



1. Introduction
Understanding the process of cosmic structure formation enables us to unravel the origins and evolution of the Universe and provides valuable insights into the fundamental laws that govern its behaviour. The first surveys that accurately catalogued the sky by measuring distances (e.g. Huchra et al., Reference Huchra, Davis, Latham and Tonry1983; Geller and Huchra, Reference Geller and Huchra1989) noted a non-uniform distribution, cosmic web-like structure. Subsequent surveys dramatically increased the number of objects measured, and today it is undoubted that the distribution of galaxies in the Universe is not random but follows a cosmic spider-web-like pattern (see, for instance, Turner and Gott, Reference Turner and Gott1975; Soneira and Peebles, Reference Soneira and Peebles1977, for the first quantifications of non-randomness). All galaxy redshift surveys further unveiled a rich tapestry of galaxies, each with unique properties and characteristics, providing valuable insights into the nature of our Universe, its expansion, and the intricate web of cosmic structures. This large-scale structure and cosmic web, respectively, can be readily explained within the framework of the concordance cosmological model that induces hierarchical structure formation (e.g. Zel’dovich, Reference Zel’dovich1970; Frenk et al., Reference Frenk, White and Davis1983; Davis et al., Reference Davis, Efstathiou, Frenk and White1985). Starting from tiny seed inhomogeneities, gravity amplifies these first matter perturbations eventually leading to the observed distribution of galaxies, galaxy clusters, and the cosmic web in general. However, seed inhomogeneities are needed whose origin is believed to be in the very early Universe, caused by a brief inflationary period during which primordial Gaussian-like fluctuations are generated (Guth, Reference Guth1981; Linde, Reference Linde1982).
Since the first surveys and systematic observations of the Local Universe, workers in the field aimed at characterising and quantifying the distribution of galaxies using various statistical methods, revealing various regular patterns in it. For instance, De Lapparent et al. (Reference De Lapparent, Geller and Huchra1986) measured – starting from the CfA2 catalogue (Huchra et al., Reference Huchra, Davis, Latham and Tonry1983) – 584 redshifts from galaxies located in the Coma cluster direction and interpreted this as ‘bubble-like’ structures of a typical diameter of 25
 $h^{-1}$
Mpc (which these days are rather called cosmic voids). Tully and Fisher (Reference Tully, Fisher, Longair and Einasto1978) obtained redshifts for another set of 412 galaxies – starting from the Palomar Sky Atlas – finding a peak in the two-point correlation function at a scale of ca. 2.5 Mpc in the Local Universe. Another regularity in the galaxy distribution are the so-called Baryonic Acoustic Oscillations (BAO), that is, fluctuations in the density of the visible baryonic material, caused by acoustic density waves in the primordial plasma of the early universe (Peebles and Yu, Reference Peebles and Yu1970; Bond and Efstathiou, Reference Bond and Efstathiou1984; Holtzman, Reference Holtzman1989). The BAO signal shows up as a bump in the two-point correlation function at scale equal to the sound horizon at photon decoupling. While first only theoretically predicted, early hints suggested an observational counterpart (Percival et al., Reference Percival, Baugh, Bland-Hawthorn, Bridges, Cannon, Cole and Colless2001) which was eventually statistically confirmed by two-point correlation function analysis applied to the SDSS data by Eisenstein et al. (Reference Eisenstein, Zehavi, Hogg, Scoccimarro, Blanton, Nichol and Scranton2005) and to 2dF data by Cole et al. (Reference Cole, Percival, Peacock, Norberg, Baugh, Frenk and Baldry2005). And there are nowadays even recent claims to actually have found a single such oscillation in the Cosmicflows-4 data (Tully et al., Reference Tully, Kourkchi, Courtois, Anand, Blakeslee, Brout and de Jaeger2023).
$h^{-1}$
Mpc (which these days are rather called cosmic voids). Tully and Fisher (Reference Tully, Fisher, Longair and Einasto1978) obtained redshifts for another set of 412 galaxies – starting from the Palomar Sky Atlas – finding a peak in the two-point correlation function at a scale of ca. 2.5 Mpc in the Local Universe. Another regularity in the galaxy distribution are the so-called Baryonic Acoustic Oscillations (BAO), that is, fluctuations in the density of the visible baryonic material, caused by acoustic density waves in the primordial plasma of the early universe (Peebles and Yu, Reference Peebles and Yu1970; Bond and Efstathiou, Reference Bond and Efstathiou1984; Holtzman, Reference Holtzman1989). The BAO signal shows up as a bump in the two-point correlation function at scale equal to the sound horizon at photon decoupling. While first only theoretically predicted, early hints suggested an observational counterpart (Percival et al., Reference Percival, Baugh, Bland-Hawthorn, Bridges, Cannon, Cole and Colless2001) which was eventually statistically confirmed by two-point correlation function analysis applied to the SDSS data by Eisenstein et al. (Reference Eisenstein, Zehavi, Hogg, Scoccimarro, Blanton, Nichol and Scranton2005) and to 2dF data by Cole et al. (Reference Cole, Percival, Peacock, Norberg, Baugh, Frenk and Baldry2005). And there are nowadays even recent claims to actually have found a single such oscillation in the Cosmicflows-4 data (Tully et al., Reference Tully, Kourkchi, Courtois, Anand, Blakeslee, Brout and de Jaeger2023).
About a decade ago, McCall (Reference McCall2014) reported the existence of a so-called ‘Council of Giants’ (CoGs), that is, a ring-like structure about the Local Group made up of 11 massive galaxies with stellar masses ranging between
 $M_* \sim 3 \times 10^{10} M_{\odot}$
(M64) and
$M_* \sim 3 \times 10^{10} M_{\odot}$
(M64) and
 $M_* \sim 9 \times 10^{10} M_{\odot}$
(Maffei 2). Please note that this structure was identified by eye, with no quantification of its stability with respects to variations in distance to and/or luminosity of its member galaxies. However, a related work by Neuzil et al. (Reference Neuzil, Mansfield and Kravtsov2020) confirmed its presence in the Local Volume Galaxy (LVG) catalogue (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013), an updated version of the catalogue upon which McCall based his study. In their work, they placed the observer at the centre of the Milky Way (MW) and found the CoGs as a jump in the spherically averaged, cumulative number density of galaxies. This is a similar approach to Karachentsev and Telikova (Reference Karachentsev and Telikova2018) who calculated the (again spherically averaged) mean density of stellar matter within a distance D in the Local Volume. They also found a peak at
$M_* \sim 9 \times 10^{10} M_{\odot}$
(Maffei 2). Please note that this structure was identified by eye, with no quantification of its stability with respects to variations in distance to and/or luminosity of its member galaxies. However, a related work by Neuzil et al. (Reference Neuzil, Mansfield and Kravtsov2020) confirmed its presence in the Local Volume Galaxy (LVG) catalogue (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013), an updated version of the catalogue upon which McCall based his study. In their work, they placed the observer at the centre of the Milky Way (MW) and found the CoGs as a jump in the spherically averaged, cumulative number density of galaxies. This is a similar approach to Karachentsev and Telikova (Reference Karachentsev and Telikova2018) who calculated the (again spherically averaged) mean density of stellar matter within a distance D in the Local Volume. They also found a peak at
 $D\sim 3.5$
Mpc where the CoGs is located. However, they neither call it a ring-like structure nor make reference to the CoGs.
$D\sim 3.5$
Mpc where the CoGs is located. However, they neither call it a ring-like structure nor make reference to the CoGs.
Motivated by the possible existence of the CoGs and ring-like structures in general, we have developed a method to find mathematically defined patterns in 3D point distributions such as galaxy catalogues. However, our aim is to make as few assumptions about the location, size, and orientation of such features as possible. We therefore developed a tool that takes as input a 3D distribution of points and automatically searches in it for – in our case – toroidal structures, that is, tori with a certain radius and thickness (i.e. a doughnut-like shape). In doing so, we make no assumptions about the centre-position of these tori. Using this newly developed tool, called HINORA (HIgh-NOise RANdom SAmple Consensus), we study the LVG data of Karachentsev et al. (Reference Karachentsev, Makarov and Kaisina2013) in search of the CoGs and other similar structures for various cuts in K-band luminosity (reminiscant of stellar mass cuts, Bell et al., Reference Bell, McIntosh, Katz and Weinberg2003; Karachentsev and Telikova, Reference Karachentsev and Telikova2018). The detection of possible rings formed by baryonic (or possibly dark) matter in the nearby small-scale structure could change our understanding of the nature of these components, as well as their behaviour. We remark that the HINORA code can universally be applied to any 3D point distribution and hence could also serve to detect aforementioned BAO peak(s). This is possible since this method can be generalised to the search of any simple figure, so its application to spherical shapes would only imply minor geometric changes.
In a follow-up work we will apply the HINORA code to cosmological simulations, both random (such as Illustris, Vogelsberger et al., Reference Vogelsberger, Genel, Springel, Torrey, Sijacki, Xu, Snyder, Bird, Nelson and Hernquist2014) as well as constrained (such as HESTIA, Libeskind et al., Reference Libeskind, Carlesi, Grand, Khalatyan, Knebe, Pakmor and Pilipenko2020). This will provide insight into the origin of these formations and how common they are in the cosmos. Are such galaxy rings an unknown part of the cosmic web distribution? What if they are merely a coincidence? However, here we restrict ourselves to the description of the HINORA method as well as its application to observational data of the Local Universe.
The outline of the paper is as follows: in Section 2 we will describe the LVG catalogue used for the analysis. In Section 3, we will present the HINORA method capable of recognising rings or any other regular geometric patterns in point clouds with high noise levels and a substantial degree of background, respectively. In Section 4, we will apply the method to the LVG data, presenting the occurance of two distinct ring-like features in our Local Universe. In Section 5, we briefly discuss the mode of operation and limitations of HINORA, based on the results obtained in the previous Section. We close with a summary and the conclusions in Section 6.
2. The Local Volume Galaxies data
Real-space positions and magnitudes of the galaxies under consideration here are taken from the LVG catalog (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013).Footnote a These data contain the largest amount of current information on nearby galaxies within the Local Volume. This set is based on both own observations (see for instance Karachentsev and Kaisina, Reference Karachentsev and Kaisina2019) as well as measurements from other sources and is continuously updated. In it, Karachentsev et al. (Reference Karachentsev, Makarov and Kaisina2013) compiled measures with a distance up to
 $D\lesssim 11$
Mpc from the MW, providing the distances of each galaxy, magnitudes in B and K filters, radial velocities, and other information. To deal with the region with the lowest error estimates, we restrict our study to objects found within a sphere of radius 10 Mpc centred on the MW, which leaves us with 1069 galaxies in total. All coordinates have been transformed to supergalactic, having the MW at the centre. Other catalogues of relevance, such as for instance Cosmic Flows (CF, Tully et al. (Reference Tully, Courtois and Sorce2016, CF3) and Tully et al. (Reference Tully, Kourkchi, Courtois, Anand, Blakeslee, Brout and de Jaeger2023, CF4)) cover a much larger volume and provide estimates of radial velocities with respect to the Local Group. However, since we want to cover both the most massive galaxies and the least bright dwarf galaxies, we will prefer to work with the LVG catalogue: LVG provides us with approximately three times as many measured objects in the
$D\lesssim 11$
Mpc from the MW, providing the distances of each galaxy, magnitudes in B and K filters, radial velocities, and other information. To deal with the region with the lowest error estimates, we restrict our study to objects found within a sphere of radius 10 Mpc centred on the MW, which leaves us with 1069 galaxies in total. All coordinates have been transformed to supergalactic, having the MW at the centre. Other catalogues of relevance, such as for instance Cosmic Flows (CF, Tully et al. (Reference Tully, Courtois and Sorce2016, CF3) and Tully et al. (Reference Tully, Kourkchi, Courtois, Anand, Blakeslee, Brout and de Jaeger2023, CF4)) cover a much larger volume and provide estimates of radial velocities with respect to the Local Group. However, since we want to cover both the most massive galaxies and the least bright dwarf galaxies, we will prefer to work with the LVG catalogue: LVG provides us with approximately three times as many measured objects in the
 $\leqslant 10$
Mpc range than CF3 and about 70% more than CF4.
$\leqslant 10$
Mpc range than CF3 and about 70% more than CF4.
Further, a remarkable difference between LVG and CF is the considerable systematic discrepancy in the distances provided for some galaxies, such as those belonging to the Maffei Group. As Neuzil et al. (Reference Neuzil, Mansfield and Kravtsov2020) also points out, the distances to Maffei 1 and Maffei 2 are particularly sensitive since they are in the ‘Zone of Avoidance’ of our galaxy and hence subject to redening. In case of the Maffei 2, we took into account recent works by Tikhonov and Galazutdinova (Reference Tikhonov and Galazutdinova2018) and Anand et al. (Reference Anand, Tully, Rizzi and Karachentsev2019), where the authors discovered that this galaxy lies at a distance of 5.7 Mpc, instead of 3.5 Mpc, as previously thought. The sample of LVG galaxies was taken from the current version of the database of galaxies of the Local Volume (Kaisina et al. (Reference Kaisina, Makarov, Karachentsev and Kaisin2012)). Inside 6–7 Mpc, the distances to most galaxies have been measured by high-precision photometric methods (Cepheids, RR-Lyres, and the top of the red giant branch) with accuracy of the order of or better than 5%. Distances to more distant galaxies have generally been measured by less accurate methods, such as the Tully–Fisher relation, fundamental plane, the luminosity of the brightest stars, giving the error of more than 20–25%.
Another argument in favour of LVG is that CF provides the luminosity in the B filter, whereas we are interested in K-band magnitudes: the B-band is not a reliable estimator of stellar mass given its sensitivity to galactic internal extinction and its dependence on various inhomogeneously distributed features, such as age, metallicity, or SFH of the nearby galaxies. Those magnitudes in the near-infrared K-band in LVG are taken from the 2MASS sky survey (Jarrett et al., Reference Jarrett, Chester, Cutri, Schneider, Skrutskie and Huchra2000, Reference Jarrett, Chester, Cutri, Schneider and Huchra2003), supported by measurements by Fingerhut et al. (Reference Fingerhut, McCall, Argote, Cluver, Nishiyama, Rekola, Richer, Vaduvescu and Woudt2010) as well as Vaduvescu et al. (Reference Vaduvescu, McCall, Richer and Fingerhut2005, Reference Vaduvescu, Richer and McCall2006). However, as already noted by Kirby et al. (Reference Kirby, Jerjen, Ryder and Driver2008) and McCall (Reference McCall2014), even if the 2MASS survey has obtained measurements with a uniform methodology, for certain very low luminosity galaxies it can overestimate the K magnitude by up to 2.5 mag due to short integration time, while for bright galaxies the luminosity may not be correctly measured given the finite extrapolation of the radii. This uncertainty will be important, and we will take it into account by reabsorbing it into the error in the distance measurement. If there is no data available for the K-band of one of the objects, the authors Karachentsev et al. (Reference Karachentsev, Makarov and Kaisina2013) estimate its value using methods that rely on other measured bands, as detailed in their paper. The K-band is a reliable stellar mass
 $M_*\sim (M_\odot/L_\odot) L_K$
indicator that follows a stellar
$M_*\sim (M_\odot/L_\odot) L_K$
indicator that follows a stellar
 $M/L$
relation with less colour dependence than the other bands (Bell and de Jong, Reference Bell and de Jong2001; Bell et al., Reference Bell, McIntosh, Katz and Weinberg2003; Beare et al., Reference Beare, Brown, Pimbblet and Taylor2019). While in the K-band, the
$M/L$
relation with less colour dependence than the other bands (Bell and de Jong, Reference Bell and de Jong2001; Bell et al., Reference Bell, McIntosh, Katz and Weinberg2003; Beare et al., Reference Beare, Brown, Pimbblet and Taylor2019). While in the K-band, the
 $M/L$
ratios for spiral galaxies in the study of Bell and de Jong (Reference Bell and de Jong2001) vary by as much as a factor of 2, in the B-band, they vary by a factor of 7. The work by Bell et al.(Reference Bell, McIntosh, Katz and Weinberg2003) updates these estimates using SDSS and 2MASS photometry and provides
$M/L$
ratios for spiral galaxies in the study of Bell and de Jong (Reference Bell and de Jong2001) vary by as much as a factor of 2, in the B-band, they vary by a factor of 7. The work by Bell et al.(Reference Bell, McIntosh, Katz and Weinberg2003) updates these estimates using SDSS and 2MASS photometry and provides
 $M/L_{K}$
ratios. Whenever needed or of interest, we will simply convert the K magnitude to stellar mass assuming
$M/L_{K}$
ratios. Whenever needed or of interest, we will simply convert the K magnitude to stellar mass assuming
 $M/L_{K}\sim 1$
, as done by the authors of LVG (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013).
$M/L_{K}\sim 1$
, as done by the authors of LVG (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013).
3. The method
Our prime objective is to find and quantify ring-like structures in a point distribution (i.e. in our case the LVG catalogue). We need to approach the problem through a systematic process that quantifies and confirms the presence of patterns within a system composed of a spatial distribution of discrete points. The main techniques for the systematic search of basic patterns in 3D point distributions are the Point Cloud Segmentation (PCS) algorithms (Xie et al., Reference Xie, Tian and Zhu2020). PCS is based on the use of simple geometric rules to find 2 or 3 dimensional structures with low noise levels. It is an unsupervised method, so the algorithm locates system relationships by analysing the data without the need for an external instructor during the process, and without a previous sample dataset. The PCS family in turn contains several independent algorithms that have been developed in recent years (Xie et al., Reference Xie, Tian and Zhu2020). One of them is RANdom SAmple Consensus (RANSAC), an algorithm based on testing models that fit a randomly chosen subset of the data (Fischler and Bolles, Reference Fischler and Bolles1981). Each model is evaluated by calculating how many points of the total set are adequately approximated by it. After multiple steps, the algorithm chooses the model that contains the largest number of points. RANSAC is the basis of the methodology chosen in this work, and its way of operation will be explained in more detail below.
3.1 The RANSAC algorithm and its variants
RANSAC is a randomised pattern search algorithm applied to point clouds (Choi et al., Reference Choi, Kim and Yu2009; Raguram et al., Reference Raguram, Frahm, Pollefeys, Forsyth, Torr and Zisserman2008, Reference Raguram, Chum, Pollefeys, Matas and Frahm2013). For its application, it is necessary to define the pattern to be searched and the size of the model
 $\tau$
. The distance
$\tau$
. The distance
 $\tau$
will characterise the maximum distance that a point of the figure is allowed to have for it to still be considered part of it. The pattern is defined by basic geometry from the starting subset. If we were looking for lines, the subset would have to have 2 points. RANSAC would pick 2 random points from the data, and join them with a line. All the points at smaller distance than
$\tau$
will characterise the maximum distance that a point of the figure is allowed to have for it to still be considered part of it. The pattern is defined by basic geometry from the starting subset. If we were looking for lines, the subset would have to have 2 points. RANSAC would pick 2 random points from the data, and join them with a line. All the points at smaller distance than
 $\tau$
from that line would be considered as inliers and would form part of the model. The model is therefore composed of the points closest to the geometric line formed by the random points matched by RANSAC. In our case, we work with circles: to draw a circle in space, at least 3 points are needed. Therefore, the subset that RANSAC collects will be composed of 3 random points of the data, for which it will draw a circle that joins them. The rest of the points are checked for possible inclusion in the model via distance
$\tau$
from that line would be considered as inliers and would form part of the model. The model is therefore composed of the points closest to the geometric line formed by the random points matched by RANSAC. In our case, we work with circles: to draw a circle in space, at least 3 points are needed. Therefore, the subset that RANSAC collects will be composed of 3 random points of the data, for which it will draw a circle that joins them. The rest of the points are checked for possible inclusion in the model via distance
 $\tau$
to this ring. As a consequence our model points will lie inside a torus. RANSAC operates in the following two phases:
$\tau$
to this ring. As a consequence our model points will lie inside a torus. RANSAC operates in the following two phases:
Phase 1: In the first phase, RANSAC generates a hypothesis of the model. A small subgroup is formed from randomly selected points of the data, and these points will be used to geometrically draw the figure in space. This figure will be called a ‘model’. In our case, it consists of 3 points at this stage.
Phase 2: The second phase consist in evaluating the hypothesis generated by the random subgroup. The minimum distance to the figure of all the points belonging to the full cloud is calculated. Those points that are at a distance less than
 $\tau$
from the model are considered to belong to it and will be called inliers. All other points of the cloud will be considered outliers.
$\tau$
from the model are considered to belong to it and will be called inliers. All other points of the cloud will be considered outliers.
If the number of inliers is higher than that calculated for previous hypotheses, both the coordinates of the generated figure and its inliers are saved and the process is started again form Phase 1, trying to find again the ring with more inliers. The final ‘correct’ model will be the one that contains the highest number of inliers after numerous iterations of the code. Equation (1) gives the number of iterations N required to find a particular model in a point cloud with a probability of success p (Choi et al., Reference Choi, Kim and Yu2009)
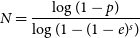 \begin{equation}N=\frac{\log(1-p)}{\log(1-(1-e)^s)} \,\end{equation}
\begin{equation}N=\frac{\log(1-p)}{\log(1-(1-e)^s)} \,\end{equation}
where s is the number of points forming the sample subset, and e is the proportion of system outliers. In our case
 $s=3$
(as we start with 3 points in the Phase 1). We further set the desired success rate to
$s=3$
(as we start with 3 points in the Phase 1). We further set the desired success rate to
 $p=0.99$
and
$p=0.99$
and
 $e=0.85$
. In our case, higher values of p do not alter the results so even if the algorithm does not converge exactly it is not necessary to increase this number. On the other hand, the value of e allows us to find patterns with inliers of at least 15% of the data, which will be important as we will explain in Section 4. Substituting these numbers into Eq. (1) reveals that we need of order 1400 iterations of Phase 1+Phase 2 before analysing the possibly found rings. We also need to mention that several runs of RANSAC on the same data may return the same pattern but with slightly different characteristics if it has been formed by a different subset of inliers. We will take advantage of this to enable our method to locate a certain ring more precisely.
$e=0.85$
. In our case, higher values of p do not alter the results so even if the algorithm does not converge exactly it is not necessary to increase this number. On the other hand, the value of e allows us to find patterns with inliers of at least 15% of the data, which will be important as we will explain in Section 4. Substituting these numbers into Eq. (1) reveals that we need of order 1400 iterations of Phase 1+Phase 2 before analysing the possibly found rings. We also need to mention that several runs of RANSAC on the same data may return the same pattern but with slightly different characteristics if it has been formed by a different subset of inliers. We will take advantage of this to enable our method to locate a certain ring more precisely.
RANSAC has several variants that modify the original algorithm in favour of enhancing certain features (Choi et al., Reference Choi, Kim and Yu2009). The Randomized RANSAC (R-RANSAC) technique used to reduce the computation time consists of a prior evaluation of the hypothesis. R-RANSAC introduces a preliminary test of the data before evaluating it completely in each iteration (Matas and Chum, Reference Matas and Chum2004), which will allow discarding rings generated > 10 Mpc from the MW. Further, to adapt RANSAC to search for faint figures in data with noise levels greater than 90
 $\%$
of the total points, we will make modifications to the original algorithm, to be explained now.
$\%$
of the total points, we will make modifications to the original algorithm, to be explained now.
3.2 HINORA: Adaptation of the algorithm to small inliers ratios
In order for RANSAC to give credible results for the data at hand, we need make some adjustments. The reason for that is illustrated in Figure 1. There two situations are depicted for which RANSAC will return a positively found ring-like structures:
-
(a) A random distribution of points can be recognised as a valid model just because it contains a large amount of data.
-
(b) Clusters of points, distributed anisotropically on the circumference of a ring match the pattern constraints, too.
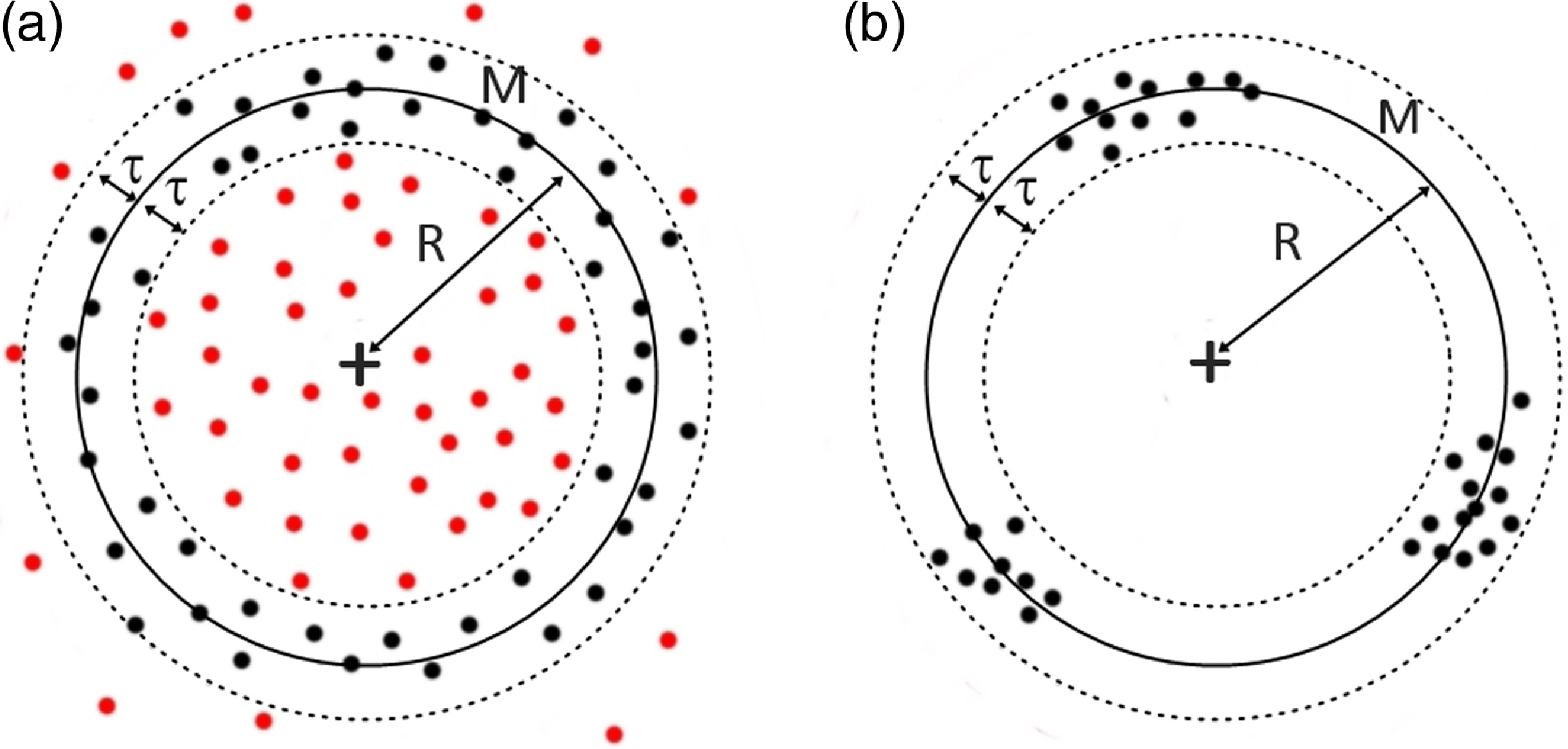
Figure 1. 2D examples of the failures of RANSAC when applied to noisy data. Panel a represents how the method mistakes a big noise accumulation for a valid ring. Panel b shows how the algorithm mistakes small noise clusters for a valid ring. The cross marks the centre of the ring. The black solid line represents the model M, located at a distance R from the centre and with an inner radius
 $\tau$
bounded by the dashed lines. The black and red dots correspond to inliers and outliers, respectively.
$\tau$
bounded by the dashed lines. The black and red dots correspond to inliers and outliers, respectively.
Regarding point (a), the original RANSAC code seeks to maximise points that are inside the model, without considering anything else. However, this is fatal when dealing with noisy environments, because RANSAC will only look for sites with many points – whether they are noisy or not. For instance, if the data contains 90% noise, the original RANSAC will tell you that the model is where it finds the most points. In other words, the original RANSAC code identifies overdensities following the shape of the desired model. By introducing the
 $\unicode{x03B1}$
parameter (see Section 3.2.1 below), we punish the algorithm when it finds only large overdensities and force it to focus only on overdensities that have the shape of the model and that have an environment without many points outside the ring.
$\unicode{x03B1}$
parameter (see Section 3.2.1 below), we punish the algorithm when it finds only large overdensities and force it to focus only on overdensities that have the shape of the model and that have an environment without many points outside the ring.
Both situations are problematic since clearly neither of them corresponds to a hypothesis that should be approved. In the first case, the algorithm does not distinguish rings and accumulations of symmetric noise distribution. Structures such as spheres or simple concentrations of random data can be mistaken for rings since the algorithm does not take into account the shape of the outliers in the near environment of the model (panel a). RANSAC will only look for sites with many points – whether they are noisy or not. The original version of RANSAC seeks to maximise points that are inside the model, which could be interpreted as searching for overdensities in the data. But in our case we also care about the embedding within the environment, aiming at the lowest possible number of outliers about the identified structure. In the second case, the algorithm does not take into account the distribution of inliers. Although the points are concentrated without noise around them, for RANSAC they can form rings from concentrated clusters of points. This is again a situation we try to avoid.
In order to address these issues, we made modifications to the evaluation step in RANSAC. The most important quantity for each model will be the number of inliers, as this will decide its relevance in the total data. However, this information is not sufficient to solve the problems seen in Figure 1, and therefore we will below define two new parameters calculated at each iteration that passes the original hypothesis test of RANSAC. The first one will be the the noise level (the relationship between the model and the points of the environment that are not part of it); and the second one will be the level of regularity that the inliers have (the relationship that the points of the model have with each other). Note that these parameters are provided for each successful ring returned by RANSAC and only evaluated in post-processing.
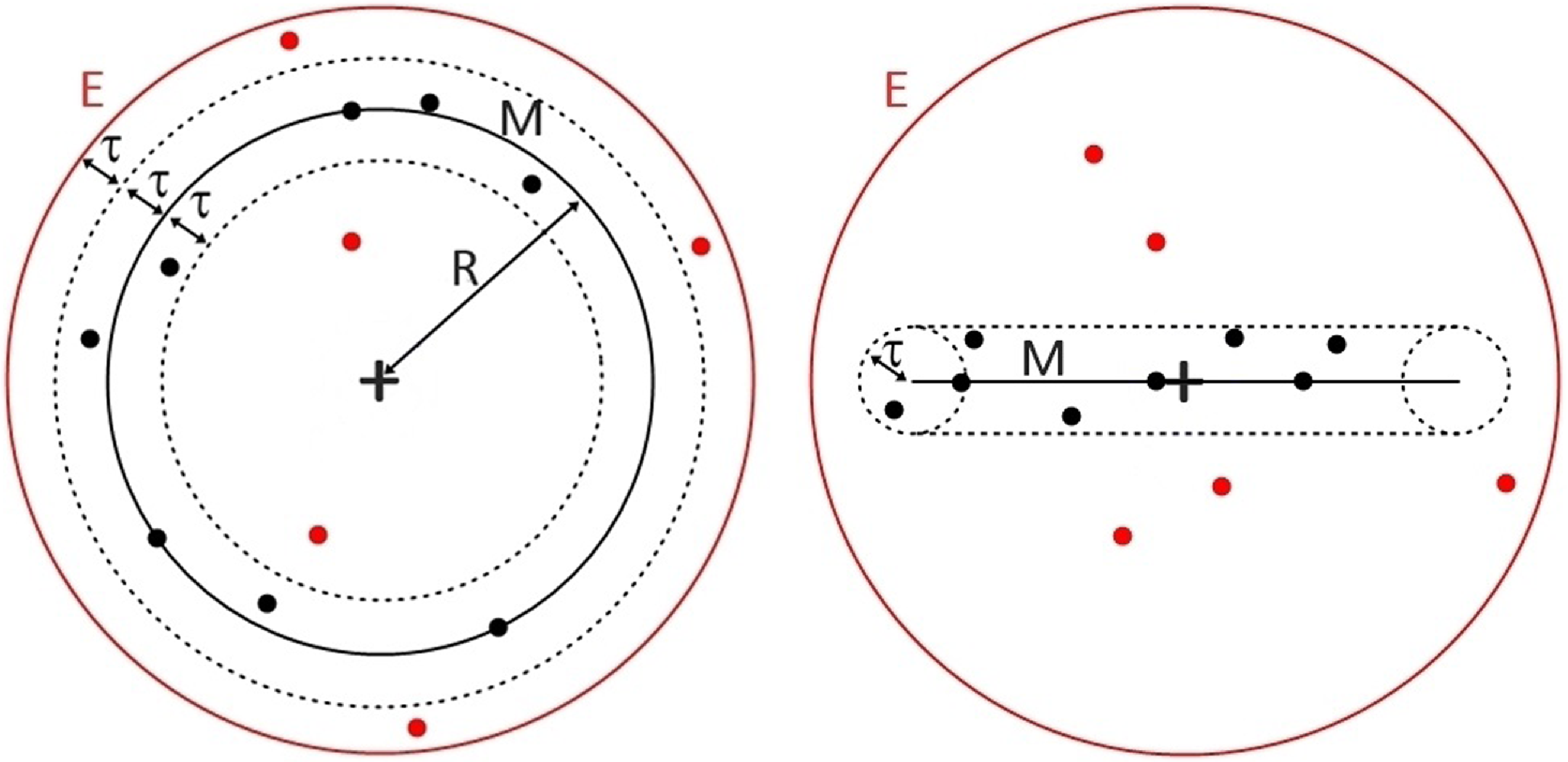
Figure 2. 3D example of the defined point types used during the calculation of the data noise parameter
 $\unicode{x03B1}$
. The image on the left represents a projection in the plane of the ring (i.e. model M that forms a torus), and the image on the right an edge-on view. The plus sign marks the centre of the ring. The red solid line denotes the range of the environment E, and the black solid line the model M with
$\unicode{x03B1}$
. The image on the left represents a projection in the plane of the ring (i.e. model M that forms a torus), and the image on the right an edge-on view. The plus sign marks the centre of the ring. The red solid line denotes the range of the environment E, and the black solid line the model M with
 $R\pm\tau$
being the outer and inner radius of that torus, respectively. The dashed lines represent the range of the model, distanced
$R\pm\tau$
being the outer and inner radius of that torus, respectively. The dashed lines represent the range of the model, distanced
 $\tau$
from M. The black and red dots correspond to ‘inliers’ and ‘outliers’, respectively. Since the hypothesis has 8 inliers and 5 outliers, the value of
$\tau$
from M. The black and red dots correspond to ‘inliers’ and ‘outliers’, respectively. Since the hypothesis has 8 inliers and 5 outliers, the value of
 $\unicode{x03B1}$
is 0.38.
$\unicode{x03B1}$
is 0.38.
3.2.1 Quantification of data noise
The first parameter we define will categorise all points within an environment E, larger than and hence encompassing the model M that can be considered a torus. This will relate points that are part of an existing pattern to nearby, but not relevant points. The volume E will be that of a sphere that shares its centre with the circular pattern and will have a radius of
 $R + 2\tau$
. The motivation for this maximal extends characterised by
$R + 2\tau$
. The motivation for this maximal extends characterised by
 $2\tau$
is to stay within the local environment E of the ring
$2\tau$
is to stay within the local environment E of the ring
 $R \pm \tau$
. The points within that sphere E will be categorised as either ‘inliers’ (points within the model, denoted by the letter ‘I’) or ‘outliers’ (points within the environment but outside the model, denoted by the letter ‘O’). Note, while our ‘inliers’ are identical to the inliers defined by RANSAC, our ‘outliers’ are limited to the volume defined by E. Figure 2 shows an example of how these categories are distributed in environment E (red circle): All inliers are at a distance less than
$R \pm \tau$
. The points within that sphere E will be categorised as either ‘inliers’ (points within the model, denoted by the letter ‘I’) or ‘outliers’ (points within the environment but outside the model, denoted by the letter ‘O’). Note, while our ‘inliers’ are identical to the inliers defined by RANSAC, our ‘outliers’ are limited to the volume defined by E. Figure 2 shows an example of how these categories are distributed in environment E (red circle): All inliers are at a distance less than
 $\tau$
from M and are represented as black dots; the remaining points of E are outliers, denoted by red dots.
$\tau$
from M and are represented as black dots; the remaining points of E are outliers, denoted by red dots.
With these considerations, we define the data noise parameter
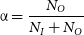 \begin{equation}\unicode{x03B1}=\frac{N_O}{N_I + N_O}\end{equation}
\begin{equation}\unicode{x03B1}=\frac{N_O}{N_I + N_O}\end{equation}
where
 $N_I$
(
$N_I$
(
 $N_O$
) denotes the number of ‘inliers’ (‘outliers’). Note, both
$N_O$
) denotes the number of ‘inliers’ (‘outliers’). Note, both
 $N_I$
and
$N_I$
and
 $N_O$
are functions of
$N_O$
are functions of
 $\tau$
whose value we will motivate later on in Section 4. By means of the parameter
$\tau$
whose value we will motivate later on in Section 4. By means of the parameter
 $\unicode{x03B1}$
, we have related the hypothesis to its environment and we can distinguish situations such as those seen (in the left side of) Figure 1. This quantity varies between 0 and 1. If
$\unicode{x03B1}$
, we have related the hypothesis to its environment and we can distinguish situations such as those seen (in the left side of) Figure 1. This quantity varies between 0 and 1. If
 $\unicode{x03B1}$
is small, most of the points belong to the model and the hypothesis is of quality. If
$\unicode{x03B1}$
is small, most of the points belong to the model and the hypothesis is of quality. If
 $\unicode{x03B1}$
is close to 1 it will be difficult to detect a ring. However,
$\unicode{x03B1}$
is close to 1 it will be difficult to detect a ring. However,
 $\unicode{x03B1}\rightarrow 1$
does not always indicate the non-existence of rings, but it does rule out that they have a statistically more relevant presence in the studied environment than in the rest of the data. To be considered, the models have to overcome the local noise.
$\unicode{x03B1}\rightarrow 1$
does not always indicate the non-existence of rings, but it does rule out that they have a statistically more relevant presence in the studied environment than in the rest of the data. To be considered, the models have to overcome the local noise.
3.2.2 Quantification of data regularity
To quantify the isotropy of the points, we need a parameter that quantifies how evenly the angles of the inliers are distributed in the model. All the inliers are projected onto the plane in which the hypothesis torus is located. Subsequently, each inlier is expressed in polar coordinates, giving us the azimuthal angle
 $\theta_i$
with
$\theta_i$
with
 $i\in1,2,...,N_I$
. We determine
$i\in1,2,...,N_I$
. We determine
 $\unicode{x03D5}_j$
as
$\unicode{x03D5}_j$
as
 $\unicode{x03D5}_j=\theta_{j+1}-\theta_j$
with
$\unicode{x03D5}_j=\theta_{j+1}-\theta_j$
with
 $j\in1,2,...,$
$j\in1,2,...,$
 $N_I-1$
, satisfying that
$N_I-1$
, satisfying that
 $\sum_{j=1}^{N_I-1}\unicode{x03D5}_j=2\pi$
(exemplified in Figure 3). We then quantify the isotropy as
$\sum_{j=1}^{N_I-1}\unicode{x03D5}_j=2\pi$
(exemplified in Figure 3). We then quantify the isotropy as
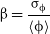 \begin{equation}\unicode{x03B2}=\frac{\unicode{x03C3}_{\unicode{x03D5}}}{\langle{\unicode{x03D5}}\rangle} \,\end{equation}
\begin{equation}\unicode{x03B2}=\frac{\unicode{x03C3}_{\unicode{x03D5}}}{\langle{\unicode{x03D5}}\rangle} \,\end{equation}
with
 $\unicode{x03C3}_{\unicode{x03D5}}$
the standard deviation of the
$\unicode{x03C3}_{\unicode{x03D5}}$
the standard deviation of the
 $\unicode{x03D5}_j$
, and
$\unicode{x03D5}_j$
, and
 $\langle{\unicode{x03D5}}\rangle$
their mean.
$\langle{\unicode{x03D5}}\rangle$
their mean.
 $\unicode{x03B2}$
measures how different the
$\unicode{x03B2}$
measures how different the
 $\unicode{x03D5}_j$
are from each other by normalising to the mean of this quantity so that it becomes independent of the number of inliers (note that in general the more inliers, the smaller the values of
$\unicode{x03D5}_j$
are from each other by normalising to the mean of this quantity so that it becomes independent of the number of inliers (note that in general the more inliers, the smaller the values of
 $\unicode{x03D5}_j$
). Although this is not the only spherical coordinate involved in the pattern, the quality of the ring does neither depend on the standard deviation of the polar angle nor on the radius. However, it is critical not to approve irregularities in the angle
$\unicode{x03D5}_j$
). Although this is not the only spherical coordinate involved in the pattern, the quality of the ring does neither depend on the standard deviation of the polar angle nor on the radius. However, it is critical not to approve irregularities in the angle
 $\theta_i$
such as those in panel b of Figure 1. If the term
$\theta_i$
such as those in panel b of Figure 1. If the term
 $\unicode{x03B2}$
is small it means that there is no variety in the angular separation of the data and therefore the distribution forms a uniform ring. Or put differently, values
$\unicode{x03B2}$
is small it means that there is no variety in the angular separation of the data and therefore the distribution forms a uniform ring. Or put differently, values
 $\unicode{x03B2} >> 1$
entail that the variation of angles is larger than the mean angle itself, which should not happen.
$\unicode{x03B2} >> 1$
entail that the variation of angles is larger than the mean angle itself, which should not happen.
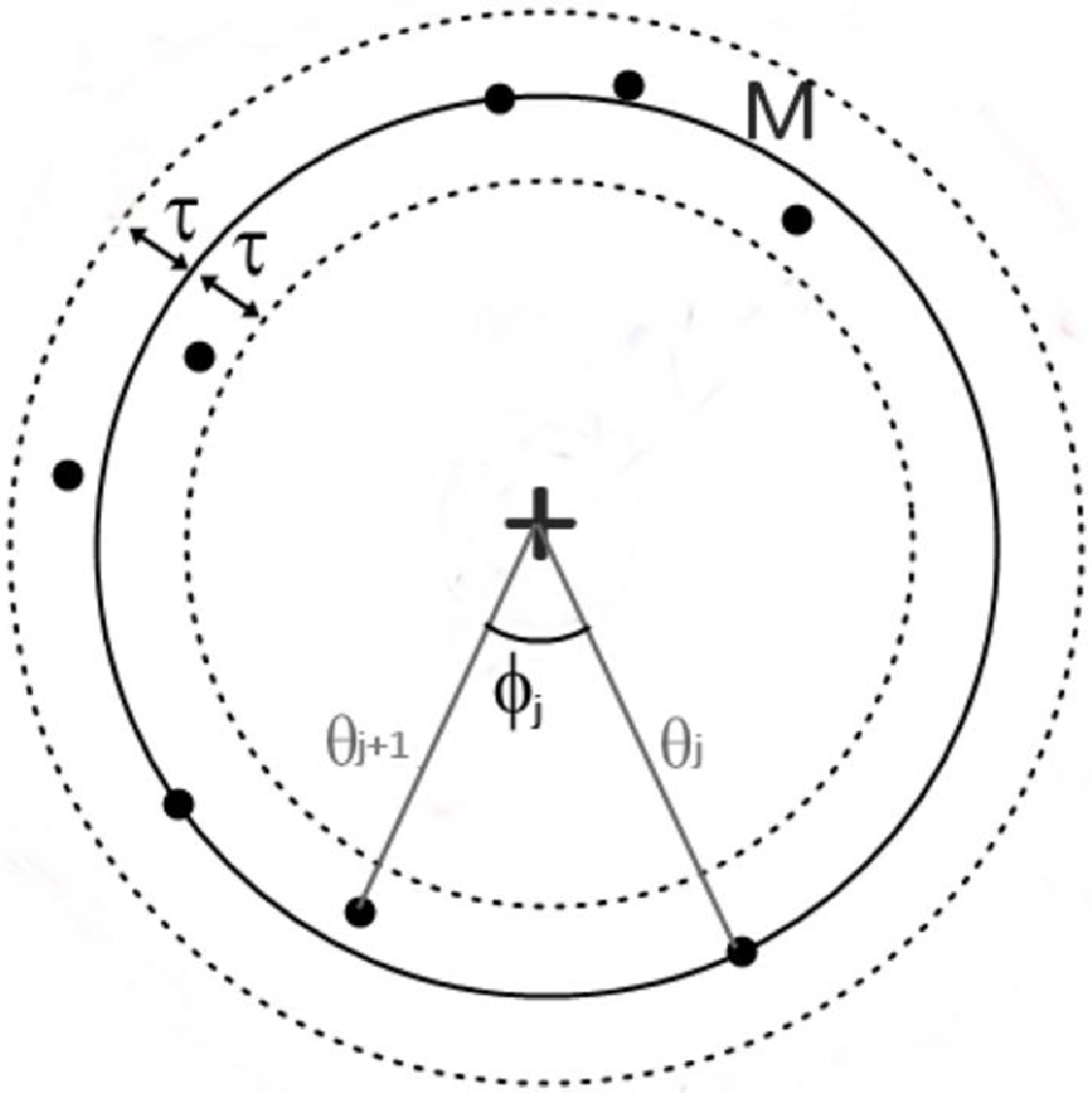
Figure 3. Example of the projection of a ring on its plane, on which the angular coordinate of the sample inliers
 $\theta_j$
and the angular separation
$\theta_j$
and the angular separation
 $\unicode{x03D5}_j$
are shown. The value of
$\unicode{x03D5}_j$
are shown. The value of
 $\unicode{x03B2}$
here is 0.69.
$\unicode{x03B2}$
here is 0.69.
3.3 Validity margin estimation
During each evaluation of a hypothesis as defined by a random subgroup (Phase 2 of RANSAC, see above), the three values
 $N_I$
,
$N_I$
,
 $\unicode{x03B1}$
, and
$\unicode{x03B1}$
, and
 $\unicode{x03B2}$
will be calculated for that putative ring. The hypothesis will be accepted, if these three parameters exceed a certain limit
$\unicode{x03B2}$
will be calculated for that putative ring. The hypothesis will be accepted, if these three parameters exceed a certain limit
 $\bar{N_I}$
,
$\bar{N_I}$
,
 $\bar{\unicode{x03B1}}$
, and
$\bar{\unicode{x03B1}}$
, and
 $\bar{\unicode{x03B2}}$
defined for the respective data set.Therefore, a model will only be considered valid, if it satisfies
$\bar{\unicode{x03B2}}$
defined for the respective data set.Therefore, a model will only be considered valid, if it satisfies
 $N_I\geq\bar{N_I}$
,
$N_I\geq\bar{N_I}$
,
 $\unicode{x03B1}\leq\bar{\unicode{x03B1}}$
, and
$\unicode{x03B1}\leq\bar{\unicode{x03B1}}$
, and
 $\unicode{x03B2}\leq\bar{\unicode{x03B2}}$
(models with values worse than the established
$\unicode{x03B2}\leq\bar{\unicode{x03B2}}$
(models with values worse than the established
 $\bar{N_I}$
,
$\bar{N_I}$
,
 $\bar{\unicode{x03B1}}$
, and
$\bar{\unicode{x03B1}}$
, and
 $\bar{\unicode{x03B2}}$
values are considered as spurious objects caused by noise).
$\bar{\unicode{x03B2}}$
values are considered as spurious objects caused by noise).
 $\bar{N_I}$
is completely determined as soon as we decide the maximum fraction of outliers e, since it satisfies
$\bar{N_I}$
is completely determined as soon as we decide the maximum fraction of outliers e, since it satisfies
 $\bar{N_I} = (1-e) N_{tot}$
where
$\bar{N_I} = (1-e) N_{tot}$
where
 $N_{tot}$
is the total number of points that the data contains. The maximum generalisation of this method is always sought, which implies that values for
$N_{tot}$
is the total number of points that the data contains. The maximum generalisation of this method is always sought, which implies that values for
 $\bar{\unicode{x03B1}}$
and
$\bar{\unicode{x03B1}}$
and
 $\bar{\unicode{x03B2}}$
need to be estimated by procedures independent of the input data, thus turning the algorithm into a black box. If that can be achieved, it is only necessary to set the model size
$\bar{\unicode{x03B2}}$
need to be estimated by procedures independent of the input data, thus turning the algorithm into a black box. If that can be achieved, it is only necessary to set the model size
 $\tau$
and the minimum number of desired inliers
$\tau$
and the minimum number of desired inliers
 $\bar{N_I}$
. Note that R is a free parameter that is allowed to vary within a reasonable range: it does not make sense to have
$\bar{N_I}$
. Note that R is a free parameter that is allowed to vary within a reasonable range: it does not make sense to have
 $R\leq\tau$
or R greater than the extent of the 3D data.
$R\leq\tau$
or R greater than the extent of the 3D data.
 $\bar{\unicode{x03B1}}$
margin estimation. To estimate
$\bar{\unicode{x03B1}}$
margin estimation. To estimate
 $\bar{\unicode{x03B1}}$
, we will calculate the expected number of noise points in a given data environment E. Let N be the total number of points in a volume
$\bar{\unicode{x03B1}}$
, we will calculate the expected number of noise points in a given data environment E. Let N be the total number of points in a volume
 $V_T$
. If our hypothesis now conatins
$V_T$
. If our hypothesis now conatins
 ${N_I}$
inliers, that total space will contain
${N_I}$
inliers, that total space will contain
 $N-N_I$
points (that are all outliers of the model). Recall that in each if our refined evaluation a spherical environment E of radius
$N-N_I$
points (that are all outliers of the model). Recall that in each if our refined evaluation a spherical environment E of radius
 $R_E=R+2\tau$
is constructed, with R being the radius of the ring. Therefore, the expected number of outliers in E would be
$R_E=R+2\tau$
is constructed, with R being the radius of the ring. Therefore, the expected number of outliers in E would be
 $N-N_I$
multiplied by the fraction of the total volume
$N-N_I$
multiplied by the fraction of the total volume
 $V_T$
occupied by the environment E. Combining these expressions with Eq. (2), we obtain:
$V_T$
occupied by the environment E. Combining these expressions with Eq. (2), we obtain:
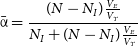 \begin{equation}\bar{\unicode{x03B1}}=\frac{(N-{N_I})\frac{V_E}{V_T}}{{N_I} + (N-{N_I})\frac{V_E}{V_T}} \,\end{equation}
\begin{equation}\bar{\unicode{x03B1}}=\frac{(N-{N_I})\frac{V_E}{V_T}}{{N_I} + (N-{N_I})\frac{V_E}{V_T}} \,\end{equation}
where
 $V_E=\frac{4}{3}\pi R_E^{3}$
is the volume of environment E defined for a certain ring. This will be the reference value against which we are comparing the actual
$V_E=\frac{4}{3}\pi R_E^{3}$
is the volume of environment E defined for a certain ring. This will be the reference value against which we are comparing the actual
 $\unicode{x03B1}$
value for a given hypothesis.
$\unicode{x03B1}$
value for a given hypothesis.
 $\bar{\unicode{x03B2}}$
margin estimation. To estimate
$\bar{\unicode{x03B2}}$
margin estimation. To estimate
 $\bar{\unicode{x03B2}}$
we will calculate the standard deviation and the mean of the distribution of all the 3D points that make up the data. Let
$\bar{\unicode{x03B2}}$
we will calculate the standard deviation and the mean of the distribution of all the 3D points that make up the data. Let
 $\vec{r_{i}}$
be the position of each point belonging to the data, with
$\vec{r_{i}}$
be the position of each point belonging to the data, with
 $i=1,2,...,N$
. The position of the centroid of the point cloud is calculated by
$i=1,2,...,N$
. The position of the centroid of the point cloud is calculated by
 $\vec{r_C}=\frac{\sum_{i=1}^{N}\vec{r_{i}}}{N}$
. Subsequently, the distance
$\vec{r_C}=\frac{\sum_{i=1}^{N}\vec{r_{i}}}{N}$
. Subsequently, the distance
 $D_i$
from each point
$D_i$
from each point
 $\vec{r_{i}}$
to the centroid
$\vec{r_{i}}$
to the centroid
 $\vec{r_C}$
is computed. Defining
$\vec{r_C}$
is computed. Defining
 $d_j$
as
$d_j$
as
 $d_j=D_{j+1}-D_j$
with
$d_j=D_{j+1}-D_j$
with
 $j\in1,2,...,N-1$
(the
$j\in1,2,...,N-1$
(the
 $D_j$
terms are ordered from smallest to largest), we can calculate
$D_j$
terms are ordered from smallest to largest), we can calculate
 $\bar{\unicode{x03B2}}$
as follows:
$\bar{\unicode{x03B2}}$
as follows:
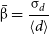 \begin{equation}\bar{\unicode{x03B2}}=\frac{\unicode{x03C3}_d}{\langle{d}\rangle} \,\end{equation}
\begin{equation}\bar{\unicode{x03B2}}=\frac{\unicode{x03C3}_d}{\langle{d}\rangle} \,\end{equation}
with
 $\unicode{x03C3}_d$
the standard deviation of d, and
$\unicode{x03C3}_d$
the standard deviation of d, and
 $\langle{d}\rangle$
its mean. The term
$\langle{d}\rangle$
its mean. The term
 $\langle{d}\rangle$
in Eq. (5) has a similar function to
$\langle{d}\rangle$
in Eq. (5) has a similar function to
 $\langle{\unicode{x03D5}}\rangle$
in Eq. (3). On the one hand, it makes the parameter dimensionless, and on the other hand it makes it independent of the number of points. One of the reasons for choosing this methodology among others to find the standard deviation of the point cloud is because for data where all points form a symmetric ring,
$\langle{\unicode{x03D5}}\rangle$
in Eq. (3). On the one hand, it makes the parameter dimensionless, and on the other hand it makes it independent of the number of points. One of the reasons for choosing this methodology among others to find the standard deviation of the point cloud is because for data where all points form a symmetric ring,
 $\bar{\unicode{x03B2}}$
tends to be 0.
$\bar{\unicode{x03B2}}$
tends to be 0.
For brevity, in the following we will refer to this method as ‘HINORA’. The most important input parameter to HINORA is the size of the pattern
 $\tau$
. Upon exit, HINORA provides us with the following information, in case a ring has been successfully found: the position of the ring centre, the radius of the ring,Footnote b the normal vector to the plane of the ring, and our newly defined quality assessments
$\tau$
. Upon exit, HINORA provides us with the following information, in case a ring has been successfully found: the position of the ring centre, the radius of the ring,Footnote b the normal vector to the plane of the ring, and our newly defined quality assessments
 $\unicode{x03B1}$
and
$\unicode{x03B1}$
and
 $\unicode{x03B2}$
. As mentioned before, the algorithm can find the same structure multiple times, but with marginally different inliers. This is corrected for by identifying all rings that share 30% of inliers and then only keeping the one with the best values of
$\unicode{x03B2}$
. As mentioned before, the algorithm can find the same structure multiple times, but with marginally different inliers. This is corrected for by identifying all rings that share 30% of inliers and then only keeping the one with the best values of
 $N_I$
,
$N_I$
,
 $\unicode{x03B1}$
and
$\unicode{x03B1}$
and
 $\unicode{x03B2}$
.
$\unicode{x03B2}$
.
Before eventually applying HINORA to the observed galaxy catalogue LVG, we have subjected the newly designed code to a series of credibility tests. The results of these validations are summarised in Appendix A. Those final assessments have revealed that HINORA reliably identifies ring-like structures, if they are really present.
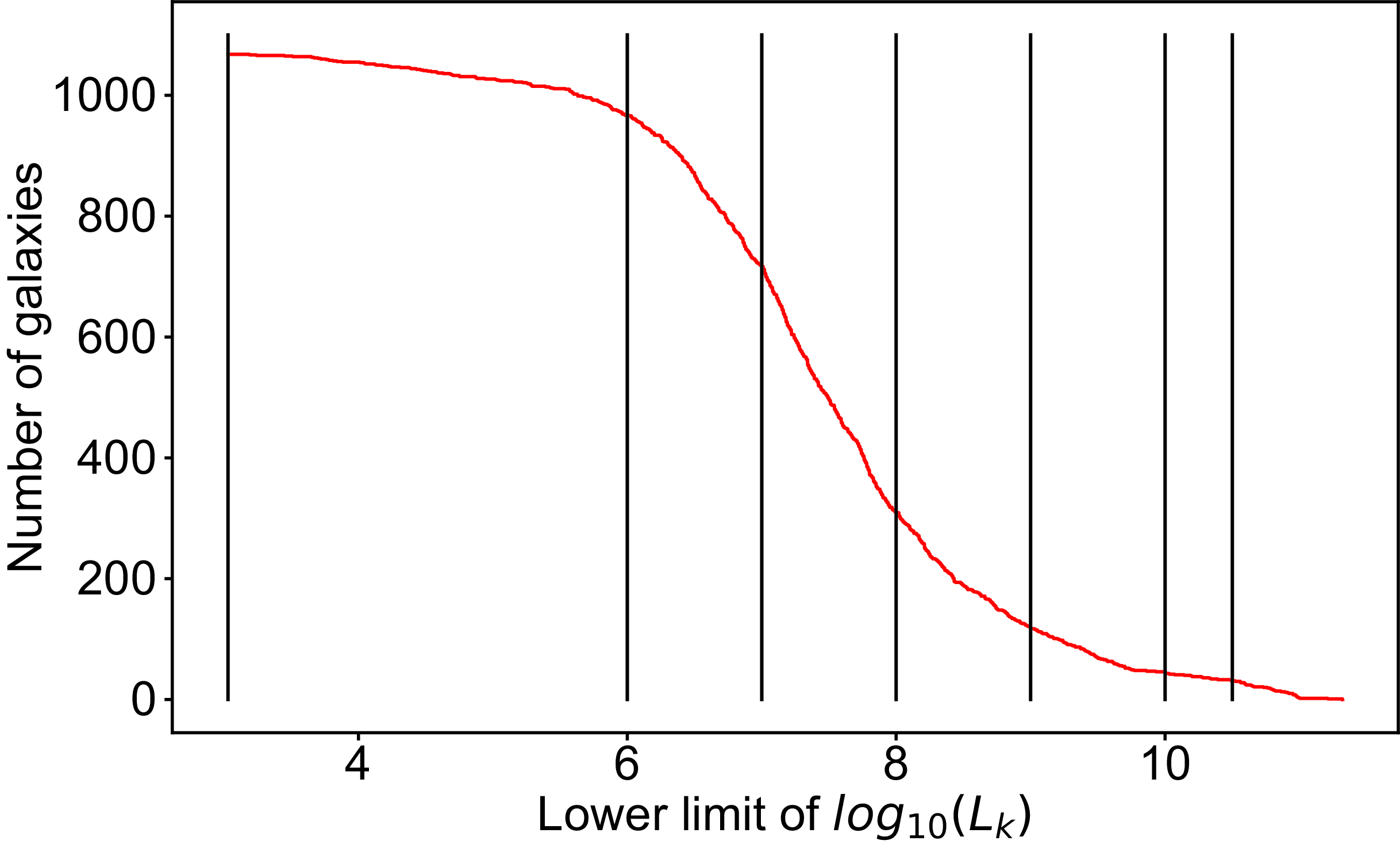
Figure 4. Cumulative luminosity of the LVG catalogue limited to nearby galaxies with a distance < 10 Mpc to the MW. The vertical lines represent the luminosity cuts applied to the data, that is,
 $\log_{10}L_{K}$
= 3, 6, 7, 8, 9, 10, and 10.5.
$\log_{10}L_{K}$
= 3, 6, 7, 8, 9, 10, and 10.5.
4. Ring-like structures in LVG
The main motivation for this work (i.e. the development of an automated finder for pre-defined structures in 3D point distributions) comes from the observations first put forward by McCall (Reference McCall2014) who reported the existence of a so-called CoGs, that is, ring-like structure about the Local Group made up of 11 massive galaxies with stellar masses ranging between
 $M_*=10^{10.496} M_{\odot}$
(M64) and
$M_*=10^{10.496} M_{\odot}$
(M64) and
 $M_*=10^{10.928} M_{\odot}$
(Maffei 2). However, as argued above in Section 2, we prefer to work with the to-date most complete survey of galaxies in the Local Universe, that is, the LVG catalogue (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013). By applying HINORA to it, we have higher statistical reliability and use more current measurements of, for instance, distance (which is crucial to our objective). These data contain about a thousand galaxies with both distance and K-band luminosity
$M_*=10^{10.928} M_{\odot}$
(Maffei 2). However, as argued above in Section 2, we prefer to work with the to-date most complete survey of galaxies in the Local Universe, that is, the LVG catalogue (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013). By applying HINORA to it, we have higher statistical reliability and use more current measurements of, for instance, distance (which is crucial to our objective). These data contain about a thousand galaxies with both distance and K-band luminosity
 $L_K$
measurements. When translating
$L_K$
measurements. When translating
 $L_K$
into stellar mass, we will assume a bilateral linear relationship. In this work we are not going to go beyond such a simple approximation which is sufficient to indicate whether or not the galaxies can be considered massive (see, for instance, Jarrett et al., Reference Jarrett, Masci, Tsai, Petty, Cluver, Assef and Benford2013; Ziparo et al., Reference Ziparo, Smith, Mulroy, Lieu, Willis, Hudelot and McGee2016) And in order to find any possible mass trends in our ring-finding, we are going to apply several cuts in K-band magnitude. To find the most suitable lower
$L_K$
into stellar mass, we will assume a bilateral linear relationship. In this work we are not going to go beyond such a simple approximation which is sufficient to indicate whether or not the galaxies can be considered massive (see, for instance, Jarrett et al., Reference Jarrett, Masci, Tsai, Petty, Cluver, Assef and Benford2013; Ziparo et al., Reference Ziparo, Smith, Mulroy, Lieu, Willis, Hudelot and McGee2016) And in order to find any possible mass trends in our ring-finding, we are going to apply several cuts in K-band magnitude. To find the most suitable lower
 $L_K$
limits, we show in Figure 4 the cumulative K-band luminosity function. The first cut applied by us is at the luminosity of the least bright LVG object (
$L_K$
limits, we show in Figure 4 the cumulative K-band luminosity function. The first cut applied by us is at the luminosity of the least bright LVG object (
 $\log_{10}L_{K} = 3.03$
)Footnote c and thus includes 100% of the galaxies in this catalogue. The following cuts are simply taken at
$\log_{10}L_{K} = 3.03$
)Footnote c and thus includes 100% of the galaxies in this catalogue. The following cuts are simply taken at
 $\log_{10}L_{K} = 6, 7, 8, 9, 10$
, and
$\log_{10}L_{K} = 6, 7, 8, 9, 10$
, and
 $10.5$
corresponding to about 90, 65, 30, 10, 4, and 3% of the total objects, giving us successively more massive galaxies. Each of the seven (sub-)sets has been passed to HINORA for the possible detection of ring-like structures. For that we set the size
$10.5$
corresponding to about 90, 65, 30, 10, 4, and 3% of the total objects, giving us successively more massive galaxies. Each of the seven (sub-)sets has been passed to HINORA for the possible detection of ring-like structures. For that we set the size
 $\tau$
of the pattern to
$\tau$
of the pattern to
 $\tau=1$
Mpc, and the number of minimum inliers
$\tau=1$
Mpc, and the number of minimum inliers
 $\bar{N_I}$
to
$\bar{N_I}$
to
 $\bar{N_I} = 0.15 N_{tot}$
. Note that the choice of
$\bar{N_I} = 0.15 N_{tot}$
. Note that the choice of
 $\tau$
is driven by our motivation to detect ring-like structures in the LVG data that have radii larger than 1 Mpc yet still lie within the domain of the catalogue. We also varied
$\tau$
is driven by our motivation to detect ring-like structures in the LVG data that have radii larger than 1 Mpc yet still lie within the domain of the catalogue. We also varied
 $\tau$
in-between 0.5 Mpc and 2 Mpc, counting the number of rings found for each of our applied luminosity cuts. Though not explicitly shown here, we found that for
$\tau$
in-between 0.5 Mpc and 2 Mpc, counting the number of rings found for each of our applied luminosity cuts. Though not explicitly shown here, we found that for
 $\tau=1$
Mpc we always do find a ring while for larger and smaller values the likelihood for it decreases towards zero. Note that another value we have set is
$\tau=1$
Mpc we always do find a ring while for larger and smaller values the likelihood for it decreases towards zero. Note that another value we have set is
 $\bar{N_I}$
. Our choice of
$\bar{N_I}$
. Our choice of
 $\bar{N_I} = 0.15 N_{tot}$
is motivated because we wish to capture the possible existence of the CoGs, which represents
$\bar{N_I} = 0.15 N_{tot}$
is motivated because we wish to capture the possible existence of the CoGs, which represents
 $\sim 0.2 N_{tot}$
in the McCall (Reference McCall2014) catalogue. Using values higher than
$\sim 0.2 N_{tot}$
in the McCall (Reference McCall2014) catalogue. Using values higher than
 $0.2 N_{tot}$
would prevent us from finding the possible CoGs or rings similar to it, while lower values would capture false models coming from noise. For example, for the highest luminosity cuts, choosing
$0.2 N_{tot}$
would prevent us from finding the possible CoGs or rings similar to it, while lower values would capture false models coming from noise. For example, for the highest luminosity cuts, choosing
 $\bar{N_I} = 0.1 N_{tot} \approx 3$
causes the algorithm to find correct rings consisting of only 3 points.
$\bar{N_I} = 0.1 N_{tot} \approx 3$
causes the algorithm to find correct rings consisting of only 3 points.
 $\tau$
and
$\tau$
and
 $\bar{N_I}$
are the only parameters to be chosen beforehand, since the radius of the ring and all other return values (cf. Section 3.1) are determined by HINORA itself. And as mentioned before in Section 2, we are only working with galaxies with a maximum distance of 10 Mpc to the MW.
$\bar{N_I}$
are the only parameters to be chosen beforehand, since the radius of the ring and all other return values (cf. Section 3.1) are determined by HINORA itself. And as mentioned before in Section 2, we are only working with galaxies with a maximum distance of 10 Mpc to the MW.
The results can be viewed in Figures 5 (face-on view in supergalactic coordinates) and 6 (edge-on view in supergalactic coordinates), however, we prefer to simply focus and discuss the former face-on representations. In these plots, we show the ring found by HINORA (red solid line), the applied
 $\tau$
range (red dashed lines), and additionally the CoGs as reported by McCall (Reference McCall2014, blue solid line). The galaxies belonging to the rings are colour-coded, too. Note that galaxies belonging to both rings are shown in magenta. There are obviously several interesting points to notice in these plots. First and foremost, HINORA always found a ring in the LVG data; and it only ever found a single ring. This structure appears to be rather stable (see stability discussion below), but we actually have to distinguish two scenarios here: one ring up to luminosity cut
$\tau$
range (red dashed lines), and additionally the CoGs as reported by McCall (Reference McCall2014, blue solid line). The galaxies belonging to the rings are colour-coded, too. Note that galaxies belonging to both rings are shown in magenta. There are obviously several interesting points to notice in these plots. First and foremost, HINORA always found a ring in the LVG data; and it only ever found a single ring. This structure appears to be rather stable (see stability discussion below), but we actually have to distinguish two scenarios here: one ring up to luminosity cut
 $\log_{10}(L_K)<9$
, and yet another one for
$\log_{10}(L_K)<9$
, and yet another one for
 $\log_{10}(L_K)>9$
. The former one even includes the MW and M31, and all its satellites. In fact, that particular structure is predominantly defined via satellites in general and not their (massive) host galaxies, something that we will later see is reflected in the quality parameter
$\log_{10}(L_K)>9$
. The former one even includes the MW and M31, and all its satellites. In fact, that particular structure is predominantly defined via satellites in general and not their (massive) host galaxies, something that we will later see is reflected in the quality parameter
 $\unicode{x03B2}$
(i.e. the one that measures isotropy) of the two rings. We will refer to this structure also as ‘satellite ring’. Only when taking into account the most massive galaxies with
$\unicode{x03B2}$
(i.e. the one that measures isotropy) of the two rings. We will refer to this structure also as ‘satellite ring’. Only when taking into account the most massive galaxies with
 $\log_{10}(L_K)>9$
we identify a structure akin to McCall’s CoGs. In fact, for galaxies
$\log_{10}(L_K)>9$
we identify a structure akin to McCall’s CoGs. In fact, for galaxies
 $\log_{10}(L_K)\geq 10$
we do recover the orginal CoGs, though excluding Maffei 1 and 2 due to their different distances in the LVG catalogue (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013). This finding now confirms two things: (a) the massive galaxies in the Local Volume do form a CoGs, and (b) there appears to be a another (ring-like/circular) structure associated with a selection of host and their satellite galaxies. However, it remains unclear why both rings show comparable sizes of approximately 4 Mpc in radius, yet having their centres in different places.
$\log_{10}(L_K)\geq 10$
we do recover the orginal CoGs, though excluding Maffei 1 and 2 due to their different distances in the LVG catalogue (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013). This finding now confirms two things: (a) the massive galaxies in the Local Volume do form a CoGs, and (b) there appears to be a another (ring-like/circular) structure associated with a selection of host and their satellite galaxies. However, it remains unclear why both rings show comparable sizes of approximately 4 Mpc in radius, yet having their centres in different places.
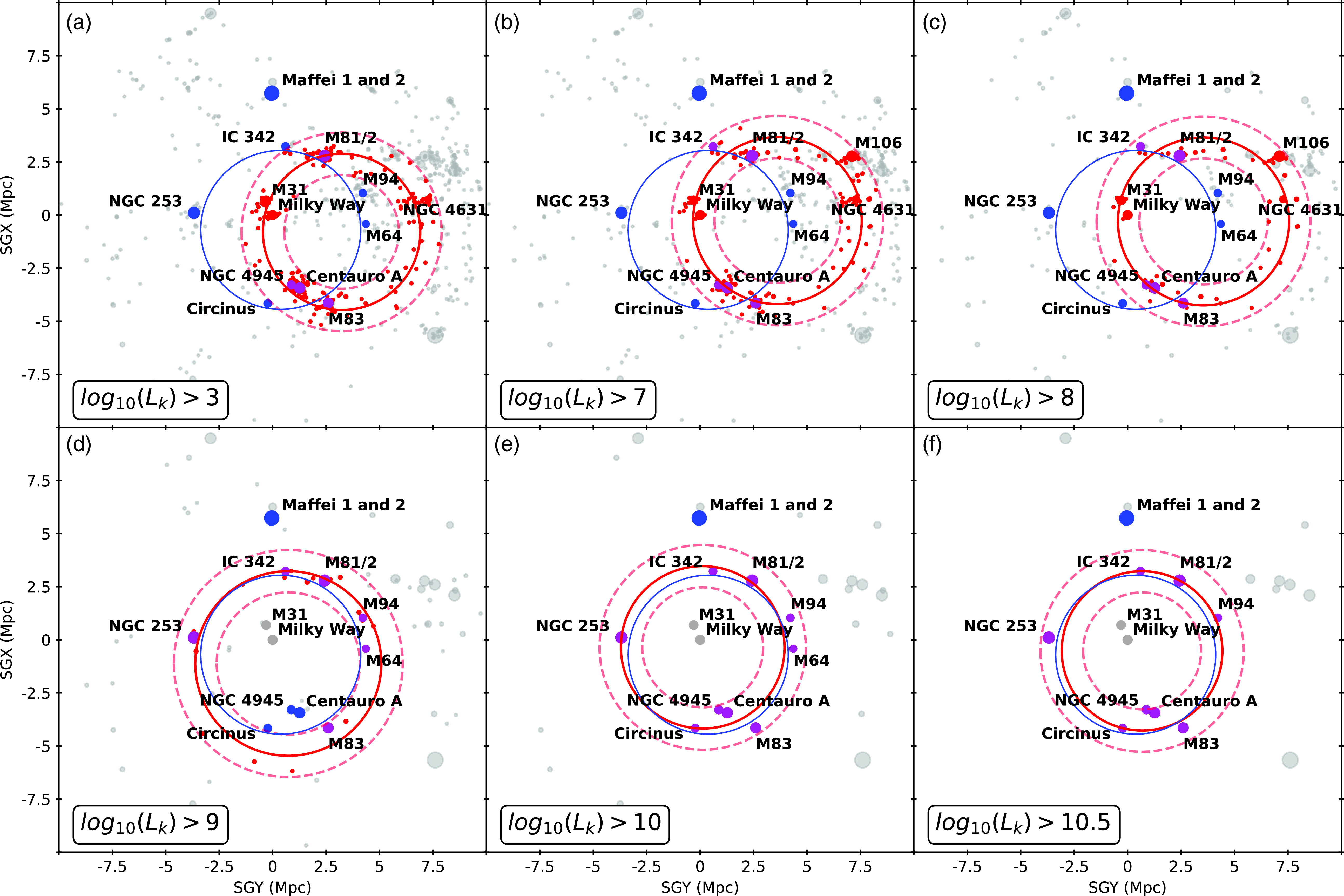
Figure 5. Projection along the z-axis of LVG galaxies (in supergalactic coordinates) for four K-band luminosity cuts
 $L_K=[3,7,8]$
(upper panel) and
$L_K=[3,7,8]$
(upper panel) and
 $L_K=[9,10,10.5]$
(lower panel). The size of the dot is proportional to
$L_K=[9,10,10.5]$
(lower panel). The size of the dot is proportional to
 $\log_{10}(L_K)$
. In red and magenta, we show galaxies belonging to the ring as identified by HINORA, where the ring and its respective
$\log_{10}(L_K)$
. In red and magenta, we show galaxies belonging to the ring as identified by HINORA, where the ring and its respective
 $\tau$
are also indicated by solid and dashed red lines, respectively. The original galaxies making up McCall’s Council of Giants are represented as blue and magenta points, also highlighting the corresponding ring as a solid blue line. Note, magenta points belong to both rings.
$\tau$
are also indicated by solid and dashed red lines, respectively. The original galaxies making up McCall’s Council of Giants are represented as blue and magenta points, also highlighting the corresponding ring as a solid blue line. Note, magenta points belong to both rings.
Figure 6, which shows the same data but viewed edge-on, simply confirms that both these structures are planar rings, lying within the Local Sheet. The Local Sheet is part of a larger flat structure, the Local Supercluster with the centre in the Virgo cluster (Tully et al. (Reference Tully, Shaya, Karachentsev, Courtois, Kocevski, Rizzi and Peel2008)). Immediately above it in supergalactic coordinates the Local Void begins. On the opposite side, parallel to the plane of the Local Supercluster lie the Leo Spur and Dorado cloud (Tully and Fisher (Reference Tully and Fisher1987)). The so-called Avoidance Zone (ZoA) in the MW is shown by solid lines. ZoA cuts the Local Sheet into two halves. Fortunately, due to its orientation, it covers a quite small portion of the Local Sheet and should not significantly affect the detection of the ring structures. Nevertheless, it should be emphasised that due to the extremely strong extinction near the MW plane, the detection of galaxies, as well as the determination of their parameters, becomes an extremely difficult task. In our case, this manifested itself in the erroneous distances to the Maffei 1 and 2 galaxies adopted in earlier works. In turn, this is the main reason for the differences between the CoGs detected by us and those found in McCall (Reference McCall2014). Further, in principle one should adjust HINORA to allow for such incomplete data sets. But we also acknowledge that the ZoA does not significantly affect the measure of the distribution of positions in the LVG catalogue. This is because Eq. (5) works with the distances from the centroid to the position of the rest of the data. And since the LVG catalogue is centred on the MW, the centroid will tend to be located close to our galaxy and therefore the ZoA will have no effect on the calculation of these distances. However, in other cases (such as working only with areas far from the MW) and when working with less uniform data, we might have to change our strategy and use some kind of privileged axis along which to project the points and calculate distances.
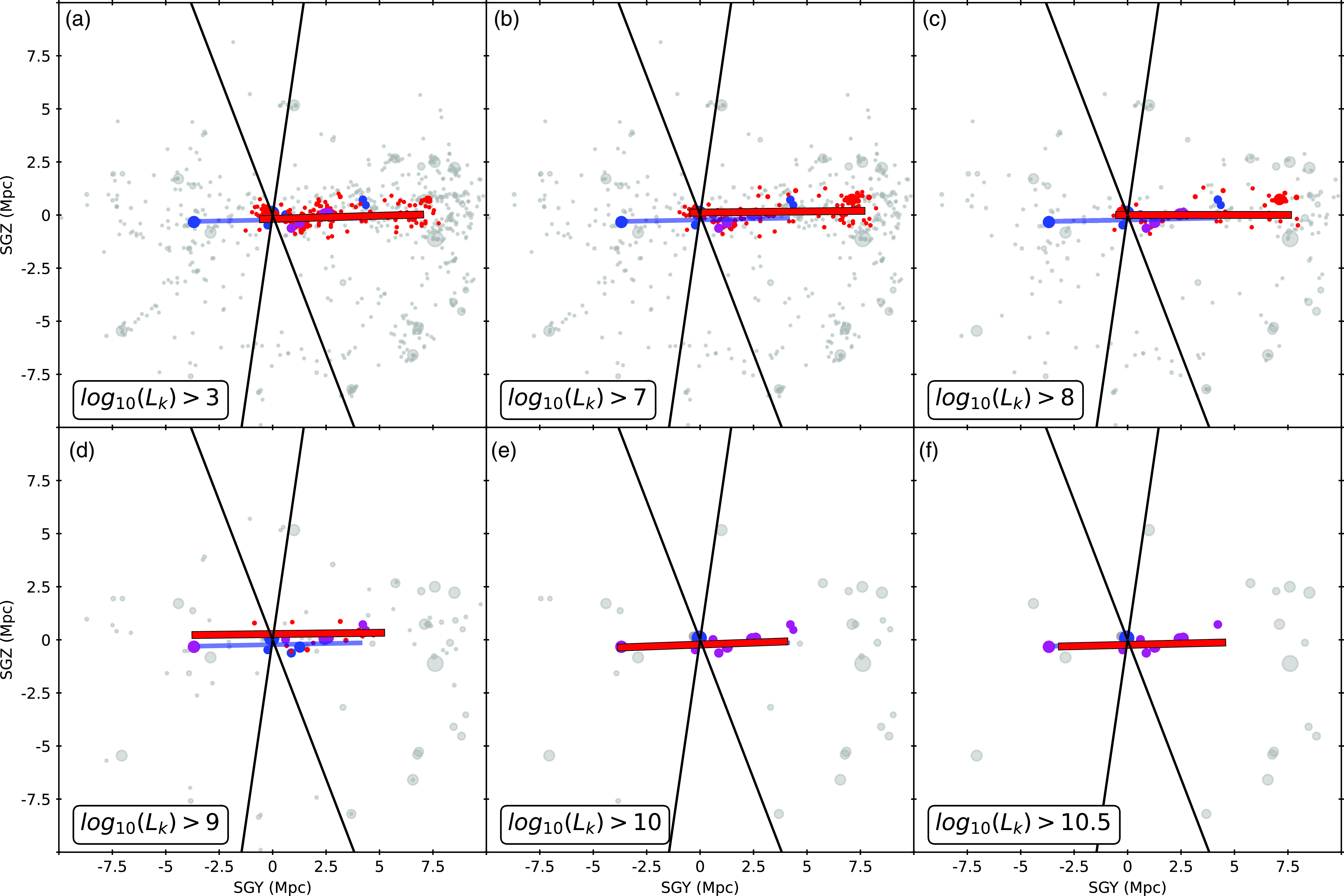
Figure 6. Same as Figure 5, but now projecting along the supergalactic x-axis. The two solid lines delineate the Zone of Avoidance (|b|
 $\leqslant 10^{\circ}$
).
$\leqslant 10^{\circ}$
).
We like to mention that we have repeated the ring-finding, but assigning a weight to each data point by accordingly adjusting Eqs. (2) and 4. We have used both the K-band luminosity
 $L_K$
as well as its logarithm
$L_K$
as well as its logarithm
 $\log_{10}L_K$
as weight. While not explicitly shown here, we find that in both cases the CoGs ring (i.e. the lower panel of Figure 5) shifts to include both Maffei 1 and 2 (excluding IC342, M81/2, M94, and M64). This same ring – which obviously has a much lower isotropy level – is also found for the lower luminosity cuts (i.e. the upper panel of Figure 5) when using linear K-band weights, indicating that Maffei 1 clearly dominates the sample when taken its K-band luminosity (and hence stellar mass) linearly into account. Finally, using the logarithm of the K-band luminosity as a weight, the so-called satellite ring is not affected.
$\log_{10}L_K$
as weight. While not explicitly shown here, we find that in both cases the CoGs ring (i.e. the lower panel of Figure 5) shifts to include both Maffei 1 and 2 (excluding IC342, M81/2, M94, and M64). This same ring – which obviously has a much lower isotropy level – is also found for the lower luminosity cuts (i.e. the upper panel of Figure 5) when using linear K-band weights, indicating that Maffei 1 clearly dominates the sample when taken its K-band luminosity (and hence stellar mass) linearly into account. Finally, using the logarithm of the K-band luminosity as a weight, the so-called satellite ring is not affected.
One might now question the importance of these rings as their manifestation depends on the way they are searched for. Answering this is actually beyond the scope of this particular work, in which we primarily introduce the ring-finding algorithm and showcase its performance by applying it to astrophysical data. But we nevertheless like to share our thoughts here. While McCall (Reference McCall2014) reported the existence of the CoGs simply by visual inspection, we now confirm that this structure can be found, even when using an unbiased and automated method. But while investigating possible cuts and weighing schemes using a proxy for stellar mass (remember, the peculiarity of the Council is the fact that it is made up of ‘Giants’) we found that this structure is not necessarily unique. This is primarily driven by Maffei 1, a giant elliptical galaxy in the Zone of Avoidance whose distance is not the best established one: when basically forcing HINORA to include it by using linear K-band weights, other lower-mass galaxies are removed from the non-weighted ring. We believe that, given the special situation for Maffei 1 (and 2), the results shown here in Figure 5 should be the ones to interpret, which is also why we defer from showing the results for the different weighing schemes. Note that both Maffei 1 and 2 do lie in the Local Sheet, which is why HINORA picks them up as inliers in the rings found by it. Maybe the real scientific question here is why there is a Local Sheet of galaxies, with massive galaxies arranged in such peculiar ring-like way. We will address these problem in a follow-up paper where we make use of simulations of cosmic structure formation to gauge the likehood of the existence of such galaxy arrangements. To that extent both constrained Local Universe as well as standard cosmological simulations shall be applied.
Before quantifying the stability of the two rings seen in the previous figures, we will first show the quality assessment of them. To that extent we show in Figure 7 the relation between
 $\unicode{x03B1}$
(upper panel) and
$\unicode{x03B1}$
(upper panel) and
 $\unicode{x03B2}$
(lower panel), respectively, and the luminosity cut. We have also drawn in each case
$\unicode{x03B2}$
(lower panel), respectively, and the luminosity cut. We have also drawn in each case
 $\bar{\unicode{x03B1}}$
and
$\bar{\unicode{x03B1}}$
and
 $\bar{\unicode{x03B2}}$
with a red line, emphasising the overall behaviour of the data for these definitions. We observe that while
$\bar{\unicode{x03B2}}$
with a red line, emphasising the overall behaviour of the data for these definitions. We observe that while
 $\unicode{x03B1}$
has a constant value of less than unity,
$\unicode{x03B1}$
has a constant value of less than unity,
 $\unicode{x03B2}$
and
$\unicode{x03B2}$
and
 $\bar{\unicode{x03B2}}$
drops substantially towards
$\bar{\unicode{x03B2}}$
drops substantially towards
 $\unicode{x03B2}\approx1$
as massive galaxies become more and more important.
$\unicode{x03B2}\approx1$
as massive galaxies become more and more important.
 $\unicode{x03B2}$
is particularly small for the CoGs, confirming its isotropy. Since in principle
$\unicode{x03B2}$
is particularly small for the CoGs, confirming its isotropy. Since in principle
 $\unicode{x03B2}$
and
$\unicode{x03B2}$
and
 $\bar{\unicode{x03B2}}$
are a normalised parameters with respect to the number of objects, they does not depend on the number of inliers, but on their distribution. And we have qualitatively seen in Figure 5 that non-uniformly distributed satellite galaxies substantially contribute to the inliers for low
$\bar{\unicode{x03B2}}$
are a normalised parameters with respect to the number of objects, they does not depend on the number of inliers, but on their distribution. And we have qualitatively seen in Figure 5 that non-uniformly distributed satellite galaxies substantially contribute to the inliers for low
 $\log_{10}L_K$
values: they are clustered about their hosts, however, these hosts are not necessarily the ones that eventually form the CoGs. We further note that the actual CoGs ring has a substantially lower
$\log_{10}L_K$
values: they are clustered about their hosts, however, these hosts are not necessarily the ones that eventually form the CoGs. We further note that the actual CoGs ring has a substantially lower
 $\unicode{x03B1}$
than
$\unicode{x03B1}$
than
 $\bar{\unicode{x03B1}}$
, indicative of a more stable structure.
$\bar{\unicode{x03B1}}$
, indicative of a more stable structure.
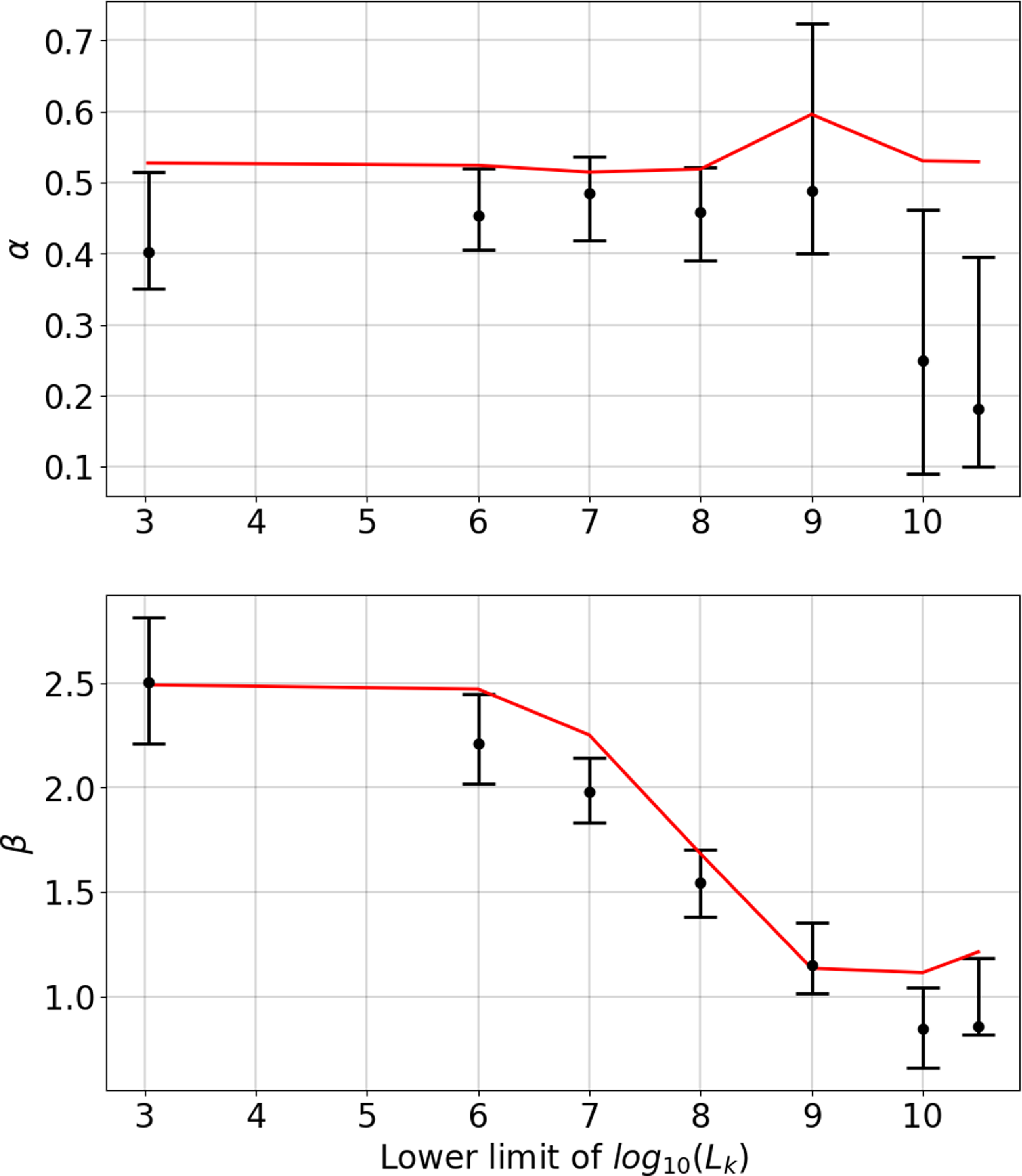
Figure 7. The median of the
 $\unicode{x03B1}$
and
$\unicode{x03B1}$
and
 $\unicode{x03B2}$
parameters (explained in sections 3.2.1 and 3.2.2, respectively) of the models found by HINORA for each LVG luminosity cut-off. The red line represents the values of
$\unicode{x03B2}$
parameters (explained in sections 3.2.1 and 3.2.2, respectively) of the models found by HINORA for each LVG luminosity cut-off. The red line represents the values of
 $\bar{\unicode{x03B1}}$
and
$\bar{\unicode{x03B1}}$
and
 $\bar{\unicode{x03B2}}$
, which define the maximum of
$\bar{\unicode{x03B2}}$
, which define the maximum of
 $\unicode{x03B1}$
and
$\unicode{x03B1}$
and
 $\unicode{x03B2}$
in the LVG catalogue.
$\unicode{x03B2}$
in the LVG catalogue.
We need to remark that Figure 7 features error bars attached to the measured values of
 $\unicode{x03B1}$
and
$\unicode{x03B1}$
and
 $\unicode{x03B2}$
. These have been derived the following way. The LVG catalogue not only lists the distance to a galaxy, but also an error on that estimate. We have now generated thousand ‘mock LVG’ catalogues in which we varied the distance of each galaxy as:
$\unicode{x03B2}$
. These have been derived the following way. The LVG catalogue not only lists the distance to a galaxy, but also an error on that estimate. We have now generated thousand ‘mock LVG’ catalogues in which we varied the distance of each galaxy as:
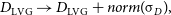 \begin{equation} D_\mathrm{LVG} \rightarrow D_\mathrm{LVG} + norm(\unicode{x03C3}_D), \end{equation}
\begin{equation} D_\mathrm{LVG} \rightarrow D_\mathrm{LVG} + norm(\unicode{x03C3}_D), \end{equation}
where norm(x) is a normal distribution centred at 0 with standard deviation x, and
 $\unicode{x03C3}_D$
the distance error as given in the LVG catalogue.Footnote d HINORA had been applied to each of these mock catalogues and the dots shown are the median, and the error bars contain 85% of the generated models. This causes that in Figure 7 we can see
$\unicode{x03C3}_D$
the distance error as given in the LVG catalogue.Footnote d HINORA had been applied to each of these mock catalogues and the dots shown are the median, and the error bars contain 85% of the generated models. This causes that in Figure 7 we can see
 $\unicode{x03B1}$
and
$\unicode{x03B1}$
and
 $\unicode{x03B2}$
values above their defined limits, since we have represented with the red line only the
$\unicode{x03B2}$
values above their defined limits, since we have represented with the red line only the
 $\bar{\unicode{x03B1}}$
and
$\bar{\unicode{x03B1}}$
and
 $\bar{\unicode{x03B2}}$
values for the unaltered LVG catalogue. We do not explicitly show this here, but for each of the mock catalogues, HINORA finds again the same ring as for the original data shown in Figure 5, but with marginally different values that eventually give rise to the shown error bars. This alone is already a confirmation of the stability of the identified structure, something to be investigated in more quantitative detail now.
$\bar{\unicode{x03B2}}$
values for the unaltered LVG catalogue. We do not explicitly show this here, but for each of the mock catalogues, HINORA finds again the same ring as for the original data shown in Figure 5, but with marginally different values that eventually give rise to the shown error bars. This alone is already a confirmation of the stability of the identified structure, something to be investigated in more quantitative detail now.
Figure 8 shows the variation of ring radius (upper panel), ring centre (middle panel), and ring orientation (lower panel) with applied luminosity cut for
 $L_K$
. The units are Mpc and given within the supergalactic frame, and for centre and orientation the three components of the respective vector are shown, which is further normalised to unity in the latter case of the vector normal to the plane defined by the ring. We note that the ring based on the satellite galaxies (i.e. up to luminosity cut
$L_K$
. The units are Mpc and given within the supergalactic frame, and for centre and orientation the three components of the respective vector are shown, which is further normalised to unity in the latter case of the vector normal to the plane defined by the ring. We note that the ring based on the satellite galaxies (i.e. up to luminosity cut
 $\log_{10}L_K=8$
) is remarkably stable. There are hardly any noticeable variations, and if there are they are certainly within the error bars. We further find a change for the cut
$\log_{10}L_K=8$
) is remarkably stable. There are hardly any noticeable variations, and if there are they are certainly within the error bars. We further find a change for the cut
 $\log_{10}L_K=9$
as we have seen that this corresponds to another ring, a one akin to the original CoGs. But also for the Council ring we confirm stability within the error bars.
$\log_{10}L_K=9$
as we have seen that this corresponds to another ring, a one akin to the original CoGs. But also for the Council ring we confirm stability within the error bars.
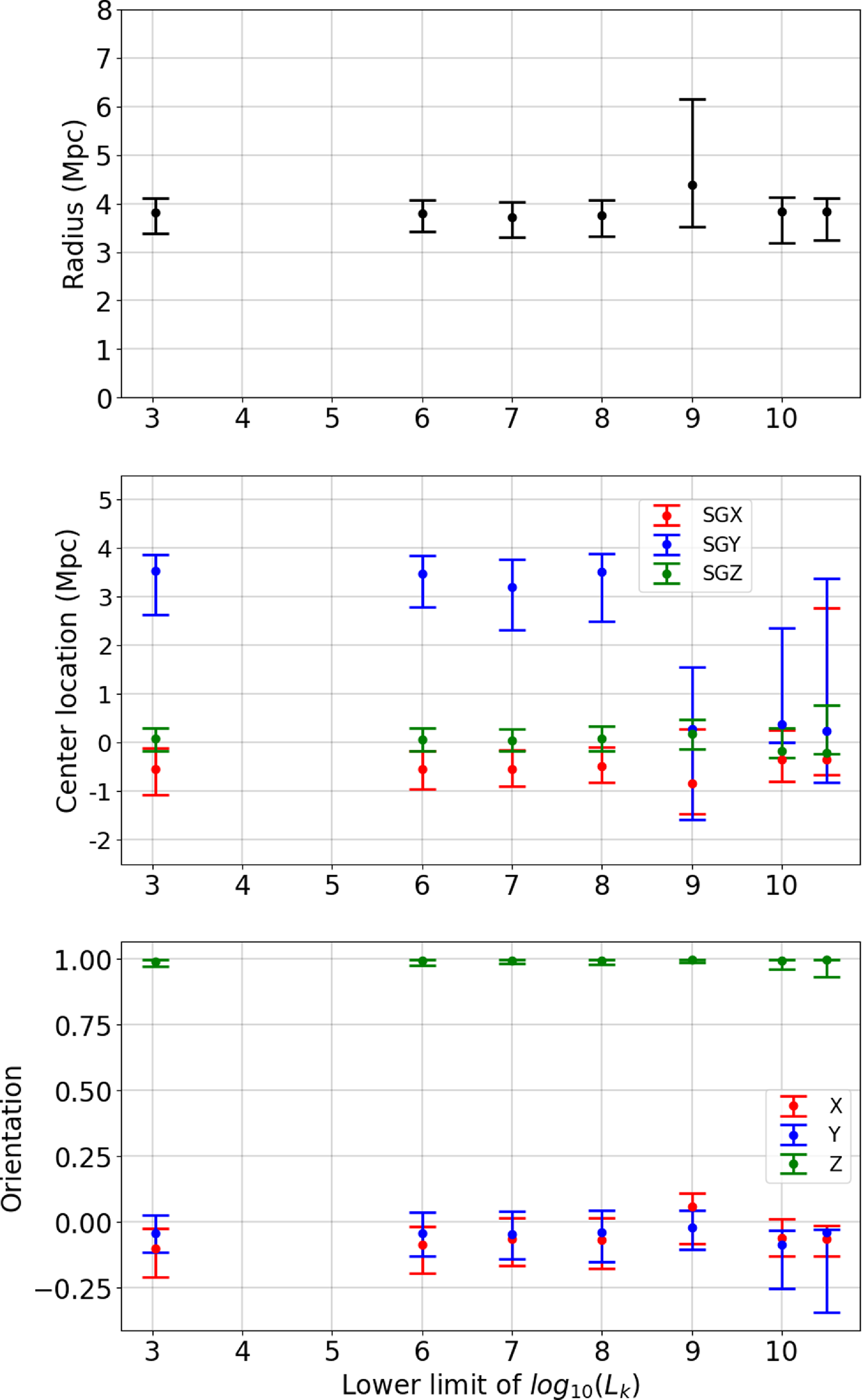
Figure 8. Characteristics of the ring found by HINORA as a function of K-band cut. The upper panel shows the radius of the ring in Mpc, the middle panel the three components of the position vector of the ring centre in supergalactic coordinates, and the lower panel the three components of the unit vector normal to the plane defined by the ring.
We have seen (qualitatively) in Figure 5 that the number of galaxies in the identified ring reduces when increasing the luminosity cut. We now like to quantify this by showing in Figure 9 the percentage of inliers as a function of
 $\log_{10}L_K$
. In order to verify the actual number of ring member galaxies, one would need to compare this against all the galaxies in the sample for a given cut as presented in Figure 4. It is obvioues that, as
$\log_{10}L_K$
. In order to verify the actual number of ring member galaxies, one would need to compare this against all the galaxies in the sample for a given cut as presented in Figure 4. It is obvioues that, as
 $\log_{10}L_{K}$
increases, the number of ring galaxies decreases. We also note that for the last two cuts that focus on the CoGs rings the inlier ratio rises again. This is due to the fact that there are only very few such bright galaxies in the whole sample, with of order 25–30% making up the ring. But it is also remarkable that ca. 30 % of all galaxies from the LVG catalogue (within 10 Mpc distance to the MW, no cut applied) are forming part of the ‘satellite ring’. Such a structure should manifest itself not only in our ring-finding approach, but should in fact also emerge in other quantifications of possible structures, such as – for instance – the two-point correlation function (2PCF), as already reported by Tully and Fisher (Reference Tully, Fisher, Longair and Einasto1978): even though not directly related to the structure finding algorithm HINORA but motivated by the apparent existence of two distinct ring-like features in the Local Universe, we also calculated the 2PCFFootnote e for the same subset of LVG galaxies as used in the previous figures. The result is explained and shown in Appendix B.
$\log_{10}L_{K}$
increases, the number of ring galaxies decreases. We also note that for the last two cuts that focus on the CoGs rings the inlier ratio rises again. This is due to the fact that there are only very few such bright galaxies in the whole sample, with of order 25–30% making up the ring. But it is also remarkable that ca. 30 % of all galaxies from the LVG catalogue (within 10 Mpc distance to the MW, no cut applied) are forming part of the ‘satellite ring’. Such a structure should manifest itself not only in our ring-finding approach, but should in fact also emerge in other quantifications of possible structures, such as – for instance – the two-point correlation function (2PCF), as already reported by Tully and Fisher (Reference Tully, Fisher, Longair and Einasto1978): even though not directly related to the structure finding algorithm HINORA but motivated by the apparent existence of two distinct ring-like features in the Local Universe, we also calculated the 2PCFFootnote e for the same subset of LVG galaxies as used in the previous figures. The result is explained and shown in Appendix B.
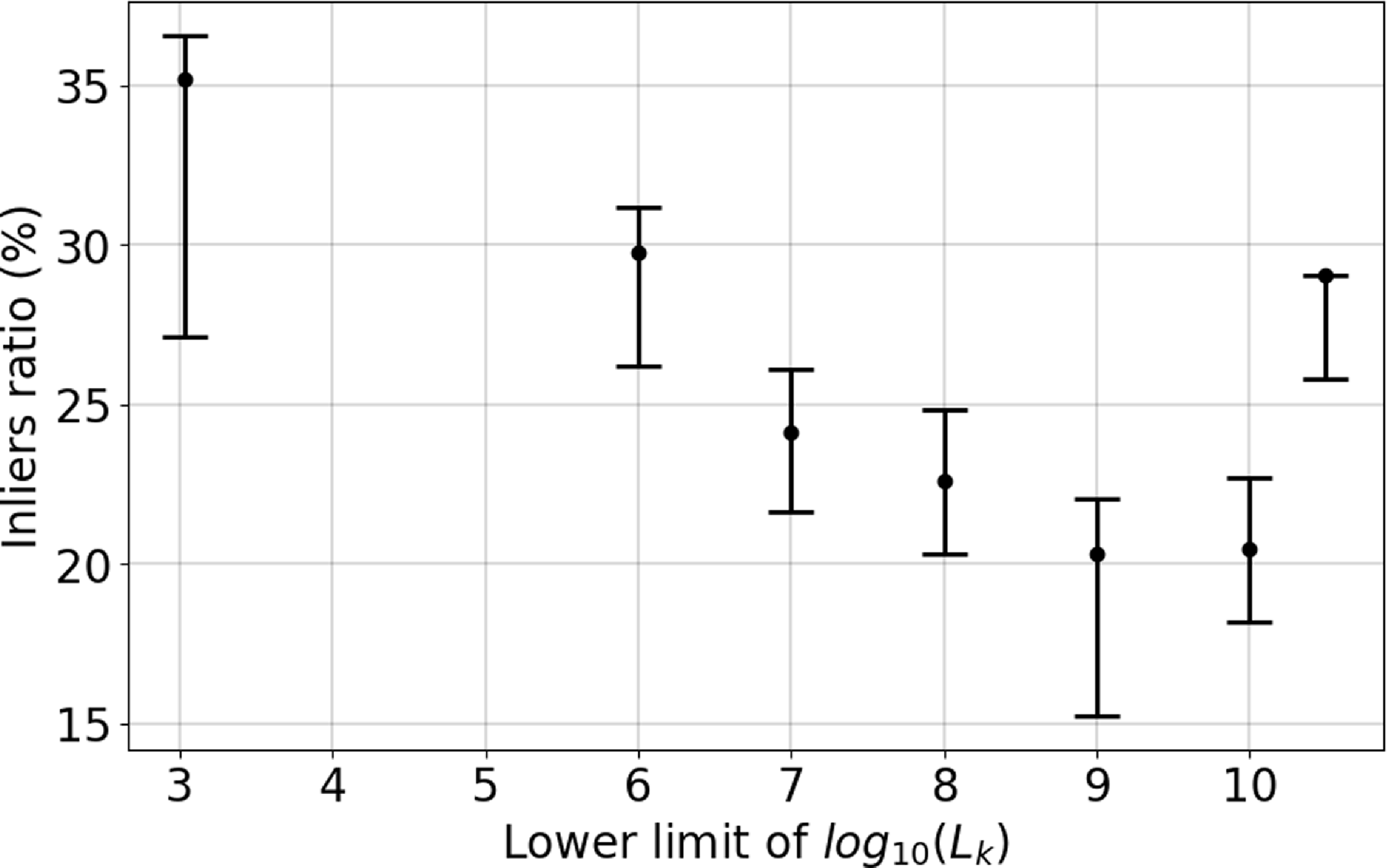
Figure 9. Percentage of data belonging to the model (inliers) found by HINORA for different LVG luminosity cutoffs. The values are the mean of the method repetition, and the error corresponds to 85% of the cases.
5. Discussion of HINORA
Throughout this work, we have described a computational method that allows us to identify simple patterns in complex point clouds, where most of the data may be noise. By analysing the density and dispersion of data, this algorithm not only provides us with a way to locate specific distributions in arbitrarily large databases, but also gives us the intrinsic characteristics of the patterns we are looking for. By applying it to search for CoGs-like galaxy rings, we detected two such structures that maintain their properties stable in their respective mass regimes. The ‘satellite ring’ was found to be stable in the K-band luminosity range
 $log_{10}L_{K} > [3,...,9]$
cuts, and the CoGs predominates for the more massive galaxies between
$log_{10}L_{K} > [3,...,9]$
cuts, and the CoGs predominates for the more massive galaxies between
 $log_{10}L_{K} > 9$
and
$log_{10}L_{K} > 9$
and
 $10.5$
). While the ‘satellite ring’ shows higher stability and smaller variations in its characteristics over the wide mass range in which it dominates, the ‘Council’ nevertheless has better statistical properties such as higher uniformity and lower noise. The differences between the two rings can be explained by the influence of the haloes on the distribution of matter they contain, because smaller galaxies tend to cluster around certain massive galaxies that form specific groups.
$10.5$
). While the ‘satellite ring’ shows higher stability and smaller variations in its characteristics over the wide mass range in which it dominates, the ‘Council’ nevertheless has better statistical properties such as higher uniformity and lower noise. The differences between the two rings can be explained by the influence of the haloes on the distribution of matter they contain, because smaller galaxies tend to cluster around certain massive galaxies that form specific groups.
Before taking the next step and applying to HINORA to other, larger datasets, it is essential to establish the capabilities and limitations of the method used in order to correctly interpret the results it provides. The operating range of HINORA has been tested in the Appendix A, which shows that this method loses efficiency below 8% inliers for a density of 100 points in a spherical volume of radius 10 in arbitrary units. The lowest ratios achieved in our analysis are found at the
 $log_{10}L_{K}> 9$
cutoff, with 118 galaxies and approximately 15% inliers. This ensures a high level of reliability close to 100% in the regime in which we have used HINORA so far, that is, in the LVG catalogue. Note that the method has high resilience to noise due to the fact that in its operating regime it lacks false positives, thus we will have the same level of efficiency if we double the analysis volume but without adding more inliers (thus achieving an accuracy of 4%). Since this exercise can be performed an arbitrary number of times without losing efficiency, the HINORA algorithm is able to deal with arbitrarily large noise, at the cost of a logarithmic increase in the number of iterations governed by equation 1. Given the generalisability, the method is potentially useful for any field that requires locating simple patterns in large databases where most of them are not of interest.
$log_{10}L_{K}> 9$
cutoff, with 118 galaxies and approximately 15% inliers. This ensures a high level of reliability close to 100% in the regime in which we have used HINORA so far, that is, in the LVG catalogue. Note that the method has high resilience to noise due to the fact that in its operating regime it lacks false positives, thus we will have the same level of efficiency if we double the analysis volume but without adding more inliers (thus achieving an accuracy of 4%). Since this exercise can be performed an arbitrary number of times without losing efficiency, the HINORA algorithm is able to deal with arbitrarily large noise, at the cost of a logarithmic increase in the number of iterations governed by equation 1. Given the generalisability, the method is potentially useful for any field that requires locating simple patterns in large databases where most of them are not of interest.
One of the reasons why HINORA may be defective for low densities (or few inliers) is its need for the existence of certain points forming the desired figure. For this reason, for ranges that only take into account the most luminous galaxies, the method loses efficiency. This is because decreasing the density of points decreases the probability that a subgroup of 3 points will accurately generate the model. In the case of CoGs, it is unfeasible to 100% recreate it. However, the method does not seek to be precise but resilient to noise. In this sense, the results for the last cuts lose precision given the performance of HINORA itself, although this is negligible compared to the uncertainty in the estimated distance for the galaxies.
Another important factor to consider is the possibility that more than one ring may be considered correct for the same cut-off in luminosity. In Figures 7 and 8, the main source of the error bars for the cuts smaller than
 $log_{10}L_{K} > 9$
are mainly coming from the error in the distance/luminosity estimated in LVG. However, for the cuts
$log_{10}L_{K} > 9$
are mainly coming from the error in the distance/luminosity estimated in LVG. However, for the cuts
 $log_{10}L_{K}>10$
and
$log_{10}L_{K}>10$
and
 $10.5$
the error bars exhibit noticeable anomalies in the lower left panel of Figure 8. The increase in the observed uncertainty is due to the fact that the models considered correct differ more in their location, to the point that they may even be formed by different galaxies. For the last two cuts, the shifts of the centre towards higher SGY values suggest that the ‘satellite ring’ is still weakly favoured in these ranges.
$10.5$
the error bars exhibit noticeable anomalies in the lower left panel of Figure 8. The increase in the observed uncertainty is due to the fact that the models considered correct differ more in their location, to the point that they may even be formed by different galaxies. For the last two cuts, the shifts of the centre towards higher SGY values suggest that the ‘satellite ring’ is still weakly favoured in these ranges.
We like to close this discussion with reminding the reader that HINORA is not limited to ring-like structures. But when searching for different patterns, one would need to bear in mind that this also entails changes to our quality assessment that currently assume spherical symmetry. But in that regards,
 $\unicode{x03B1}$
is fully generalisable since one would only have to change the shape of the volume of the environment depending on the figure to be studied. For example, if we are looking for planes, the environment to be studied is a box. Further,
$\unicode{x03B1}$
is fully generalisable since one would only have to change the shape of the volume of the environment depending on the figure to be studied. For example, if we are looking for planes, the environment to be studied is a box. Further,
 $\unicode{x03B2}$
uses generalised coordinates (since it is a normalised and dimensionless term). In our case we have used angles, but any other choice can be applied. For example, for straight lines we could use the distances that separate the projections of the points on the line; for a plane, the centroid strategy used in
$\unicode{x03B2}$
uses generalised coordinates (since it is a normalised and dimensionless term). In our case we have used angles, but any other choice can be applied. For example, for straight lines we could use the distances that separate the projections of the points on the line; for a plane, the centroid strategy used in
 $\bar{\unicode{x03B2}}$
can be employed.
$\bar{\unicode{x03B2}}$
can be employed.
6. Summary & conclusions
We have presented a novel method to detect patterns in 3D point distributions, called HINORA. For the moment we have restricted ourselves to search for ring-like structures, but this is easily extendable to any other geometrical patterns. The method makes little assumptions, but the mathematical description of the pattern to search for, and the size of the model, that is, in our case the width of the 3D torus encompassing the ring-like feature. Our first target for applying HINORA to a set of science data was the Local Volume Galaxies catalogue (Karachentsev et al., Reference Karachentsev, Makarov and Kaisina2013), the most complete catalogue of local galaxies that has been compiled to date. This choice was motivated by the observation that massive galaxies in the Local Universe arrange themselves as a so-called ‘Council of Giants’ (CoGs) (McCall, Reference McCall2014).
We confirm the existence of the CoGs, though – according to our findings – Maffei 1 and 2 apparently do not belong to it. This can be attributed to the different distance of these two galaxies in the LVG data compared to the data used by McCall (Reference McCall2014). However, HINORA has also found another ring-like structure that is primarily defined via low-mass satellite galaxies and hence does not have the isotropic distribution as the former CoGs. Both these rings do lie within the Local Sheet, and it also needs to be said that these are the only rings detected by HINORA. It remains to be seen which of these two rings (i.e. the ‘satellite ring’ or the ‘Council’) do in fact relate to structures of astrophysical interest. They might be mere chance configurations or actually reflecting something more profound in the formation history of the Local Universe. For the moment the detection of them in the LVG data should be interpreted with care. Their existence rather verifies the mode of operation of HINORA, and it yet remains to be seen whether this is of physical significance or not.
As the application of the novel structure finder HINORA to astrophysical data left us with more open questions than answers, we aim applying HINORA also to simulations of cosmic structure formation. First and foremost, we will use the constrained Local Universe simulations as provided by the CLUES-HESTIA project (Libeskind et al., Reference Libeskind, Carlesi, Grand, Khalatyan, Knebe, Pakmor and Pilipenko2020). That suite of simulations resemble with great accuracy the actual observed Local Universe, including the correct properties for the MW and M31. However, to fully understand the requirements to form such galaxy rings, we will also use ‘Local Group candidates’ as found in the Illustris-TNG simulation (Vogelsberger et al., Reference Vogelsberger, Genel, Springel, Torrey, Sijacki, Xu, Snyder, Bird, Nelson and Hernquist2014) as a control sample. This will allow for a deeper understanding of the physical implications of rings and whether they are indeed a common structure in the universe or a mere coincidental formation.
Acknowledgement
All authors thank the referee for their constructive comments that helped to improve the paper. EO thanks Ingridi Teixeira for her translation assistance and Clara Rebanal for her advice. AK thanks Biohazard for urban discipline.
Funding statement
EO and AK are supported by the Ministerio de Ciencia e Innovación (MICINN) under research grant PID2021-122603NB-C21. DIM is supported by the grant
 $\textrm{N}^{\circ}$
075–15–2022–262 (13.MNPMU.21.0003) of the Ministry of Science and Higher Education of the Russian Federation.
$\textrm{N}^{\circ}$
075–15–2022–262 (13.MNPMU.21.0003) of the Ministry of Science and Higher Education of the Russian Federation.
Data availability statement
The LVG data used here is publicly available from https://www.sao.ru/lv/lvgdb/introduction.php. The analysis tools (incl. the HINORA code) are provided upon reasonable request.
Appendix A. Operating range of HINORA
To test the HINORA method described in Section 3, we have performed two tests to validate the range of its credibility. The HINORA settings are identical to the ones used in the main part of the study, but lowering the minimum number of inliers. The first test consists of determining the performance limit for a constant density of 100 points in a volume of 10 radius units, where the inliers ratio drops smoothly. For this purpose, we generate random data sets in which we introduce perfect circles (i.e. equidistant points on the circumference with constant radius) with randomly chosen orientation, location, and radius. As we decrease the number of points composing this ring, we should see a limit where the success ratio of HINORA decreases when applied to find the rings. We define the success rate as the percentage of rings successfully found by HINORA with respect to those placed in the data (ignoring false positives). A ring is considered successfully found when the ratio of inliers that HINORA finds is above 90%. A failed ring has either a smaller inliers ratio is a test where a ring is passed or is not found at all (which is the most common case for failure). In Figure 10 we now show this success rate as a function of the percentage of manually placed inliers with respects to the total number of (random) points in the test data. We observe that, if the ring contains less than ca. Eight percent of the full data, HINORA is not able to find it anymore, even though it is a perfect ring. We are therefore confident that all the rings found and analysed in this work were correctly found as the inliers ratio for them is always above 10% of the respective full data sample (see Figure 9).
Figure 10. Placing perfect rings into otherwise random data: HINORA’s success rate for finding a ring-like structure as a function of percentage of inliers.
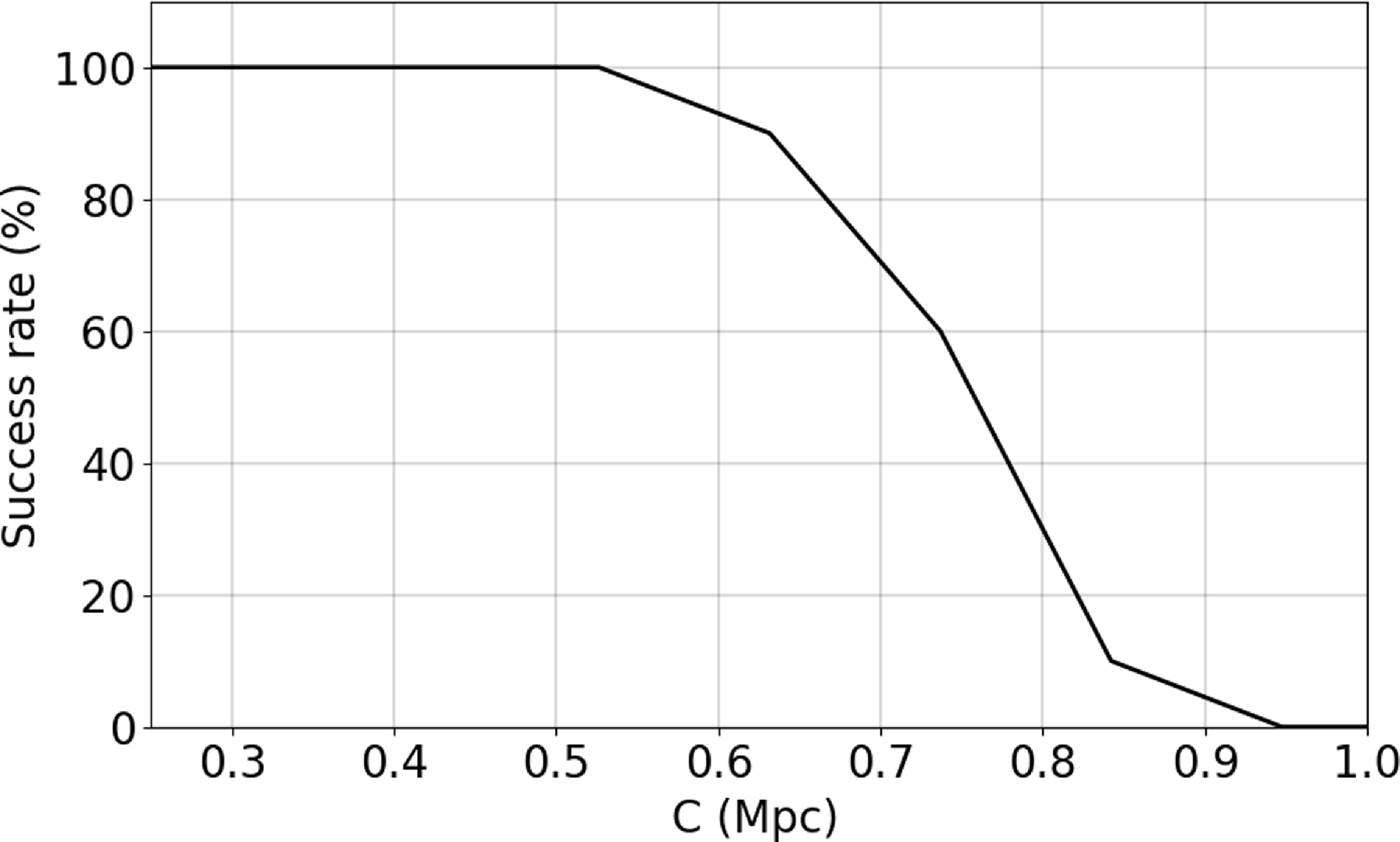
Figure 11. Placing imperfect rings into otherwise random data: HINORA’s success rate for finding a ring-like structure as a function of distance C (in Mpc) to the perfect ring circumference.
The second test consists of determining how the algorithm reacts to more realistic rings. To this extent we place rings into the same random data as used in the previous test, but now allowing for deviations by adding a random vector to each of the otherwise on a perfect circle placed points
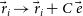 \begin{equation} \vec{r}_i \rightarrow \vec{r}_i + C \ \vec{e} \, \end{equation}
\begin{equation} \vec{r}_i \rightarrow \vec{r}_i + C \ \vec{e} \, \end{equation}
where
 $\vec{e}$
is a unit vector with random orientation, and C measures the distance from the perfect ring circumference of radius 10 Mpc. For the test presented in Figure 11 we continuously vary C between 0 and 1. That figure clearly shows how the success rate to find a ring drops towards zero for
$\vec{e}$
is a unit vector with random orientation, and C measures the distance from the perfect ring circumference of radius 10 Mpc. For the test presented in Figure 11 we continuously vary C between 0 and 1. That figure clearly shows how the success rate to find a ring drops towards zero for
 $C\rightarrow1$
, noting that we used the same
$C\rightarrow1$
, noting that we used the same
 $\tau=1$
Mpc as in the main body of the paper, which then in turn tells us that rings will only be successfully found when the inliers are within a torus of
$\tau=1$
Mpc as in the main body of the paper, which then in turn tells us that rings will only be successfully found when the inliers are within a torus of
 $\pm0.5$
Mpc. We further like to remark these tests were performed using a constant inliers ratio of 20% of the data, and the algorithm uses
$\pm0.5$
Mpc. We further like to remark these tests were performed using a constant inliers ratio of 20% of the data, and the algorithm uses
 $\bar{N_I}$
= 15% of the data. Despite these tests, there are experimental gaps that produce alterations that are difficult to quantify. Observational effects like ZoA, involving apparent over/under density in the data, can alter the
$\bar{N_I}$
= 15% of the data. Despite these tests, there are experimental gaps that produce alterations that are difficult to quantify. Observational effects like ZoA, involving apparent over/under density in the data, can alter the
 $\unicode{x03B1}$
value of the models near these conflict zones and have to be studied individually when interpreting the results. In our case, no LVG ring is seriously affected by this type of gap caused by ZoA, although of importance are the distance errors in this region, which have been taken into account in the error bars in the figures of Section 4.
$\unicode{x03B1}$
value of the models near these conflict zones and have to be studied individually when interpreting the results. In our case, no LVG ring is seriously affected by this type of gap caused by ZoA, although of importance are the distance errors in this region, which have been taken into account in the error bars in the figures of Section 4.
Figure 12. Two-point correlation function applied to four K-band luminosity cuts. The inset panel is a zoom into the r-range [1, 6] Mpc.
Appendix B. Two-point correlation analysis
The significant presence of the rings detected by HINORA in the LVG data motivates to look for their footprint in statistical functions. In Figure 12 we show the 2PCF for the luminosity cuts up to (and including)
 $\log_{10}=8$
. We confirm the existence of a prominent peak when using all galaxies (i.e. no cut) right at the scale of the radius of the ring found by HINORA. However, when restricting the data set to brighter and brighter galaxies this peak actually diminishes. Note that the peak seen by us for the complete sample of galaxies does not coincide with the one reported by Tully and Fisher (Reference Tully, Fisher, Longair and Einasto1978), which is at ca. 2 Mpc as opposed to ca. 4 Mpc in our case. Further, the peak in the 2PCF of the LVG galaxies cannot be directly related to our satellite ring that persists even up to a
$\log_{10}=8$
. We confirm the existence of a prominent peak when using all galaxies (i.e. no cut) right at the scale of the radius of the ring found by HINORA. However, when restricting the data set to brighter and brighter galaxies this peak actually diminishes. Note that the peak seen by us for the complete sample of galaxies does not coincide with the one reported by Tully and Fisher (Reference Tully, Fisher, Longair and Einasto1978), which is at ca. 2 Mpc as opposed to ca. 4 Mpc in our case. Further, the peak in the 2PCF of the LVG galaxies cannot be directly related to our satellite ring that persists even up to a
 $\log_{10}{L_K}$
cut of 8. To better understand the relation between ring-like structures and peaks in the 2PCF we have performed some additional experiments, again not explicitly shown here: we placed perfect rings into otherwise random data, calculating the resulting 2PCF. We find that this leads to peaks at distances comparable to the inter-point separation on the circumference of the ring and not to peaks at the scale of the radius of the ring. The connection between the rings and the peaks therefore remain to be investigated in more detail. However, when actually reversing the K-band luminosity cuts, that is, using galaxiese with
$\log_{10}{L_K}$
cut of 8. To better understand the relation between ring-like structures and peaks in the 2PCF we have performed some additional experiments, again not explicitly shown here: we placed perfect rings into otherwise random data, calculating the resulting 2PCF. We find that this leads to peaks at distances comparable to the inter-point separation on the circumference of the ring and not to peaks at the scale of the radius of the ring. The connection between the rings and the peaks therefore remain to be investigated in more detail. However, when actually reversing the K-band luminosity cuts, that is, using galaxiese with
 $\log_{10}{L_K}<[6,7,8]$
we always observe the peak at ca. 4 Mpc, the stronger the smaller the applied cut. This reassures us that this feature is driven by the low-mass galaxies in the Local Universe. It appears that low-mass galaxies are correlated on a scale of approximately 4 Mpc, whereas the massive galaxies in the Local Universe arrange themselves as the CoGs that lies within the Local Sheet.
$\log_{10}{L_K}<[6,7,8]$
we always observe the peak at ca. 4 Mpc, the stronger the smaller the applied cut. This reassures us that this feature is driven by the low-mass galaxies in the Local Universe. It appears that low-mass galaxies are correlated on a scale of approximately 4 Mpc, whereas the massive galaxies in the Local Universe arrange themselves as the CoGs that lies within the Local Sheet.






































