



1. Introduction
Young children are routinely confronted with objects in their environment which are unfamiliar to them. Knowledge about these objects is typically acquired in instructional settings where informed adults tell them the names of these objects or show them the scope of actions that can be performed on them. For example, caregivers might tell the child that the animal frog is called a ‘frog’ and show them that it hops around. Indeed, studies suggest that children are frequently provided with information about both the names of objects and the actions that can be performed on objects in their daily input. For instance, Gogate et al. (Reference Gogate, Bahrick and Watson2000) find that between 36% and 76% of interactions with children contain synchronous temporally aligned bimodal object associations.
Given such input, infants appear to be able to learn to associate words with objects. For example, already around 6 months of age, infants show successful picture recognition upon hearing their own name, the words ‘mommy’ or ‘daddy’ or frequently heard labels for body parts (Bergelson & Swingley, Reference Bergelson and Swingley2012; Tincoff & Jusczyk, Reference Tincoff and Jusczyk1999, Reference Tincoff and Jusczyk2012). Similarly, early in development, they can discriminate between matching and mismatching actions for objects (e.g., using a hairbrush to brush hair versus teeth, Bahrick et al., Reference Bahrick, Gogate and Ruiz2002; Hunnius & Bekkering, Reference Hunnius and Bekkering2010). In other words, from a very early age, children appear to be able to learn to associate both words and actions with objects in their environment. Therefore, the mechanisms underlying such associative learning in both domains might be in place already during the first year of life. The current study examines the extent to which these mechanisms are shared across domains based on examination of the developmental trajectory of word-object and action-object association learning in early childhood.
Indeed, research has long debated the generality or specificity of the mechanisms underlying learning in these domains. On the one hand, the ease with which children learn language led researchers like Chomsky (Reference Chomsky1965) to suggest that children are born with linguistic core knowledge that can be adapted to the language of the child when provided with language-specific input (Chomsky, Reference Chomsky1993, Reference Chomsky2014). Thus, he suggested that language learning is facilitated by domain-specific mechanisms that are in place prenatally (see also Fodor, Reference Fodor1983). In contrast, other researchers highlighted the role of the environment in children’s development (Piaget, Reference Piaget1952; Vygotsky, Reference Vygotsky1980). Here, it is postulated that children are born with some low-level domain-general innate structures that foster learning from an early age. Knowledge acquisition, including language, is then shaped by a dynamic interaction between the environment and the child (see also Elman, Reference Elman2005; Montessori, Reference Montessori1914; Smith & Thelen, Reference Smith and Thelen2003; Thelen & Smith, Reference Thelen and Smith1996; Tomasello, Reference Tomasello1999). A synthesis of these accounts was suggested by Karmiloff-Smith (Reference Karmiloff-Smith1992). She wrote that children might be born with biological predispositions for learning and implicit representations (e.g., numerosity, rule following) and that such representations only develop into explicit representations through the child’s interaction with the environment (e.g., counting, metalinguistic awareness). In this context, such general predispositions might include domain-general processes that may become specialized over time to adapt to the needs of a certain domain. Thus, over time, such mechanisms might turn into domain-specific mechanisms being applicable to only a certain domain.
Examining the developmental trajectory of learning in different domains can provide insights into the extent to which learning is driven by domain-general or domain-specific mechanisms. For instance, if learning in two domains (e.g., words and actions) develops in synchrony, this could support the argument that learning in these domains is driven by similar mechanisms. On the other hand, if learning does not develop in synchrony, this would either suggest that learning in these two domains is driven by different mechanisms or at the very least that it is driven by similar mechanisms which share a mediator (e.g., attention, categorization) that differently weights information from the two domains.
Studies investigating parallels in word-object and action-object association learning have shown that learning in both these domains appears to develop at a similar time scale and adhere to similar mechanisms. For example, Childers and Tomasello (Reference Childers and Tomasello2002) presented 30-month-olds with novel nouns, novel verbs or novel actions for objects and found successful retention in comprehension tests in all conditions (see also Hahn & Gershkoff-Stowe, Reference Hahn and Gershkoff-Stowe2010). Childers and Tomasello (Reference Childers and Tomasello2003) further showed that 30-month-olds’ extension of novel actions and nouns to novel objects followed a similar pattern across modalities. Similarly, Riggs et al. (Reference Riggs, Mather, Hyde and Simpson2016) found that 3- to 4-year-olds map novel nouns and novel actions to novel objects, that children retained both types of mappings after a week and that they could extend such actions to other category members. With regard to shared mediators influencing learning across domains, Dysart et al. (Reference Dysart, Mather and Riggs2016) suggest that extending learning to other novel category members appears to be guided by novelty in both domains. Such findings have spurred suggestions that domain-general mechanisms might be at play during learning.
These studies have typically investigated children’s behavior from around 30 months onward. To what extent are similarly synchronous developmental trajectories observable at younger ages? A recent study by Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) finds that word-object and action-object association learning may follow different trajectories in early childhood. Here, 12-, 24- and 36-month-olds (as well as adults) were trained on novel actions and novel words for novel objects and tested on their recognition of the newly learned word-object and action-object associations. Twelve-month-olds learned action-object but not word-object associations, 24-month-olds learned neither action-object nor word-object associations, 36-month-olds learned word-object but not action-object associations and adults learned both types of associations.
In keeping with such differences across domains, studies on the production of novel words and actions for objects suggest an advantage for action-object associations. Childers and Tomasello (Reference Childers and Tomasello2002) showed that 30-month-olds’ performance in production tests was better in action trials than in noun or verb trials. Similarly, 3-to 5-year-olds showed more correct productions of novel actions for objects relative to novel words for objects (Hahn & Gershkoff-Stowe, Reference Hahn and Gershkoff-Stowe2010). Together, these results might hint toward differences in the developmental trajectory across the two domains.
The inconsistencies across the studies could be explained either by the ages of the children tested or differences in the structure of the input. However, Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) find differences across domains at 3 years of age, where Hahn and Gershkoff-Stowe (Reference Hahn and Gershkoff-Stowe2010) find none in the comprehension task, suggesting that age alone cannot capture the differences across the studies. One possible explanation for the differences reported relates to the amount of information from multiple modalities presented concurrently across the studies.
Most of these studies have tested children in unimodal contexts (Childers & Tomasello, Reference Childers and Tomasello2002, Reference Childers and Tomasello2003; Dysart et al., Reference Dysart, Mather and Riggs2016; Riggs et al., Reference Riggs, Mather, Hyde and Simpson2016). Here, one group of children was presented with novel words for objects (in the absence of any action information) and tested on their recognition of these novel word-object associations, and a separate group of children was presented with novel actions for objects and subsequently tested on their recognition of the novel action-object associations. In contrast, Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) presented children with bimodal contexts, where they saw both the actions that could be performed on an object and heard the label for this object within the same trial, before being tested on their recognition of the novel word- and action-object associations.
As suggested by the Intersensory Redundancy Hypothesis (Bahrick et al., Reference Bahrick, Gogate and Ruiz2002; Bahrick & Lickliter, Reference Bahrick and Lickliter2000; Gogate & Hollich, Reference Gogate and Hollich2010), the presentation of information in unimodal and bimodal contexts could have implications for learning. Here, the presentation of information from multiple modalities in synchrony provides redundant information across senses (amodal information) which can foster learning in multimodal settings. Specifically, the presentation of synchronous multimodal information fosters learning, while the presentation of asynchronous modality-specific information in multimodal settings, as in Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b), may attenuate learning. However, the presentation of multimodal information can also lead to referential ambiguity since a label that is presented together with an action and an object could refer to either of the two. Only grammatical information would help to disambiguate (i.e., the different (sentence) structure of a noun versus a verb) in such a situation. Thus, unimodal information can provide a simplified learning environment without any ambiguity.
However, Puccini and Liszkowski (Reference Puccini and Liszkowski2012) found that, at 15 months of age, children learned words for objects but not the referential actions associated with these objects only when the words were presented in unimodal contexts but not when words and actions were presented together (in synchrony, but see (Werker et al., Reference Werker, Lloyd, Cohen, Casasola and Stager1998)). Furthermore, the literature on modality dominance suggests a more differentiated picture of cross-domain learning, with information from different domains being prioritized, attended to and learned differently across development. Infants prioritize auditory information early on (Gogate et al., Reference Gogate, Prince and Matatyaho2009); 4-year-olds switch between a visual and an auditory preference, while adults show a preference for information from the visual modality (Robinson & Sloutsky, Reference Robinson and Sloutsky2004). Importantly, 4-year-olds process both visual and auditory information when information is presented separately, while maintaining an auditory preference when visual and auditory information are presented simultaneously (Sloutsky & Napolitano, Reference Sloutsky and Napolitano2003).
Taken together, this literature suggests that while word- and action-object association learning might follow similar trajectories (e.g., Childers & Tomasello, Reference Childers and Tomasello2002), this might only hold for unimodal contexts where children need only to attend to information from one domain at a given time. When presented with information from multiple domains, children might prioritize information from one domain over the other.
To further evaluate the influence of bimodal and unimodal contexts on word- and action-object association learning, the current study examined the developmental trajectory of 1- and 2-year-olds’ word- and action-object association learning in unimodal contexts. We presented 12- and 24-month-old children with the same novel word-object and action-object associations as in Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b), albeit now in a unimodal context. In particular, presented children with the words for an object and the actions that could be performed on an object together in the same trial, i.e., in a bimodal context. In contrast, here, in one session, children were exposed to two distinct labels for two novel objects and tested on their learning of the novel word-object associations. In a separate session, they were exposed to two distinct actions that could be performed on the same novel objects and tested on their learning of the novel action-object associations. Thus, only one modality (either a word or an action) is presented together with the object during learning, reflecting a unimodal mapping.
Three hypotheses were tested: If unimodal contexts make it easier for children to attend to information from both the word and action domain, then children in the current study, in contrast to Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) might learn both word- and action-object associations at the two ages tested. Alternatively, if bimodal contexts facilitate learning—at least with regard to the reported action-object association learning at 12 months of age (Eiteljoerge et al., Reference Eiteljoerge, Adam, Elsner and Mani2019b)—both age groups might show difficulties in learning both word- and action-object associations in the unimodal context of the current study. Differences between the two age groups may also be found, given suggestions that redundant information in multimodal contexts may be especially valuable for younger children (Gogate, Reference Gogate2010). Thus, 12-month-olds might benefit from bimodal contexts, while 24-month-olds might be less affected by the presentation of information in unimodal contexts.
2. Methods
2.1. Participants
Forty German monolingual, typically developing 12-month-olds (mean = 11.74 months, range = 11.01–12.9 months, female = 21) and forty 24-month-olds (mean = 23.64 months, range = 21.93–25.68 months, female = 18) participated in the study. Additional participants were excluded because of preterm birth (12-month-olds: 2), visual disorder (24-month-olds: 1), unwillingness to complete the experiment (12-month-olds: 1) or because the participant did not provide sufficient data for both conditions (12-month-olds: 6; 24-month-olds: 8, see also Preprocessing). Participants were recruited via the BabyLab database, caregivers signed a written informed consent form before the study and children received a book as a reward for their participation. Ethics approval was granted by the Ethics Committee of the Georg-Elias-Müller-Institute for Psychology, University of Göettingen (Project 123).
2.2. Material
We used the same material as in Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b): two germs served as novel objects (https://www.giantmicrobes.com/us/, see Figure 1), and we used two novel labels that adhere to German phonotactic rules (‘Tanu’ and ‘Löki’) and two novel actions (‘moving up and down while tilting to the sides’ and ‘moving sideways with back and forward leaning’).

Figure 1. Blue and yellow germ toys were used as novel objects. As novel actions, an upward movement with tilting to the sides (Panel a) and a sideways movement with tilting backward and forward were used (Panel b). Figure adapted from Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b).
For the training phase, we created word and action videos. In the word videos, the object was statically presented as a still frame image while it was labeled (‘Schau mal, ein Tanu!’ meaning ‘Look, a Tanu!’). In the action videos, the object was presented in motion according to one of the actions without any linguistic information (see Figure 1). Each video was 10 s long, 720 × 420 pixels in size and presented in the middle of the screen.
For all test trials in the test phase, we used pictures of the germs which were 640 x 480 pixels in size and presented next to each other in the center of the right and left half of the screen during the baseline and the recognition phase. For the prime phase, we created recordings of a female voice asking for one of the two labels (‘Wo ist das Tanu?’ meaning ‘Where is the Tanu?’) and created videos of an empty hand moving according to one of the actions as primes (materials and data can be found on OSF at https://doi.org/10.17605/OSF.IO/KUJPN). This ensured that word and action prime videos were as similar as possible regarding the absence of a referent. Each of the prime videos lasted 7 s and was presented in the center of the screen.
2.3. Procedure
Participants sat in a dimly lit and quiet experimental room at a distance of 65 cm from a TV screen (92 x 50 cm), where the visual stimuli were presented. A remote eye tracker (Tobii X 120, Technology, 2008), set on a platform underneath the TV screen, was used to record gaze data at 60 Hz. Stimuli were presented using E-Prime software with the Tobii extension (Schneider et al., Reference Schneider, Eschman and Zuccolotto2002). Auditory stimuli were presented through two loudspeakers above the screen. Further, two video cameras centered above the screen served to monitor the participant during the experiment. Prior to testing, gaze was calibrated using a 5-point calibration procedure, in which a red point appeared successively in every corner and also at the center of the screen. The experiment only started after successful calibration.
2.4. Experimental design
Each child included in the analysis participated in a word learning task and an action learning task which were administered in the same testing session but with a temporal delay between word learning and action learning sessions. For example, a child first saw the training and test phase of the word learning task, then took part in an offline administration of another task for about 30 minutes and then saw the training and test phase of the action learning task. Across children, we counterbalanced whether they received training and testing on word-object or action-object associations first.
The training phase consisted of eight trials that presented the child with the two novel objects which were either labeled (word learning task) or were moved (action learning task). Each object was presented in four trials in the center of the screen. Specific word-object and action-object associations were counterbalanced across lists, and the order of trials was randomized. Thus, 25% of the children were told that the blue object was called a Loki (in the word learning task) and saw it being moved upward and downward (in the action learning task), while the yellow object was called Tanu and saw it being moved sideways. Another 25% of the children saw the exact opposite pairings, e.g., the yellow object was called Loki and it moved upward and downward. Another 25% of the children were told that the blue object was called a Loki (in the word learning task) and saw it being moved sideways (in the action learning task), while the yellow object was called Tanu and saw it being moved upward and downward. Another 25% saw again the exact opposite of pairings. Every child heard both labels and saw both actions. Only the mappings differed across children.
Each test phase consisted of four test trials, and each test trial consisted of a baseline phase, a prime phase and a recognition phase. The stimuli used in the test trials were identical to the stimuli used in the training phase. When the blue object from the training phase was the target of the test trial, the yellow one served as a distractor and vice versa. In the baseline phase, both objects from the training phase were presented side-by-side on-screen in silence for 2.5 s. In the word learning task, during the prime phase (7 s), both objects disappeared, and children heard the label for one of the objects while a central fixation star was on-screen. In the action learning task, children saw an empty hand performing the action for one of the objects during the same priming phase. In the following recognition phase that began 300 ms after the offset of the prime phase, in both word and action learning tasks, the two objects reappeared on-screen in the same positions for another 2.5 s.
2.5. Preprocessing
The eye tracker provided an estimate of where participants were looking at during each time stamp of the trial, with one data point approximately every 16 ms. All data (gaze data and trial information) were exported from E-Prime and then further processed in R (R Core Team, 2019). For each time stamp, data were only included when one or both eyes of the participant were tracked reliably (validity less than 2 on E-Prime scale). When both eyes were tracked, the mean gaze point for both eyes was computed for further analysis. Gaze data were then aggregated into 40 ms bins. Areas of interest identical in size to one another were defined based on the size and location of the videos and images on screen. For each trial in the test phase, we coded whether the participant looked at the correct object (i.e., the target), at the distractor or at neither of these on-screen.
Typically, fixation data are analyzed from 240 ms to 2000 ms from the onset of a label (see also Swingley et al., Reference Swingley, Pinto and Fernald1999), since only these fixations can be reliably construed as a response to an auditory stimulus. Following this convention, we analyzed the data from 240 ms from the onset of the baseline phase. This ensured that we avoided early fluctuations in fixations as a result of the images appearing on-screen. Furthermore, we corrected the recognition phase for any preferences in the baseline phase on an individual trial level (i.e., each time point in the recognition phase was corrected for the overall looking score in the baseline phase on that particular trial).
To ensure high data quality, single test trials were excluded if the participant looked less than M – 3 × SD of the time to the displayed stimuli. Accordingly, trials were excluded where 12-month-olds looked less than 43% and 24-month-olds looked less than 33% to the pictures in the test trials. This led to an exclusion of 17 trials (5.15%) for 12-month-olds and 15 trials (4.46%) for 24-month-olds. Furthermore, it was important for comparing across conditions that each child contributed valid data for both conditions in the test phase. This criterion led to the exclusion of six 12-month-olds and eight 24-month-olds. Following all exclusions, a total of 80 participants with 40 in each age group were included in the final data analysis.
2.6. Data analysis
All analyses were done in R using the lmer function of the lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2014) with Gaussian error structure and identity link function. All models were checked for reasonable collinearity and absence of dispersion and influential cases, and any diversions from expected values are reported. Here, we first report generalized linear mixed models (GLMMs) that evaluate the influence of condition on proportional target looking averaged across the trial in the age groups. We then turn to GLMMs that include the factor time to model target looking throughout the recognition phase (also coined Growth Curve Analysis, see Mirman et al., Reference Mirman, Dixon and Magnuson2008, which allows us to evaluate the influence of condition on target looking with a high temporal resolution. In all models, we included session order (i.e., word learning task followed by action learning task or action learning task followed by word learning task) as a covariate and id, id by condition, object, name and action as random effects (see Tables 1, 2 and 3 for exact model descriptions). In the models including time, we included a linear, quadratic and cubic polynomial of time in the model. Only poly1 and poly2 were included as random effects in the model to simplify the model structure and allow for convergence. The inclusion of three polynomials is based on theoretical expectations and practical observations, outlined in detail in Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b). In principle, if children show successful recognition of the target, target looking for young children should follow a quadratic or cubic curve if participants’ target looking is first at chance level looking back and forth between both objects, then increases to the target upon hearing the matching label or seeing the according action and returns to chance level when they disengage from the target stimulus (in contrast to adults who usually show a steep increase in target looking that then plateaus toward the end of the trial). A cubic term is included to reflect any looking toward the end of the trial which often stays slightly above chance level. Otherwise, if children do not show successful target recognition, target looking should stay around chance level throughout the trial.
Table 1. LMM testing the influence of condition on baseline-corrected proportional target looking

a Not applicable for intercept.
SE: standard error; CI: confidence interval; LRT: Likelihood ratio test.
Table 2. GLMM evaluating the influence of condition and time on baseline-corrected proportional target looking
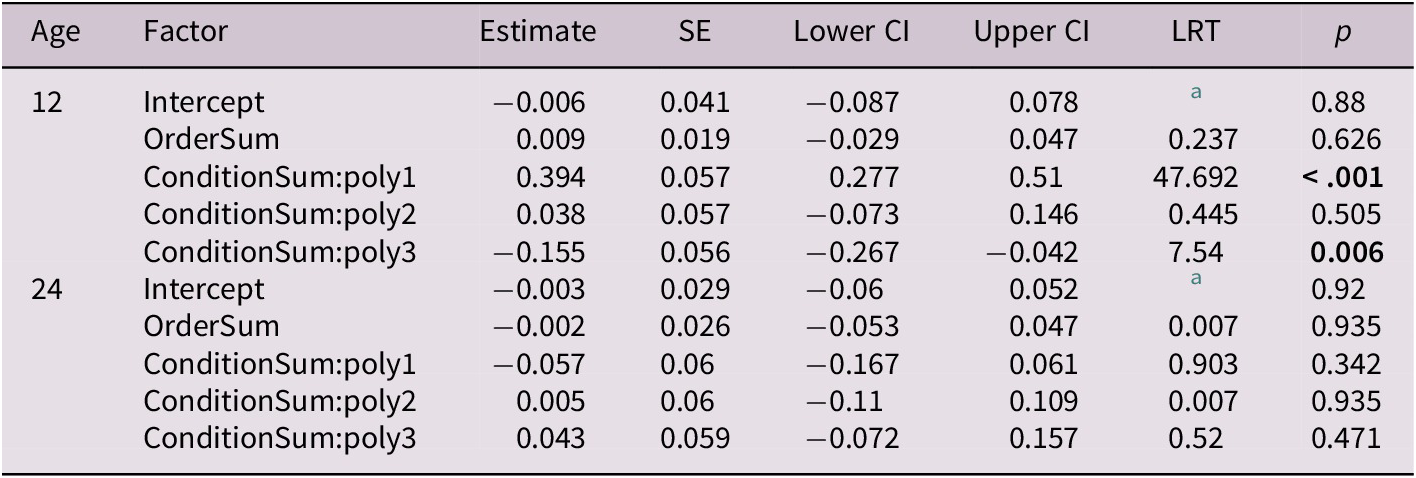
a Not applicable for intercept.
SE: standard error; CI: confidence interval; LRT: Likelihood ratio test.
Significant at alpha = 0.05.
Table 3. GLMM evaluating the influence of time on baseline-corrected proportional target looking in the word and action condition separately

a Not applicable for intercept.
SE: standard error; CI: confidence interval; LRT: Likelihood ratio test.
Significant at alpha = 0.05.
3. Results
3.1. GLMM
For each age group, we evaluated the influence of condition on children’s proportion of fixations to the target (upon being primed by either the word or the action associated with this target) averaged across time within the trial, by running model comparisons comparing a base model without the factor condition to a model including condition. Note that the proportion of target looking during the recognition phase was baseline-corrected for any visual preferences children might show in the beginning of the test trial, i.e., during the baseline phase. Model description and results can be found in Table 1.
The model comparison revealed that condition did not improve model fit relative to a model without this factor at either 12 months (χ2 = 0.011, df = 1, p = 0.92) or 24 months of age (χ2 = 0.24, df = 1, p = 0.63). In other words, there were no differences in children’s fixations to the target when primed by either the label for this target or the action to be associated with this target when examining the total proportion of looks to the target across the entire post-priming window.

3.2. GLMM with temporal resolution
Next, we then added the factor Time and its linear, quadratic and cubic polynomial to the model to examine how children’s target looking changed across the course of the trial in the different age groups and across conditions. For each age group, we first evaluated the influence of condition on baseline-corrected proportional target looking using model comparisons (as above) and then split the data according to condition to evaluate learning in each condition individually. The detailed results can be seen in Figure 2 and Tables 2 and 3.

Figure 2. Time course of 12- and 24-month-old baseline-corrected proportional target looking (PTL) in the word-object (yellow) and the action=object (blue) condition during the recognition phase. The line at 0 represents chance level (increase from baseline); fixations above this line indicate target looking, whereas fixations below this line indicate distractor looking. The first 240 ms are cut to allow for fixation time, and time within the trial has been corrected, so that the x-axis starts at 0.
For the 12-month-olds, comparing a model with the factor condition to a reduced model without condition revealed that condition contributed significantly to the model (χ 2 = 58.24, df = 4, p < 0.001). Using drop1, the model revealed a significant interaction of condition*poly1 (χ 2 = 47.69, df = 1, p < 0.001) and condition*poly3 (χ 2 = 7.54, df = 1, p = 0.006). These results suggest that target looking varied across time between the two conditions. We then split the data according to condition. Using drop1 revealed that there was no change in the pattern of target looking across any of the time terms in the word learning task. As is visible in Figure 2, there was a slow but non-significant decrease in target looking throughout the trial (poly1: χ 2 = 2.86, df = 1, p = 0.09). This does not provide evidence for successful recognition of the target upon hearing its label at 12 months of age. Again, using drop1, the action-only model revealed a significant cubic change in target looking across the time course of the trial (χ2 = 10.36, df = 1, p = 0.001). There was no effect of order in which children were exposed to word-object and action-object associations in the model, i.e., the change in target looking following priming by the actions that were associated with this target was not influenced by whether children received training in word-object or action-object associations first. Thus, we found no evidence that exposure to the objects in the first block influenced target looking across conditions when seeing these objects again in the second block.
As is visible in Figure 2, 12-month-olds’ target looking in the action condition was first at chance, then increased toward the target, before it decreased again slightly toward the end of the trial.
For the 24-month-olds, comparing a model with the factor condition to a reduced model without condition revealed that condition did not contribute significantly to the model (χ2 = 1.65, df = 4, p = 0.8). Using drop1, the model revealed no significant interactions between condition and any of the time terms. Thus, there was no evidence for differences in the pattern of children’s target looking across the time course of the trial across the two conditions. For comparability with the 12-month-olds, we split the data by condition for exploratory analyses to examine the change in children’s target looking in each condition separately. Neither model revealed any change in target looking across any of the time terms. As can be seen in Figure 2, the absence of any effects on the polynomials was due to target looking staying mostly around chance level with a slight increase toward the end of the trial in both the action-object and word-object conditions. There was no effect of presentation order in any of the models; in other words, children did not show any change in target looking across the time course of the trial in either condition regardless of whether they were first trained on word-object or action-object associations.
These results suggest that 12-month-olds showed increased looks to the target object when presented with the trained action association for this object, but not when presented with the trained word association for this object, suggesting that they recognized the action-object associations but not the word-object associations. 24-month-olds showed no recognition of either action-object or word-object associations in the current setting.


4. Discussion
The literature on word and action learning suggests that children appear to learn word-object and action-object associations from early on in unimodal contexts, i.e., when presented with either the labels or the actions to be associated with different novel objects (e.g., Childers & Tomasello, Reference Childers and Tomasello2002, Reference Childers and Tomasello2003; Dysart et al., Reference Dysart, Mather and Riggs2016). However, they display a different pattern of learning in bimodal contexts, i.e., when presented with both the labels and actions to be associated with novel objects, showing greater attention to action-object associations early on and word-object associations later in development. Against this background, the current study re-examined children’s learning of novel word-object and action-object associations in unimodal contexts. In separate eye-tracking sessions on the same day, we presented 12-month-old and 24-month-old children with novel objects that were associated either first with a novel label and then separately with a novel action (or vice versa) and tested their recognition of the trained word-object and action-object associations. The results indicate that 12-month-olds learned action-object associations when the time course of target looking was considered, but we found no evidence for learning of word-object associations in this age group. Neither did we find any evidence of learning of either word- or action-object associations at 24 months of age. This extends the findings of Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) to word and action learning in 12- and 24-month-olds in a unimodal context.
Taken together with the results of Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b), these results highlight, on the one hand, differences in children’s learning of action-object and word-object associations across development with early attention to and learning of action-object associations in both unimodal and bimodal contexts. Toward the end of the second year of life, this early focus on action information appears to recede with no evidence that children learned either word- or action-object associations. Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) suggest that this changes further in development with 3-year-olds learning word-object associations and adults learning both. Thus, we find evidence for differences in learning of word- and action-object associations at each of the different ages tested across development.
Early in life, 12-month-olds may prioritize action information more than language information due to the greater salience of the content presented in this condition, relative to linguistic content. While language has been shown to be highly salient to young children (e.g., Fulkerson & Waxman, Reference Fulkerson and Waxman2007), the changing dynamic visual content of the action presentations may be particularly attractive to young children, drawing their attention further in this condition as opposed to the word-object condition. Later in life, from around 2 years, with greater language experience and during a phase of particularly robust language development (e.g., Goldfield & Reznick, Reference Goldfield and Reznick1990), there may be changes in the prioritization of different kinds of information, with reduced attention to action and greater attention to auditory, and in particular, language input (Sloutsky & Napolitano, Reference Sloutsky and Napolitano2003). Indeed, Barnhart et al. (Reference Barnhart, Rivera and Robinson2018) suggested that this period may be associated with dynamically changing attention to different kinds of input, potentially at the individual level (c.f., Barnhart et al., Reference Barnhart, Rivera and Robinson2018; Robinson & Sloutsky, Reference Robinson and Sloutsky2004). In other words, it could be that some children attended more to actions at this age, while others might attend more to the language cues (Eiteljoerge et al., Reference Eiteljoerge, Adam, Elsner and Mani2020), leading to some of them learning the action-object associations and others learning the word-object associations. Thus, children as a group at this age may not display learning of either word-object or action-object associations. Later on, with increased language proficiency, as Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2020) find, children between 2 and 3 years of age then reliably learn word-object associations in the context of the task tested in the current study.
We had earlier suggested that this study could potentially also provide insights into the mechanisms underlying learning in the different domains. Indeed, the current study, together with the study by Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b), highlights developmental differences in the time course of action and word learning in young children, with 1-year-old children learning action-object associations, 2-year-olds learning neither of the associations and only older children at 3 years of age showing evidence of learning of word-object associations in the original study. This is despite children being very attentive in the training phase (looking to training stimuli was at 90% across age groups in the current study). As noted above, this may either suggest different mechanisms underlying learning in the different domains across development or that attentional constraints moderate children’s learning in different domains across development. The latter possibility would also be in keeping with suggestions that early in life, children prioritize attention to certain sources of information, in this case, actions, and later, with increased perceptual abilities, find it easier to learn both word and action associations for objects simultaneously.
Indeed, there are suggestions for differential weighting of action and word information across development. For instance, Sloutsky and Napolitano (Reference Sloutsky and Napolitano2003) suggest that children younger than 4 show auditory dominance, with greater attention to auditory as opposed to visual information early in development. Around 4, there is individual-level variation with regard to auditory and visual dominance, moving to visual dominance in adulthood (see also Barnhart et al., Reference Barnhart, Rivera and Robinson2018; Robinson & Sloutsky, Reference Robinson and Sloutsky2004). Alternatively, one might also suggest a change across development, with the mechanisms underlying learning early on being shared across domains (mediated by attentional constraints as above), developing with further language experience into potentially language-oriented mechanisms that highlight the connections between language and the world.
The pattern of findings reported in the current study, however, contrasts with the results of previous comprehension and production studies, albeit in older children, examining learning of novel words and novel actions for objects (Childers & Tomasello, Reference Childers and Tomasello2003; Hahn & Gershkoff-Stowe, Reference Hahn and Gershkoff-Stowe2010; Riggs et al., Reference Riggs, Mather, Hyde and Simpson2016). In tasks examining children’s comprehension of novel words and actions for objects, for instance, studies report no differences in learning of either kind of association in older age groups, i.e., at the age at which Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) report improved learning of word-object associations. Indeed, if anything, at these older ages, there appear to be domain differences in production tasks, with children showing improved learning of actions for objects relative to words (Childers & Tomasello, Reference Childers and Tomasello2002; Hahn & Gershkoff-Stowe, Reference Hahn and Gershkoff-Stowe2010). This disparity might be due to differences in children’s attentional and perceptual abilities at the different ages tested. Above 30 months of age, children might be able to demonstrate learning and recognition of novel word-object and action-object associations in parallel in unimodal contexts. At younger ages, however, children may show different patterns of learning across domains. Indeed, Hahn and Gershkoff-Stowe (Reference Hahn and Gershkoff-Stowe2010) report that 24-month-olds showed successful comprehension of words 59.4% of the time and of actions 35.9% of the time (with opposite results for production), similar to the more robust learning of word-object associations at later ages in Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b).
The differences in performance at 24 months between the current study and Hahn and Gershkoff-Stowe (Reference Hahn and Gershkoff-Stowe2010) may lie in the design. In their study, children heard the label on average 8.42 times (range: 3 to 15 times). In our study, each child heard the label or saw the action for each object four times. Thus, the absence of evidence for either word or action learning in the present study might be due to the limited amount of input children received (but see Horst & Samuelson, Reference Horst and Samuelson2008 for successful learning at 24 months after a single labeling event). Importantly, the finding that 12-month-olds showed learning of action-object associations despite this limited input (in both unimodal and bimodal contexts) highlights the early attention to action information in development.
The disparities in the findings could also be attributed to the fact that, in our design, the word or action prime was presented prior to the presentation of the target object, requiring children to maintain this prime in memory and recall it upon being presented with the target. This may have impacted how robustly children fixated the target, although we note that children at the same age show robust priming effects (Arias-Trejo & Plunkett, Reference Arias-Trejo and Plunkett2009; Mani & Plunkett, Reference Mani and Plunkett2011). Furthermore, children were not required to disambiguate an ambiguous learning context or to retain the mapping long term which might be easier when tested in a single modality (Bion et al., Reference Bion, Borovsky and Fernald2013). Similarly, we note that, in contrast to previous studies on action-object learning (e.g., Dysart et al., Reference Dysart, Mather and Riggs2016), we did not explicitly instruct the child to fixate the object associated with the action. Doing so in the current study would have led to an imbalance across word and action conditions, with the latter being bimodal. However, this may have led to reduced action-object learning in the 24-month-olds.
Furthermore, with regard to the comparison between Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) and the current study, the pattern of results does not appear to differ based on whether children are presented with both action and word associations for objects together or whether they are presented with information from the two domains successively. In particular, based on previous findings that children have difficulties processing auditory and visual information when they are presented together, Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) had suggested that the difficulties observed in 2-year-olds may have been related to the simultaneous presentation of information from both domains concurrently. The finding that 1-year-olds struggle to show word-object association learning and that 2-year-olds continue to struggle to show recognition of word-object and action-object associations in both unimodal (current study) and bimodal (Eiteljoerge et al., Reference Eiteljoerge, Adam, Elsner and Mani2019b) contexts highlights additional constraints on learning at these ages.
Indeed, Taxitari et al. (Reference Taxitari, Twomey, Westermann and Mani2019) highlight similar limits to children’s early word learning at 10 months of age. In that study, while 10-month-olds learned object associations for the words cow and horse (and did not show recognition of the word-object associations prior to training), the extent to which they would have been able to learn these associations without potential prior familiarity with either the objects or the labels to be trained on remains uncertain. Furthermore, children showed limited generalization of the learned labels to other members of the same category as well as limited learning from multiple exemplars of the object category. The present finding that 12-month-olds learned action-object associations but not word-object associations would, therefore, be in keeping with the constraints on early word learning suggested in Taxitari et al. (Reference Taxitari, Twomey, Westermann and Mani2019). While we had anticipated that learning at this younger age may have been facilitated by the simultaneous presentation of words and action information in Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b), the finding of a very similar pattern of results in unimodal contexts in the current study suggests increased attention to and learning of action information at a young age, generally.
Note that while being presented with information from different modalities at different times did not boost learning in the current study, the Intersensory Redundancy Hypothesis (Bahrick & Lickliter, Reference Bahrick and Lickliter2000) suggests that presenting children with information from both modalities in a temporally aligned manner boosts learning in multimodal contexts. A recent registered report finds that 2-year-olds, but not 1-year-olds, learned both word-object and action-object associations when the object was presented with both words and actions in temporal synchrony (Bothe et al., Stage2, Reference Bothe, Trouillet, Eiteljoerge, Elsner and Maniaccepted). Thus, presenting multimodal information with temporal alignment seems to facilitate learning for young children, compared to bimodal presentations without synchrony as in Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) or unimodal presentations as in the current study. Indeed, the combination of the Intersensory Redundancy Hypothesis and modality dominance provides interesting avenues for new hypotheses. While the Intersensory Redundancy Hypothesis suggests that redundant information in multimodal contexts can facilitate learning, this might only hold for the dominant domain. According to Sloutsky and Napolitano (Reference Sloutsky and Napolitano2003), children below age 4 show auditory dominance. Thus, children might learn words when temporally aligned with actions (Gogate, Reference Gogate2010) because words are provided as auditory information in these studies. In such a context, actions might be more difficult to learn because visual information only becomes dominant at later ages (Barnhart et al., Reference Barnhart, Rivera and Robinson2018). It could also be the case that the predictions of the Intersensory Redundancy Hypothesis are suited for studies investigating cross-domain influences such as the influence of actions on word learning (Eiteljoerge et al., Reference Eiteljoerge, Adam, Elsner and Mani2019a), but when learning in both domains is under question, the predictions might no longer hold. In such a multimodal setting, children might choose to learn only one type of information which could then be the dominant one in the scenario (Sloutsky & Napolitano, Reference Sloutsky and Napolitano2003).
Taken together, here, we replicate and extend earlier findings that 12-month-olds learn action-object associations but not word-object associations and that 24-month-olds learned neither action-object nor word-object associations when presented with both word and action information. Importantly, the findings remain consistent across contexts where children are presented with both word and action information concurrently as well as when this information is presented successively. The similarity in the findings between Eiteljoerge et al. (Reference Eiteljoerge, Adam, Elsner and Mani2019b) and the current study highlights, at the very least, that presenting children with multimodal contexts does not impair learning in general. Thus, across development, children show dynamic patterns of attention to information from different domains and learning of such information remains flexible across development.
Acknowledgements
We thank all families for participating in the study. Furthermore, we would like to thank Maurits Adam for fruitful discussions and Katharina von Zitzewitz for helping with data collection.
Author contribution
Sarah Eiteljoerge: Conceptualization, data curation, formal analysis, investigation, methodology, project administration, resources, software, validation, visualization, roles/writing—original draft and writing—review and editing. Birgit Elsner: Conceptualization, funding acquisition, methodology, supervision and writing—review and editing. Nivedita Mani: conceptualization, formal analysis, funding acquisition, methodology, project administration, supervision, validation, visualization, roles/writing—original draft and writing—review and editing.
Funding statement
This research was supported by the German Research Foundation (DFG) as part of the research unit ‘Crossing the borders: The interplay of language, cognition, and the brain in early human development’ (Project: FOR 2253, grant no. EL 253/7-1), the RTG 2070 Understanding Social Relationships and the Leibniz ScienceCampus ‘Primate Cognition’.
Competing interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.






 Open access
Open access