

I. INTRODUCTION
The objective of traditional video coding approaches like H.264/AVC [Reference Wiegand, Sullivan, Bjontegaard and Luthra1] and high efficiency video coding (HEVC) [Reference Sullivan, Ohm, Han and Wiegand2] is to minimize mean squared error (MSE) for a given bitrate, but they do not explicitly consider visually salient regions for the rate allocation. From a psycho-visual point of view, or for a well-defined task involving certain objects, these approaches may not be optimal. For defense and security applications, with limited infrastructure and bandwidth, video transmission is often constrained to low data rates. In this context, the transmitted information has to be the most pertinent for human understanding, at the lowest possible rate. The overall image quality, as generally estimated by video codecs, is not a well-suited criterion. The objective is rather that the users can correctly interpret the content and take decisions in critical conditions by maintaining the semantic meaning of the sequences. Based on these considerations, in this paper, we consider that the background can be partly suppressed, still preserving enough information to understand the context, while objects should be preserved and well-positioned.
For this purpose, a semantic content-aware video coding scheme based on seam carving is proposed in this paper. Seam carving is a content-aware resizing method, initially introduced in [Reference Avidan and Shamir3]. The advantage of using seam carving for video compression is that salient information is concentrated in a reduced resolution sequence and the non-informative background is suppressed, leading to a significant bitrate reduction and a better preservation of the salient regions. Since the seam carving process is not reversible, the correct position of the objects may be lost during the seam reduction. It is therefore necessary to transmit some additional information about the seams in order to properly recover the original dimension of the video sequence and the position of the salient regions. In most of the papers using seam carving for image or video compression, the cost of the seams texture is too important and synthesis algorithms are usually applied to reconstruct the background. As our objective is to concentrate on transmitting the salient information, no background texture synthesis will be applied in the proposed approach. Nevertheless, any kind of inpainting algorithms [Reference Bertalmío, Bertozzi and Sapiro4] or other synthesis algorithms could be used for this purpose.
Approaches in [Reference Anh, Yang and Cai5–Reference Tanaka, Hasegawa and Kato7] use seam carving to perform image compression, trying to find at each iteration an optimal seam that minimizes a cost function combining coding cost and visual distortion. Moreover, in order to obtain a reduced resolution video without annoying temporal artifacts, the seams have to be temporally linked. The temporal constraint on the seams during their computation further reduces the flexibility. The ratio of spatial resizing is also often limited due to the lack of flexibility when fast moving objects are crossing the scene. Alternatively, in [Reference Décombas, Capman, Renan, Dufaux and Pesquet-Popescu8,Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman9], the temporal constraint is added after having computed all the suppressible seams, showing better efficiency. Significant bitrate savings have been reached compared with conventional H.264/AVC, while salient objects are preserved and the scene geometry is well reconstructed. But some limitations remain. The seam carving is applied on group of pictures (GOPs) with a predefined length. As the same number of seams has to be suppressed in each GOP, one frame with several salient objects will hinder the seam carving process.
This paper builds upon our earlier work in [Reference Décombas, Capman, Renan, Dufaux and Pesquet-Popescu8,Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman9] and proposes new contributions, as follows: (1) a content-aware adaptive GOP segmentation algorithm that automatically defines the GOP depending on the content, (2) a spatio-temporal seam clustering based on spatial and temporal distances, (3) an isolated seam discarding algorithm, improving the seam encoding, (4) a new seam modeling approach, avoiding geometric distortions and resulting in a better control of the seam shapes at the decoder without the need of a saliency map, and (5) a new encoder that reduces the number of bits to be transmitted. Our experiments show that, using full intra coding and compared with a traditional H.264/AVC encoding, we achieve better performances for numerous test sequences, leading to bitrate savings between 7.02 and 21.77% using the Bjontegaard's metric in conjunction with a full reference object-oriented quality metric.
The remaining of this paper is structured as follows. We will first give an overview of the related work in Section II. In Section III, the proposed approach with its new contributions will be presented. Section IV will introduce the methodology of evaluation and the influence of the different parameters on the final results. For different sequences, the encoding cost of the seams and the rate-distortion performances will be assessed. Our proposed scheme will be compared with a traditional H.264/AVC encoding and the bitrate savings will be detailed. Section V will conclude this paper and present some perspectives for future work.
II. RELATED WORK
Seam carving has been proposed by Avidan and Shamir and developed to resize images or video sequences while preserving the semantic content [Reference Avidan and Shamir3]. This iterative algorithm suppresses/adds at each iteration a seam in the image, passing through its less significant parts. A seam is an optimal 8 connected path of pixels in an image, crossing from left to right or from top to bottom. Let I be an N × M image. A vertical seam is characterized by the set of points:
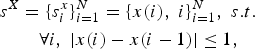 $$\eqalign{s^X & = \lcub s_i^x\rcub _{i=1}^N =\lcub x\lpar i\rpar \comma \; i\rcub _{i=1}^N\comma \; s.t.\cr & \quad \forall i\comma \; \vert x\lpar i\rpar -x\lpar i-1\rpar \vert\le 1\comma \; } $$
$$\eqalign{s^X & = \lcub s_i^x\rcub _{i=1}^N =\lcub x\lpar i\rpar \comma \; i\rcub _{i=1}^N\comma \; s.t.\cr & \quad \forall i\comma \; \vert x\lpar i\rpar -x\lpar i-1\rpar \vert\le 1\comma \; } $$where x is the horizontal coordinate of the point. Similar to the removal of a row or column from an image, removing the pixels of a seam from an image has only a local effect: all the pixels of the image are shifted left (or up) to compensate the missing path. The cost of a seam is defined as a cumulative energy function. The energy function highlights the important parts in the image and the cumulative energy function defines the optimal path.
A) Energy function
The energy function e defines the salient parts of an image. In [Reference Avidan and Shamir3], Avidan and Shamir proposed an energy function based on a gradient on the luminance, which has the advantage to efficiently highlight the borders of the objects. However, textured areas are not necessarily linked to salient parts of the image and if a salient object is smooth and the background is textured, the seam carving will first suppress the salient object. To solve this kind of problems, Anh et al. use a combination of a saliency map and the magnitude of gradient in the image [Reference Anh, Yang and Cai5]. Domingues et al. use another approach in [Reference Domingues, Alahi and Vandergheynst10] to generate saliency maps by merging several features like gradient magnitude, faces, edge, and straight line detection. In [Reference Achanta and Susstrunk11], Achanta and Susstrunk apply their saliency map [Reference Achanta, Hemami, Estrada and Susstrunk12] that uniformly assigns saliency values to the entire salient regions, rather than just edges or texture regions. This is achieved by relying on the global contrast rather than local contrast, measured in terms of both color and intensity features.
B) Cumulative energy function
After having defined the salient areas in the image, it is necessary to find the optimal seam.
The cumulative energy function E is used to determine the optimal path by using dynamic programming. Let I be an N × M image, s a seam, and i the pixel position index. The pixels of the path of seams s will be noted:
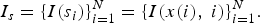 $$I_s =\lcub I\lpar s_i\rpar \rcub _{i=1}^N =\lcub I\lpar x\lpar i\rpar \comma \; i\rpar \rcub _{i=1}^N. $$
$$I_s =\lcub I\lpar s_i\rpar \rcub _{i=1}^N =\lcub I\lpar x\lpar i\rpar \comma \; i\rpar \rcub _{i=1}^N. $$Given an energy function e, the cost of a seam s is defined as:
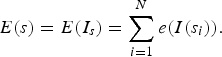 $$E\lpar s\rpar =E\lpar I_s\rpar =\sum_{i=1}^N e\lpar I\lpar s_i\rpar \rpar . $$
$$E\lpar s\rpar =E\lpar I_s\rpar =\sum_{i=1}^N e\lpar I\lpar s_i\rpar \rpar . $$We look for the optimal seam s* that minimizes the following seam cost:
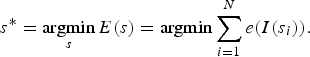 $$s^{\ast} = \mathop{\arg\!\min}\limits_s E\lpar s\rpar =\arg\!\min \sum_{i=1}^N e\lpar I\lpar s_i\rpar \rpar . $$
$$s^{\ast} = \mathop{\arg\!\min}\limits_s E\lpar s\rpar =\arg\!\min \sum_{i=1}^N e\lpar I\lpar s_i\rpar \rpar . $$In the case of a vertical seam, the first step is to scan the image from top to bottom and compute the cumulative minimum energy CM = E(S*) for all possible connected seams for each entry (i,j).
Avidan and Shamir [Reference Avidan and Shamir3] propose to find the optimal seam path using backward energy, defined as:
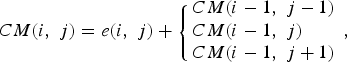 $$CM\lpar i\comma \; j\rpar =e\lpar i\comma \; j\rpar +\left\{{\matrix{CM\lpar i-1\comma \; j-1\rpar \hfill \cr CM\lpar i-1\comma \; j\rpar \hfill \cr CM\lpar i-1\comma \; j+1\rpar \hfill } }\right.\comma \; $$
$$CM\lpar i\comma \; j\rpar =e\lpar i\comma \; j\rpar +\left\{{\matrix{CM\lpar i-1\comma \; j-1\rpar \hfill \cr CM\lpar i-1\comma \; j\rpar \hfill \cr CM\lpar i-1\comma \; j+1\rpar \hfill } }\right.\comma \; $$where e represents the energy function computed on the image. However, this approach suppresses the seam having the smallest energy in the image without taking into account the consequence of this suppression. After the suppression, a new border may be created and some artifacts may appear. Therefore, Rubinstein et al. propose in [Reference Rubinstein, Shamir and Avidan13] to take into account the new neighbors created after the suppression of a seam. This new cumulative function, referred to as forward energy, is defined as:
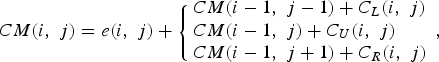 $$CM\lpar i\comma \; j\rpar =e\lpar i\comma \; j\rpar +\left\{{\matrix{ CM\lpar i-1\comma \; j-1\rpar +C_L \lpar i\comma \; j\rpar \hfill \cr CM\lpar i-1\comma \; j\rpar +C_U \lpar i\comma \; j\rpar \hfill \cr CM\lpar i-1\comma \; j+1\rpar +C_R \lpar i\comma \; j\rpar \hfill } }\right. \comma \; $$
$$CM\lpar i\comma \; j\rpar =e\lpar i\comma \; j\rpar +\left\{{\matrix{ CM\lpar i-1\comma \; j-1\rpar +C_L \lpar i\comma \; j\rpar \hfill \cr CM\lpar i-1\comma \; j\rpar +C_U \lpar i\comma \; j\rpar \hfill \cr CM\lpar i-1\comma \; j+1\rpar +C_R \lpar i\comma \; j\rpar \hfill } }\right. \comma \; $$with
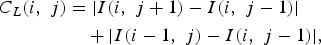 $$\eqalign{C_L \lpar i\comma \; j\rpar & = \vert I\lpar i\comma \; j+1\rpar -I\lpar i\comma \; j-1\rpar \vert \cr & \quad +\vert I\lpar i-1\comma \; j\rpar -I\lpar i\comma \; j-1\rpar \vert\comma \; } $$
$$\eqalign{C_L \lpar i\comma \; j\rpar & = \vert I\lpar i\comma \; j+1\rpar -I\lpar i\comma \; j-1\rpar \vert \cr & \quad +\vert I\lpar i-1\comma \; j\rpar -I\lpar i\comma \; j-1\rpar \vert\comma \; } $$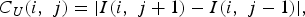 $$C_U \lpar i\comma \; j\rpar =\vert I\lpar i\comma \; j+1\rpar -I\lpar i\comma \; j-1\rpar \vert\comma \; $$
$$C_U \lpar i\comma \; j\rpar =\vert I\lpar i\comma \; j+1\rpar -I\lpar i\comma \; j-1\rpar \vert\comma \; $$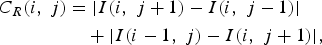 $$\eqalign{C_R \lpar i\comma \; j\rpar & =\vert I\lpar i\comma \; j+1\rpar -I\lpar i\comma \; j-1\rpar \vert \cr & \quad + \vert I\lpar i-1\comma \; j\rpar -I\lpar i\comma \; j+1\rpar \vert\comma \; } $$
$$\eqalign{C_R \lpar i\comma \; j\rpar & =\vert I\lpar i\comma \; j+1\rpar -I\lpar i\comma \; j-1\rpar \vert \cr & \quad + \vert I\lpar i-1\comma \; j\rpar -I\lpar i\comma \; j+1\rpar \vert\comma \; } $$where C L, C U, and C R represent the cost of the new edges created after removing a seam and e(i, j) is an additional pixel based on energy function as above. This function has proven its efficiency in numerous cases and is used in most of the seam carving literature.
C) Temporal aspects
As our objective is to use seam carving for video applications, we will shortly review different improvements that have been proposed to pass from still images to video.
Rubinstein et al. are the first ones to define seam carving for video retargeting [Reference Rubinstein, Shamir and Avidan13]. Dynamic programming is replaced by graph cuts that are suitable for handling three-dimensional (3D) volumes. Temporal coherence of the energy maps is obtained through a linear combination of the temporal and spatial gradients of the luminance. As the human visual system (HVS) is more sensitive to motion than to texture, larger weighting is given to the temporal gradient. The seam can only move from one pixel to the left or to the right following the temporal axis, which can be a severe limitation in the case of a moving object that crosses the scene. Chao et al. [Reference Chao, Su, Chien, Hsu and Ding14] propose a solution to this problem of seams flexibility following the temporal axis. A seam is computed in a frame and block-based motion estimation and Gaussian masks are used to predict the coarse location of the seam in the next frame. This allows both a reduction of the search range of dynamic programming and having seams that can move with more than one pixel from one frame to another.
In [Reference Décombas, Capman, Renan, Dufaux and Pesquet-Popescu8,Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman9], the idea is to add temporal coherence in the saliency map to manage the temporal aspect, instead of constraining the seam. The optical flow proposed by Chambolle and Pock [Reference Chambolle and Pock15] is directly used in the saliency map, based on Rahtu and Heikkila [Reference Rahtu and Heikkila16], by taking into account the intensity of the movement. In addition, the optical flow is also used for temporal tracking of the saliency map. In this way, the current saliency map can be combined with the previous one to improve the temporal coherence.
D) Content-aware compression
Having reviewed existing seam carving approaches, we will now focus on compression applications. Content-aware video compression is a broad subject. An overview of different perceptual video coding approaches is first presented hereafter; thorough reviews can be found in [Reference Wu and Rao17–Reference Mancas, De Beul, Riche and Siebert20]. Then, we will see in detail the existing seam carving techniques used in compression applications.
In [Reference Wu and Rao17], Wu and Rao present a review of the basics of compression and HVS modeling. They describe subjective quality evaluation methods and objective quality metrics. Some practical applications such as video codecs based on the HVS, restoration or error correction are finally presented.
In [Reference Chen, Lin and Ngan18], Chen et al. address the incorporation of the human perception in video coding systems to enhance the perceptual quality. This topic is challenging, given the limited understanding and high complexity of computational models of the HVS. First, the visual attention and sensitivity modeling is treated, considering bottom-up and top-down attention modeling, contrast sensitivity functions, and masking effects. Then, perceptual quality optimization for constrained video coding is described. Finally, an overview of the impact of the human perception on new applications like high dynamic range video or 3D video is presented.
In [Reference Ndjiki-Nya, Doshkov, Kaprykowsky, Zhang, Bull and Wiegand19], Ndjiki-Nya et al. survey perception-oriented video coding based on image analysis and completion. The relevance, limitations, and challenges of these coders for future codec designs are brought forward. It is also concluded that additional work on the evaluation has to be carried out to obtain a new rate-quality metric.
In [Reference Mancas, De Beul, Riche and Siebert20], Mancas et al. present a review of human attention modeling and its application for data reduction. After a presentation of attention modeling and saliency maps, they address perceptual coding, but also the application of attention modeling for perceptual spatial resizing.
Perceptual video coding is a coding approach based on the HVS and trying to give more detailed, bitrate, to the important parts. The using of a coder and attention modeling is needed. Three main approaches can be considered: the interactive one, the indirect, and the direct one.
The “interactive approach” requires eyes tracking device and are consequently not common at all. The idea is to follow where the user is watching and allocate more bitrate to this region. Other problems are that it works only if there is one viewer, it is dependent of the viewing distance, and it changes also with the eye tracking system. The idea to automate this system without eye tracking device is very challenging. The use of saliency maps is necessary, and some problems may appear when, for example, no salient objects are in the scene, people will watch in all the video. Two approaches are possible. The first one is the indirect approach and will modify the video before being encoded. In this approach, the coder is not modified. The second approach uses direct approach and modifies directly the coders.
In the “indirect approaches”, the idea is to modify the video in input in order not to modify the coder.
Itti propose in [Reference Itti21] to use their model [Reference Itti, Koch and Niebur22] and apply a smooth filter in all the non-salient regions. This allows to have a higher spatial correlation, a better prediction, and consequently to reduce the bitrate of the video. This allows to reduce by 50% the number of bit needed with MPEG-1 and MPEG-4 encoders. Another approach proposed by Tsapatsoulis et al. [Reference Tsapatsoulis, Rapantzikos and Pattichis23] combine bottom-up and top-down information in a wavelet decomposition to obtain a multi-scale analysis. A bitrate saving of 10.4–28.3% with a MPEG-4 coder is obtained. Mancas apply in [Reference Mancas, Gosselin and Macq24] their saliency model in image compression. An anisotropic filtering is applied on non-salient regions and allows to decrease twice the number of bit compared with the Joint Photographic Experts Group (JPEG) standards. Some approach use resizing before the encoding to reduce the bitrate and obtain more flexibility on the spatial dimension of the image or video.
In the direct approach, the coder is directly modified to reduce the quantity of information to encode. These approaches can also use image synthesis.
Li et al. [Reference Li, Qin and Itti25] use a saliency map to generate a guidance map that will modify the quantization parameter of the coder. By this way, more bitrate will be allocated for the salient regions. It is underlined that some studies should be done to measure the influence of the artifacts in the non-salient areas that can become salient if the artifacts are too disturbing. Gupta and Chaudhury [Reference Gupta and Chaudhury26] improve the model of Li et al. [Reference Li, Qin and Itti25] and propose a learning-based feature integration algorithm incorporating visual saliency propagation that decreases the complexity of the method. Hou and Zhang [Reference Hou and Zhang27] and Guo and Zhang [Reference Guo and Zhang28] propose approaches based on the spectrum of the images: the Spectral Residual for Hou and Zhang and the Phase spectrum of Quaternion Fourier Transform for Guo and Zhang. In the Guo approach, the object in the spectrum domain is identified and some frequencies in the background are suppressed. A bitrate saving between 32.6 and 38% compared with the traditional H.264/AVC is reported. These methods have the advantage to be less computationally intensive but are also less linked to the HVS. This approach does not work when the salient object is too important because only the boundaries will be detected and the background is more textured than the salient objects. In [Reference Chen, Hu, Mao, Thong and Wang29], Chen et al. notice that temporal prediction does not work well for video sequences with nonlinear motion and global illumination change between the frames. They propose a new algorithm for dynamic texture extrapolation using H.264/AVC encoding and decoding system. They use as virtual reference frames some synthetized frames that are built with a dynamic texture synthesis. Their evaluation was for a range of QP = {22–37} and IPPP coding. The idea here is to use dynamic texture synthesis to improve some parts of the video sequences. The perceptual results are improved for the entire video sequences. In [Reference Bosch, Zhu and Delp30], Bosch integrates several spatial texture tools into a texture based video coding scheme by testing different texture techniques and segmentation strategies to detect texture regions in video sequences. These textures are analyzed using temporal motion techniques and are labeled as skipped areas that are not encoded. After the decoding process, frame reconstruction is performed by inserting the skipped texture areas into the decoded frames. Some side information, such as texture, masks motion parameters which ensure that temporal consistency of the decoder is sent with the modified video sequence. In terms of data rate savings, it is shown that a combination of the gray level co-occurrence matrix to describe the textures and a K-means algorithm to classify them performed the best. On all the sequences tested, the average shows that when the quantization parameter is larger than 36, the side information becomes an overcost. In [Reference Bosch, Zhu and Delp31], the coding efficiency of the texture based approaches relative to fast motion objects has been improved. A texture analyzer and a motion analyzer have also been tested. These methods were incorporated into a conventional video coder, e.g. H.264/AVC, where the regions modeled by both the texture analyzer and the motion analyzer were not coded in the usual manner as texture and motion model parameters were sent to the decoder as side information. Both schemes are strongly influenced by the HVS, and described as a set of subjective experiments to determine the acceptability of these methods in terms of visual quality. During the experiment, two sequences are compared, one with a traditional coding and one with their approach. The subjects had no limit on making their decisions and had three options: the first sequence is better in terms of perceptual quality than the second one, the second is better than the first one, and there is no difference between the two sequences. At a quantization parameter equal to 44, a bitrate savings around −20% for the texture based approach and around 3% for the motion based approach are reached. The second approach gives better results because more skip blocks are identified but, in terms of quality their subjective evaluation, it shows that 49% prefer H.264/AVC, only 14% prefer motion based method, and 37% see no difference. Their approach based on skip block is working only on B frame. The I and P frames, which open and close the GOP, are not modified.
Seam carving has been applied to image/video compression using different approaches.
As existing spatial scalable codecs [Reference Schwarz, Marre and Wiegand32] only support fixed down-sampled resolutions and are not content-aware, Anh et al. propose in [Reference Anh, Yang and Cai5] a content-aware multi-size image compression based on seam carving. Seam carving is used for content-aware reduction until reaching the region of interest (ROI). However, the reduced image and all the information of the seams (position and texture) are encoded, leading to an important bitrate overhead. Moreover, severe block artifacts occur on the boundaries of the ROI and non-ROI regions. In [Reference Deng, Lin and Cai33], Deng et al. solve this problem by combining the advantages of seam carving and wavelet-based coding. A novel content-based spatially scalable compression scheme is thus obtained.
To address the problem of overhead information, a seam can be simplified by a straight line. This approach named selective “data pruning” has been used by Võ et al. in [Reference Vō, Sole, Yin, Gomila and Nguyen34] to spatially reduce the frames and encode them with H.264/AVC. In this approach, the seam is strongly constrained and cannot easily avoid salient objects, which may lead to visual distortions or to a low spatial reduction.
Tanaka et al. [Reference Tanaka, Hasegawa and Kato6] introduce a compromise between selective data pruning and seam carving. The seam positions are encoded using piecewise vertical or horizontal straight lines, referred to as “pillars”. To define the pillar length, a top-down approach is applied on a modified cumulative energy function. This function is a combination of the forward energy and the seams bitrate using a Lagrangian multiplier. The process stops when the seam defined by this function has a cumulative energy superior to a threshold.
The method proposed in [Reference Tanaka, Hasegawa and Kato7] is improved compared with [Reference Tanaka, Hasegawa and Kato6] and limit artifacts created during interpolation. Artifacts appear during interpolation when seams are in texture areas, around/near objects or too close to each other. Instead of changing the interpolation method, they propose to change the seams path. A bottom-up approach is used instead of a top-down one to define the length of an optimal pillar and to update the Lagrangian multiplier. Therefore, seams can pass through salient regions of the image. In [Reference Tanaka, Hasegawa and Kato35], a piecewise linear approximation is proposed to find the optimal seam. The novelty is that the pieces of seams can have different directions and lengths. In [Reference Tanaka, Yoshida, Hasegawa, Kato and Ikehara36], the work of Tanaka et al. is extended by approximating each seam with piecewise functions after a rate-dependent optimization. The rest of the image is encoded with a set partitioning in hierarchical trees (SPIHT)-based wavelet coding scheme.
In [Reference Tanaka, Hasegawa and Kato37], the authors apply the method used in [Reference Tanaka, Hasegawa and Kato6] for video reduction based on the graph-cut approach from [Reference Rubinstein, Shamir and Avidan13]. The same seam is deleted for the current GOP and an 8-connexity is allowed from the previous seam to the next GOP in order to avoid artifacts at the transition between GOPs. To compute the seam for the current GOP, all its frames are used but the intra-frame is given more importance.
The temporal aspect is further considered in [Reference Tanaka, Hasegawa and Kato38]. The authors propose a trade-off between seam carving and selective data pruning called generalized selective data pruning (GenSDP). GenSDP considers both the retargeted image quality and the bitrate for side information, and a suitable compromise must be considered between these two extreme cases. GenSDP significantly reduces the required bitrates for seam path information compared with the approach based on the original seam carving.
All these techniques perform well when the bitrate is sufficiently high, but at very low bitrates, the overhead information for the seam positions becomes too significant. To solve this problem, only little information should be transmitted and an approach that encodes seams independently is thus not optimal. In [Reference Décombas, Capman, Renan, Dufaux and Pesquet-Popescu8,Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman9], the idea is to transmit just enough information to reposition the salient objects. We observe that seams are mostly concentrated between the salient objects. By defining groups of seams between the salient objects and only transmitting their positions, seam shapes are well approximated and correctly positioned between the salient objects. This approach was validated in [Reference Décombas, Capman, Renan, Dufaux and Pesquet-Popescu8]. In [Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman9], a new energy map with a better temporal component has been proposed, along with a better combination of the saliency and gradient maps. This approach allows a better preservation of the salient objects. Groups of seams are defined with a k-median algorithm in a manner that each cluster is modeled independently and with more flexibility. All these contributions have improved the coding performance and led to better visual results.
In most of the previous approaches, the texture of seams cannot be transmitted in order to avoid an overhead. Thus, seam synthesis is needed at the decoder. A quick overview of seam synthesis is presented here. Linear interpolation, one of the simplest methods to synthesize missing areas, is used in [Reference Avidan and Shamir3,Reference Rubinstein, Shamir and Avidan13]. It performs well as long as seams do not cross textured areas nor get too close to each other. In [Reference Vō, Sole, Yin, Gomila and Nguyen34], Võ et al. propose a multi-frame interpolation using neighboring frames. However, these interpolation techniques tend to fail when the areas to be recovered are too large. Domingues et al. propose in [Reference Domingues, Alahi and Vandergheynst10] to use the inpainting approach from Bertalmio et al. [Reference Bertalmío, Bertozzi and Sapiro4]. This inpainting is quite efficient for rebuilding structures, but often fails to reconstruct textured areas. Seam synthesis remains a challenging issue; however, it is not the focus in our seam carving video coding system.
III. PROPOSED SEAM CARVING APPROACH FOR SEMANTIC CODING
In this section, after reviewing the general approach of semantic coding by seam carving, we present the main contributions of this paper: (1) an algorithm that automatically and adaptively separates the sequence into GOPs depending on the content, (2) a spatio-temporal seam clustering method based on spatial and temporal distances, (3) an isolated seam discarding technique, improving the seam encoding, (4) a new seam modeling, avoiding geometric distortion and resulting in a better control of the seam shapes at the decoder without the need of a saliency map, and (5) a new encoder that reduces the global bitrate.
A) General approach
The proposed seam carving approach for semantic coding builds upon [Reference Décombas, Capman, Renan, Dufaux and Pesquet-Popescu8,Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman9]. Seam carving is used to reduce the spatial dimensions of the video sequence as much as possible, while still preserving the salient objects. Then, the reduced video is encoded with a traditional encoder such as H.264/AVC [Reference Wiegand, Sullivan, Bjontegaard and Luthra1]. In parallel, the seams are modeled and encoded with our proposed scheme. After transmission, the video sequence is reconstructed at the decoder side, in order to recover the original dimensions and to preserve the scene geometry. Finally, a technique such as image inpainting can optionally be used to synthesize the missing texture. Figure 1 shows the global approach.

Fig. 1. Architecture of the proposed semantic video coding using seam carving.
Figure 2 details the seam carving module in Fig. 1. During the seam carving process, lists of seams are computed for each frame of the sequence and used to identify the variation of the number of seams in time. The sequence is then adaptively subdivided into GOPs. This is executed during the content-aware GOP segmentation. Then, for each GOP, a spatio-temporal seam clustering is performed in order to model the groups of seams and to discard isolated seams. In this way, a list of modeled seams is obtained for each frame of the sequence; which are all subsequently suppressed from the original video sequence to obtain a reduced video.
Fig. 2. Overall scheme of the proposed seam carving process (corresponding to the module “seam carving” in Fig. 1).
The seam computation module depicted at the top of Fig. 2 is further detailed in Fig. 3. An energy function is defined for each frame from the saliency model in [Reference Riche, Décombas, Mancas, Dufaux, Pesquet-Popescu, Gosselin, Dutoit and Fellah39]. This model identifies the salient objects by finding the rarity on different maps. The most pertinent maps are combined together to obtain a unique saliency map. The model uses static (L,a,b) and dynamic (motion amplitude and direction) components in order to identify salient areas for static and moving scenes. The saliency map is then combined with a gradient map that highlights the outlines of the objects. On this energy map, a spatial median filter is then applied to remove the noise, followed by a dilation filter to preserve salient objects and their neighborhood. The forward cumulative energy map is then computed to define the seams to suppress.
Fig. 3. Seam computation process to obtain from a frame a list of seams (corresponding to the module “seam computation” in Fig. 2).
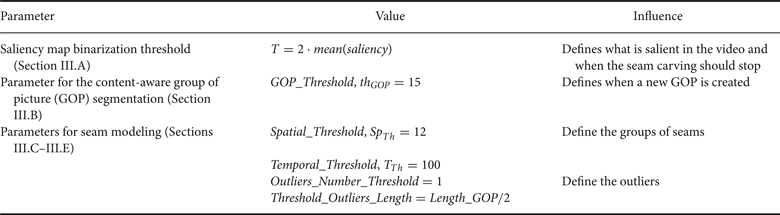
In parallel, the energy map is binarized to obtain a control map. The binarization threshold is defined as T = 2 · mean (Saliency) as proposed in [Reference Achanta, Hemami, Estrada and Susstrunk40]. The control map is used to decide when the process of seam suppression is stopped. More precisely, seam carving is iterated until reaching an object in the control map. Thus, a list of seams is obtained for each frame. The process is successively applied vertically and horizontally.
B) Content-aware adaptive GOP segmentation
To use seam carving in a video compression application, the sequence is divided into GOPs. In a GOP, in order to avoid padding, it is preferable that all the frames have the same spatial dimension, defined as a multiple of 16 pixels (corresponding to the size of a macro block in the subsequent video coding scheme). In our previous work [Reference Décombas, Capman, Renan, Dufaux and Pesquet-Popescu8,Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman9], the length of the GOP was predefined and the number of seams suppressed for each GOP was linked with the frame having the largest salient objects. That led however to a suboptimal reduction of the sequence dimensions.
In this paper, we propose to adaptively split the sequence as a function of the number of seams that can be suppressed. This way, the GOP can be further spatially reduced without damaging the salient objects and the quantity of information to transmit is lowered. Three main cases can be identified: (1) an object of interest is appearing into the video and the number of seams that can be suppressed is decreasing; (2) an object is disappearing from the video and the number of seams that can be suppressed is increasing; and (3) a constant number of still or moving salient objects are present in the scene and the number of seams that can be suppressed remains constant.
To implement these cases, rupture detection is applied on the number of vertical and horizontal seams to identify important changes. More specifically, let us define Nb_VertSeam(t), the number of vertical seams for the frame at time t. The first step is to apply a median filter on Nb_VertSeam(t) to reduce the local variations due to noise or salient object detection errors. Then, rupture detection is applied to define the segments. Formally, for a new segment starting at the frame t g, the median value at the current frame t cur is defined as:
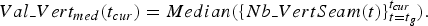 $$Val{\_}Vert_{med} \lpar t_{cur}\rpar =Median\lpar \lcub Nb{\_}VertSeam\lpar t\rpar \rcub_{t=t_g}^{t_{cur}}\rpar . $$
$$Val{\_}Vert_{med} \lpar t_{cur}\rpar =Median\lpar \lcub Nb{\_}VertSeam\lpar t\rpar \rcub_{t=t_g}^{t_{cur}}\rpar . $$If the condition
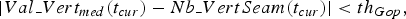 $$\vert Val{\_}Vert_{med} \lpar t_{cur}\rpar -Nb{\_}VertSeam\lpar t_{cur}\rpar \vert \lt th_{Gop}\comma \; $$
$$\vert Val{\_}Vert_{med} \lpar t_{cur}\rpar -Nb{\_}VertSeam\lpar t_{cur}\rpar \vert \lt th_{Gop}\comma \; $$holds, the current frame is included into the segment, otherwise a new segment is created. For this purpose, a GOP_Threshold th GOP is used to define when a new segment is created.
Likewise, the same process is applied to the horizontal seams Nb_HorizSeam(t).
The number of removable seams for a segment is defined as the median of the number of seams over this segment. This way, the reduction process is improved while preserving the salient objects, especially for the monotonic segments. Finally, the number of removable seams in each segment is rounded to the nearest multiple of 16.
The combination of these two analyses gives an adaptive cut of the video with different dimensions. More precisely, if a rupture appears horizontally or vertically, a new GOP is created.
Figure 4 summarizes this approach. For the horizontal and the vertical seams, the rupture detection is applied, as illustrated in Figs 4(a) and 4(c). Then, for each segment, a number of seams is calculated and rounded to a multiple of 16, as shown in Figs 4(b) and 4(d). By combining the vertical and the horizontal analyses, the GOPs are defined with their dimensions as in Fig. 4(e).
Fig. 4. Group of picture (GOP) definition based on the content. Horizontal continuous lines represent the number of seams. Vertical dotted lines represent the GOP segmentation. Blue, resp. red, indicates horizontal, resp. vertical, seams.
C) Spatio-temporal seam clustering
After having defined the GOP and the corresponding number of seams that can be suppressed, spatio-temporal clustering is applied to identify groups of seams. These groups of seams will be used to model and encode the most important seams and to identify isolated ones. Figure 5 highlights the different step to obtain from a redefined list of seams by GOP, a list of spatio-temporal clusters of seams.
Fig. 5. Spatio-temporal clustering process to obtain a list of spatio-temporal clusters of seams from a list of seams by GOP (corresponding to the module “spatio-temporal seam clustering” in Fig. 2).
As the seam carving is an iterative process, the coordinates of the seams position at iteration k are expressed in function of the reduced image at iteration k-1. In addition, subsequent seams can cross one another. Therefore, in order to unequivocally define them, the seams positions are changed to be stated in the coordinates of the original image and then rearranged by ordering the horizontal, respectively, vertical, coordinates in an increasing order as in [Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman9]. Figure 6 illustrates the seam reordering process with three seams that are represented in blue, orange, and green. In the first schema, before reordering, seams can cross each other. But in the second schema, it is no longer the case after reordering. At the same time, it can be noticed that the new seams go through the same coordinates.
Fig. 6. Seams reordering: on the left, seams before reordering; on the right, seams after reordering.
To perform spatio-temporal grouping, the seams are first grouped together spatially and then temporally. The process is explained for vertical seams and can be easily transposed for horizontal ones. For this purpose, the Spatial Distance (SD) is defined as:
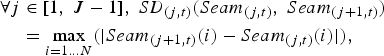 $$\eqalign{\forall j & \in [ 1\comma \; J-1] \comma \; SD_{\lpar j\comma t\rpar } \lpar Seam_{\lpar j\comma t\rpar }\comma \; Seam_{\lpar j+1\comma t\rpar }\rpar \cr & = \max_{i=1\ldots N} \lpar \vert Seam_{\lpar j+1\comma t\rpar } \lpar i\rpar -Seam_{\lpar j\comma t\rpar } \lpar i\rpar \vert\rpar \comma \; } $$
$$\eqalign{\forall j & \in [ 1\comma \; J-1] \comma \; SD_{\lpar j\comma t\rpar } \lpar Seam_{\lpar j\comma t\rpar }\comma \; Seam_{\lpar j+1\comma t\rpar }\rpar \cr & = \max_{i=1\ldots N} \lpar \vert Seam_{\lpar j+1\comma t\rpar } \lpar i\rpar -Seam_{\lpar j\comma t\rpar } \lpar i\rpar \vert\rpar \comma \; } $$where N is the length of a vertical seam (in the case of a N × M image), i the pixel position index inside the seam, and J the number of seams suppressed for the frame at t. For a vertical seam, Seam (j,t) is the horizontal coordinate of the jth seam in the frame t and Seam (j+1,t) is the horizontal coordinate of the seam (j + 1)th in the frame t. This maximum distance has been chosen as it successfully identifies salient objects between seams, contrary to the mean distance or the median distance.
The groups of seams are spatially defined for each frame independently: 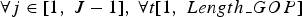 $\forall j \in [ 1\comma \; J-1] \comma \; \forall t[ 1\comma \; Length{\_}GOP ] $, b = 1 and
$\forall j \in [ 1\comma \; J-1] \comma \; \forall t[ 1\comma \; Length{\_}GOP ] $, b = 1 and
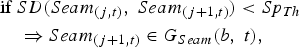 $$\eqalign{&\hbox{if } SD\lpar Seam_{\lpar j\comma t\rpar }\comma \; Seam_{\lpar j+1\comma t\rpar }\rpar \lt Sp_{Th} \cr & \quad \Rightarrow Seam_{\lpar j+1\comma t\rpar } \in G_{Seam} \lpar b\comma \; t\rpar \comma \; } $$
$$\eqalign{&\hbox{if } SD\lpar Seam_{\lpar j\comma t\rpar }\comma \; Seam_{\lpar j+1\comma t\rpar }\rpar \lt Sp_{Th} \cr & \quad \Rightarrow Seam_{\lpar j+1\comma t\rpar } \in G_{Seam} \lpar b\comma \; t\rpar \comma \; } $$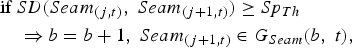 $$\eqalign{&\hbox{if } SD\lpar Seam_{\lpar j\comma t\rpar }\comma \; Seam_{\lpar j+1\comma t\rpar }\rpar \ge Sp_{Th} \cr & \quad \Rightarrow b=b+1\comma \; Seam_{\lpar j+1\comma t\rpar } \in G_{Seam} \lpar b\comma \; t\rpar \comma \; }$$
$$\eqalign{&\hbox{if } SD\lpar Seam_{\lpar j\comma t\rpar }\comma \; Seam_{\lpar j+1\comma t\rpar }\rpar \ge Sp_{Th} \cr & \quad \Rightarrow b=b+1\comma \; Seam_{\lpar j+1\comma t\rpar } \in G_{Seam} \lpar b\comma \; t\rpar \comma \; }$$G Seam(b, t) is the bth group of seams in the frame t and b is initialized at 1 for each new frame. Sp Th is the Spatial Threshold and represents the maximal distance between two consecutive seams found in the same group. It has been experimentally set to 12 pixels. Consequently, the maximal number of groups of seams B(t) can be different in each frame.
Then, the groups are temporally linked together using the symmetric difference between the groups of seams at time t and t + 1. Let Border_Seam_Left (b,t) (resp. Border_Seam_Right (b,t)) the most leftward (resp. rightward) seam of the bth group. Define G Seam(b,t) by all the pixels between Border_Seam_Left (b,t) and Border_Seam_Right (b,t):
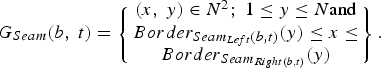 $$G_{Seam} \lpar b\comma \; t\rpar =\left\{\matrix{\lpar x\comma \; y\rpar \in N^2\semicolon \; 1\le y\le N \hbox{and} \cr Border_{Seam_{Left}\lpar b\comma t\rpar } \lpar y\rpar \le x \le \cr Border_{Seam_{Right\lpar b\comma t\rpar }} \lpar y\rpar } \right\}. $$
$$G_{Seam} \lpar b\comma \; t\rpar =\left\{\matrix{\lpar x\comma \; y\rpar \in N^2\semicolon \; 1\le y\le N \hbox{and} \cr Border_{Seam_{Left}\lpar b\comma t\rpar } \lpar y\rpar \le x \le \cr Border_{Seam_{Right\lpar b\comma t\rpar }} \lpar y\rpar } \right\}. $$The Symmetric Difference SymDif between the group G Seam(b, t) and G Seam(k, t+1) is defined as the area of the union of G Seam(b, t) with G Seam(k, t+1) minus the area of the intersection of G Seam(b, t) with G Seam(k, t+1):
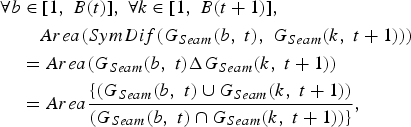 $$\eqalign{\forall b & \in [ 1\comma \; B\lpar t\rpar ] \comma \; \forall k \in [ 1\comma \; B\lpar t+1\rpar ] \comma \; \cr & \quad Area \lpar SymDif \lpar G_{Seam} \lpar b\comma \; t\rpar \comma \; G_{Seam} \lpar k\comma \; t+1\rpar \rpar \rpar \cr & = Area\lpar G_{Seam} \lpar b\comma \; t\rpar \Delta G_{Seam} \lpar k\comma \; t+1\rpar \rpar \cr & = Area \displaystyle{{\lcub \lpar G_{Seam} \lpar b\comma \; t\rpar \cup G_{Seam} \lpar k\comma \; t+1\rpar \rpar } \over {\lpar G_{Seam} \lpar b\comma \; t\rpar \cap G_{Seam} \lpar k\comma \; t+1\rpar \rpar \rcub }}\comma \; } $$
$$\eqalign{\forall b & \in [ 1\comma \; B\lpar t\rpar ] \comma \; \forall k \in [ 1\comma \; B\lpar t+1\rpar ] \comma \; \cr & \quad Area \lpar SymDif \lpar G_{Seam} \lpar b\comma \; t\rpar \comma \; G_{Seam} \lpar k\comma \; t+1\rpar \rpar \rpar \cr & = Area\lpar G_{Seam} \lpar b\comma \; t\rpar \Delta G_{Seam} \lpar k\comma \; t+1\rpar \rpar \cr & = Area \displaystyle{{\lcub \lpar G_{Seam} \lpar b\comma \; t\rpar \cup G_{Seam} \lpar k\comma \; t+1\rpar \rpar } \over {\lpar G_{Seam} \lpar b\comma \; t\rpar \cap G_{Seam} \lpar k\comma \; t+1\rpar \rpar \rcub }}\comma \; } $$where B(t) is the number of groups of seams for the frame t.
Then, temporal regrouping is applied using SymDif. More precisely, the groups of seams in frame t, respectively, in frame t + 1, with the smallest distance, are linked together.
l is defined as the label of the group of seams in the complete GOP and is initialized at 1 at the beginning of the GOP. If SymDif is inferior to the Temporal_ThresholdTTh, these two groups of seams will share the same label l. Otherwise, a new class is created and l = l + 1.
Figure 7 illustrates the spatio-temporal clustering of two consecutive frames. The seams are represented with different colors. The spatial clustering is first applied on the first frame and leads to two groups of seams. The first group G Seam(1, 1) contains three seams (red, dark blue, and green) and takes the label l = 1. The second group G Seam(2, 1) contains two seams (purple, blue) and takes the label l = 2.
Fig. 7. Illustration of the spatio-temporal seam clustering.
The Area_G Seam(b, t) is illustrated by the orange outlines. For the second frame, three groups of seams are identified. The first one contains the red and dark blue seams, the second one the green seam, and the third one the purple and blue seams.
Then, the temporal clustering is carried out using Area_G Seam(b, t) and SymDif, and each group of seams in frame 2 is compared with the group of seams in frame 1. G Seam(1, 2) takes the same label than G Seam(1, 1) and G Seam(3, 2) takes the same label than G Seam(2, 1). G Seam(2, 2) is considered as a new group of seams and take the label l = 3.
In Fig. 8, seams are illustrated in green in two consecutive frames of the coastguard sequence. Blue and red arrows show examples of group of seams that are clustered together.
Fig. 8. Illustration of seams in two consecutive frames of the Coastguard sequence. Arrows show examples of group of seams.
D) Isolated seam discarding
During the previous step, groups of seams are defined for the whole GOP. Moreover, for each group, we know the number of seams associated with each group and the number of frames where it is present. As each group will be modeled and encoded, it is important to encode only meaningful groups in order to avoid a high overhead.
For this purpose, all the small groups, with a percentage of the total number of seams inferior to a threshold Outliers_Number_Threshold, are deleted. In addition, groups of seams have to be present in a sufficient number of consecutive frames to be temporally consistent. Therefore, groups that are only present in a few frames are also discarded, using a threshold Threshold_Outliers_Length. In Fig. 9, examples of isolated seam are indicated by red arrows.
Fig. 9. Example of isolated seams for a frame of the Ducks sequence (left) and the Parkrun sequence (right). Isolated seams are shown by the red arrows.
Finally, since the number of seams in each frame should be constant throughout the GOP, discarded seams have to be reallocated to other groups of seams in the same frame. This will also stabilize the temporal variations of the groups of seams. For this purpose, in each frame, the group having the strongest temporal variation of its number of seams will receive the same number of seams as those subtracted by the isolated seam discarding.
E) Group of seams modeling
After being defined, the groups of seams have to be modeled before being encoded. As we assume that salient regions do not contain seams, the modeling should not modify the outside of the groups of seams while creating the maximum of diversity within the groups of seams.
In the proposed approach, border seams are approximated in a different way than seams within the group. Figure 10 illustrates two groups of seams, with the border seams in red and the inner seams in blue. The first group has three inner seams between the two border seams and the second group has one inner seam between the two border seams.
Fig. 10. Illustration of two groups of seams with in red the border seams and in blue the inner seams within the group of seams.
Figure 11 summarizes the process of modeling both the border seams (red seams in Fig. 10) and the inner seams (blue seams in Fig. 10). Each border seam will be approximated by a polynomial that needs less information to be encoded. As the outside of the group of seams may include salient regions, the polynomial seams have to be totally included inside the group. In other words, the whole approximated left polynomial seam should be at the right of the left border seam. Conversely, the whole approximated right polynomial seam should be at the left of the right border seam. The first step of the group of seam modeling is the combination between the polynomial seam and the border seam to create a combined seam, with the following operations:
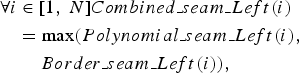 $$\eqalign{\forall i & \in [ 1\comma \; N] Combined\_seam\_Left\lpar i\rpar \cr & = \max\lpar Polynomial\_seam\_Left\lpar i\rpar \comma \; \cr & \quad \ Border\_seam\_Left\lpar i\rpar \rpar \comma \; } $$
$$\eqalign{\forall i & \in [ 1\comma \; N] Combined\_seam\_Left\lpar i\rpar \cr & = \max\lpar Polynomial\_seam\_Left\lpar i\rpar \comma \; \cr & \quad \ Border\_seam\_Left\lpar i\rpar \rpar \comma \; } $$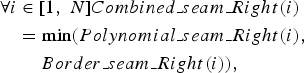 $$\eqalign{\forall i & \in [ 1\comma \; N] Combined\_seam\_Right\lpar i\rpar \cr & = \min\lpar Polynomial\_seam\_Right\lpar i\rpar \comma \; \cr & \quad \ Border\_seam\_Right\lpar i\rpar \rpar \comma \; } $$
$$\eqalign{\forall i & \in [ 1\comma \; N] Combined\_seam\_Right\lpar i\rpar \cr & = \min\lpar Polynomial\_seam\_Right\lpar i\rpar \comma \; \cr & \quad \ Border\_seam\_Right\lpar i\rpar \rpar \comma \; } $$where N is the length of the seam, Polynomial_seam_Left is the left polynomial seam, and Border_seam_Left is the seam border at the left of the group of seam. Polynomial_seam_Right is the right polynomial seam and Border_seam_Right is the seam border at the right of the group of seams. For the first iteration, the combined seam is initialized with the border seam.
Fig. 11. Group of seams modeling (corresponding to the module “group of seams modeling” in Fig. 2).
The combined seam obtained is then approximated by a polynomial seam during the border seams approximation step. Next, we check if the polynomial seam is totally included within the group of seams:
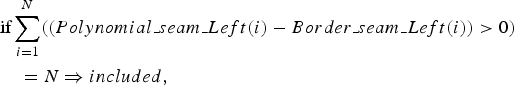 $$\eqalign{& \hbox{if} \sum_{i=1}^N \lpar \lpar Polynomial\_seam\_Left\lpar i\rpar -Border\_seam\_Left\lpar i\rpar \rpar \gt 0\rpar \cr & \quad =N \Rightarrow included\comma \; } $$
$$\eqalign{& \hbox{if} \sum_{i=1}^N \lpar \lpar Polynomial\_seam\_Left\lpar i\rpar -Border\_seam\_Left\lpar i\rpar \rpar \gt 0\rpar \cr & \quad =N \Rightarrow included\comma \; } $$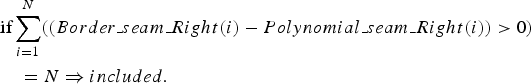 $$\eqalign{&\hbox{if} \sum_{i=1}^N \lpar \lpar Border\_seam\_Right\lpar i\rpar - Polynomial\_seam\_Right\lpar i\rpar \rpar \gt 0\rpar \cr & \quad = N \Rightarrow included.} $$
$$\eqalign{&\hbox{if} \sum_{i=1}^N \lpar \lpar Border\_seam\_Right\lpar i\rpar - Polynomial\_seam\_Right\lpar i\rpar \rpar \gt 0\rpar \cr & \quad = N \Rightarrow included.} $$If the polynomial seam is totally included, its shape is encoded, otherwise the process of combination and approximation is reiterated.
As for the inner seams in the group of seams (blue seams in Fig. 10), they are modeled by a uniform distribution between the two approximated polynomial border seams. If the distance between two modeled border seams is locally narrower than the number of seams in the group, it is obviously not possible for all inner seams to pass between the two borders. In this case, some inner seams are allowed to locally go over the borders.
Figure 12 illustrates the result after having applied the seam clustering, the isolated seam discarding, and the group of seams modeling. In this example, six vertical groups of seams are identified and an isolated vertical seam is discarded. The shape borders of groups of seams are approximated by polynomial seams. In this way, the quantity of information to transmit is reduced and the texture outside the groups of seams is preserved. Horizontally, only one group of seams is identified.
Fig. 12. Illustration of the original seams (left) and the modeled seams (right) for the Parkjoy sequence.
F) Seam encoding
To rebuild the seams at the decoder side, some information has to be transmitted. More specifically, for each group of seams in each frame, the numbers of seams and border seams polynomial models are sent. As previously detailed, the border seams are polynomials of degree m, with m = 3. A vertical (resp. horizontal) border seam of length N (resp. M), is totally defined by its horizontal position (resp. vertical) for each vertical position y, y∈ {1…N}. The Matlab function polyfit and polyval are used for this purpose. Due to the degree 3 of the polynomial, each border seam can be represented with four horizontal positions at {1, N/m, 2N/m, and 3N/m}.
A list of symbol containing the horizontal (resp. vertical) position in four points for all the vertical (resp. horizontal) border seams in the GOP is obtained and used in the predictive scheme. Figure 13 illustrates with more details the predictive encoding models of the border seams models. For the whole process, the prediction is a subtraction and the residuals are encoded in a lossless way.
Fig. 13. Predictive model for the group of border seams and encoding (corresponding to the module “group of seams modeling” in Fig. 1).
The first horizontal (resp. vertical) position of the first vertical (resp. horizontal) border seam in the first frame of the GOP is simply represented by its horizontal (resp. vertical) position. Then, the next horizontal (resp. vertical) position of this seam is predicted from the previous one. For the next seams, if it is a Border_seam_Right, the first horizontal (resp. vertical) position is predicted from the first horizontal (resp. vertical) position of the previous seam plus the number of seams inside the group of seams. Otherwise, it is a Border_seam_Left and the prediction of the first horizontal (resp. vertical) position is just the difference with the first horizontal (resp. vertical) position of the previous seam, Border_seam_Right. After having performed the prediction of the first frame of the GOP, the prediction is done temporally for the other frames.
Finally, the list of predicted residuals is encoded by using an arithmetic coder [Reference Sayood41].
IV. PERFORMANCE ASSESSMENT RESULTS
A) Evaluation methodology
To perform the evaluation, four test sequences in 352 × 288 pixels (CIF) format have been chosen: Coastguard, Ducks, Parkrun, and Parkjoy. These sequences show different spatial and temporal characteristics representative of a broad range of application scenarios.
Traditional image quality metrics, such as peak signal to noise ratio (PSNR) or structural SIMilarity (SSIM) [Reference Wang, Bovik, Sheikh and Simoncelli42], compare corresponding pixels or blocks in the reference and processed images. However, they provide a global quality measure rather than an object-oriented measure. In addition, they commonly fail in the presence of geometric deformations, object displacements, and background synthesis. In our context, a quality metric has to compare the salient regions, and to match the pixel positions in the original and processed images. The full reference image retargeting metric proposed by Azuma et al. in [Reference Azuma, Tanaka, Hasegawa and Kato43] solves the problem of matching by using scale-invariant feature transform (SIFT) [Reference Lowe44] and SSIM. With the same idea, Liu et al. presented in [Reference Liu, Luo, Xuan, Chen and Fu45] an objective metric simulating the HVS based on global geometric structures and local pixel correspondence based on SIFT. However, these two metrics are not designed to evaluate compression artifacts, do not take into account geometric deformations and are influenced by a synthesized background. In [Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman46], a metric, referred to as SSIM_SIFT, especially designed for the problem at hand has been presented. More precisely, it uses windows around SIFT points to measure by SSIM the compression artifacts due to encoders like H.264/AVC and return also the quantity of geometric deformation introduced by the approximation of the seam carving encoding. Since these windows are totally included in the salient parts, the result is not degraded by the synthesized parts in the background. This metric has been validated with subjective tests [Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman46] and obtained a Spearman and a Pearson correlation of 0.86. As our approach creates no geometric artifacts, evaluation has been done with another simple metric, referred to as SSIM_MASK. It consists in merely computing SSIM on a predefined region of the image only.
B) Evaluation protocol
When using the proposed seam carving scheme, perceived visual quality can be assessed in two steps. The first one is the evaluation of the salient object (object deformation, displacement, and quality) and the second one is the interpretability of the background. To the best of our knowledge, no techniques can reliably evaluate the second step. For this reason, the evaluation is focused hereafter on the salient object only.
Figure 14 illustrates the proposed evaluation protocol for the salient object using SSIM_MASK. After computing the saliency map as proposed in [Reference Riche, Décombas, Mancas, Dufaux, Pesquet-Popescu, Gosselin, Dutoit and Fellah39], seam carving is applied as described in Section II.B. Then, the proposed seam modeling (Section III) is applied to approximate the seams. The white parts of the saliency maps illustrate the important regions and the black parts the less important ones. The seams are illustrated in green. The reduced-size sequence is encoded, along with the modeled seams. To evaluate the results, the reduced sequence is expanded at the decoder side and the final results are compared with the reference using the SSIM_MASK.
Fig. 14. Evaluation protocol. Comparison of the decoded video with seam carving approach with the original video. SSIM_MASK is computed on the ground-truth binary mask.
The SSIM_MASK metric use a ground-truth binary segmentation mask to identify the salient object. In our experiments, we have used the manual binary masks from [Reference Riche, Décombas, Mancas, Dufaux, Pesquet-Popescu, Gosselin, Dutoit and Fellah39]. It should be underlined that these binary masks are only used in the quality metrics and are not involved in the encoding process. With this metric, a SSIM score is computed only on the salient object.
C) Parameters
In our approach, several parameters have been defined. Their theoretical optimization is quite complex due to the fact that the proposed approach depends on the video content. Moreover, the evaluation is difficult due to the lack of appropriate metrics for some improvements like the seam modeling. The influence of each parameter is described in Table 1. Extensive experimental tests have been done on different sequences with different ranges of values in order to heuristically define the optimal value of the parameters.
Table 1. Value and influence of various parameters.
D) Ratio of spatial resizing
As our approach reduces the spatial dimensions of the sequences depending on the content, the ratio of spatial resizing varies accordingly. The performance is directly linked to two parameters: the binarization coefficient applied on the saliency maps to obtain the control maps and the content-aware GOP segmentation. The ratio of spatial resizing, or in other words the percentage of suppressed pixels, is defined as:
 $$\eqalign{R_{Resizing} &= 100 \cr & \quad \ast \left(1-\displaystyle{{\hbox{Spatial dimension of the reduced sequence}} \over {\hbox{Spatial dimension of the original sequence}}} \right).} $$
$$\eqalign{R_{Resizing} &= 100 \cr & \quad \ast \left(1-\displaystyle{{\hbox{Spatial dimension of the reduced sequence}} \over {\hbox{Spatial dimension of the original sequence}}} \right).} $$Figure 15 illustrates the evolution of the seams as a function of time for the Parkjoy sequence. The number of seams that can be suppressed without any constraint is shown in blue, and the proposed approximation in green. A compromise is obtained between a high number of GOPs, giving a better approximation, but more subsequences to encode.
Fig. 15. Approximation of the number of suppressed seams for Parkjoy: evolution of the number of vertical seams (top) and horizontal seams (bottom).
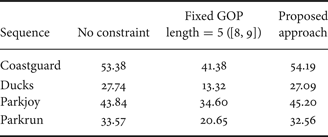
In Table 2, a comparison of the ratio of spatial resizing between an approach without any constraint on the number of suppressible seams, an approach with fixed length GOP = 5 [Reference Décombas, Capman, Renan, Dufaux and Pesquet-Popescu8,Reference Décombas, Dufaux, Renan, Pesquet-Popescu and Capman9] and our approach is presented. We can see that the proposed approach achieves a very good ratio of spatial resizing, nearly equal to an approach without any constraint. In contrast, the fixed GOP approach has a much smaller ratio of spatial resizing.
Table 2. Comparison of the ratio of spatial resizing between different approaches.
E) Seams approximation
Our approach tries to find a trade-off between the flexibility of seam representation and their coding cost. Figure 16 illustrates some visual results for the different test sequences. In general, in all the sequences, the salient objects obtained using [Reference Riche, Décombas, Mancas, Dufaux, Pesquet-Popescu, Gosselin, Dutoit and Fellah39] are preserved after modeling. Isolated seams are deleted and reallocated to other groups of seams. Some isolated seams are however kept, when they are consistent in time. Figure 17 illustrates the temporal aspect of the modeling for the Coastguard sequence.
Fig. 16. Visual seam modeling for Coastguard/Ducks/ParkJoy/ParkRun sequences. First column: sample original frame; second column: salient objects [39]; third column: initial seams; and fourth column: seams after the proposed modeling.
Fig. 17. Visual seam modeling for Coastguard at different times t = 27, 28, 29, 30. On first line, initial seams, on second line, the seams after the proposed modeling.
F) Evaluation of the seams modeling
In this experiment, we evaluate the efficiency of our seam modeling.
Different methods have been compared:
• The first one is based on the reduced video after the seam carving without modeling. No seam is encoded and this approach illustrates the achievable bitrate saving due to the spatial resizing. In this case, the scene geometry cannot be correctly reconstructed at the decoder.
• The second approach is based on the same reduced video and all seams positions are fully encoded without seam modeling. The first horizontal position (in the case of a vertical seam) of each seam is encoded on 10 bits. Then the next coordinate is predicted from the previous one. As the seam has only three possible position (right, straight, and left), it is encoded on 2 bits.
• The third approach is based on the new reduced video after the seam carving with modeling. The seams are not encoded and this approach illustrates the achievable bitrate saving due to the spatial resizing when the seams suppressed are grouped and modeled. In this case, the scene geometry cannot be correctly reconstructed at the decoder.
• The fourth approach is based on the new reduced video after the seam carving with modeling and the seams are modeled and encoded with our approach. This is the result of our proposed approach.
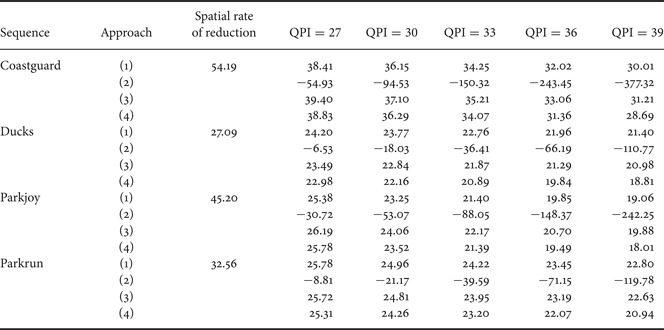
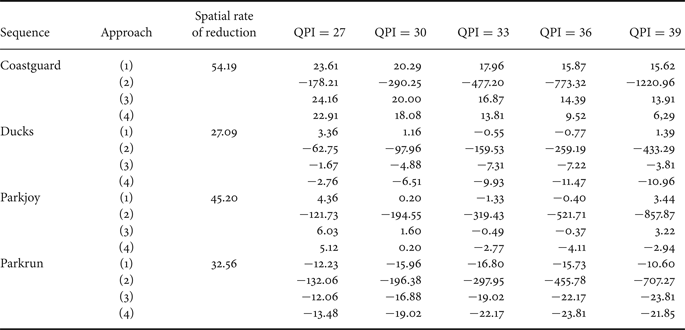
H.264/AVC [Reference Wiegand, Sullivan, Bjontegaard and Luthra1] is used in full intra coding that is consistent with video surveillance applications. The bitrate of the entire sequence is taken into account during the comparison. The quantization parameter intra (QPI) varies from 27 to 39 with a step of 3. Table 3 illustrates the percentage of bitrate saved compared with conventional H.264/AVC as a function of QPI.
Table 3. Percentage of bitrate saved compared with H.264/AVC as a function of quantization parameter intra (QPI) (positive value means bitrate is decreased, negative value means bitrate is increased): (1) reduced video after the seam carving without seam coding, (2) reduced video after the seam carving with seam position encoded without modeling, (3) reduced video after the seam carving modeled without seam coding, and (4) our proposed approach with reduced video after the seam carving modeled and the seams modeled and encoded.
We can see that the rate of spatial reduction is not directly linked to the bitrate saved following (1) and (3). This is due to the fact that seams can pass in areas that did not need many bits to be encoded and that some high frequencies can be created after the seam carving. The approach (3) shows that the reduced video after grouping and modeling the seams leads to better bitrate saving compared with (1) for Coastguard, Parkjoy, and Parkrun. This is due to the fact that the modeling limits the creation of high frequencies in the reduced video. But in the approach (1) and (3), it is not possible to reconstruct the geometry scene because no seam information is transmitted and as the seam carving is not a reversible process, artifacts may appear at the decoder in this case. In the approach (2), all the seam positions are encoded with the reduced video after the seam carving. The overhead cost is too important and a classical video encoding performs better. This justifies the fact that the seams positions have to be approximated. It is possible to see that with our proposed approach in (4), the overhead due to the seam encoding is low and the bitrate saving is very close to the (3).
Table 4 illustrates the percentage of bitrate saved compared with conventional H.264/AVC as a function of quantization parameter in inter coding. As in Table 3, QPI varies from 27 to 39 with a step of 3 and the quantization parameter P-frame (QPP) is defined as: QPP = QPI + 1.
Table 4. Percentage of bitrate saving compared with H.264/AVC as a function of QP (positive value means bitrate is decreased, negative value means bitrate is increased): (1) reduced video after the seam carving without seam coding, (2) reduced video after the seam carving with seam position encoded without modeling, (3) reduced video after the seam carving modeled without seam coding, and (4) our proposed approach with reduced video after the seam carving modeled and the seams modeled and encoded.
It is interesting to see that even if a good rate of spatial reduction is reached and no seam are encoded, like in (1) and (3), the bitrate saving is very small for Ducks and Parkjoy at QPI = 27. For Parkrun, the reduced sequence has a more important bitrate than the original one. This highlights the importance to have a really good temporal saliency model and consistent seams in the time. For Coastguard, the saliency model and the seam modeling performs well and lead to a bitrate saving in (1) and (3) even at QPI = 39.
G) Rate-distortion performance assessment
Finally, we assess the rate-distortion performance of the proposed semantic video coding scheme based on seam carving. For this purpose, comparison is made in full intra coding, which is very common and pertinent in security applications. Experiment in inter coding are also done to highlight the next challenges. The sizes of the GOP are defined by the content-aware adaptive GOP segmentation. The traditional H264/AVC [Reference Wiegand, Sullivan, Bjontegaard and Luthra1] encoder is used as reference, with the same GOP structure than our proposed approach. Figure 18 illustrates different processes on the Coastguard sequence. Figures 18(a) and 18(d) are used to plot the rate-distortion performance.
Fig. 18. Illustration of the different processes on Coastguard sequence: (a) original image, (b) binary mask of reference, (c) saliency model, (d) image with proposed seam carving and seams in green, and (e) image reduced with proposed seam carving.
Experimental results on the four test sequences with the metrics SSIM_MASK are presented in Fig. 19 and Table 5.
Fig. 19. Rate-distortion performance in full intra coding for Coastguard, Ducks, Parkrun, and Parkjoy, using the SSIM_MASK. In green, H.264/AVC and in red the proposed approach.
Table 5. Bjontegaard's scores (percentage and Delta SSIM_MASK) in full intra coding for Coastguard, Ducks, Parkrun, and Parkjoy, using the SSIM_MASK.
The scores are computed between H.264/AVC and our content-aware video compression approach.
With SSIM_MASK, the proposed approach consistently outperforms H.264/AVC for all test sequences. A bitrate saving between 7.02 and 21.77% can be reached using the Bjontegaard's metric. The Delta SSIM_MASK is between −0.0078 and −0.0356. We remind that the Bjontegaard's metric with the SSIM_MASK allows to compute the average gain in SSIM only computed on the binary mask or the average per cent saving in bitrate between two rate-distortion curves. We use the Matlab implementation from Giuseppe Valenzise done in 2010.
Figure 20 illustrates a bitrate saving of 23% in intra coding on the Parkrun sequence with the same SSIM_MASK quality on the object of interest. Figure 21 illustrates the visual result for Coastguard at an equivalent bitrate of 488 Kbits/s. The compression by seam carving has been done with a QP = 36, while the traditional compression has been done with a QP = 39. The video obtained without our approach has a SSIM_MASK = 0.88 and the video with the H.264/AVC has a SSIM_MASK = 0.85. Perceptually, the quality of the object is a little bit better even if we are in the presence of strong artifacts. For example, both the body and the head of the driver in the boat are better.
Fig. 20. Rate-distortion performance. Visual results for Parkrun in intra coding with a SSIM_MASK = 0.83 and a bitrate saving of 23%.
Fig. 21. Rate-distortion performance. Visual results for Coastguard in intra coding with a bitrate of 488 Kbits/s.
To generalize our performance and highlight the next challenge, experiments with inter coding were also carried out. The GOP coding structure is IPPP, and the QPP is defined in function of the quantization parameter of the I frame, QPI, as QPP = QPI + 1.
Experimental results are presented in Fig. 22 and Table 6.
Fig. 22. Rate-distortion performance in inter coding for Coastguard, Ducks, Parkrun, and Parkjoy, using the SSIM_MASK. In green, H.264/AVC and in red the proposed approach.
Table 6. Bjontegaard's scores in inter coding for Coastguard, Ducks, Parkrun, and Parkjoy, using the SSIM_MASK.
The scores are computed between H.264/AVC and our content-aware video compression approach.
We can observe that with inter coding, the performance of the proposed approach cannot do better than H.264/AVC. This lower performance in inter coding, as opposed to intra coding, can be explained by the lack of temporal stability for the saliency model. In addition, motion compensated prediction is not as efficient when encoding the reduced video. More precisely, some static parts in the original video are shifted in the reduced sequence and from frame to frame. Also, seam carving is not always suppressing the same paths. For these reasons, the bitrates of the P frames sometimes increase and lead to these results.
Table 6 shows the performance with the Bjontegaard's metric based on the SSIM_MASK. The performance is an increase of bitrate between 5.49 and 22.34% and a Delta SSIM_MASK between 0.0063 and 0.044.
V. CONCLUSION AND FUTURE WORK
In conclusion, we have proposed in this paper a new approach based on seam modeling for semantic video compression in video surveillance applications. More precisely, (1) a method was first presented that automatically segments the GOP as a function of the content. For each GOP, (2) a spatio-temporal seam clustering based on spatial and temporal distances and (3) an isolated seam discarding technique have been applied to improve the encoding of the reduced-size sequence and to help seam modeling. (4) A new seam modeling, avoiding geometric distortion and resulting in a better control of the seam shapes at the decoder without the need of a saliency map and (5) a new encoder that reduces the global bitrate have also been proposed.
The seam modeling was first validated, both visually and in terms of bitrate overhead to transmit the seam information. Next, the proposed semantic video coding scheme was compared with H.264/AVC using the SSIM_MASK quality metric. We used full intra coding, which is consistent with security applications but also inter coding to evaluate the temporal consistency of our approach and define future works. For the Coastguard, Ducks, Parkrun, Parkjoy test sequences, our approach outperforms H.264/AVC in intra coding with a bit-rate reduction ranging from 7.02 to 21.77% using Bjontegaard's metric [Reference Bjontegarrd47].
In future works, we will pursue the improvement of this scheme. As we have seen, several parameters have been experimentally defined. One upgrading is to automatically define them depending on the content. In our results, the seam texture is not synthesized at the decoder side. For this purpose, some inpainting algorithms can be used. Studying the influence of the synthesis quality would also be a valuable continuation of this study. Others improvements could be done on temporal stability of saliency models and seam carving clustering to obtain better performance in inter coding.
Marc Décombas graduated in 2010 from the French engineering school Telecom Sud-Paris has obtained his PhD about “Content aware video compression for very low bitrates application” with Telecom ParisTech and Thales Communications & Security, Paris, France in 2013. His research areas are content aware video compression, saliency models, video summary, subjective evaluation and people reidentification. He is the author or co-author of more than 10 research publications and holds 1 international patents issued or pending.
Frédéric Dufaux is a CNRS Research Director at Telecom ParisTech. He is also Editor-in-Chief of Signal Processing: Image Communication. He received his M.Sc. in physics and Ph.D. in electrical engineering from EPFL in 1990 and 1994 respectively. Frédéric has over 20 years of experience in research, previously holding positions at EPFL, Emitall Surveillance, Genimedia, Compaq, Digital Equipment, MIT, and Bell Labs. He has been involved in the standardization of digital video and imaging technologies, participating both in the MPEG and JPEG committees. He is currently co-chairman of JPEG 2000 over wireless (JPWL) and co-chairman of JPSearch. He is the recipient of two ISO awards for these contributions. Frédéric is an elected member of the IEEE Image, Video, and Multidimensional Signal Processing (IVMSP) and Multimedia Signal Processing (MMSP) Technical Committees. His research interests include image and video coding, distributed video coding, 3D video, high dynamic range imaging, visual quality assessment, video surveillance, privacy protection, image and video analysis, multimedia content search and retrieval, and video transmission over wireless network. He is the author or co-author of more than 100 research publications and holds 17 patents issued or pending.
Beatrice Pesquet-Popescu (IEEE Fellow) is a Full Professor at Télécom ParisTech since 2007, Head of the Multimedia Group. She was also the Scientific Director of the UBIMEDIA common research laboratory between Alcatel-Lucent Bell Labs and Institut Mines Télécom. She is a member of the FET Advisory Board of the European Commission for the H2020 program, as well as member of the Advisory Group on Part IV of Horizon 2020, “Spreading Excellence and Widening Participation” (2014–2016). She was an EURASIP Board of Governors member between 2003–2010, and an IEEE Signal Processing Society IVMSP TC (2008–2013, Vice-Chair 2015) and IDSP SC (2010–2015, Vice-Chair 2012) member and an MMSP TC member (2006–2009). In 2013–2014 she served as a Chair for the Industrial DSP Standing Committee. She is also a member of the IEEE Comsoc Technical Committee on Multimedia Communications (2009–2014, chair of the Awards Board, 2015). In 2008–2009 she was a Member at Large and Secretary of the Executive Subcommittee of the IEEE Signal Processing Society (SPS) Conference Board, and she was (2012–2014) a member of the IEEE SPS Awards Board and of the IEEE SPS Conference Board (2015–2016). Beatrice Pesquet-Popescu served as an Editorial Team member for IEEE Signal Processing Magazine (2012–2014), as an Associate Editor for IEEE Trans. on Multimedia (2008–2014), IEEE Trans. on Circuits and Systems for Video Technology, IEEE Transactions on Image Processing, Area Editor for Elsevier Image Communication journal, Associate Editor for APSIPA Transactions on Signal and Information Processing, and Associate Editor for the Hindawi Int. J. Digital Multimedia Broadcasting journal and for Elsevier Signal Processing (2007–2010). She was a Technical Co-Chair for the PCS 2004 conference, and General Co-Chair for IEEE SPS MMSP2010, EUSIPCO 2012, and IEEE SPS ICIP 2014 conferences. She is a recipient of the “Best Student Paper{} Award” in the IEEE Signal Processing Workshop on Higher-Order Statistics in 1997, of the Bronze Inventor Medal from Philips Research and in 1998 she received a “Young Investigator Award” granted by the French Physical Society. In 2006, she was co-recipient of the IEEE Trans. on Circuits and Systems for Video Technology “Best Paper Award”. In April 2012, Usine Nouvelle cited her among the “100 who matter in the digital world” in France. She holds 29 patents in video coding and has authored more than 320 book chapters, journal and conference papers in the field. She is a co-editor of the book “Emerging Technologies for 3D Video: Creation, Coding, Transmission, and Rendering”, Wiley Eds., 2013. She has (co-)directed 27 PhD students and was in 30+ PhD committee defense juries. Her current research interests are in source coding, scalable,robust and distributed video compression, multi-view video, 3DTV, holography, sparse representations and convex optimisation.




 Open access
Open access