



Introduction
Epidemiology uses a wide variety of mathematical tools to model the spread of infectious diseases. ‘Mathematical models […] take many forms, depending on the level of biological knowledge of processes involved and data available. Such models also have many different purposes, influencing the level of detailed required’ [Reference Heesterbeek1]. Examples of the most common model types that use highly aggregated data (infection counts over time) are trend models, as considered in this paper (another example is GGM of [Reference Ganyani2]), and compartmental dynamical systems models (including the classical continuous and deterministic SIR in [Reference Hethcote3], or stochastic SIR and SEIR in [Reference Getz4] or [Reference Han, Li and Meng5], respectively). By contrast, individual-based simulation models describe the interactions of large numbers of individuals and therefore need detailed information to characterise them [Reference Julian6]. This paper focuses on trend-models with sigmoidal (S-shaped) growth curves, as these have been useful for practitioners. For example, the simple logistic growth model correctly predicted the slowing down of the 2013–2016 Ebola outbreak in West Africa [Reference Asher7–Reference Pell11].
In this paper, we considered the more general Bertalanffy–Pütter (BP) differential equation (details in the section ‘Method’) for modelling epidemic trajectories. For an illustration, we fitted BP models to data from the 2013–2016 Ebola outbreak in West Africa, using the method of least-squares (nonlinear regression). In order to assess the practical significance of this model-fitting exercise, we used initial data from the Ebola outbreak to forecast the final disease size. Forecasting the final size of an epidemic is an important task for modelling; underestimating it may lead to a false sense of security.
In previous papers, we have studied the BP equation for modelling the growth of tumours, chicken, dinosaurs and fish [Reference Kühleitner12–Reference Renner-Martin15] and we found that it was a versatile tool that resulted in significant improvements in the fit of the model to the data, when compared to previous results in the literature. However, in that papers we also found that the least-squares method underestimated the potential of further growth. We therefore proposed a calibration that for the considered size-at-age data provided more realistic asymptotic size estimates.
For the Ebola data, we observed the same problem; using ordinary least-squares the final disease size was underestimated. As to the reason, ordinary least-squares assumes equal variances while animal sizes and epidemic data displayed size-dependent variances (heteroscedasticity). However, the pattern of heteroscedasticity was different: although for the size of smaller/larger animals the variance was lower/higher, for epidemic data (total disease counts) the variance was highest at the epidemic peak (most new cases) and low at the initial and final phases. For the Ebola data, we therefore used a weighted least-squares method with a new weight function (details in the section ‘Method’): Using this calibration, prediction of the final disease size became reliable for the late phase of the outbreak (after it has peaked).
Method
Materials
The data and the results of the optimisations were recorded in spreadsheets (Microsoft Excel); see the Supporting information. The computations used Mathematica 12.0 software (Wolfram Research). We used commercially available PCs and laptops (Intel i7 core). For them, CPU-time for fitting the BP model to monthly data was 1 week per dataset (less for SSE). However, for weekly data and SWSE, data fitting used 8 weeks. Therefore, the paper reports the results for the monthly data.
Data
CDC [16] compiled data from three countries of West Africa, based on weekly Ebola reports by the WHO (Fig. 1) that counted the confirmed, probable and suspected infections and fatalities in each country. CDC [16] added the numbers of infections since the start of the outbreak to the number of total cases.

Unfortunately, there were some flaws in the data. First, there were false-positive and false-negative diagnoses: initially Ebola was diagnosed as fatal diarrhoea (December 2013 and January 2014) and at the peak of the outbreak villages reported Ebola cases that were later falsified, but the total counts in the reports were not corrected retrospectively. Second, the published data contained typos, incorrect arithmetic and an obvious outlier at 24 June of 2015. (We suppose that it resulted from a typo: 24 472 instead of 27 472.) We therefore aggregated the CDC list to Table 1, which eliminated data uncertainty as much as possible without altering the data. It also reduced random fluctuations. Nevertheless, it still was representative of the raw data (Fig. 1).
Table 1. Total monthly count of Ebola cases in West Africa
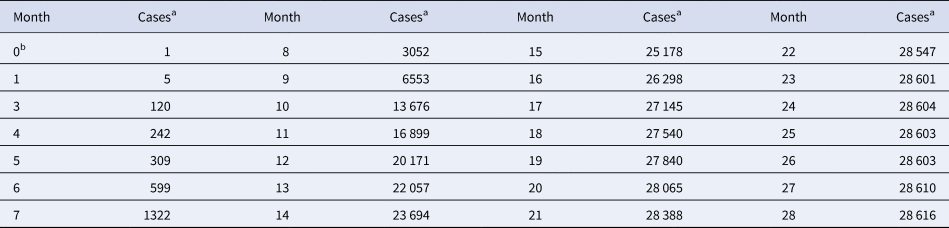
a For each month, the table records the maximum of the total number of cases reported from Guinea, Liberia and Sierra Leone since the beginning of the outbreak.
b Month 0 is December 2013 (index patient).
Source: Adapted from [16].
In addition, we also fitted the BP models to the full set of data from CDC [16] about West Africa. As amongst the 265 data-points (brown rings in Fig. 1) there were contradictory values for 19 April, 3 May and 30 June of 2015, we took the larger counts (reducing the size of the dataset to 262 data-points) and left the data otherwise unaltered (not removing the outlier).
The BP model class
The BP differential equation (1) describes the cumulative count of infected individuals, y(t), as a function of time, t, since the start of an infection. It uses five model parameters that are determined from fitting the model to cumulative epidemiological data; non-negative exponent pair a < b, non-negative scaling constants p and q and the initial value y(0) = c > 0:
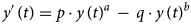
Equation (1) appeared originally in Pütter [Reference Pütter17]; von Bertalanffy [Reference Bertalanffy18, Reference Bertalanffy19] popularised it as a model for animal growth. In epidemiology, and for a ≤ 1, this model has been proposed as the generalised Richards model [20, 21]. It can be solved analytically, although in general not by means of elementary functions [Reference Ohnishi, Yamakawa and Akamine22].
We interpret equation (1) as a model class, where each exponent pair (a, b) defines a unique model BP(a, b) in the BP class of models; BP(a, b) has three free parameters (c, p, q). Equation (1) then includes several trend models that have been used to describe epidemic trajectories [Reference Bürger, Chowell and Lara-Diaz23–Reference Zhao25], such as the Brody [Reference Brody26] model of bounded exponential growth BP(0, 1), [Reference Verhulst27] logistic growth BP(1, 2), the model BP(2/3, 1) of von Bertalanffy [Reference Bertalanffy18] or the model BP(3/4, 1) of West et al. [Reference West, Brown and Enquist28]. Also, the Gompertz [Reference Gompertz29] model fits into this scheme: it is the limit case BP(1, 1), with a different differential equation, where b converges to a = 1 from above [Reference Marusic and Bajzer30]. Equation (1) also includes several classes of models, such as the generalised Bertalanffy model (b = 1 with a variable) and the Richards [Reference Richards31] model (a = 1 with b variable). However (Fig. 2), when compared to the range of models searched for this paper (yellow area), these named models appear as rather exceptional.
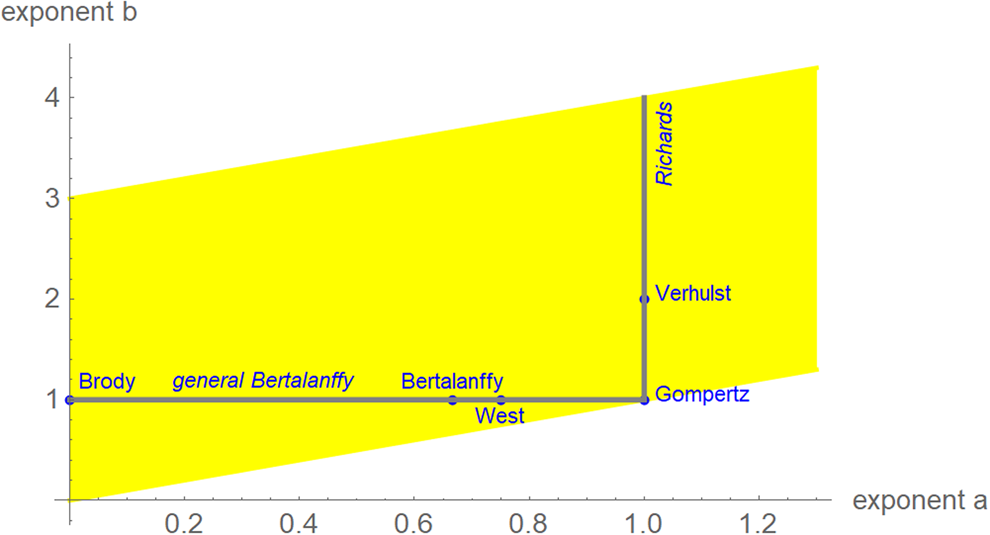
Fig. 2. Named models (blue) and initial search region (yellow) of BP models (plot using Mathematica 12.0): 0 ≤ a ≤ 1.3, a < b ≤ a + 3, step size in both directions 0.01. When needed, the grid was extended.
Some authors added further assumptions about the parameter values in order to simplify the model (e.g. setting c = 1 in advance for the indicator case). We do not consider such simplifications.
Model calibration
The (ordinary) least-squares method is common in epidemiology for large case counts, as for the present data [Reference Smirnova and Chowell32]. It measures the goodness of the fit to the data by means of SSE, the sum of squared errors (fit residuals). In the present context, we sought parameters a, b, c, p and q so that for the solution y(t) of equation (1) the following sum SSE was minimised, whereby (ti, yi) were the first n total case counts yi at time ti (here 10 ≤ n ≤ 28):
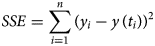
An implicit assumption of the least-squares method is a normal distribution of the errors: in formal terms, SSE is equivalent to the maximum-likelihood estimate under the assumption of normally distributed data with expected value y(t) and time-independent variance s > 0. If this assumption is not satisfied, as for the animal size-at-age data or the outbreak data, other methods of calibration need to be considered. For the animal data we could work well under the assumption of a log-normal distribution, where the variance increases with the size. However, for the Ebola data (total case counts) this assumption was problematic, too, as the variance was maximal at an intermediate stage (epidemic peak).
We therefore developed another measure for the goodness of fit, weighted least-squares that aimed at finding parameters to minimise the following sum of weighted squared errors SWSE:
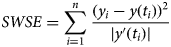
This weight function tolerates a higher variability in the total count during the epidemic peak. In formal terms, SWSE identifies the maximum-likelihood estimate under the assumptions that the data are normally distributed with expected value y(t) and a variance s⋅y′(t) with s a constant. (Thus, the variance of the total counts is assumed to be proportional to the absolute value of the derivative of y. This derivative corresponds to the number of new cases.)
In the following subsections, we will explain our notation using SSE; the same definitions will also apply to SWSE.
Optimisation
For model class (1) standard optimisation tools (e.g. Mathematica: NonLinearModelFit) may not identify the best-fit parameters (numerical instability). To overcome this difficulty, we used a custom-made variant of the method of simulated annealing [Reference Vidal33] which solves the optimisation problem to a prescribed accuracy [Reference Kühleitner12]. Note that using simulated annealing to optimise all five parameters of equation (1) at once may not always come close to the optimum parameters, because the region of nearly optimal parameters may have a peculiar pancake-like shape ([Reference Renner-Martin15]; extremely small in one direction and extremely large in other ones).
We confined optimisation to a grid (Fig. 2). For each exponent pair on the grid 0 ≤ a ≤ 1.3 and a < b ≤ 3 with distance 0.01 in both directions we searched for the best-fit model BP(a, b); i.e. we minimised SSE for the model BP(a, b). Thus, we defined the following function SSEopt on the grid:

Summarising this notation, for each exponent pair (a, b) on the grid we identified the best-fit model BP(a, b) with certain parameters c, p, q and the corresponding least sum of squared errors SSEopt(a, b). These values were recorded in a spreadsheet. Finally, the best-fit model had the overall least sum of squared errors (SSEmin). It minimised the function SSEopt at the optimal exponent pair (amin, bmin). From the above-mentioned spreadsheet we could then read off the other parameters pmin, qmin, cmin that minimised SSEopt(amin, bmin) of the model BP(amin, bmin). However, if that optimal exponent pair was on the edge of the search grid, then we extended the search grid and continued the optimisation. (Otherwise, if the optimal exponent pair was surrounded by suboptimal ones, then we stopped the search for an optimum.)
Model comparison
For each exponent pair (a, b) of the search grid we identified a best-fitting model BP(a, b), whose fit was given by SSEopt(a, b) of formula (4). Amongst these models we selected the model with the least SSEopt. In the literature, there are various alternative criteria for the comparison of models, amongst them the root mean squared error RMSE and the Akaike's [Reference Akaike34] information criterion (AIC). RMSE is the square-root of SSE/n and AIC = n ⋅ ln (SSE/n) + 2K, where n is the number of data-points (between 10 and 28 for the monthly truncated data), K = 4 is the number of optimised parameters of the model BP(a, b) with a given exponent pair (counting c, p, q and SSE), and SSE = SSEopt(a, b). As an additional measure to compare the goodness of fit, we used formula (5) for the relative Akaike weight:
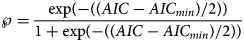
This formula has been interpreted as probability, $\wp$ , that the (worse) model with higher AIC would be ‘true’, when compared to the model with the least AIC [Reference Burnham and Anderson35, Reference Motulsky and Christopoulos36]. Thereby (citation from [Reference Burnham and Anderson37], on p. 272, referring to information theory of [Reference Kullback and Leibler38]) ‘true’ means that the model ‘is, in fact, the K-L best model for the data… This latter inference about model selection uncertainty is conditional on both the data and the full set of a priori models [in formula 5: the models with AIC and with AICmin] considered’. Furthermore, as does AIC, the Akaike weight assumes a normal distribution of the (weighted) fit residuals.
, that the (worse) model with higher AIC would be ‘true’, when compared to the model with the least AIC [Reference Burnham and Anderson35, Reference Motulsky and Christopoulos36]. Thereby (citation from [Reference Burnham and Anderson37], on p. 272, referring to information theory of [Reference Kullback and Leibler38]) ‘true’ means that the model ‘is, in fact, the K-L best model for the data… This latter inference about model selection uncertainty is conditional on both the data and the full set of a priori models [in formula 5: the models with AIC and with AICmin] considered’. Furthermore, as does AIC, the Akaike weight assumes a normal distribution of the (weighted) fit residuals.
Using SSE or AIC is only meaningful with reference to a fixed dataset (different models are fitted to the same data), whereas RMSE and $\wp$ make also sense, if we consider datasets with different sizes, as for the forecasts, where we successively use truncated initial data with 10, 11, …, 28 months. Thereby, we prefer the probabilities for their more intuitive appearance. Note that $\wp \equals 50\percnt$
make also sense, if we consider datasets with different sizes, as for the forecasts, where we successively use truncated initial data with 10, 11, …, 28 months. Thereby, we prefer the probabilities for their more intuitive appearance. Note that $\wp \equals 50\percnt$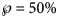 is the maximal value that can be attained by $\wp$
is the maximal value that can be attained by $\wp$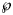 (comparison of the best-fit model with its copy).
(comparison of the best-fit model with its copy).
Multi-model approach
For each exponent pair (a, b) of the search grid we identified the best-fit growth curve ya,b(t) for the model BP(a, b); its parameters p, q and c were optimised according to formula (4). Thereby, we could observe a high variability in the best-fit exponents: even for exponent pairs (a, b) with notable differences from the optimal exponent pair (amin, bmin) the best-fit growth curve ya,b(t) barely differed from the data. To describe this phenomenon, we used the following terminology: a model BP(a, b) and its exponent pair (a, b) are u-near-optimal with model-uncertainty u, if SSE opt(a, b) ≤ (1 + u) ⋅ SSE min. Figure 3 illustrates this concept by plotting near-optimal exponent pairs for different levels u = 0.17 and u = 0.5 of model-uncertainty (red and blue dots).
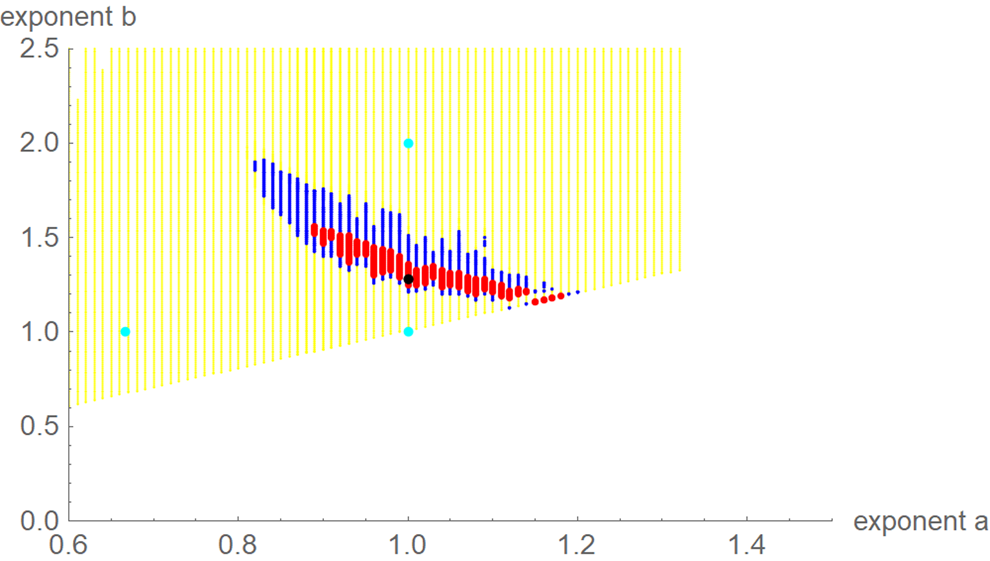
Fig. 3. Optimal exponent-pair (black) for fitting the data of Table 1 with respect to SSE; red and black dots for 245 and 1330 exponent pairs with up to 17% and 50% higher SSE; exponent-pairs of the Bertalanffy, Gompertz and Verhulst models (cyan) and part of the search grid (yellow).
Using formula (5), we translated the level u of near optimality into a probability $\wp = 1/ \lpar 1 + \sqrt {{\lpar {1 + u} \rpar }^n} \rpar$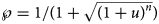 . For example, if we wish to consider models (exponent pairs) with a probability of at least 10%, this corresponds to a model uncertainty of at most u = 0.55 for the 10-month data (n = 10) and u = 0.17 for the 28-month data.
. For example, if we wish to consider models (exponent pairs) with a probability of at least 10%, this corresponds to a model uncertainty of at most u = 0.55 for the 10-month data (n = 10) and u = 0.17 for the 28-month data.
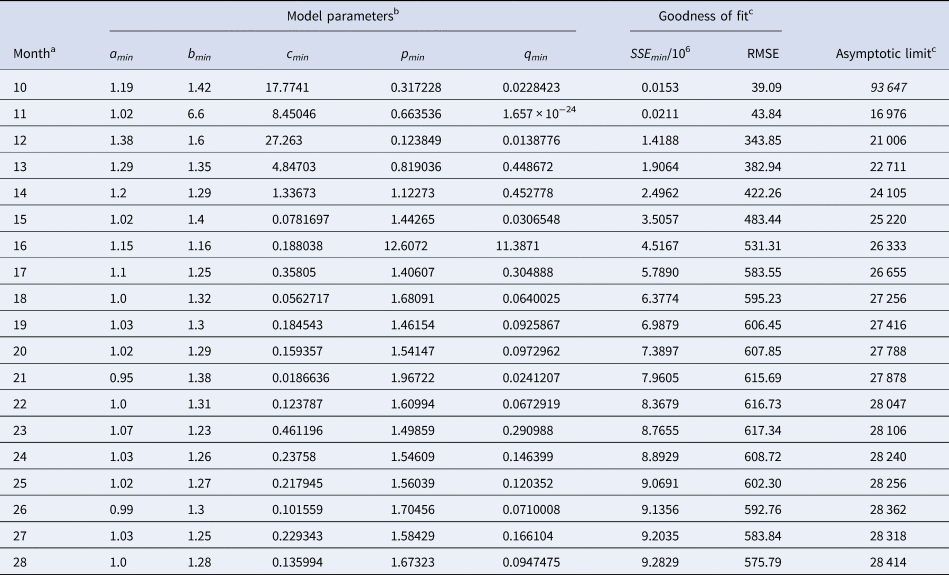
For each dataset, we then may ask about the forecasts that would be supported by models with e.g. $\wp \equals 10\percnt$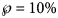 or higher, discarding other possible forecasts as unlikely, given the data. Thus, given a model probability, $\wp$
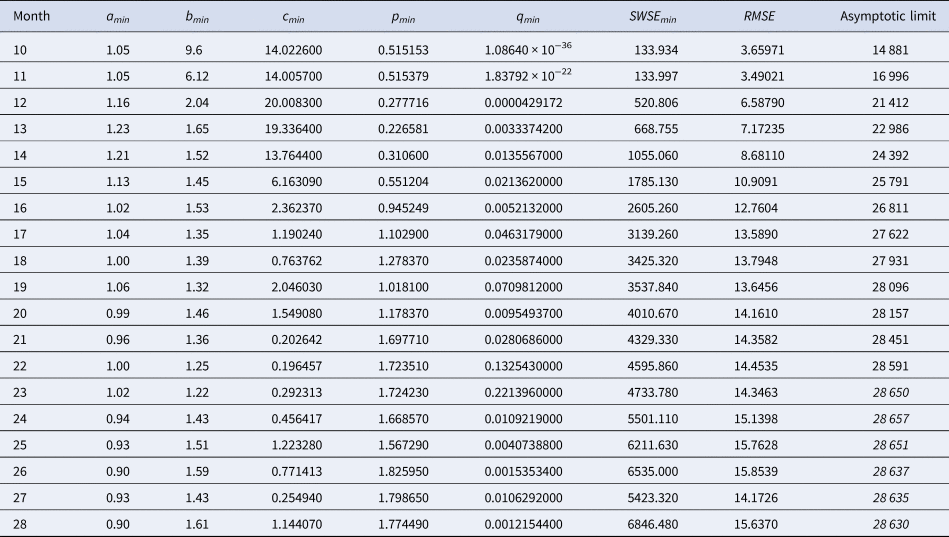
or higher, discarding other possible forecasts as unlikely, given the data. Thus, given a model probability, $\wp$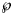 , we studied the forecasts that came from the ensemble of the growth curves ya,b(t) corresponding to the near-optimal models BP(a, b) with that probability or higher. For example, for each of these ya,b(t) we estimated its final disease size by the asymptotic limit. The upper and lower bounds for these estimates defined a prediction interval that informed about the likely disease size. Note that this is an analysis of model uncertainty, not of data uncertainty, whence the prediction interval is not a confidence interval. (Confidence intervals assess data uncertainty by means of simulations that add random errors to the data and use best-fit functions to compute bounds for the confidence interval. For prediction intervals, different models are fitted to the same data.)
, we studied the forecasts that came from the ensemble of the growth curves ya,b(t) corresponding to the near-optimal models BP(a, b) with that probability or higher. For example, for each of these ya,b(t) we estimated its final disease size by the asymptotic limit. The upper and lower bounds for these estimates defined a prediction interval that informed about the likely disease size. Note that this is an analysis of model uncertainty, not of data uncertainty, whence the prediction interval is not a confidence interval. (Confidence intervals assess data uncertainty by means of simulations that add random errors to the data and use best-fit functions to compute bounds for the confidence interval. For prediction intervals, different models are fitted to the same data.)
Results
Best fits
Table 2 identified the optimal parameters of BP models that were fitted by ordinary least-squares, equation (2) for SSE, to initial segments of the monthly data, meaning the data of Table 1 for the first 10 ≤ n ≤ 28 months. As slight changes in the parameter values could result in highly suboptimal growth curves, from which standard optimisation tools could not find back to the region of near optimality, certain parameters were given with an accuracy of 30 or more decimals. Table 3 identified the optimal parameters for initial segments, using the method of weighted least-squares, formula (3) for SWSE.
Table 2. Parameters for the best-fit (SSE) model (1) to the data up to the indicated month
a This indicates the data from month 0 to the displayed month.
b The table reports the parameters based on the best-fit grid-point exponent pairs (the overall optima were slightly different).
c Estimates above the actual count of 28 616 cases in italics.
Table 3. Best-fit parameters with respect to SWSE for the data up to the indicated month
Notes as in Table 2 (referring to SWSE rather than to SSE).
At a first glance, the growth curves for the same data looked similar, regardless of the method of calibration. Figure 4 plots the monthly data and the growth curves that were fitted to the initial segments by means of ordinary least-squares and Figure 5 plots the monthly data and the best-fit curves using weighted least-squares. The two figures look alike and for both methods good forecasts (asymptotic limits in Tables 2 and 3) for the final disease size of 28 616 cases could be obtained from the data truncated at month n, n between 16 and 28, whereby the forecasts using weighted least-squares were more accurate: the relative error of the forecasts was 1–8% for SSE and 0–6% for SWSE. All growth curves were bounded, whereby for SSE the first curve (data truncated at month 10) exceeded the data and the following curves approached the data from below; all asymptotic limits remained below the actual final disease size. For SWSE the growth curves initially approached the data from below and starting with month 23 their asymptotic limits were slightly above the final disease size.
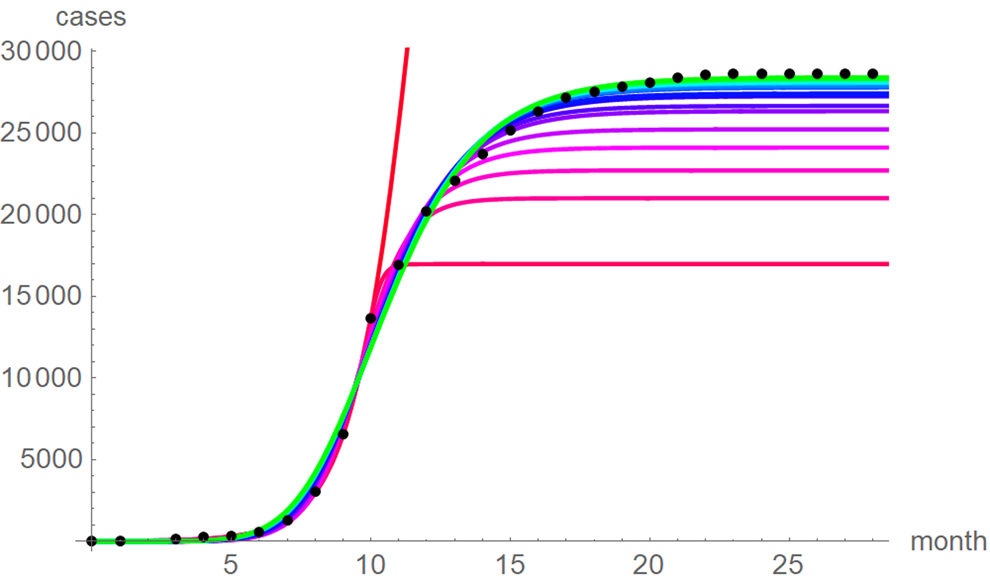
Fig. 4. Monthly data (black dots) with the best-fit growth curves (SSE) for the data until month 10 (red), 11, … 28 (green); month 0 is December 2013. The best-fit parameters are from Table 2 (plotted using Mathematica 12.0).
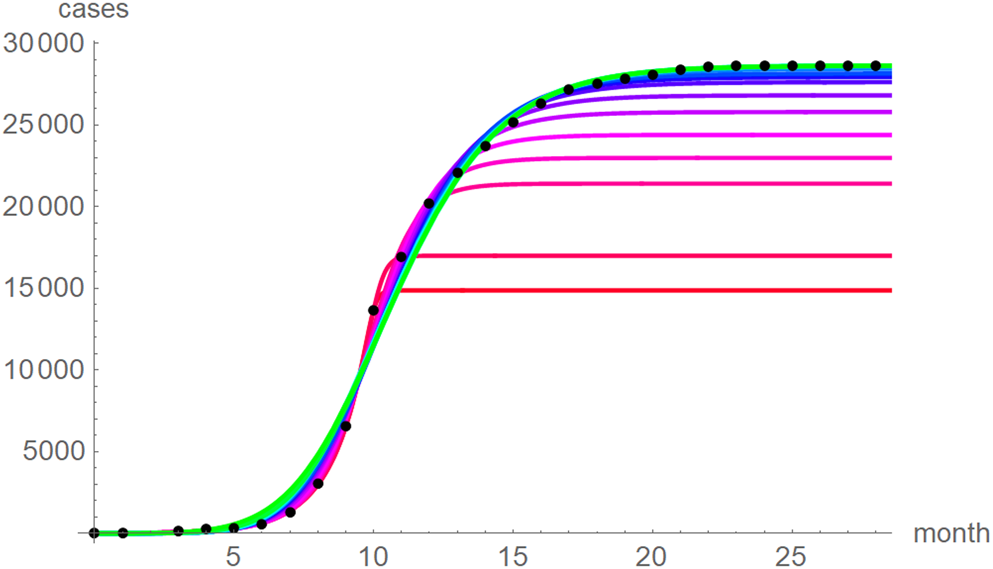
Fig. 5. Monthly data (black dots) with the best-fit growth curves (SWSE) for the data until month 10 (red), 11, … 28 (green); month 0 is December 2013. The best-fit parameters are from Table 5 (plotted using Mathematica 12.0).
The best fit curves to the full data were analysed in more detail, including for the weekly data (details given in the Supporting information). Figure 6 plots the growth curves that were fitted to the full sets of monthly and weekly data, respectively, using the two calibrations. Again, there were only slight differences between the curves that used ordinary and weighted least-squares; for SSE and SWSE the asymptotic limits were below and above the final disease size, respectively. Furthermore, the growth curves for the weekly and monthly data that were calibrated by the same method were largely overlapping.
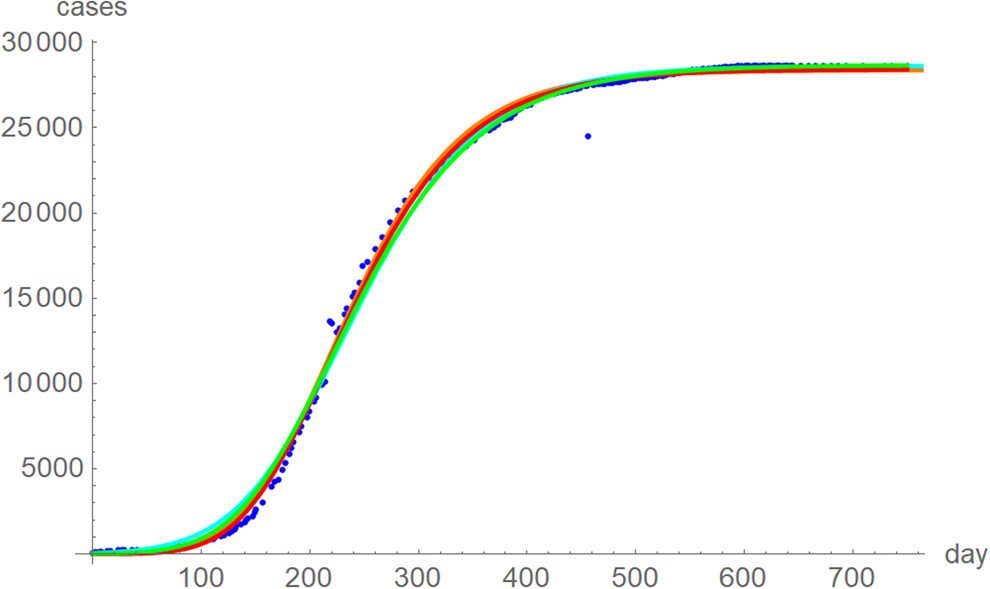
Fig. 6. Weekly data (blue dots, with correction of three inconsistencies), best-fitting growth curve to these data using SSE (red) and SWSE (green) and best-fitting growth curves fitted to the monthly data using SSE (orange) and SWSE (cyan), whereby at day x we evaluated the growth function at month (x + 84)/30.4, because the daily data started later. The parameters are given in the Supporting information; plotted using Mathematica 12.0.
Despite these similarities there were obvious differences for the exponent pairs that were computed using different calibrations; Figure 7 plots them. Thereby, except for the SSE fit to the 28-month-data (Richards' model), all exponent pairs were clearly distinct from the exponent pairs of the named models mentioned in the section ‘Method’.
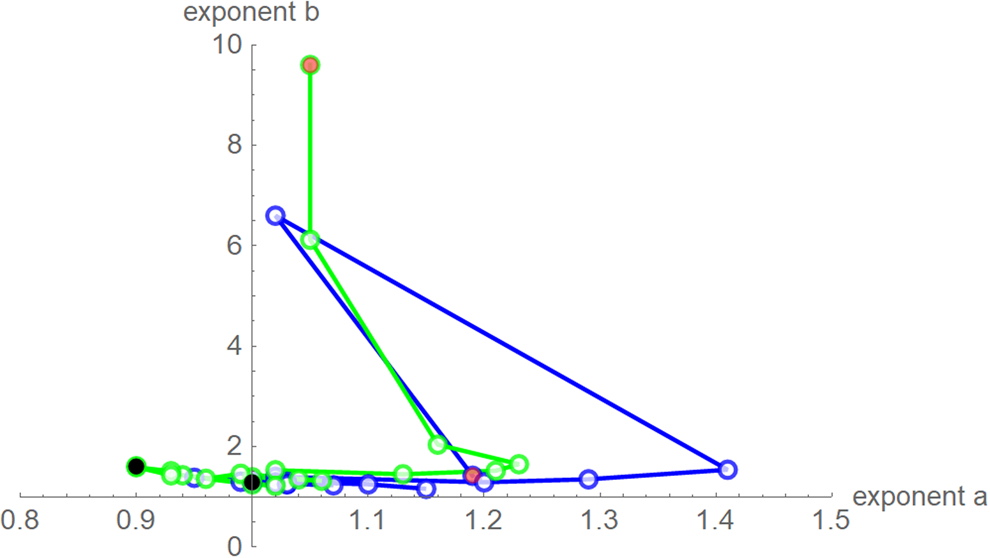
Fig. 7. Best-fit exponent pairs for the truncated monthly data using SSE (blue) from Table 2 and SWSE (green) from Table 3. Lines connect exponent pairs for successive data, starting with the exponent pair for the 10-month data (red) and ending with the exponent pair for the 28-month data (black); plotted using Mathematica 12.0.
Testing distribution assumptions
We now explain, why despite the apparent utility of the ordinary least-squares method we will recommend our method of weighted least-squares. One reason was that for the present data its implicit distribution assumption was not outright false: the criteria weights for SWSE were motivated from the observation that the variance of the cumulative count depends on the number of new cases (derivative of the cumulative count), as it was low at the beginning and end of an outbreak and maximal at the peak of the epidemics, while SSE assumed equal variances for all data. We checked these distribution assumptions for the full dataset by testing for SSE the normal distribution hypothesis for the residuals and for SWSE the normal distribution hypothesis for the residuals divided by the square root of y′.
Table 4 summarises the results. We tested the fits to the full set of monthly data and for both calibration methods we took the residuals from the best-fit models that we obtained from additional simulated annealing steps (parameters given in the Supporting information). We applied a set of the most common distribution fit tests to the residuals; they relate to different aspects for normality [Reference Evans, Drew, Leemis, Glen and Leemis39]. For ordinary least-squares (SSE) with one exception (skewness) the tests supported the conclusion that at 95% confidence the residuals were not normally distributed (P-values below 5%). Hence, an implicit assumption of this method (and of the AIC) was refuted. For weighted least-squares (SWSE) this difficulty did not occur: none of the tests rejected the assumption of a normal distribution for the residuals divided by the square root of the best-fit trajectory y′, as all tests had sufficiently large P-values (20–70%).
Table 4. Testing the normal distribution hypothesis for SSE and SWSE
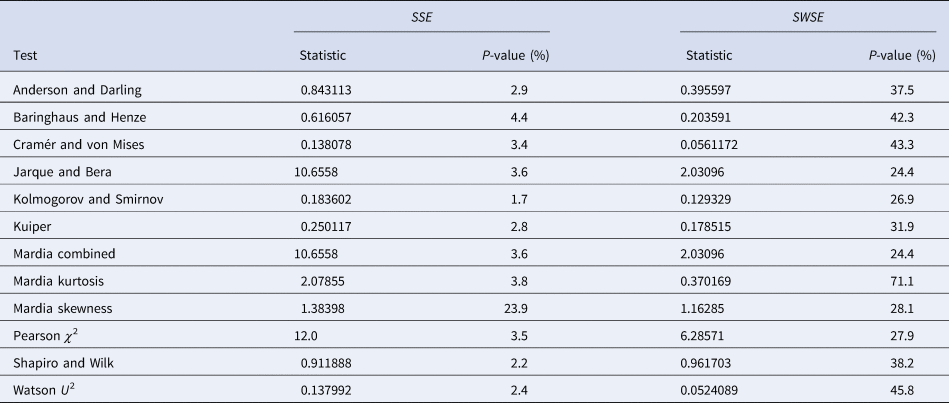
Note: Based on the best-fit growth curves y to the 28-month data, distribution-fit tests were applied to the residuals (SSE) and to the residuals divided by the square-root of y′ (SWSE), respectively. The best-fit parameters are described in the text.
Multi-model comparisons
In this section, we outline another drawback of the ordinary least-squares method (SSE): using SSE, for the present data good conservative forecasts for the estimated final disease size could not be obtained with models that fitted well to the data. Thus, paradoxically, a prudent forecaster using ordinary least-squares would deliberately use models that are highly unlikely in terms of their probability $\wp$ (Akaike weight) of equation (5). By contrast, for weighted least-squares (SWSE) the prediction intervals for the asymptotic limit contained the final disease size, whereby the prediction intervals used only likely models (high probability $\wp$
(Akaike weight) of equation (5). By contrast, for weighted least-squares (SWSE) the prediction intervals for the asymptotic limit contained the final disease size, whereby the prediction intervals used only likely models (high probability $\wp$ ).
).
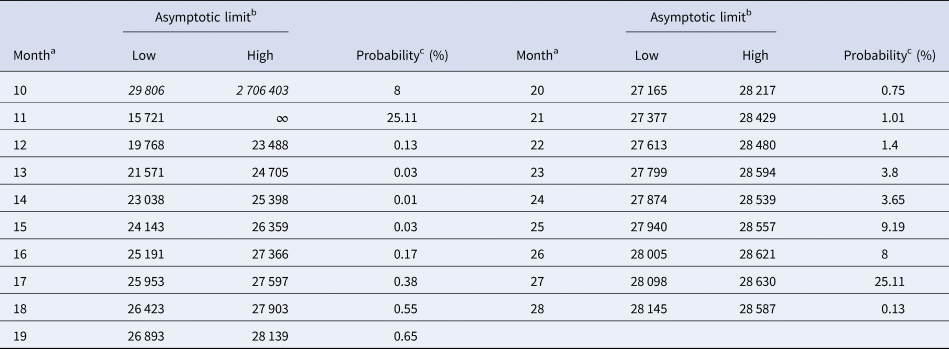
Tables 5 and 6 inform about the 10% prediction intervals for the asymptotic limits, using truncated monthly data, best-fit models using ordinary and weighted least-squares, respectively, and assuming for all models a probability $\wp \ge 10\percnt$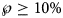 . If the data were truncated at month 10, then for both methods of calibration the 10% prediction intervals were useless: for SSE, already the lower estimate was too pessimistic and for SWSE the interval was unbounded above. For SSE there were only two data with 10% prediction intervals that contained the final disease size of 28 616 cases: the data truncated at months 26 and 27. By contrast, using SWSE for all datasets truncated at any of the months 21–28, the 10% prediction intervals contained the final disease size.
. If the data were truncated at month 10, then for both methods of calibration the 10% prediction intervals were useless: for SSE, already the lower estimate was too pessimistic and for SWSE the interval was unbounded above. For SSE there were only two data with 10% prediction intervals that contained the final disease size of 28 616 cases: the data truncated at months 26 and 27. By contrast, using SWSE for all datasets truncated at any of the months 21–28, the 10% prediction intervals contained the final disease size.
Table 5. 10% prediction intervals for asymptotic limits (SSE) and probabilities for predicting the month-28 count
a Truncated data from month 0 to the displayed month.
b Minimum and maximum of the asymptotic limits for models with 10% probability to be true, based on SSE, with limits above 28 616 cases displayed in italics.
c Minimum of the maximal probabilities of models BP(a, b), whose trajectories at month 28 were above or below the actual count of 28 616 cases.
Table 6. 10% prediction intervals for asymptotic limits (SWSE) and probabilities for predicting the month-28 count
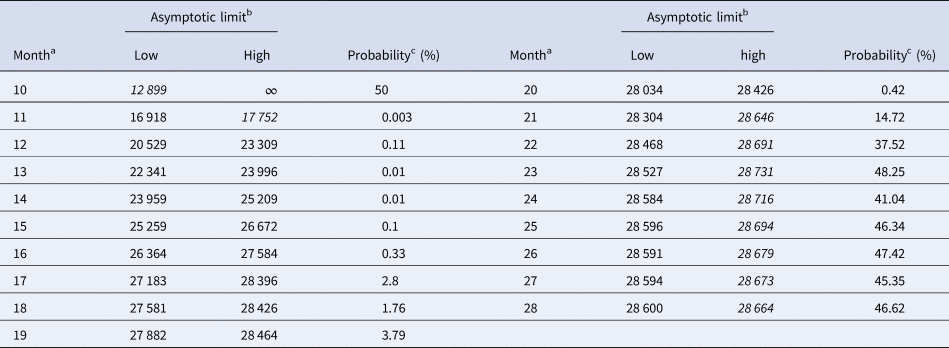
Notes as for Table 5 (referring to SWSE rather than to SSE).
We applied the notion of the prediction interval also to other predictors, such as the forecasted disease size at month 28 (and in the Supporting information, Tables S1–S3: best-fit model parameters for SSE and SWSE and coordinates of the inflection point). Tables 5 and 6 inform about these intervals in an abbreviated form, informing about the least probability $\wp$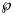 so that the actual disease size of 28 616 cases could be found in the $\wp$
so that the actual disease size of 28 616 cases could be found in the $\wp$ prediction interval. For example, the month-10 entry of Table 5 was obtained as follows: the best-fit model was BP(1.07, 1.29) and for its epidemic trajectory y 1.07, 1.29(t) the value y(28) was above the actual disease size, while for the model BP(1.19, 1.42) and for its best fitting epidemic trajectory y 1.19, 1.42(t) the value y(28) was below the actual disease size. The probabilities for these models were $\wp \equals 50\percnt$
prediction interval. For example, the month-10 entry of Table 5 was obtained as follows: the best-fit model was BP(1.07, 1.29) and for its epidemic trajectory y 1.07, 1.29(t) the value y(28) was above the actual disease size, while for the model BP(1.19, 1.42) and for its best fitting epidemic trajectory y 1.19, 1.42(t) the value y(28) was below the actual disease size. The probabilities for these models were $\wp \equals 50\percnt$ and $\wp \equals 8\percnt$
and $\wp \equals 8\percnt$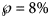 (this was the maximal probability for such a model); the minimum of these probabilities was reported in the table. For ordinary least-squares, models with a probability below 10% were needed to enclose the actual disease size in the prediction interval. Specifically, for the full data (month 28), only unlikely trajectories ($\wp \equals 0.13\percnt$
(this was the maximal probability for such a model); the minimum of these probabilities was reported in the table. For ordinary least-squares, models with a probability below 10% were needed to enclose the actual disease size in the prediction interval. Specifically, for the full data (month 28), only unlikely trajectories ($\wp \equals 0.13\percnt$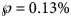 , meaning 0.0013) exceeded the true count at month 28. Again, for weighted least-squares and all datasets truncated at any of the month 21–28, the 10% prediction intervals contained the final disease size. Furthermore, for the data truncated at any of the months 21–28, all likely growth curves (probability 10% to be true) deviated from the final case count by at most ±2%. Thereby, there were both likely curves above and below the final case count. Thus, other than for ordinary least-squares, for weighted least-squares there was no bias towards too optimistic forecasts, and forecasts were not too pessimistic, either.
, meaning 0.0013) exceeded the true count at month 28. Again, for weighted least-squares and all datasets truncated at any of the month 21–28, the 10% prediction intervals contained the final disease size. Furthermore, for the data truncated at any of the months 21–28, all likely growth curves (probability 10% to be true) deviated from the final case count by at most ±2%. Thereby, there were both likely curves above and below the final case count. Thus, other than for ordinary least-squares, for weighted least-squares there was no bias towards too optimistic forecasts, and forecasts were not too pessimistic, either.
Discussion
Our results have several implications for practical applications. With respect to the choice of BP models, Viboud et al. [Reference Viboud, Simonsen and Chowell21] recommended to use only exponents a ≤ 1 to model the initial phases of epidemics. However, for most truncated data better fits were achieved for a > 1. Therefore, such a restriction appears premature.
Concerning the two methods (SSE and SWSE) for the calibration of the models, we observed that the best-fit BP models obtained by means of ordinary least-squares in general had asymptotic limits that were too low, when compared to the final disease size. For the modelling of epidemics this resulted in overly optimistic forecast of the final disease sizes. Better estimates for the final disease size could be obtained by weighted least-squares. Thereby, different types of data needed different weight functions. For epidemic data (total case counts) we recommend using as weight function the reciprocal of the derivative of the growth function; formula (3). This recommendation was supported by an analysis of the (weighted) fit residuals. The normal distribution assumption of the ordinary least-squares method was refuted, but the similar assumption for weighted least-squares was not refuted.
For the present data we concluded that a reasonable prognosis of upper and lower bounds of the final disease size was possible much earlier when using this weight function rather than ordinary least-squares, namely already at month 21 or later, while for ordinary least-squares it was not sure, if that prognosis was feasible at all. However (Supporting information, Table S3), as follows from the prediction intervals for the inflection point, the peak of the disease was attained around tinfl ≈ 10 months regardless of the method of calibration. Thus, even with a suitable weight function the prognosis of the final disease size may be possible only at a surprisingly late phase of a disease.
Obviously, no calibration can extract more information about the future trajectories than is available from the given data. Forecasts using data from an early stage of epidemics prior to its peak (e.g. 10-month data) remained uninformative also with the new calibration. Thus, for precise forecasts about the final size enough data-points beyond the peak of the epidemics were needed to inform about how fast the epidemics slowed down. However, for the present data the proposed weight function had the advantage that its estimates of the final size of the disease were reliable earlier than for the ordinary least-squares method that currently is the standard method for such purposes.
Conclusion
This paper proposes a new calibration of phenomenological models in the context of modelling infectious disease outbreaks. We recommend weighted least-squares using the reciprocals of the derivatives of the growth function (this corresponds to the numbers of new cases) as weights.
We tested this calibration for the modelling of the West African Ebola outbreak of 2013–2016 by means of the BP model. Although for these data the estimates remained comparable to those of the least-squares method, we conducted several tests (distribution of the fit residuals and forecasting intervals for estimating the final disease size) that confirmed that the new calibration was superior to ordinary least-squares.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0950268820003039
Data availability statement
The comparisons of models are based on the data in Table 1. As explained in the section ‘Data’, these data are based on the raw data published in CDC [16]; see Figure 1 for a comparison of Table 1 with the raw data from the literature. In addition, the computations of the paper generated new data about the best-fit parameters; for details see the Supporting information.
















 Open access
Open access