





Introduction
Learning new words is a continuous process throughout our lifetime. Starting from our first words in early childhood, we keep accumulating vocabulary in our native language (L1) and any additional language we learn (Davies et al., Reference Davies, Arnell, Birchenough, Grimmond and Houlson2017). Child and adult learners can rapidly pick up new words, most of the time without explicitly being taught. This is impressive given the highly variable environment in which language learning happens. As illustrated by the classic Gavagai problem in word learning (Quine, Reference Quine1960), upon the first encounter with a new word, it is often hard to define the appropriate referent as the word could refer to anything in the environment, and more often than not the learner does not get explicit instruction on the word-referent mapping. Similar situations arise when second or foreign language (L2) learners hear new words outside of the language classroom. Recent research on statistical learning has found a potential solution to this problem: child and adult learners can keep track of the linguistic information across multiple situations to aid word learning (known as cross-situational learning, CSL) (e.g., Escudero et al., Reference Escudero, Smit and Mulak2022; Monaghan et al., Reference Monaghan, Schoetensack and Rebuschat2019; Rebuschat et al., Reference Rebuschat, Monaghan and Schoetensack2021; Suanda & Namy, Reference Suanda and Namy2012). That is, when the word occurs repeatedly over time, learners can follow the pattern across contexts and identify the always-co-occurring referent. In the classic CSL paradigm used in most studies (e.g., Yu & Smith, Reference Yu and Smith2007), referential ambiguity was created by presenting multiple objects together with multiple pseudowords, with no clear indication of the word-referent mappings. This can be seen as a simplified representation of the real-life situation, as in the real world, there are usually more potential referents in the environment.
However, in learning a novel language, the challenge is more complex. In addition to referential uncertainty, in naturalistic language learning conditions, numerous words sound similar but have contrasting meanings (e.g., bag vs. beg in English; pāo vs. gāo in Mandarin). Learners need to accurately perceive and discriminate these unfamiliar non-native sound contrasts to learn words, which is an ability that starts diminishing during infancy (Kuhl et al., Reference Kuhl, Stevens, Hayashi, Deguchi, Kiritani and Iverson2006; Werker & Tees, Reference Werker and Tees1984). In the bilingualism literature, this perceptual issue has not been well examined and little research has directly investigated how non-native sounds interfere with word learning (for exceptions, see Chandrasekaran et al., Reference Chandrasekaran, Sampath and Wong2010; Silbert et al., Reference Silbert, Smith, Jackson, Campbell, Hughes and Tare2015; Wong & Perrachione, Reference Wong and Perrachione2007). Our current study will address this gap by exploring the effect of phonology on non-native word learning using a CSL paradigm. It also provides insights into the role of awareness in statistical learning.
Statistical learning of non-native vocabulary
Although learners of non-native languages usually have already developed sophisticated representations of various conceptual meanings, they face similar challenges to those children face in connecting these concepts to the appropriate forms. Thus, understanding how language learners deal with this referential uncertainty problem is not only an important topic in early word learning literature (e.g., Markman, Reference Markman1990; L. Smith & Yu, Reference Smith and Yu2008; Tomasello & Barton, Reference Tomasello and Barton1994), but also has implications for second and foreign language research (e.g. Monaghan et al., Reference Monaghan, Ruiz and Rebuschat2021; K. Smith et al., Reference Smith, Smith and Blythe2011; Walker et al., Reference Walker, Monaghan, Schoetensack and Rebuschat2020). One influential approach is the statistical learning account, which shows that learners can extract statistical regularities from the linguistic contexts to facilitate language learning (e.g., Maye & Gerken, Reference Maye and Gerken2000 and Maye et al., Reference Maye, Werker and Gerken2002 for sound discrimination; Saffran et al., Reference Saffran, Aslin and Newport1996 for word segmentation; see Isbilen & Christiansen, Reference Isbilen and Christiansen2022; Siegelman, Reference Siegelman2020; Williams & Rebuschat, Reference Williams, Rebuschat, Godfroid and Hopp2022, for reviews). For word learning specifically, a classic cross-situational statistical learning paradigm has been widely explored (L. Smith & Yu, Reference Smith and Yu2008; Yu & Smith, Reference Yu and Smith2007). CSL proposes that learners can extract and accumulate information about word-referent co-occurrences across multiple ambiguous encounters to eventually identify the correct referents.
There has been extensive evidence on the effectiveness of CSL for both children (e.g., Childers & Pak, Reference Childers and Pak2009; L. Smith & Yu, Reference Smith and Yu2008; Suanda et al., Reference Suanda, Mugwanya and Namy2014; Yu & Smith, Reference Yu and Smith2011) and adults (e.g., Gillette et al., Reference Gillette, Gleitman, Gleitman and Lederer1999; K. Smith et al., Reference Smith, Smith, Blythe, Taatgen and van Rijn2009, Reference Smith, Smith and Blythe2011; Yurovsky et al., Reference Yurovsky, Smith and Yu2013). For example, in an early study, Yu and Smith (Reference Yu and Smith2007) created referentially ambiguous learning conditions for adult learners, presenting multiple words and pictures at the same time, and tested whether learners made use of the word-picture co-occurrence information across learning events to acquire the appropriate mappings. It was found that after only six minutes of exposure, learners were able to match pictures to words at above chance levels even in highly ambiguous conditions with four words and four pictures presented in each learning event. Monaghan et al. (Reference Monaghan, Schoetensack and Rebuschat2019) extended the CSL settings and presented participants with motions rather than referent objects. The results showed that participants were able to extract syntactic information from cross-situational statistics and acquire words from different syntactic categories (i.e., nouns, verbs). And more recently, it has been reported that CSL can also drive syntactic acquisition of word order (Rebuschat et al., Reference Rebuschat, Monaghan and Schoetensack2021).
However, most of the CSL literature left aside the important impact of phonology on word learning. There are two potential issues related to this. First, in most CSL studies, the stimuli (words or pseudowords) used were phonologically distinct (e.g., pseudowords such as barget, chelad in Monaghan et al., Reference Monaghan, Schoetensack and Rebuschat2019). However, as reported by Escudero et al. (Reference Escudero, Mulak and Vlach2016b), the degree of phonological similarity between words can affect learning outcomes. Escudero and colleagues found that minimal pairs that differ in only one vowel (e.g., DEET-DIT) were harder to identify after cross-situational learning than consonant minimal pairs (e.g., BON-TON) and non-minimal pairs (e.g., BON-DEET). Thus, to better resemble natural learning conditions, it is necessary to examine the effects of both phonologically similar and distinct words in CSL and the first aim of our study is to provide further evidence for this.
Second, previous research has largely included pseudowords that contained phonemes that were familiar to the participants (in the sense that they existed in their native languages) and phoneme combinations that followed the phonotactics of their native language(s) (e.g., Escudero et al., Reference Escudero, Mulak and Vlach2016b; Monaghan & Mattock, Reference Monaghan and Mattock2012; Monaghan et al., Reference Monaghan, Schoetensack and Rebuschat2019; see Hu, Reference Hu2017, and Junttila & Ylinen, Reference Junttila and Ylinen2020, for an exception). In other words, CSL studies tended to create a situation for learning additional words in L1. Naturally, the use of familiar phonemes and phoneme combinations could make the discrimination between these pseudowords less challenging. To extend the results to second language research, it is important to consider the phonological difficulties associated with non-native sounds (e.g., Dupoux et al., Reference Dupoux, Sebastián-Gallés, Navarrete and Peperkamp2008; Iverson et al., Reference Iverson, Kuhl, Akahane-Yamada, Diesch, Kettermann and Siebert2003; Rato, Reference Rato2018; Rato & Carlet, Reference Rato and Carlet2020; Takagi & Mann, Reference Takagi and Mann1995; Wong & Perrachione, Reference Wong and Perrachione2007). Tuninetti et al. (Reference Tuninetti, Mulak and Escudero2020) trained Australian English speakers with novel Dutch and Brazilian Portuguese vowel minimal pairs in a CSL setting. The vowel pairs were classified into perceptually difficult or easy pairs based on acoustic measurements (Escudero, Reference Escudero2005). The perceptually easy minimal pairs contained vowel contrasts that could be mapped to two separate L1 vowel categories, and the perceptually difficult ones had no clear corresponding L1 contrasts (Escudero, Reference Escudero2005 – Second Language Linguistic Perception model (L2LP); Best & Tyler, Reference Best, Tyler, Munro and Bohn2007 – Perceptual Assimilation-L2 model (PAM-L2)). It was found that learners performed the best in non-minimal pair trials, followed by perceptually easy pairs and then perceptually difficult pairs, suggesting the role of L1-L2 phonetic and phonological similarity in CSL. A more recent study by Escudero et al. (Reference Escudero, Smit and Mulak2022) directly compared cross-situational word learning by L1 and L2 speakers of English. The authors presented the same set of English pseudowords as in Escudero et al. (Reference Escudero, Mulak and Vlach2016b) to English-native and Mandarin-native speakers, either in a consonant, vowel or non-minimal pair condition. Overall, the English group performed better in identifying word-picture mappings in all minimal pair conditions than the Mandarin group, though the Mandarin group also showed some degree of learning.
These previous CSL studies provided evidence for the crucial role of phonology in the acquisition of novel, non-native words. However, there are several gaps in our knowledge of how non-native cues affect learning. Firstly, previous studies focused primarily on segmental contrasts (i.e., vowels and consonants), leaving aside the suprasegmental cues (e.g., tone). Suprasegmental development can diverge from segmental development in L2 acquisition (e.g., Hao & Yang, Reference Hao and Yang2018; Sun et al., Reference Sun, Saito and Tierney2021), and the integration of suprasegmental and segmental features can be challenging for beginner learners (Zou et al., Reference Zou, Chen and Caspers2017). It is thus important to explore how suprasegmental cues affect cross-situational learning of non-native words. Furthermore, previous research looked at the reconfiguration of phonological features (phonemes) from L1 to the novel language, and the perceptual difficulty and learning depended on L1-L2 phonemic differences (e.g., Tuninetti et al., Reference Tuninetti, Mulak and Escudero2020). But in natural word learning, there also exist phonological features that, in the learners’ L1s, are not used contrastively at the lexical level at all. In such cases, perception and learning are not only affected by L1-L2 phonemic differences, but also depend on learners tuning in to these novel features in the first place. Our study specifically addresses these issues by exploring how English-native speakers with no prior experience in learning tonal languages develop their ability to use lexical tones in word learning.
Another important aspect of our study design is that we presented only one word per trial together with multiple referents. This mirrors natural language learning situations more closely as it requires learners to keep track of the minimal pairs throughout learning. Previous CSL studies, following the paradigm used by Yu and Smith (Reference Yu and Smith2007), usually presented several words together with several referents in one trial. This means that minimal pairs were presented to participants in a single situation during training, which might make the phonological differences more salient to learners (Escudero et al., Reference Escudero, Mulak and Vlach2016b, Reference Escudero, Smit and Mulak2022; Tuninetti et al., Reference Tuninetti, Mulak and Escudero2020). However, in natural language learning settings, minimal pairs tend not to occur in immediate proximity but have to be acquired by uncovering the contrastive property of certain phonological features across situations. This raises the question of how it is possible for learners to distinguish minimally contrasting words when the contrast is not explicitly available during learning, but must be extracted from correspondences that occur in the wider communicative environment.
Research questions and predictions
The current study explored how non-native phonology influences cross-situational word learning. The following research questions are addressed:
RQ1: Do minimal pairs pose difficulty during cross-situational learning compared to phonologically distinct words?
RQ2: Do minimal pairs that differ in non-native phonological contrasts pose further difficulty compared to minimal pairs with contrasts that are similar to native sounds?
RQ3: Does learners’ non-native sound perception develop during cross-situational learning?
We predicted that minimal pairs would be more difficult to learn compared to non-minimal pairs even when those minimal pairs are presented across multiple experiences of the language as in natural language learning (RQ1). Moreover, minimal pairs with non-native phonological contrasts would generate the greatest difficulty in learning (RQ2). We also hypothesized that the learning process would lead to non-native phonological advances, and learners would improve in their performance on the non-native minimal pairs over time (RQ3).
To compare the performance on native versus non-native contrasts, we created a pseudoword vocabulary based on Mandarin Chinese and recruited Mandarin-native and English-native speakers to take part. Mandarin Chinese is a tonal language employing syllable-level pitch changes to contrast word meanings, which is particularly difficult for learners whose native languages lack such prosodic cues (e.g., Chan & Leung, Reference Chan and Leung2020; Francis et al., Reference Francis, Ciocca, Ma and Fenn2008; So & Best, Reference So and Best2010). In the tonal perception literature, many studies have reported that Mandarin Tone 1 vs Tone 4 is hard for non-native listeners when tested in monosyllables (e.g., Kiriloff, Reference Kiriloff1969; So & Best, Reference So and Best2010, Reference So and Best2014). However, in Mandarin Chinese, over 70% of the vocabulary consists of multi-syllabic words (two or more syllables), and learners encounter tones more often in di- or multi-syllables rather than isolated monosyllables (Jin, Reference Jin and Jing-Schmidt2011). Thus, the previous work on monosyllabic perception may not be representative in the case of Mandarin word learning. In our design, we decided to use disyllabic words to better reflect the real Mandarin word-learning situation. In disyllabic structures, the prosodic positions (initial vs final syllable) and tonal contexts (the preceding and following tones) play a role in perception as well (Chang & Bowles, Reference Chang and Bowles2015; Ding, Reference Ding2012; Hao, Reference Hao2018). There are relatively few studies taking into account this tonal environment effect, but according to Hao (Reference Hao2018), English-native learners of Mandarin can identify T1 and T4 at word-initial positions better compared to T2 and T3. Thus, we decided to use T1 and T4 as they are likely to be easier for non-native listeners in the disyllabic environment. We wanted the tones to be relatively easily captured by the non-native (English) participants before learning because previous studies have found that better tonal word learning outcome is associated with better pre-learning tonal perception (e.g., Cooper & Wang, Reference Cooper and Wang2013; Wong & Perrachione, Reference Wong and Perrachione2007). Since our learning task is short (~10 min), the use of the easier tones might allow us to observe clearer learning effects.
We predicted that for English-native speakers, minimal pairs that contrast in lexical tones would be the most difficult (i.e., with lowest accuracy), followed by minimal pairs that differ in consonants and vowels. The non-minimal pairs would be relatively easy to learn. For Mandarin-native speakers, previous studies suggested that tonal language speakers rely more on segmental than tonal information in word processing (e.g., Cutler & Chen, Reference Cutler and Chen1997; Sereno & Lee, Reference Sereno and Lee2015; Yip, Reference Yip2001). Thus, we predicted that learning of tonal pairs would still be lower than that in consonant/vowel pairs, but Mandarin speakers would learn tonal minimal pairs better than English speakers. It was also hypothesized that English-native speakers’ performance on tonal contrasts would improve across the task.
Experiment 1: Learning non-native sound contrasts from cross-situational statistics
The study was preregistered on the Open Science Framework (OSF) platform. The preregistration, the materials, anonymized data and R scripts are available at: https://osf.io/2j6pe/.
Method
Participants
Fifty-six participants were recruited through either the Department of Psychology at Lancaster University (N = 28) or the social media platform WeChat (N = 28). To estimate the sample size needed for expected effects, we ran power analyses for the interaction effect of language group, learning trial type and block with Monte Carlo simulations of data. (The power analysis R script can be found on the OSF site referred to above.). All participants were university students (aged 18~30) and spoke either English or Mandarin Chinese as a native language. The L1 English participants had no previous experience learning any tonal languages before taking part in the study. Thirteen participants in the L1 English group reported knowing more than one language or language varietyFootnote 1 (Arabic, Dutch, French, German, Korean, Russian, Spanish,) at beginner, intermediate or advanced levelsFootnote 2. Twenty-four L1 Mandarin participants reported speaking more than one language (English, French, Indonesian, Italian, Japanese, Korean, other Chinese varieties), among which 22 participants spoke English as a second/foreign language. Participation was voluntary and the Psychology Department participants received credits for their university courses.
Materials
Cross-situational learning task The CSL task involved learning 12 pseudoword-referent mappings. All pseudowords were disyllabic, with CVCV structure, which satisfies the phonotactic constraints of both Mandarin Chinese and English. The pseudowords contained phonemes that were similar between the two languages. This made the pseudowords sound familiar to both groups of participants. Each syllable in the pseudowords carried a lexical tone which is either Tone 1 (high) or Tone 4 (falling) in Mandarin Chinese, which created a simplified lexical tone system.
Six different consonants /p, t, k, l, m, f/ and four different vowels /a, i, u, ei/ were combined to form eight distinct base syllables (/pa, ta, ka, li, lu, lei, mi, fa/), which were further paired to form six minimally distinct base words (/pami, tami, kami, lifa, lufa, leifa/). Three of the base pseudowords differed in the consonant of the first syllable (/pami, tami, kami/), which were assigned to the consonantal set; and the other three differing in the vowel of the first syllable were assigned to the vocalic set (/lifa, lufa, leifa/). The second syllables in the pseudowords were held constant in each set to ensure that the words in each set were minimal pairs. These base words were then superimposed with lexical tones. The first syllable of each of the six base words was paired with either T1 or T4, and the second syllable always carried T1. This resulted in an additional tonal minimal pair contrast (e.g., /pa1mi1/ vs /pa4mi1/) among the pseudowords. Therefore, a total of 12 pseudowords were created (full list shown in Table 1). The pseudowords (with their corresponding referent objects) were later paired to create consonantal, vocalic, tonal, and non-minimal pair trials, and each pseudoword-referent mapping could occur in different trial types based on the paired foil. All pseudowords have no corresponding meanings in English or Mandarin Chinese, though the base syllables are phonotactically legal in the languages. The audio stimuli were produced by a female native speaker of Mandarin Chinese. The mean length of the audio stimuli was 800ms.
Table 1. Pseudowords in the consonantal set and the vocalic set

Note. Numbers “1” and “4” refer to the lexical tones T1 and T4 carried by the syllables
Twelve pictures of novel objects were selected from Horst and Hout's (Reference Horst and Hout2016) NOUN database and used as referents. The pseudowords were randomly mapped to the objects, and we created four lists of word-referent mappings to minimize the influence of a particular mapping being easily memorisable. Each participant was randomly assigned to one of the mappings.
Background questionnaire We collected information on participants’ gender, age and history of language learning. The questionnaire was adapted from Marian et al.'s (Reference Marian, Blumenfeld and Kaushanskaya2007) Language Experience and Proficiency Questionnaire (LEAP-Q). Participants were asked to specify their native languages and all non-native languages they have learned, including the age of learning onset, contexts of learning, lengths of learning, and self-estimated general proficiency levels.
Debriefing questionnaire After the CSL task, participants were given a debriefing questionnaire to elicit retrospective verbal reports about their awareness of the phonological patterns of the pseudowords and whether they noticed the tonal contrasts in the language. The questionnaire was adapted from Rebuschat et al. (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) and Monaghan et al. (Reference Monaghan, Schoetensack and Rebuschat2019). It contained seven short questions ordered in a way that gradually provided more explicit information about the language, which reduced the possibility that participants learn about the explicit patterns of the language from questions. The first three questions were general questions about the strategies used when choosing referents. The next two questions narrowed down the scope and asked if participants noticed any patterns or rules about the artificial language and the sound system. The final two questions explicitly asked if participants noticed the lexical tones.
Experimental design and procedure
All participants were directed to the experiment platform Gorilla to complete the tasks. After providing informed consent, participants completed the background questionnaire, followed by the CSL task. The latter took approximately 10 minutes to complete and consisted of a 2-alternative forced-choice task, where learners selected the referent for a spoken word from two objects. There were four types of trials in CSL – consonantal, vocalic, tonal and non-minimal pair trials. We manipulated the target and foil objects in each trial to create the different trial types. Each target object was paired with different foils according to the trial type. For instance, the target object for pa1mi1 was paired with the (foil) object for ta1mi1 in a consonantal minimal pair trial; and the same object for pa1mi1 was paired with the (foil) object for pa4mi1 in a tonal minimal pair trial. Taking an example of a consonantal minimal pair trial, participants saw two objects – object A for pa1mi1 and object B for ta1mi1 – and heard the word pa1mi1. They needed to select object A and reject object B. The labels of these two objects only differ in the first consonant, and hence participants had to be able to distinguish pa1mi1 from ta1mi1, as well as to learn the associations between each of these words and the object to which they are paired, in order to make the correct selection. Similarly, in vocalic minimal pair trials, the labels of the two objects differed in one vowel (e.g., li1fa1 vs lu1fa1), and in tonal minimal pair trials, the labels of the two objects differed in the lexical tone (e.g., pa1mi1 vs pa4mi1). The non-minimal pair trials contained objects that were mapped onto phonologically more distinct words (e.g., pa1mi1 vs li4fa1). Choosing the correct referent object was expected to be harder if participants were not able to distinguish the labels associated with the two objects. For example, English-native participants may have difficulty distinguishing the tonal pairs such as pa1mi1 vs pa4mi1. And when they see two objects referring to pa1mi1 and pa4mi1 and hear the word pa1mi1, they may not be able to select the corresponding object. This manipulation allowed us to explore whether and to what extent minimal pairs cause difficulty in CSL, and if non-native minimal pairs such as the tonal pairs pose even greater difficulty for English-native speakers. And, more importantly, whether adult learners improve in the perception of non-native sounds (i.e., tones in this study) through a short CSL session.
The occurrence of each trial type was controlled in each block and throughout the experiment. There were six CSL blocks, with 24 trials each, resulting in 144 trials in total. Each of the four trial types occurred six times in one block, leading to a total of 36 trials across the experiment. Within each learning block, each of the 12 pseudowords was played twice, and each of the novel objects was used as the target referent twice (in two different trial types). The foil object was randomly selected from all the possible minimal pairs using the randomization function in excel. Hence, in each block, each pseudoword occurred twice with the target object, and once each with two other foil objects. Throughout the experiment, each pseudoword occurred 12 times with the target object, and no more than three times with each of the six possible foils. Thus, the associations between pseudowords and their targets were strengthened over the co-occurrences, and the associations between pseudowords and foil objects remained low. Additionally, the correct referent picture was presented on the left side in half of the trials and the position of the target was determined by the randomization function as well. There were four types of word-referent mappings randomly created, and each participant was randomly allocated to one of the mapping types. Participants’ accuracy at selecting the correct referent was recorded throughout the experiment, and their response time in each trial was measured.
After the CSL task, participants completed the debriefing questionnaire, in the question sequence outlined above. Only one question was presented on the screen each time.
Trial procedure
In each CSL trial, participants first saw a fixation cross at the centre of the screen for 500ms to gather their attention. They were then shown two objects on the screen, one on the left side and one on the right, and were played a single pseudoword. After the pseudoword was played, participants were prompted to decide which object the pseudoword referred to. They were instructed to press ‘Q’ on the keyboard if they thought the picture on the left was the correct referent of the word and ‘P’ for the picture on the right. The objects remained on the screen during the entire trial, but the pseudoword was only played once. The next trial only started after participants made a choice for the current trial. No feedback was provided after each response. Figure 1 provides an example of a CSL trial.
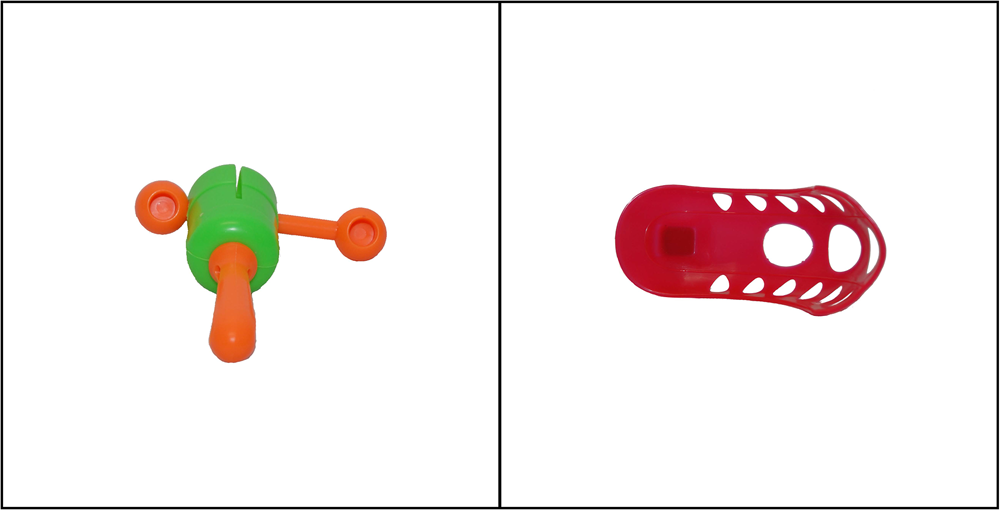
Figure 1. Example of cross-situational learning trial. Participants were presented with two novel objects and one spoken word (e.g., pa1mi1). Participants had to decide, as quickly and accurately as possible, if the word refers to the object on the left or right of the screen.
The keyboard response recorded participants’ answers in each trial and was used to calculate accuracy. It also allowed us to measure reaction time more accurately than mouse clicking on the pictures, as it avoided interference from the time taken to move the cursor.
Data analysis
We excluded participants who failed to successfully complete the initial sound check or failed to complete the CSL task within one hour. We also excluded individual responses that lasted over 30 seconds. This was because these participants failed to follow the instructions to respond as quickly and accurately as possible. After excluding these data points, we visualized the data using R for general descriptive patterns. We then used generalized linear mixed effects modelling for statistical data analysis. Mixed effects models were constructed from null model (containing only random effects of item and participant) to models containing fixed effects. We tested if each of the fixed effects improved model fit using log-likelihood comparisons between models. A quadratic effect of block was also tested for its contribution to model fit, as block may exert a quadratic rather than linear effect. The planned analyses were explained in our preregistration.
Results
Performance on cross-situational learning task
Accuracy Figure 2A presents the overall percentage correct responses of the L1 English and L1 Mandarin groups. Both groups showed learning effects – with improvements in accuracy from chance level to 66.8% (L1 English group) and 70.5% (L1 Mandarin group) at the end of the learning. For the different minimal pair trials (as in Figure 2B & 2C), there was a common pattern across groups that accuracy was the highest in non-minimal pair trials. For the L1 English group, the learning of tonal minimal pair trials was not clear, with participants performing at around chance level throughout the task. But there seemed to be improvement in the vocalic (block 6 accuracy 66.1%) and consonantal (block 6 accuracy 56.5%) trials, as the mean accuracies showed an increasing pattern throughout the experiment. For the L1 Mandarin group, the accuracies in the tonal, vocalic and consonantal trials were all above chance at the end of the CSL session.
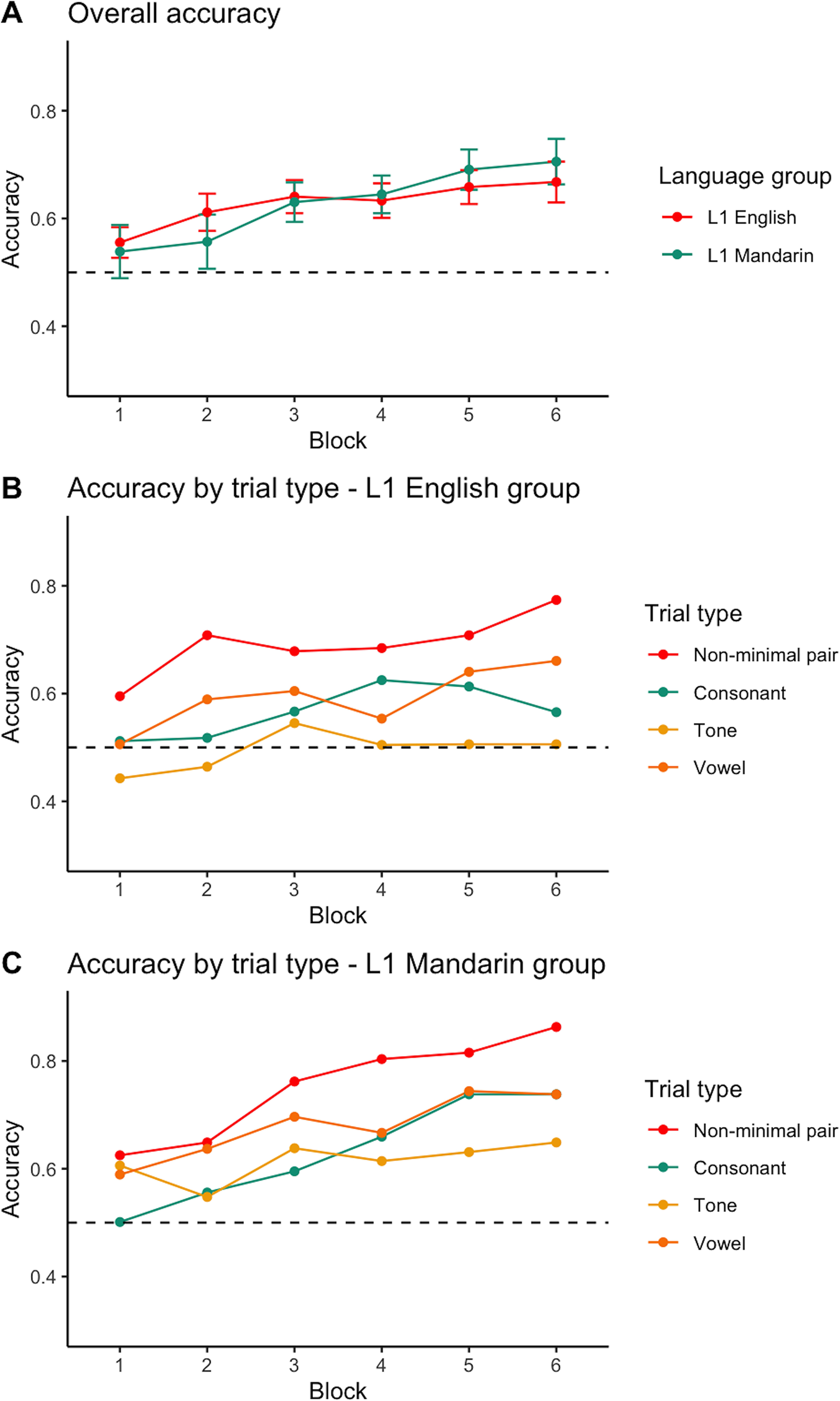
Figure 2. Experiment 1: Mean proportion of correct pictures selected in each learning block - overall (A) and in different trial types (B & C).
Note. Error bars represent 95% Confidence Intervals.
As outlined in our preregistration, to investigate whether learning was different across language groups and trial types, we ran generalized linear mixed effects models to examine performance accuracy across learning blocks. We started with a model with the maximal random effects that converge, which included item slope for learning block, language group and trial type, and participant slope for learning block and trial type. Then we added fixed effects of learning block, language group, trial type and the 3-way interaction to test if they improve model fit. We also tested for a quadratic effect for block.
Compared to the model with only random effects, adding the fixed effect of learning block improved model fit significantly (χ2(1) = 5.478, p = .019), adding English versus Mandarin language group did not significantly improve fit (χ2(1) = 0.072, p = .789), adding trial type (consonant, vowel, tone, non-minimal pair) improved model fit further (χ2(3) = 32.246, p < .001) as well as the 3-way interaction (χ2(7) = 26.847, p < .001). The quadratic effect for block did not result in a significant difference (χ2(8) = 9.740, p = .284). The best-fitting model is reported in Table 2.Footnote 3, Footnote 4
Table 2. Best fitting model for accuracy in Experiment 1, showing fixed effects

Number of observations: 8038, Participants: 56, Item, 12. AIC = 10025.3, BIC = 10367.9, log-likelihood = -4963.7.
R syntax: glmer(acc ~ block + langgroup + TrialType + langgroup:TrialType:block + ( 1 + block + langgroup + TrialType | item ) + (1 + block + TrialType | subjectID), family = binomial, data = fulld, glmerControl(optCtrl=list(maxfun=2e5), optimizer = “nloptwrap”, calc.derivs = FALSE)).
We carried out exploratory analyses to examine the effect of block and language group on each trial type separately. For tonal trials, adding the fixed effect of language group (χ2(1) = 4.2111, p = .040) and block (χ2(1) = 3.8967, p = .048) significantly improved fit, whereas the interaction effect did not improve model fit further (χ2(1) = 0.0012, p = .973). In Table 3 we presented the best-fitting model for tonal trials. The L1 English group scored significantly lower than the L1 Mandarin group in tonal trials, but both groups of learners showed overall improvement across blocks. In all other trial types, language group did not significantly improve model fit (consonantal χ2(1) = 0, p = 1; vocalic χ2(1) = 0.1928, p = .661; non-minimal pair χ2(1) = 0.7839, p = .376) and learning block did improve fit (consonantal: χ2(1) = 15.606, p < .001; vocalic: χ2(1) = 5.7728, p = .016; non-minimal pair: χ2(1) = 15.452, p < .001). Adding the language group by block interaction significantly influenced the model fit for consonantal (χ2(1) = 5.0314, p = .025) and non-minimal pair trials (χ2(1) = 4.4963, p = .034), but not for vocalic trials (χ2(1) = 0.8722, p = .350).
Table 3. Best fitting model for accuracy in tonal trials in Experiment 1, showing fixed effects
Number of observations: 2008, Participants: 56, Item, 12. AIC = 2732.9, BIC = 2822.6, log-likelihood = -1350.4.
R syntax: glmer(acc ~ langgroup + block + ( 1 + langgroup + block + langgroup:block | item) + (1 + block | subjectID), family = binomial, data = ttrials, glmerControl(optCtrl=list(maxfun=2e5), optimizer = “nloptwrap”, calc.derivs = FALSE))
To disentangle the performance of the two language groups in each trial type, we ran separate mixed-effects models on the Mandarin-native and the English-native dataset. For the Mandarin-native group, adding the effect of block (χ2(1) = 11.01, p <.001), trial type (χ2(3) = 18.576, p < .001) and block by trial type interaction (χ2(3) = 22.067, p < .001) significantly improved model fit. The Mandarin-native participants performed best in non-minimal pair trials, followed by consonant/vowel trials, and then tonal trials (as illustrated in Table S3). A similar pattern was observed for the English-native group (Table S4).
Reaction time There was a general tendency of reducing reaction time across learning blocks for both groups of participants, especially from Block 1 to the following blocks (Figure S1). But no clear relationship between trial type and response time can be observed. As reaction time is not our focus here, all figures are presented in supplementary materials. To investigate whether the fixed effects of block, language group and trial type affected participants’ reaction time, we used generalized mixed effects models with a log-link Gamma function, as the raw reaction time data were positively skewed. The inclusion of block (χ2(1) = 24.159, p < .001) and language group (χ2(1) = 9.881, p = .002) significantly improved model fit. The effects of trial type (χ2(3) = 6.221, p = .101) and the 3-way interaction (χ2(7) = 4.436, p = .728) did not further improve fit. The best-fitting model can be found in Table S5. There were significant effects of learning block and language group on participants’ reaction time. L1 English participants reacted significantly faster than L1 Mandarin participants.
Retrospective verbal reports
Participants’ answers to the debriefing questions were coded to explore if awareness or explicit knowledge of the pseudoword phonology predicts performance on the CSL task. We focused primarily on the awareness measure of the English-native speakers, as the Mandarin-native speakers were all expected to be aware of the tonal differences.
The awareness coding followed the guidance of Rebuschat et al.'s (Reference Rebuschat, Hamrick, Riestenberg, Sachs and Ziegler2015) coding scheme, ranking from full awareness to complete unawareness. Participants who reported using lexical tones to distinguish words strategically were considered “full awareness” (Q1~3), those who mentioned lexical tones in response to the questions on patterns of the language or the sound system were considered “partial awareness” (Q4~5), and those who only mentioned that they noticed lexical tones after the question was explicitly asked were coded as “minimal awareness” (Q6~7). Participants who reported that they did not think lexical tones contrast word meanings were deemed “unaware”. All participants who reported minimal, partial or full awareness were included as “aware” participants and others as “unaware”. Two researchers independently coded the retrospective verbal reports to ensure consistency and agreement on criteria.
Following the criteria outlined above, we found that no learners developed full awareness of the tonal cues. Participants reported no specific strategy and simply guessed (e.g., I guessed some with how similar it was to the word in English) at the beginning of the study. Twenty-one participants reported at least noticing the pitch-related change, with wording differing among tone, intonation, pitch, and high/low sound (e.g., One of the syllables changed tone). The remaining seven participants reported no awareness of pitch-related changes. Among the aware learners, we observed different degrees of awareness. Following Schmidt (Reference Schmidt1990, Reference Schmidt and Schmidt1995), eight participants were classified as being aware at the level of understanding as they specifically mentioned that tones change meanings. The remaining thirteen participants were classified as being aware at the level of noticing as they perceived the tonal changes but did not link them to meaning changes. However, we did not find significant differences between the noticing and understanding groups in an exploratory analysis, and hence the two groups were pooled as a single ‘aware’ group in further analyses.
Performance of aware and unaware participants in CSL task
As shown in Figure 3, the learning trajectories of aware and unaware participants are not significantly different. There was an unexpected drop in accuracy for the unaware participants at learning block 6, specifically in the tonal and vocalic minimal pair trials.

Figure 3. Experiment 1: Proportion of correct responses in each learning block for aware and unaware participants (L1 English group only) – overall (A) and in different trial types (B).
Note. Error bars represent 95% Confidence Intervals.
To explore the influence of awareness on learning performance for the L1 English group, we constructed models with fixed effects of block, trial type, awareness status (aware vs unaware), and the 3-way interaction in order. The inclusion of trial type (χ2(3) = 10.770, p = .013) and block (χ2(1) = 11.925, p < .001) led to better model fit. Awareness (χ2(1) = 0, p = 1) and the interaction effect (χ2(7) = 5.172, p = .639) did not further influence model fit significantly. Table 4 summarizes the final model.Footnote 5
Table 4. Best fitting model for accuracy for the L1 English group in Experiment 1, testing awareness effect

Number of observations: 4025, Participants: 28, Item, 12. AIC = 5383.5, BIC = 6171.0, log-likelihood = -2566.7.
R syntax: glmer(acc ~ block + TrialType + (1 + block + awareness + TrialType + block:awareness:TrialType | item ) + (1 + block + TrialType | subjectID), family = binomial, data = fulld.awareness, glmerControl(optCtrl=list(maxfun=2e5), optimizer = “nloptwrap”, calc.derivs = FALSE))
We investigated if aware and unaware participants differ at the end of the CSL task. The results showed that only trial type (χ2(3) = 13.943, p = .003) significantly improved fit, but not awareness (χ2(1) = 3.037, p = .081) nor the interaction (χ2(3) = 1.897, p = .594). The best-fitting model is provided in Table S7. Considering only the most challenging tonal minimal pair trials in the last block, we found that the aware participants performed significantly better than the unaware ones (t(26) = 2.2193, p = .035), with an average accuracy of 0.55 and 0.38 respectively.
Discussion
Experiment 1 confirmed that adults can learn non-native words by keeping track of cross-situational statistics (Escudero et al., Reference Escudero, Mulak and Vlach2016b, Reference Escudero, Smit and Mulak2022; Tuninetti et al., Reference Tuninetti, Mulak and Escudero2020), and this was possible even when those minimal pairs were not immediately apparent and available within a single learning trial. The experiment also showed that the presence of minimal pairs and non-native speech sounds can interfere with learning outcomes. As predicted, we found that phonologically distinct items (non-minimal pairs) resulted in better learning than phonologically similar items (RQ1). Additionally, learners’ familiarity with the phonological contrasts influenced learning as words with non-native contrasts (tonal minimal pairs) were less accurately identified (RQ2). It is worth noting that Mandarin participants’ performance in tonal trials was also lower than that in consonant/vowel trials, despite lexical tone being in their native phonology. This is consistent with our prediction and previous studies, as Mandarin speakers might weigh segmental information greater than tonal information.
The three-way interaction between trial type, language group, and learning block showed that learners’ language background and knowledge of the new phonology are critical in how they perform in the CSL task. Specifically, the English-native speakers were significantly less accurate in tonal trials compared to the Mandarin-native speakers but were comparable in all other types of trials. Although these non-native contrasts resulted in more difficulties, we found that learners improved on these challenging contrasts after CSL (RQ3). The block effect and language group effect (without interaction) on tonal trials means that both L1 English and L1 Mandarin groups improved in tonal minimal pairs over time. However, the learning effect was still small, especially for L1 English participants. Their performance on the tonal trials was not significantly above chance after six learning blocks. One possible explanation is that the amount of exposure was insufficient. The CSL task took, on average, less than 10 minutes to complete. Thus, the training might be too minimized for participants to capture a subtle non-native cue, especially when this non-native tonal cue was embedded in minimal pairs, and learning required a highly accurate perception of the acoustic contrast. Therefore, we carried out Experiment 2 to explore if doubled exposure to the same materials can lead to improved learning outcomes.
Regarding participants’ awareness of the phonological properties of the words, we did not observe the effect of awareness among L1 English participants across learning blocks, though at the final block (Block 6), aware participants scored significantly higher than unaware participants in tonal trials. However, this difference resulted from a drop in unaware participants’ performance in the final block, rather than a rise in aware learners’ performance. Thus, it is unlikely that being aware of the tones benefited the learning outcomes. Rather, as shown in Figure 3, the unaware learners showed an accuracy decline in all trial types at the final block, which might reflect a loss of attention (e.g., due to distraction or fatigue) towards the end of the task. In Experiment 2, we further investigated if awareness would play a role after a longer learning exposure.
Experiment 2: The effect of extended training on learning
Method
Participants
Twenty-eight participants were recruited through the Department of Psychology at Lancaster University for course credits. This sample size matched the group size in Experiment 1. One participant was excluded because their native language was Cantonese. The remaining 27 participants were university students (aged 18~26) who spoke English as a native language and had no previous experience learning tonal languages. Eleven participants reported knowing more than one languageFootnote 6.
Materials and procedure
Auditory and visual stimuli were the same as in Experiment 1. The procedure replicated Experiment 1, except with twice the amount of CSL trials (i.e., participants went through the Experiment 1 CSL task twice, 12 blocks in total). Experiment 2 was preregistered on OSF: https://osf.io/2m4nw/.
Results
Performance on cross-situational task
Accuracy Figure 4A presents the overall performance of participants across the 12 learning blocks. There is a clear improvement in accuracy from chance level to 70.5% at the end of the learning. Like Experiment 1, the L1 English participants performed best in non-minimal pair trials, followed by clear learning in consonantal and vocalic trials. However, learning in tonal trials was still not observed (Figure 4B).
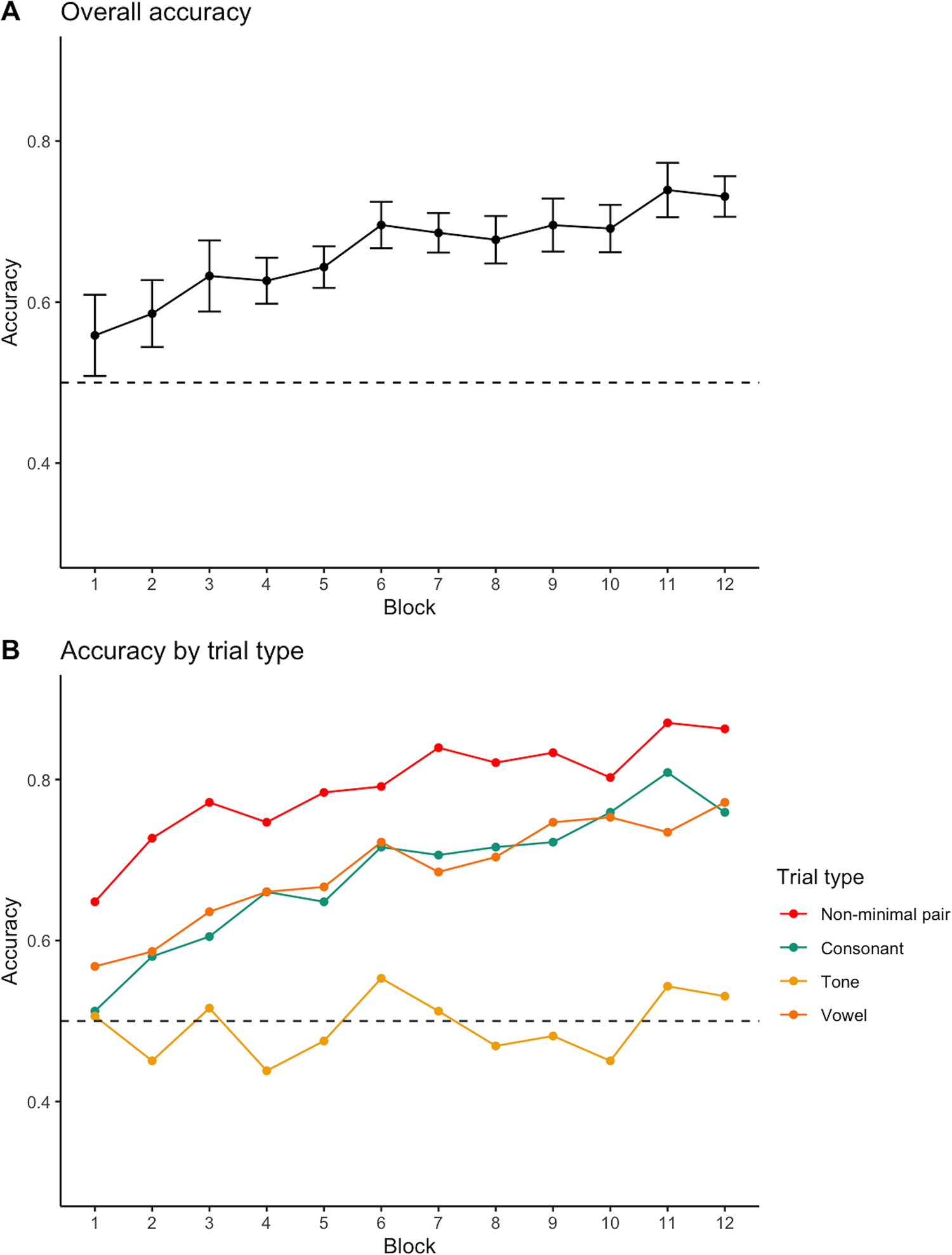
Figure 4. Experiment 2: Mean proportion of correct pictures selected in each learning block - overall (A) and in different trial types (B).
Note. Error bars represent 95% Confidence Intervals.
To be comparable to Experiment 1, we ran similar mixed effects models to examine the effect of learning block and trial types. We included a comparison between L1 English participants in Experiment 1 and participants in Experiment 2 to test the effect of short versus long (doubled) exposure. The fixed effect of learning block (χ2(1) = 3.394, p = .065) and exposure (χ2(1) = 0.656, p = .418) did not significantly improve model fit. But adding trial type (χ2(3) = 29.146, p < .001) and the 3-way interaction (χ2(7) = 42.022, p < .001) led to significant improvement. The quadratic effect for block did not result in a significant difference (χ2(8) = 14.274, p = .075). The best-fitting model is reported in Table 5Footnote 7.
Table 5. Best fitting model for accuracy in Experiment 2, showing fixed effects
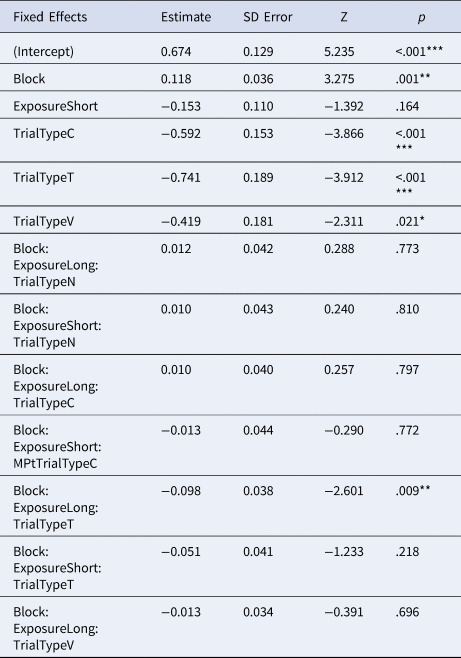
Number of observations: 11793, Participants: 55, Item, 12. AIC = 14100.7, BIC = 14462.1, log-likelihood = -7001.4.
R syntax: glmer(acc ~ block + exposure + TrialType + exposure:TrialType:block + (1 + block + exposure + TrialType | item) + (1 + block + TrialType | subjectID), family = binomial, data = fulld, glmerControl(optCtrl=list(maxfun=2e5), optimizer = “nloptwrap”, calc.derivs = FALSE))
We further ran separate models to test if exposure played a role in any particular trial type. The results showed that exposure effect was not significant in all trial types.
Reaction time Participants’ reaction time for correct responses showed a similar decreasing tendency as in Experiment 1 (Figure S2). The generalized mixed effect models revealed that adding exposure (χ2(1) = 0, p = 1) did not improve fit, but the effect of trial type (χ2(3) = 9.193, p = .027) and block (χ2(1) = 38.15, p < .001) and the 3-way interaction (χ2(7) = 28.852, p < .001) all improved model fit significantly. The best-fitting model is provided in Table S9.
Retrospective verbal reports
Three participants were coded as fully aware as they reported using tonal cues strategically without being explicitly asked (e.g., …after I loosely assigned words to pictures, I more listened out for the differences in the tones of the words…). A further eighteen participants reported that they noticed the tone/pitch difference in the language when explicitly asked (e.g., The tones of the words did change, which is how I correlated the word to the picture). The remaining six participants reported no awareness of the tonal difference. The total number of aware participants was the same in Experiment 1 and 2, though in Experiment 2 a few participants developed full awareness of the tones but none in Experiment 1.
Performance of aware and unaware participants in CSL task
As in Experiment 1, the aware and unaware participants shared similar learning trajectories (Figure 5).
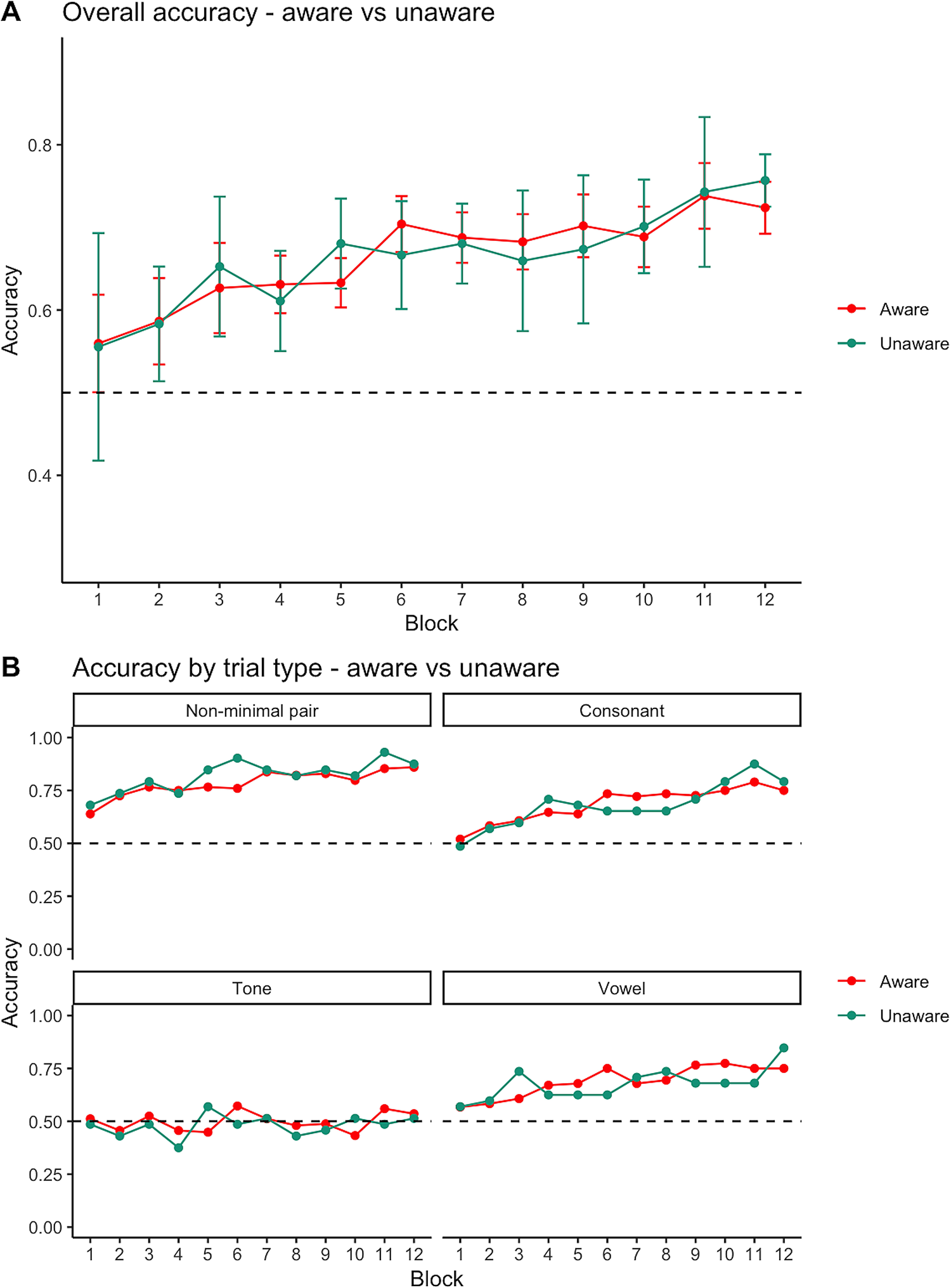
Figure 5. Experiment 2: Proportion of correct responses in each learning block for aware and unaware participants - overall (A) and in different trial types (B).
Note. Error bars represent 95% Confidence Intervals.
Since the aware and unaware subgroups did not differ in general accuracy, we ran mixed effects models for tonal trials specifically to explore if participants who noticed the existence of tones performed better. The results showed that none of the fixed effects improve model fit compared to a random effect model (learning block: χ2(1) = 3.3854, p = .066; exposure: χ2(1) = 0.107, p = .744; awareness: χ2(1) <.001, p = .976; 3-way interaction: χ2(3) = 1.2278, p = .746). In Experiment 1, we found a significant difference between aware and unaware participants in tonal trials at the end of the CSL task, but in Experiment 2, no such difference was detected (t(25) = 0.57781, p = .569).
Discussion
Experiment 2 revealed a significant overall learning effect for L1 English participants, even when the words involved unfamiliar sounds and were phonologically overlapping. Also, minimal pairs led to greater difficulty in learning. That is, when participants were presented with two objects that were associated with two phonological overlapping words (minimal pairs), their performance (accuracy) was reduced. These confirm the findings from Experiment 1. However, we did not find the expected exposure effect. Critically, participants did not improve significantly in tonal trials with doubled exposure, suggesting that the lack of improvement in tonal trials in Experiment 1 is not merely a lack of input exposure. Furthermore, we did not observe the effect of awareness on learning outcomes, either in overall accuracy or in the tonal trials. In Experiment 1, we observed better performance among aware participants in tonal trials at the last learning block, but this difference was not found in Experiment 2. This observation supports our explanation above that the different performances between aware and unaware learners in Experiment 1 might result from factors (e.g., attention loss due to distraction or fatigue) other than awareness of the tones. Simply being aware of the tonal difference may not be sufficient for learners to accurately use the tonal cue in word learning. Mapping spoken tonal words to meanings requires categorical perception of tones and forming representations of tonal words in the mental lexicon. To summarize, Experiment 2 confirmed the findings in Experiment 1 but did not provide further evidence for the learning of the tonal contrast.
General discussion
In this study, we explored the impact of phonology on non-native vocabulary learning using a cross-situational learning paradigm which combines implicit and statistical learning research (see Monaghan et al., Reference Monaghan, Schoetensack and Rebuschat2019). We found evidence that CSL is effective when words contain non-native suprasegmental features. Furthermore, we manipulated the phonological similarity between words and generated different (non)minimal pair types to assimilate the natural language learning situation. Learners’ performance was significantly influenced by how similar the words sounded, thus suggesting that future word learning research needs to take into account the role of phonology more fully.
RQ1: Do minimal pairs pose difficulty during cross-situational learning compared to phonologically distinct words? As predicted (and outlined in our preregistration), in both experiments, learners performed better in non-minimal pair trials as compared to other minimal pair trials. One explanation is that, in non-minimal pair trials, learners can rely on several phonological cues (e.g., consonants, vowels, tones) to activate the corresponding referent; but in minimal pair trials, most of the cues are uninformative and activate both objects, with only one informative cue indicating the correct referent. Our finding is consistent with Escudero et al. (Reference Escudero, Mulak and Vlach2016b) results of lower performance for minimal pairs, though we included not only segmental but also suprasegmental minimal pairs. Our study tested effects of minimal pairs in disyllabic words without context, but for acquiring a larger vocabulary under more naturalistic circumstances, the learner is likely to be affected by other properties of the language. For instance, Thiessen (Reference Thiessen2007) found that infants could distinguish and learn minimal pairs more easily after being exposed to the specific phonemic contrasts in dissimilar contexts – hence, the prevalence of minimal pairs may play a role. Therefore, in real-life word learning, though minimal pairs are widespread in natural language vocabularies (e.g., in CELEX, Baayen et al., Reference Baayen, Piepenbrock and Rijn1993), 28% of English word types have a neighbour with one letter different, and in Mandarin, most words have at least one neighbour with only tonal differences (Duanmu, Reference Duanmu2007)), context can provide information about the likely meaning of the word to support identification (e.g., Levis & Cortes, Reference Levis and Cortes2008).
RQ2: Do minimal pairs that differ in non-native phonological contrasts pose further difficulty compared to minimal pairs with contrasts that are similar to native sounds? As predicted, in both experiments, English-native speakers’ accuracy in tonal minimal pair trials was lowest, as compared to consonantal and vocalic minimal pair trials. It is also worth noting that in Experiment 1, only in the tonal trials did L1 English participants score lower than L1 Mandarin participants, whereas in all other trials, the two groups were comparable. This finding is important when we extend the CSL paradigm to L2 acquisition research, where difficulty in non-native sound perception may impede learning. Our results also provide insights into more immersive learning situations, such as living abroad, in which learners are not explicitly pre-trained with the phonological and phonetic details of the new language and are required instead to divine the important phonemic distinctions from exposure to the language. In our study, minimal pairs were not immediately available to the participant in a learning trial (in contrast to the methods used by Escudero et al., Reference Escudero, Mulak and Vlach2016b, 2022; Tuninetti et al., Reference Tuninetti, Mulak and Escudero2020), but, as in natural language, emerged as a result of experience of phonologically overlapping words across contexts. Under these conditions, we found that it may be harder for learners to pick up words incidentally from the environment when they contain such minimal pair contrasts.
RQ3: Does learners’ non-native sound perception develop during cross-situational learning? Contrary to our predictions, no significant improvement was found in L1 English participants’ performance in tonal trials across learning. Learners’ difficulty in dealing with non-native contrasts remained after implicit-statistical learning, and simply increasing exposure to stimuli was not greatly facilitative. It is worth noting that in a previous statistical learning study, Nixon (Reference Nixon2020) did observe successful learning of non-native tonal words. This is likely due to the differences in experimental settings. For example, Nixon's (Reference Nixon2020) Experiment 1 involved feedback during training, but it is critical in our CSL paradigm that no feedback is given throughout. In Nixon's Experiment 2, participants learned the word-picture mappings in an unambiguous way – one word and one picture were presented in each trial, whereas our CSL paradigm involved ambiguous learning trials. Moreover, Nixon (Reference Nixon2020) presented words and referents in a sequential order to enable learning from prediction and prediction error, whereas we presented words and referents simultaneously. This could potentially provide evidence for the role of error-driven learning (Rescorla & Wagner, Reference Rescorla, Wagner, Black and Prokasy1972). One follow-up is that we could replicate the current study with a sequential presentation of words and referents, and compare the results with simultaneous presentation to discern the effect of cue order in learning.
There are multiple possible explanations for this lack of improvement in L1 English participants’ tonal trial performance. Firstly, the training task in our experiments was relatively short, with only one CSL session of 10 to 20 minutes. In the classic L2 speech learning studies that target non-native sound acquisition, the length and number of training sessions are typically much greater than our design and sometimes run over several days (e.g., Cheng et al., Reference Cheng, Zhang, Fan and Zhang2019; Fuhrmeister & Myers, Reference Fuhrmeister and Myers2020; Godfroid et al., Reference Godfroid, Lin and Ryu2017; Iverson & Evans, Reference Iverson and Evans2009). Thus, despite the qualitative difference in the training processes (i.e., explicitness of training), the quantity of input exposure in our design is not as intensive as in previous studies, which may account for the minimal improvement in our results.
Secondly, our CSL task involves different levels of lexical tone processing rather than simply discrimination. Some participants reported that they noticed but intentionally ignored the tones to avoid confusion. The ignoring of tonal cues results from the interpretive narrowing process in early native language development (Hay et al., Reference Hay, Graf Estes, Wang and Saffran2015). Infants with non-tonal native languages learn to constrain the type of acoustic details used in word learning and learn not to attend to the pitch contour information, as variations in pitch are mostly irrelevant at the lexical level. This process happens as early as around 17 months old, which leads to difficulty in interpreting tonal cues as meaningful in word learning (Hay et al., Reference Hay, Graf Estes, Wang and Saffran2015; Liu & Kager, Reference Liu and Kager2018). However, at the same age, infants can still discriminate the tonal differences. This suggests stages in the decreasing tonal processing ability among non-tonal infants – interpretation of tones reduces greatly before perception of tones. When it comes to learning a tonal language, the challenge, therefore, may not be the perception but the referential use of lexical tones. Therefore, it is possible that our learners were able to discriminate the acoustic details between the tonal contrasts after learning, but they could not use them contrastively in learning. For non-tonal language speakers to learn a tonal language, it may be more important to restore their interpretation of tones than perceptual training. The presentation of minimal pairs, as in our design, may serve this purpose well, as it creates ambiguity if tones are not interpreted referentially and hence leads listeners to pay attention to tones. But the minimal pair training paradigm may need to last longer and be more focused on tones. In our study, we introduced different minimal pair trials, and this may reduce the emphasis on tones.
Additionally, we did not observe a relationship between tonal awareness and learning performance. This contradicts previous CSL findings that learners aware of the linguistic features start to improve earlier in the learning process (Monaghan et al., Reference Monaghan, Schoetensack and Rebuschat2019). One possibility is that awareness affects different aspects of language learning differently. Monaghan et al. (Reference Monaghan, Schoetensack and Rebuschat2019) examined the acquisition of morphosyntactic rules, where explicit knowledge of the rules can lead to direct application of the rules in processing. However, as for phonological development, even the advanced learners of tonal languages who performed well at tone discrimination showed difficulty in tone processing at a lexical level (Pelzl et al., Reference Pelzl, Lau, Guo and DeKeyser2019). Thus, merely being aware of the unfamiliar phonological feature may not allow learners to explicitly make use of the cues in word learning.
Limitations and further directions
We tested learners’ vocabulary and phonological development with a single accuracy measure in the CSL task. However, as discussed, it is possible that English-native participants’ tonal perception ability improved in terms of acoustic discrimination of tones, which, using the CSL task, cannot be separated from their vocabulary knowledge. Future studies can incorporate direct tests of sound perception and discrimination before and after the CSL task to explore more precisely how CSL interferes with perceptual abilities (for pre-registered study, see: https://osf.io/kqagx). It would also be interesting to examine learners’ categorical perception of lexical tones after learning sessions to investigate at which level (acoustic, phonological, or lexical) the difficulties arise. Furthermore, not many studies have explicitly compared perception and production training in lexical tone acquisition. One relevant study by Lu et al. (Reference Lu, Wayland and Kaan2015) reported no significant benefit of adding a production component in explicit lexical tone training. However, it is not clear whether there could be an interaction between training type (explicit/implicit) and training mode (perception/production). One potential follow-up on the current design is that we could add a production task to the perceptual CSL task. Imitation of the tonal stimuli may direct more attention to the tonal contrast and facilitate learners’ understanding of tonal use. Lastly, we noticed that there was great variation among L1 English participants’ performance in tonal trials, especially in Experiment 2 where some learners reached an accuracy of over 80% after learning. We will carry out further individual difference studies to investigate the various predictors that contribute to better word learning outcomes, from auditory processing (Saito et al., Reference Saito, Kachlicka, Sun and Tierney2020a, Reference Saito, Sun and Tierney2020b), working memory, to implicit and explicit language aptitudes.
Supplementary Material
For supplementary material accompanying this paper, visit https://doi.org/10.1017/S1366728923000986
Table S1. List of minimal pairs in the four trial types.
Table S2. Best fitting models for accuracy in Experiment 1, with consonantal (A), vocalic (B), and tonal (C) minimal pair trials as the reference level, respectively.
Table S3. Best fitting model for accuracy for L1 Mandarin group in Experiment 1, with non-minimal pair (A), consonantal (B), vocalic (C), and tonal (D) minimal pair trials as the reference level, respectively.
Table S4. Best fitting model for accuracy for L1 English group in Experiment 1, with non-minimal pair (A), consonantal (B), vocalic (C), and tonal (D) minimal pair trials as the reference level, respectively.
Table S5. Best fitting model for reaction time in Experiment 1, showing fixed effects.
Table S6. Best fitting model for accuracy for the L1 English group in Experiment 1, testing awareness effect, with consonantal (A), vocalic (B), and tonal (C) minimal pair trials as the reference level, respectively.
Table S7. Best fitting model for accuracy in Block 6 for the L1 English group in Experiment 1, testing awareness effect.
Table S8. Best fitting model for accuracy in Experiment 2, with consonantal (A), vocalic (B), and tonal (C) minimal pair trials as the reference level, respectively.
Table S9. Best fitting model for reaction time in Experiment 2, showing fixed effects.
Figure S1. Experiment 1: Mean reaction time for correct responses in each learning block – overall (A) and in different trial types (B & C).
Figure S2. Experiment 2: Mean reaction time for correct responses in each learning block - overall (A) and in different trial types (B).
Data availability statement
Data availability: the data that support the findings of this study are openly available in Open Science Framework at https://osf.io/2j6pe/ (for Experiment 1) and https://osf.io/2m4nw/ (for Experiment 2).
Acknowledgments
We are very grateful to our colleagues in Lancaster University's Language Learning Lab (4L, https://www.lancaster.ac.uk/language-learning/) and in the NLT L2 Phonology Forum for helpful discussions, feedback and suggestions. We gratefully acknowledge the financial support provided by Lancaster University's Camões Institute Cátedra for Multilingualism and Diversity and the Linguistics Research Centre of NOVA University Lisbon (CLUNL, UIDB/LIN/03213/2020 and UIDP/LIN/03213/2020 funding programme). P. M. and P. R. contributed equally to the supervision of this project and are joint senior authors in this report. Our power analysis, materials, anonymized data and R scripts are available on our project site on the Open Science Framework (OSF) platform (https://osf.io/2j6pe/ and https://osf.io/2m4nw/).
Publishing ethics
The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008.













 Open access
Open access