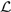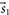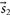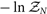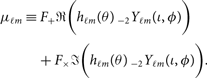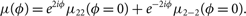1. Preface: why study Bayesian inference?
Bayesian inference is an essential part of modern astronomy. It finds particularly elegant application in the field of gravitational-wave astronomy thanks to the clear predictions of general relativity and the extraordinary simplicity with which compact binary systems are described. An astrophysical black hole is completely characterised by just its mass and its dimensionless spin vector. The gravitational waveform from a black hole binary is typically characterised by just 15 parameters. Since sources of gravitational waves are so simple, and since we have a complete theory describing how they emit gravitational waves, there is a direct link between data and model. The significant interest in Bayesian inference within the gravitational-wave community reflects the great possibilities of this area of research.
Bayesian inference and parameter estimation are the tools that allow us to make statements about the Universe based on data. In gravitational-wave astronomy, Bayesian inference is the tool that allows us to reconstruct sky maps of where a binary neutron star merged (Abbott et al. Reference Abbott2017c), to determine that GW170104 merged 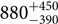 $[880^{+450}_{-390}]{\rm {Mpc}}$ away from Earth (Abbott et al. Reference Abbott2017b), and that the black holes in GW150914 had masses of
$[880^{+450}_{-390}]{\rm {Mpc}}$ away from Earth (Abbott et al. Reference Abbott2017b), and that the black holes in GW150914 had masses of 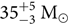 $[35^{+5}_{-3}]{{\rm {M}}_\odot}$ and
$[35^{+5}_{-3}]{{\rm {M}}_\odot}$ and 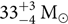 $[33^{+3}_{-4}]{{\rm {M}}_\odot}$ (Abbott et al. Reference Abbott2016b). We use it to determine the Hubble constant (Abbott et al. Reference Abbott2017d), to study the formation mechanism of black hole binaries (Vitale et al. Reference Wysocki, Lange and O’shaughnessy2017; Stevenson, Berry, & Mandel Reference Talbot and Thrane2017; Talbot & Thrane Reference Talbot and Thrane2017; Gerosa & Berti Reference Gregory2017; Farr et al. Reference Fishbach and Holz2017; Wysocki, Lange, & O’Shaughnessy Reference Wysocki, Lange and O’shaughnessy2018; Lower et al. Reference Mandel2018), and to probe how stars die (Fishbach & Holz Reference Fishbach and Holz2017; Talbot & Thrane Reference Umstätter, Meyer, Dupuis, Veitch, Woan, Christensen, Fischer, Preuss and von Toussaint2018; Abbott et al. Reference Abbott2018a). Increasingly, Bayesian inference and parameter estimation are the language of gravitational-wave astronomy. In this note, we endeavour to provide a primer on Bayesian inference with examples from gravitational-wave astronomy.Footnote a
$[33^{+3}_{-4}]{{\rm {M}}_\odot}$ (Abbott et al. Reference Abbott2016b). We use it to determine the Hubble constant (Abbott et al. Reference Abbott2017d), to study the formation mechanism of black hole binaries (Vitale et al. Reference Wysocki, Lange and O’shaughnessy2017; Stevenson, Berry, & Mandel Reference Talbot and Thrane2017; Talbot & Thrane Reference Talbot and Thrane2017; Gerosa & Berti Reference Gregory2017; Farr et al. Reference Fishbach and Holz2017; Wysocki, Lange, & O’Shaughnessy Reference Wysocki, Lange and O’shaughnessy2018; Lower et al. Reference Mandel2018), and to probe how stars die (Fishbach & Holz Reference Fishbach and Holz2017; Talbot & Thrane Reference Umstätter, Meyer, Dupuis, Veitch, Woan, Christensen, Fischer, Preuss and von Toussaint2018; Abbott et al. Reference Abbott2018a). Increasingly, Bayesian inference and parameter estimation are the language of gravitational-wave astronomy. In this note, we endeavour to provide a primer on Bayesian inference with examples from gravitational-wave astronomy.Footnote a
Before beginning, we highlight additional resources, useful for researchers interested in Bayesian inference in gravitational-wave astronomy. Sivia & Skilling (Reference Sivia and Skilling2006) and Gregory (Reference Hannam, Schmidt, Bohé, Haegel, Husa, Ohme, Pratten and Pürrer2005) are useful references that are accessible to physicists and astronomers (see also the Springer Series in Astrostatistics; Manuel et al. Reference Metropolis, Rosenbluth, Rosenbluth, Teller and Teller2012; Hilbe Reference Hilbe2013; Chattopadhyay & Chattopadhyay Reference Cornish and Littenberg2014; Andreon & Weaver Reference Babak2015). The chapter in Hilbe (Reference Hilbe2013) by Loredo discusses hierarchical models, but refers to them as ‘multilevel’ models (Loredo Reference Lower, Thrane, Lasky and Smith2012). Seasoned veterans may find Gelman et al. (Reference Gerosa and Berti2013) to be a thorough reference.
2. Fundamentals: likelihoods, priors, and posteriors
A primary aim of modern Bayesian inference is to construct a posterior distribution
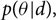 \begin{equation}p(\theta | d) ,\end{equation}
\begin{equation}p(\theta | d) ,\end{equation}
where θ is the set of model parameters and d is the data associated with a measurement.Footnote b For illustrative purposes, let us say that θ are the 15 parameters describing a binary black hole coalescence and d is the strain data from a network of gravitational-wave detectors. The posterior distribution p(θ|d) is the probability density function for the continuous variable θ given the data d. The probability that the true value of θ is between (θ′, θ′ + dθ) is given by p(θ′|d)dθ′. It is normalised so that
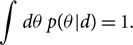 \begin{equation}\int d\theta \, p(\theta | d) = 1.\end{equation}
\begin{equation}\int d\theta \, p(\theta | d) = 1.\end{equation}The posterior distribution is what we use to construct credible intervals that tell us, for example, the component masses of a binary black hole event like GW150914. For details about the construction of credible intervals, see Appendix A.
According to Bayes theorem, the posterior distribution is given by
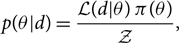 \begin{equation}\label{eq:posterior}p(\theta | d) = \frac{\mathcal{L}(d | \theta) \,\pi(\theta)}{\mathcal{Z}},\end{equation}
\begin{equation}\label{eq:posterior}p(\theta | d) = \frac{\mathcal{L}(d | \theta) \,\pi(\theta)}{\mathcal{Z}},\end{equation}where 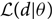 $\mathcal{L}(d|\theta)$ is the likelihood function of the data given the parameters θ, π(θ) is the prior distribution for θ, and
$\mathcal{L}(d|\theta)$ is the likelihood function of the data given the parameters θ, π(θ) is the prior distribution for θ, and 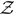 $\mathcal{Z}$ is a normalisation factorFootnote c, Footnote d called the ‘evidence’
$\mathcal{Z}$ is a normalisation factorFootnote c, Footnote d called the ‘evidence’
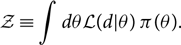 \begin{equation}\label{eq:evidence}
\mathcal{Z} \equiv \int d\theta \mathcal{L}(d | \theta) \, \pi(\theta) .
\end{equation}
\begin{equation}\label{eq:evidence}
\mathcal{Z} \equiv \int d\theta \mathcal{L}(d | \theta) \, \pi(\theta) .
\end{equation}
The likelihood function is something that we choose. It is a description of the measurement. By writing down a likelihood, we implicitly introduce a noise model. For gravitational-wave astronomy, we typically assume a Gaussian-noise likelihood function that looks something like this
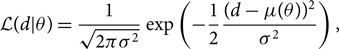 \begin{equation}\label{eq:mu}
\mathcal{ L}(d | \theta) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{1}{2}\frac{(d-\mu(\theta))^2}{\sigma^2}\right) ,
\end{equation}
\begin{equation}\label{eq:mu}
\mathcal{ L}(d | \theta) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{1}{2}\frac{(d-\mu(\theta))^2}{\sigma^2}\right) ,
\end{equation}
where μ(θ) is a template for the gravitational strain waveform given θ and σ is the detector noise. Note that π with no parentheses and no subscript is the mathematical constant, not a prior distribution. This likelihood function reflects our assumption that the noise in gravitational-wave detectors is Gaussian.Footnote e Note that the likelihood function is not normalised with respect to θ and soFootnote f
 \begin{equation}
\int d\theta \, \mathcal{ L}(d | \theta) \neq 1 .
\end{equation}
\begin{equation}
\int d\theta \, \mathcal{ L}(d | \theta) \neq 1 .
\end{equation}
For a more detailed discussion of the Gaussian noise likelihood in the context of gravitational-wave astronomy, see Appendix B.
Like the likelihood function, the prior is something we get to choose. The prior incorporates our belief about θ before we carry out a measurement. In some cases, there is an obvious choice of prior. For example, if we are considering the sky location of a binary black hole merger, it is reasonable to choose an isotropic prior that weights each patch of sky as equally probable. In other situations, the choice of prior is not obvious. For example, before the first detection of gravitational waves, what would have been a suitable choice for the prior on the primaryFootnote g black hole mass π(m 1)? When we are ignorant about θ, we often express our ignorance by choosing a distribution that is either uniform or log-uniform.Footnote h
While θ may consist of a large number of parameters, we usually want to look at just one or two at a time. For example, the posterior distribution for a binary black hole merger is a fifteen-dimensionalFootnote i function that includes information about black hole masses, sky location, spins, etc. What if we want to look at the posterior distribution for just the primary mass? To answer this question we marginalise (integrate) over the parameters that we are not interested in (called ‘nuisance parameters’) so as to obtain a marginalised posterior
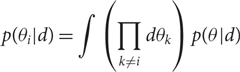 \begin{align}p(\theta_i | d) & = \int \left(\prod_{k\neq i} d\theta_k\right)p(\theta | d)\end{align}
\begin{align}p(\theta_i | d) & = \int \left(\prod_{k\neq i} d\theta_k\right)p(\theta | d)\end{align}
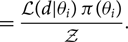 \begin{align} = \dfrac{\mathcal{ L}(d | \theta_i) \, \pi(\theta_i)}{\mathcal{ Z}}.\end{align}
\begin{align} = \dfrac{\mathcal{ L}(d | \theta_i) \, \pi(\theta_i)}{\mathcal{ Z}}.\end{align}
The quantity 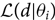 $\mathcal{ L}(d | \theta_i)$ is called the ‘marginalised likelihood’. It can be expressed as follows:
$\mathcal{ L}(d | \theta_i)$ is called the ‘marginalised likelihood’. It can be expressed as follows:
 \begin{equation}
\mathcal{ L}(d | \theta_i) =
\int \left(\prod_{k\neq i} d\theta_k\right) \pi(\theta_k)
\, \mathcal{ L}(d | \theta).
\end{equation}
\begin{equation}
\mathcal{ L}(d | \theta_i) =
\int \left(\prod_{k\neq i} d\theta_k\right) \pi(\theta_k)
\, \mathcal{ L}(d | \theta).
\end{equation}
When we marginalise over one variable θa in order to obtain a posterior on θb, we are calculating our best guess for θb given uncertainty in θa. Speaking somewhat colloquially, if θa and θb are covariant, then marginalising over θa ‘injects’ uncertainty into the posterior for θb. When this happens, the marginalised posterior p(θb|d) is broader than the conditional posterior p(θb|d, θa). The conditional posterior p(θb|d, θa) represents a slice through the p(θb|d) posterior at a fixed value of θa.
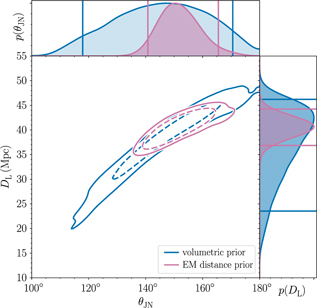
This is nicely illustrated with an example. There is a well-known covariance between the luminosity distance of a merging compact binary from Earth DL and the inclination angle θJN. For the binary neutron star coalescence GW170817, we are able to constrain the inclination angle much better when we use the known distance and sky location of the host galaxy compared to the constraint obtained using the gravitational-wave measurement alone.Footnote j Results from (Abbott et al. Reference Abbott2017a) are shown in Figure 1.
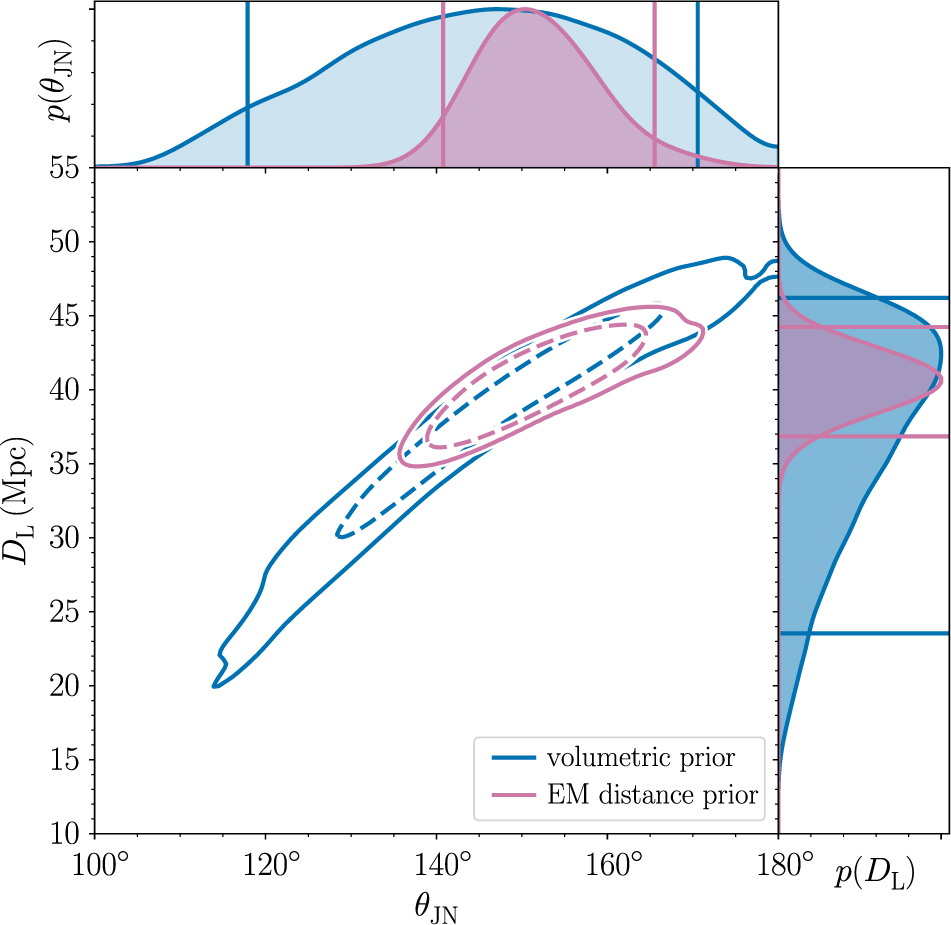
Figure 1: The joint posterior for luminosity distance and inclination angle for GW170817 from Abbott et al. (Reference Abbott2017a). The blue contours show the credible region obtained using gravitational-wave data alone. The purple contours show the smaller credible region obtained by employing a relatively narrow prior on distance obtained with electromagnetic measurements. Publicly available posterior samples for this plot are available here: LIGO/Virgo (LIGO/Virgo).
3. Models, evidence and odds
In Eq. (4), reproduced here, we defined the Bayesian evidence:
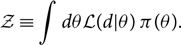 \begin{equation*}
\mathcal{ Z} \equiv \int d\theta \mathcal{ L}(d | \theta) \, \pi(\theta).
\end{equation*}
\begin{equation*}
\mathcal{ Z} \equiv \int d\theta \mathcal{ L}(d | \theta) \, \pi(\theta).
\end{equation*}
In practical terms, the evidence is a single number. It usually does not mean anything by itself, but becomes useful when we compare one evidence with another evidence. Formally, the evidence is a likelihood function. Specifically, it is the completely marginalised likelihood function. It is therefore sometimes denoted 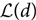 $\mathcal{ L}(d)$ with no θ dependence. However, we prefer to use
$\mathcal{ L}(d)$ with no θ dependence. However, we prefer to use 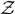 $\mathcal{ Z}$ to denote the fully marginalised likelihood function.
$\mathcal{ Z}$ to denote the fully marginalised likelihood function.
Above, we described how the evidence serves as a normalisation constant for the posterior p(θ|d). However, the evidence is also used to do model selection. Model selection answers the question: Which model is statistically preferred by the data and by how much? There are different ways to think about models. Let us return to the case of binary black holes. We may compare a ‘signal model’ in which we suppose that there is a binary black hole signal present in the data with a prior π(θ) to the ‘noise model’, in which we suppose that there is no binary black hole signal present. While the signal model is described by the fifteen binary parameters θ, the noise model is described by no parameters. Thus, we can define a signal evidence 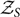 $\mathcal{ Z}_S$ and a noise evidence
$\mathcal{ Z}_S$ and a noise evidence 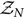 $\mathcal{ Z}_N$
$\mathcal{ Z}_N$
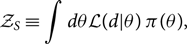 \begin{align}\mathcal{ Z}_S & \equiv \int d\theta \mathcal{ L}(d | \theta) \, \pi(\theta),\end{align}
\begin{align}\mathcal{ Z}_S & \equiv \int d\theta \mathcal{ L}(d | \theta) \, \pi(\theta),\end{align}
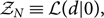 \begin{align}\mathcal{ Z}_N & \equiv \mathcal{ L}(d | 0) ,\end{align}
\begin{align}\mathcal{ Z}_N & \equiv \mathcal{ L}(d | 0) ,\end{align}
where
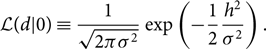 \begin{equation}
\mathcal{ L}(d | 0) \equiv \frac{1}{\sqrt{2\pi\sigma^2}}
\exp\left(-\frac{1}{2}\frac{h^2}{\sigma^2}\right) .
\end{equation}
\begin{equation}
\mathcal{ L}(d | 0) \equiv \frac{1}{\sqrt{2\pi\sigma^2}}
\exp\left(-\frac{1}{2}\frac{h^2}{\sigma^2}\right) .
\end{equation}
The noise evidence 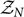 $\mathcal{ Z}_N$ is sometimes referred to as the ‘null likelihood’.
$\mathcal{ Z}_N$ is sometimes referred to as the ‘null likelihood’.
The ratio of the evidence for two different models is called the Bayes factor. In this example, the signal/noise Bayes factor is
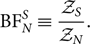 \begin{equation}
{\rm BF}^S_N \equiv \frac{\mathcal{ Z}_S}{\mathcal{ Z}_N} .
\end{equation}
\begin{equation}
{\rm BF}^S_N \equiv \frac{\mathcal{ Z}_S}{\mathcal{ Z}_N} .
\end{equation}
It is often convenient to work with the log of the Bayes factor:Footnote k
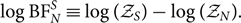 \begin{equation}
\log{\rm BF}^S_N \equiv \log(\mathcal{ Z}_S) - \log(\mathcal{ Z}_N) .
\end{equation}
\begin{equation}
\log{\rm BF}^S_N \equiv \log(\mathcal{ Z}_S) - \log(\mathcal{ Z}_N) .
\end{equation}
When the absolute value of log BF is large, we say that one model is preferred over the other. The sign of log BF tells us which model is preferred. A threshold of | log BF | = 8 is often used as the level of ‘strong evidence’ in favour of one hypothesis over another (Jeffreys Reference Khan, Husa, Hannam, Ohme, Pürrer, Forteza and Bohé1961).
The signal/noise Bayes factor is just one example of a Bayes factor comparing two models. We can calculate a Bayes factor comparing identical models but with different priors. For example, we can calculate the evidence for a binary black hole with a uniform prior on dimensionless spin and compare that to the evidence obtained using a zero-spin prior. The Bayes factor comparing these models would tell us if the data prefer spin:
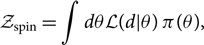 \begin{align}\mathcal{Z}_{\rm spin}& = \int d\theta \mathcal{L}(d | \theta) \, \pi(\theta),\end{align}
\begin{align}\mathcal{Z}_{\rm spin}& = \int d\theta \mathcal{L}(d | \theta) \, \pi(\theta),\end{align}
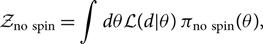 \begin{align}\mathcal{Z}_{\rm no\ spin}& = \int d\theta \mathcal{L}(d | \theta) \, \pi_{\rm no\ spin}(\theta),\end{align}
\begin{align}\mathcal{Z}_{\rm no\ spin}& = \int d\theta \mathcal{L}(d | \theta) \, \pi_{\rm no\ spin}(\theta),\end{align}
where π no spin(θ) is a prior with zero spins. The spin/no spin Bayes factor is
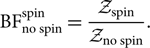 \begin{equation}
{\rm BF}^{{\rm spin}}_{\text{no spin}} = \frac{\mathcal{ Z}_{\text{spin}}}{\mathcal{ Z}_{\text{no spin}}} .
\end{equation}
\begin{equation}
{\rm BF}^{{\rm spin}}_{\text{no spin}} = \frac{\mathcal{ Z}_{\text{spin}}}{\mathcal{ Z}_{\text{no spin}}} .
\end{equation}
We may also compare two disparate signal models. For example, we can compare the evidence for a binary black hole waveform predicted by general relativity (model MA with parameters θ) with a binary black hole waveform predicted by some other theory (model MB with parameters υ):
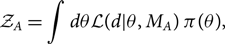 \begin{align}\mathcal{ Z}_A &= \int d\theta \mathcal{ L}(d | \theta, M_A) \, \pi(\theta),\end{align}
\begin{align}\mathcal{ Z}_A &= \int d\theta \mathcal{ L}(d | \theta, M_A) \, \pi(\theta),\end{align}
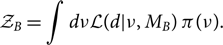 \begin{align}\mathcal{ Z}_B &= \int d\nu \mathcal{ L}(d | \nu, M_B) \, \pi(\nu) .\end{align}
\begin{align}\mathcal{ Z}_B &= \int d\nu \mathcal{ L}(d | \nu, M_B) \, \pi(\nu) .\end{align}
The A/B Bayes factor is
 \begin{equation}
\text{BF}^A_B = \frac{\mathcal{ Z}_A}{\mathcal{ Z}_B} .
\end{equation}
\begin{equation}
\text{BF}^A_B = \frac{\mathcal{ Z}_A}{\mathcal{ Z}_B} .
\end{equation}
Note that the number of parameters in ν can be different from the number of parameters in θ.
Our presentation of model selection so far has been a bit fast and loose. Formally, the correct metric to compare two models is not the Bayes factor, but rather the odds ratio
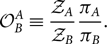 \begin{equation}
\mathcal{ O}^A_B \equiv \frac{\mathcal{ Z}_A}{\mathcal{ Z}_B} \frac{\pi_A}{\pi_B} .
\end{equation}
\begin{equation}
\mathcal{ O}^A_B \equiv \frac{\mathcal{ Z}_A}{\mathcal{ Z}_B} \frac{\pi_A}{\pi_B} .
\end{equation}
The odds ratio is the product of the Bayes factor with the prior odds πA / πB, which describes our prior belief about the relative likelihood of hypotheses A and B. In many practical applications, we set the prior odds ratio to unity, and so the odds ratio is the Bayes factor. This practice is sensible in many applications where our intuition tells us: until we do this measurement both hypotheses are equally likely.Footnote l
Bayesian evidence encodes two pieces of information. First, the likelihood tells us how well our model fits the data. Second, the act of marginalisation tell us about the size of the volume of parameter space we used to carry out a fit. This creates a sort of tension. We want to get the best fit possible (high likelihood) but with a minimum prior volume. A model with a decent fit and a small prior volume often yields a greater evidence than a model with an excellent fit and a huge prior volume. In these cases, the Bayes factor penalises the more complicated model for being too complicated.
This penalty is called an Occam factor. It is a mathematical formulation of the statement that all else equal, a simple explanation is more likely than a complicated one. If we compare two models where one model is a superset of the other—for example, we might compare general relativity and general relativity with non-tensor modes—and if the data are better explained by the simpler model, the log Bayes factor is typically modest, log BF ≈ (−2, −1). Thus, it is difficult to completely rule out extensions to existing theories. We just obtain ever tighter constraints on the extended parameter space.
4. Samplers
Thanks to the creation of phenomenological gravitational waveforms (called ‘approximants’), it is now computationally straightforward to make a prediction about what the data d should look like given some parameters θ. That is a forward problem. Calculating the posterior, the probability of parameters θ given the data as in Eq. (3), reproduced here, is a classic inverse problem:Footnote m
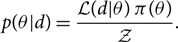 \begin{equation*}
p(\theta | d) = \frac{
\mathcal{ L}(d | \theta) \,
\pi(\theta)
}
{\mathcal{ Z}}.
\end{equation*}
\begin{equation*}
p(\theta | d) = \frac{
\mathcal{ L}(d | \theta) \,
\pi(\theta)
}
{\mathcal{ Z}}.
\end{equation*}
In general, inverse problems are computationally challenging compared to forward problems. To illustrate why let us imagine that we wish to calculate the posterior probability for the 15 parameters describing a binary black hole merger. If we do this naively, we might create a grid with 10 bins in every dimension and evaluate the likelihood at each grid point. Even with this coarse resolution, our calculation suffers from ‘the curse of dimensionality’. It is computationally prohibitive to carry out 1015 likelihood evaluations. The problem becomes worse as we add dimensions. As a rule of thumb, brute-force bin approaches become painful once one exceeds three dimensions.
The solution is to use a stochastic sampler (although recent work has shown progress carrying out these calculations using the alternative technique of iterative fitting; Pankow et al. Reference Pürrer2015; Lange, O’Shaughnessy, & Rizzo Reference Lange, O’shaughnessy and Rizzo2018). Commonly used sampling algorithms can be split into two broad categories of method: Markov chain Monte Carlo (MCMC) (Metropolis et al. Reference Ng, Vitale, Zimmerman, Chatziioannou, Gerosa and Haster1953; Hastings Reference Hilbe1970) and nested sampling (Skilling Reference Skilling, Fischer, Preuss and von Toussaint2004). These algorithms generate a list of posterior samples {θ} drawn from the posterior distribution such that the number of samples on the interval (θ, θ + Δθ) ∝ p(θ) (Veitch et al. Reference Veitch2015). Some samplers also produce an estimate of the evidence. We can visualise the posterior samples as a spreadsheet. Each column is a different parameter, for example, primary black hole mass, secondary black hole mass, etc. For binary black hole mergers, there are typically fifteen columns. Each row represents a different posterior sample.
Posterior samples have two useful properties. First, they can be used to compute expectation values of quantities of interest since (Hogg & Foreman-Mackey Reference Jade Powell, Logue and Heng2018)
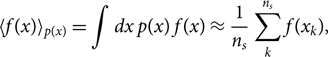 \begin{equation}
\langle f(x) \rangle_{p(x)} =
\int dx \, p(x) \, f(x) \approx \frac{1}{n_s}
\sum_k^{n_s} f(x_k),
\label{eq:sampling}
\end{equation}
\begin{equation}
\langle f(x) \rangle_{p(x)} =
\int dx \, p(x) \, f(x) \approx \frac{1}{n_s}
\sum_k^{n_s} f(x_k),
\label{eq:sampling}
\end{equation}
where p(x) is the posterior distribution that we are sampling, f(x) is some function we want to find the expectation value of, and the sum over k runs over ns posterior samples. Eq. (22) will prove useful simplifying our calculation of the likelihood of data given hyper-parameters.
The second useful property of posterior samples is that, once we have samples from an N-dimensional space, we can generate the marginalised probability for any subset of the parameters by simply selecting the corresponding columns in our spreadsheet. This property is used to help visualise the output of these samplers by constructing ‘corner plots’, which show the marginalised one- and two-dimensional posterior probability distributions for each of the parameters. For an example of a corner plot, see Figure 1. A handy python package exists for making corner plots (Foreman-Mackey Reference Foreman-Mackey, Hogg, Lang and Goodman2016).
4.1. MCMC
MCMC sampling was first introduced in Metropolis et al. (Reference Ng, Vitale, Zimmerman, Chatziioannou, Gerosa and Haster1953) and extended in Hastings (Reference Hilbe1970). For a recent overview of MCMC methods in astronomy, see Sharma (Reference Sidery2017). In MCMC methods, particles undergo a random walk through the posterior distribution where the probability of moving to any given point is determined by the transition probability of the Markov chain. By noting the position of the particles—or ‘walkers’ as they are sometimes called—at each iteration, we generate draws from the posterior probability distribution.
There are some subtleties that must be considered when using MCMC samplers. First, the early-time behaviour of MCMC walkers is strongly dependent on the initial conditions. It is therefore necessary to include a ‘burn-in’ phase to ensure that the walker has settled into a steady state before beginning to accumulate samples from the posterior distribution. Once the walker has reached a steady state, the algorithm can continue indefinitely and so it is necessary for the user to define a termination condition. This is typically chosen to be when enough samples have been acquired for the user to believe an accurate representation of the posterior has been obtained. Thus, MCMC requires a degree of artistry, developed from experience.
Additionally, the positions of a walker in a chain are often autocorrelated. Because of this correlation, the positions of the walkers do not represent a faithful sampling from the posterior distribution. If no remedy is applied, the width of the posterior distribution is underestimated. It is thus necessary to ‘thin’ the chain by selecting samples separated by the autocorrelation length of the chain.
MCMC walkers can also fail to find multiple modes of a posterior distribution if there are regions of low posterior probability between the modes. However, this can be mitigated by running many walkers which begin exploring the space at different points. This also demonstrates a simple way to parallelise MCMC computations to quickly generate many samples. Many variants of MCMC sampling have been proposed in order to improve the performance of MCMC algorithms with respect to these and other issues. For a more in-depth discussion of MCMC methods, see e.g. chapter 11 of Gelman et al. (Reference Gerosa and Berti2013), or Hogg & Foreman-Mackey (Reference Jade Powell, Logue and Heng2018). The most widely used MCMC code in astronomy is emcee (Foreman-Mackey et al. Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013).Footnote n
4.2. Nested sampling
The first widely used alternative to MCMC was introduced by Skilling (Reference Skilling, Fischer, Preuss and von Toussaint2004). While MCMC methods are designed to draw samples from the posterior distribution, nested sampling is designed to calculate the evidence. Generating samples from the posterior distribution is a by-product of the nested sampling evidence calculation algorithm. By weighting each of the samples used to calculate the evidence by the posterior probability of the sample, nested samples are converted into posterior samples.
Nested sampling works by populating the parameter space with a set of ‘live points’ drawn from the prior distribution. At each iteration, the lowest likelihood point is removed from the set of live points and new samples are drawn from the prior distribution until a point with higher likelihood than the removed point is found. The evidence is evaluated by assigning each removed point a prior volume and then computing the sum of the likelihood multiplied by the prior volume for each sample.
Since the nested sampling algorithm continually moves to higher likelihood regions, it is possible to estimate an upper limit on the evidence at each iteration. This is done by imagining that the entire remaining prior volume has a likelihood equal to that of the highest likelihood live point. This is used to inform the termination condition for the nested sampling algorithm. The algorithm stops when the current estimate of the evidence is above a certain fraction of the estimated upper limit.Footnote o Unlike MCMC algorithms nested sampling is not straightforwardly parallelisable, and posterior samples do not accumulate linearly with run time.
5. Hyper-parameters and hierarchical models
As more and more gravitational-wave events are detected, it is increasingly interesting to study the population properties of binary black holes and binary neutron stars. These are the properties common to all of the events in some set. Examples include the neutron star equation of state and the distribution of black hole masses. Hierarchical Bayesian inference is a formalism, which allows us to go beyond individual events in order to study population properties.Footnote p
The population properties of some set of events is described by the shape of the prior. For example, two population synthesis models might yield two different predictions for the prior distribution of the primary black hole mass π(m 1). In order to probe the population properties of an ensemble of events, we make the prior for θ conditional on a set of ‘hyper-parameters’ Λ:
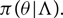 \begin{equation}
\pi(\theta | \Lambda) .
\end{equation}
\begin{equation}
\pi(\theta | \Lambda) .
\end{equation}
The hyper-parameters parameterise the shape of the prior distribution for the parameters θ. An example of a (parameter, hyper-parameter) relationship is (θ = primary black hole mass m 1, Λ = the spectral index of the primary mass spectrum α). In this example
 \begin{equation}
\pi(m_1 | \alpha) \propto m_1^\alpha .
\end{equation}
\begin{equation}
\pi(m_1 | \alpha) \propto m_1^\alpha .
\end{equation}
A key goal of population inference is to estimate the posterior distribution for the hyper-parameters Λ. In order to do this, we marginalise over the entire parameter space θ in order to obtain a marginalised likelihood:
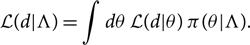 \begin{equation}\mathcal{ L}(d | \Lambda) = \int d\theta \, \mathcal{ L}(d | \theta) \, \pi(\theta | \Lambda) .\end{equation}
\begin{equation}\mathcal{ L}(d | \Lambda) = \int d\theta \, \mathcal{ L}(d | \theta) \, \pi(\theta | \Lambda) .\end{equation}
Normally, we would call this completely marginalised likelihood an evidence, but because it still depends on Λ, we call it the likelihood for the data d given the hyper-parameters Λ. The hyper-posterior is given simply by
 \begin{equation}
p(\Lambda | d) = \frac{
\mathcal{ L}(d | \Lambda) \,
\pi(\Lambda)
}
{\int d\Lambda \, \mathcal{ L}(d | \Lambda) \,
\pi(\Lambda)} .
\end{equation}
\begin{equation}
p(\Lambda | d) = \frac{
\mathcal{ L}(d | \Lambda) \,
\pi(\Lambda)
}
{\int d\Lambda \, \mathcal{ L}(d | \Lambda) \,
\pi(\Lambda)} .
\end{equation}
Note that we have introduced a hyper-prior π(Λ), which describes our prior belief about the hyper-parameters Λ. The term in the denominator
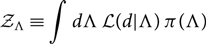 \begin{equation}
\mathcal{ Z}_\Lambda \equiv \int d\Lambda \, \mathcal{ L}(d | \Lambda) \,
\pi(\Lambda)
\end{equation}
\begin{equation}
\mathcal{ Z}_\Lambda \equiv \int d\Lambda \, \mathcal{ L}(d | \Lambda) \,
\pi(\Lambda)
\end{equation}
is the ‘hyper-evidence’, which we denote 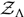 $\mathcal{ Z}_\Lambda$ in order to distinguish it from the regular evidence
$\mathcal{ Z}_\Lambda$ in order to distinguish it from the regular evidence 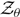 $\mathcal{ Z}_\theta$. In Appendix D we discuss posterior predictive distributions (PPD), which represent the updated prior on θ in light of the data d and given some hyper-parameterisation.
$\mathcal{ Z}_\theta$. In Appendix D we discuss posterior predictive distributions (PPD), which represent the updated prior on θ in light of the data d and given some hyper-parameterisation.
We now generalise the discussion of hyper-parameters in order to handle the case of N independent events. In this case, the total likelihood for all N events 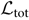 $\mathcal{ L}_{\rm tot}$ is simply the product of each individual likelihood
$\mathcal{ L}_{\rm tot}$ is simply the product of each individual likelihood
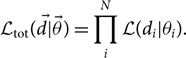 \begin{equation}\label{eq:product}
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \vec\theta) = \prod_i^N \mathcal{ L}(d_i | \theta_i) .
\end{equation}
\begin{equation}\label{eq:product}
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \vec\theta) = \prod_i^N \mathcal{ L}(d_i | \theta_i) .
\end{equation}
Here, we use vector notation so that 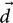 $\skew8\vec{d}$ is the set of measurements of N events, each of which has its own parameters, which make up the vector
$\skew8\vec{d}$ is the set of measurements of N events, each of which has its own parameters, which make up the vector 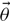 $\vec\theta$. Since we suppose that every event is drawn from the same population prior distribution—hyper-parameterised by Λ—the total marginalised likelihood is
$\vec\theta$. Since we suppose that every event is drawn from the same population prior distribution—hyper-parameterised by Λ—the total marginalised likelihood is
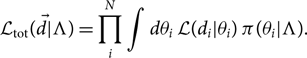 \begin{equation}
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) = \prod_i^N \int d\theta_i \,
\mathcal{ L}(d_i | \theta_i)
\, \pi(\theta_i | \Lambda) .
\end{equation}
\begin{equation}
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) = \prod_i^N \int d\theta_i \,
\mathcal{ L}(d_i | \theta_i)
\, \pi(\theta_i | \Lambda) .
\end{equation}
The associated (hyper-) posterior is
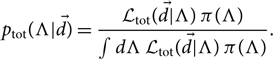 \begin{equation}\label{eq:hyperp}
p_{\rm tot}(\Lambda | \skew8\vec{d}) = \frac{
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) \, \pi(\Lambda)
}
{\int d\Lambda \, \mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) \, \pi(\Lambda)} .
\end{equation}
\begin{equation}\label{eq:hyperp}
p_{\rm tot}(\Lambda | \skew8\vec{d}) = \frac{
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) \, \pi(\Lambda)
}
{\int d\Lambda \, \mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) \, \pi(\Lambda)} .
\end{equation}
The denominator, of course, is the total hyper-evidence:
 \begin{equation}\label{eq:Ztot}
\mathcal{ Z}_\Lambda^{\rm tot} = \int d\Lambda \, \mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) \, \pi(\Lambda).
\end{equation}
\begin{equation}\label{eq:Ztot}
\mathcal{ Z}_\Lambda^{\rm tot} = \int d\Lambda \, \mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) \, \pi(\Lambda).
\end{equation}
We may calculate the Bayes factor comparing different hyper-models in the same way that we calculate the Bayes factor for different models.
Examining Eq. (31), we see that the total hyper-evidence involves a large number of integrals. For the case of binary black hole mergers, every event has 15 parameters, and so the dimension of the integral is 15N + M taking where M is the number of hyper-parameters in Λ. As N gets large, it becomes difficult to sample such a large prior volume all at once. Fortunately, it is possible to break the integral into individual integrals for each event, which are then combined through a process sometimes referred to as ‘recycling’.
Thus, the total marginalised likelihood in Eq. (29) can be written as follows:
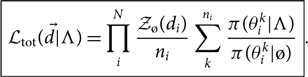 \begin{equation}
\boxed{
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) = \prod_i^N
\frac{\mathcal{ Z}_{\o}(d_i)}{n_i}
\sum_k^{n_i} \frac{\pi(\theta^k_i|\Lambda)}{\pi(\theta^k_i|{\o})}
}.
\end{equation}
\begin{equation}
\boxed{
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) = \prod_i^N
\frac{\mathcal{ Z}_{\o}(d_i)}{n_i}
\sum_k^{n_i} \frac{\pi(\theta^k_i|\Lambda)}{\pi(\theta^k_i|{\o})}
}.
\end{equation}
Here, the sum over k is a sum over the ni posterior samples associated with event i. The posterior samples for each event are generated with some default prior π(θk|ø). The default prior is ultimately canceled from the final answer, so it not so important what we choose for the default prior so long as it is sufficiently uninformative. Using the ø prior, we obtain an evidence 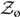 $\mathcal{ Z}_{\o}$. In this way, we are able to analyse each event individually before recycling the posterior samples to obtain a likelihood of the data given Λ.
$\mathcal{ Z}_{\o}$. In this way, we are able to analyse each event individually before recycling the posterior samples to obtain a likelihood of the data given Λ.
To see where this formula comes from, we note that
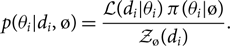 \begin{equation}
p(\theta_i | d_i, \o) =
\frac{
\mathcal{ L}(d_i | \theta_i) \, \pi(\theta_i | \o)
}
{\mathcal{ Z}_{\o}(d_i)}.
\end{equation}
\begin{equation}
p(\theta_i | d_i, \o) =
\frac{
\mathcal{ L}(d_i | \theta_i) \, \pi(\theta_i | \o)
}
{\mathcal{ Z}_{\o}(d_i)}.
\end{equation}
Rearranging terms,
 \begin{equation}
\mathcal{ L}(d_i | \theta_i) =
\mathcal{ Z}_{\o}(d_i) \, \frac{p(\theta_i | d_i, \o)
}
{\pi(\theta_i | \o)} .
\end{equation}
\begin{equation}
\mathcal{ L}(d_i | \theta_i) =
\mathcal{ Z}_{\o}(d_i) \, \frac{p(\theta_i | d_i, \o)
}
{\pi(\theta_i | \o)} .
\end{equation}
Plugging this into Eq. (29), we obtainFootnote q
 \begin{equation}
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) = \prod_i^N \int d\theta_i \,
p(\theta_i | d_i, \o) \, \mathcal{ Z}_{\o}(d_i) \,
\frac{\pi(\theta_i | \Lambda)}{\pi(\theta_i | \o)} .
\end{equation}
\begin{equation}
\mathcal{ L}_{\rm tot}(\skew8\vec{d} | \Lambda) = \prod_i^N \int d\theta_i \,
p(\theta_i | d_i, \o) \, \mathcal{ Z}_{\o}(d_i) \,
\frac{\pi(\theta_i | \Lambda)}{\pi(\theta_i | \o)} .
\end{equation}
Finally, we use Eq. (22) to convert the integral over θi to a sum over posterior samples, thereby arriving at Eq. (32).
All of the results derived up until this point ignore selection effects where an event with parameters θ 1 is easier to detect than an event with parameters θ 2. There are cases where selection effects are important. For example, the visible volume for binary black hole mergers scales as approximately V ∝ M 2.1, which means that higher mass mergers are relatively easier to detect than lower mass mergers (Fishbach & Holz Reference Fishbach, Holz and Farr2017). In Appendix E, we show how this method is extended to accommodate selection effects.
Author ORCIDs
Eric Thrane https://orcid.org/0000-0002-4418-3895, Colm Talbot https://orcid.org/0000-0003-2053-5582.
Acknowledgements
This document is the companion paper to a lecture at the 2018 OzGrav Inference Workshop held July 16–18, 2018 at Monash University in Clatyon, Australia. Thank you to the organisers: Greg Ashton, Paul Lasky, Hannah Middleton, and Rory Smith. This work was supported by OzGrav through the Australian Research Council CE170100004. For helpful comments on a draft of this manuscript, we thank Sylvia Biscoveanu, Paul Lasky, Nikhil Sarin, and Shanika Galaudage. We are indebted to Will Farr who clarified our understanding of selection effects and to Patricia Schmidt who helped our understanding of phase marginalisation. We thank Rory Smith and John Veitch for drawing our attention to the explicit distance marginalisation work of Leo Singer. Finally, we thank the anonymous referee for helpful suggestions, which improved the manuscript. ET and CT are supported by CE170100004. ET is supported by FT150100281.
Appendix A. Credible intervals
It is often convenient to use the posterior to construct ‘credible intervals’, regions of parameter space containing some fraction of posterior probability. (Note that Bayesian inference yields credible intervals while frequentist inference yields confidence intervals.) For example, one can plot one-, two-, and three-sigma contours. By definition, a two-sigma credible region includes 95% of the posterior probability, but this requirement does not uniquely determine a single credible region. One well-motivated method for constructing confidence intervals is the highest posterior density interval (HPDI) method.
We can visualise the HPDI method as follows. We draw a horizontal line through a posterior distribution and calculate the area of above the line. If we move the line down, the area goes up. If we place the line such that the area is 95%, then the posterior above the line is the HPDI two-sigma credible interval. In general, the HPDI is neither symmetric nor unimodal. The advantage of HPDI over other methods is that it yields the minimum width credible interval. This method is sometimes referred to as ‘draining the bathtub’.
Another commonly used method for calculating credible intervals is to construct symmetric intervals. Symmetric credible intervals are constructed using the cumulative distribution function,
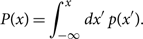 \begin{equation}
P(x) = \int_{-\infty}^{x} dx' \, p(x').
\end{equation}
\begin{equation}
P(x) = \int_{-\infty}^{x} dx' \, p(x').
\end{equation}
The X% credible region is the region:
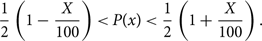 \begin{equation}
\frac{1}{2} \left(1 - \frac{X}{100}\right) \lt P(x) \lt \frac{1}{2} \left(1 + \frac{X}{100}\right).
\end{equation}
\begin{equation}
\frac{1}{2} \left(1 - \frac{X}{100}\right) \lt P(x) \lt \frac{1}{2} \left(1 + \frac{X}{100}\right).
\end{equation}
While symmetric credible intervals are simpler to construct than HPDI, particularly from samples drawn from a distribution, they can be misleading for multi-modal distributions and for distributions which peak near prior boundaries.
Credible intervals are useful for testing and debugging inference projects. Before applying an inference calculation to real data, it is useful to test it on simulated data. The standard test (see e.g. Sidery et al. Reference Sidery2014) is to simulate data d according to parameters θ true drawn at random from the prior distribution π(θ). Then, we analyse this data in order to obtain a posterior p(θ|d). The true value should fall inside the 90% credible interval 90% of the time. Testing that this is true provides a powerful validation of the inference algorithm. Note that we do not expect the posterior to peak precisely at θ true, just within the one-sigma region.
Appendix B. Gaussian noise likelihood
In this appendix, we introduce additional notation that is helpful for talking about the Gaussian noise likelihood frequently used in gravitational-wave astronomy. In the main body of the manuscript, d has been taken to represent data. Now, we take d to represent the Fourier transform of the strain time series d(t) measured by a gravitational-wave detector. In the language of computer programming,
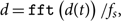 \begin{equation}
d = {\tt fft}\left(d(t)\right) / f_s ,
\end{equation}
\begin{equation}
d = {\tt fft}\left(d(t)\right) / f_s ,
\end{equation}
where fs is the sampling frequency and fft is a Fast Fourier transform. The noise in each frequency bin is characterised by the single-sided noise power spectral density P(f), which is proportional to strain squared and which has units of Hz−1.
The likelihood for the data in a single frequency bin j given θ is
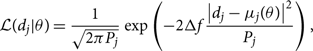 \begin{equation}
\mathcal{ L}(d_j | \theta) = \frac{1}{\sqrt{2\pi P_j}} \exp\left(-2\Delta f \frac{\left|d_j-\mu_j(\theta)\right|^2}{P_j}\right),
\end{equation}
\begin{equation}
\mathcal{ L}(d_j | \theta) = \frac{1}{\sqrt{2\pi P_j}} \exp\left(-2\Delta f \frac{\left|d_j-\mu_j(\theta)\right|^2}{P_j}\right),
\end{equation}
where Δf is the frequency resolution. The factor of 2Δf comes about from a factor of 1/2 in the normal distribution and a factor of 4Δf needed to convert the square of the Fourier transforms into units of one-sided power spectral density. The template μ(θ) is related to the metric perturbation h +,×(θ) via antenna response factors F +,× (Anderson et al. Reference Andreon and Weaver2001):
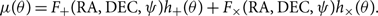 \begin{equation}
\mu(\theta) =
F_+(\text{RA},\text{DEC},\psi) h_+(\theta)
+ F_\times(\text{RA},\text{DEC},\psi) h_\times(\theta).
\end{equation}
\begin{equation}
\mu(\theta) =
F_+(\text{RA},\text{DEC},\psi) h_+(\theta)
+ F_\times(\text{RA},\text{DEC},\psi) h_\times(\theta).
\end{equation}
Gravitational-wave signals are typically spread over many (M) frequency bins. Assuming the noise in each bin is independent, the combined likelihood is a product of the likelihoods for each bin:
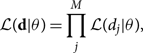 \begin{equation}
\mathcal{ L}({\bf d} | \theta) = \prod_j^M \mathcal{ L}(d_j | \theta),\vspace*{-2pt}
\label{eq:frequency_product}
\end{equation}
\begin{equation}
\mathcal{ L}({\bf d} | \theta) = \prod_j^M \mathcal{ L}(d_j | \theta),\vspace*{-2pt}
\label{eq:frequency_product}
\end{equation}
where d is the set of data including all frequency bins and dj represents the data associated with frequency bin j. If we consider a measurement with multiple detectors, the product over j frequency bins gains an additional index l for each detector. Combining data from different detectors is like combining data from different frequency bins.
It is frequently useful to work with the log likelihood, which allows us to replace products with sums of logs. The log also helps dealing with small numbers. The log likelihood is
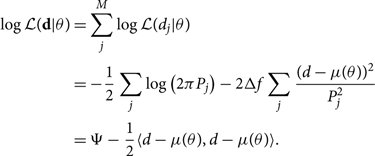 \begin{align}
\log\mathcal{ L}({\bf d} | \theta) & = \sum_j^M \log\mathcal{ L}(d_j | \theta) \nonumber\\
& = -\dfrac{1}{2}\sum_j \log\left(2\pi P_j\right)
-2 \Delta f \sum_j \dfrac{(d-\mu(\theta))^2}{P_j^2} \nonumber\\
& = \Psi
-\dfrac{1}{2} \langle d-\mu(\theta), d-\mu(\theta) \rangle \nonumber .
\end{align}
\begin{align}
\log\mathcal{ L}({\bf d} | \theta) & = \sum_j^M \log\mathcal{ L}(d_j | \theta) \nonumber\\
& = -\dfrac{1}{2}\sum_j \log\left(2\pi P_j\right)
-2 \Delta f \sum_j \dfrac{(d-\mu(\theta))^2}{P_j^2} \nonumber\\
& = \Psi
-\dfrac{1}{2} \langle d-\mu(\theta), d-\mu(\theta) \rangle \nonumber .
\end{align}
In the last line, we define the noise-weighted inner productFootnote r (Cutler & Flanagan Reference Damour, Iyer and Sathyaprakash1994):
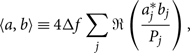 \begin{equation}\label{eq:inner_product}
\langle a,b \rangle \equiv 4\Delta f
\sum_j \Re\left( \frac{a_j^* b_j}{P_j} \right),\vspace*{-2pt}
\end{equation}
\begin{equation}\label{eq:inner_product}
\langle a,b \rangle \equiv 4\Delta f
\sum_j \Re\left( \frac{a_j^* b_j}{P_j} \right),\vspace*{-2pt}
\end{equation}
and the constant
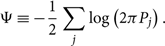 \begin{equation}
\Psi \equiv -\frac{1}{2}\sum_j \log\left(2\pi P_j\right) .
\end{equation}
\begin{equation}
\Psi \equiv -\frac{1}{2}\sum_j \log\left(2\pi P_j\right) .
\end{equation}
Since constants do not change the shape of the log likelihood, we often ‘leave off’ this normalising term and work with log likelihood minus Ψ. This is permissible as long as we do so consistently because when we take the ratio of two evidences—or equivalently, the difference of two log evidences—the Ψ factor cancels anyway. For the remainder of this appendix, we set Ψ = 0. Now that we have introduced the inner product notation, we are going to stop bold-facing the data d as it is implied that we are dealing with many frequency bins.
Using the inner product notation, we may expand out the log likelihood:
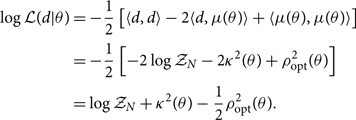 \begin{align}
\log \mathcal{ L}(d|\theta) &= -\dfrac{1}{2} \left[ \langle d,d \rangle -2\langle d,\mu(\theta) \rangle + \langle \mu(\theta),\mu(\theta) \rangle \right] \nonumber\\ &= -\dfrac{1}{2} \left[ -2\log\mathcal{ Z}_N -2 {\kappa^2 }(\theta) + \rho_{\rm opt}^2(\theta) \right] \nonumber\\ &= \log\mathcal{ Z}_N + {\kappa^2 }(\theta) - \dfrac{1}{2} \rho_{\rm opt}^2(\theta) .\end{align}
\begin{align}
\log \mathcal{ L}(d|\theta) &= -\dfrac{1}{2} \left[ \langle d,d \rangle -2\langle d,\mu(\theta) \rangle + \langle \mu(\theta),\mu(\theta) \rangle \right] \nonumber\\ &= -\dfrac{1}{2} \left[ -2\log\mathcal{ Z}_N -2 {\kappa^2 }(\theta) + \rho_{\rm opt}^2(\theta) \right] \nonumber\\ &= \log\mathcal{ Z}_N + {\kappa^2 }(\theta) - \dfrac{1}{2} \rho_{\rm opt}^2(\theta) .\end{align}
We see that the log likelihood can be expressed with three terms. The first is proportional to the log noise evidence:
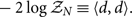 \begin{equation}
-2\log\mathcal{ Z}_N \equiv \langle d,d \rangle .\end{equation}
\begin{equation}
-2\log\mathcal{ Z}_N \equiv \langle d,d \rangle .\end{equation}
For debugging purposes, it is useful to keep in mind that if we calculate 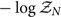 $-\log\mathcal{ Z}_N$ on actual Gaussian noise (with Ψ = 0), we expect a typical value nearly equal to the number of frequency bins M (multiplied by the number of detectors) since each term in the inner product contributes a value close to unity.Footnote s We skip over the second term κ 2 for a moment. The third term is the optimal matched filter signal-to-noise ratio squared:
$-\log\mathcal{ Z}_N$ on actual Gaussian noise (with Ψ = 0), we expect a typical value nearly equal to the number of frequency bins M (multiplied by the number of detectors) since each term in the inner product contributes a value close to unity.Footnote s We skip over the second term κ 2 for a moment. The third term is the optimal matched filter signal-to-noise ratio squared:
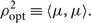 \begin{equation}
\rho_{\rm opt}^2 \equiv \langle \mu,\mu \rangle .
\end{equation}
\begin{equation}
\rho_{\rm opt}^2 \equiv \langle \mu,\mu \rangle .
\end{equation}
Returning now to the second term, we express κ 2 as the product of the matched filter signal-to-noise ratio and the optimal signal-to-noise ratio:
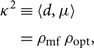 \begin{align}
{\kappa^2 } & \equiv \langle d,\mu \rangle \nonumber\\
& = \rho_{\rm mf} \, \rho_{\rm opt} ,
\end{align}
\begin{align}
{\kappa^2 } & \equiv \langle d,\mu \rangle \nonumber\\
& = \rho_{\rm mf} \, \rho_{\rm opt} ,
\end{align}
where
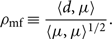 \begin{equation}
\rho_{\rm mf} \equiv
\frac{\langle d, \mu\rangle}{\langle\mu,\mu\rangle^{1/2}} .
\end{equation}
\begin{equation}
\rho_{\rm mf} \equiv
\frac{\langle d, \mu\rangle}{\langle\mu,\mu\rangle^{1/2}} .
\end{equation}
Readers familiar with gravitational-wave astronomy are likely acquainted with the concept of matched filtering, which is the maximum likelihood technique for gravitational-wave detection. By writing the likelihood in this way, we highlight how parameter estimation is related to matched filtering. Rapid evaluation of the likelihood function in Eq. (B7) has been made possible through reduced order methods (Smith et al. Reference Smith and Thrane2016; Pürrer Reference Röver, Meyer and Christensen2014; Canizares et al. Reference Chattopadhyay and Chattopadhyay2013).
Appendix C. Explicitly marginalised likelihoods
The most computationally expensive step in computing the likelihood for compact binary coalescences is creating the waveform template (μ in Eq. (5)). This is done in two steps. The first step is to use the intrinsic parameters to calculate the metric perturbation. The second (much faster) step is to use the extrinsic parameters to project the metric perturbation onto the detector response tensor. In some cases, it is possible to reduce the dimensionality of the inverse problem—thereby speeding up calculations and improving convergence—by using a likelihood, which explicitly marginalises over extrinsic parameters. The improvement is especially marked for comparatively weak signals, which can be important for population studies (see e.g. Smith & Thrane Reference Stevenson, Berry and Mandel2018). In this appendix, we show how to calculate  $\mathcal{ L}_{\rm marge}$—a likelihood, which explicitly marginalise over coalescence time, phase at coalescence, and/or luminosity distance. We continue with notation introduced in Appendix B.
$\mathcal{ L}_{\rm marge}$—a likelihood, which explicitly marginalise over coalescence time, phase at coalescence, and/or luminosity distance. We continue with notation introduced in Appendix B.
C.1. Time marginalization
In this subsection, we follow Farr (Reference Farr, Stevenson, Miller, Mandel, Farr and Vecchio2014) to derive a likelihood, which explicitly marginalises over time of coalescence t. Given a waveform with a reference coalescence time of t 0, we can calculate the waveform at some new coalescence time t by multiplying by the appropriate phasor:
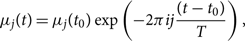 \begin{equation}
\mu_{j}(t)
= \mu_{j}(t_0) \exp\left(-2 \pi i j \frac{(t - t_0)}{T}\right),
\end{equation}
\begin{equation}
\mu_{j}(t)
= \mu_{j}(t_0) \exp\left(-2 \pi i j \frac{(t - t_0)}{T}\right),
\end{equation}
where T = 1/Δf is the duration of data segment and j is the index of the frequency bin as in Appendix B. It is understood that μ is a function of whatever parameters we are not explicitly marginalising over. We can therefore write κ 2 (see Eq. B10) as
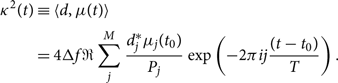 \begin{align}
\begin{split}
{\kappa^2 }(t) &\equiv \langle d, \mu(t) \rangle \\
&= 4\Delta f
\Re \sum_{j}^{M} \frac{d_{j}^{*} \mu_j( t_0)}{P_{j}} \exp\left(-2 \pi i j \frac{(t - t_0)}{T}\right).
\end{split}
\end{align}
\begin{align}
\begin{split}
{\kappa^2 }(t) &\equiv \langle d, \mu(t) \rangle \\
&= 4\Delta f
\Re \sum_{j}^{M} \frac{d_{j}^{*} \mu_j( t_0)}{P_{j}} \exp\left(-2 \pi i j \frac{(t - t_0)}{T}\right).
\end{split}
\end{align}
However, this sum is the discrete Fourier transform. By recasting this equation in terms of the fast Fourier transform fft, it is possible to take advantage of a highly optimised tool.
We discretise t – t 0 = kΔt where k takes on integer values between 0 and M = T/Δt. Having made this definition, marginalising over coalescence time becomes summing over k. The variable ;κ; 2 is a function of (discretised) coalescence time k. We can write in terms of a fast Fourier transform:
 \begin{align}
\begin{split}
{\kappa^2 }(k) &= 4\Delta f
\Re \sum_{j}^{M} \frac{d_{j}^{*} \mu_j( t_0)}{P_{j}} \exp\left(-2 \pi i j \frac{k \Delta t}{M}\right) \\
&= 4 \Delta f \Re \, {\tt fft}_{k}\left(\frac{d_{j}^{*} \mu_j(t_0)}{P_{j}} \right),
\end{split}
\end{align}
\begin{align}
\begin{split}
{\kappa^2 }(k) &= 4\Delta f
\Re \sum_{j}^{M} \frac{d_{j}^{*} \mu_j( t_0)}{P_{j}} \exp\left(-2 \pi i j \frac{k \Delta t}{M}\right) \\
&= 4 \Delta f \Re \, {\tt fft}_{k}\left(\frac{d_{j}^{*} \mu_j(t_0)}{P_{j}} \right),
\end{split}
\end{align}
where fftk refers to the k bin of a fast Fourier transform.
The other terms in Eq. (B7) are independent of the time at coalescence of the template. The marginalised likelihood is therefore
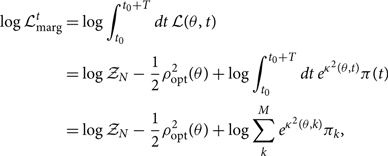 \begin{eqnarray}
\begin{split}
\log \mathcal{L}_{\rm marg}^t &= \log \int_{t_0}^{t_0 + T} dt \, \mathcal{L}(\theta, t) \\
&= \log\mathcal{ Z}_N - \frac{1}{2} \rho_{\rm opt}^2(\theta) + \log \int_{t_0}^{t_0 + T} dt \, e^{{\kappa^2 }(\theta, t)} \pi(t) \\
&= \log\mathcal{ Z}_N - \frac{1}{2} \rho_{\rm opt}^2(\theta) + \log \sum_{k}^{M} e^{{\kappa^2 }(\theta, k)} \pi_k ,
\end{split}
\end{eqnarray}
\begin{eqnarray}
\begin{split}
\log \mathcal{L}_{\rm marg}^t &= \log \int_{t_0}^{t_0 + T} dt \, \mathcal{L}(\theta, t) \\
&= \log\mathcal{ Z}_N - \frac{1}{2} \rho_{\rm opt}^2(\theta) + \log \int_{t_0}^{t_0 + T} dt \, e^{{\kappa^2 }(\theta, t)} \pi(t) \\
&= \log\mathcal{ Z}_N - \frac{1}{2} \rho_{\rm opt}^2(\theta) + \log \sum_{k}^{M} e^{{\kappa^2 }(\theta, k)} \pi_k ,
\end{split}
\end{eqnarray}
where πk is the prior on the discretised coalescence time.
Caution should be taken to avoid edge effects. If we employ a naive prior, the waveform will exhibit unphysical wrap-around. Similarly, care must be taken to ensure that the time-shifted waveform is consistent with time-domain data conditioning (e.g. windowing). (This is usually not a problem for confident detections because the coalescence time is well-known and so the segment edges can be avoided.) A good solution is to choose a suitable prior, which is uniform over some values of k, but with some values set to zero in order to prevent the signal from wrapping around the edge of the data segment. Note that Eq. (C1) breaks down for when the detector changes significantly over T due to the rotation of the Earth. It can also fail in the high signal-to-noise ratio limit when the t array becomes insufficiently fine-grained.
C.2. Phase marginalisation
In this subsection, we follow Veitch & Del Pozzo (Reference Veitch and Del Pozzo2013) (see also Veitch et al. (Reference Veitch2015)) to derive a likelihood, which explicitly marginalises over phase of coalescence φc. To begin, we assume a gravitational-waveform approximant consisting entirely of the dominant ℓ = 2, |m| = 2 modes so thatFootnote t
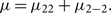 \begin{equation}
\mu = \mu_{22}+\mu_{2-2} .
\end{equation}
\begin{equation}
\mu = \mu_{22}+\mu_{2-2} .
\end{equation}
This is a valid assumption e.g. for the widely used waveform approximants—e.g. TaylorF2 (Damour, Iyer, & Sathyaprakash Reference Dupuis and Woan2005), IMRPhenomD (Khan et al. Reference Lange, O’shaughnessy and Rizzo2016), and IMRPhenomP (Hannam et al. Reference Hastings2014)—but not for waveforms that employ higher order modes (e.g. Blackman et al. Reference Callister2017). Given this approximation,Footnote u
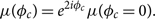 \begin{equation}\label{eq:phi}
\mu(\phi_c) = e^{2i\phi_c} \mu(\phi_c=0) .
\end{equation}
\begin{equation}\label{eq:phi}
\mu(\phi_c) = e^{2i\phi_c} \mu(\phi_c=0) .
\end{equation}
The optimal signal-to-noise ratio ρ opt is invariant under rotations in φc. However, the matched filter signal-to-noise ratio is not. Thus, the phase-marginalised likelihood is
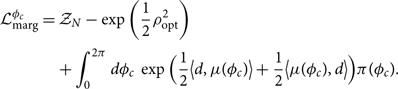 \begin{align}
\begin{split}
\mathcal{L}_{\rm marg}^{\phi_c} &= \mathcal{ Z}_N - \exp\left(\frac{1}{2} \rho_{\rm opt}^2\right) \\
&\quad + \int_{0}^{2\pi} d\phi_c \, \exp\Big(\frac{1}{2}
\big\langle d, \mu(\phi_c)\big\rangle + \frac{1}{2}\big\langle \mu(\phi_c) , d \big\rangle \Big) \pi(\phi_c).\\[4pt]
\end{split}
\end{align}
\begin{align}
\begin{split}
\mathcal{L}_{\rm marg}^{\phi_c} &= \mathcal{ Z}_N - \exp\left(\frac{1}{2} \rho_{\rm opt}^2\right) \\
&\quad + \int_{0}^{2\pi} d\phi_c \, \exp\Big(\frac{1}{2}
\big\langle d, \mu(\phi_c)\big\rangle + \frac{1}{2}\big\langle \mu(\phi_c) , d \big\rangle \Big) \pi(\phi_c).\\[4pt]
\end{split}
\end{align}
Using Eq. (C8), we can rewrite the phase-marginalised likelihood:
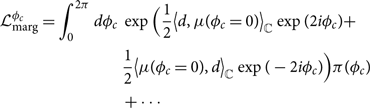 \begin{align}
\begin{split}
\mathcal{L}_{\rm marg}^{\phi_c} = \int_{0}^{2\pi} d\phi_c \, & \exp\Big(\frac{1}{2}
\big\langle d, \mu(\phi_c=0)\big\rangle_\mathbb{C}\exp(2i\phi_c) + \nonumber\\
& \frac{1}{2}\big\langle \mu(\phi_c=0) , d \big\rangle_\mathbb{C}\exp(-2i\phi_c) \Big) \pi(\phi_c) \nonumber\\
& + \cdots
\end{split}
\end{align}
\begin{align}
\begin{split}
\mathcal{L}_{\rm marg}^{\phi_c} = \int_{0}^{2\pi} d\phi_c \, & \exp\Big(\frac{1}{2}
\big\langle d, \mu(\phi_c=0)\big\rangle_\mathbb{C}\exp(2i\phi_c) + \nonumber\\
& \frac{1}{2}\big\langle \mu(\phi_c=0) , d \big\rangle_\mathbb{C}\exp(-2i\phi_c) \Big) \pi(\phi_c) \nonumber\\
& + \cdots
\end{split}
\end{align}
The parts that do not depend on φc are implied by the ellipsis. Here we introduce the ‘complex inner product’ denoted with a subscript ℂ:
 \begin{equation}\label{eq:inner_product_complex}
\langle a,b \rangle_\mathbb{C} \equiv 4\Delta f
\sum_j \left( \frac{a_j^* b_j}{P_j} \right) ,
\end{equation}
\begin{equation}\label{eq:inner_product_complex}
\langle a,b \rangle_\mathbb{C} \equiv 4\Delta f
\sum_j \left( \frac{a_j^* b_j}{P_j} \right) ,
\end{equation}
which is identical to the regular inner product defined in Eq. (B5) except we do not take the real part in order to preserve phase information that will be useful later on. Employing a uniform prior on φc and grouping terms, the integral can be rewritten yet again:
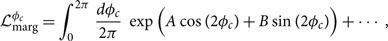 \begin{equation}
\mathcal{L}_{\rm marg}^{\phi_c} = \int_{0}^{2\pi} \frac{d\phi_c}{2\pi} \, \exp\Big(A\cos(2\phi_c) + B\sin(2\phi_c) \Big) + \cdots,
\end{equation}
\begin{equation}
\mathcal{L}_{\rm marg}^{\phi_c} = \int_{0}^{2\pi} \frac{d\phi_c}{2\pi} \, \exp\Big(A\cos(2\phi_c) + B\sin(2\phi_c) \Big) + \cdots,
\end{equation}
where
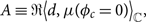 \begin{align} A & \equiv \Re \big\langle d, \mu(\phi_c=0) \big\rangle_\mathbb{C},\end{align}
\begin{align} A & \equiv \Re \big\langle d, \mu(\phi_c=0) \big\rangle_\mathbb{C},\end{align}
 \begin{align}B & \equiv \Im \big\langle d, \mu(\phi_c=0) \big\rangle_\mathbb{C} .\end{align}
\begin{align}B & \equiv \Im \big\langle d, \mu(\phi_c=0) \big\rangle_\mathbb{C} .\end{align}
The integral yields modified Bessel function of the first kind:
 \begin{equation}
I_{0}\left(\sqrt{A^2 + B^2}\right) = \frac{1}{2\pi} \int_{0}^{2\pi} d\phi \, e^{A c_{\phi} + B s_{\phi}} .
\end{equation}
\begin{equation}
I_{0}\left(\sqrt{A^2 + B^2}\right) = \frac{1}{2\pi} \int_{0}^{2\pi} d\phi \, e^{A c_{\phi} + B s_{\phi}} .
\end{equation}
Thus, we have
 \begin{align}
\sqrt{A^2 + B^2} &= \sqrt{\Re \big\langle d, \mu(0) \big\rangle^2_\mathbb{C} +
\Im \big\langle d, \mu(\phi_c=0) \big\rangle^2_\mathbb{C}} \nonumber\\
& = \left| \big\langle d, \mu(\phi_c=0) \big\rangle_\mathbb{C} \right| \nonumber\\
& = \left|{\kappa^2 }_\mathbb{C}\right| ,
\end{align}
\begin{align}
\sqrt{A^2 + B^2} &= \sqrt{\Re \big\langle d, \mu(0) \big\rangle^2_\mathbb{C} +
\Im \big\langle d, \mu(\phi_c=0) \big\rangle^2_\mathbb{C}} \nonumber\\
& = \left| \big\langle d, \mu(\phi_c=0) \big\rangle_\mathbb{C} \right| \nonumber\\
& = \left|{\kappa^2 }_\mathbb{C}\right| ,
\end{align}
where 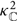 ${\kappa^2 }_\mathbb{C}$ is calculated the same way as κ (Eq. B10), except we use a complex inner product. The φc marginalised likelihood becomes
${\kappa^2 }_\mathbb{C}$ is calculated the same way as κ (Eq. B10), except we use a complex inner product. The φc marginalised likelihood becomes
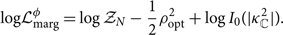 \begin{align}\label{eq:phase_marge}
\begin{split}
\log &\mathcal{L}_{\rm marg}^\phi = \log \ \mathcal{ Z}_N - \frac{1}{2} \rho_{\rm opt}^2 + \log I_0(|{\kappa^2 }_\mathbb{C}|) .
\end{split}
\end{align}
\begin{align}\label{eq:phase_marge}
\begin{split}
\log &\mathcal{L}_{\rm marg}^\phi = \log \ \mathcal{ Z}_N - \frac{1}{2} \rho_{\rm opt}^2 + \log I_0(|{\kappa^2 }_\mathbb{C}|) .
\end{split}
\end{align}
We reiterate that this marginalised likelihood is valid only insofar as we trust our initial assumption, that the signal is dominated by l = 2, |m| = 2 modes.
C.3. Distance marginalisation
In this subsection, we follow Singer & Price (Reference Singer2016) (see also Singer et al. Reference Singer2016) to derive a likelihood, which explicitly marginalises over luminosity distance DL. Given a waveform at some reference distance μ(D 0), the waveform at an arbitrary distance is obtained by multiplication of a scale factor:
 \begin{equation}
\mu_{j}(D_{L}) = \mu_{j}(D_{0})\, \left( \frac{D_{0}}{D_L} \right).
\end{equation}
\begin{equation}
\mu_{j}(D_{L}) = \mu_{j}(D_{0})\, \left( \frac{D_{0}}{D_L} \right).
\end{equation}
As before, it is understood that μ is a function of whatever parameters are not explicitly marginalising over. Unlike time and phase, distance affects ρ opt in addition to κ 2 (Eq. B10),
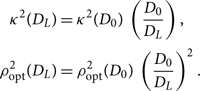 \begin{align}\label{eq:rhoD}
\begin{split}
{\kappa^2 }(D_{L}) &= {\kappa^2 }(D_{0})\, \left( \frac{D_{0}}{D_L} \right), \\
\rho_{{\rm opt}}^2(D_{L}) &= \rho_{{\rm opt}}^2(D_{0})\, \left( \frac{D_{0}}{D_L} \right)^2 .
\end{split}
\end{align}
\begin{align}\label{eq:rhoD}
\begin{split}
{\kappa^2 }(D_{L}) &= {\kappa^2 }(D_{0})\, \left( \frac{D_{0}}{D_L} \right), \\
\rho_{{\rm opt}}^2(D_{L}) &= \rho_{{\rm opt}}^2(D_{0})\, \left( \frac{D_{0}}{D_L} \right)^2 .
\end{split}
\end{align}
Note that κ 2 and ρ opt are implicit functions of whatever parameters we are not explicitly marginalising over.
At a fixed distance, the likelihood is
 \begin{equation}
\log \mathcal{L}(D_{L}) = \log\mathcal{ Z}_N + {\kappa^2 }(D_{L}) - \frac{1}{2} \rho_{\rm opt}^2(D_{L}),
\end{equation}
\begin{equation}
\log \mathcal{L}(D_{L}) = \log\mathcal{ Z}_N + {\kappa^2 }(D_{L}) - \frac{1}{2} \rho_{\rm opt}^2(D_{L}),
\end{equation}
and the likelihood marginalised over luminosity distance is
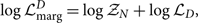 \begin{align}
\begin{split}
\log \mathcal{L}_{\rm marg}^D &= \log\mathcal{ Z}_N + \log \mathcal{ L}_D ,
\end{split}
\end{align}
\begin{align}
\begin{split}
\log \mathcal{L}_{\rm marg}^D &= \log\mathcal{ Z}_N + \log \mathcal{ L}_D ,
\end{split}
\end{align}
where
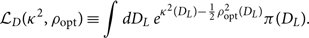 \begin{equation}
\mathcal{ L}_D({\kappa^2 },\rho_{\rm opt}) \equiv \int d D_{L}\, e^{{\kappa^2 }(D_{L}) - \frac{1}{2} \rho_{\rm opt}^2(D_{L})} \pi(D_{L}) .
\end{equation}
\begin{equation}
\mathcal{ L}_D({\kappa^2 },\rho_{\rm opt}) \equiv \int d D_{L}\, e^{{\kappa^2 }(D_{L}) - \frac{1}{2} \rho_{\rm opt}^2(D_{L})} \pi(D_{L}) .
\end{equation}
This integral to calculate 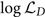 $\log \mathcal{ L}_D$ can be evaluated numerically. This explicitly marginalised form is generally true for all gravitational-waves sources. Its validity is only limited by the resolution of the numerical integral, though, cosmological redshifts adds additional complications, which we discuss in the next subsection. One can construct a pre-computed lookup table
$\log \mathcal{ L}_D$ can be evaluated numerically. This explicitly marginalised form is generally true for all gravitational-waves sources. Its validity is only limited by the resolution of the numerical integral, though, cosmological redshifts adds additional complications, which we discuss in the next subsection. One can construct a pre-computed lookup table 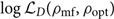 $\log\mathcal{ L}_D(\rho_{\rm mf}, \rho_{\rm opt})$ to facilitate fast and precise evaluation.
$\log\mathcal{ L}_D(\rho_{\rm mf}, \rho_{\rm opt})$ to facilitate fast and precise evaluation.
C.4. Distance marginalisation with cosmological effects
There is a caveat for our discussion of distance marginalisation in the previous subsection: when considering events at cosmological distances, the prior distributions for lab-frame masses become covariant with luminosity distance DL due to cosmological redshift. A signal emitted with source-frame mass ms is observed with lab-frame mass given by
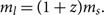 \begin{equation}
m_l = (1+z) m_s .
\end{equation}
\begin{equation}
m_l = (1+z) m_s .
\end{equation}
In this subsection, ‘mass’ m is shorthand for an array of both primary and secondary mass.
Now we derive an expression for 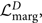 $\mathcal{ L}_{\rm marg}^D$, which can be applied to cosmological distances. We start by specifying the prior on redshift and source-frame massFootnote v:
$\mathcal{ L}_{\rm marg}^D$, which can be applied to cosmological distances. We start by specifying the prior on redshift and source-frame massFootnote v:
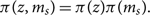 \begin{equation}
\pi(z, m_s) = \pi(z)\pi(m_s) .
\end{equation}
\begin{equation}
\pi(z, m_s) = \pi(z)\pi(m_s) .
\end{equation}
Both π(z) and π(ms) can be chosen using astrophysically motivated priors (see e.g. Talbot & Thrane Reference Umstätter, Meyer, Dupuis, Veitch, Woan, Christensen, Fischer, Preuss and von Toussaint2018; Fishbach & Holz Reference Fishbach, Holz and Farr2017; Fishbach,Holz, & Farr Reference Fishbach, Holz and Farr2018). Whatever priors we choose for π(z) and π(ms), they imply some prior for the lab-frame mass:
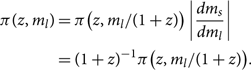 \begin{align}
\pi(z, m_l) &= \pi\big(z, m_l/(1+z)\big)
\left|\dfrac{dm_s}{dm_l}\right| \nonumber\\
& = (1+z)^{-1} \pi\big(z, m_l/(1+z)\big) .
\end{align}
\begin{align}
\pi(z, m_l) &= \pi\big(z, m_l/(1+z)\big)
\left|\dfrac{dm_s}{dm_l}\right| \nonumber\\
& = (1+z)^{-1} \pi\big(z, m_l/(1+z)\big) .
\end{align}
Now that we have converted the source-frame prior into a lab-frame prior, we can write down the distance-marginalised (redshift-marginalised) likelihood in terms of lab-frame quantities:
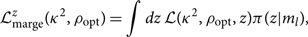 \begin{equation}\label{eq:zsum}
\mathcal{ L}_{\rm marge}^z({\kappa^2 },\rho_{\rm opt}) = \int dz \,
\mathcal{ L}({\kappa^2 },\rho_{\rm opt}, z)
\pi(z|m_l) ,
\end{equation}
\begin{equation}\label{eq:zsum}
\mathcal{ L}_{\rm marge}^z({\kappa^2 },\rho_{\rm opt}) = \int dz \,
\mathcal{ L}({\kappa^2 },\rho_{\rm opt}, z)
\pi(z|m_l) ,
\end{equation}
where
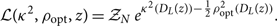 \begin{equation}
\mathcal{ L}({\kappa^2 },\rho_{\rm opt}, z) = \mathcal{ Z}_N\, e^{{\kappa^2 }\left(D_L(z)\right) - \frac{1}{2}\rho_{\rm opt}^2\left(D_L(z)\right)}.
\end{equation}
\begin{equation}
\mathcal{ L}({\kappa^2 },\rho_{\rm opt}, z) = \mathcal{ Z}_N\, e^{{\kappa^2 }\left(D_L(z)\right) - \frac{1}{2}\rho_{\rm opt}^2\left(D_L(z)\right)}.
\end{equation}
Note that κ 2 and ρ opt are implicit functions of whatever parameters we are not explicitly marginalising over.
By creating a grid of z, we can create a look-up table for 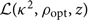 $\mathcal{ L}({\kappa^2 },\rho_{\rm opt},z)$, which allows for rapid evaluation of Eq. (C25). However, this means we will also need to create a look-up table for π(z|ml). In order to derive this look-up table, we rewrite the joint prior on redshift and lab-frame mass can be rewritten as follows:
$\mathcal{ L}({\kappa^2 },\rho_{\rm opt},z)$, which allows for rapid evaluation of Eq. (C25). However, this means we will also need to create a look-up table for π(z|ml). In order to derive this look-up table, we rewrite the joint prior on redshift and lab-frame mass can be rewritten as follows:
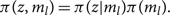 \begin{equation}
\pi(z, m_l) = \pi(z|m_l) \pi(m_l) .
\end{equation}
\begin{equation}
\pi(z, m_l) = \pi(z|m_l) \pi(m_l) .
\end{equation}
The marginalised lab-mass prior is
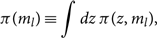 \begin{equation}
\pi(m_l) \equiv \int dz \, \pi(z, m_l) ,
\end{equation}
\begin{equation}
\pi(m_l) \equiv \int dz \, \pi(z, m_l) ,
\end{equation}
which can be calculated numerically. (We also need this distribution to provide to the sampler.) Thus, the conditional prior we need for our look-up table is as follows:
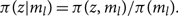 \begin{equation}
\pi(z | m_l) = \pi(z, m_l) / \pi(m_l) .
\end{equation}
\begin{equation}
\pi(z | m_l) = \pi(z, m_l) / \pi(m_l) .
\end{equation}
With look-up tables for 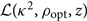 $\mathcal{ L}({\kappa^2 }, \rho_{\rm opt}, z)$ and π(z|ml), the sampler can quickly evaluate
$\mathcal{ L}({\kappa^2 }, \rho_{\rm opt}, z)$ and π(z|ml), the sampler can quickly evaluate 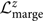 $\mathcal{ L}_{\rm marge}^z$ by summing over the grid of z:
$\mathcal{ L}_{\rm marge}^z$ by summing over the grid of z:
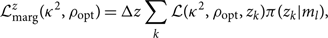 \begin{equation}
\mathcal{ L}_{\rm marg}^z({\kappa^2 },\rho_{\rm opt}) = \Delta z \sum_k \mathcal{ L}({\kappa^2 }, \rho_{\rm opt}, z_k)
\pi(z_k| m_l) ,
\end{equation}
\begin{equation}
\mathcal{ L}_{\rm marg}^z({\kappa^2 },\rho_{\rm opt}) = \Delta z \sum_k \mathcal{ L}({\kappa^2 }, \rho_{\rm opt}, z_k)
\pi(z_k| m_l) ,
\end{equation}
where Δz is the spacing of the redshift grid. This allows us to carry out explicit distance marginalisation while taking into account cosmological redshift.
C.5. Marginalisation withmultiple parameters
One must take care with the order of operations when implementing these marginalisation schemes simultaneously. We describe how to combine the three marginalisation techniques described above. The correct procedure is to start with Eq. (C16) and then marginalise over distance:
 \begin{align}
\begin{split}
\log \mathcal{L}_{\rm marg}^{\phi,D} &= \log\mathcal{ Z}_N \\
&\quad +
\log \int dD_{L}
e^{I_0(|{\kappa^2 }_\mathbb{C}(D_L)|)
-\frac{1}{2} \rho_{\rm opt}^2(D_L)} \pi(dD_L) .
\end{split}
\end{align}
\begin{align}
\begin{split}
\log \mathcal{L}_{\rm marg}^{\phi,D} &= \log\mathcal{ Z}_N \\
&\quad +
\log \int dD_{L}
e^{I_0(|{\kappa^2 }_\mathbb{C}(D_L)|)
-\frac{1}{2} \rho_{\rm opt}^2(D_L)} \pi(dD_L) .
\end{split}
\end{align}
Carrying out this integral numerically, one obtains a look-up table 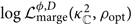 $\log\mathcal{ L}_{\rm marge}^{\phi,D}({\kappa^2}_\mathbb{C},\rho_{\rm opt})$, which marginalises over φ and DL. Finally, we add in t marginalisation by combining the look-up table with a fast Fourier transform:
$\log\mathcal{ L}_{\rm marge}^{\phi,D}({\kappa^2}_\mathbb{C},\rho_{\rm opt})$, which marginalises over φ and DL. Finally, we add in t marginalisation by combining the look-up table with a fast Fourier transform:
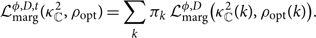 \begin{equation}
\mathcal{ L}_{\rm marg}^{\phi, D, t}({\kappa^2 }_\mathbb{C},\rho_{\rm opt}) =
\sum_k \pi_k \,
\mathcal{ L}_{\rm marg}^{\phi, D}\big({\kappa^2 }_\mathbb{C}(k),\rho_{\rm opt}(k)\big) .
\end{equation}
\begin{equation}
\mathcal{ L}_{\rm marg}^{\phi, D, t}({\kappa^2 }_\mathbb{C},\rho_{\rm opt}) =
\sum_k \pi_k \,
\mathcal{ L}_{\rm marg}^{\phi, D}\big({\kappa^2 }_\mathbb{C}(k),\rho_{\rm opt}(k)\big) .
\end{equation}
C.6. Reconstructing the unmarginalised posterior
While explicitly marginalising over parameters improves convergence and reduces runtime, the sampler will generate no posterior samples for the marginalised parameters. Sometimes, we want posterior samples for these parameters. In this subsection, we explain how it is possible to generate them with an additional post-processing step.
The parameter we are most likely to be interested in reconstructing is the luminosity distance DL. Let us assume for the moment that this is the only parameter over which we have explicitly marginalised. The first step to calculate the matched filter signal-to-noise ratio ρ mf and optimal signal-to-noise ratio ρ opt for each sample. For one posterior sample k, the likelihood for distance is
 \begin{equation}
\mathcal{ L}_k(d|D_{L}) = \mathcal{ Z}_N \,
e^{{\kappa^2 }(\theta_k, D_{L}) - \frac{1}{2} \rho_{\rm opt}^2(\theta_k, D_{L})} ,
\end{equation}
\begin{equation}
\mathcal{ L}_k(d|D_{L}) = \mathcal{ Z}_N \,
e^{{\kappa^2 }(\theta_k, D_{L}) - \frac{1}{2} \rho_{\rm opt}^2(\theta_k, D_{L})} ,
\end{equation}
where κ 2(DL) and ρ opt(DL) are defined in Eq. (C18). (When comparing with Eq. (C18), note that we have again made explicit the dependence on θk = whatever parameters we are not explicitly marginalising over.) Since this likelihood is one-dimensional, it is easy to calculate the posterior for sample k using Bayes’ theorem:
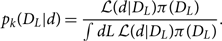 \begin{equation}
p_k(D_L|d) = \frac{\mathcal{ L}(d|D_{L}) \pi(D_L)}
{\int dL \, \mathcal{ L}(d|D_{L}) \pi(D_L)} .
\end{equation}
\begin{equation}
p_k(D_L|d) = \frac{\mathcal{ L}(d|D_{L}) \pi(D_L)}
{\int dL \, \mathcal{ L}(d|D_{L}) \pi(D_L)} .
\end{equation}
Using the posterior, one can construct a cumulative posterior distribution for sample k:
 \begin{equation}
P_k(D_L|d) = \int dD_L \, p_k(D_L|d) .
\end{equation}
\begin{equation}
P_k(D_L|d) = \int dD_L \, p_k(D_L|d) .
\end{equation}
The integral can be carried out numerically. The cumulative posterior distribution can be used to generate random values of DL for each posterior sample:
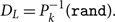 \begin{equation}
D_L = P_k^{-1}({\tt rand}).
\end{equation}
\begin{equation}
D_L = P_k^{-1}({\tt rand}).
\end{equation}
Reconstructing the likelihood or posterior when multiple parameters have been explicitly marginalised over is more complicated. However, one may use the following iterative algorithm:
1. For each sample θk marginalise over all originally marginalised parameters except one (λ).
2. Draw a single λ sample from the marginalised likelihood times prior.
3. Add this λ sample to the θk and return to step 1, this time not marginalising over λ.
Alternatively, one can skip the step of generating new samples in distance and calculate the likelihood of the data given DL marginalised over all other parameters,
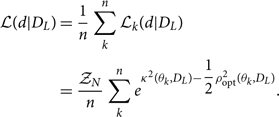 \begin{align}
\mathcal{ L}(d|D_L) & = \dfrac{1}{n}
\sum_k^n \mathcal{ L}_k(d|D_L) \nonumber\\
& = \dfrac{\mathcal{ Z}_N}{n}\sum_k^n e^{{\kappa^2 }(\theta_k, D_{L}) - \dfrac{1}{2} \rho_{\rm opt}^2(\theta_k, D_{L})} .
\end{align}
\begin{align}
\mathcal{ L}(d|D_L) & = \dfrac{1}{n}
\sum_k^n \mathcal{ L}_k(d|D_L) \nonumber\\
& = \dfrac{\mathcal{ Z}_N}{n}\sum_k^n e^{{\kappa^2 }(\theta_k, D_{L}) - \dfrac{1}{2} \rho_{\rm opt}^2(\theta_k, D_{L})} .
\end{align}
This likelihood can be used in Eq. (29) to perform population inference on the distribution of source distances and/or redshifts.
Appendix D. Posterior predictive distributions
The PPD represents the updated prior on the parameters θ given the data d. Recall that the hyper-posterior p(Λ|d) describes our post-measurement knowledge of the hyper-parameters that describe the shape of the prior distribution π(θ). The PPD answers the question: given this hyper-posterior, what does the distribution of π(θ) look like? More precisely, it is the probability that the next event will have true parameter values θ given what we have learned about the population hyper-parameters Λ:
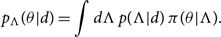 \begin{equation}
p_\Lambda(\theta|d) = \int d\Lambda \, p(\Lambda|d)
\, \pi(\theta|\Lambda) .
\end{equation}
\begin{equation}
p_\Lambda(\theta|d) = \int d\Lambda \, p(\Lambda|d)
\, \pi(\theta|\Lambda) .
\end{equation}
The Λ subscript helps us distinguish the PPD from the posterior p(θ|d). The hyper-posterior sample version is
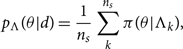 \begin{equation}
p_\Lambda(\theta|d) = \frac{1}{n_s}\sum_k^{n_s}
\pi(\theta|\Lambda_k) ,
\end{equation}
\begin{equation}
p_\Lambda(\theta|d) = \frac{1}{n_s}\sum_k^{n_s}
\pi(\theta|\Lambda_k) ,
\end{equation}
where k runs over ns hyper-posterior samples. While the PPD is the best guess for what the distribution π(θ) looks like, it does not communicate information about the variability possible in π(θ) given uncertainty in Λ. In order to convey this information, it can be useful to overplot many realisations of π(θ|Λk), where Λk is a randomly selected hyper-posterior sample. An example of a PPD is included in Figure 2.
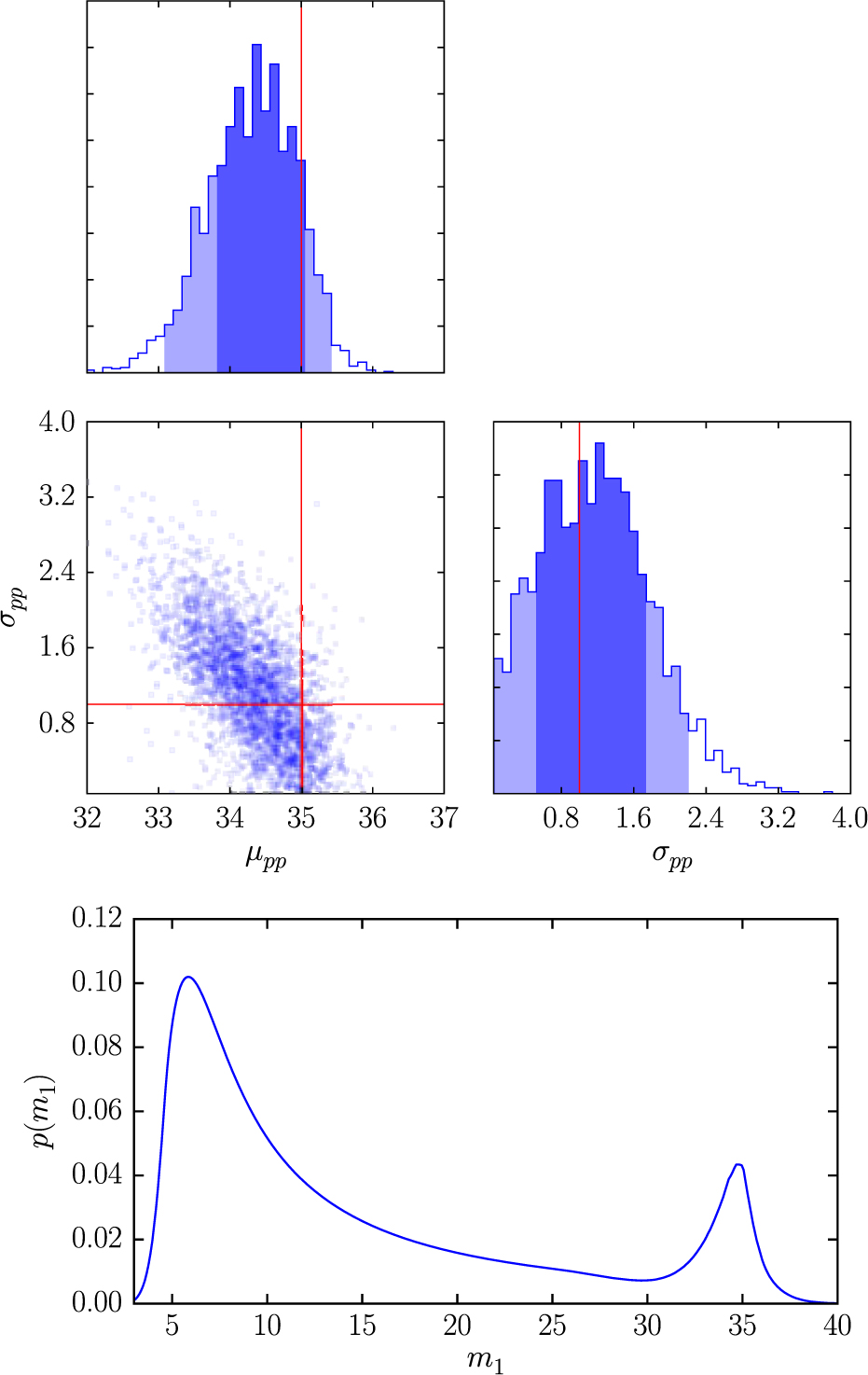
Figure 2: Top: an example corner plot from Talbot and Thrane (Reference Umstätter, Meyer, Dupuis, Veitch, Woan, Christensen, Fischer, Preuss and von Toussaint2018) showing posteriors for hyper-parameters μ PP and σPP. These two hyper-parameters describe, respectively, the mean and width of a peak in the primary mass spectrum due to the presence of pulsational pair instability supernovae. Bottom: an example of a posterior predictive distribution (PPD) for primary black hole mass, calculated using the hyper-posterior distributions in the top panel (adapted from Talbot and Thrane (Reference Umstätter, Meyer, Dupuis, Veitch, Woan, Christensen, Fischer, Preuss and von Toussaint2018)). The PPD has a peak near m 1 = 35 because the hyper-posterior for μ PP is maximal near this value. The width of the PPD peak is consistent with the hyper-posterior for σPP.
Appendix E. Selection Effects
In this section, we discuss how to carry out inference while taking into account selection effects, which arise from the fact that some events are easier to detect than others. We loosely follow the arguments from Abbott et al. (Reference Abbott2016a); however, see also Mandel, Farr, & Gair (Reference Mandel and O’shaughnessy2018) and Fishbach et al. (Reference Foreman-Mackey2018). In Section E.1, we discuss selection effects in the context of an individual detection. In Section E.2, we generalise these results to populations of events.
E.1. Selection effects with a single event
Some gravitational-wave events are easier to detect than others. All else equal, it is easier to detect binaries if they are closer, higher mass (at least, up until the point that they start to go out of the observing band), and with face-on/off inclination angles. More subtle selection effects arise due to black hole spin (e.g. Ng et al. Reference Pankow, Brady, Ochsner and O’shaughnessy2018). Typically, a gravitational-wave event is said to have been detected if it is observed with a matched-filter signal-to-noise ratio—maximised over extrinsic parameters θ extrinsic—above some threshold ρ th:
 \begin{equation}
\rho_{\rm mf}' \equiv
\max_{\theta_{\rm extrinsic}} \left(\rho_{\rm mf}\right) > \rho_{\rm th} .
\end{equation}
\begin{equation}
\rho_{\rm mf}' \equiv
\max_{\theta_{\rm extrinsic}} \left(\rho_{\rm mf}\right) > \rho_{\rm th} .
\end{equation}
Usually, ρ th = 8 for a single detector or ρ th = 12 for a ≥ 2 detector network.
Focusing on events with a ρ mf > ρ th detection forces us to modify the likelihood function:
 \begin{equation}\label{eq:Ldet}
\mathcal{ L}({\bf d} | \theta, {\rm det}) =
\begin{cases}
\frac{1}{p_{\rm det}(\theta)} \, \mathcal{ L}({\bf d} | \theta) & \rho_{\rm mf}'(\theta)\geq\rho_{\rm th} \\
0 & \rho_{\rm mf}'(\theta)<\rho_{\rm th}
\end{cases} ,
\end{equation}
\begin{equation}\label{eq:Ldet}
\mathcal{ L}({\bf d} | \theta, {\rm det}) =
\begin{cases}
\frac{1}{p_{\rm det}(\theta)} \, \mathcal{ L}({\bf d} | \theta) & \rho_{\rm mf}'(\theta)\geq\rho_{\rm th} \\
0 & \rho_{\rm mf}'(\theta)<\rho_{\rm th}
\end{cases} ,
\end{equation}
where
 \begin{equation}
p_{\rm det}(\theta) \equiv \int_{\rho_{\rm mf}'(\theta)>\rho_{\rm th}} d{\bf d} \,
\mathcal{ L}({\bf d} | \theta) .
\end{equation}
\begin{equation}
p_{\rm det}(\theta) \equiv \int_{\rho_{\rm mf}'(\theta)>\rho_{\rm th}} d{\bf d} \,
\mathcal{ L}({\bf d} | \theta) .
\end{equation}
(Here, we temporarily switch to data = d to avoid confusing data with the differential d; we switch back to data = d in a moment once we are finished with this normalisation constant.) This modification enforces the fact that we are not looking at data with  $\rho'_{\rm mf}<\rho_{\rm th}$. The p det factor ensures that the likelihood is properly normalised.
$\rho'_{\rm mf}<\rho_{\rm th}$. The p det factor ensures that the likelihood is properly normalised.
There are different ways to calculate p det in practice. The probability density function for ρ mf given θ—the distribution of ρ mf arising from random noise fluctuations—is a normal distribution with mean ρ opt and unit variance:
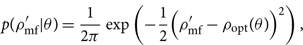 \begin{equation}\label{eq:rhomf}
p(\rho_{\rm mf}'|\theta) = \frac{1}{2\pi}
\exp\left(-\frac{1}{2}\Big(\rho_{\rm mf}'-\rho_{\rm opt}(\theta)\Big)^2\right) ,
\end{equation}
\begin{equation}\label{eq:rhomf}
p(\rho_{\rm mf}'|\theta) = \frac{1}{2\pi}
\exp\left(-\frac{1}{2}\Big(\rho_{\rm mf}'-\rho_{\rm opt}(\theta)\Big)^2\right) ,
\end{equation}
see Figure 3. Thus, we have
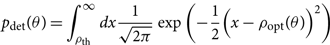 \begin{align}
p_{\rm det}(\theta)& =
\int_{\rho_{\rm th}}^\infty dx \frac{1}{\sqrt{2\pi}}
\exp\left({-\frac{1}{2}\Big(x-\rho_{\rm opt}(\theta)\Big)^2}\right)
\end{align}
\begin{align}
p_{\rm det}(\theta)& =
\int_{\rho_{\rm th}}^\infty dx \frac{1}{\sqrt{2\pi}}
\exp\left({-\frac{1}{2}\Big(x-\rho_{\rm opt}(\theta)\Big)^2}\right)
\end{align}
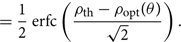 \begin{align}= \frac{1}{2}\,{\rm erfc}\left(\frac{\rho_{\rm th}-\rho_{\rm opt}(\theta)}{\sqrt{2}}\right) .\end{align}
\begin{align}= \frac{1}{2}\,{\rm erfc}\left(\frac{\rho_{\rm th}-\rho_{\rm opt}(\theta)}{\sqrt{2}}\right) .\end{align}
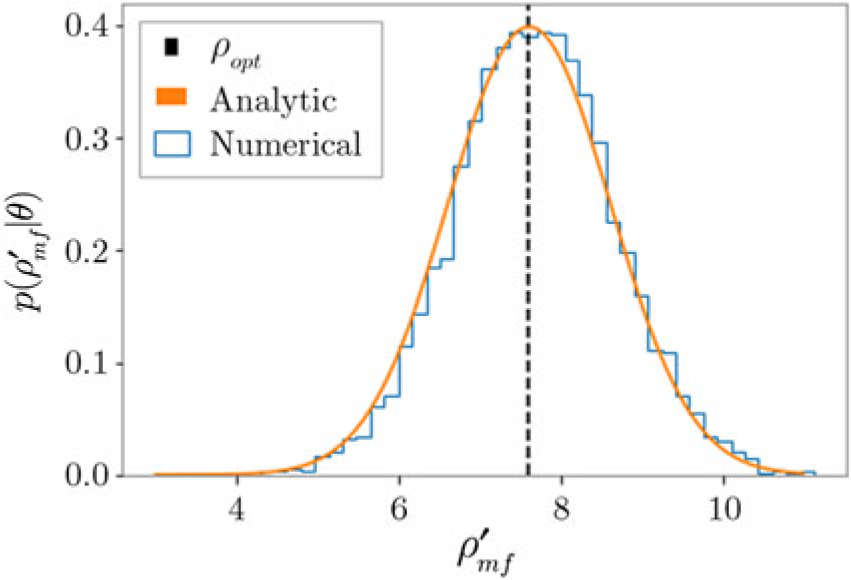
Figure 3: The distribution of matched filter signal-to-noise ratio maximised over phase for the same template in many noise realisations (blue). The distribution peaks at ρ opt = 7.6 (dashed black). The theoretical distribution (Eq. E4) is shown in orange.
Alternatively, if we are interested in the selection effects of intrinsic parameters, one may express p det as the ratio of the ‘visible volume’ 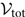 $\mathcal{ V}(\theta)$ to the total spacetime volume
$\mathcal{ V}(\theta)$ to the total spacetime volume 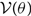 $\mathcal{ V}_{\rm tot}$:
$\mathcal{ V}_{\rm tot}$:
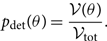 \begin{equation}\label{eq:Vtheta}
p_{\rm det}(\theta) = \frac{\mathcal{ V}(\theta)}{\mathcal{ V}_{\rm tot}} .
\end{equation}
\begin{equation}\label{eq:Vtheta}
p_{\rm det}(\theta) = \frac{\mathcal{ V}(\theta)}{\mathcal{ V}_{\rm tot}} .
\end{equation}
The visible volume is typically calculated numerically with injected signals.
E.2. Selection effects with a population of events
When considering a population of events, Eq. (E2) generalises to
 \begin{equation}
\mathcal{ L}(d,N|\Lambda,{\rm det}) =
\begin{cases}
\frac{1}{p_{\rm det}(\Lambda|N)}
\mathcal{ L}(d,N|\Lambda,R) .
& \rho_{\rm mf}\geq\rho_{\rm th} \\
0 & \rho_{\rm mf}<\rho_{\rm th}
\end{cases} .
\end{equation}
\begin{equation}
\mathcal{ L}(d,N|\Lambda,{\rm det}) =
\begin{cases}
\frac{1}{p_{\rm det}(\Lambda|N)}
\mathcal{ L}(d,N|\Lambda,R) .
& \rho_{\rm mf}\geq\rho_{\rm th} \\
0 & \rho_{\rm mf}<\rho_{\rm th}
\end{cases} .
\end{equation}
In analogy to Eq. (E7), the p det normalisation factor can be calculated using the visible volume as a function of the hyper-parameters Λ:
 \begin{equation}
\mathcal{ V}(\Lambda) \equiv \int d\theta
\mathcal{ V}(\lambda) \pi(\theta|\Lambda) .
\end{equation}
\begin{equation}
\mathcal{ V}(\Lambda) \equiv \int d\theta
\mathcal{ V}(\lambda) \pi(\theta|\Lambda) .
\end{equation}
Naively, one might expect that
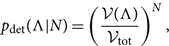 \begin{equation}
p_{\rm det}(\Lambda|N) = \left(\frac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N ,
\end{equation}
\begin{equation}
p_{\rm det}(\Lambda|N) = \left(\frac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N ,
\end{equation}
but this expression is incorrect because it does not marginalise over the Poisson-distributed rate, which ends up changing the answer. Marginalising over the rate, we obtain
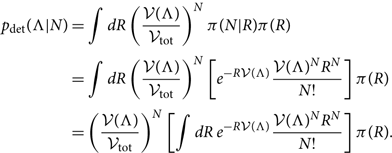 \begin{align}
p_{\rm det}(\Lambda|N)& =
\int dR
\left(\dfrac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N
\pi(N|R) \pi(R) \nonumber\\[1pt]
& = \int dR
\left(\dfrac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N
\left[e^{-R \mathcal{ V}(\Lambda)} \dfrac{\mathcal{ V}(\Lambda)^N R^N}{N!} \right] \pi(R) \nonumber\\[1pt]
& = \left(\dfrac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N \left[ \int dR \, e^{-R \mathcal{ V}(\Lambda)} \dfrac{\mathcal{ V}(\Lambda)^N R^N}{N!}\right] \pi(R) .
\end{align}
\begin{align}
p_{\rm det}(\Lambda|N)& =
\int dR
\left(\dfrac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N
\pi(N|R) \pi(R) \nonumber\\[1pt]
& = \int dR
\left(\dfrac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N
\left[e^{-R \mathcal{ V}(\Lambda)} \dfrac{\mathcal{ V}(\Lambda)^N R^N}{N!} \right] \pi(R) \nonumber\\[1pt]
& = \left(\dfrac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N \left[ \int dR \, e^{-R \mathcal{ V}(\Lambda)} \dfrac{\mathcal{ V}(\Lambda)^N R^N}{N!}\right] \pi(R) .
\end{align}
Note that p det depends on our prior for the rate R. If we choose a uniform-in-log prior π(R) ∝ 1/R, we obtain
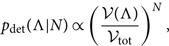 \begin{equation}
p_{\rm det}(\Lambda|N) \propto \left(\frac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N ,
\end{equation}
\begin{equation}
p_{\rm det}(\Lambda|N) \propto \left(\frac{\mathcal{ V}(\Lambda)}{\mathcal{ V}_{\rm tot}}\right)^N ,
\end{equation}
which reproduces the results from Abbott et al. (Reference Abbott2018a). Note that
 \begin{equation}
\mathcal{ L}(d|\Lambda,{\rm det}) \neq \int d\theta
\mathcal{ L}(d|\theta,{\rm det}) \, \pi(\theta | \Lambda) .
\end{equation}
\begin{equation}
\mathcal{ L}(d|\Lambda,{\rm det}) \neq \int d\theta
\mathcal{ L}(d|\theta,{\rm det}) \, \pi(\theta | \Lambda) .
\end{equation}