



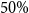
1. Introduction
1.1 Background
Lapse rate risk modeling is an important issue that is getting attention from insurance markets. In the context of life insurance, this is an even more important issue, since contracts usually have longer policy term and higher surrender rates. Originally, the term lapse means termination of an insurance policy and loss of coverage because the policyholder has failed to pay premiums (Gatzert et al., Reference Gatzert, Hoermann and Schmeiser2009; Kuo et al., Reference Kuo, Tsai and Chen2003; Eling & Kochanski, Reference Eling and Kochanski2013). In this paper, lapse risk refers to the life policies surrendered before their maturity or canceled contracts when the policyholder fails to comply with their obligations (e.g., premium payment). In other words, when a customer cancels their policy or surrenders this policy, either to switch insurance companies or because someone is no longer interested, we consider that the customer has churned.
Due to the large impact lapses may produce on an insurer’s portfolio, particularly in the first periods of the contracts, it is important to understand the factors that drive its risk. Large changes in lapse rates can potentially lead to financial losses which can prevent insurers from complying with their contractual obligations. Furthermore, lapse rates can be difficult to model due to the fact that while doing so, one needs not only to take into account the policyholder’s behavioral features but also the characteristics of the life insurance products being acquired. Once factors associated with cancelation or surrender are identified, customer retention programs can be developed and actions can be taken (Günther et al., Reference Günther, Tvete, Aas, Sandnes and Borgan2014). Moreover, good persistence is of vital importance to the financial performance of life insurance companies.
We aim to address some issues related to churning, such as the existence of trends in the persistence of specific products or groups of products. Those factors may enhance the persistence curve in the insurance company. In addition, churning/lapsing impacts many actuarial tasks, such as product design, pricing, hedging, and risk management.
Cancelation rates vary through product policyholders’ profiles. Statistical models can be used to identify risk factors associated with persistency (or lapse) rate over time as well as with pricing, taking the cancelation risk into account. In this context, the adoption of hierarchical regression models, survival regression models, and time series models can be useful.
Several works address lapse risk through binary (lapse vs. persistency) classification models along a single period of interest. Logistic regression models and machine learning classification techniques have been proposed to predict lapse. In this context, Brockett et al. (Reference Brockett, Golden, Guillen, Nielsen, Parner and Perez-Marin2008) pay particular attention to household customer behavior considering households for which at least one policy has lapsed and investigating the effects of the lapse rates of other policies owned by the same household. They use logistic regression and survival analysis techniques to assess the probability of total customer withdrawal. Günther et al. (Reference Günther, Tvete, Aas, Sandnes and Borgan2014) consider a logistic longitudinal regression model that incorporates time-dynamic explanatory variables and their interactions. Other examples of churn modeling via binary classification models, including binary regressions, decision trees, and neural networks, can be seen in Guillen et al. (Reference Guillen, Parner, Densgsoe and Perez-Marin2003), Ishwaran et al. (Reference Ishwaran, Kogalur, Blackstone and Lauer2008), Bolancé et al. (Reference Bolancé, Guillen and Padilla Barreto2016), and Hu et al. (Reference Hu, Yang, Chen and Zhu2020, Reference Hu, O’Hagan, Sweeney and Ghahramani2021).
In the present work, instead of binary classification of individuals, as to their lapse or persistence, our focus is on characterization of the temporal evolution of the instantaneous potential for lapse – equivalently, on the survival curve
 $S(t)$
, which describes, for each time
$S(t)$
, which describes, for each time
 $t$
, the probability that a policyholder will persist in a contract. We adopt survival analysis techniques aiming at jointly capturing, in a unique survival curve for each policy profile, the aggregate behavior of policyholders with a high or low potential for early cancelation. The survivor curves are stratified by policyholders’ profiles defined through structured regression which can help identify modifiable features, aiming at customers’ retention.
$t$
, the probability that a policyholder will persist in a contract. We adopt survival analysis techniques aiming at jointly capturing, in a unique survival curve for each policy profile, the aggregate behavior of policyholders with a high or low potential for early cancelation. The survivor curves are stratified by policyholders’ profiles defined through structured regression which can help identify modifiable features, aiming at customers’ retention.
The use of survival regression analysis in the context of lapse risk is not a novelty. Milhaud & Dutang (Reference Milhaud and Dutang2018) consider a competing risk approach, Eling & Kiesenbauer (Reference Eling and Kiesenbauer2014) consider the proportional hazard models and generalized linear models to show that contracts’ features such as product type or contract age, as well as policyholders’ characteristics, are important drivers for lapse rates, illustrated by a dataset provided by a German life insurer. In this same line of work, Brockett et al. (Reference Brockett, Golden, Guillen, Nielsen, Parner and Perez-Marin2008) use survival analysis techniques to evaluate the time between the first cancelation and subsequent customer withdrawal. Guillen et al. (Reference Guillen, Nielsen, Scheike and Pérez-Marín2012) considers survival analysis to study how long policyholders maintain their policy after the first policy lapsing. Dong et al. (Reference Dong, Frees, Huang and Hui2022) propose multistate modeling using multinomial logistic regression that allows specific behavior over a large number of different combinations of insurance coverage and across multiple periods. Our work is based on the experience gained from data of a specific company, in which higher cancelation rates are observed at the beginning of the contracts, decreasing after some months. In the database that motivated this study, the frequency of surrender is much higher than that of other events that can lead to the termination of a contract (e.g., the death of the policyholder). Thus, unlike competing or multinomial risk approaches, we implicitly assume independence between the lapse behavior of a policyholder and policy termination due to reasons other than a lapse. The interest lies in investigating, through regression structures, issues such as if there are specific persistency patterns associated with different products or groups of products, and if there are factors that can enhance the persistency curve in the company. Possibly, these factors can be controlled by the insurer, leading to increased persistency.
Traditional parametric survival models, such as Weibull, Gamma, and Log-Normal, may fail to properly capture the shape of the instantaneous potential for lapse (known as hazard function), through time, for instance, in situations where the risk of cancelation is quite high in the first months of a contract, assuming more stable patterns in the following months. Some works seek to produce more flexible survival models by adopting semi-parametric approaches in which the modeling focus on the hazard function, indirectly inducing the descriptor model for the time to the event under analysis. In this context, constructions based on the piece-wise exponential model (PEM) are quite frequent (Friedman, Reference Friedman1982; Gamerman, Reference Gamerman1994; Hemming & Shaw, Reference Hemming and Shaw2002; Kim et al., Reference Kim, Chen, Dey and Gamerman2007; Demarqui et al., Reference Demarqui, Dey, Loschi and Colosimo2014; Mayrink et al., Reference Mayrink, Duarte and Demarqui2021). PEM assumes a piece-wise constant hazard function (thus an Exponential model for the time to event), per time interval. Some of the literature on PEM is dedicated to the specification of the number and cut points of the time interval partition, as well as on the transition of the constant hazard rate between consecutive time intervals. According to Demarqui et al. (Reference Demarqui, Dey, Loschi and Colosimo2014) although parametric in the strict sense, the PEM can be considered as a nonparametric approach due to the large and unspecified number of parameters involved in modeling the hazard function. We propose a more parsimonious approach, directly focusing on the mixture of single-parametric components for the modeling of times to event, making the behavior of the mixed survival functions (and the implied hazard functions) more flexible than the ones associated with usual single-component parametric choices. A detailed description of Bayesian mixture models is found in Frühwirth-Schnatter (Reference Frühwirth-Schnatter2006). We propose a mixture based on Log-Normal components, to describe the time to lapse. As will be shown further, mixing a finite and small number of Log-Normal components is sufficient to ensure flexibility to lapse risk curves that escape the rigid standards dictated by single-parametric component specifications. Although the proposed formulation depends on regressors, we assume that the heterogeneity in the persistence curves may not be completely captured by the features which are available in the analysis. Mixing components can naturally accommodate extra variability due to latent or unobserved factors, such as unobserved regressors or different temporal regimes. For instance, different economic scenarios could affect the persistence behavior, and some works explicitly take time-varying features into account (see Kuo et al., Reference Kuo, Tsai and Chen2003; Knoller et al., Reference Knoller, Kraut and Schoenmaekers2015). In our formulation, the temporal indexation of observations is not exploited. Instead, we assume that a finite number of regime changes associated with temporal dynamics could be captured by latent clusters of persistence patterns. The particular choice of Log-Normal components enables the use of an efficient computational scheme for a fully Bayesian approach.
Specifically, the focus of this work is on modeling the time to lapse of a contract (or surrender). This includes the contracts which are terminated by the policyholder or terminated by the insurer due to lack of premium payment and do not include external events such as death. Policies that are not canceled are defined as censored, as the actual time to cancelation has not yet been observed in the study period.
Our contribution lies in the combination of the following points: (i) specification of a simple model, based on the mixture of Log-Normal survival regression models, which extends usual survival approaches to censored data (Ibrahim et al., Reference Ibrahim, Chen and Sinha2001; Kalbfleisch & Prentice, Reference Kalbfleisch and Prentice2002) in the sense of making survival and hazard curves more flexible and fitting specific policyholders’ profiles, especially in the presence of complex censoring schemes; (ii) adoption of a fully Bayesian approach, based on data augmentation and Gibbs sampler as well as other Markov chain Monte Carlo (MCMC) techniques, allowing for fast and feasible computations (see Tanner & Wong, Reference Tanner and Wong1987) which results in efficiency to deal with datasets of thousands of policyholders; (iii) frequentist estimation based on Expectation–Maximization (EM) algorithms, which provides point estimates for the mixture model parameters.
In short, our proposed method for lapse risk analysis allows accommodating heterogeneous behavior in the lapse hazard/survivor function via a Bayesian mixture model, taking into account a usually large volume of censored data, with computational efficiency.
1.2 Outline of the paper
The remaining of the paper is organized as follows. Section 2 presents the Bayesian mixture model for lapse risk, beginning with a brief review on single-component parametric survival models (section 2.1), followed by the proposed mixture models and their properties (section 2.2). The mixture formulation based on Log-Normal components is presented in section 2.2.1. Sections 2.2.2 and 2.2.3 provide details on the fully Bayesian inferential and computational procedures for mixture survival modeling via data augmentation, and section 2.2.4 describes the adoption of a frequentist EM algorithm which produces point estimates. Section 3 presents two applications of the proposed method considering different simulated datasets. For the first one, the analysis focuses on the effectiveness of our proposal in modeling survival curves that have different behaviors over time with low computational costs. In the second application, a mixture of survival Log-Normal regressions is adopted to emulate a life insurance company lapse modeling, through an artificial dataset, aiming to obtain feasible results via our proposed method. As the applications show, the proposed formulation enables to compute churning probabilities, in specified time intervals, for groups of policyholders sharing similar features. Also, we consider a case study based on the Telco customer churn data which are available in IBM Business Analytics Community Connect, containing information about home phone and internet services (IBM, 2019). The idea is to illustrate the flexibility of our proposed model when compared to well-known models used in the literature of survival analysis. Section 4 concludes with a final discussion and remarks. Some aspects of the posterior distribution and simulated datasets are presented in Appendices A and B, respectively.
2. Modeling Lapse Risk Via Bayesian Mixture of Parametric Survival Models
This section presents a detailed description of the proposed mixture model, as well as the adopted inferential and computational schemes. It begins with a brief review of fundamentals on parametric single-component survival models, and an illustration is presented, based on a simulated dataset, aiming at showing that traditional parametric models can result in more rigid patterns for the hazard and survivor functions than demanded by the data.
2.1 Single-component parametric survival models
For the purpose of survival analysis, interest lies on the nonnegative random variable
 $T_i$
, which denotes the duration of a policy
$T_i$
, which denotes the duration of a policy
 $i$
before termination (cancelation). The adoption of a probability density function
$i$
before termination (cancelation). The adoption of a probability density function
 $f(t)$
for
$f(t)$
for
 $T_i$
implies a survival function given by:
$T_i$
implies a survival function given by:
 \begin{equation} S(t)= P(T_i \gt t) = \int _{t}^{\infty } f(u) du, \end{equation}
\begin{equation} S(t)= P(T_i \gt t) = \int _{t}^{\infty } f(u) du, \end{equation}
which describes persistency probability evolution, through time.
 $S(t)$
is monotonic and decreasing function, starting at
$S(t)$
is monotonic and decreasing function, starting at
 $S(0) = 1$
and converging numerically to zero, since
$S(0) = 1$
and converging numerically to zero, since
 $S(\infty ) = \lim \limits _{t \to \infty } S(t) = 0$
.
$S(\infty ) = \lim \limits _{t \to \infty } S(t) = 0$
.
The hazard function
 $\lambda (t)$
describes the instantaneous potential for cancelation and is given by:
$\lambda (t)$
describes the instantaneous potential for cancelation and is given by:
 \begin{equation} \lambda (t) = \lim _{\Delta t \to 0} \frac{P(t\lt T_i\leq t+ \Delta t\mid T_i\gt t)}{\Delta t} \approx \frac{f(t)}{S(t)} = -\frac{S'(t)}{S(t)}, \end{equation}
\begin{equation} \lambda (t) = \lim _{\Delta t \to 0} \frac{P(t\lt T_i\leq t+ \Delta t\mid T_i\gt t)}{\Delta t} \approx \frac{f(t)}{S(t)} = -\frac{S'(t)}{S(t)}, \end{equation}
where
 $\Delta t$
is a small-time increment. In particular,
$\Delta t$
is a small-time increment. In particular,
 $\lambda (t)\Delta t$
is the approximate probability of a cancelation occurring in the interval
$\lambda (t)\Delta t$
is the approximate probability of a cancelation occurring in the interval
 $(t,t+\Delta t)$
, that is, the lapse rate, given that the policy has survived until time
$(t,t+\Delta t)$
, that is, the lapse rate, given that the policy has survived until time
 $t$
(for more details, see Ibrahim et al., Reference Ibrahim, Chen and Sinha2001; Kalbfleisch & Prentice, Reference Kalbfleisch and Prentice2002).
$t$
(for more details, see Ibrahim et al., Reference Ibrahim, Chen and Sinha2001; Kalbfleisch & Prentice, Reference Kalbfleisch and Prentice2002).
Survival analysis data typically contain censored observations, that is, data on sample units for which the event of interest was not observed during the study time. In the context of the present work, we define censored data as current (not canceled) policies, claim occurrences (death of the insured), and terminations of contracts.
To illustrate the larger surrender rates at the first months of a contract and a smaller rate later in time, we consider an example and assume an usual single-component parametric survival model, which proves to be inadequate for this kind of insurer portfolio behavior. An artificial database was simulated in order to emulate the cancelation behavior in insurance products with 1,000 policies, 40% censored data, and considering a dichotomous covariate
 $x$
(0/no attribute, 1/yes attribute). We let the observed failure-time data be denoted by:
$x$
(0/no attribute, 1/yes attribute). We let the observed failure-time data be denoted by:
 \begin{equation} d_i= (t_i, \delta _i, x_i), \quad i=1, \ldots, 1,000, \end{equation}
\begin{equation} d_i= (t_i, \delta _i, x_i), \quad i=1, \ldots, 1,000, \end{equation}
where the
 $t_i$
is the time recorded for the ith policy,
$t_i$
is the time recorded for the ith policy,
 $x_i$
is a covariate associated with the i-th policy, and
$x_i$
is a covariate associated with the i-th policy, and
 $\delta _i$
is an indicator of the censoring status, given by:
$\delta _i$
is an indicator of the censoring status, given by:
 \begin{equation*} \delta _i = \begin {cases} 1 & \text {if} \quad t_i \quad \text {is an observed lapse time}\\[5pt] 0 & \text {if} \quad t_i \quad \text {is a censored time}. \end {cases} \end{equation*}
\begin{equation*} \delta _i = \begin {cases} 1 & \text {if} \quad t_i \quad \text {is an observed lapse time}\\[5pt] 0 & \text {if} \quad t_i \quad \text {is a censored time}. \end {cases} \end{equation*}
Thus,
 $\{\delta _i=1\}$
is the event representing the occurrence of lapse or cancelation (with
$\{\delta _i=1\}$
is the event representing the occurrence of lapse or cancelation (with
 $f(t_i)$
probability density), whereas
$f(t_i)$
probability density), whereas
 $\{\delta _i= 0\}$
denotes censored lapse time or, equivalently, nonoccurrence of lapse during the study period (with survival probability
$\{\delta _i= 0\}$
denotes censored lapse time or, equivalently, nonoccurrence of lapse during the study period (with survival probability
 $S(t_i)$
), that is, lapse/cancelation time is only known to be greater than
$S(t_i)$
), that is, lapse/cancelation time is only known to be greater than
 $t_i$
. The observations on different policies are assumed to be independent. The data were simulated considering variable
$t_i$
. The observations on different policies are assumed to be independent. The data were simulated considering variable
 $Y_i= \log(T_i)$
as the logarithmic the duration of a policy
$Y_i= \log(T_i)$
as the logarithmic the duration of a policy
 $i$
before termination from a mixture of Gaussian distributions. For a more detailed discussion about data generation, see Appendix B.
$i$
before termination from a mixture of Gaussian distributions. For a more detailed discussion about data generation, see Appendix B.
Fig. 1 presents the empirical Kaplan–Meier survival curve (dashed line) adjusted to the simulated data, for both attributes, and it is clear that there is a heterogeneous behavior between the levels of the dichotomous covariate. The absence of the attribute described by the covariate is associated with an increased premature risk of cancelation. In addition, for both levels of the covariate, there is a difference in the survival behavior in the initial times when compared to the following ones.

Figure 1 Simulated dataset: empirical Kaplan–Meier survival curves (dashed line) and Exponential, Weibull and Log-Normal (solid line) fitted models.
In the context of survival analysis, parametric models play a key role in modeling the phenomenon of interest. If
 $T_i$
follows an Exponential model, then
$T_i$
follows an Exponential model, then
 $\lambda (t) = \lambda$
is constant over time. If a Weibull model with parameters
$\lambda (t) = \lambda$
is constant over time. If a Weibull model with parameters
 $\lambda$
and
$\lambda$
and
 $\kappa$
is considered for
$\kappa$
is considered for
 $T_i$
, then
$T_i$
, then
 $\lambda (t)= \lambda \kappa t^{\kappa -1}$
, resulting in constant (
$\lambda (t)= \lambda \kappa t^{\kappa -1}$
, resulting in constant (
 $\kappa =1$
), growing (
$\kappa =1$
), growing (
 $\kappa \gt 1$
), or decreasing (
$\kappa \gt 1$
), or decreasing (
 $\kappa \lt 1$
) hazard through time. The Log-Normal model with parameters
$\kappa \lt 1$
) hazard through time. The Log-Normal model with parameters
 $\mu$
(mean of the logarithmic failure time) and
$\mu$
(mean of the logarithmic failure time) and
 $\sigma$
(standard deviation of the logarithmic failure time) is an usual choice when the hazard function is not monotonous, reaching a maximum point and then decreasing. Structured regression models based on covariates are usually considered, relating the parameters in the sampling model with covariates responsible for the description of each contract profile. The simulated data were fit by the Exponential, the Weibull, and the Log-Normal survival regression models.
$\sigma$
(standard deviation of the logarithmic failure time) is an usual choice when the hazard function is not monotonous, reaching a maximum point and then decreasing. Structured regression models based on covariates are usually considered, relating the parameters in the sampling model with covariates responsible for the description of each contract profile. The simulated data were fit by the Exponential, the Weibull, and the Log-Normal survival regression models.
Panels in Fig. 1 (see solid line) make it clear that usual survival models are not flexible enough to accommodate the behavior of the empirical survival function, per stratum, over time. Even though the Log-Normal model produces a good performance when compared with the competing models in the initial instants, it fails to adapt in later times as in the other competing models. That is, the rates tend to decrease faster over time, and usual parametric survival models are not able to accommodate this behavior. Our working premise is that simple parametric models can serve as block builders of more flexible models, via mixtures.
2.2 Bayesian mixture of parametric survival models
In this section, we present our proposal of a mixture of parametric models for censored survival data. Finite mixture models are described in detail in Frühwirth-Schnatter (Reference Frühwirth-Schnatter2006). As seen in the illustration with artificial data presented in section 2.1, the competing fitted models apparently do not reflect the empirical distribution of the data. A possible alternative is to use more flexible structures such as mixture models, which allow the incorporation of behavioral change in the probability distribution of the data. Our proposal is based on the classical finite mixture model, where observations are assumed to arise from the mixture distribution given by:
 \begin{equation} f(t_i) = \sum _{j=1}^{K} \eta _j f_j(t_i), \end{equation}
\begin{equation} f(t_i) = \sum _{j=1}^{K} \eta _j f_j(t_i), \end{equation}
where
 $f(t_i)$
is the probability density function of
$f(t_i)$
is the probability density function of
 $T_i$
and
$T_i$
and
 $f_j(t_i)$
denotes
$f_j(t_i)$
denotes
 $K$
component densities occurring with unknown proportions
$K$
component densities occurring with unknown proportions
 $\eta _j$
, with
$\eta _j$
, with
 $0 \leq \eta _j \leq 1$
and
$0 \leq \eta _j \leq 1$
and
 $\sum _{j=1}^{K} \eta _j=1$
. It follows that the survival function
$\sum _{j=1}^{K} \eta _j=1$
. It follows that the survival function
 $S(t)$
has the mixed form:
$S(t)$
has the mixed form:
 \begin{equation} S(t) = \sum _{j=1}^{K} \eta _j S_j(t) = \sum _{j=1}^{K} \eta _j \int _{t}^{\infty } f_j(u)du, \end{equation}
\begin{equation} S(t) = \sum _{j=1}^{K} \eta _j S_j(t) = \sum _{j=1}^{K} \eta _j \int _{t}^{\infty } f_j(u)du, \end{equation}
and the hazard function has the mixed form:
 \begin{equation} \lambda (t)= -\frac{S'(t)}{S(t)}=- \frac{\sum _{j=1}^{K} \eta _j S'_j(t)}{S(t)} =\frac{\sum _{j=1}^{K} \eta _j \lambda _j(t)S_j(t)}{S(t)}=\sum _{j=1}^{K} \eta _j h_j(t), \end{equation}
\begin{equation} \lambda (t)= -\frac{S'(t)}{S(t)}=- \frac{\sum _{j=1}^{K} \eta _j S'_j(t)}{S(t)} =\frac{\sum _{j=1}^{K} \eta _j \lambda _j(t)S_j(t)}{S(t)}=\sum _{j=1}^{K} \eta _j h_j(t), \end{equation}
where
 $h_j(t)=\lambda _j(t)S_j(t)/S(t).$
$h_j(t)=\lambda _j(t)S_j(t)/S(t).$
For each policy
 $i$
, we define a latent group indicator
$i$
, we define a latent group indicator
 $I_i \mid \boldsymbol{\eta } \sim Categorical(K, \boldsymbol{\eta })$
, with
$I_i \mid \boldsymbol{\eta } \sim Categorical(K, \boldsymbol{\eta })$
, with
 $\boldsymbol{\eta }=(\eta _1, \ldots, \eta _K)$
, following a categorical distribution given by
$\boldsymbol{\eta }=(\eta _1, \ldots, \eta _K)$
, following a categorical distribution given by
 $P(I_i \mid \boldsymbol{\eta })= \prod _{j=1}^{K} [\eta _j]^{I_{ij}}$
, where
$P(I_i \mid \boldsymbol{\eta })= \prod _{j=1}^{K} [\eta _j]^{I_{ij}}$
, where
 $I_{ij}=1$
if observation
$I_{ij}=1$
if observation
 $i$
is allocated to group
$i$
is allocated to group
 $j$
and is null, otherwise. These auxiliary non-observable variables aim to identify which mixture component each observation has been generated from and their introduction in the formulation makes it simple to express the likelihood function for observation
$j$
and is null, otherwise. These auxiliary non-observable variables aim to identify which mixture component each observation has been generated from and their introduction in the formulation makes it simple to express the likelihood function for observation
 $i$
:
$i$
:
 \begin{equation} f_{T_i}(t_i \mid I_i) = \prod _{j=1}^{K} [f_j(t_i)]^{I_{ij}}, \quad i=1, \ldots, n. \end{equation}
\begin{equation} f_{T_i}(t_i \mid I_i) = \prod _{j=1}^{K} [f_j(t_i)]^{I_{ij}}, \quad i=1, \ldots, n. \end{equation}
Notice that in the example shown in section 2.1,
 $K=2$
components are assumed in addition to a regressor with two levels, for the generation of the artificial lapse risk data. In this case, the lapse risk can be decomposed into two overlapping processes in time. The first process is associated with the period that immediately follows the contracting of the policy. In general, it covers the first three months when the lapse risk is relatively high. The second process refers to the subsequent period when persistence decreases smoothly over time. Thus, the mixture distribution is written as
$K=2$
components are assumed in addition to a regressor with two levels, for the generation of the artificial lapse risk data. In this case, the lapse risk can be decomposed into two overlapping processes in time. The first process is associated with the period that immediately follows the contracting of the policy. In general, it covers the first three months when the lapse risk is relatively high. The second process refers to the subsequent period when persistence decreases smoothly over time. Thus, the mixture distribution is written as
 $f_{T_i}(t_i \mid I_i) = [f_1(t_i)]^{I_{i1}}[f_2(t_i)]^{(1-I_{i1})}$
. It is worth noting that single-component models are obtained as a particular case of the mixture structure when
$f_{T_i}(t_i \mid I_i) = [f_1(t_i)]^{I_{i1}}[f_2(t_i)]^{(1-I_{i1})}$
. It is worth noting that single-component models are obtained as a particular case of the mixture structure when
 $\eta _1=1$
,
$\eta _1=1$
,
 $\eta _j=0, j\gt 1.$
$\eta _j=0, j\gt 1.$
For the estimation process in this work, the number
 $K$
of mixture components is assumed to be known and subjective to a sensitivity analysis. As usual in applied contexts,
$K$
of mixture components is assumed to be known and subjective to a sensitivity analysis. As usual in applied contexts,
 $K$
is subject to uncertainty. Frühwirth-Schnatter (Reference Frühwirth-Schnatter2006, Chap 4) provides a good discussion of informal methods seeking to identify the number of components in a mixture, including the evaluation of the predictive behavior of a statistic
$K$
is subject to uncertainty. Frühwirth-Schnatter (Reference Frühwirth-Schnatter2006, Chap 4) provides a good discussion of informal methods seeking to identify the number of components in a mixture, including the evaluation of the predictive behavior of a statistic
 $T(Y)$
for future realizations of the response, conditional on its past values
$T(Y)$
for future realizations of the response, conditional on its past values
 $y_1,\ldots, y_n$
and on a model with fixed
$y_1,\ldots, y_n$
and on a model with fixed
 $K$
components, for different specifications of
$K$
components, for different specifications of
 $K$
. The choice of
$K$
. The choice of
 $K$
is then indicated by the specification that leads to the best value of the predictive performance evaluation statistic, among the proposed mixture structures. We performed sensitivity analysis to choose the number of components, observing the quality of the fit of the survival and hazard curves, compared to their respective empirical versions, which can be summarized by statistics indicating the performance of the fit. If
$K$
is then indicated by the specification that leads to the best value of the predictive performance evaluation statistic, among the proposed mixture structures. We performed sensitivity analysis to choose the number of components, observing the quality of the fit of the survival and hazard curves, compared to their respective empirical versions, which can be summarized by statistics indicating the performance of the fit. If
 $K$
is not fixed, its estimation would lead to models with variable-dimensional parametric space. Details on Bayesian methods in this context can be seen in Frühwirth-Schnatter (Reference Frühwirth-Schnatter2006, Chap 5). As shown in the following subsections, we offer a computationally efficient method for estimating a model with fixed
$K$
is not fixed, its estimation would lead to models with variable-dimensional parametric space. Details on Bayesian methods in this context can be seen in Frühwirth-Schnatter (Reference Frühwirth-Schnatter2006, Chap 5). As shown in the following subsections, we offer a computationally efficient method for estimating a model with fixed
 $K$
, and we consider that the sensitivity analysis to different specifications of
$K$
, and we consider that the sensitivity analysis to different specifications of
 $K$
, which can be performed in reduced time, is sufficient for our purposes.
$K$
, which can be performed in reduced time, is sufficient for our purposes.
2.2.1 Mixture of Log-Normal components
In this paper, interest lies in modeling
 $Y_i = \log(T_i)$
, the logarithmic duration of a policy
$Y_i = \log(T_i)$
, the logarithmic duration of a policy
 $i$
before termination (cancelation), such that
$i$
before termination (cancelation), such that
 $Y_i \sim \mathcal{N}(\mu _i,\sigma ^2)$
, implying that in the original scale
$Y_i \sim \mathcal{N}(\mu _i,\sigma ^2)$
, implying that in the original scale
 $T_i \sim \mathcal{LN}(\mu _i,\sigma ^2)$
,
$T_i \sim \mathcal{LN}(\mu _i,\sigma ^2)$
,
 $i=1, \ldots, n$
. Survival times associated with a different outcome than the lapse, such as survival times past the end of our study and deaths, are assumed to be censored for policies,
$i=1, \ldots, n$
. Survival times associated with a different outcome than the lapse, such as survival times past the end of our study and deaths, are assumed to be censored for policies,
 $i= h+1, \ldots, n$
., then
$i= h+1, \ldots, n$
., then
 \begin{equation} f(t_i\mid \mu, \sigma ^2) = (2\pi )^{-\frac{1}{2}}(t_i\sigma )^{-1}\exp \!\left \{-\frac{1}{2\sigma ^2}(\log (t_i)-\mu _i,)^2\right \}. \end{equation}
\begin{equation} f(t_i\mid \mu, \sigma ^2) = (2\pi )^{-\frac{1}{2}}(t_i\sigma )^{-1}\exp \!\left \{-\frac{1}{2\sigma ^2}(\log (t_i)-\mu _i,)^2\right \}. \end{equation}
The resulting survival function is given by:
 \begin{equation} S(t_i \mid \mu _i, \sigma ^2)= 1 - \Phi \!\left (\frac{\log (t_i)- \mu _i}{\sigma }\right ). \end{equation}
\begin{equation} S(t_i \mid \mu _i, \sigma ^2)= 1 - \Phi \!\left (\frac{\log (t_i)- \mu _i}{\sigma }\right ). \end{equation}
We can thus write the survival likelihood function of
 $(\mu, \sigma ^2)$
implied by a Log-Normal model and based on data
$(\mu, \sigma ^2)$
implied by a Log-Normal model and based on data
 $D$
as:
$D$
as:
 \begin{equation} L(\mu _i, \sigma ^2 \mid D) = \prod _{i=1}^{n} f(t_i \mid \mu _i, \sigma ^2)^{\delta _i} S(t_i \mid \mu _i, \sigma ^2)^{(1- \delta _i)}. \end{equation}
\begin{equation} L(\mu _i, \sigma ^2 \mid D) = \prod _{i=1}^{n} f(t_i \mid \mu _i, \sigma ^2)^{\delta _i} S(t_i \mid \mu _i, \sigma ^2)^{(1- \delta _i)}. \end{equation}
Adopting the finite mixture approach and assuming
 $Y_i= log(T_i) \mid \mu _i, \sigma ^2 \sim \mathcal{N}(\mu _i, \sigma ^2)$
and latent variables
$Y_i= log(T_i) \mid \mu _i, \sigma ^2 \sim \mathcal{N}(\mu _i, \sigma ^2)$
and latent variables
 $I_{ij}$
,
$I_{ij}$
,
 $i=1,\ldots, n$
, it follows that:
$i=1,\ldots, n$
, it follows that:
 \begin{equation} f_{Y_i}\!\left (y_{i} \mid \mathrm{I}_{i}, \mu _i, \sigma ^2 \right )= \prod _{j=1}^{K}{[\mathcal{N}_j}(y_i \mid \mu _{ij}, \sigma ^2_j)]^{\mathrm{I}_{ij}}, \end{equation}
\begin{equation} f_{Y_i}\!\left (y_{i} \mid \mathrm{I}_{i}, \mu _i, \sigma ^2 \right )= \prod _{j=1}^{K}{[\mathcal{N}_j}(y_i \mid \mu _{ij}, \sigma ^2_j)]^{\mathrm{I}_{ij}}, \end{equation}
where
 $\mathcal{N}_j$
is a normal distribution for the component group
$\mathcal{N}_j$
is a normal distribution for the component group
 $j$
,
$j$
,
 $j=1,\ldots,K$
. Then,
$j=1,\ldots,K$
. Then,
 \begin{eqnarray*}{y}_{i}\mid \{\mathrm{I}_{i1}=1 \}, \boldsymbol{\beta }_1, \sigma ^2_1 &\sim & \mathcal{N}_{1}(\mu _{i1}(\boldsymbol{\beta }_1),\sigma ^2_{1}) \\[5pt] {y}_{i}\mid \{\mathrm{I}_{i2} = 1 \}, \boldsymbol{\beta }_2, \sigma ^2_2 &\sim & \mathcal{N}_{2}(\mu _{i2}(\boldsymbol{\beta }_2),\sigma ^2_{2}) \\[5pt] \vdots && \vdots \\[5pt] {y}_{i}\mid \{\mathrm{I}_{iK}=1 \}, \boldsymbol{\beta }_K, \sigma ^2_K &\sim & \mathcal{N}_{K}(\mu _{iK}(\boldsymbol{\beta }_K),\sigma ^2_{K}), \end{eqnarray*}
\begin{eqnarray*}{y}_{i}\mid \{\mathrm{I}_{i1}=1 \}, \boldsymbol{\beta }_1, \sigma ^2_1 &\sim & \mathcal{N}_{1}(\mu _{i1}(\boldsymbol{\beta }_1),\sigma ^2_{1}) \\[5pt] {y}_{i}\mid \{\mathrm{I}_{i2} = 1 \}, \boldsymbol{\beta }_2, \sigma ^2_2 &\sim & \mathcal{N}_{2}(\mu _{i2}(\boldsymbol{\beta }_2),\sigma ^2_{2}) \\[5pt] \vdots && \vdots \\[5pt] {y}_{i}\mid \{\mathrm{I}_{iK}=1 \}, \boldsymbol{\beta }_K, \sigma ^2_K &\sim & \mathcal{N}_{K}(\mu _{iK}(\boldsymbol{\beta }_K),\sigma ^2_{K}), \end{eqnarray*}
with
 $\mu _{ij}= \textbf{x}_{ij}^T \boldsymbol{\beta }_j$
and
$\mu _{ij}= \textbf{x}_{ij}^T \boldsymbol{\beta }_j$
and
 $\boldsymbol{\beta }_j = (\beta _{0j}, \beta _{1j}, \ldots, \beta _{pj})$
characterizing the unknown mean and
$\boldsymbol{\beta }_j = (\beta _{0j}, \beta _{1j}, \ldots, \beta _{pj})$
characterizing the unknown mean and
 $ \sigma ^2_{j}$
, the variance, respectively, for
$ \sigma ^2_{j}$
, the variance, respectively, for
 $j=1,\ldots, K$
and
$j=1,\ldots, K$
and
 $i=1,\ldots, n$
.
$i=1,\ldots, n$
.
Using the latent indicators of categorical allocation, the likelihood simplifies to
 \begin{eqnarray} f(\textbf{y}\mid \boldsymbol{\eta }, \boldsymbol{\beta }, \sigma ^2) &=& \prod _{j=1}^{K}\prod _{i=1}^{n}\eta _j^{I_{ij}} [\mathcal{N}_j(y_i \mid \boldsymbol{\beta }_{j}, \sigma ^2_{j})]^{I_{ij}} \nonumber \\[5pt] &=& \prod _{j=1}^{K} \eta _j^{n_j} \!\left [ \prod _{i: I_{ij}=1} \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_{j}, \sigma ^2_j)\right ], \end{eqnarray}
\begin{eqnarray} f(\textbf{y}\mid \boldsymbol{\eta }, \boldsymbol{\beta }, \sigma ^2) &=& \prod _{j=1}^{K}\prod _{i=1}^{n}\eta _j^{I_{ij}} [\mathcal{N}_j(y_i \mid \boldsymbol{\beta }_{j}, \sigma ^2_{j})]^{I_{ij}} \nonumber \\[5pt] &=& \prod _{j=1}^{K} \eta _j^{n_j} \!\left [ \prod _{i: I_{ij}=1} \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_{j}, \sigma ^2_j)\right ], \end{eqnarray}
where
 $n_j=\sum _{i}I_{ij}$
is the number of observations allocated to group
$n_j=\sum _{i}I_{ij}$
is the number of observations allocated to group
 $j$
and
$j$
and
 $n= \sum _{j=1}^{K}n_j$
, for
$n= \sum _{j=1}^{K}n_j$
, for
 $j=1,\ldots, K$
,
$j=1,\ldots, K$
,
 $i=1,\ldots, n$
. Thus, the mixture survival likelihood function is given by:
$i=1,\ldots, n$
. Thus, the mixture survival likelihood function is given by:
 \begin{equation} f(\textbf{y} \mid \boldsymbol{\eta }, \boldsymbol{\beta }, \sigma ^2) = \prod _{j=1}^{K} \eta _j^{n_j} \!\left [ \prod _{i: I_{ij}=1} \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_{j}, \sigma ^2_j)^{\delta _i} S(y_i \mid \boldsymbol{\beta }_j, \sigma ^2_j)^{1-\delta _i}\right ], \end{equation}
\begin{equation} f(\textbf{y} \mid \boldsymbol{\eta }, \boldsymbol{\beta }, \sigma ^2) = \prod _{j=1}^{K} \eta _j^{n_j} \!\left [ \prod _{i: I_{ij}=1} \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_{j}, \sigma ^2_j)^{\delta _i} S(y_i \mid \boldsymbol{\beta }_j, \sigma ^2_j)^{1-\delta _i}\right ], \end{equation}
where
 $\delta _i$
in the censorship indicator, as previously seen in section 2.1.
$\delta _i$
in the censorship indicator, as previously seen in section 2.1.
From a Bayesian point of view, we are interested in the posterior
 $p(\boldsymbol{\eta }, \boldsymbol{\beta }, \sigma ^2 \mid \textbf{y})$
. The posterior distribution are generally not available analytically, and numerical integration and simulation are considered, in particular, MCMC methods (Gamerman & Lopes, Reference Gamerman and Lopes2006) are used in this paper. Notice that to compute posterior distributions, we need to take into account the censored quantities, which in practice can be computationally prohibitive, depending on the percentage of censored data and the large dataset. Thus, inference is facilitated through data augmentation.
$p(\boldsymbol{\eta }, \boldsymbol{\beta }, \sigma ^2 \mid \textbf{y})$
. The posterior distribution are generally not available analytically, and numerical integration and simulation are considered, in particular, MCMC methods (Gamerman & Lopes, Reference Gamerman and Lopes2006) are used in this paper. Notice that to compute posterior distributions, we need to take into account the censored quantities, which in practice can be computationally prohibitive, depending on the percentage of censored data and the large dataset. Thus, inference is facilitated through data augmentation.
2.2.2 Inference based on data augmentation
The presence of censored data is a common feature when considering time data until the occurrence of an event and the likelihood function takes this fact into account, as seen in equation (10). Following the Bayesian approach, the estimation procedure can be based on MCMC algorithm using the data augmentation technique (see Tanner & Wong, Reference Tanner and Wong1987). Suppose we observe logarithmic survival times
 $\textbf{y}^{obs}= (y^{obs}_1, \ldots, y^{obs}_h)$
. Then the idea is to define the logarithmic survival times for the
$\textbf{y}^{obs}= (y^{obs}_1, \ldots, y^{obs}_h)$
. Then the idea is to define the logarithmic survival times for the
 $n-h$
censored policies as missing data which we denote as
$n-h$
censored policies as missing data which we denote as
 $\textbf{z}= (z_{h+1}, \ldots, z_{n})$
.
$\textbf{z}= (z_{h+1}, \ldots, z_{n})$
.
Assume that the full data is given by:
 \begin{equation} \textbf{y}= (\textbf{y}^{obs}, \textbf{z}). \end{equation}
\begin{equation} \textbf{y}= (\textbf{y}^{obs}, \textbf{z}). \end{equation}
Let
 $\boldsymbol{\theta }$
be the parametric vector of interest. The data augmentation approach is motivated by the following representation of the posterior density:
$\boldsymbol{\theta }$
be the parametric vector of interest. The data augmentation approach is motivated by the following representation of the posterior density:
 \begin{equation} p(\boldsymbol{\theta } \mid \textbf{y}^{obs}, \boldsymbol{\delta }) = \int _{\textbf{Z}} p(\boldsymbol{\theta } \mid \textbf{y}^{obs}, \textbf{z}, \boldsymbol{\delta })p(\textbf{z} \mid \textbf{y}^{obs}, \boldsymbol{\delta }) d\textbf{z}, \end{equation}
\begin{equation} p(\boldsymbol{\theta } \mid \textbf{y}^{obs}, \boldsymbol{\delta }) = \int _{\textbf{Z}} p(\boldsymbol{\theta } \mid \textbf{y}^{obs}, \textbf{z}, \boldsymbol{\delta })p(\textbf{z} \mid \textbf{y}^{obs}, \boldsymbol{\delta }) d\textbf{z}, \end{equation}
where the vector
 $\boldsymbol{\delta }$
is composed by censorship indicators
$\boldsymbol{\delta }$
is composed by censorship indicators
 $\delta _i \in \!\left \{0, 1\right \}$
;
$\delta _i \in \!\left \{0, 1\right \}$
;
 $p(\boldsymbol{\theta } \mid \textbf{y}^{obs},\boldsymbol{\delta })$
denotes the posterior density of the parameter
$p(\boldsymbol{\theta } \mid \textbf{y}^{obs},\boldsymbol{\delta })$
denotes the posterior density of the parameter
 $\boldsymbol{\theta }$
given the observed data
$\boldsymbol{\theta }$
given the observed data
 $\textbf{y}^{obs}$
;
$\textbf{y}^{obs}$
;
 $p(\textbf{z} \mid \textbf{y}^{obs}, \boldsymbol{\delta })$
denotes the predictive density of latent data
$p(\textbf{z} \mid \textbf{y}^{obs}, \boldsymbol{\delta })$
denotes the predictive density of latent data
 $\textbf{z}$
given
$\textbf{z}$
given
 $\textbf{y}^{obs}$
; and
$\textbf{y}^{obs}$
; and
 $p(\boldsymbol{\theta } \mid \textbf{y}^{obs}, \textbf{z}, \boldsymbol{\delta })$
denotes the conditional density of
$p(\boldsymbol{\theta } \mid \textbf{y}^{obs}, \textbf{z}, \boldsymbol{\delta })$
denotes the conditional density of
 $\boldsymbol{\theta }$
given the augmented data
$\boldsymbol{\theta }$
given the augmented data
 $\textbf{y}$
.
$\textbf{y}$
.
In practice, we do not know a priori to which group a given observation belongs. Thus, in addition to the censored observations, whose outcome is unknown, the variable
 $I_i$
in equation (7) is also latent and is estimated in our inferential algorithm. Assuming that policies are independent, the likelihood function for the complete data can be written as:
$I_i$
in equation (7) is also latent and is estimated in our inferential algorithm. Assuming that policies are independent, the likelihood function for the complete data can be written as:
 \begin{eqnarray} f(\textbf{y}^{obs}, \textbf{z}, \boldsymbol{\delta } \mid \boldsymbol{\theta }) &=&{ \prod _{j=1}^{K} \eta _j^{n_j}} \!\left [\prod _{i : \delta _i=1, I_{ij}=1}f{_{j}}(y_i^{obs} \mid \boldsymbol{\theta }_j) \prod _{i : \delta _i=0,I_{ij}=1}f{_j}(z_i \mid \boldsymbol{\theta }_j)\mathcal{I}(z_i \geq y_i^{obs}) \right ], \end{eqnarray}
\begin{eqnarray} f(\textbf{y}^{obs}, \textbf{z}, \boldsymbol{\delta } \mid \boldsymbol{\theta }) &=&{ \prod _{j=1}^{K} \eta _j^{n_j}} \!\left [\prod _{i : \delta _i=1, I_{ij}=1}f{_{j}}(y_i^{obs} \mid \boldsymbol{\theta }_j) \prod _{i : \delta _i=0,I_{ij}=1}f{_j}(z_i \mid \boldsymbol{\theta }_j)\mathcal{I}(z_i \geq y_i^{obs}) \right ], \end{eqnarray}
where
 $\boldsymbol{\theta }_j= (\eta _j, \boldsymbol{\beta }_j, \sigma ^2_j)$
,
$\boldsymbol{\theta }_j= (\eta _j, \boldsymbol{\beta }_j, \sigma ^2_j)$
,
 $n_j= \sum _i I_{ij}$
,
$n_j= \sum _i I_{ij}$
,
 $\sum _{j=1}^{k} n_j=n$
, and
$\sum _{j=1}^{k} n_j=n$
, and
 $\mathcal{N}_j \sim f_j( \cdot \mid \boldsymbol{\theta }_j)$
. Following Bayes’ theorem, the posterior distribution of the model parameters and latent variables, given the complete data
$\mathcal{N}_j \sim f_j( \cdot \mid \boldsymbol{\theta }_j)$
. Following Bayes’ theorem, the posterior distribution of the model parameters and latent variables, given the complete data
 $\textbf{y} = (\textbf{y}_1, \ldots, \textbf{y}_{K})'$
, is proportional to
$\textbf{y} = (\textbf{y}_1, \ldots, \textbf{y}_{K})'$
, is proportional to
 \begin{eqnarray} p\!\left (\boldsymbol{\eta }, \boldsymbol{\beta }, \sigma ^2 \mid \textbf{y}, \boldsymbol{\delta } \right ) &\propto & f(\textbf{y}^{obs}, \textbf{z}, \boldsymbol{\delta } \mid \boldsymbol{\theta }) p(I \mid \boldsymbol{\eta }) \pi (\boldsymbol{\eta }, \boldsymbol{\beta },\sigma ^2) \\[5pt] &\propto &{ \prod _{j=1}^{K} \eta _j^{n_j}} \!\left [\prod _{i : \delta _i=1, I_{ij}=1}f{_{j}}(y_i^{obs} \mid \boldsymbol{\theta }_j) \prod _{i : \delta _i=0,I_{ij}=1}f{_j}(z_i \mid \boldsymbol{\theta }_j)\mathcal{I}(z_i \geq y_i^{obs}) \right ] \nonumber \\[5pt] &\times & \prod _{i=1}^{n} p(I_i \mid \boldsymbol{\eta }) \pi (\boldsymbol{\eta }, \boldsymbol{\beta },\sigma ^2). \nonumber \end{eqnarray}
\begin{eqnarray} p\!\left (\boldsymbol{\eta }, \boldsymbol{\beta }, \sigma ^2 \mid \textbf{y}, \boldsymbol{\delta } \right ) &\propto & f(\textbf{y}^{obs}, \textbf{z}, \boldsymbol{\delta } \mid \boldsymbol{\theta }) p(I \mid \boldsymbol{\eta }) \pi (\boldsymbol{\eta }, \boldsymbol{\beta },\sigma ^2) \\[5pt] &\propto &{ \prod _{j=1}^{K} \eta _j^{n_j}} \!\left [\prod _{i : \delta _i=1, I_{ij}=1}f{_{j}}(y_i^{obs} \mid \boldsymbol{\theta }_j) \prod _{i : \delta _i=0,I_{ij}=1}f{_j}(z_i \mid \boldsymbol{\theta }_j)\mathcal{I}(z_i \geq y_i^{obs}) \right ] \nonumber \\[5pt] &\times & \prod _{i=1}^{n} p(I_i \mid \boldsymbol{\eta }) \pi (\boldsymbol{\eta }, \boldsymbol{\beta },\sigma ^2). \nonumber \end{eqnarray}
The Bayesian mixture model is completed by the prior distribution specification. We assume independence in the prior distribution with
 $\boldsymbol{\eta } \sim Dirichlet(K, \alpha )$
, where
$\boldsymbol{\eta } \sim Dirichlet(K, \alpha )$
, where
 $\sum _{j=1}^{K} \eta _j = 1$
and
$\sum _{j=1}^{K} \eta _j = 1$
and
 $\alpha =(\alpha _1, \ldots, \alpha _K)$
is a vector of hyperparameters, such that
$\alpha =(\alpha _1, \ldots, \alpha _K)$
is a vector of hyperparameters, such that
 $\alpha _j \gt 0$
;
$\alpha _j \gt 0$
;
 $\phi _j=\frac{1}{\sigma ^2_j} \sim Gamma(a_j,b_j)$
, the regression coefficients,
$\phi _j=\frac{1}{\sigma ^2_j} \sim Gamma(a_j,b_j)$
, the regression coefficients,
 $\boldsymbol{\beta }_j \sim \mathcal{N}_j(\boldsymbol{m}_j, \tau ^2_j\boldsymbol{I}_p)$
and
$\boldsymbol{\beta }_j \sim \mathcal{N}_j(\boldsymbol{m}_j, \tau ^2_j\boldsymbol{I}_p)$
and
 $P(I_{ij}=1)=\eta _j$
, for
$P(I_{ij}=1)=\eta _j$
, for
 $i=1, \ldots, n$
and
$i=1, \ldots, n$
and
 $j=1, \ldots, K$
.
$j=1, \ldots, K$
.
The resulting posterior distribution in equation (17) does not have closed form, and we appeal to MCMC methods to obtain samples from the posterior distribution. In particular, posterior samples are obtained through a Gibbs sampler algorithm, where the Markov chain is constructed by considering the complete conditional distribution of each hidden variable given the others and the observations. The scheme is presented in the following section.
2.2.3 Computational scheme for the mixture of Log-Normal components
Assuming
 $K$
groups, it is possible to consider the Gibbs sampler algorithm in order to overcome the numerical integration condition of the data augmentation techniques, resulting in a computationally efficient algorithm.
$K$
groups, it is possible to consider the Gibbs sampler algorithm in order to overcome the numerical integration condition of the data augmentation techniques, resulting in a computationally efficient algorithm.
We consider the following Bayesian Gaussian mixture survival model with data augmentation:
 \begin{eqnarray*} \textbf{y}_j \mid I_i, \boldsymbol{\beta }_j, \phi _j &\sim & \mathcal{N}_j(x_i^T \boldsymbol{\beta }_j, \phi ^{-1}_j) \\[5pt] I_i \mid \boldsymbol{\eta } &\sim & Categorical(K, \boldsymbol{\eta }) \\[5pt] \boldsymbol{\eta } &\sim & Dirichlet(\alpha _1, \ldots, \alpha _K) \\[5pt] \boldsymbol{\beta }_j &\sim & \mathcal{N}_j(\boldsymbol{m}_j, \tau ^2_j\boldsymbol{I}_p) \end{eqnarray*}
\begin{eqnarray*} \textbf{y}_j \mid I_i, \boldsymbol{\beta }_j, \phi _j &\sim & \mathcal{N}_j(x_i^T \boldsymbol{\beta }_j, \phi ^{-1}_j) \\[5pt] I_i \mid \boldsymbol{\eta } &\sim & Categorical(K, \boldsymbol{\eta }) \\[5pt] \boldsymbol{\eta } &\sim & Dirichlet(\alpha _1, \ldots, \alpha _K) \\[5pt] \boldsymbol{\beta }_j &\sim & \mathcal{N}_j(\boldsymbol{m}_j, \tau ^2_j\boldsymbol{I}_p) \end{eqnarray*}
 \begin{eqnarray*} \phi _j &\sim & Gamma(a_j,b_j) \\[5pt] p(z_i) &\propto & \mathcal{I}\!\left \{ z_i \geq y_i\right \} \end{eqnarray*}
\begin{eqnarray*} \phi _j &\sim & Gamma(a_j,b_j) \\[5pt] p(z_i) &\propto & \mathcal{I}\!\left \{ z_i \geq y_i\right \} \end{eqnarray*}
Algorithm 1 shows the scheme to estimate the parameters via data augmentation with censored observations. Details involved in obtaining the full conditional distributions can be seen in Appendix A.
Algorithm 1. Gibbs sampler for a finite Gaussian mixture survival model with data augmentation.

2.2.4 Point estimation via EM
Optimization methods to obtain maximum likelihood estimates are less computationally expensive than Monte Carlo estimation because they depend uniquely on numerical convergence. In order to obtain point estimates efficiently, we consider the maximization of log-likelihoods for the mixture model.
Consider
 $K$
mixture components. In the classical context, the mixture model without censored data is described by equations (11) and (12), respectively. Furthermore, without considering censored data and latent indicators of the mixture components, the log-likelihood function to be maximized is given by:
$K$
mixture components. In the classical context, the mixture model without censored data is described by equations (11) and (12), respectively. Furthermore, without considering censored data and latent indicators of the mixture components, the log-likelihood function to be maximized is given by:
 \begin{equation} l\!\left (\!\left \{\eta _j\right \}_{j=1}^{K}, \!\left \{\boldsymbol{\beta }_j\right \}_{j=1}^{K}, \!\left \{\sigma ^2_j\right \}_{j=1}^{K}\right ) = \sum _{i=1}^{n}\log \sum _{j=1}^{K} \eta _j f_j(Y_i \mid \boldsymbol{\beta }_j, \sigma ^2_j). \end{equation}
\begin{equation} l\!\left (\!\left \{\eta _j\right \}_{j=1}^{K}, \!\left \{\boldsymbol{\beta }_j\right \}_{j=1}^{K}, \!\left \{\sigma ^2_j\right \}_{j=1}^{K}\right ) = \sum _{i=1}^{n}\log \sum _{j=1}^{K} \eta _j f_j(Y_i \mid \boldsymbol{\beta }_j, \sigma ^2_j). \end{equation}
Notice that the expression depends on logarithms of sums, which cannot be simplified through logarithmic properties. The estimation, in this context, is exhaustive and without analytic or recursive forms for the maximum likelihood estimators (MLEs) of the model parameters.
In the mixture distribution context, it is very common to use the EM algorithm proposed by Dempster et al. (Reference Dempster, Laird and Rubin1977) which is an iterative mechanism to calculate the MLE in the presence of missing observations. Given the use of latent variables, and conditional on
 $I$
, equation (11) is valid. Thus, it provides a probability distribution over the latent variables together with a point estimate for parameters. If a prior distribution is assumed for the parameters, the joint posterior mode is obtained by the method.
$I$
, equation (11) is valid. Thus, it provides a probability distribution over the latent variables together with a point estimate for parameters. If a prior distribution is assumed for the parameters, the joint posterior mode is obtained by the method.
Besides that, when we take into account the censored observed data, the data augmentation technique, as previously seen, can be applied by including a new latent variable vector
 $\textbf{z}$
. According to our model, censored observations are originated from a truncated normal distribution.
$\textbf{z}$
. According to our model, censored observations are originated from a truncated normal distribution.
Assume that observation
 $y_i$
is censored. That is, there is an unobserved datum
$y_i$
is censored. That is, there is an unobserved datum
 $z_i$
such that
$z_i$
such that
 $z_i \mid \!\left \{I_{ij}=1 \right \} \sim f_j$
and
$z_i \mid \!\left \{I_{ij}=1 \right \} \sim f_j$
and
 $y_i^{obs} \mid z_i, \!\left \{I_{ij}=1\right \} \sim \mathcal{NT}_{(-\infty,z_i)}(x_{ij}' \boldsymbol{\beta }_j, \sigma ^2_j)$
. The strategy that we will adopt in the algorithm is to remove the truncation from the observed data
$y_i^{obs} \mid z_i, \!\left \{I_{ij}=1\right \} \sim \mathcal{NT}_{(-\infty,z_i)}(x_{ij}' \boldsymbol{\beta }_j, \sigma ^2_j)$
. The strategy that we will adopt in the algorithm is to remove the truncation from the observed data
 $y_i^{obs}$
to obtain
$y_i^{obs}$
to obtain
 $z_i$
, at each iteration
$z_i$
, at each iteration
 $(k)$
, so that
$(k)$
, so that
 $y_{1:n}^{(k)} = (y_1^{obs}, y_2^{obs}, \ldots, y_{h}^{obs}, z_{h+1}^{(k)}, \ldots, z_{n}^{(k)})$
, as previously seen in section 2.2.2.
$y_{1:n}^{(k)} = (y_1^{obs}, y_2^{obs}, \ldots, y_{h}^{obs}, z_{h+1}^{(k)}, \ldots, z_{n}^{(k)})$
, as previously seen in section 2.2.2.
Algorithm 2 is adapted for this context. For more details, see Jedidi et al. (Reference Jedidi, Ramaswamy and DeSarbo1993). Notice that
 $E(z_i \mid y_i^{obs}, \!\left \{I_{ij}=1\right \})$
and
$E(z_i \mid y_i^{obs}, \!\left \{I_{ij}=1\right \})$
and
 $Var(z_i \mid y_i^{obs}, \!\left \{I_{ij}=1\right \})$
denote the expected value and variance of a truncated Gaussian distribution, respectively. Although the computational cost (to obtain a point estimate) is smaller when compared to the proposal in sections 2.2.2 and 2.2.3, a disadvantage of this approach is that the EM algorithm is quite sensitive to the choice of initial parameters and does not take into account the uncertainty associated with parameter estimates. Besides, the EM algorithm will converge very slowly if a poor choice of initial value
$Var(z_i \mid y_i^{obs}, \!\left \{I_{ij}=1\right \})$
denote the expected value and variance of a truncated Gaussian distribution, respectively. Although the computational cost (to obtain a point estimate) is smaller when compared to the proposal in sections 2.2.2 and 2.2.3, a disadvantage of this approach is that the EM algorithm is quite sensitive to the choice of initial parameters and does not take into account the uncertainty associated with parameter estimates. Besides, the EM algorithm will converge very slowly if a poor choice of initial value
 $\boldsymbol{\eta }^{(0)}$
,
$\boldsymbol{\eta }^{(0)}$
,
 $\boldsymbol{\beta }_j^{(0)}$
, and
$\boldsymbol{\beta }_j^{(0)}$
, and
 $\sigma _j^{2(0)}$
is selected.
$\sigma _j^{2(0)}$
is selected.
Algorithm 2. Expectation–Maximization algorithm for a finite Gaussian mixture survival model with data augmentation.

3. Applications
This section presents three applications of our proposed model: (i) a simulated dataset study to evaluate the performance and computational cost of our proposed methodology via data augmentation; (ii) a realistic simulated dataset that emulates a real portfolio and features often present in real actuarial data; and (iii) a case study based on the Telco customer churn data which are available in IBM Business Analytics Community Connect, containing information about home phone and internet services https://community.ibm.com/community/ user/businessanalytics/home , IBM (2019). The idea of the case study is to illustrate the flexibility of our proposed model when compared to well-known models used in the literature of survival analysis. Codes with descriptive data analysis, inference procedure, and database are available at https://github.com/vivianalobo/LapseRiskAAS .

Figure 2 Simulated with 40% censored dataset: posterior survival probabilities with mean (gray line) and limits of 95% credible interval: (a) the Bayesian Log-Normal model (BLN), (b) the point estimation mixture Log-Normal model via EM algorithm (EMMLN), (c) the Bayesian mixture Log-Normal model (BMLN) with data augmentation, and (d) Bayesian mixture Log-Normal model via Stan (SBMLN), considering
 $n= 1,000$
policies. Categories: yes attribute (black dashed line) and no attribute (black solid line).
$n= 1,000$
policies. Categories: yes attribute (black dashed line) and no attribute (black solid line).
3.1 Simulated dataset
In this section, we return to the illustrative dataset seen in section 2.1. Our aim is to compare the usual and mixture survival Log-Normal models under a Bayesian approach through our proposals described in sections 2.2.1 and 2.2.2.
We simulate three scenarios: (i) a dataset with 10% of censored data; (ii) a dataset with 40% of censored data; and (iii) a dataset with 60% of censored data, considering a mixture of
 $K=2$
components, with
$K=2$
components, with
 $\eta _1=\eta =0.6$
. We would like to assess whether our proposal is efficient in sampling from the posterior distribution as well as its computational efficiency, for the model of interest. In addition, we vary the sample size (
$\eta _1=\eta =0.6$
. We would like to assess whether our proposal is efficient in sampling from the posterior distribution as well as its computational efficiency, for the model of interest. In addition, we vary the sample size (
 $n=1,000; 10,000; 50,000; 100,000$
) in order to evaluate the computational cost through (a) our proposal with data augmentation for censored data. To allow fast computations, we perform part of the code implementation with the C++ programming language to build improved loops of complete conditional distributions through the RcppArmadillo package available in R software (see Eddelbuettel & Sanderson, Reference Eddelbuettel and Sanderson2014); and (b) without data augmentation via RStan package available in R (Stan Development Team, 2018; Carpenter et al., Reference Carpenter, Gelman, Hoffman, Lee, Goodrich, Betancourt, Brubaker, Guo, Li and Riddell2017), that is, considering the survival likelihood given by equation (13). Stan is a C++ library for Bayesian modeling and inference that primarily uses the No-U-Turn sampler (NUTS) (see Hoffman & Gelman, Reference Hoffman and Gelman2014) to obtain posterior simulations given a user-specified model and data.
$n=1,000; 10,000; 50,000; 100,000$
) in order to evaluate the computational cost through (a) our proposal with data augmentation for censored data. To allow fast computations, we perform part of the code implementation with the C++ programming language to build improved loops of complete conditional distributions through the RcppArmadillo package available in R software (see Eddelbuettel & Sanderson, Reference Eddelbuettel and Sanderson2014); and (b) without data augmentation via RStan package available in R (Stan Development Team, 2018; Carpenter et al., Reference Carpenter, Gelman, Hoffman, Lee, Goodrich, Betancourt, Brubaker, Guo, Li and Riddell2017), that is, considering the survival likelihood given by equation (13). Stan is a C++ library for Bayesian modeling and inference that primarily uses the No-U-Turn sampler (NUTS) (see Hoffman & Gelman, Reference Hoffman and Gelman2014) to obtain posterior simulations given a user-specified model and data.
The survival time can be analyzed according to
 $\log(T_i)= \beta _0 + \beta _1 x_i + \varepsilon _i$
, with
$\log(T_i)= \beta _0 + \beta _1 x_i + \varepsilon _i$
, with
 $x$
the covariate that takes values (
$x$
the covariate that takes values (
 $x=0$
or
$x=0$
or
 $x=1$
) and error
$x=1$
) and error
 $\varepsilon _i \sim N(0, \phi ^{-1})$
. We assign vague independent priors to the parameters in
$\varepsilon _i \sim N(0, \phi ^{-1})$
. We assign vague independent priors to the parameters in
 $\boldsymbol{\theta }$
with
$\boldsymbol{\theta }$
with
 $\phi _j \sim Gamma(0.01,0.01)$
,
$\phi _j \sim Gamma(0.01,0.01)$
,
 $\boldsymbol{\beta }_j \sim \mathcal{N}_j(\textbf{0}, 100\boldsymbol{I}_2)$
, and
$\boldsymbol{\beta }_j \sim \mathcal{N}_j(\textbf{0}, 100\boldsymbol{I}_2)$
, and
 $\boldsymbol{\eta }\sim Dirichilet(\alpha _1=2, \alpha _2=2)$
, for
$\boldsymbol{\eta }\sim Dirichilet(\alpha _1=2, \alpha _2=2)$
, for
 $j=1,2$
. We run an MCMC chain for 20,000 iterations and consider the first 10,000 out as burn-in. The burn-in and lag for spacing of the chain were selected so that the effective sample size was around 1,000 samples.
$j=1,2$
. We run an MCMC chain for 20,000 iterations and consider the first 10,000 out as burn-in. The burn-in and lag for spacing of the chain were selected so that the effective sample size was around 1,000 samples.
Fig. 2 illustrates the fit of the survival curves by the competing models considering a sample with 1,000 policies and 40% rate of censorship (as seen in Fig. 1 (a)), the usual Bayesian Log-Normal (BLN) model (without mixture, like in Fig. 1 (d)) and the Bayesian mixture Log-Normal model (BMLN) (see panels (c) and (d) in Fig. 2). As can be seen, the proposed mixture model is able to accommodate different behaviors in the survival curves when compared to the usual Log-Normal model. In addition, the uncertainty associated with estimates is lower for our proposed mixture model. Panel (b), in Fig. 2, exhibits the point estimation via EM for the Log-Normal mixture modeling. The estimated survival curves via the EM algorithm follow the behavior of the empirical Kaplan–Meier curves. Point estimates of the parameters of interest are reasonable compared to those obtained via Gibbs sampler techniques. See more details about the simulated dataset in Appendix B.
Table 1 shows the posterior summaries for the survival Log-Normal model without mixture (Bayes LN) and considering Log-Normal mixtures via our proposal via data augmentation (BMLN) and via Stan (BMLN and SBMLN), respectively. As already mentioned, the non-mixture model is not able to capture the behavior of the survival curve. The structure of the non-mixture model does not allow the incorporation of mixture components in the coefficient estimates. On the other hand, the mixture Log-Normal model is capable of producing suitable estimates for the true parameters. Although the data augmentation proposal and the Stan method lead to similar point and interval estimates, the processing computational cost via Stan is much higher for all scenarios, as can be seen in Table 2. In this way, the use of Stan for large samples, highly censored observations, and considering more covariates in the survival model can be prohibitive. For the EM algorithm, 58 iterations were required until the parameters converged, which resulted in a computational time of 3.32 seconds. However, as already stated, the EM algorithm does not generate uncertainty measures associated with estimates.
Table 1. Posterior summaries comparison: with mean and 95% credibility for the Bayes LN, the Bayes Mixture LN via Stan, and the Bayes Mixture LN; the point estimation via EM Mixture LN, for a simulated dataset with 40% censorship rate and considering
 $n=1,000$
policies.
$n=1,000$
policies.

Table 2. Comparison of computational times (in seconds) involved in the Bayesian competing methods for simulated datasets with 10%, 40%, and 60% rates of censorship and considering
 $n$
(size) policies.
$n$
(size) policies.

Computational system Ubuntu, Intel Core i5-10400F CPU 2.90 GHZ, 16 GB RAM.
3.2 A simulated dataset in insurance
In this section, we simulated a dataset aiming to emulate the behavior of a realistic portfolio in the private life insurance sector. We simulate a large dataset emulating 100,000 policies over 100 months, taking into account heterogeneous lapse rates and realistic censored data with an approximate
 $ 42.7\%$
censorship rate and two mixing components based on
$ 42.7\%$
censorship rate and two mixing components based on
 $\eta =0.6$
, via the mixture Log-Normal model previously seen in section 2.2.1. To illustrate, this dataset contains individual policyholder information as well as information about the subscription.
$\eta =0.6$
, via the mixture Log-Normal model previously seen in section 2.2.1. To illustrate, this dataset contains individual policyholder information as well as information about the subscription.
The factors considered in this study are gender (male and female), age group (18–29 years, 30–49 years, and 60+ years), policy type (standard and gold), where the level gold represents a segmentation of insureds that have a high insured capital and the premium payment mode (monthly, yearly, i.e., regular premium or single premium) of the policy. Time to churn is the response variable of interest.

Figure 3 Simulated dataset: a summary about the survival time with (a) survival time in log scale, (b) empirical survival curve, and (c) churn hazard curve.
Panel (a) in Fig. 3 presents the simulated survival times in the log scale, indicating the mixing of two distributions. In panels (b)–(c), the empirical survival curve and hazard rate behavior show that the lapse rate is higher and sharply falls for the first periods of time after subscription initiation, then it stabilizes for some time, exhibits a peak close to 20 months, and then gradually decreases.
Fig. 4 presents the marginal empirical Kaplan–Meier survival curve for the variables of this study. As we can be seen, categories for each variable present particular behavior and could be useful to understand the time to churn. There is a noticeable drop in active insured in the first periods after the policy subscription. Some reasons could be discussed, such as the policyholders who subscribe just to test a service or there may be some association with the premium payment mode. For the age group, there is no visible difference in patterns of survival probability between the 18–29 years and 30–59 years of age groups, except for a drop in during the first months of subscription and nearby the final portion of the survival curve.
Fig. 5 shows the performance of the fitted curves for the competing models, the Log-Normal model, and the Log-Normal mixture model for some scenarios. Panel (a) represents the characteristics of the policyholder in scenario 1 (male, standard, 30–59 years of age, and monthly payment), panel (b) exhibits the fitted curves for scenario 2 (male, gold, 60+ years of age, and year), and panel (c) exhibits the estimated survival curves for scenario 3 (female, standard, 60+ years of age, and month). As we can see, policyholders in scenario 1 have lower persistence when compared to scenarios 2 and 3, respectively. This behavior is understood due to the fact of the standard group and 30–59 years of age group present survival empirical curves with more abrupt decay than 60+ years of age and gold categories.

Figure 4 Simulated dataset: marginal empirical survival curves via Kaplan–Meier for the covariates: gender, type policy, age, and payment.

Figure 5 Simulated dataset: summary survival curves with the empirical (dashed line), and the Bayes LN, the EM mixture LN, and the Bayes mixture LN with 95% credible interval (solid gray line): scenario 1 (first row), scenario 2 (second row), and scenario 3 (third row).
Our proposed Bayesian mixture survival model is able to capture the behavior of the empirical curves (see Fig. 5). Note that the BLN produces a poor fit due to the fact this model is not allowed to access distinct behavior of the curve at different times of the study. Besides that, the BMLN and EMMLN converge for the true values generated from the simulated dataset. In order to understand the lapse of the policyholders, especially in the initial periods of the contract, we consider obtaining some probabilities to profile the policyholder to customer retention via the BMLN. We hope that the longer customers are with the insurance company, the less likely they are to cancel a policy. Table 3 shows a summary of the probabilities conditional on the hypothesis that the policyholder has survived the first three months, that is, conditional on the event
 $L = \left \{T \gt 3 \right \}$
for the scenarios in Fig. 5. As one can see, the risk probability of a lapse occurring in the first year is higher for scenario 1 (0.394) when compared to scenarios 2 and 3 (0.247 and 0.123), respectively. On the other hand, the conditional probability that the policyholder maintains the contract term after 36 months, having survived to the first months (
$L = \left \{T \gt 3 \right \}$
for the scenarios in Fig. 5. As one can see, the risk probability of a lapse occurring in the first year is higher for scenario 1 (0.394) when compared to scenarios 2 and 3 (0.247 and 0.123), respectively. On the other hand, the conditional probability that the policyholder maintains the contract term after 36 months, having survived to the first months (
 $P(T \geq 36 \mid T\gt 3)$
), is high for all considered scenarios. Other probabilities can be evaluated in order to understand the profile of the company’s policyholders. To illustrate, Table 4 exhibits the results obtained conditioning on other events, such as
$P(T \geq 36 \mid T\gt 3)$
), is high for all considered scenarios. Other probabilities can be evaluated in order to understand the profile of the company’s policyholders. To illustrate, Table 4 exhibits the results obtained conditioning on other events, such as
 $\!\left \{ T\gt 12\right \}$
,
$\!\left \{ T\gt 12\right \}$
,
 $\!\left \{T\gt 24\right \}$
, and
$\!\left \{T\gt 24\right \}$
, and
 $\!\left \{T\gt 36\right \}$
. As expected, the probability of churn decreases, having the insured persisted in the insurance company for long periods, that is, the lapses reduce substantially with increasing policy age. Furthermore, when identifying insured profiles, we are able to understand which profiles need more attention; thus, the insurance company could develop retention strategies focused on these policyholders.
$\!\left \{T\gt 36\right \}$
. As expected, the probability of churn decreases, having the insured persisted in the insurance company for long periods, that is, the lapses reduce substantially with increasing policy age. Furthermore, when identifying insured profiles, we are able to understand which profiles need more attention; thus, the insurance company could develop retention strategies focused on these policyholders.
3.3 Case study: Telco customer churn
The Telco customer churn data is available on IBM Business Analytics Community Connect (IBM, 2019) and contains information about a Telco company that provides home phone and internet services to 7,043 customers in California in the United States. The dataset contains 18 variables about the profile of the customers and a variable indicating who has left or stayed in the service resulting in approximately 73.4% of censoring. The response variable tenure represents the number of months the customer has stayed with the company with an average of 32 months. Lifetimes equal to zero were removed resulting in a dataset of 7,032 customers. Demographic characteristics are included for each customer, as well as customer account information and service information. Following previous studies, we aim to predict customer churn rate behavior and identify the most important factors that contribute to high- or low-lapse risks.
Panels in Fig. 6 illustrate the pattern of the lifetime of the customers. Although a large admission of new customers is observed for the first months of contract, panel (c) indicates that there is a high lapse rate at the beginning, that is, there is a large portion of customers that will leave the company after just a few months of service. In the other months, the lapse risk rate remains around 0.005. Note that after 60 months of contract, there is a steep increase in the lapse rate. We expect that our proposed model is able to capture these sudden changes of pattern in the hazard function over time.
Table 3. Simulated dataset: probability for the time to churn conditional on the event
 $L=\{T \gt 3 \}$
for the scenarios 1, 2, and 3.
$L=\{T \gt 3 \}$
for the scenarios 1, 2, and 3.

Table 4. Simulated dataset: probability for the time to churn conditional on the events
 $\{ T\gt 12\}$
,
$\{ T\gt 12\}$
,
 $\{T\gt 24\}$
and
$\{T\gt 24\}$
and
 $\{T\gt 36\}$
for the scenarios 1, 2, and 3.
$\{T\gt 36\}$
for the scenarios 1, 2, and 3.


Figure 6 Case study: summary about the survival time with (a) lifetime distribution, (b) empirical survival curve, and (c) churn hazard rate.

Figure 7 Case study: model comparison compared with the empirical lapse curve for the Exponential model, the Weibull model, the Log-Normal model, and the Bayesian mixture Log-Normal model considering
 $K=2,3,4,5,6$
mixture components, respectively. The gray line represents the fitted model and the black line is the empirical curve.
$K=2,3,4,5,6$
mixture components, respectively. The gray line represents the fitted model and the black line is the empirical curve.

Figure 8 Case study: model comparison compared with the empirical lapse curve (first row) and the hazard curve (second row) for the Exponential model, the Weibull model, the Log-Normal model, and the Bayesian mixture Log-Normal model considering
 $K=2,3,4,5,6$
mixture components, respectively. The gray line represents the fitted model and the black line is the empirical curve.
$K=2,3,4,5,6$
mixture components, respectively. The gray line represents the fitted model and the black line is the empirical curve.
To check if usual parametric models are able to accommodate the different regimes of the survival curve over time, we consider fitting three alternative models: Exponential, Weibull, and Log-Normal and compare them with the BMLN model proposed in this paper. We present the Bayesian solution as follows instead of EM point estimates as it is desirable to access uncertainty in the curves. Figs. 7 and 8 present the general survival and hazard curves for model comparison, respectively. Indeed, the Exponential alternative seems naive, since it is a well-known fact that it assumes constant lapse rates over time. This hypothesis does not reflect reality and in this case, we will not take into account this model to model the profiles risk. Regarding our proposed mixture model, a sensitivity analysis for the number of components
 $K$
was performed. Thus, the time to churn is modeled based on the mixture model with
$K$
was performed. Thus, the time to churn is modeled based on the mixture model with
 $K$
components for different values of
$K$
components for different values of
 $K$
. Then, the best model can be selected based on model comparison measures computed for each value of
$K$
. Then, the best model can be selected based on model comparison measures computed for each value of
 $K$
. As we can see, the BMLN with
$K$
. As we can see, the BMLN with
 $K=2$
and
$K=2$
and
 $K=3$
components return fits that are similar to the Weibull model, failing to capture the curves from 30 to 70 months of contract. For
$K=3$
components return fits that are similar to the Weibull model, failing to capture the curves from 30 to 70 months of contract. For
 $K\gt 4$
, the mixture models provide better fits, with the general curve recovering the risk to churn in all periods of time including the first and last months of the contract. This indicates that our proposed model allows for more flexibility, besides being computationally efficient even for a large proportion of censorship in the data.
$K\gt 4$
, the mixture models provide better fits, with the general curve recovering the risk to churn in all periods of time including the first and last months of the contract. This indicates that our proposed model allows for more flexibility, besides being computationally efficient even for a large proportion of censorship in the data.

Figure 9 Case study: marginal empirical survival curve (first row) and hazard curves (second row) for covariates Payment Method, Contract, and Internet Service.
Although there is a large set of covariates available to explain the lapse risk, a group of them is not informative for the survival time under study. For example, the lapse rates for the two categories of gender in the data are nearly the same. Similar behavior is observed for some customer service information such as PhoneService, MutipleLines, and OnlineSecurity. Also, there is multicollinearity for groups of variables, in particular OnlineSecurity, TechSupport, OnlineBackup, and DeviceProtection are all dependent on the OnlineService variable. For instance, the covariates MonthlyCharges and TotalCharges present high collinearity. A detailed descriptive analysis for this data is presented at https://github.com/vivianalobo/LapseRiskAAS . We discuss ways to aggregate categories in each covariate considered in the analysis to achieve more interpretability of effects.
In the final models, we considered the covariates PaymentMethod, InternetService, and Contract resulting in eight risk profiles after rearranging the categories established in the descriptive analysis. Fig. 9 presents empirical survival and hazard curves for these risk profiles. For the customer account information, see that customers with Month-to-Month contracts have higher lapse rates compared to clients with One-year and Two-year contracts. Notice that the hazard curve of those with One-year payment is very similar to the one associated with more than one-year payment regime. Thus, we considered aggregating these categories in a unique group called “One-year +”. For the payment method, see that the behavior of survival curves and churn rates for Credit Card (automatic) and Bank Transfer (automatic) are quite similar. On the other hand, when we consider the instantaneous lapse curve, notice that customers that prefer an Electronic check as a payment method are the majority to leave the company, so we merged the other classes in a new category called “others.”
Figs. 10 and 11 present some scenarios for the profile risks. The first scenario (first row) refers to customers that have Fiber optics internet service and others (DSL, No) (for Month-to-Month and Electronic check). See that individuals that own Fiber optics internet service tend to have a higher propensity to churn when compared to others. Notice that the choice of the BMLN with
 $K=4$
components is enough to capture the trend of the lapse curve and the lapse instantaneous rate. The posterior mean mixture weights estimated for the BMLN with four components (and respective 95% credible interval) are:
$K=4$
components is enough to capture the trend of the lapse curve and the lapse instantaneous rate. The posterior mean mixture weights estimated for the BMLN with four components (and respective 95% credible interval) are:
 $\eta _1=0.603 (0.719, 0.888), \eta _2= 0.229 (0.174, 0.298), \eta _3= 0.102 (0.095, 0.107), \eta _4= 0.066 (0.048, 0.085)$
. A posterior summary of this model is detailed in Table 5 which gives some insights into the parameters of the model.
$\eta _1=0.603 (0.719, 0.888), \eta _2= 0.229 (0.174, 0.298), \eta _3= 0.102 (0.095, 0.107), \eta _4= 0.066 (0.048, 0.085)$
. A posterior summary of this model is detailed in Table 5 which gives some insights into the parameters of the model.

Figure 10 Case study: model comparison survival curves for the scenarios “varying Internet Service” (first row), “varying Payment Method” (second row), and “varying both Payment Method and Contract” (third row) for the Weibull model, the Log-Normal model, and the Bayesian mixture Log-Normal model with
 $K=4,5,6$
components. The solid line represents the fitted curve and the dashed line is the empirical curve. For the BMLN, the 95% credible interval is provided in gray.
$K=4,5,6$
components. The solid line represents the fitted curve and the dashed line is the empirical curve. For the BMLN, the 95% credible interval is provided in gray.

Figure 11 Case study: model comparison hazard curves for the scenarios “varying Internet Service” (first row), “varying Payment Method” (second row), and “varying both Payment Method and Contract” (third row) for the Weibull model, the Log-Normal model, and the Bayesian mixture Log-Normal model with
 $K=4,5,6$
components. The solid line represents the fitted curve and the dashed line is the empirical curve. For the BMLN, the 95% credible interval is provided in gray.
$K=4,5,6$
components. The solid line represents the fitted curve and the dashed line is the empirical curve. For the BMLN, the 95% credible interval is provided in gray.
Table 5. Posterior summary for regressors of the BMLN model with
 $K=4$
mixture components: with mean, standard error, and 95% credible interval, for the case study.
$K=4$
mixture components: with mean, standard error, and 95% credible interval, for the case study.

As customers who have internet services via Fiber optics have the propensity to churn faster, we would like to understand whether this trend is maintained by varying the payment method. For this purpose, scenario 2 (second row) presents customers’ profiles that prefer to deal through Electronic versus customers with Bank Transfer, Credit Card, or Mailed Check (for Month-to-Month and Fiber optics). Again, the BMLN shows to be the best model, compared to the Weibull and Log-Normal. Notice that there is a significant difference between customers that prefer Electronic check and others: the churn risk for the profile Electronic check, Month-to-Month, and Fiber optics presents higher lapses over several months (see Fig. 10, second row, after Month 40).
In scenario 3, four profile risks are considered taking into account both types of contracts and payment regimes. As we can see, customers whose contract is for One year or more (One year +) have a lower chance of lapsing when compared to Month-to-Month contracts. This can be seen if one varies the payment method (for the ones who have Fiber optics). See that risk lapse rates are higher for Electronic check payment method.
Overall the proposed mixture models with
 $K\geq 4$
present the best fits when compared with well-known survival models such as the Weibull model. The flexibility of our proposal captures changes of regimes in the lapse rates over time, exhibited by the data.
$K\geq 4$
present the best fits when compared with well-known survival models such as the Weibull model. The flexibility of our proposal captures changes of regimes in the lapse rates over time, exhibited by the data.
4. Conclusions
We have proposed a flexible survival mixture model that extends the usual models usually considered for censored data and accommodates different behavior of
 $T_i$
over time. This is done via mixtures of parametric models that accommodate censored survival times. The proposal combines the mixture distributions based on Frühwirth-Schnatter (Reference Frühwirth-Schnatter2006) and data augmentation techniques proposed by Tanner & Wong (Reference Tanner and Wong1987). Full uncertainty quantification is available through the Bayesian distributions which are obtained via MCMC methods. Furthermore, we proposed an efficient sampling algorithm for inference summarized in point estimates, via the EM algorithm. Notice that the Bayesian and frequentist solutions provide similar results in terms of point estimation for the regression coefficients. However, the Bayesian posterior distribution also allows for uncertainty quantification and estimation of nonlinear functions such as the survival curve with no asymptotic approximation required.
$T_i$
over time. This is done via mixtures of parametric models that accommodate censored survival times. The proposal combines the mixture distributions based on Frühwirth-Schnatter (Reference Frühwirth-Schnatter2006) and data augmentation techniques proposed by Tanner & Wong (Reference Tanner and Wong1987). Full uncertainty quantification is available through the Bayesian distributions which are obtained via MCMC methods. Furthermore, we proposed an efficient sampling algorithm for inference summarized in point estimates, via the EM algorithm. Notice that the Bayesian and frequentist solutions provide similar results in terms of point estimation for the regression coefficients. However, the Bayesian posterior distribution also allows for uncertainty quantification and estimation of nonlinear functions such as the survival curve with no asymptotic approximation required.
We performed extensive simulation studies to investigate the ability of the proposed mixture model to capture different survival curves. Our simulated examples indicate that the data-generating model with a mixture of distributions provides the best fit and indicates that the usual survival models are not able to capture the change in behavior for the churn times. Besides, our designed solution combining the Gibbs sampler and data augmentation is faster than the solution provided by the Stan package.
We have exploited three applications to illustrate the usefulness of our proposed mixture model for fitting time to churn. The first one is a simulated study that shows that our model is feasible even for very large datasets (order of thousands) and that our proposed implementation is computationally efficient and recovers well all model parameters and risk behaviors studied. The second application emulates an insurance dataset with risks changing over time and high censoring. The proposed model is also able to recover well all risk behaviors. Lastly, our case study illustrates that our mixture model is more flexible than the well-known survival models usually fitted in these applications.
We conclude that allowing for a flexible survival model enables more realistic description of the behavior of the survival probability curves, for the factors affecting times to an event such as surrender. In particular, this is crucial when the lapse rates change regime over time. An alternative way to accommodate heterogeneity in the hazard and survival functions is to define a dummy variable indicating the first months of contract. However, this solution would work for this period, but often it is not easy to set a priori which are the periods of time when changes of regime occur. In that context, our model allows the data to inform which are the regime changes necessary for a good fit of the regression model. In the present work, calendar effects were not considered. As an extension, we could investigate if changes in regime would be observed over several years, in which case dynamic models would be necessary. It is also a research interest to investigate if a finite number of components, as proposed in our work, could capture changes in the regime.
Regarding model complexity, an excessive number of components could lead to overfitting, while too few might not be able to accommodate heterogeneities in the hazard and survival curves. In this work, different values of
 $K$
were set, subject to subsequent sensitivity analysis based on the quality of fit metric. If our interest lies in the estimation of the effects to understand the profile customer retention, then a large number of parameters and components would not be a concern. However, if the purpose of the analysis is to predict whether a customer will be subject to churn or not, an alternative would be to apply regularization methods, which take into account both the quality and the complexity of the fit, penalizing the model’s coefficients and shrinking them towards zero. Among such methods, least absolute shrinkage and selection operator (LASSO) (Tibshirani, Reference Tibshirani1996; Park & Casella, Reference Park and Casella2008) can be seen as a form of variable selection, as it is able to nullify coefficients and could be used to select the number of components while preserving the adequacy of the fit.
$K$
were set, subject to subsequent sensitivity analysis based on the quality of fit metric. If our interest lies in the estimation of the effects to understand the profile customer retention, then a large number of parameters and components would not be a concern. However, if the purpose of the analysis is to predict whether a customer will be subject to churn or not, an alternative would be to apply regularization methods, which take into account both the quality and the complexity of the fit, penalizing the model’s coefficients and shrinking them towards zero. Among such methods, least absolute shrinkage and selection operator (LASSO) (Tibshirani, Reference Tibshirani1996; Park & Casella, Reference Park and Casella2008) can be seen as a form of variable selection, as it is able to nullify coefficients and could be used to select the number of components while preserving the adequacy of the fit.
Data availability statement
Codes for reproducing the descriptive data analysis, inference procedure, and database of the paper are available at https://github.com/vivianalobo/LapseRiskAAS.
Acknowledgments
We are grateful to LabMA/UFRJ (Laboratório de Matemática Aplicada of the Universidade Federal do Rio de Janeiro) based in Brazil for financial support and to its members for the very enriching discussions. We are very thankful to Vitor Gabriel Capdeville da Silva for reading the preview of this paper and providing support in this research developing a user-friendly interface using a smart implementation with C++ library through RcppArmadillo tool available in R allowing fast computations to take into account different values of mixture components.
A. Posterior distribution
The prior distributions considered for the parameters, the complete conditional distributions, and proposal densities used in the MCMC algorithm are detailed as follows.
A.1 Bayesian mixture survival model
Consider the likelihood given in equation (16) and mixture components in equation (11).
The conditional distribution of each
 $I_i$
,
$I_i$
,
 $i=1, \ldots, n$
, given all other parameters and prior distribution
$i=1, \ldots, n$
, given all other parameters and prior distribution
 $I_i \mid \boldsymbol{\eta } \sim Categorical(K, \boldsymbol{\eta })$
,
$I_i \mid \boldsymbol{\eta } \sim Categorical(K, \boldsymbol{\eta })$
,
 $\boldsymbol{\eta }=(\eta _1, \ldots, \eta _K)$
is given by:
$\boldsymbol{\eta }=(\eta _1, \ldots, \eta _K)$
is given by:
 \begin{eqnarray*} p(I_{ij}= 1 \mid y_i, \boldsymbol{\eta }, \cdot ) &\propto & f(y_i \mid \!\left \{I_{ij}=1\right \}, \boldsymbol{\eta })\pi (I_{ij}= 1 \mid \boldsymbol{\eta }) \\[5pt] &\propto & \frac{\eta _j f_j(y_i)}{\sum _{j=1}^{K} \eta _j f_j(y_i)}. \end{eqnarray*}
\begin{eqnarray*} p(I_{ij}= 1 \mid y_i, \boldsymbol{\eta }, \cdot ) &\propto & f(y_i \mid \!\left \{I_{ij}=1\right \}, \boldsymbol{\eta })\pi (I_{ij}= 1 \mid \boldsymbol{\eta }) \\[5pt] &\propto & \frac{\eta _j f_j(y_i)}{\sum _{j=1}^{K} \eta _j f_j(y_i)}. \end{eqnarray*}
If
 $y_i \mid \!\left \{I_{ij}=1\right \} \sim \mathcal{N}_j(\mu _{ij}, \phi _j^{-1})$
, then
$y_i \mid \!\left \{I_{ij}=1\right \} \sim \mathcal{N}_j(\mu _{ij}, \phi _j^{-1})$
, then
 \begin{equation} p(\!\left \{I_{ij}=1\right \} \mid y_i, \boldsymbol{\eta }, \boldsymbol{\beta }_j, \phi _j) = \frac{\eta _j \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_j, \phi _j)}{\sum _{j=1}^{K} \eta _j \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_j, \phi _j)}. \end{equation}
\begin{equation} p(\!\left \{I_{ij}=1\right \} \mid y_i, \boldsymbol{\eta }, \boldsymbol{\beta }_j, \phi _j) = \frac{\eta _j \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_j, \phi _j)}{\sum _{j=1}^{K} \eta _j \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_j, \phi _j)}. \end{equation}
Thus, the marginal posterior distribution is
 $I \mid \textbf{y} \sim Categorical\bigg (K;\; \frac{\eta _1 \mathcal{N}_1(y_i \mid \boldsymbol{\beta }_1, \phi _1)}{\sum _{j=1}^{K} \eta _j \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_j, \phi _j)}, \ldots \frac{\eta _K \mathcal{N}_K(y_i \mid \boldsymbol{\beta }_K, \phi _K)}{\sum _{j=1}^{K} \eta _j \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_j, \phi _j)} \bigg ),$
.
$I \mid \textbf{y} \sim Categorical\bigg (K;\; \frac{\eta _1 \mathcal{N}_1(y_i \mid \boldsymbol{\beta }_1, \phi _1)}{\sum _{j=1}^{K} \eta _j \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_j, \phi _j)}, \ldots \frac{\eta _K \mathcal{N}_K(y_i \mid \boldsymbol{\beta }_K, \phi _K)}{\sum _{j=1}^{K} \eta _j \mathcal{N}_j(y_i \mid \boldsymbol{\beta }_j, \phi _j)} \bigg ),$
.
The conditional distribution for, considering a prior distribution as
 $\boldsymbol{\eta } \sim Dirichilet(K;\; \alpha _1, \ldots, \alpha _K)$
is given by:
$\boldsymbol{\eta } \sim Dirichilet(K;\; \alpha _1, \ldots, \alpha _K)$
is given by:
 \begin{eqnarray} p(\boldsymbol{\eta } \mid I, \cdot ) &\propto & f(I \mid \boldsymbol{\eta }, \cdot )\pi (\boldsymbol{\eta }) = \prod _{i=1}^{K} p(I_i \mid \boldsymbol{\eta }, \cdot ) \pi (\boldsymbol{\eta }) = \!\left [ \prod _{i=1}^{n} \prod _{j=1}^{K} \eta _j^{[I_{ij}=1]}\right ] \prod _{j=1}^{K} \eta _j^{\alpha _j-1}\\[5pt] &\propto & \prod _{j=1}^{K} \eta _j^{\alpha _j- 1+ \sum _{i: I_{ij}=1}[I_{ij}=1]} = \prod _{j=1}^{K} \eta _j^{(\alpha _j+ n_j)-1}, \nonumber \end{eqnarray}
\begin{eqnarray} p(\boldsymbol{\eta } \mid I, \cdot ) &\propto & f(I \mid \boldsymbol{\eta }, \cdot )\pi (\boldsymbol{\eta }) = \prod _{i=1}^{K} p(I_i \mid \boldsymbol{\eta }, \cdot ) \pi (\boldsymbol{\eta }) = \!\left [ \prod _{i=1}^{n} \prod _{j=1}^{K} \eta _j^{[I_{ij}=1]}\right ] \prod _{j=1}^{K} \eta _j^{\alpha _j-1}\\[5pt] &\propto & \prod _{j=1}^{K} \eta _j^{\alpha _j- 1+ \sum _{i: I_{ij}=1}[I_{ij}=1]} = \prod _{j=1}^{K} \eta _j^{(\alpha _j+ n_j)-1}, \nonumber \end{eqnarray}
where
 $n_j= \sum _{i} I_{ij}$
. Thus,
$n_j= \sum _{i} I_{ij}$
. Thus,
 $\boldsymbol{\eta } \mid I, \cdot \sim Dirichilet(\alpha _1^{*}, \ldots, \alpha _K^{*})$
, with
$\boldsymbol{\eta } \mid I, \cdot \sim Dirichilet(\alpha _1^{*}, \ldots, \alpha _K^{*})$
, with
 $\alpha _j^{*}= n_j + \alpha _j$
,
$\alpha _j^{*}= n_j + \alpha _j$
,
 $j=1, \ldots, K$
.
$j=1, \ldots, K$
.
For each group
 $j$
, we can compute a sample from each of the components
$j$
, we can compute a sample from each of the components
 $\phi _j= 1/\sigma _j^2$
individually. For
$\phi _j= 1/\sigma _j^2$
individually. For
 $\phi _j \sim Gamma(a_j, b_j)$
,
$\phi _j \sim Gamma(a_j, b_j)$
,
 \begin{eqnarray} p(\phi _j \mid \textbf{y}_j, \cdot ) &\propto & f(\textbf{y}_j \mid \phi _j, I, \cdot )\pi (\phi _j) \nonumber \\[5pt] &\propto & (\phi _j)^{n_j/2} exp\!\left \{-\phi _j \!\left (\frac{(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)^{T}(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)}{2}\right )\right \}\phi _j^{a_j-1} \exp \!\left \{ -\phi _j{b_j}\right \} \nonumber \\[5pt] &\propto & \phi _j^{a_j + n_j/2 - 1} exp\!\left \{-\phi _j \!\left ({b_j} + \frac{(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)^{T}(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)}{2}\right )\right \}. \end{eqnarray}
\begin{eqnarray} p(\phi _j \mid \textbf{y}_j, \cdot ) &\propto & f(\textbf{y}_j \mid \phi _j, I, \cdot )\pi (\phi _j) \nonumber \\[5pt] &\propto & (\phi _j)^{n_j/2} exp\!\left \{-\phi _j \!\left (\frac{(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)^{T}(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)}{2}\right )\right \}\phi _j^{a_j-1} \exp \!\left \{ -\phi _j{b_j}\right \} \nonumber \\[5pt] &\propto & \phi _j^{a_j + n_j/2 - 1} exp\!\left \{-\phi _j \!\left ({b_j} + \frac{(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)^{T}(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)}{2}\right )\right \}. \end{eqnarray}
The conditional distribution of
 $\phi _j \mid \textbf{y}_j, \cdot \sim Gamma\!\left ({a_j} + \frac{n_j}{2} ;{b_j} + \frac{(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)^{T}(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)}{2} \right )$
.
$\phi _j \mid \textbf{y}_j, \cdot \sim Gamma\!\left ({a_j} + \frac{n_j}{2} ;{b_j} + \frac{(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)^{T}(\textbf{y}_j - \textbf{x}_i^{T}\boldsymbol{\beta }_j)}{2} \right )$
.
For
 $\boldsymbol{\beta }_j \sim \mathcal{N}_j(m_j, \tau ^2_j)$
, with
$\boldsymbol{\beta }_j \sim \mathcal{N}_j(m_j, \tau ^2_j)$
, with
 $\boldsymbol{\beta }_j= (\beta _{0j}, \beta _{1j}, \ldots, \beta _{pj})$
. The conditional distribution is given by:
$\boldsymbol{\beta }_j= (\beta _{0j}, \beta _{1j}, \ldots, \beta _{pj})$
. The conditional distribution is given by:
 \begin{eqnarray} p(\boldsymbol{\beta }_j \mid \textbf{y}_j, \cdot ) &\propto & f(\textbf{y}_j \mid \boldsymbol{\beta }_j, \cdot )\pi (\boldsymbol{\beta }_j) \end{eqnarray}
\begin{eqnarray} p(\boldsymbol{\beta }_j \mid \textbf{y}_j, \cdot ) &\propto & f(\textbf{y}_j \mid \boldsymbol{\beta }_j, \cdot )\pi (\boldsymbol{\beta }_j) \end{eqnarray}
For latent variable
 $Z$
, when
$Z$
, when
 $\delta _i=0$
,
$\delta _i=0$
,
 $i=1, \ldots, n$
, we consider the data augmentation. Thus,
$i=1, \ldots, n$
, we consider the data augmentation. Thus,
 $p(z_i \mid \!\left \{I_{ij}=1\right \}, \boldsymbol{\beta }_j, \phi _j, \cdot ) \propto \mathcal{I}(y_i \geq y_i)$
, we have
$p(z_i \mid \!\left \{I_{ij}=1\right \}, \boldsymbol{\beta }_j, \phi _j, \cdot ) \propto \mathcal{I}(y_i \geq y_i)$
, we have
 \begin{eqnarray} p(z_i \mid I\!\left \{I_{ij}=1\right \}, y_i, \cdot ) &\propto & f(y_i \mid \!\left \{I_{ij}=1\right \}, \cdot )\pi (z_i \mid \!\left \{I_{ij}=1\right \}) \nonumber \\[5pt] &\propto & f(y_i^{obs}, z_i \mid \!\left \{I_{ij}=1\right \}, \cdot )\pi (z_i) \\[5pt] &\propto & f(z_i \mid \!\left \{I_{ij}=1\right \})\pi (z_i)= \exp \!\left \{ - \frac{\phi _j}{2}(z_i - \textbf{x}_i^{T}\boldsymbol{\beta }_j)^2\right \}\mathcal{I}(z_i \geq y_i). \nonumber \end{eqnarray}
\begin{eqnarray} p(z_i \mid I\!\left \{I_{ij}=1\right \}, y_i, \cdot ) &\propto & f(y_i \mid \!\left \{I_{ij}=1\right \}, \cdot )\pi (z_i \mid \!\left \{I_{ij}=1\right \}) \nonumber \\[5pt] &\propto & f(y_i^{obs}, z_i \mid \!\left \{I_{ij}=1\right \}, \cdot )\pi (z_i) \\[5pt] &\propto & f(z_i \mid \!\left \{I_{ij}=1\right \})\pi (z_i)= \exp \!\left \{ - \frac{\phi _j}{2}(z_i - \textbf{x}_i^{T}\boldsymbol{\beta }_j)^2\right \}\mathcal{I}(z_i \geq y_i). \nonumber \end{eqnarray}
The conditional distribution of
 $z_i \mid \!\left \{I_{ij}=1\right \}, y_i \sim \mathcal{NT}(\textbf{x}_i^{T}\boldsymbol{\beta }_j, \phi ^{-1}_j)$
.
$z_i \mid \!\left \{I_{ij}=1\right \}, y_i \sim \mathcal{NT}(\textbf{x}_i^{T}\boldsymbol{\beta }_j, \phi ^{-1}_j)$
.
B. Some results for simulated datasets
In this appendix, we present the generation of observations via mixture distribution considering the presence of censored data introduced in section 2.1 and explored in section 3.1. The dataset was simulated considering variable
 $Y_i= \log(T_i)$
as the logarithmic the duration of a policy
$Y_i= \log(T_i)$
as the logarithmic the duration of a policy
 $i$
before termination from a mixture of Gaussian distribution with
$i$
before termination from a mixture of Gaussian distribution with
 $K=2$
components given by:
$K=2$
components given by:
 \begin{equation} f(y_i \mid \boldsymbol{\theta }) = \eta \thinspace \mathcal{N}_1 (\mu _{i1},\sigma ^2_1) + (1-\eta ) \mathcal{N}_2(\mu _{i2}, \sigma ^2_2), \thinspace \thinspace i=1,\ldots,n, \end{equation}
\begin{equation} f(y_i \mid \boldsymbol{\theta }) = \eta \thinspace \mathcal{N}_1 (\mu _{i1},\sigma ^2_1) + (1-\eta ) \mathcal{N}_2(\mu _{i2}, \sigma ^2_2), \thinspace \thinspace i=1,\ldots,n, \end{equation}
where
 $\boldsymbol{\theta }=(\eta, \boldsymbol{\beta }, \sigma ^2)$
the parametric vector of interest. The mean for
$\boldsymbol{\theta }=(\eta, \boldsymbol{\beta }, \sigma ^2)$
the parametric vector of interest. The mean for
 $j=1,2$
is given by
$j=1,2$
is given by
 $\mu _{i,j=1}=\beta _{01} + \beta _{11} x = 3.3 + 0.5x$
and
$\mu _{i,j=1}=\beta _{01} + \beta _{11} x = 3.3 + 0.5x$
and
 $\mu _{i,j=2}=\beta _{02} + \beta _{12} x = 4.0 + 0.8x$
and variance as
$\mu _{i,j=2}=\beta _{02} + \beta _{12} x = 4.0 + 0.8x$
and variance as
 $\sigma ^2_1=0.3$
and
$\sigma ^2_1=0.3$
and
 $\sigma ^2_2=0.039$
, respectively. The weight
$\sigma ^2_2=0.039$
, respectively. The weight
 $\eta _1=\eta$
is equal to 0.6 and
$\eta _1=\eta$
is equal to 0.6 and
 $x$
represents the covariate that takes values (
$x$
represents the covariate that takes values (
 $x=0$
, no attribute and
$x=0$
, no attribute and
 $x=1$
, yes attribute). In the presence of censored observation, that is,
$x=1$
, yes attribute). In the presence of censored observation, that is,
 $\delta _i=0$
, we generate the censored observation
$\delta _i=0$
, we generate the censored observation
 $y_i^c$
from a truncated Gaussian distribution as:
$y_i^c$
from a truncated Gaussian distribution as:
 \begin{equation} y_i^c \mid \cdot \sim \mathcal{NT}_{(-\infty, y_i]}\!\left (\mu _{ij}, \sigma ^2_j\right ), \forall \thinspace \thinspace j=1, \ldots, K. \end{equation}
\begin{equation} y_i^c \mid \cdot \sim \mathcal{NT}_{(-\infty, y_i]}\!\left (\mu _{ij}, \sigma ^2_j\right ), \forall \thinspace \thinspace j=1, \ldots, K. \end{equation}
Thus, in inferential processes with simulated data, the likelihood will be based on the original observations
 $y_i$
for
$y_i$
for
 $\delta _i=1$
and the censored ones,
$\delta _i=1$
and the censored ones,
 $ y_i^c$
, for
$ y_i^c$
, for
 $\delta _i=0$
, emulating the observable information in real practical situations. Fig. B.1 shows the mixture distribution with 40% censored data considering
$\delta _i=0$
, emulating the observable information in real practical situations. Fig. B.1 shows the mixture distribution with 40% censored data considering
 $n=1,000$
policies. Panels (a) show the behavior in the original scale, that is,
$n=1,000$
policies. Panels (a) show the behavior in the original scale, that is,
 $T_i$
from a Log-Normal distribution, and (b) in the log scale. See that the mixture proportions are indeed based on the probabilities that were defined, that is,
$T_i$
from a Log-Normal distribution, and (b) in the log scale. See that the mixture proportions are indeed based on the probabilities that were defined, that is,
 $\eta =0.6$
and
$\eta =0.6$
and
 $1-\eta =0.4$
, respectively.
$1-\eta =0.4$
, respectively.

Figure B.1 Simulated with 40% censored dataset considering
 $n=1,000$
policies: (a) original scale
$n=1,000$
policies: (a) original scale
 $T_i$
and (b) log scale
$T_i$
and (b) log scale
 $\log(T_i)$
. Besides, 60% come from
$\log(T_i)$
. Besides, 60% come from
 $\mathcal{N}_1(\cdot, \cdot )$
and 40% come from
$\mathcal{N}_1(\cdot, \cdot )$
and 40% come from
 $\mathcal{N}_2(\cdot, \cdot )$
. Dashed lines are the mean for
$\mathcal{N}_2(\cdot, \cdot )$
. Dashed lines are the mean for
 $\delta =0$
and
$\delta =0$
and
 $\delta =1$
, respectively.
$\delta =1$
, respectively.






































