We used capture-recapture analyses to estimate the density of a tiger Panthera tigris population in the tropical forests of Huai Kha Khaeng Wildlife Sanctuary, Thailand, from photographic capture histories of 15 distinct individuals. The closure test results (z = 0.39, P = 0.65) provided some evidence in support of the demographic closure assumption. Fit of eight plausible closed models to the data indicated more support for model Mh, which incorporates individual heterogeneity in capture probabilities. This model generated an average capture probability 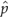 = 0.42 and an abundance estimate of
= 0.42 and an abundance estimate of 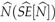 = 19 (9.65) tigers. The sampled area of
= 19 (9.65) tigers. The sampled area of  = 477.2 (58.24) km2 yielded a density estimate of
= 477.2 (58.24) km2 yielded a density estimate of 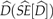 = 3.98 (0.51) tigers per 100 km2. Huai Kha Khaeng Wildlife Sanctuary could therefore hold 113 tigers and the entire Western Forest Complex c. 720 tigers. Although based on field protocols that constrained us to use sub-optimal analyses, this estimated tiger density is comparable to tiger densities in Indian reserves that support moderate prey abundances. However, tiger densities in well-protected Indian reserves with high prey abundances are three times higher. If given adequate protection we believe that the Western Forest Complex of Thailand could potentially harbour >2,000 wild tigers, highlighting its importance for global tiger conservation. The monitoring approaches we recommend here would be useful for managing this tiger population.
= 3.98 (0.51) tigers per 100 km2. Huai Kha Khaeng Wildlife Sanctuary could therefore hold 113 tigers and the entire Western Forest Complex c. 720 tigers. Although based on field protocols that constrained us to use sub-optimal analyses, this estimated tiger density is comparable to tiger densities in Indian reserves that support moderate prey abundances. However, tiger densities in well-protected Indian reserves with high prey abundances are three times higher. If given adequate protection we believe that the Western Forest Complex of Thailand could potentially harbour >2,000 wild tigers, highlighting its importance for global tiger conservation. The monitoring approaches we recommend here would be useful for managing this tiger population.

