Contents
Article
A Partisan Solution to Partisan Gerrymandering: The Define–Combine Procedure
-
- Published online by Cambridge University Press:
- 13 December 2023, pp. 295-310
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Redistricting reformers have proposed many solutions to the problem of partisan gerrymandering, but they all require either bipartisan consensus or the agreement of both parties on the legitimacy of a neutral third party to resolve disputes. In this paper, we propose a new method for drawing district maps, the Define–Combine Procedure, that substantially reduces partisan gerrymandering without requiring a neutral third party or bipartisan agreement. One party defines a map of
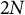 $2N$ equal-population contiguous districts. Then the second party combines pairs of contiguous districts to create the final map of N districts. Using real-world geographic and electoral data, we employ simulations and map-drawing algorithms to show that this procedure dramatically reduces the advantage conferred to the party controlling the redistricting process and leads to less-biased maps without requiring cooperation or non-partisan actors.
$2N$ equal-population contiguous districts. Then the second party combines pairs of contiguous districts to create the final map of N districts. Using real-world geographic and electoral data, we employ simulations and map-drawing algorithms to show that this procedure dramatically reduces the advantage conferred to the party controlling the redistricting process and leads to less-biased maps without requiring cooperation or non-partisan actors.
Inference in Linear Dyadic Data Models with Network Spillovers
-
- Published online by Cambridge University Press:
- 01 December 2023, pp. 311-328
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Using Machine Learning to Test Causal Hypotheses in Conjoint Analysis
-
- Published online by Cambridge University Press:
- 08 February 2024, pp. 329-344
-
- Article
-
- You have access
- HTML
- Export citation
Estimating the Ideology of Political YouTube Videos
-
- Published online by Cambridge University Press:
- 13 February 2024, pp. 345-360
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Vote Choices and Valence: Intercepts and Alternate Specifications
-
- Published online by Cambridge University Press:
- 18 January 2024, pp. 361-378
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Letter
On Finetuning Large Language Models
-
- Published online by Cambridge University Press:
- 28 November 2023, pp. 379-383
-
- Article
-
- You have access
- HTML
- Export citation
-
A recent paper by Häffner et al. (2023, Political Analysis 31, 481–499) introduces an interpretable deep learning approach for domain-specific dictionary creation, where it is claimed that the dictionary-based approach outperforms finetuned language models in predictive accuracy while retaining interpretability. We show that the dictionary-based approach’s reported superiority over large language models, BERT specifically, is due to the fact that most of the parameters in the language models are excluded from finetuning. In this letter, we first discuss the architecture of BERT models, then explain the limitations of finetuning only the top classification layer, and lastly we report results where finetuned language models outperform the newly proposed dictionary-based approach by 27% in terms of
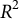 $R^2$ and 46% in terms of mean squared error once we allow these parameters to learn during finetuning. Researchers interested in large language models, text classification, and text regression should find our results useful. Our code and data are publicly available.
$R^2$ and 46% in terms of mean squared error once we allow these parameters to learn during finetuning. Researchers interested in large language models, text classification, and text regression should find our results useful. Our code and data are publicly available.