



1. Introduction
Promises and threats play a central role in human communication, from family life to negotiation and politics. They are often formulated as conditionals:
(1) If you do the dishes, I’ll let you go out.
(2) If you don’t eat the dinner, I won’t buy you this toy.
Comprehension of conditional promises and threats has been studied in psychology, linguistics, and philosophy. However, there has been little agreement as to what exactly the encoded semantics of conditional sentences is.
In grammatical terms, conditionals are complex sentences which consist of an if-clause, often referred to as the antecedent, and the main clause, which is also known as the consequent. In terms of their semantics, conditionals have been traditionally (i.e., following Grice, Reference Grice1989) assumed to encode the logical, truth-functional operator of Material Implication (henceforth, MI). This approach is justified insofar as it allows making some interesting predictions about what speakers are committing themselves to when they use conditionals.
The logical operator MI is typically represented by means of a truth table (see Table 1), where the variable p stands for the antecedent, q for the consequent, and the horseshoe symbol ‘⊃’ represents MI (other symbols used in the paper are: ‘&’ for conjunction and ‘∼’ for negation). In the truth table and throughout the paper, T stands for ‘true’ and F for ‘false’.
table 1. The truth table of Material Implication (T=true, F=false)

Let us now look at the predictions that MI makes for a conditional promise like that in (1), repeated below for convenience.
(1) If you do the dishes, I’ll let you go out.
In the first line of the truth table, p⊃q is T in a situation in which p is T and q is T. Applying this to our example, the conditional in (1) would be T – i.e. the speaker would have spoken truly – in a situation in which the speaker lets the hearer go out (q is T) after the hearer has done the dishes (p is T). It is worth noticing that this situation (or such a combination of truth values for p and q) corresponds to an intuitive understanding of what it means for the speaker of (1) to keep the terms of the conditional promise she made (the pronoun ‘she’ is used to refer to the speaker and ‘he’ to the hearer, unless specified otherwise in our examples).
Moving on to line two of Table 1, here the speaker has spoken falsely (as p⊃q is F), which corresponds to a situation in which the hearer does the dishes (p is T) and the speaker does not let him go out (q is F). Note the further predictive power of MI here: line two formally excludes the possibility of a true conditional where p is T and q is F – i.e., it excludes (p & ∼q) – and, interestingly, this truth value combination corresponds to an intuitive understanding of what would count as breaking the terms of a conditional promise by the speaker.
Line 3 may initially seem counter-intuitive as here MI predicts a situation in which a truthful promisor (p⊃q is T) is over-generous in that she lets the hearer go out (q is T) even though the hearer hasn’t done the dishes (p is F). However, on reflection, the speaker of (1) only said what she will do in a situation in which the hearer does the dishes, i.e., in which the hearer makes p true (henceforth, makes p). Thus, it may be argued that, in uttering (1), the speaker has not committed herself to any action in a situation in which the hearer doesn’t do the dishes, i.e., in which the hearer makes p false (henceforth, makes ∼p). The predictions on line 4 are straightforward: a truthful promisor (p⊃q is T) has the option of not letting the hearer go out, i.e., of making ∼q (because q is F) in a situation in which the hearer hasn’t done the dishes, i.e., made ∼p (because p is F).
MI licenses two inferences. The first of these, Modus Ponens, follows from the combination of lines 1 and 2 in the truth table and states that if the conditional is T and p is T, q must also be T. This can be expressed using the following logical notation: ((p⊃q) & p) ⊃ q. Applying this to our example, if the speaker of (1) has spoken truly (p⊃q) and the hearer has done the dishes (p), it is certain that the speaker will let the hearer go out (q), all other things being equal.
The second inference, Modus Tollens, follows from the combination of lines 2 and 4, and states that if the conditional is T and q is F, p must be F: ((p⊃q) & ∼q) ⊃ ∼p. In example (1), this means that if the speaker has spoken truly (p⊃q) and the hearer hasn’t been allowed to go out (∼q), we can be certain that the hearer has not done the dishes (∼p), all other things being equal.
According to the truth-functional approach, Modus Ponens and Modus Tollens follow semantically – i.e., independently of context – from a conditional statement. Nothing else follows semantically. For example, we have already seen that in (1) the speaker is semantically permitted to let the hearer go out (to make q) regardless of whether the hearer does the dishes or not. Hence, according to the logic of MI, one cannot infer with certainty that a truthful speaker of (1) will refrain from letting the hearer go out (make ∼q) in a situation in which the hearer hasn’t done the dishes (has made ∼p). Such inference, called the Fallacy of Denying the Antecedent – formally, ((p⊃q) & ∼p) ⊃ ∼q – is not licensed by MI. Neither is the Fallacy of Affirming the Consequent – formally, ((p⊃q) & q) ⊃ p – which would allow one to infer with certainty that the hearer has done the dishes (made p) based on the information that a truthful speaker of (1) has let the hearer go out (has made q).
Nevertheless, people often embark on these two fallacious inferences. They do so when they interpret the utterance of a conditional “if p, q” as a biconditional “if and only if p, q”. For example, the hearer of (1) may believe that he will be let out by the speaker if and only if he does the dishes; that is, if he doesn’t do the dishes, the speaker will not let him go out. Standard approaches assume that when people interpret if as if and only if, they do so via a pragmatic, context-dependent process of biconditionalisation (Levinson, Reference Levinson1983; Comrie, Reference Comrie, Traugott, ter Meulen, Reilly and Ferguson1986; Smith & Smith, Reference Smith, Smith, Hyman and Charles1988; Grice, Reference Grice1989; van der Auwera, Reference van der Auwera1997; Horn, Reference Horn2000; Noh, Reference Noh2000).
The traditional truth-functional approaches have enjoyed relative popularity in post-Gricean linguistics (e.g., Comrie, Reference Comrie, Traugott, ter Meulen, Reilly and Ferguson1986; Smith & Smith, Reference Smith, Smith, Hyman and Charles1988; Noh, Reference Noh2000) and in some main theoretical approaches in the psychology of reasoning (e.g., Rips Reference Rips1994; Braine & O’Brien, Reference Braine and O’Brien1998). Philosophers generally agree that conditionals cannot be semantically modelled on MI (e.g., Adams, Reference Adams1965; Stalnaker, Reference Stalnaker1975; Edgington, Reference Edgington1995; Lycan, Reference Lycan2001), a position in which they are joined by some psychologists (e.g., Oaksford & Chater, Reference Oaksford and Chater2003; Evans & Over, Reference Evans and Over2004; Evans, Handley, Neilens, & Over, Reference Evans, Handley, Neilens and Over2007) and linguists (e.g., van der Auwera, Reference van der Auwera1997; Sweetser, Reference Sweetser1990, pp. 113–141). There are also approaches (e.g., Johnson-Laird & Byrne, Reference Johnson-Laird and Byrne2002; Johnson-Laird, Byrne, & Girotto, Reference Johnson-Laird, Byrne and Girotto2009) positing what looks like an MI-based analysis of the ‘core meaning’ of a conditional – one which includes the three possibilities licensed by MI (p & q, ∼p & q, ∼p & ∼q) and excludes the possibility of p & ∼q – whose proponents, however, explicitly state that their theory is not truth-functional (Johnson-Laird et al., Reference Johnson-Laird, Byrne and Girotto2009, p. 75).
Now, regardless of the issue of truth-functional commitments, it appears that all theories of conditionals – including the co-called sufficient conditionality approach developed within cognitive linguistics (e.g., Sweetser, Reference Sweetser1990, pp. 113–141) – share the view that the possibility of (p & ∼q) should be excluded from the theory of conditionals. This cross-theoretical view is succinctly summed up by Lycan (2001, p. 24), who points out that “it is natural to be squeamish about a theory of conditionals that allows a conditional to be true even though its antecedent is true and its consequent is false”. Following Sztencel (Reference Sztencel2018), we are going to refer to this cross-theoretical constraint on conditionals as the ∼(p & ∼q) constraint (‘it is not the case that p and not q’ constraint). The question that we are interested in is whether the ∼(p & ∼q) constraint really is some sort of unitary constraint on the interpretation of “if p, q” conditionals, one which could be considered to constitute the context-independent semantics of conditionals. The current paper deals with this question by looking at conditional promises and threats.
In recent years, there has been a series of experiments in social psychology which report on a promise versus threat asymmetry in establishing when a conditional promise versus a conditional threat count as false (Beller, Reference Beller, Gray and Schunn2002; Beller & Bender, Reference Beller, Bender, Forbus, Gentner and Regier2004; Beller, Bender, & Kuhnmünch, Reference Beller, Bender and Kuhnmünch2005; Beller, Bender, & Song, Reference Beller, Bender and Song2009). The authors’ deontic commitment and emotional level analysis uncovers systematic differences in how conditional promises versus threats are interpreted. In particular, these studies found that breaking the terms of a conditional promise corresponds to (p & ∼q), which is predicted by the logic of MI, whereas breaking the terms of a conditional threat corresponds to (∼p & q), which is not predicted by MI. Relatedly, the authors have found that the conditional threatener is not obliged to make q in a situation in which the hearer made p (see also Searle & Vanderveken, Reference Searle and Vanderveken1985; Verbrugge, Dieussaert, Schaeken, & Van Belle, 2004, 2005). This is important since a lack of obligation to (p & q) entails permission to (p & ∼q), which is inconsistent with MI or, more generally, with the ∼(p & ∼q) constraint. Now, Beller (Reference Beller, Gray and Schunn2002) and Beller et al. (Reference Beller, Bender and Kuhnmünch2005) concur with Johnson-Laird and Byrne’s (Reference Johnson-Laird and Byrne2002) MI-based analysis of the ‘core meaning’ of a conditional. The authors argue that their findings are consistent with this theory and that their account explains how the ‘core meaning’ of a conditional – i.e., meaning which excludes the possibility of (p & ∼q) – is modulated in use.
The aim of the current paper is twofold. Firstly, Beller et al.’s studies were carried out in German (Beller, Reference Beller, Gray and Schunn2002; Beller et al., Reference Beller, Bender and Kuhnmünch2005), Tongan (Beller & Bender, Reference Beller, Bender, Forbus, Gentner and Regier2004), and Mandarin Chinese (Beller et al., Reference Beller, Bender and Song2009). We want to strengthen the cross-linguistic validity of the results by replicating the study on English conditionals. Secondly, we want to extend the previous studies by considering the aforementioned asymmetry between conditional promises and threats with regard to the cross-theoretically assumed ∼(p & ∼q) constraint.
If it is found that the ∼(p & ∼q) constraint does not apply to all conditionals, then the question arises whether it can actually be thought of as constituting the core meaning, or schematic representation, of conditionals. We will consider this question in relation to exemplar semantics.
2. Beller’s deontic commitments hypothesis
Examples (1) and (2), repeated below for convenience, exemplify two types of conditional inducements, i.e., statements made to influence hearers’ behaviour by telling them about the consequences of their behaviour (Searle Reference Searle and Searle1971).
(1) If you do the dishes, I’ll let you go out.
(2) If you don’t eat the dinner, I won’t buy you this toy.
(1) is used to influence the hearer’s behaviour by promising that q (I’ll let you go out) will be true if p (you do the dishes) is true, and (2) is used to influence the hearer’s behaviour by threatening that q (I won’t buy you this toy) will be true if p (you don’t eat the dinner) is true. As is well-known from the literature (e.g., Searle & Vanderveken, Reference Searle and Vanderveken1985; Fillenbaum, Reference Fillenbaum, Traugott, ter Meulen, Reilly and Ferguson1986; Beller, Reference Beller, Gray and Schunn2002), there is a motivational-level difference between conditional promises and threats: whereas with promises, p is a desired behaviour for which there is a reward (q), with threats, p is an undesired behaviour for which there is a punishment (q). Thus with promises the hearer is motivated (and thus expected) to make p, whereas with threats the hearer is motivated (and thus expected) to make ∼p. As pointed out by Beller (Reference Beller, Gray and Schunn2002), this difference at the motivational level gives rise to a difference in deontic commitments.
Beller (Reference Beller, Gray and Schunn2002) argues that crucial to the interpretation of conditional inducements is the question of what the speaker is obliged to do and what the speaker is permitted to do when p is false (i.e., when ∼p is the case). With promises, a cooperative hearer is one who makes p (does the dishes). When the hearer cooperates, the speaker is obliged to make q (let the hearer go out). From this it follows that the speaker is not permitted to make ∼q (refrain from letting the hearer go out) – this is because making ∼q would amount to breaking the terms of the conditional promise. With threats, however, a cooperative hearer is one who makes ∼p (eats the dinner). When the hearer cooperates, the speaker is obliged to make ∼q (buy the hearer the toy). From this it follows that the speaker is not permitted to make q (refrain from buying the hearer the toy) as this would amount to breaking the terms of the conditional threat.
But what if the hearer doesn’t cooperate? With promises, an uncooperative hearer is one who makes ∼p (doesn’t do the dishes). When the hearer doesn’t cooperate, then, according to Beller, there is no obligation on the speaker to reward the hearer with q (letting the hearer go out), yet she is permitted to do so. With threats, on the other hand, an uncooperative hearer is one who makes p (doesn’t eat the dinner). Beller (Reference Beller, Gray and Schunn2002) argues that, when the hearer doesn’t cooperate, the speaker is permitted to make q (refrain from buying the hearer the toy), but, at least intuitively, it is not clear whether the speaker is obliged to make q in such a scenario. This last point is important. If the speaker is not obliged to make q in a situation in which the hearer made p, then she is permitted to make ∼q. If the speaker is permitted to make ∼q, then the question arises of whether the speaker of a conditional threat is committed to ∼(p & ∼q) in the first place.
The predictions of Beller’s (2002) deontic commitments hypothesis delineate our main research questions in this project. Is there any evidence that not keeping a conditional promise in English corresponds to (p & ∼q), whereas not keeping a conditional threat to (∼p & q)? Relatedly, is it really the case that the speaker of a conditional threat is permitted to make ∼q in a situation in which the hearer made p? And, finally, what consequences do answers to these questions have for the assumption that the ∼(p & ∼q) constraint applies uniformly to all “if p, q” conditionals?
2.1. levels of analysis
Beller’s (2002) original study was designed to test predictions for the interpretation of conditional threats and promises at five levels of analysis: motivational, linguistic, deontic, pragmatic, and emotional. Following Beller, the levels are defined as follows.
The motivational level has to do with the speaker’s expectations as to what the hearer would do in the normal course of action, i.e., if not induced (see also Fillenbaum, Reference Fillenbaum1977; Evans & Twyman-Musgrove, Reference Evans and Twyman-Musgrove1998). The speaker’s expectation that the hearer would not make p for promises or ∼p for threats of his own accord results in the utterance of a conditional inducement and concurrent offering of an incentive to motivate the hearer’s behaviour (q for promises and ∼q for threats). The speaker’s expectations and incentives reflect her desire for the hearer’s goal-orientated behaviour (behaviour with a purpose of getting a reward or avoiding a punishment). It is predicted that the hearer’s goal-orientated behaviour should temporally precede the implementation of the incentive. Otherwise, the speaker risks that what was intended as an incentive will not motivate the desired hearer’s behaviour.
The linguistic level, as defined by Beller (Reference Beller, Gray and Schunn2002), has to do with how a conditional inducement is formulated. In line with the motivational level predictions, the linguistic formulation in which the information about the desired hearer’s behaviour temporally/linearly precedes the information about the incentive (as in (1) and (2) above) should be chosen most often. Such a formulation, which corresponds to “if p, then q” is referred to as canonical. Furthermore, it follows from the motivational level analysis that the information about the desired hearer’s behaviour would not appear in the formulation of an inducement if it was not intended to be a condition on the implementation of the incentive. Thus, according to Beller (and consistently with Geis & Zwicky, Reference Geis and Zwicky1971, but see von Fintel, Reference von Fintel2001), the hearers of conditional inducements should readily embark on the inference of Denying the Antecedent and chose a complementary formulation of an inducement, i.e., “if ∼p, then ∼q”, as representing such an inference (If you don’t do the dishes, I won’t let you go out; If you eat the dinner, I will buy you this toy). Now, it transpires that conditional promises can also be formulated using a reversed form of “if q, then p” (If I let you go out, then you’ll do the dishes). However, the reversed formulation seems inappropriate for conditional threats (?If I don’t buy you this toy, then you won’t eat the dinner). Conversely, conditional threats can be formulated using a reversed-complementary form of “if ∼q, then ∼p” (If I buy you this toy, then you’ll eat the dinner), but promises cannot (?If I don’t let you go out, then you won’t do the dishes). Nevertheless, the reversed formulation for promises and the reversed-complementary formulation for threats should not be chosen very often as the reversal of the temporal/linear order means that the desired hearer’s behaviour is no longer under the speaker’s control.
The analysis at the deontic level deals with the predictions of the deontic commitment hypothesis as discussed earlier. The pragmatic level, as specified by Beller (Reference Beller, Gray and Schunn2002), is concerned with the actions which are undertaken following the utterance of an inducement. Linked to the temporal/linear order discussed above is the prediction that the hearer decides first whether to cooperate with the speaker or not. After this, the speaker is in position to decide whether to cooperate with the hearer. Finally, the emotional level deals with emotional reactions which are elicited by goal-congruent versus goal-incongruent events (e.g., Roseman, Antoniou, & Jose, Reference Roseman, Antoniou and Jose1996). From the perspective of the hearer of a conditional inducement, a goal-congruent event corresponds to the hearer getting a reward or avoiding a punishment as a result of performing the action desired by the speaker. A goal-incongruent event is when the hearer does not get a reward or receives a punishment despite performing the action desired by the speaker. Accordingly, hearers are predicted to feel joy when they receive a deserved reward, relief when a negative event – such as punishment – does not happen, and anger when the speaker does not cooperate in a situation in which the hearer has cooperated by performing the action desired by the speaker. Thus, the hearer’s emotional reaction to the events that have occurred allows detecting whether the speaker has kept or broken the terms of their conditional inducement.
We tested the predictions of this multilevel analysis in two parts of the experiment, which are described in the next section.
3. The replication
3.1. participants
Seventy students took part in the experiment. The students came from different disciplines (e.g., literature, history, theology, education, sports sciences, business studies) at York St John University, UK. Thirty-four students were male and 36 female, with a mean age 20.14 years (range: 18–32). They all indicated that English was their first language.
3.2. materials
For the current study, the instrument used in the German studies by Beller (Reference Beller, Gray and Schunn2002) and Beller et al. (Reference Beller, Bender and Kuhnmünch2005) was translated into English. The emotional analysis was simplified (as in Beller, Reference Beller, Gray and Schunn2002) to include two situations – mutual cooperation and unexpected non-cooperation. The extended analysis of mutual non-cooperation and unexpected cooperation was not included because the emotional analysis was not the main focus of the current paper. We had to make several translation decisions that need to be explained here. The first decision concerned the translation of the emotions. The German emotion adjectives were translated into English in the following way: erleichtert (relieved), erfreut (happy), beschämt (ashamed), traurig (sad), gelangweilt (bored), ärgerlich (annoyed), and ängstlich (anxious). We used the Berlin Affective Word List Reloaded (Võ, Conrad, Kuchinke, Urton, Hofmann, & Jacobs, Reference Võ, Conrad, Kuchinke, Urton, Hofmann and Jacobs2009) to examine the affective valence and arousal ratings of the German emotion expressions. The German word Ärger,Footnote 1 which can be translated into English as annoyance or anger, is rated for affective valence at –1.9 on a 7-point scale ranging from ‘very negative’ –3 to ‘very positive’ 3, and for arousal at 3.94 on a 5-point scale ranging from ‘low’ 1 to ‘high’ 5 (Võ et al., Reference Võ, Conrad, Kuchinke, Urton, Hofmann and Jacobs2009). For the English expressions, we used Bradley and Lang’s (1999) 9-point scale. The English translations have the following ratings: angry (valence 2.85, arousal 7.17), annoyed (valence 2.74, arousal 6.49). This suggests that annoyed matches Ärger better on valence and arousal than angry does; however, the ratings of annoyed are nevertheless slightly higher (by 2–3%) than the ratings for Ärger. Accordingly, we decided to translate ärgerlich as annoyed, rather than angry.
The second decision concerned the use of modal verbs for the obligation (must, doesn’t have to) and permission (may, must not) questions in the second part of the experiment. Due to the epistemic/deontic ambiguity pertaining especially to the modals doesn’t have to and may in our scenarios, we decided to use the modal verbs in the options (e.g., Peter doesn’t have to lend Claire his computer game; Peter may lend Claire his computer game) but use the modal expressions obliged and permitted in the questions (i.e., Is Peter obliged to lend Claire his computer game?; Is Peter permitted to lend Claire his computer game?). This, we believe, has minimised the risk of the epistemic interpretation. Additionally, there was a ‘Please explain your choice’ section after each of the deontic tasks, which allowed identifying any issues with ambiguity and also potential issues with the strength of the modals.
The questionnaire consisted of two parts, Part I and Part II.
3.2.1. Part I
In Part I, conditional inducements were embedded in scenarios of mutual exchange. The characters try to achieve their goals by either making a promise (If you lend me your bike, then I’ll help you with your homework; If you help me with my homework, then I’ll lend you my bike) or making a threat (If you do not lend me your bike, then I will not help you with your homework; If you do not help me with my homework, then I will not lend you my bike). In half of the questionnaires, Henry was the speaker and Frank the hearer; in the other half, the roles were reversed. Each scenario was followed by four tasks: formulation, inference, sequence, and emotions.
In the formulation task, the participants were provided with one of the mutual exchange scenarios, like the one below, and told which inducement type (promise or threat) the speaker will use.
Usually, Frank doesn’t lend his bike to his schoolmates. However, Henry wants to borrow it today. Henry tries to reach this goal by promising Frank something. Henry knows that Frank would like his help with today’s homework, but usually Henry doesn’t help him.
The participants were then presented with four conditionals (canonical, complementary, reversed, and reversed-complementary) and instructed to select the one that seemed ‘the best choice’ for the speaker’s intended inducement.
Beginning from the inference task, the participants were given the context stories along with the canonical conditional, as in the example below.
Henry promised:
“Frank, if you lend me your bike, then I will help you with your homework.”
The instructions asked participants to choose ‘the most probable’ conclusion that could be made based on the given conditional. The participants were choosing between three options: complementary, reversed, and reversed-complementary.
In the sequence task, the participants were instructed to decide on the order of actions that will follow once the conditional inducement has been made.
In the emotion task, a conditional inducement was given in a context story and the task mentioned that the hearer cooperated (made p for promises, made ∼p for threats), as in the example below.
Henry promised: “Frank, if you lend me your bike, then I will help you with your homework.” After that, Frank lent his bike to Henry.
Informants were then to decide:
- what the speaker does (makes q or makes ∼q) if he acts versus doesn’t act according to the terms of the given inducement; and
- which feeling the hearer will have towards the speaker (relieved, happy, annoyed, ashamed, sad, bored, or anxious).
The tasks were ordered as described above. However, as the answers to the inference task could potentially influence the answers to the sequence task, the order of these two tasks was varied to avoid order effects (see Beller et al., Reference Beller, Bender and Kuhnmünch2005). The formulation task, inference task, sequence task, and emotion task (the last of which had four subsections) were each presented on a separate page.
3.2.2. Part II
In Part II, there were also four scenarios. This time they differed with respect to the speech act variable (promise or threat) and content variable (mutual lending or mutual destruction). Part II was devised to elicit deontic inferences about what the speaker is obliged and permitted to do in a situation where the hearer cooperated and in a situation where the hearer did not cooperate. Of particular interest here was the question of whether the findings from Part I could be replicated in a different set of tasks and extended to include the conditional threatener’s deontic commitments in a situation in which the hearer didn’t cooperate. This last point will help us establish whether (p & ∼q) is permitted for conditional threats in English.
In this part, conditional threats and promises were embedded in context stories constructed from two different content scenarios: mutual lending of things and mutual destruction of toys (amounting to four context stories).
Mutual lending scenarios stated that Peter would like to borrow Claire’s comic book:
- Peter’s threat: If you do not lend me your comic book, then I will not lend you my computer game
- Peter’s promise: If you lend me your comic book, then I’ll lend you my computer game
Mutual destruction scenarios stated that Sarah is about to smash George’s Lego car. George would like to prevent Sarah from smashing his car and he knows that Sarah has set up her Playmobil farm.
- George’s threat: If you smash my car, then I will smash your farm
- George’s promise: If you do not smash my car, then I will not smash your farm
Each context story was followed by four tasks: two for a situation in which the hearer cooperated, and two for a situation in which the hearer did not cooperate. An example is presented below.
Peter threatens Claire: “If you don’t lend me your comic book, I will not lend you my computer game.”
Following Peter’s threat, Claire lends Peter her comic book. What applies in this situation?
1. Is Peter obliged to lend Claire his computer game? Choose only one of the options:
a) Peter must lend Claire his computer game
b) Peter doesn’t have to lend Claire his computer game
c) It cannot be decided
The mutual lending and mutual destruction scenarios were set to ask different questions: whether the speaker is obliged/permitted to cooperate (lend the computer game) and whether the speaker is obliged/permitted not to cooperate (smash the Playmobil farm), respectively, each for the cooperative hearer and the non-cooperative hearer scenarios. These questions allowed us to obtain data on:
- Obligation and permission to keep the terms of a given inducement, which amounts to (p & q) for promises and (∼p & ∼q) for threats
- Obligation and permission to break the terms of an inducement, which amounts to (p & ∼q) for promises and (∼p & q) for threats
- Obligation and permission to be the better person (where X is the better person if X does Y a good turn even though Y hasn’t done X a good turn), which amounts to (∼p & q) for promises and (p & ∼q) for threats
- Obligation and permission to follow through with negative consequences of one’s inducement, which amounts to (∼p & ∼q) for promises and (p & q) for threats
In Part II, tasks 1 and 2 were presented on one page as they shared the same scenario. The same obtained for tasks 3 and 4. The participants were instructed to work on the tasks in the given order, not to return to a previous question, and to take as much time as they needed. All materials were presented in English.
3.3. design and procedure
There were four experimental groups corresponding to four different scenarios. The four scenarios varied between groups, and the speech acts were balanced between parts of the questionnaire. In assigning participants to groups, we controlled for the degree they were studying for (humanities versus non-humanities) and gender.
The questionnaire was administered in a teaching room on several days during a two-week period. Some participants were recruited via an email invitation; others were recruited on-the-spot on campus. The participants received a voucher as an incentive. All participants were asked not to discuss the study with anyone until the end of the two-week period. After a general introduction page, four tasks of Part I were followed by four tasks of Part II.
3.4. results
3.4.1. Part I
Formulation task. The results for the formulation task are presented in Table 2. The results indicate that there is a significant association between the type of inducement used and whether the person chose a canonical formulation or not. 31 out of 36 (86.1%) of the participants within the promise scenario chose the canonical formulation over the total of other possibilities (p<.001, binomial distribution with N=36 and r=1/4). However, only 21 out of 34 (61.8%) of the participants within the threat scenario chose the canonical formulation over the total of the other possibilities (p=.23, binomial distribution with N=34 and r=1/4). A χ 2 test of this difference between the promise versus threat formulation preferences was significant (χ 2 (1, N=70)=5.43, p=.028). The effect size was medium with phi=.278. Out of the other possibilities, reformulating a conditional threat as its complementary promise was more frequent than the reversed-complementary conditional option. For promises, the reversed formulation was chosen four times.
table 2. Results of the formulation task: choice of conditional formulation by type of inducement

Inference task. The results for the inference task are presented in Table 3. Similarly to Beller (Reference Beller, Gray and Schunn2002) and Beller et al. (Reference Beller, Bender and Kuhnmünch2005), we found that promises and threats did not differ with respect to choosing the complementary conditional compared to the total of other possibilities (χ 2 (1, N=70)=.23, p=.768). Aggregated over both speech acts, 56 (80%) of the participants chose the complementary conditional (p<.001, binomial distribution with N=70 and r=1/3).
table 3. Results of the inference task: choice of ‘the most probable’ conclusion by type of inducement

Sequence task. The predicted action sequence was that the ‘hearer decides first’ whether to cooperate with the speaker, after which it will become clear whether the speaker should cooperate. Similarly to Beller (Reference Beller, Gray and Schunn2002) and Beller et al. (Reference Beller, Bender and Kuhnmünch2005), the predicted action sequence was chosen by 63 (87%) of the participants (p<.001, binomial distribution with N=70 and r=1/2).
Emotion task: speaker’s action. For promises, a cooperative speaker will make q (help with homework or lend bike). 100% of informants answered that following the rule of the promise (i.e., acting according to the terms of the promise) corresponds to (p & q). For threats, a cooperative speaker will make ∼q (help with homework or lend bike). 28 out of 33 (84.8%) informants answered that following the rule of the threat corresponds to (∼p & ∼q) (p<.001, binomial distribution with N=33 and r=1/2).
For promises, an uncooperative speaker will make ∼q (not help with homework or not lend bike). 35 out of 36 (97.2%) informants answered that not following the rule of the promise (i.e., not acting according to the terms of the promise) corresponds to (p & ∼q) (p<.001, binomial distribution with N=36 and r=1/2). For threats, an uncooperative speaker will make q (not help with homework or not lend bike). 28 out of 34 (82.4%) informants answered that not following the rule of the threat corresponds to (∼p & q) (p<.001, binomial distribution with N=34 and r=1/2).
Emotion task: hearer’s emotion. In the study conducted by Beller (Reference Beller, Gray and Schunn2002), the speech act factor did not contribute significantly to this part of the Emotion task. Aggregated over both speech acts, 85.4% of the informants in Beller’s study said that, if the speaker keeps the rule of the inducement, then the hearer will feel a positive emotion, and 97.7% of the informants said that the hearer will feel a negative emotion if the speaker doesn’t keep the rule. However, in Beller et al.’s (2005) study, the speech act factor was found to contribute significantly where the speaker cooperated (χ 2 (2, N=67)=15.36, p<.001). Beller et al. report that, whereas the hearer was said to feel a negative emotion if the speaker didn’t keep the rule 100% of the time (aggregated over both speech acts) and a positive emotion if the speaker kept the rule 80.6% of the time (aggregated over both speech acts), 24.2% of the informants in the threat scenario indicated that the hearer feels annoyed even if the speaker cooperated.
In our study, the speech act factor was found to contribute significantly in both situations: where the speaker followed and didn’t follow the rule of the inducement. The results are summarised in Table 4.
table 4. Results of the emotion task, hearer’s emotion: choice of positive or negative emotion by inducement type and whether the speaker followed or didn’t follow the rule of the inducement

The variable Emotion was classified into two categories: positive and negative. Feeling ‘relieved’ or ‘happy’ was counted as having a positive emotion, whereas feeling ‘ashamed’, ‘sad’, ‘bored’, ‘annoyed’, or ‘anxious’ counted as having a negative emotion. With promises, if the speaker acts according to the terms of the inducement, the hearer is said to feel a positive emotion by 34 out of 36 (94.4%) of the participants. With threats, if the speaker acts according to the terms of the inducement, the hearer is said to feel a positive emotion by only 17 of the 33 (51.5%) participants. A χ 2 analysis reveals that this difference is significant (χ 2 (1, N=69)=16.46, p<.001). The effect size is medium with phi=.488.
Looking at the emotions in more detail, following the rule of the promise by the speaker resulted predominantly in the hearer feeling happy (55.6%) or relieved (38.8%). As for the negative emotions, 45.5% of our informants chose ‘annoyed’ in a situation where the speaker followed the rule of the threat. This number is higher than 15% (Beller, Reference Beller, Gray and Schunn2002) or 24.2% (Beller et al., Reference Beller, Bender and Kuhnmünch2005) of the German participants who chose ‘annoyed’ in this situation.
Moving on to the uncooperative speaker scenarios, with promises, the hearer is said to feel a negative emotion 100% of the time, 88.9% of which is comprised by ‘annoyed’ (comparable to Beller, Reference Beller, Gray and Schunn2002, and Beller et al., Reference Beller, Bender and Kuhnmünch2005). With threats, the hearer is said to feel a negative emotion by 26 out of 34 participants (76.5%) in our study (p<.003, binomial distribution with N=34 and r=5/7). Looking at the negative emotions in more detail, 52.9% of the participants in our study said that the hearer will feel ‘annoyed’ and 23.6% said that the hearer will feel ‘sad’. In the German studies, feeling ‘annoyed’ was chosen more often than the overall number for negative emotions in our study: by over 90% of participants in Beller (Reference Beller, Gray and Schunn2002) and Beller et al. (Reference Beller, Bender and Kuhnmünch2005).
3.4.2. Part II
The χ 2 test revealed that the speech act factor (promise or threat) did not contribute significantly to any of the tasks (p=0.34). Hence, the data for promise and threat scenarios were aggregated.Footnote 2 The tasks, which are discussed in detail below, looked into the speakers’ obligation and permission to keep the terms of a given inducement, to break the terms of an inducement, to be the better person, and to follow through with the negative consequences of one’s inducement. In each of the tasks, the difference between the most frequent response and the total of the other possibilities was tested with a binomial test. The results we significant with p<.05. With the exception of the results for the speaker’s permission to follow through with the negative consequences of the inducement (discussed below), our findings are comparable to Beller et al. (Reference Beller, Bender and Kuhnmünch2005).
Hearer cooperated: speaker’s obligation and permission to keep the terms of the inducement. The informants were asked whether the speaker is obliged to keep the terms of the inducement (i.e., Peter must lend Claire his computer game) if the hearer cooperated (if Claire lent Peter her comic book). For promises, mutual cooperation would correspond to the speaker making q (lend computer game) if the hearer makes p (lend comic book) – i.e., (p & q). For threats, that would correspond to speaker making ∼q (lend computer game) if the hearer makes ∼p (lends comic book) – i.e., (∼p & ∼q). 69.5% of the people in the mutual lending scenario indicated that the speaker is obliged to cooperate (lend out his computer game) if the hearer cooperated (lent out her comic book), 25% of the informants indicated that there is no obligation for the speaker to cooperate if the hearer cooperated, and 5.5% were undecided.
As for permission to keep the terms of the inducement, 82.8% of the participants indicated that the speaker is permitted to keep the terms of the inducement, 14.3% indicated it cannot be decided, and 2.9% indicated that the speaker is not permitted to keep the terms of the inducement.
Hearer cooperated: speaker’s permission and obligation to break the terms of the inducement. The informants were asked whether the speaker is permitted to break the terms of the inducement (i.e., to destroy Sarah’s farm) in a situation where the hearer cooperated (Sarah didn’t destroy George’s car). For promises, lack of cooperation on the part of the speaker corresponds to (p & ∼q), whereas for threats to (∼p & q). 85.3% of the participants in this scenario said that the speaker is not permitted to destroy Sarah’s farm, 8.9% said that the speaker is permitted to destroy Sarah’s farm, and 5.8% said it cannot be decided.
As for obligation to break the terms of the inducement, 88.2% of the participants said that there is no obligation for the speaker to break the terms of the inducement, whereas 11.8% said it cannot be decided.
Hearer didn’t cooperate: speaker’s permission and obligation to be the better person. The informants were asked whether the speaker is permitted to be the better person, i.e., to lend Claire his computer game if Claire didn’t lend Peter her comic book. For promises, the question is about whether the speaker is permitted to make q (lend computer game) if the hearer makes ∼p (doesn’t lend comic book) – i.e., (∼p & q). For threats, the question is about whether the speaker is permitted to make ∼q (lend computer game) if the hearer makes p (not lend comic book) – i.e., (p & ∼q). 86.1% of respondents said that the speaker is permitted to lend his computer game, 11.1% said it cannot be decided, and 2.8% said the speaker is not permitted to lend his computer game.
As for obligation to be the better person, 88.9% of the respondents said that the speaker is not obliged to lend his computer game, 8.3% said that it cannot be decided, and 2.8% said the speaker is obliged to lend his computer game.
Hearer didn’t cooperate: speaker’s obligation and permission to follow through with the negative consequences of the inducement. The informants were asked whether the speaker is obliged to follow through with the negative consequences of the inducement (destroy Sarah’s Playmobil farm) if the hearer didn’t cooperate (Sarah destroyed George’s Lego car). For promises, the speaker would follow through with the terms of the inducement by making ∼q (destroy Playmobil farm) if the hearer makes ∼p (destroys Lego car) – i.e., (∼p & ∼q). For threats, that would correspond to speaker making q (destroy Playmobil farm) if the hearer makes p (destroy Lego car) – i.e., (p & q). 70.6% of respondents said that the speaker is not obliged to follow through with the negative consequences of the inducement, 23.5% said the speaker is obliged to follow through with the negative consequences of the inducement, and 5.9% said that it cannot be decided.
As for permission, 73.5% of respondents said that the speaker is permitted to follow through with the negative consequences of the inducement, 17.7% of people were undecided, and 8.8% said that the speaker is not permitted to follow through with the negative consequences of the inducement. The number for permission is much higher than the 36% of informants who chose this option in Beller et al.’s (2005) study. Beller et al. explain this content effect by reference to an implicit social rule that people are not permitted to destroy other’s belongings.
3.5. discussion
3.5.1. Part I
The findings from the formulation task (86.1% canonical promise, 61.8% canonical threat) raise an interesting question, which potentially concerns socio-cultural differences in the strategies for formulating conditional inducements. We merely point to this issue here, as a meaningful interpretation of the results would require further research. Beller’s studies on German participants found no significant difference in the formulation preferences for promises and threats (Beller, Reference Beller, Gray and Schunn2002; Beller et al., Reference Beller, Bender and Kuhnmünch2005). However, Beller and Bender’s (2004) study found a significant difference in the Tongan participants’ formulation preferences. 64% of Tongan participants chose the canonical promise formulation (reversed at 18%, complementary at 12%, and reversed-complementary at 6% were the other choices), compared to 100% (Beller, Reference Beller, Gray and Schunn2002) and 94% (Beller et al., Reference Beller, Bender and Kuhnmünch2005) of German participants; and only 41% of Tongan participants chose the canonical threat formulation (complementary at 38% and reversed-complementary at 21% were the other choices), compared to 90% (Beller, Reference Beller, Gray and Schunn2002) and 85% (Beller et al., Reference Beller, Bender and Kuhnmünch2005) of German participants. Beller and Bender (Reference Beller, Bender, Forbus, Gentner and Regier2004, p. 89) argue that because “cooperation and particularly sharing with others are core values in the Tongan society, threats may simply be not appropriate as a means of initiating an exchange”. Looking at our data, the English participants were more likely to choose a canonical threat formulation than the Tongan participants, but less likely to do so than the German informants.
However, caution is needed before we attribute the differences in the formulation task to cross-cultural differences. Firstly, Beller and Bender’s (2004) Tongan participants were secondary school students with the mean age of 15.4, whereas the German participants were university students with the mean age of 23.8 (Beller, Reference Beller, Gray and Schunn2002) and 22.7 (Beller et al., Reference Beller, Bender and Kuhnmünch2005). This opens up the possibility that the more mature German students may have been better at putting aside the sociolinguistic appropriateness bias whilst engaging in the inducement formulation task: despite their formulation choices in the experiment, in real life they may as well prefer to formulate their threats as promises. This hypothesis receives some support from Beller et al.’s (2009) study, which investigated the responses of secondary school German participants with the mean age of 16.6. This study found that only 16% of the participants chose the canonical threat formulation (59% complementary, 22% reversed). In our view, the differences in the formulation of conditional inducements require further investigation. Nevertheless, the overall results obtained from the Tongan study, Beller et al.’s (2009) German study, and the present study reveal an interesting difference. If conditional threats, but not promises, are more strongly associated with the complementary formulation, then, potentially, the biconditional interpretation is more prominent with this type of inducement.
The inference task revealed no reliable difference in the most probable inference for conditional promises versus threats. However, we do not think that the results give a conclusive answer as to the question of whether there are differences in ‘the most probable’ inferential patterns associated with conditional promises versus threats. It is known from the literature that people tend to make more negative inferences (Modus Tollens and Denying the Antecedent) than positive inferences (Modus Ponens and Affirming the Consequent) with threats when compared to promises (see Egan & Byrne, Reference Egan and Byrne2012, for a useful summary). But the design of our inference task did not allow making a full comparison; note that we could not compare the rates of the negative inferences we obtained (especially the high rates of Denying the Antecedent) with the rates of Modus Ponens across the different inducement types, as no formulation corresponding to Modus Ponens was given as an option to participants. On the assumption that there is a tendency (as per Geis & Zwicky, Reference Geis and Zwicky1971, though see von Fintel, Reference von Fintel2001) to embark on the inference of Denying the Antecedent, the participants will naturally choose this inference as ‘the most probable’ one. An inference acceptance rating task, where participants are given the major premise plus the relevant minor premise and are asked whether a given conclusion follows, or what conclusion follows, would be better suited to test whether there are differences in the most probable inferential patterns associated with promises and threats (see, e.g., Cummins, Lubart, Alksnis, & Rist, Reference Cummins, Lubart, Alksnis and Rist1991; Thompson, Reference Thompson1994).
The results of the sequence task confirm the predicted action sequence: the hearer decides first whether to cooperate, after which it becomes clear whether the speaker should cooperate. This result strengthens the findings from the emotion tasks.
The results of the Speaker’s action part of the Emotion task support Beller’s (2002) deontic commitments hypothesis: breaking the terms of a promise (i.e., promising falsely) tends to correspond to (p & ∼q), whereas breaking the terms of a threat (i.e., falsely threatening) tends to correspond to (∼p & q). This answers the first of our research questions about the deontic commitments. As for the second question, Part II deals with the speaker’s deontic commitments in a situation in which the hearer didn’t cooperate. But before we turn to this issue, let us look at the hearer’s emotional reactions to see whether they support the results obtained in this part.
There are several interesting findings in the Emotion task. With respect to the hearer’s positive emotions in a situation in which the speaker followed the rule of the promise, our overall findings are similar to Beller (Reference Beller, Gray and Schunn2002) and Beller et al. (Reference Beller, Bender and Kuhnmünch2005) but differ in that the German participants chose ‘relieved’ less frequently than the English participants: 75% ‘happy’ and 25% ‘relieved’ in Beller (Reference Beller, Gray and Schunn2002) and 67% ‘happy’ and 27% ‘relieved’ in Beller et al. (Reference Beller, Bender and Kuhnmünch2005), compared with 55.6% ‘happy’ and 38.5% ‘relieved’ in the present study. Despite being classified as a positive emotion, the more frequent choice of ‘relieved’ among the English participants seems to suggest higher levels of anxiety in anticipation of the speaker’s action – typically, one feels ‘relieved’ if some negative event that one has been anticipating hasn’t happened. Indeed, these results are consistent with Beller’s motivational-level analysis and the resulting predicted action sequence. It follows from the hearer-first–speaker-second action sequence that once the speaker has uttered the inducement and the hearer has fulfilled the speaker’s goal, the hearer has to wait for the speaker to fulfil his goal. Since the speaker has the temporal advantage, relief on the part of hearer is plausible for both promises and threats.
As for the finding that 48.5% of the English participants chose a negative emotion when the speaker followed the rule of a conditional threat, this kind of emotional choice is likely to stem from the fact that the formulation of conditional threats involves the expression of aversive, or punishment-maximising, motives rather than appetitive, or reward-maximising, motives, as is the case with promises (Roseman et al., Reference Roseman, Antoniou and Jose1996). So the hearer is judged as feeling a negative emotion because the hearer was forced to participate by a threat (Heilmann & Garner, Reference Heilman and Garner1975; Beller et al., Reference Beller, Bender and Kuhnmünch2005).
Overall, our findings for the hearer’s emotion part of this task support the results obtained for the speaker’s action part. If the speaker follows the rule of the inducement, the hearer is said to feel a positive emotion, and any statistically significant choice of a negative emotion in such a situation is dictated by the fact that the hearer was induced by a threat. If the speaker did not follow the rule of the inducement, the hearer is said to feel a negative emotion most of the time.
To summarise, in the first part of the experiment, we have found that (a) conditional threats tend to be more strongly associated with the complementary formulation, suggesting that the biconditional interpretation, in particular the inference of Denying the Antecedent, may be more prominent for this type of a conditional inducement. We have also found that (b) breaking the terms of a conditional promise in English is associated with (p & ∼q), whereas (c) breaking the terms of a conditional threat is associated with (∼p & q). These findings were further supported by the results of the hearer’s emotion task.
3.5.2. Part II
Overall, the results obtained for the cooperative hearer scenarios corroborate Beller’s deontic commitments hypothesis. When the hearer cooperated, speakers are obliged to keep the terms of the inducement (which corresponds to (p & q) for promises and (∼p & ∼q) for threats) and are not permitted to break the terms of the inducement (which would correspond to (p & ∼q) for promises and (∼p & q) for threats). These results indicate that threats tend to be strongly associated with (∼p & ∼q) whereas promises with (p & q).
Given the slightly lower than expected result for the speaker’s obligation to keep the terms of the inducement (69.5%), we decided to see whether there was any explanation for it in the qualitative data. Interestingly, out of eleven participants who did not give the predicted answer, five participants working in the threat scenario said that the speaker is not obliged to lend Claire his computer game because he did not promise that he would. This suggests that these participants did not interpret the utterance of a conditional threat as giving rise to the deontic commitments of its complementary promise, and calls for more research into individual variation in the interpretation of conditional inducements. We come back to this point in section 4.
The results obtained for the uncooperative speaker scenarios also strengthen the findings from the previous studies. When the hearer doesn’t cooperate, the speaker is permitted but not obliged to be the better person (which corresponds to (∼p & q) for promises and (p & ∼q) for threats), and permitted but not obliged to follow through with the negative consequences of the inducement (which corresponds to (∼p & ∼q) for promises and (p & q) for threats). These findings further indicate that threats are more strongly associated with (∼p & ∼q), whereas promises with (p & q).
In the next section, we discuss our findings – about the speaker’s obligation/permission to keep the terms of a given inducement, to break the terms of an inducement, to be the better person, and to follow through with negative consequences of one’s inducement – in relation to the ∼(p & ∼q) constraint.
4. Implications: the ∼(P & ∼Q) constraint
Table 5 summarises the findings from Part II which are relevant to the research questions with which we have started this project: Is there any evidence that not keeping a conditional promise in English corresponds to (p & ∼q), whereas not keeping a conditional threat to (∼p & q)? What are the speaker’s deontic commitments in a situation where the hearer of a conditional threat made p? And, finally, what consequences do answers to these questions have for the assumption that the ∼(p & ∼q) constraint applies uniformly to all “if p, q” conditionals?
table 5. Summary of Part II findings which are relevant to the discussion of the ∼(p & ∼q) constraint (line numbers in the final column are referenced in the discussion in section 4)
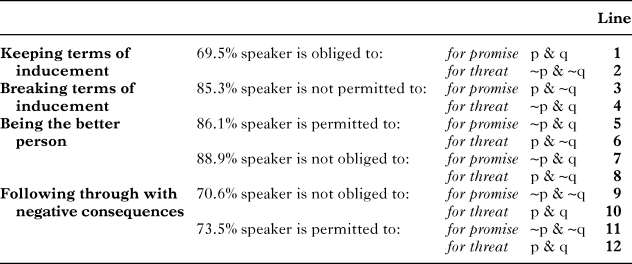
As predicted by Beller’s (2002) deontic commitments hypothesis, whereas the majority of participants feel that the speaker of a conditional threat is obliged to (line 2 in Table 5) make ∼q in a situation in which the hearer made ∼p, the speaker of a conditional promise is typically judged as permitted to (line 11), but not obliged to (line 9), make ∼q in a situation in which the hearer made ∼p. These results show that (∼p & ∼q) is more strongly associated with conditional threats than promises.
As for breaking the terms of a conditional inducement, from the threatener’s obligation to make ∼q in a situation in which the hearer made ∼p (line 2), it follows that breaking the terms of a conditional threat should correspond to (∼p & q). Indeed, the majority of participants indicated that the conditional threatener is not permitted to make q in a situation in which the hearer made ∼p (line 4). With conditional promises, the majority of participants feel that the conditional promisor is obliged to (line 1) make q in a situation in which the hearer made p and, consequently, not permitted to (line 3) make ∼q in a situation in which the hearer made p. These results indicate that breaking the terms of a conditional promise in English is associated with (p & ∼q), whereas breaking the terms of a conditional threat is associated with (∼p & q).
With regard to our last question – concerning the conditional threatener’s deontic commitments in a situation in which the hearer didn’t cooperate (i.e., made p) – the majority of participants indicated that the conditional threatener is permitted to make ∼q in a such situation (line 6). Crucially, this permission to make ∼q in such a situation is equivalent to the lack of obligation to ∼(p & ∼q).
The findings reported in this paper are controversial in the light of the standard, and cross-theoretical, assumption that the ∼(p & ∼q) constraint applies uniformly to “if p, q” conditionals. More generally, the findings are controversial in the light of the traditional theories that require some schematised representation, abstracted from past experiences, to be involved in the process of utterance interpretation. However, the findings are in line with the theory of illocutionary acts (Searle & Vanderveken, Reference Searle and Vanderveken1985) and with previous empirical work on languages other than English (Beller, Reference Beller, Gray and Schunn2002; Verbrugge et al., Reference Verbrugge, Dieussaert, Schaeken and Van Belle2004, Reference Verbrugge, Dieussaert, Schaeken and Van Belle2005; Beller et al., Reference Beller, Bender and Kuhnmünch2005).
This gives rise to two questions. Firstly, we need to consider whether it is actually possible for a threat which does not involve the ∼(p & ∼q) constraint to function as a successful inducement. Secondly, assuming a positive answer to the first question, we need to consider which type of approach to utterance interpretation is most compatible with the findings.
4.1. what makes a successful inducement?
Put simply, the first question amounts to this. Imagine that George threatens Sarah by saying: If you smash my Lego car, then I’ll smash your Playmobil farm. Due to the fact that, on multiple occasions in the past, George did not follow through with the negative consequences of his threats, Sarah assumes that George is actually unlikely to smash her farm in revenge and George knows that Sarah assumes so. Given this context, is it possible for George’s threat to induce Sarah to refrain from smashing George’s car?
A threat which does not involve the ∼(p & ∼q) constraint, i.e., one which permits (p & ∼q), essentially allows for a situation in which the threatener is the better person – where X is the better person if X does Y a good turn (here: George doesn’t smash Sarah’s farm) even though Y hasn’t done X a good turn (here: Sarah smashed George’s car).
Notice that our results (lines 6 and 8 in Table 5) indicate that, even though a conditional threatener is permitted to be the better person, they are not obliged to be the better person. Therefore, it is plausible to assume that, in a situation in which the hearer of a conditional threat made p (did not cooperate), a lack of the ∼(p & ∼q) constraint will keep two possibilities open: the possibility that the speaker makes ∼q (is the better person) and the possibility that the speaker makes q (follows through with the negative consequences of the inducement). One of the factors which would make such a threat a successful inducement then – in fact, one which would make it a threat – is the mere possibility of the threatener following through with the negative consequences of the inducement. Coming back to our example, even though Sarah assumes that George is unlikely to make q (smash her farm), there’s always the possibility that he might behave in an untypical way and this time follow through with the negative consequences of his threat. Being aware of this possibility, coupled with a desire to prevent it from becoming true, is sufficient to induce Sarah into cooperation.
As hypothesised by Sztencel (Reference Sztencel2018), threats which do not involve the ∼(p & ∼q) constraint, i.e., threats which can be called ‘the better person possibility threats’, can function as successful inducements for two reasons:
(i) such threats involve the ∼(∼p & q) constraint; and
(ii) they involve the possibility of the speaker choosing to (p & q)
This hypothesis is supported by our findings in the following way. The constraint in (i) is evidenced by lines 2 and 4 in Table 5 and it prevents the threatener from breaking the terms of the inducement. Thus, assuming that the threatener has spoken truly, this constraint gives the hearer grounds to believe that his cooperative behaviour will be met with the speaker’s cooperative behaviour. This guarantees that making ∼p will actually be beneficial to the hearer; in other words, (i) provides an appetitive motive for the hearer to make ∼p. On top of this, the uncertainty which follows from (ii) – evidenced by lines 6 and 12 taken together – gives the hearer an additional, aversive, motive to make ∼p and thus avoid the possibility of the speaker making q.
Now, if the better person possibility threats can function as successful inducements (in the light of (i) and (ii)), then the ∼(p & ∼q) constraint cannot be said to uniformly apply to conditionals.
A further support for the existence of the better person possibility threats comes from the observation that the better person possibility promises also exist. Such promises would involve (i) the ∼(p & ∼q) constraint, which ensures that the speaker doesn’t break the terms of the promise made, and (ii) the possibility of the speaker choosing to ∼q (follow through with the negative consequences of the inducement) in a situation in which the hearer didn’t cooperate, i.e., made ∼p (Sztencel, Reference Sztencel2018). The existence of such promises (i.e., promises whose use and interpretation is underlain by such assumptions) is evidenced in our findings. When interpreted materially, conditional promises involve the hearer’s assumption that the speaker is obliged to cooperate in response to the hearer’s cooperative behaviour (lines 1 and 3) and they may involve the assumption that the speaker can choose to be the better person (lines 5 and 11).Footnote 3 The parallel findings for the promises and threats are thus mutually supportive of the hypothesis that the better person possibility inducements are a real phenomenon.
4.2. towards an exemplar semantics for conditionals
Now that we have established that the better person possibility threats can be successful inducements, we need to face a possible objection to the argument that the existence of such threats undermines the claim that the ∼(p & ∼q) constraint is the ‘core meaning’ of conditionals. It’s plausible to imagine an objection along the following lines: any theory which takes the ∼(p & ∼q) constraint to be the ‘core meaning’, or abstract representation, of a conditional is capable of dealing with the findings of this paper – it could be argued that the lack of application of the ∼(p & ∼q) constraint is established via a pragmatic inference. But there are several issues with such a hypothetical objection.
The first issue is illustrated by the following example:
(3) If you do it again, I’ll play the guitar.
As argued in Sztencel (Reference Sztencel2014, Reference Sztencel2018), (3) can be interpreted as a conditional promise or a threat (see also Van Canegem-Ardijns & Van Belle, Reference Van Canegem-Ardijns and Van Belle2008; Bonnefon Reference Bonnefon2009). How it is interpreted depends on whether the hearer finds listening to the speaker playing the guitar desirable or not and whether the hearer knows that the speaker knows that. So before it is established whether the ∼(p & ∼q) constraint applies in this case, it needs to be established whether we are dealing with a promise or a threat, which, in turn, depends on the hearer’s assumptions about the speaker’s knowledge of the hearer’s likes and dislikes. In other words, it is not the case that the context merely modulates or enriches the purportedly encoded abstract representation – in fact, contextual, holistic, inference, which involves complex assumptions about one’s interlocutor, leads one to establish that the ∼(p & ∼q) constraint applies or that it does not.
The second issue concerns the explanatory potentials of a logico-semantic approach versus a socio-cognitive approach to conditional inducements (Sztencel, Reference Sztencel2018). One problem for a logico-semantic approach is that it would have to square the claim that the ∼(p & ∼q) constraint is the ‘core meaning’ of conditionals with the issue illustrated by (3) above. Another, very significant, problem is that the logico-semantic ∼(p & ∼q) constraint makes different predictions for conditional promises and threats with regards to the deontic commitments. Notice that the lack of permission to make ∼q when the hearer made p amounts to:
- for promises, the lack of permission to break the terms of the promise in a situation in which the hearer cooperates
- for threats, the lack of permission for the speaker to be the better person
Furthermore, the obligation to (p & q), which follows logically from the ∼(p & ∼q) constraint, amounts to:
- for promises, the obligation for the speaker to keep the terms of the promise in a situation in which the hearer cooperates
- for threats, the obligation for the speaker to follow through with the negative consequences of the threat
Thus, on the logico-semantic approach, the conditional promisor and threatener are semantically committed to different things. Crucially, on this approach, the conditional promisor is semantically committed to cooperate (i.e., to keep the terms of the inducement) in a situation in which the hearer cooperates, whereas the conditional threatener isn’t. For a conditional threatener, this commitment arises via a pragmatic modulation. So assuming the logical symmetry for all conditionals, in the form of the ∼(p & ∼q) constraint, introduces an intuitively incorrect socio-cognitive asymmetry pertaining to what rules of cooperation are thought to hold for which inducements. Apart from being intuitively incorrect, this socio-cognitive asymmetry is inconsistent with the empirical findings.
A more explanatory approach, one which is consistent with the empirical findings reported in this paper, would see the observed logical asymmetry (i.e., the lack of across-the-board application of the ∼(p & ∼q) constraint) as a mere epiphenomenon of the socio-cognitive symmetry pertaining to the deontic commitments of conditional inducers generally. Inducers are obliged to keep the terms of the inducements and not permitted to break them; inducers are permitted but not obliged to be the better person or to follow through with the negative consequences of the inducements (see Sztencel, Reference Sztencel2018, for more details).
This brings us to the importance of interlocutor-specific memories and their influence on the interpretation of conditional inducements. Admittedly, the picture gleaned from our data is a bit simplistic in that it does not tap into individual variation which is likely to pertain to conditional threats. Now, in our examples, the majority of participants indicated that the speaker is permitted to be the better person. However, research has shown that interlocutor-specific information is one of many cues which are simultaneously integrated during language processing and thus may place immediate/direct constraints on the processes of utterance production and comprehension (e.g., Horton & Gerrig, Reference Horton and Gerrig2005; Horton, Reference Horton, Kecsekes and Mey2008; Gerrig, Horton, & Stent, Reference Gerrig, Horton and Stent2011; Horton & Slaten, Reference Horton and Slaten2012). These studies are important for two reasons. First, they show that, in utterance interpretation, interlocutor-specific memories of past experiences are directly compared to the current experience of an utterance (in context). This is in keeping with the supporting evidence for exemplar models of categorisation coming in from studies of sensory and sensorimotor memories (see Chandler, Reference Chandler2017, for the most recent review). Second, they predict that we can expect individual – inter-speaker and intra-speaker – variation in the application of the ∼(p & ∼q) constraint in the case of conditional threats. For example, if a hearer knows the speaker of a conditional threat well enough to assume with certainty that she will follow through with the negative consequences of the threat, such holistic assumptions are likely to lead the hearer to infer that the ∼(p & ∼q) constraint is in place. But if the hearer, like Sarah from our earlier scenario, assumes that the speaker – George – is unlikely to follow through with the negative consequences of the threat (assumptions based on memories of George’s relevant past behaviour), then she is likely to infer that the ∼(p & ∼q) constraint is not in place and that George’s threat is the better person possibility threat – i.e., that George may or may not retaliate.
Now, two things have been evident in our discussion so far: specific contextual information, which includes assumptions about one’s interlocutors, determines whether the interpretation of a conditional inducement is constrained by ∼(p & ∼q); and relatedly, the ∼(p & ∼q) constraint does not uniformly, i.e., generally, apply to all conditional inducements. As pointed out by Bybee (2013, p. 52), “specific information finds a natural expression in an exemplar model, where the storage and categorization of all detail both predictable and idiosyncratic is considered to be a basic response to linguistic input”. Furthermore, Chandler (2017, p. 81) argues that exemplar models eliminate the need to try to identify “resident linguistic generalisations” and fare better to explain categorisation. In relation to conditionals specifically, compatible proposals have been made in epistemology. Douven (Reference Douven2015), for example, argues that instead of searching for a unitary semantics of if – an approach that has so far proven fruitless – the time has come to address conditionals from an epistemological perspective (see also Douven, Reference Douven2013; Krzyżanowska, Wenmackers, & Douven, Reference Krzyżanowska, Wenmackers and Douven2013; Rescher, Reference Rescher2007), a perspective which foregrounds the importance of knowledge structures in the comprehension of conditionals.
Exemplar approaches to semantics are based on exemplar models of categorisation (e.g., Hintzman, Reference Hintzman1986; Nosofsky, Reference Nosofsky1988; Skousen, Reference Skousen1989). At the heart of exemplar semantics lies the hypothesis that the meaning, or rather meaning potential, of words as expression types is no more and no less than the collection of token-experiences they are associated with (e.g., Hintzman, Reference Hintzman1986; Recanati, Reference Recanati1998; Sztencel, Reference Sztencel2012, Reference Sztencel2014, Reference Sztencel2018). For example, on Hintzman’s (1986) model, every event to which a person attends is stored in long-term memory as an individual memory trace. Each memory trace is constituted by a configuration of primitive properties (e.g., modality-specific sensory features, simple emotional tones, temporal relations, abstract relations) in terms of which experiences are cognised. Memory traces are aggregated based on their similarity, which is established by the matching of the constitutive primitive properties. Abstract representations do not have a special status and are not stored in a functionally separate memory system but can be retrieved on-line from a pool of episodic memory traces, or exemplars, and stored as another memory trace (see also Barsalou, Reference Barsalou, Gershkoff-Stowe and Rakison2005). For conditional inducements, this means that any abstractions that may be retrieved on-line will be stored in the memory aggregate representing the category of conditional utterances along with other, more specific, experience records. We can represent such abstractions using the logical notation such as ∼(p & ∼q), ∼(∼p & q), (p & q), (∼p & ∼q), etc.
How would the two approaches – the traditional and exemplar – fare to explain our example in which George threatened Sarah that he will smash her farm if she smashes his car, in a context in which it is assumed that George is unlikely to follow through with the negative consequences of his threat? On the traditional approach, some specifically linguistic/lexical system would provide the ∼(p & ∼q) constraint presumably to aid the process of utterance interpretation. This constraint would then have to be dropped/disregarded in response to the context. In contrast to this, the exemplar approach (e.g., Hinztman’s, 1986) would require us to assume that a mental representation of the acoustic properties of George’s utterance (i.e., a mental representation of the utterance’s form) combines with Sarah’s assumptions about George (those which are salient to her at the time) to constitute a retrieval probe which is sent to all memory traces stored in Sarah’s long-term memory. The traces in Sarah’s long-term memory are then activated according to their similarity to the probe – that is, the traces which are records of experiences of relevant forms and of George’s past behaviour will be most strongly activated. The pattern of most strongly activated properties that resonates back from the long-term memory in response to the probe is called the ‘echo’. The echo, on the exemplar approach, constitutes the meaning of a given utterance. Given the context that we imagined for this scenario, the echo is likely to be consistent with the ∼(∼p & q) but not the ∼(p & ∼q) constraint. Observe further that the exemplar semantics’ assumption that all traces are activated in the process of echo retrieval is essential to George’s threat functioning as a successful inducement. This is because Sarah’s assumption that George may after all behave in a way which is untypical for him must also be based on her knowledge that some threateners follow through with the negative consequences of their threats and that people do not always behave in predictable ways. It is this wealth of knowledge (wealth of records of experiences) that saves Sarah from making an error of inductive reasoning (i.e., from assuming that George won’t retaliate because he’s never done so) and makes her act in a way wished for by George.
Admittedly, the above has provided a sketch of how an exemplar account would deal with Sarah’s interpretation of George’s threat. Furthermore, there is no space on this occasion to provide a more substantial argument for an exemplar semantics approach as opposed to more generally understood encyclopaedic approaches. But we hope to have shown that it is worth exploring the explanatory potential of exemplar models. We would like to argue that there is a real need for research into the interaction between (a) the interlocutor-specific information and (b) the inferential patterns that lead to the assumption, or otherwise, of the ∼(p & ∼q) constraint to particular uses of “if p, q” threats. We believe that, if the deontic commitments of conditional inducers (e.g., Searle & Vanderveken, Reference Searle and Vanderveken1985; Verbrugge et al., Reference Verbrugge, Dieussaert, Schaeken and Van Belle2004, Reference Verbrugge, Dieussaert, Schaeken and Van Belle2005; Beller et al., Reference Beller, Bender and Kuhnmünch2005) are to be explained, attention needs to be refocused from the search for schematic representations of ‘core meaning’ to the direct relevance, to utterance interpretation, of stored exemplars.
5. Conclusion
The results of both parts of the experiment corroborate the predictions of Beller’s (2002) deontic commitments hypothesis for conditional promises and threats in English. With regard to our specific research questions, we have found that breaking the terms of a conditional promise in English is associated with (p & ∼q), whereas breaking the terms of a conditional threat is associated with (∼p & q). We also found that (p & ∼q) is permitted for conditional threats, which undermines the claim that the ∼(p & ∼q) constraint is definitional of the encoded semantics, or ‘core meaning’, of conditionals. We have found evidence for a usage category of conditional threats called the better person possibility threats and, relatedly, put forward a proposal that an exemplar semantics fares better to explain the interpretation of conditional inducements.





