that we performed for the problem of digits. Some variants were considered trying to understand if a different counting function could help to regularize the problem and reduce the error term. In every histogram, on the x-axis, we have the digit r, and the height of the bar represents
 $\Phi (T; b, r; 1)$
(in the cases with
$\Phi (T; b, r; 1)$
(in the cases with
 $i>1$
, the difference is less noticeable, so we did not report examples) normalized by dividing by
$i>1$
, the difference is less noticeable, so we did not report examples) normalized by dividing by
 $\sum _{r=0}^{b-1}\Phi (T; b, r; 1)$
. We recall that
$\sum _{r=0}^{b-1}\Phi (T; b, r; 1)$
. We recall that
 $\Phi (T; b, r; 1) := \left \vert \mathcal {A}(T; b, r; 1)\right \vert $
. The continuous line, instead, is the graph of
$\Phi (T; b, r; 1) := \left \vert \mathcal {A}(T; b, r; 1)\right \vert $
. The continuous line, instead, is the graph of
 $c(b, r; i)$
as a function of r; we indicated with a dot the values corresponding to integer values of r, which are the ones appearing in the theorems.
$c(b, r; i)$
as a function of r; we indicated with a dot the values corresponding to integer values of r, which are the ones appearing in the theorems.
We do not report cases with a very large sample (
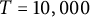 $T = 10,000$
), because in these circumstances, the histogram is really close to the expected value. But for smaller T, we can see some phenomenon taking place: for
$T = 10,000$
), because in these circumstances, the histogram is really close to the expected value. But for smaller T, we can see some phenomenon taking place: for
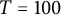 $T = 100$
, the irregularities seem all but random. If you look at the case
$T = 100$
, the irregularities seem all but random. If you look at the case
 $b=30$
(see Figure 2), which has many divisors, some numerical values noticeably exceed the expected ones. We do not report the plots where b is prime, because they actually show the behavior we expect and that we have calculated in (7.2): an anomalous peak in
$b=30$
(see Figure 2), which has many divisors, some numerical values noticeably exceed the expected ones. We do not report the plots where b is prime, because they actually show the behavior we expect and that we have calculated in (7.2): an anomalous peak in
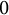 $0$
and a monotonically decreasing trend.
$0$
and a monotonically decreasing trend.

Figure 2 The histogram for
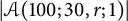 $\left \vert \mathcal {A}(100; 30, r; 1)\right \vert $
.
$\left \vert \mathcal {A}(100; 30, r; 1)\right \vert $
.
Actually, the main problem for small T is a simple fact of multiplicities: fractions with small numerator and denominator (like
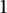 $1$
,
$1$
,
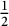 $\frac {1}{2}$
,
$\frac {1}{2}$
,
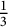 $\frac {1}{3}$
,
$\frac {1}{3}$
,
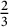 $\frac {2}{3}$
, etc.) will be counted many times: in both of them, we can recognize high counting values for the fractions that we have just mentioned.
$\frac {2}{3}$
, etc.) will be counted many times: in both of them, we can recognize high counting values for the fractions that we have just mentioned.
To avoid this phenomenon, we can just count the fractions with multiplicity one, which means taking just the reduced ones: in Figure 3, we represent
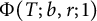 $\Phi (T; b, r; 1)$
, with
$\Phi (T; b, r; 1)$
, with
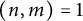 $(n,m)=1$
.
$(n,m)=1$
.
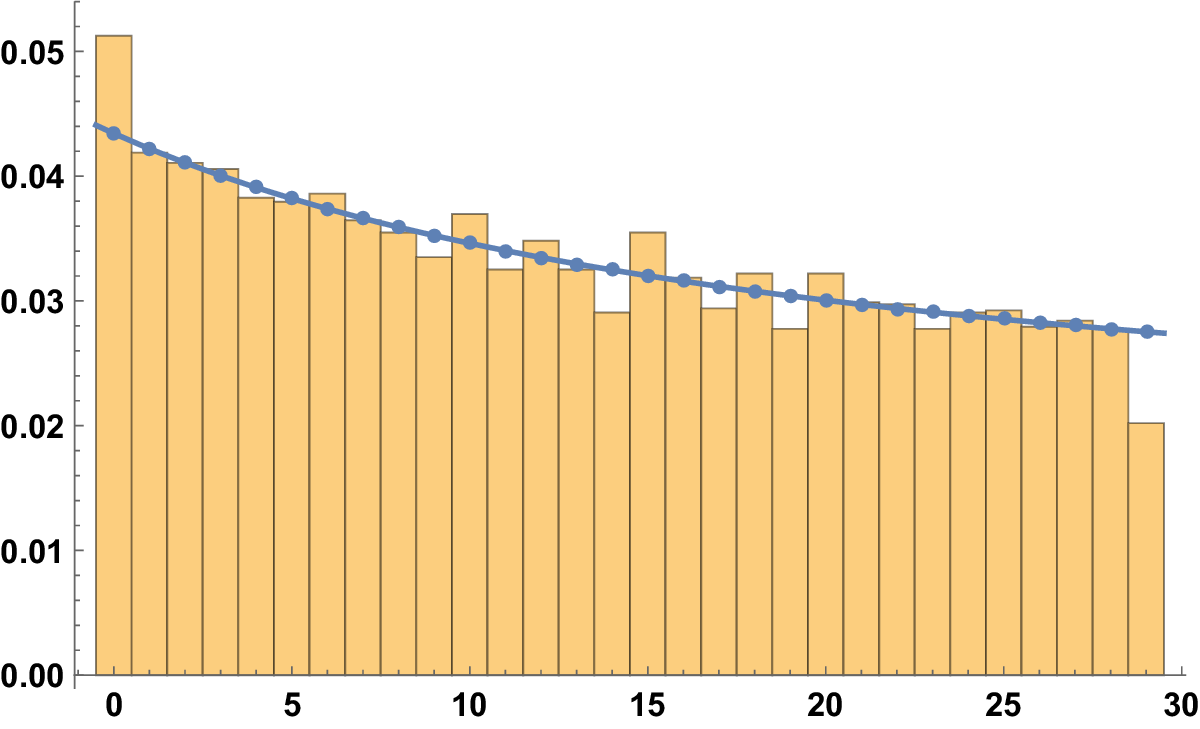
Figure 3 The histogram for
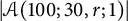 $\left \vert \mathcal {A}(100; 30, r; 1)\right \vert $
(with
$\left \vert \mathcal {A}(100; 30, r; 1)\right \vert $
(with
 $(n,m)=1)$
.
$(n,m)=1)$
.
There is a regularization, but some other phenomenon emerged: it seems that the divisors and, in general, the numbers with prime factors in common with
 $30$
tend to be have higher values. The explanation for this lies in the discontinuity of the system of digits: if we perturbed just a bit a number that has no digits to the right of the first one, we could reduce its first digit by one. To be more formal, if a rational number admits a finite representation (when, after reducing the fraction, the denominator divides the base), it admits also a periodic infinite one. Just to make an example, if we think about the base
$30$
tend to be have higher values. The explanation for this lies in the discontinuity of the system of digits: if we perturbed just a bit a number that has no digits to the right of the first one, we could reduce its first digit by one. To be more formal, if a rational number admits a finite representation (when, after reducing the fraction, the denominator divides the base), it admits also a periodic infinite one. Just to make an example, if we think about the base
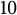 $10$
, we have
$10$
, we have
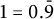 $1 = 0.\bar {9}$
.
$1 = 0.\bar {9}$
.
So, in our case, any number that admits any ambiguity in its first digit in base b should morally be divided into the two digits with an equal weight: assigning half weight to two digits if
 $b\{n/m\}\in \mathbb {Z}$
, the rate of convergence is very good already for small values of T. See Figure 4.
$b\{n/m\}\in \mathbb {Z}$
, the rate of convergence is very good already for small values of T. See Figure 4.
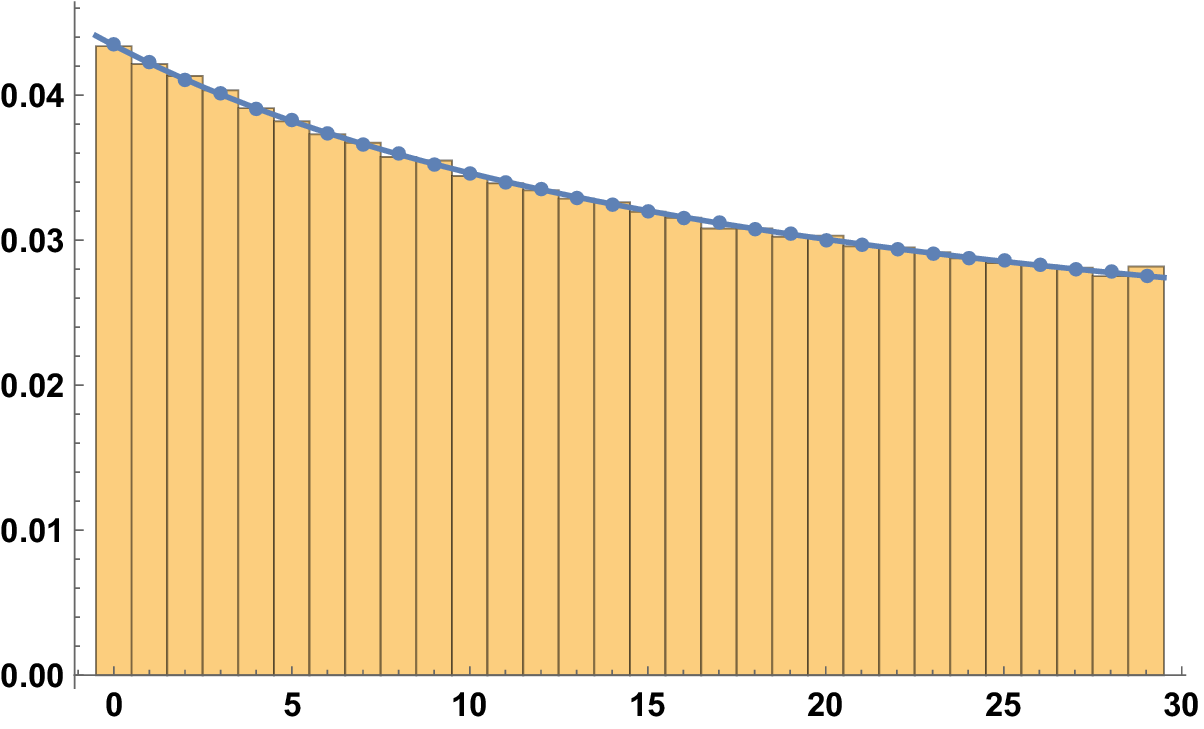
Figure 4 The histogram for
 $\mathcal {A}(100; 30, r; 1)$
with
$\mathcal {A}(100; 30, r; 1)$
with
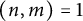 $(n,m)=1$
and assigning half weight to two digits if
$(n,m)=1$
and assigning half weight to two digits if
 $b\{n/m\}\in \mathbb {Z}$
.
$b\{n/m\}\in \mathbb {Z}$
.
7.3 Primes
We made similar computations also in the case of prime numbers. Two positive primes are not coprime if and only if they are equal: to avoid such a possibility, we just ignore the diagonal
 $p=q$
in every histogram.
$p=q$
in every histogram.
Figure 5 represents the counting function that we obtained assigning half weight to two digits if
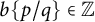 $b\{p /q\}\in \mathbb {Z}$
.
$b\{p /q\}\in \mathbb {Z}$
.
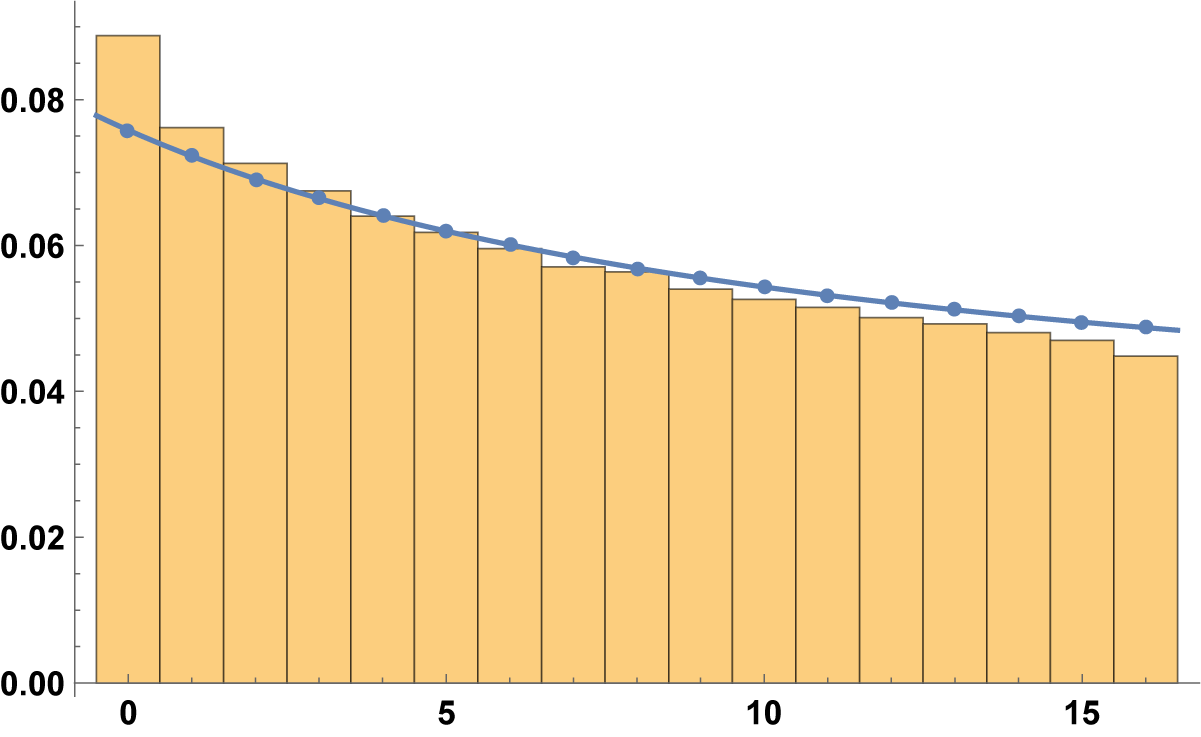
Figure 5 The histogram for
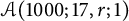 $\mathcal {A}(1000; 17, r; 1)$
for primes
$\mathcal {A}(1000; 17, r; 1)$
for primes
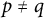 $p\neq q$
, assigning half weight to two digits if
$p\neq q$
, assigning half weight to two digits if
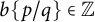 $b\{p/q\}\in \mathbb {Z}$
.
$b\{p/q\}\in \mathbb {Z}$
.
The trend is, however, monotonic and decreasing also for primes; the assignment of the half weight influences only the cases
 $r=0$
and
$r=0$
and
 $r=b-1$
with the effect of a further regularization. This regularity is intrinsic in the fact that we automatically exclude points with multiplicity, so we would expect something better than
$r=b-1$
with the effect of a further regularization. This regularity is intrinsic in the fact that we automatically exclude points with multiplicity, so we would expect something better than
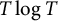 $T\log T$
even if we cannot prove it. The leading constant is decreasing in r, and it is about
$T\log T$
even if we cannot prove it. The leading constant is decreasing in r, and it is about
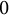 $0$
for r around
$0$
for r around
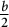 $\frac {b}{2}$
. This would explain why, in the above figures, for T sufficiently large, the first blocks are always above the trend line, while the latest are below.
$\frac {b}{2}$
. This would explain why, in the above figures, for T sufficiently large, the first blocks are always above the trend line, while the latest are below.
Acknowledgment
We thank Sandro Bettin for many conversations on the subject, and for his help with the plots at the end of the present paper.
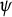
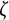


















 Open access
Open access