


To refer to a male adult, speakers of English have several lexical items to choose from, such as man, guy, chap, dude, fella, bloke, gent, gentleman, and geezer. Data from the Spoken British National Corpus (BNC; Love, Dembry, Hardie, Brezina, & McEnery, Reference Love, Dembry, Hardie, Brezina and McEnery2017) indicate that these variants are widespread and can be found in a range of referentially comparable contexts, as in (1). Because these variants have entered the English language at different intervals in time, this domain exhibits lexical layering, which, like other aspects of variation, may be influenced by linguistic and external conditioning factors.

While this semantic field has been explored in Present Day English (Franco & Tagliamonte, Reference Franco and Tagliamonte2021; Tagliamonte, Reference Tagliamonte, Kytö and Siebers2022) and a list of variants pertaining to this semantic field has been compiled for Old and Middle English (Elsweiler, Reference Elsweiler2011; Grygiel, Reference Grygiel, McConchie, Timofeeva, Tissari and Säili2006; Kleparski, Reference Kleparski2003, Reference Kleparski2005; Stenroos, Reference Stenroos and Díaz Vera2002), how this domain has evolved over time, especially in the earlier stages of the English language, remains unclear.
One of the reported hallmarks of linguistic change is the presence of an s-shaped distribution where incoming forms are adopted at a rate of slow to fast to slow (Bailey, Reference Bailey1973:77; Weinreich, Labov, & Herzog, Reference Weinreich, Labov and Herzog1968:113-114). A comparison of the current system of variants (e.g., man, guy) with variants used in earlier stages of the language (e.g., wer ‘man’) clearly shows lexical change within this semantic field. However, whether lexical change follows a traditional s-curve trajectory remains to be investigated. Although lexical replacement is expected to follow an s-curve distribution (Blythe & Croft, Reference Blythe and Croft2012:278-279; Chambers, Reference Chambers, Chambers, Trudgill and Schilling Estes2002:361), to date s-curve patterns have been modeled predominantly on phonetic (e.g., Labov, Reference Labov1994), morphological (e.g., Nevalainen, Reference Nevalainen and Sanchez-Stockhammer2015), and discourse-pragmatic features (e.g., Tagliamonte & Smith, Reference Tagliamonte and Smith2021). While s-curve patterns for lexical change can be found in the literature (e.g., Chambers, Reference Chambers1995), they are typically based on apparent time as opposed to real time data. However, in work on short-term high density lexical change, Grieve, Nini, and Guo (Reference Grieve, Nini and Guo2017) found s-shaped patterns for several “emerging words” such as baeless and fleek, suggesting that lexical change also follows a prototypical s-curve trajectory. Nevertheless, research on long-term s-curve patterns for lexical change is lacking. Given that the semantic field of third-person male adult noun referents is rife with variation, examining how this system has evolved holds promise for insights into the factors governing lexical variation and change in real time. Recent work on Ontario English shows that this lexical domain is in flux, with factors such as gender and age influencing speakers’ choices (Franco & Tagliamonte, Reference Franco and Tagliamonte2021; Tagliamonte, Reference Tagliamonte, Kytö and Siebers2022). Against the backdrop of this work, the present study examines the system of third-person male adult noun referents in earlier stages of the English language, specifically in Old and Middle English.
Two research questions are addressed. First, what was the distribution of third-person male adult noun referents in Old and Middle English? A quantitative comparison of this domain over time can document changes within this semantic field while also providing a platform to test patterns of lexical change. Second, based on the extant metadata, is there any evidence to suggest that the use of third-person male adult noun referents was conditioned, constrained, or influenced by any attested factors of variation? To answer these questions, the Helsinki Corpus of English Texts (Kytö, Reference Kytö1996; Rissanen, Kytö, Kahlas-Tarkka, Kilpiö, Nevanlinna, Taavitsainen, Nevalainen, & Raumolin-Brunberg, Reference Rissanen, Kytö, Kahlas-Tarkka, Kilpiö, Nevanlinna, Taavitsainen, Nevalainen and Raumolin-Brunberg1991) was used as the principal source of linguistic data, as it contains texts from Old English and Middle English, as well as metadata for potentially influential conditioning factors, such as text type and text origin. Although larger corpora are available, given the size of the system of third-person male adult noun referents, with over ten thousand tokens of man attested in the Helsinki Corpus of English Texts alone (Rauer, Reference Rauer2017:142-143), to ensure confidence in the circumscription of the variable context, larger corpora were avoided.
Background
Lexical Variation
In recent decades, variationist quantitative methods have been used to examine a range of discourse-pragmatic phenomena, such as intensifiers (e.g., Stratton, Reference Stratton2020, Reference Stratton2022a; Stratton & Sundquist, Reference Stratton and Sundquist2022; Tagliamonte, Reference Tagliamonte2008), quotatives (e.g., Tagliamonte & D'Arcy, Reference Tagliamonte and D'Arcy2004), general extenders (e.g., Cheshire, Reference Cheshire2007), and evidentiality markers (e.g., Tagliamonte & Smith, Reference Tagliamonte and Smith2021). Although geography is often reported as the predominant explanatory factor for lexical variation, lexis is highly structured along the axes of social and stylistic variation. In recent work, several lexical sets have been explored, such as dinner versus tea (Jankowski & Tagliamonte, Reference Jankowski and Tagliamonte2019), words of profanity (Tagliamonte & Jankowski, Reference Tagliamonte and Jankowski2019), adjectives of strangeness (Tagliamonte & Brooke, Reference Tagliamonte and Brooke2014), and adjectives of positive evaluation (Stratton, Reference Stratton2022b; Tagliamonte & Pabst, Reference Tagliamonte and Pabst2020).
Based on the premise that lexical choices are influenced by similar conditioning factors that operate on grammatical and phonological variation, Tagliamonte and colleagues probed the sociolinguistic underpinnings of the system of third-person male adult noun referents in Ontario English (Franco & Tagliamonte, Reference Franco and Tagliamonte2021; Tagliamonte, Reference Tagliamonte, Kytö and Siebers2022). The authors found that guy was making traction over competing variants such as man, a change led predominantly by young men. While guy was used more frequently by men than women, other factors such as socioeconomic status were also found to play a role. Following the “Uniformitarian Principle” (Lyell, Reference Lyell1830-1833; cf., Labov, Reference Labov1972:275), one might expect similar conditioning factors to have affected this system diachronically. Although the lack of similar types of sociolinguistic metadata in the earlier stages of the English language rules out a quantitative analysis of the effect of social factors on this system in Old and Middle English, this scholarship serves as a point of departure for the present analysis.
History of third-person male referents
Variants for describing third-person male adult noun referents have a long history of lexical replacement in the English language. According to A Thesaurus of Old English (2017) and The Historical Thesaurus of English (2023), there are at least twenty-five attested lexical items that denote “man” in Old English, including, but not limited to ceorl, carlmon, esne, freca, folcagende, folcwer, guma, gumrinc, hæle[þ], hyse, leod, mæcg, man, scealc, wer, woruldman, wiga, wæpnedmann, and wæpenmann. While some of these variants (e.g., gumrinc) are reportedly more frequent in Old English verse (A Thesaurus of Old English, “13.02.10.01 A man, warrior”), others (e.g., wer, guma, man) are found in both prose and verse (Kleparski, Reference Kleparski2003:49; Stenroos, Reference Stenroos and Díaz Vera2002:382-383). Wer, guma, and man are variants that can refer to a male adult in Old English, but the word form man has additional functions: it can be used gender-inclusively to refer to both male and female referents (Curzan, Reference Curzan2003:64-65), it can be used to refer to human beings (Rauer, Reference Rauer2017:139-140), and it can be used as an indefinite pronoun, corresponding in translation to “one” (Raumolin-Brunberg & Kahlas-Tarkka, Reference Raumolin-Brunberg, Kahlas-Tarkka, Rissanen, Kytö and Heikkonen1997).Footnote 1 Examples of wer, guma, and man referring to male referents are provided in (2).Footnote 2

By Middle English, only half of the Germanic words for “man” (e.g., beorn, cerl, freca, guma, hearra, leod, man, rinc, scealc, secg, wæpenmann, wer, wiga) are reported to have remained in use (Stenroos, Reference Stenroos and Díaz Vera2002:385). Contact with Anglo-Norman led to the emergence of new variants through lexical borrowing, such as sire ‘man’ (Kleparski, Reference Kleparski2005:48) and sergeant ‘servant/serving individual’ (Kleparski, Reference Kleparski2003:51). Modern English gentleman emerged during Middle English by compounding the French loanword gentil ‘noble’ with Germanic mon ‘man’ (literally ‘nobleman’). Meanwhile, other variants underwent semantic shifts, such as Old English æþeling ‘prince/nobleman’ which became Middle English hathel ‘man’ (Middle English Dictionary [MED] 2021; hathel, n.). However, like in Old English, it is possible that many variants were affected by text type, with some variants occurring more frequently in verse than in prose due to metrical and alliterative demands. According to Eduard Siever's Altgermanische Metrik (Reference Sievers1893), lines in Old English verse, called Langzeile, consist of two short lines (Kurzzeile), and at least one lexical item in each short line alliterates. This alliterative tradition was transmitted into Middle English to a lesser extent, with rhyme emerging as a new feature of verse. Examples in (3) from the Middle English text Sir Gawain and the Green Knight illustrate the rich variation present within the semantic field, seemingly due to the alliterative demands. According to the Oxford English Dictionary (OED, 2021), few of the Middle English variants survived into Early Modern English. For instance, tulk (ON tulk-r ‘interpreter’) and renk (ON rekk-r ‘warrior,’ OS rink) were rarely used after the mid-sixteenth century, and gome (OE guma), freke (OE freca), berne (OE beorn ‘man of valor,’ ON bjǫrn ‘bear’), schalk (OE scealc ‘servant/man,’ ON skalk-r ‘slave/servant’), and lede (OE leoda ‘people,’ German Leute ‘people’) are not attested after the seventeenth century.Footnote 4

The linguistic variable
In traditional variationist work, the linguistic variable is defined as “alternate ways of saying ‘the same’ thing” (Labov, Reference Labov1972:188). Although this definition was originally applied to phonological variation, over time this concept was extended to the study of grammatical and lexical variation (Terkourafi, Reference Terkourafi2011). In early work on distributional semantics, Firth (Reference Firth1957:11) highlighted the importance of context when determining referential meaning, and in modern studies of variation, forms do not need to have the exact same denotation, but overlapping uses or a shared history is often a prerequisite to be treated as variants of the same thing. So long as the analyst identifies and includes the contexts in which the referential meaning is equivalent, and removes instances in which they are not, a two-step process known as the Principle of Accountability (Labov, Reference Labov1969:737-738), and circumscription of the variable context (Labov, Reference Labov1969:729), the linguistic variable can be used to study variation outside of phonology.
Although there are semantic nuances between Middle English nouns such as segge, hathel, freke, wyȝe, and mon, at the discourse level, they can have the same referential meaning, that is, in some contexts they can be used to refer to the same male adult. The examples in (4) from Sir Gawain and the Green Knight illustrate that these forms could be used interchangeably, as they appear in the same contexts to refer to the same green knight (i.e., quoþ the … ‘said the…’). Since these nouns occurred in the same contexts to refer to the same referent, these variants were, at least at the level of discourse and in specific contexts, referentially equivalent.

As Tagliamonte and Brooke (Reference Tagliamonte and Brooke2014:11-12) point out, using semantic fields as a foundation for circumscribing the variable context is not new. For instance, Sankoff, Thibault, and Bérubé (Reference Sankoff, Thibault, Bérubé and Sankoff1978) analyzed the semantic field of verbs which mean “to dwell,” which led to the notion of “weak complementarity”: the idea that linguistic variables can be identified through distributional properties and distribution across a speech community (Sankoff & Thibault, Reference Sankoff, Thibault, Johns and Strong1981:207). Recent studies have followed in this tradition when analyzing lexical variation (e.g., Stratton, Reference Stratton2022b; Tagliamonte & Brooke, Reference Tagliamonte and Brooke2014; Tagliamonte & Pabst, Reference Tagliamonte and Pabst2020). The concept of a semantic field, however, predates the variationist tradition and has its roots in structuralist semantics (Trier, Reference Trier1931), with the important distinction between semasiology and onomasiology (Geeraerts, Reference Geeraerts2010). Semasiology, a concept that emerged in prestructuralist work, “considers the isolated word and the way its meanings are manifest” (Baldinger, Reference Baldinger1980:278) and is therefore concerned with polysemy, that is, the various meanings a given word form can have (Geeraerts, Reference Geeraerts2010:84). In contrast, onomasiology “looks at the designations of a particular concept” (Baldinger, Reference Baldinger1980:278), which can be conceived as studying varying levels of synonymy (Geeraerts, Reference Geeraerts2010:84). Studying the variants used to denote third-person male adult noun referents can therefore be viewed as onomasiology, which, unlike semasiology, starts with the concept and examines how it can be expressed. In a variationist framework, variants within a semantic field, lexical field, or onomasiological set can be studied as a linguistic variable. Therefore, the present study uses the notion of a semantic field, following “weak complementarity,” to study the system of third-person male adult noun referents in Old and Middle English.
Methodology
Data
To examine the semantic field of third-person male adult noun referents in Old English, the Helsinki Corpus of English Texts (Kytö, Reference Kytö1996; Rissanen et al., Reference Rissanen, Kytö, Kahlas-Tarkka, Kilpiö, Nevanlinna, Taavitsainen, Nevalainen and Raumolin-Brunberg1991) was used, which contains 413,250 words, divided into four subperiods: O1 (2,190 words), O2 (92,050 words), O3 (251,630 words), and O4 (67,380 words). While many texts from the same corpus were also included for the analysis of variants in Middle English, because the corpus of Middle English is substantially larger than the Old English counterpart, to ensure confidence in the circumscription of the variable context only a sample of the texts from the Middle English part of the corpus was used. However, because there are fewer verse texts in the Middle English corpus, to ensure that text type could be included as a factor in the analysis, additional verse texts were added from Sisam (Reference Sisam1928). The Middle English dataset in the present study therefore had three subperiods: M1 (48,336 words), M2 (30,554 words), and M3 (50,069 words), with M1 and M2 representing Early Middle English, and M3 representing Late Middle English.Footnote 5 The texts included for the Middle English analysis were as follows: M1: Ormulum, Hali Meidhad, Peterborough Chronicle, Layamon's Brut; M2: Dame Sirith, Man in the Moon, Havelok, The Thrush and the Nightingale, Sir Orfeo, Ayenbite of Inwyt; M3: The General Prologue to the Canterbury Tales, The Wife of Bath's Prologue, The Dancers of Colbek, Sir Gawain and the Green Knight, The Pearl, Henry V: Letters to a Bishop, The New Testament: Wycliffe, Chaucer's Astrolabe, The Cloud of Unknowing, John Travisa: Polychronicon.Footnote 6
Circumscribing the variable context
A list of third-person male adult noun referents for Old and Middle English was compiled through previous literature (Elsweiler, Reference Elsweiler2011; Grygiel, Reference Grygiel, McConchie, Timofeeva, Tissari and Säili2006; Kleparski, Reference Kleparski2003, Reference Kleparski2005; Stenroos, Reference Stenroos and Díaz Vera2002), dictionaries (Bosworth-Toller [Reference Bosworth-Toller, Northcote Toller, Sean and Tichy2014]; Middle English Dictionary [2021], Oxford English Dictionary [2021]), and thesauruses (The Historical Thesaurus of English [2023], A Thesaurus of Old English [2017]). Then, search queries were run to find these variants in the data. Since word forms are not lemmatized in the Helsinki corpus, a list of spelling variants and inflectional forms was compiled with the aid of the Dictionary of Old English (Cameron, Amos, & Healey, Reference Cameron, Amos and Healey2018) and was subsequently searched for in the corpus data. Tokens were then downloaded and manually inspected for the removal of any nonequivalent instances.
Since the variable context was circumscribed to third-person male adult noun referents, variants such as OE man ‘man’ were only included in the analysis when they unambiguously referred to a male adult, as in (5). The presence of names, as in (5a), as well as the sociohistorical context, helped determine the gender of the referent. For instance, in (5b) it is evident that the referent Priam is male because he is a preost ‘priest,’ a role traditionally confined to men. Similarly, in (5c) the referent is King Arthur, referred to as a god mon ‘good man,’ who is presumably male. In (5d), the six men are biologically male as we are told they were castrated (their stanes ‘testicles’ were removed).Footnote 7 In contrast, examples in (6) were not included in the envelope of variation. While differentiating the gender-specific, gender-inclusive, and indefinite use of man is no simple task (Curzan, Reference Curzan2003:135; Rauer, Reference Rauer2017), indicators such as a preceding negative particle (e.g., no mon here vnmanerly þe mysboden habbez ‘no one here has treated you in an unmannerly fashion’) or indefinite adjectives (e.g., forþam nat nænig man ‘therefore, nobody knows’) helped disambiguate possible readings. Special attention was taken to ensure that the anachronistically homophonous and semantically nonequivalent form mān ‘crime,’ identified by a macron in editorial textual editions, was excluded. A number of functionally nonequivalent uses, such as the indefinite use of man, as in (6a), vocatives of address, as in (6b), as well as instances where the referential meaning was different, such as ‘husband/boyfriend’ in (6c), were excluded.Footnote 8 Instances in which wer meant ‘wergild,’ that is, a compensation tariff, were also excluded on grounds of being semantically nonequivalent.Footnote 9 Eorl ‘earl’ was not included when used as a term of address or rank (e.g., Harold eorl ‘Earl Harold,’ Godwine eorl ‘Earl Godwin’).

For texts translated from Latin, comparisons between the Old English variants and the Latin counterparts aided in identifying the gender of the referents. For instance, in (7) it is evident that the people the idesa ‘women’ have not slept with are male, not only from context, but also because vir ‘man’ was found in the Latin text (habeo duas filias, quae necdum cognoverunt virum ‘I have two daughters who are yet to have known/slept with men’).Footnote 10 Old English wer is cognate with Latin vir, but beorn was likely used because it alliterates with gebedscipe (cf., ge- prefixes are unstressed in Old English verse).

After circumscribing the variable context, each token was coded according to the available metadata: text type, text origin, and time. The factor text type had two levels (prose, verse), text origin had two levels (translated, not translated), and time had four levels for Old English (O1, O2, O3, O4) and three levels for Middle English (M1, M2, M3). While some metadata for dialect was available, dialect was not included as a factor for three reasons. First, not all texts contained such metadata. Second, there is some disagreement regarding the dialect in which specific manuscripts are written. Third, for Old English, there is a bias toward West Saxon texts, which substantially outweigh Northumbrian, Kentish, and Mercian texts. To test whether alliteration had a significant effect on lexical choices in verse, each variant in verse texts was coded binomially for the presence or absence of neighboring words with which the variant could alliterate. For the multivariate analyses, binary mixed effects logistic regressions were developed in Rbrul (Johnson, Reference Johnson2009), with text id run as a random intercept. In all models, the most frequent variant of the period (i.e., wer in Old English, and man in Middle English) was run against all other variants within that period, coded binomially.
Results
Old English distributional analysis
For Old English, a total of 631 tokens were included in the envelope of variation. Of the twenty-five attested variants (beorn, carlman, cempa, ceorl, cniht, duguð, eorl, freca, guma, hæle[þ], hildedeor, hyse, leod, magu, man, rinc, scealc, secg, sundbuend, þegn, wæpman, wæpned, wer, wiga, wigmen), wer was most frequent, which made up 42.2% of the semantic field. The variants man and guma competed for second place, each occupying approximately 13.5% of the system. The overall distribution of variants is reported in Table 1, with some examples of use in (8).

Table 1. Distribution of third-person male adult noun referents in Old English
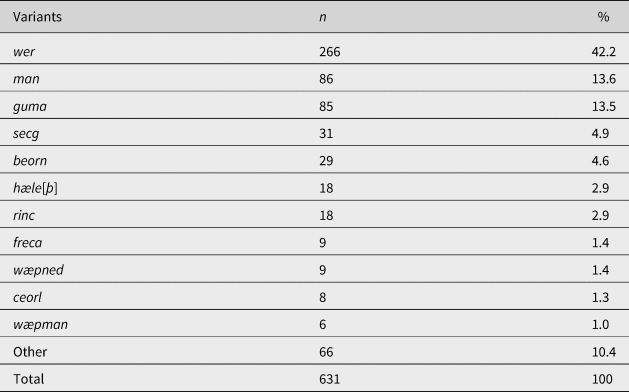
To explore differences in use across prose and verse, the variants were cross-tabulated by text type (see Table 2). Different variants were favored by different text types. In prose texts, wer was the number one variant, at 63.6%, compared with 19.7% in verse texts. In contrast, guma was the number one variant in verse texts, at 24.8%, compared with 2.2% in prose. The type-token ratio (TTR), a common measure of lexical density, indicates that a wider range of variants was found in verse (n = 23 types, 314 tokens → TTR = .073) than in prose (n = 12 types, 317 tokens → TTR = .037). Of the 314 tokens found in verse, 76% (n = 239) alliterated with words in proximity. A chi-square test found that alliteration had a significant effect (p < .001) on the lexical choices within the semantic domain of variants found in Old English verse. The need for alliteration may explain the wider range of variants found in verse compared to prose.
Table 2. Distribution of Old English variants by text type
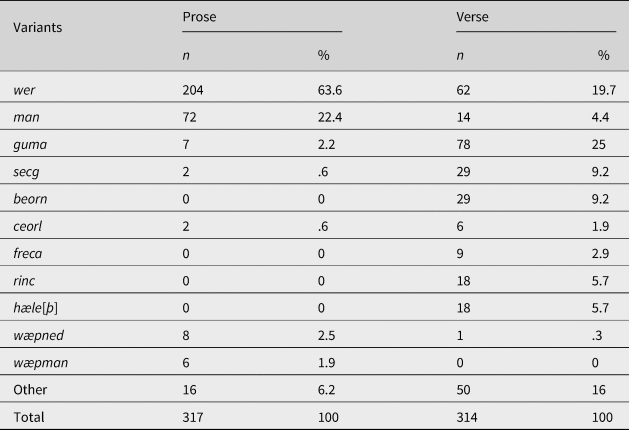
As for the effect of provenance (Table 3), nontranslated texts contained a wider a range of variants (types = 25, tokens = 409 → TTR = .06) than translated texts (types = 13, tokens = 222 → TTR = .058), but the type-token ratio was almost identical. In translated texts, wer made up 68.3% of the semantic field. In contrast, although wer was also the most widely used variant in nontranslated texts, it made up a smaller share of the system (28.1%).
Table 3. Distribution of Old English variants by origin

Old English multivariate analysis
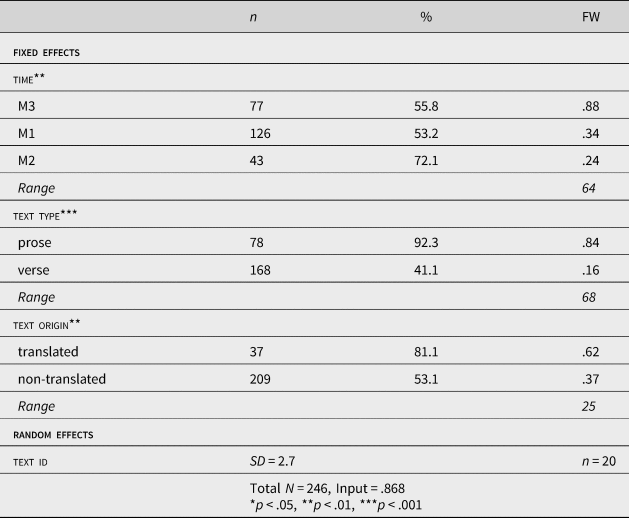
To examine the statistical significance and relative strength of the factors operating on this semantic field, a binary mixed effects logistic regression was computed in Rbrul (Johnson, Reference Johnson2009). time, text origin, and text type were run as fixed effects, with all possible interactions. The output is summarized in Table 4. Factor weights (FW) indicate the probability of the application value (i.e., wer) to occur in the listed context. Factor weights closer to 1 indicate a favoring effect whereas factor weights closer to zero indicate a disfavoring effect. Although text was originally coded with four levels (O1, O2, O3, O4), due to the limited data available for O1 (2,190 words), for which only two tokens were included, O1 and O2 were collapsed into one level.
Table 4. Logistic regression of the factors influencing the use of wer versus all other Old English variants

All three factors were found to significantly affect the probability of wer to occur in the Old English texts, with a significant interaction between time and text origin. Wer occurred more frequently at the beginning of the Old English period (O2) than at the end (O4), in prose than verse, and in translated texts than non-translated texts. The range for the factor groups, calculated by subtracting the lowest factor weight from the highest, indicates that, of the three factors, text type had the strongest effect on the absence or occurrence of wer in Old English. A random forest (Hothorn, Hornik, Strobl, & Zeileis, Reference Hothorn, Hornik, Strobl and Zeileis2015) was run to confirm the hierarchical ordering of the constraints: text type ranked first, followed by text origin, and then time. Although the higher frequency of wer in O4 (46.6%) than in O3 (32.3%) suggests the decrease in wer was not linear, when only prose texts are considered it is evident that wer continued to decrease throughout Old English. To confirm this, two follow-up models were run using data from only prose texts: wer occurred at a significantly greater frequency in O2 than O3 and significantly more frequently in O3 than O4, illustrating a significant downward trajectory over time.
Middle English distributional analysis
For Middle English, 246 tokens were included in the envelope of variation, with twenty-seven attested variants (bachelor, baroun, beorn, burne, carlman, cherl, duȝeðe, erl, freke, gome, hathel, kempe, knape, kniȝt, ladde, lede, man, rahȝe, renk, schalk, segge, swein, þein, tulk, wepmann, wer, wyȝe). The number one variant was man, with 57.3% (see Table 5). Examples of use are provided in (9). In contrast with Old English, the only attestation of wer referring to a male individual came from the Early Middle English text Ormulum (9b). The low frequency of wer is consistent with evidence from the OED of its reported demise by Late Middle English (OED, were, n.1).Footnote 13 With the exception of (9b), when wer occurred in the Middle English data, it referred to a specific type of man, namely a married man, a use which was later usurped by the lexical item ‘husband.’Footnote 14

Table 5. Distribution of third-person male adult noun referents in Middle English

As for the distribution by text type (see Table 6), man was the overwhelming choice in Middle English prose (92%) but occupied 41.1% of the field in verse. Of the 168 tokens of third-person male adult noun referents in Middle English verse, forty-eight (18%) alliterated, suggesting that while alliteration still influenced lexical choices in Middle English verse, it played less of a role than in Old English verse. The diminished role of alliteration in Middle English, however, is indicative of a larger change in verse style, as 34% of the Middle English variants that did not alliterate in verse, instead rhymed (e.g., kniȝt - riȝt, man - þan). In texts such as Sir Orfeo and the Dancers of Colbek, rhyme is the emphasis, not alliteration.
Table 6. Distribution of Middle English variants by text type

Middle English multivariate analysis
A binary mixed effects logistic regression was run on the Middle English data, using man (the most frequent variant) as the application value. The output is reported in Table 7. The model found text type to significantly influence the probability of man to occur over any other variant, appearing more frequently in prose than in verse. text origin and time also significantly affected the occurrence of man. While, like in Old English, the model suggests that the increase in frequency of man was not consistent across time, when only prose texts are considered it is evident that man continued to increase in frequency throughout Middle English. text type significantly interacted with time due to high frequency of genre-specific variants in verse (e.g., knight). These variants occur frequently, not necessarily because they were used frequently in everyday discourse, but due to the nature of verse content, wherein references to knights and chivalry are common. The range for the factor weights, along with a random forest indicates that text type had the strongest effect on the variation, followed by time and text origin.
Table 7. Logistic regression of the factors influencing the use of man versus all other Middle English variants
Changes from Old English to Middle English
To examine changes from Old English to Middle English, the frequency of wer, guma, and man was plotted across time (Figures 1 and 2). Frequency was measured by comparing the number of times a variant occurred versus the total number of referentially equivalent tokens by subperiod. Figure 1 shows the demise of wer from Old English to Middle English and its gradual replacement by man. The spike in frequency of wer in O4 (Old English: 1050-1150 CE) and the dip in frequency of man in M3 (Middle English: 1350-1420 CE) is a function of text type interference. When only prose texts are considered, the trend is clearer (see Figure 2). The change from wer to man follows a clearly identifiable s-curve pattern.

Figure 1. The frequency of wer, guma, and man from Old English to Middle English.
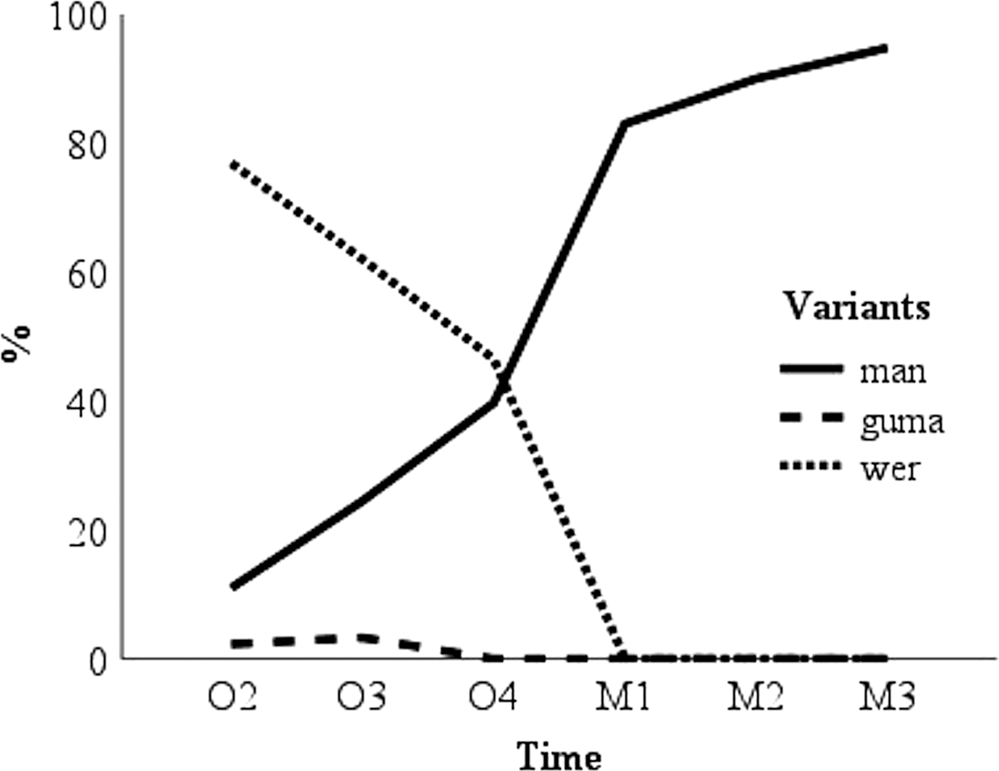
Figure 2. The frequency of wer, guma, and man in Old and Middle English prose texts.
Discussion
To examine changes within the set of third-person male adult noun referents in the early history of the English language, the present study examined the frequency of variants pertaining to this semantic field from Old English to Middle English. Distributional and multivariate analyses show a clear shift from wer in Old English to man in Middle English. Although the gender-inclusive use of man continued into Middle English, the number of instances in which man was used with reference to male-only individuals increased. The shift from wer to man follows an s-shaped distribution, a pattern typically observed in other areas of linguistic change (Nevalainen, Reference Nevalainen and Sanchez-Stockhammer2015; Tagliamonte & Smith, Reference Tagliamonte and Smith2021). While language change does not have to follow an s-shaped pattern (Kauhanen, Reference Kauhanen2017; Newberry, Ahern, Clark, & Plotkin, Reference Newberry, Ahern, Clark and Plotkin2017), an s-curve temporal trajectory is often viewed as a clear indication of lexical replacement (Blythe & Croft, Reference Blythe and Croft2012:278-279; Chambers, Reference Chambers, Chambers, Trudgill and Schilling Estes2002:361). Assuming the data in the present study are representative, the low frequency of wer and its eventual demise in Middle English illustrates lexical change within this onomasiological set. While the actuation problem occludes the causation of this change (Weinreich et al., Reference Weinreich, Labov and Herzog1968:102), one might speculate that the Anglo-Norman loanword werre ‘war’ (MED, werre, n.), which shows up in twelfth century texts, had an influence on the demise of wer, as wer and werre could have been homophonous.Footnote 15 Although homophony of forms may be too simplistic of an explanation to account for the loss of wer “man,” an explanation of this kind would be in line with the notion of a “homonymic clash” (Samuels, Reference Samuels1972:67-75), which has been proposed as a mechanism of change for several lexical items in Middle English. Since data show that wer was already decreasing throughout Old English, a homonymic clash could not have been the sole cause of this change, but this clash may have accelerated a change that was already underway.
Wer temporarily retreats to use as part of a related, but different, semantic field, namely “husband,” which later too was replaced by the competing lexical item husband.Footnote 16 To the question Where did wer go?, the present study shows that wer was gradually replaced by the competing variant man from Old English to Middle English, with a clear relationship between the increase in frequency of man and the decrease in frequency of wer. The present-day compound werewolf, literally ‘man-wolf,’ is one of the few remaining breadcrumbs of this once frequently used noun and remains in the language today only as a vestige.Footnote 17
One implication of this study is that lexical replacement is gradual, as the shift from wer to man appears to have taken place over approximately 400-500 years. However, there are two alternative explanations for the tardiness of this change. First, because frequently used lexical items are typically replaced less frequently (Pagel, Atkinson, & Meade, Reference Pagel, Atkinson and Meade2007), the high frequency of wer in Old English may account for why this replacement took centuries to be complete. The second factor to consider is the written transmission. Given that lexical choices are known to shift from generation to generation (Tagliamonte & Brooke, Reference Tagliamonte and Brooke2014; Tagliamonte & Jankowski, Reference Tagliamonte and Jankowski2019; Tagliamonte & Pabst, Reference Tagliamonte and Pabst2020), and the locus of linguistic change is generally acknowledged to be in spoken as opposed to written language (Milroy, Reference Milroy1992:32), the Old and Middle English extant manuscripts may leave the impression that this replacement was gradual even though the change may have been accelerated in spoken language but remained in the language in formal written contexts, as is attested in the extant manuscripts.Footnote 18 After all, there are well documented register effects that condition and constrain language variation and change (Biber, Reference Biber2012), which may have contributed to the longevity of this lexical replacement. The seemingly gradual nature of this change may therefore be a byproduct of the limited data that remain, that is, the notorious “bad data problem” (Labov, Reference Labov1994:11), as it is inevitable that an analysis of this kind would be construed through a written lens.
As for the factors contributing to variation, distributional and multivariate analyses indicate that text type and text origin significantly affected lexis. Variants such as wer and man were more frequent in prose than in verse, with Old English verse texts making use of a wider range of variants, likely due to alliterative requirements. Variants such as shalk (OE scealc) and renk (OE rinc) rarely occurred in Old English prose, suggesting that these variants were bound by stylistic tradition. Whether a text was translated from a Latin source also significantly influenced the lexical decisions in Old English, with wer occurring more frequently in translated texts. In contrast, in nontranslated texts a wider range of variants was employed (e.g., freca, rink), but this effect may be due to the skewed proportion of verse in nontranslated texts compared to translated ones. The higher frequency of wer in translated texts may also be attributed to the fact that Old English wer and Latin vir ‘man’ are cognates (Proto Germanic *uiraz/uiraR), although counterexamples in translation choice were found, as in (7) above.
Conclusion
The semantic field of third-person male adult noun referents is a dynamic and heterogeneous one, with analyses of present-day varieties of English pointing to recent changes within this domain. The present study showed that variation within this onomasiological set is not new and has existed since the beginning of the history of the English language. Wer was once the most frequently used variant to refer to a male adult, but it was gradually replaced over time by man. This diachronic shift in lexical preference followed a prototypical s-shaped distribution, suggesting that, like other areas of linguistic change, lexis may follow similar patterns of change. While research using apparent time data (Chambers, Reference Chambers1995) or short periods of time (Grieve et al., Reference Grieve, Nini and Guo2017) point to the applicability of s-shaped trajectories for lexical change, the analysis of change within the semantic field of third-person male adult noun referents over approximately six hundred years adds an important diachronic dimension to this discussion.
Acknowledgments
This paper was the recipient of the Richard M. Hogg Prize, awarded by the International Society for the Linguistics of English (ISLE, 2021). The author would like to thank Karen Beaman, Laurel Brinton, Thijs Porck, and Mo Pareles for their comments on the paper, along with the three anonymous reviewers.


















 Open access
Open access