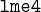 /. From the diachronic perspective, our findings may help to explain why the reflex of modal pre-voiced stops (*b) can be either aspirated or unaspirated voiceless stops.
/. From the diachronic perspective, our findings may help to explain why the reflex of modal pre-voiced stops (*b) can be either aspirated or unaspirated voiceless stops.1 Introduction
In languages where tonal contrasts are already established, it is widely agreed that subsequent loss of voicing contrasts can trigger a binary or ternary tone split that doubles or triples the number of tones (Haudricourt Reference Haudricourt1954, Reference Haudricourt1961, Reference Gedney and Smith1972). While the precise details vary, a common scenario is illustrated by the development of the four-tone system of Sgaw Karen (Figure 1). Historically, this language had a system of two tones, high (A) and falling (B). These two tones later split into four under the influence of the laryngeal specification of the initial consonant, with modal voiced stops and voiced sonorants conditioning a low register and other onsets conditioning a high register (Haudricourt Reference Haudricourt, Harris and Noss1972).

Figure 1 Binary tone split in Sgaw Karen, adapted from Haudricourt (Reference Haudricourt, Harris and Noss1972: 62).
Voice quality has long been thought to play an important role in mediating this process of tonal split. Breathiness, in particular, is thought to arise as a redundant phonetic cue to onset voicing, with its subsequent loss hypothesized to mediate the emergence of new tonal categories in many languages (Haudricourt Reference Haudricourt1954; Pulleyblank Reference Pulleyblank1971, Reference Pulleyblank1978; Kingston Reference Kingston, van Oostendorp, Ewen, Hume and Rice2001; Thurgood Reference Thurgood2002). In the Karen scenario, for example, this would mean that the proto-voiced stops (*b, *d, *g) first passed through a breathy stage prior to tone split and subsequent devoicing. However, it is unclear whether such a voice quality stage is a strictly necessary condition for a tone split. In addition, it remains a puzzle precisely how the system of laryngeal contrasts is restructured in response to tonal register split. This lack of understanding is due in no small part to the fact that languages that have doubled their existing tonal inventory without subsequent loss of the original laryngeal distinction are extremely rare, the best-known case being Shanghai Chinese (Norman Reference Norman1988; Chen Reference Chen2008: 199–200). Such ‘intermediate’ languages are nonetheless crucial to our understanding of tonogenesis, tonal register split, and related phenomena.
The Tai dialect of Cao Bằng (CBT), spoken in a remote and mountainous region of northeastern Vietnam, is that rare specimen of a tonal language caught in the middle of a tone split. In most Tai languages, the three-tone system of Proto-Tai split into six tones following the collapse of the voicing contrast. What makes CBT special is that it has been reported to retain a four-way laryngeal contrast between voiceless unaspirated, voiceless aspirated, modal voiced, and breathy voiced obstruents that has been lost in the majority of Tai languages (Haudricourt Reference Haudricourt1949, Reference Haudricourt1961, Reference Haudricourt, Harris and Noss1972, Reference Haudricourt, L-Thongkum, Kullavanijaya, Panupong and Tingsabadh1979; Hoàng Reference Hoàng1997; Pittayaporn Reference Pittayaporn2009). If this four-way contrast is in fact preserved, an acoustic study could provide important new data on the role of voice quality in the evolution of tone systems.
In this paper, we present the first instrumental phonetic analysis of CBT, with the aim of better understanding how its four-way laryngeal contrast is signaled phonetically. In particular, we examine the roles of fundamental frequency (f0), voice onset time (VOT), and voice quality in cueing the different categories, with a special focus on the role that breathiness plays in the phonological system. We find that different speakers use different patterns of acoustic cues to signal the same phonological categories. Crucially, it appears that breathiness may either be tightly linked to pre-voicing or decoupled from it. We then discuss how this variation might reflect the divergent outcomes of the tonal register split in the Tai family.
2 Background: Voice quality and tonal register splits
Transphonologization of laryngeal contrasts into lexical tones is a common phenomenon in many parts of the world, especially in China and Mainland Southeast Asia. The simplest scenario involves languages that are non-tonal. A well-known example is Northern Kammu, in which the loss of onset voicing yielded a two-way tonal contrast (Svantesson & House Reference Svantesson and House2006). Words that used to have voiceless onsets now occur with a high lexical tone, while those with voiced onsets now occur with a low tone. However, this transformation did not come directly from onset voicing itself, but appears to have been crucially mediated by voice quality differences that first arise as redundant cues to laryngeal contrasts (Premsrirat Reference Premsrirat2001, Svantesson & House Reference Svantesson and House2006).
A more complex scenario is when laryngeal contrasts induce tonal splits in languages that already have lexical tones. The best-known case may be that of Vietnamese. This language first developed three contrastive tones from original contrasts in syllable-final consonants (Maspero Reference Maspero1912, Haudricourt Reference Haudricourt1954, Thurgood Reference Thurgood2002, Ferlus Reference Ferlus2004); subsequently, each of the three tones split into two under the influence of the syllable-initial voicing contrast. The six pitch patterns only became fully contrastive tones when the original voicing contrast in the onsets was lost. Similar to the onset-based tonogenesis, the tonal register split has been proposed to include an intermediate stage during which voice quality plays an important role in the contrast system of the language (Pulleyblank Reference Pulleyblank1970, Reference Pulleyblank1971; Thurgood Reference Thurgood2002).
This type of tonal register split has occurred in virtually all Tai, Chinese, and Hmong-Mien varieties as well as individual languages in the other major families of Southeast Asia (Haudricourt Reference Haudricourt1961, Reference Haudricourt, Harris and Noss1972; Gedney Reference Gedney and Smith1972; Matisoff Reference Matisoff and Hyman1973, Reference Matisoff, Aikhenvald and Dixon2001, Reference Matisoff2003; Li Reference Li1977; Thurgood Reference Thurgood1999; Thurgood & Thurgood Reference Thurgood and Thurgood2005; Pittayaporn Reference Pittayaporn2009: 238–285; Ratliff Reference Ratliff2010). Pittayaporn (Reference Pittayaporn2009: 248) schematizes the interrelated processes of tonal register split and neutralization of laryngeal contrasts in the onset in four major stages, as illustrated in Figure 2. In this framework, Proto-Tai is reconstructed as being in Stage I (Haudricourt Reference Haudricourt1956, Li Reference Li1977, Pittayaporn Reference Pittayaporn2009), while the grand majority of modern Tai varieties have reached Stage IV, or have undergone additional tonal splits and mergers. CBT represents a language at Stage III, one that has neutralized the voicing contrast in initial sonorants but has retained it in initial obstruents, along with voice quality differences most other Tai languages have lost. As a result, while the modern language has six lexical tones, the tones in CBT are fully contrastive only on sonorant-initial syllables. For obstruent-initial syllables, three of the six tones can occur only with voiced fricatives and breathy voiced stops, with the other three being restricted to modal pre-voiced, voiceless aspirated, and voiceless unaspirated stops.

Figure 2 Tonal register split and neutralization of laryngeal contrast (from Pittayaporn Reference Pittayaporn2009: 248).
One issue that is often left undiscussed in the literature on tonal register split is the fate of breathiness after tonal split has occurred. Previous studies have revealed at least three types of outcomes. First, breathiness may be reanalyzed as a property of a subset of tones. In this type of systems, the tones in syllables that originally had voiced onsets are predictably breathy. Shanghai Chinese (Norman Reference Norman1988: 199–200), Sach/Ruc (Ferlus Reference Ferlus1998) and Tamang (Mazaudon & Michaud Reference Mazaudon and Michaud2008) are examples of languages of this type. Second, breathiness can be completely lost. This seems to be the default outcome, as in most languages the original voiced stops turn into voiceless unaspirated stops. Examples include Tsat (Thurgood & Thurgood Reference Thurgood and Thurgood2005), Khuen (Owen Reference Owen2012), Shan (Edmondson Reference Edmondson1997, Edmondson Reference Edmondson, Diller, Edmondson and Luo2008) and most other Tai varieties (Chamberlain Reference Chamberlain, Harris and Chamberlain1975). In the last and least understood type of outcomes, breathiness is reanalyzed as aspiration, i.e. as a property of the onset. Pulleyblank (Reference Pulleyblank1978) explains the fact that Middle Chinese voiced onsets are reflected as voiceless aspirated in Mandarin when occurring with level tone by postulating that the breathiness of the onset was reanalyzed as aspiration, i.e. pʱ
![]() > pʰ
> pʰ
![]() . Comparing to the complete loss of breathiness, this type of development occurs in a smaller number of languages. Some examples include Gan dialects (Sagart Reference Sagart1984, Reference Sagart1992), Central Thai (Abramson Reference Abramson1962, Brown Reference Brown and Brown1965, Abramson & Erickson Reference Abramson and Erickson1978), Lao (Brown Reference Brown and Brown1965, Ostananda Reference Ostananda1997), and a few other Tai varieties (Chamberlain Reference Chamberlain, Harris and Chamberlain1975). We are hopeful that additional synchronic studies of languages of these types will help us to understand the role and fate of voice quality in the emergence of tone systems more generally.
. Comparing to the complete loss of breathiness, this type of development occurs in a smaller number of languages. Some examples include Gan dialects (Sagart Reference Sagart1984, Reference Sagart1992), Central Thai (Abramson Reference Abramson1962, Brown Reference Brown and Brown1965, Abramson & Erickson Reference Abramson and Erickson1978), Lao (Brown Reference Brown and Brown1965, Ostananda Reference Ostananda1997), and a few other Tai varieties (Chamberlain Reference Chamberlain, Harris and Chamberlain1975). We are hopeful that additional synchronic studies of languages of these types will help us to understand the role and fate of voice quality in the emergence of tone systems more generally.
3 Tones and onsets in CBT
The Tai language of Cao Bằng is a member of the Tai branch of the Kra-Dai language family. The specific variety investigated in the current study is spoken by ethnic Tày in Trùng Khánh District, Cao Bằng Province, in the extreme northeast of Vietnam (Figure 3). As described by Hoàng (Reference Hoàng1997) and Pittayaporn (Reference Pittayaporn2009), it is very similar to varieties spoken in other districts of Cao Bằng reported by Haudricourt (Reference Haudricourt1960) and Ross (Reference Ross1996), and shows a strong overall resemblance to the dialect spoken just across the border in Daxin County in Guangxi Zhuang Autonomous Region as reported by Zhang et al. (Reference Zhang, Ouyang, Zheng, Li and Xie1999). Estimating from the total population of the district, there are approximately 50,000 speakers of the Trùng Khánh variety of CBT (Socialist Republic of Vietnam Government 2013).
Like all its Tai relatives, CBT features multiple laryngeal contrasts in the onset and a sizeable inventory of level and contour tones. Table 1 shows the consonant inventory of CBT, including the four types of labial and alveolar onsets. The phonological analysis of CBT in this study is based on the first author's fieldwork carried out in 2008, which differs slightly from the sketch by Hoàng (Reference Hoàng1997).Footnote
1
As shown in Table 1, voicing in CBT is contrastive for stops and fricatives but not for nasals, liquids, or glides, which are always voiced. The distinction among the voiceless aspirated /pʰ/, voiceless unaspirated /p/, modal voiced /b/, and breathy voiced /
![]() / stops is clearly illustrated by the contrastive sets in example (1) below. Note that the breathy voiced stops have different tones from the other three types of stops.
/ stops is clearly illustrated by the contrastive sets in example (1) below. Note that the breathy voiced stops have different tones from the other three types of stops.
-
(1)


Table 1 Consonant inventory of the Tai dialect of Cao Bằng.
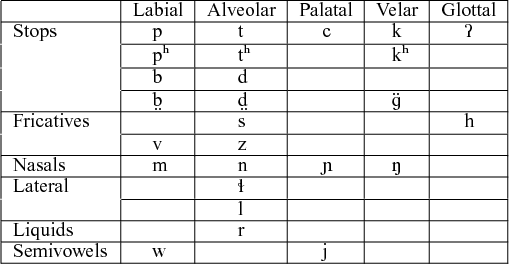

Figure 3 The location of Cao Bằng province (red) in northern Vietnam. Administrative boundaries based on GADM database version 2.7 (Global Administrative Area 2015).
It is important to note that what we transcribe as modal and breathy voiced stops are transcribed as modal and pre-glottalized by Hoàng (Reference Hoàng1997), who analyzed the CBT phonemic system based on his native-speaker intuition. Moreover, we transcribe Hoàng's /ɣ/ as a breathy-voiced stop /
![]() /. This modal-vs.-breathy analysis is supported by the acoustic results discussed in Section 5. One plausible explanation for the difference might in fact be a carry-over from the transcription convention for Vietnamese: Hoàng may have chosen /ɣ/ rather than /ɡ/ to transcribe this sound because the former is the only voiced velar sound in Vietnamese.
/. This modal-vs.-breathy analysis is supported by the acoustic results discussed in Section 5. One plausible explanation for the difference might in fact be a carry-over from the transcription convention for Vietnamese: Hoàng may have chosen /ɣ/ rather than /ɡ/ to transcribe this sound because the former is the only voiced velar sound in Vietnamese.
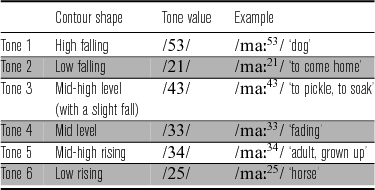
With respect to lexical tones, CBT makes a six-way contrast in terms of both pitch height and pitch contour, illustrated by the contrastive set in Table 2. The pitch value for each tone given here is based on the description by Hoàng (Reference Hoàng1997).Footnote 2 These six tones can be divided into two subsets according to the pitch height at the tonal onset. If we compare Tone 1 with Tone 2, Tone 3 with Tone 4, and Tone 5 with Tone 6, we see that the even-number tones have similar contours but higher starting pitch than their respective odd-number tones; for example, Tone 5 (/34/) and Tone 6 (/25/) are both rising tones. The odd- and even-number tones can thus be said to belong to upper and lower registers, respectively.
Table 2 Descriptive tonal inventory of CBT (after Hoàng Reference Hoàng1997). Low-register tones (2, 4, 6) are shaded.
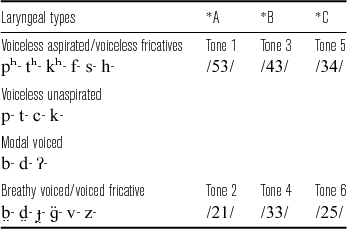
Obstruents and sonorants in CBT also differ with respect to tonal contrasts. While the six tones are fully contrastive in syllables with sonorant onsets, the occurrence of high and low register tones are restricted by the laryngeal type of the obstruent onset. High register tones (/53 43 34/) only occur with the voiceless aspirated, voiceless unaspirated, and modal voiced stops, while low register tones (/21 33 25/) only occur when the onset is /
![]() / or /
/ or /
![]() /. As for fricative-initial syllables, high and low register tones are restricted to voiceless and voiced onsets, respectively.
/. As for fricative-initial syllables, high and low register tones are restricted to voiceless and voiced onsets, respectively.
This co-occurrence restriction is a result of the binary tone split that occurred in the history of CBT. The six tones in the modern language have their origins in the three contrastive tones in the proto-language (Gedney Reference Gedney and Smith1972; Li Reference Li1977: 24–55; Pittayaporn Reference Pittayaporn2009: 238–285). Proto-Tai is conventionally reconstructed with threeFootnote 3 tonal categories in open syllables, usually labeled *A, *B, and *C. However, the four-way contrast among CBT initial consonants is a considerable modification of the three-way Proto-Tai system. At the time of the binary tonal register split, CBT also had four distinctive series of stops but contrasted them in a different way from present-day CBT: the stop series contrasted voiceless aspirated (*pʰ-, . . .), voiceless unaspirated (*p-, . . .), implosive (*ɓ-, . . .), and modally voiced (*b-, . . .) stops, while for fricatives only the voiceless (*f-, . . .) and voiced (*v-, . . .) series were present. Crucially, there were also two series of sonorants that contrasted in terms of voicing, namely voiced (*m-, . . .) and voiceless (pre-)aspirated (*ʰm-, . . .). These laryngeal categories could co-occur with any of the three original tonal categories (Gedney Reference Gedney and Smith1972; Li Reference Li1977: 24–55; Pittayaporn Reference Pittayaporn2009: 238–285).
The important change that transformed CBT from a three-tone to a six-tone language is the binary tonal register split that took place concomitantly with the loss of pre-aspiration of the voiceless sonorants. Such loss of laryngeal contrast between sonorants was not a unique change, but a (hypothesized) step that all other Tai languages have also passed through (Figure 2 above). In addition to the variety of CBT discussed here, a few varieties spoken in other localities in Cao Bằng Province including Cao Bình, Nguyên Bình, Đông Mu, Bảo Lạc, and Đào NgạnFootnote 4 (L’École Française d'Extême-Orient 1938; Haudricourt Reference Haudricourt1949, Reference Haudricourt1960, Reference Haudricourt, L-Thongkum, Kullavanijaya, Panupong and Tingsabadh1979; Ross Reference Ross1996) have also been reported to preserve this state of affairs. In southeastern Yunnan province, a pocket of conservative varieties known as Dai Zhuang, Dai Tho, or Bu Dai among other names have also been reported to still retain the laryngeal contrast (L-Thongkum Reference L-Thongkum1997, Zhang et al. Reference Zhang, Ouyang, Zheng, Li and Xie1999, Kullavanijaya & L-Thongkum Reference Kullavanijaya, L-Thongkum and Burusphat2000). Unfortunately, none of these varieties have been studied instrumentally.
According to Pittayaporn's (Reference Pittayaporn2009: 248) model of Tai tonal splits shown in Figure 2 above, these conservative varieties remain in Stage III, in which the full complement of tonal contrasts is only active in the sonorant sub-system. In the obstruent sub-system, the tones in the lower register predictably co-occur with the breathy voiced stops, which developed from earlier modal voiced stops (*b- >
![]() -). In contrast, the tones in the upper series predictably co-occur with voiceless unaspirated, voiceless aspirated and modal voiced stops, which historically came from aspirated (*pʰ-), unaspirated (*p-) and implosive (*ɓ- > b-) onsets, respectively. For fricatives, upper register tones occur only with voiceless fricatives and lower register tones only with voiced ones. The co-occurrence restrictions are summarized in Table 3.
-). In contrast, the tones in the upper series predictably co-occur with voiceless unaspirated, voiceless aspirated and modal voiced stops, which historically came from aspirated (*pʰ-), unaspirated (*p-) and implosive (*ɓ- > b-) onsets, respectively. For fricatives, upper register tones occur only with voiceless fricatives and lower register tones only with voiced ones. The co-occurrence restrictions are summarized in Table 3.
Table 3 Co-occurrence restriction between tones and obstruent onsets in CBT.
To summarize, CBT appears to be a language that has stopped one stage before transphonologization of laryngeal contrast to tonal contrast is complete. From the phonetic point of view, CBT provides an opportunity to see how a now-redundant laryngeal contrast is realized acoustically, given that the lexical contrast is now completely predictable from lexical tones. Not only does an instrumental study of CBT advance our understanding of the relationship between tone and laryngeal contrast, it also sheds light on the fine details of the restructuring of laryngeal contrasts in response to the tonal register split.
4 Method
4.1 Materials
A master wordlist of 188 items was constructed to cover all attested monosyllables with single labial consonants as onsets and the vowels /a/ or /aː/ as nuclei. The list was so designed to avoid possible effects of places of articulation and vowel qualities. It was also verified and enriched by a native speaker who is a trained linguist. For this study, we focused on the 143 sonorant-final items of type CV(V)(C), where C could be one of /m n ŋ j w/ and V was either /a/ or /aː/. For each monosyllable, the speaker was first given the meaning in Vietnamese; three repetitions of the CBT equivalent were then recorded in the carrier phrase /kʰɔj 34 pʰuəj 43 ____ ɬaːm 53 pɤj 43/ ‘I say ____ three times’. This gave a potential total corpus of 1,278 tokens (142 syllables × 3 repetitions × 3 speakers). As some words in the wordlist were not known to all speakers, the analysis reported here is based on a total of 1,144 tokens. A complete list of words is provided in the appendix.
4.2 Speakers
Conducting phonetic fieldwork on CBT is particularly challenging due to its relative inaccessibility. The variety we investigated is spoken in the town of Trùng Khánh, Cao Bằng Province, Vietnam, located approximately 9 hours (325 km) northeast of Hanoi (see Figure 3 above). Given the circumstances, the first author was only able to record three speakers during a short visit to northern Vietnam in August 2010. The first speaker M1, a 75-year-old retired linguist, was recorded at his home in Hanoi. However, the other two speakers were both recorded in Trùng Khánh. While F1 was a 57-year-old woman, M2 was a 50-year-old man. Although the three speakers are fluent in Vietnamese, they use CBT as their first language and still speak it with their families on a daily basis.
Recordings were made at 44.1 kHz using a Marantz PMD660 digital recorder with a Shure SM10 head-mounted dynamic microphone. All recordings were made in relatively quiet rooms in the house of each speaker. Because of time, budget, and logistical limits, the trip to Trùng Khánh only lasted for five days, half of which were spent in transit. Although three speakers clearly cannot be taken as representative of the entire language community, our small sample already reveals a number of interesting aspects of how the laryngeal contrast is realized in CBT.
4.3 Acoustic analysis
The onset and rime components of each token were labeled using Praat 5.4.04 (Boersma & Weenink Reference Boersma and Weenink2014). Oral and laryngeal events were labeled on separate tiers. The onset of closure was determined as the first zero-crossing point after disappearance of clear formant structure. The onset of voicing was marked as the first upward-going zero crossing preceding the first periodic wave component of the acoustic waveform (Francis, Ciocca & Yu Reference Francis, Ciocca and Yu2003). We attempted to note the point, if any, where voicing died off during the closure, as shown in Figure 4; however, it was often difficult to distinguish between true cessation and simply low-amplitude voicing during the closure, so any conclusions that can be drawn from this measure are impressionistic at best. The status of the oral cavity (open or closed) was marked on a separate tier, with the open phase coinciding with the onset of the release burst if present as illustrated in Figure 4. Time from release of closure to first onset of voicing (VOT) was then measured for each token; thus in the case of pre-voicing, this value is negative.

Figure 4 Segmentation criteria for an instance of /
![]() a
a
n
2
1
/ ‘to crawl’, speaker M2.
a
a
n
2
1
/ ‘to crawl’, speaker M2.
Acoustic measurements on the rime portion (vowel + sonorant final, if any) of each token were then made using VoiceSauce (Shue et al. Reference Shue, Keating, Vicenik and Yu2011). Measures were taken at each millisecond of the target region and then averaged over eleven equally spaced segments. Measures included fundamental frequency (f0) as calculated by the STRAIGHT algorithm (Kawahara, de Cheveigne & Patterson Reference Kawahara, de Cheveigne and Patterson1998), the amplitudes of the first and second harmonics (H1 and H2), and the highest-amplitude component of the first three formants (A1, A2, and A3). Harmonic measures were all corrected for the effects of the surrounding formant frequencies and bandwidths using the algorithm of Iseli, Shue & Alwan (Reference Iseli, Shue and Alwan2007); they are reported here as H1*, H2*, etc. Raw f0 measures were converted into semitones using the formula 12 log2 (f0/mf0) / log2 2, where mf0 represents each speaker's mean f0.
To look for differences in voice quality, we examined differences in four acoustic measures of spectral balance (H1*-H2*, H1*-A1*, H1*-A2* and H1*-A3*) which have been shown to correlate with various physiological parameters such as the open quotient (OQ) (Holmberg et al. Reference Holmberg, Hillman, Perkell, Guiod and Goldman1995, Ní Chasaide & Gobl Reference Ní Chasaide, Gobl, Hardcastle and Laver1997, Iseli & Alwan Reference Iseli and Alwan2004) and abruptness of vocal fold closure (Stevens Reference Stevens1977). These measures were selected as they have been reported to reliably distinguish breathy vs. modal vowels in a number of languages including Gujarati (Fischer-Jørgensen Reference Fischer-Jørgensen1967, Khan Reference Khan2012), Green Mong (Andruski & Ratliff Reference Andruski and Ratliff2000, Esposito Reference Esposito2012), Eastern Cham (Brunelle Reference Brunelle2005), Takhian Thong Chong (DiCanio Reference DiCanio2009), Khmu’ Rawk (Abramson, Nye & Luangthongkum Reference Abramson, Nye and Luangthongkum2007), Santa Ana Del Valle Zapotec (Esposito Reference Esposito2010), and many others (see also Gordon & Ladefoged Reference Gordon and Ladefoged2001, Keating & Esposito Reference Keating and Esposito2006). While VoiceSauce provides a number of other acoustic measures that are known to correlate with voice quality difference in some languages (e.g. cepstral peak prominence, harmonic-to-noise ratios, etc.), for brevity, and given the somewhat exploratory nature of our study, we focus here on the four most-reported measures mentioned above.
In Figure 4, voicing onset (vo, tier 2) is coextensive with the onset of oral closure (onset of interval marked o, tier 1). Voicing appears to die off around four-fifths of the way through the closure (marked as vc, tier 2), followed by closure release (onset of interval marked v, tier 1). The resumption of periodic voicing is indicated as vn (tier 2).
5 Results
Due to the small number of speakers in this study and the considerable variation in realization of phonetic cues, results are presented on a per-speaker basis.
5.1 Fundamental frequency
Figure 5 shows f0 contours (in semitones) measured over the rime by subject and onset. We first consider data from nasal and approximant onsets, which are the only onsets that can bear the full range of tonal contrasts. Impressionistically, the tone shapes are consistent within speakers for the three types of voiced sonorant initial. The exception is the mid-rising tone /34/: for speaker M1 this is realized as a (mid/high) level tone, without any rising contour as seen for speakers M2 and F1. The low-rising tone /25/ also displays some interspeaker variability, with a more pronounced final rise in the speech of M1 and F1 compared to M2. In general, however, the tone shapes are (impressionistically) consistent with the values reported in Hoàng (Reference Hoàng1997), as summarized in Table 1 above.

Figure 5 Tone realizations (in semitones) over syllable rime by speaker and onset.
Turning to the obstruent and fricative onsets, the redundancy of pitch and voicing becomes immediately apparent: the high-register tones /53 43 34/ (i.e. those derived from PT voiceless onsets) only occur with the onsets /b
p
p
h
/, while low-register tones /21 33 25/ (i.e. those derived from PT voiced onsets) only occur with syllables beginning with /
![]() / and /v/. In addition to the interspeaker differences in tones /34/ and /25/ observed for the sonorant series, considerable variation in the realization of tone /53/ is also apparent, particularly for speakers M1 and F1: when pronounced on syllables with the onset /b/, this tone is realized as (mid) level, but is high (rising-)falling when following voiceless obstruents /p
pʰ/. This is most pronounced for speaker F1, for whom the tone of words like /b
aŋ53/ ‘to run’ closely resembles that of words such as /
/ and /v/. In addition to the interspeaker differences in tones /34/ and /25/ observed for the sonorant series, considerable variation in the realization of tone /53/ is also apparent, particularly for speakers M1 and F1: when pronounced on syllables with the onset /b/, this tone is realized as (mid) level, but is high (rising-)falling when following voiceless obstruents /p
pʰ/. This is most pronounced for speaker F1, for whom the tone of words like /b
aŋ53/ ‘to run’ closely resembles that of words such as /
![]() aːn
33/ ‘to wander’. For speaker M2, tone /53/ on /b/-initial syllables appears to be more similar to its realization on syllables with other obstruents, but with a less pronounced mid/final rise. This suggests a potential ambiguity involving the laryngeal and tonal contrasts (see Section 6).Footnote
5
aːn
33/ ‘to wander’. For speaker M2, tone /53/ on /b/-initial syllables appears to be more similar to its realization on syllables with other obstruents, but with a less pronounced mid/final rise. This suggests a potential ambiguity involving the laryngeal and tonal contrasts (see Section 6).Footnote
5
5.2 VOT
Figure 6 shows the distribution of Voice Onset Time (VOT) for each speaker and onset type. Speakers M2 and M1 produce similar VOT values for each type of stop, differing significantlyFootnote
6
only for /p
h
/ and then only by < 10 ms. More striking is the behavior of /
![]() /, which is pre-voiced for M2 and M1 but voiceless unaspirated for F1. Figure 6 suggests a two- or three-way distribution of VOT values for each speaker, with categories /b/ ~ /
/, which is pre-voiced for M2 and M1 but voiceless unaspirated for F1. Figure 6 suggests a two- or three-way distribution of VOT values for each speaker, with categories /b/ ~ /
![]() / vs. /p/ and /p
h
/ for M2 and M1, and /b/ vs. /
/ vs. /p/ and /p
h
/ for M2 and M1, and /b/ vs. /
![]() / ~ /p/ vs. /p
h
/ for F1. Post-hoc pairwise comparisons suggest that while all four categories are statistically separable for all three speakers (with the exception of /
/ ~ /p/ vs. /p
h
/ for F1. Post-hoc pairwise comparisons suggest that while all four categories are statistically separable for all three speakers (with the exception of /
![]() / ~ /p/ for speaker F1), the difference in VOT between categories is in some cases rather small. Whether or not these categories are perceptually distinct would naturally require a perceptual study, but we suspect that VOT itself is no longer the primary acoustic cue distinguishing /
/ ~ /p/ for speaker F1), the difference in VOT between categories is in some cases rather small. Whether or not these categories are perceptually distinct would naturally require a perceptual study, but we suspect that VOT itself is no longer the primary acoustic cue distinguishing /
![]() / from /p/ for F1 (see Section 5.3 below).
/ from /p/ for F1 (see Section 5.3 below).

Figure 6 Distributions of VOT for voiced /b/, breathy-voiced /
![]() /, voiceless unaspirated /p/ and voiceless aspirated /p
h
/ stops by speaker.
/, voiceless unaspirated /p/ and voiceless aspirated /p
h
/ stops by speaker.
Both the stops /b/ and (for speakers M2 and M1) /
![]() / are consistently (if sometimes weakly) pre-voiced. Impressionistically, cessation of voicing during the closure was not uncommon in tokens of /
/ are consistently (if sometimes weakly) pre-voiced. Impressionistically, cessation of voicing during the closure was not uncommon in tokens of /
![]() / by speaker M2, although as noted in Section 4.3 above, the relatively low amplitude of the recordings impedes accurate quantification of how often this may in fact occur.Footnote
7
Further inspection of the acoustic waveform did not reveal any obvious indication that either /b/ or /
/ by speaker M2, although as noted in Section 4.3 above, the relatively low amplitude of the recordings impedes accurate quantification of how often this may in fact occur.Footnote
7
Further inspection of the acoustic waveform did not reveal any obvious indication that either /b/ or /
![]() / is regularly realized as implosive (as indicated by e.g. amplitude/closure duration correlation or linearly increasing amplitude of voicing during the closure; Lindau Reference Lindau1984) nor of the presence of pre-glottalization or pre-laryngealization (as indicated by e.g. irregular phonation of the vowel preceding the stop; Dilley, Shattuck-Hufnagel & Ostendorf Reference Dilley, Shattuck-Hufnagel and Ostendorf1996, Esling, Fraser & Harris Reference Esling, Fraser and Harris2005). However, additional (aerodynamic, electroglottographic, laryngoscopic) data would be necessary to rule out the presence (or absence) of these features.
/ is regularly realized as implosive (as indicated by e.g. amplitude/closure duration correlation or linearly increasing amplitude of voicing during the closure; Lindau Reference Lindau1984) nor of the presence of pre-glottalization or pre-laryngealization (as indicated by e.g. irregular phonation of the vowel preceding the stop; Dilley, Shattuck-Hufnagel & Ostendorf Reference Dilley, Shattuck-Hufnagel and Ostendorf1996, Esling, Fraser & Harris Reference Esling, Fraser and Harris2005). However, additional (aerodynamic, electroglottographic, laryngoscopic) data would be necessary to rule out the presence (or absence) of these features.
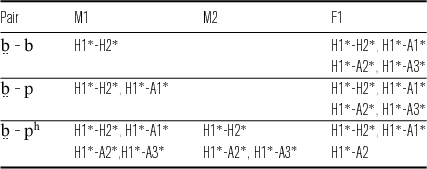
5.3 Voice quality
Figure 7 shows four corrected spectral balance measures (H1*-H2*, H1*-A1*, H1*-A2* and H1*-A3*) by speaker, averaged over all tokens for each of the five onsets /b
![]() p
p
h
m/. All four measures appear to distinguish voiceless stops (i.e. /p/ from /p
h
/) for all speakers, at least in the first half of the vowel, probably the result of aspiration noise caused by glottal turbulence extending beyond the release of oral closure (Klatt Reference Klatt1975). Table 4 lists the measures that distinguish breathy from modal stops at vowel onset for each of the three speakers at a statistically significant level. H1*-H2* distinguishes the voiced stop /b/ from /
p
p
h
m/. All four measures appear to distinguish voiceless stops (i.e. /p/ from /p
h
/) for all speakers, at least in the first half of the vowel, probably the result of aspiration noise caused by glottal turbulence extending beyond the release of oral closure (Klatt Reference Klatt1975). Table 4 lists the measures that distinguish breathy from modal stops at vowel onset for each of the three speakers at a statistically significant level. H1*-H2* distinguishes the voiced stop /b/ from /
![]() / for speakers M1 and F1, but not M2. H1*-A1* also distinguished this pair for speaker M1. For speaker F1, all four measures distinguish /
/ for speakers M1 and F1, but not M2. H1*-A1* also distinguished this pair for speaker M1. For speaker F1, all four measures distinguish /
![]() / from both /b/ and /p/. None of the four measures distinguished /b/ from /
/ from both /b/ and /p/. None of the four measures distinguished /b/ from /
![]() / (or /p/) for speaker M2.
/ (or /p/) for speaker M2.

Figure 7 Four corrected spectral balance measures (H1*-H2*, H1*-A1*, H1*-A2* and H1*-A3*) by speaker. For clarity, only obstruents and the sonorant /m/ are shown.
Table 4 Measures distinguishing breathy/modal onset pairs at vowel onset by speaker. Measures listed show a statistically significant difference (p ≤ .001) between the pair in question.
5.4 Spectrographic examples
Figure 8 provides spectrographic examples of each onset type for each speaker. For speaker M1, these suggest four phonetic categories are maintained for stops: a voiceless unaspirated stop /p/, with onset of voicing almost coextensive with the release of the oral closure; a modally pre-voiced stop /b/; a breathy pre-voiced stop /
![]() / with evidence of spectral degradation immediately following vowel onset; and a lightly aspirated stop /p
h
/, with aspiration noise visible well past the onset of periodic voicing. For speaker M2, visual interpretation of the spectrogram reveals little obvious difference between tokens with the onsets /b/, /p/ and /
/ with evidence of spectral degradation immediately following vowel onset; and a lightly aspirated stop /p
h
/, with aspiration noise visible well past the onset of periodic voicing. For speaker M2, visual interpretation of the spectrogram reveals little obvious difference between tokens with the onsets /b/, /p/ and /
![]() / (although this particular example does nicely illustrate the cessation of voicing during the closure that characterizes many tokens of /
/ (although this particular example does nicely illustrate the cessation of voicing during the closure that characterizes many tokens of /
![]() / for this speaker). There is, however, clear aspiration noise/weakening of higher formants in the token of /p
h
/. For speaker F1, the only (pre-)voiced stop is /b/, which in this example shows a weak but visible and constant voicing during the closure period. However, the breathy and aspirated stops for this speaker have almost identical spectral signatures, with significant weakening/aspiration noise visible in the formant structure beginning around F2/1750 Hz, as suggested by the spectral balance analysis presented above.
/ for this speaker). There is, however, clear aspiration noise/weakening of higher formants in the token of /p
h
/. For speaker F1, the only (pre-)voiced stop is /b/, which in this example shows a weak but visible and constant voicing during the closure period. However, the breathy and aspirated stops for this speaker have almost identical spectral signatures, with significant weakening/aspiration noise visible in the formant structure beginning around F2/1750 Hz, as suggested by the spectral balance analysis presented above.

Figure 8 Spectrographic examples of bilabial obstruent onsets (rows) by speaker (columns). Items from top: /p
aːn
4
3
/ ‘hemp’, /b
aːn
4
3
/ ‘spirit table’, /
![]() aːn
3
3
/ ‘to wander’ and /p
h
aːn
5
3
/ ‘to peel (fruit skin)’.
aːn
3
3
/ ‘to wander’ and /p
h
aːn
5
3
/ ‘to peel (fruit skin)’.
6 Discussion
As the first instrumental study on CBT, this paper has examined how the historically four-way laryngeal contrast of the language is signaled phonetically. Due to logistic limitations, the study is based on only a small number of speakers who vary in age, gender, and location. Although this shortcoming prevents us from making any firm claim regarding the nature of the variation, our results on f0, voice quality, and VOT present a picture of breathiness in CBT as a phonetic property with variable phonological significance across speakers.
The system of M1, the oldest speaker in our sample, appears to be the most conservative. In his phonological system, voice quality (as indicated by H1*-H2*) serves to enhance the contrast between modal and breathy voiced stops, despite the fact that they co-occur with two different sets of tones.Footnote
8
There is some evidence that speaker M2 may also use voice quality as a redundant cue to this distinction as well. However, when compared to M1, VOT seems less reliable as an acoustic cue to laryngeal contrasts, as pre-voicing often terminates early in /
![]() /. The variable cessation of pre-voicing makes many instances of /
/. The variable cessation of pre-voicing makes many instances of /
![]() / very similar to /p/ in terms of VOT. This suggests that breathiness is no longer strictly associated with voicing, but may instead be in the process of becoming an independent laryngeal property. However, given that voice quality does not seem to distinguish between /
/ very similar to /p/ in terms of VOT. This suggests that breathiness is no longer strictly associated with voicing, but may instead be in the process of becoming an independent laryngeal property. However, given that voice quality does not seem to distinguish between /
![]() / and /b/ (or /p/) for this speaker, it is also conceivable that both voice quality and pre-voicing will be lost in the breathy-voiced series, resulting in a three-way laryngeal contrast where the categories /b
p
p
h
/ are distinguished primarily by voice onset time. If that indeed occurs, breathy voiced /
/ and /b/ (or /p/) for this speaker, it is also conceivable that both voice quality and pre-voicing will be lost in the breathy-voiced series, resulting in a three-way laryngeal contrast where the categories /b
p
p
h
/ are distinguished primarily by voice onset time. If that indeed occurs, breathy voiced /
![]() / would be predicted to merge with voiceless unaspirated /p/, resulting in a full complement of tones similar to syllables with onsets /m/ or /v/.
/ would be predicted to merge with voiceless unaspirated /p/, resulting in a full complement of tones similar to syllables with onsets /m/ or /v/.
The most innovative system seems to be that of F1. In contrast to the other two speakers, the breathy voiced stop /
![]() / is no longer voiced during closure, but instead has a phonetic realization similar to voiceless unaspirated /p/. However, /
/ is no longer voiced during closure, but instead has a phonetic realization similar to voiceless unaspirated /p/. However, /
![]() / may still be distinguished from both /b/ and /p/ by voice quality (Section 5.3). This suggests that breathiness, while still redundant, has become decoupled from (pre-)voicing. In fact, for F1, the acoustic realization of /
/ may still be distinguished from both /b/ and /p/ by voice quality (Section 5.3). This suggests that breathiness, while still redundant, has become decoupled from (pre-)voicing. In fact, for F1, the acoustic realization of /
![]() / is much more similar to /pʰ/ than to /p/ (Figures 7–8). Thus, it is possible that breathiness will one day be reanalyzed as aspiration, also resulting in a three-way VOT-based contrast among /b/, /p/ and /p
h
/. The difference between the resulting systems of F1 and the path hypothesized for M2 would hinge on whether breathy voiced /
/ is much more similar to /pʰ/ than to /p/ (Figures 7–8). Thus, it is possible that breathiness will one day be reanalyzed as aspiration, also resulting in a three-way VOT-based contrast among /b/, /p/ and /p
h
/. The difference between the resulting systems of F1 and the path hypothesized for M2 would hinge on whether breathy voiced /
![]() / merges with /pʰ/ or /p/, and thus which voiceless stop would be the first to co-occur with all six of the CBT tones.
/ merges with /pʰ/ or /p/, and thus which voiceless stop would be the first to co-occur with all six of the CBT tones.
Strikingly, the synchronic variation found among the laryngeal system of the three speakers reflects the different diachronic outcomes of tonal register split. The most common path taken after the breathy voiced /
![]() / seems to be to merge with voiceless unaspirated /p/, as occurred in many Tai languages, e.g. Shan, Lue, Khuen, Black Tai, Red Tai, White Tai, Western Nung, Longzhou, Wuming, or Bouyei (Chamberlain Reference Chamberlain, Harris and Chamberlain1975, Reference Chamberlain and Chamberlain1991; Li Reference Li1977; Pittayaporn Reference Pittayaporn2009). Alternatively, the breathy voice quality of /
/ seems to be to merge with voiceless unaspirated /p/, as occurred in many Tai languages, e.g. Shan, Lue, Khuen, Black Tai, Red Tai, White Tai, Western Nung, Longzhou, Wuming, or Bouyei (Chamberlain Reference Chamberlain, Harris and Chamberlain1975, Reference Chamberlain and Chamberlain1991; Li Reference Li1977; Pittayaporn Reference Pittayaporn2009). Alternatively, the breathy voice quality of /
![]() / might also be reanalyzed as voicing lag characteristic of aspirated stops (i.e. as aspiration). In the resulting system, the reflex of /
/ might also be reanalyzed as voicing lag characteristic of aspirated stops (i.e. as aspiration). In the resulting system, the reflex of /
![]() / would merge with the voiceless aspirated stop /pʰ/. If such a change is in fact conditioned by reanalysis of breathiness as aspiration, it is perhaps not surprising that this path of development has been taken by a smaller number of languages, e.g. Thai, Lao, Phuan and Phu Thai (Chamberlain Reference Chamberlain, Harris and Chamberlain1975, Reference Chamberlain and Chamberlain1991; Li Reference Li1977; Pittayaporn Reference Pittayaporn2009). As noted above, we may tentatively hypothesize that F1’s system represents an intermediate system on its path toward this type of outcome.
/ would merge with the voiceless aspirated stop /pʰ/. If such a change is in fact conditioned by reanalysis of breathiness as aspiration, it is perhaps not surprising that this path of development has been taken by a smaller number of languages, e.g. Thai, Lao, Phuan and Phu Thai (Chamberlain Reference Chamberlain, Harris and Chamberlain1975, Reference Chamberlain and Chamberlain1991; Li Reference Li1977; Pittayaporn Reference Pittayaporn2009). As noted above, we may tentatively hypothesize that F1’s system represents an intermediate system on its path toward this type of outcome.
However, we stress that while the various systems illustrated here may be more likely to change in some ways than in others, we can do no more than speculate if the observed differences represent a change in progress, synchronically stable variation, or simply speaker idiosyncrasies. That is, while CBT may represent an ‘intermediate’ language in the sense that other Tai languages have evolved into systems with no active voice quality component, this does not mean that CBT itself will eventually evolve to such a state (although, as noted above and in the Introduction, Tai languages with the particular constellation of features found in CBT do appear to be rather thin on the ground). Indeed, given the small number of speakers in the present study, it would be dangerous to draw any firm conclusions about ongoing change in the language. A future apparent-time study of the system of CBT laryngeal contrasts would be one means of shedding further light on this issue, as well as discovering other (e.g. sociolinguistic or age-based) factors that may underlie the variation.
7 Conclusion
The Tai dialect of Cao Bằng is an example of a language at an intermediate stage between tonal register split and the complete transphonologization of laryngeal contrasts into tones. This first instrumental study on CBT revealed considerable interspeaker variation with respect to how the four historical onset categories (aspirated, voiceless, modal voiced, and breathy voiced) are phonetically distinguished. Although f0, VOT, and voice quality measures were all found to correlate in one way or another with laryngeal contrast, we found that different speakers use different patterns of cues to signal the same laryngeal types.
All three of the speakers examined here were shown to use VOT to distinguish between at least some types of onsets, but speakers varied in terms of their acoustic realization of breathy voiced stop /
![]() /, which could be consistently pre-voiced, partially voiced or completely devoiced depending on the speaker. In addition, we observed important differences involving voice quality and its relation to VOT, suggesting that the acoustic realization of voice quality in this language may also vary across speakers. For two of our speakers, breathiness always occurred with full or partial pre-voicing, but for the other speaker, breathiness (as indicated by a number of spectral balance measures) could be realized independently from pre-voicing and may serve to distinguish /p/ from /
/, which could be consistently pre-voiced, partially voiced or completely devoiced depending on the speaker. In addition, we observed important differences involving voice quality and its relation to VOT, suggesting that the acoustic realization of voice quality in this language may also vary across speakers. For two of our speakers, breathiness always occurred with full or partial pre-voicing, but for the other speaker, breathiness (as indicated by a number of spectral balance measures) could be realized independently from pre-voicing and may serve to distinguish /p/ from /
![]() /. Given that the laryngeal contrast is still partially predictable from lexical tone, such variation in the system of laryngeal contrasts is perhaps not entirely surprising.
/. Given that the laryngeal contrast is still partially predictable from lexical tone, such variation in the system of laryngeal contrasts is perhaps not entirely surprising.
From the diachronic perspective, the variation observed here helps to fine-tune our understanding of how laryngeal systems are restructured in response to a tonal register split. As pre-voicing progressively loses ground, previously redundant breathiness may become an increasingly important acoustic cue to voicing. If the variation observed here is found to generalize to a larger population, it may provide a clue as to why the reflex of the historically voiced stop (*b) can be either an aspirated or an unaspirated voiceless stop. It is only when voice quality is no longer associated with the system of laryngeal contrasts that the process of transphonologization may be said to be complete.
Acknowledgements
This research was supported by the Ratchadaphiseksomphot Endowment Fund of Chulalongkorn University (RES560530179-HS). We would like to thank our host research institutes in Vietnam: Institute of Linguistics, Vietnam Academy of Social Sciences; and the Faculty of Linguistics, VNU University of Social Sciences and Humanities. In addition, we would like to extend our gratitude to Kingkarn Thepkanjana, Amalia Arvaniti, Trần Trí Dõi, Hoàng Văn Ma, John Phan, Phan Lương Hùng, Marc Brunelle, Alexis Michaud, Thanasak Sirikanerat, Chawadon Ketkaew, and three anonymous reviewers, without whose help this paper would not have been possible.
Appendix. Wordlist