
 $\boldsymbol{\ell}_{\mathbf{1}}$–Regularization for Simple Structure
$\boldsymbol{\ell}_{\mathbf{1}}$–Regularization for Simple Structure
Multidimensional item response theory (MIRT) offers psychometric models for various data settings, most popularly for dichotomous and polytomous data. Less attention has been devoted to count responses. A recent growth in interest in count item response models (CIRM)—perhaps sparked by increased occurrence of psychometric count data, e.g., in the form of process data, clinical symptom frequency, number of ideas or errors in cognitive ability assessment—has focused on unidimensional models. Some recent unidimensional CIRMs rely on the Conway–Maxwell–Poisson distribution as the conditional response distribution which allows conditionally over-, under-, and equidispersed responses. In this article, we generalize to the multidimensional case, introducing the Multidimensional Two-Parameter Conway–Maxwell–Poisson Model (M2PCMPM). Using the expectation-maximization (EM) algorithm, we develop marginal maximum likelihood estimation methods, primarily for exploratory M2PCMPMs. The resulting discrimination matrices are rotationally indeterminate. Recently, regularization of the discrimination matrix has been used to obtain a simple structure (i.e., a sparse solution) for dichotomous and polytomous data. For count data, we also (1) rotate or (2) regularize the discrimination matrix. We develop an EM algorithm with lasso (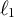 $\ell _1$) regularization for the M2PCMPM and compare (1) and (2) in a simulation study. We illustrate the proposed model with an empirical example using intelligence test data.
$\ell _1$) regularization for the M2PCMPM and compare (1) and (2) in a simulation study. We illustrate the proposed model with an empirical example using intelligence test data.

