



1. Introduction
Robustness is a core concern in machine learning, as models are deployed in classification tasks such as facial recognition [Reference Xu, Raja, Ramachandra and Busch36], medical imaging [Reference Paschali, Conjeti, Navarro and Navab25] and identifying traffic signs in self-driving cars [Reference Deng, Zheng, Zhang, Chen, Lou and Kim13]. Deep learning models exhibit a concerning security risk – small perturbations imperceptible to the human eye can cause a neural net to misclassify an image [Reference Biggio, Corona, Maiorca, Nelson, Šrndić, Laskov, Giacinto and Roli9, Reference Szegedy, Zaremba and Sutskever32]. The machine learning literature has proposed many defenses, but many of these techniques remain poorly understood. This paper analyzes the statistical consistency of a popular defense method that involves minimizing an adversarial surrogate risk.
The central goal in a classification task is minimizing the proportion of mislabeled data-points – also known as the classification risk. Minimizers to the classification risk are easy to compute analytically and are known as Bayes classifiers. In the adversarial setting, each point is perturbed by a malicious adversary before the classifier makes a prediciton. The proportion of mislabelled data under such an attack is called the adversarial classification risk, and minimizers to this risk are called adversarial Bayes classifiers. Unlike the standard classification setting, computing minimizers to the adversarial classification risk is a nontrivial task [Reference Bhagoji, Cullina and Mittal8, Reference Pydi and Jog27]. Further studies [Reference Frank15, Reference Gnecco-Heredia, Chevaleyre, Negrevergne, Meunier and Pydi18, Reference Pydi and Jog28, Reference Trillos and Murray33, Reference Trillos, Jacobs and Kim35] investigate additional properties of these minimizers, and Frank [Reference Frank15] describes a notion of uniqueness for adversarial Bayes classifiers. The main result in this paper will connect this notion of uniqueness the statistical consistency of a popular defense method.
The empirical adversarial classification error is a discrete notion and minimizing this quantity is computationally intractable. Instead, typical machine learning algorithms minimize a surrogate risk in place of the classification error. In the robust setting, the adversarial training algorithm uses a surrogate risk that computes the supremum of loss over the adversary’s possible attacks, which we refer to as adversarial surrogate risks. However, one must verify that minimizing this adversarial surrogate will also minimize the classification risk. A loss function is adversarially consistent for a particular data distribution if every minimizing sequence of the associated adversarial surrogate risk also minimizes the adversarial classification risk. A loss is simply called adversarially consistent if it is adversarially consistent for all possible data distributions. Surprisingly, Meunier et al. [Reference Meunier, Ettedgui, Pinot, Chevaleyre and Atif23] show that no convex surrogate is adversarially consistent, in contrast to the standard classification setting where most convex losses are statistically consistent [Reference Bartlett, Jordan and McAuliffe6, Reference Lin22, Reference Zhang24, Reference Steinwart31, Reference Zhang37].
Our contributions. We relate the statistical consistency of losses in the adversarial setting to the uniqueness of the adversarial Bayes classifier. Specifically, under reasonable assumptions, a convex loss is adversarially consistent for a specific data distribution iff the adversarial Bayes classifier is unique.
Prior work [Reference Frank15] further demonstrates several distributions for which the adversarial Bayes classifier is unique, and thus a typical convex loss would be consistent. Understanding general conditions under which uniqueness occurs is an open question.
Paper outline. Section 2 discusses related works, and Section 3 presents the problem background. Section 4 states our main theorem and presents some examples. Subsequently, Section 5 discusses intermediate results necessary for proving our main theorem. Next, our consistency results are proved in Sections 6 and 7. Appendices A and B present deferred proofs from Section 5, while Appendix C presents deferred proofs on surrogate risks from Sections 5 and 6. Finally, Appendix D presents deferred proofs from Section 7.
2. Related works
Our results are inspired by prior work that showed that no convex loss is adversarially consistent [Reference Awasthi, Mao, Mohri, Zhong, Chaudhuri, Jegelka, Song, Szepesvari, Niu and Sabato3, Reference Meunier, Ettedgui, Pinot, Chevaleyre and Atif23] yet a wide class of adversarial losses is adversarially consistent [Reference Frank and Niles-Weed16]. These consistency results rely on the theory of surrogate losses, studied by Bartlett et al. [Reference Bartlett, Jordan and McAuliffe6], Lin [Reference Lin22] in the standard classification setting; and by Frank and Niles-Weed Frank and Niles-Weed [Reference Frank and Niles-Weed17], Li and Telgarsky [Reference Li and Telgarsky21] in the adversarial setting. Furthermore, [Reference Awasthi, Mao, Mohri and Zhong2, Reference Bao, Scott and Sugiyama5, Reference Steinwart31] study a property of related to consistency called calibration, which [Reference Meunier, Ettedgui, Pinot, Chevaleyre and Atif23] relate to consistency. Complimenting this analysis, another line of research studies
 $\mathcal {H}$
-consistency, which refines the concept of consistency to specific function classes [Reference Awasthi, Mao, Mohri, Zhong, Chaudhuri, Jegelka, Song, Szepesvari, Niu and Sabato3, Reference Long26]. Our proof combines results on losses with minimax theorems for various adversarial risks, as studied by [Reference Frank and Niles-Weed16, Reference Frank and Niles-Weed17, Reference Pydi and Jog28, Reference Trillos, Jacobs and Kim34].
$\mathcal {H}$
-consistency, which refines the concept of consistency to specific function classes [Reference Awasthi, Mao, Mohri, Zhong, Chaudhuri, Jegelka, Song, Szepesvari, Niu and Sabato3, Reference Long26]. Our proof combines results on losses with minimax theorems for various adversarial risks, as studied by [Reference Frank and Niles-Weed16, Reference Frank and Niles-Weed17, Reference Pydi and Jog28, Reference Trillos, Jacobs and Kim34].
Furthermore, our result leverages recent results on the adversarial Bayes classifier, which are extensively studied by [Reference Awasthi, Frank and Mohri4, Reference Bhagoji, Cullina and Mittal8, Reference Bungert, Trillos and Murray10, Reference Frank and Niles-Weed16, Reference Pydi and Jog27, Reference Pydi and Jog28]. Specifically, [Reference Awasthi, Frank and Mohri4, Reference Bhagoji, Cullina and Mittal8, Reference Bungert, Trillos and Murray10] prove the existence of the adversarial Bayes classifier, while Trillos and Murray [Reference Trillos and Murray33] derive necessary conditions that describe the boundary of the adversarial Bayes classifier. Frank [Reference Frank15] defines the notion of uniqueness up to degeneracy and proves that in one dimension, under reasonable distributional assumptions, every adversarial Bayes classifier is equivalent up to degeneracy to an adversarial Bayes classifier which satisfies the necessary conditions of [Reference Trillos and Murray33]. Finally, [Reference Bhagoji, Cullina and Mittal8, Reference Pydi and Jog27] also calculate the adversarial Bayes classifier for distributions in dimensions higher than one by finding an optimal coupling, but whether this method can calculate the equivalence classes under equivalence up to degeneracy remains an open question.
3. Notation and background
3.1 Surrogate risks
This paper investigates binary classification on
 $\mathbb {R}^d$
with labels
$\mathbb {R}^d$
with labels
 $\{-1,+1\}$
. Class
$\{-1,+1\}$
. Class
 $-1$
is distributed according to a measure
$-1$
is distributed according to a measure
 ${\mathbb P}_0$
while class
${\mathbb P}_0$
while class
 $+1$
is distributed according to measure
$+1$
is distributed according to measure
 ${\mathbb P}_1$
. A classifier is a Borel set
${\mathbb P}_1$
. A classifier is a Borel set
 $A$
and the classification risk of a set
$A$
and the classification risk of a set
 $A$
is the expected proportion of errors when label
$A$
is the expected proportion of errors when label
 $+1$
is predicted on
$+1$
is predicted on
 $A$
and label
$A$
and label
 $-1$
is predicted on
$-1$
is predicted on
 $A^C$
:
$A^C$
:
 \begin{align*} R(A)=\int {\mathbf {1}}_{A^C} d{\mathbb P}_1+\int {\mathbf {1}}_{A}d{\mathbb P}_0. \end{align*}
\begin{align*} R(A)=\int {\mathbf {1}}_{A^C} d{\mathbb P}_1+\int {\mathbf {1}}_{A}d{\mathbb P}_0. \end{align*}
A minimizer to
 $R$
is called a Bayes classifier.
$R$
is called a Bayes classifier.
However, minimizing the empirical classification risk is a computationally intractable problem [Reference Ben-David, Eiron and Long7]. A common approach is to instead learn a function
 $f$
and then threshold at zero to obtain the classifier
$f$
and then threshold at zero to obtain the classifier
 $A=\{{\mathbf x}\,:\, f({\mathbf x})\gt 0\}$
. We define the classification risk of a function
$A=\{{\mathbf x}\,:\, f({\mathbf x})\gt 0\}$
. We define the classification risk of a function
 $f$
by
$f$
by
 \begin{align} R(f)=R(\{f\gt 0\})=\int {\mathbf {1}}_{f\leq 0}d{\mathbb P}_1+\int {\mathbf {1}}_{{-}f\lt 0}d{\mathbb P}_0 \end{align}
\begin{align} R(f)=R(\{f\gt 0\})=\int {\mathbf {1}}_{f\leq 0}d{\mathbb P}_1+\int {\mathbf {1}}_{{-}f\lt 0}d{\mathbb P}_0 \end{align}

Figure 1. Several common loss functions for classification along with the indicator
 ${\mathbf {1}}_{\alpha \leq 0}$
.
${\mathbf {1}}_{\alpha \leq 0}$
.
In order to learn
 $f$
, machine learning algorithms typically minimize a better-behaved alternative to the classification risk called a surrogate risk. To obtain this risk, we replace the indicator functions in (1) with the loss
$f$
, machine learning algorithms typically minimize a better-behaved alternative to the classification risk called a surrogate risk. To obtain this risk, we replace the indicator functions in (1) with the loss
 $\phi$
, resulting in:
$\phi$
, resulting in:
 \begin{align} R_\phi (f)=\int \phi (f)d{\mathbb P}_1+\int \phi ({-}f) d{\mathbb P}_0\,. \end{align}
\begin{align} R_\phi (f)=\int \phi (f)d{\mathbb P}_1+\int \phi ({-}f) d{\mathbb P}_0\,. \end{align}
We restrict to losses with similar properties to the indicator functions in (1) yet are easier to optimize. In particular we require:
Assumption 1.
The loss
 $\phi$
is nonincreasing, continuous, and
$\phi$
is nonincreasing, continuous, and
 $\lim _{\alpha \to \infty } \phi (\alpha )=0$
.
$\lim _{\alpha \to \infty } \phi (\alpha )=0$
.
See Figure 1 for a comparison of the indicator function and a several common losses. Losses on
 $\mathbb {R}$
-valued functions in machine learning typically satisfy Assumption1.
$\mathbb {R}$
-valued functions in machine learning typically satisfy Assumption1.
3.2 Adversarial surrogate risks
In the adversarial setting, a malicious adversary corrupts each data point. We model these corruptions as bounded by
 $\epsilon$
in some norm
$\epsilon$
in some norm
 $\|\cdot \|$
. The adversary knows both the classifier
$\|\cdot \|$
. The adversary knows both the classifier
 $A$
and the label of each data point. Thus, a point
$A$
and the label of each data point. Thus, a point
 $({\mathbf x},+1)$
is misclassified when it can be displaced into the set
$({\mathbf x},+1)$
is misclassified when it can be displaced into the set
 $A^C$
by a perturbation of size at most
$A^C$
by a perturbation of size at most
 $\epsilon$
. This statement can be conveniently written in terms of a supremum. For any function
$\epsilon$
. This statement can be conveniently written in terms of a supremum. For any function
 $g\,:\,\mathbb {R}^d\to \mathbb {R}$
, define
$g\,:\,\mathbb {R}^d\to \mathbb {R}$
, define
 \begin{align*} S_\epsilon (g)({\mathbf x})=\sup _{{\mathbf x}^{\prime} \in \overline {B_\epsilon ({\mathbf x})}} g({\mathbf x}^{\prime}), \end{align*}
\begin{align*} S_\epsilon (g)({\mathbf x})=\sup _{{\mathbf x}^{\prime} \in \overline {B_\epsilon ({\mathbf x})}} g({\mathbf x}^{\prime}), \end{align*}
where
 $\overline {B_\epsilon ({\mathbf x})}=\{{\mathbf x}^{\prime}\,:\,\|{\mathbf x}^{\prime}-{\mathbf x}\|\leq \epsilon \}$
is the ball of allowed perturbations. The expected error rate of a classifier
$\overline {B_\epsilon ({\mathbf x})}=\{{\mathbf x}^{\prime}\,:\,\|{\mathbf x}^{\prime}-{\mathbf x}\|\leq \epsilon \}$
is the ball of allowed perturbations. The expected error rate of a classifier
 $A$
under an adversarial attack is then
$A$
under an adversarial attack is then
 \begin{align*} R^\epsilon (A)=\int S_\epsilon ({\mathbf {1}}_{A^C}) d{\mathbb P}_1+\int S_\epsilon ({\mathbf {1}}_{A})d{\mathbb P}_0, \end{align*}
\begin{align*} R^\epsilon (A)=\int S_\epsilon ({\mathbf {1}}_{A^C}) d{\mathbb P}_1+\int S_\epsilon ({\mathbf {1}}_{A})d{\mathbb P}_0, \end{align*}
which is known as the adversarial classification risk.Footnote 1 Minimizers of
 $R^\epsilon$
are called adversarial Bayes classifiers.
$R^\epsilon$
are called adversarial Bayes classifiers.
Just like (1), we define
 $R^\epsilon (f)=R^\epsilon (\{f\gt 0\})$
:
$R^\epsilon (f)=R^\epsilon (\{f\gt 0\})$
:
 \begin{align*} R^\epsilon (f)=\int S_\epsilon ({\mathbf {1}}_{f\leq 0})d{\mathbb P}_1+\int S_\epsilon ({\mathbf {1}}_{f\gt 0})d{\mathbb P}_0 \end{align*}
\begin{align*} R^\epsilon (f)=\int S_\epsilon ({\mathbf {1}}_{f\leq 0})d{\mathbb P}_1+\int S_\epsilon ({\mathbf {1}}_{f\gt 0})d{\mathbb P}_0 \end{align*}
Again, minimizing an empirical adversarial classification risk is computationally intractable. A surrogate to the adversarial classification risk is formulated asFootnote 2
 \begin{align} R_\phi ^\epsilon (f)=\int S_\epsilon ( \phi \circ f)d{\mathbb P}_1 +\int S_\epsilon ( \phi \circ -f)d{\mathbb P}_0. \end{align}
\begin{align} R_\phi ^\epsilon (f)=\int S_\epsilon ( \phi \circ f)d{\mathbb P}_1 +\int S_\epsilon ( \phi \circ -f)d{\mathbb P}_0. \end{align}
3.3 The statistical consistency of surrogate risks
Learning algorithms typically minimize a surrogate risk using an iterative procedure, thereby producing a sequence of functions
 $f_n$
. One would hope that that
$f_n$
. One would hope that that
 $f_n$
also minimizes that corresponding classification risk. This property is referred to as statistical consistency.Footnote
3
$f_n$
also minimizes that corresponding classification risk. This property is referred to as statistical consistency.Footnote
3
Definition 1.
-
• If every sequence of functions
 $f_n$
that minimizes
$R_\phi$
also minimizes
$R$
for the distribution
${\mathbb P}_0,{\mathbb P}_1$
, then the loss
$\phi$
is consistent for the distribution
${\mathbb P}_0,{\mathbb P}_1$
. If
$R_\phi$
is consistent for every distribution
${\mathbb P}_0,{\mathbb P}_1$
, we say that
$\phi$
is consistent.
$f_n$
that minimizes
$R_\phi$
also minimizes
$R$
for the distribution
${\mathbb P}_0,{\mathbb P}_1$
, then the loss
$\phi$
is consistent for the distribution
${\mathbb P}_0,{\mathbb P}_1$
. If
$R_\phi$
is consistent for every distribution
${\mathbb P}_0,{\mathbb P}_1$
, we say that
$\phi$
is consistent.
-
• If every sequence of functions
$f_n$
that minimizes
$R_\phi ^\epsilon$
also minimizes
$R^\epsilon$
for the distribution
${\mathbb P}_0,{\mathbb P}_1$
, then the loss
$\phi$
is adversarially consistent for the distribution
${\mathbb P}_0,{\mathbb P}_1$
. If
$R_\phi ^\epsilon$
is adversarially consistent for every distribution
${\mathbb P}_0,{\mathbb P}_1$
, we say that
$\phi$
is adversarially consistent.


















A case of particular interest is convex
 $\phi$
, as these losses are ubiquitous in machine learning. In the non-adversarial context, Theorem2 of [Reference Bartlett, Jordan and McAuliffe6] shows that a convex loss
$\phi$
, as these losses are ubiquitous in machine learning. In the non-adversarial context, Theorem2 of [Reference Bartlett, Jordan and McAuliffe6] shows that a convex loss
 $\phi$
is consistent iff
$\phi$
is consistent iff
 $\phi$
is differentiable at zero and
$\phi$
is differentiable at zero and
 $\phi ^{\prime}(0)\lt 0$
. In contrast, Meunier et al. [Reference Meunier, Ettedgui, Pinot, Chevaleyre and Atif23] show that no convex loss is adversarially consistent. Further results of [Reference Frank and Niles-Weed16] characterize the adversarially consistent losses in terms of the function
$\phi ^{\prime}(0)\lt 0$
. In contrast, Meunier et al. [Reference Meunier, Ettedgui, Pinot, Chevaleyre and Atif23] show that no convex loss is adversarially consistent. Further results of [Reference Frank and Niles-Weed16] characterize the adversarially consistent losses in terms of the function
 $C_\phi ^*$
:
$C_\phi ^*$
:
Theorem 1.
The loss
 $\phi$
is adversarially consistent if and only if
$\phi$
is adversarially consistent if and only if
 $C_\phi ^*(1/2)\lt \phi (0)$
.
$C_\phi ^*(1/2)\lt \phi (0)$
.
Notice that all convex losses satisfy
 $C_\phi ^*(1/2)=\phi (0)$
: By evaluating at
$C_\phi ^*(1/2)=\phi (0)$
: By evaluating at
 $\alpha =0$
, one can conclude that
$\alpha =0$
, one can conclude that
 $C_\phi ^*(1/2)= \inf _\alpha C_\phi (1/2,\alpha )\leq C_\phi (1/2,0)=\phi (0)$
. However,
$C_\phi ^*(1/2)= \inf _\alpha C_\phi (1/2,\alpha )\leq C_\phi (1/2,0)=\phi (0)$
. However,
 \begin{align*} C_\phi ^*(1/2)=\inf _\alpha \frac 12 \phi (\alpha )+\frac 12 \phi (-\alpha )\geq \phi (0) \end{align*}
\begin{align*} C_\phi ^*(1/2)=\inf _\alpha \frac 12 \phi (\alpha )+\frac 12 \phi (-\alpha )\geq \phi (0) \end{align*}
due to convexity. Notice that Theorem1 does not preclude the adversarial consistency of a loss satisfying
 $C_\phi ^*(1/2)=\phi (0)$
for some particular
$C_\phi ^*(1/2)=\phi (0)$
for some particular
 ${\mathbb P}_0,{\mathbb P}_1$
. Prior work [Reference Frank and Niles-Weed16, Reference Meunier, Ettedgui, Pinot, Chevaleyre and Atif23] provides a counterexample to consistency only for a single, atypical distribution. The goal of this paper is characterizing when adversarial consistency fails for losses satisfying
${\mathbb P}_0,{\mathbb P}_1$
. Prior work [Reference Frank and Niles-Weed16, Reference Meunier, Ettedgui, Pinot, Chevaleyre and Atif23] provides a counterexample to consistency only for a single, atypical distribution. The goal of this paper is characterizing when adversarial consistency fails for losses satisfying
 $C_\phi ^*(1/2)=\phi (0)$
.
$C_\phi ^*(1/2)=\phi (0)$
.
4. Main result
Prior work has shown that there always exists minimizers to the adversarial classification risk, which are referred to as adversarial Bayes classifiers (see Theorem3 below). Furthermore, Frank [Reference Frank15] developed a notion of uniqueness for adversarial Bayes classifiers.
Definition 2.
The adversarial Bayes classifiers
 $A_1$
and
$A_1$
and
 $A_2$
are equivalent up to degeneracy if any Borel set
$A_2$
are equivalent up to degeneracy if any Borel set
 $A$
with
$A$
with
 $A_1\cap A_2\subset A\subset A_1\cup A_2$
is also an adversarial Bayes classifier. The adversarial Bayes classifier is unique up to degeneracy if any two adversarial Bayes classifiers are equivalent up to degeneracy.
$A_1\cap A_2\subset A\subset A_1\cup A_2$
is also an adversarial Bayes classifier. The adversarial Bayes classifier is unique up to degeneracy if any two adversarial Bayes classifiers are equivalent up to degeneracy.
When the measure
 \begin{align*} {\mathbb P}={\mathbb P}_0+{\mathbb P}_1 \end{align*}
\begin{align*} {\mathbb P}={\mathbb P}_0+{\mathbb P}_1 \end{align*}
is absolutely continuous with respect to Lebesgue measure, then equivalence up to degeneracy is an equivalence relation [Reference Frank15, Theorem 3.3]. The central result of this paper relates the consistency of convex losses to the uniqueness of the adversarial Bayes classifier.
Theorem 2.
Assume that
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure and let
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure and let
 $\phi$
be a loss with
$\phi$
be a loss with
 $C_\phi ^*(1/2)=\phi (0)$
. Then
$C_\phi ^*(1/2)=\phi (0)$
. Then
 $\phi$
is adversarially consistent for the distribution
$\phi$
is adversarially consistent for the distribution
 ${\mathbb P}_0$
,
${\mathbb P}_0$
,
 ${\mathbb P}_1$
iff the adversarial Bayes classifier is unique up to degeneracy.
${\mathbb P}_1$
iff the adversarial Bayes classifier is unique up to degeneracy.
Prior results of Frank [Reference Frank15] provide the tools for verifying when the adversarial Bayes classifier is unique up to degeneracy for a wide class of one dimensional distributions. Below we highlight two interesting examples. In the examples below, the function
 $p_1$
will represent the density of
$p_1$
will represent the density of
 ${\mathbb P}_1$
and the function
${\mathbb P}_1$
and the function
 $p_0$
will represent the density of
$p_0$
will represent the density of
 ${\mathbb P}_0$
.
${\mathbb P}_0$
.
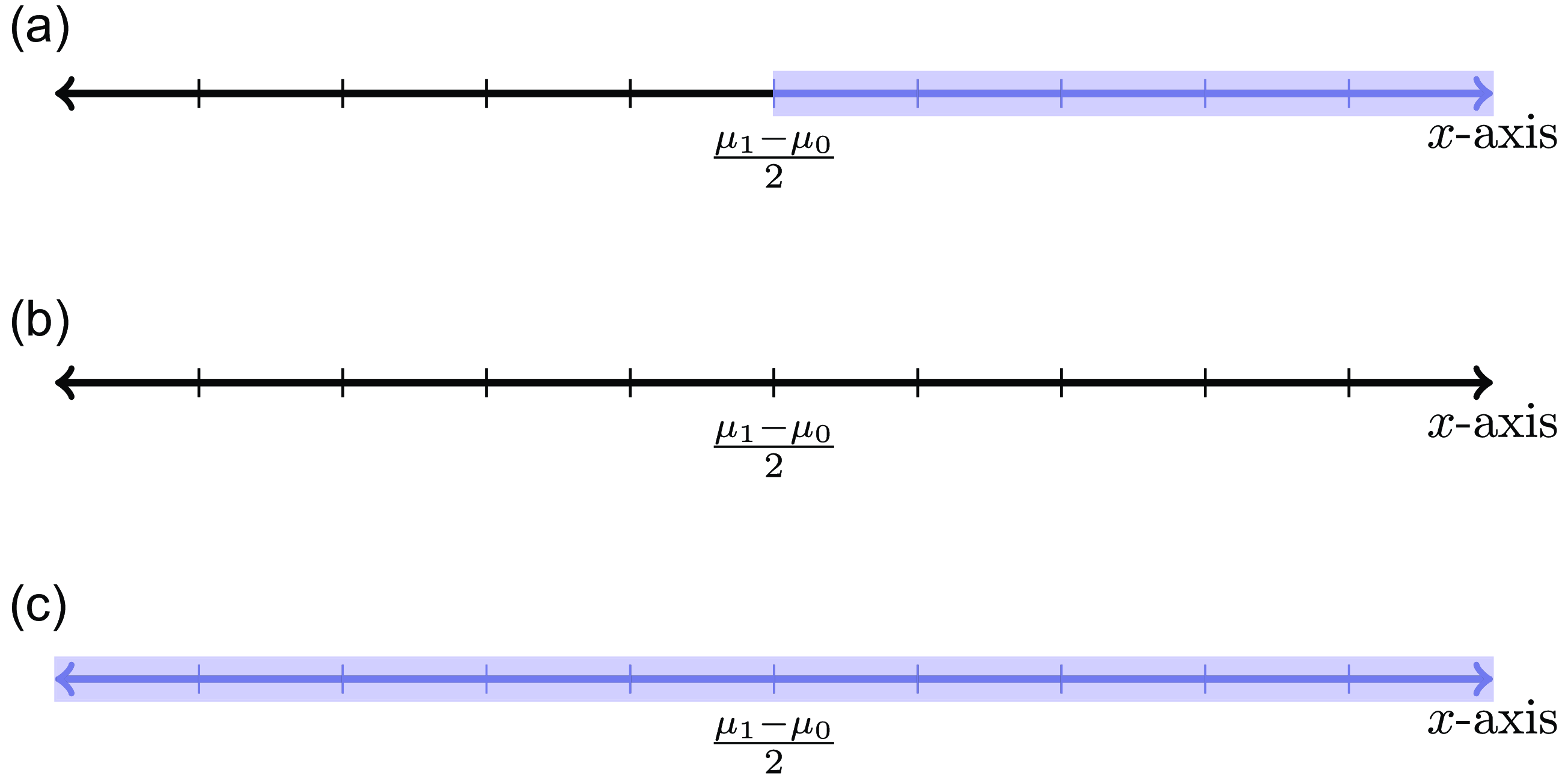
Figure 2. The adversarial Bayes classifier for two gaussians with equal variances and differing means. We assume in this figure that
 $\mu _1\gt \mu _0$
. The shaded blue area depicts the region inside the adversarial Bayes classifier. Figure 2a depicts an adversarial Bayes when
$\mu _1\gt \mu _0$
. The shaded blue area depicts the region inside the adversarial Bayes classifier. Figure 2a depicts an adversarial Bayes when
 $\epsilon \leq (\mu _1-\mu _0)/2$
and Figure 2b and 2c depict the adversarial Bayes classifier when
$\epsilon \leq (\mu _1-\mu _0)/2$
and Figure 2b and 2c depict the adversarial Bayes classifier when
 $\epsilon \geq (\mu _1-\mu _0)/2$
. (See [Reference Frank15, Example 4.1] for a justification of these illustrations.) the adversarial Bayes classifiers in Figure 2b and 2c are not equivalent up to degeneracy.
$\epsilon \geq (\mu _1-\mu _0)/2$
. (See [Reference Frank15, Example 4.1] for a justification of these illustrations.) the adversarial Bayes classifiers in Figure 2b and 2c are not equivalent up to degeneracy.
-
• Consider mean zero gaussians with different variances:
$p_0(x)=\frac 1 {2\sqrt {2\pi } \sigma _0}e^{-x^2/2\sigma _0^2}$
and
$p_1(x)=\frac 1 {2\sqrt {2\pi } \sigma _1}e^{-x^2/2\sigma _1^2}$
. The adversarial Bayes classifier is unique up to degeneracy for all
$\epsilon$
[Reference Frank15, Example 4.2]. -
• Consider gaussians with variance
$\sigma$
and means
$\mu _0$
and
$\mu _1$
:
$p_0(x)=\frac 1 {\sqrt {2\pi } \sigma }e^{-(x-\mu _0)^2/2\sigma ^2}$
and
$p_1(x)=\frac 1 {\sqrt {2\pi } \sigma }e^{-(x-\mu _1)^2/2\sigma ^2}$
. Then the adversarial Bayes classifier is unique up to degeneracy iff
$\epsilon \lt |\mu _1-\mu _0|/2$
[Reference Frank15, Example 4.1]. See Figure 2 for an illustration of the adversarial Bayes classifiers for this distribution.









Theorem2 implies that a convex loss is always adversarially consistent for the first gaussian mixture above. Furthermore, a convex loss is adversarially consistent for the second gaussian mixture when the perturbation radius
 $\epsilon$
is small compared to the differences between the means. However, Frank [Reference Frank15, Example 4.5] provides an example of a distribution for which the adversarial Bayes classifier is not unique up to degeneracy for all
$\epsilon$
is small compared to the differences between the means. However, Frank [Reference Frank15, Example 4.5] provides an example of a distribution for which the adversarial Bayes classifier is not unique up to degeneracy for all
 $\epsilon \gt 0$
, even though the Bayes classifier is unique. At the same time, one would hope that if the Bayes classifier is unique and
$\epsilon \gt 0$
, even though the Bayes classifier is unique. At the same time, one would hope that if the Bayes classifier is unique and
 ${\mathbb P}_0$
,
${\mathbb P}_0$
,
 ${\mathbb P}_1$
are sufficiently regular, then the adversarial Bayes classifier would be unique up to degeneracy for sufficiently small
${\mathbb P}_1$
are sufficiently regular, then the adversarial Bayes classifier would be unique up to degeneracy for sufficiently small
 $\epsilon$
. In general, understanding when the adversarial Bayes classifier is unique up to degeneracy for well-behaved distributions is an open problem.
$\epsilon$
. In general, understanding when the adversarial Bayes classifier is unique up to degeneracy for well-behaved distributions is an open problem.
The examples above rely on the techniques of [Reference Frank15] for calculating the equivalence classes under uniqueness up to degeneracy. Frank [Reference Frank15] proves that in one dimension, if
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure, every adversarial Bayes classifier is equivalent up to degeneracy to an adversarial Bayes classifier whose boundary points are strictly more than
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure, every adversarial Bayes classifier is equivalent up to degeneracy to an adversarial Bayes classifier whose boundary points are strictly more than
 $2\epsilon$
apart [Reference Frank15, Theorem 3.5]. Therefore, to find all adversarial Bayes classifiers under equivalence under degeneracy, it suffices to consider all sets whose boundary points satisfy the first order necessary conditions obtained by differentiating the adversarial classification risk of a set
$2\epsilon$
apart [Reference Frank15, Theorem 3.5]. Therefore, to find all adversarial Bayes classifiers under equivalence under degeneracy, it suffices to consider all sets whose boundary points satisfy the first order necessary conditions obtained by differentiating the adversarial classification risk of a set
 $A$
with respect to its boundary points [Reference Frank15, Theorem 3.7]. The corresponding statement in higher dimensions is false – there exist distributions for which no adversarial Bayes classifier has enough regularity to allow for an equivalent statement. For instance, Bungert et al. [Reference Bungert, Trillos and Murray10] demonstrate a distribution for which there is no adversarial Bayes classifier with two-sided tangent balls at all points in the boundary. Developing a general method for calculating these equivalence classes in dimensions higher than one remains an open problem.
$A$
with respect to its boundary points [Reference Frank15, Theorem 3.7]. The corresponding statement in higher dimensions is false – there exist distributions for which no adversarial Bayes classifier has enough regularity to allow for an equivalent statement. For instance, Bungert et al. [Reference Bungert, Trillos and Murray10] demonstrate a distribution for which there is no adversarial Bayes classifier with two-sided tangent balls at all points in the boundary. Developing a general method for calculating these equivalence classes in dimensions higher than one remains an open problem.
Proposition2 in Section 6 presents a condition under which one can conclude consistency without the absolute continuity assumption. This result proves consistency whenever the optimal adversarial classification risk is zero, see the discussion after Proposition2 for details. Consequently, if
 $\mathrm {supp} {\mathbb P}_0$
and
$\mathrm {supp} {\mathbb P}_0$
and
 $\mathrm {supp} {\mathbb P}_1$
are separated by more than
$\mathrm {supp} {\mathbb P}_1$
are separated by more than
 $2\epsilon$
, then consistent losses are always adversarially consistent for such distributions. On the other hand, our analysis of the reverse direction of Theorem2 requires the absolute continuity assumption. Using Proposition2 to further understand consistency is an open question.
$2\epsilon$
, then consistent losses are always adversarially consistent for such distributions. On the other hand, our analysis of the reverse direction of Theorem2 requires the absolute continuity assumption. Using Proposition2 to further understand consistency is an open question.
5. Preliminary results
5.1 Minimizers of standard risks
Minimizers to the classification risk can be expressed in terms of the measure
 $\mathbb P$
and the function
$\mathbb P$
and the function
 $\eta =d{\mathbb P}_1/d{\mathbb P}$
. The risk
$\eta =d{\mathbb P}_1/d{\mathbb P}$
. The risk
 $R$
in terms of these quantities is
$R$
in terms of these quantities is
 \begin{align*} R(A)= \int C(\eta, {\mathbf {1}}_A)d{\mathbb P}. \end{align*}
\begin{align*} R(A)= \int C(\eta, {\mathbf {1}}_A)d{\mathbb P}. \end{align*}
and
 $\inf _A R(A)=\int C^*(\eta )d{\mathbb P}$
where the functions
$\inf _A R(A)=\int C^*(\eta )d{\mathbb P}$
where the functions
 $C\,:\,[0,1]\times \{0,1\}\to \mathbb {R}$
and
$C\,:\,[0,1]\times \{0,1\}\to \mathbb {R}$
and
 $C^*\,:\,[0,1]\to \mathbb {R}$
are defined by
$C^*\,:\,[0,1]\to \mathbb {R}$
are defined by
 \begin{align} C(\eta, b)=\eta b+(1-\eta )(1-b),\quad C^*(\eta )=\inf _{b\in \{0,1\}} C(\eta, b)=\min \!(\eta, 1-\eta ). \end{align}
\begin{align} C(\eta, b)=\eta b+(1-\eta )(1-b),\quad C^*(\eta )=\inf _{b\in \{0,1\}} C(\eta, b)=\min \!(\eta, 1-\eta ). \end{align}
Thus, if
 $A$
is a minimizer of
$A$
is a minimizer of
 $R$
, then
$R$
, then
 ${\mathbf {1}}_A$
must minimize the function
${\mathbf {1}}_A$
must minimize the function
 $C(\eta, \cdot )$
$C(\eta, \cdot )$
 $\mathbb P$
-almost everywhere. Consequently, the sets
$\mathbb P$
-almost everywhere. Consequently, the sets
 \begin{align} \{{\mathbf x}\,:\,\eta ({\mathbf x})\gt 1/2\} \quad \text {and} \quad \{{\mathbf x}\,:\,\eta ({\mathbf x})\geq 1/2\} \end{align}
\begin{align} \{{\mathbf x}\,:\,\eta ({\mathbf x})\gt 1/2\} \quad \text {and} \quad \{{\mathbf x}\,:\,\eta ({\mathbf x})\geq 1/2\} \end{align}
are both Bayes classifiers.
Similarly, one can compute the infimum of
 $R_\phi$
by expressing the risk in terms of the quantities
$R_\phi$
by expressing the risk in terms of the quantities
 $\mathbb P$
and
$\mathbb P$
and
 $\eta$
:
$\eta$
:
 \begin{align} R_\phi (f)=\int C_\phi (\eta ({\mathbf x}),f({\mathbf x}))d{\mathbb P} \end{align}
\begin{align} R_\phi (f)=\int C_\phi (\eta ({\mathbf x}),f({\mathbf x}))d{\mathbb P} \end{align}
and
 $\inf _f R_\phi (f)=\int C_\phi ^*(\eta ({\mathbf x}))d{\mathbb P}({\mathbf x})$
where the functions
$\inf _f R_\phi (f)=\int C_\phi ^*(\eta ({\mathbf x}))d{\mathbb P}({\mathbf x})$
where the functions
 $C_\phi (\eta, \alpha )$
and
$C_\phi (\eta, \alpha )$
and
 $C_\phi ^*(\eta )$
are defined by
$C_\phi ^*(\eta )$
are defined by
 \begin{align} C_\phi (\eta, \alpha ) = \eta \phi (\alpha )+(1-\eta )\phi (-\alpha ),\quad C_\phi ^*(\eta )=\inf _\alpha C_\phi (\eta, \alpha ) \end{align}
\begin{align} C_\phi (\eta, \alpha ) = \eta \phi (\alpha )+(1-\eta )\phi (-\alpha ),\quad C_\phi ^*(\eta )=\inf _\alpha C_\phi (\eta, \alpha ) \end{align}
for
 $\eta \in [0,1]$
. Thus, a minimizer
$\eta \in [0,1]$
. Thus, a minimizer
 $f$
of
$f$
of
 $R_\phi$
must minimize
$R_\phi$
must minimize
 $C_\phi (\eta ({\mathbf x}),\cdot )$
almost everywhere according to the probability measure
$C_\phi (\eta ({\mathbf x}),\cdot )$
almost everywhere according to the probability measure
 $\mathbb P$
. Because
$\mathbb P$
. Because
 $\phi$
is continuous, the function
$\phi$
is continuous, the function
 \begin{align} \alpha _\phi (\eta )=\inf \{\alpha \in \overline {\mathbb {R}}\,:\, \alpha \text { is a minimizer of }C_\phi (\eta, \cdot )\} \end{align}
\begin{align} \alpha _\phi (\eta )=\inf \{\alpha \in \overline {\mathbb {R}}\,:\, \alpha \text { is a minimizer of }C_\phi (\eta, \cdot )\} \end{align}
maps each
 $\eta$
to the smallest minimizer of
$\eta$
to the smallest minimizer of
 $C_\phi (\eta, \cdot )$
. Consequently, the function
$C_\phi (\eta, \cdot )$
. Consequently, the function
 \begin{align} \alpha _\phi (\eta ({\mathbf x})) \end{align}
\begin{align} \alpha _\phi (\eta ({\mathbf x})) \end{align}
minimizes
 $C_\phi (\eta ({\mathbf x}),\cdot )$
at each point
$C_\phi (\eta ({\mathbf x}),\cdot )$
at each point
 $\mathbf x$
. Next, we will argue this function is measurable, and therefore is a minimizer of the risk
$\mathbf x$
. Next, we will argue this function is measurable, and therefore is a minimizer of the risk
 $R_\phi$
.
$R_\phi$
.
Lemma 1.
The function
 $\alpha _\phi \,:\,[0,1]\to \overline {\mathbb {R}}$
that maps
$\alpha _\phi \,:\,[0,1]\to \overline {\mathbb {R}}$
that maps
 $\eta$
to the smallest minimizer of
$\eta$
to the smallest minimizer of
 $C_\phi (\eta, \cdot )$
is non-decreasing.
$C_\phi (\eta, \cdot )$
is non-decreasing.
The proof of this result is presented below Lemma7 in Appendix C. Because
 $\alpha _\phi$
is monotonic, the composition in (9) is always measurable, and thus this function is a minimizer of
$\alpha _\phi$
is monotonic, the composition in (9) is always measurable, and thus this function is a minimizer of
 $R_\phi$
. Allowing for minimizers in extended real numbers
$R_\phi$
. Allowing for minimizers in extended real numbers
 $\overline {\mathbb {R}}=\{-\infty, +\infty \}\cup \mathbb {R}$
is necessary for certain losses – for instance when
$\overline {\mathbb {R}}=\{-\infty, +\infty \}\cup \mathbb {R}$
is necessary for certain losses – for instance when
 $\phi$
is the exponential loss, then
$\phi$
is the exponential loss, then
 $C_\phi (1,\alpha )= e^{-\alpha }$
does not assume its infimum on
$C_\phi (1,\alpha )= e^{-\alpha }$
does not assume its infimum on
 $\mathbb {R}$
.
$\mathbb {R}$
.
5.2 Dual problems for the adversarial risks
The proof Theorem2 relies on a dual formulation of the adversarial classification problem involving the Wasserstein-
 $\infty$
metric. Informally, a measure
$\infty$
metric. Informally, a measure
 ${\mathbb Q}^{\prime}$
is within
${\mathbb Q}^{\prime}$
is within
 $\epsilon$
of
$\epsilon$
of
 $\mathbb Q$
in the Wasserstein-
$\mathbb Q$
in the Wasserstein-
 $\infty$
metric if one can produce
$\infty$
metric if one can produce
 ${\mathbb Q}^{\prime}$
by perturbing each point in
${\mathbb Q}^{\prime}$
by perturbing each point in
 $\mathbb {R}^d$
by at most
$\mathbb {R}^d$
by at most
 $\epsilon$
under the measure
$\epsilon$
under the measure
 $\mathbb Q$
. The formal definition of the Wasserstein-
$\mathbb Q$
. The formal definition of the Wasserstein-
 $\infty$
metric involves couplings between probability measures: a coupling between two Borel measures
$\infty$
metric involves couplings between probability measures: a coupling between two Borel measures
 $\mathbb Q$
and
$\mathbb Q$
and
 ${\mathbb Q}^{\prime}$
with
${\mathbb Q}^{\prime}$
with
 ${\mathbb Q}(\mathbb {R}^d)={\mathbb Q}^{\prime}(\mathbb {R}^d)$
is a measure
${\mathbb Q}(\mathbb {R}^d)={\mathbb Q}^{\prime}(\mathbb {R}^d)$
is a measure
 $\gamma$
on
$\gamma$
on
 $\mathbb {R}^d\times \mathbb {R}^d$
with marginals
$\mathbb {R}^d\times \mathbb {R}^d$
with marginals
 $\mathbb Q$
and
$\mathbb Q$
and
 ${\mathbb Q}^{\prime}$
:
${\mathbb Q}^{\prime}$
:
 $\gamma (A\times \mathbb {R}^d)={\mathbb Q}(A)$
and
$\gamma (A\times \mathbb {R}^d)={\mathbb Q}(A)$
and
 $\gamma (\mathbb {R}^d\times A)={\mathbb Q}^{\prime}(A)$
for any Borel set
$\gamma (\mathbb {R}^d\times A)={\mathbb Q}^{\prime}(A)$
for any Borel set
 $A$
. The set of all such couplings is denoted
$A$
. The set of all such couplings is denoted
 $\Pi ({\mathbb Q},{\mathbb Q}^{\prime})$
. The Wasserstein-
$\Pi ({\mathbb Q},{\mathbb Q}^{\prime})$
. The Wasserstein-
 $\infty$
distance between the two measures is then
$\infty$
distance between the two measures is then
 \begin{align*} W_\infty ({\mathbb Q},{\mathbb Q}^{\prime})= \inf _{\gamma \in \Pi ({\mathbb Q},{\mathbb Q}^{\prime})} \mathop {\textrm{ess sup}}\limits_{({\mathbf x},{\mathbf x}^{\prime})\sim \gamma } \|{\mathbf x}-{\mathbf x}^{\prime}\| \end{align*}
\begin{align*} W_\infty ({\mathbb Q},{\mathbb Q}^{\prime})= \inf _{\gamma \in \Pi ({\mathbb Q},{\mathbb Q}^{\prime})} \mathop {\textrm{ess sup}}\limits_{({\mathbf x},{\mathbf x}^{\prime})\sim \gamma } \|{\mathbf x}-{\mathbf x}^{\prime}\| \end{align*}
Theorem 2.6 of [Reference Jylhä19] proves that this infimum is always assumed. Equivalently,
 $W_\infty ({\mathbb Q},{\mathbb Q}^{\prime})\leq \epsilon$
iff there is a coupling between
$W_\infty ({\mathbb Q},{\mathbb Q}^{\prime})\leq \epsilon$
iff there is a coupling between
 $\mathbb Q$
and
$\mathbb Q$
and
 ${\mathbb Q}^{\prime}$
supported on
${\mathbb Q}^{\prime}$
supported on
 \begin{align*} \Delta _\epsilon =\{({\mathbf x},{\mathbf x}^{\prime})\,:\, \|{\mathbf x}-{\mathbf x}^{\prime} \|\leq \epsilon \}. \end{align*}
\begin{align*} \Delta _\epsilon =\{({\mathbf x},{\mathbf x}^{\prime})\,:\, \|{\mathbf x}-{\mathbf x}^{\prime} \|\leq \epsilon \}. \end{align*}
Let
 ${{\mathcal {B}}^\infty _{\epsilon }}({\mathbb Q})=\{{\mathbb Q}^{\prime}\,:\, W_\infty ({\mathbb Q},{\mathbb Q}^{\prime})\leq \epsilon \}$
be the set of measures within
${{\mathcal {B}}^\infty _{\epsilon }}({\mathbb Q})=\{{\mathbb Q}^{\prime}\,:\, W_\infty ({\mathbb Q},{\mathbb Q}^{\prime})\leq \epsilon \}$
be the set of measures within
 $\epsilon$
of
$\epsilon$
of
 $\mathbb Q$
in the
$\mathbb Q$
in the
 $W_\infty$
metric. The minimax relations from prior work leverage a relationship between the Wasserstein-
$W_\infty$
metric. The minimax relations from prior work leverage a relationship between the Wasserstein-
 $\infty$
metric and the integral of the supremum function over an
$\infty$
metric and the integral of the supremum function over an
 $\epsilon$
-ball.
$\epsilon$
-ball.
Lemma 2.
Let
 $E$
be a Borel set. Then
$E$
be a Borel set. Then
 \begin{align*} \int S_\epsilon ({\mathbf {1}}_E)d{\mathbb Q}\geq \sup _{{\mathbb Q}^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb Q}) } \int {\mathbf {1}}_E d{\mathbb Q}^{\prime} \end{align*}
\begin{align*} \int S_\epsilon ({\mathbf {1}}_E)d{\mathbb Q}\geq \sup _{{\mathbb Q}^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb Q}) } \int {\mathbf {1}}_E d{\mathbb Q}^{\prime} \end{align*}
Proof. Let
 ${\mathbb Q}^{\prime}$
be a measure in
${\mathbb Q}^{\prime}$
be a measure in
 ${{\mathcal {B}}^\infty _{\epsilon }} ({\mathbb Q})$
, and let
${{\mathcal {B}}^\infty _{\epsilon }} ({\mathbb Q})$
, and let
 $\gamma ^*$
be a coupling between these two measures supported on
$\gamma ^*$
be a coupling between these two measures supported on
 $\Delta _\epsilon$
. Then if
$\Delta _\epsilon$
. Then if
 $({\mathbf x},{\mathbf x}^{\prime})\in \Delta _\epsilon$
, then
$({\mathbf x},{\mathbf x}^{\prime})\in \Delta _\epsilon$
, then
 ${\mathbf x}^{\prime}\in \overline {B_\epsilon ({\mathbf x})}$
and thus
${\mathbf x}^{\prime}\in \overline {B_\epsilon ({\mathbf x})}$
and thus
 $S_\epsilon ({\mathbf {1}}_E)({\mathbf x})\geq {\mathbf {1}}_E({\mathbf x}^{\prime})$
$S_\epsilon ({\mathbf {1}}_E)({\mathbf x})\geq {\mathbf {1}}_E({\mathbf x}^{\prime})$
 $\gamma ^*$
-a.e. Consequently,
$\gamma ^*$
-a.e. Consequently,
 \begin{align*} \int S_\epsilon ({\mathbf {1}}_E)({\mathbf x})d{\mathbb Q}_1=\int S_\epsilon ({\mathbf {1}}_E)({\mathbf x})d\gamma ^*({\mathbf x},{\mathbf x}^{\prime})\geq \int {\mathbf {1}}_E({\mathbf x}^{\prime}) d\gamma ^*({\mathbf x},{\mathbf x}^{\prime})=\int {\mathbf {1}}_E d{\mathbb Q}^{\prime} \end{align*}
\begin{align*} \int S_\epsilon ({\mathbf {1}}_E)({\mathbf x})d{\mathbb Q}_1=\int S_\epsilon ({\mathbf {1}}_E)({\mathbf x})d\gamma ^*({\mathbf x},{\mathbf x}^{\prime})\geq \int {\mathbf {1}}_E({\mathbf x}^{\prime}) d\gamma ^*({\mathbf x},{\mathbf x}^{\prime})=\int {\mathbf {1}}_E d{\mathbb Q}^{\prime} \end{align*}
Taking a supremum over all
 ${\mathbb Q}^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb Q})$
proves the result.
${\mathbb Q}^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb Q})$
proves the result.
Lemma2 implies:
 \begin{align*} \inf _f R^\epsilon (f)\geq \inf _f\sup _{\substack {{\mathbb P}_1^{\prime}\in {\mathcal {B}}_\epsilon ({\mathbb P}_1)\\ {\mathbb P}_0^{\prime}\in {\mathcal {B}}_\epsilon ({\mathbb P}_0) }}\int {\mathbf {1}}_{f\leq 0} d{\mathbb P}_1^{\prime}+\int {\mathbf {1}}_{f\gt 0} d{\mathbb P}_0^{\prime}. \end{align*}
\begin{align*} \inf _f R^\epsilon (f)\geq \inf _f\sup _{\substack {{\mathbb P}_1^{\prime}\in {\mathcal {B}}_\epsilon ({\mathbb P}_1)\\ {\mathbb P}_0^{\prime}\in {\mathcal {B}}_\epsilon ({\mathbb P}_0) }}\int {\mathbf {1}}_{f\leq 0} d{\mathbb P}_1^{\prime}+\int {\mathbf {1}}_{f\gt 0} d{\mathbb P}_0^{\prime}. \end{align*}
Does equality hold and can one swap the infimum and the supremum? Frank and Niles-Weed [Reference Frank and Niles-Weed16], Pydi and Jog [Reference Pydi and Jog28] answer this question in the affirmative:
Theorem 3.
Let
 ${\mathbb P}_0$
,
${\mathbb P}_0$
,
 ${\mathbb P}_1$
be finite Borel measures. Define
${\mathbb P}_1$
be finite Borel measures. Define
 \begin{align*} \bar R({\mathbb P}_0^*,{\mathbb P}_1^*)=\int C^*\left (\frac {d{\mathbb P}_1^*}{d({\mathbb P}_0^*+d{\mathbb P}_1^*)} \right )d({\mathbb P}_0^*+{\mathbb P}_1^*) \end{align*}
\begin{align*} \bar R({\mathbb P}_0^*,{\mathbb P}_1^*)=\int C^*\left (\frac {d{\mathbb P}_1^*}{d({\mathbb P}_0^*+d{\mathbb P}_1^*)} \right )d({\mathbb P}_0^*+{\mathbb P}_1^*) \end{align*}
where the function
 $C^*$
is defined in (
4
). Then
$C^*$
is defined in (
4
). Then
 \begin{align*} \inf _{\substack {f\text { Borel}\\\mathbb {R}\text {-valued}}} R^\epsilon (f)=\sup _{\substack {{\mathbb P}_1^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)\\{\mathbb P}_0^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)}}\bar R({\mathbb P}_0^{\prime},{\mathbb P}_1^{\prime}) \end{align*}
\begin{align*} \inf _{\substack {f\text { Borel}\\\mathbb {R}\text {-valued}}} R^\epsilon (f)=\sup _{\substack {{\mathbb P}_1^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)\\{\mathbb P}_0^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)}}\bar R({\mathbb P}_0^{\prime},{\mathbb P}_1^{\prime}) \end{align*}
and furthermore equality is attained for some
 $f^*$
,
$f^*$
,
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
.
${\mathbb P}_1^*$
.
See Theorem1 of [Reference Frank and Niles-Weed16] for a proof. Theorems6, 8, and 9 of [Reference Frank and Niles-Weed17] show an analogous minimax theorem for surrogate risks.
Theorem 4.
Let
 ${\mathbb P}_0$
,
${\mathbb P}_0$
,
 ${\mathbb P}_1$
be finite Borel measures. Define
${\mathbb P}_1$
be finite Borel measures. Define
 \begin{align*} {\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)=\int C_\phi ^*\left (\frac {d{\mathbb P}_1^*}{d({\mathbb P}_0^*+d{\mathbb P}_1^*)} \right )d({\mathbb P}_0^*+{\mathbb P}_1^*) \end{align*}
\begin{align*} {\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)=\int C_\phi ^*\left (\frac {d{\mathbb P}_1^*}{d({\mathbb P}_0^*+d{\mathbb P}_1^*)} \right )d({\mathbb P}_0^*+{\mathbb P}_1^*) \end{align*}
with the function
 $C_\phi ^*$
is defined in (
7
). Then
$C_\phi ^*$
is defined in (
7
). Then
 \begin{align*} \inf _{\substack {f\text { Borel,}\\\overline {\mathbb {R}}\text {-valued}}} R_\phi ^\epsilon (f)=\sup _{\substack {{\mathbb P}_0^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)\\ {\mathbb P}_1^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)}}{\bar {R}_\phi }({\mathbb P}_0^{\prime},{\mathbb P}_1^{\prime}) \end{align*}
\begin{align*} \inf _{\substack {f\text { Borel,}\\\overline {\mathbb {R}}\text {-valued}}} R_\phi ^\epsilon (f)=\sup _{\substack {{\mathbb P}_0^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)\\ {\mathbb P}_1^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)}}{\bar {R}_\phi }({\mathbb P}_0^{\prime},{\mathbb P}_1^{\prime}) \end{align*}
and furthermore equality is attained for some
 $f^*$
,
$f^*$
,
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
.
${\mathbb P}_1^*$
.
Just like
 $R_\phi$
, the risk
$R_\phi$
, the risk
 $R_\phi ^\epsilon$
may not have an
$R_\phi ^\epsilon$
may not have an
 $\mathbb {R}$
-valued minimizer. However, Lemma8 of [Reference Frank and Niles-Weed16] states that
$\mathbb {R}$
-valued minimizer. However, Lemma8 of [Reference Frank and Niles-Weed16] states that
 \begin{align*} \inf _{\substack {f\text { Borel}\\\overline {\mathbb {R}}\text {-valued}}} R_\phi ^\epsilon (f)=\inf _{\substack {f\text { Borel}\\ \mathbb {R}\text {-valued}}} R_\phi ^\epsilon (f). \end{align*}
\begin{align*} \inf _{\substack {f\text { Borel}\\\overline {\mathbb {R}}\text {-valued}}} R_\phi ^\epsilon (f)=\inf _{\substack {f\text { Borel}\\ \mathbb {R}\text {-valued}}} R_\phi ^\epsilon (f). \end{align*}
5.3 Minimizers of adversarial risks
A formula analogous to (9) defines minimizers to adversarial risks. Let
 $I_\epsilon$
denote the infimum of a function over an
$I_\epsilon$
denote the infimum of a function over an
 $\epsilon$
ball:
$\epsilon$
ball:
 \begin{align} I_\epsilon (g)=\inf _{{\mathbf x}^{\prime}\in \overline {B_\epsilon ({\mathbf x})}}g({\mathbf x}^{\prime}) \end{align}
\begin{align} I_\epsilon (g)=\inf _{{\mathbf x}^{\prime}\in \overline {B_\epsilon ({\mathbf x})}}g({\mathbf x}^{\prime}) \end{align}
Lemma 24 of [Reference Frank and Niles-Weed17] and Theorem9 of [Reference Frank and Niles-Weed17] prove the following result:
Theorem 5.
There exists a function
 $\hat \eta \,:\, \mathbb {R}^d\to [0,1]$
and measures
$\hat \eta \,:\, \mathbb {R}^d\to [0,1]$
and measures
 ${\mathbb P}_0^*\in {{\mathcal {B}}^\infty _{\epsilon }} ({\mathbb P}_0)$
,
${\mathbb P}_0^*\in {{\mathcal {B}}^\infty _{\epsilon }} ({\mathbb P}_0)$
,
 ${\mathbb P}_1^*\in {{\mathcal {B}}^\infty _{\epsilon }} ({\mathbb P}_1)$
for which
${\mathbb P}_1^*\in {{\mathcal {B}}^\infty _{\epsilon }} ({\mathbb P}_1)$
for which
I)
$\hat \eta =\eta ^*$
${\mathbb P}^*$
-a.e., where
${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
and
$\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
-
II)
$I_\epsilon (\hat \eta )({\mathbf x})=\hat \eta ({\mathbf x}^{\prime})$
$\gamma _0^*$
-a.e. and
$S_\epsilon (\hat \eta )({\mathbf x})=\hat \eta ({\mathbf x}^{\prime})$
$\gamma _1^*$
-a.e., where
$\gamma _0^*$
,
$\gamma _1^*$
are couplings between
${\mathbb P}_0$
,
${\mathbb P}_0^*$
and
${\mathbb P}_1$
,
${\mathbb P}_1^*$
supported on
$\Delta _\epsilon$
. -
III) The function
$\alpha _\phi (\hat \eta ({\mathbf x}))$
is a minimizer of
$R_\phi ^\epsilon$
for any loss
$\phi$
, where
$\alpha _\phi$
is the function defined in (
8
).



















The function
 $\hat \eta$
can be viewed as the conditional probability of label
$\hat \eta$
can be viewed as the conditional probability of label
 $+1$
under an ‘optimal’ adversarial attack [Reference Frank and Niles-Weed17]. Just as in the standard learning scenario, the function
$+1$
under an ‘optimal’ adversarial attack [Reference Frank and Niles-Weed17]. Just as in the standard learning scenario, the function
 $\alpha (\hat \eta ({\mathbf x}))$
may be
$\alpha (\hat \eta ({\mathbf x}))$
may be
 $\overline {\mathbb {R}}$
-valued. Item 3 is actually a consequence of Item 1 and Item 2: Item 1 and Item 2 imply that
$\overline {\mathbb {R}}$
-valued. Item 3 is actually a consequence of Item 1 and Item 2: Item 1 and Item 2 imply that
 $R_\phi ^\epsilon (\alpha _\phi (\hat \eta ))={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)$
and Theorem4 then implies that
$R_\phi ^\epsilon (\alpha _\phi (\hat \eta ))={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)$
and Theorem4 then implies that
 $\alpha _\phi (\hat \eta )$
minimizes
$\alpha _\phi (\hat \eta )$
minimizes
 $R_\phi ^\epsilon$
and
$R_\phi ^\epsilon$
and
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
maximize
${\mathbb P}_1^*$
maximize
 $\bar {R}_\phi$
. (A similar argument is provided later in this paper in Lemma6 of Appendix D.1.) Furthermore, the relation
$\bar {R}_\phi$
. (A similar argument is provided later in this paper in Lemma6 of Appendix D.1.) Furthermore, the relation
 $R_\phi ^\epsilon (\alpha _\phi (\hat \eta ))={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)$
also implies
$R_\phi ^\epsilon (\alpha _\phi (\hat \eta ))={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)$
also implies
Lemma 3.
The
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
of Theorem
5
maximize
${\mathbb P}_1^*$
of Theorem
5
maximize
 $\bar {R}_\phi$
over
$\bar {R}_\phi$
over
 ${{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)\times {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)$
for every
${{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)\times {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)$
for every
 $\phi$
.
$\phi$
.
We emphasize that a formal proof of Theorems5 and 3 is not included in this paper, and refer to Lemma 26 and Theorem9 of [Reference Frank and Niles-Weed17] for full arguments.
Next, we derive some further results about the function
 $\hat \eta$
. Recall that Bayes classifiers can be constructed by thesholding the conditional probability
$\hat \eta$
. Recall that Bayes classifiers can be constructed by thesholding the conditional probability
 $\eta$
at
$\eta$
at
 $1/2$
, see Equation 5). The function
$1/2$
, see Equation 5). The function
 $\hat \eta$
plays an analogous role for adversarial learning.
$\hat \eta$
plays an analogous role for adversarial learning.
Theorem 6.
Let
 $\hat \eta$
be the function described by Theorem
5
. Then the sets
$\hat \eta$
be the function described by Theorem
5
. Then the sets
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
are adversarial Bayes classifiers. Furthermore, any adversarial Bayes classifier
$\{\hat \eta \geq 1/2\}$
are adversarial Bayes classifiers. Furthermore, any adversarial Bayes classifier
 $A$
satisfies
$A$
satisfies
 \begin{align} \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \geq 1/2\}^C})d{\mathbb P}_1\leq \int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1\leq \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2)^C})d{\mathbb P}_1 \end{align}
\begin{align} \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \geq 1/2\}^C})d{\mathbb P}_1\leq \int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1\leq \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2)^C})d{\mathbb P}_1 \end{align}
and
 \begin{align} \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}})d{\mathbb P}_0\leq \int S_\epsilon ({\mathbf {1}}_{A})d{\mathbb P}_0\leq \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \geq 1/2\}})d{\mathbb P}_0 \end{align}
\begin{align} \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}})d{\mathbb P}_0\leq \int S_\epsilon ({\mathbf {1}}_{A})d{\mathbb P}_0\leq \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \geq 1/2\}})d{\mathbb P}_0 \end{align}
See Appendix A for a formal proof; these properties follow direction from Item 1 and Item 2 of Theorem5. Equations (11) and (12) imply that the sets
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
can be viewed as ‘minimal’ and ‘maximal’ adversarial Bayes classifiers.
$\{\hat \eta \geq 1/2\}$
can be viewed as ‘minimal’ and ‘maximal’ adversarial Bayes classifiers.
Theorem6 is proved in Appendix A– Item 1 and Item 2 imply that
 $ R^\epsilon (\{\hat \eta \gt 1/2\})=\bar R({\mathbb P}_0^*,{\mathbb P}_1^*)=R^\epsilon (\hat \eta \geq 1/2\})$
and consequently Theorem3 implies that
$ R^\epsilon (\{\hat \eta \gt 1/2\})=\bar R({\mathbb P}_0^*,{\mathbb P}_1^*)=R^\epsilon (\hat \eta \geq 1/2\})$
and consequently Theorem3 implies that
 $\{\hat \eta \gt 1/2\}$
,
$\{\hat \eta \gt 1/2\}$
,
 $\{\hat \eta \geq 1/2\}$
minimize
$\{\hat \eta \geq 1/2\}$
minimize
 $R^\epsilon$
and
$R^\epsilon$
and
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
maximize
${\mathbb P}_1^*$
maximize
 $\bar R$
. This proof technique is analogous to the approach employed by [Reference Frank and Niles-Weed17] to establish Theorem5. Lastly, uniqueness up to degeneracy can be characterized in terms of these
$\bar R$
. This proof technique is analogous to the approach employed by [Reference Frank and Niles-Weed17] to establish Theorem5. Lastly, uniqueness up to degeneracy can be characterized in terms of these
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
.
${\mathbb P}_1^*$
.
Theorem 7.
Assume that
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure. Then the following are equivalent:
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure. Then the following are equivalent:
A) The adversarial Bayes classifier is unique up to degeneracy
B)
${\mathbb P}^*(\eta ^*=1/2)=0$
, where
${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
and
$\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
for the measures
${\mathbb P}_0^*,{\mathbb P}_1^*$
of Theorem
5
.




See Appendix B for a proof of Theorem7. In relation to prior work – the proof of [Reference Frank15, Theorem 3.4] shows Theorem7 but a full proof of Theorem7 is included in this paper for clarity as [Reference Frank15] did not discuss the role of the function
 $\hat \eta$
.
$\hat \eta$
.
6. Uniqueness up to degeneracy implies consistency
Before presenting the full proof of consistency, we provide an overview of the strategy of this argument. First, a minimizing sequence of
 $R_\phi ^\epsilon$
must satisfy the approximate complementary slackness conditions derived in [Reference Frank and Niles-Weed16, Proposition 4].
$R_\phi ^\epsilon$
must satisfy the approximate complementary slackness conditions derived in [Reference Frank and Niles-Weed16, Proposition 4].
Proposition 1.
Assume that the measures
 ${\mathbb P}_0^*\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)$
,
${\mathbb P}_0^*\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)$
,
 ${\mathbb P}_1^*\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)$
maximize
${\mathbb P}_1^*\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)$
maximize
 $\bar {R}_\phi$
. Then any minimizing sequence
$\bar {R}_\phi$
. Then any minimizing sequence
 $f_n$
of
$f_n$
of
 $R_\phi ^\epsilon$
must satisfyr
$R_\phi ^\epsilon$
must satisfyr
 \begin{align} \lim _{n\to \infty } \int C_\phi (\eta ^*,f_n)d{\mathbb P}^*= \int C_\phi ^*(\eta ^*)d{\mathbb P}^* \\[-18pt] \nonumber \end{align}
\begin{align} \lim _{n\to \infty } \int C_\phi (\eta ^*,f_n)d{\mathbb P}^*= \int C_\phi ^*(\eta ^*)d{\mathbb P}^* \\[-18pt] \nonumber \end{align}
 \begin{align} \lim _{n\to \infty } \int S_\epsilon (\phi \circ f_n)d{\mathbb P}_1-\int \phi \circ f_nd{\mathbb P}_1^*=0, \quad \lim _{n\to \infty } \int S_\epsilon (\phi \circ -f_n) d{\mathbb P}_0- \int \phi \circ -f_nd{\mathbb P}_0^*=0, \\[6pt] \nonumber \end{align}
\begin{align} \lim _{n\to \infty } \int S_\epsilon (\phi \circ f_n)d{\mathbb P}_1-\int \phi \circ f_nd{\mathbb P}_1^*=0, \quad \lim _{n\to \infty } \int S_\epsilon (\phi \circ -f_n) d{\mathbb P}_0- \int \phi \circ -f_nd{\mathbb P}_0^*=0, \\[6pt] \nonumber \end{align}
where
 ${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
and
${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
and
 $\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
.
$\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
.
We will show that when
 ${\mathbb P}^*(\eta ^*=1/2)=0$
, every sequence of functions satisfying (13) and (14) must minimize
${\mathbb P}^*(\eta ^*=1/2)=0$
, every sequence of functions satisfying (13) and (14) must minimize
 $R^\epsilon$
. Specifically, we will prove that every minimizing sequence
$R^\epsilon$
. Specifically, we will prove that every minimizing sequence
 $f_n$
of
$f_n$
of
 $R_\phi ^\epsilon$
must satisfy
$R_\phi ^\epsilon$
must satisfy
 \begin{align} \limsup _{n\to \infty } \int S_\epsilon ({\mathbf {1}}_{f_n\leq 0}) d{\mathbb P}_1\leq \int {\mathbf {1}}_{\eta ^*\leq \frac 12} d{\mathbb P}_1^*, \\[-18pt] \nonumber \end{align}
\begin{align} \limsup _{n\to \infty } \int S_\epsilon ({\mathbf {1}}_{f_n\leq 0}) d{\mathbb P}_1\leq \int {\mathbf {1}}_{\eta ^*\leq \frac 12} d{\mathbb P}_1^*, \\[-18pt] \nonumber \end{align}
 \begin{align} \limsup _{n\to \infty } \int S_\epsilon ({\mathbf {1}}_{f_n\geq 0}) d{\mathbb P}_0\leq \int {\mathbf {1}}_{\eta ^*\geq \frac 12} d{\mathbb P}_0^* \\[6pt] \nonumber \end{align}
\begin{align} \limsup _{n\to \infty } \int S_\epsilon ({\mathbf {1}}_{f_n\geq 0}) d{\mathbb P}_0\leq \int {\mathbf {1}}_{\eta ^*\geq \frac 12} d{\mathbb P}_0^* \\[6pt] \nonumber \end{align}
for the measures
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
in Theorem5. Consequently,
${\mathbb P}_1^*$
in Theorem5. Consequently,
 ${\mathbb P}^*(\eta ^*=1/2)=0$
would imply that
${\mathbb P}^*(\eta ^*=1/2)=0$
would imply that
 $\limsup _{n\to \infty } R^\epsilon (f_n)\leq \bar R({\mathbb P}_0^*,{\mathbb P}_1^*)$
and the strong duality relation in Theorem3 implies that
$\limsup _{n\to \infty } R^\epsilon (f_n)\leq \bar R({\mathbb P}_0^*,{\mathbb P}_1^*)$
and the strong duality relation in Theorem3 implies that
 $f_n$
must in fact be a minimizing sequence of
$f_n$
must in fact be a minimizing sequence of
 $R^\epsilon$
.
$R^\epsilon$
.
Next, we summarize the argument establishing Equation 15. We make several simplifying assumptions in the following discussion. First, we assume that the functions
 $\phi$
,
$\phi$
,
 $\alpha _\phi$
are strictly monotonic and that for each
$\alpha _\phi$
are strictly monotonic and that for each
 $\eta$
, there is a unique value of
$\eta$
, there is a unique value of
 $\alpha$
for which
$\alpha$
for which
 $\eta \phi (\alpha )+(1-\eta )\phi (-\alpha )=C_\phi ^*(\eta )$
. (For instance, the exponential loss
$\eta \phi (\alpha )+(1-\eta )\phi (-\alpha )=C_\phi ^*(\eta )$
. (For instance, the exponential loss
 $\phi (\alpha )=e^{-\alpha }$
satisfies these requirements.) Let
$\phi (\alpha )=e^{-\alpha }$
satisfies these requirements.) Let
 $\gamma _1^*$
be a coupling between
$\gamma _1^*$
be a coupling between
 ${\mathbb P}_1$
and
${\mathbb P}_1$
and
 ${\mathbb P}_1^*$
supported on
${\mathbb P}_1^*$
supported on
 $\Delta _\epsilon$
.
$\Delta _\epsilon$
.
Because
 $C_\phi (\eta ^*,f_n)\geq C_\phi ^*(\eta ^*)$
, the condition (13) implies that
$C_\phi (\eta ^*,f_n)\geq C_\phi ^*(\eta ^*)$
, the condition (13) implies that
 $C_\phi (\eta ^*,f_n)$
converges to
$C_\phi (\eta ^*,f_n)$
converges to
 $C_\phi ^*(\eta ^*)$
in
$C_\phi ^*(\eta ^*)$
in
 $L^1({\mathbb P}^*)$
, and the assumption that there is a single value of
$L^1({\mathbb P}^*)$
, and the assumption that there is a single value of
 $\alpha$
for which
$\alpha$
for which
 $\eta \phi (\alpha )+(1-\eta )\phi (-\alpha )=C_\phi ^*(\eta )$
implies that the function
$\eta \phi (\alpha )+(1-\eta )\phi (-\alpha )=C_\phi ^*(\eta )$
implies that the function
 $\phi (f_n({\mathbf x}^{\prime}))$
must converge to
$\phi (f_n({\mathbf x}^{\prime}))$
must converge to
 $\phi (\alpha _\phi (\eta ^*({\mathbf x}^{\prime}))$
in
$\phi (\alpha _\phi (\eta ^*({\mathbf x}^{\prime}))$
in
 $L^1({\mathbb P}_1^*)$
. Similarly, because Lemma2 states that
$L^1({\mathbb P}_1^*)$
. Similarly, because Lemma2 states that
 $S_\epsilon (\phi \circ f_n)({\mathbf x})\geq \phi \circ f_n({\mathbf x}^{\prime})$
$S_\epsilon (\phi \circ f_n)({\mathbf x})\geq \phi \circ f_n({\mathbf x}^{\prime})$
 $\gamma _1^*$
-a.e., Equation 14) implies that
$\gamma _1^*$
-a.e., Equation 14) implies that
 $S_\epsilon (\phi \circ f_n)({\mathbf x})-\phi \circ f_n({\mathbf x}^{\prime})$
converges to 0 in
$S_\epsilon (\phi \circ f_n)({\mathbf x})-\phi \circ f_n({\mathbf x}^{\prime})$
converges to 0 in
 $L^1(\gamma _1^*)$
. Consequently
$L^1(\gamma _1^*)$
. Consequently
 $S_\epsilon (\phi \circ f_n)({\mathbf x})$
must converge to
$S_\epsilon (\phi \circ f_n)({\mathbf x})$
must converge to
 $\phi (\alpha _\phi (\eta ^*({\mathbf x}^{\prime})))$
in
$\phi (\alpha _\phi (\eta ^*({\mathbf x}^{\prime})))$
in
 $L^1(\gamma _1^*)$
. As
$L^1(\gamma _1^*)$
. As
 $L^1$
convergence implies convergence in measure [Reference Folland14, Proposition 2.29], one can conclude that
$L^1$
convergence implies convergence in measure [Reference Folland14, Proposition 2.29], one can conclude that
 \begin{align} \lim _{n\to \infty } \gamma _1^*\big (S_\epsilon (\phi \circ f_n)({\mathbf x})-\phi \circ ( \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})))\gt c\big )=0 \end{align}
\begin{align} \lim _{n\to \infty } \gamma _1^*\big (S_\epsilon (\phi \circ f_n)({\mathbf x})-\phi \circ ( \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})))\gt c\big )=0 \end{align}
for any
 $c\gt 0$
. The lower semi-continuity of
$c\gt 0$
. The lower semi-continuity of
 $\alpha \mapsto {\mathbf {1}}_{\alpha \leq 0}$
implies that
$\alpha \mapsto {\mathbf {1}}_{\alpha \leq 0}$
implies that
 $\int S_\epsilon ({\mathbf {1}}_{f_n\leq 0})d{\mathbb P}_1\leq \int {\mathbf {1}}_{S_\epsilon (\phi (f_n))({\mathbf x})\geq \phi (0)}d{\mathbb P}_1$
and furthermore (17) implies
$\int S_\epsilon ({\mathbf {1}}_{f_n\leq 0})d{\mathbb P}_1\leq \int {\mathbf {1}}_{S_\epsilon (\phi (f_n))({\mathbf x})\geq \phi (0)}d{\mathbb P}_1$
and furthermore (17) implies
 \begin{align} \limsup _{n\to \infty } \int {\mathbf {1}}_{S_\epsilon (\phi (f_n))({\mathbf x})\geq \phi (0)}d\gamma _1^*\leq \int {\mathbf {1}}_{\phi (\alpha _\phi (\eta ^*({\mathbf x}^{\prime})))\lt \phi (0)-c}d\gamma _1^* = \int {\mathbf {1}}_{\eta ^*\geq \alpha _\phi ^{-1}\circ \phi ^{-1}(\phi (0)-c)}d{\mathbb P}_1^*. \end{align}
\begin{align} \limsup _{n\to \infty } \int {\mathbf {1}}_{S_\epsilon (\phi (f_n))({\mathbf x})\geq \phi (0)}d\gamma _1^*\leq \int {\mathbf {1}}_{\phi (\alpha _\phi (\eta ^*({\mathbf x}^{\prime})))\lt \phi (0)-c}d\gamma _1^* = \int {\mathbf {1}}_{\eta ^*\geq \alpha _\phi ^{-1}\circ \phi ^{-1}(\phi (0)-c)}d{\mathbb P}_1^*. \end{align}
Next, we will also assume that
 $\alpha _\phi ^{-1}$
is continuous and
$\alpha _\phi ^{-1}$
is continuous and
 $\alpha _\phi (1/2)=0$
. (The exponential loss satisfies these requirements as well.) Due to our assumptions on
$\alpha _\phi (1/2)=0$
. (The exponential loss satisfies these requirements as well.) Due to our assumptions on
 $\phi$
and
$\phi$
and
 $\alpha _\phi$
, the quantity
$\alpha _\phi$
, the quantity
 $\phi ^{-1}(\phi (0)-c)$
is strictly smaller than 0, and consequently,
$\phi ^{-1}(\phi (0)-c)$
is strictly smaller than 0, and consequently,
 $\alpha _\phi ^{-1}\circ \phi ^{-1}(\phi (0)-c)$
is strictly smalaler than
$\alpha _\phi ^{-1}\circ \phi ^{-1}(\phi (0)-c)$
is strictly smalaler than
 $1/2$
. However, if
$1/2$
. However, if
 $\alpha _\phi ^{-1}$
is continuous, one can choose
$\alpha _\phi ^{-1}$
is continuous, one can choose
 $c$
small enough so that
$c$
small enough so that
 ${\mathbb P}^*( |\eta -1/2|\lt 1/2- \alpha _\phi ^{-1}\circ \phi ^{-1}(\phi (0)-c))\lt \delta$
for any
${\mathbb P}^*( |\eta -1/2|\lt 1/2- \alpha _\phi ^{-1}\circ \phi ^{-1}(\phi (0)-c))\lt \delta$
for any
 $\delta \gt 0$
when
$\delta \gt 0$
when
 ${\mathbb P}^*(\eta ^*=1/2)=0$
. This choice of
${\mathbb P}^*(\eta ^*=1/2)=0$
. This choice of
 $c$
along with (18) proves (15).
$c$
along with (18) proves (15).
To avoid the prior assumptions on
 $\phi$
and
$\phi$
and
 $\alpha$
, we prove that when
$\alpha$
, we prove that when
 $\eta$
is bounded away from
$\eta$
is bounded away from
 $1/2$
and
$1/2$
and
 $\alpha$
is bounded away from the minimizers of
$\alpha$
is bounded away from the minimizers of
 $C_\phi (\eta, \cdot )$
, then
$C_\phi (\eta, \cdot )$
, then
 $C_\phi (\eta, \alpha )$
is bounded away from
$C_\phi (\eta, \alpha )$
is bounded away from
 $C_\phi ^*(\eta )$
.
$C_\phi ^*(\eta )$
.
Lemma 4.
Let
 $\phi$
be a consistent loss. For all
$\phi$
be a consistent loss. For all
 $r\gt 0$
, there is a constant
$r\gt 0$
, there is a constant
 $k_r\gt 0$
and an
$k_r\gt 0$
and an
 $\alpha _r\gt 0$
for which if
$\alpha _r\gt 0$
for which if
 $|\eta -1/2|\geq r$
and
$|\eta -1/2|\geq r$
and
 $\textrm {sign}(\eta -1/2) \alpha \leq \alpha _r$
then
$\textrm {sign}(\eta -1/2) \alpha \leq \alpha _r$
then
 $C_\phi (\eta, \alpha _r)-C_\phi ^*(\eta )\geq k_r$
, and this
$C_\phi (\eta, \alpha _r)-C_\phi ^*(\eta )\geq k_r$
, and this
 $\alpha _r$
satisfies
$\alpha _r$
satisfies
 $\phi (\alpha _r)\lt \phi (0)$
.
$\phi (\alpha _r)\lt \phi (0)$
.
See Appendix C for a proof. A minor modification of the argument above our main result:
Proposition 2.
Assume there exist
 ${\mathbb P}_0^*\in {{\mathcal {B}}^\infty _{\epsilon }} ({\mathbb P}_0)$
,
${\mathbb P}_0^*\in {{\mathcal {B}}^\infty _{\epsilon }} ({\mathbb P}_0)$
,
 ${\mathbb P}_1^*\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)$
that maximize
${\mathbb P}_1^*\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)$
that maximize
 $\bar {R}_\phi$
for which
$\bar {R}_\phi$
for which
 ${\mathbb P}^*(\eta ^*=1/2)=0$
. Then any consistent loss is adversarially consistent.
${\mathbb P}^*(\eta ^*=1/2)=0$
. Then any consistent loss is adversarially consistent.
When
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure, uniqueness up to degeneracy of the adversarial Bayes classifier implies the assumptions of this proposition due to Theorem7. However, this result applies even to distributions which are not absolutely continuous with respect to Lebesgue measure. For instance, if the optimal classification risk is zero, the
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure, uniqueness up to degeneracy of the adversarial Bayes classifier implies the assumptions of this proposition due to Theorem7. However, this result applies even to distributions which are not absolutely continuous with respect to Lebesgue measure. For instance, if the optimal classification risk is zero, the
 ${\mathbb P}^*(\eta ^*=1/2)=0$
. To show this statement, notice that if
${\mathbb P}^*(\eta ^*=1/2)=0$
. To show this statement, notice that if
 $\inf _A R^\epsilon (A)=0$
, then Theorem3 implies that for any measures
$\inf _A R^\epsilon (A)=0$
, then Theorem3 implies that for any measures
 ${\mathbb P}_0^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)$
,
${\mathbb P}_0^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_0)$
,
 ${\mathbb P}_1^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)$
, one can conclude that
${\mathbb P}_1^{\prime}\in {{\mathcal {B}}^\infty _{\epsilon }}({\mathbb P}_1)$
, one can conclude that
 ${\mathbb P}^{\prime}(\eta ^{\prime}=1/2)=0$
, where
${\mathbb P}^{\prime}(\eta ^{\prime}=1/2)=0$
, where
 ${\mathbb P}^{\prime}={\mathbb P}_0^{\prime}+{\mathbb P}_1^{\prime}$
and
${\mathbb P}^{\prime}={\mathbb P}_0^{\prime}+{\mathbb P}_1^{\prime}$
and
 $\eta ^{\prime}=d{\mathbb P}_1^{\prime}/d{\mathbb P}^{\prime}$
.
$\eta ^{\prime}=d{\mathbb P}_1^{\prime}/d{\mathbb P}^{\prime}$
.
Proof of Proposition
2. We will show that every minimizing sequence of
 $R_\phi ^\epsilon$
must satisfy (15) and (16). These equations together with the assumption
$R_\phi ^\epsilon$
must satisfy (15) and (16). These equations together with the assumption
 ${\mathbb P}^*(\eta ^*=1/2)=0$
imply that
${\mathbb P}^*(\eta ^*=1/2)=0$
imply that
 \begin{align*} \limsup _{n\to \infty } R^\epsilon (f_n)\leq \int {\mathbf {1}}_{\eta ^*\leq \frac 12} d{\mathbb P}_1^*+\int {\mathbf {1}}_{\eta ^*\geq \frac 12} d{\mathbb P}_0^*=\int \eta ^*{\mathbf {1}}_{\eta ^*\leq 1/2} +(1-\eta ^*){\mathbf {1}}_{\eta ^*\gt 1/2}d{\mathbb P}^*=\bar R({\mathbb P}_0^*,{\mathbb P}_1^*). \end{align*}
\begin{align*} \limsup _{n\to \infty } R^\epsilon (f_n)\leq \int {\mathbf {1}}_{\eta ^*\leq \frac 12} d{\mathbb P}_1^*+\int {\mathbf {1}}_{\eta ^*\geq \frac 12} d{\mathbb P}_0^*=\int \eta ^*{\mathbf {1}}_{\eta ^*\leq 1/2} +(1-\eta ^*){\mathbf {1}}_{\eta ^*\gt 1/2}d{\mathbb P}^*=\bar R({\mathbb P}_0^*,{\mathbb P}_1^*). \end{align*}
The strong duality result of Theorem3 then implies that
 $f_n$
must be a minimizing sequence of
$f_n$
must be a minimizing sequence of
 $R^\epsilon$
.
$R^\epsilon$
.
Let
 $\delta$
be arbitrary. Due to the assumption
$\delta$
be arbitrary. Due to the assumption
 ${\mathbb P}^*(\eta ^*=1/2)=0$
, one can pick an
${\mathbb P}^*(\eta ^*=1/2)=0$
, one can pick an
 $r$
for which
$r$
for which
 \begin{align} {\mathbb P}^*(|\eta ^* -1/2|\lt r)\lt \delta . \end{align}
\begin{align} {\mathbb P}^*(|\eta ^* -1/2|\lt r)\lt \delta . \end{align}
Next, let
 $\alpha _r$
,
$\alpha _r$
,
 $k_r$
be as in Lemma4. Let
$k_r$
be as in Lemma4. Let
 $\gamma _i^*$
be couplings between
$\gamma _i^*$
be couplings between
 ${\mathbb P}_i$
and
${\mathbb P}_i$
and
 ${\mathbb P}_i^*$
supported on
${\mathbb P}_i^*$
supported on
 $\Delta _\epsilon$
. Lemma2 implies that
$\Delta _\epsilon$
. Lemma2 implies that
 $S_\epsilon (\phi \circ f_n)({\mathbf x})\geq \phi \circ f_n({\mathbf x}^{\prime})$
$S_\epsilon (\phi \circ f_n)({\mathbf x})\geq \phi \circ f_n({\mathbf x}^{\prime})$
 $\gamma _1^*$
-a.e., and thus (14) implies that
$\gamma _1^*$
-a.e., and thus (14) implies that
 $S_\epsilon (\phi \circ f_n)({\mathbf x})- \phi \circ f_n({\mathbf x}^{\prime})$
converges to 0 in
$S_\epsilon (\phi \circ f_n)({\mathbf x})- \phi \circ f_n({\mathbf x}^{\prime})$
converges to 0 in
 $L^1(\gamma _1^*)$
. Because convergence in
$L^1(\gamma _1^*)$
. Because convergence in
 $L^1$
implies convergence in measure [Reference Folland14, Proposition 2.29], the quantity
$L^1$
implies convergence in measure [Reference Folland14, Proposition 2.29], the quantity
 $S_\epsilon (\phi \circ f_n)({\mathbf x})- \phi \circ f_n({\mathbf x}^{\prime})$
converges to 0 in
$S_\epsilon (\phi \circ f_n)({\mathbf x})- \phi \circ f_n({\mathbf x}^{\prime})$
converges to 0 in
 $\gamma _1^*$
-measure. Similarly, one can conclude that
$\gamma _1^*$
-measure. Similarly, one can conclude that
 $S_\epsilon (\phi \circ -f_n)({\mathbf x})- \phi \circ -f_n({\mathbf x}^{\prime})$
converges to zero in
$S_\epsilon (\phi \circ -f_n)({\mathbf x})- \phi \circ -f_n({\mathbf x}^{\prime})$
converges to zero in
 $\gamma _0^*$
-measure. Analogously, as
$\gamma _0^*$
-measure. Analogously, as
 $C_\phi ^*(\eta ^*,f_n)\geq C_\phi ^*(\eta ^*)$
, Equation 13) implies that
$C_\phi ^*(\eta ^*,f_n)\geq C_\phi ^*(\eta ^*)$
, Equation 13) implies that
 $C_\phi ^*(\eta ^*,f_n)$
converges in
$C_\phi ^*(\eta ^*,f_n)$
converges in
 ${\mathbb P}^*$
-measure to
${\mathbb P}^*$
-measure to
 $C_\phi ^*(\eta ^*)$
. Therefore, Proposition1 implies that one can choose
$C_\phi ^*(\eta ^*)$
. Therefore, Proposition1 implies that one can choose
 $N$
large enough so that
$N$
large enough so that
 $n\gt N$
implies
$n\gt N$
implies
 \begin{align} \gamma _1^*\Big ( S_\epsilon (\phi \circ f_n)({\mathbf x})- \phi \circ f_n({\mathbf x}^{\prime})\geq {\phi (0)-\phi (\alpha _r)} \Big )\lt \delta, \\[-18pt] \nonumber \end{align}
\begin{align} \gamma _1^*\Big ( S_\epsilon (\phi \circ f_n)({\mathbf x})- \phi \circ f_n({\mathbf x}^{\prime})\geq {\phi (0)-\phi (\alpha _r)} \Big )\lt \delta, \\[-18pt] \nonumber \end{align}
 \begin{align} \gamma _0^*\Big ( S_\epsilon (\phi \circ -f_n)({\mathbf x})- \phi \circ -f_n({\mathbf x}^{\prime})\geq {\phi (0)-\phi (\alpha _r)} \Big )\lt \delta, \\[6pt] \nonumber \end{align}
\begin{align} \gamma _0^*\Big ( S_\epsilon (\phi \circ -f_n)({\mathbf x})- \phi \circ -f_n({\mathbf x}^{\prime})\geq {\phi (0)-\phi (\alpha _r)} \Big )\lt \delta, \\[6pt] \nonumber \end{align}
and
 ${\mathbb P}^*(C_\phi ^*(\eta ^*, f_n)\gt C_\phi ^*(\eta ^*)+k_r)\lt \delta$
. The relation
${\mathbb P}^*(C_\phi ^*(\eta ^*, f_n)\gt C_\phi ^*(\eta ^*)+k_r)\lt \delta$
. The relation
 ${\mathbb P}^*(C_\phi ^*(\eta ^*, f_n)\gt C_\phi ^*(\eta ^*)+k_r)\lt \delta$
implies
${\mathbb P}^*(C_\phi ^*(\eta ^*, f_n)\gt C_\phi ^*(\eta ^*)+k_r)\lt \delta$
implies
 \begin{align} {\mathbb P}^*\Big ( |\eta ^* -1/2|\geq r, f_n\textrm {sign}(\eta ^* -1/2)\leq \alpha _r\Big )\lt \delta \end{align}
\begin{align} {\mathbb P}^*\Big ( |\eta ^* -1/2|\geq r, f_n\textrm {sign}(\eta ^* -1/2)\leq \alpha _r\Big )\lt \delta \end{align}
due to Lemma4. Because
 $\phi$
is non-increasing,
$\phi$
is non-increasing,
 ${\mathbf {1}}_{f_n\leq 0}\leq {\mathbf {1}}_{\phi \circ f_n\geq \phi (0)}$
and since the function
${\mathbf {1}}_{f_n\leq 0}\leq {\mathbf {1}}_{\phi \circ f_n\geq \phi (0)}$
and since the function
 $z \mapsto {\mathbf {1}}_{z\geq \phi (0)}$
is upper semi-continuous,
$z \mapsto {\mathbf {1}}_{z\geq \phi (0)}$
is upper semi-continuous,
 \begin{align*} \int S_\epsilon ({\mathbf {1}}_{f_n\leq 0}) d{\mathbb P}_1\leq \int {\mathbf {1}}_{S_\epsilon (\phi \circ f_n)\geq \phi (0)} d{\mathbb P}_1=\int {\mathbf {1}}_{S_\epsilon (\phi \circ f_n)({\mathbf x})\geq \phi (0)}d\gamma _1^* =\gamma _1^*\big (S_\epsilon (\phi \circ f_n)({\mathbf x})\geq \phi (0)\big ). \end{align*}
\begin{align*} \int S_\epsilon ({\mathbf {1}}_{f_n\leq 0}) d{\mathbb P}_1\leq \int {\mathbf {1}}_{S_\epsilon (\phi \circ f_n)\geq \phi (0)} d{\mathbb P}_1=\int {\mathbf {1}}_{S_\epsilon (\phi \circ f_n)({\mathbf x})\geq \phi (0)}d\gamma _1^* =\gamma _1^*\big (S_\epsilon (\phi \circ f_n)({\mathbf x})\geq \phi (0)\big ). \end{align*}
Now (20) implies that for
 $n\gt N$
,
$n\gt N$
,
 $S_\epsilon (\phi \circ f_n)({\mathbf x})\lt (\phi \circ f_n)({\mathbf x}^{\prime})+\phi (0)-\phi (\alpha _r)$
outside a set of
$S_\epsilon (\phi \circ f_n)({\mathbf x})\lt (\phi \circ f_n)({\mathbf x}^{\prime})+\phi (0)-\phi (\alpha _r)$
outside a set of
 $\gamma _1^*$
-measure
$\gamma _1^*$
-measure
 $\delta$
and thus
$\delta$
and thus
 \begin{align} \int S_\epsilon ({\mathbf {1}}_{f_n\leq 0})d{\mathbb P}_1\leq \gamma _1^*\big (\phi \circ f_n ({\mathbf x}^{\prime})+\phi (0)-\phi (\alpha _r)\gt \phi (0)\big )+\delta \leq {\mathbb P}_1^*\big (\phi \circ f_n\gt \phi (\alpha _r)\big ) +\delta \end{align}
\begin{align} \int S_\epsilon ({\mathbf {1}}_{f_n\leq 0})d{\mathbb P}_1\leq \gamma _1^*\big (\phi \circ f_n ({\mathbf x}^{\prime})+\phi (0)-\phi (\alpha _r)\gt \phi (0)\big )+\delta \leq {\mathbb P}_1^*\big (\phi \circ f_n\gt \phi (\alpha _r)\big ) +\delta \end{align}
Next, the monotonicity of
 $\phi$
implies that
$\phi$
implies that
 ${\mathbb P}_1^*(\phi \circ f_n({\mathbf x}^{\prime})\gt \phi (\alpha _r))\leq {\mathbb P}_1^*(f_n\lt \alpha _r)$
and thus
${\mathbb P}_1^*(\phi \circ f_n({\mathbf x}^{\prime})\gt \phi (\alpha _r))\leq {\mathbb P}_1^*(f_n\lt \alpha _r)$
and thus
 \begin{align} &\int S_\epsilon ({\mathbf {1}}_{f_n\leq 0})d{\mathbb P}_1\leq {\mathbb P}_1^*(f_n\lt \alpha _r)+\delta \leq {\mathbb P}_1^*(f_n\lt \alpha _r, |\eta ^* -1/2|\geq r)+2\delta . \end{align}
\begin{align} &\int S_\epsilon ({\mathbf {1}}_{f_n\leq 0})d{\mathbb P}_1\leq {\mathbb P}_1^*(f_n\lt \alpha _r)+\delta \leq {\mathbb P}_1^*(f_n\lt \alpha _r, |\eta ^* -1/2|\geq r)+2\delta . \end{align}
by (19). Next, (22) implies
 ${\mathbb P}_1^*(\eta ^*\geq 1/2+r, f_n\leq \alpha _r)\lt \delta$
and consequently
${\mathbb P}_1^*(\eta ^*\geq 1/2+r, f_n\leq \alpha _r)\lt \delta$
and consequently
 \begin{align*} &\int S_\epsilon ({\mathbf {1}}_{f_n\leq 0})d{\mathbb P}_1\leq {\mathbb P}_1^*(f_n\lt \alpha _r, \eta ^* \leq 1/2 -r)+3\delta \leq {\mathbb P}_1^*( \eta ^*\leq 1/2)+3\delta . \end{align*}
\begin{align*} &\int S_\epsilon ({\mathbf {1}}_{f_n\leq 0})d{\mathbb P}_1\leq {\mathbb P}_1^*(f_n\lt \alpha _r, \eta ^* \leq 1/2 -r)+3\delta \leq {\mathbb P}_1^*( \eta ^*\leq 1/2)+3\delta . \end{align*}
Because
 $\delta$
is arbitrary, this relation implies (15). Next, to prove (16), observe that
$\delta$
is arbitrary, this relation implies (15). Next, to prove (16), observe that
 ${\mathbf {1}}_{f\geq 0}={\mathbf {1}}_{-f\leq 0}$
, and thus the inequalities (23) and (24) hold with
${\mathbf {1}}_{f\geq 0}={\mathbf {1}}_{-f\leq 0}$
, and thus the inequalities (23) and (24) hold with
 $-f_n$
in place of
$-f_n$
in place of
 $f_n$
,
$f_n$
,
 ${\mathbb P}_0,$
${\mathbb P}_0,$
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 $\gamma _0^*$
in place of
$\gamma _0^*$
in place of
 ${\mathbb P}_1,{\mathbb P}_1^*$
,
${\mathbb P}_1,{\mathbb P}_1^*$
,
 $\gamma _1^*$
, and (21) in place of (20). Equation 22 further implies
$\gamma _1^*$
, and (21) in place of (20). Equation 22 further implies
 ${\mathbb P}_1^*(\eta ^*\leq 1/2-r, f_n\geq -\alpha _r)\lt \delta$
, and these relations imply (16).
${\mathbb P}_1^*(\eta ^*\leq 1/2-r, f_n\geq -\alpha _r)\lt \delta$
, and these relations imply (16).
7. Consistency requires uniqueness up to degeneracy
We prove the reverse direction of Theorem2 by constructing a sequence of functions
 $f_n$
that minimize
$f_n$
that minimize
 $R_\phi ^\epsilon$
for which
$R_\phi ^\epsilon$
for which
 $R^\epsilon (f_n)$
is constant in
$R^\epsilon (f_n)$
is constant in
 $n$
and not equal to the minimal adversarial Bayes risk.
$n$
and not equal to the minimal adversarial Bayes risk.
Proposition 3.
Assume that
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure and that the adversarial Bayes classifier is not unique up to degeneracy. Then any consistent loss
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure and that the adversarial Bayes classifier is not unique up to degeneracy. Then any consistent loss
 $\phi$
satisfying
$\phi$
satisfying
 $C_\phi ^*(1/2)=\phi (0)$
is not adversarially consistent.
$C_\phi ^*(1/2)=\phi (0)$
is not adversarially consistent.
We will outline the proof in this section below, and the full argument is presented in Appendix D. Before discussing the components of this argument, we illustrate this construction using the adversarial Bayes classifiers depicted in Figure 2. In this example, when
 $\epsilon \leq (\mu _1-\mu _0)/2$
, two adversarial Bayes classifiers are
$\epsilon \leq (\mu _1-\mu _0)/2$
, two adversarial Bayes classifiers are
 $A_1=\emptyset$
and
$A_1=\emptyset$
and
 $A_2=\mathbb {R}$
, as depicted in Figure 2b and 2c. These sets are not equivalent up to degeneracy, and in particular the set
$A_2=\mathbb {R}$
, as depicted in Figure 2b and 2c. These sets are not equivalent up to degeneracy, and in particular the set
 $\{1\}$
is not an adversarial Bayes classifier. However, the fact that both
$\{1\}$
is not an adversarial Bayes classifier. However, the fact that both
 $\emptyset$
and
$\emptyset$
and
 $\mathbb {R}$
are adversarial Bayes classifiers suggests that
$\mathbb {R}$
are adversarial Bayes classifiers suggests that
 $\hat \eta (x) \equiv 1/2$
on all of
$\hat \eta (x) \equiv 1/2$
on all of
 $\mathbb {R}$
, and thus
$\mathbb {R}$
, and thus
 $f(x)\equiv 0$
is a minimizer of
$f(x)\equiv 0$
is a minimizer of
 $R_\phi ^\epsilon$
. Consequently, the function sequence
$R_\phi ^\epsilon$
. Consequently, the function sequence
 \begin{align*} f_n(x)=\begin{cases} \frac 1 n &\text {if }x\in \{1\}\\ -\frac 1n&\text {otherwise} \end{cases} \end{align*}
\begin{align*} f_n(x)=\begin{cases} \frac 1 n &\text {if }x\in \{1\}\\ -\frac 1n&\text {otherwise} \end{cases} \end{align*}
is a minimizing sequence of
 $R_\phi ^\epsilon$
for which
$R_\phi ^\epsilon$
for which
 $R^\epsilon (f_n)$
is constant in
$R^\epsilon (f_n)$
is constant in
 $n$
and not equal to the adversarial Bayes risk.
$n$
and not equal to the adversarial Bayes risk.
To generalize this construction to an arbitrary distribution, one must find a set
 $\tilde A$
contained between two adversarial Bayes classifiers that is not itself an adversarial Bayes classifier. The absolute continuity assumption is key in this step of the argument. Theorem6 together with a result of [Reference Frank15] imply that when
$\tilde A$
contained between two adversarial Bayes classifiers that is not itself an adversarial Bayes classifier. The absolute continuity assumption is key in this step of the argument. Theorem6 together with a result of [Reference Frank15] imply that when
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure, the adversarial Bayes classifier is unique iff
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure, the adversarial Bayes classifier is unique iff
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
are equivalent up to degeneracy, see Appendix D for a proof.
$\{\hat \eta \geq 1/2\}$
are equivalent up to degeneracy, see Appendix D for a proof.
Lemma 5.
Assume
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure. Then adversarial Bayes classifier is unique up to degeneracy iff the adversarial Bayes classifiers
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure. Then adversarial Bayes classifier is unique up to degeneracy iff the adversarial Bayes classifiers
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
are equivalent up to degeneracy.
$\{\hat \eta \geq 1/2\}$
are equivalent up to degeneracy.
Consequently, if the adversarial Bayes classifier is not unique up to degeneracy, then there is a set
 $\tilde A$
that is not an adversarial Bayes classifier but
$\tilde A$
that is not an adversarial Bayes classifier but
 $\{\hat \eta \gt 1/2\}\subset \tilde A\subset \{\hat \eta \geq 1/2\}$
. Next, we prove that one can replace the value of
$\{\hat \eta \gt 1/2\}\subset \tilde A\subset \{\hat \eta \geq 1/2\}$
. Next, we prove that one can replace the value of
 $\alpha _\phi (1/2)$
by 0 in the minimizer
$\alpha _\phi (1/2)$
by 0 in the minimizer
 $\alpha _\phi (\hat \eta ({\mathbf x}))$
and still retain a minimizer of
$\alpha _\phi (\hat \eta ({\mathbf x}))$
and still retain a minimizer of
 $R_\phi ^\epsilon$
. Formally:
$R_\phi ^\epsilon$
. Formally:
Lemma 6.
Let
 $\alpha _\phi \,:\,[0,1]\to \mathbb {R}$
be as in Lemma
1
and define a function
$\alpha _\phi \,:\,[0,1]\to \mathbb {R}$
be as in Lemma
1
and define a function
 $\tilde \alpha _\phi \,:\,[0,1]\to \overline {\mathbb {R}}$
by
$\tilde \alpha _\phi \,:\,[0,1]\to \overline {\mathbb {R}}$
by
 \begin{align} \tilde \alpha _\phi (\eta )=\begin{cases} \alpha _\phi (\eta )&\text {if }\eta \neq 1/2\\ 0&\text {otherwise} \end{cases} \end{align}
\begin{align} \tilde \alpha _\phi (\eta )=\begin{cases} \alpha _\phi (\eta )&\text {if }\eta \neq 1/2\\ 0&\text {otherwise} \end{cases} \end{align}
Let
 $\hat \eta \,:\,\mathbb {R}^d\to [0,1]$
be the function described in Theorem
5
. If
$\hat \eta \,:\,\mathbb {R}^d\to [0,1]$
be the function described in Theorem
5
. If
 $\phi$
is consistent and
$\phi$
is consistent and
 $C_\phi ^*(1/2)=\phi (0)$
, then
$C_\phi ^*(1/2)=\phi (0)$
, then
 $\tilde \alpha (\hat \eta ({\mathbf x}))$
is a minimizer of
$\tilde \alpha (\hat \eta ({\mathbf x}))$
is a minimizer of
 $R_\phi ^\epsilon$
.
$R_\phi ^\epsilon$
.
See Appendix D.1 for a proof of this result. Thus, we select a sequence
 $f_n$
that is strictly positive on
$f_n$
that is strictly positive on
 $\tilde A$
, strictly negative on
$\tilde A$
, strictly negative on
 $\tilde A^C$
, and approaches 0 on
$\tilde A^C$
, and approaches 0 on
 $\{\hat \eta =1/2\}$
. Consider the sequence
$\{\hat \eta =1/2\}$
. Consider the sequence
 \begin{align} f_n({\mathbf x})=\begin{cases} \tilde \alpha _\phi (\hat \eta ({\mathbf x})) &\hat \eta ({\mathbf x})\neq 1/2\\ \frac 1n & \hat \eta ({\mathbf x})=1/2, {\mathbf x} \in \tilde A\\ -\frac 1n & \hat \eta ({\mathbf x})=1/2, {\mathbf x} \not \in \tilde A \end{cases} \end{align}
\begin{align} f_n({\mathbf x})=\begin{cases} \tilde \alpha _\phi (\hat \eta ({\mathbf x})) &\hat \eta ({\mathbf x})\neq 1/2\\ \frac 1n & \hat \eta ({\mathbf x})=1/2, {\mathbf x} \in \tilde A\\ -\frac 1n & \hat \eta ({\mathbf x})=1/2, {\mathbf x} \not \in \tilde A \end{cases} \end{align}
Then
 $R^\epsilon (f_n)=R^\epsilon (\tilde A)\gt \inf _AR^\epsilon (A)$
for all
$R^\epsilon (f_n)=R^\epsilon (\tilde A)\gt \inf _AR^\epsilon (A)$
for all
 $n$
and one can show that
$n$
and one can show that
 $f_n$
is a minimizing sequence of
$f_n$
is a minimizing sequence of
 $R_\phi ^\epsilon$
. However,
$R_\phi ^\epsilon$
. However,
 $f_n$
may assume the values
$f_n$
may assume the values
 $\pm \infty$
because the function
$\pm \infty$
because the function
 $\alpha _\phi$
is
$\alpha _\phi$
is
 $\overline {\mathbb {R}}$
-valued. Truncating these functions produces an
$\overline {\mathbb {R}}$
-valued. Truncating these functions produces an
 $\mathbb {R}$
-valued sequence that minimizes
$\mathbb {R}$
-valued sequence that minimizes
 $R_\phi ^\epsilon$
but
$R_\phi ^\epsilon$
but
 $R^\epsilon (f_n)=R^\epsilon (\tilde A)$
for all
$R^\epsilon (f_n)=R^\epsilon (\tilde A)$
for all
 $n$
, see Appendix C for details.
$n$
, see Appendix C for details.
8. Conclusion
In summary, we prove that under a reasonable distributional assumption, a convex loss is adversarially consistent if and only if the adversarial Bayes classifier is unique up to degeneracy. This result connects an analytical property of the adversarial Bayes classifier to a statistical property of surrogate risks. Analyzing adversarial consistency in the multiclass setting remains an open problem. Prior work [Reference Robey, Latorre, Pappas, Hassani and Cevher29] has proposed an alternative loss function to address the issue of robust overfitting. Furthermore, many recent papers suggest that classification with a rejection option is a better framework for robust learning – a non-exhaustive list includes [Reference Chen, Raghuram, Choi, Wu, Liang and Jha11, Reference Chen, Raghuram, Choi, Wu, Liang and Jha12, Reference Kato, Cui and Fukuhara20, Reference Shah, Chaudhari and Manwani30]. Analyzing the behavior of these alternative risks using the tools developed in this paper is an open problem as well. Hopefully, our results will aid in the analysis and development of further algorithms for adversarial learning.
Acknowledgements
Special thanks to Jonathan Niles-Weed for helpful conversations.
Funding
Natalie Frank was supported in part by the Research Training Group in Modeling and Simulation funded by the National Science Foundation via grant RTG/DMS – 1646339 and NSF grant DMS-2210583.
Competing interests
Author declares no competing interests.
Appendix A. Further Results on the Function
$\hat \eta$
— Proof of Theorem6

We prove that the sets
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
minimize
$\{\hat \eta \geq 1/2\}$
minimize
 $R_\phi ^\epsilon$
by showing that their adversarial classification risks equal
$R_\phi ^\epsilon$
by showing that their adversarial classification risks equal
 $\bar R({\mathbb P}_0^*,{\mathbb P}_1^*)$
, for the measures
$\bar R({\mathbb P}_0^*,{\mathbb P}_1^*)$
, for the measures
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
in Theorem5.
${\mathbb P}_1^*$
in Theorem5.
Proposition 4.
Let
 $\hat \eta$
be the function in Theorem
5
. Then the sets
$\hat \eta$
be the function in Theorem
5
. Then the sets
 $\{\hat \eta \gt 1/2\}$
,
$\{\hat \eta \gt 1/2\}$
,
 $\{\hat \eta \geq 1/2\}$
are both adversarial Bayes classifiers.
$\{\hat \eta \geq 1/2\}$
are both adversarial Bayes classifiers.
Proof. We prove the statement for
 $\{\hat \eta \gt 1/2\}$
, the argument for the set
$\{\hat \eta \gt 1/2\}$
, the argument for the set
 $\{\hat \eta \geq 1/2\}$
is analogous.
$\{\hat \eta \geq 1/2\}$
is analogous.
Let
 ${\mathbb P}_0^*, {\mathbb P}_1^*$
be the measures of Theorem5 and set
${\mathbb P}_0^*, {\mathbb P}_1^*$
be the measures of Theorem5 and set
 ${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
,
${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
,
 $\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
. Furthermore, let
$\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
. Furthermore, let
 $\gamma _0^*$
,
$\gamma _0^*$
,
 $\gamma _1^*$
be the couplings between
$\gamma _1^*$
be the couplings between
 ${\mathbb P}_0$
,
${\mathbb P}_0$
,
 ${\mathbb P}_0^*$
and
${\mathbb P}_0^*$
and
 ${\mathbb P}_1$
,
${\mathbb P}_1$
,
 ${\mathbb P}_1^*$
supported on
${\mathbb P}_1^*$
supported on
 $\Delta _\epsilon$
.
$\Delta _\epsilon$
.
First, Item 2 implies that the function
 $\hat \eta ({\mathbf x})$
assumes its infimum on an ball
$\hat \eta ({\mathbf x})$
assumes its infimum on an ball
 $\overline {B_\epsilon ({\mathbf x})}$
$\overline {B_\epsilon ({\mathbf x})}$
 $\gamma _1^*$
-a.e. and therefore
$\gamma _1^*$
-a.e. and therefore
 $S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}^C})({\mathbf x})={\mathbf {1}}_{\{I_\epsilon (\hat \eta )({\mathbf x})\gt 1/2\}^C}$
$S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}^C})({\mathbf x})={\mathbf {1}}_{\{I_\epsilon (\hat \eta )({\mathbf x})\gt 1/2\}^C}$
 $\gamma _1^*$
-a.e. (Recall the notation
$\gamma _1^*$
-a.e. (Recall the notation
 $I_\epsilon$
was defined in (10). Item 2 further implies that
$I_\epsilon$
was defined in (10). Item 2 further implies that
 ${\mathbf {1}}_{\{I_\epsilon (\hat \eta )({\mathbf x})\gt 1/2\}^C}={\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}^C}$
${\mathbf {1}}_{\{I_\epsilon (\hat \eta )({\mathbf x})\gt 1/2\}^C}={\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}^C}$
 $\gamma _1^*$
-a.e. and consequently,
$\gamma _1^*$
-a.e. and consequently,
 \begin{align} S_\epsilon ({\mathbf {1}}_{\{\hat \eta ({\mathbf x})\gt 1/2\}^C})({\mathbf x})={\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}^C}\quad \gamma _1^*\text {-a.e.} \end{align}
\begin{align} S_\epsilon ({\mathbf {1}}_{\{\hat \eta ({\mathbf x})\gt 1/2\}^C})({\mathbf x})={\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}^C}\quad \gamma _1^*\text {-a.e.} \end{align}
An analogous argument shows
 \begin{align} S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}})({\mathbf x})={\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}}\quad \gamma _0^*\text {-a.e.} \end{align}
\begin{align} S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}})({\mathbf x})={\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}}\quad \gamma _0^*\text {-a.e.} \end{align}
Equations (27) and (28) then imply that
 \begin{align*} \begin{aligned} R^\epsilon (\{\hat \eta \gt 1/2\})&=\int {\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}^C}d\gamma _1^*+\int {\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}}d\gamma _0^*\\ &=\int {\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}^C}d{\mathbb P}_1^*+\int {\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}}d{\mathbb P}_0^*=\int C(\eta ^*,{\mathbf {1}}_{\{\hat \eta \gt 1/2\}})d{\mathbb P}^*. \end{aligned} \end{align*}
\begin{align*} \begin{aligned} R^\epsilon (\{\hat \eta \gt 1/2\})&=\int {\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}^C}d\gamma _1^*+\int {\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}}d\gamma _0^*\\ &=\int {\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}^C}d{\mathbb P}_1^*+\int {\mathbf {1}}_{\{\hat \eta ({\mathbf x}^{\prime})\gt 1/2\}}d{\mathbb P}_0^*=\int C(\eta ^*,{\mathbf {1}}_{\{\hat \eta \gt 1/2\}})d{\mathbb P}^*. \end{aligned} \end{align*}
Next Item 1 of Theorem5 implies that
 $\hat \eta ({\mathbf x}^{\prime})=\eta ^*({\mathbf x}^{\prime})$
$\hat \eta ({\mathbf x}^{\prime})=\eta ^*({\mathbf x}^{\prime})$
 ${\mathbb P}^*$
-a.e. and consequently
${\mathbb P}^*$
-a.e. and consequently
 \begin{align*} R^\epsilon (\{\hat \eta \gt 1/2\})=\int C(\eta ^*,{\mathbf {1}}_{\{\eta ^*\gt 1/2\}})d{\mathbb P}^*=\bar R({\mathbb P}_0^*,{\mathbb P}_1^*). \end{align*}
\begin{align*} R^\epsilon (\{\hat \eta \gt 1/2\})=\int C(\eta ^*,{\mathbf {1}}_{\{\eta ^*\gt 1/2\}})d{\mathbb P}^*=\bar R({\mathbb P}_0^*,{\mathbb P}_1^*). \end{align*}
Therefore, the strong duality result in Theorem3 implies that
 $\{\hat \eta \gt 1/2\}$
must minimize
$\{\hat \eta \gt 1/2\}$
must minimize
 $R^\epsilon$
.
$R^\epsilon$
.
Finally, the complementary slackness conditions from [Reference Frank15, Theorem 2.4] characterize minimizers of
 $R^\epsilon$
and maximizers of
$R^\epsilon$
and maximizers of
 $\bar R$
, and this characterization proves Equations (11) and (12). Verifying these conditions would be another method of proving Proposition4.
$\bar R$
, and this characterization proves Equations (11) and (12). Verifying these conditions would be another method of proving Proposition4.
Theorem 8.
The set
 $A$
is a minimizer of
$A$
is a minimizer of
 $R^\epsilon$
and
$R^\epsilon$
and
 $({\mathbb P}_0^*,{\mathbb P}_1^*)$
is a maximizer of
$({\mathbb P}_0^*,{\mathbb P}_1^*)$
is a maximizer of
 $\bar R$
over the
$\bar R$
over the
 $W_\infty$
balls around
$W_\infty$
balls around
 ${\mathbb P}_0$
and
${\mathbb P}_0$
and
 ${\mathbb P}_1$
iff
${\mathbb P}_1$
iff
 $W_\infty ({\mathbb P}_0^*,{\mathbb P}_0)\leq \epsilon$
,
$W_\infty ({\mathbb P}_0^*,{\mathbb P}_0)\leq \epsilon$
,
 $W_\infty ({\mathbb P}_1^*,{\mathbb P}_1)\leq \epsilon$
, and
$W_\infty ({\mathbb P}_1^*,{\mathbb P}_1)\leq \epsilon$
, and
-
1)
(29)
\begin{align} \int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1=\int {\mathbf {1}}_{A^C} d{\mathbb P}_1^*\quad \text {and} \quad \int S_\epsilon ({\mathbf {1}}_{A}) d{\mathbb P}_0= \int {\mathbf {1}}_{ A} d{\mathbb P}_0^* \end{align}
-
2)
(30)
\begin{align} C(\eta ^*,{\mathbf {1}}_A({\mathbf x}^{\prime}))=C^*(\eta ^*({\mathbf x}^{\prime}))\quad {\mathbb P}^*\text {-a.e.} \end{align}
where
${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
and
$\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
.




Let
 $\gamma _0^*$
,
$\gamma _0^*$
,
 $\gamma _1^*$
be couplings between
$\gamma _1^*$
be couplings between
 ${\mathbb P}_0$
,
${\mathbb P}_0$
,
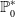 ${\mathbb P}_0^*$
and
${\mathbb P}_0^*$
and
 ${\mathbb P}_1$
,
${\mathbb P}_1$
,
 ${\mathbb P}_1^*$
supported on
${\mathbb P}_1^*$
supported on
 $\Delta _\epsilon$
. Notice that because Lemma2 implies that
$\Delta _\epsilon$
. Notice that because Lemma2 implies that
 $ S_\epsilon ({\mathbf {1}}_{A^C})({\mathbf x})\geq {\mathbf {1}}_{A^C}({\mathbf x}^{\prime})$
$ S_\epsilon ({\mathbf {1}}_{A^C})({\mathbf x})\geq {\mathbf {1}}_{A^C}({\mathbf x}^{\prime})$
 $\gamma _1^*$
-a.e. and
$\gamma _1^*$
-a.e. and
 $ S_\epsilon ({\mathbf {1}}_A)({\mathbf x})\geq {\mathbf {1}}_A({\mathbf x}^{\prime})$
, the complementary slackness condition in (29) is equivalent to
$ S_\epsilon ({\mathbf {1}}_A)({\mathbf x})\geq {\mathbf {1}}_A({\mathbf x}^{\prime})$
, the complementary slackness condition in (29) is equivalent to
 \begin{align} S_\epsilon ({\mathbf {1}}_{A^C})({\mathbf x})={\mathbf {1}}_{A^C}({\mathbf x}^{\prime})\quad \gamma _1^*\text {-a.e.}\quad \text {and}\quad S_\epsilon ({\mathbf {1}}_A)({\mathbf x})={\mathbf {1}}_A({\mathbf x}^{\prime})\quad \gamma _0^*\text {-a.e.} \end{align}
\begin{align} S_\epsilon ({\mathbf {1}}_{A^C})({\mathbf x})={\mathbf {1}}_{A^C}({\mathbf x}^{\prime})\quad \gamma _1^*\text {-a.e.}\quad \text {and}\quad S_\epsilon ({\mathbf {1}}_A)({\mathbf x})={\mathbf {1}}_A({\mathbf x}^{\prime})\quad \gamma _0^*\text {-a.e.} \end{align}
This observation completes the proof of Theorem6.
Proof of Theorem
6
. Let
 $\hat \eta$
,
$\hat \eta$
,
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
be the function and measures of Theorem5, and set
${\mathbb P}_1^*$
be the function and measures of Theorem5, and set
 ${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
,
${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
,
 $\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
. Let
$\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
. Let
 $\gamma _0^*$
,
$\gamma _0^*$
,
 $\gamma _1^*$
be couplings between
$\gamma _1^*$
be couplings between
 ${\mathbb P}_0$
,
${\mathbb P}_0$
,
 ${\mathbb P}_0^*$
and
${\mathbb P}_0^*$
and
 ${\mathbb P}_1$
,
${\mathbb P}_1$
,
 ${\mathbb P}_1^*$
supported on
${\mathbb P}_1^*$
supported on
 $\Delta _\epsilon$
.
$\Delta _\epsilon$
.
Proposition4 proves that the sets
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
are in fact adversarial Bayes classifiers. If
$\{\hat \eta \geq 1/2\}$
are in fact adversarial Bayes classifiers. If
 $A$
is any adversarial Bayes classifier, the complementary slackness condition (30) implies that
$A$
is any adversarial Bayes classifier, the complementary slackness condition (30) implies that
 ${\mathbf {1}}_{\eta ^*\gt 1/2}\leq {\mathbf {1}}_A\leq {\mathbf {1}}_{\eta ^*\geq 1/2}$
${\mathbf {1}}_{\eta ^*\gt 1/2}\leq {\mathbf {1}}_A\leq {\mathbf {1}}_{\eta ^*\geq 1/2}$
 ${\mathbb P}^*$
-a.e. Thus Item 1 implies that
${\mathbb P}^*$
-a.e. Thus Item 1 implies that
 \begin{align*} {\mathbf {1}}_{\{\hat \eta \gt 1/2\}}({\mathbf x}^{\prime})\leq {\mathbf {1}}_A({\mathbf x}^{\prime}) \leq {\mathbf {1}}_{\{\hat \eta \geq 1/2\}}({\mathbf x}^{\prime})\quad \gamma _0^*\text {-a.e.} \end{align*}
\begin{align*} {\mathbf {1}}_{\{\hat \eta \gt 1/2\}}({\mathbf x}^{\prime})\leq {\mathbf {1}}_A({\mathbf x}^{\prime}) \leq {\mathbf {1}}_{\{\hat \eta \geq 1/2\}}({\mathbf x}^{\prime})\quad \gamma _0^*\text {-a.e.} \end{align*}
and
 \begin{align*} {\mathbf {1}}_{\{\hat \eta \gt 1/2\}^C}({\mathbf x}^{\prime})\leq {\mathbf {1}}_{A^C}({\mathbf x}^{\prime}) \leq {\mathbf {1}}_{\{\hat \eta \geq 1/2\}^C}({\mathbf x}^{\prime}) \quad \gamma _1^*\text {-a.e.} \end{align*}
\begin{align*} {\mathbf {1}}_{\{\hat \eta \gt 1/2\}^C}({\mathbf x}^{\prime})\leq {\mathbf {1}}_{A^C}({\mathbf x}^{\prime}) \leq {\mathbf {1}}_{\{\hat \eta \geq 1/2\}^C}({\mathbf x}^{\prime}) \quad \gamma _1^*\text {-a.e.} \end{align*}
The complementary slackness condition (31) then implies Equations (11) and (12).
Appendix B. Uniqueness up to Degeneracy and
$\hat \eta ({\mathbf x})$
— Proof of Theorem7

Theorem 3.4 of [Reference Frank15] proves the following result:
Theorem 9.
Assume that
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure. Then the following are equivalent:
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure. Then the following are equivalent:
-
1) The adversarial Bayes classifier is unique up to degeneracy
-
2) Amongst all adversarial Bayes classifiers
$A$
, the value of
$\int S_\epsilon ({\mathbf {1}}_A)d{\mathbb P}_0$
is unique or the value of
$\int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1$
is unique



Thus it remains to show that Item 2 of Theorem9 is equivalent to Item 2 of Theorem7. We will apply the complementary slackness conditions of Theorem8.
Proof of Theorem
7. Let
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
be the measures of Theorem5.
${\mathbb P}_1^*$
be the measures of Theorem5.
First, we show that Item 2 implies Item 2. Assume that Item 2 holds. Notice that for an adversarial Bayes classifier
 $A$
,
$A$
,
 \begin{align*} \int S_\epsilon ({\mathbf {1}}_A)d{\mathbb P}_0+ \int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1 =R_*^\epsilon \end{align*}
\begin{align*} \int S_\epsilon ({\mathbf {1}}_A)d{\mathbb P}_0+ \int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1 =R_*^\epsilon \end{align*}
where
 $R_*^\epsilon$
is the minimal value of
$R_*^\epsilon$
is the minimal value of
 $R^\epsilon$
. Thus amongst all adversarial Bayes classifiers
$R^\epsilon$
. Thus amongst all adversarial Bayes classifiers
 $A$
, the value of
$A$
, the value of
 $\int S_\epsilon ({\mathbf {1}}_A)d{\mathbb P}_0$
is unique iff the value of
$\int S_\epsilon ({\mathbf {1}}_A)d{\mathbb P}_0$
is unique iff the value of
 $\int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1$
is unique. Thus Item 2 implies both
$\int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1$
is unique. Thus Item 2 implies both
 $\int S_\epsilon ({\mathbf {1}}_{A_1})d{\mathbb P}_0=\int S_\epsilon ({\mathbf {1}}_{A_2})d{\mathbb P}_0$
and
$\int S_\epsilon ({\mathbf {1}}_{A_1})d{\mathbb P}_0=\int S_\epsilon ({\mathbf {1}}_{A_2})d{\mathbb P}_0$
and
 $\int S_\epsilon ({\mathbf {1}}_{A_1^C})d{\mathbb P}_1=\int S_\epsilon ({\mathbf {1}}_{A_2^C})d{\mathbb P}_1$
for any two adversarial Bayes classifiers
$\int S_\epsilon ({\mathbf {1}}_{A_1^C})d{\mathbb P}_1=\int S_\epsilon ({\mathbf {1}}_{A_2^C})d{\mathbb P}_1$
for any two adversarial Bayes classifiers
 $A_1$
and
$A_1$
and
 $A_2$
.
$A_2$
.
Applying this statement to the adversarial Bayes classifiers
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
produces
$\{\hat \eta \geq 1/2\}$
produces
 \begin{align*} \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}^C})d{\mathbb P}_1 =\int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \geq 1/2\}^C})d{\mathbb P}_1 \quad \text {and}\quad \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}})d{\mathbb P}_0 =\int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \geq 1/2\}})d{\mathbb P}_0 \end{align*}
\begin{align*} \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}^C})d{\mathbb P}_1 =\int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \geq 1/2\}^C})d{\mathbb P}_1 \quad \text {and}\quad \int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}})d{\mathbb P}_0 =\int S_\epsilon ({\mathbf {1}}_{\{\hat \eta \geq 1/2\}})d{\mathbb P}_0 \end{align*}
The complementary slackness condition (29) implies that
 \begin{align*} \int {\mathbf {1}}_{\{\hat \eta \gt 1/2\}^C}d{\mathbb P}_1^*=\int {\mathbf {1}}_{\{\hat \eta \geq 1/2\}^C}d{\mathbb P}_1^*\quad \text {and}\quad \int {\mathbf {1}}_{\{\hat \eta \gt 1/2\}}d{\mathbb P}_0^*=\int {\mathbf {1}}_{\{\hat \eta \geq 1/2\}}d{\mathbb P}_0^* \end{align*}
\begin{align*} \int {\mathbf {1}}_{\{\hat \eta \gt 1/2\}^C}d{\mathbb P}_1^*=\int {\mathbf {1}}_{\{\hat \eta \geq 1/2\}^C}d{\mathbb P}_1^*\quad \text {and}\quad \int {\mathbf {1}}_{\{\hat \eta \gt 1/2\}}d{\mathbb P}_0^*=\int {\mathbf {1}}_{\{\hat \eta \geq 1/2\}}d{\mathbb P}_0^* \end{align*}
and subsequently, Item 1 of Theorem5 implies that
 \begin{align*} \int {\mathbf {1}}_{\{\eta ^*\gt 1/2\}^C}d{\mathbb P}_1^*=\int {\mathbf {1}}_{\{\eta ^*\geq 1/2\}^C}d{\mathbb P}_1^*\quad \text {and}\quad \int {\mathbf {1}}_{\{\eta ^*\gt 1/2\}}d{\mathbb P}_0^*=\int {\mathbf {1}}_{\{\eta ^*\geq 1/2\}}d{\mathbb P}_0^*. \end{align*}
\begin{align*} \int {\mathbf {1}}_{\{\eta ^*\gt 1/2\}^C}d{\mathbb P}_1^*=\int {\mathbf {1}}_{\{\eta ^*\geq 1/2\}^C}d{\mathbb P}_1^*\quad \text {and}\quad \int {\mathbf {1}}_{\{\eta ^*\gt 1/2\}}d{\mathbb P}_0^*=\int {\mathbf {1}}_{\{\eta ^*\geq 1/2\}}d{\mathbb P}_0^*. \end{align*}
Consequently,
 ${\mathbb P}^*(\eta ^*=1/2)=0$
.
${\mathbb P}^*(\eta ^*=1/2)=0$
.
To show the other direction, we apply the inequalities in Theorem6. The complementary slackness conditions in Theorem8 and the first inequality in Theorem6 imply that for any adversarial Bayes classifier
 $A$
,
$A$
,
 \begin{align*} \int {\mathbf {1}}_{\{\eta ^*\lt 1/2\}}d{\mathbb P}_1^*\leq \int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1\leq \int {\mathbf {1}}_{\{\hat \eta ^*\leq 1/2\}} d{\mathbb P}_1^* \end{align*}
\begin{align*} \int {\mathbf {1}}_{\{\eta ^*\lt 1/2\}}d{\mathbb P}_1^*\leq \int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1\leq \int {\mathbf {1}}_{\{\hat \eta ^*\leq 1/2\}} d{\mathbb P}_1^* \end{align*}
Consequently, if
 ${\mathbb P}^*(\eta ^*=1/2)=0$
, then
${\mathbb P}^*(\eta ^*=1/2)=0$
, then
 $\int {\mathbf {1}}_{\{\eta ^*\lt 1/2\}}d{\mathbb P}_1^*= \int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1$
, which implies that
$\int {\mathbf {1}}_{\{\eta ^*\lt 1/2\}}d{\mathbb P}_1^*= \int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1$
, which implies that
 $\int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1$
assumes a unique value over all possible adversarial Bayes classifiers.
$\int S_\epsilon ({\mathbf {1}}_{A^C})d{\mathbb P}_1$
assumes a unique value over all possible adversarial Bayes classifiers.
Appendix C. Technical loss function proofs—Proof of Lemmas1 and 4
To begin, we prove a result that compares minimizers of
 $C_\phi (\eta, \cdot )$
for differing values of
$C_\phi (\eta, \cdot )$
for differing values of
 $\eta$
.
$\eta$
.
This result is then used to prove Lemma1.
Lemma 7.
If
 $\alpha _2^*$
is any minimizer of
$\alpha _2^*$
is any minimizer of
 $C_\phi (\eta _2,\cdot )$
and
$C_\phi (\eta _2,\cdot )$
and
 $\eta _2\gt \eta _1$
, then
$\eta _2\gt \eta _1$
, then
 $\alpha _\phi (\eta _1)\leq \alpha _2^*$
.
$\alpha _\phi (\eta _1)\leq \alpha _2^*$
.
Proof. One can express
 $C_\phi (\eta _2,\alpha )$
as
$C_\phi (\eta _2,\alpha )$
as
 \begin{align*} C_\phi (\eta _2,\alpha )=C_\phi (\eta _1,\alpha )+(\eta _2-\eta _1)(\phi (\alpha )-\phi (-\alpha )) \end{align*}
\begin{align*} C_\phi (\eta _2,\alpha )=C_\phi (\eta _1,\alpha )+(\eta _2-\eta _1)(\phi (\alpha )-\phi (-\alpha )) \end{align*}
Notice that the function
 $\alpha \mapsto \phi (\alpha )-\phi (-\alpha )$
is non-increasing in
$\alpha \mapsto \phi (\alpha )-\phi (-\alpha )$
is non-increasing in
 $\alpha$
. As
$\alpha$
. As
 $\alpha _\phi (\eta _1)$
is the smallest minimizer of
$\alpha _\phi (\eta _1)$
is the smallest minimizer of
 $C_\phi (\eta _1,\cdot )$
, if
$C_\phi (\eta _1,\cdot )$
, if
 $\alpha \lt \alpha _\phi (\eta _1)$
then
$\alpha \lt \alpha _\phi (\eta _1)$
then
 $C_\phi (\eta _1,\alpha )\gt C_\phi ^*(\eta _1)$
and thus
$C_\phi (\eta _1,\alpha )\gt C_\phi ^*(\eta _1)$
and thus
 $C_\phi (\eta _2,\alpha )\gt C_\phi (\eta _2,\alpha _\phi (\eta _1))$
. Consequently, every minimizer of
$C_\phi (\eta _2,\alpha )\gt C_\phi (\eta _2,\alpha _\phi (\eta _1))$
. Consequently, every minimizer of
 $C_\phi (\eta _2,\cdot )$
must be greater than or equal to
$C_\phi (\eta _2,\cdot )$
must be greater than or equal to
 $\alpha _\phi (\eta _1)$
.
$\alpha _\phi (\eta _1)$
.
Next we use this result to prove Lemma1.
Proof of Lemma
1. For
 $\eta _2\gt \eta _1$
, apply Lemma7 with the choice
$\eta _2\gt \eta _1$
, apply Lemma7 with the choice
 $\alpha _2^*=\alpha _\phi (\eta _2)$
.
$\alpha _2^*=\alpha _\phi (\eta _2)$
.
Next, if the loss
 $\phi$
is consistent, then
$\phi$
is consistent, then
 $0$
can minimize
$0$
can minimize
 $C_\phi (\eta, \cdot )$
only when
$C_\phi (\eta, \cdot )$
only when
 $\eta =1/2$
.
$\eta =1/2$
.
Lemma 8.
Let
 $\phi$
be a consistent loss. If
$\phi$
be a consistent loss. If
 $0\in \textrm {argmin} C_\phi (\eta, \cdot )$
, then
$0\in \textrm {argmin} C_\phi (\eta, \cdot )$
, then
 $\eta =1/2$
.
$\eta =1/2$
.
Proof. Consider a distribution for which
 $\eta ({\mathbf x})\equiv \eta$
is constant. Then by the consistency of
$\eta ({\mathbf x})\equiv \eta$
is constant. Then by the consistency of
 $\phi$
, if
$\phi$
, if
 $0$
minimizes
$0$
minimizes
 $C_\phi (\eta, \cdot )$
, then it also must minimize
$C_\phi (\eta, \cdot )$
, then it also must minimize
 $C(\eta, \cdot )$
and therefore
$C(\eta, \cdot )$
and therefore
 $\eta \leq 1/2$
.
$\eta \leq 1/2$
.
However, notice that
 $C_\phi (\eta, \alpha )=C_\phi (1-\eta, -\alpha )$
. Thus if 0 minimizes
$C_\phi (\eta, \alpha )=C_\phi (1-\eta, -\alpha )$
. Thus if 0 minimizes
 $C_\phi (\eta, \cdot )$
it must also minimize
$C_\phi (\eta, \cdot )$
it must also minimize
 $C_\phi (1-\eta, \cdot )$
. The consistency of
$C_\phi (1-\eta, \cdot )$
. The consistency of
 $\phi$
then implies that
$\phi$
then implies that
 $1-\eta \leq 1/2$
as well and consequently,
$1-\eta \leq 1/2$
as well and consequently,
 $\eta =1/2$
.
$\eta =1/2$
.
Combining these two results proves Lemma4.
Proof of Lemma
4. Notice that
 $C_\phi (\eta, \alpha )=C_\phi (1-\eta, -\alpha )$
and thus it suffices to consider
$C_\phi (\eta, \alpha )=C_\phi (1-\eta, -\alpha )$
and thus it suffices to consider
 $\eta \geq 1/2+r$
.
$\eta \geq 1/2+r$
.
Lemma8 implies that
 $C_\phi (1/2+r,\alpha _\phi (1/2+r))\lt \phi (0)$
. Furthermore, as
$C_\phi (1/2+r,\alpha _\phi (1/2+r))\lt \phi (0)$
. Furthermore, as
 $\phi (-\alpha )\geq \phi (0)\geq \phi (\alpha )$
when
$\phi (-\alpha )\geq \phi (0)\geq \phi (\alpha )$
when
 $\alpha \geq 0$
, one can conclude that
$\alpha \geq 0$
, one can conclude that
 $\phi (\alpha _\phi (1/2+r))\lt \phi (0)$
. Now pick an
$\phi (\alpha _\phi (1/2+r))\lt \phi (0)$
. Now pick an
 $\alpha _r\in (0,\alpha _\phi (1/2+r))$
for which
$\alpha _r\in (0,\alpha _\phi (1/2+r))$
for which
 $\phi (\alpha _\phi (1/2+r))\lt \phi (\alpha _r)\lt \phi (0)$
. Then by Lemma7, if
$\phi (\alpha _\phi (1/2+r))\lt \phi (\alpha _r)\lt \phi (0)$
. Then by Lemma7, if
 $\eta \geq 1/2+r$
, every
$\eta \geq 1/2+r$
, every
 $\alpha$
less than or equal to
$\alpha$
less than or equal to
 $\alpha _r$
does not minimize
$\alpha _r$
does not minimize
 $C_\phi (\eta, \alpha )$
and thus
$C_\phi (\eta, \alpha )$
and thus
 $C_\phi (\eta, \alpha )-C_\phi ^*(\eta )\gt 0$
. Now define
$C_\phi (\eta, \alpha )-C_\phi ^*(\eta )\gt 0$
. Now define
 \begin{align*} k_r=\inf _{\substack {\eta \in [1/2+r,1]\\\alpha \in [-\infty, \alpha _r]}} C_\phi (\eta, \alpha )-C_\phi ^*(\eta ) \end{align*}
\begin{align*} k_r=\inf _{\substack {\eta \in [1/2+r,1]\\\alpha \in [-\infty, \alpha _r]}} C_\phi (\eta, \alpha )-C_\phi ^*(\eta ) \end{align*}
The set
 $[1/2+r,1]\times [-\infty, \alpha _r]$
is sequentially compact and the function
$[1/2+r,1]\times [-\infty, \alpha _r]$
is sequentially compact and the function
 $(\eta, \alpha )\mapsto C_\phi (\eta, \alpha )-C_\phi ^*(\eta )$
is continuous and strictly positive on this set. Therefore, the infimum above is assumed for some
$(\eta, \alpha )\mapsto C_\phi (\eta, \alpha )-C_\phi ^*(\eta )$
is continuous and strictly positive on this set. Therefore, the infimum above is assumed for some
 $\eta, \alpha$
and consequently
$\eta, \alpha$
and consequently
 $k_r\gt 0$
.
$k_r\gt 0$
.
Lastly,
 $\phi (\alpha _r)\lt \phi (0)$
implies
$\phi (\alpha _r)\lt \phi (0)$
implies
 $\alpha _r\gt 0$
.
$\alpha _r\gt 0$
.
Appendix D. Deferred arguments from Section 7— Proof of Proposition3
To start, we formally prove that if the adversarial Bayes classifier is not unique up to degeneracy, then the sets
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
are not equivalent up to degeneracy.
$\{\hat \eta \geq 1/2\}$
are not equivalent up to degeneracy.
This result in Lemma5 relies on a characterization of equivalence up to degeneracy from [Reference Frank15, Proposition 5.1].
Theorem 10.
Assume that
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure and let
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure and let
 $A_1$
and
$A_1$
and
 $A_2$
be two adversarial Bayes classifiers. Then the following are equivalent:
$A_2$
be two adversarial Bayes classifiers. Then the following are equivalent:
-
1) The adversarial Bayes classifiers
$A_1$
and
$A_2$
are equivalent up to degeneracy
-
2) Either
$S_\epsilon ({\mathbf {1}}_{A_1})=S_\epsilon ({\mathbf {1}}_{A_2})$
-
${\mathbb P}_0$
-a.e. or
$S_\epsilon ({\mathbf {1}}_{A_2^C})=S_\epsilon ({\mathbf {1}}_{A_1^C})$
-
${\mathbb P}_1$
-a.e.






Notice that when there is a single equivalence class, the equivalence between Item 1 and Item 2 of Theorem10 is simply the equivalence between Item 1 and Item 2 in Theorem9. This result together with Theorem6 proves Lemma5:
Proof of Lemma
5. Let
 $A$
be any adversarial Bayes classifier. If the adversarial Bayes classifiers
$A$
be any adversarial Bayes classifier. If the adversarial Bayes classifiers
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
are equivalent up to degeneracy, then Theorem6 and Item 2 of Theorem10 imply that
$\{\hat \eta \geq 1/2\}$
are equivalent up to degeneracy, then Theorem6 and Item 2 of Theorem10 imply that
 $S_\epsilon ({\mathbf {1}}_A)=S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}})$
$S_\epsilon ({\mathbf {1}}_A)=S_\epsilon ({\mathbf {1}}_{\{\hat \eta \gt 1/2\}})$
 ${\mathbb P}_0$
-a.e. Item 2 of Theorem10 again implies that
${\mathbb P}_0$
-a.e. Item 2 of Theorem10 again implies that
 $A$
and
$A$
and
 $\{\hat \eta \gt 1/2\}$
must be equivalent up to degeneracy, and consequently the adversarial Bayes classifier must be unique up to degeneracy.
$\{\hat \eta \gt 1/2\}$
must be equivalent up to degeneracy, and consequently the adversarial Bayes classifier must be unique up to degeneracy.
Conversely, if the adversarial Bayes classifier is unique up to degeneracy, then the adversarial Bayes classifiers
 $\{\hat \eta \gt 1/2\}$
and
$\{\hat \eta \gt 1/2\}$
and
 $\{\hat \eta \geq 1/2\}$
must be equivalent up to degeneracy.
$\{\hat \eta \geq 1/2\}$
must be equivalent up to degeneracy.
Thus, if the adversarial Bayes classifier is not unique up to degeneracy, then there is a set
 $\tilde A$
with
$\tilde A$
with
 $\{\hat \eta \gt 1/2\}\subset \tilde A\subset \{\hat \eta \geq 1/2\}$
that is not an adversarial Bayes classifier, and this set is used to construct the sequence
$\{\hat \eta \gt 1/2\}\subset \tilde A\subset \{\hat \eta \geq 1/2\}$
that is not an adversarial Bayes classifier, and this set is used to construct the sequence
 $f_n$
in (26). Next, we show that
$f_n$
in (26). Next, we show that
 $f_n$
minimizes
$f_n$
minimizes
 $R_\phi ^\epsilon$
but not
$R_\phi ^\epsilon$
but not
 $R^\epsilon$
.
$R^\epsilon$
.
Proposition 5.
Assume that
 $\mathbb P$
is absolutely continuous with respect to Lebesgue measure and that the adversarial Bayes classifier is not unique up to degeneracy. Then there is a sequence of
$\mathbb P$
is absolutely continuous with respect to Lebesgue measure and that the adversarial Bayes classifier is not unique up to degeneracy. Then there is a sequence of
 $\overline {\mathbb {R}}$
-valued functions
$\overline {\mathbb {R}}$
-valued functions
 $f_n$
that minimize
$f_n$
that minimize
 $R_\phi ^\epsilon$
but
$R_\phi ^\epsilon$
but
 $R^\epsilon (f_n)$
is constant in
$R^\epsilon (f_n)$
is constant in
 $n$
and not equal to the adversarial Bayes risk.
$n$
and not equal to the adversarial Bayes risk.
Proof. By Lemma5, there is a set
 $\tilde A$
with
$\tilde A$
with
 $\{\hat \eta \gt 1/2\}\subset \tilde A\subset \{\hat \eta \geq 1/2\}$
which is not an adversarial Bayes classifier. For this set
$\{\hat \eta \gt 1/2\}\subset \tilde A\subset \{\hat \eta \geq 1/2\}$
which is not an adversarial Bayes classifier. For this set
 $\tilde A$
, define the sequence
$\tilde A$
, define the sequence
 $f_n$
by (26) and let
$f_n$
by (26) and let
 $\tilde \alpha _\phi$
be the function in Lemma6. Lemma8 implies that
$\tilde \alpha _\phi$
be the function in Lemma6. Lemma8 implies that
 $\tilde \alpha _\phi (\eta )\neq 0$
whenever
$\tilde \alpha _\phi (\eta )\neq 0$
whenever
 $\eta \neq 1/2$
and thus
$\eta \neq 1/2$
and thus
 $\{f_n\gt 0\}=\tilde A$
for all
$\{f_n\gt 0\}=\tilde A$
for all
 $n$
. We will show that in the limit
$n$
. We will show that in the limit
 $n\to \infty$
, the function sequence
$n\to \infty$
, the function sequence
 $S_\epsilon (\phi \circ f_n)$
is bounded above by
$S_\epsilon (\phi \circ f_n)$
is bounded above by
 $S_\epsilon (\phi \circ \tilde \alpha _\phi (\hat \eta ))$
while
$S_\epsilon (\phi \circ \tilde \alpha _\phi (\hat \eta ))$
while
 $S_\epsilon (\phi \circ -f_n)$
is bounded above by
$S_\epsilon (\phi \circ -f_n)$
is bounded above by
 $S_\epsilon (\phi \circ -\tilde \alpha _\phi (\hat \eta ))$
. This result will imply that
$S_\epsilon (\phi \circ -\tilde \alpha _\phi (\hat \eta ))$
. This result will imply that
 $f_n$
is a minimizing sequence of
$f_n$
is a minimizing sequence of
 $R_\phi ^\epsilon$
due to Lemma6.
$R_\phi ^\epsilon$
due to Lemma6.
Let
 $\tilde S_\epsilon (g)$
denote the supremum of a function
$\tilde S_\epsilon (g)$
denote the supremum of a function
 $g$
on an
$g$
on an
 $\epsilon$
-ball excluding the set
$\epsilon$
-ball excluding the set
 $\hat \eta ({\mathbf x})=1/2$
:
$\hat \eta ({\mathbf x})=1/2$
:
 \begin{align*} \tilde S_\epsilon (g)({\mathbf x})=\begin{cases} \sup _{\substack {{\mathbf x}^{\prime} \in \overline {B_\epsilon ({\mathbf x})}\\ \hat \eta ({\mathbf x}^{\prime})\neq 1/2}} g({\mathbf x}^{\prime}) &\text {if } \overline {B_\epsilon ({\mathbf x})}\cap \{\hat \eta \neq 1/2\}^C \neq \emptyset \\ -\infty &\text {otherwise} \end{cases} \end{align*}
\begin{align*} \tilde S_\epsilon (g)({\mathbf x})=\begin{cases} \sup _{\substack {{\mathbf x}^{\prime} \in \overline {B_\epsilon ({\mathbf x})}\\ \hat \eta ({\mathbf x}^{\prime})\neq 1/2}} g({\mathbf x}^{\prime}) &\text {if } \overline {B_\epsilon ({\mathbf x})}\cap \{\hat \eta \neq 1/2\}^C \neq \emptyset \\ -\infty &\text {otherwise} \end{cases} \end{align*}
With this notation, because
 $\tilde \alpha _\phi (1/2)=0$
, one can express
$\tilde \alpha _\phi (1/2)=0$
, one can express
 $S_\epsilon (\phi \circ \tilde \alpha _\phi (\hat \eta ))$
,
$S_\epsilon (\phi \circ \tilde \alpha _\phi (\hat \eta ))$
,
 $S_\epsilon (\phi \circ -\tilde \alpha _\phi (\hat \eta ))$
as
$S_\epsilon (\phi \circ -\tilde \alpha _\phi (\hat \eta ))$
as
 \begin{align} S_\epsilon \big (\phi \circ \tilde \alpha _\phi (\hat \eta )\big )({\mathbf x})=\begin{cases} \max \big ( \tilde S_\epsilon \big (\phi \circ \alpha _\phi (\hat \eta )\big )({\mathbf x}), \phi (0)\big ) &{\mathbf x} \in \{\hat \eta =1/2\}^\epsilon \\ S_\epsilon \big (\phi \circ \alpha _\phi (\hat \eta )\big )({\mathbf x})&{\mathbf x} \not \in \{\hat \eta =1/2\}^\epsilon \end{cases} \end{align}
\begin{align} S_\epsilon \big (\phi \circ \tilde \alpha _\phi (\hat \eta )\big )({\mathbf x})=\begin{cases} \max \big ( \tilde S_\epsilon \big (\phi \circ \alpha _\phi (\hat \eta )\big )({\mathbf x}), \phi (0)\big ) &{\mathbf x} \in \{\hat \eta =1/2\}^\epsilon \\ S_\epsilon \big (\phi \circ \alpha _\phi (\hat \eta )\big )({\mathbf x})&{\mathbf x} \not \in \{\hat \eta =1/2\}^\epsilon \end{cases} \end{align}
 \begin{align} S_\epsilon \big (\phi \circ -\tilde \alpha _\phi (\hat \eta )\big )({\mathbf x})=\begin{cases} \max \big ( \tilde S_\epsilon \big (\phi \circ -\alpha _\phi (\hat \eta )\big )({\mathbf x}), \phi (0)\big ) &{\mathbf x} \in \{\hat \eta =1/2\}^\epsilon \\ S_\epsilon \big (\phi \circ -\alpha _\phi (\hat \eta )\big )({\mathbf x})&{\mathbf x} \not \in \{\hat \eta =1/2\}^\epsilon \end{cases} \\[6pt] \nonumber \end{align}
\begin{align} S_\epsilon \big (\phi \circ -\tilde \alpha _\phi (\hat \eta )\big )({\mathbf x})=\begin{cases} \max \big ( \tilde S_\epsilon \big (\phi \circ -\alpha _\phi (\hat \eta )\big )({\mathbf x}), \phi (0)\big ) &{\mathbf x} \in \{\hat \eta =1/2\}^\epsilon \\ S_\epsilon \big (\phi \circ -\alpha _\phi (\hat \eta )\big )({\mathbf x})&{\mathbf x} \not \in \{\hat \eta =1/2\}^\epsilon \end{cases} \\[6pt] \nonumber \end{align}
and similarly
 \begin{align} S_\epsilon (\phi \circ f_n)({\mathbf x})\leq \begin{cases} \max \big ( \tilde S_\epsilon \big (\phi \circ \alpha _\phi (\hat \eta )\big )({\mathbf x}), \phi (-\frac 1n)\big ) &{\mathbf x} \in \{\hat \eta =1/2\}^\epsilon \\ S_\epsilon (\phi \circ \alpha _\phi (\hat \eta ))({\mathbf x})&{\mathbf x} \not \in \{\hat \eta =1/2\}^\epsilon \end{cases} \end{align}
\begin{align} S_\epsilon (\phi \circ f_n)({\mathbf x})\leq \begin{cases} \max \big ( \tilde S_\epsilon \big (\phi \circ \alpha _\phi (\hat \eta )\big )({\mathbf x}), \phi (-\frac 1n)\big ) &{\mathbf x} \in \{\hat \eta =1/2\}^\epsilon \\ S_\epsilon (\phi \circ \alpha _\phi (\hat \eta ))({\mathbf x})&{\mathbf x} \not \in \{\hat \eta =1/2\}^\epsilon \end{cases} \end{align}
 \begin{align} S_\epsilon (\phi \circ -f_n)({\mathbf x})\leq \begin{cases} \max \big ( \tilde S_\epsilon \big (\phi \circ -\alpha _\phi (\hat \eta )\big )({\mathbf x}), \phi (-\frac 1n)\big ) &{\mathbf x} \in \{\hat \eta =1/2\}^\epsilon \\ S_\epsilon \big (\phi \circ -\alpha _\phi (\hat \eta )\big )({\mathbf x})&{\mathbf x} \not \in \{\hat \eta =1/2\}^\epsilon \end{cases} \\[6pt] \nonumber \end{align}
\begin{align} S_\epsilon (\phi \circ -f_n)({\mathbf x})\leq \begin{cases} \max \big ( \tilde S_\epsilon \big (\phi \circ -\alpha _\phi (\hat \eta )\big )({\mathbf x}), \phi (-\frac 1n)\big ) &{\mathbf x} \in \{\hat \eta =1/2\}^\epsilon \\ S_\epsilon \big (\phi \circ -\alpha _\phi (\hat \eta )\big )({\mathbf x})&{\mathbf x} \not \in \{\hat \eta =1/2\}^\epsilon \end{cases} \\[6pt] \nonumber \end{align}
Therefore, by comparing (34) with (32) and (35) with (33), one can conclude that
 \begin{align} \limsup _{n\to \infty } S_\epsilon (\phi \circ f_n)\leq S_\epsilon \big (\phi \circ \tilde \alpha _\phi (\hat \eta )\big )\quad \text {and}\quad \limsup _{n\to \infty } S_\epsilon (\phi \circ -f_n)\leq S_\epsilon \big (\phi \circ -\tilde \alpha _\phi (\hat \eta )\big ). \end{align}
\begin{align} \limsup _{n\to \infty } S_\epsilon (\phi \circ f_n)\leq S_\epsilon \big (\phi \circ \tilde \alpha _\phi (\hat \eta )\big )\quad \text {and}\quad \limsup _{n\to \infty } S_\epsilon (\phi \circ -f_n)\leq S_\epsilon \big (\phi \circ -\tilde \alpha _\phi (\hat \eta )\big ). \end{align}
Furthermore, the right-hand of (34) is bounded above by
 $ S_\epsilon (\phi \circ \alpha _\phi (\hat \eta ))+\phi (-1)$
while the right-hand of (35) is bounded above by
$ S_\epsilon (\phi \circ \alpha _\phi (\hat \eta ))+\phi (-1)$
while the right-hand of (35) is bounded above by
 $ S_\epsilon (\phi \circ -\alpha _\phi (\hat \eta ))+\phi (-1)$
. Thus the dominated convergence theorem and (36) implies that
$ S_\epsilon (\phi \circ -\alpha _\phi (\hat \eta ))+\phi (-1)$
. Thus the dominated convergence theorem and (36) implies that
 \begin{align*} \limsup _{n\to \infty } R_\phi ^\epsilon (f_n)\leq R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta )) \end{align*}
\begin{align*} \limsup _{n\to \infty } R_\phi ^\epsilon (f_n)\leq R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta )) \end{align*}
and thus
 $f_n$
minimizes
$f_n$
minimizes
 $R_\phi ^\epsilon$
.
$R_\phi ^\epsilon$
.
Lastly, it remains to construct an
 $\mathbb {R}$
-valued sequence that minimizes
$\mathbb {R}$
-valued sequence that minimizes
 $R_\phi ^\epsilon$
but not
$R_\phi ^\epsilon$
but not
 $R^\epsilon$
. To construct this sequence, we threshhold a subsequence
$R^\epsilon$
. To construct this sequence, we threshhold a subsequence
 $f_{n_j}$
of
$f_{n_j}$
of
 $f_n$
at an appropriate value
$f_n$
at an appropriate value
 $T_j$
. If
$T_j$
. If
 $g$
is an
$g$
is an
 $\overline {\mathbb {R}}$
-valued function and
$\overline {\mathbb {R}}$
-valued function and
 $g^{(N)}$
is the function
$g^{(N)}$
is the function
 $g$
threshholded at
$g$
threshholded at
 $N$
, then
$N$
, then
 $\lim _{N\to \infty } R_\phi ^\epsilon (g^{(N)})=R_\phi ^\epsilon (g)$
.
$\lim _{N\to \infty } R_\phi ^\epsilon (g^{(N)})=R_\phi ^\epsilon (g)$
.
Lemma 9.
Let
 $g$
be an
$g$
be an
 $\overline {\mathbb {R}}$
-valued function and let
$\overline {\mathbb {R}}$
-valued function and let
 $g^{(N)}=\min \!(\max (g,-N),N)$
. Then
$g^{(N)}=\min \!(\max (g,-N),N)$
. Then
 $\lim _{N\to \infty } R_\phi ^\epsilon (g^{(N)})=R_\phi ^\epsilon (g)$
.
$\lim _{N\to \infty } R_\phi ^\epsilon (g^{(N)})=R_\phi ^\epsilon (g)$
.
See Appendix D.2 for a proof. Proposition3 then follows from this lemma and Proposition5:
Proof of Proposition
3. Let
 $f_n$
be the
$f_n$
be the
 $\overline {\mathbb {R}}$
-valued sequence of functions in Proposition5, and let
$\overline {\mathbb {R}}$
-valued sequence of functions in Proposition5, and let
 $f_{n_j}$
be a subsequence for which
$f_{n_j}$
be a subsequence for which
 $R_\phi ^\epsilon (f_{n_j})-\inf _f R_\phi ^\epsilon (f)\lt 1/j$
. Next, Lemma9 implies that for each
$R_\phi ^\epsilon (f_{n_j})-\inf _f R_\phi ^\epsilon (f)\lt 1/j$
. Next, Lemma9 implies that for each
 $j$
one can pick a threshhold
$j$
one can pick a threshhold
 $N_j$
for which
$N_j$
for which
 $|R_\phi ^\epsilon (f_{n_j})-R_\phi ^\epsilon (f_{n_j}^{(N_j)})|\leq 1/j$
. Consequently,
$|R_\phi ^\epsilon (f_{n_j})-R_\phi ^\epsilon (f_{n_j}^{(N_j)})|\leq 1/j$
. Consequently,
 $f^{(N_j)}_{n_j}$
is an
$f^{(N_j)}_{n_j}$
is an
 $\mathbb {R}$
-valued sequence of functions that minimizes
$\mathbb {R}$
-valued sequence of functions that minimizes
 $R_\phi ^\epsilon$
. However, notice that
$R_\phi ^\epsilon$
. However, notice that
 $\{f\leq 0\}=\{f^{(T)}\leq 0\}$
and
$\{f\leq 0\}=\{f^{(T)}\leq 0\}$
and
 $\{f\gt 0\}=\{f^{(T)}\gt 0\}$
for any strictly positive threshhold
$\{f\gt 0\}=\{f^{(T)}\gt 0\}$
for any strictly positive threshhold
 $T$
. Thus
$T$
. Thus
 $R^\epsilon (f_{n_j}^{(N_j)})=R^\epsilon (f_{n_j})$
and consequently
$R^\epsilon (f_{n_j}^{(N_j)})=R^\epsilon (f_{n_j})$
and consequently
 $f_{n_j}^{(N_j)}$
does not minimize
$f_{n_j}^{(N_j)}$
does not minimize
 $R^\epsilon$
.
$R^\epsilon$
.
D.1 Proof of Lemma6
The proof of Lemma6 follows the same outline as the argument for Proposition4: we show that
 $R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta ))={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)$
for the measures
$R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta ))={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)$
for the measures
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
in Theorem5, and then Theorem4 implies that
${\mathbb P}_1^*$
in Theorem5, and then Theorem4 implies that
 $\tilde \alpha _\phi (\hat \eta )$
must minimize
$\tilde \alpha _\phi (\hat \eta )$
must minimize
 $R_\phi ^\epsilon$
. Similar to the proof of Proposition4, swapping the order of the
$R_\phi ^\epsilon$
. Similar to the proof of Proposition4, swapping the order of the
 $S_\epsilon$
operation and
$S_\epsilon$
operation and
 $\tilde \alpha _\phi$
is a key step. To show that this swap is possible, we first prove that
$\tilde \alpha _\phi$
is a key step. To show that this swap is possible, we first prove that
 $\tilde \alpha _\phi$
is monotonic.
$\tilde \alpha _\phi$
is monotonic.
Lemma 10.
If
 $C_\phi ^*(1/2)=\phi (0)$
, then the function
$C_\phi ^*(1/2)=\phi (0)$
, then the function
 $\tilde \alpha _\phi \,:\,[0,1]\to \overline {\mathbb {R}}$
defined in (
25
) is non-decreasing and maps each
$\tilde \alpha _\phi \,:\,[0,1]\to \overline {\mathbb {R}}$
defined in (
25
) is non-decreasing and maps each
 $\eta$
to a minimizer of
$\eta$
to a minimizer of
 $C_\phi (\eta, \cdot )$
.
$C_\phi (\eta, \cdot )$
.
Proof. Lemma1 implies that
 $\tilde \alpha _\phi (\eta )$
is a minimizer of
$\tilde \alpha _\phi (\eta )$
is a minimizer of
 $C_\phi (\eta, \cdot )$
for all
$C_\phi (\eta, \cdot )$
for all
 $\eta \neq 1/2$
and the assumption
$\eta \neq 1/2$
and the assumption
 $C_\phi ^*(1/2)=\phi (0)$
implies that
$C_\phi ^*(1/2)=\phi (0)$
implies that
 $\tilde \alpha _\phi (1/2)$
is a minimizer of
$\tilde \alpha _\phi (1/2)$
is a minimizer of
 $C_\phi (1/2,\cdot )$
. Furthermore, Lemma1 implies that
$C_\phi (1/2,\cdot )$
. Furthermore, Lemma1 implies that
 $\tilde \alpha _\phi$
is non-decreasing on
$\tilde \alpha _\phi$
is non-decreasing on
 $[0,1/2)$
and
$[0,1/2)$
and
 $(1/2,1]$
. However, Lemma4 implies that
$(1/2,1]$
. However, Lemma4 implies that
 $\alpha _\phi (\eta )\lt 0$
when
$\alpha _\phi (\eta )\lt 0$
when
 $\eta \in [0,1/2)$
and
$\eta \in [0,1/2)$
and
 $\alpha _\phi (\eta )\gt 0$
when
$\alpha _\phi (\eta )\gt 0$
when
 $\eta \in (1/2,1]$
. Consequently,
$\eta \in (1/2,1]$
. Consequently,
 $\tilde \alpha _\phi$
is non-decreasing on all of
$\tilde \alpha _\phi$
is non-decreasing on all of
 $[0,1]$
.
$[0,1]$
.
This result together with the properties of
 ${\mathbb P}_0^*$
,
${\mathbb P}_0^*$
,
 ${\mathbb P}_1^*$
in Theorem5 suffice to prove Lemma6.
${\mathbb P}_1^*$
in Theorem5 suffice to prove Lemma6.
Proof of Lemma
6. Let
 ${\mathbb P}_0^*, {\mathbb P}_1^*$
be the measures of Theorem5 and set
${\mathbb P}_0^*, {\mathbb P}_1^*$
be the measures of Theorem5 and set
 ${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
,
${\mathbb P}^*={\mathbb P}_0^*+{\mathbb P}_1^*$
,
 $\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
. We will prove that
$\eta ^*=d{\mathbb P}_1^*/d{\mathbb P}^*$
. We will prove that
 $R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta ))={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)$
and thus Theorem4 will imply that
$R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta ))={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*)$
and thus Theorem4 will imply that
 $\tilde \alpha _\phi (\hat \eta )$
minimizes
$\tilde \alpha _\phi (\hat \eta )$
minimizes
 $R_\phi ^\epsilon$
. Let
$R_\phi ^\epsilon$
. Let
 $\gamma _0^*$
and
$\gamma _0^*$
and
 $\gamma _1^*$
be the couplings supported on
$\gamma _1^*$
be the couplings supported on
 $\Delta _\epsilon$
between
$\Delta _\epsilon$
between
 ${\mathbb P}_0$
,
${\mathbb P}_0$
,
 ${\mathbb P}_0^*$
and
${\mathbb P}_0^*$
and
 ${\mathbb P}_1$
,
${\mathbb P}_1$
,
 ${\mathbb P}_1^*$
respectively. Item 2 of Theorem5 and Lemma10 imply that
${\mathbb P}_1^*$
respectively. Item 2 of Theorem5 and Lemma10 imply that
 \begin{align*} S_\epsilon (\phi (\tilde \alpha _\phi (\hat \eta )))({\mathbf x})= \phi (\tilde \alpha _\phi (I_\epsilon (\hat \eta ({\mathbf x})))) = \phi (\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})))\quad \gamma _1^*\text {-a.e.} \end{align*}
\begin{align*} S_\epsilon (\phi (\tilde \alpha _\phi (\hat \eta )))({\mathbf x})= \phi (\tilde \alpha _\phi (I_\epsilon (\hat \eta ({\mathbf x})))) = \phi (\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})))\quad \gamma _1^*\text {-a.e.} \end{align*}
and
 \begin{align*} S_\epsilon (\phi (-\tilde \alpha _\phi (\hat \eta )))({\mathbf x})= \phi (-\tilde \alpha _\phi (S_\epsilon (\hat \eta ({\mathbf x})))) = \phi (\tilde \alpha _\phi (-\hat \eta ({\mathbf x}^{\prime})))\quad \gamma _0^*\text {-a.e.} \end{align*}
\begin{align*} S_\epsilon (\phi (-\tilde \alpha _\phi (\hat \eta )))({\mathbf x})= \phi (-\tilde \alpha _\phi (S_\epsilon (\hat \eta ({\mathbf x})))) = \phi (\tilde \alpha _\phi (-\hat \eta ({\mathbf x}^{\prime})))\quad \gamma _0^*\text {-a.e.} \end{align*}
(Recall the the notation
 $I_\epsilon$
was introduced in (10).) Therefore,
$I_\epsilon$
was introduced in (10).) Therefore,
 \begin{align*} \begin{aligned} R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta ))&= \int \phi (\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})) d\gamma _1^*+ \int \phi (-\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})))d\gamma _0^*\\ &= \int \phi (\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime}))) d{\mathbb P}_1^*+ \int \phi (-\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})))d{\mathbb P}_0^*=\int C_\phi (\eta ^*,\tilde \alpha _\phi (\hat \eta ))d{\mathbb P}^* \end{aligned} \end{align*}
\begin{align*} \begin{aligned} R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta ))&= \int \phi (\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})) d\gamma _1^*+ \int \phi (-\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})))d\gamma _0^*\\ &= \int \phi (\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime}))) d{\mathbb P}_1^*+ \int \phi (-\tilde \alpha _\phi (\hat \eta ({\mathbf x}^{\prime})))d{\mathbb P}_0^*=\int C_\phi (\eta ^*,\tilde \alpha _\phi (\hat \eta ))d{\mathbb P}^* \end{aligned} \end{align*}
Next, Item 1 of Theorem5 implies that
 $\hat \eta ({\mathbf x}^{\prime})=\eta ^*({\mathbf x}^{\prime})$
and consequently
$\hat \eta ({\mathbf x}^{\prime})=\eta ^*({\mathbf x}^{\prime})$
and consequently
 \begin{align*} R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta ))=\int C_\phi (\eta ^*,\tilde \alpha _\phi (\hat \eta ))d{\mathbb P}^*=\int C_\phi (\eta ^*,\tilde \alpha _\phi (\eta ^*))d{\mathbb P}^*=\int C_\phi ^*(\eta ^*)d{\mathbb P}^*={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*) \end{align*}
\begin{align*} R_\phi ^\epsilon (\tilde \alpha _\phi (\hat \eta ))=\int C_\phi (\eta ^*,\tilde \alpha _\phi (\hat \eta ))d{\mathbb P}^*=\int C_\phi (\eta ^*,\tilde \alpha _\phi (\eta ^*))d{\mathbb P}^*=\int C_\phi ^*(\eta ^*)d{\mathbb P}^*={\bar {R}_\phi }({\mathbb P}_0^*,{\mathbb P}_1^*) \end{align*}
Therefore, the strong duality result in Theorem4 implies that
 $\tilde \alpha _\phi (\hat \eta )$
must minimize
$\tilde \alpha _\phi (\hat \eta )$
must minimize
 $R_\phi ^\epsilon$
.
$R_\phi ^\epsilon$
.
D.2 Proof of Lemma9
This argument is taken from the proof of Lemma8 in [Reference Frank and Niles-Weed16].
Proof of Lemma 9. Define
 \begin{align*} \sigma _{[a,b]}(\alpha )=\begin{cases} a&\text {if }\alpha \lt a\\ \alpha &\text {if }\alpha \in [a,b]\\ b&\text {if } \alpha \gt b \end{cases} \end{align*}
\begin{align*} \sigma _{[a,b]}(\alpha )=\begin{cases} a&\text {if }\alpha \lt a\\ \alpha &\text {if }\alpha \in [a,b]\\ b&\text {if } \alpha \gt b \end{cases} \end{align*}
Notice that
 \begin{align*} S_\epsilon (\sigma _{[a,b]}(h))=\sigma _{[a,b]}(S_\epsilon (h)) \end{align*}
\begin{align*} S_\epsilon (\sigma _{[a,b]}(h))=\sigma _{[a,b]}(S_\epsilon (h)) \end{align*}
and
 \begin{align*} \phi (\sigma _{[a,b]}(g))=\sigma _{[\phi (b),\phi (a)]}(\phi (g)) \end{align*}
\begin{align*} \phi (\sigma _{[a,b]}(g))=\sigma _{[\phi (b),\phi (a)]}(\phi (g)) \end{align*}
for any functions
 $g$
and
$g$
and
 $h$
. Therefore,
$h$
. Therefore,
 \begin{align*} S_\epsilon (\phi (g^{(N)}))=\sigma _{[\phi (N),\phi (-N)]}(S_\epsilon (\phi \circ g))\quad \text {and} \quad S_\epsilon (\phi \circ -g^{(N)})=\sigma _{[\phi (N),\phi (-N)]}(S_\epsilon (\phi \circ -g)), \end{align*}
\begin{align*} S_\epsilon (\phi (g^{(N)}))=\sigma _{[\phi (N),\phi (-N)]}(S_\epsilon (\phi \circ g))\quad \text {and} \quad S_\epsilon (\phi \circ -g^{(N)})=\sigma _{[\phi (N),\phi (-N)]}(S_\epsilon (\phi \circ -g)), \end{align*}
which converge to
 $S_\epsilon (\phi \circ g)$
and
$S_\epsilon (\phi \circ g)$
and
 $S_\epsilon (\phi \circ -g)$
pointwise and
$S_\epsilon (\phi \circ -g)$
pointwise and
 $N\to \infty$
. Furthermore, the functions
$N\to \infty$
. Furthermore, the functions
 $S_\epsilon (\phi \circ g^{(N)})$
and
$S_\epsilon (\phi \circ g^{(N)})$
and
 $S_\epsilon (\phi \circ -g^{(N)})$
are bounded above by
$S_\epsilon (\phi \circ -g^{(N)})$
are bounded above by
 \begin{align*} S_\epsilon (\phi \circ g^{(N)})\leq S_\epsilon (\phi \circ g)+\phi (1)\quad \text {and}\quad S_\epsilon (\phi \circ -g^{(N)})\leq S_\epsilon (\phi \circ -g)+\phi (1) \end{align*}
\begin{align*} S_\epsilon (\phi \circ g^{(N)})\leq S_\epsilon (\phi \circ g)+\phi (1)\quad \text {and}\quad S_\epsilon (\phi \circ -g^{(N)})\leq S_\epsilon (\phi \circ -g)+\phi (1) \end{align*}
for
 $N\geq 1$
. As the functions
$N\geq 1$
. As the functions
 $S_\epsilon (\phi \circ g)+\phi (1)$
and
$S_\epsilon (\phi \circ g)+\phi (1)$
and
 $S_\epsilon (\phi \circ - g)+\phi (1)$
are integrable with respect to
$S_\epsilon (\phi \circ - g)+\phi (1)$
are integrable with respect to
 ${\mathbb P}_1$
and
${\mathbb P}_1$
and
 ${\mathbb P}_0$
respectively, the dominated convergence theorem implies that
${\mathbb P}_0$
respectively, the dominated convergence theorem implies that
 \begin{align*} \lim _{n\to \infty } R_\phi ^\epsilon (g^{(N)})= R_\phi ^\epsilon (g). \end{align*}
\begin{align*} \lim _{n\to \infty } R_\phi ^\epsilon (g^{(N)})= R_\phi ^\epsilon (g). \end{align*}









 Open access
Open access