



Introduction
Chemical mechanical polishing (CMP) is the predominant method for semiconductor wafer processing. A representative process schematic is depicted in Figure 1. Material removal during CMP predominantly occurs via the synergistic actions of chemistry and machinery among the wafer, polishing slurry, and polishing pad (Zhang et al., Reference Zhang, Liu, Hu, Zhang, Xie and Liao2021). Real-time monitoring of the Material Removal Rate (MRR) during the polishing phase provides immediate insights into the processing status, delivering crucial information for subsequt applications, including electrical characterization and layout design. However, offline measurement using precision instruments is currently the main method to obtain MRR (Lee, Reference Lee2019), which falls short of facilitating real-time monitoring. In addition, measurement precision may be compromised by operator-induced variability. Consequently, there is a pressing need for a precise and efficient MRR prediction model.

Figure 1. Schematic diagram of a typical CMP process.
Table 1. Experimental environment

The Preston equation (Evans et al., Reference Evans, Paul, Dornfeld, Lucca, Byrne, Tricard and Mullany2003):
 $ MRR={K}_p{P}^{\alpha }{V}^{\beta } $
is often used to construct the MRR model, where P denotes the downward pressure applied to the wafer, V denotes the relative rotating speed between the wafer and the polishing pad,
$ MRR={K}_p{P}^{\alpha }{V}^{\beta } $
is often used to construct the MRR model, where P denotes the downward pressure applied to the wafer, V denotes the relative rotating speed between the wafer and the polishing pad,
 $ {K}_p $
is the Preston coefficient, and α and β are the parameters depending on the operating conditions. However, due to the complexity of the CMP process, the model construction method based on the Preston equation is difficult to consider various process variables more comprehensively to accurately predict the MRR. Coinciding with advancements in machine learning and deep learning, data-driven regression models for MRR prediction have emerged (Wang et al., Reference Wang, Gao and Yan2017; Li et al., Reference Li, Wang, Zhang, Mo, Zhao and Li2018; Xu et al., Reference Xu, Chen, Cao and Liu2021). The relative studies show that the integrated model performs better than the individual models therein (Di et al., Reference Di, Jia and Lee2021; Li et al., Reference Li, Wu and Yu2019), which focused on crafting MRR prediction models through ensemble learning and sought to integrate models of similar architectures or principles. Yet, the distinctive strength of data-driven model integration lies in its aptitude to assimilate samples from varied perspectives when the base models exhibit substantial divergence in structure or principle (Wolpert David, Reference Wolpert David1992).
$ {K}_p $
is the Preston coefficient, and α and β are the parameters depending on the operating conditions. However, due to the complexity of the CMP process, the model construction method based on the Preston equation is difficult to consider various process variables more comprehensively to accurately predict the MRR. Coinciding with advancements in machine learning and deep learning, data-driven regression models for MRR prediction have emerged (Wang et al., Reference Wang, Gao and Yan2017; Li et al., Reference Li, Wang, Zhang, Mo, Zhao and Li2018; Xu et al., Reference Xu, Chen, Cao and Liu2021). The relative studies show that the integrated model performs better than the individual models therein (Di et al., Reference Di, Jia and Lee2021; Li et al., Reference Li, Wu and Yu2019), which focused on crafting MRR prediction models through ensemble learning and sought to integrate models of similar architectures or principles. Yet, the distinctive strength of data-driven model integration lies in its aptitude to assimilate samples from varied perspectives when the base models exhibit substantial divergence in structure or principle (Wolpert David, Reference Wolpert David1992).
The main contribution of our work is that an MRR prediction model with high precision for CMP process has been built. By means of feature extraction first and then feature fusion, enabling the model to learn rich data features on the foundation of maintaining a low number of parameters, so as to be able to achieve high-precision real-time prediction. Specifically, it’s the first attempt to construct the MRR prediction model by integrating base models with substantial disparities, and the effectiveness of which was corroborated on the public 2016th Prognostics and Health Management dataset (Jia et al., Reference Jia, Huang, Feng, Cai and Lee2021) (PHM2016).
Related work
Existing MRR predictive models for CMP principally bifurcate into two categories: those grounded in mechanical and chemical principles, and those deriving from data-driven methodologies. Zhao and Chang (Reference Zhao and Chang2002) developed a closed-loop MRR prediction model by studying elastoplastic microcontact mechanics and polishing pad wear theory. Experimental results underscore the correlation between MRR and factors such as abrasive concentration and abrasive radius in the polishing slurry. Xu et al. (Reference Xu, Chen, Liu and Cao2020) constructed a CMP analytical model predicated on the governing equation of plate theory, chemical reaction kinetics, and wear theory, and the influence of variables including pad elastic modulus, temperature distribution, carrier rotation speed, and so forth on MRR have been explored. These scholarly endeavors invested in unraveling the relationships between diverse process parameters and MRR, aimed at formulating a theoretical model bridging process parameters and MRR. Despite the variety of wafer and slurry materials, the numerous related process parameters, and the complex conditions found in the CMP process, finding a comprehensive theory that clearly explains the inherent material removal mechanisms is still a challenge. Consequently, approaches relying on physical and chemical principles for MRR prediction are inherently constrained.
A machine learning model, in theory, retains the capability to approximate an arbitrarily complex mathematical landscape (Hanin and Rolnick, Reference Hanin and Rolnick2019). Through successive refinements in the course of optimization, the model can autonomously deduce the inherent relationships between process parameters and MRR, bypassing the requirement for strenuous theoretical analysis and computational complexities. Xu et al. (Reference Xu, Chen, Cao and Liu2021) proposed a data-driven neural network (NN) model based on CMP experiments to predict MRR and investigated the influence of the oxidizer concentration and the inhibitor concentration, as well as the chelating agent concentration and the surfactant concentration on the prediction of MRR. Li et al. (Reference Li, Wang, Zhang, Mo, Zhao and Li2018) utilized random forest (RF) to predict MRR through discriminating between fine and coarse polishing. Wang et al. (Reference Wang, Gao and Yan2017) devised an optimized Deep Belief Network (DBN) to investigate the relationship between MRR and polishing operation parameters such as pressure and rotational speeds of the wafer and pad. Furthermore, the strength of the data-driven approach in constructing MRR prediction models resides in the potential enhancement of prediction precision through integration of multiple models trained with identical samples. Di et al. (Reference Di, Jia and Lee2021) put forth an ensemble learning based model, incorporating k-nearest neighbor (KNN), support vector machine (SVM) and logistic regression (LR) to predict the MRR, and proved the validity of ensemble learning through experiments.
High-quality polishing process datasets like PHM2016 are difficult to obtain, which has prompted many scholars to conduct research using this data. For instance, Li et al. (Reference Li, Wu and Yu2019) employed a stacking ensemble learning method based on classification and regression trees (CART) and the extreme learning machine (ELM). This method had a Root Mean Squared Error (RMSE) of 4.64 on the test dataset, which far exceeds the accuracy of models based solely on the Preston equation, or single models like RF, GBT, and ERT. Zhang et al. (Reference Zhang, Jiang, Luo and Yin2021) used the residual convolutional neural network (ResCNN) to build an MRR prediction model for the CMP process and achieved a Mean Square Error (MSE) of 6.72 on the test set. Their experimental results highlight the impact that the usage quantity of each consumable in the CMP process has on MRR. However, utilizing convolutional neural networks (CNNs) demands the conversion of input attributes into two or three-dimensional matrices, putting certain requirements on the length of the input features. Additionally, the sequential computation process of CNN models could impact real-time online predictions. Thus, the use of CNN-based prediction models may be limited due to these factors.
Therefore, the goal of this study is to construct an MRR prediction model of CMP based on ensemble learning, which fuses the neural network models and tree models with significantly different structures and principles, and ultimately obtains higher prediction accuracy on the test set compared to other methods based on ensemble learning.
Stacking ensemble learning based predictive modeling
Algorithm framework
The framework of the proposed algorithm is depicted in Figure 2. Initially, the dataset was partitioned into training and testing subsets, each serving the dual purposes of model training and performance evaluation, respectively. In the training phase, noise samples within the training set were preemptively discarded. Subsequently, feature engineering techniques were employed to transform the raw input data into representative features. Finally, a stacking ensemble approach (Tang et al., Reference Tang, Tao, Li, Chen, Deng and Li2022) integrating RF (Breiman, Reference Breiman2001), light gradient boosting machine (LightGBM) (Ke et al., Reference Ke, Meng, Finley, Wang, Chen, Ma and Liu2017), and backpropagation neural network (BPNN) (Rumelhart et al., Reference Rumelhart, Hinton and Williams1986) was executed to build the MRR prediction model. In the prediction phase, the test samples were subjected to identical feature engineering procedures as in the training process, and the trained model was then harnessed to forecast the MRR.

Figure 2. Schematic diagram of algorithm framework.
Feature fusion
Potential correlations might exist among the monitored attributes during the CMP process, leading to feature redundancy. This unnecessary repetition interferes with model training by adding extra information, which takes attention away from key features and reduces accuracy (Batista et al., Reference Batista, Prati and Monard2004). Moreover, this increases the input dimensionality, substantially escalating computational demands and prediction latency, consequently restricting the feasibility of real-time prediction.
Pearson correlation coefficient analysis (PCCA) (Malik et al., Reference Malik, Nehra and Saini2021) was utilized to analyze the correlations among features. Features with strong correlation were considered as a singular group. Principal component analysis (PCA) (Pearson and Karl, Reference Pearson and Karl2010) was subsequently implemented to fuse features within the same group and diminish dimensionality. Ultimately, to assess the efficacy of feature fusion, a comparison was made between the accuracy and efficiency of MRR prediction prior to and subsequent to feature fusion.
Pearson correlation coefficient analysis
PCC quantifies the linear correlation between variables X and Y, ranging from −1 to 1. Equation (1) details the PCC calculation:
 $$ {\rho}_{X,Y}=\frac{N\sum XY-\sum X\sum Y}{\sqrt{N\sum {X}^2-{\left(\sum X\right)}^2\sqrt{N\sum {Y}^2-{\left(\sum Y\right)}^2}}} $$
$$ {\rho}_{X,Y}=\frac{N\sum XY-\sum X\sum Y}{\sqrt{N\sum {X}^2-{\left(\sum X\right)}^2\sqrt{N\sum {Y}^2-{\left(\sum Y\right)}^2}}} $$
where N represents the sample size, X and Y denote two distinct features of the sample. While covariance does indicate correlations between random variables (positive when covariance >0, negative when covariance <0), its magnitude is heavily influenced by the variances of X and Y, hence prohibiting the deduction of correlations between variables solely from covariance. Nevertheless, the PCC provides a precise portrayal of correlations between variables, independent of dimensional disparities between X and Y.
Principal component analysis
The core principle of PCA pertains to the transformation of original multi-dimensional features into orthogonal principal components. These components primarily hold the valuable information from the original features, while lessening repetition, therefore simplifying the complexity of the original feature space. Given a dataset X comprising n samples with m features each, shown by equation (2), Xm(n) represents the m-th eigenvalue of the n-th sample. The PCA process can be outlined as follows:
 $$ {X}_{n\ast m}=\left[\begin{array}{cccc}{x}_1(1)& {x}_2(1)& \cdots & {x}_m(1)\\ {}{x}_1(2)& {x}_2(2)& \cdots & {x}_m(2)\\ {}\vdots & \vdots & \ddots & \vdots \\ {}{x}_1(n)& {x}_2(n)& \cdots & {x}_m(n)\end{array}\right] $$
$$ {X}_{n\ast m}=\left[\begin{array}{cccc}{x}_1(1)& {x}_2(1)& \cdots & {x}_m(1)\\ {}{x}_1(2)& {x}_2(2)& \cdots & {x}_m(2)\\ {}\vdots & \vdots & \ddots & \vdots \\ {}{x}_1(n)& {x}_2(n)& \cdots & {x}_m(n)\end{array}\right] $$
(1) Calculating the covariance matrix P of normalized X, which can be employed to describe the correlations among m variables in the dataset, according to equation (3), and getting the eigenvalue λ and eigenvector E of P in line with equation (4), D represents the diagonal matrix.
 $$ P=\operatorname{cov}(X)=\frac{1}{m-1}{X}^TX $$
$$ P=\operatorname{cov}(X)=\frac{1}{m-1}{X}^TX $$
 $$ P={EDE}^T $$
$$ P={EDE}^T $$
(2) The cumulative contribution of the initial k principal components, symbolized as ak, is calculated as equation (5). When ak surpasses the pre-established cumulative contribution threshold T, the k principal components become viable replacements for the original m features. In other words, the PCA process contracts the feature dimensionality from m to k.
 $$ {a}_k=\frac{\lambda_k}{\sum \limits_{i=1}^m{\lambda}_i} $$
$$ {a}_k=\frac{\lambda_k}{\sum \limits_{i=1}^m{\lambda}_i} $$
Prediction model
RF, LightGBM, and BPNN models were integrated to construct the MRR prediction model. In terms of model architectures, RF and LightGBM can be conceptualized as tree-based statistical models, whereas BPNN is a neural network model. Owing to the discrepancies in their model structures, they are capable of extracting distinct information from the same set of samples (Pearson and Karl, Reference Pearson and Karl2010).
Random forest
RF, a bagging-based regression prediction model, trains each decision tree on independently sampled subsets, as depicted in Figure 3, subsequently aggregating the outputs of all trees to procure the final model output.

Figure 3. Schematic diagram of random forest.
In practical applications, the accuracy of individual decision trees within an RF can vary. Relying on simple averaging may lead to a drop in the overall accuracy of the RF model due to the influence of lower-accuracy decision trees. Consequently, a weighted ensemble method was utilized during RF training, wherein the significance of each decision tree was determined based on its MSE. The outputs of the decision trees were subsequently weighted to compute the final output of the RF model, as depicted in equation (6).
 $$ f(x)=\sum \limits_{i=1}^n{\alpha}_i\ast {T}_i(x) $$
$$ f(x)=\sum \limits_{i=1}^n{\alpha}_i\ast {T}_i(x) $$
where
 $ {\alpha}_i $
and
$ {\alpha}_i $
and
 $ {T}_i $
represents the significance and predicted value of the i-th decision tree.
$ {T}_i $
represents the significance and predicted value of the i-th decision tree.
LightGBM
LightGBM is an enhanced algorithm based on gradient boosting decision trees (GBDT) (Friedman, Reference Friedman2001), boasting superior computational efficiency and lower memory demands, thus making it ideal for high-performance prediction applications. Much like RF, GBDT also constitutes a tree-based statistical model, but its trees predict the residual or difference between the estimated and actual values from all preceding trees. Figure 4 depicts the LightGBM training process.

Figure 4. Schematic diagram of LightGBM.

Figure 5. Schematic diagram of BPNN.
For a sample x, the prediction process can be described by equation (7):
 $$ f(x)={f}_0(x)+\sum \limits_{t=1}^T\sum \limits_{j=1}^J{c}_{tj}I\left(x\in {R}_{tj}\right) $$
$$ f(x)={f}_0(x)+\sum \limits_{t=1}^T\sum \limits_{j=1}^J{c}_{tj}I\left(x\in {R}_{tj}\right) $$
where T denotes the number of CART decision trees (Zounemat-Kermani et al., Reference Zounemat-Kermani, Stephan, Barjenbruch and Hinkelmann2020), J signifies the number of leaf node regions in each tree, and ctj stands for the predicted value of the j-th leaf node region on the t-th CART tree. When x falls within the set Rtj, I equals to 1; otherwise, it equals to 0.
BP neural network
The BPNN (Ruan, Reference Ruan2021) is a foundational deep learning model. Its robust nonlinear function approximation ability can theoretically fit any complex mathematical function. Figure 5 illustrates a three-layer BPNN architecture consisting of input, hidden, and output layers. The neurons in the input layer correspond to independent variables, such as the rotation speed of the polishing pad or temperature. Meanwhile, the neurons in the output layer represent dependent variables, for instance, the MRR. The neuron count in the hidden layer, which determines the model complexity, is user-defined. Typically, this range is approximately estimated using empirical equation (8) (Yu et al., Reference Yu, Lin, Zhang, Qu, Wang, Li, Xia and Chen2022), which is based on practical observations and experiences in the field of neural network training. Where h, r, and e denote the number of neurons in the input layer, hidden layer, and output layer, respectively, and 5 is a constant between 2 and 10.
 $$ h=\sqrt{r+e}+s $$
$$ h=\sqrt{r+e}+s $$
Stacking ensemble learning
Since the models fused here have distinct architectures, stacking ensemble learning was selected to take advantage of their complementary strengths, thereby improving prediction accuracy, robustness, and generalizability. Figure 6 illustrates the stacking procedure. The secondary model plays a key role in stacking, as it determines the optimal way to integrate and assign weights to the predictions of each base model based on their performance.

Figure 6. Schematic diagram of stacking ensemble learning.
Prediction evaluation indicators
Mean square error (MSE) (Köksoy, Reference Köksoy2006) and correlation coefficient (R 2) (Zhou et al., Reference Zhou, Wang and Zhu2022) were utilized as evaluation metrics for the accuracy of MRR prediction model. As depicted in equation (9), MSE quantifies the discrepancy between the actual and predicted values of MRR. A smaller MSE value implies higher accuracy. R 2, as shown in equation (10), represents the correlation between the actual and predicted values of the MRR on the test dataset. A larger R 2 value signifies greater accuracy.
 $$ MSE=\frac{1}{N}\sum \limits_{i=1}^N{\left({MRR}_{pi}-{MRR}_{ti}\right)}^2 $$
$$ MSE=\frac{1}{N}\sum \limits_{i=1}^N{\left({MRR}_{pi}-{MRR}_{ti}\right)}^2 $$
 $$ {R}^2=1-\frac{\sum \limits_{i=1}^N{\left({MRR}_{pi}-{MRR}_{ti}\right)}^2}{\sum \limits_{i=1}^N{\left(\frac{1}{N}\sum \limits_{i=1}^N\left({MRR}_{pi}\right)-{MRR}_{ti}\right)}^2} $$
$$ {R}^2=1-\frac{\sum \limits_{i=1}^N{\left({MRR}_{pi}-{MRR}_{ti}\right)}^2}{\sum \limits_{i=1}^N{\left(\frac{1}{N}\sum \limits_{i=1}^N\left({MRR}_{pi}\right)-{MRR}_{ti}\right)}^2} $$
where MRRpi and MRRti represent the predicted and actual values of MRR for the test samples, respectively, and N signifies the total number of test samples.
Case study
Data analysis and preprocess
Dataset introduction
To validate the proposed MRR prediction model, experiments were conducted using the PHM Society’s 2016 open dataset for CMP MRR prediction on silicon wafers (Zhang et al., Reference Zhang, Jiang, Luo and Yin2021). The dataset was divided into a training set (1981 samples) and a test set (424 samples). Each sample includes CMP processing signals and MRR measurements for a wafer at a given time point. Table l shows the main experimental environment and the corresponding software versions. Table 2 briefly outlines each signal variable.
Table 2. Process variables during the CMP process

Data denoise
In the wafer polishing experiments, each process variable was obtained from sensor measurements, which could potentially produce outlier values. Incorporating such anomalous samples into model training might undermine accuracy due to skewed data distributional (Sun et al., Reference Sun, Li, Zhao, Fei, Liu and Niu2022). As depicted in Figure 7(a), the MRR of certain samples was significantly higher than that for others, indicating the presence of outliers. Figure 7(b) displays the MRR distribution following the exclusion of these abnormal samples.

Figure 7. MRR distribution of origin data and denoised data.
In addition to outliers, samples with missing values, potentially due to sensor failures, cannot serve as valid training samples. Table 3 presents a comparison of the total number of training and test set samples before and after noise removal.
Table 3. Number of training and test set samples before and after denoise

Data split
As depicted in Figure 7, the MRR significantly ranges from 50 nm/min to 160 nm/min in the dataset. This large variability in MRR values can typically be attributed to changes in processing stages or chambers, thus complicating the model learning process. Therefore, variables x5 and x6 were employed for data stratification to ensure minimal variation in MRR within each group. Prediction models were individually trained for each group to alleviate the learning complexity of the model. Table 4 illustrates the results of the data grouping. During MRR prediction, the appropriate model can be selected based on the source of process signals. Figure 8 presents the MRR distribution for each group, demonstrating a stable range.
Table 4. Result of dataset group
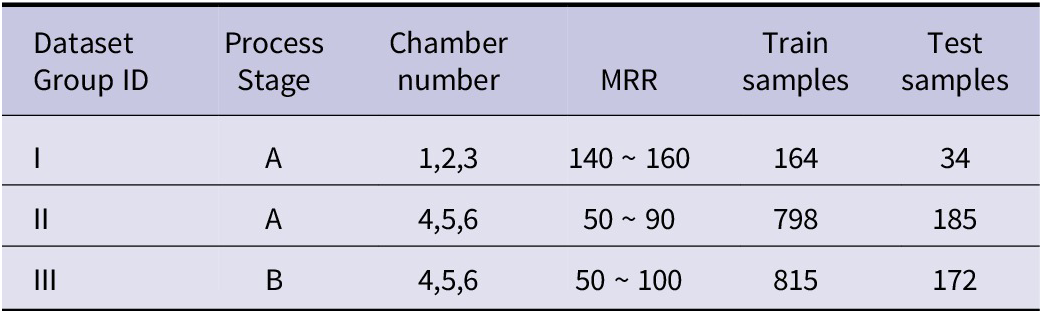

Figure 8. MRR distribution of each dataset group samples.
Feature engineering
Feature extract
The aim of feature extraction is to generate features from the continuous process signal that can capture the time-dependent characteristics of the MRR. Thus, for signals such as pressure (X11 ~ X16), flow rate (X19 ~ X21) and speed (X22 ~ X25), elementary statistical features can be initially extracted. These include Max, Mean, Median, root mean square (RMS), PEAK-TO-Peak (PP) and standard deviation (STD)—6 fundamental features in the time domain. For instance, each sample’s MRR value represents the average MRR over a period of processing time, during which multiple samplings will provide N groups of signal features. Take feature X11 as an example, its Max feature is the maximum value of the N groups of X11 features, and so forth. Subsequently, the temporal length of non-zero pressure values, indicative of normal polishing periods, can be extracted as Effective Polishing Time. Finally, given the time-series nature of the dataset, temporal neighborhood features can be employed to characterize the variation in MRR with processing time across adjacent intervals. Similarly, consumable usage neighborhood features illustrate the change in MRR with varying consumable usage. Pressure neighborhood features depict the fluctuation in MRR with altering pressure. For instance, during the process of extracting usage-based neighborhood features, the average consumables usage feature for each wafer is initially calculated during the manufacturing process. Subsequently, wafer process signals with similar usage are grouped together using the KNN clustering algorithm. Lastly, the MRR results of the wafers obtained through KNN clustering are added to the current wafer’s features as usage-based neighborhood features. As illustrated in Figures 9, 10, and 11, time, consumable usage, and pressure neighborhood features are positively correlated with MRR, respectively.

Figure 9. Correlation between time domain features and MRR.

Figure 10. Correlation between usage domain features and MRR.

Figure 11. Correlation between pressure domain features and MRR.
Feature fusion
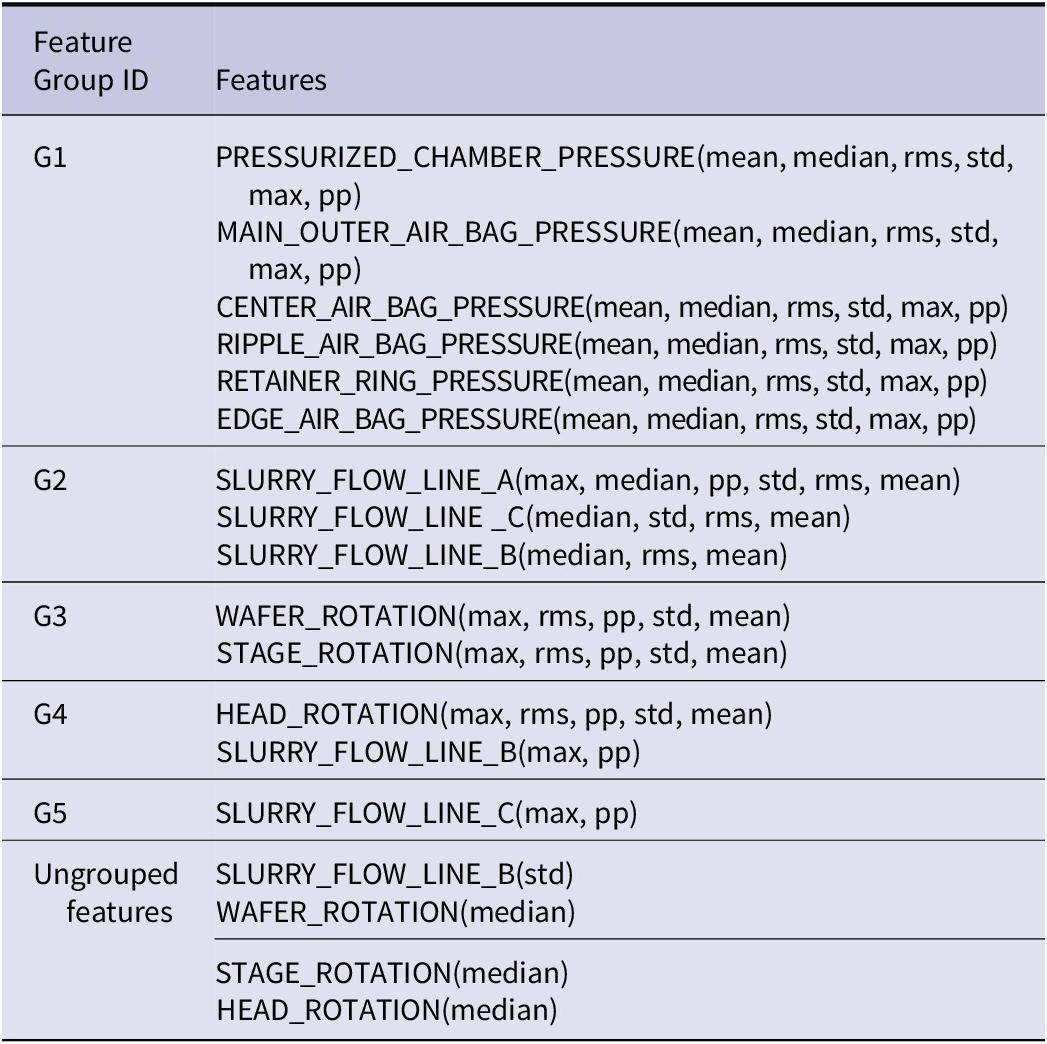
Following the mentioned feature extraction procedure above, the dimensionality of the samples increased from 26 to 112. To avoid feature redundancy and the curse of dimensionality, PCCA was applied to the extracted features of slurry flow rate, rotational speed, and pressure. As depicted in Figure 12, the correlation threshold was set at 0.8, suggesting that features with correlations exceeding 0.8 could be consolidated into a single feature group. Taking the features rms_fea_SLURRY_FLOW_LINE_A and mean_fea_SLURRY_FLOW_LINE_A in Figure 12(a) as an example, they respectively represent the RMS and Mean features of the SLURRY_FLOW_LINE_A signal. Their PCCA value is 0.96, which exceeds the threshold of 0.8. This suggests that they can be grouped into a feature group.

Figure 12. PCCA heatmap of (a) slurry flow rate, (b) speed, and (c) pressure.
Table 5 presents the results of feature grouping achieved through PCCA. Notably, Slurry B and C flow rates, which represent the flow rates of the conditioning disk and polishing pad, respectively, show weak correlations with other temporal features. Therefore, their Max and PP values form a distinct feature group. Furthermore, the STD of SLURRY_FLOW_LINE_B and the Median of each rotation feature display weak correlations with other features overall, and therefore, they were not included in any group.
Table 5. High correlation feature grouping results
PCA was employed to extract the principal components within groups G1 to G5. The Cumulative Contribution Rate(CCR) threshold was set at 80%. As exemplified in Table 6 with the first sample, the CCRs of the initial 2, 2, 2, 1, and 1 principal components of groups G1 to G5 reached the predefined CCR threshold, respectively. The term “PCV” denotes the value of each principal component. Figure 13 shows the first 5 PCVs of G1, λ1 to λ5, for each training sample. In summary, the results of principal component selection for G1 to G5 for each sample are depicted in Figure 14.
Table 6. Example of PCA analysis result


Figure 13. Groupt first 5 principal component values.

Figure 14. The final selected principal components.
Employing a similar methodology, PCA was performed on the Consumable Usage Features (X7, X8, X9, X10, X17, X18). As illustrated in Figure 15, the first 5 PCVs are obtained for each training sample. As exemplified in Table 7 with the first sample, the CCR of the first two principal components exceeded the CCR threshold. Consequently, the principal component features derived from the Consumable Usage Features were reduced to a two-dimensional representation.

Figure 15. Visualization of the first five principal component values of consumable usage features.
Table 7. Example of the first five principal component values of consumable usage features

Ultimately, upon conducting feature extraction and dimensionality reduction, 18 features are acquired to serve as inputs for the prediction model, as outlined in Table 8.
Table 8. Features after features extraction and fusion

Model training and optimization
Initially, preliminary models were trained to validate the effectiveness of feature fusion. Following this, the Bayesian hyperparameter optimization algorithm (Sicard et al., Reference Sicard, Briois, Billard, Thevenot, Boichut, Chapellier and Bernard2022) was employed to refine the accuracy of the preliminary models. Ultimately, by stacking these preliminary models, the MRR prediction model was constructed, thus further enhancing the prediction accuracy of MRR.
Preliminary model prediction
On each of the three datasets partitioned in Table 3, the RF, LightGBM, and BPNN models are individually trained for MRR prediction. The accuracy of each model was denoted by the mean value of prediction precision across the three test sets. As demonstrated in Figure 16, the fused features presented lower input dimensions, at 19 compared to the original 112, while maintaining nearly the same prediction accuracy as the original features. This proves the validity of feature fusion. Low-dimensional features will bring lower computational effort, thus achieving a faster inference speed without loss of accuracy.

Figure 16. Indicator comparison between origin and fusion feature.
Hyperparameter optimization
The precision upper limit for the stacking ensemble learning model largely depends on the accuracy of the preliminary models. Hence, optimization of these preliminary models is crucial. Traditional manual optimization methods can be time-consuming, labor-intensive, and inefficient. Conversely, the Bayesian parameter optimization algorithm can efficiently utilize the information from prior function evaluations based on the Bayesian theorem, selecting the next promising sampling point as per the objective function’s posterior distribution. This algorithm is highly suitable for the automated selection of model parameters. As displayed in Table 9, the parameters for each preliminary model were finalized following Bayesian parameter optimization, Value_1, Value_2 and Value_3 represent the model hyperparameter values corresponding to Group_I, Group_II and Group_III. For the model BPNN, a three-layers neural network is selected, that is, there is only one hidden layer, and the number of its neurons is shown as ‘hidden_layer_sizes’. Additionally, BPNN uses ReLU as the activation function and Adam as the optimizer, thereby achieving adaptive learning rate adjustment, and the initial learning rate is shown as ‘learning_rate_init’. Similarly, the accuracy of each preliminary model was denoted by the mean values of the evaluation metrics across the three test sets. As depicted in Figure 17, the prediction accuracy of each model significantly improved post-Bayesian parameter optimization.
Table 9. Model hyperparameter optimization results


Figure 17. Indicator Comparison between baseline and improved model.
Stacking model prediction
The stacking ensemble learning procedure designed is represented in Figure 18. Initially, the original fused features were input into each preliminary model to generate the prediction results. Subsequently, these prediction outcomes from each preliminary model were used as new features. These, along with the original fused features, were input into the secondary GBDT model. Through the GBDT’s forward process, the final MRR prediction value was produced.

Figure 18. Training process of MRR prediction stacking model.
Figure 19 depicts a comparison between the MRR predicted values and the actual ones from the trained Stacking MRR prediction model over the three test sets, yielding an average MSE of 7.72. As demonstrated in Figure 20, the correlation between the model output and the actual values attained an R2 value of 95.82%. Compared with each preliminary model, the evaluation metrics show further improvement, as depicted in Figure 21.

Figure 19. Predicted results on each test dataset group.

Figure 20. Correlation between prediction results and ground truth.

Figure 21. Comparison among stacking model and each preliminary models.
Discussion
As MRR prediction models of semiconductor wafer polishing process are concerned, prediction accuracy, real-time performance, and broad applicability of the application methodology are all critical. In pursuit of high prediction accuracy, this paper attempts to employ stacking models with significant structural differences, hoping that the established model can focus on data characteristics from different aspects. As depicted in Table 10, it shows the evaluation indicators of different methods on the PHM2016 dataset. Compared with simply stacking multiple tree-based models of similar structure, such as CART-Stacking and ELM-Stacking, which have MSEs of 22.88 and 21.53, respectively, the proposed method has achieved MSE of 7.72. In comparison with the Res-CNN-based model, although the overall prediction accuracy of the stacking model is slightly lower, it has also demonstrated a certain advantage in the third group of test data.
Table 10. Comparison of models developed by different approach

The establishment of predictive models not only focuses on accuracy, but also emphasizes the real-time performance of prediction, which helps researchers grasp the processing status in real-time, thereby making decisions. The developed stacking model integrates tree models with efficient calculating power and a three-layer neural network model with few parameters and powerful non-linear fitting ability. Compared with models based on full CNN structure, it achieves a balance between precision and speed. Furthermore, the broad applicability determines whether the method can be conveniently and effectively applied to other scenarios and is key to industrialization. As described above, the application of the Res-CNN-based model is, to a certain extent, limited by the dimensions of the input features. The developed stacking model can accept inputs of any dimension and can be more conveniently migrated to other scenarios.
Despite that, there is still room for improvement in terms of speed and accuracy for the developed MRR prediction model. Hence, as machine learning techniques evolve, more efficient and accurate model structures will emerge, such as the recently popular Transformer series models (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez and Polosukhin2017; Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019; Dosovitskiy et al., Reference Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner and Houlsby2020). Exploring how to apply these emerging models with novel structural forms in model fusion to push the boundaries of MRR prediction accuracy may be a worthwhile direction for future research.
Conclusion
In this paper, a CMP MRR prediction model for semiconductor wafers that integrates multiple preliminary models with significant structural differences is developed, utilizing the stacking ensemble learning method. The experiments were conducted on the PHM2016 dataset, which involved the analysis and preprocessing of raw data, followed by feature extraction and fusion. The resulting fused features served as input to train both preliminary and stacking models, and their effectiveness was validated using a test set. The main conclusions from this study are as follows:
-
(1) A feature extraction and fusion pipeline was created for the semiconductor wafer CMP process signals, relying on the PCCA and PCA. This method effectively reduced the extracted 112-dimensional features to 18 dimensions, without compromising the prediction accuracy of the model. It demonstrated potential in reducing the computational load of the model and enhancing the real-time performance of MRR prediction.
-
(2) A CMP MRR prediction model for semiconductor wafers was developed using the PHM2016 dataset. Compared with the preliminary models, the final prediction model showed further improvement in accuracy, reducing the MSE to 7.72 and raising the R2 value to 95.82%. These results validate the efficacy of the data-driven method in constructing the MRR prediction model.
-
(3) For the first time, an ensemble learning method has been employed to integrate multiple preliminary models with significant structural and principle differences into the development of a data-driven CMP MRR prediction model for semiconductor wafers. Compared to existing studies that incorporate preliminary models with similar structures or principles, our approach achieved higher prediction accuracy. This sets the stage for merging a wider array of efficient and diverse preliminary models in the future, aiming to push the boundaries of MRR prediction precision.
Data availability
The data that support the findings of this study are openly available at https://www.phmsociety.org/sites/phmsociety.org/files/2016%20PHM%20DATA%20CHALLENGE%20CMP%20DATA%20SET.zip
Funding statement
This research was supported by the financial support from the National Natural Science Foundation of China (U20A20293 and 52175441), and the Natural Science Foundation of Zhejiang Province (LD22E050010).
Competing interest
The author(s) declare none.
Author biographies
Zhi-Long Song, Ph.D. is a candidate at the School of Mechanical Engineering, Zhejiang University of Technology. His research focuses on intelligent manufacturing, precision, and ultra-precision machining technology.
Wen-Hong Zhao is a professor at the School of Mechanical Engineering, Zhejiang University of Technology. His main research focus is on ultra-precision machining and control.
Xiao Zhang is a master’s degree student at the School of Mechanical Engineering, Zhejiang University of Technology. His main research focus is on intelligent manufacturing, ultra-precision machining and control.
Ming-Feng Ke is a Ph.D. candidate at the School of Mechanical Engineering, Zhejiang University of Technology. His research focuses on intelligent manufacturing, precision, and ultra-precision machining technology.
Wei Fang is a master’s degree candidate at the School of Mechanical Engineering, Zhejiang University of Technology. Her research focuses on precision and ultra-precision abrasive machining technology.
Bing-Hai Lyu, Ph.D. is a professor at the School of Mechanical Engineering, Zhejiang University of Technology. His main research focus is on precision and ultra-precision abrasive machining technology.































