


1 On the role of distance
One of the notable properties of language is the ubiquity of dependency relationships between linearly ordered units (e.g. Gildea & Temperley Reference Gildea and Temperley2010, Futrell, Mahowald & Gibson Reference Futrell, Mahowald and Gibson2015). An adjective may depend on a noun, an object NP on a verb and a subordinate clause on a main clause. The distinction between independent units (i.e. heads) and dependent units (i.e. modifiers or dependents) in the linear representation of speech prepares for the notion of distance. If distance is a relevant factor in linguistic analysis, it may be expected to influence the interaction of heads and dependents as follows: the smaller the distance between two given units, the more likely one is to impact on the other. The issue is not only whether or not an interaction takes place but also whether different distances may have different effects.
As a matter of fact, there is solid evidence to vindicate the role of distance (e.g. Gibson Reference Gibson, Marantz, Miyashita and O’Neil2000, Pietsch Reference Pietsch2005, Gillespie & Perlmutter Reference Gillespie and Perlmutter2011; see also Rosenbaum Reference Rosenbaum, Jacobs and Rosenbaum1970 and Horn Reference Horn, Kastovsky and Szwedek1986 for early discussions of the Minimum Distance Principle). To set the stage, three related areas in which distance plays an important part will be briefly reviewed – agreement, grammatical variation and mood. What they have in common is that the head does not categorically determine the form of the dependent.
Subject–verb agreement in English provides a clear demonstration of the effect of distance. The critical case involves conflicting information from different potential controllers and their linear position relative to the target. Consider existential constructions in English, as illustrated in examples (1) and (2) from Morgan (Reference Morgan, Peranteau, Levi and Phares1972: 281; for the same effect in other languages, see Plank (Reference Plank1985: 127) on German, Sridhar (Reference Sridhar1990: 246) on Kannada (Dravidian) and Jeschull (Reference Jeschull and Haspelmath2004: 251) on Chechen (Nakh-Daghestanian)).
Except for the ordering within the logical subject, the two sentences are structurally identical. Whatever difference there is can therefore be put down to the opposite order of the nominal constituents in the coordinated NP. If the singular noun occurs next to the verb, singular agreement is the rule, as in (1). By contrast, if the plural controller is adjacent to the verb, plural agreement is observed, as in (2). It is thus the noun closest to the verb rather than the entire NP which is elected as controller. This fact assigns a role to distance.
Strictly speaking, the above pair of sentences illustrates a binary adjacency effect but remains silent on the possibility of gradient effects with varying distance. This issue will be addressed on the basis of Levin’s (Reference Levin2001) analysis of collective nouns in English which allow both singular and plural agreement on the verb, as exemplified in (3) and (4) from Levin (Reference Levin and Renouf1998: 106; Reference Levin2001: 96).
Levin’s results show a remarkable interaction of distance and agreement type. There is a gradual decrease in singular agreement and a concomitant increase in plural agreement with an increasing number of words intervening between target and controller.
The sensitivity of agreement to the distance between target and controller is restricted neither to English nor to number agreement. Köpcke, Panther & Zubin (Reference Köpcke, Panther, Zubin, Schmid and Handl2009) capitalize upon a mismatch between grammatical and referential gender in some German nouns such as das Mädchen ‘the girl’, which is grammatically neuter but referentially feminine. Their analysis reveals that the rate of referential gender increases, and that of grammatical gender decreases, with increasing distance between target and controller. This observation ties in with data from French (Corbett Reference Corbett1991: 227), Cairene Arabic (Belnap Reference Belnap1999: Table 2) and Old English (Curzan Reference Curzan2003: 99).
The choice between alternative grammatical structures is also sensitive to distance. One of the major factors determining serial order is the short-before-long principle (e.g. Behaghel Reference Behaghel1909, Hawkins Reference Hawkins1994, Lohmann & Takada Reference Lohmann and Takada2014). Hawkins’s (Reference Hawkins1994) performance theory relies, among other things, on the distance between the heads of phrases. In head-initial languages, this distance is smaller when the shorter phrase precedes the longer one. The preference for short distances can be seen in many structures ranging from so-called particle movement (e.g. Gries Reference Gries2003, Lohse, Hawkins & Wasow Reference Lohse, Hawkins and Wasow2004) to so-called dative alternation (e.g. Arnold et al. Reference Arnold, Wasow, Losongco and Ginstrom2000, Bresnan et al. Reference Bresnan, Cueni, Nikitina, Baayen, Bouma, Krämer and Zwarts2007) and the order of PPs (e.g. Hawkins Reference Hawkins1999, Wiechmann & Lohmann Reference Wiechmann and Lohmann2013). As a further domain, consider the contrast between pied-piping and preposition stranding, as exemplified in (5) and (6), respectively.

The preposition with is stranded in (6) but pied-piped in (5). The choice between the two constructions is influenced by the amount of material coming between the relativizer and the stranded preposition. The greater the distance between the two critical items, the lesser the likelihood of preposition stranding (Trotta Reference Trotta2000, Hoffmann Reference Hoffmann2011). The same result was obtained for relative clauses in Brazilian Portuguese by Tarallo (Reference Tarallo and Sankoff1986) and for English interrogative clauses by Gries (Reference Gries and Samiian2002).
A superficially different type of grammatical variation is the alternation between ‘something’ and ‘nothing’. Several structures in English display a contrast between a fully fledged and a reduced variant. The latter typically differs from the former in that there is no independent function word. This contrast is exemplified in (7) on the basis of the verb to stop which may or may not take the preposition from (Rohdenburg Reference Rohdenburg, Neumann and Schülting1999).

The three examples differ in the complexity of the object NP of the matrix verb. A nominal object expanded by a relative clause is shown in (7a), a bare nominal object in (7b) and a pronominal object in (7c). Rohdenburg (Reference Rohdenburg, Neumann and Schülting1999) argues that the use of the preposition correlates with an increasing complexity of the object. However, the empirical effect can be captured equally well by invoking distance: the greater the distance between the verb and the slot for the preposition, the higher the likelihood of choosing the prepositional option.
The third and final area moves us closer to the empirical focus of the present paper. It is distantly related to agreement and documents an influence of the verb in the main clause on the verb in the subordinate clause. In French, the mood of the embedded verb may be determined by certain triggers in the matrix clause. Some triggers permit variation between indicative (IND) and subjunctive (SUB) verb forms in the subordinate clause, as illustrated in (8) and (9) from Poplack (Reference Poplack, Laeufer and Morgan1992: 250) and Poplack, Lealess & Dion (Reference Poplack, Lealess and Dion2013: 172), respectively.

In the citation form, the impersonal verb falloir takes the form il faut que ‘it is necessary that’. The grammatical subject il was dropped in (8) while the complementizer que was dropped in (9). As a rule, the deontic nature of falloir triggers a subjunctive verb form in the embedded clause, as in (8). However, as shown in (9), this rule is not sacrosanct. Poplack et al. (Reference Poplack, Lealess and Dion2013) looked into a number of factors influencing the choice of mood after falloir and other matrix verbs. Their study showed that the rate of subjunctives decreases with increasing distance between the controller verb and the target verb. Unfortunately, distance was measured in a rather coarse-grained fashion (e.g. in terms of the presence or absence of parenthetical material). This makes it difficult to gain a precise idea of the impact of distance on mood choice. Nonetheless, we may provisionally interpret the French data to mean that the choice of the subjunctive depends on the availability of a nearby trigger whereas the choice of the indicative is insensitive to the distance of the trigger.
Variation (such as that between the indicative and the subjunctive) has been customarily understood to provide evidence of a set of factors which may generate alternative outputs (see Hilpert Reference Hilpert2008 for many others). One factor may facilitate output A while another may facilitate output B. Which of the alternatives A and B is chosen depends on the relative strength of these influences. The strength of a factor varies as a function of the relationship it contracts with other factors at the moment of production planning. It may also vary with historical time (e.g. Gries & Hilpert Reference Gries and Hilpert2010) and from dialect to dialect (e.g. Szmrecsanyi et al. Reference Szmrecsanyi, Grafmiller, Heller and Röthlisberger2016).
The vast variationist literature has conceived of factors in an essentially static manner. In particular, the temporal dimension has been largely ignored.Footnote [2] However, once these factors are assumed to have some psychological reality, we cannot afford to leave the time factor out of consideration. In language production, units unfold in real time. They have a characteristic time course of activation, with a beginning and an end as well as a particular strength at any one moment in time. The ‘life span’ of a unit will be dubbed its RANGE. Once alternative options are ‘contemporaries’, the possibility of competition arises. As in the case of the strength of an individual unit, competition between alternatives varies from one moment to another.
It is the aim of the present article to explore the notion of range in some detail and thereby enrich current modelling of linguistic variation by the temporal dimension. Distance effects are ideally suited to studying the range of linguistic units. As discussed above, they show how different decisions may be taken at different moments in time and thereby provide insight into the time course of activation of linguistic units.
In this paper, the concept of range will be applied to factors which play a part in grammatical variation. The basic idea is that different units may have different ranges. An attempt will be made to identify the principles which influence the range of a given unit and to develop a unified model of how distance effects come about. The grammatical issue on which the present work is based is the English mandative subjunctive. As will be explained in the next section, the subjunctive is an especially rewarding area to probe because it offers a ternary rather than a binary choice, the latter of which is characteristic of most other variationist phenomena.
2 The interest of the mandative subjunctive
As a conceptual category, the mandative subjunctive in Modern English can be expressed in the three ways illustrated in (10) from Greenbaum & Quirk’s (Reference Greenbaum and Quirk1990: 44) standard reference work.
The conceptual category is coded by the subjunctive in (10a), a modal auxiliary in (10b) and the indicative in (10c). The fact that the three options are compatible with the verb to demand demonstrates that the form of the verb in the subordinate clauses is not uniquely determined by a particular trigger. So there is room for grammatical variation. By common consent, the decision among these variants is influenced by region, mode (spoken vs. written language) and (historical) time (e.g. Övergaard Reference Övergaard1995, Serpollet Reference Serpollet, Rayson, Wilson, McEnery, Hardie and Khoja2001, Leech et al. Reference Leech, Hundt, Mair and Smith2009). We remain agnostic as to the role of semantics in this game – apart from the obvious requirement that the trigger of the mandative subjunctive have a deontic meaning. While it has been claimed that the different options are not semantically equivalent (e.g. Övergaard Reference Övergaard1995: 11; Hoffmann Reference Hoffmann1997), the meaning differences appear to be rather minor. A connection between mandatory force and mood choice has not as yet been established.Footnote [3] In any event, as long as the status of the three forms in (10) as variants is not in dispute, the role of semantic contrast is largely inconsequential for our investigation (see Hinrichs, Szmrecsanyi & Bohmann Reference Hinrichs, Szmrecsanyi and Bohmann2015: 814). This follows from the lack of a link between meaning and distance. Potential semantic or pragmatic differences cannot naturally predict potential differences in range.
The three options in (10) allow us to address two major issues. The first is the structural level at which the mandative subjunctive is coded. While the indicative is expressed morphologically (by means of a suffix, which can also be zero), the modal auxiliary is a free-standing, syntactically manipulable unit and therefore qualifies as a syntactic option. We may thus compare the range of the syntactic level to that of the morphological level within a structural model which recognizes different levels but also provides for a good deal of interactivity between them. Given that the syntactic level is superordinate to the morphological level in the structural hierarchy, this comparison provides an opportunity of examining the impact of hierarchical position on range. It might be that higher levels have a wider range than lower levels because high-level planning has to oversee larger domains than low-level planning.
The second issue emerges from the similarity and contrast between the indicative and the subjunctive. With a suffix or the absence thereof as their exponents, both mood values originate at the morphological level and hence allow us to study within-level effects. At the same time, the fact that the indicative is sometimes realized by a suffix while the subjunctive is realized by zero, grants insight into the contrast between explicit and implicit coding. This may not be unlike the contrast between the prepositional verb to stop OBJ from Xing and the prepositionless verb to stop OBJ Xing discussed in the opening section. If the syntactic data from the stop-construction generalize to the morphological level, we would expect a shorter range for implicit than for explicit coding.
To conclude, the English subjunctive gives us the welcome opportunity of studying the following three issues: by contrasting the modal strategy with the other two options, we can test for possible differences in range between the syntactic and the morphological level. In addition, by contrasting the subjunctive with the indicative, we can test for possible differences in range between an explicit and an implicit coding strategy. Finally, by comparing these two analyses, we can test for possible differences in the size of between-level and within-level effects. However, before we can present the empirical analysis, a variety of methodological points have to be taken care of.
3 Method
Most usually, the subjunctive depends on an explicit trigger (but see Hundt Reference Hundt, Lindquist, Klintberg, Levin and Estling1998a for some qualification). Our first task was therefore to identify subjunctive triggers. An attempt was made to set up a (more or less) exhaustive list.Footnote [4] Our starting point was Crawford’s (Reference Crawford, Rohdenburg and Schlüter2009) Appendix A, which includes 47 verbal, 38 nominal and 23 adjectival triggers. Three types of change were made to this list, one substitutive, one additive and one subtractive. Crawford’s list contains the verb to intimidate which we are unsure about. It might be an inadvertent substitution for to intimate. Be that as it may, we tested for subjunctive uses of to intimidate but did not find any. So we decided to replace to intimidate with to intimate. We deleted all items from Crawford’s list for which our own analysis (see below for details) did not yield any deontic uses at all. This was true for one adjective (i.e. convenient), five nouns (e.g. implication) and four verbs (e.g. to insure). At the same time, in the course of our research, we came across as many as 21 adjectives (e.g. adamant and critical) and one noun (i.e. urge), which were not on Crawford’s list but had the potential to trigger a subjunctive. With these changes, we ended up with a total of 120 subjunctive triggers, which divide into 43 verbs, 34 nouns and 43 adjectives. The complete list is provided in the appendix.
There are four signposts to signal a subjunctive in English. Apart from the absence of the third person singular present tense inflection, as in (10a), there is the subjunctive form be from the infinitive to be, the lack of do-support in negated clauses and the non-occurrence of backshifting of tense. The latter three options are exemplified in (11)–(13) from our corpus. For easy identification, trigger and target will henceforth be put in bold.

The exceptional status of to be facilitates the identification of the subjunctive because the subjunctive form be differs from the indicative forms in the entire person paradigm, as exemplified by the third person plural subject in (11). The fact that the subjunctive in negated clauses does not require the prop word do (as in (12)) is another indication of a subjunctive form. The lack of backshifting of tense can also be regarded as a clue to the subjunctive. In (13), the narrative is in the past tense. We would therefore expect the verb form in the subordinate clause to be spoke if it were indicative. The fact that this does not occur implies that speak is a subjunctive. However, this logic can only be reliably applied when the verb in the matrix clause is in the past or perfect tenses. When the target verb is preceded by a non-finite trigger, this criterion is obviously of no avail.
In view of the almost complete lack of formal marking of the subjunctive, verb forms ambiguous between the indicative and the subjunctive abound. One such case is (14).
As all non-third-person-singular forms of verbs other than to be do not formally distinguish between indicative and subjunctive mood, the finite form get in (14) could be either one or the other.
Owing to polysemy, one and the same trigger can have a deontic or a factual reading. In fact, almost all triggers on our list which are not too uncommon allow both uses, though to widely varying degrees. The two uses are exemplified in (15) on the basis of the trigger to suggest.
The epistemic meaning of to suggest in (15a) contrasts with its deontic meaning in (15b). In the vast majority of cases, the decision as to whether an individual token of our trigger types is used deontically or factually was a straightforward one. In making this decision, we could rely on a number of clues including the meaning of the trigger and the use of the subjunctive or a modal auxiliary. In case of indicative use, the context usually clarified whether a deontic meaning was intended. More particularly, we relied on certain clues such as the temporal relationship between the situation described by the matrix clause and that described by the subordinate clause. A deontic function can only refer to situations which follow the situation referred to. Take the following example:
The machine in question has always been from 1971, which predates the particular situation described here (the 2011 Fukushima nuclear disaster). This establishes the situation described by the subordinate clause as a fact, which does not lend itself to a deontic interpretation. That is, the reactor cannot be mandated to be from any year other than 1971, and the speaker obviously did not intend to do so. More generally, then, a tell-tale sign of a factual use is when the situation described by the subordinate clause chronologically precedes or coincides with that of the matrix clause.
Another clue is provided by the nature of the subject NP. Consider (17).
As abstract concepts, neither rationality nor experience can actually demand that someone do something. Hence, the meaning of demand in (17) cannot be deontic; in fact, it is very similar to the non-deontic meaning of suggest in (15a), where the subject is also an abstract noun. This automatically forces a more factual interpretation in (17): what other people are capable of cannot be dictated.
In the few cases where we were in doubt even after applying these criteria, our practice was to err on the side of caution and classify them as factual.
We move on to a description of our database. The (online version of the) Corpus of Contemporary American English (COCA) from 1990 to 2012 was selected mainly for two reasons. In addition to its sheer size, we preferred to examine American rather than British English because the mandative subjunctive occurs more commonly in the former than the latter variety (e.g. Erdmann Reference Erdmann, Kunsmann and Kuhn1981, Hundt Reference Hundt, Lindquist, Klintberg, Levin and Estling1998a, Crawford Reference Crawford, Rohdenburg and Schlüter2009).
COCA was searched for all the triggers on our list. The search term was ‘trigger (in all its inflectional variants) + that’. Hence, contact clauses (e.g. At the peak of Ellen Pyle’s flourishing career in the 1920s and 30s, the Post editor requested she write her life story for publication in the magazine) and cases where triggers and complementizers were non-adjacent (e.g. But I mean, it’s really important psychologically that we go up tomorrow because, otherwise, this is very painful) were not retrieved. The exclusion of contact clauses and non-adjacent triggers and complementizers was motivated by both practical and empirical reasons. If the search term had been restricted to the bare trigger or had been wide enough to include intervening material, the amount of manual editing would have been substantial. Moreover, contact clauses constitute a minority in mandative constructions (e.g. Johansson & Norheim Reference Johansson and Norheim1988, Hundt Reference Hundt, Lindquist, Klintberg, Levin and Estling1998a, Waller Reference Waller2017). The same is true of cases with non-adjacent triggers and complementizers.
For many triggers, the COCA search yielded fewer than 1,000 hits. All tokens of these verbs were subjected to scrutiny. For practical reasons, triggers for which COCA produced more than 1,000 hits were limited to a sample of 1,000 hits. COCA generates such random samples, including tokens from all years and subgenres.
The computer-assisted search turned up a number of hits where the matrix verb governed more than one embedded verb, as documented in (18).
As many as four verbs depend on the trigger essential. All these subordinate verbs were treated as separate hits because the distance between trigger and target differs from case to case. The decision for counting the individual targets separately was additionally motivated by the fact that the subordinate verbs did not necessarily have the same mood value (even though they depend on the same trigger). This suggests a certain autonomy of the individual clauses with respect to mood choice. The net effect of this procedure is that some triggers have slightly more than 1,000 hits in our corpus.
Hardly any editing of the corpus was performed. Only when the exact same string of words from the same source and the same year accidentally appeared as two or more different hits did we eliminate the duplicates. Some hits were marred by minor errors such as when she appeared as sbe. As the context almost always made clear which word was meant, these errors were rectified and the hit correctly coded. The very few cases of mistranscription which produced incomprehensible utterances were discarded.
Next, we turn to our data coding scheme.Footnote [5] Each token was coded for twelve variables – some straightforward, some necessitating some special consideration. The rest of this section introduces and discusses them in turn.
In addition to the trigger itself, its deonticity, its textual frequency and its word class was noted. Deonticity is a binary variable (yes/no). The word-class variable has three values: verb, noun or adjective. The textual frequency of the trigger was determined on the basis of its occurrences in COCA. Trigger frequency was operationalized by calculating the token frequency of the trigger alone as well as the string frequency of the trigger and the following complementizer.
Kastronic & Poplack (Reference Kastronic and Poplack2014) caution that much of what we know about the mandative subjunctive (and its history) derives from the analysis of written language and that it is anything but obvious that these results generalize to speech. It was deemed necessary therefore to distinguish between spoken and written utterances. COCA includes both spoken and written language and thus allows us to test whether this factor plays a role in the subjunctive game and, more specifically, whether possible distance effects can be observed in both modes. However, it should be acknowledged that the distinction between spoken and written language in general and in COCA in particular is not at all clear-cut. The spoken sample in COCA is based on media speech (e.g. talk shows on TV) and hence does not reflect completely natural and spontaneous conversation.
The next variable looks into the mood of the subordinate verb. We observed five values in the data: modal, subjunctive, indicative, ambiguous and imperative. A separate column was reserved for the modal auxiliaries. Technically speaking, this column is nested in the modal value of the Mood column. As many as 13 modals or functionally similar verbs such as to have to and to be to were found to occur in subordinate clauses.
The critical variable in this study is the distance between trigger and target. We decided to measure distance linearlyFootnote [6] in terms of number of words as well as number of morphemes. In the ideal case, this double strategy would allow us to argue that possible distance effects are independent of the particular measure being chosen.
Obviously, the count of words and morphemes requires working definitions of what counts as a word or a morpheme. To make the separate counts more meaningful, our overall strategy was to maximize the difference between the two types of unit. That is, units which were difficult to classify were treated as single words in the word count but as multiple morphemes in the morpheme count. Accordingly, compounds (whether hyphenated, written solid or written separately), complex proper nouns (e.g. General Motors) and contracted forms, in particular negated forms such as don’t and wasn’t, were counted as one word in the word count. However, first and last names were counted as one word each.
Every morpheme that was relatively clearly identifiable was included in the morpheme count. Minor morphophonological variation (as in ![]() ) was ignored. That is, health was counted as bimorphemic, as were irregular past tense forms such as sang and felt. However, we did not take the morpheme maximization strategy to its extreme. Derived words with no semantic relation to their base (e.g. department – to depart), derived words with a considerably higher frequency than their bases (e.g. dictionary – diction) as well as seemingly derived words with virtually no existent base (e.g. environment) were classified as monomorphemic. This is to do justice to their holistic representation in the mental lexicon (e.g. Bybee Reference Bybee1985, Marslen-Wilson et al. Reference Marslen-Wilson, Tyler, Waksler and Older1994, Hay Reference Hay2001). Words containing cranberry morphemes (e.g. aftermath) and suppletive forms were treated likewise. A surface approach was adopted according to which only ‘visible’ morphemes were taken into consideration. An example such as Americans’ in Americans’ health insurance was counted as a three- rather than a four-morphemic word. Words ending in -ical require special mention. This ending was usually categorized as bimorphemic because there is a lexical contrast between, let us say, economic and economical. However, this decision did not seem appropriate for words like radical, for example, where the holistic touch predominates.
) was ignored. That is, health was counted as bimorphemic, as were irregular past tense forms such as sang and felt. However, we did not take the morpheme maximization strategy to its extreme. Derived words with no semantic relation to their base (e.g. department – to depart), derived words with a considerably higher frequency than their bases (e.g. dictionary – diction) as well as seemingly derived words with virtually no existent base (e.g. environment) were classified as monomorphemic. This is to do justice to their holistic representation in the mental lexicon (e.g. Bybee Reference Bybee1985, Marslen-Wilson et al. Reference Marslen-Wilson, Tyler, Waksler and Older1994, Hay Reference Hay2001). Words containing cranberry morphemes (e.g. aftermath) and suppletive forms were treated likewise. A surface approach was adopted according to which only ‘visible’ morphemes were taken into consideration. An example such as Americans’ in Americans’ health insurance was counted as a three- rather than a four-morphemic word. Words ending in -ical require special mention. This ending was usually categorized as bimorphemic because there is a lexical contrast between, let us say, economic and economical. However, this decision did not seem appropriate for words like radical, for example, where the holistic touch predominates.
It turned out on later analysis that the word and the morpheme count could not be included as independent factors in the same statistical model because they are correlated to an extremely high degree (rpearson > .9) (see also Yaruss Reference Yaruss1999). We therefore decided to design two separate models, one including distance in words and the other distance in morphemes, and to examine which of the two operationalizations resulted in a better model fit. Not surprisingly, the performance of the two models was almost identical. The final model featured words as the relevant measure of distance because it yielded a minimally (non-significantly) better model fit. Thus, distance in morphemes is not given any attention in our presentation of the statistical results.
Our general strategy in measuring distance was to count the material intervening between target and trigger. In the case of the modal option, the modal auxiliary was regarded as the target and accordingly ignored. A particular challenge was presented by negation. The problem was whether the negation marker not, which is supported by to do in an indicative construction but not so in a subjunctive construction, should be counted in or out. Contrast (19) with (20).
We decided against including not in our distance counts because the occurrence of the negation marker is not independent of mood choice. Viewed from a linear perspective, at the moment that not appears in (19), the decision in favour of the subjunctive has already been taken. As noted above, the unsupported not is a special property of the subjunctive, so neither an indicative nor a modal construction may follow. Therefore, the negation marker not was not included in the distance counts. In fact, it was completely ignored because it invariably follows the modal auxiliaries (e.g. should not) and finite verbs (see (20)).
The distance between trigger and target was not only coded in terms of number of words and morphemes but also in terms of number of additional clauses, both finite and non-finite. The ordinary case was a trigger followed by the complementizer that, the subject of the embedded clause and the target. However, syntactically more complex constructions, in particular relative, conditional and complement clauses, occasionally found their way into the data, as exemplified in (21).
While we originally intended to examine the syntactically more complex cases separately, the later analysis yielded an insufficient number of relevant items for statistical testing. Therefore, this dimension was not considered further.
The last two variables that were taken into account are the nature of the target verb, in particular whether or not it is a form of to be, and the presence or absence of the negation particle not in the subordinate clause. While we do not put forward any hypotheses as to a possible influence these variables might exert on mood choice, we decided to include them because of the special role they play in the subjunctive construction (see above).
4 Data analysis
The selection procedure depicted in the previous section yielded a total of 49,154 data points, which divide into 17,626 deontic and 31,528 factual uses (35.9–64.1%). The factual uses were excluded from further analysis. The imperatives were so extremely infrequent (N = 12) that they were also discarded. Table 1 presents a descriptive survey of the remaining 17,614 data points. For the sake of completeness, it reports both the word and the morpheme count.
Table 1 Mood choice as a function of distance (N = 17,614).

Prior to looking at distance effects, it is appropriate to point out that Table 1 confirms the frequency distribution of the various mood values reported in the relevant literature (e.g. Johansson & Norheim Reference Johansson and Norheim1988, Hundt Reference Hundt1998b, Schneider Reference Schneider, Dayag and Quakenbush2005). In American English, subjunctives are clearly the majority choice (56.0%) even if ambiguous cases are counted in. If ambiguous cases are ignored, the rate of subjunctives rises to 76.8%. Modals are much less frequent, accounting for 13.7% (including ambiguous cases) or 18.8% (excluding ambiguous cases). The indicative is an unlikely choice at 3.2% (ambiguous cases included) or 4.4% (ambiguous cases excluded). The rather high rate of ambiguous cases is an immediate spin-off function of the impoverished exponence of the subjunctive (see Section 3).
Table 1 shows that the average distance between trigger and target is highest for modals, lower for indicatives and even lower for subjunctives. This difference is much larger for the contrast between modals and non-modals (5.65 – 4.28Footnote [7] = 1.37 words; 7.7 – 5.83 = 1.87 morphemes) than for the contrast between indicatives and subjunctives (4.44 – 4.3 = 0.14 words; 6.37 – 5.78 = 0.59 morphemes). As can be seen, the word and the morpheme counts yield very similar rankings.
The ambiguous cases are very close to the subjunctive. In fact, the difference in distance between ambiguous cases and subjunctives is smaller than that between ambiguous cases and indicatives. Coupled with the observation that indicatives are a rare choice in our data, this strongly suggests that ambiguous cases are more likely to be covert subjunctives than covert indicatives.
We move on to a statistical treatment of the data. Given the three mood values, two binary comparisons were performed: the between-level comparison contrasts the syntactic with the morphological cases and the within-level comparison contrasts the subjunctive with the indicative mood. The within-level comparison is subordinated to the between-level comparison since the former takes a more detailed look at the (unambiguous) morphological options, which the latter treats as an undifferentiated set.
Within each comparison we carried out two analyses. First, in order to get an overall idea of the distance effect, we calculated the ratios of the competing mood choices by distance between trigger and target and analyzed the correlation between the two by means of a regression analysis. In a second step we built mixed-effects logistic regression models, which allow us to test the effect of distance on mood choice, while controlling for the variables we introduced in the previous section.
4.1 Between-level comparison: Syntactic vs. morphological
For the between-level analysis, modal constructions were classified as syntactic but all others as morphological. The ambiguous cases were assigned to the morphological set because they are ambiguous between indicative and subjunctive, both of which belong to the morphological level.

Figure 1 Syntactic/morphological ratio by distance between trigger and target.
4.1.1 Ratio analysis
What effect does distance have on the choice between the syntactic and the morphological variants? In an attempt to answer this question, we calculated the ratio of the syntactic vs. the morphological option by distance (measured by the number of words). We excluded distances between trigger and target in excess of 15 words. This region yielded a low number of data points, which made it difficult to reliably estimate the syntactic/morphological ratio, that is, to generate a robust statistical model. This decision resulted in a loss of 574 data points (3.3% of the data). The diagram in Figure 1 plots the syntactic/morphological ratio on the y-axis versus the distance between trigger and target on the x-axis. The regression line in this figure shows quite clearly that the ratio of the syntactic variant increases with increasing distance. A regression model predicting the ratio of the syntactic variant by distance in number of words yields the following output (see Table 2).
Table 2 Output of linear regression model predicting the ratio of the syntactic option (N = 17,040).
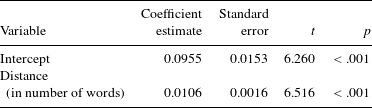
The model output indicates a highly significant effect of distance on mood choice. The coefficient of 0.0106 means that the likelihood of the syntactic option increases by about 1% with each increment of one word. The adjusted R-squared value of the model is 0.76, which indicates a very high correlation between ratio and distance (rpearson = .88). Thus, the statistical model predicts the empirical patterns quite well.
4.1.2 A mixed-effects analysis
Two limitations of the above model are its monofactorial nature and the fact that it is based on mean values but does not capture decisions at the level of individual tokens. Since it is unlikely that distance is the only explanatory factor in this game, it is necessary to perform a second statistical analysis which examines whether the choice between the syntactic and the morphological option is under the sway of distance, even when possibly confounding variables are taken into account. To this end, a mixed-effects logistic regression model fitted to the choice between the syntactic or the morphological variant was calculated. This model is based on the same sample as the ratio model, with distances larger than 15 words excluded.
In addition to Distance, our model includes as fixed effects the following five variables: Trigger Frequency, Part-of-Speech (POS), Mode, Negation and Be, all of which were discussed in Section 3 above. POS is a ternary variable (noun, verb, adjective) while the others are binary: Mode (spoken vs. written), Negation (yes vs. no) and Be (yes vs. no). The predictors Distance (in number of words) and Trigger Frequency were log-transformed before being entered into the model because their distribution was found to be more normal in logarithmic space.
The random effects structure of the model includes random intercepts for trigger and corpus file, which we use as a proxy to control for speaker/writer-specific effects. We furthermore added random slopes by trigger and by corpus file for the critical variable Distance.
Throughout the model fitting procedure, we kept the random-effects structure maximal, following a design-based approach (see Barr et al. Reference Barr, Levy, Scheepers and Tily2013). Models were built using the glmer functionFootnote [8] of the lme4 package (Bates et al. Reference Bates, Maechler, Bolker and Walker2015) in R (R Development Core Team 2014). With regard to the fixed effects, we first built a maximal model featuring all aforementioned predictors as main effects as well as all pairwise interactions of Distance with the other predictors. We subsequently removed interactions and fixed effects in a stepwise fashion, beginning with the term with the highest p-value.
The model fitting process revealed an interaction effect between the predictors Distance and Negation, which, however, led to nonconvergence of the corresponding models. An examination of the data revealed that this was due to a shortage of data points with negated subordinate clauses, for which the distance effect could thus not be properly estimated. In order to steer clear of potentially damaging effects of Negation on our model, we decided to eliminate all cases with negated subordinate clauses. This resulted in a loss of 938 data points (5.5% of the data).
Model fitting on the reduced data set showed none of the other two-way interactions with Distance to be statistically significant. Because the predictors Be and Trigger Frequency were not significant as main effects, they were discarded. Table 3 provides the complete model output of the final model and should be read as follows: positive coefficients indicate a heightened probability of choosing the syntactic option while negative coefficients indicate a heightened probability of choosing the morphological option. For the ternary variable POS the variable value ‘noun’ served as a baseline.
Table 3. Output of mixed-effects model predicting the odds of choosing the syntactic or the morphological option (N = 16,102).
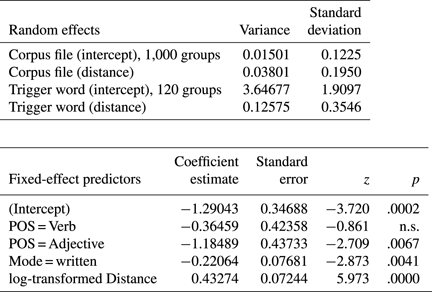
The resultant model is a minimal adequate model with all fixed-effect predictors contributing significantly to model fit. The major result is a highly significant effect of Distance. The probability of choosing the syntactic option increases with increasing distance between trigger and target. This effect is robust enough to show up in the presence of other variables which also exert a significant influence on mood choice.
For the variable POS, we observe that while there is no significant difference between nouns and verbs, nouns are more likely than adjectives to choose the syntactic variant. Mode also impacts on Mood choice: the syntactic option is significantly more likely to occur in speech than in writing.
As regards the random effects, the random intercept for trigger accounts for a considerably larger share of variance than the random intercept for filename. This shows that the choice between the syntactic and the morphological option is driven to a large extent by the individual trigger, but not so much by idiolectal variation.
The bottom line of the mixed-effects analysis is that it fully corroborates the ratio analysis, with the effect of Distance emerging in both analyses. The fact that none of the two-way interactions of Distance and the other predictors proved significant demonstrates the autonomy of the distance effect.Footnote [9]
4.1.3 Multiple targets
It was mentioned in Section 3 that our corpus contains sentences in which more than one clause is subordinated to the matrix clause (see (18) above). These cases allow us to address two additional questions. Is mood choice consistent across the different target verbs? In other words, does the mood of the first subordinate verb determine the mood of all following verbs? If not, is the switch from one mood value to another symmetrical, i.e. are switches from morphological to syntactic as likely as the reverse direction? Our previous results lead to a very clear prediction. Since the distance between trigger and target increases considerably with each additional subordinate clause, a switch from morphological to syntactic should be significantly more frequent than a switch from syntactic to morphological.
We have found 1,396 triggers with more than one target in our data. Of these, 57 (= 4.1%) involve a switch from one mood value to another. This rather low percentage indicates that switches are a dispreferred option. The mood of the first target is a highly reliable predictor of the mood of the second (and following) target verb. Two exceptions to this pattern are given in (22) and (23).

While (22) exemplifies a change from the morphological to the syntactic option, (23) illustrates a change in the opposite direction from the first to the second target verb. Of the 1,396 sentences with at least two subordinate clauses, 47 involve a switch from morphological to syntactic but only 10 a shift from syntactic to morphological. This difference is highly significant (binomial test, p < .0001). This result provides further support for the claim that the likelihood of the syntactic option rises with increasing distance between trigger and target.
4.2 Within-level comparison: Indicative vs. subjunctive
We proceed to a more detailed examination of the morphological level. The elimination of the ambiguous cases leaves us with the choice between indicative and subjunctive mood. A closer look at the two options affords us an opportunity of testing within-level effects. Does the indicative have the same range as the subjunctive effect? If Poplack’s (Reference Poplack, Laeufer and Morgan1992) data from French (discussed in the opening section) carry over to English, the answer might be in the negative. In that case, a longer range would be predicted for the indicative than the subjunctive. As in the between-level comparison, both a ratio and a mixed-effects analysis were carried out.
4.2.1 Ratio analysis
For the analysis of the effect of distance on the choice between indicative and subjunctive, items with distances of more than 15 words were discarded for the same reasons as stated above. This resulted in a loss of 311 data points (3.1% of the data) and left us with 547 indicatives and 9,568 subjunctives.
The diagram in Figure 2 plots the indicative/subjunctive ratio on the y-axis and the distance between trigger and target in number of words on the x-axis. Figure 2 suggests an effect of Distance on the choice between indicative and subjunctive mood. As the regression line indicates, the indicative/subjunctive ratio increases with increasing distance between trigger and target. The output of the corresponding regression model is reported in Table 4.

Figure 2 Indicative/subjunctive ratio by distance between trigger and target.
Table 4 Output of linear regression model predicting the indicative vs. subjunctive ratio (N = 10,115).

Table 4 shows that the regression line in Figure 2 reflects a significant effect of distance on the indicative/subjunctive ratio. The coefficient of 0.0048 indicates that the probability of the indicative increases by approximately 0.5% per word increment in distance. The adjusted R-squared value is .295, the correlation coefficient is rpearson = .59, indicating a moderate correlation between distance and mood choice.
4.2.2 A mixed-effects analysis
As before, we calculated a mixed-effects model with an eye to investigating whether Distance preserved its significant influence on mood choice in the face of competition from other variables. The random-effects structure of the model was the same as above, with random intercepts for trigger and filename as well as random slopes of Distance by trigger and filename. As the models with random slopes failed to converge, random slopes had to be left out of account.
The same fixed-effects predictors were subjected to testing as in the previous set of analyses. We tested Distance, Trigger Frequency, POS, Be and Mode as main effects as well as all pairwise interactions of Distance and the other factors. For the same reason as given in Section 4.1.2, the items with negated subordinate clauses were removed. This led to an exclusion of 726 data points (7.2% of the data).
The model output is presented in Table 5. Positive coefficients indicate an elevated likelihood of selecting the indicative while negative coefficients indicate an elevated likelihood of selecting the subjunctive.
Table 5. Output of mixed-effects model predicting the odds of choosing the indicative or the subjunctive (N = 9,389).
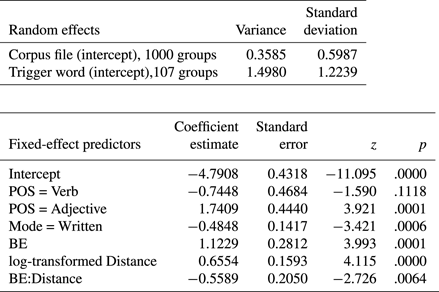
The most important result to emerge from Table 5 is the highly significant main effect of Distance, which seconds the output of the ratio model. The probability of choosing the indicative increases with increasing distance between trigger and target. With the exception of Trigger Frequency, all other main effects also turn out to be significant. While adjectives are significantly more likely to trigger the indicative than are nouns, the difference between verbs and nouns is not statistically significant. When the target verb is a form of to be, the likelihood of the indicative is increased. The coefficient for Mode reveals that the subjunctive is more typical of the written than the spoken language (in line with Peters Reference Peters, Peters, Collins and Smith2009).
Table 5 furthermore shows that Distance is involved in a statistically significant interaction with Be. The net effect is that Distance plays less of a role in mood choice when the verb in the subordinate clause is a form of to be.
Concluding, Distance emerges as a reliable predictor in the choice between indicative and subjunctive mood. The indicative tolerates larger distances better than the subjunctive does. This conclusion is consonant with Poplack’s results for French. What makes this consonance especially remarkable is that the English and the French subjunctive differ in form, function and frequency of use.
4.3 Comparing between-level and within-level effects
A comparison of the between-level and within-level analyses reveals that Distance plays a significant role in both. It remains for us to probe into a possible interaction of type of analysis and size of the distance effect. Going by the coefficients of the regression models based on the ratios of the two options (see Tables 2 and 4), the between-level effect is twice as strong as the within-level effect. We tested for significance of this difference by calculating a z-test as suggested by Clogg, Petkova & Haritou (Reference Clogg, Petkova and Haritou1995: 1276), which yields a statistically significant result (z = 2.313, p < .05). We conclude that the distance effect is stronger in the between-level scenario compared to the within-level analysis.
5 Theoretical discussion
The analysis of the English subjunctive has shown that the likelihood of choosing a particular mood value varies with the distance between trigger and target verb. The larger the distance, the more likely the syntactic option in the between-level analysis and also the more likely the indicative option in the within-level analysis. Implicationally, the syntactic level has a wider range than the morphological level, and the indicative has a wider range than the subjunctive. Owing to this difference in range, syntax can support the production of a modal auxiliary at greater distances more easily than morphology can support the production of the indicative or the subjunctive; hence there is an increasing probability of choosing modals at larger distances. The difference in range is without effect when the distance between trigger and target is small. At short lags, syntax and morphology can easily perform the same task even though their strengths need not be identical.Footnote [10] The same reasoning holds for the within-level analysis. The wider range of the indicative is conducive to an increasing likelihood of selecting the indicative at larger distances. At short lags, however, the indicative and the subjunctive can in principle do the same job.
Rather simplistically, we may divide the time course of activation of linguistic units into three parts: a rise rate in the initial stages, an average activation level in the intermediate stages (which is dynamic rather than static) and a decay rate in the final stages. At this point of our paper, we have nothing to say about the beginning of the activation process (but see next section). Our data speak more directly to the middle part. The fact that the morphological option is generally preferred in our data suggests that morphology is stronger than syntax, in particular for the more common distances between trigger and target. By the same token, the fact that the subjunctive is generally more frequently chosen than the indicative lends support to the hypothesis that the subjunctive attains a higher activation level than the indicative most of the time.
The notion of range speaks most directly to the final part of the activation process. Varying ranges can be translated most readily into varying decay rates. We maintain that all options have their individual decay rates. Because the decay rate at the syntactic level is lower than that at the morphological level, the former level increasingly facilitates the production of modals at long lags. Similarly, because the decay rate of the indicative is lower than that of the subjunctive, we observe a gradual rise in indicative options at larger distances.
Is there a connection between the activation levels in the intermediate stages and the decay rate in the final stages? It might be expected that the relative strength of a given option remains essentially the same throughout the production process. This would imply that a higher activation level correlates with a lower decay rate. Actually, the opposite is true for both the between-level and the within-level analysis. The morphological units have a higher activation level but also a higher decay rate than the modals. By the same token, the subjunctive has a higher activation level but also a higher decay rate than the indicative. This may be taken to suggest that approximately the same time span is available to all units. So when a given unit is strongly activated, it has to decay more rapidly than when it is less strongly activated.
It is possible to distinguish between a principle at work during the intermediate stages and a principle at work during the final stages. The latter is probably systemic in the sense that the linguistic system is inherently biased whereas the former is not. If there is no inherent bias, any option may predominate, as the case may be. This is what we find in the intermediate stages. While the subjunctive predominates in the modern language (see Table 1), modal constructions were the preferred choice in Middle English (Moessner Reference Moessner and Mazzon2007). Thus, the relative strength of the two options was overturned in the historical development from Middle to Modern English. A similar variation exists at the synchronic level. While some varieties of English prefer the subjunctive, others lean towards the modal construction. For example, Hundt (Reference Hundt, Lindquist, Klintberg, Levin and Estling1998a) reports a strong predominance of the subjunctive in the Brown and Frown corpora of American English but a strong predominance of the modal construction in the Lancaster–Oslo–Bergen (LOB) corpus and a weaker predominance of the modal construction in the Freiburg–Lancaster–Oslo–Bergen (FLOB) corpus of British English. It may be inferred that it is the individual variety which decides on the relative strength of the morphological and the syntactic options.
By contrast, it is likely that the final stages of the activation process are dominated by a processing bias which characterizes linguistic systems in general – at different times, in different varieties of the same language and possibly also in different languages. The decay rate of syntactic units is claimed to be lower than that of morphological units. Similarly, the decay rate of the indicative is claimed to be lower than that of the subjunctive. However, the reasons for the varying decay rates differ for the between-level and the within-level comparison. Let us look at each in turn, beginning with the former.
In hierarchical frameworks of language structure, syntax is superordinated to morphology. Range may straightforwardly be linked to the position of a given level in the structural hierarchy: the higher its position, the lower its decay rate and hence, the wider its range. This correlation can be turned into a cause. As the structural hierarchy is mainly motivated by the varying sizes of the elements (and their domains) at the various levels, the range of a level may be argued to be determined by the size of the units on which it operates. By virtue of their greater extension in time, larger units require wider-ranging effects for a smooth operation of the linguistic system.
In the within-level comparison, we would like to understand why the indicative has a longer range (or a lower decay rate) than the subjunctive. A possible answer can be found in the disparate use of the indicative and the subjunctive mood. Although the subjunctive has been found to be the majority option in mandative constructions (see Table 1), there is no denying that it occurs far less frequently than the indicative in general language usage. In fact, its use is highly restricted. Apart from mandatives, it occurs in optatives (e.g. God save the Queen), certain conditionals (e.g. Schlüter Reference Schlüter, Rohdenburg and Schlüter2009), hypotheticals (e.g. Hundt, Hoffmann & Mukherjee Reference Hundt, Hoffmann and Mukherjee2012) and lest-clauses (e.g. Auer Reference Auer, Locher and Strässler2008). What is common to all these constructions is their pronounced infrequency. We therefore propose a correlation between textual frequency and range: the higher the frequency of a particular option, the longer its range.
This hypothesis appears reasonable enough. High frequency is known to increase the availability of linguistic units. It is a relatively small step from heightened availability to long range. However, this claim is in apparent conflict with syntactic persistence effects. It has been repeatedly demonstrated that less frequent constructions engender stronger persistence effects than more frequent constructions do (e.g. Bock Reference Bock1986, Ferreira Reference Ferreira2003, Rosemeyer & Schwenter Reference Rosemeyer and Schwenter2017). We submit that persistence and mood choice represent two disparate phenomena exhibiting disparate characteristic features. Persistence involves the use of an item which was used before. That is, we are dealing with a conceptual and temporal relationship between tokens of the same type. By contrast, our study is concerned with the linear or temporal relationship between a particular trigger and a particular target, i.e. two different words subject to morphosyntactic variation. There is another fundamental difference. In mood choice, the form of the trigger does not in any way determine the form of the target whereas persistence is defined by the influence of the first token on the likelihood of producing the second. Note further that the two phenomena have different time windows. For example, Rosemeyer & Schwenter (Reference Rosemeyer and Schwenter2017) observed persistence effects over stretches of as many as 100 words. This is much more than the (average or maximum) distance between trigger and target in our data. We thus feel justified in concluding that our frequency hypothesis is not challenged by persistence effects.
Let us briefly consider an alternative explanation of the differing ranges of the indicative and the subjunctive. Rohdenburg (Reference Rohdenburg1996) made a strong case for the Complexity Principle, whereby the more explicit member of a set of alternative options is preferably used in more complex contexts. This principle derives its current relevance from the fact that the indicative is explicitly coded by a suffix (in the third person singular) whereas the subjunctive is implicitly coded by the absence thereof. If the greater distance between trigger and target is taken to imply a higher level of complexity, Rohdenburg’s principle correctly predicts a wider range of the indicative than of the subjunctive. One way of explaining this effect is to argue that the larger the distance between trigger and target, the higher the difficulty of establishing a link between them and hence the greater the need to facilitate the establishment of this link by means of explicit marking.
While we clearly see the merit of the Complexity Principle, we doubt that it can deal with Poplack’s case of French. In contradistinction to the situation in English, it is the subjunctive rather than the indicative which is explicitly marked in many French verbs. For instance, the verbs in -re such as répondre ‘to answer’ have a final /d/ in the subjunctive (qu’il réponde /repõd/) but nothing in the indicative (il répond /repõ/). Still, as noted above, the relative ranges of both effects appear to be similar in the two languages. It should be added that in French, the subjunctive is not always explicitly marked and the indicative implicitly marked. Some verbs have explicit marking of both mood values while others do not formally distinguish between indicative and subjunctive mood. In either case, the Complexity Principle cannot be straightforwardly applied to French. This at least suggests the possibility that it may also not be the adequate explanation for English.
It remains for us to explain why between-level effects are stronger than within-level effects. In point of fact, this difference in strength does not come as a surprise. Given that a certain structural level has a certain range, it is to be expected that units at the same level (e.g. indicatives and subjunctives) have basically the same range while units at different levels (e.g. modals and subjunctives) differ more noticeably in range. This is just what we find. However, being located at the same level does not imply that two units must have identical ranges. There is still room for individual units to have individual ranges even though this variability is of a more limited nature.
Having dealt with range, we proffer a few comments on the effect of word class on mood choice. In both the between-level and the within-level analyses, we observed an increasing use of modal constructions and the indicative from adjectives to verbs and nouns. Actually, this is not the order which might have been expected. In many languages, adjectives take an intermediate position between verbs and nouns (e.g. Thompson Reference Thompson and Hawkins1988, Givón Reference Givón1994, Stassen Reference Stassen1997, Pérez-Guerra Reference Pérez-Guerra2016). Irrespective of the basis for this arrangement, such an order cannot account for our findings. What we can offer at this point is a possible correlation between word-class sensitivity and deonticity. We determined deonticity by calculating the percentages of ‘yes’ cases in the column ‘deontic use’ of our coding sheet (see Section 3) for all three word classes. The results are displayed in Table 6, which also includes the 12 imperatives in our data.
Table 6 Deonticity of word classes.

It is apparent from Table 6 that nouns are rather reluctant to develop deontic uses. Verbs are much more likely and adjectives are most likely to do so. Thus, the three word classes can be ordered on a scale of increasing deonticity as follows: nouns > verbs > adjectives. This scale agrees to some extent with the effect of word class on mood choice. We therefore tentatively propose a partial correlation between deonticity and mood choice: the lower the degree of deonticity of a word class, the more likely it is to select a modal auxiliary or the indicative. However, this hypothesis fails to explain why nouns and verbs behave alike in our data. Such a partial correlation implies a semantic difference between the mood choices. The more specific claim would be that modals and indicatives carry a lower degree of deonticity than subjunctives and therefore combine more naturally with nouns, which rank low on the deonticity scale. This hypothesis is supported by the fact that modals code quite disparate types of meaning of which deonticity is only one.
Finally, it is fitting to return to the distinction between spoken and written language. Starting from the observation that most previous analyses of the subjunctive relied on written data, Kastronic & Poplack (Reference Kastronic and Poplack2014) focus on the spoken language and report major differences between the two modes. In particular, they conclude that the subjunctive has played no more than a vestigial role in speech over the past few centuries. This conclusion is important because it challenges the received wisdom of a revival of the subjunctive in the early 20th century. Our analysis of both spoken and written samples in COCA allows us to evaluate Kastronic & Poplack’s hypothesis. It will be recalled from Section 4.2.2 above that while there was no interaction between Distance and Mode, the subjunctive figured more prominently in writing than in speech. The actual numbers on which this finding is based are provided in Table 7.
Table 7 Mood choice by mode.

In broad agreement with Kastronic & Poplack’s hypothesis, the subjunctive is less frequently found in the spoken than the written data. While this difference is certainly statistically significant (
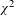 $\unicode[STIX]{x1D712}^{2}$
(1) = 27.7, p < .001), we note a difference of ‘only’ 3.3% between spoken and written English. This difference is not large enough to justify a radical separation of the spoken and the written language. What is more, Table 7 shows that the subjunctive is vastly more frequent than the indicative in speech. Thus, there is good reason to argue that the mandative subjunctive is alive and kicking in both written and spoken American English.Footnote
[11]
$\unicode[STIX]{x1D712}^{2}$
(1) = 27.7, p < .001), we note a difference of ‘only’ 3.3% between spoken and written English. This difference is not large enough to justify a radical separation of the spoken and the written language. What is more, Table 7 shows that the subjunctive is vastly more frequent than the indicative in speech. Thus, there is good reason to argue that the mandative subjunctive is alive and kicking in both written and spoken American English.Footnote
[11]
6 The wider perspective
The aim of the present section is to integrate the empirical results of this paper with previous work on distance effects. This enables us to transcend the limited scope of our study and to develop a more comprehensive model which puts our findings in a wider perspective. This leads us to a consideration of further structural levels and more radical changes in activation levels over time than were reported above.
Figures 1 and 2 in Section 4 showed that while the ratios increased with increasing distance, they stayed well below the value of .5. That is, the morphological level and the subjunctive mood remained the majority choice throughout. The fact that the minority option gains momentum while the majority option loses momentum over time raises the logical possibility that under appropriate circumstances we might be able to observe a cross-over effect, whereby the erstwhile stronger option is eventually overridden by the erstwhile weaker option. Indeed, cross-over effects can be found in Levin (Reference Levin and Renouf1998) for English, Leko (Reference Leko, King and Sekerina2000) for Bosnian and Thurmair (Reference Thurmair2006) for German. These works deal with agreement conflicts created by a competitive relationship between syntactic and semantic influences as a function of distance. Levin’s (Reference Levin and Renouf1998) analysis of agreement with collective nouns reveals that singular agreement on verbs is the rule at very short lags whereas plural agreement predominates at longer lags (see his Table 5). Similarly, Thurmair’s (Reference Thurmair2006) data show that nouns with divergent natural and grammatical gender such as das Mädchen ‘the girl’ induce grammatical agreement on neighbouring targets but predominantly referential agreement on more distant targets (see Section 1 above).
These studies demonstrate that changes in effect strength over time may be more dramatic than those observed in this paper. Why do we obtain varying change rates? The major difference between the data of Levin, Leko and Thurmair and our data is the involvement of disparate structural levels. In particular, the semantic level comes into play in Levin’s, Leko’s and Thurmair’s work but not in ours. We believe that the semantic level has a time course of activation which is rather different from that of the formal levels. To be specific, its change rate over time is relatively small. While syntactic units are gradually losing their force, semantic content persists and therefore eventually overtakes syntax. This conclusion dovetails with memory studies showing that the decay rate of semantic information is lower than that of syntactic (and other formal) information (e.g. Sachs Reference Sachs1967, Begg & Wickelgren Reference Begg and Wickelgren1974, Gurevich, Johnson & Goldberg Reference Gurevich, Johnson and Goldberg2010). Thus, the time course of activation of syntactic and morphological units may be assumed to be more similar than that of syntactic and semantic units. This is because both syntax and morphology are form-based and may perform similar jobs (see also footnote 6). On account of the relatively more similar decay rates of formal levels, it is more difficult to bring about a cross-over effect.
Prior to locating the semantic level relative to the syntactic and the morphological levels, it is fitting to bring phonology into the picture. A prime example of a syntagmatic process at the phonological level is segment or feature harmony in adult language use and child language acquisition. The range of phonological units may be determined by gauging the distance between the harmonizing and the harmonized segment. This phonological process displays a very pervasive pattern: it almost always stays within the confines of the single word. The interacting segments may, or may not, cross morpheme boundaries, but they do not usually cross word boundaries. This is true of both consonant harmony and vowel harmony (e.g. Stoel-Gammon & Stemberger Reference Stoel-Gammon, Stemberger and Yavas1994, van der Hulst & van der Weijer Reference van der Hulst, van der Weijer and Goldsmith1995, Berg Reference Berg2008, Hanson Reference Hanson2010). It is significant in this connection that Rose & Walker (Reference Rose and Walker2004) define a long-distance interaction as involving segments which are only one segment apart. The few children that have been reported to harmonize consonants from different (adjacent) words (e.g. Donahue (Reference Donahue1986)) are the exception that proves the rule. Thus, the evidence from harmony suggests that the range of phonological units roughly corresponds to a single phonological word. Other processes such as stress assignment point to exactly the same conclusion (Kaisse Reference Kaisse, Bowern, Horn and Zanuttini2017).
It is a straightforward task to integrate the four levels into a hierarchical framework. From the speaker’s or writer’s perspective, semantics is primary in that it controls the selection of linguistic units. In virtually all production models, syntax is superordinated to morphology, which in turn is superordinated to phonology. It is easy to see that the position of a level in the structural hierarchy is predictive of its range: the higher its position, the wider its range. The semantic level has the widest range and the phonological level the narrowest range. What was claimed to hold true for the syntactic and the morphological levels in the foregoing can now be claimed to hold for all four levels.
The more general view that our analysis affords of the organization of the linguistic system is one in which hierarchical position and unit size on the one hand and range and time on the other form an integrated whole. As we move from higher to lower levels, the representations gradually change. Higher levels are more strongly governed by semantic constraints while lower levels are more strongly governed by formal constraints. There are no categorical boundaries in the system. The different representational levels shade into each other. Similarly, there are no temporal boundaries. As we move from higher to lower levels, the range of linguistic units gradually diminishes. The parallelism between structure and range is all too obvious.
The agreement data also provide some insight into the initial stages of the activation process. As mentioned above, syntactic influences clearly outstrip semantic influences in agreement decisions at short lags. That is, units at the subordinate syntactic level reach a higher activation value in the initial stages than units at the superordinate semantic level. In fact, this is the prerequisite for the cross-over effect. Allowing ourselves to speculate wildly, we may generalize this claim and conjecture that the initial stages of activation witness an inverse correlation between hierarchical position and activation value. The lower the level in the hierarchy, the higher its activation value. This correlation is reversed with increasing distance. Due to differential decay rates, units at lower levels lose more of their activation than units at higher levels do in the same time frame. Thus, in the later stages of the activation process, semantic information has preserved much of its strength while phonological information has lost most or all of it. Syntactic and morphological information is in-between, with syntax losing less than morphology.
Finally, it is worthwhile comparing our account with Hawkins’s (Reference Hawkins2004) Minimize Domains Principle. Essentially, the Minimize Domains Principle is about being maximally informative within a minimum amount of time. To be specific, the closer two phrase-building units are to each other, the earlier listeners can construct a syntactic representation of the input. So in case of variation, the structure with the shorter domain will be preferred to the one with the longer domain. Hawkins’s theory applies (but is not logically restricted) to the syntactic level, i.e. it deals with (within-language and between-language) syntactic variation. This is the major difference between his model and ours. Our focus is on the comparison of different levels, in particular the syntactic and the morphological. We take it that the Minimize Domains Principle applies at all relevant levels of representation. However, what our analysis shows is that the size of the domains (what we call ‘range’) is level-specific. This is why Hawkins’s model and ours are fully compatible and neatly complement each other.
7 Outlook
This work aligns itself with the tradition of studies examining the impact of performance factors on the structure of grammar. It has gathered evidence showing that the choice of a grammatical marker is influenced by the linear distance between trigger and target. On the assumption that linear distance is at least a rough guide to temporal distance, it may be predicted that a grammatical decision is co-determined by the amount of time that has elapsed between the production of the trigger and that of the target. In view of the different ranges of morphological and syntactic elements, this reasoning leads to the bold prediction that a slower speech rate should encourage the use of a modal auxiliary while a faster speech rate should raise the likelihood of choosing the subjunctive.
Linear and temporal distance co-vary naturally with complexity. The greater the complexity of Y in a string XYZ, the greater the distance between X and Z. Complexity may therefore be a competitor to our distance account. Indeed, Rohdenburg (Reference Rohdenburg, Kaunisto, Höglund and Rickman2018) has recently made a proposal along these lines. On the basis of the analysis of a single verb, he examined the use of should in mandative sentences as a function of the complexity of the subject of the subordinate clause and found an increased use of this modal with increasing subject complexity. From the perspective of our model, this result is to be expected. Since Rohdenburg measured complexity in terms of the number of words, complexity can be viewed as a proxy for distance. It would be interesting to pit the complexity against the distance account. Complexity is typically determined at the phrase level. Consequently, several variables (minimally, the complementizer and the subject NP) would have to be taken into account and offset against one another to bridge the gap between trigger and target verb. By contrast, the distance-based account can be carried out in one pass. Methodologically at least, it is the simpler and more elegant account.
The distance account sheds some light on an interaction which has not yet been well understood. Several studies have commented on the decrease of the modal option over the past few decades (e.g. Klein Reference Klein2009, Hundt & Gardner Reference Hundt, Gardner and Brinton2017, Ruohonen Reference Ruohonen2018) while Waller (Reference Waller2017) observes an increasing rate of complementizer omission. Furthermore, Ruohonen (Reference Ruohonen2018) reports that the rate of subjunctive use is raised by complementizer deletion. Our model not only predicts Ruohonen’s finding but also provides an explanation for it. Omitting the complementizer reduces the distance between trigger and target and hence the likelihood of should productions. However, our model makes no prediction as to what is the cause and what is the effect. Exploring this connection from the diachronic perspective is a worthwhile topic for future work.
Of course, the mandative subjunctive is not the only grammatical phenomenon to span more than one level of analysis. Another area which covers both the syntactic and the morphological levels is the comparison of adjectives. English has two competing strategies of comparison – the analytic and the synthetic. The analytic technique makes use of the free-standing adverbs more and most and can therefore be located at the syntactic level. The synthetic technique relies on the suffixes -er and -est and is therefore of a morphological nature.
These disparate loci render comparison a fertile testing ground for the proposals made in this paper. Our account predicts that the range of the analytic strategy is wider than the range of the synthetic strategy. We can conceive of at least three ways in which this prediction can be put to the test.
The first analysis rests on the distinction between predication and attribution. The distance between the referent noun and the adjective differs between the predicative and the attributive use. Attributive adjectives and their nominal referents are usually adjacent whereas predicative adjectives and their referents are minimally separated by a copula. This difference allows us to predict that the analytic comparison is more frequently encountered in predicative than in attributive use while the reverse prediction holds for the synthetic comparison. This prediction was confirmed by a good number of studies (e.g. Leech & Culpeper Reference Leech, Culpeper, Nevalainen and Kahlas-Tarkka1997, Lindquist Reference Lindquist and Kirk2000, Mondorf Reference Mondorf2009, Cheung & Zhang Reference Cheung and Zhang2016).
The second analysis starts out from the disparate cohesiveness of morphemes inside words and words inside phrases. As is evidenced by the differential ease of insertion, phrases are less cohesive than words. Analytic comparatives such as more common may therefore be predicted to break up more easily than synthetic comparatives such as commoner. While this prediction may seem trivially true for synthetic comparatives, it is less obviously true for analytic comparatives. The fact that the comparative marker more is an independent word does not automatically imply that more + adjective sequences can be split. Doubly modified adjectives provide a good test case. When a graded adjective is modified by an adverb, the question arises as to where it can be put. Can it or can it not break up the more + adjective sequence? Behaghel’s Law, according to which conceptual proximity should be mirrored by linear proximity, would lead us to expect a negative answer. By contrast, the wider range of syntactic information would provide a basis for separating the comparative marker from the adjective.
Although English is generally reluctant to tolerate discontinuity, it allows graded adjectives to be split up by so-called domain adverbs (e.g. Sullivan Reference Sullivan2013). Pertinent examples include more linguistically diverse and more cognitively complex. Clearly, these are right-branching structures in which the domain adverb introduces discontinuity between the comparison marker and the adjective. It is a remarkable fact that this word order is the preferred choice (Berg Reference Berg2019). We take the well-formedness and relative frequency of these ADJPs to be consistent with the claim that the syntactic level has a relatively wide range. However, we are ready to acknowledge that this line of argument is of a rather more indirect nature.
Perhaps the most direct test can be achieved by a priming study. The prediction from our account is straightforward: ceteris paribus, analytic comparatives should prime other analytic comparatives over longer distances than synthetic comparatives should prime other synthetic comparatives. While our account makes no prediction regarding the baseline probability for suffix priming and more-priming, it does predict shorter distances for the former and longer distances for the latter. Such a priming experiment is a venue for future research.
The host of questions that can be raised about the comparative alternation alone convinces us that the related notions of distance and time deserve a more prominent place in the study of language than they have hitherto been assigned.
APPENDIX
Subjunctive triggers











 Open access
Open access