


1 Introduction
Regression discontinuity (RD), originated by Thistlethwaite and Campbell (Reference Thistlethwaite and Campbell1960), has been gaining popularity in many disciplines of social sciences. Just to name a few, Rao, Yu and Ingram (Reference Rao, Yu and Ingram2011) and Bernardi (Reference Bernardi2014) in sociology; Broockman (Reference Broockman2009) and Caughey and Sekhon (Reference Caughey and Sekhon2011) and Eggers et al. (Reference Eggers, Fowler, Hainmueller, Hall and Snyder2015) in political science; and many studies in economics as can be seen in the references of Imbens and Lemieux (Reference Imbens and Lemieux2008), Lee and Lemieux (Reference Lee and Lemieux2010), and Choi and Lee (Reference Choi and Lee2017) who also list statistical papers although there are not many.
In a typical RD with a treatment
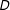 $D$
, an individual is assigned to the treatment (
$D$
, an individual is assigned to the treatment (
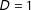 $D=1$
) or control group (
$D=1$
) or control group (
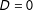 $D=0$
), depending on a single running/forcing/assignment variable
$D=0$
), depending on a single running/forcing/assignment variable
 $S$
crossing a cutoff or not. There are, however, many RD cases where multiple running variables determine a single treatment. One example is multiple test scores crossing cutoffs for school graduation or grade advancement (Jacob and Lefgren Reference Jacob and Lefgren2004). Another example is spatial/geographical RD where longitude and latitude are two running variables (Dell Reference Dell2010; Keele and Titiunik Reference Keele and Titiunik2015), although often the scalar shortest distance to a boundary is used as a running variable in the literature (Black Reference Black1999; Bayer, Ferreira and Mcmillan Reference Bayer, Ferreira and Mcmillan2007). Since the word “running variable” will appear often in this paper, we will call it simply “score” (
$S$
crossing a cutoff or not. There are, however, many RD cases where multiple running variables determine a single treatment. One example is multiple test scores crossing cutoffs for school graduation or grade advancement (Jacob and Lefgren Reference Jacob and Lefgren2004). Another example is spatial/geographical RD where longitude and latitude are two running variables (Dell Reference Dell2010; Keele and Titiunik Reference Keele and Titiunik2015), although often the scalar shortest distance to a boundary is used as a running variable in the literature (Black Reference Black1999; Bayer, Ferreira and Mcmillan Reference Bayer, Ferreira and Mcmillan2007). Since the word “running variable” will appear often in this paper, we will call it simply “score” (
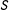 $S$
for Score).
$S$
for Score).
When there are multiple scores, two cases arise: “OR case” where any score can cross a cutoff to get treated (Jacob and Lefgren Reference Jacob and Lefgren2004; Matsudaira Reference Matsudaira2008; Wong, Steiner and Cook Reference Wong, Steiner and Cook2013), and “AND case” where all scores should cross all cutoffs to get treated. For simplification, we will examine only AND cases in this paper, because an OR case can be converted to the AND case by switching the treatment and control groups.
“Multiple-score RD (MRD) for a single treatment” that is the focus of this paper differs from “RD with multiple cutoffs for a single score” as in Angrist and Lavy (Reference Angrist and Lavy1999) and Van der Klaauw (Reference Van der Klaauw2002), which is handled by looking at each cutoff one at a time. Whereas these studies dealt only with fixed known cutoffs, say
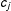 $c_{j}$
,
$c_{j}$
,
 $j=1,\ldots ,J$
, Cattaneo et al. (Reference Cattaneo, Keele, Titiunik and Vazquez-Bare2016) examined a random cutoff
$j=1,\ldots ,J$
, Cattaneo et al. (Reference Cattaneo, Keele, Titiunik and Vazquez-Bare2016) examined a random cutoff
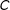 $C$
, which can occur in multiparty elections/races.
$C$
, which can occur in multiparty elections/races.
The goal of this paper is to generalize the usual “single-score mean-regression RD” in three ways. First, we consider multiple scores for a single treatment
 $D$
. Second, differently from most other RD studies for multiple scores, we allow “partial effects” due to each score crossing its own cutoff, in addition to the (full) treatment effect due to
$D$
. Second, differently from most other RD studies for multiple scores, we allow “partial effects” due to each score crossing its own cutoff, in addition to the (full) treatment effect due to
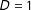 $D=1$
with all scores crossing all cutoffs. Third, although we focus on RD with the usual mean regression
$D=1$
with all scores crossing all cutoffs. Third, although we focus on RD with the usual mean regression
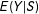 $E(Y|S)$
for a response variable
$E(Y|S)$
for a response variable
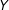 $Y$
, our approach can be easily generalized to other location measures such as conditional quantiles (Koenker Reference Koenker2005) and mode (Lee Reference Lee1989; Kemp and Santos-Silva Reference Kemp and Santos-Silva2012).
$Y$
, our approach can be easily generalized to other location measures such as conditional quantiles (Koenker Reference Koenker2005) and mode (Lee Reference Lee1989; Kemp and Santos-Silva Reference Kemp and Santos-Silva2012).
Certainly, we are not the first to deal with MRD theoretically. Wong, Steiner and Cook (Reference Wong, Steiner and Cook2013) examined “OR-case MRD,” Keele and Titiunik (Reference Keele and Titiunik2015) “AND-case MRD,” and Imbens and Zajonc (Reference Imbens and Zajonc2009) and Reardon and Robinson (Reference Reardon and Robinson2012) both cases. A critical difference between these studies (except Reardon and Robinson Reference Reardon and Robinson2012) and this paper is that we allow partial effects while they do not. To see the point, consider
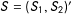 $S=(S_{1},S_{2})^{\prime }$
and
$S=(S_{1},S_{2})^{\prime }$
and
 $$\begin{eqnarray}E(Y|S)=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{1}\unicode[STIX]{x1D6FF}_{1}+\unicode[STIX]{x1D6FD}_{2}\unicode[STIX]{x1D6FF}_{2}+\unicode[STIX]{x1D6FD}_{d}D,\quad \unicode[STIX]{x1D6FF}_{j}\equiv 1[c_{j}\leqslant S_{j}]\quad \text{for }j=1,2~\text{and}~D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\end{eqnarray}$$
$$\begin{eqnarray}E(Y|S)=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{1}\unicode[STIX]{x1D6FF}_{1}+\unicode[STIX]{x1D6FD}_{2}\unicode[STIX]{x1D6FF}_{2}+\unicode[STIX]{x1D6FD}_{d}D,\quad \unicode[STIX]{x1D6FF}_{j}\equiv 1[c_{j}\leqslant S_{j}]\quad \text{for }j=1,2~\text{and}~D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\end{eqnarray}$$
where
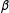 $\unicode[STIX]{x1D6FD}$
’s are parameters,
$\unicode[STIX]{x1D6FD}$
’s are parameters,
 $c\equiv (c_{1},c_{2})^{\prime }$
are known cutoffs, and
$c\equiv (c_{1},c_{2})^{\prime }$
are known cutoffs, and
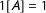 $1[A]=1$
if
$1[A]=1$
if
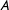 $A$
holds and
$A$
holds and
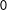 $0$
otherwise. For instance, in the school graduation (
$0$
otherwise. For instance, in the school graduation (
 $D=1$
) effect example (on lifetime income
$D=1$
) effect example (on lifetime income
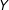 $Y$
) by passing both math (
$Y$
) by passing both math (
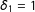 $\unicode[STIX]{x1D6FF}_{1}=1$
) and English (
$\unicode[STIX]{x1D6FF}_{1}=1$
) and English (
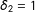 $\unicode[STIX]{x1D6FF}_{2}=1$
) exams, even if one fails to have
$\unicode[STIX]{x1D6FF}_{2}=1$
) exams, even if one fails to have
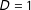 $D=1$
, still passing/failing the math exam may affect
$D=1$
, still passing/failing the math exam may affect
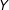 $Y$
by encouraging/stigmatizing the student.
$Y$
by encouraging/stigmatizing the student.
Ruling out partial effects, Imbens and Zajonc (Reference Imbens and Zajonc2009), Wong, Steiner and Cook (Reference Wong, Steiner and Cook2013) and Keele and Titiunik (Reference Keele and Titiunik2015) found “boundary-specific” effects, which are then weighted-averaged, in comparison to our simple effect at
 $S=c$
(under a weak continuity condition only at
$S=c$
(under a weak continuity condition only at
 $S=c$
). Reardon and Robinson (Reference Reardon and Robinson2012) seems to be the only other paper allowing for partial effects in MRD; they considered partial effects by casting MRD within a multiple treatment framework. But Reardon and Robinson (Reference Reardon and Robinson2012) did not offer formal derivations as we do in this paper.
$S=c$
). Reardon and Robinson (Reference Reardon and Robinson2012) seems to be the only other paper allowing for partial effects in MRD; they considered partial effects by casting MRD within a multiple treatment framework. But Reardon and Robinson (Reference Reardon and Robinson2012) did not offer formal derivations as we do in this paper.
The aforementioned generalization of
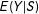 $E(Y|S)$
for conditional quantiles or mode seems feasible only for “sharp RD” where
$E(Y|S)$
for conditional quantiles or mode seems feasible only for “sharp RD” where
 $D$
is fully determined by the scores. Hence, we stick to sharp MRD in this paper, as Wong, Steiner and Cook (Reference Wong, Steiner and Cook2013) and Keele and Titiunik (Reference Keele and Titiunik2015) also did; only Imbens and Zajonc (Reference Imbens and Zajonc2009) dealt with fuzzy MRD under no partial effects. For simplification, we will examine only two scores
$D$
is fully determined by the scores. Hence, we stick to sharp MRD in this paper, as Wong, Steiner and Cook (Reference Wong, Steiner and Cook2013) and Keele and Titiunik (Reference Keele and Titiunik2015) also did; only Imbens and Zajonc (Reference Imbens and Zajonc2009) dealt with fuzzy MRD under no partial effects. For simplification, we will examine only two scores
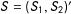 $S=(S_{1},S_{2})^{\prime }$
unless otherwise noted, as generalizations to more than two scores are conceptually straightforward. Without loss of generality, we will set the cutoffs at zero unless otherwise necessary, as
$S=(S_{1},S_{2})^{\prime }$
unless otherwise noted, as generalizations to more than two scores are conceptually straightforward. Without loss of generality, we will set the cutoffs at zero unless otherwise necessary, as
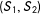 $(S_{1},S_{2})$
can be always centered as
$(S_{1},S_{2})$
can be always centered as
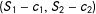 $(S_{1}-c_{1},S_{2}-c_{2})$
.
$(S_{1}-c_{1},S_{2}-c_{2})$
.
In short, we focus on AND-case two-score sharp MRD allowing partial effects for the mean-regression function
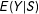 $E(Y|S)$
. Since the treatment
$E(Y|S)$
. Since the treatment
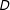 $D$
takes the interaction form
$D$
takes the interaction form
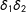 $\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
as in Equation (1) the effect is found essentially by “local difference in differences (DD)” where both partial effects are removed in DD with only the desired interaction surviving. See Lee (Reference Lee2016) for the recent developments in DD.
$\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
as in Equation (1) the effect is found essentially by “local difference in differences (DD)” where both partial effects are removed in DD with only the desired interaction surviving. See Lee (Reference Lee2016) for the recent developments in DD.
The rest of this paper is organized as follows. Section 2 examines the identification and estimation for two-score MRD. Section 3 compares our identification conditions and estimators with those in the literature. Section 4 provides an empirical illustration. Finally, Section 5 concludes. Our MRD coverage is limited, because every issue that ever occurred to single-score RD also occurs to MRD and we cannot possibly address all the issues in one paper.
2 MRD with Two Scores
Recall
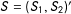 $S=(S_{1},S_{2})^{\prime }$
and
$S=(S_{1},S_{2})^{\prime }$
and
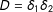 $D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
where
$D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
where
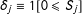 $\unicode[STIX]{x1D6FF}_{j}\equiv 1[0\leqslant S_{j}]$
,
$\unicode[STIX]{x1D6FF}_{j}\equiv 1[0\leqslant S_{j}]$
,
 $j=1,2$
. First, we introduce four potential responses corresponding to
$j=1,2$
. First, we introduce four potential responses corresponding to
 $\unicode[STIX]{x1D6FF}_{1},\unicode[STIX]{x1D6FF}_{2}=0,1$
, and examine partial effects—an issue that does not arise for the usual single-score RD. Second, we impose a continuity condition and present the main identified effect for MRD. Third, we propose a simple estimation scheme based on ordinary least squares estimator (OLS) using only some observations local to the cutoff in both scores.
$\unicode[STIX]{x1D6FF}_{1},\unicode[STIX]{x1D6FF}_{2}=0,1$
, and examine partial effects—an issue that does not arise for the usual single-score RD. Second, we impose a continuity condition and present the main identified effect for MRD. Third, we propose a simple estimation scheme based on ordinary least squares estimator (OLS) using only some observations local to the cutoff in both scores.
2.1 Four Potential Responses and Partial Effects
Define potential responses
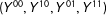 $(Y^{00},Y^{10},Y^{01},Y^{11})$
corresponding to
$(Y^{00},Y^{10},Y^{01},Y^{11})$
corresponding to
 $(\unicode[STIX]{x1D6FF}_{1},\unicode[STIX]{x1D6FF}_{2})$
being
$(\unicode[STIX]{x1D6FF}_{1},\unicode[STIX]{x1D6FF}_{2})$
being
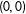 $(0,0)$
,
$(0,0)$
,
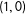 $(1,0)$
,
$(1,0)$
,
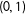 $(0,1)$
,
$(0,1)$
,
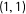 $(1,1)$
, respectively. Although our treatment of interest is the interaction
$(1,1)$
, respectively. Although our treatment of interest is the interaction
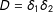 $D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
, it is possible that
$D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
, it is possible that
 $\unicode[STIX]{x1D6FF}_{1}$
and
$\unicode[STIX]{x1D6FF}_{1}$
and
 $\unicode[STIX]{x1D6FF}_{2}$
separately affect
$\unicode[STIX]{x1D6FF}_{2}$
separately affect
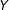 $Y$
. For instance, to graduate high school, one has to pass both math (
$Y$
. For instance, to graduate high school, one has to pass both math (
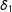 $\unicode[STIX]{x1D6FF}_{1}$
) and English (
$\unicode[STIX]{x1D6FF}_{1}$
) and English (
 $\unicode[STIX]{x1D6FF}_{2}$
) exams, but failing the math test may stigmatize the student (“I cannot do math”) to affect his/her lifetime income
$\unicode[STIX]{x1D6FF}_{2}$
) exams, but failing the math test may stigmatize the student (“I cannot do math”) to affect his/her lifetime income
 $Y$
; in this case,
$Y$
; in this case,
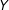 $Y$
is affected by
$Y$
is affected by
 $\unicode[STIX]{x1D6FF}_{1}$
as well as by
$\unicode[STIX]{x1D6FF}_{1}$
as well as by
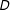 $D$
. More generally, when an interaction term appears in a regression function, it is natural to allow the individual terms in the regression function. Call the separate effects of
$D$
. More generally, when an interaction term appears in a regression function, it is natural to allow the individual terms in the regression function. Call the separate effects of
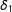 $\unicode[STIX]{x1D6FF}_{1}$
and
$\unicode[STIX]{x1D6FF}_{1}$
and
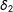 $\unicode[STIX]{x1D6FF}_{2}$
“partial effects.”
$\unicode[STIX]{x1D6FF}_{2}$
“partial effects.”
At a glance, the individual treatment effect of interest may look like
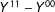 $Y^{11}-Y^{00}$
because
$Y^{11}-Y^{00}$
because
 $D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
, but this is not the case. To see why, think of the high school graduation example.
$D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
, but this is not the case. To see why, think of the high school graduation example.
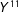 $Y^{11}$
is the lifetime income when both exams are passed, and as such,
$Y^{11}$
is the lifetime income when both exams are passed, and as such,
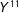 $Y^{11}$
includes the high school graduation effect on lifetime income and the partial effect of passing the math exam (“I can do math”), as well as the possible partial effect of passing the English exam (“I can do English”?). Hence the “net” effect of high school graduation should be
$Y^{11}$
includes the high school graduation effect on lifetime income and the partial effect of passing the math exam (“I can do math”), as well as the possible partial effect of passing the English exam (“I can do English”?). Hence the “net” effect of high school graduation should be
 $$\begin{eqnarray}Y^{11}-Y^{00}-(Y^{10}-Y^{00})-(Y^{01}-Y^{00})=Y^{11}-Y^{10}-Y^{01}+Y^{00}\end{eqnarray}$$
$$\begin{eqnarray}Y^{11}-Y^{00}-(Y^{10}-Y^{00})-(Y^{01}-Y^{00})=Y^{11}-Y^{10}-Y^{01}+Y^{00}\end{eqnarray}$$
where the two partial effects relative to
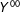 $Y^{00}$
are subtracted from
$Y^{00}$
are subtracted from
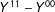 $Y^{11}-Y^{00}$
.
$Y^{11}-Y^{00}$
.
Rewrite
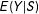 $E(Y|S)$
as
$E(Y|S)$
as
 $$\begin{eqnarray}\displaystyle E(Y|S) & = & \displaystyle E(Y^{00}|S)(1-\unicode[STIX]{x1D6FF}_{1})(1-\unicode[STIX]{x1D6FF}_{2})+E(Y^{10}|S)\unicode[STIX]{x1D6FF}_{1}(1-\unicode[STIX]{x1D6FF}_{2})\nonumber\\ \displaystyle & & \displaystyle +\,E(Y^{01}|S)(1-\unicode[STIX]{x1D6FF}_{1})\unicode[STIX]{x1D6FF}_{2}+E(Y^{11}|S)\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}.\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle E(Y|S) & = & \displaystyle E(Y^{00}|S)(1-\unicode[STIX]{x1D6FF}_{1})(1-\unicode[STIX]{x1D6FF}_{2})+E(Y^{10}|S)\unicode[STIX]{x1D6FF}_{1}(1-\unicode[STIX]{x1D6FF}_{2})\nonumber\\ \displaystyle & & \displaystyle +\,E(Y^{01}|S)(1-\unicode[STIX]{x1D6FF}_{1})\unicode[STIX]{x1D6FF}_{2}+E(Y^{11}|S)\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}.\end{eqnarray}$$
Further rewrite this so that
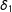 $\unicode[STIX]{x1D6FF}_{1}$
and
$\unicode[STIX]{x1D6FF}_{1}$
and
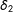 $\unicode[STIX]{x1D6FF}_{2}$
and
$\unicode[STIX]{x1D6FF}_{2}$
and
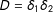 $D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
appear separately:
$D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
appear separately:
 $$\begin{eqnarray}\displaystyle E(Y|S) & = & \displaystyle E(Y^{00}|S)+\{E(Y^{10}|S)-E(Y^{00}|S)\}\unicode[STIX]{x1D6FF}_{1}+\{E(Y^{01}|S)-E(Y^{00}|S)\}\unicode[STIX]{x1D6FF}_{2}\nonumber\\ \displaystyle & & \displaystyle +\,\{E(Y^{11}|S)-E(Y^{10}|S)-E(Y^{01}|S)+E(Y^{00}|S)\}D\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle E(Y|S) & = & \displaystyle E(Y^{00}|S)+\{E(Y^{10}|S)-E(Y^{00}|S)\}\unicode[STIX]{x1D6FF}_{1}+\{E(Y^{01}|S)-E(Y^{00}|S)\}\unicode[STIX]{x1D6FF}_{2}\nonumber\\ \displaystyle & & \displaystyle +\,\{E(Y^{11}|S)-E(Y^{10}|S)-E(Y^{01}|S)+E(Y^{00}|S)\}D\end{eqnarray}$$
which will play the main role for MRD. This equation does not hold for fuzzy RD, because
 $D$
would then depend on random variables other than
$D$
would then depend on random variables other than
 $S$
on the right-hand side while the left-hand side
$S$
on the right-hand side while the left-hand side
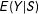 $E(Y|S)$
is a function of only
$E(Y|S)$
is a function of only
 $S$
. This is one of the reasons why we stick to sharp RD.
$S$
. This is one of the reasons why we stick to sharp RD.
The slope of
 $D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
in Equation (3) is reminiscent of the above
$D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
in Equation (3) is reminiscent of the above
 $Y^{11}-Y^{10}-Y^{01}+Y^{00}$
, and it is a DD with
$Y^{11}-Y^{10}-Y^{01}+Y^{00}$
, and it is a DD with
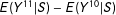 $E(Y^{11}|S)-E(Y^{10}|S)$
as the “treatment group difference” and
$E(Y^{11}|S)-E(Y^{10}|S)$
as the “treatment group difference” and
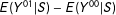 $E(Y^{01}|S)-E(Y^{00}|S)$
as the “control group difference.” Since
$E(Y^{01}|S)-E(Y^{00}|S)$
as the “control group difference.” Since
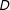 $D$
is an interaction, it is only natural that DD is used to find the treatment effect, as DD is known to isolate the interaction effect by removing the partial effects.
$D$
is an interaction, it is only natural that DD is used to find the treatment effect, as DD is known to isolate the interaction effect by removing the partial effects.
If
 $$\begin{eqnarray}\text{no partial effects}:E(Y^{10}|S)=E(Y^{01}|S)=E(Y^{00}|S),\end{eqnarray}$$
$$\begin{eqnarray}\text{no partial effects}:E(Y^{10}|S)=E(Y^{01}|S)=E(Y^{00}|S),\end{eqnarray}$$
then Equation (3) becomes
 $$\begin{eqnarray}E(Y|S)=E(Y^{00}|S)+\{E(Y^{11}|S)-E(Y^{00}|S)\}D.\end{eqnarray}$$
$$\begin{eqnarray}E(Y|S)=E(Y^{00}|S)+\{E(Y^{11}|S)-E(Y^{00}|S)\}D.\end{eqnarray}$$
It helps to see when the no partial-effect assumption is violated (recall Equation (1) with
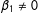 $\unicode[STIX]{x1D6FD}_{1}\neq 0$
or
$\unicode[STIX]{x1D6FD}_{1}\neq 0$
or
 $\unicode[STIX]{x1D6FD}_{2}\neq 0$
):
$\unicode[STIX]{x1D6FD}_{2}\neq 0$
):
 $$\begin{eqnarray}\displaystyle & & \displaystyle E(Y^{11})=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{1}+\unicode[STIX]{x1D6FD}_{2}+\unicode[STIX]{x1D6FD}_{d},\quad E(Y^{10})=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{1},\quad E(Y^{01})=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{2},\quad E(Y^{00})=\unicode[STIX]{x1D6FD}_{0}\nonumber\\ \displaystyle & & \displaystyle \quad \Longrightarrow E(Y^{11})-E(Y^{10})-E(Y^{01})+E(Y^{00})=\unicode[STIX]{x1D6FD}_{d},E(Y^{11})-E(Y^{00})=\unicode[STIX]{x1D6FD}_{1}+\unicode[STIX]{x1D6FD}_{2}+\unicode[STIX]{x1D6FD}_{d}.\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle E(Y^{11})=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{1}+\unicode[STIX]{x1D6FD}_{2}+\unicode[STIX]{x1D6FD}_{d},\quad E(Y^{10})=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{1},\quad E(Y^{01})=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{2},\quad E(Y^{00})=\unicode[STIX]{x1D6FD}_{0}\nonumber\\ \displaystyle & & \displaystyle \quad \Longrightarrow E(Y^{11})-E(Y^{10})-E(Y^{01})+E(Y^{00})=\unicode[STIX]{x1D6FD}_{d},E(Y^{11})-E(Y^{00})=\unicode[STIX]{x1D6FD}_{1}+\unicode[STIX]{x1D6FD}_{2}+\unicode[STIX]{x1D6FD}_{d}.\nonumber\end{eqnarray}$$
Examine squares 1–4 in the left panel of Figure 1, where
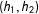 $(h_{1},h_{2})$
are the two localizing bandwidths. There is one treatment group (square 1) and three control groups (squares 2, 3 and 4). Under no partial effect, the treatment effect can be found by comparing squares 1 and 2, 1 and 4, or 1 and 3. With partial effects present, however, this is no longer the case: squares 1 and 2 give the treatment effect
$(h_{1},h_{2})$
are the two localizing bandwidths. There is one treatment group (square 1) and three control groups (squares 2, 3 and 4). Under no partial effect, the treatment effect can be found by comparing squares 1 and 2, 1 and 4, or 1 and 3. With partial effects present, however, this is no longer the case: squares 1 and 2 give the treatment effect
 $\unicode[STIX]{x1D6FD}_{d}$
plus the partial effect due to
$\unicode[STIX]{x1D6FD}_{d}$
plus the partial effect due to
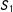 $S_{1}$
crossing
$S_{1}$
crossing
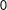 $0$
; squares 1 and 4 give
$0$
; squares 1 and 4 give
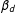 $\unicode[STIX]{x1D6FD}_{d}$
plus the partial effect due to
$\unicode[STIX]{x1D6FD}_{d}$
plus the partial effect due to
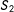 $S_{2}$
crossing
$S_{2}$
crossing
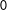 $0$
; squares 1 and 3 give
$0$
; squares 1 and 3 give
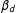 $\unicode[STIX]{x1D6FD}_{d}$
plus the two partial effects. It is only when we take DD as in Equation (3) that the desired
$\unicode[STIX]{x1D6FD}_{d}$
plus the two partial effects. It is only when we take DD as in Equation (3) that the desired
 $\unicode[STIX]{x1D6FD}_{d}$
is identified. More generally than the left panel of Figure 1, we may have the right panel where the four groups are not squares, but parts of an oval figure depending on the correlation between
$\unicode[STIX]{x1D6FD}_{d}$
is identified. More generally than the left panel of Figure 1, we may have the right panel where the four groups are not squares, but parts of an oval figure depending on the correlation between
 $S_{1}$
and
$S_{1}$
and
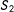 $S_{2}$
.
$S_{2}$
.

Figure 1. Two-Score RD in AND case (Square & Oval Neighborhoods).
2.2 Identification and Remarks
To simplify notation for limits of
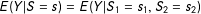 $E(Y|S=s)=E(Y|S_{1}=s_{1},S_{2}=s_{2})$
, denote
$E(Y|S=s)=E(Y|S_{1}=s_{1},S_{2}=s_{2})$
, denote
 $$\begin{eqnarray}\lim _{s_{1}\downarrow 0,s_{2}\downarrow 0}\text{ as }\lim _{+,+},\quad \lim _{s_{1}\uparrow 0,s_{2}\downarrow 0}\text{ as }\lim _{-,+},\quad \lim _{s_{1}\downarrow 0,s_{2}\uparrow 0}\text{ as }\lim _{+,-},\quad \lim _{s_{1}\uparrow 0,s_{2}\uparrow 0}\text{ as }\lim _{-,-}.\end{eqnarray}$$
$$\begin{eqnarray}\lim _{s_{1}\downarrow 0,s_{2}\downarrow 0}\text{ as }\lim _{+,+},\quad \lim _{s_{1}\uparrow 0,s_{2}\downarrow 0}\text{ as }\lim _{-,+},\quad \lim _{s_{1}\downarrow 0,s_{2}\uparrow 0}\text{ as }\lim _{+,-},\quad \lim _{s_{1}\uparrow 0,s_{2}\uparrow 0}\text{ as }\lim _{-,-}.\end{eqnarray}$$
Assume that these double limits of
 $E(\cdot |S)$
exist at
$E(\cdot |S)$
exist at
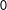 $0$
for the potential responses, and denote them using
$0$
for the potential responses, and denote them using
 $0^{-}$
and
$0^{-}$
and
 $0^{+}$
; for example,
$0^{+}$
; for example,
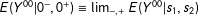 $E(Y^{00}|0^{-},0^{+})\equiv \lim _{-,+}E(Y^{00}|s_{1},s_{2})$
.
$E(Y^{00}|0^{-},0^{+})\equiv \lim _{-,+}E(Y^{00}|s_{1},s_{2})$
.
Take the double limits on Equation (2) to get
 $$\begin{eqnarray}\displaystyle \begin{array}{@{}c@{}}E(Y|0^{+},0^{+})=E(Y^{11}|0^{+},0^{+}),\quad E(Y|0^{+},0^{-})=E(Y^{10}|0^{+},0^{-}),\\ E(Y|0^{-},0^{+})=E(Y^{01}|0^{-},0^{+}),\quad E(Y|0^{-},0^{-})=E(Y^{00}|0^{-},0^{-}).\end{array} & & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \begin{array}{@{}c@{}}E(Y|0^{+},0^{+})=E(Y^{11}|0^{+},0^{+}),\quad E(Y|0^{+},0^{-})=E(Y^{10}|0^{+},0^{-}),\\ E(Y|0^{-},0^{+})=E(Y^{01}|0^{-},0^{+}),\quad E(Y|0^{-},0^{-})=E(Y^{00}|0^{-},0^{-}).\end{array} & & \displaystyle\end{eqnarray}$$
These give a limiting version of the slope of
 $D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
in Equation (3) at
$D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
in Equation (3) at
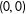 $(0,0)$
:
$(0,0)$
:
 $$\begin{eqnarray}\displaystyle & & \displaystyle E(Y|0^{+},0^{+})-E(Y|0^{+},0^{-})-E(Y|0^{-},0^{+})+E(Y|0^{-},0^{-})\nonumber\\ \displaystyle & & \displaystyle \quad =E(Y^{11}|0^{+},0^{+})-E(Y^{10}|0^{+},0^{-})-E(Y^{01}|0^{-},0^{+})+E(Y^{00}|0^{-},0^{-}).\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle E(Y|0^{+},0^{+})-E(Y|0^{+},0^{-})-E(Y|0^{-},0^{+})+E(Y|0^{-},0^{-})\nonumber\\ \displaystyle & & \displaystyle \quad =E(Y^{11}|0^{+},0^{+})-E(Y^{10}|0^{+},0^{-})-E(Y^{01}|0^{-},0^{+})+E(Y^{00}|0^{-},0^{-}).\end{eqnarray}$$
Assume the continuity condition (note that all right-hand side terms have
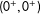 $(0^{+},0^{+})$
)
$(0^{+},0^{+})$
)
 $$\begin{eqnarray}\displaystyle \begin{array}{@{}c@{}}\text{(i):}~\,E(Y^{01}|0^{-},0^{+})=E(Y^{01}|0^{+},0^{+}),\\ \text{(ii):}~\,E(Y^{10}|0^{+},0^{-})=E(Y^{10}|0^{+},0^{+}),\\ \text{(iii):}~\,E(Y^{00}|0^{-},0^{-})=E(Y^{00}|0^{+},0^{+}).\end{array} & & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \begin{array}{@{}c@{}}\text{(i):}~\,E(Y^{01}|0^{-},0^{+})=E(Y^{01}|0^{+},0^{+}),\\ \text{(ii):}~\,E(Y^{10}|0^{+},0^{-})=E(Y^{10}|0^{+},0^{+}),\\ \text{(iii):}~\,E(Y^{00}|0^{-},0^{-})=E(Y^{00}|0^{+},0^{+}).\end{array} & & \displaystyle\end{eqnarray}$$
Equation (7)(i) is plausible because
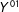 $Y^{01}$
is untreated along
$Y^{01}$
is untreated along
 $s_{1}$
, (ii) because
$s_{1}$
, (ii) because
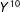 $Y^{10}$
is untreated along
$Y^{10}$
is untreated along
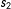 $s_{2}$
, and (iii) because
$s_{2}$
, and (iii) because
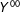 $Y^{00}$
is untreated along both
$Y^{00}$
is untreated along both
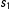 $s_{1}$
and
$s_{1}$
and
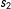 $s_{2}$
. These continuity conditions show how counterfactuals for the treatment group with
$s_{2}$
. These continuity conditions show how counterfactuals for the treatment group with
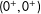 $(0^{+},0^{+})$
can be identified. For example, Equation (7)(i) is that the counterfactual
$(0^{+},0^{+})$
can be identified. For example, Equation (7)(i) is that the counterfactual
 $E(Y^{01}|0^{+},0^{+})$
for the treatment group can be identified with
$E(Y^{01}|0^{+},0^{+})$
for the treatment group can be identified with
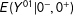 $E(Y^{01}|0^{-},0^{+})$
from the partially treated group
$E(Y^{01}|0^{-},0^{+})$
from the partially treated group
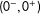 $(0^{-},0^{+})$
.
$(0^{-},0^{+})$
.
Using Equations (7), (6) becomes
 $$\begin{eqnarray}\displaystyle & & \displaystyle E(Y|0^{+},0^{+})-E(Y|0^{+},0^{-})-E(Y|0^{-},0^{+})+E(Y|0^{-},0^{-})\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle E(Y|0^{+},0^{+})-E(Y|0^{+},0^{-})-E(Y|0^{-},0^{+})+E(Y|0^{-},0^{-})\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle & & \displaystyle \quad =\unicode[STIX]{x1D6FD}_{d}\equiv E(Y^{11}|0^{+},0^{+})-E(Y^{10}|0^{+},0^{+})-E(Y^{01}|0^{+},0^{+})+E(Y^{00}|0^{+},0^{+})\nonumber\\ \displaystyle & & \displaystyle \quad =E(Y^{11}-Y^{10}-Y^{01}+Y^{00}|0^{+},0^{+});\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle \quad =\unicode[STIX]{x1D6FD}_{d}\equiv E(Y^{11}|0^{+},0^{+})-E(Y^{10}|0^{+},0^{+})-E(Y^{01}|0^{+},0^{+})+E(Y^{00}|0^{+},0^{+})\nonumber\\ \displaystyle & & \displaystyle \quad =E(Y^{11}-Y^{10}-Y^{01}+Y^{00}|0^{+},0^{+});\end{eqnarray}$$
Equation (8) is an identified entity that is characterized by Equation (9)—the mean effect on the just treated
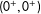 $(0^{+},0^{+})$
. We summarize this (as well as Equation (4) under no partial effect) as a theorem, with a three-score MRD extension provided in the appendix A.
$(0^{+},0^{+})$
. We summarize this (as well as Equation (4) under no partial effect) as a theorem, with a three-score MRD extension provided in the appendix A.
Theorem 1. Suppose the double limits of
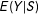 $E(Y|S)$
exist at 0 for the potential responses, the continuity condition Equation (7) holds, and the density function
$E(Y|S)$
exist at 0 for the potential responses, the continuity condition Equation (7) holds, and the density function
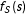 $f_{S}(s)$
of
$f_{S}(s)$
of
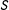 $S$
is strictly positive on a neighborhood of
$S$
is strictly positive on a neighborhood of
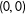 $(0,0)$
. Then the effect
$(0,0)$
. Then the effect
 $$\begin{eqnarray}\unicode[STIX]{x1D6FD}_{d}=E(Y^{11}-Y^{10}-Y^{01}+Y^{00}|0^{+},0^{+})\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D6FD}_{d}=E(Y^{11}-Y^{10}-Y^{01}+Y^{00}|0^{+},0^{+})\end{eqnarray}$$
is identified by two-score MRD Equation (8). If no partial-effect condition holds at
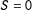 $S=0$
(i.e.,
$S=0$
(i.e.,
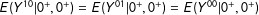 $E(Y^{10}|0^{+},0^{+})=E(Y^{01}|0^{+},0^{+})=E(Y^{00}|0^{+},0^{+})$
), then
$E(Y^{10}|0^{+},0^{+})=E(Y^{01}|0^{+},0^{+})=E(Y^{00}|0^{+},0^{+})$
), then
 $\unicode[STIX]{x1D6FD}_{d}=E(Y^{11}-Y^{00}|0^{+},0^{+})$
.
$\unicode[STIX]{x1D6FD}_{d}=E(Y^{11}-Y^{00}|0^{+},0^{+})$
.
Would partial effects really matter? Partial effects may be unlikely in certain MRDs. For instance, in two-dimensional geographic MRD with latitude
 $S_{1}$
and longitude
$S_{1}$
and longitude
 $S_{2}$
, simply crossing only one boundary may not do much of anything. But if
$S_{2}$
, simply crossing only one boundary may not do much of anything. But if
 $S_{2}\geqslant 0$
corresponds to being on the right side of mountains ranging south to north, then a partial effect due to
$S_{2}\geqslant 0$
corresponds to being on the right side of mountains ranging south to north, then a partial effect due to
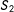 $S_{2}$
can occur, because the weather on the right side of the mountain range can be much different from that on the left side. Another example is the effects of a conservative party being the majority in both houses of parliament on the passage of bills, where the cutoff is 50% of the seats in each house. Even if the conservative party is the majority in only one of the two houses, still the passage rate can be different from when the conservative party is not the majority in either house. Given that allowing for partial effects is not difficult at all as can be seen shortly, there is no reason to simply assume away partial effects.
$S_{2}$
can occur, because the weather on the right side of the mountain range can be much different from that on the left side. Another example is the effects of a conservative party being the majority in both houses of parliament on the passage of bills, where the cutoff is 50% of the seats in each house. Even if the conservative party is the majority in only one of the two houses, still the passage rate can be different from when the conservative party is not the majority in either house. Given that allowing for partial effects is not difficult at all as can be seen shortly, there is no reason to simply assume away partial effects.
2.3 OLS
Although Equation (8) shows that
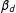 $\unicode[STIX]{x1D6FD}_{d}$
can be estimated by replacing the four identified elements in Equation (8) with their sample versions, in practice, it is easier to implement MRD with Equation (3), using only the local observations satisfying
$\unicode[STIX]{x1D6FD}_{d}$
can be estimated by replacing the four identified elements in Equation (8) with their sample versions, in practice, it is easier to implement MRD with Equation (3), using only the local observations satisfying
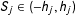 $S_{j}\in (-h_{j},h_{j})$
,
$S_{j}\in (-h_{j},h_{j})$
,
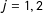 $j=1,2$
. Specifically, replace
$j=1,2$
. Specifically, replace
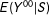 $E(Y^{00}|S)$
in Equation (3) with a (piecewise-) continuous function of
$E(Y^{00}|S)$
in Equation (3) with a (piecewise-) continuous function of
 $S$
, and replace the slopes of
$S$
, and replace the slopes of
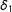 $\unicode[STIX]{x1D6FF}_{1}$
,
$\unicode[STIX]{x1D6FF}_{1}$
,
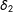 $\unicode[STIX]{x1D6FF}_{2}$
and
$\unicode[STIX]{x1D6FF}_{2}$
and
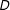 $D$
with parameters
$D$
with parameters
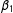 $\unicode[STIX]{x1D6FD}_{1}$
,
$\unicode[STIX]{x1D6FD}_{1}$
,
 $\unicode[STIX]{x1D6FD}_{2}$
and
$\unicode[STIX]{x1D6FD}_{2}$
and
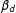 $\unicode[STIX]{x1D6FD}_{d}$
to obtain
$\unicode[STIX]{x1D6FD}_{d}$
to obtain
 $$\begin{eqnarray}E(Y|S)=E(Y^{00}|S)+\unicode[STIX]{x1D6FD}_{1}\unicode[STIX]{x1D6FF}_{1}+\unicode[STIX]{x1D6FD}_{2}\unicode[STIX]{x1D6FF}_{2}+\unicode[STIX]{x1D6FD}_{d}D\end{eqnarray}$$
$$\begin{eqnarray}E(Y|S)=E(Y^{00}|S)+\unicode[STIX]{x1D6FD}_{1}\unicode[STIX]{x1D6FF}_{1}+\unicode[STIX]{x1D6FD}_{2}\unicode[STIX]{x1D6FF}_{2}+\unicode[STIX]{x1D6FD}_{d}D\end{eqnarray}$$
where
 $E(Y^{00}|S)$
is specified as
$E(Y^{00}|S)$
is specified as
 $$\begin{eqnarray}\displaystyle \begin{array}{@{}c@{}}\mathit{linear}:\quad m_{1}(S)\equiv \text{a linear function of }S_{1},S_{2}\text{ with intercept }\unicode[STIX]{x1D6FD}_{0}\\ \mathit{quadratic}:\quad m_{2}(S)\equiv m_{1}(S)+\text{a linear function of }S_{1}^{2},S_{2}^{2},S_{1}S_{2}.\end{array} & & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \begin{array}{@{}c@{}}\mathit{linear}:\quad m_{1}(S)\equiv \text{a linear function of }S_{1},S_{2}\text{ with intercept }\unicode[STIX]{x1D6FD}_{0}\\ \mathit{quadratic}:\quad m_{2}(S)\equiv m_{1}(S)+\text{a linear function of }S_{1}^{2},S_{2}^{2},S_{1}S_{2}.\end{array} & & \displaystyle\end{eqnarray}$$
Then OLS can be applied to Equation (10) to do inference with the usual OLS asymptotic variance estimator. If
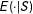 $E(\cdot |S)$
in Equation (10) is replaced with a conditional quantile/mode, quantile/mode regression can be applied to estimate the quantile/modal parameters.
$E(\cdot |S)$
in Equation (10) is replaced with a conditional quantile/mode, quantile/mode regression can be applied to estimate the quantile/modal parameters.
With
 $$\begin{eqnarray}\unicode[STIX]{x1D6FF}_{j}^{-}\equiv 1[-h_{j}<S_{j}<0],\quad \unicode[STIX]{x1D6FF}_{j}^{+}\equiv 1[0\leqslant S_{j}<h_{j}],\quad j=1,2,\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D6FF}_{j}^{-}\equiv 1[-h_{j}<S_{j}<0],\quad \unicode[STIX]{x1D6FF}_{j}^{+}\equiv 1[0\leqslant S_{j}<h_{j}],\quad j=1,2,\end{eqnarray}$$
another way to set
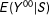 $E(Y^{00}|S)$
is a piecewise-linear function continuous at
$E(Y^{00}|S)$
is a piecewise-linear function continuous at
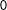 $0$
:
$0$
:
 $$\begin{eqnarray}\displaystyle & & \displaystyle E(Y^{00}|S)=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{11}\unicode[STIX]{x1D6FF}_{1}^{-}\unicode[STIX]{x1D6FF}_{2}^{-}S_{1}+\unicode[STIX]{x1D6FD}_{12}\unicode[STIX]{x1D6FF}_{1}^{-}\unicode[STIX]{x1D6FF}_{2}^{-}S_{2}+\unicode[STIX]{x1D6FD}_{21}\unicode[STIX]{x1D6FF}_{1}^{-}\unicode[STIX]{x1D6FF}_{2}^{+}S_{1}+\unicode[STIX]{x1D6FD}_{22}\unicode[STIX]{x1D6FF}_{1}^{-}\unicode[STIX]{x1D6FF}_{2}^{+}S_{2}\nonumber\\ \displaystyle & & \displaystyle +\,\unicode[STIX]{x1D6FD}_{31}\unicode[STIX]{x1D6FF}_{1}^{+}\unicode[STIX]{x1D6FF}_{2}^{-}S_{1}+\unicode[STIX]{x1D6FD}_{32}\unicode[STIX]{x1D6FF}_{1}^{+}\unicode[STIX]{x1D6FF}_{2}^{-}S_{2}+\unicode[STIX]{x1D6FD}_{41}\unicode[STIX]{x1D6FF}_{1}^{+}\unicode[STIX]{x1D6FF}_{2}^{+}S_{1}+\unicode[STIX]{x1D6FD}_{42}\unicode[STIX]{x1D6FF}_{1}^{+}\unicode[STIX]{x1D6FF}_{2}^{+}S_{2}.\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle E(Y^{00}|S)=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{11}\unicode[STIX]{x1D6FF}_{1}^{-}\unicode[STIX]{x1D6FF}_{2}^{-}S_{1}+\unicode[STIX]{x1D6FD}_{12}\unicode[STIX]{x1D6FF}_{1}^{-}\unicode[STIX]{x1D6FF}_{2}^{-}S_{2}+\unicode[STIX]{x1D6FD}_{21}\unicode[STIX]{x1D6FF}_{1}^{-}\unicode[STIX]{x1D6FF}_{2}^{+}S_{1}+\unicode[STIX]{x1D6FD}_{22}\unicode[STIX]{x1D6FF}_{1}^{-}\unicode[STIX]{x1D6FF}_{2}^{+}S_{2}\nonumber\\ \displaystyle & & \displaystyle +\,\unicode[STIX]{x1D6FD}_{31}\unicode[STIX]{x1D6FF}_{1}^{+}\unicode[STIX]{x1D6FF}_{2}^{-}S_{1}+\unicode[STIX]{x1D6FD}_{32}\unicode[STIX]{x1D6FF}_{1}^{+}\unicode[STIX]{x1D6FF}_{2}^{-}S_{2}+\unicode[STIX]{x1D6FD}_{41}\unicode[STIX]{x1D6FF}_{1}^{+}\unicode[STIX]{x1D6FF}_{2}^{+}S_{1}+\unicode[STIX]{x1D6FD}_{42}\unicode[STIX]{x1D6FF}_{1}^{+}\unicode[STIX]{x1D6FF}_{2}^{+}S_{2}.\end{eqnarray}$$
This allows different slopes across the four quadrants determined by
 $(\unicode[STIX]{x1D6FF}_{1}^{-},\unicode[STIX]{x1D6FF}_{1}^{+},\unicode[STIX]{x1D6FF}_{2}^{-},\unicode[STIX]{x1D6FF}_{2}^{+})$
.
$(\unicode[STIX]{x1D6FF}_{1}^{-},\unicode[STIX]{x1D6FF}_{1}^{+},\unicode[STIX]{x1D6FF}_{2}^{-},\unicode[STIX]{x1D6FF}_{2}^{+})$
.
The above MRD estimation requires choosing the functional form for
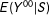 $E(Y^{00}|S)$
,
$E(Y^{00}|S)$
,
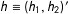 $h\equiv (h_{1},h_{2})^{\prime }$
for
$h\equiv (h_{1},h_{2})^{\prime }$
for
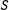 $S$
, and a weighting function within the chosen local neighborhood. First, we use only a linear or quadratic function of
$S$
, and a weighting function within the chosen local neighborhood. First, we use only a linear or quadratic function of
 $S$
in Equations (11) and (12), as Gelman and Imbens (Reference Gelman and Imbens2018) advise against using high-order polynomials in RD. Second, developing optimal bandwidths for
$S$
in Equations (11) and (12), as Gelman and Imbens (Reference Gelman and Imbens2018) advise against using high-order polynomials in RD. Second, developing optimal bandwidths for
 $h$
in MRD as Imbens and Kalyanaraman (Reference Imbens and Kalyanaraman2012) and Calonico, Cattaneo and Titiunik (Reference Calonico, Cattaneo and Titiunik2014) did for single-score RD would be very involved, going over the scope of this paper; instead, we use a rule-of-thumb bandwidth
$h$
in MRD as Imbens and Kalyanaraman (Reference Imbens and Kalyanaraman2012) and Calonico, Cattaneo and Titiunik (Reference Calonico, Cattaneo and Titiunik2014) did for single-score RD would be very involved, going over the scope of this paper; instead, we use a rule-of-thumb bandwidth
 $N^{-1/6}$
with both scores standardized, and explore cross validation (CV) schemes below to find useful reference bandwidths. Third, we do not use any weighting function within the chosen local neighborhood in the above OLS, which amounts to adopting the uniform weight; this is a common practice, as weighting seems to make little difference in practice. There is no proof that these choices that we make are optimal, which means that our proposed estimation strategy in this section to be applied in the empirical section should be taken as tentative; hopefully, further research settles the estimation issues in a more satisfactory manner.
$N^{-1/6}$
with both scores standardized, and explore cross validation (CV) schemes below to find useful reference bandwidths. Third, we do not use any weighting function within the chosen local neighborhood in the above OLS, which amounts to adopting the uniform weight; this is a common practice, as weighting seems to make little difference in practice. There is no proof that these choices that we make are optimal, which means that our proposed estimation strategy in this section to be applied in the empirical section should be taken as tentative; hopefully, further research settles the estimation issues in a more satisfactory manner.
In RD, the sample size can be small due to the localization, and the problem gets exacerbated for MRD. In case this happens, Cattaneo, Frandsen and Titiunik (Reference Cattaneo, Frandsen and Titiunik2015), Keele, Titiunik and Zubizarreta (Reference Keele, Titiunik and Zubizarreta2015) and Cattaneo, Titiunik and Vazquez-Bare (Reference Cattaneo, Titiunik and Vazquez-Bare2017) proposed “randomized inference.” But applying this to MRD is challenging, because randomly assigning each subject to one of the four groups under the null of no effect requires the null hypothesis to be
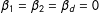 $\unicode[STIX]{x1D6FD}_{1}=\unicode[STIX]{x1D6FD}_{2}=\unicode[STIX]{x1D6FD}_{d}=0$
in Equation (10) instead of only
$\unicode[STIX]{x1D6FD}_{1}=\unicode[STIX]{x1D6FD}_{2}=\unicode[STIX]{x1D6FD}_{d}=0$
in Equation (10) instead of only
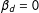 $\unicode[STIX]{x1D6FD}_{d}=0$
while allowing
$\unicode[STIX]{x1D6FD}_{d}=0$
while allowing
 $\unicode[STIX]{x1D6FD}_{1}\neq 0$
or
$\unicode[STIX]{x1D6FD}_{1}\neq 0$
or
 $\unicode[STIX]{x1D6FD}_{2}\neq 0$
, which was the very motivation for this paper. Designing a proper randomized inference for MRD is an interesting research question, but it goes beyond the scope of this paper.
$\unicode[STIX]{x1D6FD}_{2}\neq 0$
, which was the very motivation for this paper. Designing a proper randomized inference for MRD is an interesting research question, but it goes beyond the scope of this paper.
About choosing
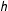 $h$
, one CV scheme for MRD is minimizing
$h$
, one CV scheme for MRD is minimizing
with respect to
 $h$
, where
$h$
, where
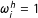 $\unicode[STIX]{x1D714}_{i}^{h}=1$
for
$\unicode[STIX]{x1D714}_{i}^{h}=1$
for
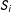 $S_{i}$
with at least 2 or 3 observations in each of the four directions within its “square neighborhood”
$S_{i}$
with at least 2 or 3 observations in each of the four directions within its “square neighborhood”
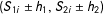 $(S_{1i}\pm h_{1},S_{2i}\pm h_{2})$
, and
$(S_{1i}\pm h_{1},S_{2i}\pm h_{2})$
, and
 $\unicode[STIX]{x1D714}_{i}^{h}=0$
otherwise; this ensures ruling out
$\unicode[STIX]{x1D714}_{i}^{h}=0$
otherwise; this ensures ruling out
 $S_{i}$
’s on its support boundaries. In this CV scheme,
$S_{i}$
’s on its support boundaries. In this CV scheme,
 $\tilde{E}_{-i}(Y|S_{i},h)$
is a nonparametric kernel predictor using an one-sided kernel estimator depending on the side of
$\tilde{E}_{-i}(Y|S_{i},h)$
is a nonparametric kernel predictor using an one-sided kernel estimator depending on the side of
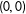 $(0,0)$
where
$(0,0)$
where
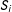 $S_{i}$
is located among the four sides, which is a generalization of the CV scheme in Ludwig and Miller (Reference Ludwig and Miller2007) who applied Equation (13) to single-score RD. As as it turned out, however, we experienced the same problem as Ludwig and Miller (Reference Ludwig and Miller2007) experienced: too large bandwidths that make most
$S_{i}$
is located among the four sides, which is a generalization of the CV scheme in Ludwig and Miller (Reference Ludwig and Miller2007) who applied Equation (13) to single-score RD. As as it turned out, however, we experienced the same problem as Ludwig and Miller (Reference Ludwig and Miller2007) experienced: too large bandwidths that make most
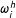 $\unicode[STIX]{x1D714}_{i}^{h}$
’s zero and predict the few remaining
$\unicode[STIX]{x1D714}_{i}^{h}$
’s zero and predict the few remaining
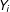 $Y_{i}$
’s well to make Equation (13) small.
$Y_{i}$
’s well to make Equation (13) small.
The problem of too large bandwidths does not occur to the “conventional CV” which uses all-sided symmetric weighting to minimize
 $$\begin{eqnarray}\frac{1}{N}\mathop{\sum }_{i}\{Y_{i}-\hat{E}_{-i}(Y|S_{i},h)\}^{2}\quad \text{where}~\hat{E}_{-i}(Y|S_{i},h)\equiv \frac{\mathop{\sum }_{j\neq i}K_{h}(S_{j}-S_{i})Y_{j}}{\mathop{\sum }_{j\neq i}K_{h}(S_{j}-S_{i})}\end{eqnarray}$$
$$\begin{eqnarray}\frac{1}{N}\mathop{\sum }_{i}\{Y_{i}-\hat{E}_{-i}(Y|S_{i},h)\}^{2}\quad \text{where}~\hat{E}_{-i}(Y|S_{i},h)\equiv \frac{\mathop{\sum }_{j\neq i}K_{h}(S_{j}-S_{i})Y_{j}}{\mathop{\sum }_{j\neq i}K_{h}(S_{j}-S_{i})}\end{eqnarray}$$
and
 $K_{h}$
is a kernel function with bandwidths
$K_{h}$
is a kernel function with bandwidths
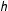 $h$
. This is known to behave well: the resulting minimand is nearly convex and the conventional CV bandwidth is asymptotically optimal. The reason why this is not used in single-score RD is that
$h$
. This is known to behave well: the resulting minimand is nearly convex and the conventional CV bandwidth is asymptotically optimal. The reason why this is not used in single-score RD is that
 $E(Y|S)$
has a break, instead of being continuous in
$E(Y|S)$
has a break, instead of being continuous in
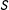 $S$
, and consequently
$S$
, and consequently
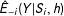 $\hat{E}_{-i}(Y|S_{i},h)$
is biased for
$\hat{E}_{-i}(Y|S_{i},h)$
is biased for
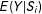 $E(Y|S_{i})$
when
$E(Y|S_{i})$
when
 $S_{i}$
is near the cutoff. Nevertheless, since the goal is finding a reasonable
$S_{i}$
is near the cutoff. Nevertheless, since the goal is finding a reasonable
 $h$
, not necessarily predicting
$h$
, not necessarily predicting
 $Y$
well, we use this conventional CV.
$Y$
well, we use this conventional CV.
Although we adopt the uniform weight within a chosen neighborhood, still the neighborhood should be chosen whose form differs as Figure 1 illustrates. With
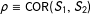 $\unicode[STIX]{x1D70C}\equiv \text{COR}(S_{1},S_{2})$
,
$\unicode[STIX]{x1D70C}\equiv \text{COR}(S_{1},S_{2})$
,
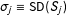 $\unicode[STIX]{x1D70E}_{j}\equiv \text{SD}(S_{j})$
and
$\unicode[STIX]{x1D70E}_{j}\equiv \text{SD}(S_{j})$
and
 $\unicode[STIX]{x1D702}_{j}\equiv h_{j}/\unicode[STIX]{x1D70E}_{j}$
(
$\unicode[STIX]{x1D702}_{j}\equiv h_{j}/\unicode[STIX]{x1D70E}_{j}$
(
 $\Longleftrightarrow h_{j}\equiv \unicode[STIX]{x1D70E}_{j}\unicode[STIX]{x1D702}_{j}$
) for
$\Longleftrightarrow h_{j}\equiv \unicode[STIX]{x1D70E}_{j}\unicode[STIX]{x1D702}_{j}$
) for
 $j=1,2$
, we use
$j=1,2$
, we use
 $$\begin{eqnarray}\displaystyle \begin{array}{@{}l@{}}\text{(i) square-neighbor kernel:}~K_{h}(S)=1\left[\left|{\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}\unicode[STIX]{x1D702}_{1}}}\right|\leqslant 1\right]\cdot 1\left[\left|{\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}\unicode[STIX]{x1D702}_{2}}}\right|\leqslant 1\right],\\[12.0pt] \text{(ii) oval-neighbor kernel:}~K_{h}(S)=1\left[\left({\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}\unicode[STIX]{x1D702}_{1}}}\right)^{2}-2\unicode[STIX]{x1D70C}{\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}\unicode[STIX]{x1D702}_{1}}}{\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}\unicode[STIX]{x1D702}_{2}}}+\left({\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}\unicode[STIX]{x1D702}_{2}}}\right)^{2}\leqslant 1\right].\end{array} & & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \begin{array}{@{}l@{}}\text{(i) square-neighbor kernel:}~K_{h}(S)=1\left[\left|{\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}\unicode[STIX]{x1D702}_{1}}}\right|\leqslant 1\right]\cdot 1\left[\left|{\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}\unicode[STIX]{x1D702}_{2}}}\right|\leqslant 1\right],\\[12.0pt] \text{(ii) oval-neighbor kernel:}~K_{h}(S)=1\left[\left({\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}\unicode[STIX]{x1D702}_{1}}}\right)^{2}-2\unicode[STIX]{x1D70C}{\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}\unicode[STIX]{x1D702}_{1}}}{\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}\unicode[STIX]{x1D702}_{2}}}+\left({\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}\unicode[STIX]{x1D702}_{2}}}\right)^{2}\leqslant 1\right].\end{array} & & \displaystyle\end{eqnarray}$$
These kernels need normalizing factors, but they are irrelevant in choosing
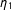 $\unicode[STIX]{x1D702}_{1}$
and
$\unicode[STIX]{x1D702}_{1}$
and
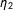 $\unicode[STIX]{x1D702}_{2}$
because they get canceled in
$\unicode[STIX]{x1D702}_{2}$
because they get canceled in
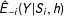 $\hat{E}_{-i}(Y|S_{i},h)$
.
$\hat{E}_{-i}(Y|S_{i},h)$
.
Setting
 $\unicode[STIX]{x1D702}_{1}=\unicode[STIX]{x1D702}_{2}\equiv \unicode[STIX]{x1D702}$
in Equation (15)(i) gives a square neighborhood of
$\unicode[STIX]{x1D702}_{1}=\unicode[STIX]{x1D702}_{2}\equiv \unicode[STIX]{x1D702}$
in Equation (15)(i) gives a square neighborhood of
 $0$
in the standardized scores
$0$
in the standardized scores
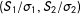 $(S_{1}/\unicode[STIX]{x1D70E}_{1},S_{2}/\unicode[STIX]{x1D70E}_{2})$
and setting
$(S_{1}/\unicode[STIX]{x1D70E}_{1},S_{2}/\unicode[STIX]{x1D70E}_{2})$
and setting
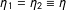 $\unicode[STIX]{x1D702}_{1}=\unicode[STIX]{x1D702}_{2}\equiv \unicode[STIX]{x1D702}$
and
$\unicode[STIX]{x1D702}_{1}=\unicode[STIX]{x1D702}_{2}\equiv \unicode[STIX]{x1D702}$
and
 $\unicode[STIX]{x1D70C}=0$
in Equation (15)(ii) gives a circle because the two kernels become
$\unicode[STIX]{x1D70C}=0$
in Equation (15)(ii) gives a circle because the two kernels become
 $$\begin{eqnarray}1\left[\left|{\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}}}\right|\leqslant \unicode[STIX]{x1D702}\right]\cdot 1\left[\left|{\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}}}\right|\leqslant \unicode[STIX]{x1D702}\right]\quad \text{and}\quad 1\left[\left({\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}}}\right)^{2}+\left({\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}}}\right)^{2}\leqslant \unicode[STIX]{x1D702}^{2}\right].\end{eqnarray}$$
$$\begin{eqnarray}1\left[\left|{\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}}}\right|\leqslant \unicode[STIX]{x1D702}\right]\cdot 1\left[\left|{\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}}}\right|\leqslant \unicode[STIX]{x1D702}\right]\quad \text{and}\quad 1\left[\left({\displaystyle \frac{S_{1}}{\unicode[STIX]{x1D70E}_{1}}}\right)^{2}+\left({\displaystyle \frac{S_{2}}{\unicode[STIX]{x1D70E}_{2}}}\right)^{2}\leqslant \unicode[STIX]{x1D702}^{2}\right].\end{eqnarray}$$
The oval shape is elongated along the 45 degree line when
 $\unicode[STIX]{x1D70C}>0$
as in the right panel of Figure 1, and such a neighborhood can better capture observations scattered along the 45 degree line; when
$\unicode[STIX]{x1D70C}>0$
as in the right panel of Figure 1, and such a neighborhood can better capture observations scattered along the 45 degree line; when
 $\unicode[STIX]{x1D70C}<0$
, the oval shape is elongated along the 135 degree line.
$\unicode[STIX]{x1D70C}<0$
, the oval shape is elongated along the 135 degree line.
3 Other Approaches in the Literature
Having presented our proposal, now we review the other approaches for MRD. First, two scores are collapsed into one so that the familiar single-score RD arsenal can be mobilized. Second, two-dimensional localization is avoided by doing, for example, one-dimensional localization for
 $S_{1}$
given
$S_{1}$
given
 $S_{2}\geqslant 0$
(i.e., given
$S_{2}\geqslant 0$
(i.e., given
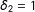 $\unicode[STIX]{x1D6FF}_{2}=1$
) to get the “effects on the boundary
$\unicode[STIX]{x1D6FF}_{2}=1$
) to get the “effects on the boundary
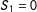 $S_{1}=0$
”; here as well, the familiar single-score RD methods can be utilized. Third, those effects on the boundary can be weight-averaged.
$S_{1}=0$
”; here as well, the familiar single-score RD methods can be utilized. Third, those effects on the boundary can be weight-averaged.
3.1 Minimum Score
Battistin et al. (Reference Battistin, Brugiavini, Rettore and Weber2009) and Clark and Martorell (Reference Clark and Martorell2014) defined
 $$\begin{eqnarray}S_{m}\equiv \min (S_{1},S_{2})~\Longrightarrow ~D=1[0\leqslant S_{m}]\end{eqnarray}$$
$$\begin{eqnarray}S_{m}\equiv \min (S_{1},S_{2})~\Longrightarrow ~D=1[0\leqslant S_{m}]\end{eqnarray}$$
to set up
 $$\begin{eqnarray}E(Y|S_{m})=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{-}S_{m}(1-D)+\unicode[STIX]{x1D6FD}_{+}S_{m}D+\unicode[STIX]{x1D6FD}_{m}D\end{eqnarray}$$
$$\begin{eqnarray}E(Y|S_{m})=\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{-}S_{m}(1-D)+\unicode[STIX]{x1D6FD}_{+}S_{m}D+\unicode[STIX]{x1D6FD}_{m}D\end{eqnarray}$$
where
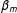 $\unicode[STIX]{x1D6FD}_{m}$
is the treatment effect of interest. Recalling Equation (10) with
$\unicode[STIX]{x1D6FD}_{m}$
is the treatment effect of interest. Recalling Equation (10) with
 $\unicode[STIX]{x1D6FD}_{1}=\unicode[STIX]{x1D6FD}_{2}=0$
, we can see that
$\unicode[STIX]{x1D6FD}_{1}=\unicode[STIX]{x1D6FD}_{2}=0$
, we can see that
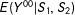 $E(Y^{00}|S_{1},S_{2})$
in Equation (10) is specified just as
$E(Y^{00}|S_{1},S_{2})$
in Equation (10) is specified just as
 $\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{-}S_{m}(1-D)+\unicode[STIX]{x1D6FD}_{+}S_{m}D$
.
$\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{-}S_{m}(1-D)+\unicode[STIX]{x1D6FD}_{+}S_{m}D$
.
This approach is problematic because the linear spline
 $\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{-}S_{m}(1-D)+\unicode[STIX]{x1D6FD}_{+}S_{m}D$
is inadequate: it approximates
$\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{-}S_{m}(1-D)+\unicode[STIX]{x1D6FD}_{+}S_{m}D$
is inadequate: it approximates
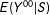 $E(Y^{00}|S)$
only with
$E(Y^{00}|S)$
only with
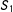 $S_{1}$
when
$S_{1}$
when
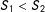 $S_{1}<S_{2}$
, and only with
$S_{1}<S_{2}$
, and only with
 $S_{2}$
when
$S_{2}$
when
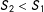 $S_{2}<S_{1}$
—there is no reason to voluntarily “ handcuff” oneself this way, and better approximations can be seen in Equations (11) and (12). Also, partial effects are ruled out because
$S_{2}<S_{1}$
—there is no reason to voluntarily “ handcuff” oneself this way, and better approximations can be seen in Equations (11) and (12). Also, partial effects are ruled out because
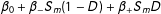 $\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{-}S_{m}(1-D)+\unicode[STIX]{x1D6FD}_{+}S_{m}D$
is continuous in
$\unicode[STIX]{x1D6FD}_{0}+\unicode[STIX]{x1D6FD}_{-}S_{m}(1-D)+\unicode[STIX]{x1D6FD}_{+}S_{m}D$
is continuous in
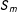 $S_{m}$
that is in turn continuous in
$S_{m}$
that is in turn continuous in
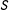 $S$
: no break along
$S$
: no break along
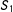 $S_{1}$
only (nor
$S_{1}$
only (nor
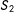 $S_{2}$
only) is allowed.
$S_{2}$
only) is allowed.
A couple of remarks are in order. First, Reardon and Robinson (Reference Reardon and Robinson2012) and Wong, Steiner and Cook (Reference Wong, Steiner and Cook2013) called this approach, respectively, “binding score approach” and “centering approach,” but “min approach” would be more fitting. Second, Battistin et al. (Reference Battistin, Brugiavini, Rettore and Weber2009) and Clark and Martorell (Reference Clark and Martorell2014) dealt with fuzzy mean-based MRDs, not sharp MRD. Third,
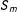 $S_{m}$
can be easily generalized to more than two scores; for example,
$S_{m}$
can be easily generalized to more than two scores; for example,
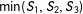 $\min (S_{1},S_{2},S_{3})$
for three scores as in Clark and Martorell (Reference Clark and Martorell2014).
$\min (S_{1},S_{2},S_{3})$
for three scores as in Clark and Martorell (Reference Clark and Martorell2014).
3.2 One-Dimensional Localization
The dominant approach in the MRD literature is looking at a subpopulation with one score already greater than its cutoff (Jacob and Lefgren Reference Jacob and Lefgren2004; Lalive Reference Lalive2008; Matsudaira Reference Matsudaira2008). For instance, on the subpopulation with
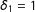 $\unicode[STIX]{x1D6FF}_{1}=1$
,
$\unicode[STIX]{x1D6FF}_{1}=1$
,
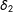 $\unicode[STIX]{x1D6FF}_{2}$
equals
$\unicode[STIX]{x1D6FF}_{2}$
equals
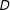 $D$
, and squares 1 and
$D$
, and squares 1 and
 $1^{\prime \prime }$
in the left panel of Figure 1 become the treatment group whereas squares 4 and
$1^{\prime \prime }$
in the left panel of Figure 1 become the treatment group whereas squares 4 and
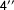 $4^{\prime \prime }$
become the control group. This raises efficiency because only one-dimensional localization is done with the larger control and treatment groups, but a bias appears if there is a partial effect. Reardon and Robinson (Reference Reardon and Robinson2012) and Wong, Steiner and Cook (Reference Wong, Steiner and Cook2013) called this “frontier approach” and “univariate approach,” respectively.
$4^{\prime \prime }$
become the control group. This raises efficiency because only one-dimensional localization is done with the larger control and treatment groups, but a bias appears if there is a partial effect. Reardon and Robinson (Reference Reardon and Robinson2012) and Wong, Steiner and Cook (Reference Wong, Steiner and Cook2013) called this “frontier approach” and “univariate approach,” respectively.
To formalize the idea, set
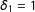 $\unicode[STIX]{x1D6FF}_{1}=1$
(
$\unicode[STIX]{x1D6FF}_{1}=1$
(
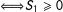 $\Longleftrightarrow S_{1}\geqslant 0$
) and
$\Longleftrightarrow S_{1}\geqslant 0$
) and
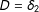 $D=\unicode[STIX]{x1D6FF}_{2}$
in Equation (3) to have
$D=\unicode[STIX]{x1D6FF}_{2}$
in Equation (3) to have
 $$\begin{eqnarray}E(Y|S)=E(Y^{10}|S)+\{E(Y^{11}|S)-E(Y^{10}|S)\}\unicode[STIX]{x1D6FF}_{2};\end{eqnarray}$$
$$\begin{eqnarray}E(Y|S)=E(Y^{10}|S)+\{E(Y^{11}|S)-E(Y^{10}|S)\}\unicode[STIX]{x1D6FF}_{2};\end{eqnarray}$$
 $E(Y^{10}|S)$
is the baseline now. Take the upper and lower limits only for
$E(Y^{10}|S)$
is the baseline now. Take the upper and lower limits only for
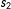 $s_{2}$
with
$s_{2}$
with
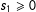 $s_{1}\geqslant 0$
:
$s_{1}\geqslant 0$
:
 $$\begin{eqnarray}\displaystyle E(Y|s_{1},0^{+}) & = & \displaystyle E(Y^{10}|s_{1},0^{+})+\lim _{s_{2}\downarrow 0}\{E(Y^{11}|s_{1},s_{2})-E(Y^{10}|s_{1},s_{2})\},\nonumber\\ \displaystyle E(Y|s_{1},0^{-}) & = & \displaystyle E(Y^{10}|s_{1},0^{-}).\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle E(Y|s_{1},0^{+}) & = & \displaystyle E(Y^{10}|s_{1},0^{+})+\lim _{s_{2}\downarrow 0}\{E(Y^{11}|s_{1},s_{2})-E(Y^{10}|s_{1},s_{2})\},\nonumber\\ \displaystyle E(Y|s_{1},0^{-}) & = & \displaystyle E(Y^{10}|s_{1},0^{-}).\nonumber\end{eqnarray}$$
Assume the continuity condition
 $$\begin{eqnarray}E(Y^{10}|s_{1},0^{+})=E(Y^{10}|s_{1},0^{-})\quad \forall s_{1}\geqslant 0;\end{eqnarray}$$
$$\begin{eqnarray}E(Y^{10}|s_{1},0^{+})=E(Y^{10}|s_{1},0^{-})\quad \forall s_{1}\geqslant 0;\end{eqnarray}$$
whereas this has “
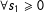 $\forall s_{1}\geqslant 0$
,” (ii) of Equation (7) is only for
$\forall s_{1}\geqslant 0$
,” (ii) of Equation (7) is only for
 $s_{1}=0^{+}$
that is weaker than Equation (17). Using Equation (17), the difference between the upper and lower limits gives
$s_{1}=0^{+}$
that is weaker than Equation (17). Using Equation (17), the difference between the upper and lower limits gives
 $$\begin{eqnarray}\unicode[STIX]{x1D6FD}^{10}(s_{1},0^{+})\equiv \lim _{s_{2}\downarrow 0}\{E(Y^{11}|s_{1},s_{2})-E(Y^{10}|s_{1},s_{2})\}=E(Y|s_{1},0^{+})-E(Y|s_{1},0^{-});\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D6FD}^{10}(s_{1},0^{+})\equiv \lim _{s_{2}\downarrow 0}\{E(Y^{11}|s_{1},s_{2})-E(Y^{10}|s_{1},s_{2})\}=E(Y|s_{1},0^{+})-E(Y|s_{1},0^{-});\end{eqnarray}$$
“
 $10$
” in
$10$
” in
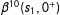 $\unicode[STIX]{x1D6FD}^{10}(s_{1},0^{+})$
refers to the baseline superscript in
$\unicode[STIX]{x1D6FD}^{10}(s_{1},0^{+})$
refers to the baseline superscript in
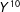 $Y^{10}$
. For Equation (1),
$Y^{10}$
. For Equation (1),
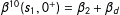 $\unicode[STIX]{x1D6FD}^{10}(s_{1},0^{+})=\unicode[STIX]{x1D6FD}_{2}+\unicode[STIX]{x1D6FD}_{d}$
, not
$\unicode[STIX]{x1D6FD}^{10}(s_{1},0^{+})=\unicode[STIX]{x1D6FD}_{2}+\unicode[STIX]{x1D6FD}_{d}$
, not
 $\unicode[STIX]{x1D6FD}_{d}$
.
$\unicode[STIX]{x1D6FD}_{d}$
.
Proceeding analogously, set
 $\unicode[STIX]{x1D6FF}_{2}=1$
(
$\unicode[STIX]{x1D6FF}_{2}=1$
(
 $\Longleftrightarrow S_{2}\geqslant 0$
) and
$\Longleftrightarrow S_{2}\geqslant 0$
) and
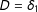 $D=\unicode[STIX]{x1D6FF}_{1}$
in Equation (3) to have
$D=\unicode[STIX]{x1D6FF}_{1}$
in Equation (3) to have
 $$\begin{eqnarray}E(Y|S)=E(Y^{01}|S)+\{E(Y^{11}|S)-E(Y^{01}|S)\}\unicode[STIX]{x1D6FF}_{1}.\end{eqnarray}$$
$$\begin{eqnarray}E(Y|S)=E(Y^{01}|S)+\{E(Y^{11}|S)-E(Y^{01}|S)\}\unicode[STIX]{x1D6FF}_{1}.\end{eqnarray}$$
Take the upper and lower limits only for
 $s_{1}$
with
$s_{1}$
with
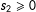 $s_{2}\geqslant 0$
:
$s_{2}\geqslant 0$
:
 $$\begin{eqnarray}\displaystyle E(Y|0^{+},s_{2}) & = & \displaystyle E(Y^{01}|0^{+},s_{2})+\lim _{s_{1}\downarrow 0}\{E(Y^{11}|s_{1},s_{2})-E(Y^{01}|s_{1},s_{2})\},\nonumber\\ \displaystyle E(Y|0^{-},s_{2}) & = & \displaystyle E(Y^{01}|0^{-},s_{2}).\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle E(Y|0^{+},s_{2}) & = & \displaystyle E(Y^{01}|0^{+},s_{2})+\lim _{s_{1}\downarrow 0}\{E(Y^{11}|s_{1},s_{2})-E(Y^{01}|s_{1},s_{2})\},\nonumber\\ \displaystyle E(Y|0^{-},s_{2}) & = & \displaystyle E(Y^{01}|0^{-},s_{2}).\nonumber\end{eqnarray}$$
Assume the continuity condition
 $$\begin{eqnarray}E(Y^{01}|0^{+},s_{2})=E(Y^{01}|0^{-},s_{2})\quad \forall s_{2}\geqslant 0.\end{eqnarray}$$
$$\begin{eqnarray}E(Y^{01}|0^{+},s_{2})=E(Y^{01}|0^{-},s_{2})\quad \forall s_{2}\geqslant 0.\end{eqnarray}$$
Using Equation (19), the difference between the upper and lower limits gives
 $$\begin{eqnarray}\unicode[STIX]{x1D6FD}^{01}(0^{+},s_{2})\equiv \lim _{s_{1}\downarrow 0}\{E(Y^{11}|s_{1},s_{2})-E(Y^{01}|s_{1},s_{2})\}=E(Y|0^{+},s_{2})-E(Y|0^{-},s_{2}).\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D6FD}^{01}(0^{+},s_{2})\equiv \lim _{s_{1}\downarrow 0}\{E(Y^{11}|s_{1},s_{2})-E(Y^{01}|s_{1},s_{2})\}=E(Y|0^{+},s_{2})-E(Y|0^{-},s_{2}).\end{eqnarray}$$
For Equation (1),
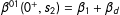 $\unicode[STIX]{x1D6FD}^{01}(0^{+},s_{2})=\unicode[STIX]{x1D6FD}_{1}+\unicode[STIX]{x1D6FD}_{d}$
, not
$\unicode[STIX]{x1D6FD}^{01}(0^{+},s_{2})=\unicode[STIX]{x1D6FD}_{1}+\unicode[STIX]{x1D6FD}_{d}$
, not
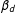 $\unicode[STIX]{x1D6FD}_{d}$
.
$\unicode[STIX]{x1D6FD}_{d}$
.
In estimation for Equation (16), the usual single-score RD approach would adopt
 $$\begin{eqnarray}E(Y|S)=E(Y^{10}|S)+\unicode[STIX]{x1D6FD}^{10}\unicode[STIX]{x1D6FF}_{2}\quad \text{for a parameter }\unicode[STIX]{x1D6FD}^{10}\end{eqnarray}$$
$$\begin{eqnarray}E(Y|S)=E(Y^{10}|S)+\unicode[STIX]{x1D6FD}^{10}\unicode[STIX]{x1D6FF}_{2}\quad \text{for a parameter }\unicode[STIX]{x1D6FD}^{10}\end{eqnarray}$$
analogously to Equation (10), where
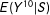 $E(Y^{10}|S)$
is specified as in Equation (11); only the subsample with
$E(Y^{10}|S)$
is specified as in Equation (11); only the subsample with
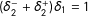 $(\unicode[STIX]{x1D6FF}_{2}^{-}+\unicode[STIX]{x1D6FF}_{2}^{+})\unicode[STIX]{x1D6FF}_{1}=1$
is used for estimation. There is no “oval-neighbor” analog, because only the observations with
$(\unicode[STIX]{x1D6FF}_{2}^{-}+\unicode[STIX]{x1D6FF}_{2}^{+})\unicode[STIX]{x1D6FF}_{1}=1$
is used for estimation. There is no “oval-neighbor” analog, because only the observations with
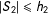 $|S_{2}|\leqslant h_{2}$
are used given
$|S_{2}|\leqslant h_{2}$
are used given
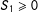 $S_{1}\geqslant 0$
.
$S_{1}\geqslant 0$
.
The model Equation (20) may be inadequate, because
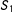 $S_{1}$
in the slope of
$S_{1}$
in the slope of
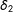 $\unicode[STIX]{x1D6FF}_{2}$
in Equation (16) is not localized. That is, replacing
$\unicode[STIX]{x1D6FF}_{2}$
in Equation (16) is not localized. That is, replacing
 $\unicode[STIX]{x1D6FD}^{10}$
in Equation (20) with a function of
$\unicode[STIX]{x1D6FD}^{10}$
in Equation (20) with a function of
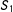 $S_{1}$
would be better, which then results in a model such as
$S_{1}$
would be better, which then results in a model such as
 $$\begin{eqnarray}E(Y|S)=E(Y^{10}|S)+\unicode[STIX]{x1D6FD}^{12}S_{1}\unicode[STIX]{x1D6FF}_{2}+\unicode[STIX]{x1D6FD}^{10}\unicode[STIX]{x1D6FF}_{2}\quad \text{for a parameter }\unicode[STIX]{x1D6FD}^{12}.\end{eqnarray}$$
$$\begin{eqnarray}E(Y|S)=E(Y^{10}|S)+\unicode[STIX]{x1D6FD}^{12}S_{1}\unicode[STIX]{x1D6FF}_{2}+\unicode[STIX]{x1D6FD}^{10}\unicode[STIX]{x1D6FF}_{2}\quad \text{for a parameter }\unicode[STIX]{x1D6FD}^{12}.\end{eqnarray}$$
For the opposite case of localizing with
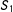 $S_{1}$
given
$S_{1}$
given
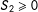 $S_{2}\geqslant 0$
, we can use analogously
$S_{2}\geqslant 0$
, we can use analogously
 $$\begin{eqnarray}E(Y|S)=E(Y^{01}|S)+\unicode[STIX]{x1D6FD}^{01}\unicode[STIX]{x1D6FF}_{1}\quad \text{or}\quad E(Y|S)=E(Y^{01}|S)+\unicode[STIX]{x1D6FD}^{21}S_{2}\unicode[STIX]{x1D6FF}_{1}+\unicode[STIX]{x1D6FD}^{01}\unicode[STIX]{x1D6FF}_{1}.\end{eqnarray}$$
$$\begin{eqnarray}E(Y|S)=E(Y^{01}|S)+\unicode[STIX]{x1D6FD}^{01}\unicode[STIX]{x1D6FF}_{1}\quad \text{or}\quad E(Y|S)=E(Y^{01}|S)+\unicode[STIX]{x1D6FD}^{21}S_{2}\unicode[STIX]{x1D6FF}_{1}+\unicode[STIX]{x1D6FD}^{01}\unicode[STIX]{x1D6FF}_{1}.\end{eqnarray}$$
3.3 Weighted Average of Boundary Effects
Imbens and Zajonc (Reference Imbens and Zajonc2009) dealt with both multiple-score sharp RD and fuzzy RD in a general set-up allowing both AND and OR cases. They discussed identification and estimation, assuming away partial effects. With
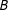 $B$
denoting the treatment and control boundary, the treatment effect at
$B$
denoting the treatment and control boundary, the treatment effect at
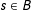 $s\in B$
for FRD is
$s\in B$
for FRD is
 $$\begin{eqnarray}\unicode[STIX]{x1D6FD}_{d}(s)\equiv \frac{\lim _{\unicode[STIX]{x1D708}\rightarrow 0}E\{Y|S\in N_{\unicode[STIX]{x1D708}}^{+}(s)\}-\lim _{\unicode[STIX]{x1D708}\rightarrow 0}E\{Y|S\in N_{\unicode[STIX]{x1D708}}^{-}(s)\}}{\lim _{\unicode[STIX]{x1D708}\rightarrow 0}E\{D|S\in N_{\unicode[STIX]{x1D708}}^{+}(s)\}-\lim _{\unicode[STIX]{x1D708}\rightarrow 0}E\{D|S\in N_{\unicode[STIX]{x1D708}}^{-}(s)\}}\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D6FD}_{d}(s)\equiv \frac{\lim _{\unicode[STIX]{x1D708}\rightarrow 0}E\{Y|S\in N_{\unicode[STIX]{x1D708}}^{+}(s)\}-\lim _{\unicode[STIX]{x1D708}\rightarrow 0}E\{Y|S\in N_{\unicode[STIX]{x1D708}}^{-}(s)\}}{\lim _{\unicode[STIX]{x1D708}\rightarrow 0}E\{D|S\in N_{\unicode[STIX]{x1D708}}^{+}(s)\}-\lim _{\unicode[STIX]{x1D708}\rightarrow 0}E\{D|S\in N_{\unicode[STIX]{x1D708}}^{-}(s)\}}\end{eqnarray}$$
where
 $N_{\unicode[STIX]{x1D708}}^{+}(s)$
and
$N_{\unicode[STIX]{x1D708}}^{+}(s)$
and
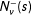 $N_{\unicode[STIX]{x1D708}}^{-}(s)$
denote the “
$N_{\unicode[STIX]{x1D708}}^{-}(s)$
denote the “
 $\unicode[STIX]{x1D708}$
-treated”- and “
$\unicode[STIX]{x1D708}$
-treated”- and “
 $\unicode[STIX]{x1D708}$
-control” neighborhoods of
$\unicode[STIX]{x1D708}$
-control” neighborhoods of
 $s$
.
$s$
.
Imbens and Zajonc (Reference Imbens and Zajonc2009) proposed also an integrated version of
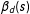 $\unicode[STIX]{x1D6FD}_{d}(s)$
:
$\unicode[STIX]{x1D6FD}_{d}(s)$
:
 $$\begin{eqnarray}\unicode[STIX]{x1D6FD}_{d}\equiv \int _{s\in B}\unicode[STIX]{x1D6FD}_{d}(s)f_{S}(s|S\in B)\unicode[STIX]{x2202}s=\frac{\int _{s\in B}\unicode[STIX]{x1D6FD}_{d}(s)f_{S}(s)\unicode[STIX]{x2202}s}{\int _{s\in B}f_{S}(s)\unicode[STIX]{x2202}s}.\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D6FD}_{d}\equiv \int _{s\in B}\unicode[STIX]{x1D6FD}_{d}(s)f_{S}(s|S\in B)\unicode[STIX]{x2202}s=\frac{\int _{s\in B}\unicode[STIX]{x1D6FD}_{d}(s)f_{S}(s)\unicode[STIX]{x2202}s}{\int _{s\in B}f_{S}(s)\unicode[STIX]{x2202}s}.\end{eqnarray}$$
Tests for the effect heterogeneity along
 $B$
and the asymptotic distribution using a multivariate local linear regression are also shown in Imbens and Zajonc (Reference Imbens and Zajonc2009).
$B$
and the asymptotic distribution using a multivariate local linear regression are also shown in Imbens and Zajonc (Reference Imbens and Zajonc2009).
Keele and Titiunik (Reference Keele and Titiunik2015; “KT”) addressed AND-case two-score sharp MRD. Consider the two boundary lines
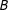 $B$
stemming from the cutoff
$B$
stemming from the cutoff
 $(c_{1},c_{2})$
rightward and upward as in the left panel of Figure 1. With partial effects ruled out in KT, only the treatment gets administered as
$(c_{1},c_{2})$
rightward and upward as in the left panel of Figure 1. With partial effects ruled out in KT, only the treatment gets administered as
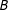 $B$
is crossed to the “treatment quadrant”
$B$
is crossed to the “treatment quadrant”
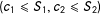 $(c_{1}\leqslant S_{1},c_{2}\leqslant S_{2})$
from any direction. Denoting a point in
$(c_{1}\leqslant S_{1},c_{2}\leqslant S_{2})$
from any direction. Denoting a point in
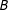 $B$
as
$B$
as
 $b$
, KT assumed the continuity at all points in
$b$
, KT assumed the continuity at all points in
 $B$
for the potential untreated and treated responses
$B$
for the potential untreated and treated responses
 $Y_{0}$
and
$Y_{0}$
and
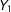 $Y_{1}$
:
$Y_{1}$
:
 $$\begin{eqnarray}\lim _{s\rightarrow b}E(Y_{0}|S=s)=E(Y_{0}|S=b)\quad \text{and}\quad \lim _{s\rightarrow b}E(Y_{1}|S=s)=E(Y_{1}|S=b).\end{eqnarray}$$
$$\begin{eqnarray}\lim _{s\rightarrow b}E(Y_{0}|S=s)=E(Y_{0}|S=b)\quad \text{and}\quad \lim _{s\rightarrow b}E(Y_{1}|S=s)=E(Y_{1}|S=b).\end{eqnarray}$$
Denoting a point in the treatment quadrant as
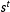 $s^{t}$
and in the control quadrants as
$s^{t}$
and in the control quadrants as
 $s^{c}$
, this continuity condition identifies the effect
$s^{c}$
, this continuity condition identifies the effect
 $\unicode[STIX]{x1D70F}(b)$
at
$\unicode[STIX]{x1D70F}(b)$
at
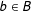 $b\in B$
:
$b\in B$
:
 $$\begin{eqnarray}\displaystyle & & \displaystyle \lim _{s^{t}\rightarrow b}E(Y|S=s^{t})-\lim _{s^{c}\rightarrow b}E(Y|S=s^{c})=\lim _{s^{t}\rightarrow b}E(Y_{1}|S=s^{t})-\lim _{s^{c}\rightarrow b}E(Y_{0}|S=s^{c})\nonumber\\ \displaystyle & & \displaystyle \quad =E(Y_{1}|S=b)-E(Y_{0}|S=b)=E(Y_{1}-Y_{0}|S=b)\equiv \unicode[STIX]{x1D70F}(b).\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle \lim _{s^{t}\rightarrow b}E(Y|S=s^{t})-\lim _{s^{c}\rightarrow b}E(Y|S=s^{c})=\lim _{s^{t}\rightarrow b}E(Y_{1}|S=s^{t})-\lim _{s^{c}\rightarrow b}E(Y_{0}|S=s^{c})\nonumber\\ \displaystyle & & \displaystyle \quad =E(Y_{1}|S=b)-E(Y_{0}|S=b)=E(Y_{1}-Y_{0}|S=b)\equiv \unicode[STIX]{x1D70F}(b).\end{eqnarray}$$
A marginal effect can be found by integrating out
 $b$
as in Equation (22). KT proposed a local polynomial regression estimator for
$b$
as in Equation (22). KT proposed a local polynomial regression estimator for
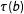 $\unicode[STIX]{x1D70F}(b)$
using a distance from
$\unicode[STIX]{x1D70F}(b)$
using a distance from
 $b$
, say the Euclidean distance
$b$
, say the Euclidean distance
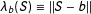 $\unicode[STIX]{x1D706}_{b}(S)\equiv ||S-b||$
, as a single “regressor.” This is to be done on the treatment and control quadrants separately to obtain sample analogs for the first term of Equation (23). The difference of the intercept estimators is then an estimator for
$\unicode[STIX]{x1D706}_{b}(S)\equiv ||S-b||$
, as a single “regressor.” This is to be done on the treatment and control quadrants separately to obtain sample analogs for the first term of Equation (23). The difference of the intercept estimators is then an estimator for
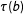 $\unicode[STIX]{x1D70F}(b)$
.
$\unicode[STIX]{x1D70F}(b)$
.
Wong, Steiner and Cook (Reference Wong, Steiner and Cook2013; “WSC”) dealt with OR-case two-score sharp MRD where
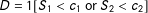 $D=1[S_{1}<c_{1}\text{ or }S_{2}<c_{2}]$
; WSC ruled out partial effects. WSC laid out four approaches, and we explain three (the remaining one does not seem tenable, and WSC did not recommend it either). The first is the aforementioned minimum of the scores. The second is essentially the one-dimensional localization along the horizontal boundary (say
$D=1[S_{1}<c_{1}\text{ or }S_{2}<c_{2}]$
; WSC ruled out partial effects. WSC laid out four approaches, and we explain three (the remaining one does not seem tenable, and WSC did not recommend it either). The first is the aforementioned minimum of the scores. The second is essentially the one-dimensional localization along the horizontal boundary (say
 $B_{1}$
) of
$B_{1}$
) of
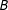 $B$
, and then along the vertical boundary (say
$B$
, and then along the vertical boundary (say
 $B_{2}$
); the difference from KT is, however, that WSC obtained
$B_{2}$
); the difference from KT is, however, that WSC obtained
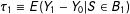 $\unicode[STIX]{x1D70F}_{1}\equiv E(Y_{1}-Y_{0}|S\in B_{1})$
and
$\unicode[STIX]{x1D70F}_{1}\equiv E(Y_{1}-Y_{0}|S\in B_{1})$
and
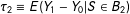 $\unicode[STIX]{x1D70F}_{2}\equiv E(Y_{1}-Y_{0}|S\in B_{2})$
instead of KT’s
$\unicode[STIX]{x1D70F}_{2}\equiv E(Y_{1}-Y_{0}|S\in B_{2})$
instead of KT’s
 $E(Y_{1}-Y_{0}|S=b)$
for all
$E(Y_{1}-Y_{0}|S=b)$
for all
 $b\in B$
. The third is getting an weighted average of
$b\in B$
. The third is getting an weighted average of
 $\unicode[STIX]{x1D70F}_{1}$
and
$\unicode[STIX]{x1D70F}_{1}$
and
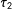 $\unicode[STIX]{x1D70F}_{2}$
, which WSC called the “frontier average treatment effect.”
$\unicode[STIX]{x1D70F}_{2}$
, which WSC called the “frontier average treatment effect.”
Although disallowing partial effects may look simplifying, to the contrary, it results in considering boundary lines instead of the single boundary point
 $(c_{1},c_{2})$
. The possibly heterogeneous effects along the boundaries may be informative, and possibly efficiency enhancing if they are homogeneous, which however also raises the issue of finding a single marginal effect as a weighted average of those boundary effects. Such a weighting requires estimating densities for the boundary lines—a complicating scenario.
$(c_{1},c_{2})$
. The possibly heterogeneous effects along the boundaries may be informative, and possibly efficiency enhancing if they are homogeneous, which however also raises the issue of finding a single marginal effect as a weighted average of those boundary effects. Such a weighting requires estimating densities for the boundary lines—a complicating scenario.
Of course, in reality, whether partial effects exist or not is an empirical question. The logical thing to do is thus to allow nonzero partial effects first with our approach, and then test for zero partial effects; if accepted, one may adopt some of the above approaches. This should be preferred than simply ruling out partial effects from the beginning, unless there is a strong prior justification to do so.
4 Empirical Illustration
This section provides an empirical example for congress “productivity”: the effects of the Republican party being dominant in both lower and upper houses on passing bills, where the sample size is only
 $104$
. We estimate the mean effect, but the inference is problematic due to the small sample size. Also, the usual RD data plots are not helpful, because dividing the range of
$104$
. We estimate the mean effect, but the inference is problematic due to the small sample size. Also, the usual RD data plots are not helpful, because dividing the range of
 $S$
to create cells leaves only a few observations for each cell. We use two measures of legislative productivity for the US Congress 1789–2004 in Grant and Kelly (Reference Grant and Kelly2008): the “legislative productivity index (LPI)” for all legislations, and the “major legislation index (MLI)” for major legislations only. We obtained the House (
$S$
to create cells leaves only a few observations for each cell. We use two measures of legislative productivity for the US Congress 1789–2004 in Grant and Kelly (Reference Grant and Kelly2008): the “legislative productivity index (LPI)” for all legislations, and the “major legislation index (MLI)” for major legislations only. We obtained the House (
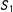 $S_{1}$
) and Senate (
$S_{1}$
) and Senate (
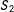 $S_{2}$
) Republican seat proportions from http://www.senate.gov/history/partydiv.htm and http://history.house.gov/Institution/Party-Divisions/Party-Divisions/.Footnote
1
$S_{2}$
) Republican seat proportions from http://www.senate.gov/history/partydiv.htm and http://history.house.gov/Institution/Party-Divisions/Party-Divisions/.Footnote
1
For the periods before 1837, we consider Jackson, Jackson Republican, Jeffersonian Republican, and Anti-Administration as Republican parties to follow the party division that the official Senate and House website makes. Since there was no official Republican party before 1857, for 1837–1856, we consider the parties opposite to the Democratic party as Republican. Among the total 108 congresses, we removed four cases where neither Democrats nor Republicans were dominant.
Table 1. Descriptive Statistics for Congress Productivity Data.

Table 1 presents descriptive statistics. On average, the Republican seat proportions are around
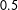 $0.5$
and they are the majority in both houses
$0.5$
and they are the majority in both houses
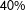 $40\%$
of the times. LPI is
$40\%$
of the times. LPI is
 $90.8$
on average and MLI is
$90.8$
on average and MLI is
 $11.1$
, and when we restrict the sample to
$11.1$
, and when we restrict the sample to
 $\pm 0.10$
around the cutoff
$\pm 0.10$
around the cutoff
 $0.5$
in both houses to have
$0.5$
in both houses to have
 $42$
observations, the average LPI increases to
$42$
observations, the average LPI increases to
 $98.5$
and MLI to
$98.5$
and MLI to
 $11.7$
. When we restrict the sample to
$11.7$
. When we restrict the sample to
 $\pm 0.05$
, the average LPI further increases to
$\pm 0.05$
, the average LPI further increases to
 $108$
and MLI to
$108$
and MLI to
 $12.1$
—but then only
$12.1$
—but then only
 $14$
observations are left.
$14$
observations are left.
Figure 2 plots LPI and MLI, which reveals an increasing trend. We do the OLS of
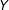 $Y$
on
$Y$
on
 $(1,t,S_{1},S_{2},\unicode[STIX]{x1D6FF}_{1},\unicode[STIX]{x1D6FF}_{2},D)$
, where
$(1,t,S_{1},S_{2},\unicode[STIX]{x1D6FF}_{1},\unicode[STIX]{x1D6FF}_{2},D)$
, where
 $t$
is to capture the trend,
$t$
is to capture the trend,
 $Y$
is standardized to ease interpretation (i.e.,
$Y$
is standardized to ease interpretation (i.e.,
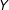 $Y$
is LPI/
$Y$
is LPI/
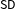 $\text{SD}$
(LPI) or MLI/
$\text{SD}$
(LPI) or MLI/
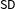 $\text{SD}$
(MLI)), and
$\text{SD}$
(MLI)), and
 $D$
is the indicator for whether the Republican party is dominant in both houses or not; other than
$D$
is the indicator for whether the Republican party is dominant in both houses or not; other than
 $t$
, we adopt Equation (10) with the linear model in Equation (11). We also tried using
$t$
, we adopt Equation (10) with the linear model in Equation (11). We also tried using
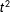 $t^{2}$
additionally, but the results are omitted as they do not differ much.
$t^{2}$
additionally, but the results are omitted as they do not differ much.

Figure 2. LPI and MLI across Congresses.
Although there is no covariate in our data, the lagged outcome can be thought of as a covariate, which may be unbalanced between the treatment and control groups. To check this out, we do the OLS of the lagged
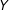 $Y$
on the same regressors to test
$Y$
on the same regressors to test
 $H_{0}:\unicode[STIX]{x1D6FD}_{1}=\unicode[STIX]{x1D6FD}_{2}=\unicode[STIX]{x1D6FD}_{d}=0$
(i.e., balance across the treatment and three control groups in the lagged
$H_{0}:\unicode[STIX]{x1D6FD}_{1}=\unicode[STIX]{x1D6FD}_{2}=\unicode[STIX]{x1D6FD}_{d}=0$
(i.e., balance across the treatment and three control groups in the lagged
 $Y$
). For three bandwidths
$Y$
). For three bandwidths
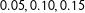 $0.05,0.10,0.15$
with both scores standardized, the
$0.05,0.10,0.15$
with both scores standardized, the
 $p$
values of the test are
$p$
values of the test are
 $$\begin{eqnarray}\displaystyle \text{LPI} & : & \displaystyle 0.008,~0.210,~0.104\nonumber\\ \displaystyle \text{MLI} & : & \displaystyle 0.245,~0.133,~0.469\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \text{LPI} & : & \displaystyle 0.008,~0.210,~0.104\nonumber\\ \displaystyle \text{MLI} & : & \displaystyle 0.245,~0.133,~0.469\nonumber\end{eqnarray}$$
The test rejects for LPI with bandwidth
 $0.05$
, which may very well be due to the small sample size 14, because 14 means
$0.05$
, which may very well be due to the small sample size 14, because 14 means
 $3.7$
observations per group for which law of large numbers can hardly work. For the other cases, the test does not reject.
$3.7$
observations per group for which law of large numbers can hardly work. For the other cases, the test does not reject.
For
 $h=(h_{1},h_{2})^{\prime }$
, we use the single rule-of-thumb bandwidth
$h=(h_{1},h_{2})^{\prime }$
, we use the single rule-of-thumb bandwidth
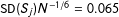 $\text{SD}(S_{j})N^{-1/6}=0.065$
for
$\text{SD}(S_{j})N^{-1/6}=0.065$
for
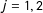 $j=1,2$
due to
$j=1,2$
due to
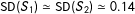 $\text{SD}(S_{1})\simeq \text{SD}(S_{2})\simeq 0.14$
in Table 1, and the CV bandwidths described in Equation (14). For CV, we try a common single bandwidth (
$\text{SD}(S_{1})\simeq \text{SD}(S_{2})\simeq 0.14$
in Table 1, and the CV bandwidths described in Equation (14). For CV, we try a common single bandwidth (
 $\unicode[STIX]{x1D702}_{c}\equiv \unicode[STIX]{x1D702}_{1}=\unicode[STIX]{x1D702}_{2}$
) or two different bandwidths
$\unicode[STIX]{x1D702}_{c}\equiv \unicode[STIX]{x1D702}_{1}=\unicode[STIX]{x1D702}_{2}$
) or two different bandwidths
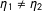 $\unicode[STIX]{x1D702}_{1}\neq \unicode[STIX]{x1D702}_{2}$
using the square or oval-neighbor kernels in Equation (15). For the common single bandwidth, the CV gave
$\unicode[STIX]{x1D702}_{1}\neq \unicode[STIX]{x1D702}_{2}$
using the square or oval-neighbor kernels in Equation (15). For the common single bandwidth, the CV gave
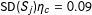 $\text{SD}(S_{j})\unicode[STIX]{x1D702}_{c}=0.09$
with the square-neighbor kernel, and
$\text{SD}(S_{j})\unicode[STIX]{x1D702}_{c}=0.09$
with the square-neighbor kernel, and
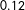 $0.12$
with the oval-neighborhood kernel. When we allowed
$0.12$
with the oval-neighborhood kernel. When we allowed
 $\unicode[STIX]{x1D702}_{1}\neq \unicode[STIX]{x1D702}_{2}$
, the square-neighbor kernel gave
$\unicode[STIX]{x1D702}_{1}\neq \unicode[STIX]{x1D702}_{2}$
, the square-neighbor kernel gave
 $(h_{1},h_{2})=(0.07,0.12)$
, and the oval-neighbor kernel gave
$(h_{1},h_{2})=(0.07,0.12)$
, and the oval-neighbor kernel gave
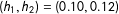 $(h_{1},h_{2})=(0.10,0.12)$
. The local observations selected by these four different bandwidths are shown in Figure 3; since
$(h_{1},h_{2})=(0.10,0.12)$
. The local observations selected by these four different bandwidths are shown in Figure 3; since
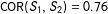 $\text{COR}(S_{1},S_{2})=0.76$
in our data, the observations are scattered along the 45 degree line with most observations in quadrants 1 and 3. Overall, the CV bandwidths range over
$\text{COR}(S_{1},S_{2})=0.76$
in our data, the observations are scattered along the 45 degree line with most observations in quadrants 1 and 3. Overall, the CV bandwidths range over
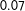 $0.07$
to
$0.07$
to
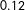 $0.12$
, and the rule-thumb bandwidth
$0.12$
, and the rule-thumb bandwidth
 $0.065$
is almost the same as the smallest CV bandwidth
$0.065$
is almost the same as the smallest CV bandwidth
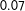 $0.07$
.
$0.07$
.

Figure 3. Square & Oval Neighbors (1 & 2 Bandwidths) Choose Different Observations.
The estimation results for LPI and MLI are in Tables 2 and 3, each with three panels. In the first panel, “Sq” stands for square-neighbor kernel, “RT” stands for rule-of-thumb bandwidth, CV1 is CV with one common bandwidth, and CV2 is CV with two bandwidths. The row “
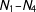 $N_{1}{-}N_{4}$
” lists the local number of observations in the four quadrants, and the row “
$N_{1}{-}N_{4}$
” lists the local number of observations in the four quadrants, and the row “
 $\sum _{j}N_{j}/N$
” shows the proportion of the used local observations relative to the total number of available observations
$\sum _{j}N_{j}/N$
” shows the proportion of the used local observations relative to the total number of available observations
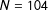 $N=104$
. The second panel shows the treatment effect estimates by our proposal (OLS) and the existing methods in the literature: BW for the boundary-estimate-weighting method in Equation (22), MIN for
$N=104$
. The second panel shows the treatment effect estimates by our proposal (OLS) and the existing methods in the literature: BW for the boundary-estimate-weighting method in Equation (22), MIN for
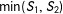 $\min (S_{1},S_{2})$
, RD1 for one-dimensional RD with
$\min (S_{1},S_{2})$
, RD1 for one-dimensional RD with
 $S_{1}|\unicode[STIX]{x1D6FF}_{2}=1$
in (3.3), and RD2 for one-dimensional RD with
$S_{1}|\unicode[STIX]{x1D6FF}_{2}=1$
in (3.3), and RD2 for one-dimensional RD with
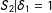 $S_{2}|\unicode[STIX]{x1D6FF}_{1}=1$
in Equation (16). The third panel presents the partial- effect estimates by our proposed OLS.
$S_{2}|\unicode[STIX]{x1D6FF}_{1}=1$
in Equation (16). The third panel presents the partial- effect estimates by our proposed OLS.
BW did not work with the rule-of-thumb bandwidth because it is too small to have enough observations in each neighbor of all boundary points. Since MIN, RD1 and RD2 use unidimensional “square” neighbor, we put their estimates in the “Sq” columns. For inference,
 $90\%$
and
$90\%$
and
 $95\%$
confidence intervals (CI) were calculated from bootstrap with
$95\%$
confidence intervals (CI) were calculated from bootstrap with
 $10,000$
repetitions because the sample size is small. The statistical significance is determined by whether the CI captures zero or not; to save space, we present only 95% CIs.
$10,000$
repetitions because the sample size is small. The statistical significance is determined by whether the CI captures zero or not; to save space, we present only 95% CIs.
In Table 2 for LPI, Oval-CV1, and Oval-CV2 use more than 50% of the available data, going away from RD localization; hence we would trust the other columns (Sq-RT, Sq-CV, and Oval-RT) more, where the treatment effects fall in
 $0.62{-}1.39$
which are statistically significant. These numbers differ much from the estimates from the existing methods in the literature. This difference is understandable in view of the significant partial effect
$0.62{-}1.39$
which are statistically significant. These numbers differ much from the estimates from the existing methods in the literature. This difference is understandable in view of the significant partial effect
 $\unicode[STIX]{x1D6FD}_{2}$
ranging over
$\unicode[STIX]{x1D6FD}_{2}$
ranging over
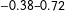 $-0.38{-}0.72$
in the columns for Sq-RT, Sq-CV, and Oval-RT, because the existing methods are inconsistent if partial effects are present. The partial effect
$-0.38{-}0.72$
in the columns for Sq-RT, Sq-CV, and Oval-RT, because the existing methods are inconsistent if partial effects are present. The partial effect
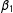 $\unicode[STIX]{x1D6FD}_{1}$
is insignificant in all cases.
$\unicode[STIX]{x1D6FD}_{1}$
is insignificant in all cases.
Table 2. LPI Estimates for Treatment and Partial Effects.

The reader may wonder why the partial effects
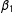 $\unicode[STIX]{x1D6FD}_{1}$
and
$\unicode[STIX]{x1D6FD}_{1}$
and
 $\unicode[STIX]{x1D6FD}_{2}$
are negative in Table 2: Would being the majority in either house still help passing bills? For this, recall the slope
$\unicode[STIX]{x1D6FD}_{2}$
are negative in Table 2: Would being the majority in either house still help passing bills? For this, recall the slope
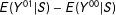 $E(Y^{01}|S)-E(Y^{00}|S)$
of
$E(Y^{01}|S)-E(Y^{00}|S)$
of
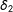 $\unicode[STIX]{x1D6FF}_{2}$
in Equation (3), which shows the effect of passing bills relative to “
$\unicode[STIX]{x1D6FF}_{2}$
in Equation (3), which shows the effect of passing bills relative to “
 $00$
,” that is, relative to the Democrats being the majority in both houses. Here, “
$00$
,” that is, relative to the Democrats being the majority in both houses. Here, “
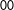 $00$
” is not really a control in the sense that no treatment is done; rather, it is almost the same treatment as “
$00$
” is not really a control in the sense that no treatment is done; rather, it is almost the same treatment as “
 $11$
.” It is hence natural that the slopes of
$11$
.” It is hence natural that the slopes of
 $\unicode[STIX]{x1D6FF}_{1}$
and
$\unicode[STIX]{x1D6FF}_{1}$
and
 $\unicode[STIX]{x1D6FF}_{2}$
are both negative.
$\unicode[STIX]{x1D6FF}_{2}$
are both negative.
The reader may wonder also why
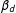 $\unicode[STIX]{x1D6FD}_{d}$
is significantly positive: Would the effect of the Republican majority in both houses not be the same as the Democratic majority to result in
$\unicode[STIX]{x1D6FD}_{d}$
is significantly positive: Would the effect of the Republican majority in both houses not be the same as the Democratic majority to result in
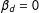 $\unicode[STIX]{x1D6FD}_{d}=0$
? For this, rewrite the slope of
$\unicode[STIX]{x1D6FD}_{d}=0$
? For this, rewrite the slope of
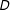 $D$
in Equation (3) as
$D$
in Equation (3) as
 $$\begin{eqnarray}\{E(Y^{11}|S)-E(Y^{00}|S)\}-\{E(Y^{10}|S)-E(Y^{00}|S)\}-\{E(Y^{01}|S)-E(Y^{00}|S)\}:\end{eqnarray}$$
$$\begin{eqnarray}\{E(Y^{11}|S)-E(Y^{00}|S)\}-\{E(Y^{10}|S)-E(Y^{00}|S)\}-\{E(Y^{01}|S)-E(Y^{00}|S)\}:\end{eqnarray}$$
the first term
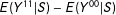 $E(Y^{11}|S)-E(Y^{00}|S)$
might be almost zero due to the symmetry of the either party being the majority in both houses, and the last two terms (i.e., the partial effects) are negative so that the slope of
$E(Y^{11}|S)-E(Y^{00}|S)$
might be almost zero due to the symmetry of the either party being the majority in both houses, and the last two terms (i.e., the partial effects) are negative so that the slope of
 $D$
becomes positive.
$D$
becomes positive.
Table 3. MLI Estimates for Treatment and Partial Effects.

In Table 3 for MLI, Sq-CV2, Oval-CV1, and Oval-CV2 use nearly 50% of the available data, and consequently we would trust the other columns (Sq-RT, Sq-CV1, and Oval-RT) more, where the treatment effects fall in
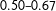 $0.50{-}0.67$
which are statistically insignificant though, differently from Table 2. These effect numbers differ much from the estimates from the existing methods in the literature. This difference is understandable in view of the partly significant partial effect
$0.50{-}0.67$
which are statistically insignificant though, differently from Table 2. These effect numbers differ much from the estimates from the existing methods in the literature. This difference is understandable in view of the partly significant partial effect
 $\unicode[STIX]{x1D6FD}_{2}$
ranging over
$\unicode[STIX]{x1D6FD}_{2}$
ranging over
 $-0.37{-}0.63$
in the columns for Sq-RT, Sq-CV1, and Oval-RT. The partial effect
$-0.37{-}0.63$
in the columns for Sq-RT, Sq-CV1, and Oval-RT. The partial effect
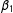 $\unicode[STIX]{x1D6FD}_{1}$
is insignificant in all cases as in Table 2.
$\unicode[STIX]{x1D6FD}_{1}$
is insignificant in all cases as in Table 2.
A simple informative “back-of-the-envelope” calculation comes from positing
 $$\begin{eqnarray}\displaystyle & & \displaystyle \unicode[STIX]{x1D6FD}_{s}\{\unicode[STIX]{x1D6FF}_{1}(1-\unicode[STIX]{x1D6FF}_{2})+(1-\unicode[STIX]{x1D6FF}_{1})\unicode[STIX]{x1D6FF}_{2}\}+\unicode[STIX]{x1D6FD}_{u}\{\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}+(1-\unicode[STIX]{x1D6FF}_{1})(1-\unicode[STIX]{x1D6FF}_{2})\}\nonumber\\ \displaystyle & & \displaystyle ~=\unicode[STIX]{x1D6FD}_{u}+(\unicode[STIX]{x1D6FD}_{s}-\unicode[STIX]{x1D6FD}_{u})\unicode[STIX]{x1D6FF}_{1}+(\unicode[STIX]{x1D6FD}_{s}-\unicode[STIX]{x1D6FD}_{u})\unicode[STIX]{x1D6FF}_{2}+2(\unicode[STIX]{x1D6FD}_{u}-\unicode[STIX]{x1D6FD}_{s})\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle \unicode[STIX]{x1D6FD}_{s}\{\unicode[STIX]{x1D6FF}_{1}(1-\unicode[STIX]{x1D6FF}_{2})+(1-\unicode[STIX]{x1D6FF}_{1})\unicode[STIX]{x1D6FF}_{2}\}+\unicode[STIX]{x1D6FD}_{u}\{\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}+(1-\unicode[STIX]{x1D6FF}_{1})(1-\unicode[STIX]{x1D6FF}_{2})\}\nonumber\\ \displaystyle & & \displaystyle ~=\unicode[STIX]{x1D6FD}_{u}+(\unicode[STIX]{x1D6FD}_{s}-\unicode[STIX]{x1D6FD}_{u})\unicode[STIX]{x1D6FF}_{1}+(\unicode[STIX]{x1D6FD}_{s}-\unicode[STIX]{x1D6FD}_{u})\unicode[STIX]{x1D6FF}_{2}+2(\unicode[STIX]{x1D6FD}_{u}-\unicode[STIX]{x1D6FD}_{s})\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\nonumber\end{eqnarray}$$
where
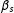 $\unicode[STIX]{x1D6FD}_{s}$
is the effect of the split congress, and
$\unicode[STIX]{x1D6FD}_{s}$
is the effect of the split congress, and
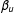 $\unicode[STIX]{x1D6FD}_{u}$
is the effect of the united congress. Recall that the slope
$\unicode[STIX]{x1D6FD}_{u}$
is the effect of the united congress. Recall that the slope
 $2(\unicode[STIX]{x1D6FD}_{u}-\unicode[STIX]{x1D6FD}_{s})$
of
$2(\unicode[STIX]{x1D6FD}_{u}-\unicode[STIX]{x1D6FD}_{s})$
of
 $D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
is
$D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}$
is
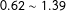 $0.62\sim 1.39$
in Table 2, and the slope
$0.62\sim 1.39$
in Table 2, and the slope
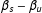 $\unicode[STIX]{x1D6FD}_{s}-\unicode[STIX]{x1D6FD}_{u}$
of
$\unicode[STIX]{x1D6FD}_{s}-\unicode[STIX]{x1D6FD}_{u}$
of
 $\unicode[STIX]{x1D6FF}_{2}$
is
$\unicode[STIX]{x1D6FF}_{2}$
is
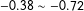 $-0.38\sim -0.72$
. Taking the middle values in these ranges, since
$-0.38\sim -0.72$
. Taking the middle values in these ranges, since
 $2(\unicode[STIX]{x1D6FD}_{u}-\unicode[STIX]{x1D6FD}_{s})\simeq 1.01$
and
$2(\unicode[STIX]{x1D6FD}_{u}-\unicode[STIX]{x1D6FD}_{s})\simeq 1.01$
and
 $\unicode[STIX]{x1D6FD}_{s}-\unicode[STIX]{x1D6FD}_{u}\simeq -0.55$
, we have
$\unicode[STIX]{x1D6FD}_{s}-\unicode[STIX]{x1D6FD}_{u}\simeq -0.55$
, we have
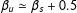 $\unicode[STIX]{x1D6FD}_{u}\simeq \unicode[STIX]{x1D6FD}_{s}+0.5$
: the effect of the united congress might be about
$\unicode[STIX]{x1D6FD}_{u}\simeq \unicode[STIX]{x1D6FD}_{s}+0.5$
: the effect of the united congress might be about
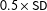 $0.5\times \text{SD}$
greater than the effect of the split congress.
$0.5\times \text{SD}$
greater than the effect of the split congress.
One final important point to make is that, even if one is interested only in the effect of being the majority in both houses, it is ill-advised to compare only the cases of being the majority in both houses versus not being the majority in neither house. This amounts to omitting
 $\unicode[STIX]{x1D6FF}_{1}$
and
$\unicode[STIX]{x1D6FF}_{1}$
and
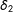 $\unicode[STIX]{x1D6FF}_{2}$
in the above OLS, which results in an omitted variable bias, as long as the partial effects are not zero as in Tables 2 and 3.
$\unicode[STIX]{x1D6FF}_{2}$
in the above OLS, which results in an omitted variable bias, as long as the partial effects are not zero as in Tables 2 and 3.
5 Conclusions
In this paper, we generalized the usual mean-based RD with a single running variable (“score”) in three ways by allowing for (i) more than one scores, (ii) partial effects due to part of the scores crossing cutoff, in addition to the full effect with all scores crossing all cutoffs, and (iii) regression functions other than the mean although we focused mostly on the mean. The critical difference between our and existing approaches for MRD is partial effects: allowed in this paper, but ruled out in most other papers.
We imposed a weak continuity assumption, presented the identified parameters, and proposed simple local difference-in-differences-type estimators implemented by ordinary least squares estimator. We applied our estimators to find the US congress “productivity”: the effect of the Republicans dominating both houses on passing bills. We found significant partial effects, and the legislative productivity is higher by about
 $0.5\times \text{SD}$
when the congress is united than divided.
$0.5\times \text{SD}$
when the congress is united than divided.
Appendix. Three-Score MRD Identification
Consider
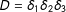 $D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\unicode[STIX]{x1D6FF}_{3}$
with
$D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\unicode[STIX]{x1D6FF}_{3}$
with
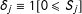 $\unicode[STIX]{x1D6FF}_{j}\equiv 1[0\leqslant S_{j}]$
,
$\unicode[STIX]{x1D6FF}_{j}\equiv 1[0\leqslant S_{j}]$
,
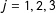 $j=1,2,3$
. Rewrite
$j=1,2,3$
. Rewrite
 $E(Y|S)$
as
$E(Y|S)$
as
 $$\begin{eqnarray}\displaystyle & & \displaystyle E(Y|S)=E(Y^{000}|S)(1-\unicode[STIX]{x1D6FF}_{1})(1-\unicode[STIX]{x1D6FF}_{2})(1-\unicode[STIX]{x1D6FF}_{3})+E(Y^{100}|S)\unicode[STIX]{x1D6FF}_{1}(1-\unicode[STIX]{x1D6FF}_{2})(1-\unicode[STIX]{x1D6FF}_{3})\nonumber\\ \displaystyle & & \displaystyle \quad +\,E(Y^{010}|S)(1-\unicode[STIX]{x1D6FF}_{1})\unicode[STIX]{x1D6FF}_{2}(1-\unicode[STIX]{x1D6FF}_{3})+E(Y^{001}|S)(1-\unicode[STIX]{x1D6FF}_{1})(1-\unicode[STIX]{x1D6FF}_{2})\unicode[STIX]{x1D6FF}_{3}+E(Y^{110}|S)\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}(1-\unicode[STIX]{x1D6FF}_{3})\nonumber\\ \displaystyle & & \displaystyle \quad +\,E(Y^{101}|S)\unicode[STIX]{x1D6FF}_{1}(1-\unicode[STIX]{x1D6FF}_{2})\unicode[STIX]{x1D6FF}_{3}+E(Y^{011}|S)(1-\unicode[STIX]{x1D6FF}_{1})\unicode[STIX]{x1D6FF}_{2}\unicode[STIX]{x1D6FF}_{3}~+E(Y^{111}|S)\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\unicode[STIX]{x1D6FF}_{3}.\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle E(Y|S)=E(Y^{000}|S)(1-\unicode[STIX]{x1D6FF}_{1})(1-\unicode[STIX]{x1D6FF}_{2})(1-\unicode[STIX]{x1D6FF}_{3})+E(Y^{100}|S)\unicode[STIX]{x1D6FF}_{1}(1-\unicode[STIX]{x1D6FF}_{2})(1-\unicode[STIX]{x1D6FF}_{3})\nonumber\\ \displaystyle & & \displaystyle \quad +\,E(Y^{010}|S)(1-\unicode[STIX]{x1D6FF}_{1})\unicode[STIX]{x1D6FF}_{2}(1-\unicode[STIX]{x1D6FF}_{3})+E(Y^{001}|S)(1-\unicode[STIX]{x1D6FF}_{1})(1-\unicode[STIX]{x1D6FF}_{2})\unicode[STIX]{x1D6FF}_{3}+E(Y^{110}|S)\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}(1-\unicode[STIX]{x1D6FF}_{3})\nonumber\\ \displaystyle & & \displaystyle \quad +\,E(Y^{101}|S)\unicode[STIX]{x1D6FF}_{1}(1-\unicode[STIX]{x1D6FF}_{2})\unicode[STIX]{x1D6FF}_{3}+E(Y^{011}|S)(1-\unicode[STIX]{x1D6FF}_{1})\unicode[STIX]{x1D6FF}_{2}\unicode[STIX]{x1D6FF}_{3}~+E(Y^{111}|S)\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\unicode[STIX]{x1D6FF}_{3}.\nonumber\end{eqnarray}$$
Here, the slope of
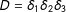 $D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\unicode[STIX]{x1D6FF}_{3}$
is
$D=\unicode[STIX]{x1D6FF}_{1}\unicode[STIX]{x1D6FF}_{2}\unicode[STIX]{x1D6FF}_{3}$
is
 $$\begin{eqnarray}\displaystyle & & \displaystyle E(Y^{111}|S)~-E(Y^{110}|S)-\{E(Y^{011}|S)-E(Y^{010}|S)\}\nonumber\\ \displaystyle & & \displaystyle \quad -\,[E(Y^{101}|S)-E(Y^{100}|S)-\{E(Y^{001}|S)-E(Y^{000}|S)\}].\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle E(Y^{111}|S)~-E(Y^{110}|S)-\{E(Y^{011}|S)-E(Y^{010}|S)\}\nonumber\\ \displaystyle & & \displaystyle \quad -\,[E(Y^{101}|S)-E(Y^{100}|S)-\{E(Y^{001}|S)-E(Y^{000}|S)\}].\nonumber\end{eqnarray}$$
Adopt the notation analogous to that for two-score MRD.
Take the triple limits on
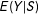 $E(Y|S)$
to get
$E(Y|S)$
to get
 $$\begin{eqnarray}\displaystyle E(Y|0^{+},0^{+},0^{+}) & = & \displaystyle E(Y^{111}|0^{+},0^{+},0^{+}),\quad E(Y|0^{+},0^{+},0^{-})=E(Y^{110}|0^{+},0^{+},0^{-}),\nonumber\\ \displaystyle E(Y|0^{-},0^{+},0^{+}) & = & \displaystyle E(Y^{011}|0^{-},0^{+},0^{+}),\quad E(Y|0^{-},0^{+},0^{-})=E(Y^{010}|0^{-},0^{+},0^{-}),\nonumber\\ \displaystyle E(Y|0^{+},0^{-},0^{+}) & = & \displaystyle E(Y^{101}|0^{+},0^{-},0^{+}),\quad E(Y|0^{+},0^{-},0^{-})=E(Y^{100}|0^{+},0^{-},0^{-}),\nonumber\\ \displaystyle E(Y|0^{-},0^{-},0^{+}) & = & \displaystyle E(Y^{001}|0^{-},0^{-},0^{+}),\quad E(Y|0^{-},0^{-},0^{-})=E(Y^{000}|0^{-},0^{-},0^{-}).\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle E(Y|0^{+},0^{+},0^{+}) & = & \displaystyle E(Y^{111}|0^{+},0^{+},0^{+}),\quad E(Y|0^{+},0^{+},0^{-})=E(Y^{110}|0^{+},0^{+},0^{-}),\nonumber\\ \displaystyle E(Y|0^{-},0^{+},0^{+}) & = & \displaystyle E(Y^{011}|0^{-},0^{+},0^{+}),\quad E(Y|0^{-},0^{+},0^{-})=E(Y^{010}|0^{-},0^{+},0^{-}),\nonumber\\ \displaystyle E(Y|0^{+},0^{-},0^{+}) & = & \displaystyle E(Y^{101}|0^{+},0^{-},0^{+}),\quad E(Y|0^{+},0^{-},0^{-})=E(Y^{100}|0^{+},0^{-},0^{-}),\nonumber\\ \displaystyle E(Y|0^{-},0^{-},0^{+}) & = & \displaystyle E(Y^{001}|0^{-},0^{-},0^{+}),\quad E(Y|0^{-},0^{-},0^{-})=E(Y^{000}|0^{-},0^{-},0^{-}).\nonumber\end{eqnarray}$$
These give the limiting version of the slope of
 $D$
:
$D$
:
 $$\begin{eqnarray}\displaystyle & & \displaystyle E(Y|0^{+},0^{+},0^{+})-E(Y|0^{+},0^{+},0^{-})-\{E(Y|0^{-},0^{+},0^{+})-E(Y|0^{-},0^{+},0^{-})\}\nonumber\\ \displaystyle & & \displaystyle \quad -\,[E(Y|0^{+},0^{-},0^{+})-E(Y|0^{+},0^{-},0^{-})-\{E(Y|0^{-},0^{-},0^{+})-E(Y|0^{-},0^{-},0^{-})\}].\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle & & \displaystyle E(Y|0^{+},0^{+},0^{+})-E(Y|0^{+},0^{+},0^{-})-\{E(Y|0^{-},0^{+},0^{+})-E(Y|0^{-},0^{+},0^{-})\}\nonumber\\ \displaystyle & & \displaystyle \quad -\,[E(Y|0^{+},0^{-},0^{+})-E(Y|0^{+},0^{-},0^{-})-\{E(Y|0^{-},0^{-},0^{+})-E(Y|0^{-},0^{-},0^{-})\}].\nonumber\end{eqnarray}$$
Assume the continuity conditions
 $$\begin{eqnarray}\displaystyle E(Y^{110}|0^{+},0^{+},0^{-}) & = & \displaystyle E(Y^{110}|0^{+},0^{+},0^{+}),\nonumber\\ \displaystyle E(Y^{011}|0^{-},0^{+},0^{+}) & = & \displaystyle E(Y^{011}|0^{+},0^{+},0^{+}),\quad E(Y^{010}|0^{-},0^{+},0^{-})=E(Y^{010}|0^{+},0^{+},0^{+}),\nonumber\\ \displaystyle E(Y^{101}|0^{+},0^{-},0^{+}) & = & \displaystyle E(Y^{101}|0^{+},0^{+},0^{+}),\quad E(Y^{100}|0^{+},0^{-},0^{-})=E(Y^{100}|0^{+},0^{+},0^{+}),\nonumber\\ \displaystyle E(Y^{001}|0^{-},0^{-},0^{+}) & = & \displaystyle E(Y^{001}|0^{+},0^{+},0^{+}),\quad E(Y^{000}|0^{-},0^{-},0^{-})=E(Y^{000}|0^{+},0^{+},0^{+}).\nonumber\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle E(Y^{110}|0^{+},0^{+},0^{-}) & = & \displaystyle E(Y^{110}|0^{+},0^{+},0^{+}),\nonumber\\ \displaystyle E(Y^{011}|0^{-},0^{+},0^{+}) & = & \displaystyle E(Y^{011}|0^{+},0^{+},0^{+}),\quad E(Y^{010}|0^{-},0^{+},0^{-})=E(Y^{010}|0^{+},0^{+},0^{+}),\nonumber\\ \displaystyle E(Y^{101}|0^{+},0^{-},0^{+}) & = & \displaystyle E(Y^{101}|0^{+},0^{+},0^{+}),\quad E(Y^{100}|0^{+},0^{-},0^{-})=E(Y^{100}|0^{+},0^{+},0^{+}),\nonumber\\ \displaystyle E(Y^{001}|0^{-},0^{-},0^{+}) & = & \displaystyle E(Y^{001}|0^{+},0^{+},0^{+}),\quad E(Y^{000}|0^{-},0^{-},0^{-})=E(Y^{000}|0^{+},0^{+},0^{+}).\nonumber\end{eqnarray}$$
With these, the slope of
 $D$
in the preceding display can be written as, not surprisingly, “difference in differences in differences”:
$D$
in the preceding display can be written as, not surprisingly, “difference in differences in differences”:
 $$\begin{eqnarray}\unicode[STIX]{x1D6FD}_{d}=E[Y^{111}-Y^{110}-(Y^{011}-Y^{010})-\{Y^{101}-Y^{100}-(Y^{001}-Y^{000})\}|0^{+},0^{+},0^{+}]\end{eqnarray}$$
$$\begin{eqnarray}\unicode[STIX]{x1D6FD}_{d}=E[Y^{111}-Y^{110}-(Y^{011}-Y^{010})-\{Y^{101}-Y^{100}-(Y^{001}-Y^{000})\}|0^{+},0^{+},0^{+}]\end{eqnarray}$$
which is the effect on the just treated
 $(0^{+},0^{+},0^{+})$
. For four scores or more, we get quadruple or higher differences; see Lee (Reference Lee2016).
$(0^{+},0^{+},0^{+})$
. For four scores or more, we get quadruple or higher differences; see Lee (Reference Lee2016).






