


1. IntroductionFootnote 1
The goal of this article is to make explicit what it takes to run a full substance-free phonology (SFP).Footnote 2 By its very essence, SFP has concentrated on the locus of substance in phonology, (i.e., the area below the skeleton). The area at and above the skeleton is not studied, or is understudied in this framework, and as far as I can see the relationship between these areas has not received any attention thus far. It is shown below that substance-free melodic primes raise non-trivial questions for how the two areas communicate: familiar syllabification algorithms, for example, cannot work with substance-free primes.
The idea of phonology being substance-free entails i) that any substance which is present in current approaches needs to be removed and ii) that there is a place where substance can and should exist, which is not the phonology. Substance being another word for phonetic properties, ii) means that SFP is necessarily modular in kind: there is a phonological system that is different from the phonetic system. They communicate but do not overlap: there is no phonology in phonetics and no phonetics in phonology. This describes exactly the Fodorian idea of modularity (on which more in section 2.4.2) where distinct computational systems work on domain-specific sets of vocabulary and communicate through a translational device (spell-out).
The consequence of i) is the starting point of the article: to date work on SFP only ever concerns melody, that is, items which in a regular autosegmental representation occur below the skeleton. The reason is that this is where phonetic properties are located and need to be removed: there is nothing to be removed from items at and above the skeleton because they have no phonetic properties. That is, the feature [±labial] has phonetic content, but an onset, a grid mark or a prosodic word do not. This is why work in SFP never talks about syllable structure or other items that occur at and above the skeleton (more on this in section 2.1).
Therefore, what it takes to make SFP a viable perspective is not only to remove substance from phonology, to show how phonology relates to phonetics, and to explain how acquisition works: it is also necessary to answer a number of non-trivial questions that arise when the area from which substance was removed and where primes and computation are therefore arbitrary (below the skeleton) communicates with a system where primes and computation are not arbitrary (at and above the skeleton). This distinction is the heart of the article (section 2).
The two phonologies at hand are active in speech production, that is, when a multi-morphemic string (a phase, or cycle) that was pieced together from items stored in long-term memory (and which also features phonological representatives of morpho-syntactic divisions, such as # in SPE) is submitted to phonological interpretation. Phonological activity also occurs prior to production, though: in order for a lexical item to be stored in long-term memory, the gradient and non-cognitive acoustic signal needs to be converted into a discrete cognitive representation. Lexicalization phonology (as opposed to production phonology) is introduced in section 3. This then amounts to three phonologies altogether (two in production, one upon lexicalization), which is one motivation for the title of the article.
Sections 4 and 5 take a closer look at the content of the two areas that are distinguished in production. It is argued in section 4 that the traditional division of the area below the skeleton into sonority, place and laryngeal primesFootnote 3 (as embodied in Feature Geometry) in fact defines three distinct computational systems (modules): Son, Place and Lar.Footnote 4 In section 5, these are shown to either live at and above (Son) or below the skeleton (Place, Lar). A lexical entry of a segment has thus three compartments hosting items of three distinct vocabulary sets (just as the lexical entry of a morpheme is made of three distinct vocabulary sets: morpho-syntax, phonology, semantics). The challenge then is to explain how the three modules communicate in general, and what guarantees segment integrity in particular (how does the system “know” which Son primes, Place primes and Lar primes belong to the same segment?). In short, the question is how does a multiple-module spell-out work, that is, how ingredients from three distinct vocabularies can be mapped onto a single phonetic item.Footnote 5 It is argued that the skeleton plays a central role in this conversion. The division into three content-defined modules Son, Place, Lar also motivates the title of the article.
Section 5 also evaluates the consequences of the idea that Son primes are phonologically meaningful (non-arbitrary), while Place and Lar primes are phonologically meaningless (arbitrary). It is argued that the former match the Concordia version of SFP (Hale, Reiss, Kissock, Volenec, see section 5.2.4) where primes and their association to phonetic categories are given at birth, while the latter instantiate the take of all other SFP approaches where both primes and their association to phonetic categories are emergent (i.e., acquired by the infant).
Section 6 considers a pervasive question raised by the presence of a spell-out in addition to regular phonological computation: how can we know whether a given alternation is due to the former (interpretational), or to the latter (phonological)? Finally, the conclusion in section 7 addresses more general issues that arise given the distinctions discussed: the so-called duplication problem (does phonological computation do the same labour twice: upon lexicalization and upon production?), the wiring of modules (why does Son, but not Place or Lar, communicate with morpho-syntax?) and the specific status of Son primes as non-arbitrary and hard-wired properties present at birth (why do Place or Lar not have this privilege?).
2. What exactly is substance-free?
This section introduces the basic distinction between phonological items below and above the skeleton: the former have a phonetic correlate, the latter do not; the former have arbitrary labels and may enjoy crazy computation (crazy rules), while the latter are drawn from a small set of cross-linguistically stable items (onset, nucleus etc.) which do not produce any crazy rules and whose labels are not interchangeable.
2.1. Phonological objects with and without phonetic correlates
The idea of substance-free phonology (SFP) concerns the melodic (or segmental) side of phonology, that is, items that are found below the skeleton in a regular autosegmental representation. The area at and above the skeleton is not within the purview of this approach.Footnote 6 The reason is that only items can be substance-free which are (wrongly, according to SFP) taken to have a substance. Substance is another word for phonetic properties, but onsets, rhymes, stress, prosodic words, metrical grids, skeletal slots or whatever other item occurs at and above the skeleton do not have any: only items below the skeleton (the world called segmental or melodic) have a phonetic correlate that SFP argues needs to be removed.
Of course, items at and above the skeleton bear on the phonetic realization of segments (e.g., a lateral is pronounced [w] in a coda, but [ł] in an onset) – but they do not have any phonetic properties themselves. The absence of phonetic properties is obvious for onsets, nuclei, prosodic words, the metrical grid etc.Footnote 7 But it also holds true for prominence: the supra-skeletal item (ictus) is lexically defined or distributed according to an algorithm, and then represented above the skeleton (as foot structure, metrical grids, extra-syllabic space etc.) with no reference to its phonetic value. The phonetic correlates of prominence are not present in the phonological representation (unlike labiality in [±labial] etc.): they are only introduced in regular phonetic interpretation thereof. That is, prominent segments bear three phonetic properties (in all languages, Ladefoged and Ferrari-Disner Reference Ladefoged and Ferrari-Disner2012: 24): loudness (measured in decibels), duration (measured in milliseconds) and pitch (measured in Hertz), the latter two being able to be phonologized (as length or tone, respectively, see Hyman Reference Hyman2006). Therefore, there is no substance to be removed from the phonological representation of prominence, and SFP is not concerned with it.Footnote 8
Note that the absence of phonetic correlates for items at and above the skeleton is not just an analytical choice that phonologists happen to have made when autosegmental representations were developed. Rather, it is a necessary property shared by all approaches that endorse items such as syllable structure on top of melodic building blocks, whether this is implemented in an autosegmental environment or not, and no matter whether melodic representations are substance-free or substance-laden. In substance-laden systems, primes carry their phonetic value in their name, while there is no such specification for items at and above the skeleton. In SFP, items below the skeleton (now in substance-free guise: α, β, γ etc.) will be specified for a phonetic correlate post-phonologically at the interface with phonetics (there are a number of ways this is done in the SFP literature; see the overview in Scheer Reference Scheer2019a): just like at the upper interface (of morpho-syntax with phonology, for example past tense ↔ -ed in English), spell-out is based on a list that infants need to acquire. This list (spell-out instructions) defines which phonological objects are associated to which phonetic categories, for example, α ↔ labiality, β ↔ backness etc. (Scheer Reference Scheer, Cyran and Szpyra-Kozlowska2014b). Certain phonological objects are part of this list, while others are absent, and the division is the one mentioned above: items below the skeleton (alphas, betas etc.) do entertain a spell-out relationship with a phonetic category, but items at and above the skeleton do not and hence are absent from this list. As was mentioned, they may influence the phonetic properties of segments (through phonological computation: ł → w in coda position, more on that in section 4.4), but are not themselves associated to any phonetic correlate (there is nothing like coda ↔ palatality etc., see section 6).
As far as I can see, the distinction between items that do (below the skeleton) and do not (at and above the skeleton) have a phonetic correlate plays no role in the literature and, being trivial, is not made explicit (Clements Reference Clements, Raimy and Cairns2009: 165 is an exception). Considered from the phonetic viewpoint, it is about the presence or absence of a phonetic correlate. Looked at from the phonological perspective, it distinguishes between meaningful and meaningless items: the phonological prime to which, say, phonetic labiality is associated when the system is built (upon acquisition), is interchangeable.Footnote 9 It may be anything and its reverse as long as it is distinct from other primes: an alpha is not any more appropriate than a beta or a gamma. By contrast, an onset is not interchangeable with a nucleus: there is no way to replace one with the other. This is because items at and above the skeleton have stable cross-linguistic properties: nuclei host vowels, not consonants (except for syllabic consonants on a certain analysis), rhymes form a unit with the onset preceding, not following them, etc. They also belong to a universal inventory (all languages have nuclei etc.). By contrast, items below the skeleton do not belong to a cross-linguistically stable inventory, and they have no cross-linguistically stable properties. This is why the only way to name them is by arbitrary alphas, betas and gammas.Footnote 10 Also consider the fact that despite substantial effort, phonologists have never been able to establish a putative universal set of melodic primes (feature inventory) – but the inventory of items at and above the skeleton is trivial and undisputed (within a given theory: moras, onset, nuclei etc.).
Items with stable cross-linguistic properties are thus phonologically meaningful, while those that are randomly interchangeable because they do not have any stable cross-linguistic properties are phonologically meaningless. Another way to put things is to say that because items at and above the skeleton belong to a universal inventory and enjoy universal properties that cannot be derived from the environment, they are innate. By contrast, items below the skeleton are not innate: the child is born with the (domain-general) ability to categorize and is predisposed to use this faculty in order to create phonological primes, that is, to reduce the acoustic signal to discrete phonological units (see Odden Reference Odden2022). That is, the child knows at birth that phonology exists and requires the construction of domain-specific primes to be put to use (more on this in sections 5.2.1 and 5.2.2).
Text under (1) sums up the discussion thus far, showing that SFP in fact operates a fundamental segregation between two types of phonology, below and (at and) above the skeleton.

2.2. Consequences of being phonologically meaningless or meaningful
Removing phonetic substance from (melodic) primes turns them into naked placeholders of phonological contrast. As such, that is, before they are associated to a phonetic correlate in an individual language, and by individual speakers upon acquisition, they lack any phonological identity, are interchangeable and hence arbitrary.Footnote 11 In fact, as seen under (2), they are arbitrary in three ways:Footnote 12

The computation of substance-free, phonologically meaningless primes is necessarily arbitrary (2b): in presence of colourless alphas, betas etc., it is not even possible to talk about “natural” or “unnatural” processes, or to distinguish any type of licit vs. illicit event for that matter. Substance-free primes do not “know” how they will eventually be pronounced and hence all logically possible processes based on them are equally probable, possible, and legal.Footnote 13 Substance-laden n → ŋ / __k is “natural” and ŋ → m / __r is not, but the same processes expressed with alphas and betas cannot even be judged for naturalness: α → β is not any more or less “natural” than α → γ since naturalness is not defined for alphas, betas and gammas. Only objects with phonetic properties can be more or less natural, but the very essence of alphas and betas is to not bear any phonetic properties in the phonology, where phonological computation occurs.
By contrast, phonologically meaningful items that occur at and above the skeleton do have an intrinsic, cross-linguistically stable phonological value and are therefore not interchangeable. As a consequence, their computation is not arbitrary: a vowel cannot be placed in a coda during syllabification, stress cannot fall on onsets etc. The following section shows that this segregation between the arbitrary workings of phonologically meaningless and the non-arbitrary workings of phonologically meaningful items is supported by an interesting empirical pattern.
2.3. Crazy rules are only ever melodically crazy
Below, the case of so-called crazy rules is examined, with a specific mention of crazy closed syllable lengthening or open syllable shortening, which are often subject to a misunderstanding.
2.3.1. Survey of crazy rules
A crazy rule is one that does not make sense phonetically speaking, that is, which is not “natural”. Since Bach and Harms (Reference Bach, Harms, Stockwell and Macaulay1972), a small literature on crazy rules has arisen that documents particular cases such as i → u / d__ (for Southern Pomoan, see Buckley Reference Buckley2000, Reference Buckley2003) (Vennemann Reference Vennemann, Stockwell and Macaulay1972, Hyman, Reference Hyman, Hume and Johnson2001). Chabot (Reference Chabot2021) has drawn an inventory of cases mentioned in the literature. A relevant generalization is that crazy rules appear to only ever be melodically crazy (see also Scheer Reference Scheer, Honeybone and Salmons2015: 333ff). That is, in a crazy rule A → B / C, A and B are only ever items that occur below the skeleton. There do not appear to be crazy rules that manipulate items at and above the skeleton: compensatory shortening, closed syllable lengthening (see section 2.3.2), tonic shortening etc. (syllable structure) or anti-Latin stress (stress falls on the antipenultimate syllable except when the penultimate syllable is short, in which case this syllable is stressed) are not on record.
But crazy rules not only appear to spare items at and above the skeleton: they also seem to make no reference to them in the conditioning context: i → u / d__ is reported for Southern Pomoan, but rules like p → r in coda position, or p → r after tonic vowels do not appear to occur.Footnote 14
Of course Chabot's (Reference Chabot2021) sample of crazy rules is incomplete and there is no guarantee that there are no syllabically or stress-wise crazy rules out there. But given the arbitrary and incomplete sample, there is no reason for all documented cases to accidentally concern only melodic properties.
Therefore the absence of crazy rules concerning syllable and stress properties is likely to be significant. This absence is exactly what is predicted by SFP: the computation of phonologically meaningless items (alphas and betas that occur below the skeleton) is arbitrary (see (2b)), but the computation of phonologically meaningful items (at and above the skeleton) is not.
2.3.2. There is no closed syllable lengthening or open syllable shortening
The notions closed syllable lengthening and open syllable shortening are frequently misunderstood. What is meant are processes whereby the syllabic position causes the effect observed, just as in regular closed syllable shortening, where shortening is specifically triggered by closed syllables, and by no other factor. That is, it occurs in all closed syllables and only in this environment. A valid closed syllable lengthening (or open syllable shortening) will thus be a process whereby all short vowels lengthen specifically in closed syllables and nowhere else (or all long vowels shorten specifically in open syllables and nowhere else).
Of course, there are cases where vowel lengthening in closed syllables occurs but is not caused by syllable structure. A recurrent pattern of this kind is due to voice-induced vowel lengthening whereby short vowels lengthen before a voiced consonant, which may be a coda. This pattern is found in German, in the evolution of Western Slavic (Scheer Reference Scheer2017), in English (where it may be called pre-fortis clipping) and beyond (Chen Reference Chen1970, Klatt Reference Klatt1973). Like other processes, it has a phonetic origin and may be phonologized in systems with distinctive vowel length (like German or Czech). When vowels lengthen before voiced consonants that happen to be codas, there is of course no closed syllable lengthening, since closed syllables play no role in the causality of the process.
In this context, an interesting case is reported from Menomini (Algonquian). In this language where vowel length is distinctive, Bloomfield (Reference Bloomfield1939) describes vowel length alternations that respond to a complex set of conditioning factors.Footnote 15 In §32 of the article, Bloomfield reports that “if the even (second, fourth, etc.) syllable after the next preceding long vowel or after the beginning of a glottal word, is open and has a long vowel, this long vowel is replaced by short.” Conversely, “if the even syllable (as [defined] in §32) is closed and contains a short vowel, this short vowel is replaced by a long” (§33). Glottal words are those “whose first syllable contains a short vowel followed by ʔ” (§31). That is, in order for a long vowel to shorten in an open syllable, or for a short vowel to lengthen in a closed syllable, the syllable at hand must be even-numbered with respect to the next long vowel to its left, or to the beginning of the word in glottal words. The even-numbered condition is translated into “head of a disyllabic (iambic) foot” by Hayes (Reference Hayes1995: 219), but this is not obvious, since the calculus is not based on the left word edge (except for glottal words), but rather on the next preceding long vowel.
In any case, the Menomini process described does not qualify as closed syllable lengthening or open syllable shortening, since the causality is multi-factored: it is not the case that all long vowels in open syllables undergo shortening, or that all short vowels in closed syllables lengthen.
2.4. An arbitrary and a non-arbitrary phonology
Below, the situation described thus far is summarized and considered with regards to modularity.
2.4.1. Below and above the skeleton
SFP thus produces a situation where an arbitrary and a non-arbitrary phonology coexist in the sense of (2a) (objects), and (2b) (the computation of these objects). Arbitrary phonology occurs below, non-arbitrary phonology at and above the skeleton in a regular autosegmental setting. This is shown under (3), which also mentions a consequence of the fact that only items below the skeleton have a phonetic correlate: these, but not items at and above the skeleton, are spelled out. This is because spelling out an item is the process of assigning it a phonetic value: items at and above the skeleton cannot be spelled out, because they do not have any phonetic correlate (more on this in section 6).
For the time being, the two phonologies are i) taken to be static (i.e., areas in the autosegmental representation, computation therein is discussed below) and ii) are called Phonology I and II. They occur in a box called production phonology under (3), referring to the computation that turns an underlying (lexical) representation into a surface representation (which is then subject to spell-out). It is opposed to lexicalization phonology, to be introduced in section 3, which includes those phonological operations that occur upon the lexicalization of morphemes, that is, when the acoustic signal is transformed into a lexically stored item. The setup under (3) will be refined as the discussion unfolds.
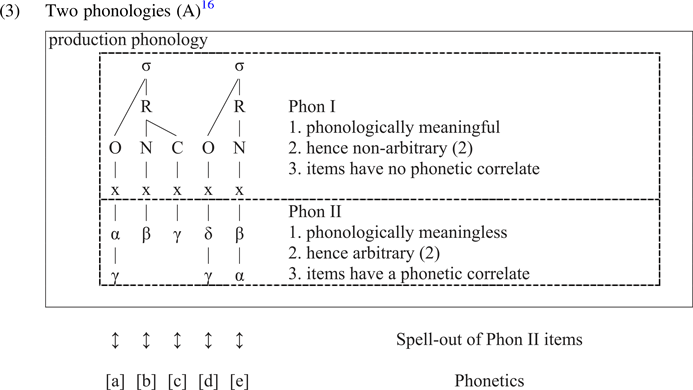
The coexistence of an arbitrary and a non-arbitrary phonology has an obvious consequence: we are dealing with two distinct computational systems, that is, two distinct modules. Computation within a single module could not possibly be arbitrary and non-arbitrary at the same time, or build phonologically meaningful items (onsets, feet etc.) on the basis of phonologically meaningless primes (alphas, betas, gammas).Footnote 17
The existence of two distinct phonological modules in production raises the non-trivial questions under (4) below.

In both cases under (4), the communication between the two phonologies is non-arbitrary: syllable structure is not just anything and its reverse, given (segmental) sonority, and the lenition / fortition that is visible on segments is not random (lenition occurs in weak, not in strong positions).Footnote 18
2.4.2. Modular workings
The previous section has drawn the conclusion that there must be two distinct computational systems in phonology, hosting phonologically meaningless and meaningful items, respectively.
Space restrictions precluding more detailed discussion of modularity, the following merely mentions some relevant properties. Fodorian modularity (Fodor Reference Fodor1983) expresses the insight that computation in the mind/brain is not all-purpose, but rather falls into a number of specialized systems that are designed to carry out a specific task. Computational systems are thus competent for a particular domain and can only parse information pertaining to this domain (domain specificity): their input is restricted to a specific vocabulary. That is, foreign vocabulary is unintelligible and communication with other modules requires a translational mechanism (spell-out). Humans are predisposed to develop modules for specific domains: the information that there will be a computational system for vision, audition, etc. (but not for filling in a tax declaration or playing the piano) is genetically coded and present at birth. Relevant literature includes Segal (Reference Segal, Carruthers and Smith1996), Coltheart (Reference Coltheart1999), Gerrans (Reference Gerrans2002), Jackendoff (Reference Jackendoff2002) and Carruthers (Reference Carruthers2006: 3ff).
Modules are thus computational systems that take a domain-specific vocabulary as an input, carry out a computation and return structure. For example, syntactic computation (Merge) operates over number, person, animacy etc. and builds hierarchical structure, the syntactic tree. In this article, vocabulary items are called primes, and the result returned by computation based on them, is structure. Hence the computation that takes sonority primes (Son) as an input returns structSon (syllable structure, feet, etc.), and the same goes for Place primes (StructPlace) as well as Lar primes (StructLar).
3. What happens upon lexicalization
Children (upon first language acquisition) and adults (when they learn new words such as acronyms, loans etc.) create new lexical entries.Footnote 19 The input of this process is the acoustic gradient waveform (first transformed into a cognitive non-linguistic form by the acoustic component of the cognitive system), and its output is a discrete symbolic (phonological) representation. This much is true for sure, and undisputed. There is a massive literature on the question of how exactly the phonetic signal is converted into lexical representations that are stored in long-term memory. For overviews see, for example, Goudbeek et al. (Reference Goudbeek, Smits, Culter, Swingley, Claire and Cohen2005) and Boersma et al. (Reference Boersma, Escudero, Hayes, Sole, Recasens and Romero2003).Footnote 20
The lexicalization process filters out linguistically irrelevant properties contained in the phonetic signal, such as pitch variations caused by male / female speakers, the emotional state of speakers, or the influence of drugs (such as alcohol) on their production.
Linguistically relevant information is transformed by the lexicalization process: the gradient non-symbolic input is stored as a sequence of discrete phonological units (segments) that decompose into melodic primes (traditionally substance-laden [±lab] etc., substance-free alphas and betas in SFP). This includes temporal order: the temporal continuum is transformed into a linear sequence of discrete phonological units (primes and segments). Linear structure in phonology is represented as a sequence of timing units (the skeleton).
Traditionally, syllable structure is absent from the lexicon: rather than being constructed upon lexicalization and stored, it is built during production phonology, that is, when the multi-morphemic string created by morpho-syntactic computation is interpreted by the phonology (underlying-to-surface). There is reason to believe that the syllabification algorithm runs already upon lexicalization, though, and that the lexicon is thus fully syllabified (rather than containing an ordered sequence of unsyllabified segments).Footnote 21
Beyond the creation of a symbolic and discrete representation that includes syllable structure, there is good reason to believe that lexicalization may also impose well-formedness conditions on items that are stored. This insight is formalized as Morpheme Structure Constraints (MSC) in SPE (Chomsky and Halle Reference Chomsky and Halle1968: 171, 382): for example, in a language like English where only clusters of rising sonority can begin a morpheme, lexical items with initial #RT clusters are prohibited, that is, will never be lexicalized. Gouskova and Becker (Reference Gouskova and Becker2016) talk about a Gatekeeper Grammar in this context (more on MSCs in section 7).
So-called Lexicon Optimization embodies the same idea. Bermúdez-Otero (Reference Bermúdez-Otero, Spenader, Eriksson and Dahl2003: 29) provides the following formulation (after Hale Reference Hale and Seboek1973: 420): prefer inputs that are well-formed outputs. Thus an item that will never be able to appear as such on the surface (e.g., an initial #RT cluster in English) will not be stored. Relevant literature includes Prince and Smolensky (Reference Prince and Smolensky2004: Section 9.3), Yip (Reference Yip, Durand and Laks1996), Bermúdez-Otero (Reference Bermúdez-Otero1999: 124) and Inkelas (Reference Inkelas1995).
This is also what motivated Kiparsky's (Reference Kiparsky and Fujimura1968–1973: 14ff) Alternation Condition, which was designed to rule out so-called absolute neutralization, that is, a situation where a morpheme has an underlying sequence that may never be inspected on the surface because it is modified by computation in all occurrences (such as nightingale whose first vowel was said to be /i/, rather than /aj/, on the analysis of Chomsky and Halle Reference Chomsky and Halle1968: 234).
Lexicalization falls into two distinct actions according to the input. The phonetic signal is a non-cognitive, gradient (real world) item that is converted into cognitive, discrete, symbolic and linearized units: the segments (or phonemes). These segments are then the input to further computation which builds phonological structure (syllable structure, feet or equivalent stress-encoding structure in lexical stress languages).Footnote 22 Items involved in both steps are subject to well-formedness conditions. The former may be called lexicalization conversion and the latter lexicalization phonology.
The two systems are different in kind because they work on dramatically different input vocabulary: lexicalization conversion counts among the human perception devices that transform real-world items into cognitive categories: light waves into colours, chemical substances into odors etc. (see footnotes 20 and 39). By contrast, lexicalization phonology is just like production phonology (see (3)) that occurs when the multi-morphemic string created by morpho-syntactic computation is interpreted (underlying-to-surface): it takes as an input cognitive, discrete and symbolic units that belong to the phonological vocabulary (primes); it produces phonological structure and assesses well-formedness.Footnote 23
Obviously there is some overlap between the phonological operations that are carried out in production and upon lexicalization: syllabification, for example, is active in both. There is reason to believe that they are not identical, though. This issue, known as duplication and regarded as a problem by some, is further discussed in the conclusion (section 7).
Summing up the discussion, (5) below depicts what happens upon lexicalization (allowing for the shortcut between the acoustic real-world object and the linguistic system: as was mentioned, cognitive processing in the acoustic component occurs between the two boxes shown).
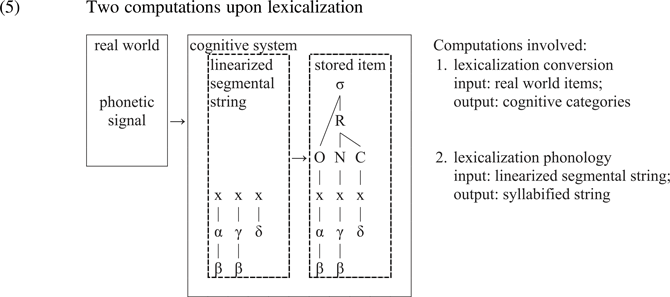
4. Sonority is different
Section 3 has described how the items that are used in production come into being, that is to say, enter the lexicon. They have the structure discussed in section 2, that is, what was called Phon I and Phon II under (3). For the time being this difference is only grossly depicted as two areas in an autosegmental representation. The present and the following sections take a closer look at how Phon I (at and above the skeleton) comes into being, what kind of items do and do not appear in this area, as well as how Phon I and Phon II communicate.
Below, the traditional partition of segmental properties (as embodied in Feature Geometry, Clements and Hume Reference Clements, Hume and Goldsmith1995) is referred to as Son (sonority defining primes), Place (place defining primes) and Lar (primes defining laryngeal properties).Footnote 24
4.1. Diagnostics
Below, a number of diagnostics are discussed which suggest that sonority is different.
4.1.1. To be heard vs. to be understood
Harris (Reference Harris2006) argues that Son is different in kind with respect to Place and Lar. Observing that “sonority differences are never contrastive in the way that differences defined in terms of individual features can be”, he argues that phonetically speaking, “speech is a modulated carrier signal: the modulations bear the linguistic message, while the carrier enables the message to be heard.” That is, the carrier signal, sonority, “is concerned primarily with the audibility of the linguistic message rather than with the message itself” (all quotes from Harris Reference Harris2006: 1484). Thus sonority is about being heard, while place and laryngeal properties are about being understood: they carry the linguistic message that sonority is not conveying.Footnote 25
4.1.2. Selective bottom-up visibility
It is a trivial, though rarely explicitly stated fact that Son is projected above the skeleton, while Place and Lar are not. Syllable structure is a function of two and only two factors: the linear order of segments and their relative sonority. That syllable structure depends on these two factors (plus parametric settings determining whether or not specific syllabic configurations such as codas, branching onsets etc. are provided for) and on no other is an undisputed and theory-independent fact which is transcribed in all syllabification algorithms (e.g., Steriade Reference Steriade1982: 72ff, Blevins Reference Blevins and Goldsmith1995: 221ff, Hayes Reference Hayes2009: 251ff).
That Son, but not Place and Lar, are present above the skeleton is also shown by reverse engineering. Sonority values may to a certain extent be predicted given syllable structure: onsets and codas contain low sonority items, nuclei contain high sonority items; the sonority of the members of a branching onset is rising; it is non-rising in a coda-onset sequence. By contrast, syllable structure does not allow us to deduce anything about Place or Lar properties of segments: the fact of being a nucleus, onset or coda tells you nothing about whether the segments associated are labial, palatal, velar etc., and onset- and codahood provide no clue whether segments are voiced or voiceless either.Footnote 26
There is thus reason to believe that Phon I under (3), that is, items which occur at and above the skeleton, are the result of a structure-building computation that is based on (phonologically meaningful) sonority primes. That is, the domain-specific vocabulary of the Son module are Son primes, and modular computation based on them returns structSon, the items familiar from above the skeleton.
4.1.3. Selective top-down visibility
The previous section has discussed the fact that syllable structure is built without reference to Place and Lar. This indicates that the Son vocabulary on the one hand, and Place / Lar vocabulary on the other hand, are distinct: if Place / Lar primes were present and available when structSon is built, they would be expected to be taken into account. The fact that they are not suggests that they occur in a different module.
This conclusion is supported by a solid empirical generalization: processes which occur at and above the skeleton may be conditioned by Son, but are blind to Place and Lar.Footnote 27 Evidence comes from linearization when the landing site of infixes is defined (see (6a)) from phonologically conditioned allomorph selection (6b), from stress placement (6c), from contour tone placement (6d) and from positional strength (6e). If the processes at hand occur in the Son module that is different from the Place / Lar module(s), it follows that they cannot see Place / Lar properties (just as syllabification is blind to them).

Note that the diagnostic for tone provided by contour tone placement (6d) appears to be consistent with the fact that tone may also influence allomorph selection (6b): Paster (Reference Paster2006: 126–130) discusses a case from the Yucunany dialect of Mixtepec Mixtec (Otomanguean, Mexico) where the first person sg is marked by a floating low tone, except when the final tone of the verb stem is low, in which case -yù is suffixed. This also ties in with the fact that tone appears to be able to influence morpho-syntactic computation, as reported by Rose and Jenks (Reference Rose and Jenks2011) (see section 5.4.2). These three diagnostics are consistent, suggesting that tone belongs to the area above the skeleton (the Son module) where it is typically located in autosegmental representations. But they conflict with the fact that tone has a phonetic correlate (pitch) and interacts with regular melodic primes (namely in Lar) (see footnote 8). The diagnostics developed in the present article thus confirm the infamous hermaphrodite nature of tone (Hyman Reference Hyman, Goldsmith, Riggle and Yu2011).
4.2. The representation of sonority
The preceding sections have provided evidence that Son is different in kind with respect to Place / Lar. There are two lines of thought that share the same diagnostic, albeit on entirely different grounds, and concluding that there are no Son primes (i.e., phonological objects that specifically represent sonority). In one, sonority is phonological but a property of structure, rather than of primes; in the other, syllable structure is the result of phonetic perceptibility, rather than of a syllabification algorithm that runs in the phonology and is based on sonority primes. Both approaches are discussed below, starting with the latter.
4.2.1. Perception-based sonority
Perception-based sonority is exposed by Steriade (Reference Steriade1994, Reference Steriade, Fujimura, Joseph and Palek1999). As Moreton et al. (Reference Moreton, Feng and Smith2005: 341) put it, “perceptibility theory […] says that a segment's compatibility with a given environment depends on how accurately it is likely to be perceived in that environment”, where “environment” refers to classical syllabic positions such as onset, coda and so forth. In this approach, syllable structure exists in phonological representations, but is directly abstracted from phonetic information and has no bearing on segmental alternations. That is, VTRV is parsed as V.TRV in Spanish but as VT.RV in Classical Arabic, but “consonantal phonotactics are best understood as syllable-independent, string-based conditions reflecting positional differences in the perceptibility of contrasts” (Steriade Reference Steriade, Fujimura, Joseph and Palek1999: 205). In this view, lenition and fortition are thus entirely unrelated to syllable structure, the latter however existing independently.
The question whether syllable structure is responsible for positional phenomena is unrelated to the issue pursued here, that is, the existence of Son primes and the way items, at and above the skeleton, are built. Regarding this issue, it seems to me that the perceptibility-based approach is in fact a notational variant of the regular perspective based on Son primes. When building (phonological) syllable structure based on perceptibility, the gradient phonetic signal will also need to be transformed into discrete phonological units, the segments, and it must also be somehow decided that certain segments are vowels, while others are consonants, and that the former will end up in a nucleus, while the latter are parsed into an onset or a coda. This is but a short version of the process described in section 3 and further discussed in section 5.2.3, that is, the construction of syllable structure based on the phonetic signal with an intermediate classification of segments in terms of sonority.
4.2.2. Structuralization of sonority
In SPE, major class features such as [±son], [±cons] or [±voc] were scrambled in a single feature matrix together with features defining melodic characteristics such as place of articulation and laryngeal properties. OT implements sonority along the same lines, except that scrambling concerns constraints, rather than features (e.g., Smith and Moreton Reference Smith, Moreton and Parker2012).
Departing from an amorphous and unstructured set of primes, Feature Geometry made a first step towards the structural representation of sonority. The theory introduced by Clements (Reference Clements1985) autosegmentalized the amorphous bundle of SPE features, aiming at grouping them into natural classes (class nodes) in a feature geometric tree. In this approach, sonority is still represented in terms of the SPE features (or some version thereof), but following the class node logic, features are grouped together and isolated from other classes of features. In Clements and Hume's (Reference Clements, Hume and Goldsmith1995) final model of Feature Geometry, the Son primes [±son], [±approximant] and [±vocoid] are borne directly by the root node, as opposed to other features which are represented in the feature geometric tree below the root node.
This structural insulation of sonority was further developed in a number of approaches sharing the idea that rather than being represented by specific primes, sonority is a function of Place and Lar primes as well as of their organization. Government Phonology has pioneered this line of thought: in this approach, sonority is a derived notion based on segmental complexity. That is, the more primes a segment is made of, the less sonorous it is (and vice versa) (Harris Reference Harris1990, Backley Reference Backley2011: 114ff). Segmental complexity has a number of issues: for example, it cannot derive vocalic sonority. High i,u and low a are made of just one prime (I, U and A, respectively), while mid vowels bear two primes (I,A or U,A) and should thus be less sonorous than high and low vowels, which of course is not the case.
Other implementations of the idea that sonority is a structural property include GP2.0 (Pöchtrager Reference Pöchtrager2006: 55ff, Pöchtrager and Kaye Reference Pöchtrager and Kaye2013); Rice (Reference Rice1992); Schwartz’ (Reference Schwartz2013, Reference Schwartz2017) Onset Prominence model; Hulst's (Reference van der Hulst1994, Reference van der Hulst, Durand and Katamba1995a, Reference van der Hulst, Rennison and Kühnhammer1999) Radical CV Phonology; and de Carvalho's (Reference de Carvalho2002a, Reference de Carvalho, de Carvalho, Scheer and Ségéral2008, Reference de Carvalho2017) perspective. These approaches are reviewed in greater detail in Hermans and Oostendorp (Reference Hermans, van Oostendorp, Broekhuis, Corver, Huybregts, Kleinhenz and Koster2005) and in Scheer (Reference Scheer2019b).
The visibility-based evidence discussed in sections 4.1.2 and 4.1.3 documents the exclusive reference to sonority for the processes mentioned, with Place and Lar being irrelevant and invisible. Given this situation, it would come as a surprise if sonority and melody cohabited the same space: were they all accessible, there would be no reason why some items should be selectively taken into account, while others are actively ignored. Therefore, Place and Lar information must not be accessible when sonority computation is carried out, irrespective of how sonority is represented (structuralized or in the guise of primes). Scheer (Reference Scheer2019b) thus concludes that the empirical situation regarding visibility warrants a segregation of sonority and Place / Laryngeal properties into distinct modules, rather than the structuralization of the former.Footnote 29
Approaches that make sonority a structural property thus take a step in the right direction by estranging sonority from Place / Lar. But they leave all players in the same computational space (module). If a further step is taken that recognizes the segregation of Son and Place / Lar in distinct computational systems, the structural representation of sonority loses its raison d’être, which is to enact the difference.
If thus sonority is a computational system of its own, there must be Son primes, since modular computation is always based on primes (see section 2.4.2).
4.3. The Place and Lar modules
Place and Lar computation appear to be mutually waterproof. While of course Place can impact Place (e.g., velar palatalization) and Lar bears on Lar (e.g., voicing assimilation), Place modifications triggered by Lar (a velar is turned into a palatal before a voiceless consonant) or the reverse (a voiceless consonant becomes voiced when followed by a labial) appear entirely outlandish and stand a good chance of being absent from the record.Footnote 30
In account of their difference, Feature Geometry has devised distinct category nodes for Place and Lar. In the same way as for the difference between Son vs. Place / Lar discussed in the previous section, structuralizing the distinction between Place and Lar is a step in the right direction, but does not forbid Place to condition a Lar process, or the reverse, since both coexist in the same computational space. Locating Place and Lar in different modules enacts the fact that process where one conditions the other appear to be absent from the record: they are excluded, since each computational system can only bear on items of its own domain; see under (7).
4.4. Impact of structSon on Son, Place and Lar
Section 4.1.3 has shown that there is no bottom-up conditioning: Son (at and above the skeleton) is not influenced by Place or Lar (which live below the skeleton). Top-down conditioning (where syllable structure or stress condition Place and Lar) exists, though.

These patterns are unexpected if Son and Place / Lar are located in different modules. But consider the fact that regular Place and regular Lar computation appears to be unimpacted by structSon: there is nothing like “velars palatalize before front vowels, but only if they belong to a coda” or “obstruents undergo progressive voice assimilation, but only if they are engaged in a branching onset”.
This suggests that Place- and Lar-internal computation is indeed insensitive to structSon, as predicted. The patterns under (7) are different: rather than bearing on regular Place- and Lar-computation that exists by itself, they describe a situation where a Place or Lar modification may occur when triggered by structSon. How could that be possible in a modular environment?
In order to approach this question, let us take a closer look at lenition and fortition. Inoffensive cases modify only Son primes, given structSon: for example, a segment whose Son primes define a stop is turned into a fricative with corresponding Son primes because it occurs in intervocalic position. The input, conditioning context and output of this process are all located in Son and that complies with modular standards.
But as was mentioned, there are also offensive cases: typical lenition trajectories move along the sonority scale but also involve steps that are defined by Lar (ph > p > b > v etc.) (7a2). This is reflected in sonority scales that scramble Son and Lar properties (Szigetvári Reference Szigetvári, de Carvalho, Scheer and Ségéral2008a, Parker 2011: 1177 counts 17 steps). The type of lenition mentioned under (7b1), debuccalization, involves the loss of Place primes and may thus not be described as a rearrangement of Son primes either. Szigetvári (Reference Szigetvári, de Carvalho, Scheer and Ségéral2008b) shows that these two types of lenition exhaust the empirical record: one makes segments more sonorous (thus involving Son primes: t > θ, b > β, t > ɾ etc.), the other makes them lose Place primes, as in t > ʔ, s > h, f > h.
In Government Phonology, lenition (of both types) is interpreted as a loss of (privative) primes (Harris Reference Harris1990). Although structSon cannot see or bear on Place primes across a module boundary, it may influence the properties of timing units. Following the GP logic, timing units that are weak because their associated syllabic constituent is weak are unable to sustain other primes in other modules. That is, positions, rather than segments, are weak or strong: this is quite trivial and encoded in the name of the phenomenon, positional strength. The effect that is visible on segments is the consequence of their positional strength or weakness, that is, of the positional status of their x-slot.
This mechanism may be generalized: structSon bears on timing units and makes them more or less apt at sustaining (licensing) primes that are associated to them. A strong position is a position that allows for a large number of primes to be associated, while a weak position can sustain only a few, or indeed no prime at all. Timing units do not belong to any individual module, but rather instantiate the temporal and linear sequence. The primes of all three modules that co-define a segment are attached to the timing unit that defines this segment (more on this in sections 5.5.1 and 5.5.2, see the representation under (11) in section 5.3). Hence restrictions that weigh on a timing unit will be visible in all three modules.
All cases under (7) share the fact that under the pressure of structSon some prime is lost: a Lar prime under (7a1) (devoicing); Son primes (b > v) or Lar primes (p > b) under (7a2) (sonority-lenition); Place primes under (7) (debuccalization-lenition); and (7b2) (centralization of unstressed vowels). Hence the analysis whereby structSon weighs on timing units whose weakness (or strength) then has consequences on Place and Lar is workable throughout.
A structSon conditioning on timing units may lead to the loss of a segment in diachronic lenition (loss of a coda consonant in s > h > ø), but also in synchronic computation: vowel-zero alternations are governed by a (cross-linguistically stable, see Scheer Reference Scheer2004: Section16) syllabic context where lexically specified vowels (schwas, short vowels, high vowels etc.) are absent in open, but present in closed syllables. In Czech for example, the root vowel of pes “dog Nsg” alternates with zero in presence of the case marker -a in ps-a “dog Gsg” (while the phonetically identical root vowel in les - les-a “forest Nsg, Gsg” is stable: alternating e is marked as such lexically).
In Strict CV, alternating vowels are underlyingly present but floating: the vowel under (8a) fails to be associated when its nucleus is governed. This is the case in Gsg where the following nucleus hosts -a (8c). In Nsg under (8b), though, the following nucleus is empty and hence cannot govern. Therefore, the nucleus containing the alternating vowel remains ungoverned, which allows the floating melody to associate.
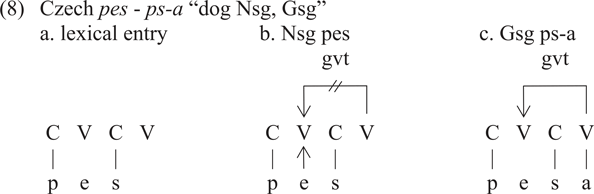
Note that in Strict CV, government (and licensing) represent syllable structure, that is, structSon. But whatever the framework used, the presence or absence of the alternating vowel is controlled by syllable structure. In Strict CV, its absence is due to the pressure that structSon puts on the nucleus (government). This is parallel to what we know from lenition: the ability of a constituent to sustain primes is curtailed under positional pressure. In the case of vowel-zero alternations, its ability to host primes is zero.
In sum, structSon may indirectly cause the loss of primes in all three modules by defining strong and weak timing units, which then may not be able to tolerate the association of certain primes. But there is no bearing of structSon on regular computation that occurs in the Place or the Lar module.Footnote 31 This setup may thus be said to kill two birds with one stone.
5. Workings of phonology with three modules
In this section, the ingredients of a full-blown SFP are considered: the nature of lexical entries and primes, computation (upon lexicalization and in production), multi-module spell-out, and phonetics (language-specific as well as universal).
5.1. Lexical entries
If Son vs. Place vs. Lar are three distinct computational systems, according to modular standards each one carries out a specific computation based on a proprietary vocabulary. A segment thus combines items from three distinct module-specific vocabularies. The situation where a single lexical entry is defined by items that belong to different vocabularies is known from the morpho-syntax – phonology interface where idiosyncratic properties of single lexical entries (morphemes) are used by multiple computational systems. The lexical entry of a morpheme stores three types of information written in three distinct vocabularies that are accessed by three different computational systems: morpho-syntax (using vocabulary items such as number, person, animacy, etc.), semantics (LF-relevant properties) and phonology (vocabulary items such as occlusion, labiality, voicing etc.). The lexical entry for cat for example may look like (9a).Footnote 32

In the same way, the lexical identity of a segment contains several compartments that host items from three distinct vocabularies, as shown under (9b) for the constituent segments of cat. Each vocabulary is then accessed by the relevant computational system. For instance, the computation that builds syllable structure is specific to Son and can only parse this vocabulary. Hence only Son primes are projected and the result of the computation, structSon, contains no information pertaining to Place or Lar. This is why other computations which occur above the skeleton and take into account items in that area are unable to access anything else than Son primes and structSon (section 4.1.3). In the same way, Place computation (e.g., palatalization) accesses only Place primes (and outputs structPlace), while Lar computation (e.g., voice assimilation) reads only Lar primes (and produces structLar).
5.2. Lexicalization conversion
This section discusses the fundamental contrast between Place and Lar primes on the one hand, and Son primes on the other: it is argued that the latter are universally associated to a phonetic category, while the former are not.
5.2.1. Primes are module-specific
It was mentioned in section 2.4.2 that modules are hard wired, that is, genetically coded: humans are predisposed for processing visual, auditory etc. information. If Son, Place and Lar are three distinct modules, their existence and domain of competence must thus be genetically coded and present at birth. That is, children know beforehand that these three modules exist, and that their working requires the construction of relevant primes in each domain.Footnote 33
An argument for the existence of three distinct and universal systems is the trivial fact that all languages appear to have distinctions in all three areas: there is no language which chooses, say, to ignore the possibility of implementing Lar distinctions, or which builds a distinctive system without some contrast in Place, or where all segments belong to the same sonority class. If primes were entirely unconstrained at birth, some language could build a contrastive system where, say, laryngeal properties play no role. What is observed, though, is that while the three types of contrast are always present independently of the language-specific environment, there is variation within each system.
A consequence of there being three distinct modules is that alphas, betas and gammas are not colourless, but rather specific to the three domains at hand. That is, primes occur in a specific module and are thus different in kind. This difference may be graphically indicated by using symbols from different alphabets, say, α, β, γ for Place primes, б, г, д for Lar primes and a, b, c for Son primes.Footnote 34
5.2.2. Place and Lar primes
Place and Lar primes bring together the three types of arbitrariness under (2): the primes themselves are arbitrary ((2a): α is not any more appropriate than β); their computation is arbitrary ((2b): any prime may be added to or removed from any segment, given any trigger and its reverse); and so is their association to a phonetic category ((2c): any association of any prime with anyphonetic category is possible).
Primes themselves are thus absent at birth. They are created and associated to relevant phonetic correlates upon exposure to contrast and phonological processing of the target language (e.g., Boersma Reference Boersma1998: 461ff, Mielke Reference Mielke2008, Dresher Reference Dresher2014, Reference Dresher2018, Odden Reference Odden2022; see also Goudbeek et al. Reference Goudbeek, Smits, Culter, Swingley, Claire and Cohen2005).
5.2.3. Son primes are hard wired
Section 2 has concluded that unlike other segmental properties, sonority is phonologically meaningful. This describes the fact that the Son module is not arbitrary. Unlike what is observed for Place and Lar, the computation of Son primes upon lexicalization is lawful (hence at odds with (2b):its result, structSon, is the same in all languages. That is, its items and their properties as well as their arrangement are universal: the list of structSon items is the same in all languages (onset, nuclei, feet, etc.), their properties are shared across languages (onsets host consonants, nuclei host vowels, or high sonority items) and their arrangement is also the same everywhere (onsets occur to the left, not to the right of rhymes, etc.).Footnote 35
The association of a Son prime with a phonetic correlate is also not arbitrary (against (2c)). As Clements (Reference Clements, Raimy and Cairns2009: 165ff) points out, there are no flip-flop systems where all items that are vowels phonetically-speaking would be interpreted as consonants in the cognitive system upon lexicalization, and thus associate to a C position, while all items that are phonetic consonants would become phonological vowels and therefore associate to a V position. This means that Son primes are extracted from the phonetic signal in a predictable way that is at least partly the same in all languages. Clements (Reference Clements, Kingston and Beckmann1990: 291) says that “in the absence of a consistent, physical basis for characterizing sonority in language-independent terms, we are unable to explain the nearly identical nature of sonority constraints across languages” (see also Clements Reference Clements, Raimy and Cairns2009: 166).
There must thus be a way for humans to recognize the difference between consonants and vowels in the acoustic signal, and this capacity is put to use in such a way that there is a hard-wired relationship between a phonetic vowel and its lexicalization as a cognitive / phonological vowel, as well as between a phonetic consonant and its lexicalization as a cognitive / phonological consonant.
Therefore, children must roughly know what a vowel sounds like at birth, and in which way a vowel is distinct from a consonant. In an SFP setting, this means that they must have Son primes that are associated with a specific phonetic correlate. The literature has identified perceptual salience as a cross-linguistically robust correlate of sonority, which owes to phonetic properties such as loudness, energy and intensity (Bloch and Trager Reference Bloch and Trager1942: 22; Heffner Reference Heffner1950: 74; Fletcher Reference Fletcher1972: 82ff; Price Reference Price and J1980; Ohala Reference Ohala1992; Wright Reference Wright, Hayes, Steriade and Kirchner2004: 39ff; Harris Reference Harris2006; Clements Reference Clements, Raimy and Cairns2009; Parker Reference Parker2008, 2011; Gordon et al. Reference Gordon, Ghushchyan, McDonnell, Rosenblum, Shaw and Parker2012; Bakst and Katz Reference Bakst and Katz2014).Footnote 36
Despite this massive literature, there are also voices saying that no phonetic correlate was ever identified: Hooper (Reference Hooper1976: 198), Ohala and Kawasaki (Reference Ohala and Kawasaki1984: 122), Ohala (Reference Ohala1990: 160),. Later on, though, Ohala (Reference Ohala1992: 325) arrives at about the same conclusion as the literature mentioned: sonority is the result of a number of acoustic parameters, that is, amplitude, periodicity, spectral shape and fundamental frequency.
The idea that no phonetic correlate of sonority is currently available may either lead to the rejection of sonority as an unscientific concept, or to consider the issue an open question whose answer is orthogonal to phonological analysis. The former position was taken by the early Ohala (Reference Ohala, Bruck, Fox and Galy1974: 252) who says that phonologists “invent meaningless labels for types of sounds and sound patterns (e.g., marked, strong, sonority, chromatic)” (on this, see Hankamer and Aissen Reference Hankamer, Aissen, Bruck, Fox and La Galy1974: 143, footnote 8).
The latter position is adopted by Hankamer and Aissen (Reference Hankamer, Aissen, Bruck, Fox and La Galy1974: 137), Hooper (Reference Hooper1976: 198) and Clements (Reference Clements, Kingston and Beckmann1990: 291): we know that sonority exists, since the analysis of phonological patterns shows it does, and there must be some phonetic correlate which, in the current state of our knowledge, we are not able to identify. Hooper (Reference Hooper1976: 198) argues that whether or not analysts are able to identify the phonetic correlate of sonority by machine measurements is irrelevant for linguistic analysis. We know that the human abstracts sonority from the acoustic signal, just as we know that the human is categorizing the gradient acoustic signal into discrete segments (or phonemes), while it is impossible to identify where exactly one segment ends and another begins, based on machine or other analysis of the signal. It would of course be enjoyable, Hooper says, to know how exactly the human extracts sonority and segments from the gradient acoustic signal, but our current ignorance is not an obstacle to taking sonority or the segment as a linguistic fact.
The situation described leaves no serious doubt that sonority does have a cross-linguistically stable phonetic correlate, and that this correlate is perceptual salience (in its various acoustic guises).
5.2.4. Sonority is phonetically composite and entropy-driven
The literature mentioned contains two ideas that are worth isolating. The observation that sonority is phonetically composite is made, among others, by Ohala (Reference Ohala1992: 325) and Harris (Reference Harris2006: 1486), the latter concluding “that sonority does not map to any unitary physical property but is rather a cover term for a collection of independent acoustic properties that contribute to an overall dimension of perceptibility or auditory-perceptual salience.” The other idea is that modulations (modifications of the signal) count, rather than static values (Ohala Reference Ohala1992: 325, Harris Reference Harris2006).
Stilp and Kluender's (Reference Stilp and Kluender2010) study is based on these two insights. It takes the latter idea to follow from Shannon's (Reference Shannon1948) more general information theory which is based on the idea that the degree of informativeness of an event depends on its entropy, that is, the uncertainty or unpredictability associated with it: the more unexpected, the more informative. Stilp and Kluender (Reference Stilp and Kluender2010: 12387) thus test “whether relative informativeness of portions of the speech signal is related to the degree to which the signal changes as a function of time.” On these grounds, they develop the notion of Cochlea-scaled Spectral Entropy (CSE), which “is a measure of the relative (un)predictability of signals that is operationalized as the extent to which successive spectral slices differ (or cannot be predicted) from preceding spectral slices. Most simply, CSE is quantified as Euclidean distances between equivalent-rectangular-bandwidth-scaled spectra of fixed-duration (16 ms) sentence slices that were processed by auditory filters” (p. 12388). They report that in their experiment “[t]his pattern of CSE decreasing from low vowels, to high vowels, to laterals/glides and nasals, to fricatives, to affricates, and finally stops closely parallels the sonority hierarchy” (p. 12389). They conclude that although in their measurements “there are no assumptions that the signal is created by a vocal tract” and “[w]ithout introduction of constructs such as distinctive features, CSE reveals distinctions between classes of speech sounds that mirror those in the sonority hierarchy. Although the present results are agnostic to linguistic constructs and theory, CSE could be construed as providing a case in which some linguistic distinctions are natural consequences of operating characteristics of the mammalian auditory system” (p. 12390).Footnote 37
This is not to say that there is no slack, of course. It is not the case that all languages build the same sonority hierarchy based on the phonetic signal: in some languages, nasals count as (pattern with) sonorants, while in others they go along with stops. Only liquids may be second members of branching onsets in some languages, while in others nasals or glides also qualify for this position. In some languages, only vowels may be sonority peaks, while in others sonorants (or a subset thereof, typically liquids) may also occur in this position and act like vowels (syllabic consonants). The slack that is observed cross-linguistically for the specific location of a given phonetic item on the sonority hierarchy is called ‘relative sonority’. This variation has produced a massive body of literature (Clements Reference Clements, Kingston and Beckmann1990; Parker 2011, Reference Parker2017).
Note that the same workings allowing for some slack in a basic invariant frame are known from other cases, where a real-world continuum is converted into discrete cognitive categories. In colour perception, some distinctions like black and white have a physiological basis (magna vs. parvo layer cells of the lateral geniculate nucleus located in the thalamus, Kay et al. Reference Kay, Berlin, Maffi, Merrifield and Cook2009: 26) and may be selectively impacted by dysfunction: there are humans with no chromatic vision (achromatipsia, i.e., seeing only black and white). Beyond physiological grounding, the World Color Survey based on colour naming in 110 languages (Kay et al. Reference Kay, Berlin, Maffi, Merrifield and Cook2009: 25) has found that there are six universal sensations (four chromatic: red, yellow, green, blue and two achromatic: black and white) related to colour along which humans partition the colour space.
This partition follows some rules that appear to be universal, but allow for slack: languages may choose to follow a number of different partition paths. Thus, if a language has only two colour-terms, they will partition the spectrum into two chunks whose foci are black (or dark) and white (or light). They are never, say, green and yellow, or black and blue, etc. If there are three colour terms, the third will refer to red/yellow, and in cases where there are four words, the fourth will either split red into red/yellow and green/blue, or into red and yellow (green and blue being versions of black), or into red and yellow/green/blue. Languages with more colour terms also obey this kind of pattern, but the parametrical possibilities increase (Kay and McDaniel Reference Kay and McDaniel1978, Kay et al. Reference Kay, Berlin, Maffi, Merrifield and Cook2009).
Coming back to sonority, this suggests that the conversion of the phonetic signal into Son primes is partly shared by all humans, but allows for some slack that is conventionalized by each language. The work by Iris Berent supports the universal and innate character of sonority. Showing that sonority sequencing is ubiquitous in productive phonological processes, that it is supported by typological data and constrains the behaviour of speakers in psycholinguistic experiments, Berent (Reference Berent2013: 165ff) concludes that sonority sequencing is a grammatical universal since it cannot be derived from extra-grammatical factors (such as phonetics) (see also Berent et al. Reference Berent, Steriade, Lennertz and Vaknin2007). She further shows that sonority sequencing does not merely extend to lexical items that speakers have never come across: it is also active in structures that are unattested in the speaker's language, such as branching onset preferences produced by Korean speakers, whose language lacks branching onsets (Berent et al. Reference Berent, Lennertz, Jun, Moreno and Smolensky2008). Finally, as was mentioned in footnote 37, Berent et al. (Reference Berent, Dupuis and Brentari2013) adduce experimental evidence for sonority being in fact amodal, that is, a single system shared by the vocal and signed modalities whose expression is loudness etc. on the former, movement on the latter side.
5.2.5. Son primes do, Place and Lar primes do not come with a phonetic category
All representatives of SFP (see footnote 6) except those located at Concordia / Montreal hold that primes are emergent, that is, absent at birth, and that their association with phonetic categories is learned during first language acquisition (2c). The work done at Concordia rejects (2c), arguing that both primes and their association to phonetic categories are genetically coded and present at birth: there is a universal set of substance-free primes (α, β, γ) from which L1 learners choose when building their system, and which are associated to specific phonetic categories (Hale et al. Reference Hale, Kissock and Reiss2007: 647ff, Volenec and Reiss Reference Volenec and Reiss2018, Reiss and Volenec 2022).Footnote 38
The former option is shown under (10a), the latter under (10b).
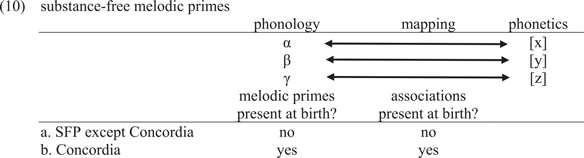
This distinction corresponds to the difference between the two types of primes discussed in the previous sections: while Place and Lar primes instantiate (10a), Son primes follow (10b).
5.3. Computation upon lexicalization
The existence of three distinct computational systems raises the question of how primes that belong to either can concur in the pronunciation of a single segment: what is the glue that holds the three sets of primes together? The answer can only be the skeleton: a segment is an item that is made of three distinct vocabulary sets which belong to the same timing unit. As is discussed in section 5.4.4 below, these timing units must be specified for consonant- and vowelhood: they therefore appear as “C” and “V” under (11) below.
The linearized string of segments thus defined is the output of the process that converts real world items (the acoustic signal) into cognitive categories (segments) upon lexicalization. The first version of this situation under (5) in section 3 is completed under (11a) with the presence of three distinct vocabulary sets (indicated by three types of symbols; see section 5.2.1): Son, Place and Lar.

In the structure under (11a), the result of lexicalization conversion are bundles of primes that are assigned to C- and V-slots; each slot together with its primes represents a segment. But the primes are unordered for the time being, since they have not yet undergone any computation in their respective module. This computation (lexicalization phonology) takes (11a) as an input and produces (11b), the object that will be stored in the lexicon (long term memory). The computation in each system is based on relevant primes and projects structure: Son primes a, b, c project structSon (i.e., syllable structure, feet etc.), Lar primes б, г, д project structLar for each segment, and Place primes α, β, γ project structPlace for each segment. What exactly the structure projected in each module looks like varies across theories, but as far as I can see all theories do warrant some organization of primes into structure (rather than having an unordered sets of primes). For example, Feature Geometry organizes primes into a feature geometric structure according to natural classes, while Dependency and Government Phonology assign head or dependent status to primes.Footnote 39
An interesting property of structSon is that it spans segments (a rhyme accommodates two or three segments, a branching onset is made of two segments, government and licensing relate different segments). By contrast, structPlace and structLar are bound by the segment.Footnote 40
5.4. Computation upon production
This section describes the workings of computation in production, that is, when a string made of lexical items is pieced together and submitted to production phonology.
5.4.1. Computational domains
In production, a computation is carried out in each module, based on the content of the lexical items (11b) that are retrieved from long-term memory, that is, the linearized string of morphemes that co-occur in a given computational domain (cycle, phase).
Upon production, computation thus takes structure (created upon lexicalization for each morpheme) as an input and returns (modified) structure. The difference between computation creating structure based on primes (lexicalization) and computation modifying existing structure (production) is reminiscent of the distinction that is made in syntax between internal Merge (creation of hierarchy based on primes) and external Merge (movement, i.e., the modification of existing structure).Footnote 41
In all cases, the domain of phonological computation is defined by the spell-out of morpho-syntactic structure which delineates specific chunks of the linear string that are called cycles or phases. It is obvious and consensual that these chunks are not defined in the phonology.Footnote 42
5.4.2. StructSon
Computation modifying structSon includes all regular syllable-based processes, stress, as well as the communication with morpho-syntax: structSon (but not structPlace or structLar) and morpho-syntax do communicate, in both directions. Before proper phonological computation can run, though, the string of morphemes over which it operates must be pieced together and linearized.
Computation of structSon caused by linearization is shown under (12a). Morphemes need to be linearized, and this process may be conditioned by phonological information pertaining to Son (infixation (6a)). But items other than morphemes also need to be linearized: there is reason to believe that the exponent of stress may be syllabic space (depending on theoretical inclinations, an x-slot, an empty CV unit, a mora, etc.: Chierchia Reference Chierchia1986, Ségéral and Scheer Reference Ségéral, Scheer, de Carvalho, Scheer and Ségéral2008b, Bucci Reference Bucci2013). This extra space thus needs to be inserted to the left or right of the tonic vowel once the location of stress (ictus) is determined. This implies a modification of the linear order present in the lexicon.
The same goes for approaches where the carrier of morpho-syntactic information in phonology is syllabic space: in Strict CV the beginning of the word (or phase) incarnates as a CV unit (the initial CV; see Lowenstamm Reference Lowenstamm1999; Scheer Reference Scheer2012a, Reference Scheer, Bendjaballah, Faust, Lahrouchi and Lampitelli2014a). Note that there are no cases on record where the exponent of morpho-syntactic information is reported to be a Place or a Lar item inserted into structPlace or structLar (such as a labial or a voicing prime at the beginning of the word; see Scheer Reference Scheer2011: Section 663).
In the reverse direction, bearing of structSon on morpho-syntactic computation is documented for the items mentioned under (12b). Again, there are no cases on record where Place, Lar, structPlace or structLar would influence morpho-syntax. That is, morpho-syntax communicates with structSon in both directions, but is completely incommunicado with Place or structPlace, Lar or structLar (Scheer Reference Scheer2012a: Section126, see footnote 27).
Finally, cases of regular phonological computation involving structSon are shown under (12c).

5.4.3. structPlace and structLar
There is also a computation concerning Place primes and structPlace, such as palatalization, vowel harmony etc.: the prime associated to palatality is absent in velar but present in palatal segments, and a palatal source may add palatality to velars (front vowel harmony in V-to-V interaction, palatalization in V-to-C interaction). There is no need for going into more detail regarding Place and Lar: relevant phenomena are well known and not any different in the present environment from what they are in regular autosegmental structure: spreading, linking and delinking of primes.
5.4.4. Timing units are specified for consonant- and vowelhood
As is obvious in general and from the preceding, Place computation is informed of whether the items computed belong to a consonant or a vowel: vowel harmony is only among vowels, and in regular palatalization the trigger is a vowel and the target, a consonant. Information about vowel- and consonanthood is absent from the Place system, though. It must therefore be present in the only other structure that Place has access to: the timing units that represent linearity.
That Place has access to consonant- and vowelhood is also shown by a fundamental insight of autosegmentalism: the same primes may produce different segments depending on whether they are associated to consonantal or vocalic slots. High vowels and corresponding glides i-j, u-w, y-ɥ are the same segmental items and distinct only through their affiliation to a consonantal or a vocalic slot (Kaye and Lowenstamm Reference Kaye and Lowenstamm1984). For instance, when an i spreads its segmental content to a vacant consonantal position, it is interpreted as j: French li-er “to link” is pronounced [li-j-e], but the j is absent from both the root (il lie [li] “he links”) and the infinitive suffix (parl-er [paʁl-e] “to talk”). The same goes for lou-er “to rent” [lu-w-e] and tu-er “to kill” [ty-ɥ-e]: in all cases the glide is a copy of the preceding vowel into a C-position. This is shown under (13) where the Element I represents the Place specification of i/j (in substance-laden guise).

The idea that timing units are specified for consonant- and vowelhood goes back to Clements and Keyser (Reference Clements and Keyser1983).
5.5. Spell-out
This section discusses the question of which unit exactly is spelled out. It is concluded that segment integrity allows for only one solution: the root node (in the sense of Feature Geometry).
5.5.1. Multiple-module spell-out
The existence of several computational systems (Son, Place and Lar) that concur in the pronunciation of a single segment raises a non-trivial challenge for the spell-out mechanism at the phonology–phonetics interface. Note that the situation is quite different from what we know from the morpho-syntax–phonology interface where the input to spell-out comes from one single system (morpho-syntax) and hence conveys one single vocabulary.
At the phonology–phonetics interface, Son, Place and Lar do not see each other and cannot communicate, but are segment-bound, that is, they must co-define the same segment. Therefore, segment integrity can only exist if the items of the three computational systems are related through a fourth player that defines the segment: the skeleton. Timing units that embody the linear structure of the string do precisely the job that is needed, that is, the definition of what does and does not belong to a segment. The difference between the upper spell-out that receives information from one single module and the lower spell-out which needs to combine inputs from three different modules is thus reflected by the presence of linearity in the latter, against its absence in the former. It is only the existence of linearity and hence the skeleton that affords the existence of a multiple-module spell-out.
It follows that the lower interface does not spell out individual primes or the set of primes defined by each one of the three computational systems, but entire segments as defined by timing units. How exactly timing units relate to segments is discussed in the following section.
5.5.2. Segment-defining root nodes are spelt out
Regular autosegmental representations allow for the association of a set of primes to multiple timing units as under (14a) where a geminate is shown. It is obvious that the primes must “know” whether they are associated to one or two timing units: this makes the difference between a short and a long item.
Let us consider the spell-out algorithm, that is, the way units are defined that are submitted to phonetic conversion. Spell-out cannot proceed timing unit by timing unit (Cs and Vs under (14)) since this would create two identical phonetic items under (14a): the association of α, β to a C would be spelt out twice, for the two Cs of the geminate. What is realized, though, is not two times the consonant in question, but the consonant with a longer duration (or with other phonetic correlates; see (19) below).Footnote 43
Spell-out cannot proceed prime by prime either, since in this case α of the geminate under (14a) will be converted into a phonetic item, followed by the conversion of β, effecting, on the phonetic side, a sequence of items. In this case the phonetics would not “know” that the representatives of α and β need to be pronounced simultaneously, rather than in sequence.
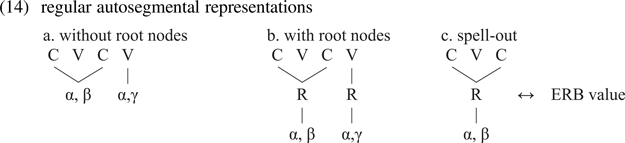
It thus appears that the representation under (14a) is not suited to identifying the geminate segment at hand, that is, “α and β associated to two consonantal timing units”: there is no single item that encompasses this set. In traditional Feature Geometry (Clements and Hume Reference Clements, Hume and Goldsmith1995), the segmental unit is defined by the root node. This option is shown under (14b) where “R” is the root node.Footnote 44 If the segment is defined by this item, spell-out may proceed root node by root node: for every root node present on the phonological side, a spell-out instruction is searched that contains all items affiliated. That is, the geminate under (14b) will be able to be spelt out by the spell-out instruction under (14c) (phonetic categories appear as ERB values; see section 5.6.2): spell-out will transmit the phonetic correlates of the primes contained in the root node (α, β), as well as the phonetic correlate (duration) corresponding to the fact that the root node is attached to two timing units (length).
This means that languages possess exactly as many spell-out instructions as there are phonemes (segments), that is, objects that are phonologically distinct. In comparison to the upper interface of morpho-syntax and phonology, the number of lexical entries whose content is inserted into the receiving module is thus very small: thousands of morphemes against 15 or 20, in very large inventories maybe 40 phonemes (segments).
5.5.3. Workings
When phonological computation (in all three modules) is completed, the result is spelled out root node by root node (i.e., segment by segment): root nodes are associated to Son, Place and Lar primes, which in turn are associated to their respective structure (see (11)). Spell-out considers only timing units and primes (Son, Place, Lar) associated to a given root node. The structure projected by primes (structSon, structPlace, structLar) is not taken into account. The restriction of spell-out to timing units and primes is motivated in section 6 below.
Spell-out matches the output of phonological computation with the phonological side of spell-out instructions, a lexicon where (language-specific and hence acquired) correspondences between phonological and phonetic categories are defined. For example, the spell-out lexicon entry under (15a) associates the Place prime α and the Son prime b, both belonging to a root node “R” and linked to a V slot, with the phonetic value “high front unrounded vowel” (or rather, the corresponding ERB value; see section 5.6.2). This assures the spell-out of the leftmost V of French li-er [lije] “to link” under (13b). By contrast, the second C under (13b) will match the spell-out entry (15b) where the same primes α (Place) and b (Son) are associated to a C position, a configuration whose phonetic correspondence is a high front unrounded glide.
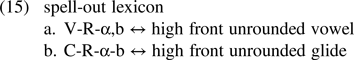
5.5.4. Spell-out mismatches
Spell-out is a list-based mapping of one vocabulary set onto another. Therefore, the relationship between the two items matched is necessarily arbitrary (2c). The overwhelming majority of mappings appears to be “natural”, that is, phonetically reasonable, though: an item that shows the phonological behaviour of a labial is also realized as a phonetic labial. The overwhelming naturalness of mappings is due to the fact that phonological categories come into being when a phonetic item or event is phonologized. At birth, phonology is thus phonetically transparent and natural, with a faithful mapping. It takes some accident in the further life of phonological processes for them to become crazy, or for phonological items to develop a non-faithful mapping (Bach and Harms Reference Bach, Harms, Stockwell and Macaulay1972, Scheer Reference Scheer, Cyran and Szpyra-Kozlowska2014b: 268ff, Chabot Reference Chabot2019). That is, processes are not born crazy and mappings are not born unfaithful – they may become crazy and unfaithful through aging. This is one aspect of the life-cycle of phonological processes (Baudoin de Courtenay Reference de Courtenay and Niecisław1895, Vennemann Reference Vennemann, Stockwell and Macaulay1972, Bermúdez-Otero Reference Bermúdez-Otero and Lacy2007, Reference Bermúdez-Otero, Honeybone and Salmons2015).
Nonetheless, nothing in the system enforces or favours faithful mappings: “naturalness” and faithfulness are imposed by workings that lie outside both phonology and spell-out (third factor in the sense of Chomsky Reference Chomsky2005; see Chabot Reference Chabot2021). Spell-out is happy to accommodate any type of mapping, faithful or arbitrary. The ability of the system to lexicalize arbitrary mappings should thus have some empirical echo: at least some phonology–phonetics mismatches should exist. The cases mentioned under (16)–(19) show that this is indeed the case for all components discussed: Son under (16), Place under (17), Lar under (18) and timing units under (19). Note that the phenomena mentioned for the sake of illustration are only a small subset of the empirical record: phonology–phonetics mismatches are pervasive cross-linguistically (Hamann Reference Hamann, Kula, Botma and Nasukawa2011, Reference Hamann2014).




5.6. Phonetics
In this section it is argued that phonology is spelt out to a language-specific phonetic system (LSP) that, following the BiPhon model, is acoustic in kind and works on a vocabulary made of ERB values. LSP is followed by articulatory universal phonetics.
5.6.1. Language-specific phonetics
There is reason to believe that phonetics falls into two distinct computations: one that is language-specific, acquired during L1 acquisition and cognitive in kind (Language-Specific Phonetics, LSP), the other being universal and located outside of the cognitive system (Universal Phonetics). While LSP is acoustic in kind and defines language-specific gradient properties that identify a specific dialect or pronunciation (e.g., t being dental, alveolar, post-alveolar etc.), Universal Phonetics is shared by all languages: it is articulatory in kind and based on coarticulation, aerodynamics and other physical / physiological properties.
Unlike phonology which manipulates discrete objects, both phonetic systems are gradient in kind. LSP thus identifies as a cognitive system which is part of the grammar that speakers acquire, and like other grammatical systems (phonology, syntax) affords well-formedness: phonetic items may be well- or ill-formed (this is expressed by articulatory constraints in BiPhon; see Boersma and Hamann Reference Boersma and Hamann2008: 227ff). Kingston (Reference Kingston, Katz and Assmann2019: 389) says that “speakers and listeners have learned a phonetic grammar along with their phonological grammar in the course of acquiring competence in their language” (emphasis in original).
Evidence for LSP comes from the fact that “speakers’ phonetic behaviour cannot be entirely predicted by the physical and physiological constraints on articulations and on the transduction of those articulations into the acoustic properties of the speech signal” (Kingston Reference Kingston, Katz and Assmann2019: 389). A classical case is vowel duration, which is variable according to the voicing of the following consonant: voiced articulations (both sonorants and voiced obstruents) provoke longer durations to their left than voiceless obstruents. This appears to be (near) universal (Chen Reference Chen1970), but the ratios of long and short vowels are quite different across languages: Cohn (Reference Cohn1998: 26) reports that while vowels before voiceless consonants are 79% of the length of vowels before voiced consonants in English, in Polish the ratio is 99%, with other languages coming in between these values. This suggests that some phonetic properties are under the control of the speaker and depend on the language they have acquired.
Relevant literature describing the properties and workings of LSP includes Keating (Reference Keating and Fromkin1985), Pierrehumbert and Beckman (Reference Pierrehumbert and Beckman1988), Cohn (Reference Cohn1998), Cho and Ladefoged (Reference Cho and Ladefoged1999), Boersma et al. (Reference Boersma, Escudero, Hayes, Sole, Recasens and Romero2003); Cho (Reference Cho, Botma, Kula and Nasukawa2011: 343-346), and Kingston (Reference Kingston, Katz and Assmann2019) provide overviews.
5.6.2. Phonetic categories
If a spell-out hands over the output of phonology to another computational system that is cognitive (and grammatical) in kind, LSP, the question arises: what does the domain-specific vocabulary look like in this system? In the BiPhon model, the auditory continuum is expressed as an auditory spectral mean along the ERB scale (Equivalent Rectangular Bandwidth) (Boersma and Hamann Reference Boersma and Hamann2008: 229).
That is, the spell-out from phonology to LSP associates a phonological and a phonetic category, for example s ↔ 20,1 ERB. This reads “s is realized with a spectral mean of 20,1 ERB” and in a substance-free environment the consonant is replaced by alphas and betas. The goal of LSP (Auditory Form in BiPhon) in production is to determine an acoustic target in form of an ERB value that is transmitted to Universal Phonetics (Articulatory Form in BiPhon). Since LSP is gradual, but a simple spell-out instruction such as s ↔ 20,1 ERB produces a discrete ERB value, the computation carried out in the LSP module creates relevant variation: given an invariable and discrete phonological s, LSP computation produces ERB values with slight variation around the input from the spell-out instruction. This is responsible for some of the phonetically variable realizations of s. Variation/gradience is thus introduced by both the variable acoustic target that LSP produces and transmits to Universal Phonetics and the undershoot/overshoot that this target is subject to in the physical implementation carried out by Universal Phonetics.
Note that the red line between the discrete and the gradual is thus crossed in LSP: the input to LSP is a discrete ERB value contained in each spell-out instruction (s ↔ 20,1 ERB etc.). The modular computation operates over this ERB value and produces a gradient output. In the BiPhon model, the generation of the gradient output is achieved by adding noise to the computation either in the guise of multiple, slightly varying ERB values for a given spell-out that undergo an OT computation (constraints such as *s ↔ 20,1 ERB, *s ↔ 20,2 ERB, *s ↔ 20,3 ERB etc., Boersma and Escudero Reference Boersma and Escudero2004, Boersma and Hamann Reference Boersma and Hamann2008: 233ff) or by having the computation done by an artificial neural network (Seinhorst et al. Reference Seinhorst, Boersma, Hamann, Calhoun, Escudero, abain and Warren2019).
5.6.3. Visibility of morpho-syntactic divisions
Since LSP is a grammar-internal computational system, like all other modules it computes specific stretches of the linear string that are defined in terms of morpho-syntactic divisions, (i.e., cycles or phases; see section 5.4.1).
The visibility of morpho-syntactic divisions for phonetic processes is a disputed issue: in a feed-forward implementation of modularity as argued for by Bermúdez-Otero and Trousdale (Reference Bermúdez-Otero, Trousdale, Nevalainen and Traugott2012), modules can only take into account information of the immediately preceding module. Since phonology intervenes between phonetics and morpho-syntax, this perspective predicts that morpho-syntactic information will never be taken into account by phonetic processes. In a diachronic perspective, on this count, it is only when phonetic processes have been phonologized that a morpho-syntactic conditioning may kick in.
In a regular modular architecture (see section 2.4.2), there is no reason to restrict the availability of morpho-syntactic divisions, though. Like all other modules, LSP necessarily applies to a given computational domain. It is unclear how a cognitive computational system could work at all in absence of a specified stretch of the linear string over which it operates: there is no computation in absence of a computational domain. Hence the chunks defined in the morpho-syntax are handed down to all subsequent computational systems until the verge of the cognitive system is reached: universal phonetics is not cognitive in kind, and hence unbound by computational domains.Footnote 48
Starting with Lehiste (Reference Lehiste1960), there is a substantial literature documenting cases where morpho-syntactic divisions are taken into account by phonetic processes. A well-studied item is l-darkening in English (Giles and Moll Reference Giles and Moll1975, Lee-Kim et al. Reference Lee-Kim, Davidson and Hwang2013, Strycharczuk and Scobbie Reference Strycharczuk and Scobbie2016, Mackenzie et al. Reference Mackenzie, Olson, Clayards and Wagner2018), but there is debate as to whether the gradient darkening overlaps with a categorical phonological process (Bermúdez-Otero and Trousdale Reference Bermúdez-Otero, Trousdale, Nevalainen and Traugott2012, Turton Reference Turton2017). If this is the case, Bermúdez-Otero and Trousdale (Reference Bermúdez-Otero, Trousdale, Nevalainen and Traugott2012), who reject the visibility of morpho-syntactic information in phonetics, can argue that l-darkening is influenced by morpho-syntactic divisions not in the phonetics, but in its phonological incarnation.Footnote 49
In order to get around this caveat, Strycharczuk and Scobbie (Reference Strycharczuk and Scobbie2016) have tested whether phonetic processes may be sensitive to morpho-syntactic divisions. They study fronting of the goose vowel [uu] (see (17) in section 5.5.4), an ongoing sound change in Southern British English that is reported to be inhibited by a following coda l as in fool. The authors have experimentally contrasted fool with intervocalic l that is (fool-ing) or is not (hula) morpheme-final. Their results show that fronting is more inhibited in the former than in the latter case, thus documenting the impact of the morphological boundary. They carefully argue that the process at hand is gradient, rather than categorical, and therefore not a case of phonologically controlled allomorphy. They conclude that “morphological boundaries may affect phenomena that are phonetically continuous and gradient, and not only clear cases of allophony” (Strycharczuk and Scobbie Reference Strycharczuk and Scobbie2016: 90).
6. Is a given alternation computational or interpretational in kind?
Approaches that provide for a spell-out operation in addition to regular phonological computation are confronted with the question whether a given modification of the lexical representation is computational (caused by phonological computation) or interpretational (due to spell-out) in kind.
Consider the trivial case of l-vocalization whereby lexical l (or ł) appears as w in coda position (for example in Brazilian Portuguese, Collischonn and Costa Reference Collischonn and Costa2003). This could be due to phonological computation (Son primes are rearranged under positional pressure), or to a spell-out instruction “l (coda) ↔ w”. On the latter count, the phonological side of the spell-out instruction not only mentions Son primes (the definition of a lateral), but also structSon, that is, the fact for the lateral to belong to a coda position.
This would mean that lenition and fortition are subjected to the arbitrariness of spell-out (2c). Thus the existence of mismatches (or crazy matches) that are typical for spell-out relations (section 5.5.4) is expected: laterals could appear as θ in coda position (l (coda) ↔ θ), or they could appear as w in strong word-initial position (anti-l vocalization: l (word-initial) ↔ w). Such mismatches do not appear to exist and, significantly, Chabot's (Reference Chabot2021) inventory of crazy rules (section 2.3) features no cases of a syllabic conditioning: i → u / d__ is reported for Southern Pomoan, but there is no case of, say, i → u in open syllables. This suggests that structSon is not used in spell-out instructions.
Thus there is reason to believe that, at least for Son, only primes are spelled out: structure is absent from spell-out. In our example, then, l-vocalization in coda position is effected by regular phonological computation of Son. Like all other segments, the result of this computation, w, undergoes spell-out and may be subject to a mismatch, say, w ↔ θ. But this will then concern all w's of the language, not just those that occur in a coda. By contrast, if spell-out instructions were sensitive to syllable structure, lexical laterals could appear as θ only in codas through a spell-out instruction “l (coda) ↔ θ”. It was mentioned that this kind of syllable-sensitive crazy rule appears to be absent from the record.
This ties in with the insight from section 2.4.1: spelling out an item is the process of assigning it a phonetic value. Items of structSon do not have any phonetic correlate, though, and therefore cannot be spelled out. Their absence from spell-out instructions is also more generally consistent with the fact that processes at and above the skeleton are not arbitrary in the empirical record (section 2.3): their computation is not arbitrary because they are based on meaningful vocabulary, (2b). In sum, Son primes may experience arbitrary distortion (through spell-out), but structSon may not: it always reaches (language-specific) phonetics faithfully.
Note, however, that illusions of arbitrary Son computation may be produced by the system. Suppose an underlying b is turned into β by Son computation and this β is then spelled out as, say, θ. This creates the impression of an arbitrary computation b > θ, but in fact involves regular computation followed by a spell-out mismatch.
7. Conclusion
The architecture discussed prompts some more general questions that are addressed below.
Phonological computation occurs twice, upon lexicalization and upon production. Syllabification, for example, runs on both occasions, the difference being the portion of the linear string that is concerned: first within the to-be-lexicalized morpheme (lexicalization), then over the plurimorphemic domain defined by morpho-syntax, that is, the cycle/phase (production).
This may be construed as an instance of the so-called Duplication Problem, a term coined by OT that describes a situation where the same labour (here syllabification) is done twice, in the lexicon and upon production. In OT, Morpheme Structure Constraints (MSC, mentioned in section 3) have motivated the principle of Richness of the Base (Prince and Smolensky Reference Prince and Smolensky2004: 191, McCarthy Reference McCarthy, Catherine Gruber, Higgins, Olson and Wysocki1998): as McCarthy (Reference McCarthy, Féry and van de Vijver2003: 29) puts it, “OT solves the Duplication Problem by denying the existence of morpheme structure constraints or other language-particular restrictions on underlying forms. OT derives all linguistically significant patterns from constraints on outputs interacting with faithfulness constraints (‘Richness of the Base’ in Prince and Smolensky Reference Prince and Smolensky2004)”. Vaux (Reference Vaux2005: 5) believes that “the duplication argument […] is the heart of the attack on MSCs and in general perhaps the most invoked OT argument against DP [Derivational Phonology]”. Morpheme Structure Constraints are restrictions on lexical representations, such as the prohibition of morpheme-initial sonorant-obstruent clusters in English, which would also be an impossible output of phonological computation upon production (the restriction is stated twice, in the lexicon and in computation). Vaux (Reference Vaux2005), Rasin and Katzir (Reference Rasin, Katzir, Bui and Özyildiz2015), Rasin (Reference Rasin2018: 93-152), argue that there is nothing wrong with this kind of redundancy because MSCs are conceptually and empirically necessary. The architecture exposed in this article is in line with this position.
Another question is why Son is related to morpho-syntax (in both directions, section 5.4.2), while Place and Lar are not: they are incommunicado with morpho-syntax in both directions (sections 4.1.3 and 5.4.2, footnote 27). There is no answer to this question other than the observation that the wiring among modules is more generally unpredictable. The McGurk effect (McGurk and MacDonald Reference McGurk and MacDonald1976) for example documents that vision influences Place: in so-called McGurk fusion, subjects who are presented with synchronized visual g (the video recording of somebody pronouncing [g]) and audio b (the audio recording of somebody pronouncing [b]), perceive d. Hence g video and b auido have combined into d, even though d is absent from the sensory input to the subject. The impact of vision is thus on Place. There is no McGurk effect reported on Son, that is, a situation where, say, visual p (an obstruent) combined with audio [a] produces the perception of m, that is, a sonorant that occurs half way on the sonority hierarchy. In the same way, synesthesia relates colours with objects or concepts in an unpredictable way: synesthetic subjects (about 4% of the population) associate this or that colour to this or that number, letter, person, concept, sound, etc. (Sagiv and Ward Reference Sagiv and Ward2006).Footnote 50
Finally, the question arises as to why Son is phonologically meaningful but Place and Lar are not. One consequence is that there must be a cross-linguistically uniform way for humans to extract Son-relevant properties from the phonetic signal, while the association of Place and Lar to phonetic categories is language-specific and emergent (section 5.2). A possible answer is that the correlate of Son, perceptual salience (loudness, energy and intensity, section 5.2.3), is used for other purposes by humans, while Place and Lar appear to do labour only in phonology. That is, salience is used to evaluate emotions, danger, relevance of noise etc., while Place and Lar distinctions do not play any role for humans outside of phonology: what would a distinction between, say, labial and velar, or voiced and voiceless, be used for outside of speech?
In an evolutionary/biolinguistic perspective, this means that humans have developed a stable means of converting salience into cognitive categories, and Son is an exaptation thereof that occurred when language emerged in the species. In evolution, an exaptation is an opportunistic adaptation of an existing device for a function that it was not designed for. That is, Son primes and their association to phonetic categories predate language in the species and are likely present in animal cognition, while this is not the case for Place and Lar. These are rather a creation ex nihilo for the specific needs created by language, that is, the expression of contrast with the anatomic devices offered by speech organs. That is, new cognitive categories representing Place and Lar needed to be created by each language individually and ex nihilo: this may be the reason why they are arbitrary (phonologically meaningless), and why their association to phonetic categories is not hard wired but rather language-specific.
