



Recent years have witnessed the emergence of network psychometrics (Borsboom, Reference Borsboom2008; Marsman and Rhemtulla, Reference Marsman and Rhemtulla2022; van der Maas et al., Reference van der Maas, Dolan, Grasman, Wicherts, Huizenga and Raijmakers2006), a family of statistical graphical models and related inference procedures, for analyzing and interpreting the dependence structure in psychometric data. These models embed psychometric items as nodes in an undirected or directed network (i.e., graph) and visualize their interrelationships through the network edges, which represent certain probabilistic conditional dependencies. Network psychometric methods concern the learning of the network structure. They have been developed under various settings, including undirected graphical models for cross-sectional data (Burger et al., Reference Burger, Isvoranu, Lunansky, Haslbeck, Epskamp, Hoekstra and Blanken2022; Epskamp et al., Reference Epskamp, Waldorp, Mõttus and Borsboom2018), directed networks for longitudinal data (Borsboom et al., Reference Borsboom, Deserno, Rhemtulla, Epskamp, Fried, McNally and Waldorp2021; Gile and Handcock, Reference Gile and Handcock2017; Ryan et al., Reference Ryan, Bringmann and Schuurman2022), and extended networks with latent variables for time series data or panel data (Epskamp, Reference Epskamp2020). These methods have received wide applications in education (Koponen et al., Reference Koponen, Asikainen, Viholainen and Hirvonen2019; Siew, Reference Siew2020; Simon de Blas et al., 2021; Sweet et al., Reference Sweet, Thomas and Junker2013; Willcox and Huang, Reference Willcox and Huang2017), psychology (Borsboom et al., Reference Borsboom, Deserno, Rhemtulla, Epskamp, Fried, McNally and Waldorp2021; Burgess and Hitch, Reference Burgess and Hitch1999; Epskamp et al., Reference Epskamp, Borsboom and Fried2018; Fried et al., Reference Fried, van Borkulo, Cramer, Boschloo, Schoevers and Borsboom2017; Van Der Maas et al., Reference Van Der Maas, Kan, Marsman and Stevenson2017), and health sciences (Brunson and Laubenbacher, Reference Brunson and Laubenbacher2018; Kohler et al., Reference Kohler, Jankowski, Bashford, Goyal, Habermann and Walker2022; Luke and Harris, Reference Luke and Harris2007; Mkhitaryan et al., Reference Mkhitaryan, Crutzen, Steenaart and de Vries2019).
Analyzing cross-sectional binary item response data with the Ising model (Ising, Reference Ising1925) is common in network psychometric analysis. This analysis is typically performed based on a conditional likelihood (Besag, Reference Besag1974) because the standard likelihood function is computationally infeasible when involving many variables. In this direction, Bayesian and frequentist methods have been developed, where sparsity-inducing priors or penalties are combined with the conditional likelihood for learning a sparse network structure (Epskamp and Fried, Reference Epskamp and Fried2018; Li et al., Reference Li, Craig and Bhadra2019; Marsman et al., Reference Marsman, Huth, Waldorp and Ntzoufras2022; Mazumder and Hastie, Reference Mazumder and Hastie2012; Van Borkulo et al., Reference Van Borkulo, Borsboom, Epskamp, Blanken, Boschloo, Schoevers and Waldorp2014; Yuan and Lin, Reference Yuan and Lin2007). Besides, the Ising model is shown to be closely related to item response theory (IRT) models (Anderson and Yu, Reference Anderson and Yu2007; Holland, Reference Holland1990). The log-multiplicative association models (Anderson and Yu, Reference Anderson and Yu2007), which are special cases of the Ising model, can be used as item response theory models and yield very similar results as IRT models. Furthermore, the Ising model and the conditional likelihood have been used for modeling the local dependence structure in locally dependent IRT models (Chen et al., Reference Chen, Li, Liu and Ying2018; Ip, Reference Ip2002).
Due to its construction, the conditional likelihood does not naturally handle data with missing values, despite the omnipresence of missing data in psychometric data. To deal with missing values in an Ising network analysis, listwise deletion (Fried et al., Reference Fried, Von Stockert, Haslbeck, Lamers, Schoevers and Penninx2020; Haslbeck and Fried, Reference Haslbeck and Fried2017) and single imputation (e.g., Huisman, Reference Huisman2009, Armour et al., Reference Armour, Fried, Deserno, Tsai and Pietrzak2017, Lin et al., Reference Lin, Fried and Eaton2020) are typically performed, which arguably may not be the best practice. In particular, it is well known that listwise deletion is statistically inefficient and requires the missing completely at random (MCAR) assumption (Little and Rubin, 2019) to ensure consistent estimation. Moreover, a naïve imputation procedure, such as mode imputation, likely introduces bias into parameter estimation. A sophisticated imputation procedure must be developed to ensure statistical validity and computational efficiency.
In this note, we propose an iterative procedure for learning an Ising network. The proposed procedure combines iterative imputation via full conditional specification (FCS; Liu et al., Reference Liu, Gelman, Hill, Su and Kropko2014, van Buuren, 2018), and Bayesian estimation of the Ising network. We show that the FCS leads to estimation consistency when the conditional models are chosen to take logistic forms. In terms of computation, we propose a joint Pólya–Gamma augmentation procedure by extending the Pólya–Gamma augmentation procedure for logistic regression (Polson et al., Reference Polson, Scott and Windle2013). It allows us to efficiently sample parameters of the Ising model. Simulations are conducted to compare the proposed procedure with estimations based on the listwise deletion and single imputation. Finally, the proposed procedure and a complete-case analysis are applied to study the network of major depressive disorder (MDD) and generalized anxiety disorders (GAD) based on data from the National Epidemiological Survey on Alcohol and Related Conditions (NESARC; Grant et al., 2003). In this analysis, data missingness is mainly due to two screening items for GAD. That is, a respondent’s responses to the rest of the MDD items are missing if they answered “no” to both screening items. This missing mechanism is Missing at Random (MAR; Little & Rubin, 2019). The complete-case analysis of missing data caused by screening items is known to be problematic in the literature of network psychometrics (Borsboom et al., Reference Borsboom, Fried, Epskamp, Waldorp, van Borkulo, van der Maas and Cramer2017; McBride et al., Reference McBride, van Bezooijen, Aggen, Kendler and Fried2023). Our Bayesian estimate of the edge coefficient between the two screening items is negative based on the complete cases, which can be seen as a result of Berkson’s paradox (De Ron et al., Reference De Ron, Fried and Epskamp2021). In contrast, the proposed method makes use of all the observed data entries and obtains a positive estimate of this edge coefficient. An identifiability result about the Ising model under this special missing data setting in Appendix, the item content, and a simulation study mimicking this setting suggest that the result given by the proposed method is sensible. A GitHub repository for the proposed algorithm is available at https://github.com/slzhang-fd/IsingNetMissing-replication.
1. Proposed Method
1.1. Ising Model
Consider a respondent answering J binary items. Let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}= (Y_1,\ldots , Y_J)^\top \in \{0,1\}^J$$\end{document}
 be a binary random vector representing the respondent’s responses. We say
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}$$\end{document}
be a binary random vector representing the respondent’s responses. We say
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}$$\end{document}
 follows an Ising model if its probability mass function satisfies
follows an Ising model if its probability mass function satisfies

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}= (s_{ij})_{J\times J}$$\end{document}
 is a J by J symmetric matrix that contains parameters of the Ising model and
is a J by J symmetric matrix that contains parameters of the Ising model and

is a normalizing constant. The parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 encodes a network with the J items being the nodes. More specifically, an edge is present between nodes i and j if and only if the corresponding entry
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij}$$\end{document}
encodes a network with the J items being the nodes. More specifically, an edge is present between nodes i and j if and only if the corresponding entry
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij}$$\end{document}
 is nonzero. If an edge exists between nodes i and j, then
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_i$$\end{document}
is nonzero. If an edge exists between nodes i and j, then
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_i$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_j$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_j$$\end{document}
 are conditionally dependent given the rest of the variables. Otherwise, the two variables are conditionally independent.
are conditionally dependent given the rest of the variables. Otherwise, the two variables are conditionally independent.
In Ising network analysis, the goal is to estimate the parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 . The standard likelihood function is computationally intensive when J is large, as it requires computing a normalizing constant
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c({{\textbf{S}}})$$\end{document}
. The standard likelihood function is computationally intensive when J is large, as it requires computing a normalizing constant
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$c({{\textbf{S}}})$$\end{document}
 which involves a summation of all the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$2^J$$\end{document}
which involves a summation of all the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$2^J$$\end{document}
 response patterns. To address this computational issue, Besag (Reference Besag1975) proposed a conditional likelihood which is obtained by aggregating the conditional distributions of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_j$$\end{document}
response patterns. To address this computational issue, Besag (Reference Besag1975) proposed a conditional likelihood which is obtained by aggregating the conditional distributions of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_j$$\end{document}
 given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{-j} = (Y_1,\ldots , Y_{j-1}, Y_{j+1},\ldots , Y_J)^\top $$\end{document}
given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{-j} = (Y_1,\ldots , Y_{j-1}, Y_{j+1},\ldots , Y_J)^\top $$\end{document}
 , for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\ldots , J$$\end{document}
, for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\ldots , J$$\end{document}
 , where the conditional distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_j$$\end{document}
, where the conditional distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_j$$\end{document}
 given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{-j}$$\end{document}
given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{-j}$$\end{document}
 takes a logistic regression form. More precisely, the conditional likelihood with one observation
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}$$\end{document}
takes a logistic regression form. More precisely, the conditional likelihood with one observation
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}$$\end{document}
 is defined as
is defined as

A disadvantage of the conditional likelihood is that it requires a fully observed dataset because missing values cannot be straightforwardly marginalized out from (2). In what follows, we discuss how missing data can be treated in the conditional likelihood.
1.2. Proposed Method
Consider a dataset with N observations. Let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Omega _{j} \subset \{1,\ldots , N\}$$\end{document}
 be the subset of observations whose data on item j are missing. For each observation i and item j,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
be the subset of observations whose data on item j are missing. For each observation i and item j,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
 denotes the observed response if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \notin \Omega _j$$\end{document}
denotes the observed response if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \notin \Omega _j$$\end{document}
 , and otherwise,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
, and otherwise,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
 is missing. Thus, the observed data include
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Omega _j$$\end{document}
is missing. Thus, the observed data include
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\Omega _j$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
 , for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i\in \{1,\ldots , N\}{\setminus }\Omega _j$$\end{document}
, for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i\in \{1,\ldots , N\}{\setminus }\Omega _j$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j = 1,\ldots , J$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j = 1,\ldots , J$$\end{document}
 .
.
The proposed procedure iterates between two steps—(1) imputing the missing values of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
 for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \in \Omega _j$$\end{document}
for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \in \Omega _j$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\ldots , J$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\ldots , J$$\end{document}
 , achieved via a full conditional specification, and (2) sampling the posterior distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
, achieved via a full conditional specification, and (2) sampling the posterior distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 given the most recently imputed data. Let t be the current iteration number. Further, let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}^{(t-1)}_i = (y_{i1}^{(t-1)},\ldots , y_{iJ}^{(t-1)})^\top , i=1,\ldots , N$$\end{document}
given the most recently imputed data. Let t be the current iteration number. Further, let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}^{(t-1)}_i = (y_{i1}^{(t-1)},\ldots , y_{iJ}^{(t-1)})^\top , i=1,\ldots , N$$\end{document}
 , be imputed data from the previous iteration, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y^{(t-1)}_{ij} = y_{ij}$$\end{document}
, be imputed data from the previous iteration, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y^{(t-1)}_{ij} = y_{ij}$$\end{document}
 for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \notin \Omega _j$$\end{document}
for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \notin \Omega _j$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y^{(t-1)}_{ij}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y^{(t-1)}_{ij}$$\end{document}
 is imputed in the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(t-1)$$\end{document}
is imputed in the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(t-1)$$\end{document}
 th iteration for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \in \Omega _j$$\end{document}
th iteration for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \in \Omega _j$$\end{document}
 . For the tth iteration, the imputation and sampling steps are described as follows.
. For the tth iteration, the imputation and sampling steps are described as follows.
Imputation
We initialize the imputation in the tth iteration with the previously imputed data set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{i1}^{(t-1)},\ldots ,y_{iJ}^{(t-1)})$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\ldots , N$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\ldots , N$$\end{document}
 . Then, we run a loop over all the items,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j = 1,\ldots , J$$\end{document}
. Then, we run a loop over all the items,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j = 1,\ldots , J$$\end{document}
 . In step j of the loop, we impute
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
. In step j of the loop, we impute
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
 for all
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \in \Omega _j$$\end{document}
for all
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \in \Omega _j$$\end{document}
 , given the most recently imputed data
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{i1}^{(t)},\ldots ,y_{i,j-1}^{(t)},y_{ij}^{(t-1)},\ldots ,y_{iJ}^{(t-1)})$$\end{document}
, given the most recently imputed data
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{i1}^{(t)},\ldots ,y_{i,j-1}^{(t)},y_{ij}^{(t-1)},\ldots ,y_{iJ}^{(t-1)})$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i = 1,\ldots , N$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i = 1,\ldots , N$$\end{document}
 . We then obtain an updated data set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{i1}^{(t)},\ldots ,y_{i,j}^{(t)},y_{i,j+1}^{(t-1)},\ldots ,y_{iJ}^{(t-1)})$$\end{document}
. We then obtain an updated data set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{i1}^{(t)},\ldots ,y_{i,j}^{(t)},y_{i,j+1}^{(t-1)},\ldots ,y_{iJ}^{(t-1)})$$\end{document}
 by incorporating the newly imputed values for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
by incorporating the newly imputed values for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
 .
.
The imputation of each variable j is based on the conditional distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_j$$\end{document}
 given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{-j}$$\end{document}
given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{-j}$$\end{document}
 . Under the Ising model, this conditional distribution takes a logistic regression form. For computational reasons to be discussed in the sequel, we introduce an auxiliary parameter vector
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j = (\beta _{j1},\ldots , \beta _{jJ})^\top $$\end{document}
. Under the Ising model, this conditional distribution takes a logistic regression form. For computational reasons to be discussed in the sequel, we introduce an auxiliary parameter vector
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j = (\beta _{j1},\ldots , \beta _{jJ})^\top $$\end{document}
 as coefficients in the logistic regression, instead of directly using
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
as coefficients in the logistic regression, instead of directly using
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 from the previous iteration to sample the missing
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
from the previous iteration to sample the missing
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
 s. Unlike the constraint of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = s_{ji}$$\end{document}
s. Unlike the constraint of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = s_{ji}$$\end{document}
 in the symmetric matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
in the symmetric matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 , no constraints are imposed on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }_j$$\end{document}
, no constraints are imposed on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }_j$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\ldots , J$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\ldots , J$$\end{document}
 , which makes the sampling computationally efficient; see discussions in Sect. 1.4. The imputation of variable j consists of the following two steps:
, which makes the sampling computationally efficient; see discussions in Sect. 1.4. The imputation of variable j consists of the following two steps:
-
1. Sample auxiliary parameter vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\beta }}_j^{(t)}$$\end{document}
 from the posterior distribution (3) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} p^{(t,j)}({\varvec{\beta }}_j) \propto \pi _j({\varvec{\beta }}_j)\prod _{i=1}^N \frac{\exp \left[ (\beta _{jj}/2+\sum _{k\ne j}\beta _{jk}y_{ik}^{(t,j-1)})y_{ij}^{(t,j-1)}\right] }{1+\exp (\beta _{jj}/2+\sum _{k\ne j}\beta _{jk}y_{ik}^{(t,j-1)})}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _j({\varvec{\beta }}_j)$$\end{document}
is the prior distribution for the auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
.
from the posterior distribution (3) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} p^{(t,j)}({\varvec{\beta }}_j) \propto \pi _j({\varvec{\beta }}_j)\prod _{i=1}^N \frac{\exp \left[ (\beta _{jj}/2+\sum _{k\ne j}\beta _{jk}y_{ik}^{(t,j-1)})y_{ij}^{(t,j-1)}\right] }{1+\exp (\beta _{jj}/2+\sum _{k\ne j}\beta _{jk}y_{ik}^{(t,j-1)})}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _j({\varvec{\beta }}_j)$$\end{document}
is the prior distribution for the auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
.
-
2. Sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$y_{ij}^{(t)}$$\end{document}
for each
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \in \Omega _j$$\end{document}
from a Bernoulli distribution with success probability (4) \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{\exp (\beta _{jj}^{(t)}/2+\sum _{k\ne j}\beta _{jk}^{(t)}y_{ik}^{(t,j-1)})}{1+\exp (\beta _{jj}^{(t)}/2+\sum _{k\ne j}\beta _{jk}^{(t)}y_{ik}^{(t,j-1)})}. \end{aligned}$$\end{document}







After these two steps, we obtain
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{i1}^{(t)},\ldots ,y_{i,j}^{(t)},y_{i,j+1}^{(t-1)},\ldots ,y_{iJ}^{(t-1)})$$\end{document}
 by incorporating the newly imputed values for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}, i\in \Omega _j$$\end{document}
by incorporating the newly imputed values for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}, i\in \Omega _j$$\end{document}
 . We emphasize that only the missing values are updated. For
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \notin \Omega _j$$\end{document}
. We emphasize that only the missing values are updated. For
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i \notin \Omega _j$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}^{(t)}$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}^{(t)}$$\end{document}
 is always the observed value of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
is always the observed value of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{ij}$$\end{document}
 . After the loop over all the items, we have the imputed data set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{i1}^{(t)},\ldots ,y_{iJ}^{(t)})$$\end{document}
. After the loop over all the items, we have the imputed data set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(y_{i1}^{(t)},\ldots ,y_{iJ}^{(t)})$$\end{document}
 as the output from this imputation step.
as the output from this imputation step.
Sampling
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 Given the most recently imputed data
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}_i^{(t)}$$\end{document}
Given the most recently imputed data
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}_i^{(t)}$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\ldots , N$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i=1,\ldots , N$$\end{document}
 , update
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}^{(t)}$$\end{document}
, update
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}^{(t)}$$\end{document}
 by sampling from the pseudo-posterior distribution
by sampling from the pseudo-posterior distribution

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi ({{\textbf{S}}})$$\end{document}
 is the prior distribution for the Ising parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
is the prior distribution for the Ising parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 and recall that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\prod _{i=1}^N p^*({{\varvec{y}}}_i^{(t)} \mid {{\textbf{S}}})$$\end{document}
and recall that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\prod _{i=1}^N p^*({{\varvec{y}}}_i^{(t)} \mid {{\textbf{S}}})$$\end{document}
 is the conditional likelihood.
is the conditional likelihood.

Figure 1 Flowchart of the updating rule for the proposed method.

Algorithm 1 Ising Network Analysis with Iterative Imputation
Figure 1 visualizes the steps performed in the proposed method. Note that it is unnecessary to sample the parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 during the burn-in period and in every iteration after the burn-in period; thus, we employ a thinning step after the burn-in period. This is done to both decrease computational cost and reduce the auto-correlation in the imputed data. Moreover, we outline the proposed algorithm in Algorithm 1. The final estimate of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
during the burn-in period and in every iteration after the burn-in period; thus, we employ a thinning step after the burn-in period. This is done to both decrease computational cost and reduce the auto-correlation in the imputed data. Moreover, we outline the proposed algorithm in Algorithm 1. The final estimate of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 is obtained by averaging all the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}^{(t)}$$\end{document}
is obtained by averaging all the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}^{(t)}$$\end{document}
 obtained after the burn-in period. The computational details, including the sampling of auxiliary parameters and Ising parameter matrix and discussions of the computational complexity, are given in Sect. 1.4.
obtained after the burn-in period. The computational details, including the sampling of auxiliary parameters and Ising parameter matrix and discussions of the computational complexity, are given in Sect. 1.4.
We remark that our method imputes the missing variables one by one for each observation. This method is chosen because simultaneously imputing all the missing variables is typically computationally infeasible, especially when some observation units have many missing values. Simultaneous imputation requires evaluating the joint distribution of the missing variables given the observed ones, whose computational complexity grows exponentially with the number of missing values. In contrast, the proposed method is based on unidimensional conditional distributions, which is computationally more feasible. We also note that the proposed method has several variants that should also work well. These variants are discussed in Sect. 3.
1.3. Statistical Consistency
As our method is not a standard Bayesian inference procedure, we provide an asymptotic theory under the frequentist setting to justify its validity. In particular, we show that the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 parameter sampled from the pseudo-posterior distribution converges to the true parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0$$\end{document}
parameter sampled from the pseudo-posterior distribution converges to the true parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0$$\end{document}
 , under the assumptions that the Ising model is correctly specified and the data are MAR.
, under the assumptions that the Ising model is correctly specified and the data are MAR.
Consider one observation with a complete data vector
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}= (Y_1,\ldots , Y_J)^\top $$\end{document}
 . Further, let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Z}}}= (Z_1,\ldots , Z_J)^\top $$\end{document}
. Further, let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Z}}}= (Z_1,\ldots , Z_J)^\top $$\end{document}
 be a vector of missing indicators, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij} = 1$$\end{document}
be a vector of missing indicators, where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij} = 1$$\end{document}
 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_{ij}$$\end{document}
if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Y_{ij}$$\end{document}
 is observed and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij} = 0$$\end{document}
is observed and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$Z_{ij} = 0$$\end{document}
 otherwise. We further let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{obs} = \{Y_j: Z_j = 1, j = 1,\ldots , J\}$$\end{document}
otherwise. We further let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{obs} = \{Y_j: Z_j = 1, j = 1,\ldots , J\}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{mis} = \{Y_j: Z_j = 0, j = 1,\ldots , J\}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}_{mis} = \{Y_j: Z_j = 0, j = 1,\ldots , J\}$$\end{document}
 be the observed and missing entries of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}$$\end{document}
be the observed and missing entries of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}$$\end{document}
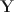 , respectively. Consider the joint distribution of observable data
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$({{\textbf{Y}}}_{obs}, {{\textbf{Z}}})$$\end{document}
, respectively. Consider the joint distribution of observable data
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$({{\textbf{Y}}}_{obs}, {{\textbf{Z}}})$$\end{document}
 , taking the form
, taking the form

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\exp \left( {{\varvec{y}}}^\top {{\textbf{S}}}{{\varvec{y}}}/2\right) /{c({{\textbf{S}}})}$$\end{document}
 is the distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}= {{\varvec{y}}}$$\end{document}
is the distribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}= {{\varvec{y}}}$$\end{document}
 under the Ising model,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q({\textbf{z}} \mid {{\varvec{y}}},\varvec{\phi })$$\end{document}
under the Ising model,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q({\textbf{z}} \mid {{\varvec{y}}},\varvec{\phi })$$\end{document}
 denotes the conditional probability of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Z}}}= {\textbf{z}}$$\end{document}
denotes the conditional probability of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Z}}}= {\textbf{z}}$$\end{document}
 given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}= {{\varvec{y}}}$$\end{document}
given
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{Y}}}= {{\varvec{y}}}$$\end{document}
 , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\phi }$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\phi }$$\end{document}
 denotes the unknown parameters of this distribution. The MAR assumption, also known as the ignorable missingness assumption, means that the conditional distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q({\textbf{z}} \mid {{\varvec{y}}},\varvec{\phi })$$\end{document}
denotes the unknown parameters of this distribution. The MAR assumption, also known as the ignorable missingness assumption, means that the conditional distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q({\textbf{z}} \mid {{\varvec{y}}},\varvec{\phi })$$\end{document}
 depends on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}$$\end{document}
depends on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}$$\end{document}
 only through the observed entries, i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q({\textbf{z}} \mid {{\varvec{y}}},\varvec{\phi }) = q(\textbf{z}\mid {{\varvec{y}}}_{obs},\varvec{\phi })$$\end{document}
only through the observed entries, i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q({\textbf{z}} \mid {{\varvec{y}}},\varvec{\phi }) = q(\textbf{z}\mid {{\varvec{y}}}_{obs},\varvec{\phi })$$\end{document}
 . In that case, (6) can be factorized as
. In that case, (6) can be factorized as

Consequently, the inference of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 does not depend on the unknown distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q({\textbf{z}} \mid {{\varvec{y}}},\varvec{\phi })$$\end{document}
does not depend on the unknown distribution
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q({\textbf{z}} \mid {{\varvec{y}}},\varvec{\phi })$$\end{document}
 .
.
As shown in Liu et al. (Reference Liu, Gelman, Hill, Su and Kropko2014), the MAR assumption, together with additional regularity conditions, ensures that the iterative imputation of the missing responses converges to the imputation distribution under a standard Bayesian procedure as the number of iterations and the sample size N go to infinity. A key to this convergence result is the compatibility of the conditional models in the imputation step—the logistic regression models are compatible with the Ising model as a joint distribution. The validity of the imputed samples further ensures the consistency of the estimated Ising parameter matrix. We summarize this result in Theorem 1.
Theorem 1
Assume the following assumptions hold: (1) The Markov chain for missing data, generated by the iterative imputation algorithm (Algorithm 1), is positive Harris recurrent and thus admits a unique stationary distribution; (2) the missing data process is ignorable; and (3) A regularity condition holds for prior distributions of Ising model parameters and auxiliary parameters, as detailed in the supplementary material. Let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi _N^*({{\textbf{S}}})$$\end{document}
 be the posterior density of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
be the posterior density of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 implied by the stationary distribution of the proposed method. Given the true parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0$$\end{document}
implied by the stationary distribution of the proposed method. Given the true parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0$$\end{document}
 for the Ising model and any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varepsilon >0,$$\end{document}
for the Ising model and any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varepsilon >0,$$\end{document}
 we have
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi _N^*({{\textbf{S}}})$$\end{document}
we have
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pi _N^*({{\textbf{S}}})$$\end{document}
 concentrates at
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0,$$\end{document}
concentrates at
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0,$$\end{document}


in probability as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N\rightarrow \infty $$\end{document}
 .
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$B_\varepsilon ({{\textbf{S}}}_0)=\{{{\textbf{S}}}:\Vert {{\textbf{S}}}-{{\textbf{S}}}_0\Vert <\varepsilon \}$$\end{document}
.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$B_\varepsilon ({{\textbf{S}}}_0)=\{{{\textbf{S}}}:\Vert {{\textbf{S}}}-{{\textbf{S}}}_0\Vert <\varepsilon \}$$\end{document}
 is the open ball of radius
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varepsilon $$\end{document}
is the open ball of radius
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varepsilon $$\end{document}
 at
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0$$\end{document}
at
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0$$\end{document}
 .
.
We provide intuitions about this consistency result. Suppose that the data are generated by an Ising model. The iterative imputation method ensures that the parameters of the logistic regressions are close to those implied by the true Ising model, and thus, the conditional distributions we use to impute the missing values are close to those under the true model. This further guarantees that the joint distribution of the imputed data given the observed ones is close to that under the true Ising model, and consequently, the Ising model parameters we learn from the imputed data are close to those of the true model.
1.4. Computational Details
In what follows, we discuss the specification of the prior distributions and the sampling of auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }_j$$\end{document}
 and Ising model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
and Ising model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 .
.
Sampling
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }_j$$\end{document}
 We set independent mean-zero normal priors for entries of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }_j$$\end{document}
We set independent mean-zero normal priors for entries of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }_j$$\end{document}
 . For the intercept parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta _{jj}$$\end{document}
. For the intercept parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta _{jj}$$\end{document}
 , we use a weakly informative prior by setting the variance to 100. For the slope parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta _{jk}$$\end{document}
, we use a weakly informative prior by setting the variance to 100. For the slope parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\beta _{jk}$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k\ne j$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k\ne j$$\end{document}
 , we set a more informative prior by setting the variance to be 1, given that these parameters correspond to the off-diagonal entries of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
, we set a more informative prior by setting the variance to be 1, given that these parameters correspond to the off-diagonal entries of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 , which are sparse and typically do not take extreme values. The sampling of the auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
, which are sparse and typically do not take extreme values. The sampling of the auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
 , following (3), is essentially a standard Bayesian logistic regression problem. We achieve it by a Markov chain Monte Carlo (MCMC) sampler called the Pólya–Gamma sampler (Polson et al., Reference Polson, Scott and Windle2013).
, following (3), is essentially a standard Bayesian logistic regression problem. We achieve it by a Markov chain Monte Carlo (MCMC) sampler called the Pólya–Gamma sampler (Polson et al., Reference Polson, Scott and Windle2013).
To obtain
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }^{(t)}_j$$\end{document}
 , this sampler starts with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }^{(t-1)}_j$$\end{document}
, this sampler starts with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }^{(t-1)}_j$$\end{document}
 from the previous step. It constructs an MCMC transition kernel by a data argumentation trick. More precisely, the following two steps are performed.
from the previous step. It constructs an MCMC transition kernel by a data argumentation trick. More precisely, the following two steps are performed.
-
1. Given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }^{(t-1)}$$\end{document}
, independently sample N augmentation variables, each from a Pólya–Gamma distribution (Barndorff-Nielsen et al., Reference Barndorff-Nielsen, Kent and Sørensen1982). -
2. Given the N augmentation variables, sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\varvec{\beta }^{(t)}$$\end{document}
from a J-variate normal distribution.


The details of these two steps are given in the supplementary material, including the forms of the Pólya–Gamma distributions and the mean and covariance matrix of the J-variate normal distribution. We choose the Pólya–Gamma sampler because it is very easy to construct and computationally efficient. It is much easier to implement than Metropolis–Hastings samplers which often need tuning to achieve good performance.
We comment on the computational complexity of the sampling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }_j$$\end{document}
 . The sampling from the Pólya–Gamma distribution has a complexity O(NJ), and the sampling from the J-variate normal distribution has a complexity of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$O(NJ^2)+O(J^3)$$\end{document}
. The sampling from the Pólya–Gamma distribution has a complexity O(NJ), and the sampling from the J-variate normal distribution has a complexity of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$O(NJ^2)+O(J^3)$$\end{document}
 . Consequently, a loop of all the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j, j=1,\ldots , J$$\end{document}
. Consequently, a loop of all the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j, j=1,\ldots , J$$\end{document}
 , has a complexity of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$O((N+J)J^3)$$\end{document}
, has a complexity of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$O((N+J)J^3)$$\end{document}
 .
.
Sampling
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 Since
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
Since
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 is a symmetric matrix, we reparametrize it by vectorizing its off-diagonal entries (including the diagonal entries). Specifically, the reparameterization is done by half-vectorization, denoted by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}= \text {vech}({{\textbf{S}}}) = (s_{11},\ldots , s_{J1}, s_{22},\ldots , s_{J2},\ldots , s_{JJ})^\top \in {\mathbb {R}}^{J(J+1)/2}$$\end{document}
is a symmetric matrix, we reparametrize it by vectorizing its off-diagonal entries (including the diagonal entries). Specifically, the reparameterization is done by half-vectorization, denoted by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}= \text {vech}({{\textbf{S}}}) = (s_{11},\ldots , s_{J1}, s_{22},\ldots , s_{J2},\ldots , s_{JJ})^\top \in {\mathbb {R}}^{J(J+1)/2}$$\end{document}
 . It is easy to see that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {vech}(\cdot )$$\end{document}
. It is easy to see that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {vech}(\cdot )$$\end{document}
 is a one-to-one mapping between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbb {R}}^{J(J+1)/2}$$\end{document}
is a one-to-one mapping between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathbb {R}}^{J(J+1)/2}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J\times J$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J\times J$$\end{document}
 symmetric matrices. Therefore, we impose a prior distribution on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}$$\end{document}
symmetric matrices. Therefore, we impose a prior distribution on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}$$\end{document}
 and sample
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}^{(t)}$$\end{document}
and sample
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}^{(t)}$$\end{document}
 in the tth iteration when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
in the tth iteration when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 is sampled. Then we let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}^{(t)} = \text {vech}^{-1}({\varvec{\alpha }}^{(t)})$$\end{document}
is sampled. Then we let
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}^{(t)} = \text {vech}^{-1}({\varvec{\alpha }}^{(t)})$$\end{document}
 .
.
Recall that a thinning step is performed, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$t_0$$\end{document}
 is the gap between two samples of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
is the gap between two samples of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 . Let t be a multiple of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$t_0$$\end{document}
. Let t be a multiple of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$t_0$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}^{(t-t_0)} = \text {vech}({{\textbf{S}}}^{(t-t_0)})$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}^{(t-t_0)} = \text {vech}({{\textbf{S}}}^{(t-t_0)})$$\end{document}
 be previous value of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}$$\end{document}
be previous value of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}$$\end{document}
 . The sampling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}^{(t)}$$\end{document}
. The sampling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}^{(t)}$$\end{document}
 is also achieved by a Pólya–Gamma sampler, which involves the following two steps similar to the sampling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }_j$$\end{document}
is also achieved by a Pólya–Gamma sampler, which involves the following two steps similar to the sampling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta }_j$$\end{document}
 .
.
-
1. Given \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\alpha }}^{(t-t_0)}$$\end{document}
, independently sample NJ augmentation variables, each from a Pólya–Gamma distribution. -
2. Given the NJ augmentation variables, sample \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\varvec{\alpha }}^{(t)}$$\end{document}
from a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J(J+1)/2$$\end{document}
-variate normal distribution.



The details of these two steps are given in the supplementary material. We note that the computational complexity of sampling the NJ augmentation variables is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$O(NJ^2)$$\end{document}
 , and that of sampling
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}^{(t)}$$\end{document}
, and that of sampling
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\alpha }}^{(t)}$$\end{document}
 is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$O(NJ^5)+O(J^6)$$\end{document}
is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$O(NJ^5)+O(J^6)$$\end{document}
 , resulting in an overall complexity
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$O((N+J)J^5)$$\end{document}
, resulting in an overall complexity
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$O((N+J)J^5)$$\end{document}
 . Comparing the complexities of the imputation and sampling
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
. Comparing the complexities of the imputation and sampling
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 steps, we notice that the latter is computationally much more intensive. This is the reason why we choose to impute data by introducing auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta _j}$$\end{document}
steps, we notice that the latter is computationally much more intensive. This is the reason why we choose to impute data by introducing auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\beta _j}$$\end{document}
 s rather than using Ising network parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
s rather than using Ising network parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 so that the iterative imputation mixes much faster in terms of the computation time. In addition, we only sample
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
so that the iterative imputation mixes much faster in terms of the computation time. In addition, we only sample
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 every
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$t_0$$\end{document}
every
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$t_0$$\end{document}
 iterations for a reasonably large
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$t_0$$\end{document}
iterations for a reasonably large
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$t_0$$\end{document}
 to avoid a high computational cost and also reduce the auto-correlation between the imputed data.
to avoid a high computational cost and also reduce the auto-correlation between the imputed data.
We remark that Marsman et al. (Reference Marsman, Huth, Waldorp and Ntzoufras2022) considered a similar Ising network analysis problem based on fully observed data, in which they proposed a Bayesian inference approach based on a spike-and-slab prior to learning
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 . Their Bayesian inference is also based on a Pólya–Gamma sampler. However, they combined Gibbs sampling with a Pólya–Gamma sampler, updating one parameter in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
. Their Bayesian inference is also based on a Pólya–Gamma sampler. However, they combined Gibbs sampling with a Pólya–Gamma sampler, updating one parameter in
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 at a time. This Gibbs scheme often mixes slower than the joint update of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
at a time. This Gibbs scheme often mixes slower than the joint update of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 as in the proposed method and, thus, is computationally less efficient. The proposed Pólya–Gamma sampler may be integrated into the framework of Marsman et al. (Reference Marsman, Huth, Waldorp and Ntzoufras2022) to improve their computational efficiency.
as in the proposed method and, thus, is computationally less efficient. The proposed Pólya–Gamma sampler may be integrated into the framework of Marsman et al. (Reference Marsman, Huth, Waldorp and Ntzoufras2022) to improve their computational efficiency.
2. Numerical Experiments
We illustrate the proposed method and show its power via simulation studies and a real-world data application. In Sect. 2.1, we conduct two simulation studies, evaluating the proposed method under two MAR scenarios, one of which involves missingness due to screening items. A further simulation study is carried out, applying our method to a 15-node Ising model governed by the MCAR mechanism. Detailed exposition of this study can be found in the supplementary materials.
2.1. Simulation
Study I We generate data from an Ising model with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J=6$$\end{document}
 variables. Missing values are generated under an MAR setting that is not MCAR. The proposed method is then compared with Bayesian inference based on (1) listwise deletion and (2) a single imputation, where the single imputation is based on the imputed data from the Tth iteration of Algorithm 1, recalling that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_0$$\end{document}
variables. Missing values are generated under an MAR setting that is not MCAR. The proposed method is then compared with Bayesian inference based on (1) listwise deletion and (2) a single imputation, where the single imputation is based on the imputed data from the Tth iteration of Algorithm 1, recalling that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_0$$\end{document}
 is the burn-in size.
is the burn-in size.
We configure the true parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0$$\end{document}
 as follows. Since
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0$$\end{document}
as follows. Since
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0$$\end{document}
 is a symmetric matrix, we only need to specify its upper triangular matrix and then the diagonal entries. For the upper triangular entries (i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{jl}$$\end{document}
is a symmetric matrix, we only need to specify its upper triangular matrix and then the diagonal entries. For the upper triangular entries (i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{jl}$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j<l$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j<l$$\end{document}
 ), we randomly assign 50% of them to zero to introduce a moderately sparse setting. In addition, the nonzero parameters are then generated by sampling from a uniform distribution over the set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$[-1, -0.4] \cup [0.4, 1]$$\end{document}
), we randomly assign 50% of them to zero to introduce a moderately sparse setting. In addition, the nonzero parameters are then generated by sampling from a uniform distribution over the set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$[-1, -0.4] \cup [0.4, 1]$$\end{document}
 . The intercept parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{jj},j=1,\ldots , J$$\end{document}
. The intercept parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{jj},j=1,\ldots , J$$\end{document}
 are set to zero. The true parameter values are given in the supplementary material. Missing data are simulated by masking particular elements under an MAR mechanism. In particular, we have
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_{i6}=1$$\end{document}
are set to zero. The true parameter values are given in the supplementary material. Missing data are simulated by masking particular elements under an MAR mechanism. In particular, we have
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_{i6}=1$$\end{document}
 , so that the sixth variable is always observed. We further allow the missingness probabilities of the first five variables (i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_{ij}=0,j=1,\ldots ,5$$\end{document}
, so that the sixth variable is always observed. We further allow the missingness probabilities of the first five variables (i.e.,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$z_{ij}=0,j=1,\ldots ,5$$\end{document}
 ) to depend on the values of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{i6}$$\end{document}
) to depend on the values of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$y_{i6}$$\end{document}
 . The specific settings on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(z_{ij}=0\mid y_{i6}),j=1,\ldots , 5$$\end{document}
. The specific settings on
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p(z_{ij}=0\mid y_{i6}),j=1,\ldots , 5$$\end{document}
 are detailed in the supplementary material. Data are generated following the aforementioned Ising model and MAR mechanism for four different sample sizes,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N = 1000, 2000, 4000$$\end{document}
are detailed in the supplementary material. Data are generated following the aforementioned Ising model and MAR mechanism for four different sample sizes,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N = 1000, 2000, 4000$$\end{document}
 , and 8000, respectively. For each sample size, 50 independent replications are created.
, and 8000, respectively. For each sample size, 50 independent replications are created.
Three methods are compared—the proposed method, Bayesian inference with a single imputation, and Bayesian inference based on complete cases from listwise deletion. The Bayesian inference for complete data is performed by sampling parameters from the posterior implied by the pseudo-likelihood and a normal prior, which is a special case of the proposed method without iterative imputation steps. All these methods shared the same initial values
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{jl}^{(0)}\sim U(-0.1,0.1),1\le j\le l\le J$$\end{document}
 . For our proposed method, we set the length of the Markov chain Monte Carlo (MCMC) iterations to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T = 5000$$\end{document}
. For our proposed method, we set the length of the Markov chain Monte Carlo (MCMC) iterations to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T = 5000$$\end{document}
 and a burn-in size of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_0 = 1000$$\end{document}
and a burn-in size of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_0 = 1000$$\end{document}
 , with a thinning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k_0=10$$\end{document}
, with a thinning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k_0=10$$\end{document}
 . This setup leads to an effective total of 400 MCMC samples for the Ising parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
. This setup leads to an effective total of 400 MCMC samples for the Ising parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}$$\end{document}
 . Notably, identical MCMC length and burn-in configuration are applied during parameters inference in the single imputation and complete-case analyses.
. Notably, identical MCMC length and burn-in configuration are applied during parameters inference in the single imputation and complete-case analyses.
Figure 2 gives the plots for the mean squared errors (MSE) of the estimated edge parameters and intercept parameters under different sample sizes and for different methods. The MSE for each parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{jl}$$\end{document}
 is defined as
is defined as

Here,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\hat{s}_{k,jl}$$\end{document}
 denotes the estimated value from the kth replication while
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{0,jl}$$\end{document}
denotes the estimated value from the kth replication while
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{0,jl}$$\end{document}
 refers to the true value. Each box in panel (a) corresponds to the 15 edge parameters, and each box in panel (b) corresponds to the 6 intercept parameters. We notice that the listwise deletion procedure introduces biases into the edge and intercept estimation, resulting in the MSEs for certain parameters not decaying toward zero as the sample size grows. Additionally, both the proposed method and the single imputation method offer accurate parameter estimation, with MSEs decaying toward zero as the sample size increases. Notably, the proposed method is substantially more accurate than the single imputation method, suggesting that aggregating over multiple imputed datasets improves the estimation accuracy. Furthermore, for smaller sample sizes, the complete-case analysis seems to yield slightly more accurate estimates of the edge parameters than the single imputation method. Across four sample sizes, the median computational times for obtaining the results of the proposed method were 33, 50, 88, and 185 s, respectively.Footnote 1
refers to the true value. Each box in panel (a) corresponds to the 15 edge parameters, and each box in panel (b) corresponds to the 6 intercept parameters. We notice that the listwise deletion procedure introduces biases into the edge and intercept estimation, resulting in the MSEs for certain parameters not decaying toward zero as the sample size grows. Additionally, both the proposed method and the single imputation method offer accurate parameter estimation, with MSEs decaying toward zero as the sample size increases. Notably, the proposed method is substantially more accurate than the single imputation method, suggesting that aggregating over multiple imputed datasets improves the estimation accuracy. Furthermore, for smaller sample sizes, the complete-case analysis seems to yield slightly more accurate estimates of the edge parameters than the single imputation method. Across four sample sizes, the median computational times for obtaining the results of the proposed method were 33, 50, 88, and 185 s, respectively.Footnote 1

Figure 2
a Boxplots of MSEs for edge parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{jl}$$\end{document}
 . b Boxplots of MSEs for intercept parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{jj}$$\end{document}
. b Boxplots of MSEs for intercept parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{jj}$$\end{document}
 .
.
Study II: Missing due to screening items Missingness due to screening items is commonly encountered in practice, posing challenges to the network analysis (Borsboom et al., Reference Borsboom, Fried, Epskamp, Waldorp, van Borkulo, van der Maas and Cramer2017; McBride et al., Reference McBride, van Bezooijen, Aggen, Kendler and Fried2023). This occurs, for example, in surveys where initial screening questions determine respondents’ eligibility or relevance for subsequent questions. Suppose respondents indicate a lack of relevant experience (i.e., their answers to the screening items are all negative). In that case, they are not prompted to answer certain follow-up questions, making the missingness of these responses depend on their answers to the screening questions and, thus, MAR. Our real data example in Sect. 2.2 involves two screening items, which results in a large proportion of missing data.
Table 1 MSEs and biases for edge parameters.

We consider a simulation setting involving two screening items to evaluate the proposed method’s performance under this setting. Similar to Study I, we consider a setting with six items, the first two of which are the screening items. The full data are generated under an Ising model, whose parameters are given in the supplementary material, where the corresponding network has six positive edges including one between the two screening items. The responses to the screening items are always set as observed for any observation. When an observation’s responses to the screening items are both zero, their responses to the rest of the four items are regarded as missing.
We consider a single sample size
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$N=8000$$\end{document}
 and generate 50 independent datasets. We apply the proposed method, the single imputation method, and the complete-case analysis. For each estimation procedure, we set the MCMC iterations
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T = 5000$$\end{document}
and generate 50 independent datasets. We apply the proposed method, the single imputation method, and the complete-case analysis. For each estimation procedure, we set the MCMC iterations
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T = 5000$$\end{document}
 , the burn-in size
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_0 = 1000$$\end{document}
, the burn-in size
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_0 = 1000$$\end{document}
 , and the thinning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k_0=10$$\end{document}
, and the thinning parameter
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k_0=10$$\end{document}
 . These methods are compared in terms of MSEs and biases for parameter estimation.
. These methods are compared in terms of MSEs and biases for parameter estimation.
Table 1 presents the result. For all the edge parameters except for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{12}$$\end{document}
 , the three estimation methods work well, though the single imputation method is slightly less accurate, as indicated by its slightly larger MSEs. However, the complete-case estimate is substantially negatively biased for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{12}$$\end{document}
, the three estimation methods work well, though the single imputation method is slightly less accurate, as indicated by its slightly larger MSEs. However, the complete-case estimate is substantially negatively biased for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{12}$$\end{document}
 , the edge between two screening items. At the same time, the imputation-based methods are still accurate, with the proposed method having a smaller MSE than that of the single imputation method. This result confirms that running a complete-case analysis on data involving screening items is problematic while performing the imputation-based methods, especially the proposed method, yields valid results.
, the edge between two screening items. At the same time, the imputation-based methods are still accurate, with the proposed method having a smaller MSE than that of the single imputation method. This result confirms that running a complete-case analysis on data involving screening items is problematic while performing the imputation-based methods, especially the proposed method, yields valid results.
We provide discussions on this result. The negative bias for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{12}$$\end{document}
 in the complete-case analysis is due to a selection bias, typically referred to as Berkson’s paradox (De Ron et al., Reference De Ron, Fried and Epskamp2021). The complete-case analysis excludes all the response vectors with negative responses to both screening items. Consequently, a positive response on one screening item strongly suggests a negative response on the other, regardless of the responses to the rest of the items. This results in a falsely negative conditional association between the two screening items. In fact, one can theoretically show that the frequentist estimate of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{12}$$\end{document}
in the complete-case analysis is due to a selection bias, typically referred to as Berkson’s paradox (De Ron et al., Reference De Ron, Fried and Epskamp2021). The complete-case analysis excludes all the response vectors with negative responses to both screening items. Consequently, a positive response on one screening item strongly suggests a negative response on the other, regardless of the responses to the rest of the items. This results in a falsely negative conditional association between the two screening items. In fact, one can theoretically show that the frequentist estimate of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{12}$$\end{document}
 based on the maximum pseudo-likelihood is negative infinity. The finite parameter estimate in Table 1 for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{12}$$\end{document}
based on the maximum pseudo-likelihood is negative infinity. The finite parameter estimate in Table 1 for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{12}$$\end{document}
 is due to the shrinkage effect of the prior distribution that we impose. On the other hand, the proposed method makes use of the observed frequency of the (0, 0) response pattern for the two screening items, in addition to the frequencies of the fully observed response vectors. As shown by the identifiability result in Appendix, these frequencies are sufficient for identifying all the parameters of the Ising model.
is due to the shrinkage effect of the prior distribution that we impose. On the other hand, the proposed method makes use of the observed frequency of the (0, 0) response pattern for the two screening items, in addition to the frequencies of the fully observed response vectors. As shown by the identifiability result in Appendix, these frequencies are sufficient for identifying all the parameters of the Ising model.
2.2. A Real Data Application
We analyze the dataset for the 2001–2002 National Epidemiological Survey of Alcohol and Related Conditions (NESARC), which offers valuable insights into alcohol consumption and associated issues in the US population (Grant et al., 2003). The dataset consists of 43,093 civilian non-institutionalized individuals aged 18 and older. In this analysis, we focus on two specific sections of the survey that concern two highly prevalent mental health disorders—major depressive disorder (MDD) and generalized anxiety disorder (GAD). Because MDD and GAD have high symptom overlap (Hettema, Reference Hettema2008) and often co-occur (Hasin et al., Reference Hasin, Goodwin, Stinson and Grant2005), it is important to perform a joint analysis of the symptoms of the two mental health disorders and study their separation. In particular, Blanco et al. (Reference Blanco, Rubio, Wall, Secades-Villa, Beesdo-Baum and Wang2014) performed factor analysis based on the same data and found that the two mental health disorders have distinct latent structures. We reanalyze the data, hoping to gain some insights from the network perspective of the two mental health disorders.
Table 2 Descriptions of MDD and GAD items and their missing rates.

Following Blanco et al. (Reference Blanco, Rubio, Wall, Secades-Villa, Beesdo-Baum and Wang2014), we consider data with nine items measuring MDD and six items measuring GAD. These items are designed according to the Diagnostic and Statistical Manual of Mental Disorders, Fourth Edition (DSM-IV) (American Psychiatric Association, 2000). These items ask the participants if they have recently experienced certain symptoms; see Table 2 for their short descriptions. After eliminating samples with entirely absent values across the 15 items, a total of 42,230 cases remain in the dataset. Note that any “Unknown” responses in the original data are converted into missing values. The dataset exhibits a significant degree of missingness, with only 2,412 complete cases for the 15 items, representing approximately 6% of the total cases. Specifically, the missing rate for each item is given in Table 2. Importantly, items D1 and D2 function as screening items and, thus, have a very low missing rate. The respondents did not need to answer items D3–D9 if the responses to D1 and D2 were “No” or “Unknown,” resulting in high missing rates for these items. This pattern suggests that the missing data in this study is not MCAR. The GAD items A1–A6 also have a screening item, which results in the high missing rates in A1 through A6. Following the treatment in Blanco et al. (Reference Blanco, Rubio, Wall, Secades-Villa, Beesdo-Baum and Wang2014), these screening items are not included in the current analysis.

Figure 3 Estimated network structure for MDD and GAD. a Complete-case analysis. b Proposed method.
We apply the proposed method and the complete-case analysis to the data. For each method, 10 MCMC chains with random starting values are used, each having 10,000 MCMC iterations and a burn-in size 5000. The Gelman–Rubin statistics are always below 1.018, confirming the satisfactory convergence of all 120 parameters for both methods. The estimated network structures for MDD and GAD items are presented in Fig. 3, where an edge is shown between two variables when the absolute value of the estimated parameter is greater than 0.5. We emphasize that this threshold is applied only for visualization purposes, rather than for edge selection. Consequently, the edges in Fig. 3 should only be interpreted as edges with large estimated parameters, rather than truly nonzero edges. The nine MDD items are shown as blue nodes at the bottom, and the six GAD items are shown as orange nodes at the top. The edges are colored blue and orange, which represent positive and negative parameter estimates, respectively. In addition, the line thickness of the edges indicates their magnitude. A clear difference between the two methods is the edge between D1 “depressed mood most of the day, nearly every day,” and D2 “markedly diminished interest or pleasure in all, or almost all, activities most of the day, nearly every day,” which are two screening questions in the survey that all the participants responded to. The estimated parameter for this edge has a large absolute value under each of the two methods, but the estimated parameter is negative in the complete-case analysis, while it is positive according to the proposed method. As revealed by the result of Study II in Sect. 2.1, the negative edge estimate of the edge between the screening items given by the complete-case analysis is spurious. Considering the content of these items, we believe that the estimate from the proposed method is more sensible. Other than this edge, the remaining structure of the two networks tends to be similar, but with some differences. In particular, we see that the complete-case analysis yields more edges than the proposed method; for example, the edges of A4–A5, A1–D5, D1–D6, D1–D7, D1–D8, and D8–D9 appear in the estimated network from the complete-case analysis but not in that of the proposed method, while only two edges, A3–A5 and D3–D4, are present in the network estimated by the proposed method but absent in the network from the complete-case analysis. We believe this is due to the higher estimation variance of the complete-case analysis caused by its relatively small sample size.
Finally, our analysis shows that the symptoms of each mental health disorder tend to densely connect with each other in the Ising network, while the symptoms are only loosely but positively connected between the two mental health disorders. The edges between the two mental health disorders identify the overlapping symptoms, including “D4: Insomnia or hypersomnia” and “A6: Sleep disturbance,” “A2: Easily fatigued” and “D6: Fatigue/loss of energy,” and “A3: Difficulty concentrating” and “D8: Diminished concentration.” These results suggest that MDD and GAD are two well-separated mental health disorders, despite their high symptom overlap and frequent co-occurrence. This result confirms the conclusion of Blanco et al. (Reference Blanco, Rubio, Wall, Secades-Villa, Beesdo-Baum and Wang2014) that GAD and MDD are closely related but different nosological entities.
3. Concluding remarks
In this paper, we propose a new method for Ising network analysis in the presence of missing data. The proposed method integrates iterative imputation into a Bayesian inference procedure based on conditional likelihood. An asymptotic theory is established that guarantees the consistency of the proposed estimator. Furthermore, a Pólya–Gamma machinery is proposed for the sampling of Ising model parameters, which yields efficient computation. The power of the proposed method is further shown via simulations and a real data application. An R package has been developed that will be made publicly available upon the acceptance of the paper.
The current work has several limitations that require future theoretical and methodological developments. First, this manuscript concentrates on parameter estimation for the Ising model in the presence of missing data. However, the problem of edge selection (Borsboom, Reference Borsboom2022; Marsman et al., Reference Marsman, Huth, Waldorp and Ntzoufras2022; Noghrehchi et al., Reference Noghrehchi, Stoklosa, Penev and Warton2021; Roçkovóa, Reference Roçkovóa2018) requires future investigation. There are several possible directions. One direction is to view it as a multiple testing problem and develop procedures that control certain familywise error rates or the false discovery rate for the selection of edges. To do so, one needs to develop a way to quantify the uncertainty for the proposed estimator. It is non-trivial, as the proposed method is not a standard Bayesian procedure, and we still lack a theoretical understanding of the asymptotic distribution of the proposed procedure. In particular, it is unclear whether the Bernstein–von Mises theorem that connects Bayesian and frequentist estimation holds under the current setting. Another direction is to view it as a model selection problem. In this direction, we can use sparsity-inducing priors to better explore the Ising network structure when it is sparse. We believe that the proposed method, including the iterative imputation and the Pólya–Gamma machinery, can be adapted when we replace the normal prior with the spike-and-slab prior considered in Marsman et al. (Reference Marsman, Huth, Waldorp and Ntzoufras2022). This adaptation can be done by adding some Gibbs sampling steps. In addition, it is of interest to develop an information criterion that is computationally efficient while statistically consistent. This may be achieved by computing an information criterion, such as the Bayesian information criterion, for each imputed dataset and then aggregating them across multiple imputations. Finally, the proposed method has several variants that may be useful for problems of different scales. For problems of a relatively small scale (i.e., when J is small), we may perform data imputation using the sampled
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{S}}$$\end{document}
 instead of using auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
instead of using auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
 s. This choice will make the algorithm computationally more intensive, as the sampling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{S}}$$\end{document}
s. This choice will make the algorithm computationally more intensive, as the sampling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{S}}$$\end{document}
 has a high computational complexity. On the other hand, it may make the estimator statistically more efficient as it avoids estimating the auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
has a high computational complexity. On the other hand, it may make the estimator statistically more efficient as it avoids estimating the auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
 s, whose dimension is higher than
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{S}}$$\end{document}
s, whose dimension is higher than
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{S}}$$\end{document}
 . For very large-scale problems, one may estimate the Ising model parameters based only on the auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
. For very large-scale problems, one may estimate the Ising model parameters based only on the auxiliary parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{\beta }}_j$$\end{document}
 s. For example, we may estimate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij}$$\end{document}
s. For example, we may estimate
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij}$$\end{document}
 by averaging the value of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(\beta _{ij}+\beta _{ji})/2$$\end{document}
by averaging the value of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(\beta _{ij}+\beta _{ji})/2$$\end{document}
 over the iterations. This estimator is computationally more efficient than the proposed one, as it avoids sampling
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{S}}$$\end{document}
over the iterations. This estimator is computationally more efficient than the proposed one, as it avoids sampling
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{S}}$$\end{document}
 given the imputed datasets. This estimator should still be consistent but may be statistically slightly less efficient than the proposed one.
given the imputed datasets. This estimator should still be consistent but may be statistically slightly less efficient than the proposed one.
Acknowledgements
We thank the editor, associate editor, and three anonymous referees for their careful review and valuable comments. Siliang Zhang’s research is partially supported by Shanghai Science and Technology Committee Rising-Star Program (22YF1411100) and National Natural Science Foundation of China (12301373).
Appendix: Identifiability of Ising Model with Two Screening Items
We investigate the identifiability of the Ising model parameters when there are two screening items.
Proposition 1
Consider an Ising model with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J \ge 3$$\end{document}
 , true parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0 = (s_{ij}^0)_{J\times J}$$\end{document}
, true parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}_0 = (s_{ij}^0)_{J\times J}$$\end{document}
 , and the first two items being the screening items. We define
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0 ({\textbf{y}}):= P({\textbf{Y}} = \textbf{y}|{{\textbf{S}}}_0), $$\end{document}
, and the first two items being the screening items. We define
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0 ({\textbf{y}}):= P({\textbf{Y}} = \textbf{y}|{{\textbf{S}}}_0), $$\end{document}
 for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{y}} \in {\mathcal {A}} = \{(x_1,\ldots , x_J)^\top \in \{0,1\}^J:x_1 = 1 \text{ or } x_2=1 \}$$\end{document}
for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{y}} \in {\mathcal {A}} = \{(x_1,\ldots , x_J)^\top \in \{0,1\}^J:x_1 = 1 \text{ or } x_2=1 \}$$\end{document}
 , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0):= P(Y_1 = 0, Y_2 =0|{{\textbf{S}}}_0)$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0):= P(Y_1 = 0, Y_2 =0|{{\textbf{S}}}_0)$$\end{document}
 under the Ising model. Then there does not exist an Ising parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}\ne {{\textbf{S}}}_0$$\end{document}
under the Ising model. Then there does not exist an Ising parameter matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}\ne {{\textbf{S}}}_0$$\end{document}
 such that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0 ({\textbf{y}}) = P({\textbf{Y}} = {\textbf{y}}|{{\textbf{S}}}), $$\end{document}
such that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0 ({\textbf{y}}) = P({\textbf{Y}} = {\textbf{y}}|{{\textbf{S}}}), $$\end{document}
 for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\textbf{y}\in {\mathcal {A}}$$\end{document}
for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\textbf{y}\in {\mathcal {A}}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0) = P(Y_1 = 0, Y_2 =0|{{\textbf{S}}})$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0) = P(Y_1 = 0, Y_2 =0|{{\textbf{S}}})$$\end{document}
 under the Ising model.
under the Ising model.
Proof
We first prove the statement for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J\ge 4$$\end{document}
 . Suppose that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0 ({\textbf{y}}) = P({\textbf{Y}} = {\textbf{y}}|{{\textbf{S}}}), $$\end{document}
. Suppose that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0 ({\textbf{y}}) = P({\textbf{Y}} = {\textbf{y}}|{{\textbf{S}}}), $$\end{document}
 for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{y}} \in {\mathcal {A}}$$\end{document}
for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\textbf{y}} \in {\mathcal {A}}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0) = P(Y_1 = 0, Y_2 =0|{{\textbf{S}}})$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0) = P(Y_1 = 0, Y_2 =0|{{\textbf{S}}})$$\end{document}
 . We will prove that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}={{\textbf{S}}}_0$$\end{document}
. We will prove that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}={{\textbf{S}}}_0$$\end{document}
 .
.
We start by considering items 1, 2, 3, 4. We define the set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathcal {A}}_{3,4} = \{(x_1,\ldots , x_J)^\top \in {\mathcal {A}}: x_5 =... = x_J=0\}$$\end{document}
 . We note that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathcal {A}}_{3,4}$$\end{document}
. We note that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathcal {A}}_{3,4}$$\end{document}
 has 12 elements. Using
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}_d = (1, 0,0,0,0,\ldots ,0)^\top \in {\mathcal {A}}_{3,4}$$\end{document}
has 12 elements. Using
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}_d = (1, 0,0,0,0,\ldots ,0)^\top \in {\mathcal {A}}_{3,4}$$\end{document}
 as the baseline pattern, for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}\in {\mathcal {A}}_{3,4}$$\end{document}
as the baseline pattern, for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}\in {\mathcal {A}}_{3,4}$$\end{document}
 such that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}\ne {{\varvec{y}}}_d$$\end{document}
such that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}\ne {{\varvec{y}}}_d$$\end{document}
 we have
we have

That gives us 11 linear equations for 10 parameters,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij}$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i,j\le 4$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i,j\le 4$$\end{document}
 . By simplifying these equations, we have (1) two linear equations for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(s_{11}, s_{12}, s_{22})$$\end{document}
. By simplifying these equations, we have (1) two linear equations for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(s_{11}, s_{12}, s_{22})$$\end{document}


and (2)
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{1i} = s_{1i}^0$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{2i} = s_{2i}^0$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{2i} = s_{2i}^0$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = s_{ij}^0$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = s_{ij}^0$$\end{document}
 for all
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i,j = 3, 4$$\end{document}
for all
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i,j = 3, 4$$\end{document}
 .
.
We repeat the above calculation for any four-item set involving items 1 and 2. By choosing any item pair
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i,j > 2$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i\ne j$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i\ne j$$\end{document}
 and repeating the above calculation with patterns in the set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathcal A_{i,j} = \{(x_1,\ldots , x_J)^\top \in {\mathcal {A}}: x_l = 0, l \ne 1, 2, i, j\}$$\end{document}
and repeating the above calculation with patterns in the set
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mathcal A_{i,j} = \{(x_1,\ldots , x_J)^\top \in {\mathcal {A}}: x_l = 0, l \ne 1, 2, i, j\}$$\end{document}
 , we have
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{1i} = s_{1i}^0$$\end{document}
, we have
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{1i} = s_{1i}^0$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{2i} = s_{2i}^0$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{2i} = s_{2i}^0$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = s_{ij}^0$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = s_{ij}^0$$\end{document}
 for all
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i,j > 2$$\end{document}
for all
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i,j > 2$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i\ne j$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i\ne j$$\end{document}
 . With the above argument and (10), we only need to show
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
. With the above argument and (10), we only need to show
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
 to prove
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}= {{\textbf{S}}}_0$$\end{document}
to prove
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}= {{\textbf{S}}}_0$$\end{document}
 . To prove
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
. To prove
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
 , we use
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0)/p_0({{\varvec{y}}}_d) = P(Y_1 = 0, Y_2 =0|{{\textbf{S}}})/P({{\textbf{Y}}}= {{\varvec{y}}}_d|{{\textbf{S}}})$$\end{document}
, we use
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0)/p_0({{\varvec{y}}}_d) = P(Y_1 = 0, Y_2 =0|{{\textbf{S}}})/P({{\textbf{Y}}}= {{\varvec{y}}}_d|{{\textbf{S}}})$$\end{document}
 and that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = s_{ij}^0$$\end{document}
and that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{ij} = s_{ij}^0$$\end{document}
 for all
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i,j > 2$$\end{document}
for all
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i,j > 2$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i\ne j$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$i\ne j$$\end{document}
 which we have proved. We have
which we have proved. We have

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathcal {A}}_0 = \{(x_1,\ldots , x_J)^\top \in \{0,1\}^J: x_1 = x_2 = 0\}$$\end{document}
 . As the right-hand side of the above equation is a strictly monotone decreasing function of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11}$$\end{document}
. As the right-hand side of the above equation is a strictly monotone decreasing function of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11}$$\end{document}
 , we know that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
, we know that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
 is the only solution to the above equation. This proves the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J \ge 4$$\end{document}
is the only solution to the above equation. This proves the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J \ge 4$$\end{document}
 case.
case.
We now move on to the case when
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J = 3$$\end{document}
 . We consider
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathcal {A}} = \{(x_1, x_2, x_3)^\top \in \{0,1\}^3:x_1 = 1 \text{ or } x_2=1 \}$$\end{document}
. We consider
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\mathcal {A}} = \{(x_1, x_2, x_3)^\top \in \{0,1\}^3:x_1 = 1 \text{ or } x_2=1 \}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}_d = (1, 0,0)^\top $$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}_d = (1, 0,0)^\top $$\end{document}
 . Using
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}_d$$\end{document}
. Using
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}_d$$\end{document}
 as the baseline, for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}\in {\mathcal {A}}$$\end{document}
as the baseline, for any
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}\in {\mathcal {A}}$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}\ne {{\varvec{y}}}_d$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\varvec{y}}}\ne {{\varvec{y}}}_d$$\end{document}
 , we construct five linear equations given by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\log (p_0({{\varvec{y}}})/p_0({{\varvec{y}}}_d) )= \log (P({{\textbf{Y}}}={{\varvec{y}}}\vert {{\textbf{S}}})/P({{\textbf{Y}}}={{\varvec{y}}}_d\vert {{\textbf{S}}}))$$\end{document}
, we construct five linear equations given by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\log (p_0({{\varvec{y}}})/p_0({{\varvec{y}}}_d) )= \log (P({{\textbf{Y}}}={{\varvec{y}}}\vert {{\textbf{S}}})/P({{\textbf{Y}}}={{\varvec{y}}}_d\vert {{\textbf{S}}}))$$\end{document}
 . From these equations, we obtain: (1) two linear equations for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(s_{11},s_{12},s_{22})$$\end{document}
. From these equations, we obtain: (1) two linear equations for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$(s_{11},s_{12},s_{22})$$\end{document}


and (2)
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{13} = s_{13}^0, s_{23}=s_{23}^0, s_{33} = s_{33}^0$$\end{document}
 . Again, with the above equations,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}= {{\textbf{S}}}^0$$\end{document}
. Again, with the above equations,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${{\textbf{S}}}= {{\textbf{S}}}^0$$\end{document}
 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
 . To show
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
. To show
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
 , we use
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0)/p_0({{\varvec{y}}}_d) = P(Y_1 = 0, Y_2 =0|{{\textbf{S}}})/P({{\textbf{Y}}}= {{\varvec{y}}}_d|{{\textbf{S}}})$$\end{document}
, we use
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p_0(0,0)/p_0({{\varvec{y}}}_d) = P(Y_1 = 0, Y_2 =0|{{\textbf{S}}})/P({{\textbf{Y}}}= {{\varvec{y}}}_d|{{\textbf{S}}})$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{33} = s_{33}^0$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{33} = s_{33}^0$$\end{document}
 . We have
. We have

As the right-hand side is a strictly monotone decreasing function of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11}$$\end{document}
 , we know that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
, we know that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11} = s_{11}^0$$\end{document}
 is the only solution to the above equation. This proves the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J=3$$\end{document}
is the only solution to the above equation. This proves the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$J=3$$\end{document}
 case, which completes the proof.
case, which completes the proof.
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\square $$\end{document}

Following the same proof strategy as above, it can be further shown that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11}, s_{12},$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{22}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{22}$$\end{document}
 are not identified in the complete-case analysis, while the rest of the parameters are. This is consistent with the result of Simulation Study II, where the other model parameters can be accurately estimated while the estimates of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11}, s_{12},$$\end{document}
are not identified in the complete-case analysis, while the rest of the parameters are. This is consistent with the result of Simulation Study II, where the other model parameters can be accurately estimated while the estimates of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{11}, s_{12},$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{22}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$s_{22}$$\end{document}
 are substantially different from the corresponding true parameters.
are substantially different from the corresponding true parameters.









 Open access
Open access