



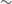
1. Introduction
The Square Kilometre Array (SKA) (Dewdney et al. Reference Dewdney2016) will open a golden era in radio astronomy due to its anticipated sensitivity, frequency coverage, and angular resolution. While the SKA is currently in the construction phase, SKA precursor telescopes have already started their planned survey programs, delivering valuable scientific results even during the commissioning phase. Among them, the Evolutionary Map of the Universe (EMU) program (Norris et al. Reference Norris2011) of the Australian SKA Pathfinder (ASKAP, Johnston et al. Reference Johnston2008; Hotan et al. Reference Hotan2021) will survey
 $\sim$
75% of the sky at
$\sim$
75% of the sky at
 $\sim$
940 MHz with an angular resolution of 10′′ and a target rms of 15
$\sim$
940 MHz with an angular resolution of 10′′ and a target rms of 15
 $\unicode{x03BC}$
Jy/beam. As EMU is expected to detect
$\unicode{x03BC}$
Jy/beam. As EMU is expected to detect
 $\sim$
50 million sources, the cataloguing process will require a significant degree of automation and knowledge extraction compared to previous surveys. Source finding is a major stage involved in such post-processing of observations.
$\sim$
50 million sources, the cataloguing process will require a significant degree of automation and knowledge extraction compared to previous surveys. Source finding is a major stage involved in such post-processing of observations.
In the last years, several developments were made within the SKA precursor community, and new tools were produced to improve compact source extraction and measurement capabilities (e.g. completeness, reliability, positional, and flux density accuracy) and processing speed, also employing parallel computing methodologies (e.g. see Riggi et al. Reference Riggi2019 and references therein). Fewer efforts, however, has been spent on source classification, particularly for Galactic science targets, as almost all source finders do not provide any information (e.g. labels or tags) on the extracted source class identity. The implication for Galactic plane observations is that, after taking out source classifications made through automated cross-matching to previously classified objects (e.g.
 $\sim$
5% in the Scorpio field in Riggi et al. Reference Riggi2021a), the vast majority of the catalogued sources are unclassified. Of these, more than 90% are typically single-island and single-component sources.Footnote a From the number of previously classified objects, it is reasonable to expect that the majority of unknown sources are extragalactic (radio galaxies, quasars) and Hii regions, with a smaller fractionFootnote b of Planetary Nebulae (PNe) and pulsars, and an even smaller fraction (
$\sim$
5% in the Scorpio field in Riggi et al. Reference Riggi2021a), the vast majority of the catalogued sources are unclassified. Of these, more than 90% are typically single-island and single-component sources.Footnote a From the number of previously classified objects, it is reasonable to expect that the majority of unknown sources are extragalactic (radio galaxies, quasars) and Hii regions, with a smaller fractionFootnote b of Planetary Nebulae (PNe) and pulsars, and an even smaller fraction (
 $<$
10%) of radio stars of different types and evolution stage (e.g. including evolved massive stars like Luminous Blue Variables or Wolf-Rayet), or even completely new or unexpected classes of objects. Classification tools could therefore significantly increase the number of known sources in the Galaxy, or at least guide science groups in proposing follow-up multi-wavelength observations for selected source samples. Machine learning, in general, and specifically deep learning techniques, have proven to be very powerful for this kind of analysis. We summarise here the developments made on radio source classification in recent works.
$<$
10%) of radio stars of different types and evolution stage (e.g. including evolved massive stars like Luminous Blue Variables or Wolf-Rayet), or even completely new or unexpected classes of objects. Classification tools could therefore significantly increase the number of known sources in the Galaxy, or at least guide science groups in proposing follow-up multi-wavelength observations for selected source samples. Machine learning, in general, and specifically deep learning techniques, have proven to be very powerful for this kind of analysis. We summarise here the developments made on radio source classification in recent works.
Most of the contributions focused on galaxy morphology classification for extragalactic science cases. For example, Aniyan & Thorat (Reference Aniyan and Thorat2017) employed convolutional neural networks (CNNs) for classification of Fanaroff–Riley (FR) type I and type II (Fanaro_ & Riley Reference Fanaroff and Riley1974), and bent-tailed radio galaxies, using images from the Very Large Array (VLA) FIRSTFootnote c survey. Similar analysis were conducted using CNNs (Lukic et al. Reference Lukic2018; Wu et al. Reference Wu2019; Maslej-Krešňáková et al. Reference Maslej-Krešňáková2021; Rustige et al. Reference Rustige2023) or capsule networks (Lukic et al. Reference Lukic2019) on FIRSTFootnote d and LOFAR (Low Frequency Array) images (Alegre et al. Reference Alegre2022). Sadeghi et al. (Reference Sadeghi2021) studied morphological-based classification of FRI/FRII radio galaxies with support vector machine (SVM) (Cortes & Vapnik Reference Cortes and Vapnik1995) models, using computed Zernike moments of source images from the FIRST survey. Radio galaxy morphology was also studied using semi-supervised (Slijepcevic et al. Reference Slijepcevic2022) and unsupervised learning methods, for example employing Kohonen maps (Polsterer Reference Polsterer2016; Gupta et al. Reference Gupta2022; Galvin et al. Reference Galvin2020) or K-means clustering algorithm applied to compressed features learnt by convolutional autoencoders and Self-Organising Maps (SOMs) (Ralph et al. Reference Ralph2019).
Various works used ML techniques to target Galactic science objectives, such as the identification of Galactic objects or selected object classes from the dominant background of extragalactic sources, or the discovery of anomalous/unexpected objects. Among them, Akras et al. (Reference Akras2019) employed decision trees for classifying PNe against mimics (Hii regions, stars, YSO) using near- and mid-infrared colours. Awang Iskandar et al. (Reference Awang Iskandar2020) tested several deep network architectures to identify PNe from rejected PNe listed in the HASHFootnote e and Pan-STARRSFootnote f databases, using infrared (WISEFootnote g) and optical (IPHAS,Footnote h VPHAS+,Footnote i SHSFootnote j/SSSFootnote k) images. Anderson et al. (Reference Anderson2012) considered mid- and far-infrared colours, providing diagnostic selection criteria for discriminating PNe and Hii regions. Morello et al. (Reference Morello2018) also considered near-infrared (2MASSFootnote l) colours to identify new Wolf-Rayet star candidates from other stellar populations contaminants (Young Stellar Objects (YSOs), asymptotic giant branch (AGB) candidates, Be/M
 $-$
S type stars), using variants of the k-nearest neighbours algorithm. None of these studies, however, included radio data in their analysis or had the radio domain as their primary target. In this context, various ML applications were instead primarily developed for classification of radio sources in the Galactic plane. Among them, Liu et al. (Reference Liu2019) used radio data from different surveys (MGPS,Footnote m MAGPIS,Footnote n NVSS,Footnote o CGPSFootnote p) to train a deep CNN to identify Supernova Remnants (SNRs) from non-SNRs (e.g. regions surrounding the SNRs in their analysis). Several studies (Bates et al. Reference Bates2012; Lyon et al. Reference Lyon2016; Tan et al. Reference Tan2018) employed machine learning methodologies to classify pulsars from non-pulsars or to filter pulsar candidates. We also recently provided some contributions in this field. In Riggi et al. (Reference Riggi2023) we have applied the Mask R-CNN object detection framework to detect and classify compact point-source, extended radio galaxies, and imaging artefacts, making use of radio data from the FIRST, Scorpio ATCAFootnote q(Umana et al. Reference Umana2015a) and ASKAP EMU pilot surveys. In Riggi et al. (Reference Riggi2021a) we have trained a decision tree to identify Galactic-like sources from extragalactic ones on the basis of their radio-infrared colours. The classifier was also applied to a set of 284 unclassified sources selected in the ASKAP Scorpio survey field, highlighting potential Galactic objects for future studies. This analysis was however limited by the size and reliability of the dataset used for model training, mostly based on past low-resolution Galactic plane surveys.
$-$
S type stars), using variants of the k-nearest neighbours algorithm. None of these studies, however, included radio data in their analysis or had the radio domain as their primary target. In this context, various ML applications were instead primarily developed for classification of radio sources in the Galactic plane. Among them, Liu et al. (Reference Liu2019) used radio data from different surveys (MGPS,Footnote m MAGPIS,Footnote n NVSS,Footnote o CGPSFootnote p) to train a deep CNN to identify Supernova Remnants (SNRs) from non-SNRs (e.g. regions surrounding the SNRs in their analysis). Several studies (Bates et al. Reference Bates2012; Lyon et al. Reference Lyon2016; Tan et al. Reference Tan2018) employed machine learning methodologies to classify pulsars from non-pulsars or to filter pulsar candidates. We also recently provided some contributions in this field. In Riggi et al. (Reference Riggi2023) we have applied the Mask R-CNN object detection framework to detect and classify compact point-source, extended radio galaxies, and imaging artefacts, making use of radio data from the FIRST, Scorpio ATCAFootnote q(Umana et al. Reference Umana2015a) and ASKAP EMU pilot surveys. In Riggi et al. (Reference Riggi2021a) we have trained a decision tree to identify Galactic-like sources from extragalactic ones on the basis of their radio-infrared colours. The classifier was also applied to a set of 284 unclassified sources selected in the ASKAP Scorpio survey field, highlighting potential Galactic objects for future studies. This analysis was however limited by the size and reliability of the dataset used for model training, mostly based on past low-resolution Galactic plane surveys.
In this work, we made significant steps further, building a much larger and curated dataset of different Galactic and extragalactic compact objects, including previous and newest radio data in the Galactic plane, combined with mid- and far-infrared data, and measuring the radio spectral index for a portion of them. Such a dataset will be used as a reference for performing classification studies with different machine learning methodologies in a series of planned papers. The scope of this first paper, besides presenting the dataset, is firstly to explore and select suitable parameters for source classification, from more traditional science-aware features (e.g. radio-infrared colours, spectral indices), to more abstract features automatically learnt in convolutional neural network architectures. Secondly, we would like to build and test a supervised learning model able to predict a classification label for an input set of unknown sources, from the considered set of class categories, providing also the relative membership score. As a final goal, we aim to deliver the trained model and the classification tool/service to end users, supporting SKA and precursor science projects planned in the Galactic plane (e.g. production of added-value catalogues from pipeline catalogue products, source selection for follow-up analysis, and so forth). In future papers we will focus on testing unsupervised techniques for cluster search and anomaly detection on the same dataset.
This paper is organised as follows. In Section 2 we describe the observational radio data and supplementary surveys used to create our compact source image dataset. The source classes considered for the analysis, the methodology followed to prepare the dataset, and summary dataset information, are reported in Section 3. In Section 4 we describe the techniques explored to extract a set of sensitive features for classification from the produced dataset. The results of our classification analysis are reported in Section 5. Details on the analysis pipeline and the implemented tool are provided in Section 6. In Section 7, we summarised our findings, and highlighted future steps and analysis that are planned to be done with the produced dataset.
2. Observational data
2.1. ASKAP radio surveys
We searched for sources of different classes in ASKAP pilot survey observations, carried out both far and towards the Galactic plane. Details are reported in the following sections.
2.1.1. ASKAP EMU pilot survey data
The ASKAP-EMU survey (Norris et al. Reference Norris2011) started observations at the end of 2022. This work makes use of different radio continuum maps that were produced with the ASKAP telescope during the commissioning and science preparation activities for EMU:
-
Early Science data: The Scorpio field was the only region observed in the Galactic plane by ASKAP at multiple radio frequencies during the Early Science and pilot 1 phase. First observations, done in 2018 with 15 antennas at 912 MHz, and covering
 $\sim\!40$
square degrees centred on (l,b) = (343.5
$^{\circ}$
, 0.75
$^{\circ}$
), were described in Umana et al. (Reference Umana2021) along with data reduction, while scientific results on compact sources were presented in Riggi et al. (Reference Riggi2021a).
$\sim\!40$
square degrees centred on (l,b) = (343.5
$^{\circ}$
, 0.75
$^{\circ}$
), were described in Umana et al. (Reference Umana2021) along with data reduction, while scientific results on compact sources were presented in Riggi et al. (Reference Riggi2021a).



As the array was nearly completed, new observations of the same region were carried out with 30 antennas in band 1 (900 MHz), 2 (1 250 MHz), and 3 (1 550 MHz), each with a 288 MHz bandwidth, thus providing a much better sensitivity and an almost full frequency coverage from 0.75 to 1.7 GHz when combining all observations. Observation configuration and data reduction were described in more detail in Ingallinera et al. (Reference Ingallinera2022). Final data productsFootnote r include a total intensity map at the reference frequency of 1 243 MHz and 5 sub-band maps (reference frequencies: 871, 1 015, 1 356, 1 480, 1 615 MHz).
The synthesised beam of the total intensity maps is 9.4′′
 $\times$
7.7′′ at a position angle of 84
$\times$
7.7′′ at a position angle of 84
 $^{\circ}$
. The background rms noise in regions far from the Galactic plane and point-sources was found of the order of 50
$^{\circ}$
. The background rms noise in regions far from the Galactic plane and point-sources was found of the order of 50
 $\unicode{x03BC}$
Jy/beam.
$\unicode{x03BC}$
Jy/beam.
• Pilot data: When the array was completed, a pilot survey program was undertaken within EMU. In Phase 1, the survey covered
 $\sim$
270 deg
$\sim$
270 deg
 $^{2}$
of the Dark Energy Survey area, reaching an angular resolution of 11′′
$^{2}$
of the Dark Energy Survey area, reaching an angular resolution of 11′′
 $-$
18′′ and
$-$
18′′ and
 $\sim$
30
$\sim$
30
 $\unicode{x03BC}$
Jy/beam noise rms at 944 MHz (Norris et al. Reference Norris2021). Observations towards the Galactic plane were carried out in Phase 2. They consist of 5 tiles, each covering
$\unicode{x03BC}$
Jy/beam noise rms at 944 MHz (Norris et al. Reference Norris2021). Observations towards the Galactic plane were carried out in Phase 2. They consist of 5 tiles, each covering
 $\sim$
40 deg
$\sim$
40 deg
 $^{2}$
. Their coordinate centers and corresponding observation scheduling blocks are reported in Table 1. The achieved angular resolution of the total intensity maps varies from 14′′ to 20′′, and the noise rms is of the order of 200
$^{2}$
. Their coordinate centers and corresponding observation scheduling blocks are reported in Table 1. The achieved angular resolution of the total intensity maps varies from 14′′ to 20′′, and the noise rms is of the order of 200
 $\unicode{x03BC}$
Jy/beam far from the Galactic plane and from regions of diffuse emission.
$\unicode{x03BC}$
Jy/beam far from the Galactic plane and from regions of diffuse emission.
Table 1. Centres of the ASKAP EMU pilot phase 2 images used in this work. Each image covers an area of
 $\sim$
40 deg
$\sim$
40 deg
 $^{2}$
. Column (1) indicates the observation scheduling blocks.
$^{2}$
. Column (1) indicates the observation scheduling blocks.
2.1.2. The Rapid ASKAP Continuum Survey
The RACS survey (McConnell et al. Reference McConnell2020) is the first large area survey carried out at 887.5 MHz with ASKAP. It reached an angular resolution of 15′′
 $-$
25′′, a rms sensitivity of 0.2
$-$
25′′, a rms sensitivity of 0.2
 $-$
0.4 mJy/beam, and source positional accuracy better than 1′′, delivering a catalogue of 2 123 638 sources, 95% complete above 3 mJy (Hale et al. Reference Hale2021).Footnote s
$-$
0.4 mJy/beam, and source positional accuracy better than 1′′, delivering a catalogue of 2 123 638 sources, 95% complete above 3 mJy (Hale et al. Reference Hale2021).Footnote s
2.2. Previous radio surveys
We also searched for sources in the following previous radio surveys carried out between 1.4 and 5 GHz. Some of them cover a large portion of the Galactic plane in the first quadrant. Details are reported below:
-
The HI/OH/Recombination line survey of the Milky Way: THOR (Wang et al. Reference Wang2018) is a Galactic plane survey (14.0
$^{\circ}$
< l < 67.4
$^{\circ}$
,
$|b|$
< 1.25
$^{\circ}$
) carried out with the VLA in C-configuration at 1.42 GHz. Observations achieved an angular resolution of 10′′
$-$
25′′ with a noise rms of 0.3
$-$
1.0 mJy/beam.Footnote t
-
The Global view on Star formation in the Milky Way: GLOSTAR (Brunthaler et al. Reference Brunthaler2021; Medina et al. Reference Medina2019) is a Galactic plane survey (28
$^{\circ}$
< l < 36
$^{\circ}$
,
$|b|$
< 1
$^{\circ}$
) carried out with the VLA in B and D configuration at 4
$-$
8 GHz. The integrated map has a resolution of 18′′ and a sensitivity of
$\sim$
60
$-$
150
$\unicode{x03BC}$
Jy/beam at the effective frequency of 5.8 GHz.Footnote u
-
Multi-Array Galactic Plane Imaging Survey: MAGPIS (Helfand et al. Reference Helfand2006) is a Galactic plane survey (5
$^{\circ}$
< l < 48.5
$^{\circ}$
,
$|b|$
< 0.8
$^{\circ}$
) carried out with the VLA in B, C, and D configurations at 1.4 GHz. Observations achieved an angular resolution of 6′′ with a noise rms of 0.3 mJy/beam.Footnote v
-
The Coordinated Radio and Infrared Survey for High-Mass Star Formation: CORNISH (Hoare et al. Reference Hoare2012; Purcell Reference Purcell2013) is a Galactic plane survey (10
$^{\circ}<l<$
65
$^{\circ}$
,
$|b|<$
1.1
$^{\circ}$
) carried out with the VLA in B and BnA configurations at 5 GHz. Observations achieved an angular resolution of 1.5′′ with a noise rms of 0.4 mJy/beam.Footnote w
-
Faint Images of the Radio Sky at Twenty cm (FIRST) survey: The FIRST survey (Becker et al. Reference Becker1995) is a large area (
$\sim$
10 500 deg
$^{2}$
,
$\sim$
80% covering the north Galactic cap) carried out at 1.4 GHz with the NRAO VLA. It reached an angular resolution of
$\sim$
5.4′′, a rms sensitivity of 0.15 mJy/beam, and source positional accuracy better than 1′′, delivering a catalogue of 946 432 sources in its latest version (Helfand, White, & Becker Reference Helfand, White and Becker2015), 95% complete above 2 mJy.Footnote x


























2.3. Supplementary infrared data
In this study, we complemented the radio observations with mid- and far-infrared data from the following surveys:
-
AllWISE (Cutri et al. Reference Cutri2013): This WISE survey is fully covering the Galactic plane in four bands at 3.4
$\unicode{x03BC}\mathrm{m}$
(W1), 4.6
$\unicode{x03BC}\mathrm{m}$
(W2), 12
$\unicode{x03BC}\mathrm{m}$
(W3), and 22
$\unicode{x03BC}\mathrm{m}$
(W4). The angular resolutions are 6.1′′, 6.4′′, 6.5′′, and 12′′ and the 5
$\sigma$
flux sensitivities for point sources are 0.08, 0.11, 1, and 6 mJy, respectively. -
GLIMPSE (Galactic Legacy Infrared MidPlane Survey Extraordinaire) 8.0
$\unicode{x03BC}\mathrm{m}$
surveys (Churchwell et al. Reference Churchwell2009) of the Spitzer Space Telescope (Werner et al. Reference Werner2004): GLIMPSE (I, II) fully covers this Galactic coordinate range: 0
$^{\circ}$
< l < 65
$^{\circ}$
, 295
$^{\circ}$
< l < 360
$^{\circ}$
,
$|b|\le$
1Footnote y. The angular resolution is 2′′ and the 5
$\sigma$
flux sensitivity
$\sim$
0.4 mJy. -
Hi-GAL (Herschel infrared Galactic plane Survey) 70
$\unicode{x03BC}\mathrm{m}$
survey (Molinari et al. Reference Molinari2016) of the Herschel Space Observatory (Pilbratt et al. Reference Pilbratt2010): The survey covers
$|l|\le$
60
$^{\circ}$
,
$|b|\le$
1
$^{\circ}$
, with an angular resolution of
$\sim$
8.5′′ and a 1
$\sigma$
flux sensitivity
$\sim$
20 MJy/sr.





















3. Generating training/testing datasets
3.1. Compact source sample
To build our dataset, we searched for compact sources in the available radio data (Section 2), using the following selection criteria:
-
1. Isolated single-island point-sources or slightly resolved sources. We assumed an upper threshold of 10
$\times$
synthesized beam sizeFootnote z; -
2. No diffuse, extended or complex radio morphologies, e.g. no child point-sources or inner filaments inside source contour;
-
3. Source position cross-matching to known or candidate objects in reference catalogues, within a match radius equal to the synthesised beam size;
-
4. Source island clearly distinguishable from the background, e.g. peak flux larger than 3
$\sigma$
and number of island pixels larger than 6; -
5. Source island not located at radio map borders.


Table 2. Reference catalogues considered for searching radio stars in our dataset.
* As the authors stated, this sample is expected to be contaminated by optically faint radio quasars, with only few tens of candidates expected to be truly radio stars.
# http://pacrowther.staff.shef.ac.uk/WRcat/index.php
## Counts include 60 Galactic LBVs and extragalactic LBVs from the Local Group (LMC, SMC).
 $\dagger$
https://heasarc.gsfc.nasa.gov/W3Browse/all/lmxbcat.html
$\dagger$
https://heasarc.gsfc.nasa.gov/W3Browse/all/lmxbcat.html
 $\ddagger$
https://heasarc.gsfc.nasa.gov/w3browse/all/hmxbcat.html
$\ddagger$
https://heasarc.gsfc.nasa.gov/w3browse/all/hmxbcat.html
We considered possible associations to these classes of astrophysical objects (Galactic or Extragalactic), having a compact radio morphology (as defined above), in most of the cases (e.g. pulsars or radio stars), or in a considerable fraction of cases (e.g. Hii regions, PNe) compared to more extended morphologies:
-
Radio stars: We included in this class stars of different spectral types and evolution stages, including late stages, like Wolf-Rayet (WR) stars or Luminous Blue Variables (LBVs), and X-ray binaries (hereafter abbreviated as XBs for brevity). The sensitivity of existing telescopes has been the major limitation in radio star searches, as the emission is rather faint, often below the mJy level. Furthermore, a limited angular resolution, e.g. above 1′′ (Helfand et al. Reference Helfand1999), makes cross-matching with densely populated optical catalogues ineffective. In fact, the number of reported radio stars is rather low, and no comprehensive catalogue, including all possible stellar types, is currently available. To build a sufficiently large dataset, we considered different reference catalogues of known and candidate radio stars, to be cross-matched with available radio data. References are reported in Table 2.
-
Hii regions: We have used the WISE Catalogue of Galactic Hii regions (Anderson et al. Reference Anderson2014; Makai Reference Makai2017), as a reference for searching Hii region associations in our radio data. The catalogue is actively updated online.Footnote aa The version used for this work (v2.2) contains 8 412 entries,
$\sim$
10% of them with measured radio flux information reported at 20
$-$
21 cm. -
Planetary Nebulae (PNe): We have used the Hong Kong/AAO/Strasbourg H-alpha (HASH) Planetary Nebula Database (Parker et al. Reference Parker2016), representing the largest compilation to date, as a reference for searching PNe in our radio data. The HASH catalogue is actively updated online.Footnote bb The version used for this work contains 5 591 entries,
$\sim$
24% of them with measured radio flux density reported at 20 cm or 36 cm. -
Young Stellar Objects (YSOs): We carried out a search for possible associations to confirmed YSOs in our radio data, using the SIMBAD databaseFootnote cc as a reference. No distinction is made among possible evolution or mass classes of YSOs. In the search, we discarded all matches found to compact radio sources, previously labelled as Hii regions and PNe.
-
Pulsars: We have searched for pulsar matches in our radio data, using the ATNF Pulsar CatalogueFootnote dd (Manchester et al. Reference Manchester, Hobbs, Teoh and Hobbs2005) as a reference. The version used (version 1.63) for this work contains 2 800 entries, 67% of them with measured radio flux density reported at 21 cm.
-
Active Galactic Nuclei: For our analysis, we considered a catalogue of radio galaxies and quasars obtained by Kimball & Ivezić (Reference Kimball and Ivezić2008) through cross-matching of different radio surveys (FIRST, primarily) with optical data from the Sloan Digital Sky Survey (SDSS) (York et al. Reference York2000), providing source spectroscopic classification (‘GALAXY’, ‘QSO’) (see Bolton et al. Reference Bolton2012 for details). After applying the criteria given by Kimball & Ivezić (Reference Kimball and Ivezić2008) to select compact and unresolved sources, we selected 7 967 radio galaxies (RG), and 5 994 QSOs. By visual inspection, we removed residual extended sources passing the selection cuts, and sources found with incorrect/unclear position reported in the catalogue, as compared to FIRST images. The final selected sample includes: 6 646 radio galaxies and 5 213 QSOs.



A brief description of physical properties for each of these source classes is reported in Appendix A. As we expect these types to be the most abundant classes of compact sources found in Galactic plane observations, we did not consider other rarer classes. Actually, star-forming galaxies (SFG) are expected to become dominant over AGNs at sub-mJy flux levels (<100
 $\unicode{x03BC}$
Jy) (Mancuso et al. Reference Mancuso2017) but their counts should be very small in FIRST/ASKAP-RACS surveys, given their sensitivities. This is, however, not the case for future ASKAP-EMU observations, so future studies should aim to incorporate SFGs in our dataset, once reference labelled catalogues become available within EMU.
$\unicode{x03BC}$
Jy) (Mancuso et al. Reference Mancuso2017) but their counts should be very small in FIRST/ASKAP-RACS surveys, given their sensitivities. This is, however, not the case for future ASKAP-EMU observations, so future studies should aim to incorporate SFGs in our dataset, once reference labelled catalogues become available within EMU.
Table 3. Summary information on the compact source data extracted from previous radio surveys (FIRST, THOR, GLOSTAR, MAGPIS, CORNISH). Columns (3) and (4) are the average radio source angular size and its standard deviation in arcsec. Column (5) lists the number of sources from previous radio surveys for each considered class or sub-class in columns (1) and (2) with available Mid-Infrared data (3.4
 $\unicode{x03BC}\mathrm{m}$
, 4.6
$\unicode{x03BC}\mathrm{m}$
, 4.6
 $\unicode{x03BC}\mathrm{m}$
, 12
$\unicode{x03BC}\mathrm{m}$
, 12
 $\unicode{x03BC}\mathrm{m}$
, 22
$\unicode{x03BC}\mathrm{m}$
, 22
 $\unicode{x03BC}\mathrm{m}$
) from AllWISE survey. Column (6) lists the number of radio sources with available Mid-Infrared data (3.4
$\unicode{x03BC}\mathrm{m}$
) from AllWISE survey. Column (6) lists the number of radio sources with available Mid-Infrared data (3.4
 $\unicode{x03BC}\mathrm{m}$
, 4.6
$\unicode{x03BC}\mathrm{m}$
, 4.6
 $\unicode{x03BC}\mathrm{m}$
, 8
$\unicode{x03BC}\mathrm{m}$
, 8
 $\unicode{x03BC}\mathrm{m}$
, 12
$\unicode{x03BC}\mathrm{m}$
, 12
 $\unicode{x03BC}\mathrm{m}$
, 22
$\unicode{x03BC}\mathrm{m}$
, 22
 $\unicode{x03BC}\mathrm{m}$
) from AllWISE and GLIMPSE surveys, and Far-Infrared data (70
$\unicode{x03BC}\mathrm{m}$
) from AllWISE and GLIMPSE surveys, and Far-Infrared data (70
 $\unicode{x03BC}\mathrm{m}$
) from Hi-GAL survey. Column (7) reports the number of radio sources with average spectral index information available (see text). Columns (8) and (9) reports how many sources listed in columns (5) and (6), respectively, also have a measured spectral index.
$\unicode{x03BC}\mathrm{m}$
) from Hi-GAL survey. Column (7) reports the number of radio sources with average spectral index information available (see text). Columns (8) and (9) reports how many sources listed in columns (5) and (6), respectively, also have a measured spectral index.
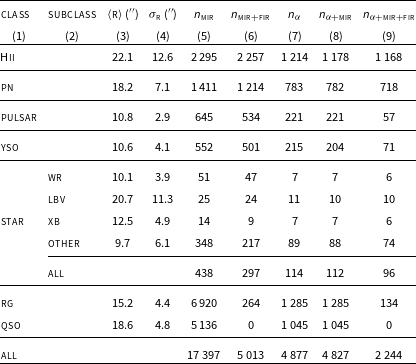
Table 4. Summary information on the compact source data extracted from different ASKAP radio surveys (RACS, EMU pilot). See Table 3 caption for column description.
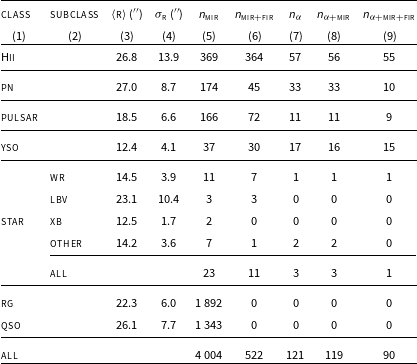

Figure 1. Template source (G324.161+00.264, Hii region) from the dataset, observed in 7-bands (3.4
 $\unicode{x03BC}\mathrm{m}$
, 4.6
$\unicode{x03BC}\mathrm{m}$
, 4.6
 $\unicode{x03BC}\mathrm{m}$
, 8
$\unicode{x03BC}\mathrm{m}$
, 8
 $\unicode{x03BC}\mathrm{m}$
, 12
$\unicode{x03BC}\mathrm{m}$
, 12
 $\unicode{x03BC}\mathrm{m}$
, 22
$\unicode{x03BC}\mathrm{m}$
, 22
 $\unicode{x03BC}\mathrm{m}$
, 70
$\unicode{x03BC}\mathrm{m}$
, 70
 $\unicode{x03BC}\mathrm{m}$
, and ASKAP radio 944 MHz), shown in left to right panels, respectively.
$\unicode{x03BC}\mathrm{m}$
, and ASKAP radio 944 MHz), shown in left to right panels, respectively.
Sources detected in our considered radio maps are reported in Tables 3 and 4. The resulting dataset is not expected to be completely free of spurious associations, due to the cross-matching procedure and to possible object misclassifications affecting the reference catalogues. Indeed, one of the goal of this and future studies is to make these unlikely classifications discoverable by means of both supervised and unsupervised techniques. The uncertainty associated with the automated cross-matching procedure was evaluated on the ASKAP data by comparing the observed Hii regions matches (i.e. the most densely populated reference catalogue) against the expected number of matches purely arising by chance. Following Riggi et al. (Reference Riggi2021a), Mauch & Sadler (Reference Mauch and Sadler2007), Ching et al. (Reference Ching2017), the latter was estimated by averaging the number of matches found with multiple random catalogues in which the measured source positions were uniformly randomised inside the radio map. We found that less than 3% of the selected matches are spurious. For each class, the obtained matches were all validated by visual inspection to reduce the number of spurious associations.
3.2. Image dataset preparation
Using the scutout tool,Footnote ee we extracted postage-stamp images around each compact source detected in reference radio maps listed in Section 2. Additionally, source cutouts were extracted from the supplementary infrared survey maps described in Section 2.3. Cutout raw size was set to 10
 $\times$
the source radius
$\times$
the source radius
 $r_{s}$
.Footnote ff The image cutout set for each source, including the radio plus a configurable number of infrared bands (3.4
$r_{s}$
.Footnote ff The image cutout set for each source, including the radio plus a configurable number of infrared bands (3.4
 $\unicode{x03BC}\mathrm{m}$
, 4.6
$\unicode{x03BC}\mathrm{m}$
, 4.6
 $\unicode{x03BC}\mathrm{m}$
, 8
$\unicode{x03BC}\mathrm{m}$
, 8
 $\unicode{x03BC}\mathrm{m}$
, 12
$\unicode{x03BC}\mathrm{m}$
, 12
 $\unicode{x03BC}\mathrm{m}$
, 22
$\unicode{x03BC}\mathrm{m}$
, 22
 $\unicode{x03BC}\mathrm{m}$
, 70
$\unicode{x03BC}\mathrm{m}$
, 70
 $\unicode{x03BC}\mathrm{m}$
), were all re-processed (e.g. re-gridding/re-projection, re-scaling, cropping) to bring them to the same pixel size, sky coordinate system, resolution, flux density units (Jy/pixel), and final image size (2.5
$\unicode{x03BC}\mathrm{m}$
), were all re-processed (e.g. re-gridding/re-projection, re-scaling, cropping) to bring them to the same pixel size, sky coordinate system, resolution, flux density units (Jy/pixel), and final image size (2.5
 $\times r_{s}$
). Final images have a different size in pixels, depending on the source size radius
$\times r_{s}$
). Final images have a different size in pixels, depending on the source size radius
 $r_{s}$
. In the analysis reported in Section 5.2, all source images will be resized to a common size in pixels.
$r_{s}$
. In the analysis reported in Section 5.2, all source images will be resized to a common size in pixels.
As the 8
 $\unicode{x03BC}\mathrm{m}$
and far-infrared surveys only cover the Galactic plane, in contrast to the full WISE sky coverage, we considered two possible radio-infrared combinations when making the image cutouts, denoted throughout the paper as follows:
$\unicode{x03BC}\mathrm{m}$
and far-infrared surveys only cover the Galactic plane, in contrast to the full WISE sky coverage, we considered two possible radio-infrared combinations when making the image cutouts, denoted throughout the paper as follows:
-
5-bands (or radio+MIRFootnote gg) dataset: comprising radio, 3.4, 4.6, 12, and 22
$\unicode{x03BC}\mathrm{m}$
images; -
7-bands (or radio+MIR+FIRFootnote hh) dataset: comprising radio, 3.4, 4.6, 8, 12, 22, and 70
$\unicode{x03BC}\mathrm{m}$
images.


In Fig. 1 we report the image data for a sample source (G324.161+00.264 Hii region) detected in 7 different channels. Infrared (3.4
 $\unicode{x03BC}\mathrm{m}$
, 4.6
$\unicode{x03BC}\mathrm{m}$
, 4.6
 $\unicode{x03BC}\mathrm{m}$
, 8
$\unicode{x03BC}\mathrm{m}$
, 8
 $\unicode{x03BC}\mathrm{m}$
, 12
$\unicode{x03BC}\mathrm{m}$
, 12
 $\unicode{x03BC}\mathrm{m}$
, 22
$\unicode{x03BC}\mathrm{m}$
, 22
 $\unicode{x03BC}\mathrm{m}$
, 70
$\unicode{x03BC}\mathrm{m}$
, 70
 $\unicode{x03BC}\mathrm{m}$
) and radio (ASKAP) data are shown in left to right panels, respectively.
$\unicode{x03BC}\mathrm{m}$
) and radio (ASKAP) data are shown in left to right panels, respectively.
The number of available images finally selected in previous radio surveys (FIRST, THOR, GLOSTAR, MAGPIS, CORNISH) and in ASKAP surveys is reported for each source class in Tables 3 and 4, respectively. Columns (5) and (6) report the number of sources detected in radio, for which MIR and FIR images are available.Footnote ii Overall,
 $\sim$
17 400 radio sources are available in the first dataset with MIR (5-bands) information,
$\sim$
17 400 radio sources are available in the first dataset with MIR (5-bands) information,
 $\sim$
30% of them with also FIR information (7-bands). Extragalactic sources are almost completely missing in our 7-bands dataset, due to the limited coverage of far-infrared surveys. A major consequence is that, unfortunately, galactic-extragalactic source separation studies can be carried out only with the 5-bands dataset. On the other hand, this is, to the best of our knowledge, the largest radio data compilation simultaneously including different classes of Galactic and extragalactic compact objects, suitable for machine-learning and other algorithmic studies.
$\sim$
30% of them with also FIR information (7-bands). Extragalactic sources are almost completely missing in our 7-bands dataset, due to the limited coverage of far-infrared surveys. A major consequence is that, unfortunately, galactic-extragalactic source separation studies can be carried out only with the 5-bands dataset. On the other hand, this is, to the best of our knowledge, the largest radio data compilation simultaneously including different classes of Galactic and extragalactic compact objects, suitable for machine-learning and other algorithmic studies.
4. Feature extraction and data exploration
In this section, we describe the methods used to process our dataset and extract parameters suitable for data inspection and source classification.
4.1. Infrared-radio color parameters
Colour indices
 $c_{i,j}$
are defined as the magnitude difference between measured fluxes
$c_{i,j}$
are defined as the magnitude difference between measured fluxes
 $F_{i}$
and
$F_{i}$
and
 $F_{j}$
in band i and j where
$F_{j}$
in band i and j where
 $\lambda_j$
>
$\lambda_j$
>
 $\lambda_i$
(Nikutta et al. Reference Nikutta2014), e.g.
$\lambda_i$
(Nikutta et al. Reference Nikutta2014), e.g.
 $c_{i,j}=\log_{10}(F_j/F_i)$
. We considered these radio-infrared colour indices (
$c_{i,j}=\log_{10}(F_j/F_i)$
. We considered these radio-infrared colour indices (
 $c_{radio,3.4\,\unicode{x03BC}\mathrm{m}}$
,
$c_{radio,3.4\,\unicode{x03BC}\mathrm{m}}$
,
 $c_{radio,4.6\,\unicode{x03BC}\mathrm{m}}$
,
$c_{radio,4.6\,\unicode{x03BC}\mathrm{m}}$
,
 $c_{radio,8\,\unicode{x03BC}\mathrm{m}}$
,
$c_{radio,8\,\unicode{x03BC}\mathrm{m}}$
,
 $c_{radio,12\,\unicode{x03BC}\mathrm{m}}$
,
$c_{radio,12\,\unicode{x03BC}\mathrm{m}}$
,
 $c_{radio,22\,\unicode{x03BC}\mathrm{m}}$
,
$c_{radio,22\,\unicode{x03BC}\mathrm{m}}$
,
 $c_{radio,70\,\unicode{x03BC}\mathrm{m}}$
), in which source fluxes F were computed for each band as follows:
$c_{radio,70\,\unicode{x03BC}\mathrm{m}}$
), in which source fluxes F were computed for each band as follows:
-
Compute background level B and noise rms
$\sigma_{rms}$
from median and standard deviation of 3
$\sigma$
-clipped pixel flux distribution; -
Find local maxima (or peaks) in image;
-
Extract sources with a flood-fill algorithm, assuming a 5
$\sigma$
and 2.5
$\sigma$
seed and merge detection thresholds, respectively, with respect to previously computed background. Further, require at least one peak detected inside extracted source aperture; -
Compute flux information by standard aperture photometry, i.e.
$F=\sum_{i}^{N}F_{i}-N\times B$
, where
$F_{i}$
and N are the flux of i-th pixel and number of pixels in source aperture, respectively.






Besides colour indices, we also computed these additional parameters for radio-infrared band combinations (radio, j with j = [3.4
 $\unicode{x03BC}\mathrm{m}$
, 4.6
$\unicode{x03BC}\mathrm{m}$
, 4.6
 $\unicode{x03BC}\mathrm{m}$
, 8
$\unicode{x03BC}\mathrm{m}$
, 8
 $\unicode{x03BC}\mathrm{m}$
, 12
$\unicode{x03BC}\mathrm{m}$
, 12
 $\unicode{x03BC}\mathrm{m}$
, 22
$\unicode{x03BC}\mathrm{m}$
, 22
 $\unicode{x03BC}\mathrm{m}$
, 70
$\unicode{x03BC}\mathrm{m}$
, 70
 $\unicode{x03BC}\mathrm{m}$
]) to quantify the likelihood of source cross-match association:
$\unicode{x03BC}\mathrm{m}$
]) to quantify the likelihood of source cross-match association:
-
${\textit{IoU}}_{\text{radio},j}$
: Intersection-Over-Union (IoU) between source islands detected in radio and infrared band j. IoU is computed as: where
\begin{equation*}\text{IoU}=\frac{n_{overlap}}{n_{union}}\end{equation*}
$n_{overlap}$
is the number of pixels that overlap in radio and infrared islands, while
$n_{union}$
is the number of pixels of island union. IoU is set to 0 if no source is detected in band j;
-
${\textit{SSIM}}_{\text{radio},j}$
: Average Structural Similarity (SSIM, Wang et al. Reference Wang2004) computed between source image in radio and infrared band j. SSIM metric is computed on various image windows and measures the perceptual difference between two images. For two windows x and y of size
$K\times K$
, SSIM is computed asFootnote jj: (1)where
\begin{equation}\text{SSIM}_{x,y}=\frac{(2\unicode{x03BC}_x\unicode{x03BC}_y+c_1)(2\sigma_{xy}+c_2)}{(\unicode{x03BC}^2_x+\unicode{x03BC}^2_y+c_1)(\sigma^2_x+\sigma^2_y+c_2)}\end{equation}
$\unicode{x03BC}_x$
/
$\sigma_x$
,
$\unicode{x03BC}_y$
/
$\sigma_y$
are the pixel sample mean/variance of x and y, respectively, and
$\sigma_{xy}$
is their covariance.
$c_1$
and
$c_2$
are constant values used to stabilise the ratio. SSIM index close to 1 indicates high similarity, while negative or close to zero indices denote a high discrepancy.














Overall, 12 (18) parameters are selected for classification analysis with the 5-band (7-band) dataset (see feature summary Table 5). In Figs. B1 and B2 we explored the degree of correlation among the extracted features, reporting the Pearson correlation coefficient r for each class in both the 5-band and 7-band datasets, respectively. In general, we observe a moderate correlation trend (r = 0.5-0.7) for many variables in all classes. The strongest correlation (r > 0.8) is found between radio-3.4
 $\unicode{x03BC}\mathrm{m}$
and radio-4.6
$\unicode{x03BC}\mathrm{m}$
and radio-4.6
 $\unicode{x03BC}\mathrm{m}$
colors, but also among SSIM and IoU parameters computed for these infrared bands. For galactic classes, the correlation becomes more important also among 12 and 22
$\unicode{x03BC}\mathrm{m}$
colors, but also among SSIM and IoU parameters computed for these infrared bands. For galactic classes, the correlation becomes more important also among 12 and 22
 $\unicode{x03BC}\mathrm{m}$
parameters. Given the computed 2-tailed p-values, we conclude that these correlations are significant at the 1% confidence level.
$\unicode{x03BC}\mathrm{m}$
parameters. Given the computed 2-tailed p-values, we conclude that these correlations are significant at the 1% confidence level.
Table 5. Summary of extracted color features used for classification analysis. See Section 4.1 for details.

In Table 6 we report the fraction of sources detected in each infrared band (according to the above criteria) having a minimum overlap (IoU > 0) with the radio source. These counts include possible spurious detections. On the other hand, missed counts may include IR sources failing to pass the applied detection criteria. In Fig. 2 we report scatter plots of (
 $c_{\text{radio},3.4\unicode{x03BC}\mathrm{m}}$
,
$c_{\text{radio},3.4\unicode{x03BC}\mathrm{m}}$
,
 $c_{\text{radio},22\,\unicode{x03BC}\mathrm{m}}$
), (
$c_{\text{radio},22\,\unicode{x03BC}\mathrm{m}}$
), (
 $c_{\text{radio},8\,\unicode{x03BC}\mathrm{m}}$
,
$c_{\text{radio},8\,\unicode{x03BC}\mathrm{m}}$
,
 $c_{\text{radio},70\,\unicode{x03BC}\mathrm{m}}$
) colour indices obtained for sources simultaneously detected (IoU > 0) in both bands over the entire dataset. As can be seen, extragalactic objects tend to cluster on the bottom left region of near- and mid-infrared colour space. Unfortunately, no data for extragalactic sources are available at 8 and 70
$c_{\text{radio},70\,\unicode{x03BC}\mathrm{m}}$
) colour indices obtained for sources simultaneously detected (IoU > 0) in both bands over the entire dataset. As can be seen, extragalactic objects tend to cluster on the bottom left region of near- and mid-infrared colour space. Unfortunately, no data for extragalactic sources are available at 8 and 70
 $\unicode{x03BC}\mathrm{m}$
in our dataset, where a larger separation is found among classes of Galactic sources, compared to other colour parameters.
$\unicode{x03BC}\mathrm{m}$
in our dataset, where a larger separation is found among classes of Galactic sources, compared to other colour parameters.
Table 6. Percentage of radio sources potentially detected (e.g. IoU > 0) in each infrared band.
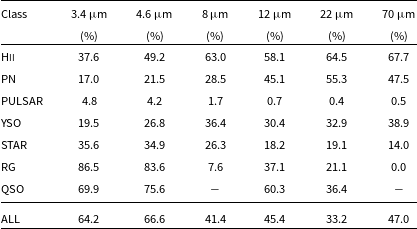
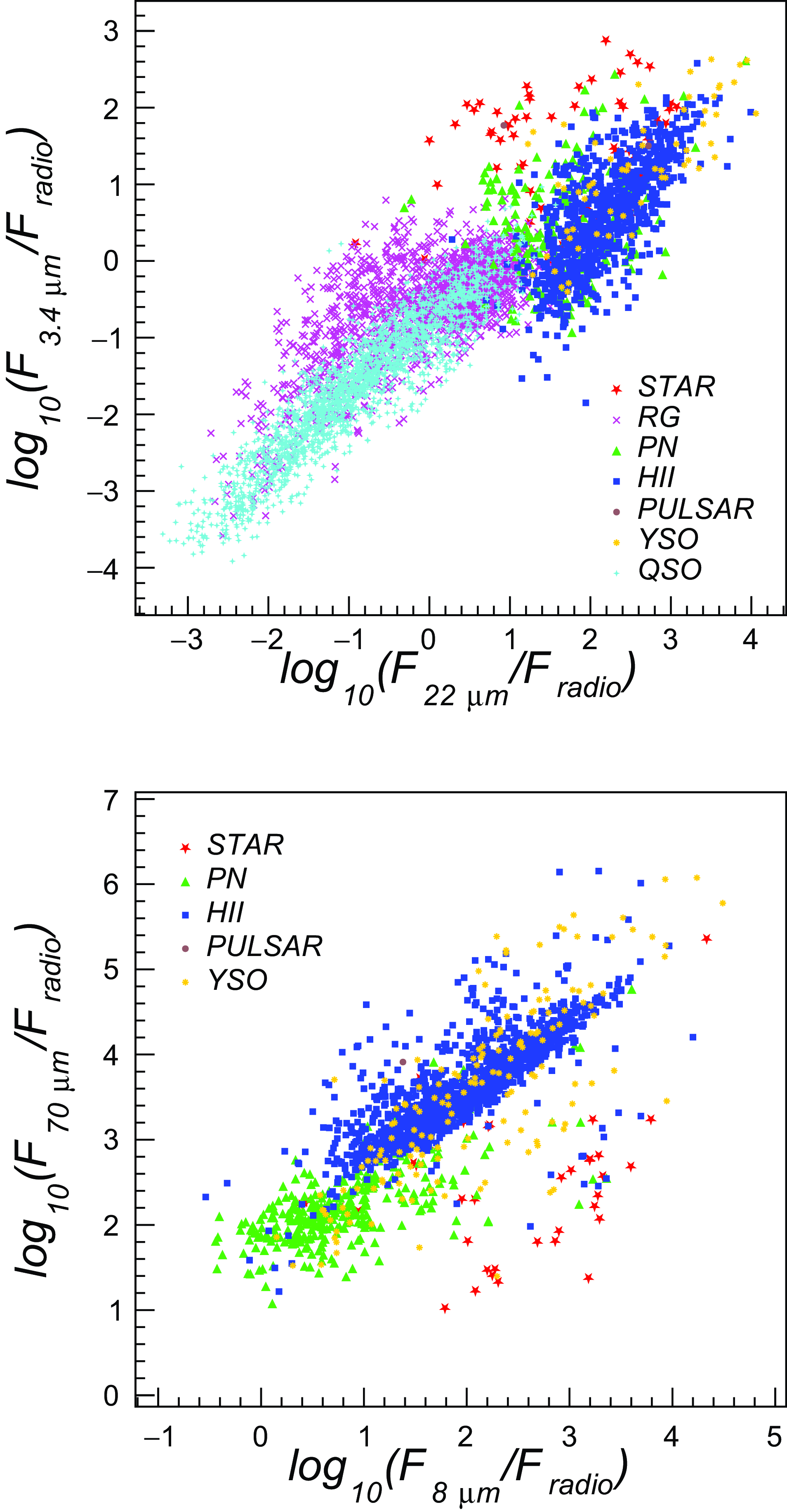
Figure 2. Scatter plots of representative infrared/radio colour indices computed over the entire dataset for images with detected sources in both the radio and infrared channels (IoUs > 0). Radio flux densities are obtained at different frequencies ranging from 0.912 GHz (ASKAP Early Science survey data) to 5.8 GHz (GLOSTAR). See Section 2 for details on survey frequencies.
Figure 3. Radio spectral indices measured for different source classes with the T-T plot method. Spectral indices for RG and QSO sources were computed using RACS-FIRST radio frequencies (887.5–1 400 MHz). Indices for the remaining Galactic classes were computed from survey selected sub-bands (when available), i.e. 871–1 480 MHz (ASKAP Scorpio), 1 060–1 440 MHz (THOR), 4 240–4 670 MHz (GLOSTAR).
4.2. Radio spectral indices
We computed the radio spectral index
 $\alpha$
(
$\alpha$
(
 $F\propto\nu^{\alpha}$
) of sources in our dataset using the T-T plot method (Turtle et al. Reference Turtle1962), e.g. taking the slope of a linear regression of pixel flux densities for source images at two different radio frequencies. This method enables a measurement of the spectral index that is less dependent on the zero level of each image, under the hypothesis of background isotropy and constant
$F\propto\nu^{\alpha}$
) of sources in our dataset using the T-T plot method (Turtle et al. Reference Turtle1962), e.g. taking the slope of a linear regression of pixel flux densities for source images at two different radio frequencies. This method enables a measurement of the spectral index that is less dependent on the zero level of each image, under the hypothesis of background isotropy and constant
 $\alpha$
. These conditions are holding since we are considering compact sources and regions of size comparable with the synthesised beam of the instrument.
$\alpha$
. These conditions are holding since we are considering compact sources and regions of size comparable with the synthesised beam of the instrument.
A subset of our survey data (THOR, ASKAP pilot, GLOSTAR) provide sub-band data that can be used for T-T spectral fit. For VLA FIRST data, instead, we resorted to use data from the ASKAP RACS survey to obtain an estimate of the radio spectral index. It is worth to note that such two-point spectral index estimate is not accurate for sources having a curved spectrum, not well described by a power-law model. Indeed, some classes of sources, such as PN (Hajduk et al. Reference Hajduk2018) or UC Hii regions (Yang et al. Reference Yang2021), could present a turnover frequency in the frequency range (0.8–5 GHz). The frequency coverage of our in-band survey data is, however, rather limited (e.g. 0.87–1.6 GHz for ASKAP) to expect a reliable measurement of any spectral turnovers. Nevertheless, we inspected the ASKAP dataset to search for possible departures from the power-law assumption, by fitting ASKAP source SEDs with different curved spectrum models (e.g. free-free, synchrotron with free-free absorption, see Tingay & de Kool Reference Tingay and de Kool2003). We found only 5 sources (out of 190 sources with flux measurement available in all five ASKAP sub-bands) that can be fitted (
 $\tilde{\chi}^{2}$
< 5) with a curved model.
$\tilde{\chi}^{2}$
< 5) with a curved model.
In Fig. 3 we report the obtained spectral indices for different source classes in our dataset. To select more reliable measurements, we selected sources for which the spectral regression correlation coefficient was larger than 0.9. The number of sources per class with measured spectral index (and infrared data) have been reported in Tables 3 and 4 (columns 7–9). The obtained values follow expectations (e.g. see Appendix A) or previous measurements for some source classes. For example, pulsars have the steepest radio spectrum, while Hii regions and PNe have predominantly flatter radio spectra (
 $\alpha\sim$
0), with a significantly smaller fraction peaking around
$\alpha\sim$
0), with a significantly smaller fraction peaking around
 $\alpha$
= 1. The observed spectral indices of radio galaxies and quasars peak around
$\alpha$
= 1. The observed spectral indices of radio galaxies and quasars peak around
 $-$
0.9, in general agreement with the
$-$
0.9, in general agreement with the
 $-$
0.95 value reported by Randall et al. (Reference Randall2012) (Fig. 8) in the frequency range 0.843–2.3 GHz, but slightly steeper than conventional value
$-$
0.95 value reported by Randall et al. (Reference Randall2012) (Fig. 8) in the frequency range 0.843–2.3 GHz, but slightly steeper than conventional value
 $ \langle\alpha\rangle$
=
$ \langle\alpha\rangle$
=
 $-$
0.7 (Condon et al. Reference Condon2002; Best et al. Reference Best2005) or measured averages reported at different frequency ranges, e.g.
$-$
0.7 (Condon et al. Reference Condon2002; Best et al. Reference Best2005) or measured averages reported at different frequency ranges, e.g.
 $\langle\alpha\rangle$
=
$\langle\alpha\rangle$
=
 $-$
0.79 (0.147–1.4 GHz) (de Gasperin et al. Reference de Gasperin2018) or
$-$
0.79 (0.147–1.4 GHz) (de Gasperin et al. Reference de Gasperin2018) or
 $\langle\alpha\rangle$
=
$\langle\alpha\rangle$
=
 $-$
0.71 (1.4–3.0 GHz) (Gordon et al. Reference Gordon2021). This comparison is only indicative as the measured average spectral indices are known to steepen (from
$-$
0.71 (1.4–3.0 GHz) (Gordon et al. Reference Gordon2021). This comparison is only indicative as the measured average spectral indices are known to steepen (from
 $-$
0.7 to
$-$
0.7 to
 $-$
1) with increasing flux densities, and vary with other parameters such as the size of the source or the flux density threshold (e.g. see de Gasperin et al. Reference de Gasperin2018 and references therein).
$-$
1) with increasing flux densities, and vary with other parameters such as the size of the source or the flux density threshold (e.g. see de Gasperin et al. Reference de Gasperin2018 and references therein).
Considering the large synthesised beams, it is worth to note that for some radio star types (e.g. LBVs) we could be actually measuring a composite spectral index of the point-source (typically
 $\alpha\sim$
0.6) and the surrounding nebula (which could be
$\alpha\sim$
0.6) and the surrounding nebula (which could be
 $\alpha$
< 0). This may represent a potential source of misclassification of radio stars when incorporating the spectral index information in the classification analysis (Section 5.1.4). We also note the absence of radio stars with spectral indices in the range [0.2
$\alpha$
< 0). This may represent a potential source of misclassification of radio stars when incorporating the spectral index information in the classification analysis (Section 5.1.4). We also note the absence of radio stars with spectral indices in the range [0.2
 $-$
0.3], where we would expect about 4 counts. This is not understood at present and should be investigated in the future with an extended source sample.
$-$
0.3], where we would expect about 4 counts. This is not understood at present and should be investigated in the future with an extended source sample.
5. Source classification analysis
We used the dataset described in Section 3 to perform classification studies with supervised learning algorithms. We carried out two different analysis. The first one, reported in Section 5.1, uses the set of conventional features (color indices, spectral indices) extracted from the dataset, as described in Section 4, and gradient-boosted decision trees as classifier method. A second analysis, reported in Section 5.2, employs convolutional neural networks for automated feature extraction and source image classification.
The entire dataset, including data from all radio surveys, was split into three ‘mixed’ survey subsets (train, validation, test sets), containing 55%/15%/30% of the original data, respectively. Five train/validation/test splits were randomly generated to estimate the model performance uncertainties. We also produced additional data splits with exclusively ASKAP data in the test set, and previous radio surveys in train and validation sets (with a 70%/30% data proportion). These samples were used to estimate how the classifier performs on a specific survey, when trained on a mixture of completely different surveys.
In both analysis, we made use of the following metrics,Footnote kk widely adopted in multi-class classification problems, to estimate the achieved classification performances:
-
Recall (
$\mathcal{R}$
): Fraction of sources of a given class that were correctly classified by the model out of all sources labelled in that class, computed as:
\begin{equation*}\mathcal{R}=\frac{TP}{TP + FN}\end{equation*}
-
Precision (
$\mathcal{P}$
): Fraction of sources correctly classified as belonging to a specific class, out of all sources the model predicted to belong to that class, computed as:
\begin{equation*}\mathcal{P}=\frac{TP}{TP+FP}\end{equation*}
-
F1-score: the harmonic mean of precision and recall:
(2)
\begin{equation}\text{F1-score}=2\times\frac{\mathcal{P}\times\mathcal{R}}{\mathcal{P}+\mathcal{R}}\end{equation}





where TP, FP, FN are the number of true positives, false positives, and false negatives, respectively. These metrics were computed for each source class individually, and cumulatively over all dataset. In the latter case, individual class metrics were first weighted by the number of sources present for each class to account for class unbalance, and then averaged.
5.1. LightGBM classification
5.1.1. Model training
We trained a LightGBMFootnote ll (Ke et al. Reference Ke2017) classifier over the produced 5-band and 7-band dataset splits (‘mixed’ surveys sets and non-ASKAP survey sets), using the set of feature parameters described in Section 4 as inputs. LightGBM is a distributed and high-performance gradient boosting framework based on decision tree algorithm, widely adopted for classification tasks as known to reach comparable (or even better) performances on tabular data with considerably lower training times and memory usage with respect to other popular libraries (e.g. XGBoost). The most important algorithm hyperparameters controlling the model accuracy and overfitting are: max_depth, num_leaves, min_data_in_leaf, num_iterations.Footnote mm
To select suitable hyperparameter values, we performed several training runs in which we varied max_depth values in the [2,12] range, and num_leaves
 $\le$
2
$\le$
2
 $^{\texttt{max_depth}}$
, observing the resulting model F1-score on the test set. For each training run, we used early stopping on validation data to select the optimal num_iterations parameter (typically found <100 in all performed runs). For a given tree depth choice, we also scanned different values of min_data_in_leaf from 5 to 100.
$^{\texttt{max_depth}}$
, observing the resulting model F1-score on the test set. For each training run, we used early stopping on validation data to select the optimal num_iterations parameter (typically found <100 in all performed runs). For a given tree depth choice, we also scanned different values of min_data_in_leaf from 5 to 100.
Classification results achieved over the available feature subsets and dataset splits are summarised in Fig. 4 and Table 7, and discussed with more details in the following paragraphs.
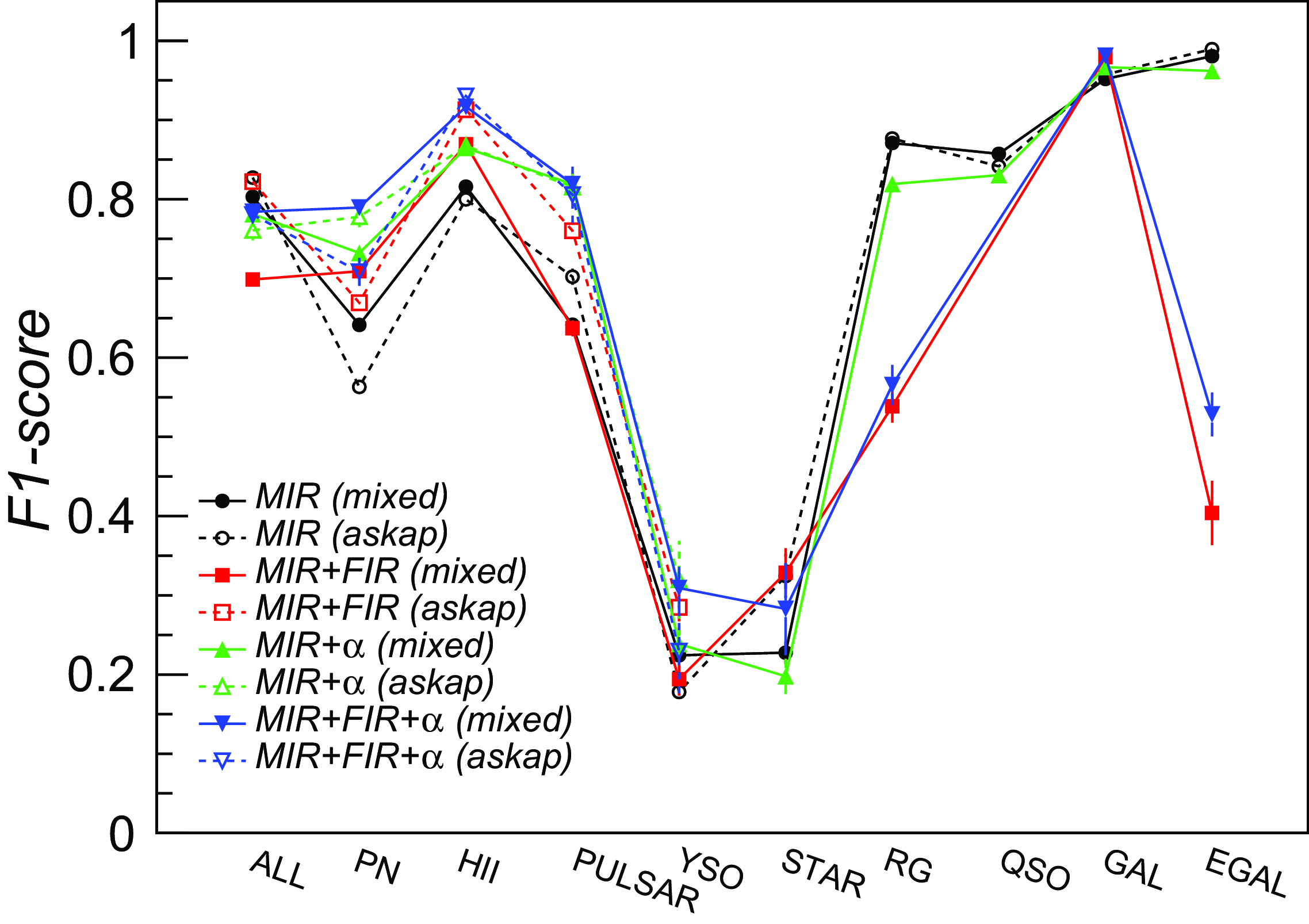
Figure 4. Average F1-score metric achieved by the LightGBM trained classifier for binary classification of Galactic and Extragalactic source groups and for multiclass classification, computed over five ‘mixed’ survey test sets (labelled as ‘mixed’ and shown with filled markers) and pure ASKAP test sets (labelled as ‘askap’ and shown with open markers). The error bars are the F1-score standard deviations obtained over the five test sets. Results obtained over the 5-band (radio+MIR) datasets without and with the spectral index (
 $\alpha$
) information are, respectively, shown with black dots and green triangles, while results obtained over the 7-band (radio+MIR+FIR) datasets are, respectively, shown with red squares and blue inverted triangles.
$\alpha$
) information are, respectively, shown with black dots and green triangles, while results obtained over the 7-band (radio+MIR+FIR) datasets are, respectively, shown with red squares and blue inverted triangles.
Table 7. Average F1-score metrics achieved by the LightGBM trained classifier for binary classification of Galactic and Extragalactic source groups and for multiclass classification, computed over five ‘mixed’ survey test sets (labelled as ‘mixed’) and pure ASKAP test sets (labelled as ‘askap’). Metrics were not reported if less than 10 sources are available in the test set. Column groups (2-3) and (6-7) report the results obtained over the 5-band (radio+MIR) datasets without and with the spectral index (
 $\alpha$
) information, respectively. Results in column groups (4-5) and (8-9) are relative to the 7-band (radio+MIR+FIR) dataset. Parameters for binary (multiclass) models were set to: num_leaves = 2 (32), min_data_in_leaf = 20 (20), max_depth = 1 (5).
$\alpha$
) information, respectively. Results in column groups (4-5) and (8-9) are relative to the 7-band (radio+MIR+FIR) dataset. Parameters for binary (multiclass) models were set to: num_leaves = 2 (32), min_data_in_leaf = 20 (20), max_depth = 1 (5).
In Figs. B3, B4, B5 and B6, we inspected the relative importance of each feature provided to trained LightGBM classifiers, finding that radio-infrared colour indices are always ranked among the top most sensitive features, along with the radio spectral index, while morphological parameters (radio-infrared IoUs) are ranked last.
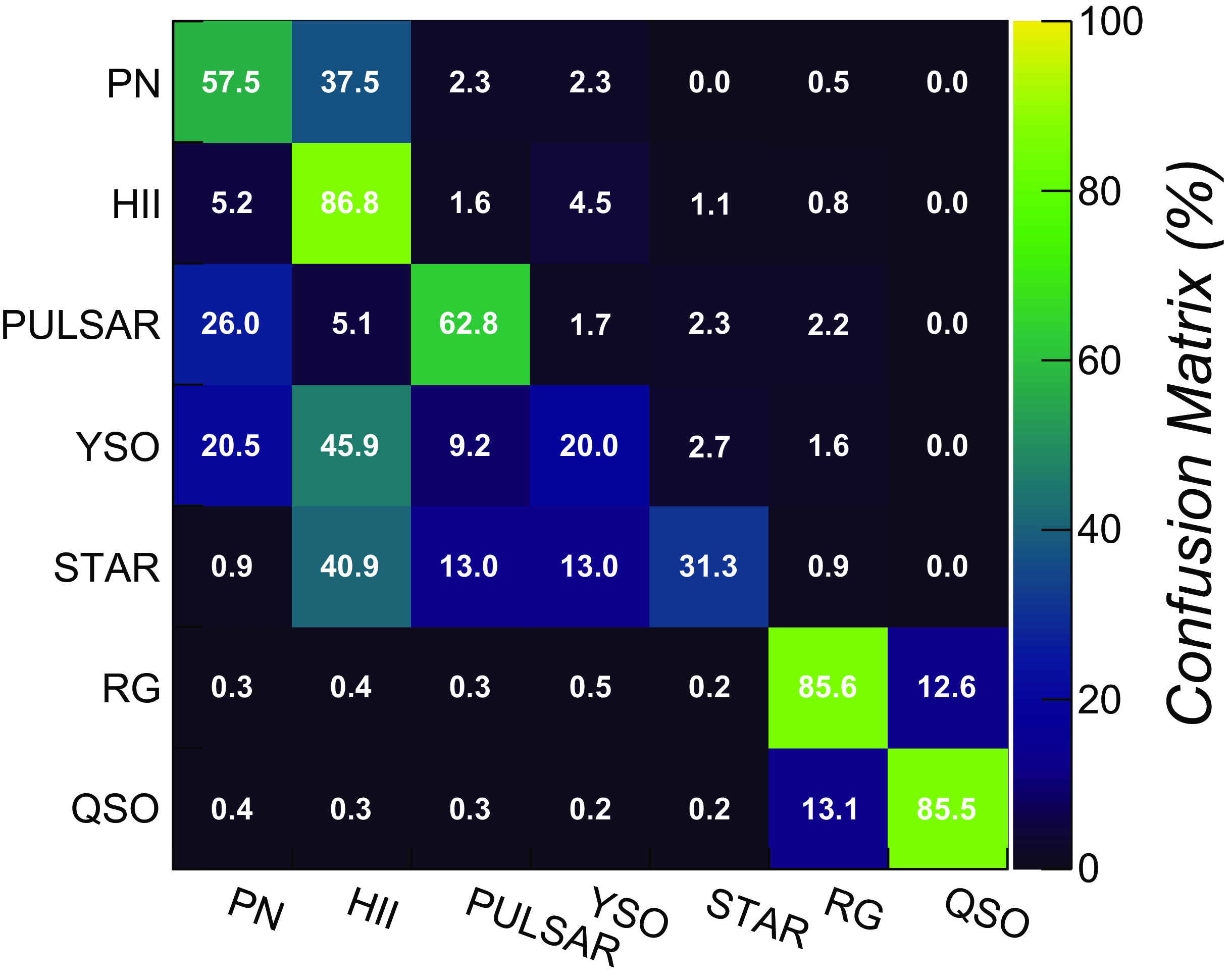
Figure 5. Confusion matrix of the trained LightGBM classifier obtained over the 5-band (radio+MIR) pure ASKAP test datasets.
5.1.2. Results on radio+MIR data
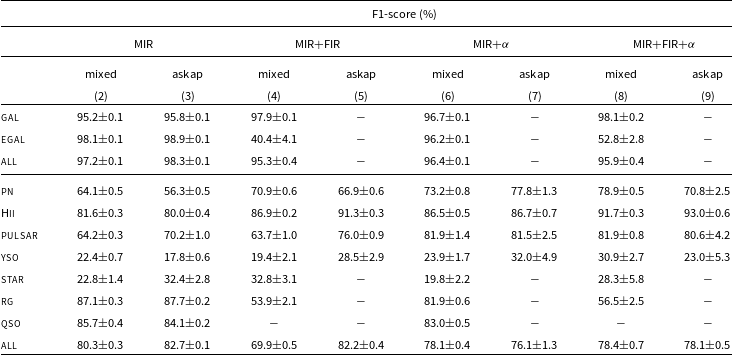
In Table 7 (rows 1-3, columns 2, 3), we report the F1-score metric of the trained LightGBM model, obtained on the 5-band ‘mixed’ and ‘askap’ test datasets, for classifying sources into two groups: Galactic (i.e. including target object classes of interest for Galactic science studies, such as PNe, Hii regions, pulsars, YSO, and stars), and Extragalactic (i.e. including radio galaxies and quasars). The model is able to identify sources belonging to the two groups with very high accuracy (above 90%), with a relatively shallow tree configuration (max_depth = 1 or 2), even when presented with data observed with a completely different survey (ASKAP) with respect to those used in the training sample. As the Galactic-Extragalactic discrimination analysis can only be done using this dataset, due to the existing survey coverage and catalogue availability, this is a remarkable and encouraging result (e.g. there is no strong need for additional multi-wavelength data).
Discrimination of individual source classes was also studied. A deeper model (max_depth = 5) was found to provide the best performances in the parameter scan. Classification metrics obtained over both ‘mixed’ and ‘askap’ test set are reported in Table 7 (rows 4-11, columns 2, 3), while the source confusion matrix obtained over the ‘mixed’ survey test sets is plotted in Fig. 5. In this case, extragalactic sources (radio galaxies, QSO) can be identified with
 $\sim$
85% accuracy, with a rate of misclassified sources of the order of 15%, almost entirely in the direction of the other extragalactic source category (e.g. QSO
$\sim$
85% accuracy, with a rate of misclassified sources of the order of 15%, almost entirely in the direction of the other extragalactic source category (e.g. QSO
 $\rightarrow$
galaxy, and vice versa). PNe, Hii regions and pulsars are the best classified sources within the Galactic group. Lowest misclassification rates towards other classes are obtained for Hii regions, found below 15%. PNe are more likely (38%) to be misclassified as Hii regions. As reported in previous studies (Anderson et al. Reference Anderson2012), we expect that a better discrimination power between the two types can be achieved by employing far-infrared and 8
$\rightarrow$
galaxy, and vice versa). PNe, Hii regions and pulsars are the best classified sources within the Galactic group. Lowest misclassification rates towards other classes are obtained for Hii regions, found below 15%. PNe are more likely (38%) to be misclassified as Hii regions. As reported in previous studies (Anderson et al. Reference Anderson2012), we expect that a better discrimination power between the two types can be achieved by employing far-infrared and 8
 $\unicode{x03BC}\mathrm{m}$
data (see next paragraph). Poor classification results are obtained on the radio stars and YSO samples, with F1-scores ranging from 20% to 30%. YSOs are largely (
$\unicode{x03BC}\mathrm{m}$
data (see next paragraph). Poor classification results are obtained on the radio stars and YSO samples, with F1-scores ranging from 20% to 30%. YSOs are largely (
 $\sim$
66%) misclassified as Hii regions or PNe. This is somewhat expected, as a fraction of SIMBAD objects classified as YSO (used as a reference for building the training sample) were also found listed in the WISE Hii region and HASH PN catalogues. Future data releases shall therefore focus on assessing the reliability of our YSO candidates, removing the identification ambiguities before repeating the classification analysis. The same labelling issue is also potentially affecting the radio star classification. Poor results on some Galactic class may be therefore not only due to the limited training sample, but also ascribed to the reliability of original source classification present in the literature.
$\sim$
66%) misclassified as Hii regions or PNe. This is somewhat expected, as a fraction of SIMBAD objects classified as YSO (used as a reference for building the training sample) were also found listed in the WISE Hii region and HASH PN catalogues. Future data releases shall therefore focus on assessing the reliability of our YSO candidates, removing the identification ambiguities before repeating the classification analysis. The same labelling issue is also potentially affecting the radio star classification. Poor results on some Galactic class may be therefore not only due to the limited training sample, but also ascribed to the reliability of original source classification present in the literature.
In Fig. 6 (top panel) we reported the F1 classification score for all classes in the 5-band ASKAP test dataset as a function of the computed radio source signal-to-noise ratio (SNR). The overall classification performance is mostly flat over the SNR range, while individual classes do show some dependency on the SNR, e.g. F1-score is increasing with SNR for PNe/QSOs and decreasing for pulsars/radio galaxies. As shown in Fig. 6 (bottom panel), the observed trends for each class seem to correlate with the number of corresponding images available in each SNR bin.
5.1.3. Results on radio+MIR+FIR data
In Table 7 (columns 4, 5) we report the F1-score metric of the trained LightGBM model, obtained on the 7-band ‘mixed’ and ‘askap’ test datasets. Only 5 Galactic classes are available in the latter case, but we did not report classification metrics for the ‘STAR’ class, as less than 10 sources are available in the test set. Inclusion of 8 and 70
 $\unicode{x03BC}\mathrm{m}$
data lead to a slight improvement (5–10%) in classification for most classes, except for pulsars that are infrared-quiet at these bands. Misclassification rates, shown in Fig. 7, also improved considerably for Hii regions and PNe, e.g. the fraction of PNe misclassified as Hii regions decreased by
$\unicode{x03BC}\mathrm{m}$
data lead to a slight improvement (5–10%) in classification for most classes, except for pulsars that are infrared-quiet at these bands. Misclassification rates, shown in Fig. 7, also improved considerably for Hii regions and PNe, e.g. the fraction of PNe misclassified as Hii regions decreased by
 $\sim$
20% compared to the 5-band analysis, highlighting how the far-infrared information is crucial for separation of certain Galactic classes. Although a slight improvement is also seen on radio star and YSO identification, the limitations highlighted in the previous paragraph prevent to eventually obtain an effective classification of both types.
$\sim$
20% compared to the 5-band analysis, highlighting how the far-infrared information is crucial for separation of certain Galactic classes. Although a slight improvement is also seen on radio star and YSO identification, the limitations highlighted in the previous paragraph prevent to eventually obtain an effective classification of both types.
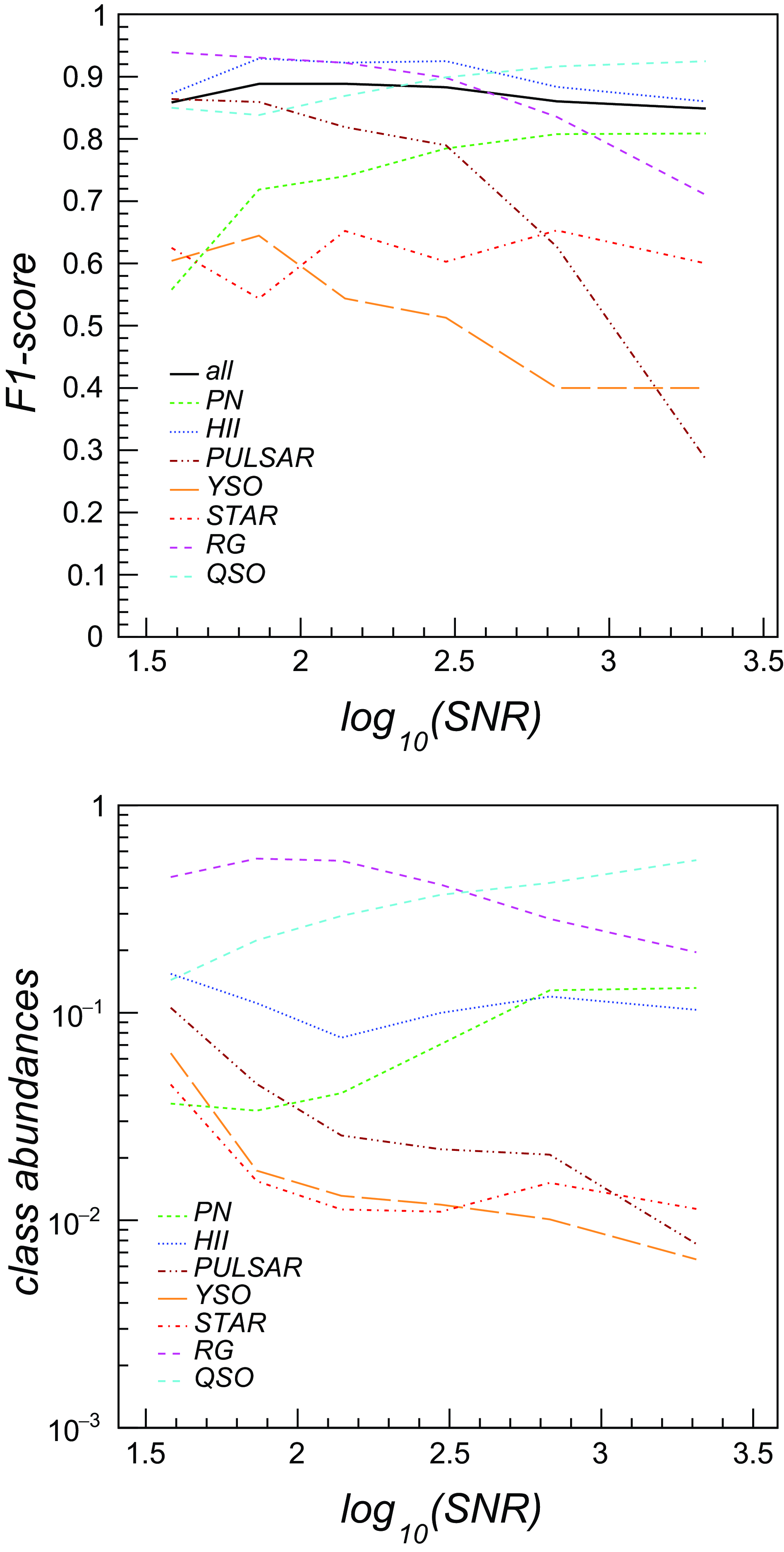
Figure 6. Top: F1-score of the LightGBM classifier as a function of radio source signal-to-noise (SNR) obtained over the 5-band (radio+MIR) dataset. Bottom: Fraction of source images available in the 5-band dataset as a function of SNR.
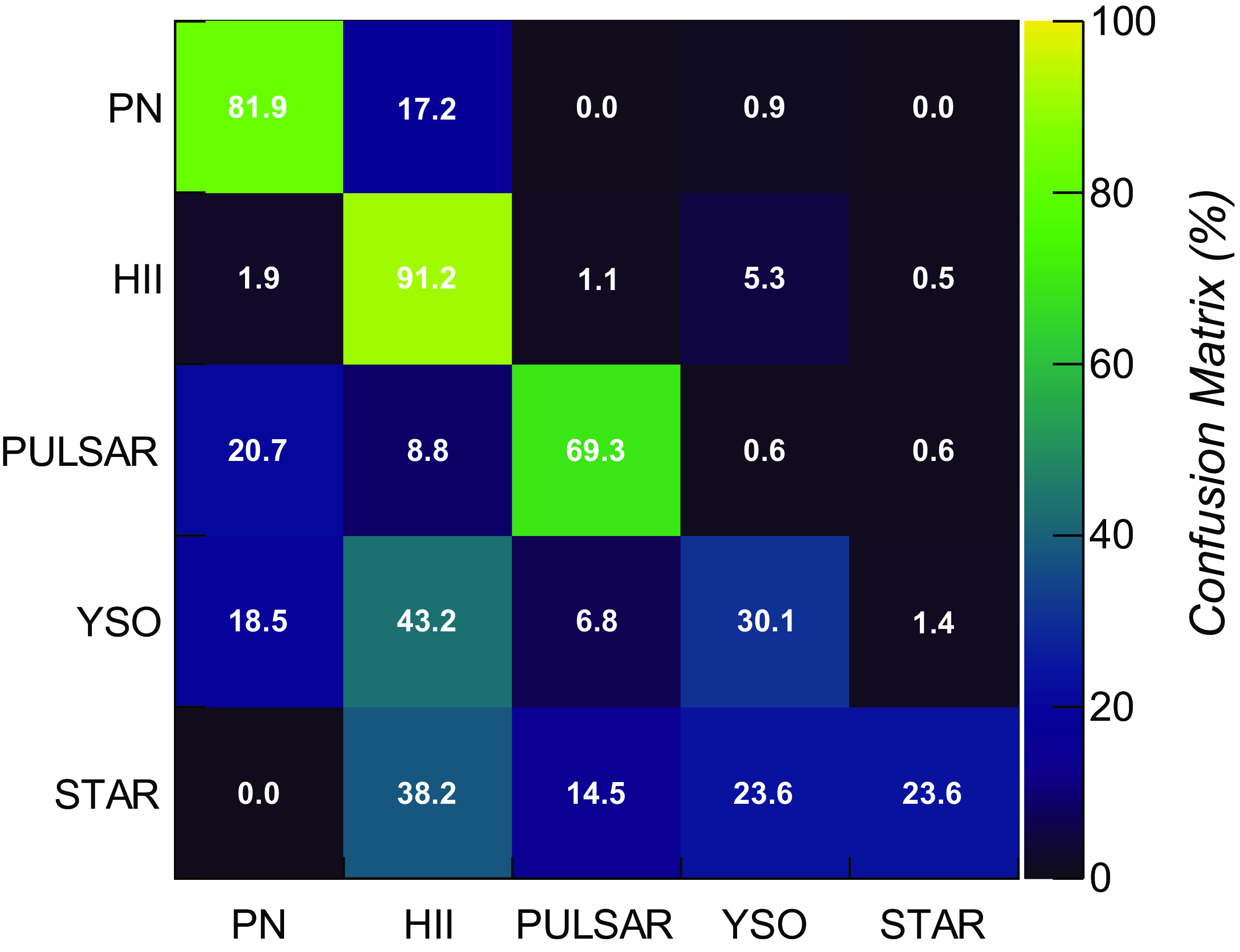
Figure 7. Confusion matrix of the trained LightGBM classifier obtained over 7-band (radio+MIR+FIR) pure ASKAP test datasets.
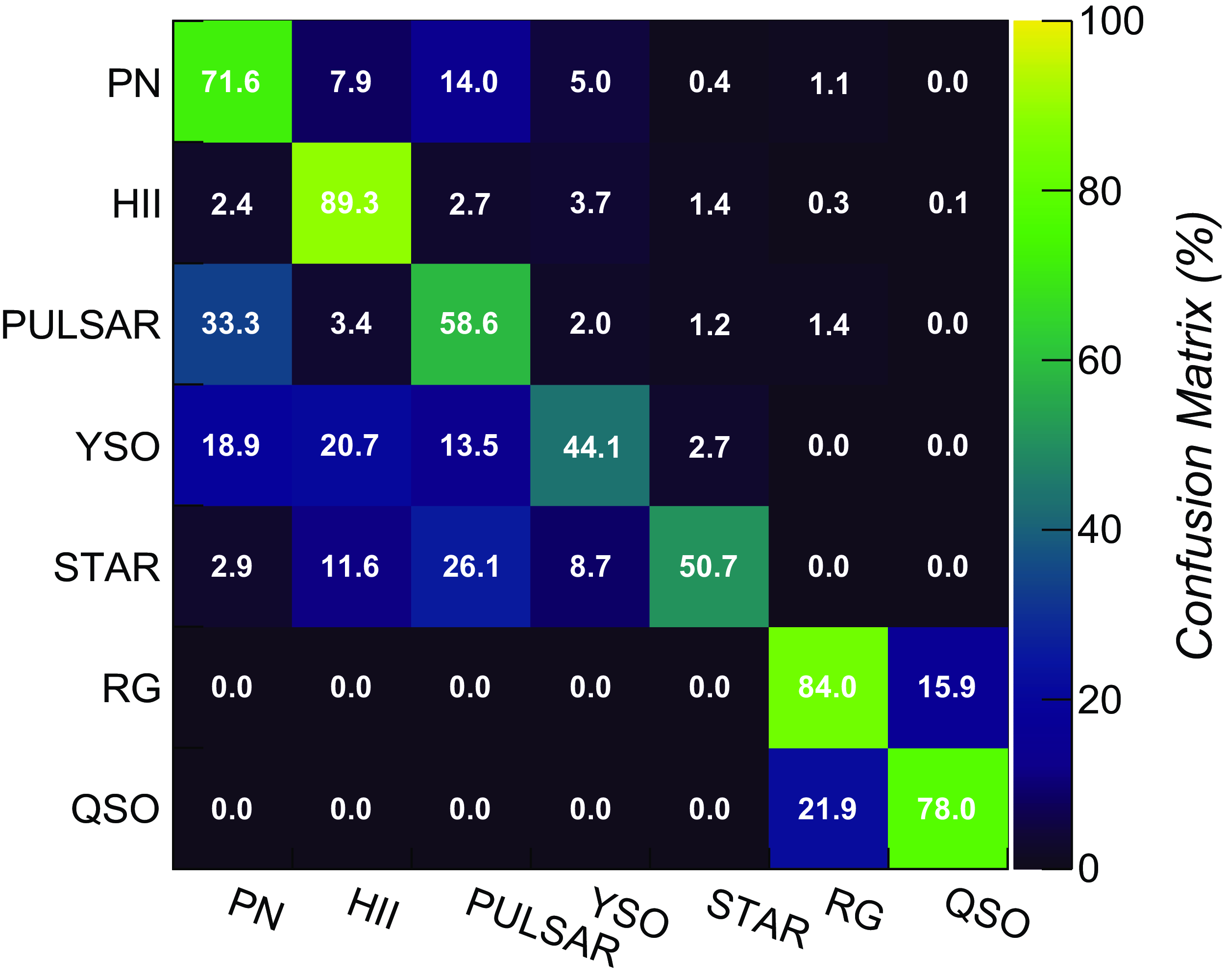
Figure 8. Confusion matrix of the trained CNN custom_v1 classifier obtained over 5-band (radio+MIR) pure ASKAP test datasets.
5.1.4. Results with radio spectral index information
In Table 7 (columns 6–9) we reported the classification results obtained on the 5-band and 7-band ‘mixed’ survey and pure ASKAP test datasets, after including the radio spectral index
 $\alpha$
as an additional input feature. A clear increase in performance was obtained for PNe, Hii regions, and pulsars, while no sensible improvements were observed on the remaining classes. Unfortunately, the training and test samples are very limited in size for some classes, e.g. less than 70 (40) radio stars in the 5-band (7-band) datasets, and therefore their corresponding metrics may not be precisely estimated.
$\alpha$
as an additional input feature. A clear increase in performance was obtained for PNe, Hii regions, and pulsars, while no sensible improvements were observed on the remaining classes. Unfortunately, the training and test samples are very limited in size for some classes, e.g. less than 70 (40) radio stars in the 5-band (7-band) datasets, and therefore their corresponding metrics may not be precisely estimated.
5.2. CNN classification
In this section we explored the capabilities of supervised classification models, such as CNNs, that automatically extract features directly from images, e.g. they do not require the extra image processing applied in Section 4.1. More importantly, contrarily to the previous analysis, a CNN classifier is less tied to the source compact morphology assumption, and would be thus also potentially suited for extended source classification.
5.2.1. Model training
We considered two alternative CNN architectures: a custom shallow network with only two convolutional layer blocks, and a standard deep ResNet18 architecture. Network configurations are reported in Table 8. We trained six custom model configurations (denoted as custom_v1, custom_v2,
 $\ldots$
, custom_v6) on our data, varying the convolutional or dense layer structure (e.g. number of filters, kernel or stride size, etc). Columns (2) and (3) report the network backbone and classification head structure, following this notation:
$\ldots$
, custom_v6) on our data, varying the convolutional or dense layer structure (e.g. number of filters, kernel or stride size, etc). Columns (2) and (3) report the network backbone and classification head structure, following this notation:
-
16C3BnP2-32C3BnP2-32-16: indicate a network with two convolutional layer blocks and two dense layers with 32 and 16 neurons, respectively. Convolution blocks (C) have 16 and 32 3
$\times$
3 filters, respectively, each followed by batch normalisation (Bn)Footnote nn and max pooling (P) layersFootnote oo using 2
$\times$
2 filter and stride 2; -
16C3-32C5S2-16: indicate a network with two convolutional layer blocks and a single dense layer with 16 neurons. The first convolution block has 16 3
$\times$
3 filters (no max pooling layer), while the second one has 32 5
$\times$
5 filters using stride 2.




All configurations were trained (Adam optimiser, learning rate
 $\eta$
= 5
$\eta$
= 5
 $\times$
10
$\times$
10
 $^{-4}$
, batch_size = 64) over five multiple train/validation/test dataset splits until overfitting is detected on the validation set (typically after 300 epochs). Classification metrics are finally computed over the test sets. In Fig. B7 we report the classification F1-score obtained as a function of the training epoch with a representative model (custom_v1) over train (blue graph) and validation (red (graph) 5-band datasets. Shaded areas correspond to the minimum and maximum F1-scores found in different training runs.
$^{-4}$
, batch_size = 64) over five multiple train/validation/test dataset splits until overfitting is detected on the validation set (typically after 300 epochs). Classification metrics are finally computed over the test sets. In Fig. B7 we report the classification F1-score obtained as a function of the training epoch with a representative model (custom_v1) over train (blue graph) and validation (red (graph) 5-band datasets. Shaded areas correspond to the minimum and maximum F1-scores found in different training runs.
To avoid learning features from other nearby sources, we masked pixels not belonging to the source in all input images. Masks for each source were obtained from the radio channel in an automated way using caesar source finder (Riggi et al. Reference Riggi2016, Reference Riggi2019), refined manually (if not accurate enough), and eventually enlarged using a morphological dilation transform.Footnote pp The resulting masks were finally applied to radio and infrared channels to produce masked image dataFootnote qq that are provided as CNN inputs.
Different image pre-processing stages were applied to the masked input data during the training and inference stages:
-
1. Channel max scaling: For each source, we scaled each channel by the maximum pixel value among all channels for that source. This step is introduced to preserve the original radio/infrared flux ratios (very sensitive to the source type) and remove the flux density degeneracy, e.g. two identical sources (e.g. same class and radio/infrared ratios) with just an absolute flux density offset will be treated as the same input by the classifier.
-
2. Augmentation: we randomly applied a series of transformations to input cutout channels, including horizontal and vertical flipping, and [–90
$^{\circ}$
, 90
$^{\circ}$
] rotation. This step is only applied during training to improve the model generalisation capabilities; -
3. Resizing: Finally, we resized all image cutouts in the dataset to the same size in pixels (64
$\times$
64 pixels by default), as the first convolutional layer of the network requires tensor of the same shape in input;



Results are reported in the following paragraphs only for the 5-band dataset, as the 7-band and spectral index datasets are too limited in size for training a deep network.
5.2.2. Results on radio+MIR data
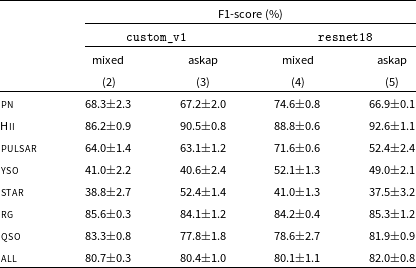
Classifications scores obtained by trained CNN classifiers on ‘mixed’ survey test datasets, reported in Table 8 (column 4), are rather comparable (within 1%) across shallow and deep model configurations and training runs. A larger kernel size (5
 $\times$
5 pixels, custom_v3 model) slightly improved (
$\times$
5 pixels, custom_v3 model) slightly improved (
 $\sim$
1%) the results, while batch normalisation layers (custom_v5 model) produce a
$\sim$
1%) the results, while batch normalisation layers (custom_v5 model) produce a
 $\sim$
2% decrease in performance. In Table 9 we report the classification scores obtained with the resnet18 model and a representative shallow model (custom_v1) trained on ‘mixed’ survey data over both ‘mixed’ survey and pure ASKAP test sets. Misclassification rates obtained on pure ASKAP test sets are reported in Fig. 8 for the custom_v1 model. Overall, we conclude that the achieved metrics are comparable to those found with the LightGBM classifier (Table 7, columns 2, 3). We also observe that, with regard to the individual classes, the CNN classifiers tend to better classify Galactic sources (
$\sim$
2% decrease in performance. In Table 9 we report the classification scores obtained with the resnet18 model and a representative shallow model (custom_v1) trained on ‘mixed’ survey data over both ‘mixed’ survey and pure ASKAP test sets. Misclassification rates obtained on pure ASKAP test sets are reported in Fig. 8 for the custom_v1 model. Overall, we conclude that the achieved metrics are comparable to those found with the LightGBM classifier (Table 7, columns 2, 3). We also observe that, with regard to the individual classes, the CNN classifiers tend to better classify Galactic sources (
 $\sim$
10% improvement in scores and misclassification rates for some classes) with a corresponding performance drop on the extragalactic source group. Despite the already noted dataset limitations, we believe that this analysis represent a first valuable baseline for future studies aiming to explore other image-based classifiers and optimised normalisation strategies for multi-wavelength data.
$\sim$
10% improvement in scores and misclassification rates for some classes) with a corresponding performance drop on the extragalactic source group. Despite the already noted dataset limitations, we believe that this analysis represent a first valuable baseline for future studies aiming to explore other image-based classifiers and optimised normalisation strategies for multi-wavelength data.
Table 8. Average F1-score metrics achieved by trained CNN models for multiclass classification, computed over five ‘mixed’ survey 5-band (radio+MIR) test sets.
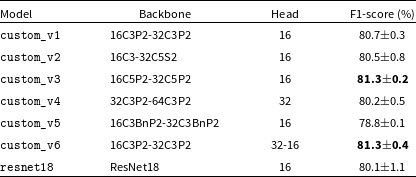
Table 9. Average F1-score metrics achieved by trained shallow and deep CNN models for source multiclass classification, computed over five ‘mixed; survey 5-band (radio+MIR) test sets (labelled as ‘mixed’) and pure ASKAP 5-band (radio+MIR) test sets (labelled as ‘askap’).
6. sclassifier: A radio source classifier tool
We developed a tool, dubbed sclassifier,Footnote rr for performing radio source classification using the dataset and the methods adopted in this work. An end-to-end pipeline was implemented, allowing users to obtain source classification information (e.g. predicted class labels and probabilities) and supplementary products (source image cutouts, feature data tables) from a radio continuum 2D map (FITS format) and a source catalogue (DS9 polygon regions) supplied as inputs. Additional algorithms and models (e.g. convolutional autoencoders, outlier finder, clustering, etc) were also implemented and will be presented in a future work focusing on an unsupervised analysis of the dataset.
sclassifier is developed in python (3.x), and based on several libraries for astronomical data analysis and image processing – Astropy (Astropy Collaboration et al. Reference Robitaille2013, Reference Price-Whelan2018, Reference Price-Whelan2022), Montage (Jacob et al. Reference Jacob2010), OpenCV (Bradski Reference Bradski2000) – and machine learning – TensorFlow (Abadi et al. Reference Abadi2016), Keras (Chollet et al. Reference Chollet2015), scikit-learn (Pedregosa et al. Reference Pedregosa2011). As some stages, e.g. source cutout provision, regridding/reprojection, are quite computationally intensive for large catalogues, we parallelised them using the mpi4py library (Dalcin et al. Reference Dalcin2005), splitting the computation for all sources across multiple computing nodes.
7. Summary
In this work, we carried out a supervised classification analysis of compact radio sources over a large annotated dataset of
 $\sim$
20 000 Galactic and Extragalactic objects, extracted from novel ASKAP radio observations and previous radio and infrared surveys. We trained two different classifiers on the produced data. The first uses the LightGBM gradient-boosting framework and is trained on a set of pre-computed features derived from the multi-wavelength data, including the radio-infrared colour indices and the radio spectral index. The second model uses convolutional neural networks and is trained directly on multi-channel images.
$\sim$
20 000 Galactic and Extragalactic objects, extracted from novel ASKAP radio observations and previous radio and infrared surveys. We trained two different classifiers on the produced data. The first uses the LightGBM gradient-boosting framework and is trained on a set of pre-computed features derived from the multi-wavelength data, including the radio-infrared colour indices and the radio spectral index. The second model uses convolutional neural networks and is trained directly on multi-channel images.
The LightGBM classifier achieved very high performances (above 90%) for the identification of Galactic objects against sources belonging to the extragalactic group, using only radio and mid-infrared data. Classification metrics largely vary among individual source classes. Extragalactic objects (radio galaxies, QSO) are best classified, with F1-scores exceeding 85%. PNe, Hii regions, and pulsars are the second group of best classified objects, with F1-scores ranging from 60% to 75%. Poor performances are obtained on radio star group and YSOs, due to the limited sample size, object spectral type heterogeneity, and unreliable classification information reported in the reference catalogues. We also tested how the classification performances changed for Galactic objects when including additional infrared band data (8
 $\unicode{x03BC}\mathrm{m}$
, 70
$\unicode{x03BC}\mathrm{m}$
, 70
 $\unicode{x03BC}\mathrm{m}$
) and the radio spectral index information in the analysis. We obtained a significant boost in performance (
$\unicode{x03BC}\mathrm{m}$
) and the radio spectral index information in the analysis. We obtained a significant boost in performance (
 $\sim$
10%) for PNe, Hii regions, and pulsars.
$\sim$
10%) for PNe, Hii regions, and pulsars.
CNN classifier was only trained on 5-band (radio+MIR) data due to the limited number of images available in the FIR band. The classification metrics achieved by trained shallow and deep network architectures are overall comparable to LightGBM, with better classifications observed on the Galactic source group at the expense of the extragalactic source group.
The obtained results motivate further analysis to be done to improve overall source classification results and tackle some reported limitations, before applying the method on unclassified ASKAP sources. Firstly, test data sample size can be slightly increased once new ASKAP observations towards the Galactic plane will be completed. This would increase the reliability of the reported classification metrics for some classes. Secondly, analysis should be repeated with a revised YSO and star reference catalogue, as the ones used in this work may contain spurious association to Hii regions or extragalactic objects, that could partly explain the misclassification rates obtained. In this context, we foresee to carry out a completely unsupervised analysis of the dataset to detect possible label anomalies and perform new classification studies.
As commented in Section 3.1, our training set does not contain star-forming galaxies, expected to contribute with a non-negligible fraction (
 $\sim$
25%) in EMU survey data, and therefore our current classifier could potentially misclassify them as Galactic sources, if their radio-infrared colors are similar. Luckily, there are ongoing studies within EMU, aiming to produce a curated sample of SFGs from EMU pilot observations, that would allow us to extend the training dataset, study SFG color parameter distribution and re-train our classifiers.
$\sim$
25%) in EMU survey data, and therefore our current classifier could potentially misclassify them as Galactic sources, if their radio-infrared colors are similar. Luckily, there are ongoing studies within EMU, aiming to produce a curated sample of SFGs from EMU pilot observations, that would allow us to extend the training dataset, study SFG color parameter distribution and re-train our classifiers.
On a longer term, we also would like to extend our dataset with additional complementary data (e.g. optical, H
 $\alpha$
or radio polarisation information), that could potentially lead to improved classification results.
$\alpha$
or radio polarisation information), that could potentially lead to improved classification results.
In this work, we produced a python-based tool, enabling users to run source classification on their new data. The implemented methods are rather general-purpose, allowing for the future to include additional image wavelength data, or to perform a similar analysis on extended sources. We plan to integrate it in the list of source analysis applications supported in the caesar-rest service,Footnote ss developed within the CIRASA (Collaborative and Integrated platform for Radio Astronomical Source Analysis) project (Riggi et al. Reference Riggi2021b) to enable SKA Galactic science teams or high-level service API to run source analysis tasks (source extraction, classification, cross-matching, etc) over an http interface. This service is currently deployed on the European Open Science Cloud (EOSC) prototype, setup for the H2020 NEANIAS (Novel EOSC Services for Emerging Atmosphere, Underwater & Space Challenges) projectFootnote tt (Sciacca et al. Reference Sciacca2021).
Acknowledgement
The Australian SKA Pathfinder is part of the Australia Telescope National Facility which is managed by CSIRO. Operation of ASKAP is funded by the Australian Government with support from the National Collaborative Research Infrastructure Strategy. Establishment of the Murchison Radio-astronomy Observatory was funded by the Australian Government and the Government of Western Australia. This work was supported by resources provided by the Pawsey Supercomputing Centre with funding from the Australian Government and the Government of Western Australia. We acknowledge the Wajarri Yamatji people as the traditional owners of the Observatory site.
This research has made use of the HASH PN database at hashpn.space. This publication makes use of data products from the Wide-field Infrared Survey Explorer, which is a joint project of the University of California, Los Angeles, and the Jet Propulsion Laboratory/California Institute of Technology, funded by the National Aeronautics and Space Administration. Additionally, this research has made use of the SIMBAD database, operated at CDS, Strasbourg, France (Wenger et al. Reference Wenger2000).
Data availability statement
The software code used in this work is publicly available under the GNU General Public License v3.0Footnote uu on the GitHub repository https://github.com/SKA-INAF/sclassifier/. The trained model weights have been made available on Zenodo repository at https://doi.org/10.5281/zenodo.10477860.
Funding statement
This research was supported by the INAF CIRASA & SCIARADA grants. C.B. acknowledges support from European Commission Horizon 2020 research and innovation programme under the grant agreement No. 863448 (NEANIAS).
Competing interests
None.
A. Source class physical properties
A.1. Young Stellar Objects (YSOs)
Young Stellar Objects (YSOs) denote the early stages of star development, e.g. protostars and pre-main sequence stars. They have been classified into different classes (0, I, II, III), depending on their evolution phase (Gómez de Castro Reference Gómez de Castro2013). Class 0 objects are characterised by an embedded central core, surrounded by a larger (not visible yet) accreting envelope, typically observed through far-infrared and millimetre wavelength emission from the dust. Class I objects denote the late mass accretion phase, in which the central core grows, a flattened circumstellar accretion disk develops, and the protostar also expels matter via bipolar jets and outflows. Typically, their SEDs rise in the far- and mid-infrared range (
 $\alpha_{IR}>$
0.3). In Class II objects, the majority of the circumstellar material is found in a disk of gas and dust. Flatter infrared spectral indices are typically observed in this stage. In Class III objects, the gas has been cleared out, the young planetary disk is formed, and the stellar atmosphere is recognisable. The emission from the disk becomes now negligible, and the SED is dominated by the pure stellar photosphere contribution (
$\alpha_{IR}>$
0.3). In Class II objects, the majority of the circumstellar material is found in a disk of gas and dust. Flatter infrared spectral indices are typically observed in this stage. In Class III objects, the gas has been cleared out, the young planetary disk is formed, and the stellar atmosphere is recognisable. The emission from the disk becomes now negligible, and the SED is dominated by the pure stellar photosphere contribution (
 $\alpha_{IR}<-$
1.6).
$\alpha_{IR}<-$
1.6).
YSOs are observed in the radio continuum, mainly through thermal free-free emission from ionised regions in their components (disks, winds, coronae, and jets), specially in massive YSOs. For low mass YSOs, however, the emission is thought to be driven by outflow processes that shock the surrounding material causing the required gas ionisation (Anglada et al. Reference Anglada1998). The radio spectral indices
 $\alpha$
are expected in the range
$\alpha$
are expected in the range
 $-$
0.1 <
$-$
0.1 <
 $\alpha$
< 1.1, depending on the evolution phase and emission mechanism (Scaife Reference Scaife2012). For example, in collimated outflows, typical of early protostar stages (Class 0, I), a radio spectral index
$\alpha$
< 1.1, depending on the evolution phase and emission mechanism (Scaife Reference Scaife2012). For example, in collimated outflows, typical of early protostar stages (Class 0, I), a radio spectral index
 $\alpha\sim$
0.25 is favoured, while, for standard conical jets, spectral indices around 0.6 are expected (Reynolds Reference Reynolds1986; Anglada et al. Reference Anglada1998). Non-thermal emission can be found around more developed pre-main sequence stages (Class II, III), like T Tauri stars, and may partially contribute to the very negative indices observed in some YSOs (Ainsworth et al. Reference Ainsworth2012).
$\alpha\sim$
0.25 is favoured, while, for standard conical jets, spectral indices around 0.6 are expected (Reynolds Reference Reynolds1986; Anglada et al. Reference Anglada1998). Non-thermal emission can be found around more developed pre-main sequence stages (Class II, III), like T Tauri stars, and may partially contribute to the very negative indices observed in some YSOs (Ainsworth et al. Reference Ainsworth2012).
A.2. Radio stars
Thermal and non-thermal radio emission has been detected so far from stars of different types and evolution stages across the entire Hertzsprung-Russell (H-R) diagram, among them magnetic stars, early-type stars (e.g. O-B) with winds and strong mass loss, later stages like Wolf-Rayet (WR) stars and LBVs, binaries (also bright in X-rays), and ultra cool-dwarfs (Güdel Reference Güdel2002; Matthews Reference Matthews2013). Thermal free-free emission, as in the stellar wind emission, originates from stellar outflows and chromospheres. Stars with spherically symmetric, isothermal, and stationary outflows are expected to have a radio spectrum S
 $_{\nu}\propto\nu^{\alpha}$
(
$_{\nu}\propto\nu^{\alpha}$
(
 $\alpha$
= 0.6) (Panagia & Felli Reference Panagia and Felli1975), although spectral indices deviating from the canonic value may be obtained when variating the wind parameters (e.g. electron densities, velocity gradients, mass loss rate). Non-thermal gyrosynchrotron and synchrotron emission is generated in flares and also found in stars with magnetic activity and colliding winds in binaries. Negative spectral indices (
$\alpha$
= 0.6) (Panagia & Felli Reference Panagia and Felli1975), although spectral indices deviating from the canonic value may be obtained when variating the wind parameters (e.g. electron densities, velocity gradients, mass loss rate). Non-thermal gyrosynchrotron and synchrotron emission is generated in flares and also found in stars with magnetic activity and colliding winds in binaries. Negative spectral indices (
 $\alpha<$
0) are expected in this case (Umana et al. Reference Umana2015b). The stable non-thermal radio emission from the MCP stars is instead expected with an almost flat spectrum (Leto et al. Reference Leto2021) and partially polarised, with the circularly polarised emission increasing as the radio frequency increases (Leto et al. Reference Leto2020). In stars with high radio brightness temperatures, coherent emission mechanisms, like plasma radiation or electron cyclotron maser emission (Trigilio et al. Reference Trigilio2000), are also operating.
$\alpha<$
0) are expected in this case (Umana et al. Reference Umana2015b). The stable non-thermal radio emission from the MCP stars is instead expected with an almost flat spectrum (Leto et al. Reference Leto2021) and partially polarised, with the circularly polarised emission increasing as the radio frequency increases (Leto et al. Reference Leto2020). In stars with high radio brightness temperatures, coherent emission mechanisms, like plasma radiation or electron cyclotron maser emission (Trigilio et al. Reference Trigilio2000), are also operating.
A.3. Hii regions
regions Hii regions are discrete ionised clouds surrounding young and massive hot stars (type O-B), thus enabling to trace massive star formation across the entire Galaxy, particularly in their youngest and compact stages, known as hyper-compact Hii (HCHii, diameter
 $\le$
0.05 pc) and ultra-compact Hii (UCHii, diameter
$\le$
0.05 pc) and ultra-compact Hii (UCHii, diameter
 $\le$
0.1 pc) regions (Kurtz et al. Reference Kurtz, Cesaroni, Felli, Churchwell and Walmsley2005). They are detected through their bright radio and infrared emission. The observed radio continuum spectrum can be described by a standard thermal free-free model assuming an optically thin regime above
$\le$
0.1 pc) regions (Kurtz et al. Reference Kurtz, Cesaroni, Felli, Churchwell and Walmsley2005). They are detected through their bright radio and infrared emission. The observed radio continuum spectrum can be described by a standard thermal free-free model assuming an optically thin regime above
 $\sim$
1 GHz, with spectral indices
$\sim$
1 GHz, with spectral indices
 $\alpha\sim-$
0.1, and an optically thick scenario at lower frequencies (e.g. below a turnover frequency), leading to increased spectral indices (
$\alpha\sim-$
0.1, and an optically thick scenario at lower frequencies (e.g. below a turnover frequency), leading to increased spectral indices (
 $\alpha\sim$
2) due to self-absorption mechanisms. Younger Hii regions with higher density typically remain optically thick at higher frequencies, with a positive spectral index and turnover at
$\alpha\sim$
2) due to self-absorption mechanisms. Younger Hii regions with higher density typically remain optically thick at higher frequencies, with a positive spectral index and turnover at
 $\nu\sim$
5 GHz for UCHii and
$\nu\sim$
5 GHz for UCHii and
 $\nu\sim10\div100$
GHz for HCHii (Yang et al. Reference Yang2019, Reference Yang2021).
$\nu\sim10\div100$
GHz for HCHii (Yang et al. Reference Yang2019, Reference Yang2021).
The infrared emission comes from different dust populations (Robitaille et al. Reference Robitaille2012), mostly located in the photodissociation regions, e.g. polycyclic aromatic hydrocarbons (PAHs) at 8 and 12
 $\unicode{x03BC}\mathrm{m}$
, small and large grains at 22–24
$\unicode{x03BC}\mathrm{m}$
, small and large grains at 22–24
 $\unicode{x03BC}\mathrm{m}$
and above 70
$\unicode{x03BC}\mathrm{m}$
and above 70
 $\unicode{x03BC}\mathrm{m}$
, respectively.
$\unicode{x03BC}\mathrm{m}$
, respectively.
A.4. Planetary nebulae
Planetary nebulae are shells of ionised gas, ejected from central hot stars of low to intermediate mass (
 $\sim$
1
$\sim$
1
 $- 8 \,\,\text{M}_\odot)$
at the end of their asymptotic giant branch (AGB) phase. A more precise definition, and a summary of their observational characteristics, were presented in Frew & Parker (Reference Frew and Parker2010).
$- 8 \,\,\text{M}_\odot)$
at the end of their asymptotic giant branch (AGB) phase. A more precise definition, and a summary of their observational characteristics, were presented in Frew & Parker (Reference Frew and Parker2010).
Radio continuum radiation (thermal free–free) is observed from the nebula shell, due to the gas ionised by the ultra-violet radiation produced by the central star (Kwok Reference Kwok2000). Typical radio spectral indices observed range from
 $\sim -$
0.1 in an optically thin regime, to positive indices, up to
$\sim -$
0.1 in an optically thin regime, to positive indices, up to
 $\sim$
2 (Pottasch Reference Pottasch and Pottasch1984), for for optically thick PNe. Infrared emission is due to cool dust (T
$\sim$
2 (Pottasch Reference Pottasch and Pottasch1984), for for optically thick PNe. Infrared emission is due to cool dust (T
 $\sim$
100– 200 K) material surrounding the ionised region, peaking at
$\sim$
100– 200 K) material surrounding the ionised region, peaking at
 $\sim$
20
$\sim$
20
 $\unicode{x03BC}\mathrm{m}$
for most PNe. Polycyclic aromatic hydrocarbon (PAH) emission at 8
$\unicode{x03BC}\mathrm{m}$
for most PNe. Polycyclic aromatic hydrocarbon (PAH) emission at 8
 $\unicode{x03BC}\mathrm{m}$
from the photodissociation region (PDR) surrounding the ionised gas, can also be present in more compact objects.
$\unicode{x03BC}\mathrm{m}$
from the photodissociation region (PDR) surrounding the ionised gas, can also be present in more compact objects.
A.5. Pulsars
Pulsars are highly magnetised rotating neutron stars, emitting beams of radiation from their magnetic poles, observed as they point towards Earth, with periods ranging from milliseconds to seconds. The radio emission shows a high degree of linear polarisation, and a small fraction of circular polarisation. Pulsars are known to have steep flux-density spectra, with observed average spectral indices around
 $-$
1.8
$-$
1.8
 $\pm$
0.2 (Maron Reference Maron2000), in some cases (
$\pm$
0.2 (Maron Reference Maron2000), in some cases (
 $\sim$
10%) described by double power-laws with spectral breaks around 1 GHz. The emission is thought to be due to coherent processes, but its origin and generation mechanism is still debated (Beskin et al. Reference Beskin2015; Beskin Reference Beskin2018; Melrose et al. Reference Melrose, Rafat and Mastrano2021).
$\sim$
10%) described by double power-laws with spectral breaks around 1 GHz. The emission is thought to be due to coherent processes, but its origin and generation mechanism is still debated (Beskin et al. Reference Beskin2015; Beskin Reference Beskin2018; Melrose et al. Reference Melrose, Rafat and Mastrano2021).
A.6. Active Galactic Nuclei
Active Galactic Nuclei (AGN) of different radio-loud (RL) and radio-quiet (RQ) types (e.g. RL/RQ quasars, FR I/FR II/Seyfert radio galaxies, blazars) dominate the observed counts of continuum radio sources above the mJy level, the latter type representing
 $\sim$
90% of all AGNs. In the unification schema (Urry & Padovani Reference Urry and Padovani1995), much of their observational properties (e.g. radio components, multi-wavelength spectral features) arise from the orientation of the accretion disk and the observer’s line-of-sight.
$\sim$
90% of all AGNs. In the unification schema (Urry & Padovani Reference Urry and Padovani1995), much of their observational properties (e.g. radio components, multi-wavelength spectral features) arise from the orientation of the accretion disk and the observer’s line-of-sight.
The radio emission at cm wavelengths, explained as synchrotron radiation from GeV electrons, has a relatively steep spectrum for extended regions (jets, lobes) with
 $\alpha\sim -$
0.7, while compact regions have flatter or inverted spectra (
$\alpha\sim -$
0.7, while compact regions have flatter or inverted spectra (
 $\alpha\ge -$
0.5), resulting from the superposition of multiple self-absorbed components. The latter scenario is observed in core-dominated sources, such as blazars or FSRQs. On the other hand, Gigahertz-Peaked Spectrum (GPS) and Compact Steep Spectrum (CSS) compact sources, with their observed steep spectra and well-defined spectral turnovers (around 1 GHz for GPS sources, and 100 MHz for CSS), are a notable exception. They are believed to be young objects eventually evolving into more extended radio objects of type FR I/II, and overall they represent a considerable fraction (around 10% for GPS, and 30% for CSS) of the bright compact radio source population (O’Dea Reference O’Dea1998; O’Dea & Saikia Reference O’Dea and Saikia2021; Sadler Reference Sadler2016). A high degree of linear polarisation (up to 30%) is also observed, particularly in extended components.
$\alpha\ge -$
0.5), resulting from the superposition of multiple self-absorbed components. The latter scenario is observed in core-dominated sources, such as blazars or FSRQs. On the other hand, Gigahertz-Peaked Spectrum (GPS) and Compact Steep Spectrum (CSS) compact sources, with their observed steep spectra and well-defined spectral turnovers (around 1 GHz for GPS sources, and 100 MHz for CSS), are a notable exception. They are believed to be young objects eventually evolving into more extended radio objects of type FR I/II, and overall they represent a considerable fraction (around 10% for GPS, and 30% for CSS) of the bright compact radio source population (O’Dea Reference O’Dea1998; O’Dea & Saikia Reference O’Dea and Saikia2021; Sadler Reference Sadler2016). A high degree of linear polarisation (up to 30%) is also observed, particularly in extended components.
B. Supplementary plots
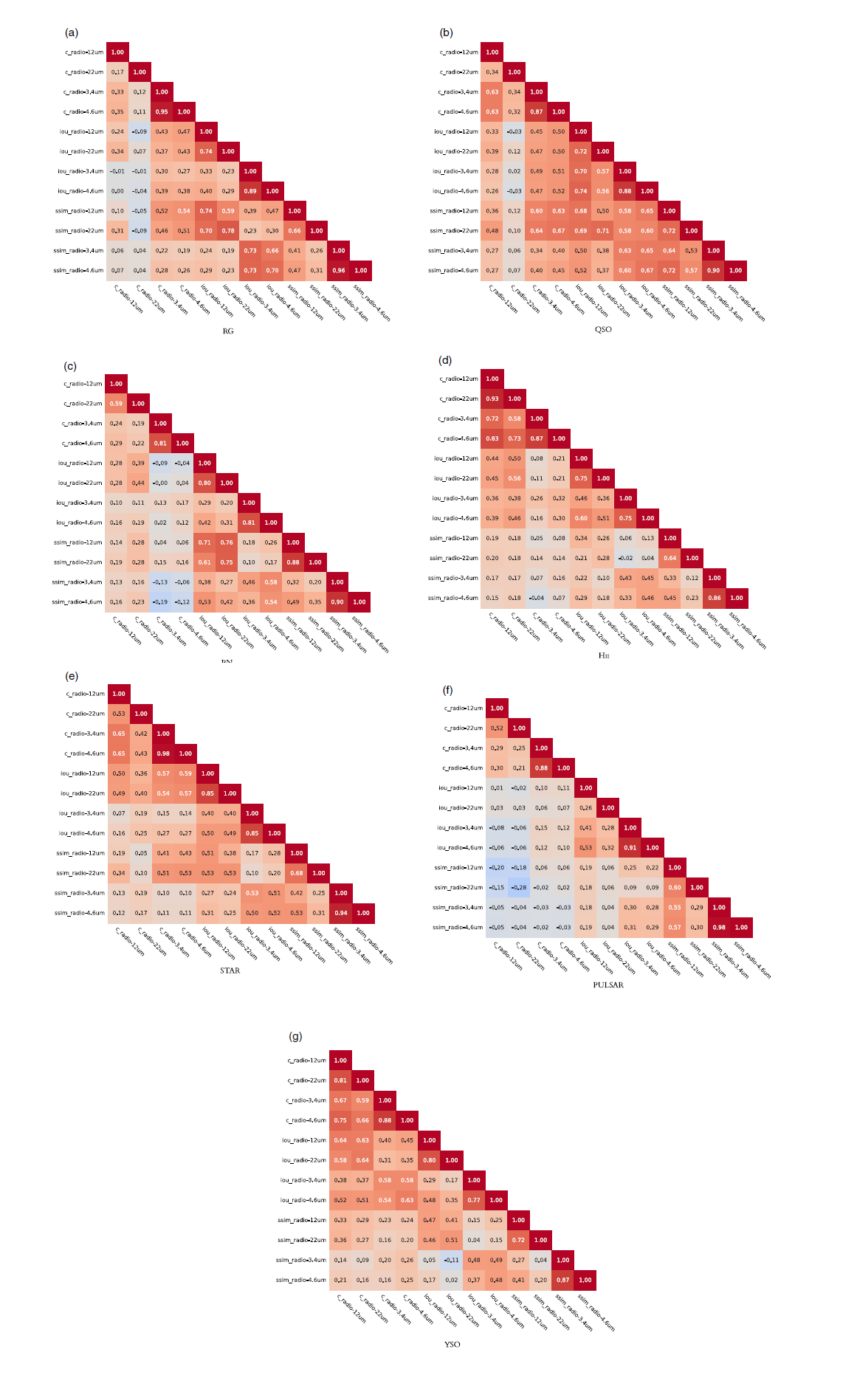
Figure B1. Pearson correlation coefficient matrix computed over for the 5-band color feature sets (see Table 5).

Figure B2. Pearson correlation coefficient matrix computed over for the 7-band color feature set (see Table 5).

Figure B3. Feature importance for LightGBM classifier trained on 5 bands (MIR+FIR) data.

Figure B4. Feature importance for LightGBM classifier trained on 5 bands (MIR+FIR) +
 $\alpha$
data.
$\alpha$
data.

Figure B5. Feature importance for LightGBM classifier trained on 7 bands (MIR+FIR) data.

Figure B6. Feature importance for LightGBM classifier trained on 7 bands (MIR+FIR) +
 $\alpha$
data.
$\alpha$
data.

Figure B7. F1-score of CNN classifier (custom_v1 model) computed as a function of the training epoch over five ‘mixed’ survey 5-bands (MIR+FIR) train (blue graph) and validation (red graph) datasets. Shaded areas correspond to the range of minimum and maximum F1-scores obtained in different training runs, each with different train/validation/test data splits.


























































