



The National Institutes of Health (NIH), in collaboration with over 200 field-specific experts, developed the NIH Toolbox (NIH-TB), which is an assessment of cognitive, motor, and emotional functioning that is standardized for persons 3–85 years of age (Beaumont et al., Reference Beaumont, Havlik, Cook, Hays, Wallner-Allen, Korper and Gershon2013; Weintraub et al., Reference Weintraub, Bauer, Zelazo, Wallner-Allen, Dikmen, Heaton and Gershon2013a, Reference Weintraub, Dikmen, Heaton, Tulsky, Zelazo, Bauer and Gershonb). Of particular interest to researchers and clinicians, the NIH-TB Cognitive Battery was designed to measure abilities within the domains of working (Tulsky et al., Reference Tulsky, Carlozzi, Chevalier, Espy, Beaumont and Mungas2013) and episodic memory (Bauer et al., Reference Bauer, Dikmen, Heaton, Mungas, Slotkin and Beaumont2013), attention and executive functioning (Zelazo et al., Reference Zelazo, Anderson, Richler, Wallner-Allen, Beaumont and Weintraub2013), processing speed (Carlozzi, Tulsky, Kail, & Beaumont, Reference Carlozzi, Tulsky, Kail and Beaumont2013), and language (Gershon et al., Reference Gershon, Slotkin, Manly, Blitz, Beaumont, Schnipke and Weintraub2013), and was created to be efficacious for assessing longitudinal outcomes in research studies (http://www.healthmeasures.net/explore-measurement-systems/nih-toolbox). The Cognitive Battery was validated against gold-standard neuropsychological assessments and showed good short-term (7 to 21 days) test-retest reliability in adults and children (Heaton et al., Reference Heaton, Akshoomoff, Tulsky, Mungas, Weintraub, Dikmen and Gershon2014; Mungas et al., Reference Mungas, Heaton, Tulsky, Zelazo, Slotkin, Blitz and Gershon2014; Weintraub et al., Reference Weintraub, Bauer, Zelazo, Wallner-Allen, Dikmen, Heaton and Gershon2013a, Reference Weintraub, Dikmen, Heaton, Tulsky, Zelazo, Bauer and Gershonb). Perhaps unsurprisingly, the NIH-TB has garnered wide-spread interest in the scientific community and has been adopted as a primary tool for assessing cognitive abilities in numerous investigations, including large-scale longitudinal projects like the Adolescent Brain and Cognitive Development (ABCD) study (Luciana et al., Reference Luciana, Bjork, Nagel, Barch, Gonzalez, Nixon and Banich2018). In its early release, experts cautioned that the NIH-TB Cognitive Battery was not designed to assess neuropsychological status or injury, and had not been tested for its sensitivity to neuropsychological disparities (Bauer & Zelazo, Reference Bauer and Zelazo2013; Beaumont et al., Reference Beaumont, Havlik, Cook, Hays, Wallner-Allen, Korper and Gershon2013).
In response to this potential shortcoming, researchers developed fully normed T-scores for the NIH-TB Cognitive Battery using a normative sample of children and adults (Casaletto et al., Reference Casaletto, Umlauf, Beaumont, Gershon, Slotkin, Akshoomoff and Heaton2015). Specifically, the fully normed T-scores correct for a swath of demographic factors known to impact and potentially bias scores on neuropsychological assessments, including age, sex, ethnicity, race, and educational attainment (for children, the NIH-TB uses the mother's level of education). The original report demonstrating the fully normed T-scores notes that, of all the standardized scores available from the Toolbox, including uncorrected and age-corrected standard scores, the T-scores are the best indicator of potential individual impairment and could be used to determine deviations from previous levels of neurocognitive functioning (Casaletto et al., Reference Casaletto, Umlauf, Beaumont, Gershon, Slotkin, Akshoomoff and Heaton2015). Several studies have since examined the potential utility of the NIH-TB's fully normed T-scores in clinical populations, including individuals with neurological disorders (Carlozzi et al., Reference Carlozzi, Goodnight, Casaletto, Goldsmith, Heaton, Wong and Tulsky2017) and persons with social anxiety (Troller-Renfree, Barker, Pine, & Fox, Reference Troller-Renfree, Barker, Pine and Fox2015). Expressing high confidence, the NIH-TB manual for scoring and interpretation now explicitly states that the fully normed T-scores, ‘are primarily intended for neuropsychological applications…’ (NIH, Reference NIH2016, p. 2)
Despite rapidly growing interest in utilizing the NIH-TB Cognitive Battery for neuropsychological assessments (Tulsky & Heinemann, Reference Tulsky and Heinemann2017), including by our own team, research has yet to establish the longer-term stability of these fully normed T-score metrics of cognitive performance. As mentioned previously, studies have shown good short-term test-retest reliability of the NIH-TB Cognitive Battery assessments with a retest period of 7–21 days (Weintraub et al., Reference Weintraub, Bauer, Zelazo, Wallner-Allen, Dikmen, Heaton and Gershon2013a, Reference Weintraub, Dikmen, Heaton, Tulsky, Zelazo, Bauer and Gershonb), However, retesting individuals over longer intervals to determine treatment effects lasting longer than 21 days, and/or gains and losses over time would also be of major interest to both clinicians and scientists (Harvey, Reference Harvey2012). This matter is of exceptional importance given the growing adoption of the NIH-TB in large-scale longitudinal studies aiming to examine the development of cognitive abilities across the lifespan, often testing participants only on an annual basis.
The purpose of the present study was to determine the long-term temporal stability of the fully normed T-scores from the NIH-TB Cognitive Battery in children and adolescents (ages 9–15 years-old). For completeness and proper comparison, we also assessed the stability of the uncorrected and the age-corrected standardized scores. All participants were enrolled at one of two sites, with near equal enrollment at each site, and were invited to return annually for 3 years. Thus, we were able to examine test-retest reliability of the NIH-TB Cognitive Battery at three intervals: (1) from Year 1 to Year 2, (2) from Year 2 to Year 3, and (3) from Year 1 to Year 3. We determined temporal stability metrics (e.g. intraclass correlation coefficients; ICCs) for the full sample, and separately for each site. Analyses were conducted for each of the seven tests comprising the NIH-TB Cognitive Battery, as well as the three composite scores (crystalized, fluid, and total composite scores) yielded by the assessment. Based on prior literature, good test-retest reliability was determined based on the lower bound of the 95% confidence interval (CI) for each ICC, where >0.70 is acceptable for research use, and >0.90 is acceptable for clinical use (Aldridge, Dovey, & Wade, Reference Aldridge, Dovey and Wade2017; Drost, Reference Drost2011; Streiner, Norman, & Cairney, Reference Streiner, Norman and Cairney2015). We hypothesized that, based on prior short-term reliability studies, the NIH-TB measures would have good test-retest reliability among samples recruited from both sites. In particular, the fully normed T-scores should express strong reliability given the strict norming procedures employed and thus were expected to account for maturational changes over time, and to be robust to any demographic differences in samples participating at the two sites.
Methods
Participants
A total of 212 typically-developing children and adolescents were recruited across two sites during Year 1 of the National Science Foundation-funded Developmental Chronnecto-Genomics (Dev-CoG) study (http://devcog.mrn.org/). Participants had no diagnosed neurological, psychiatric, or developmental disorders and no history of head trauma or substance use disorder. Additionally, no participants were using medications that might alter neural functioning. Participants were between 9 and 15 years-of-age at the time of their first visit (M site 1 = 11.75 years, s.d. = 1.79; M site 2 = 11.80 years, s.d. = 1.87), and all participants were invited to return annually for 3 years (time between visits 1 and 2: M site 1 = 1.09 years, s.d. = 0.16; M site 2 = 1.16 years, s.d. = 0.23; time between visits 2 and 3: M site 1 = 1.02 years, s.d. = 0.084; M site 2 = 1.13 years, s.d. = 0.32). All demographic data were reported by a parent or legal guardian as part of the intake process during Year 1. Parents of the child participants signed informed consent forms, and child participants signed assent forms before proceeding with the study. All procedures were approved by the appropriate Institutional Review Board for each site.
NIH-TB cognitive battery
All participants completed the NIH-TB Cognitive Battery on a tablet during each year of the study. All tests were administered in a fixed order per instructions in the manual. It took approximately 1 hour to complete the battery each year. Each data collection site had trained research assistants who administered the computerized protocol in accordance with the manual and ensured participants' compliance and understanding throughout the testing process. The Cognitive Battery of the NIH-TB consists of seven assessments, each purporting to measure a different cognitive construct. Briefly, Dimensional Change Card Sort (DCCS) is a measure of executive functioning; the Flanker test assesses attention and inhibitory control; List Sorting Working Memory (WM) assesses working memory abilities; Pattern Comparison measures processing speed; Picture Sequence Memory is an indicator of episodic memory; Oral Reading assesses reading and language abilities; and Picture Vocabulary assesses vocabulary comprehension. Three composite scores are derived from the subtests: Crystallized Cognition, Fluid Cognition, and Total Cognition. Complete details of each Cognitive Battery test are reported in prior work (Heaton et al., Reference Heaton, Akshoomoff, Tulsky, Mungas, Weintraub, Dikmen and Gershon2014; Mungas et al., Reference Mungas, Widaman, Zelazo, Tulsky, Heaton, Slotkin and Gershon2013, Reference Mungas, Heaton, Tulsky, Zelazo, Slotkin, Blitz and Gershon2014; Weintraub et al., Reference Weintraub, Bauer, Zelazo, Wallner-Allen, Dikmen, Heaton and Gershon2013a, Reference Weintraub, Dikmen, Heaton, Tulsky, Zelazo, Bauer and Gershonb). Following standard procedure, the fully normed T-scores were calculated within the NIH-TB software and used for further analyses. According to prior literature, these T-scores were normed for age, sex, ethnicity, race, and mother's educational attainment, and should result in a mean of 50 with a standard deviation of 10 (Casaletto et al., Reference Casaletto, Umlauf, Beaumont, Gershon, Slotkin, Akshoomoff and Heaton2015; NIH, Reference NIH2016). Additionally, both uncorrected and age-corrected standard scores were also extracted from the NIH-TB software; reliability indices for these scores are reported in Supplemental Materials.
Data analysis
We assessed the long-term test-retest reliability of each NIH-TB Cognitive Battery assessment using multiple indices of stability, including concordance correlation coefficients (CCCs), root mean squared differences (RMSDs), Pearson correlations, and intraclass correlation coefficients (ICCs). For CCCs and RMSDs, we calculated both consistency (C,1) and absolute agreement (A,1) measures (Barchard, Reference Barchard2012; Scott, Sorrell, & Benitez, Reference Scott, Sorrell and Benitez2019). With respect to ICCs, we calculated two-way mixed-effects models [ICC(3,1)] of both consistency and agreement (Berchtold, Reference Berchtold2016; Koo & Li, Reference Koo and Li2016; Stratford, Reference Stratford1989; Streiner et al., Reference Streiner, Norman and Cairney2015; Weir, Reference Weir2005). Based on prior literature, good test-retest reliability was determined based on the lower bound of the 95% CI for each ICC, where >0.70 is acceptable for research use, and >0.90 is acceptable for clinical use (Aldridge et al., Reference Aldridge, Dovey and Wade2017; Drost, Reference Drost2011; Streiner et al., Reference Streiner, Norman and Cairney2015). Finally, we compared reliability metrics for each NIH-TB Cognitive Battery test between sites using Fisher's r to Z transformations of Pearson correlation coefficients for each of the three periods of interest. Analyses were performed in SPSS version 26.
Results
Descriptives
Of 212 recruited participants, 192 reported complete demographic data necessary for calculating fully normed T-scores during Year 1. Demographic data for the final sample are reported in Table 1, separately for each site and each year of data collection. Overall, participants were relatively well matched demographically across sites with one notable exception; Site 2 had a larger proportion of participants who identified as Hispanic/Latino compared to Site 1 (Year 1: χ2(1) = 37.98, p < 0.001). Regardless, fully normed T-scores obtained from the NIH-TB Cognitive Battery should be robust in controlling for demographic differences between participant samples. Means and standard deviations of the T-scores for each test, by site and year, are detailed in Table 2. Means were generally near or slightly above the expected mean of 50, with the exception of the Flanker test where average fully normed T-scores were about 0.5 s.d. below 50 and consistently lower than all other test scores across both sites. However, overall, group means for each year were relatively consistent, with only minor shifts in the group averaged T-scores over time.
Table 1. Participant demographic distributions for the total sample and separately by site for each year of data collection for participants included in reliability analyses
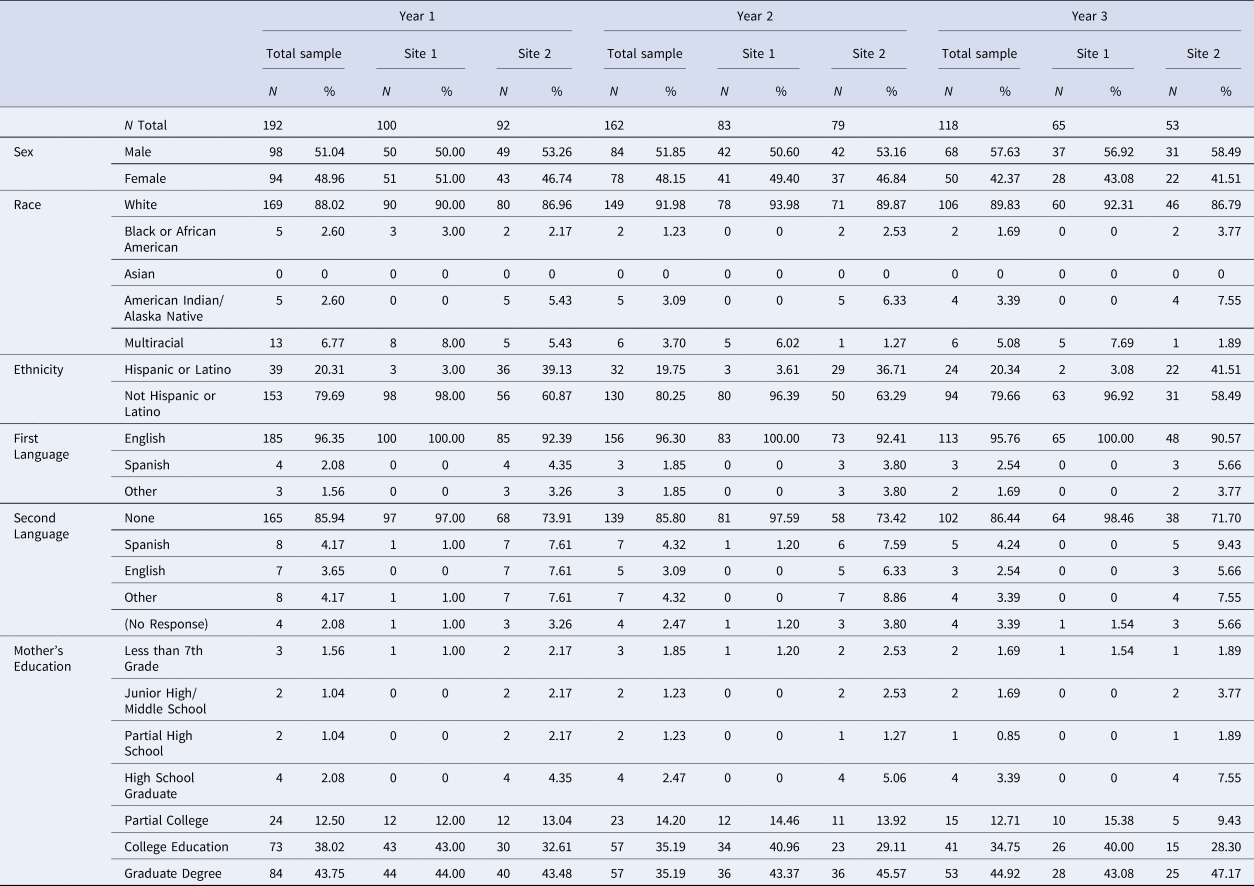
Note: The demographics table above does not report characteristics of participants who were excluded from the present study (N = 20) due to missing demographic data necessary for calculating fully normed T-scores for the NIH Toolbox measures.
Table 2. Means and standard deviations of fully normed T-scores for each NIH Toolbox Cognitive Battery assessment fully normed T-score by year, for the full sample and separately for each site
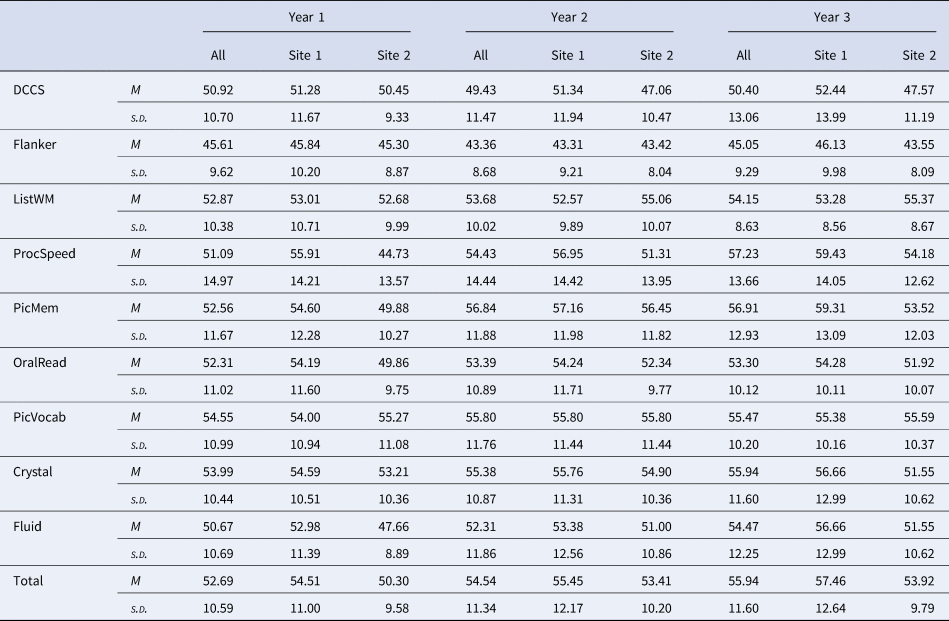
Note: Total sample (‘All’): nyear1 = 192, nyear2 = 162, nyear3 = 118; Site 1: nyear1 = 100, nyear2 = 83, nyear3 = 65. Site 2: nyear1 = 92, nyear2 = 79, nyear3 = 53. DCCS = Dimensional Change Card Sorting; Flanker = Flanker Test of Inhibitory Control and Attention; ListWM = List Sorting Working Memory; ProcSpeed = Pattern Comparison Processing Speed; PicMem = Picture Sequence Memory; OralRead = Oral Reading; PicVocab = Picture Vocabulary; Crystal = Crystalized Cognition composite score; Fluid = Fluid Cognition composite score; Total = Total Cognition composite score.
Test-Retest reliability
As demonstrated in Figs 1 and 2, there was substantial individual variability in patterns of change over time (for site-specific data, see online Supplementary Figs. S1-S2). Pearson r, and consistency and absolute agreement CCCs and ICCs generally exhibited good agreement, with similar conclusions drawn about stability regardless of the reliability metric utilized (Table 3). Examination of the absolute agreement ICCs indicated a broad range of stability estimates, with coefficients ranging between 0.31 and 0.76 for the full sample collapsed across sites (Table 3, online Supplementary Table 1). Reliability tended to be better between Year 2 and Year 3 compared to reliabilities between other time points. Most importantly, the lower bound of the 95% CI for each ICC suggested that only three of the tests within the NIH-TB Cognitive Battery met reliability criteria for use in research, though results were mixed across sites and time points (e.g. see Pattern Comparison Processing Speed from Year 2 to Year 3, site 1 and site 2; Crystallized Composite from Year 1 to Year 3, site 1 only; Total Composite from Year 1 to Year 2, site 1 only). Importantly, none of the tests met criteria for clinical use in the full sample, nor within either site for any of the time periods (ranges for minimum bounds of 95% CIs: full sample = 0.17–0.66; Site 1 = 0.061–0.74; Site 2 = 0.013–0.74). This is perhaps unsurprising when viewing the Bland-Altman plots (Fig. 2), which demonstrate deviations in fully normed T-scores across years for each test. There were marked disparities in data clustering across tests and time points; for instance, the data for the Flanker test clustered relatively consistently to the left (poorer average scores), whereas the data for Processing Speed were widely variable and did not seem to follow any specific clustering. Moreover, online Supplementary Table 2 describes the number and percentage of participants whose T-scores deviated by more than one standard deviation (10 points) from one year to another; between 14.72% and 77.97% of the sample deviated by at least one standard deviation for a given test and time period.

Fig. 1. Bland-Altman plots depicting patterns of deviation in fully normed T-scores over time for the full sample, collapsed across study sites. The solid black line in each plot is the bias (i.e. the mean difference between years); dashed lines are the upper and lower limits of agreement (bias ± 1.96*s.d.). DCCS = Dimensional Change Card Sorting; Flanker = Flanker Test of Inhibitory Control and Attention; List WM = List Sorting Working Memory; Proc Speed = Pattern Comparison Processing Speed; Pic Mem = Picture Sequence Memory; Oral Read = Oral Reading; Pic Vocab = Picture Vocabulary; Crystal = Crystalized Cognition composite score; Fluid = Fluid Cognition composite score; Total = Total Cognition composite score.

Fig. 2. Scatterplots depicting the correlations between fully normed T-scores for each NIH-TB Cognitive Battery subtest, collapsed across study sites, for each of the three tested intervals. Solid black lines indicate the line of best fit (i.e. the Pearson correlation) through the data. Dashed black lines show the upper and lower bounds of the 95% confidence interval around the line of best fit. DCCS = Dimensional Change Card Sorting; Flanker = Flanker Test of Inhibitory Control and Attention; List WM = List Sorting Working Memory; Proc Speed = Pattern Comparison Processing Speed; Pic Mem = Picture Sequence Memory; Oral Read = Oral Reading; Pic Vocab = Picture Vocabulary; Crystal = Crystalized Cognition composite score; Fluid = Fluid Cognition composite score; Total = Total Cognition composite score.
Table 3. Consistency and absolute agreement reliability indices for the NIH Toolbox Cognitive Battery subtests and composite scores for the full sample collapsed across data collection sites
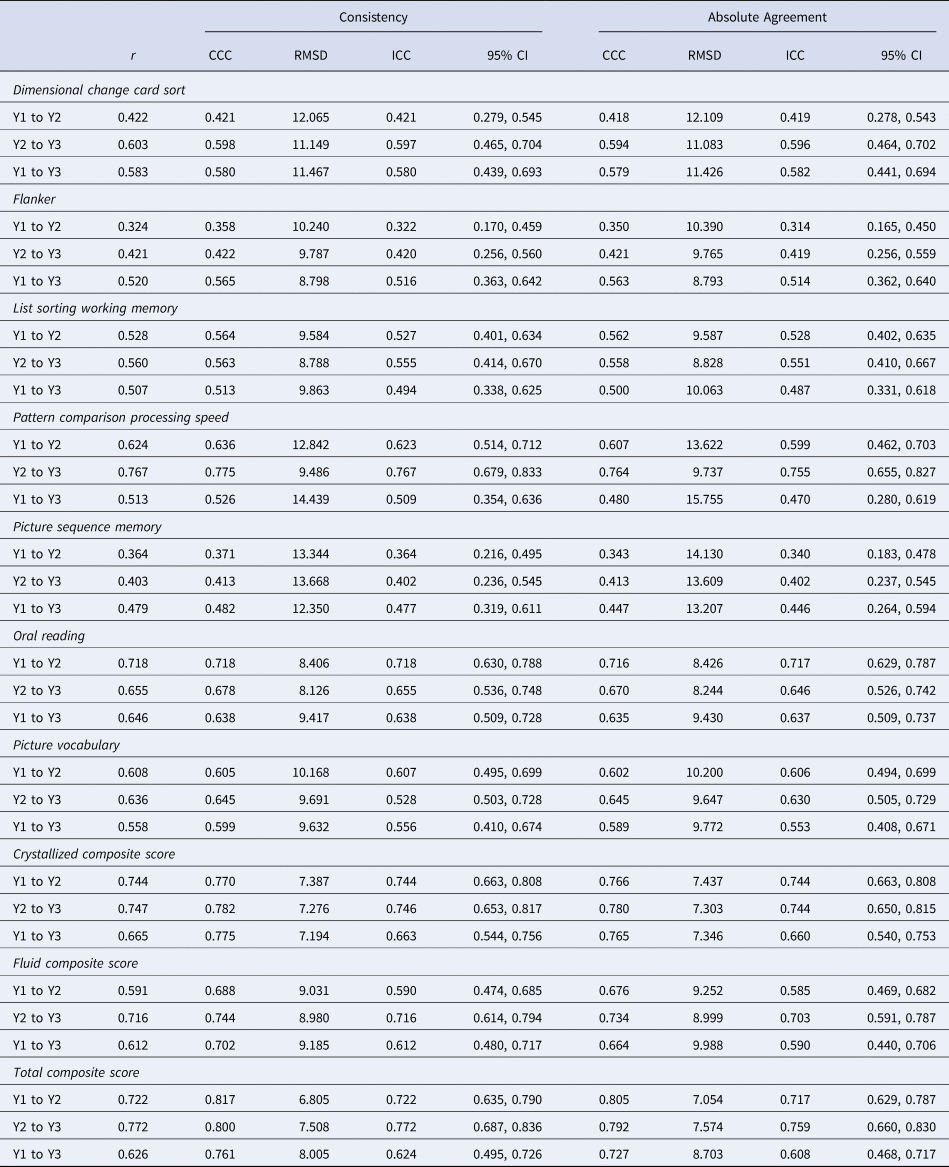
Note: Year 1 to Year 2 N = 162, Year 2 to Year 3 N = 118; Year 1 to Year 3 N = 118; ‘r’ = Pearson correlation; ‘CCC’ = concordance correlation coefficient; ‘RMSD’ = root mean squared difference; ‘ICC’ = intraclass correlation coefficient; ‘95% CI’ = 95% confidence interval about the ICC; ‘Y1 to Y2’ = reliability measured between year 1 and year 2 of the study; ‘Y2 to Y3’ = reliability measured between year 2 and year 3 of the study; ‘Y1 to Y3’ = reliability measured between year 1 and year 3 of the study.
This is also evidenced by the relatively large RMSD values reported in Table 3, many of which are near or above 10 indicating that a large portion of the sample exhibited shifts in scores near or exceeding one full standard deviation. Such large shifts, if meaningful, could be interpreted as extreme gains or deficits in cognitive functioning year-over-year. For example, a T score of 50 in a given year falls into the 50th percentile for performance. Jumping to a score of 60 the following year (+1SD) would place that child in the 84th percentile, whereas a falling to a score of 40 the following year (−1SD) would place that child in the 16th percentile for performance (NIH, Reference NIH2016, p. 38). Such wide variability could have widespread impacts for interpreting changes in cognitive functioning among youth over time.
Reliability metrics for the uncorrected and the age-corrected standardized scores are reported in online Supplementary Tables 3 and 4, respectively. Briefly, uncorrected standardized scores yielded some of the largest ICC absolute agreement estimates, ranging from 0.30 to 0.79; in fact, when comparing reliability metrics between all three types of scores (T-scores, uncorrected, age-corrected) across all combinations of samples and time points, the uncorrected scores had the largest ICC estimate in 46.67% of cases (age-corrected: 32.22%; T-score: 21.11%). Unfortunately, these metrics are deceptive. Further examination of the lower bound of the 95% CI about the ICC showed that uncorrected standardized scores had the poorest reliability in 68.89% of all cases (age-corrected: 24.44%; T-score: 6.67%), with values ranging from −0.09 to 0.63. T-scores tended to have the best reliability as defined by the lower bound of the 95% CI of the ICC and were the only scores stable enough for use in research in select instances.
Comparison by site, ethnicity, age, and sex
Fisher's r to Z transformations comparing test-retest correlations are embedded within online Supplementary Tables 1, 3, and 4. Of note, sites significantly differed in the reliability of List Sorting Working Memory T-scores during all three time periods (p's < 0.05). Additionally, sites differed in T-score reliability in seven out of the ten tests when examining the longest-term reliability, from Year 1 to Year 3 (all p's < 0.05), with Site 1 showing better test-retest reliability compared to Site 2 in all cases. Bland-Altman plots by site are illustrated in online Supplementary Fig. 1 and indicate significant variability in patterns of score deviations between sites. Scatterplots demonstrating the correlations between T-scores for each of the three retest intervals, separately by site, with plotted CI about the correlation can be viewed in online Supplementary Fig. 2. Notably, many of the children's data points are broadly distributed outside of the 95% CI for the correlations. Given the pattern of differences in the reliability, and the earlier noted difference in ethnic distributions between sites, we hypothesized that the norming procedures for Hispanic/Latino children may be inadequate. However, follow up testing comparing reliability indices between Hispanic/Latino v. non-Hispanic/Latino children showed similar reliabilities between ethnic groups in the present sample (see Supplemental Results, online Supplementary Table 5). We additionally explored any potential deviations in reliability related to age at the start of the study and related to sex (see Supplemental Results, online Supplementary Tables 6 and 7).
Discussion
The present study investigated the long-term test-retest reliability of the NIH-TB Cognitive Battery in a large cohort of children and adolescents enrolled in a two-site study of typical cognitive and brain development. Specifically, we examined stability across 3 years of fully normed T-scores, which are intended for use in neuropsychological assessment (Casaletto et al., Reference Casaletto, Umlauf, Beaumont, Gershon, Slotkin, Akshoomoff and Heaton2015; NIH, Reference NIH2016). We found wide-ranging levels of score stability across the NIH-TB Cognitive Battery measures, with most tests exhibiting only moderate reliability. When comparing reliability metrics between data collection sites, we noted significant differences primarily emerging in the longest-term interval, between Year 1 and Year 3. Most importantly, despite site differences, a select few of the NIH-TB Cognitive Battery tests exhibited strong enough temporal stability for use in research, but none were reliable enough for use in clinical settings according to field standards (Drost, Reference Drost2011; Streiner et al., Reference Streiner, Norman and Cairney2015). Among the tests meeting criteria for research, results were disparate across time points and were specific to data collection sites. In accordance with prior work (e.g. Watkins and Smith, Reference Watkins and Smith2013), the composite scores of the NIH-TB did tend to show stronger reliability than many of the individual subtests, at least for the full sample and for Site 1. However, the composite scores also showed some of the most robust and temporally-persistent site differences in stability (online Supplementary Table 1). Thus, it seems that the composite scores were not immune to site-specific temporal variability over time.
It is also worth noting that the uncorrected and age-corrected standardized scores generally exhibited poorer reliability than the fully normed T-scores, with the lowest metrics observed for uncorrected standardized composite scores between Year 1 and Year 3 (online Supplementary Tables 3 and 4). These results come in direct contrast to recommendations by the NIH manual for scoring and interpretation, which suggests that uncorrected standard scores above all other metrics may be used to monitor an individual's performance over time (NIH, Reference NIH2016).
The poorer-than-expected temporal stability of the T-scores may indicate inadequate norming, or measurement error due to test administration or other unforeseen factors. However, differences in test administration are unlikely with the NIH-TB because a computer delivers the majority of instructions and administers the tests. Additionally, a trained research assistant remained in the room for the duration of testing to supply any verbal instructions in accordance with the NIH-TB manual and to ensure participant compliance and understanding. That said, we did observe site differences in this study, which could suggest nuances in the administration can affect the results. For instance, research has shown that such wide-ranging factors as participant fatigue (Johnson, Lange, DeLuca, Korn, & Natelson, Reference Johnson, Lange, DeLuca, Korn and Natelson1997), administrator-participant rapport (Barnett, Parsons, Reynolds, & Bedford, Reference Barnett, Parsons, Reynolds and Bedford2018), and aspects of the testing environment (e.g. lighting, ambient noise, etc.; Gavin, Davies, Schmidt, and Segalowitz, Reference Gavin, Davies, Schmidt and Segalowitz2008) can contribute to an individual's performance during neuropsychological testing. With so much room for variability, and thus measurement error, further work is required to sufficiently dissect the source of variability contributing to the noted site-based differences identified in the present study. Additionally, multi-site studies must closely monitor and control these potential sources of variability in neuropsychological performance.
We did pursue analyses to determine whether norming procedures for ethnically-divergent youth may have contributed to the site differences. Post hoc testing comparing children who identified as Hispanic/Latino v. Non-Hispanic/Latino suggested that differences in ethnic distributions between sites were not the likely cause of our inter-site variability. Of course, it is possible that other demographic differences may have driven the noted site differences; the authors who originally developed the fully normed T-scores did note that certain demographic groups' norms may need further refinement due to an initially small sample (Casaletto et al., Reference Casaletto, Umlauf, Beaumont, Gershon, Slotkin, Akshoomoff and Heaton2015). However, we were unable to adequately test for differences between other racially or linguistically-diverse groups in the present study due to the limited demographic diversity of the overall sample. Likewise, our exploratory analyses of age-related differences in reliability were somewhat limited due to small sample sizes per age group, though we did not detect any specific effects of age on reliability. Finally, exploration of sex-related variability in ICCs suggested that males in the present study may have had greater test-retest reliability compared to females in most subtests, though CI were largely overlapping among males and females. Further work is needed to determine the extent to which demographic differences may drive test-retest reliability of the NIH-TB scores.
These findings were largely surprising given earlier reports on the test-retest reliability of NIH-TB measures in children, and the expected robustness of the norming procedures used to derive the T-scores. For instance, Weintraub et al. (Reference Weintraub, Bauer, Zelazo, Wallner-Allen, Dikmen, Heaton and Gershon2013a, Reference Weintraub, Dikmen, Heaton, Tulsky, Zelazo, Bauer and Gershonb) reported ICCs ranging from 0.76 to 0.99 in children ages 3–15 years-old (lower bound of 95% CI range: 0.64–0.98); however, these psychometrics were based on raw or computed scores for each subtest, rather than standardized or fully normed scores, and the retest date was between 7 and 21 days after the first test (i.e. very short term). A more recent study assessed long-term stability (average 15.03 ± 3.11 months between retest) of NIH-TB uncorrected standardized scores in older adults (Scott et al., Reference Scott, Sorrell and Benitez2019), with results indicating a pattern more similar to our investigation. Namely, reliability indices were predominantly moderate in magnitude, though values ranged from 0.46 to 0.87 for individual tests (lower bound of 95% CI range: 0.14–0.77; Scott et al., Reference Scott, Sorrell and Benitez2019). It is possible that the long retest interval of the present study, as well as that of Scott et al., may have attenuated reliability estimates, and that in agreement with previous literature a shorter retest interval may have yielded better stability estimates. Further work is needed to determine the degree to which NIH-TB scores are temporally stable over different time intervals. That said, for many applications (e.g. clinical assessments, longitudinal studies) reliability over longer time intervals is vitally important.
The data in the present study suggest that the fully normed T-scores from the NIH-TB Cognitive Battery may not be suitable for neuropsychological assessments in children and adolescents, especially in the context of long-term, repeated measurements. For instance, a researcher conducting a longitudinal investigation of neurocognitive development may examine composite T-scores across years to determine which children develop improvements or declines in cognitive function relative to their peers. However, a significant change in T-scores may simply be the result of poor reliability of the measure rather than true neurocognitive decline. Such a concern is critical for large-scale studies like ABCD, which intend to track cognitive function and the emergence and progression of mental health disorders throughout adolescence (Luciana et al., Reference Luciana, Bjork, Nagel, Barch, Gonzalez, Nixon and Banich2018). Similar issues arise when considering efficacy studies in clinical trials research, educational programming success, and etcetera. Researchers and clinicians alike must interpret scores with caution, as any long-term shifts in T-scores may be the result of measurement error rather than a clinically-relevant shift in functioning.
Of course, poor reliability also raises questions about each test administration in isolation. The reliability of any neuropsychological assessment is paramount to establishing the validity of the instrument; one cannot determine what cognitive construct a test is tapping into without the foundation of consistent measurements (Aldridge et al., Reference Aldridge, Dovey and Wade2017; Drost, Reference Drost2011; Harvey, Reference Harvey2012; Streiner et al., Reference Streiner, Norman and Cairney2015). Thus, the results from the present study raise serious concerns regarding the validity of the NIH-TB Cognitive Battery as an assessment of attention, executive functions, memory, and language abilities over time. Given our findings, researchers and clinicians who work with children are urged to interpret fully normed T-scores and their functional significance with caution. Similar caution is recommended when interpreting the uncorrected and age-corrected standardized scores.
The present study is not without limitations. First, we focused on children and adolescents and did not have a normative adult sample for comparison. Thus, it is difficult to ascertain to what extent our findings are specific to youth. It is possible that, at the two data collection sites of the present study, long-term temporal stability may be excellent for typical adults. Such a finding would suggest that the NIH-TB needs refinement only for administration to children and adolescents, although note that adult studies have raised points of concern as well (e.g. Scott et al., Reference Scott, Sorrell and Benitez2019). Second, we did not administer accompanying gold-standard neuropsychological assessments for comparison in the present study. To better interpret the within-person variability over time, it would be helpful to compare test-retest reliability in performance on comparable cognitive tests; one would not expect significant age-related variation in normed scores for gold-standard tests. Third, we were unable to compare reliabilities across linguistically and racially diverse groups given the low diversity in the study sample. Samples were recruited to match the demographic makeup of the surrounding region for each study site (based on census data), which includes predominantly Caucasian, native English-speaking individuals. Further work is needed to decipher demographic differences that may contribute to test-retest reliability. Finally, we did not explore shorter retest periods in the present study. To the best of our knowledge, the fully normed T-scores have yet to be assessed for their short-term test-retest reliability. It is possible (and likely) that shorter-term retest periods may yield stronger stability, thereby supporting the use of fully normed T-scores over limited periods of time. However, the current investigation cannot address this potential strength of the T-scores.
The present study examined the long-term temporal stability of the NIH-TB Cognitive Battery in a large cohort of children and adolescents using fully normed T-scores. Study findings suggested only moderate test-retest reliability over any tested duration, with notable differences in reliability between two data collection sites. Given the unexpectedly low consistency in scores, we recommend further refinement of the NIH-TB Cognitive Battery tool and/or norming procedures before the fully normed T-scores become more widely used as viable resources for determining impairment or tracking longitudinal changes in neurocognitive abilities.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0033291720003487.
Acknowledgements
This work was supported by the National Science Foundation (TWW, JMS, VDC, and Y-PW, grant number #1539067) and the National Institutes of Health (TWW, grant numbers R01-MH103220, R01-MH116782, R01-MH118013, R01-MH121101, P20-GM130447), (VCD, grant numbers R01-EB020407 and P20-GM103472), (AIW, grant number F31-AG055332).
Conflict of interest
None.
Ethical standards
The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008.








 Open access
Open access