



Introduction
Just as more powerful telescopes empower astronomers, the accelerating influx of data about the political, social, and economic worlds has enabled considerable progress in understanding and ameliorating the challenges of human society. Yet, although we have more data than ever before, we may now have a smaller fraction of the data in the world than ever before because huge amounts are now locked up inside private companies, governments, political campaigns, hospitals, and other organizations, in part because of privacy concerns. In a study of corporate data sharing with academics, “Privacy and security were cited as the top concern for companies that hold personal data because of the serious risk of re-identification,” and government regulators obviously agree (FPF 2017, 11; see also King and Persily Reference King and Persily2020). If we are to do our jobs as social scientists, we have no choice but to find ways of unlocking these datasets, as well as sharing more seamlessly with other researchers. We might hope that government or society will take actions to support this mission, but we can also take responsibility ourselves and begin to develop technological solutions to these political problems.
Among all the academic fields, political science scholarship may be especially affected by the rise in the concerns over privacy because so many of the issues are inherently political. Consider an authoritarian government seeking out its opponents; a democratic government creating an enemies list; tax authorities (or an ex spouse in divorce proceedings) searching for an aspiring politician’s unreported income sources; an employer trying to weed out employees with certain political beliefs; or even political candidates searching for private information to tune advertising campaigns. The same respondents may also be hurt by political, financial, sexual, or health scams made easier by using illicitly obtained personal information to construct phishing email attacks. Political science access to data from business, governments, and other organizations may be particularly difficult to ensure because the subject we study—politics—is also the reason for our lack of access, as is clear from analyses of decades of public opinion polls, laws, and regulations (Robbin Reference Robbin2001).
We develop methods to foster an emerging change in the paradigm for sharing research information. Under the familiar data sharing regime, data providers protect the privacy of those in the data via de-identification (removing readily identifiable personal information such as names and addresses) and then simply giving a copy to trusted researchers, perhaps with a legal agreement. Yet, with the public’s increasing concerns over privacy, an increasingly hard line taking by regulators worldwide, and data holders’ (companies, governments, researchers, and others) need to respond, this regime is failing. Fueling these concerns is a new computer science subfield showing that, although de-identification surely makes it harder to learn the personal information of some research subjects, it offers no guarantee of thwarting a determined attacker (Henriksen-Bulmer and Jeary Reference Henriksen-Bulmer and Jeary2016).
For example, Sweeney (Reference Sweeney1997) demonstrates that knowing only a respondent’s gender, zip code, and birth date is sufficient to personally identify 87% of the U.S. population, and most datasets of interest to political scientists are far more informative. For another example, the U.S. Census was able to re-identify the personal answers of as many as three-quarters of Americans from publicly released and supposedly anonymous 2010 census data (Abowd Reference Abowd2018; see also https://bit.ly/privCC). Unfortunately, other privacy-protection techniques used in the social sciences—such as aggregation, legal agreements, data clean rooms, query auditing, restricted viewing, and paired programmer models—can often be broken by intentional attack (Dwork and Roth Reference Dwork and Roth2014). And not only does the venerable practice of trusting researchers to follow the rules fail spectacularly at times (like the Cambridge Analytica scandal, sparked by the behavior of a single social scientist), but it turns out that even trusting a researcher who is known to be trustworthy does not always guarantee privacy (Dwork and Ullman Reference Dwork and Ullman2018). Fast-growing recent evidence is causing many other major organizations to change policies as well (e.g., Al Aziz et al. Reference Al Aziz, Ghasemi, Waliullah and Mohammed2017; Carlini et al. Reference Carlini, Tramer, Wallace, Jagielski, Herbert-Voss, Lee and Roberts2020).
An alternative approach to the data sharing regime that may help persuade some data holders to allow academic research is the two-part data access regime. In the first part, the confidential data reside on a trusted computer server protected by best practices in cybersecurity, just as it does before sharing under the data sharing regime. The distinctive aspect of the data access regime is its second step, which treats researchers as potential “adversaries” (i.e., who may try to violate respondents’ privacy while supposedly doing their job seeking knowledge for public good) and thus adds mathematical guarantees of the privacy of research subjects. To provide these guarantees, we construct a “differentially private” algorithm that makes it possible for researchers to discover population-level insights but impossible to reliably detect the effect of the inclusion or exclusion of any one individual in the dataset or the value of any one person’s variables. Researchers are permitted to run statistical analyses on the server and receive “noisy” results computed by this privacy-preserving algorithm (but are limited by the total number of runs so they cannot repeat the same query and average away the noise).
Differential privacy is a widely accepted mathematical standard for data access systems that promises to avoid some of the zero-sum policy debates over balancing the interests of individuals with the public good that can come from research. It also seems to satisfy regulators and others. Differential privacy was introduced by Dwork et al. (Reference Dwork, McSherry, Nissim and Smith2006) and generalizes the social science technique of “randomized response” to elicit sensitive information in surveys; it does this by randomizing the answer to a question rather than the question itself (see Evans et al. Reference Evans, King, Smith and ThakurtaForthcoming). See Dwork and Roth (Reference Dwork and Roth2014) and Vadhan (Reference Vadhan2017) for overviews and Wood et al. (Reference Wood, Altman, Bembenek, Bun, Gaboardi, Honaker, Nissim, O’Brien, Steinke and Vadhan2018) for a nontechnical introduction.
A fast-growing literature has formed around differential privacy, seeking to balance privacy and utility, but the current measures of “utility” provide little utility to social scientists or other statistical analysts. Statistical inference in our field usually involves choosing a target population of interest, identifying the data generation process, and then using the resulting dataset to learn about features of the population. Valid inferences require methods with known statistical properties (such as identification, along with unbiasedness, and consistency) and honest assessments of uncertainty (e.g., standard errors). In contrast, privacy researchers typically begin with the choice of a target (confidential) dataset, add privacy-protective procedures, and then use the resulting differentially private dataset or analyses to infer to the confidential dataset—usually without regard to the data generation process or valid population inferences. This approach is useful for designing privacy algorithms but, as Wasserman (Reference Wasserman2012, 52) puts it, “I don’t know of a single statistician in the world who would analyze data this way.” Because social scientists understand not to confuse internal and external validity, they will aim to infer, not to the data they would see without privacy protections, but to the world from which the data were generated.Footnote 1
To make matters worse, although the privacy-protective procedures introduced by differential privacy work well for their intended purpose, they induce severe bias in estimating population quantities of interest to social scientists. These procedures include adding random error, which induces measurement error bias, and censoring (known as “clamping” in computer science), which when uncorrected induces selection bias (Blackwell, Honaker, and King Reference Blackwell, Honaker and King2017; Stefanski Reference Stefanski2000; Winship and Mare Reference Winship and Mare1992). We have not found a single prior study that tries to correct for both (although some avoid the effects of censoring in theory at the cost of considerable additional noise and far larger standard errors in practice; Karwa and Vadhan Reference Karwa and Vadhan2017; Smith Reference Smith2011) and few have uncertainty estimates. This is crucial because inferentially invalid data access systems can harm societies, organizations, and individuals—such as by inadvertently encouraging the distribution of misleading medical, policy, scientific, and other conclusions—even if it successfully protects individual privacy. For these reasons, using existing differentially private systems needs correction before being used in social science analysis.Footnote 2
Social scientists and others need algorithms on data access systems with both inferential validity and differential privacy. We offer one such algorithm that is approximately unbiased with sufficient prior information, has lower variance than uncorrected estimates, and comes with accurate uncertainty estimates. The algorithm also turns censoring from a problem that severely increases bias or inefficiency in statistical estimation in order to protect privacy to an attractive feature that greatly reduces the amount of noise needed to protect privacy while still leaving estimates approximately unbiased. The algorithm is easy to implement, computationally efficient even for very large datasets, and, because the entire dataset never needs to be stored in the same place, may offer additional security protections.
Our algorithm is generic, designed to minimally restrict the choice among statistical procedures, quantities of interest, data generating processes, and statistical modeling assumptions. The algorithm may therefore be especially well suited for building research data access systems. When valid inferential methods exist or are developed for more restricted use cases, they may sometimes allow less noise for the same privacy guarantee. As such, one productive plan is to first implement our algorithm and to then gradually add these more specific approaches when they become available as preferred choices.Footnote 3
We begin, in the next section, with an introduction to differential privacy and description of the inferential challenges in analyzing data from a differentially private data access system. We then give a generic differentially private algorithm which, like most such algorithms, is statistically biased. We therefore introduce bias corrections and variance estimators which, together with the private algorithm, accomplishes our goals. Technical details appear in the Supplementary Material. We illustrate the performance of our approach in finite samples via Monte Carlo simulations; we then replicate key results from two recent published articles and shows how to obtain almost the same conclusions while guaranteeing the privacy of all research subjects. The limitations of our methodology must be understood to use it appropriately, a topic we take up throughout the paper, while discussing practical advice for implementation, and in our Supplementary Material. As a companion to this paper, we offer open-source software (called UnbiasedPrivacy) to illustrate all the methods described herein.
Differential Privacy and its Inferential Challenges
We now define the differential privacy standard, describe its strengths, and highlight the challenges it poses for proper statistical inference. Throughout, we modify notation standard in computer science so that it is more familiar to social scientists.
Definitions
Begin with a confidential dataset D, defined as a collection of N rows of numerical measurements constructed so that each individual whose privacy is to be protected is represented in at most one row.Footnote 4
Statistical analysts would normally calculate a statistic s (such as a count, mean, and parameter estimate) from the data D, which we write as
 $ s(D) $
. In contrast, under differential privacy, we construct a privacy-protected version of the same statistic, called a “mechanism”
$ s(D) $
. In contrast, under differential privacy, we construct a privacy-protected version of the same statistic, called a “mechanism”
 $ M(s,D) $
, by injecting noise and censoring at some point before returning the result (so even if we treat
$ M(s,D) $
, by injecting noise and censoring at some point before returning the result (so even if we treat
 $ s(D) $
as fixed,
$ s(D) $
as fixed,
 $ M(s,D) $
is random). As we will show, the specific types of noise and censoring are specially designed to satisfy differential privacy.
$ M(s,D) $
is random). As we will show, the specific types of noise and censoring are specially designed to satisfy differential privacy.
The core idea behind the differential privacy standard is to prevent a researcher from reliably learning anything different from a dataset regardless of whether an individual has been included or excluded. To formalize this notion, consider two datasets D and
 $ {D}^{\prime } $
that differ in at most one row. Then, the standard requires that the probability (or probability density) of any analysis result m from dataset D,
$ {D}^{\prime } $
that differ in at most one row. Then, the standard requires that the probability (or probability density) of any analysis result m from dataset D,
 $ \Pr [M(s,D)=m] $
, be indistinguishable from the probability that the same result is produced by the same analysis of dataset
$ \Pr [M(s,D)=m] $
, be indistinguishable from the probability that the same result is produced by the same analysis of dataset
 $ {D}^{\prime } $
,
$ {D}^{\prime } $
,
 $ \Pr [M(s,{D}^{\prime })=m] $
, where the probabilities take D as fixed and are computed over the noise.
$ \Pr [M(s,{D}^{\prime })=m] $
, where the probabilities take D as fixed and are computed over the noise.
We write an intuitive version of the differential privacy standard (using the fact that
 $ {e}^{\epsilon}\approx 1+\epsilon $
for small
$ {e}^{\epsilon}\approx 1+\epsilon $
for small
 $ \epsilon $
) by defining “indistinguishable” as the ratio of the probabilities falling within
$ \epsilon $
) by defining “indistinguishable” as the ratio of the probabilities falling within
 $ \epsilon $
of equality (which is 1). Thus, a mechanism is said to be
$ \epsilon $
of equality (which is 1). Thus, a mechanism is said to be
 $ \epsilon $
-differentially private if
$ \epsilon $
-differentially private if
 $$ {\displaystyle \begin{array}{r}\frac{\Pr [M(s,D)=m]}{\Pr [M(s,{D}^{\prime })=m]}\in \hskip0.35em 1\pm \epsilon, \end{array}} $$
$$ {\displaystyle \begin{array}{r}\frac{\Pr [M(s,D)=m]}{\Pr [M(s,{D}^{\prime })=m]}\in \hskip0.35em 1\pm \epsilon, \end{array}} $$
where
 $ \epsilon $
is a pre-chosen level of possible privacy leakage, with smaller values potentially giving away less privacy (by requiring more noise or censoring).Footnote
5 Many variations and extensions of Equation 1 have been proposed (Desfontaines and Pejó Reference Desfontaines and Pejó2019). We use the most popular, known as “
$ \epsilon $
is a pre-chosen level of possible privacy leakage, with smaller values potentially giving away less privacy (by requiring more noise or censoring).Footnote
5 Many variations and extensions of Equation 1 have been proposed (Desfontaines and Pejó Reference Desfontaines and Pejó2019). We use the most popular, known as “
 $ (\epsilon, \delta ) $
-differential privacy” or “approximate differential privacy,” which adds a small chosen offset
$ (\epsilon, \delta ) $
-differential privacy” or “approximate differential privacy,” which adds a small chosen offset
 $ \delta $
to the numerator of the ratio in Equation 1, with
$ \delta $
to the numerator of the ratio in Equation 1, with
 $ \epsilon $
remaining the main privacy parameter. This second privacy parameter, which the user sets to a small value such that
$ \epsilon $
remaining the main privacy parameter. This second privacy parameter, which the user sets to a small value such that
 $ \delta <1/N $
, allows mechanisms with (statistically convenient) Gaussian (i.e., Normal) noise processes. This relaxation also has Bayesian interpretations, with the posterior distribution of
$ \delta <1/N $
, allows mechanisms with (statistically convenient) Gaussian (i.e., Normal) noise processes. This relaxation also has Bayesian interpretations, with the posterior distribution of
 $ M(s,D) $
close to that of
$ M(s,D) $
close to that of
 $ M(s,{D}^{\prime }) $
, and also that an
$ M(s,{D}^{\prime }) $
, and also that an
 $ (\epsilon, \delta ) $
-differentially private mechanism is
$ (\epsilon, \delta ) $
-differentially private mechanism is
 $ \epsilon $
-differentially private with probability at least
$ \epsilon $
-differentially private with probability at least
 $ 1-\delta $
(Vadhan Reference Vadhan2017, 355ff). We can also express approximate differential privacy more formally as requiring that each of the probabilities be bounded by a linear function of the other:Footnote
6
$ 1-\delta $
(Vadhan Reference Vadhan2017, 355ff). We can also express approximate differential privacy more formally as requiring that each of the probabilities be bounded by a linear function of the other:Footnote
6
 $$ \begin{array}{rl}\Pr [M(s,D)=m]\le \delta +{e}^{\epsilon}\cdot \Pr [M(s,{D}^{\prime })=m].& \end{array} $$
$$ \begin{array}{rl}\Pr [M(s,D)=m]\le \delta +{e}^{\epsilon}\cdot \Pr [M(s,{D}^{\prime })=m].& \end{array} $$
Consistent with political science research showing that secrecy is best thought of as continuous rather than dichotomous (Roberts Reference Roberts2018), the differential privacy standard quantifies privacy leakage of statistics released via a randomized mechanism through the choice of
 $ \epsilon $
(and
$ \epsilon $
(and
 $ \delta $
). Differential privacy is expressed in terms of the maximum possible privacy loss, but the expected privacy loss is considerably less than this worst case analysis, often by orders of magnitude (Carlini et al. Reference Carlini, Liu, Erlingsson, Kos and Song2019; Jayaraman and Evans Reference Jayaraman and Evans2019). It also protects small groups in the same way as individuals, with the maximum risk
$ \delta $
). Differential privacy is expressed in terms of the maximum possible privacy loss, but the expected privacy loss is considerably less than this worst case analysis, often by orders of magnitude (Carlini et al. Reference Carlini, Liu, Erlingsson, Kos and Song2019; Jayaraman and Evans Reference Jayaraman and Evans2019). It also protects small groups in the same way as individuals, with the maximum risk
 $ k\epsilon $
rising linearly in group size k.
$ k\epsilon $
rising linearly in group size k.
Example
To fix ideas, consider a confidential database of donations given by individuals to an organization bent on defeating an authoritarian leader, with the mean donation in a region as the quantity of interest:
 $ \overline{y}=\frac{1}{N}{\sum}_{i=1}^N{y}_i $
. (The mean is a simple statistic, but we will use the mean to generalize to most other commonly used statistics.) Suppose also that the region includes many poor, and one more wealthy, individual. Our goal is to enable researchers to infer the mean without any material possibility of revealing information about any individual in the region (even if not in the dataset).
$ \overline{y}=\frac{1}{N}{\sum}_{i=1}^N{y}_i $
. (The mean is a simple statistic, but we will use the mean to generalize to most other commonly used statistics.) Suppose also that the region includes many poor, and one more wealthy, individual. Our goal is to enable researchers to infer the mean without any material possibility of revealing information about any individual in the region (even if not in the dataset).
Consider three methods of privacy protection. First, aggregation to the mean alone fails as a method of privacy protection: the differential privacy standard requires that every individual is protected even in the worst-case scenario, but clearly disclosing
 $ \overline{y} $
may be enough to reveal whether the wealthy individual made a large contribution.
$ \overline{y} $
may be enough to reveal whether the wealthy individual made a large contribution.
Second, suppose instead we disclose only the sum of
 $ \overline{y} $
and noise (a draw from a mean-zero normal distribution). This mechanism is unbiased, with larger confidence intervals being the cost of privacy protection. The difficulty with this approach is that we may need to add so much noise to protect the one wealthy outlier that our confidence intervals may be too large to be useful.
$ \overline{y} $
and noise (a draw from a mean-zero normal distribution). This mechanism is unbiased, with larger confidence intervals being the cost of privacy protection. The difficulty with this approach is that we may need to add so much noise to protect the one wealthy outlier that our confidence intervals may be too large to be useful.
Finally, we describe the intuitive Gaussian mechanism that will solve the problem for this example and will aid in the development of our general purpose methodology. The idea is to first censor donations that are larger than some pre-chosen value
 $ \Lambda $
, set the censored values to
$ \Lambda $
, set the censored values to
 $ \Lambda $
, average the (partially censored) donations, and finally add noise to the average. Censoring has the advantage of requiring less noise to protect individual outliers, but has the disadvantage of inducing statistical bias. (We show how to correct this bias in a subsequent section, turning censoring into an attractive tool enabling both privacy and utility.)
$ \Lambda $
, average the (partially censored) donations, and finally add noise to the average. Censoring has the advantage of requiring less noise to protect individual outliers, but has the disadvantage of inducing statistical bias. (We show how to correct this bias in a subsequent section, turning censoring into an attractive tool enabling both privacy and utility.)
The bound on privacy loss can be entirely quantified via the noise variance,
 $ {S}^2 $
, even though privacy protection comes from both censoring and random noise. This is because, if we choose to censor less by setting
$ {S}^2 $
, even though privacy protection comes from both censoring and random noise. This is because, if we choose to censor less by setting
 $ \Lambda $
to be high, then we must add more random noise. To set the noise variance, we consider the values of
$ \Lambda $
to be high, then we must add more random noise. To set the noise variance, we consider the values of
 $ \epsilon $
and
$ \epsilon $
and
 $ \delta $
that would be satisfied in Equation 2. Since we are converting one number,
$ \delta $
that would be satisfied in Equation 2. Since we are converting one number,
 $ {S}^2 $
, into two, there are many such
$ {S}^2 $
, into two, there are many such
 $ (\epsilon, \delta ) $
pairs. (A related notion of differential privacy, known as zero-concentrated differential privacy, captures the privacy loss of the Gaussian mechanism in a single parameter denoted by
$ (\epsilon, \delta ) $
pairs. (A related notion of differential privacy, known as zero-concentrated differential privacy, captures the privacy loss of the Gaussian mechanism in a single parameter denoted by
 $ \rho \hskip-0.15em $
, but requires a more complicated definition of differential privacy [Bun and Steinke Reference Bun and Steinke2016]. Some applications of differential privacy report the privacy loss in terms of
$ \rho \hskip-0.15em $
, but requires a more complicated definition of differential privacy [Bun and Steinke Reference Bun and Steinke2016]. Some applications of differential privacy report the privacy loss in terms of
 $ \rho $
, rather than
$ \rho $
, rather than
 $ \epsilon $
and
$ \epsilon $
and
 $ \delta $
, and a simple formula can be used to convert between the two.)
$ \delta $
, and a simple formula can be used to convert between the two.)
To guide intuition about how the noise variance must change to satisfy a particular
 $ \epsilon $
privacy level at a fixed
$ \epsilon $
privacy level at a fixed
 $ \delta $
, it is useful to write
$ \delta $
, it is useful to write
 $$ {\displaystyle \begin{array}{r}S(\Lambda, \epsilon, N;\delta )\hskip0.35em \propto \hskip0.35em \frac{\Lambda}{N\epsilon }.\end{array}} $$
$$ {\displaystyle \begin{array}{r}S(\Lambda, \epsilon, N;\delta )\hskip0.35em \propto \hskip0.35em \frac{\Lambda}{N\epsilon }.\end{array}} $$
Thus, Equation 3 shows that ensuring differential privacy allows us to add less noise if (1) each person is submerged in a sea of many others (larger N), (2) less privacy is required (we choose a larger
 $ \epsilon $
), or (3) more censoring is used (we choose a smaller
$ \epsilon $
), or (3) more censoring is used (we choose a smaller
 $ \Lambda $
).
$ \Lambda $
).
With censoring,
 $ \widehat{\theta} $
is a biased estimate of
$ \widehat{\theta} $
is a biased estimate of
 $ \overline{y} $
:
$ \overline{y} $
:
 $ E(\widehat{\theta})\ne \overline{y} $
. To reduce censoring bias, we can choose larger values of
$ E(\widehat{\theta})\ne \overline{y} $
. To reduce censoring bias, we can choose larger values of
 $ \Lambda $
, but that unfortunately increases the noise, statistical variance, and uncertainty; however, reducing noise by choosing a smaller value of
$ \Lambda $
, but that unfortunately increases the noise, statistical variance, and uncertainty; however, reducing noise by choosing a smaller value of
 $ \Lambda $
increases censoring and thus bias. We resolve this tension in our section on ensuring valid inference.
$ \Lambda $
increases censoring and thus bias. We resolve this tension in our section on ensuring valid inference.
Inferential Challenges
We now discuss four issues differential privacy poses for statistical inference. For some, we offer corrections; for others, we suggest how to adjust statistical analysis practices.
First, censoring induces selection bias. Avoiding censoring by setting
 $ \Lambda $
large enough adds more noise but is unsatisfactory because any amount of noise induces bias in estimates of all but the simplest quantities of interest. Moreover, even for unbiased estimators (like the uncensored mean above), the added noise makes unadjusted standard errors statistically inconsistent. Ignoring either measurement error bias or selection bias is a major inferential mistake as it may change substantive conclusions, estimator properties, or the validity of uncertainty estimates, often in negative, unknown, or surprising ways.Footnote
7
$ \Lambda $
large enough adds more noise but is unsatisfactory because any amount of noise induces bias in estimates of all but the simplest quantities of interest. Moreover, even for unbiased estimators (like the uncensored mean above), the added noise makes unadjusted standard errors statistically inconsistent. Ignoring either measurement error bias or selection bias is a major inferential mistake as it may change substantive conclusions, estimator properties, or the validity of uncertainty estimates, often in negative, unknown, or surprising ways.Footnote
7
Second, it would be sufficient for a proper scientific statements to have (1) an estimator
 $ \widehat{\theta} $
with known statistical properties (such as unbiasedness, consistency, and efficiency) and (2) accurate uncertainty estimates. Unfortunately, as Appendix B of the Supplementary Material demonstrates, accurate uncertainty estimates cannot be constructed by using differentially private versions of classical uncertainty estimates, meaning we must develop new approaches.
$ \widehat{\theta} $
with known statistical properties (such as unbiasedness, consistency, and efficiency) and (2) accurate uncertainty estimates. Unfortunately, as Appendix B of the Supplementary Material demonstrates, accurate uncertainty estimates cannot be constructed by using differentially private versions of classical uncertainty estimates, meaning we must develop new approaches.
Third, to avoid researchers rerunning the same analysis many times and averaging away the noise, their analyses must be limited. This limitation is formalized via a differential privacy property known as composition: if mechanism k is (
 $ {\epsilon}_k,{\delta}_k $
)-differentially private, for
$ {\epsilon}_k,{\delta}_k $
)-differentially private, for
 $ k=1,\dots, K $
, then disclosing all K estimates is (
$ k=1,\dots, K $
, then disclosing all K estimates is (
 $ {\sum}_{k=1}^K{\epsilon}_k,{\sum}_{k=1}^K{\delta}_k $
)-differentially private.Footnote
8 The composition property enables the data provider to enforce a privacy budget by allocating a total value of
$ {\sum}_{k=1}^K{\epsilon}_k,{\sum}_{k=1}^K{\delta}_k $
)-differentially private.Footnote
8 The composition property enables the data provider to enforce a privacy budget by allocating a total value of
 $ \epsilon $
to a researcher who can then divide it up and run as many analyses, of whatever type, as they choose, so long as the sum of all the
$ \epsilon $
to a researcher who can then divide it up and run as many analyses, of whatever type, as they choose, so long as the sum of all the
 $ \epsilon $
s across all their analyses does not exceed their total privacy budget.
$ \epsilon $
s across all their analyses does not exceed their total privacy budget.
Enabling the researcher to decide how to allocate a privacy budget enables scarce information to be better directed to scholarly goals than a central authority such as the data provider. However, when the total privacy budget is used up, no researcher can run new analyses unless the data provider chooses to increase the budget. This constraint is useful to protect privacy but utterly changes the nature of statistical analysis. To see this, note that best practice recommendations have long included trying to avoid being fooled by the data—by running every possible diagnostic and statistical check, fully exploring the dataset—and by the researcher’s personal biases—such as by preregistration to constrain the number of analyses run to eliminate “p-hacking” or correcting for “multiple comparisons” ex post (Monogan Reference Monogan2015). One obviously needs to avoid being fooled in any way, and so researchers normally try to balance the resulting contradictory advice. In contrast, differential privacy tips the scales: remarkably, it makes solving the second problem almost automatic (Dwork et al. Reference Dwork, Feldman, Hardt, Pitassi, Rein-gold and Roth2015), but it also reduces the probability of serendipitous discovery and increases the odds of being fooled by unanticipated data problems. Successful data analysis with differential privacy thus requires careful planning, although less stringently than with pre-registration. In a sense, differential privacy turns the best practices for analyzing a private observational dataset (which might otherwise be inaccessible) into something closer to the best practices for designing a single, expensive field experiment.
In order to ensure researchers can follow the replication standard (King Reference King1995), and to preserve their privacy budget, we recommend that differentially private systems cache results so that rerunning the same analysis adds the identical noise every time and reproduces the identical estimate and standard errors. (Researchers could of course choose to rerun the same analysis with a fresh draw of noise to reduce standard errors at the cost of spending more from their privacy budget.) In addition, authors of politically sensitive studies now often omit information from replication datasets entirely which, instead, could be made available in differentially private ways.
Finally, learning about population quantities of interest is not an individual-level privacy violation (e.g., https://bit.ly/Noviol). A researcher can even learn about an individual from a differentially private mechanism, but no more than if that individual were excluded from the dataset. For example, suppose research indicates that women are more likely to share fake news with friends on social media than men; then, if you are a woman, everyone knows you have a higher risk of sharing fake news. But the researcher would have learned this social science generalization whether or not you were included in the dataset and you have no privacy-related reason to withhold your information.
A key point, however, is that we ensure a chosen differentially private mechanism is inferentially valid or else we will draw the wrong conclusions about social science generalizations. In particular, if researchers use privacy-preserving mechanisms without bias corrections, social scientists and ultimately society can be misled. (In fact, it is older people, not women, who are more likely to share fake news! See Guess, Nagler, and Tucker [Reference Guess, Nagler and Tucker2019].) Fortunately, all of differential privacy’s properties are preserved under post-processing, so no privacy loss will occur when, below, we correct for inferential biases (or if results are published or mixed with any other data sources). In particular, for any data analytic function f not involving private data D, if
 $ M(s,D) $
is differentially private, then
$ M(s,D) $
is differentially private, then
 $ f[M(s,D)] $
is differentially private, regardless of assumptions about potential adversaries or threat models.
$ f[M(s,D)] $
is differentially private, regardless of assumptions about potential adversaries or threat models.
Although differential privacy may seem to follow a “do no more harm” principle, careless use of it can harm individuals and society if we do not also provide inferential validity. The biases from ignoring measurement error and selection can each separately or together reverse, attenuate, exaggerate, or nullify statistical results. Helpful public policies could be discarded. Harmful practices may be promoted. Of course, when providing access to confidential data, not using differential privacy may also have grave costs to individuals. Data providers must therefore ensure that data access systems are both differentially private and inferentially valid.
A Differentially Private Generic Estimator
We now introduce an approximately unbiased approach which, like our software, we call UnbiasedPrivacy (or UP); it has two parts: (1) a differentially private mechanism introduced in this section and (2) a bias correction of the differentially private result, using the algorithm in the next section, along with accurate uncertainty estimates in the form of standard errors. Our work builds on the algorithm in Smith (Reference Smith2011), but results in an estimator with a root-mean-square error that, in simulations, is hundreds of times smaller (see Appendix C of the Supplementary Material).
Let
 $ \mathbf{D} $
denote a population data matrix, from which N observations are selected to form our observed data matrix D. Our goal is to estimate some (fixed scalar) quantity of interest,
$ \mathbf{D} $
denote a population data matrix, from which N observations are selected to form our observed data matrix D. Our goal is to estimate some (fixed scalar) quantity of interest,
 $ \theta =s(\mathbf{D}) $
with the researcher’s choice of statistical procedure s. The statistical procedure
$ \theta =s(\mathbf{D}) $
with the researcher’s choice of statistical procedure s. The statistical procedure
 $ s(\cdot ) $
refers to the results of running a chosen statistical methodology from among the many statistical methods in widespread use in political science—based on maximum likelihood, Bayesian, nonparametric approaches, or others—and finally computing a quantity of interest computed from them—such as a prediction, probability, first difference, and forecast. Multiple quantities of interest can be estimated by repeating the algorithm (dividing
$ s(\cdot ) $
refers to the results of running a chosen statistical methodology from among the many statistical methods in widespread use in political science—based on maximum likelihood, Bayesian, nonparametric approaches, or others—and finally computing a quantity of interest computed from them—such as a prediction, probability, first difference, and forecast. Multiple quantities of interest can be estimated by repeating the algorithm (dividing
 $ \epsilon $
among the runs).
$ \epsilon $
among the runs).
Our procedure is “generic,” by which we mean that researchers may choose among a wide variety of methods, including most now in use across the social sciences, but of course there are constraints. For example, the data must be arranged so that each research subject whose privacy we wish to protect contributes information to only one row of D (see Footnote 4) and, technically, we must select from among the many methods that are statistically valid under bootstrapping.Footnote 9
Let
 $ \widehat{\theta}=s(D) $
denote an estimate of
$ \widehat{\theta}=s(D) $
denote an estimate of
 $ \theta $
using statistical estimator
$ \theta $
using statistical estimator
 $ s(\cdot ) $
, which we would use if we could see the private data; also denote a differentially private estimate of
$ s(\cdot ) $
, which we would use if we could see the private data; also denote a differentially private estimate of
 $ \theta $
by
$ \theta $
by
 $ {\widehat{\theta}}^{\mathrm{dp}} $
. To compute
$ {\widehat{\theta}}^{\mathrm{dp}} $
. To compute
 $ {\widehat{\theta}}^{\mathrm{dp}} $
, the researcher chooses a statistical method, a quantity of interest estimated from the statistical method (causal effect, risk difference, predicted value, etc.), and values for each of the privacy parameters (
$ {\widehat{\theta}}^{\mathrm{dp}} $
, the researcher chooses a statistical method, a quantity of interest estimated from the statistical method (causal effect, risk difference, predicted value, etc.), and values for each of the privacy parameters (
 $ \Lambda $
,
$ \Lambda $
,
 $ \epsilon $
, and
$ \epsilon $
, and
 $ \delta $
; we discuss how to make these choices in practice below).
$ \delta $
; we discuss how to make these choices in practice below).
Below, we give the details of our proposed mechanism
 $ M(s,D)={\widehat{\theta}}^{\mathrm{dp}} $
followed by the privacy and then inferential properties of this strategy.
$ M(s,D)={\widehat{\theta}}^{\mathrm{dp}} $
followed by the privacy and then inferential properties of this strategy.
Mechanism
We give here a generic differentially private estimator based on a simple version of the Gaussian mechanism (described above) applied to estimates from subsets of the data rather than to individual observations. To be more specific, the algorithm uses a partitioning version of the “sample and aggregate” algorithm (Nissim, Raskhodnikova, and Smith Reference Nissim, Raskhodnikova and Smith2007), to ensure the differential privacy standard will apply for almost any statistical method and quantity of interest. We also incorporate an optional application of the computationally efficient “bag of little bootstraps” algorithm (Kleiner et al. Reference Kleiner, Talwalkar, Sarkar and Jordan2014) to ensure an aspect of inferential validity generically, by not having to worry about differences in how to scale up different statistics from each partition to the entire dataset.
Figure 1 gives a visual representation of the algorithm we now detail. We first randomly sort observations from D into P separate partitions
 $ \{{D}_1,\dots, {D}_P\} $
, each of size
$ \{{D}_1,\dots, {D}_P\} $
, each of size
 $ n\approx N/P $
(we discuss the choice of P below), and then follow this algorithm.
$ n\approx N/P $
(we discuss the choice of P below), and then follow this algorithm.

Figure 1. Differentially Private Algorithm (Before Bias Correction)
-
1. From the data in partition p (
 $ p=1,\dots, P $
):
$ p=1,\dots, P $
):-
(a) Compute an estimate
$ {\widehat{\theta}}^p $
(using the same method as we would apply to the full private data, and scaling up to the full dataset, or via the general purpose bag of little bootstrap algorithm; see Appendix D of the Supplementary Material). -
(b) Censor the estimate
$ {\widehat{\theta}}^p $
as
$ c({\widehat{\theta}}^p,\Lambda ) $
.
-
-
2. Compute
$ {\widehat{\theta}}^{\mathrm{dp}} $
by averaging the censored estimates (over partitions instead of observations) and adding mean-zero noise: (4)where
$$ \begin{array}{rl}{\widehat{\theta}}^{\mathrm{dp}}=\widehat{\theta}+e,& \end{array} $$
(5)where S is explained intuitively here and formally in Appendix A of the Supplementary Material.
$$ {\displaystyle \begin{array}{r}\hat{\theta}=\frac{1}{P}\sum_{p=1}^Pc({\hat{\theta}}^p,\Lambda ),\hskip1.5em e\sim \mathcal{N}(0,{S}_{\hat{\theta}}^2),\hskip1.5em {S}_{\hat{\theta}}=S(\Lambda, \epsilon, \delta, P),\end{array}} $$







Privacy Properties
Privacy is ensured in this algorithm by each individual appearing in at most one partition, and by the censoring and noise in the aggregation mechanism ensuring that data from any one individual can have no meaningful effect on the distribution of possible outputs. Each partition can even be sequestered on a separate server, which may reduce security risks.
The advantage of always using the censored mean of estimates across partitions, regardless of the statistical method used within each partition, is that the variance of the noise can be calibrated generically to the sensitivity of this mean rather than having to derive the sensitivity anew for each estimator. The cost of this strategy is additional noise because P rather than N appears in the denominator of the variance. Thus, from the perspective of reducing noise, we should set P as large as possible, subject to the constraints that (1) the number of units in each partition
 $ n\approx N/P $
gives valid statistical results in each bootstrap and the estimate being sensible (such as regression covariates being of full rank) and (2) n is large enough and growing faster than P (to ensure the applicability of the central limit theorem or, for a precise rate of convergence, the Berry–Esseen theorem). See also our simulations below. Subsampling itself increases the variance of nonlinear estimators, but usually much less than the increased variance due to privacy-protective procedures; see Mohan et al. (Reference Mohan, Thakurta, Shi, Song and Culler2012) for methods of optimizing P.
$ n\approx N/P $
gives valid statistical results in each bootstrap and the estimate being sensible (such as regression covariates being of full rank) and (2) n is large enough and growing faster than P (to ensure the applicability of the central limit theorem or, for a precise rate of convergence, the Berry–Esseen theorem). See also our simulations below. Subsampling itself increases the variance of nonlinear estimators, but usually much less than the increased variance due to privacy-protective procedures; see Mohan et al. (Reference Mohan, Thakurta, Shi, Song and Culler2012) for methods of optimizing P.
Inferential Properties
To study the statistical properties of our point estimator and its uncertainty estimates, consider two conditions: (1) an assumption we maintain until the next section that
 $ \Lambda $
is large enough so that censoring has no effect (
$ \Lambda $
is large enough so that censoring has no effect (
 $ c({\widehat{\theta}}^p,\Lambda )={\widehat{\theta}}^p $
) and (2) a method that is unbiased when applied to the private data.
$ c({\widehat{\theta}}^p,\Lambda )={\widehat{\theta}}^p $
) and (2) a method that is unbiased when applied to the private data.
If these two conditions hold, our point estimates are unbiased:
 $$ {\displaystyle \begin{array}{r}E({\hat{\theta}}^{\mathrm{dp}})=\frac{1}{P}\sum_{p=1}^PE({\hat{\theta}}^p)+E(e)=\theta .\end{array}} $$
$$ {\displaystyle \begin{array}{r}E({\hat{\theta}}^{\mathrm{dp}})=\frac{1}{P}\sum_{p=1}^PE({\hat{\theta}}^p)+E(e)=\theta .\end{array}} $$
In practice, however, choosing the bounding parameter
 $ \Lambda $
involves a bias-variance trade-off: if
$ \Lambda $
involves a bias-variance trade-off: if
 $ \Lambda $
is set large enough, censoring has no effect and
$ \Lambda $
is set large enough, censoring has no effect and
 $ {\widehat{\theta}}^{\mathrm{dp}} $
is unbiased, but the noise and resulting uncertainty estimates will be large (see Equation 5). Alternatively, choosing a smaller value of
$ {\widehat{\theta}}^{\mathrm{dp}} $
is unbiased, but the noise and resulting uncertainty estimates will be large (see Equation 5). Alternatively, choosing a smaller value of
 $ \Lambda $
will reduce noise and the resulting uncertainty estimates, but it increases censoring and bias. Of course, if the chosen estimator is biased when applied to the private data, perhaps due to violating statistical assumptions or merely being a nonlinear function of the data like logit or an event count model, then our algorithm will not magically remove the bias, but it will not add bias.
$ \Lambda $
will reduce noise and the resulting uncertainty estimates, but it increases censoring and bias. Of course, if the chosen estimator is biased when applied to the private data, perhaps due to violating statistical assumptions or merely being a nonlinear function of the data like logit or an event count model, then our algorithm will not magically remove the bias, but it will not add bias.
Uncertainty estimators, in contrast, require adjustment even if both conditions are met. For example, the variance of the differentially private estimator is
 $ V({\widehat{\theta}}^{\mathrm{dp}})=V(\widehat{\theta})+{S}_{\widehat{\theta}}^2 $
, but its naive variance estimator (the differentially private version of an unbiased nonprivate variance estimator) is biased:
$ V({\widehat{\theta}}^{\mathrm{dp}})=V(\widehat{\theta})+{S}_{\widehat{\theta}}^2 $
, but its naive variance estimator (the differentially private version of an unbiased nonprivate variance estimator) is biased:
 $$ {\displaystyle \begin{array}{c}E\left[\widehat{V}({\widehat{\theta}}^{\mathrm{dp}})\right]=E\left[\widehat{V}(\widehat{\theta})+e\right]=V(\widehat{\theta})+E(e)\\ {}\hskip-0.5em =V(\widehat{\theta})\ne V({\widehat{\theta}}^{\mathrm{dp}}).\end{array}} $$
$$ {\displaystyle \begin{array}{c}E\left[\widehat{V}({\widehat{\theta}}^{\mathrm{dp}})\right]=E\left[\widehat{V}(\widehat{\theta})+e\right]=V(\widehat{\theta})+E(e)\\ {}\hskip-0.5em =V(\widehat{\theta})\ne V({\widehat{\theta}}^{\mathrm{dp}}).\end{array}} $$
Fortunately, we can compute an unbiased estimate of the variance of the differentially private estimator by simply adding back in the (known) variance of the noise:
 $ \widehat{V}({\widehat{\theta}}^{\mathrm{dp}})=\widehat{V}(\widehat{\theta})+{S}_{\widehat{\theta}}^2 $
, which is unbiased:
$ \widehat{V}({\widehat{\theta}}^{\mathrm{dp}})=\widehat{V}(\widehat{\theta})+{S}_{\widehat{\theta}}^2 $
, which is unbiased:
 $ E\left[\widehat{V}({\widehat{\theta}}^{\mathrm{dp}})\right]=V({\widehat{\theta}}^{\mathrm{dp}}) $
. Of course, because censoring will bias our estimates, we must bias correct and then compute the variance of the corrected estimate, which will ordinarily require a more complicated expression.
$ E\left[\widehat{V}({\widehat{\theta}}^{\mathrm{dp}})\right]=V({\widehat{\theta}}^{\mathrm{dp}}) $
. Of course, because censoring will bias our estimates, we must bias correct and then compute the variance of the corrected estimate, which will ordinarily require a more complicated expression.
Ensuring Valid Statistical Inference
We now correct our differentially private estimator for the bias due to censoring, which has the effect of reducing the impact of the choice of
 $ \Lambda $
. The correction thus allows users to choose smaller values of
$ \Lambda $
. The correction thus allows users to choose smaller values of
 $ \Lambda $
, and consequentially reduce the variance and use less of the privacy budget (see also our section on practical suggestions below). Because we introduce the correction by post-processing, we retain the same privacy-preserving properties. It even turns out that the variance of this bias-corrected estimate is actually smaller than the uncorrected estimate, which is unusual for bias corrections. We know of no prior attempt to correct for biases due to censoring in any differentially private mechanism.
$ \Lambda $
, and consequentially reduce the variance and use less of the privacy budget (see also our section on practical suggestions below). Because we introduce the correction by post-processing, we retain the same privacy-preserving properties. It even turns out that the variance of this bias-corrected estimate is actually smaller than the uncorrected estimate, which is unusual for bias corrections. We know of no prior attempt to correct for biases due to censoring in any differentially private mechanism.
We now describe our bias-corrected point estimator,
 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
, and variance estimate,
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
, and variance estimate,
 $ \widehat{V}({\overset{\sim }{\theta}}^{\mathrm{dp}}) $
.
$ \widehat{V}({\overset{\sim }{\theta}}^{\mathrm{dp}}) $
.
Bias Correction
Our goal here is to correct the bias due to censoring in our estimate of
 $ \theta $
. Figure 2 helps visualize the underlying distributions and notation we will introduce, with the original uncensored distribution in blue and the censored distribution in orange, which is made up of an unnormalized truncated distribution and the spikes (which replace the area in the tails) at
$ \theta $
. Figure 2 helps visualize the underlying distributions and notation we will introduce, with the original uncensored distribution in blue and the censored distribution in orange, which is made up of an unnormalized truncated distribution and the spikes (which replace the area in the tails) at
 $ -\Lambda $
and
$ -\Lambda $
and
 $ \Lambda $
. Although
$ \Lambda $
. Although
 $ \Lambda $
and
$ \Lambda $
and
 $ -\Lambda $
are of course symmetric around zero, the uncensored distribution is centered at
$ -\Lambda $
are of course symmetric around zero, the uncensored distribution is centered at
 $ \theta $
.
$ \theta $
.

Figure 2. Underlying Distributions (Before Estimation). The censored distribution includes the orange area and spikes at
 $ -\Lambda $
and
$ -\Lambda $
and
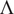 $ \Lambda $
$ \Lambda $
Our strategy is to approximate the distribution of
 $ {\widehat{\theta}}^p $
by a normal distribution, which is correct asymptotically for most commonly used statistical methods in political science. Thus, the distribution of
$ {\widehat{\theta}}^p $
by a normal distribution, which is correct asymptotically for most commonly used statistical methods in political science. Thus, the distribution of
 $ {\widehat{\theta}}^p $
across partitions, before censoring at
$ {\widehat{\theta}}^p $
across partitions, before censoring at
 $ [-\Lambda, \Lambda ] $
, is approximately
$ [-\Lambda, \Lambda ] $
, is approximately
 $ \mathcal{N}(\theta, {\sigma}^2/n) $
, where
$ \mathcal{N}(\theta, {\sigma}^2/n) $
, where
 $ n=N/P $
.
$ n=N/P $
.
The proportion left and right censored, respectively (the area under distribution’s tails) is therefore approximated by
 $$ \begin{array}{rl}{\alpha}_1={\displaystyle \int_{-\infty}^{-\Lambda}}\mathcal{N}(t \mid \theta, {\sigma}^2/n)dt,\hskip2em {\alpha}_2={\displaystyle \int_{\Lambda}^{\infty }}\mathcal{N}(t \mid \theta, {\sigma}^2/n)dt.& \end{array} $$
$$ \begin{array}{rl}{\alpha}_1={\displaystyle \int_{-\infty}^{-\Lambda}}\mathcal{N}(t \mid \theta, {\sigma}^2/n)dt,\hskip2em {\alpha}_2={\displaystyle \int_{\Lambda}^{\infty }}\mathcal{N}(t \mid \theta, {\sigma}^2/n)dt.& \end{array} $$
Under technical regularity conditions (see Appendix E of the Supplementary Material for a proof), we can bound the error on the terms such that
 $ \Pr ({\widehat{\theta}}_n^p<-\Lambda )={\alpha}_1\pm O(1/\sqrt{n}) $
and
$ \Pr ({\widehat{\theta}}_n^p<-\Lambda )={\alpha}_1\pm O(1/\sqrt{n}) $
and
 $ \Pr ({\widehat{\theta}}_n^p>\Lambda )={\alpha}_2\pm O(1/\sqrt{n}) $
. This means that the difference between the true proportion censored and our approximation of it,
$ \Pr ({\widehat{\theta}}_n^p>\Lambda )={\alpha}_2\pm O(1/\sqrt{n}) $
. This means that the difference between the true proportion censored and our approximation of it,
 $ {\alpha}_1+{\alpha}_2 $
, is decreasing proportional to
$ {\alpha}_1+{\alpha}_2 $
, is decreasing proportional to
 $ 1/\sqrt{n} $
, which is typically very small. We thus ignore this (generally negligible) error when constructing our estimator.
$ 1/\sqrt{n} $
, which is typically very small. We thus ignore this (generally negligible) error when constructing our estimator.
We then write the expected value of
 $ {\widehat{\theta}}^{\mathrm{dp}} $
as the weighted average of the mean of the truncated normal, the spikes at
$ {\widehat{\theta}}^{\mathrm{dp}} $
as the weighted average of the mean of the truncated normal, the spikes at
 $ -\Lambda $
and
$ -\Lambda $
and
 $ \Lambda $
, and the term we ignore:
$ \Lambda $
, and the term we ignore:
 $$ \begin{array}{rl}E\left({\widehat{\theta}}_n^{\mathrm{dp}}\right)=-{\alpha}_1\Lambda +(1-{\alpha}_2-{\alpha}_1){\theta}_T+{\alpha}_2\Lambda \pm O(1/\sqrt{n}),& \end{array} $$
$$ \begin{array}{rl}E\left({\widehat{\theta}}_n^{\mathrm{dp}}\right)=-{\alpha}_1\Lambda +(1-{\alpha}_2-{\alpha}_1){\theta}_T+{\alpha}_2\Lambda \pm O(1/\sqrt{n}),& \end{array} $$
with truncated normal mean
 $$ \begin{array}{rll}{\theta}_T=\theta +\sigma /\sqrt{n}\cdot \left(\frac{\mathcal{N}(-\Lambda \mid \theta, {\sigma}^2/n)-\mathcal{N}(\Lambda \mid \theta, {\sigma}^2/n)}{1-{\alpha}_2-{\alpha}_1}\right).& & \end{array} $$
$$ \begin{array}{rll}{\theta}_T=\theta +\sigma /\sqrt{n}\cdot \left(\frac{\mathcal{N}(-\Lambda \mid \theta, {\sigma}^2/n)-\mathcal{N}(\Lambda \mid \theta, {\sigma}^2/n)}{1-{\alpha}_2-{\alpha}_1}\right).& & \end{array} $$
We then construct a plug-in estimator by substituting our point estimate
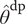 $ {\widehat{\theta}}^{\mathrm{dp}} $
for the expected value at the left of Equation 9. We are left with three equations (Equation 9 and the two in Equation 8) and four unknowns (
$ {\widehat{\theta}}^{\mathrm{dp}} $
for the expected value at the left of Equation 9. We are left with three equations (Equation 9 and the two in Equation 8) and four unknowns (
 $ \theta $
,
$ \theta $
,
 $ \sigma $
,
$ \sigma $
,
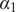 $ {\alpha}_1 $
, and
$ {\alpha}_1 $
, and
 $ {\alpha}_2 $
). We therefore use some of the privacy budget to obtain an estimate of
$ {\alpha}_2 $
). We therefore use some of the privacy budget to obtain an estimate of
 $ {\alpha}_2 $
(or
$ {\alpha}_2 $
(or
 $ {\alpha}_1 $
) as
$ {\alpha}_1 $
) as
 $ {\widehat{\alpha}}_2=\frac{1}{P}{\sum}_p1({\widehat{\theta}}^p>\Lambda ) $
, which we release via the Gaussian mechanism.Footnote
10 How to use the privacy budget is up to the user, but we find that splitting the expenditure equally between the original quantity of interest and this parameter works well.
$ {\widehat{\alpha}}_2=\frac{1}{P}{\sum}_p1({\widehat{\theta}}^p>\Lambda ) $
, which we release via the Gaussian mechanism.Footnote
10 How to use the privacy budget is up to the user, but we find that splitting the expenditure equally between the original quantity of interest and this parameter works well.
With the same three equations, and our remaining three unknowns (
 $ \theta $
,
$ \theta $
,
 $ \sigma $
, and
$ \sigma $
, and
 $ {\alpha}_1 $
), our open-source software gives a fast numerical solution. The result is
$ {\alpha}_1 $
), our open-source software gives a fast numerical solution. The result is
 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
, the approximately unbiased estimate of
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
, the approximately unbiased estimate of
 $ \theta $
(and estimates of
$ \theta $
(and estimates of
 $ {\widehat{\sigma}}_{\mathrm{dp}} $
and
$ {\widehat{\sigma}}_{\mathrm{dp}} $
and
 $ {\widehat{\alpha}}_1^{\mathrm{dp}} $
). See Appendix F of the Supplementary Material.
$ {\widehat{\alpha}}_1^{\mathrm{dp}} $
). See Appendix F of the Supplementary Material.
We use the term “approximate unbiasedness” to mean unbiasedness with respect to the private estimator (which itself may not be unbiased), rather than the true parameter. This unbiasedness is approximate for two reasons. First, most plug-in estimators, including ours, are guaranteed to be strictly unbiased only asymptotically. Second, as discussed, our estimating equations have a small error from approximating the partition distribution as normal. And finally, our simulations below show that in finite samples the bias introduced from these two sources is negligible in practice, and considerably smaller than the bias introduced by censoring.
Variance Estimation
We now derive a procedure for computing an estimate of the variance of our estimator,
 $ \widehat{V}({\overset{\sim }{\theta}}^{\mathrm{dp}}) $
, without any additional privacy budget expenditure. We have the two directly estimated quantities,
$ \widehat{V}({\overset{\sim }{\theta}}^{\mathrm{dp}}) $
, without any additional privacy budget expenditure. We have the two directly estimated quantities,
 $ {\widehat{\theta}}^{\mathrm{dp}} $
and
$ {\widehat{\theta}}^{\mathrm{dp}} $
and
 $ {\widehat{\alpha}}_2^{\mathrm{dp}} $
, and the three (deterministically post-processed) functions of these computed during bias correction:
$ {\widehat{\alpha}}_2^{\mathrm{dp}} $
, and the three (deterministically post-processed) functions of these computed during bias correction:
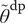 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
,
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
,
 $ {\widehat{\sigma}}_{\mathrm{dp}}^2 $
, and
$ {\widehat{\sigma}}_{\mathrm{dp}}^2 $
, and
 $ {\widehat{\alpha}}_1^{\mathrm{dp}} $
. We then use standard simulation methods (King, Tomz, and Wittenberg Reference King, Tomz and Wittenberg2000): we treat the estimated quantities as random variables, bias correct to generate the others, and take the sample variance of the simulations of
$ {\widehat{\alpha}}_1^{\mathrm{dp}} $
. We then use standard simulation methods (King, Tomz, and Wittenberg Reference King, Tomz and Wittenberg2000): we treat the estimated quantities as random variables, bias correct to generate the others, and take the sample variance of the simulations of
 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
. Thus, to represent estimation uncertainty, we draw the random quantities from a multivariate normal with plug-in parameter estimates, none of which need to be newly disclosed and so the procedure does not use more of the privacy budget. Appendix G of the Supplementary Material provides all the derivations.
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
. Thus, to represent estimation uncertainty, we draw the random quantities from a multivariate normal with plug-in parameter estimates, none of which need to be newly disclosed and so the procedure does not use more of the privacy budget. Appendix G of the Supplementary Material provides all the derivations.
Simulations
We now evaluate the finite-sample properties of our estimator. We show that while (uncorrected) differentially private point estimates are inferentially invalid, our estimators are approximately unbiased and come with accurate uncertainty estimates. In addition, in part because our bias correction uses an additional disclosed parameter estimate (
 $ {\widehat{\alpha}}_2 $
), the variance of our estimator is usually lower than the variance of the uncorrected estimator. (Simulations under alternative assumptions appear in Appendix H of the Supplementary Material; replication information is available in Evans et al. [Reference Evans, King, Schwenzfeier and Thakurta2023].)
$ {\widehat{\alpha}}_2 $
), the variance of our estimator is usually lower than the variance of the uncorrected estimator. (Simulations under alternative assumptions appear in Appendix H of the Supplementary Material; replication information is available in Evans et al. [Reference Evans, King, Schwenzfeier and Thakurta2023].)
The results appear in Figure 3, which we discuss after first detailing the data generation process. For four different types of simulations (in separate panels of the figure), we draw data for each row i from an independent linear regression model:
 $ {y}_i\sim \mathcal{N}(1+3{x}_i,1{0}^2) $
, with
$ {y}_i\sim \mathcal{N}(1+3{x}_i,1{0}^2) $
, with
 $ {x}_i\sim \mathcal{N}(0,{7}^2) $
drawn once and fixed across simulations. Our chosen quantity of interest is the coefficient on
$ {x}_i\sim \mathcal{N}(0,{7}^2) $
drawn once and fixed across simulations. Our chosen quantity of interest is the coefficient on
 $ {x}_i $
with value
$ {x}_i $
with value
 $ \theta =3 $
. We study the bias of the (uncorrected) differentially private estimator
$ \theta =3 $
. We study the bias of the (uncorrected) differentially private estimator
 $ {\widehat{\theta}}^{\mathrm{dp}} $
, and our corrected version,
$ {\widehat{\theta}}^{\mathrm{dp}} $
, and our corrected version,
 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
, as well as their standard errors.Footnote
11
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
, as well as their standard errors.Footnote
11

Figure 3. Monte Carlo Simulations: Bias of the Uncorrected (
 $ {\widehat{\theta}}^{\mathrm{dp}} $
) and Corrected (
$ {\widehat{\theta}}^{\mathrm{dp}} $
) and Corrected (
 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
) Estimates, and (in the Bottom-Right Panel) the Standard Error of the True Uncorrected (
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
) Estimates, and (in the Bottom-Right Panel) the Standard Error of the True Uncorrected (
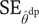 $ {\mathrm{SE}}_{{\widehat{\theta}}^{\mathrm{dp}}} $
), True Corrected (
$ {\mathrm{SE}}_{{\widehat{\theta}}^{\mathrm{dp}}} $
), True Corrected (
 $ {\mathrm{SE}}_{{\overset{\sim }{\theta}}^{\mathrm{dp}}} $
), and Estimated Corrected (
$ {\mathrm{SE}}_{{\overset{\sim }{\theta}}^{\mathrm{dp}}} $
), and Estimated Corrected (
 $ {\hat{\mathrm{SE}}}_{{\overset{\sim }{\theta}}^{\mathrm{dp}}} $
) Estimates (the Latter Two Having Almost Identical Values)
$ {\hat{\mathrm{SE}}}_{{\overset{\sim }{\theta}}^{\mathrm{dp}}} $
) Estimates (the Latter Two Having Almost Identical Values)
Note: “True” SEs refer to the actual standard deviation of a point estimate.
Begin with the top-left panel, which plots bias on the vertical axis (with zero bias indicated by a dashed horizontal line at zero near the top) and the degree of censoring on the horizontal axis increasing from left to right (quantified by
 $ {\alpha}_2 $
). The orange line in this panel vividly shows how statistical bias in the (uncorrected) differentially private estimator
$ {\alpha}_2 $
). The orange line in this panel vividly shows how statistical bias in the (uncorrected) differentially private estimator
 $ {\widehat{\theta}}^{\mathrm{dp}} $
sharply increases with censoring. In contrast, our (bias-corrected) estimate in blue
$ {\widehat{\theta}}^{\mathrm{dp}} $
sharply increases with censoring. In contrast, our (bias-corrected) estimate in blue
 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
is approximately unbiased regardless of the level of censoring.
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
is approximately unbiased regardless of the level of censoring.
The top-right and bottom-left panels also plot bias on the vertical axis with zero bias indicated by a horizontal dashed line. The bottom-left panel shows the bias in the uncorrected estimate (in orange) for sample sizes from 10,000 to 1 million, and the top-right panel shows the same for different values of
 $ \epsilon $
. Our corrected estimate (in blue) is approximately zero in both panels, regardless of the value of N or
$ \epsilon $
. Our corrected estimate (in blue) is approximately zero in both panels, regardless of the value of N or
 $ \epsilon $
.
$ \epsilon $
.
Finally, the bottom-right panel reveals that the standard error of
 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
is approximately correct (i.e., equal to the true standard deviation across estimates, which can be seen because the blue and gray lines are almost on top of one another). It is even smaller for most of the range than the standard error of the uncorrected estimate
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
is approximately correct (i.e., equal to the true standard deviation across estimates, which can be seen because the blue and gray lines are almost on top of one another). It is even smaller for most of the range than the standard error of the uncorrected estimate
 $ {\widehat{\theta}}^{\mathrm{dp}} $
. (Appendix I of the Supplementary Material gives an example and intuition for how to avoid analyses where our approach does not work as expected.)
$ {\widehat{\theta}}^{\mathrm{dp}} $
. (Appendix I of the Supplementary Material gives an example and intuition for how to avoid analyses where our approach does not work as expected.)
These simulations suggest that
 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
is to be preferred to
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
is to be preferred to
 $ {\widehat{\theta}}^{\mathrm{dp}} $
with respect to bias and variance in finite samples.
$ {\widehat{\theta}}^{\mathrm{dp}} $
with respect to bias and variance in finite samples.
We also show in Figure 4 how our procedure performs across different partition sizes (P) for fixed
 $ \epsilon $
, n, and
$ \epsilon $
, n, and
 $ \Lambda $
, using same data generation process. With small P, both
$ \Lambda $
, using same data generation process. With small P, both
 $ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
and
$ {\overset{\sim }{\theta}}^{\mathrm{dp}} $
and
 $ {\widehat{\theta}}^{\mathrm{dp}} $
are biased because our estimate of the censoring level is noisy in this case (note, however, that in simulations where we use the bag-of-little-bootstraps to estimate the proportion of censored partitions, we perform more favorably with low P, since the asymptotics are in n rather than P). However, when
$ {\widehat{\theta}}^{\mathrm{dp}} $
are biased because our estimate of the censoring level is noisy in this case (note, however, that in simulations where we use the bag-of-little-bootstraps to estimate the proportion of censored partitions, we perform more favorably with low P, since the asymptotics are in n rather than P). However, when
 $ P>100 $
, our procedure corrects the bias from censoring. Our procedure even performs well when
$ P>100 $
, our procedure corrects the bias from censoring. Our procedure even performs well when
 $ P=500 $
and so
$ P=500 $
and so
 $ n=20 $
. Such a small sample size can be less optimal for other estimators and in skewed data. Analysts should consider the trade-off between noise and partition sample size when choosing P.
$ n=20 $
. Such a small sample size can be less optimal for other estimators and in skewed data. Analysts should consider the trade-off between noise and partition sample size when choosing P.

Figure 4. Performance across P (Number of Data Partitions) for Fixed Privacy Budget (ϵ=1) and Sample Size (N=100k)
Empirical Examples
We now show that the same quantities of interest to political scientists can still be accurately estimated even while guaranteeing the privacy of their respondents. We do this by replicating two important recent articles from major journals. We then treat these datasets as if they were private and not accessible to researchers, except through our algorithm. We then use the algorithm to estimate the same quantities and show that we can recover the same estimates. We also quantify the costs of our approach by the size of the standard errors. See Evans et al. (Reference Evans, King, Schwenzfeier and Thakurta2023) for replication information.
Home Ownership and Local Political Participation
We begin with Yoder (Reference Yoder2020), a study of the effect of home ownership on participation in local politics that uses an unusually informative and diverse array of datasets the author combined via probabilistic matching. Although all the information used in this article is publicly available in separate datasets, combining datasets can be exponentially more informative about each person represented. Some people represented in data like these might well rankle about a researcher being able to easily obtain their name, address, how much of a fuss they made at various city council meetings, all the times during the last 18 years in which they voted or failed to turn out, the dollar value of their home, and which candidates and how much they contributed to each. Moreover, with this profile on any individual, it would be easy to add other variables from other sources.
Yoder (Reference Yoder2020) followed current best practices by appropriately de-identifying the data, which meant being forced to strip the replication dataset of many substantively interesting variables, hence limiting the range of discoveries other researchers can make. And yet, we now know that even these procedures do not always protect research subjects, as re-identification remains possible.
In a dataset with
 $ n=83,\hskip-1pt 580 $
observations, the author regresses a binary indicator for whether an individual comments at a local city council meeting on an indicator for home ownership, controlling for year and zip code fixed effects, and correcting for uncertainties in the data matching procedure. This causal estimate, which we replicated exactly, indicates that owning a home increases the probability of commenting at a city council meeting by 5 percentage points (0.05) (Yoder Reference Yoder2020, Table 2, Model 1). We focus on this main effect, not the large number of other statistics in the original paper, many of which are of secondary relevance to the core argument. To release all these statistics would require either a large privacy budget (and possibly an unacceptable privacy loss) or excessively large standard errors. Differential privacy hence changes the nature of research, necessitating choices about which statistics are published.
$ n=83,\hskip-1pt 580 $
observations, the author regresses a binary indicator for whether an individual comments at a local city council meeting on an indicator for home ownership, controlling for year and zip code fixed effects, and correcting for uncertainties in the data matching procedure. This causal estimate, which we replicated exactly, indicates that owning a home increases the probability of commenting at a city council meeting by 5 percentage points (0.05) (Yoder Reference Yoder2020, Table 2, Model 1). We focus on this main effect, not the large number of other statistics in the original paper, many of which are of secondary relevance to the core argument. To release all these statistics would require either a large privacy budget (and possibly an unacceptable privacy loss) or excessively large standard errors. Differential privacy hence changes the nature of research, necessitating choices about which statistics are published.
Since there is limited prior research on this question, it is difficult to make an informed choice about the parameter,
 $ \Lambda $
, which defines where to censor. We therefore dedicate a small portion of the privacy budget to private quantile estimation (Smith Reference Smith2011). Specifically, we make a private query for an estimate of the
$ \Lambda $
, which defines where to censor. We therefore dedicate a small portion of the privacy budget to private quantile estimation (Smith Reference Smith2011). Specifically, we make a private query for an estimate of the
 $ 0.6 $
quantile of the absolute value of the partition-level estimates of our quantity of interest. We dedicate
$ 0.6 $
quantile of the absolute value of the partition-level estimates of our quantity of interest. We dedicate
 $ \epsilon =0.2 $
of our privacy budget to this query, and the returned value was
$ \epsilon =0.2 $
of our privacy budget to this query, and the returned value was
 $ 0.07 $
(this means approximately
$ 0.07 $
(this means approximately
 $ 40\% $
of partition-level statistics were greater in magnitude than
$ 40\% $
of partition-level statistics were greater in magnitude than
 $ 0.07 $
). Then, for our main algorithm, we set
$ 0.07 $
). Then, for our main algorithm, we set
 $ \Lambda =0.075 $
. Below, we also discuss the sensitivity of our estimator to this choice.
$ \Lambda =0.075 $
. Below, we also discuss the sensitivity of our estimator to this choice.
The main causal estimate is portrayed in Figure 5a as a dark blue dot, in the middle of a vertical line representing a 95% confidence interval.

Figure 5. Original versus Privacy-Protected Data Analyses
When we estimate the same quantity using our algorithm, the result is a point estimate and confidence interval portrayed in the middle of Figure 5a. As can be seen, the point estimate (in light blue) is almost the same as in the original, and the confidence interval is similar but widened somewhat, leaving essentially the same overall substantive conclusion as in the original about how home ownership increases the likelihood of commenting in a city council meeting. The wider confidence intervals is the cost necessary to guarantee privacy for the research subjects. This inferential cost could be overcome, if desired, by a proportionately larger sample.Footnote 12 (For comparison, we also present the biased privatized point estimate without correction on the right side of the same graph.)
In Figure 6, we show how our estimate varies over 200 runs of the algorithm for different values of
 $ \Lambda $
(which dictates the amount of censoring and noise). We see a trade-off between pre-noise information, which decreases in the level of censoring, and the variance of the noise. In this example, we find that censoring approximately 25% of partitions (corresponding to
$ \Lambda $
(which dictates the amount of censoring and noise). We see a trade-off between pre-noise information, which decreases in the level of censoring, and the variance of the noise. In this example, we find that censoring approximately 25% of partitions (corresponding to
 $ \Lambda =0.1 $
) induces the lowest estimate variability. However, the results are not significantly or substantively different if we set
$ \Lambda =0.1 $
) induces the lowest estimate variability. However, the results are not significantly or substantively different if we set
 $ \Lambda $
to somewhat lower (
$ \Lambda $
to somewhat lower (
 $ 0.07 $
) or higher (
$ 0.07 $
) or higher (
 $ 0.15 $
) values. But if we set
$ 0.15 $
) values. But if we set
 $ \Lambda $
to be very high (
$ \Lambda $
to be very high (
 $ 0.3 $
or
$ 0.3 $
or
 $ 0.5 $
), so that censoring is nearly nonexistent, then we have to add large amounts of noise. This demonstrates a key benefit of our estimator that allows us to obtain approximately unbiased estimates in the presence of censoring and with less noise.
$ 0.5 $
), so that censoring is nearly nonexistent, then we have to add large amounts of noise. This demonstrates a key benefit of our estimator that allows us to obtain approximately unbiased estimates in the presence of censoring and with less noise.

Figure 6. Distribution of Estimate across 200 Runs of Our Algorithm, at Varying Levels of
 $ \Lambda $
$ \Lambda $
Effect of Affirmative Action on Bureaucratic Performance in India
We also replicate Bhavnani and Lee (Reference Bhavnani and Lee2021), a study showing that affirmative action hires do not reduce bureaucratic output in India, using “unusually detailed data on the recruitment, background, and careers of India’s elite bureaucracy” (5).
The key analysis in this study involves a regression of bureaucratic output on the proportion of bureaucrats who were affirmative action hires. Bureaucratic output was defined as the standardized log of the number of households that received 100 or more days of employment under MGNREGA, India’s (and the world’s largest) poverty program. The causal estimate, based on
 $ n=2,047 $
observations, is positive and confirms the authors’ hypothesis.
$ n=2,047 $
observations, is positive and confirms the authors’ hypothesis.
We easily replicate these results, which appear in dark blue on the left side of Figure 5b. As above, we now treat the data as private and accessible only through our algorithm and estimate the same quantity. The result appears in light blue in the middle. The overall substantive conclusion is essentially unchanged—indicating the absence of any evidence that affirmative action hires decrease bureaucratic output. The increase in the size of the confidence interval reflects the cost of the privacy protections we chose to apply.Footnote 13
In both applications, our algorithm provides privacy in the form of deniability for any person who is or could be in the data: reidentification is essentially impossible, regardless of how much external information an attacker may have. It also enables scholars to produce approximately the same results and the same substantive conclusion as without privacy protections. The inferential cost of the procedure is the increase in confidence intervals and standard errors, as a function of the user-determined choice of
 $ \epsilon $
. This cost can be compensated for by collecting a larger sample. Of course, in many situations, not paying this “cost” may mean no data access at all.
$ \epsilon $
. This cost can be compensated for by collecting a larger sample. Of course, in many situations, not paying this “cost” may mean no data access at all.
Practical Suggestions and Limitations
Like any data analytic approach, how the methods proposed here are used in practice can be as important as their formal properties. We discuss here issues of reducing the societal risks of differential privacy, choosing
 $ \epsilon $
, choosing
$ \epsilon $
, choosing
 $ \Lambda $
, and theory and practice differences. See also Appendix F of the Supplementary Material on suggestions for software design.
$ \Lambda $
, and theory and practice differences. See also Appendix F of the Supplementary Material on suggestions for software design.
Reducing Differential Privacy’s Societal Risks
Data access systems with differential privacy are designed to reduce privacy risks to individuals. Correcting the biases due to noise and censoring, and adding proper uncertainty estimates, greatly reduces the remaining risks to researchers and, in turn, to society. There is, however, another risk we must tackle: consider a firm seeking public relations benefits by making data available for academics to create public good but, concerned about bad news for the firm that might come from the research, takes an excessively conservative position on the total privacy budget. In this situation, the firm would effectively be providing a big pile of useless random numbers while claiming public credit for making data available. No public good could be created, no bad news for the firm could come from the research results because all causal estimates would be approximately zero, and still the firm would benefit from great publicity.
To avoid this unacceptable situation, we quantify the statistical cost to researchers of differential privacy or, equivalently, how much information the data provider is actually providing to the scholarly community. To do this, we note that making population-level inferences in a differentially private data access system is equivalent to an ordinary data access system with some specific proportion of the data discarded. This means we can provide an intuitive statistic, the proportion of observations effectively lost due to the privacy-protective procedures. Appendix J of the Supplementary Material formally defines and shows how to estimate this quantity, which we call L for loss.
Because L can be computed after from the results of our algorithm, without any additional expenditure from the privacy budget, we recommend it be regularly reported publicly by data providers or researchers using differentially private data access systems. For example, in the applications we replicate, the proportion of observations effectively lost is
 $ L=0.36 $
for the study of home ownership and
$ L=0.36 $
for the study of home ownership and
 $ L=0.43 $
for the study of affirmative action in India. These could have been changed by adjusting the privacy parameters
$ L=0.43 $
for the study of affirmative action in India. These could have been changed by adjusting the privacy parameters
 $ \epsilon $
,
$ \epsilon $
,
 $ \delta $
, and
$ \delta $
, and
 $ \Lambda $
in how the data were disclosed.
$ \Lambda $
in how the data were disclosed.
Choosing
$ \epsilon $

From the point of view of the statistical researcher,
 $ \epsilon $
directly influences the standard error of the quantity of interest, although with our algorithm this choice will not affect the degree of bias. Because we show above that typically
$ \epsilon $
directly influences the standard error of the quantity of interest, although with our algorithm this choice will not affect the degree of bias. Because we show above that typically
 $ \widehat{V}({\overset{\sim }{\theta}}^{\mathrm{dp}})<\widehat{V}[c({\widehat{\theta}}^{\mathrm{dp}},\Lambda )]<\widehat{V}({\widehat{\theta}}^{\mathrm{dp}}) $
, we can simplify and provide some intuition by writing an upper bound on the standard error
$ \widehat{V}({\overset{\sim }{\theta}}^{\mathrm{dp}})<\widehat{V}[c({\widehat{\theta}}^{\mathrm{dp}},\Lambda )]<\widehat{V}({\widehat{\theta}}^{\mathrm{dp}}) $
, we can simplify and provide some intuition by writing an upper bound on the standard error
 $ {\mathrm{SE}}_{{\overset{\sim }{\theta}}^{\mathrm{dp}}}\equiv \sqrt{\widehat{V}({\overset{\sim }{\theta}}^{\mathrm{dp}})} $
as
$ {\mathrm{SE}}_{{\overset{\sim }{\theta}}^{\mathrm{dp}}}\equiv \sqrt{\widehat{V}({\overset{\sim }{\theta}}^{\mathrm{dp}})} $
as
 $$ \begin{array}{rl}{\mathrm{SE}}_{{\overset{\sim }{\theta}}^{\mathrm{dp}}}<\sqrt{V({\widehat{\theta}}^{\mathrm{dp}})+S{(\Lambda, \epsilon, \delta, P)}^2}.& \end{array} $$
$$ \begin{array}{rl}{\mathrm{SE}}_{{\overset{\sim }{\theta}}^{\mathrm{dp}}}<\sqrt{V({\widehat{\theta}}^{\mathrm{dp}})+S{(\Lambda, \epsilon, \delta, P)}^2}.& \end{array} $$
A researcher can use this expression to judge how much of their allocation of
 $ \epsilon $
to assign to the next run by using their prior information about the likely value of
$ \epsilon $
to assign to the next run by using their prior information about the likely value of
 $ \widehat{V}({\widehat{\theta}}^{\mathrm{dp}}) $
(as they would in a power calculation), plugging in the chosen values of
$ \widehat{V}({\widehat{\theta}}^{\mathrm{dp}}) $
(as they would in a power calculation), plugging in the chosen values of
 $ \Lambda $
,
$ \Lambda $
,
 $ \delta $
, and P, and then trying different values of
$ \delta $
, and P, and then trying different values of
 $ \epsilon $
. See also Hsu et al. (Reference Hsu, Gaboardi, Haeberlen, Khanna, Narayan, Pierce and Roth2014) and Abowd and Schmutte (Reference Abowd and Schmutte2019) for an economic theory approach.
$ \epsilon $
. See also Hsu et al. (Reference Hsu, Gaboardi, Haeberlen, Khanna, Narayan, Pierce and Roth2014) and Abowd and Schmutte (Reference Abowd and Schmutte2019) for an economic theory approach.
Choosing
$ \Lambda $

Although our bias correction procedure makes the choice of
 $ \Lambda $
less consequential, researchers with extra knowledge should use it. In particular, reducing
$ \Lambda $
less consequential, researchers with extra knowledge should use it. In particular, reducing
 $ \Lambda $
increases the chance of censoring while reducing noise, whereas larger values reduce censoring but increase noise. This Heisenberg-like property is an intentional feature, designed to keep researchers from being able to see certain information with too much precision.
$ \Lambda $
increases the chance of censoring while reducing noise, whereas larger values reduce censoring but increase noise. This Heisenberg-like property is an intentional feature, designed to keep researchers from being able to see certain information with too much precision.
We can, however, choose among the unbiased estimators our method produces that have the smallest variance. To do that, researchers should set
 $ \Lambda $
by trying to capture the point estimate of the mean. Although this cannot be done with certainty, researchers can often do this without seeing the data. For example, consider the absolute value of coefficients from any real application of logistic regression. Although technically unbounded, empirical regularities in how researchers typically scale their input variables lead to logistic regression coefficients reported in the literature rarely having absolute values above about five. Similar patterns are easy to identify across many statistical procedures. A good software interface would thus not only include appropriate defaults, but also enable users to enter asymmetric censoring intervals. Then the software, rather than the user, takes responsibility in the background for rescaling the variables as necessary.
$ \Lambda $
by trying to capture the point estimate of the mean. Although this cannot be done with certainty, researchers can often do this without seeing the data. For example, consider the absolute value of coefficients from any real application of logistic regression. Although technically unbounded, empirical regularities in how researchers typically scale their input variables lead to logistic regression coefficients reported in the literature rarely having absolute values above about five. Similar patterns are easy to identify across many statistical procedures. A good software interface would thus not only include appropriate defaults, but also enable users to enter asymmetric censoring intervals. Then the software, rather than the user, takes responsibility in the background for rescaling the variables as necessary.
Applied researchers are good at making choices like this as they have considerable experience with scaling variables, a task that is an essential part of most data analyses. Researchers also frequently predict the values of their quantities of interest both informally, when deciding what analysis to run next, and formally for power calculations. If the data surprise us, we will learn this because the
 $ {\widehat{\alpha}}_1^{\mathrm{dp}} $
and
$ {\widehat{\alpha}}_1^{\mathrm{dp}} $
and
 $ {\widehat{\alpha}}_2^{\mathrm{dp}} $
are disclosed as part of our procedure. If either quantity is more than about 60%, we recommend researchers consider adjusting
$ {\widehat{\alpha}}_2^{\mathrm{dp}} $
are disclosed as part of our procedure. If either quantity is more than about 60%, we recommend researchers consider adjusting
 $ \Lambda $
and rerunning their analysis (see Appendix K of the Supplementary Material) or adapting Smith (Reference Smith2011) procedure to learn the value of
$ \Lambda $
and rerunning their analysis (see Appendix K of the Supplementary Material) or adapting Smith (Reference Smith2011) procedure to learn the value of
 $ \Lambda $
where censoring begins (See Appendix C of the Supplementary Material).
$ \Lambda $
where censoring begins (See Appendix C of the Supplementary Material).
Implementation Choices
In the literature, differential privacy theorists tend to be conservative in setting privacy parameters and budgets; practitioners take a more lenient perspective. Both perspectives make sense: theorists analyze worst-case scenarios using mathematical certainty as the standard of proof, and are ever wary of scientific adversaries hunting for loopholes in their mechanisms. This divergence even makes sense both theoretically, because privacy bounds are much higher than expected in practice (Erlingsson et al. Reference Erlingsson, Mironov, Raghunathan and Song2019), and empirically, because those responsible for implementing data access systems have little choice but to make some compromises in turning math into physical reality. Common implementations thus sometimes allow larger values of
 $ \epsilon $
for each run or reset the privacy budget periodically.
$ \epsilon $
for each run or reset the privacy budget periodically.
We add two practical suggestions. First, although the data sharing regime can be broken by intentional attack, because re-identification from de-identified data is often possible, de-identification is still helpful in practice. It is no surprise that university Institutional Review Boards have rephrased their regulations from “de-identified” to “not readily identifiable” rather than disallowing data sharing entirely. Adding our new privacy-protective procedures to de-identified data provides further protection. Other practical steps can be prudent, such as disallowing repeated runs with new draws of noise of any one analysis.
Second, potential data providers and regulators should ask themselves Are these researchers trustworthy? They almost always have been. When this fact provides insufficient reassurance, we can move to the data access regime. However, a middle ground exists by trusting researchers (perhaps along with auxiliary protections, such as data use agreements by university employers, sanctions for violations, and auditing of analyses to verify compliance). With trust, researchers can be given full access, be allowed to run any analyses, but be required to use the algorithm proposed here to disclose data publicly. The data holder could then maintain a strict privacy budget summed over published analyses, which is far more useful for scientific research than counting every exploratory data analysis run against the budget. This plan approximates the differential privacy ideal more closely than the typical data access regime, as the privacy protections among results published are then protected by mathematical guarantees. There are theoretical risks (Dwork and Ullman Reference Dwork and Ullman2018), but the advantages to the public good that can come from research with fewer constraints may be substantial.
Limits of Differential Privacy
Finally, differential privacy is a new, rapidly advancing technology. Off-the-shelf methods to optimally balance privacy and utility do not exist for many dataset types. Although we provide a generic method, with an approximately unbiased estimator, methods tuned to specific datasets with better properties may sometimes be feasible. Some applications of differential privacy make compromises by setting high privacy budgets, post-processing in intentionally damaging ways, or periodically resetting the budget (Domingo-Ferrer, Sánchez, and Blanco-Justicia Reference Domingo-Ferrer, Sánchez and Blanco-Justicia2021), actions that render privacy or utility guarantees more limited than the math implies. These and other shortcomings of how differentially private has been applied pose a valuable opportunity for researchers to develop tools to reduce the utility-privacy trade-off and develop statistical methods of analyzing these data capable of answering important social science questions. For other more specific limitations of our methodology, see also Appendices F, I, and K of the Supplementary Material.
Concluding Remarks
The differential privacy literature focuses appropriately on the utility-privacy trade-off. We propose to revise the definition of “utility,” so it offers value to researchers who seek to use confidential data to learn about the world, beyond inferences to the inaccessible private data. A scientific statement is not one that is necessarily correct, but one that comes with known statistical properties and an honest assessment of uncertainty. Utility to scholarly researchers involves inferential validity, the ability to make these informative scientific statements about populations. While differential privacy can guarantee privacy to individuals, researchers also need inferential validity to make a data access system safe for drawing proper scientific statements, for society using the results of that research, and for individuals whose privacy must be protected. Inferential validity without differential privacy may mean beautiful theory without data access, but differential privacy without inferential validity may result in biased substantive conclusions that mislead researchers and society at large.
Together, approaches that are differentially private and inferentially valid may begin to convince companies, governments, and others to let researchers access their unprecedented storehouses of informative data about individuals and societies. If this happens, it will generate guarantees of privacy for individuals, scholarly results for researchers, and substantial value for society at large.
Supplementary Material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0003055422001411.
Data Availability Statement
Research documentation and data that support the findings of this study are openly available in the APSR Dataverse at https://doi.org/10.7910/DVN/ASUFTY.
Acknowledgments
Many thanks for helpful comments to Adam Breuer, Merce Crosas, Cynthia Dwork, Max Golperud, Roubin Gong, Andy Guess, Chase Harrison, Kosuke Imai, Dan Kifer, Patrick Lam, Xiao-Li Meng, Solomon Messing, Nate Persily, Aaron Roth, Paul Schroeder, Adam Smith, Salil Vadhan, Sergey Yekhanin, and Xiang Zhou. Thanks also for help from the Alexander and Diviya Maguro Peer Pre-Review Program at Harvard’s Institute for Quantitative Social Science.
Conflict of Interest
The authors declare no ethical issues or conflicts of interest in this research.
Ethical Standards
The authors affirm this research did not involve human subjects.





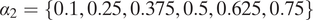













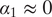















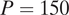

















 Open access
Open access
Comments
No Comments have been published for this article.