



1. INTRODUCTION
Addressees might face difficulties when interpreting ambiguous expressions in context. It is therefore possible that, in the case of spoken communication, speakers will try to avoid misunderstandings by exploiting prosodic features to clarify the meaning they want to get across. Indeed, experimental evidence demonstrates that speakers use prosodic cues to aid in the disambiguation of syntactically ambiguous utterances (Price et al. Reference Price, Ostendorf, Shattuck-Hufnagel and Fong1991; Beach Reference Beach1991; Snedeker & Trueswell Reference Snedeker and Trueswell2003) and in the recognition of irony (e.g., Cheang & Pell Reference Cheang and Pell2008; Bryant & Fox Tree Reference Bryant and Fox Tree2002, Reference Bryant and Fox Tree2005). Previous research also indicates that prosody enables speech act (SA) disambiguation. For instance, intonational contours can be reliably used to interpret one-word utterances, such as beer, as the SAs of criticism, doubt, warning, suggestion, naming, and wish (Hellbernd & Sammler Reference Hellbernd and Sammler2016). Does prosody also play a role in the performance and the interpretation of indirect speech acts (ISAs), for example “indirect requests” (Ruytenbeek Reference Ruytenbeek, Depraetere and Salkie2017)?
The findings reported on by Nickerson & Chu-Carroll (Reference Nickerson and Chu-Carroll1999) provide evidence for a rising intonational pattern associated with polar questions in English. These authors collected data about the intonational patterns of the utterance’s nucleus (the accented syllable of the intonation unit), the maximal f0 at the final high boundary tone (corresponding to a rise or fall in f0), and the f0 mean of the unstressed vowel in the intonational phrase. In their experiment, they asked participants to read aloud parts of small dialogues including the utterance of an indirect request (IR) construction consisting in one of the following (the remainder of the dialogues were played by a recorded voice):

Each utterance was produced in each condition: direct speech act (DSA) condition, where the utterance had the meaning of a polar question (direct request for information), and indirect speech act (ISA) condition, where it was meant as an IR. Nickerson & Chu-Carroll found that the majority of all utterances were produced with an intonational contour typical of polar questions (“L*HH%” in autosegmental terms, i.e., an intonational contour consisting in a low plateau of f0 followed by a rise). However, utterances intended as requests were more likely to have low boundary tones (falling f0 curve at the end of the utterance): 19 utterances with this intonational contour were IRs vs. seven direct requests for information. In addition, while DSAs and ISAs were similar in terms of the mean f0 of the vowel carrying the nuclear pitch accent, they differed in the f0 values of their boundary tones.
Concerning the relationship between prosody and SAs, Ward (Reference Ward2019: 79–82) notes the absence of a final rise in intonation for polar (or “yes-no”) information questions. He also discusses intonational differences for an English utterance such as (4) meant as a request for information (“Is it the case that you like tea?” asked as part of a survey) or as an invitation (offering one’s guest a cup of tea).
While, according to Ward, a flat intonational contour is associated with the force of a request for information, the presence of a late increase in fundamental frequency (f0) (late pitch peak) would be expected in the case of an invitation. He also comments that utterances that could otherwise be taken as invitations would be perceived as rude when they lack a late rise in f0.
More recently, Trott et al. (Reference Trott, Reed, Ferreira and Bergen2019) asked, like Nickerson & Chu-Carroll (Reference Nickerson and Chu-Carroll1999), whether speakers use prosodic information to differentiate indirect requests and their literal counterparts, and whether listeners use the same information to distinguish between these two sorts of SA interpretations. They considered seven possible prosodic cues: mean f0, f0 range (maximum f0 minus minimum f0), standard deviation of f0, duration (i.e., number of voiced frames: this amounts to the duration of the utterance for which there was voicing, i.e., no pauses or non-voiced consonants), mean intensity, standard deviation of intensity, and slope of f0 (i.e., the coefficient obtained by regressing f0 against time). They also considered two distinct grammatical forms: modal interrogatives (e.g., Can you open the window?) and remarks such as (5) intended as a request e.g., to open the window.
To do this, they recorded native speakers uttering sentences formatted in both kinds of grammatical constructions (i.e., both modal interrogatives and declarative remarks describing negative states of affairs – “negative state remarks”). Each speaker produced two versions of each utterance: once as a request, and once as a literal or direct speech act – i.e., a question for the modal interrogatives, and a complaint for the negative state remarks. Trott et al. (Reference Trott, Reed, Ferreira and Bergen2019) found that the intent of modal interrogatives was predicted by their duration (longer utterances were more likely to be questions), their variation in intensity (utterances with more variation were more likely to be questions), and their f0 slope (utterances with a more positive f0 slope were more likely to be questions). In contrast, longer negative state remarks were more likely to be intended as requests. If one considers that a request performed with a modal interrogative such as Can you…? is a conventionalized request, it makes sense to say that the less predictable speech act is marked with duration in both modal interrogatives and negative state remarks.Footnote 1 For both kinds of constructions, utterances intended as requests had a higher mean for intensity.
In a separate experiment, Trott et al. (Reference Trott, Reed, Ferreira and Bergen2019) also asked whether listeners could identify – in the absence of any other contextual information – the speaker’s intended interpretation at a rate above chance, and whether the same acoustic features predicted their accuracy. In their study, participants listened to a series of paired utterances of the same speaker producing the same sentence – once as a request, and once as a non-request (i.e., either a question or direct statement). Participants were instructed to identify which of the two was meant as a request for action (IR). They were presented with a total of 12 pairs of utterances (six for modal interrogatives and six for the negative state remarks) spoken by five different speakers.
They found that listeners could discriminate which utterance was intended as a request, and that listener accuracy was predicted by f0 slope, mean f0, mean intensity and standard deviation of intensity. Modal interrogative pairs with a larger difference in mean f0, as well as a larger difference in their f0 slope, were more likely to be answered correctly. Utterance pairs with a larger difference in mean intensity were also more likely to be answered correctly.
The results of the task designed by Trott et al. (Reference Trott, Reed, Ferreira and Bergen2019) provide important insights into the processing of pragmatically ambiguous constructions. They demonstrate that speakers produce reliable prosodic cues to enable interpreters to arrive at the intended meaning, and that interpreters effectively use these cues to disambiguate between alternative readings. They also demonstrate that, at least in some cases, different grammatical constructions (i.e., modal interrogatives vs. declaratives) may be disambiguated by distinct grammatical cues.
Interestingly, Trott et al.’s (Reference Trott, Reed, Ferreira and Bergen2019) study differs from previous work on prosody and SA interpretation in that these authors examined two types of constructions that differ in terms of degree of conventionalization qua requests: Can you VP?, which has a high degree of conventionalization, and negative state remarks, which are associated with a lower degree of conventionalization. It should be borne in mind that, first, these English constructions, and their French counterparts, might be associated with different cues to their IR interpretation. Second, it is possible that these two types of constructions have different default interpretations: while the request meaning has become the more salient (or the more easily accessible) interpretation of Can you VP? interrogatives (see Ruytenbeek Reference Ruytenbeek2021 for a discussion), this is less likely to be the case for negative state remarks such as My soup is cold (or maybe in very specific contexts, such as addressed to a waiter in a restaurant). Both kinds of differences might interact with the prosodic cues used by speakers to signal their pragmatic intent. The question whether prosody should play a more important role for one type of construction or for the other is a difficult one to answer. It is possible that prosody plays a stronger role when the “prior distribution” (i.e., the relative likelihood of each interpretation) over interpretations is very flat, e.g., [.5., .5]. Alternatively, prosody could play a stronger role when the prior distribution is very skewed, and speakers need to signal the non-default interpretation, e.g., [.1, .9]. At this stage, it is unclear which hypothesis is correct. In addition, we do not believe that Trott et al.’s data can resolve this issue because the range of “priors” is very small, i.e., only 12 utterances in Trott et al.’s (Reference Trott, Reed, Ferreira and Bergen2019) study, and these utterances are mostly defined in terms of their grammatical form.
The results of Trott et al.’s (Reference Trott, Reed, Ferreira and Bergen2019) study were obtained using English stimuli with a population of native English speakers. Importantly, it remains unknown whether similar findings would be obtained in other languages. This article makes a first step in that direction by exploring the prosodic features associated with IRs in French, a language closely related to English but for which the prosodic patterns associated with different sentence-types and SAs types are rarely substantiated with empirical data. In Section 2, we address available research on the relationship between intonation and SAs in French, focusing on the prosody of polar interrogatives (Section 2.1) and the prosody of non-inverted interrogatives in particular (Section 2.2). Section 3 is devoted to a production study in which we collected spoken utterances of remarks either used as direct speech acts (question/statement) or as indirect requests. These utterances were used as experimental stimuli for a perception study reported on in Section 4, in which we tested whether native speakers of French are able to identify the request and non-request uses of the same remarks. Section 5 offers a general discussion of our results and outlines directions for future research on SAs and prosody.
2. INTONATION AND SPEECH ACT DISAMBIGUATION IN FRENCH
In French as in other languages, intonation plays different roles, the two most relevant ones for our present purposes being the expression of attitudes and emotions and an illocutionary function (for an overview, see Di Cristo Reference Di Cristo2016). To the best of our knowledge, the prosody of negative state remarks and that of ‘conventional’ IRs such as modal polar interrogatives has not been investigated yet in the French language. We will therefore concentrate, in Section 2.1, on French interrogative sentence-types, which are ambiguous between a direct, question interpretation, and an IR interpretation.
2.1 The prosody of polar interrogatives
As in languages such as English, Dutch, and Italian (for a review, see Shriberg et al. Reference Shriberg, Stolcke and Jurafsky1998), French polar questions correlate with rising intonation (Safarova et al. Reference Safarova, Muller and Prevot2005), and questions are shorter than statements because of their shorter final vowels in particular (Torreira & Valtersson Reference Torreira and Valtersson2015; but see Smith Reference Smith2002). In addition, French questions have a more pronounced final intensity drop compared to statements (Rossi et al. Reference Rossi, Hirst, Di Cristo, Rossi, Di Cristo, Hirst, Martin and Nishinuma1981; Valtersson & Torreira Reference Valtersson and Torreira2014; Torreira & Valtersson Reference Torreira and Valtersson2015) and their pitch contours start at a higher register than those of statements (Torreira & Valtersson Reference Torreira and Valtersson2015). The automatic classification of questions and statements carried out by Torreira & Valtersson (Reference Torreira and Valtersson2015) reveals an increase in accuracy from 60–65% for most individual cues to almost 80% if all the phonetic cues we have just mentioned are present. Concerning the rising intonation associated with polar questions and continuation statements (H*H% in autosegmental terms), Valtersson & Torreira (Reference Valtersson and Torreira2014) propose that, while both SAs make use of a pattern of rising intonation, the phonetic realization of this pattern is conditioned by the interactive and communicative parameters of the contexts in which these utterances are produced.
French interrogatives with different pragmatic interpretations can be identified on the basis of their prosodic properties. For instance, Michelas et al. (Reference Michelas, Portes and Champagne-Lavau2015) have shown that, unlike unbiased questions such as in (6), questions that are uttered in a negatively biasing context have a f0 peak in the penultimate syllable of the final word of the utterance (a noun, here guéridon).

Another interesting case study concerns rhetorical questions (Delais-Roussarie & Beyssade Reference Delais-Roussarie and Beyssade2019). These authors demonstrate that polar and Wh- interrogatives such as (8)–(9) respectively more often have a rising intonational contour and are spoken faster when they are used as information-seeking questions.Footnote 2
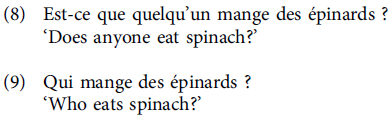
When they are used as rhetorical questions, these interrogatives more frequently exhibit a falling intonational contour.Footnote 3 These authors remark, however, that not all utterances of rhetorical vs. information-seeking questions contain these prosodic cues. According to them, the rise-fall contour typical of rhetorical questions is used by speakers to signal an implicit meaning (Beyssade & Marandin Reference Beyssade and Marandin2006), i.e., that nobody eats spinach in the case of (8)–(9).
2.2 The prosody of French non-inverted interrogatives
Delattre (Reference Delattre1966) identifies ten different patterns for French prosodic units, based on a combination of three acoustic features, i.e., f0, intensity and duration. With respect to interrogative sentences, he distinguishes between two intonational profiles corresponding, on the one hand, to non-inverted interrogatives (what he ambiguously calls questions, which also seem to include polar interrogatives), such as (10), and Wh- interrogatives (what he calls interrogations) such as (11).

The intonational pattern for polar interrogatives is a rising f0 curve (Fig. 1), while for Wh- interrogatives, it is characterized by a falling f0 curve (Fig. 2).

Figure 1. Intonational pattern for polar interrogatives (Delattre Reference Delattre1966: 4)

Figure 2. Intonational pattern for Wh- interrogatives (Delattre Reference Delattre1966: 4)
Even though sentences produced with these intonational contours will certainly sound familiar to native speakers of French, their accuracy and representativeness have been criticized. For example, Di Cristo (Reference Di Cristo2016: 294) points out that a distinction between different intonational patterns in terms of morphosyntactic criteria is missing from Delattre’s approach, and that his repertoire of interrogative sentence-types is incomplete. Following Di Cristo, polar questions can be asked using declaratives with a rising intonation such as (12), subject-verb inverted interrogatives such as (13), interrogatives initiated by the Est-ce que (“is it the case that”) such as (14), with or without a linguistic negation.


He observes that, while some utterances can be understood as questions without having a final rising f0 curve, the majority of questions in contemporary French are asked using non-inverted interrogatives, typically uttered with rising intonation. In fact, non-inverted interrogatives have overwhelmingly replaced inverted polar interrogatives in casual conversation (this is discussed by Coveney Reference Coveney2011, see e.g., Wall Reference Wall1985 for empirical evidence that inverted interrogatives are rare in casual conversation).
Di Cristo (Reference Di Cristo2016) does not discuss possible prosodic differences in the final contour between the use of a non-inverted modal interrogative such as (15) as a direct question (“I am asking you whether it is the case that you are passing me the keys”) or as an indirect request for action (“I am requesting that you pass me the keys”).
Some non-inverted modal interrogatives can also be used with the illocutionary force of a threat, as (16) illustrates, in which case, again, Di Cristo proposes that no departure from the final f0 curve is necessary for the threat to be distinguished from the SA of request for information.
This example is particularly interesting, as it suggests that other prosodic features would be used by the speaker to indicate that the utterance is to be interpreted as a threat, e.g., a higher intensity and louder speech.
3. PRODUCTION STUDY
To address the question whether native speakers of French use prosodic information to differentiate indirect requests and their literal counterparts, and, if so, which prosodic cues they produce when uttering these sentences, we carried out a production study.
3.1 Method
For the data collection phase of our study, we recruited 14 French native speakers after posting an announcement on Facebook. Of these participants, 13 self-identified as female (one male). The average self-reported age was 23 (median = 23). Ten speakers originated from Belgium, and the remaining four from France. Each speaker received 7,5€ for participating.
Each speaker was given 24 utterances to read aloud and record (see Appendix 1 for a complete list).Footnote 4 Twelve of these had the modal interrogative form “Tu peux + verbal phrase (VP) ?” (”Can you (2nd person singular) VP?”), e.g., “Tu peux ouvrir cette fenêtre ?” (“Can you open that window?”); these will be referred to as modal interrogatives. Twelve took the form of “My X is Y”, e.g., “Mon verre est vide” (“My glass is empty”); these utterances will be referred to as negative state remarks. Speakers were instructed to say each utterance twice – once as a request and once as a literal question or statement (counterbalanced for order). In order to make the recording process as naturalistic as possible, speakers were given a few words of explanation about a possible situation in which the utterance was produced. We provided them with (minimal) contextual information about the situations in which they could imagine producing the stimuli. Here is an example of contexts for the Tu peux ouvrir la fenêtre? (“Can you open the window?”) stimuli: a) As a question: Your friend broke his arm and you want to know whether he is able to open the window. (Votre ami s’est cassé le bras et vous voulez savoir s’il est capable d’ouvrir la fenêtre.) b) As a request: You feel too warm and you ask your friend to open the window. (Vous avez trop chaud et vous demandez à votre ami d’ouvrir la fenêtre.) They were also given examples at the beginning of the instruction sheet demonstrating how the same sentence could be used either as a request or as a statement (or question). The example sentences did not appear in the target stimuli, and the different versions of each utterance were not spoken aloud to the participants (so that they could not imitate the prosody of the experimenter). Two complementary lists of stimuli were created: in one list, participants were instructed to utter the first sentence as a request first, the second one as a literal SA first, and so on; in the other list, participants were instructed to utter the first sentence as a literal SA first, the second one as a request first, and so on. Speakers were randomly assigned to either list.
Due to the COVID-19 health situation at the time, the speakers could not perform any audio recordings at the university lab, and they were instead asked to make their recordings at home using the microphone of their laptop or phone. Detailed instructions regarding the recording process, including three training items, were provided to them, along with a list of utterances to produce and self-record. Each speaker was instructed to make their recordings in a quiet room with closed windows and door, sitting down, while remaining at a distance of approximately 30cm from their laptop microphone. They were also told to keep their voice intensity constant across the recording process. The recorded data was listened to and verified by the first author, and three speakers were asked to record a few utterances again.
3.2 Predictions
Based on available experimental data for indirect requests in English (Banuazizi & Creswell Reference Banuazizi and Creswell1999; Hedberg et al. Reference Hedberg, Sosa and Görgülü2014; Trott et al. Reference Trott, Reed, Ferreira and Bergen2019, Reference Trott, Reed, Kaliblotzky, Ferreira and Bergen2022), we focused on the seven utterance-level acoustic features identified by Trott et al. (Reference Trott, Reed, Ferreira and Bergen2019), i.e., mean f0, f0 range, standard deviation of f0, duration, mean intensity, standard deviation of intensity, and slope of f0. We extracted the mean f0, the range of f0, mean intensity, and the number of voiced frames (as a proxy for duration). We also included measures of dispersion for both pitch (standard deviation of f0) and intensity (standard deviation of intensity).Footnote 5 Finally, because the non-request interpretation of our modal interrogatives is a yes-no question about the addressee’s ability, and because prototypical French questions have a low-rise pitch contour (e.g., Di Cristo Reference Di Cristo2016), we used the slope of the f0 component (slope of regressing f0 against time) to measure the degree to which an utterance exhibits a rising or falling contour (Roche et al. Reference Roche, Morgan, Fissel Brannick and Bryndel2019; Trott et al. Reference Trott, Reed, Ferreira and Bergen2019).
Following the results of Trott et al.’s (Reference Trott, Reed, Ferreira and Bergen2019; Reference Trott, Reed, Kaliblotzky, Ferreira and Bergen2022) studies, we predicted, across all utterances, i.e., for both interrogatives and declaratives, that items with higher mean f0 would be more likely to be requests. We also predicted, across all utterances, that items with more positive f0 slopes would be less likely to be requests. As we explained in the introduction, it is very difficult, on the basis of available experimental evidence, to determine whether prosody should play a more important role for one type of construction (e.g., the more conventionalized modal interrogatives) or for the other (the less conventionalized negative state remarks). Therefore, we will not make any specific predictions regarding the possible role of conventionalization on the production and interpretation of prosodic cues disambiguating between the IR and the ‘literal’ uses of modal interrogatives and negative state remarks.
We predicted that, for non-inverted modal interrogatives, requests would have a less positive f0 slope than their question counterparts, given that the hallmark of information seeking questions in French is the rising intonation (low-rise pitch contour) (Di Cristo Reference Di Cristo2016). We also predicted, as Trott et al. (Reference Trott, Reed, Ferreira and Bergen2019; Reference Trott, Reed, Kaliblotzky, Ferreira and Bergen2022) did for English, that negative state remarks in French should have a longer duration (i.e., contain more voiced frames) when intended as requests than when intended as literal statements. That is, we expected speakers to “signal” a deviation from the default interpretation of these remarks as statements by putting the emphasis on specific words or syntactic constituents, which should be detectable in the number of voiced frames. By contrast, we approached the remaining acoustic features that could help distinguish between the literal and IR uses of our stimuli from a more exploratory perspective.
3.3 Data processing
For each of the 336 recordings (14 speakers producing 12 utterances with two versions each), we used Parselmouth (Jadoul et al. Reference Jadoul, Thompson and De Boer2018), a Python interface to Praat, to extract the seven acoustic features described above. We then z-scored each of these features with respect to each speaker’s mean and standard deviation for that particular feature, to account for considerable inter-speaker variability. The acoustic features and the original audio recordings will be made available on the Open Science Framework.Footnote 6
3.4 Results
3.4.1 Analysis of individual acoustic features
To analyse individual acoustic features, we first asked how much independent variance in Meaning (request vs. literal) was explained by each individual feature. To do this, we first constructed a full generalized linear mixed model with a logit link, with Meaning as a dependent variable, and seven acoustic features as predictors (along with random intercepts for each item). We compared this full model to a series of reduced models omitting each feature in turn; model comparisons were performed using log-likelihood ratio tests, and the p-values obtained from each comparison were adjusted for multiple comparisons using Holm-Bonferroni correction (Holm Reference Holm1979).
In each case, a positive coefficient represents a higher likelihood of a request meaning, while a negative coefficient represents a higher likelihood of a literal meaning. We first conducted these analyses across all utterances, then conducted subset analyses focusing on interrogatives and declaratives independently.
When predicting Meaning across interrogatives and declaratives (i.e., all utterances), mean f0 and f0 slope emerged as significant predictors after controlling for multiple comparisons [X 2 (1) = 35.697, p < .001]. Specifically, items with higher mean f0 were more likely to be requests (β = 0.92, SE = 0.17), and items with more positive f0 slopes were less likely to be requests (β = −1.1, SE = 0.17).
For interrogative items only, model fit was improved by the inclusion of only f0 slope [X 2 (1) = 68.07, p < .001]. Consistent with our predictions and with past work (Trott et al. Reference Trott, Reed, Ferreira and Bergen2019), items with more positive f0 slopes were less likely to be requests [β = −1.57, SE = 0.25] (see the example sentences in Figure 3).
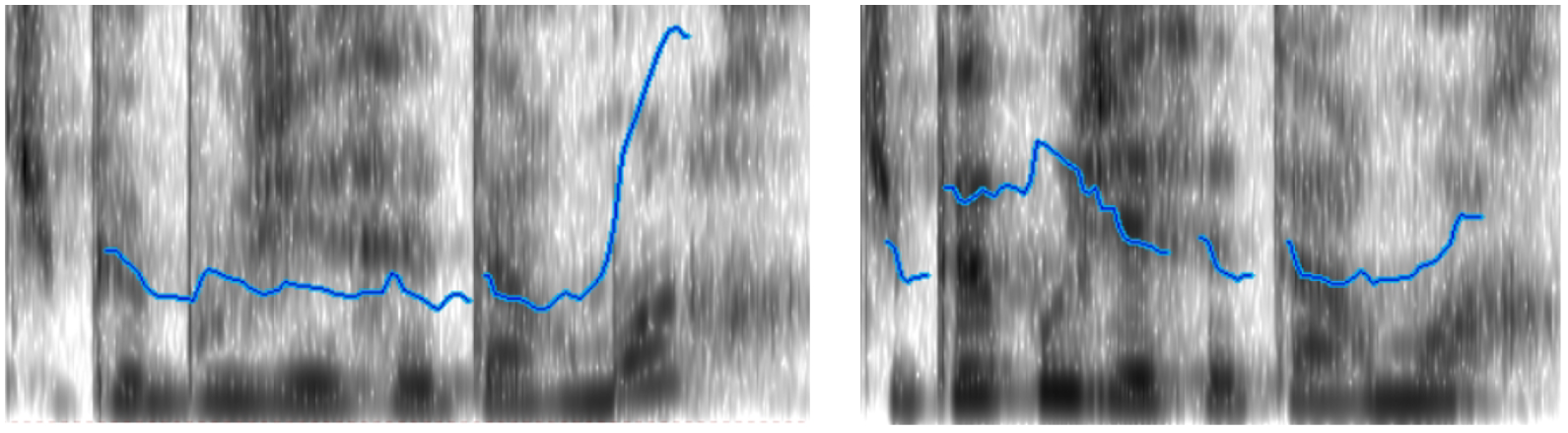
Figure 3. F0 curves for Tu peux bouger cette armoire ? as a literal question (left) and as a request (right)
Finally, for declarative items only, model fit was improved by mean f0 (X 2 (1) = 28.36, p < .001). As predicted, utterances with higher mean f0 were more likely to be requests [β = 1.62, SE = 0.35] (see the example sentence in Fig. 4).

Figure 4. F0 curves for Mon verre est vide as a literal statement (left) and as a request (right)
Model fit was also improved by the number of voiced frames (X 2 (1) = 7.53, p = .04]. Consistent with Trott et al. (Reference Trott, Reed, Ferreira and Bergen2019), longer utterances were more likely to be requests [β = 0.56, SE = 0.21].
3.4.2 Machine learning classifier
While the analysis above indicates which features are informative about the meaning of the recorded utterances, it does not specify how much information a particular feature contains, in particular when all seven features are combined.
Building on Trott et al. (Reference Trott, Reed, Ferreira and Bergen2019), one way to address this question is to ask how accurately a classifier can predict Meaning from all seven features combined. We used leave-one-out cross-validation (LOOCV) to quantify the ability of a classifier to generalize from its training set to novel samples. That is, a model was fitted to every item in the dataset but one; the model was then used to classify the held-out test item, enabling us to determine whether the model successfully generalized across to other items (i.e., whether the predicted label from the model matches the actual label for the held-out test item). This leave-one-out procedure was performed for every item in the dataset, ultimately providing an accuracy score, i.e., the percentage of correctly classified held-out items. For each of the 336 splits of the data (336 recorded utterances in total), we thus fitted a logistic regression classifier to the 335 training utterances. The classifier was trained to predict an utterance’s original Meaning from all seven acoustic features and their interaction with Form (interrogative or declarative). This classifier was then used to predict the Meaning of the held-out test item.
The classifier successfully predicted Meaning on 76% of held-out test items, a rate substantially above chance. As shown in Figure 5, held-out test items that were estimated as being more likely to be requests (i.e., a larger value for p(Request)) were more likely to have originally been meant as requests.
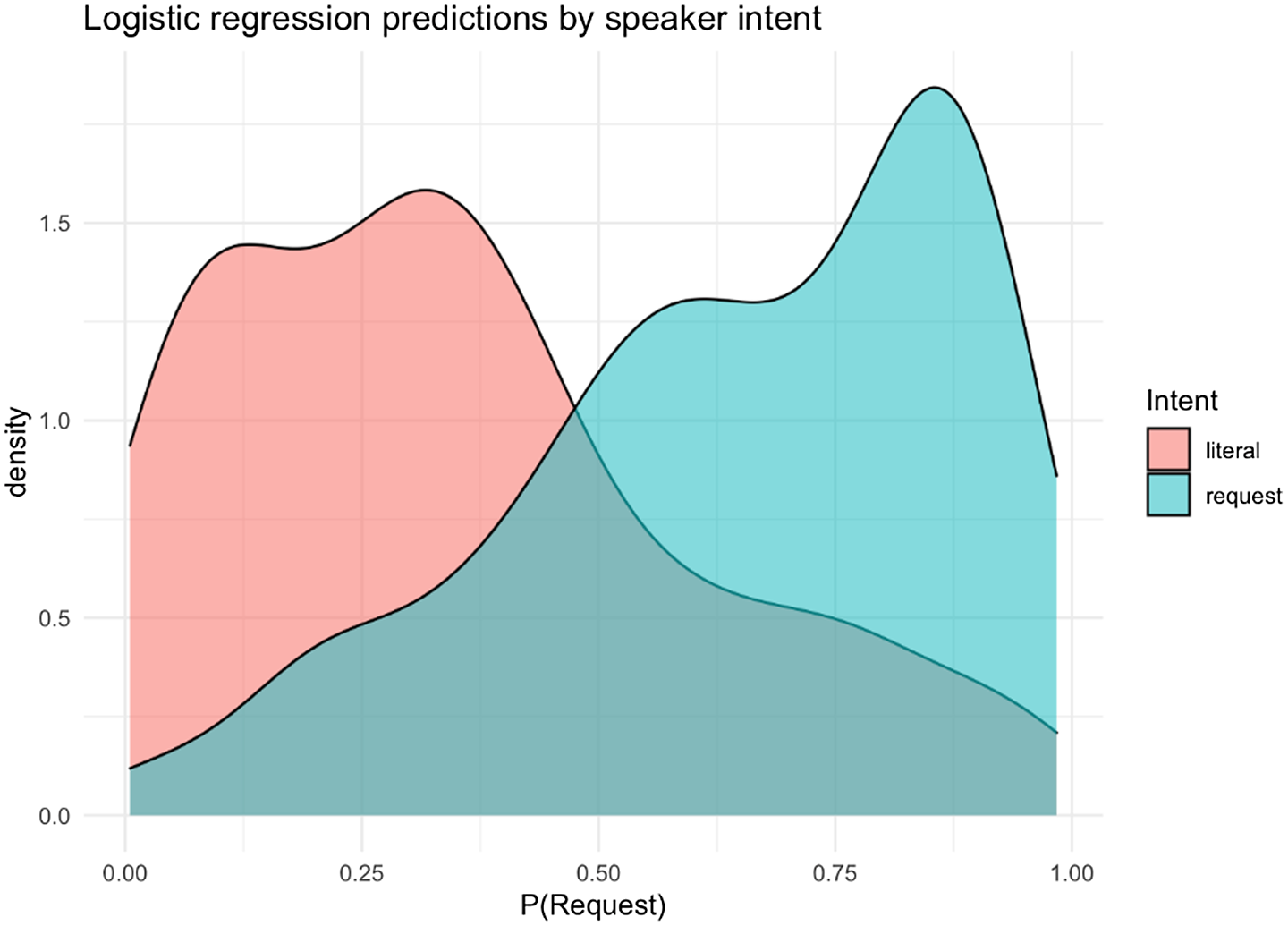
Figure 5. A classifier equipped with the seven acoustic features correctly predicted a held-out test item’s Meaning 76% of the time; the figure illustrates the distribution of classifier probabilities over classes (e.g., literal, request), coloured by the original Meaning of a given item.
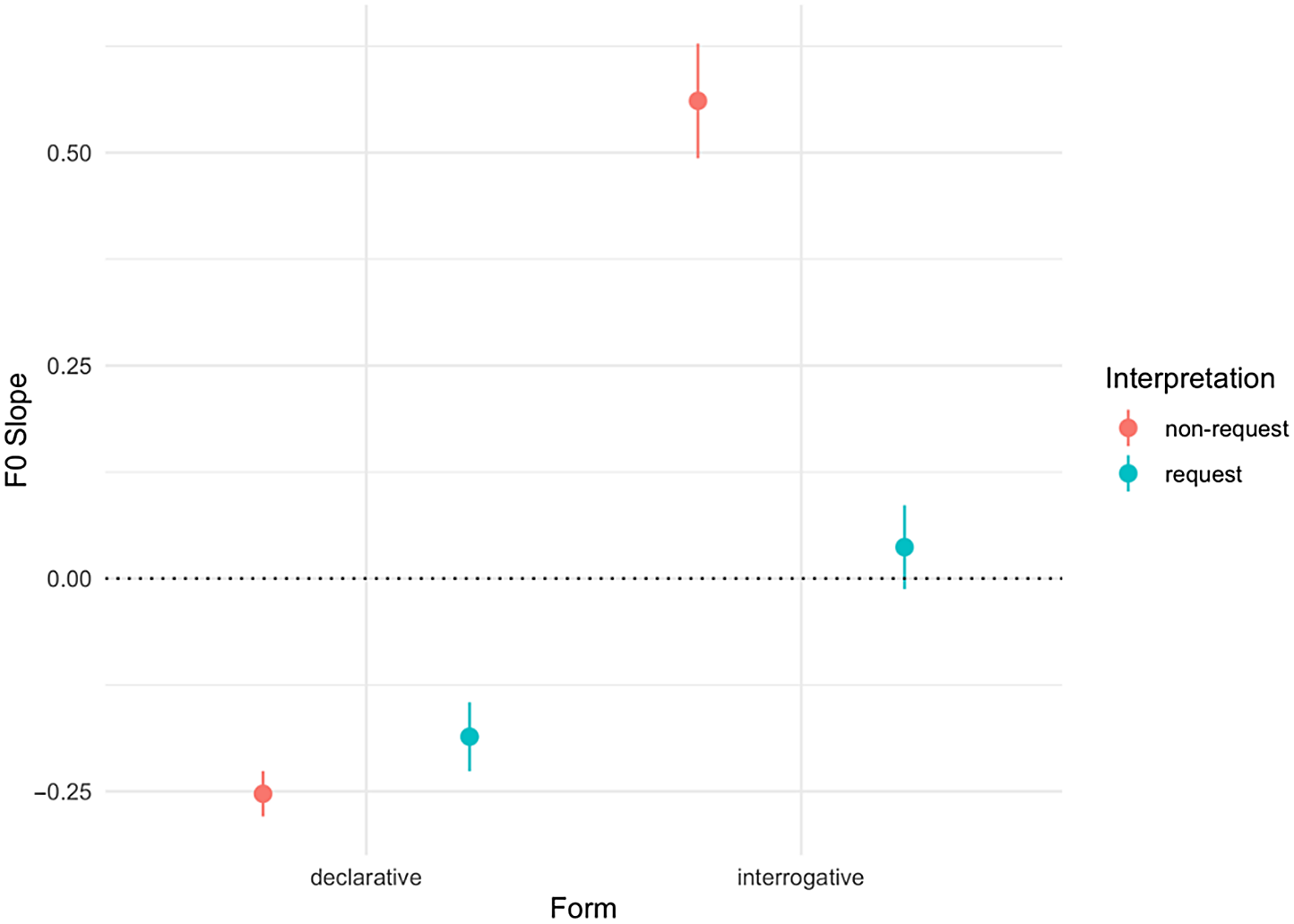
Figure 6. Z-scored f0 slope by Form and Interpretation.
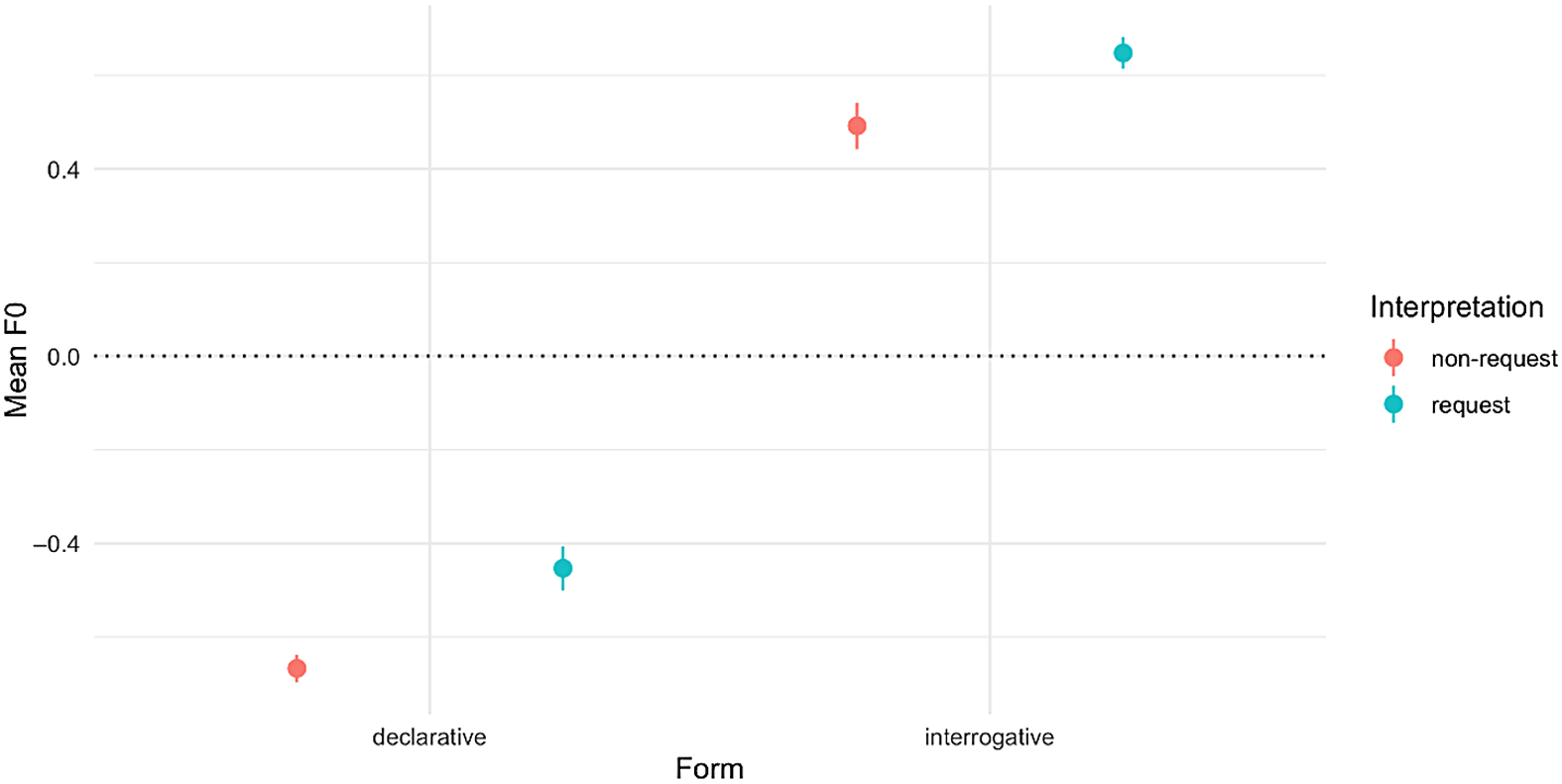
Figure 7. Z-scored mean f0 slope by Form and Interpretation.
3.5 Interim conclusion
To summarize the results of our production study, our data confirm our prediction that, for both modal interrogatives and negative state remarks, the higher the mean f0 of the utterance, the higher the likelihood that it was intended as a request. In addition, our second prediction according to which both types of utterances with more a positive f0 slope should be less likely to have been meant as requests was borne out. We also confirmed our third prediction: for negative state remarks stimuli, longer utterances were more likely to be requests. Furthermore, a classifier equipped with seven acoustic features correctly predicted the meaning of the stimuli 76% of the time.
4. PERCEPTION STUDY
The results of our production study indicate that mean f0, f0 slope, and duration play a role in the disambiguation of IR expressions by speakers producing these utterances. However, at this stage, it remains unknown whether listeners actually use the cues produced by speakers to interpret ambiguous utterances such as IRs. To answer this question, we designed a perception study in which we presented native speakers of French with a sample of utterances recorded in the production study, and asked them to identify which of these utterances have a request meaning.
4.1 Method
Participants
We recruited 80 participants on the online testing platform Prolific; 39 self-identified as female, 39 as male, and two as non-binary. The average self-reported age was 27.8 (SD = 9.6; median = 24; range 18–59). A number of 74 participants originated from France, and the remaining six participants from Belgium. Each participant received £2.50 for participating (Prolific is a UK-based platform).
Materials
Four complementary lists of 84 stimuli (six sentences x two intents x seven speakers) were created. The first and second lists contained all declarative utterances from speakers 1–7 or 8–14 (“Mon X est Y”, e.g., Mon verre est vide – My glass is empty), respectively. The third and fourth lists contained the interrogative utterances from speakers 1–7 or 8–14 (“Tu peux VP ?”, e.g., Tu peux ouvrir cette fenêtre ? – Can you open that window?), respectively.
Procedure
Each participant was presented with a total of 84 utterances to discriminate. Participants were randomly assigned to a list. Within each list, the utterances were blocked by the speaker, and the order of blocks was randomized across participants.
In order to help participants perform the task successfully, they were informed that many French sentences can be interpreted in different ways, e.g., the sentence Tu peux passer le sel? can be a request (as in saying Passe le sel s’il te plait), or a question about the physical ability to do some action (as in asking whether or not the addressee would be able to pass the salt). Similarly, the sentence Mon steak est trop cuit could be a complaint about the quality of the meal, or it could be a request for the waiter to bring another steak. They were then told that they would listen to recorded utterances and that, after listening to a particular utterance, they would have to indicate whether they believe the utterance is a request or not (decide whether the speaker had the intention that the utterance be interpreted as a request) by responding to a question just below the audio file, and that, if necessary, they could replay the file several times.
4.2 Predictions
We first predicted that, as in English, participants’ pragmatic interpretations would be predicted by the speaker’s original intent – that is, participants should interpret requests as requests, and questions (or negative state remarks) as non-requests.
We also had predictions about which acoustic features ought to predict participants’ pragmatic interpretations. For both types of constructions, we predicted that longer duration would increase the likelihood of a request interpretation (Trott et al. Reference Trott, Reed, Ferreira and Bergen2019). In addition, we expected non-inverted modal interrogatives with less positive f0 slopes to be more likely to be interpreted as requests.
4.3 Results
All analyses were conducted in R (R Core Team 2020). Mixed effects models were constructed using the lme4 package (Bates et al. Reference Bates, Maechler, Bolker and Walker2015), and log likelihood ratio tests were compared using the anova function.
Our first question was whether participants’ pragmatic interpretations were reliably predicted by the speaker’s original Intent. To address this question, we constructed a generalized linear mixed effects model with Interpretation (Request vs. Non-Request) as a dependent variable, fixed effects of Intent (Request vs. Non-Request) and Form (Interrogative vs. Declarative), by-subject random slopesFootnote 7 for the effects of Intent and Form, by-item random slopes for the effect of Intent, and random intercepts for items, subjects, lists, and speakers. We compared this model to a model omitting only the effect of Intent, and found that the full model exhibited a better fit, as demonstrated by a log likelihood ratio test [X2(1) = 17.78, p < .001]. As predicted, Request interpretations were more likely for utterances originally intended as Requests [β = 1.18, SE = 0.2]; participants responded correctly for 61.38% of items. Altogether, these results indicate that our participants successfully made use of prosodic information to infer a speaker’s intent. Participants’ responses were also influenced by the form of the utterance: the log-odds of Request interpretations was higher for interrogative utterances than declaratives [β = 1.36, SE = 0.41]
Second, we asked whether participants’ pragmatic interpretations could be predicted by any of four acoustic features (Mean f0, f0 Slope, and Number of Voiced Frames), and their interaction with Form. Consistent with past work (Trott et al. Reference Trott, Reed, Ferreira and Bergen2019), we constructed a full model with Interpretation as a dependent variable, fixed effects for each of the seven features mentioned earlier, as well as their interaction with Form, and random intercepts for subjects, items, lists, and speakers. We then compared this full model to a series of reduced models, each of which omitted an interaction term between Form and one of the critical four acoustic features; we also compared each of those reduced models to a model omitting the acoustic feature entirely (i.e., to ask about a main effect of that acoustic feature). After correcting for multiple comparisons, we found that model fit was improved by the interactions between Form and f0 Slope [X2(1) = 45.38, p < .001], as well as a main effect of f0 Slope [X2(1) = 153.06, p < .001]. The log odds of a request interpretation increased for utterances with a more positive f0 Slope [β = 0.12, SE = 0.08], but this effect reversed for interrogative utterances [β = −0.62, SE = 0.09] (Fig. 6). In other words, declarative utterances with a more positive f0 slope were more likely to be interpreted as requests, while interrogatives with a more positive f0 slope were less likely to be interpreted as requests (i.e., they were more likely to be interpreted as yes/no questions).
Additionally, we found a main effect of Mean f0 [X2(1) = 141.91, p < .001] (Fig. 7). Utterances with a higher Mean f0 were more likely to be interpreted as requests, regardless of Form [β = 0.47, SE = 0.07]. Finally, we found an interaction between Number of Voiced Frames and Form [X2(1) = 14.43, p < .001], and a main effect of Number of Voiced Frames [X2(1) = 29.5, p < .001]. Declarative utterances with a larger number of voiced frames were more likely to be interpreted as requests [β = 0.42, SE = 0.06], but this effect reversed for interrogatives [−0.37, SE = 0.1].
5. GENERAL DISCUSSION AND CONCLUSION
In this research, we asked whether listeners use the prosodic cues produced by speakers to disambiguate the meaning of French IR expressions. To answer this question, we collected native speakers’ spoken utterances and presented these to participants in a request classification task.
We found, first, that, several acoustic features reliably predicted a speaker’s original intent. For modal interrogatives, intent was predicted by f0 slope (requests had a less positive f0 slope). For negative state remarks, intent was predicted by mean f0 (requests had a higher mean f0) and number of voiced frames (requests were longer on average). Second, in the perception experiment, listeners were able to detect a speaker’s original intent at a rate above chance, indicating that they relied on some form of prosodic information to make their decision. Specifically, listeners’ decisions were predicted by mean f0, f0 slope, and number of voiced frames. In each case, their pragmatic interpretations mirrored the relationship between prosodic features and intent. For example, modal interrogatives with a more positive f0 slope were more likely to be interpreted as requests (see Figure 4).
Importantly, these results bear several similarities to the findings of Trott et al.’s (Reference Trott, Reed, Ferreira and Bergen2019) study conducted on English. For example, in both studies, the intent and interpretation of modal interrogatives was predicted by f0 slope: utterances with a more positive f0 slope – consistent with a rising intonation – were less likely to be intended and interpreted as requests. Similarly, in both studies, the intent of negative state remarks was predicted by the number of voiced frames: longer utterances were more likely to be intended as requests. Of course, English and French are similar languages along a number of dimensions, such as, to name but a few, their Indo-European origin and their lexicon. An interesting question for future work would be to ask whether these consistent relationships between intent (or interpretation) and specific prosodic features are obtained in other, more distant languages. We would assume that, if prosody and grammar are linked in some way, then the extent to which languages share grammatical constructions might influence the degree to which we observe similar prosodic outcomes. That is, assuming a given language has a modal interrogative construction that can be used as a request or a yes/no question, do speakers consistently use more positive f0 slopes when producing the utterance as a yes/no question? More generally, researchers could consider the systematicity with which three crucial factors correlate across languages: the form of an utterance (e.g., modal interrogatives), the prosodic contours with which it is produced (e.g., rising intonation), and its pragmatic intent (e.g., a yes/no question vs. a request).
An important issue that cannot be settled on the basis of the present results alone is whether the specific prosody we found for sentences performing a request are related to the request act in itself, or to the more general fact that the sentence has a noncanonical or indirect interpretation (for a discussion, see e.g., Brunetti et al. Reference Brunetti, Yoo, Tovena, Albar, Trotzke and Villalba2021). This question is difficult to answer. It is possible that the answer is “both, and it depends on the feature and the construction”. For example, in the English data that serve as a starting point for the present work, modal interrogatives have the default interpretation as a request – so the “prosodic marking” would actually serve as a deviation from a request and towards a yes/no question. And, critically, in this case, those prosodic markings are actually consistent with yes/no question prosody. We observe a similar phenomenon in our French data, in the sense that the f0 slope is more exaggerated for the yes/no question interpretation (See e.g., Figures 3 and 4). Furthermore, rising intonation is there for both literal/IR uses. It is possible that there is an interaction between the default pragmatic interpretation of a particular form (e.g., modal interrogatives = request) and the degree to which particular prosodic features are emphasized. A related issue is that the prosodic features analysed in the present study may not necessarily correspond to what listeners actually attend to when interpreting pragmatically ambiguous utterances (Trott et al. Reference Trott, Reed, Kaliblotzky, Ferreira and Bergen2022). Rather, it is possible that these features correlate with other, finer-grained cues to pragmatic meaning. For example, F0 slope and duration might be a proxy for the focal stress put on the verb pouvoir in non-inverted modal interrogatives. It will therefore be important to adopt, as Trott et al. (Reference Trott, Reed, Kaliblotzky, Ferreira and Bergen2022) suggest, a more fine-grained approach to the prosody of ISAs in future research.
A limitation of the present study is that, in our production task, participants were asked to read aloud pairs of utterances, one of which as a request and the other one e.g., as a statement/request for information. It remains to be investigated whether participants would produce similar prosodic cues when asked to read ambiguous utterances randomly instead of one pair after the other. It is difficult, of the basis of the present production data, to generalize our results to real life interactions and claim that people use prosodic information to differentiate indirect requests and their literal counterparts in authentic situations of speech. We thus believe that our study constitutes the starting point of a wider research program that first aims to establish the viability of an effect before assessing the extent to which this effect is reliable different conditions.
SA types and (im)politeness are not completely independent. For instance, insofar as a command is more face-threatening than a request (Brown & Levinson Reference Brown and Levinson1987), it is also more likely to be perceived as (more) impolite than a request. To ensure that the respective effects of (im)politeness differences and SA interpretations on prosody can be disentangled, we did not provide any (social) information about face-threat or politeness in the instructions of our production study and of our experiment. Of course, it is possible that the degree of face-threat associated with each utterance and the implied request did vary across stimuli, but we did not manipulate or otherwise confound the context of our stimuli. Further work will be necessary to document the prosodic features that signal the degree of (im)politeness associated with different request utterances.
Despite the insights contributed by our findings, very little is known about the exact circumstances under which speakers would use these prosodic cues, such as the social aspects of conversational interaction. It also remains to be seen whether these cues signal indirect interpretations or are simply contrastive markers that receive their SA interpretation in context. In addition, with the exception of Hellbernd & Sammler’s (Reference Hellbernd and Sammler2016) work on one-word utterances, little empirical research has been devoted to the prosodic features specific to less grammaticalized SA types, such as advices, warnings, and offers. This is problematic, as the prosodic features observed in our study and in Trott et al.’s (Reference Trott, Reed, Ferreira and Bergen2019) are not necessarily specific to indirect communication nor to the SA of requesting, as distinct from the DSAs of questioning or stating. In addition, we are aware that the prosodic cues associated with the indirect interpretations of IR constructions have an emotional component that is not necessarily unique to these requests, but can also be found in other SA types. Future research should also address the role of prosody on the interpretation of imperative sentences, which can be used in the performance of a variety of SAs.
Data Availability
The present study has been preregistered on the Open Science Framework platform. Our results will be available upon request.
Competing Interests
The authors declare that they have no competing interests of any kind associated with the present research manuscript.
Appendices
Appendix 1. List of recorded utterances

Appendix 2. Instructions for the production task
Consignes
-
Utilisez le micro de votre ordinateur portable (PAS de votre téléphone) .
-
Réalisez vos enregistrements au calme , dans un local dont vous aurez fermé la porte et les fenêtres, en vous installant confortablement en position assise.
-
Gardez la même distance (environ 30 centimètres ) entre votre bouche et votre micro tout au long des enregistrements.
-
Gardez l’intensité de votre voix constante d’une phrase à l’autre.
Tâche
-
Vous allez prononcer au total 12 phrases, avec à chaque fois 2 enregistrements par phrase. Cela fait donc 24 fichiers audio au total (.wav ou.mp3).
-
Pour chacune des phrases à enregistrer, nous vous donnerons un contexte afin que vous puissiez mieux vous imaginer dans quelles circonstances ces phrases pourraient être dites.
Exemple 1 : Prononcez la phrase : Tu peux éteindre la télé ?
-
a) Comme une question : vous posez à un ami une question sur sa capacité à éteindre la télévision, ce qui correspond au sens : « Es-tu capable d’éteindre la télé ? »
-
b) Comme une demande : vous demandez à un ami d’éteindre la télévision, ce qui correspond au sens de : « S’il te plait, éteins la télé ».
Exemple 2 : Prononcez la phrase : Il fait froid ici.
-
a) Comme une affirmation : vous constatez simplement qu’il fait froid dans la pièce, vous ne demandez pas à quelqu’un d’agir en conséquence. Ce qui correspond au sens : « Je trouve qu’il fait froid ici ».
-
b) Comme une demande : vous dites cela pour que votre ami agisse en allumant le chauffage, ce qui correspond au sens de : « S’il te plait, allume le chauffage ».
-
-
Attention à l’ordre : l’ordre de la prononciation comme question/demande ou affirmation change à chaque nouvelle phrase.
-
Renommez vos fichiers un par un comme indiqué en vert : [nom du fichier : …]
-
N’hésitez pas à faire plusieurs essais avant d’enregistrer vos phrases.
-
En cas de nécessité, vous pouvez me contacter: [email protected]
Voici les phrases à prononcer par deux fois (ordre à respecter)
-
1) Tu peux ouvrir cette fenêtre ?
Contextes :
-
a) Comme une question : votre ami s’est cassé le bras et vous voulez savoir s’il est capable d’ouvrir la fenêtre. [nom du fichier : 1question]
-
b) Comme une demande : vous avez trop chaud et vous demandez à votre ami d’ouvrir la fenêtre. [nom du fichier : 1demande]
-
-
2) Tu peux porter cette valise ?
Contextes :
-
a) Comme une demande : vous avez une volée d’escaliers à franchir avec vos deux valises et vous demandez à votre ami d’en porter une. [nom du fichier : 2demande]
-
b) Comme une question : la valise de votre ami est très lourde et vous voulez savoir s’il est capable de la porter. [nom du fichier : 2question]
-
-
3) Tu peux lire cette facture ?
Contextes :
-
a) Comme une question : le texte de la facture de votre ami est presque effacé ; vous voulez savoir s’il est capable de le lire. [nom du fichier : 3question]
-
b) Comme une demande : vous avez reçu une facture, et vous demandez à votre ami de vous en lire le contenu. [nom du fichier : 3demande]
-
-
4) Tu peux bouger cette armoire ?
Contextes :
-
a) Comme une demande : vous préparez votre déménagement et vous demandez à votre ami (qui est costaud) de bouger l’armoire. [nom du fichier : 4demande]
-
b) Comme une question : votre ami prépare son déménagement et vous voulez savoir s’il est capable de bouger son armoire. [nom du fichier : 4question]
-
-
5) Tu peux ranger ces bouquins ?
Contextes :
-
a) Comme une question : votre ami s’est foulé le poignet et vous voulez savoir s’il est capable de ranger ses bouquins. [nom du fichier : 5question]
-
b) Comme une demande : votre ami a fini de lire plusieurs de vos bouquins et vous lui demandez de les ranger. [nom du fichier : 5demande]
-
-
6) Tu peux suivre cet itinéraire ?
Contextes :
-
a) Comme une demande : votre ami vous reconduit chez vous et vous lui demandez de suivre l’itinéraire indiqué par le GPS. [nom du fichier : 6demande]
-
b) Comme une question : votre ami n’est pas encore habitué à son nouveau GPS et vous voulez savoir s’il est capable de suivre l’itinéraire proposé. [nom du fichier : 6question]
-
-
7) Ma soupe est froide.
Contextes :
-
a) Comme une affirmation : vous êtes au restaurant avec votre ami et vous lui faites savoir que votre soupe est froide. [nom du fichier : 7affirmation]
-
b) Comme une demande : vous êtes au restaurant avec votre ami et vous dites cela pour que le serveur vous apporte une soupe chaude. [nom du fichier : 7demande]
-
-
8) Mon téléphone est cassé.
Contextes :
-
a) Comme une demande : vous être en rue avec votre ami et vous dites cela pour qu’il vous prête son téléphone. [nom du fichier : 8demande]
-
b) Comme une affirmation : vous appelez votre ami depuis un téléphone fixe et vous lui faites savoir que votre téléphone est cassé. [nom du fichier : 8affirmation]
-
-
9) Mon verre est vide.
Contextes :
-
a) Comme une affirmation : vous êtes au restaurant avec votre ami et vous lui faites savoir que votre verre de vin est vide. [nom du fichier : 9affirmation]
-
b) Comme une demande : vous êtes au restaurant avec votre ami et vous dites cela pour que le serveur remplisse votre verre. [nom du fichier : 9demande]
-
-
10) Mon ordi est hors service.
Contextes :
-
a) Comme une demande : vous vous rendez chez votre ami et vous dites cela pour qu’il vous prête son ordinateur. [nom du fichier : 10demande]
-
b) Comme une affirmation : vous vous promenez avec votre ami et vous lui faites savoir que votre ordinateur est hors service.
[nom du fichier : 10affirmation]
-
-
11) Mes mains sont gercées.
Contextes :
-
a) Comme une affirmation : vous avez jardiné toute la matinée, et en téléphonant à votre ami vous lui faites savoir que vos mains sont gercées. [nom du fichier : 11affirmation]
-
b) Comme une demande : vous avez jardiné toute la matinée, et vous dites cela pour que votre ami vous passe la crème pour les mains. [nom du fichier : 11demande]
-
-
12) Mes cheveux sont trempés .
Contextes :
-
a) Comme une demande : vous avez marché sous la pluie, et en rentrant chez vous, vous dites cela pour que votre ami vous passe le sèche-cheveux. [nom du fichier : 12demande]
-
b) Comme une affirmation : vous avez marché sous la pluie et, en arrivant dans le local de cours, vous faites savoir à votre ami que vos cheveux sont trempés. [nom du fichier : 12affirmation]
-
Nicolas Ruytenbeek gratefully acknowledges the research grant BOF.PDO. 2019.0010.01 from the Special Research Fund at Ghent University (2019–2022). The authors are very grateful to the anonymous reviewers and to the editor for their useful comments and suggestions.








 Open access
Open access