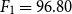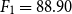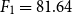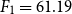1 results
Urdu paraphrase detection: A novel DNN-based implementation using a semi-automatically generated corpus
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 29 May 2023, pp. 354-384
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Automatic paraphrase detection is the task of measuring the semantic overlap between two given texts. A major hurdle in the development and evaluation of paraphrase detection approaches, particularly for South Asian languages like Urdu, is the inadequacy of standard evaluation resources. The very few available paraphrased corpora for these languages are manually created. As a result, they are constrained to smaller sizes and are not very feasible to evaluate mainstream data-driven and deep neural networks (DNNs)-based approaches. Consequently, there is a need to develop semi- or fully automated corpus generation approaches for the resource-scarce languages. There is currently no semi- or fully automatically generated sentence-level Urdu paraphrase corpus. Moreover, no study is available to localize and compare approaches for Urdu paraphrase detection that focus on various mainstream deep neural architectures and pretrained language models.
This research study addresses this problem by presenting a semi-automatic pipeline for generating paraphrased corpora for Urdu. It also presents a corpus that is generated using the proposed approach. This corpus contains 3147 semi-automatically extracted Urdu sentence pairs that are manually tagged as paraphrased (854) and non-paraphrased (2293). Finally, this paper proposes two novel approaches based on DNNs for the task of paraphrase detection in Urdu text. These are Word Embeddings n-gram Overlap (henceforth called WENGO), and a modified approach, Deep Text Reuse and Paraphrase Plagiarism Detection (henceforth called D-TRAPPD). Both of these approaches have been evaluated on two related tasks: (i) paraphrase detection, and (ii) text reuse and plagiarism detection. The results from these evaluations revealed that D-TRAPPD (
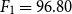 $F_1 = 96.80$ for paraphrase detection and
$F_1 = 96.80$ for paraphrase detection and 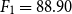 $F_1 = 88.90$ for text reuse and plagiarism detection) outperformed WENGO (
$F_1 = 88.90$ for text reuse and plagiarism detection) outperformed WENGO (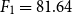 $F_1 = 81.64$ for paraphrase detection and
$F_1 = 81.64$ for paraphrase detection and 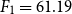 $F_1 = 61.19$ for text reuse and plagiarism detection) as well as other state-of-the-art approaches for these two tasks. The corpus, models, and our implementations have been made available as free to download for the research community.
$F_1 = 61.19$ for text reuse and plagiarism detection) as well as other state-of-the-art approaches for these two tasks. The corpus, models, and our implementations have been made available as free to download for the research community.