


Introduction
The problem of identifying models from data is central to designing and verifying cyber-physical systems (CPS). These models can predict the output of a subsystem for a given input or the next state of a dynamical system from the current state. Even if there is a physical basis for constructing a model of the system under investigation, it is often necessary to use data-driven modeling to augment these models to incorporate aspects of the system that cannot be easily modeled. CPS are often nonlinear and multimodal, wherein different regions of the input/state space have different laws that govern the relationship between the inputs and outputs. In this paper, we study piecewise affine (PWA) regression. The goal of PWA regression is to fit a PWA function to a given data set of input–output pairs
 $\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
. The PWA function splits the input domain into finitely many regions
$\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
. The PWA function splits the input domain into finitely many regions
 ${H_1}, \ldots, {H_M}$
and associates an affine function
${H_1}, \ldots, {H_M}$
and associates an affine function
 ${f_i}\left( x \right) = {A_i}x + {b_i}$
to each region
${f_i}\left( x \right) = {A_i}x + {b_i}$
to each region
 ${H_i}$
. This is illustrated in Figure 1.
${H_i}$
. This is illustrated in Figure 1.

Figure 1. PWA regression of a set of input–output data points with rectangular template.
Further, we seek a PWA model that fits the given data while respecting a user-provided error bound
 $\varepsilon $
and minimizing the number of regions (pieces). This problem has numerous applications including the identification of hybrid systems with state-based switching and simplifying nonlinear models using PWA approximations. Existing PWA regression approaches usually do not restrict how the input domain is split. For instance, an approach that simply specifies that the input domain is covered by polyhedral sets leads to high computational complexity for the regression algorithm (Lauer and Bloch Reference Lauer and Bloch2019).
$\varepsilon $
and minimizing the number of regions (pieces). This problem has numerous applications including the identification of hybrid systems with state-based switching and simplifying nonlinear models using PWA approximations. Existing PWA regression approaches usually do not restrict how the input domain is split. For instance, an approach that simply specifies that the input domain is covered by polyhedral sets leads to high computational complexity for the regression algorithm (Lauer and Bloch Reference Lauer and Bloch2019).
In this paper, we restrict the possible shape of the polyhedral regions by requiring that each region
 ${H_i}$
is described by a vector inequality
${H_i}$
is described by a vector inequality
 $p\left( x \right) \le {c_i}$
, wherein
$p\left( x \right) \le {c_i}$
, wherein
 $p$
is a fixed, user-provided, vector-valued function, called the template, while the regions are obtained by varying the offset vector
$p$
is a fixed, user-provided, vector-valued function, called the template, while the regions are obtained by varying the offset vector
 ${c_i}$
. The resulting problem, called template-based PWA regression, allows us to split the input domain into prespecified shapes using a suitable template. For instance, in Figure 1, the input domain is divided into rectangular regions. Our contributions are as follows:
${c_i}$
. The resulting problem, called template-based PWA regression, allows us to split the input domain into prespecified shapes using a suitable template. For instance, in Figure 1, the input domain is divided into rectangular regions. Our contributions are as follows:
After introducing and formalizing the problem of template-based PWA regression (Sec. ‘Problem Statement’), we show that – similarly to the classical PWA regression problem (Lauer and Bloch Reference Lauer and Bloch2019) – the problem of template-based PWA regression is NP-hard in the dimension of the input space and the size of the template, but polynomial in the size of the data set (Sec. ‘Computational Complexity’). Next, we provide an algorithm for optimal bounded-error template-based PWA regression, i.e., with minimal number of regions while fitting the data within the given error tolerance (Sec. ‘Top-Down Algorithm’). Our algorithm is top-down because it breaks large sets of data into smaller ones until those can be fit by an affine function. A more detailed overview of the algorithm is provided later in this introduction, after the ‘Related Work’. Finally, we apply our algorithm on two practical problems (Sec. ‘Numerical Experiments’): the approximation of a nonlinear system, namely the insulin–glucose regulation process (Dalla Man, Rizza, and Cobelli Reference Dalla Man, Rizza and Cobelli2007), with affine functions with rectangular domains, and the identification of a hybrid linear system consisting in an inverted double pendulum with soft contacts on the joints. For both applications, we show that template-based PWA regression is favorable compared to classical PWA regression both in terms of computation time and our ability to formulate models from the results. We also compare different templates for the identification of a hybrid linear system consisting of two carts with springs.
This paper is an extension of a preliminary version that appeared as part of the Learning for Decision and Control (L4DC) conference in May 2023 (Berger and Sankaranarayanan Reference Berger, Sankaranarayanan, Matni, Morari and Pappas2023). This paper extends our previous version by providing more detailed explanations of the algorithms and complete proofs of all the results. We have also added a new numerical example involving the identification of a hybrid linear system consisting of two carts with springs.
Related work
PWA systems and hybrid linear systems appear naturally in a wide range of applications (Jungers Reference Jungers2009), or as approximations of more complex systems (Breiman Reference Breiman1993). Therefore, the problems of switched affine (SA) and PWA regression have received a lot of attention in the literature; see, e.g., Paoletti et al. (Reference Paoletti, Juloski, Ferrari-Trecate and Vidal2007) and Lauer and Bloch (Reference Lauer and Bloch2019) for surveys. Both problems are known to be NP-hard (Lauer and Bloch Reference Lauer and Bloch2019). The problem of SA regression can be formulated as a Mixed-Integer Program (MIP) and solved using MIP solvers, but the complexity is exponential in the number of data points (Paoletti et al. Reference Paoletti, Juloski, Ferrari-Trecate and Vidal2007). Vidal et al. (Reference Vidal, Soatto, Ma and Sastry2003) propose an efficient algebraic approach to solve the problem, but it is restricted to noiseless data. Heuristics to solve the problem in the general case include greedy algorithms (Bemporad et al. Reference Bemporad, Garulli, Paoletti and Vicino2005), continuous relaxations of the MIP (Münz and Krebs Reference Münz and Krebs2005), block–coordinate descent (similar to k-mean regression) algorithms (Bradley and Mangasarian Reference Bradley and Mangasarian2000; Lauer Reference Lauer2013) and refinement of the algebraic approach using sum-of-squares relaxations (Ozay, Lagoa, and Sznaier Reference Ozay, Lagoa and Sznaier2009); however, these methods offer no guarantees of finding an (optimal) solution to the problem. As for PWA regression, classical approaches include clustering-based methods (Ferrari-Trecate et al. Reference Ferrari-Trecate, Muselli, Liberati and Morari2003), data classification followed by geometric clustering (Nakada, Takaba, and Katayama Reference Nakada, Takaba and Katayama2005) and block–coordinate descent algorithms (Bemporad Reference Bemporad2023); however, these methods are not guaranteed to find a (minimal) PWA model. In this regard, our approach considers a novel ‘top-down’ approach that focuses on searching for subsets of the data that can be part of the same affine model for the given error bounds.
Our approach contrasts with most other approaches in that it is top-down and focuses on refining the domains (using the template assumption) of the pieces until affine fitting is possible. Indeed, most approaches for PWA regression (e.g., Bemporad et al. Reference Bemporad, Garulli, Paoletti and Vicino2005, Ferrari-Trecate et al. Reference Ferrari-Trecate, Muselli, Liberati and Morari2003, Bemporad Reference Bemporad2023) use a two-step approach in which the data are first clustered by solving a SA regression problem and then the clusters are separated into polyhedral regions. Medhat et al. (Reference Medhat, Ramesh, Bonakdarpour and Fischmeister2015) and Yuan et al. (Reference Yuan, Tang, Zhou, Pan, Li, Zhang, Ding and Goncalves2019) use a similar two-step approach for learning hybrid linear automata. There are also approaches that learn the function and the domains in one step: for instance, Breiman (Reference Breiman1993) for a special class of continuous PWA functions called Hinging Hyperplanes, Sadraddini and Belta (Reference Sadraddini and Belta2018) using mixed-integer linear programming (MILP), and Berger, Narasimhamurthy, and Sankaranarayanan (Reference Berger, Narasimhamurthy and Sankaranarayanan2024) for a class of PWA systems, called guarded linear systems. The class of Hinging Hyperplanes and guarded linear systems are not comparable in general with those studied in this work.Footnote 1 Soto, Henzinger, and Schilling (Reference Soto, Henzinger and Schilling2021) also learn the function and the domains simultaneously for hybrid linear systems; however, their incremental approach is greedy, so that it does not come with guarantees of minimality. By contrast, our approach guarantees to find a PWA function with minimal number of regions from the template.
PWA systems with constraints on the domain appear naturally in several applications including biology (Porreca et al. Reference Porreca, Drulhe, de Jong and Ferrari-Trecate2009) and mechanical systems with contact forces (Aydinoglu, Preciado, and Posa Reference Aydinoglu, Preciado and Posa2020), or as approximations of nonlinear systems (Smarra et al. Reference Smarra, Di Girolamo, De Iuliis, Jain, Mangharam and D’Innocenzo2020). Techniques for PWA regression with rectangular domains have been proposed in Münz and Krebs (Reference Münz and Krebs2002) and Smarra et al. (Reference Smarra, Di Girolamo, De Iuliis, Jain, Mangharam and D’Innocenzo2020); however, these approaches impose further restrictions on the arrangement of the domains of the functions (e.g., forming a grid) and they are not guaranteed to find a solution with a minimal number of pieces. In the one-dimensional case (time series), optimal time series segmentation can be computed efficiently by using dynamic programming (Bellman Reference Bellman1961; Bellman and Roth Reference Bellman and Roth1969; Ozay et al. Reference Ozay, Sznaier, Lagoa and Camps2012; Ozay Reference Ozay2016), but the approach does not extend to higher dimension and solves a different problem (min. # switches vs. min. # pieces). Our approach bears similarities with the ‘split-and-merge’ algorithm of Pavlidis and Horowitz (Reference Pavlidis and Horowitz1974), except that (i) we only split regions and never merge them because by construction merging would lead to incompatible regions; (ii) our algorithm comes with guarantees of optimality; and (iii) we address the problem of PWA regression and not segmentation. As for the application involving mechanical systems with contact forces, a recent work by Jin et al. (Reference Jin, Aydinoglu, Halm, Posa, Firoozi, Mehr, Yel, Antonova, Bohg, Schwager and Kochenderfer2022) proposes a heuristic based on minimizing a loss function to learn linear complementary systems.
Approach at a glance
Figure 2 below shows the working of our algorithm on a simple data set with
 $N\,=\,11$
points
$N\,=\,11$
points
 $\left( {{x_k},{y_k}} \right) \in \mathbb{R} \times \mathbb{R}$
(see Plot I). We seek a PWA function that fits the data with error tolerance
$\left( {{x_k},{y_k}} \right) \in \mathbb{R} \times \mathbb{R}$
(see Plot I). We seek a PWA function that fits the data with error tolerance
 $\varepsilon\,=\,0.1$
and with the smallest number of affine pieces (green lines in III, V and VI).
$\varepsilon\,=\,0.1$
and with the smallest number of affine pieces (green lines in III, V and VI).

Figure 2.
Left. Illustration of our algorithm on a simple data set with 11 data points
 $\left( {{x_k},{y_k}} \right) \in \mathbb{R} \times \mathbb{R}$
. Right. the index sets explored by our algorithm.
$\left( {{x_k},{y_k}} \right) \in \mathbb{R} \times \mathbb{R}$
. Right. the index sets explored by our algorithm.
The algorithm works as follows. At the very first step, the approach tries to fit a single straight line through all the
 $11$
points. This corresponds to the index set
$11$
points. This corresponds to the index set
 ${I_0} = \left\{ {1, \ldots, 11} \right\}$
(see II) where the points are indexed as in I. However, no such line can fit the points for the given
${I_0} = \left\{ {1, \ldots, 11} \right\}$
(see II) where the points are indexed as in I. However, no such line can fit the points for the given
 $\varepsilon $
. Hence, our approach generates an infeasibility certificate that identifies the indices
$\varepsilon $
. Hence, our approach generates an infeasibility certificate that identifies the indices
 ${C_0} = \left\{ {4,5,6} \right\}$
as a cause of infeasibility (see II). In other words, we cannot have all three points in
${C_0} = \left\{ {4,5,6} \right\}$
as a cause of infeasibility (see II). In other words, we cannot have all three points in
 ${C_0}$
be part of the same piece of the PWA function we seek. As explained in the paper, infeasibility certificates can be computed efficiently using Linear Programming. Moreover, in case of infeasibility, we can always find an infeasibility certificate with cardinality at most
${C_0}$
be part of the same piece of the PWA function we seek. As explained in the paper, infeasibility certificates can be computed efficiently using Linear Programming. Moreover, in case of infeasibility, we can always find an infeasibility certificate with cardinality at most
 $d+2$
, where
$d+2$
, where
 $d$
is the dimension of the input (here,
$d$
is the dimension of the input (here,
 $d = 1$
).Footnote
2
Our approach then splits
$d = 1$
).Footnote
2
Our approach then splits
 ${I_0}$
into two subsets
${I_0}$
into two subsets
 ${I_1} = \left\{ {1, \ldots, 5} \right\}$
and
${I_1} = \left\{ {1, \ldots, 5} \right\}$
and
 ${I_2} = \left\{ {5, \ldots, 11} \right\}$
. These two sets are maximal intervals with respect to set inclusion and do not contain
${I_2} = \left\{ {5, \ldots, 11} \right\}$
. These two sets are maximal intervals with respect to set inclusion and do not contain
 ${C_0}$
. The set
${C_0}$
. The set
 ${I_1}$
can be fit by a single straight line with tolerance
${I_1}$
can be fit by a single straight line with tolerance
 $\varepsilon $
(see III). However, considering
$\varepsilon $
(see III). However, considering
 ${I_2}$
, we notice once again that a single straight line cannot be fit (see IV). We identify the set
${I_2}$
, we notice once again that a single straight line cannot be fit (see IV). We identify the set
 ${C_2} = \left\{ {6,7,8} \right\}$
as an infeasibility certificate and our algorithm splits
${C_2} = \left\{ {6,7,8} \right\}$
as an infeasibility certificate and our algorithm splits
 ${I_2}$
into maximal subsets
${I_2}$
into maximal subsets
 ${I_3} = \left\{ {5,6,7} \right\}$
and
${I_3} = \left\{ {5,6,7} \right\}$
and
 ${I_4} = \left\{ {7, \ldots, 11} \right\}$
. Each of these subsets can be fit by a straight line (see V and VI). Thus, our approach finishes by discovering three affine pieces that cover all the points
${I_4} = \left\{ {7, \ldots, 11} \right\}$
. Each of these subsets can be fit by a straight line (see V and VI). Thus, our approach finishes by discovering three affine pieces that cover all the points
 $\left\{ {1, \ldots, 11} \right\}$
. Note that although the data point indexed by
$\left\{ {1, \ldots, 11} \right\}$
. Note that although the data point indexed by
 $5$
is part of two pieces, we can resolve this ‘tie’ in an arbitrary manner by assigning
$5$
is part of two pieces, we can resolve this ‘tie’ in an arbitrary manner by assigning
 $5$
to the first piece and removing it from the second; the same holds for the data point indexed by
$5$
to the first piece and removing it from the second; the same holds for the data point indexed by
 $7$
.
$7$
.
Notation Given two vectors or matrices
 $u$
and
$u$
and
 $v$
, their horizontal (resp. vertical) concatenation is denoted by
$v$
, their horizontal (resp. vertical) concatenation is denoted by
 $\left[ {u,v} \right]$
(resp.
$\left[ {u,v} \right]$
(resp.
 $\left[ {u,v} \right]$
). For positive integers
$\left[ {u,v} \right]$
). For positive integers
 $d$
and
$d$
and
 $e$
and a scalar
$e$
and a scalar
 $\alpha $
, we denote by
$\alpha $
, we denote by
 ${[\alpha ]_d}$
(resp.
${[\alpha ]_d}$
(resp.
 ${[\alpha ]_{e,d}}$
) the vector in
${[\alpha ]_{e,d}}$
) the vector in
 ${{\mathbb{R}}^d}$
(resp. matrix in
${{\mathbb{R}}^d}$
(resp. matrix in
 ${{\mathbb{R}}^{e \times d}}$
) whose components are all equal to
${{\mathbb{R}}^{e \times d}}$
) whose components are all equal to
 $\alpha $
. Finally, given an natural number
$\alpha $
. Finally, given an natural number
 $n$
, we let
$n$
, we let
 $\left[ n \right] = \left\{ {1, \ldots, n} \right\}$
.
$\left[ n \right] = \left\{ {1, \ldots, n} \right\}$
.
Problem statement
Given a data set
 $N\in\mathbb{N}$
>0 of input–output pairs
$N\in\mathbb{N}$
>0 of input–output pairs
 $\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N \subseteq {{\mathbb{R}}^d} \times {{\mathbb{R}}^e}$
, the problem of PWA regression aims at finding a PWA function that fits the data within some given error tolerance
$\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N \subseteq {{\mathbb{R}}^d} \times {{\mathbb{R}}^e}$
, the problem of PWA regression aims at finding a PWA function that fits the data within some given error tolerance
 $\varepsilon \ge 0$
. Formally, a PWA function
$\varepsilon \ge 0$
. Formally, a PWA function
 $f$
over a
$f$
over a
 $D \subseteq {{\mathbb{R}}^d}$
domain is defined by covering
$D \subseteq {{\mathbb{R}}^d}$
domain is defined by covering
 $D$
with
$D$
with
 $M$
regions
$M$
regions
 ${H_1}, \ldots, {H_M}$
and associating an affine function
${H_1}, \ldots, {H_M}$
and associating an affine function
 ${f_i}\left( x \right) = {A_i}x + {b_i}$
with each
${f_i}\left( x \right) = {A_i}x + {b_i}$
with each
 ${H_i}$
:
${H_i}$
:
 $$f(x) = \left\{ \matrix {{{A_1}x + {b_1}}& {{\rm{if\;\;}}x \in {H_1},}\cr{{A_2}x + {b_2}}& {{\rm{if\;\;}}x \in {H_2},}\cr{{\rm{\;\;\;\;}} \vdots }& {}\cr{{A_M}x + {b_M}}& {{\rm{if\;\;}}x \in {H_M}.}} \right.$$
$$f(x) = \left\{ \matrix {{{A_1}x + {b_1}}& {{\rm{if\;\;}}x \in {H_1},}\cr{{A_2}x + {b_2}}& {{\rm{if\;\;}}x \in {H_2},}\cr{{\rm{\;\;\;\;}} \vdots }& {}\cr{{A_M}x + {b_M}}& {{\rm{if\;\;}}x \in {H_M}.}} \right.$$
Note that if
 ${H_i} \cap {H_j} \ne \emptyset $
for some
${H_i} \cap {H_j} \ne \emptyset $
for some
 $i =\hskip-7pt/ j$
, then
$i =\hskip-7pt/ j$
, then
 $f$
is no longer a function. However, in such a case, we may ‘break the tie’ by defining
$f$
is no longer a function. However, in such a case, we may ‘break the tie’ by defining
 $f\left( x \right) = {f_i}\left( x \right)$
wherein
$f\left( x \right) = {f_i}\left( x \right)$
wherein
 $i = {\rm{min\;}}\left\{ {j:x \in {H_j}} \right\}$
.
$i = {\rm{min\;}}\left\{ {j:x \in {H_j}} \right\}$
.
Problem 1 (PWA regression). Given a data set
 $\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
and an error bound
$\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
and an error bound
 $\varepsilon \ge 0$
, find
$\varepsilon \ge 0$
, find
 $M$
regions
$M$
regions
 ${H_i} \subseteq {{\mathbb{R}}^d}$
and affine functions
${H_i} \subseteq {{\mathbb{R}}^d}$
and affine functions
 ${f_i}\left( x \right) = {A_i}x + {b_i}$
such that
${f_i}\left( x \right) = {A_i}x + {b_i}$
such that
 $$\small{\forall {\rm{\;}}k,{\rm{\;}}\exists {\rm{\;}}i:{x_k} \in {H_i}{\rm{\;\;\;\;and\;\;\;\;}}\forall {\rm{\;}}k,{\rm{\;}}\forall {\rm{\;}}i:{x_k} \in {H_i} \Rightarrow \parallel {y_k} - {f_i}\left( {{x_k}} \right){\parallel _\infty } \le \varepsilon .}$$
$$\small{\forall {\rm{\;}}k,{\rm{\;}}\exists {\rm{\;}}i:{x_k} \in {H_i}{\rm{\;\;\;\;and\;\;\;\;}}\forall {\rm{\;}}k,{\rm{\;}}\forall {\rm{\;}}i:{x_k} \in {H_i} \Rightarrow \parallel {y_k} - {f_i}\left( {{x_k}} \right){\parallel _\infty } \le \varepsilon .}$$
Furthermore, we restrict the domain
 ${H_i}$
of each affine piece by specifying a template, which can be any function
${H_i}$
of each affine piece by specifying a template, which can be any function
 $p: {\mathbb{R}}^d \rightarrow{\mathbb{R}}^h$
. Given a template
$p: {\mathbb{R}}^d \rightarrow{\mathbb{R}}^h$
. Given a template
 $p$
and a vector
$p$
and a vector
 $c \in {{\mathbb{R}}^h}$
, we define the set
$c \in {{\mathbb{R}}^h}$
, we define the set
 $H\left( c \right)$
as
$H\left( c \right)$
as
 $$H\left( c \right) = \left\{ {x \in {{\mathbb{R}}^d}:p\left( x \right) \le c} \right\},$$
$$H\left( c \right) = \left\{ {x \in {{\mathbb{R}}^d}:p\left( x \right) \le c} \right\},$$
wherein
 $ \le $
is elementwise and
$ \le $
is elementwise and
 $c \in {{\mathbb{R}}^h}$
parameterizes the set
$c \in {{\mathbb{R}}^h}$
parameterizes the set
 $H\left( c \right)$
. We let
$H\left( c \right)$
. We let
 ${\cal H} = \left\{ {H\left( c \right):c \in {{\mathbb{R}}^h}} \right\}$
denote the set of all regions in
${\cal H} = \left\{ {H\left( c \right):c \in {{\mathbb{R}}^h}} \right\}$
denote the set of all regions in
 ${{\mathbb{R}}^d}$
described by the template
${{\mathbb{R}}^d}$
described by the template
 $p$
.
$p$
.
Fixing a template allows to control the complexity of the domains, and thus of the overall PWA function. This allows among others to mitigate overfitting. The rectangular template
 $p\left( x \right) = \left[ {x; - x} \right]$
defines regions
$p\left( x \right) = \left[ {x; - x} \right]$
defines regions
 $H\left( c \right)$
that form boxes in
$H\left( c \right)$
that form boxes in
 ${{\mathbb{R}}^d}$
. Indeed, for two vectors
${{\mathbb{R}}^d}$
. Indeed, for two vectors
 ${c_1} \le {c_2}$
,
${c_1} \le {c_2}$
,
 $H\left( {\left[ {{c_2}; - {c_1}} \right]} \right)$
defines the box
$H\left( {\left[ {{c_2}; - {c_1}} \right]} \right)$
defines the box
 $\left\{ {x \in {{\mathbb{R}}^d}:{c_1} \le x \le {c_2}} \right\}$
. Similarly, allowing pairwise differences between individual variables as components of
$\left\{ {x \in {{\mathbb{R}}^d}:{c_1} \le x \le {c_2}} \right\}$
. Similarly, allowing pairwise differences between individual variables as components of
 $p$
yields the octagon domain (Miné Reference Miné2006). Figure 1 illustrates PWA functions with rectangular domains. Thus, we define the template-based piecewise affine (TPWA) regression problem:
$p$
yields the octagon domain (Miné Reference Miné2006). Figure 1 illustrates PWA functions with rectangular domains. Thus, we define the template-based piecewise affine (TPWA) regression problem:
Problem 2 (TPWA regression). Given a data set
 $\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
, a template
$\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
, a template
 $p:{{\mathbb{R}}^d} \to {{\mathbb{R}}^h}$
and an error bound
$p:{{\mathbb{R}}^d} \to {{\mathbb{R}}^h}$
and an error bound
 $\varepsilon \gt 0$
, find
$\varepsilon \gt 0$
, find
 $M$
regions
$M$
regions
 ${H_i} \in {\cal H}$
and affine functions
${H_i} \in {\cal H}$
and affine functions
 ${f_i}\left( x \right) = {A_i}x + {b_i}$
such that (1) is satisfied.
${f_i}\left( x \right) = {A_i}x + {b_i}$
such that (1) is satisfied.
Prob. 2 can be posed as a decision problem: Given a bound
 $\hat M$
, is there a TPWA function with
$\hat M$
, is there a TPWA function with
 $M \le \hat M$
pieces? Alternatively, we can pose it as an optimization problem: Find a TPWA function with minimum number
$M \le \hat M$
pieces? Alternatively, we can pose it as an optimization problem: Find a TPWA function with minimum number
 $M$
of pieces.
$M$
of pieces.
Although a solution to the decision problem can be used repeatedly to solve the optimization problem, we will focus on directly solving the optimization problem in this paper. Prob. 2 is closely related to the well-known problem of SA regression, in which one aims to explain the data with a finite number of affine functions, but there is no assumption on which function may explain each data point
 $\left( {{x_k},{y_k}} \right)$
. In other words, SA aims to identify a sufficient number of modes and dynamics corresponding to each mode without necessarily explaining how the modes are assigned to each point in the domain.
$\left( {{x_k},{y_k}} \right)$
. In other words, SA aims to identify a sufficient number of modes and dynamics corresponding to each mode without necessarily explaining how the modes are assigned to each point in the domain.
Problem 3 (SA regression). Given a data set
 $\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
and an error bound
$\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
and an error bound
 $\varepsilon \ge 0$
, find
$\varepsilon \ge 0$
, find
 $M$
affine functions
$M$
affine functions
 ${f_i}\left( x \right) = {A_i}x + {b_i}$
such that
${f_i}\left( x \right) = {A_i}x + {b_i}$
such that
 $\forall \;k$
,
$\forall \;k$
,
 $\exists \;i$
:
$\exists \;i$
:
 $\parallel {y_k} - {f_i}\left( x \right){\parallel _\infty } \le \varepsilon $
.
$\parallel {y_k} - {f_i}\left( x \right){\parallel _\infty } \le \varepsilon $
.
Computational complexity
The problem of SA regression (Prob. 3) is known to be NP-hard, even for
 $M = 2$
(Lauer and Bloch Reference Lauer and Bloch2019, Sec. 5.2.4). In this section, we show that the same holds for the decision version of Prob. 2. We study the problem in the RAM model, wherein the problem input size is
$M = 2$
(Lauer and Bloch Reference Lauer and Bloch2019, Sec. 5.2.4). In this section, we show that the same holds for the decision version of Prob. 2. We study the problem in the RAM model, wherein the problem input size is
 $N\left( {d + e} \right) + h$
, where
$N\left( {d + e} \right) + h$
, where
 $p:{{\mathbb{R}}^d} \to {{\mathbb{R}}^h}$
.
$p:{{\mathbb{R}}^d} \to {{\mathbb{R}}^h}$
.
Theorem 1 (NP-hardness). The decision version of Prob. 2 is NP-hard, even for
 $M = 2$
and rectangular templates (
$M = 2$
and rectangular templates (
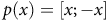 $p\left( x \right) = \left[ {x; - x} \right]$
).
$p\left( x \right) = \left[ {x; - x} \right]$
).
The proof reduces Prob. 3 which is known to be NP-hard to Prob. 2.
Proof. Without loss of generality, we restrict to piecewise linear models since PWA models can be obtained from linear ones by augmenting each data point
 ${x_k}$
with a component equal to
${x_k}$
with a component equal to
 $1$
.
$1$
.
We reduce Prob. 3 to Prob. 2 as follows. Consider an instance of Prob. 3 consisting of a data set
 ${\cal D} = \{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N \subseteq {{\mathbb{R}}^d} \times {{\mathbb{R}}^e}$
and tolerance
${\cal D} = \{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N \subseteq {{\mathbb{R}}^d} \times {{\mathbb{R}}^e}$
and tolerance
 $\varepsilon $
. From
$\varepsilon $
. From
 ${\cal D}$
, we build another data set
${\cal D}$
, we build another data set
 ${\cal D}{\mathbb{'}} \subseteq {{\mathbb{R}}^{d + N}} \times {{\mathbb{R}}^e}$
with
${\cal D}{\mathbb{'}} \subseteq {{\mathbb{R}}^{d + N}} \times {{\mathbb{R}}^e}$
with
 $\left| {{\cal D}^{\rm{\prime}}} \right| = 4N$
as follows. For each
$\left| {{\cal D}^{\rm{\prime}}} \right| = 4N$
as follows. For each
 $k \in \left[ N \right]$
, we let be the indicator vector of the
$k \in \left[ N \right]$
, we let be the indicator vector of the
 $k$
th component. We define
$k$
th component. We define
 $${\cal D}{\rm{'}} = \bigcup\limits_{\sigma \in \left\{ { - 1,1} \right\}} {\bigcup\limits_{k = 1}^N {[\{ \left( {\left[ {\sigma {x_k};{\chi _k}} \right],\sigma {y_k}} \right),([\left[ {0{]_d};{\chi _k}\left], \right[\sigma \varepsilon {]_e}} \right)\} ]} } $$
$${\cal D}{\rm{'}} = \bigcup\limits_{\sigma \in \left\{ { - 1,1} \right\}} {\bigcup\limits_{k = 1}^N {[\{ \left( {\left[ {\sigma {x_k};{\chi _k}} \right],\sigma {y_k}} \right),([\left[ {0{]_d};{\chi _k}\left], \right[\sigma \varepsilon {]_e}} \right)\} ]} } $$
In other words, for each data point
 $\left( {{x_k},{y_k}} \right)$
in the original dataset
$\left( {{x_k},{y_k}} \right)$
in the original dataset
 ${\cal D}$
, we add four data points of the form
${\cal D}$
, we add four data points of the form
 $\left( {\left[ {{x_k};{\chi _k}} \right],{y_k}} \right),\left( {\left[ { - {x_k};{\chi _k}} \right], - {y_k}} \right),([\left[ {0{]_d};{\chi _k}\left], \right[\varepsilon {]_e}} \right),([\left[ {0{]_d};{\chi _k}\left], \right[\!\!- \!\varepsilon {]_e}} \right)$
wherein
$\left( {\left[ {{x_k};{\chi _k}} \right],{y_k}} \right),\left( {\left[ { - {x_k};{\chi _k}} \right], - {y_k}} \right),([\left[ {0{]_d};{\chi _k}\left], \right[\varepsilon {]_e}} \right),([\left[ {0{]_d};{\chi _k}\left], \right[\!\!- \!\varepsilon {]_e}} \right)$
wherein
 ${\chi _k}$
is a vector of size
${\chi _k}$
is a vector of size
 $N$
with a
$N$
with a
 $1$
entry in the
$1$
entry in the
 ${k^{th}}$
position and a
${k^{th}}$
position and a
 $0$
entry everywhere else and
$0$
entry everywhere else and
 ${[0]_d}$
is a vector of
${[0]_d}$
is a vector of
 $d$
zeros wherein
$d$
zeros wherein
 ${[\varepsilon ]_e}$
is a vector with
${[\varepsilon ]_e}$
is a vector with
 $e$
entries each of which is
$e$
entries each of which is
 $\varepsilon $
.
$\varepsilon $
.
Also, we let
 ${\cal p}: {\mathbb R}^{d+N}\to {\mathbb R}^{2(d+N)}$
be the rectangular template in
${\cal p}: {\mathbb R}^{d+N}\to {\mathbb R}^{2(d+N)}$
be the rectangular template in
 ${\mathbb R}^{d+N}$
.
${\mathbb R}^{d+N}$
.
Main step: We show that Prob. 3 with
 ${\cal D}$
,
${\cal D}$
,
 $\varepsilon $
and
$\varepsilon $
and
 $M = 2$
has a solution if and only if Prob. 2 with
$M = 2$
has a solution if and only if Prob. 2 with
 ${\cal D}^{\rm{\prime}}$
,
${\cal D}^{\rm{\prime}}$
,
 $p$
,
$p$
,
 $\varepsilon $
and
$\varepsilon $
and
 $M = 2$
has a solution.
$M = 2$
has a solution.
Proof of ‘if direction’. Assume that Prob. 2 has a solution given by and, and for each
 $i$
, decompose
$i$
, decompose
 ${A_i} = \left[ {{B_i},{C_i}} \right]$
, wherein and . We will show that
${A_i} = \left[ {{B_i},{C_i}} \right]$
, wherein and . We will show that
 ${B_1},{B_2}$
provide a solution to Prob. 3.
${B_1},{B_2}$
provide a solution to Prob. 3.
Therefore, fix
 $k \in \left[ N \right]$
. Using the pigeon-hole principle, let
$k \in \left[ N \right]$
. Using the pigeon-hole principle, let
 $i \in \left\{ {1,2} \right\}$
be such that at least two points in
$i \in \left\{ {1,2} \right\}$
be such that at least two points in
 ${\{ [ {{x_k};{\chi _k}], [-\!{x_k};{\chi _k}]}}$
,
${\{ [ {{x_k};{\chi _k}], [-\!{x_k};{\chi _k}]}}$
,
 ${[[0]_d};{\chi _k}]\} $
belong to
${[[0]_d};{\chi _k}]\} $
belong to
 ${H_i}$
. Then, by the convexity of
${H_i}$
. Then, by the convexity of
 ${H_i}$
, it holds that
${H_i}$
, it holds that
 $[\left[ {0{]_d};{\chi _k}} \right] \in {H_i}$
. For definiteness, assume that
$[\left[ {0{]_d};{\chi _k}} \right] \in {H_i}$
. For definiteness, assume that
 $\left[ {{x_k};{\chi _k}} \right] \in {H_i}$
. Since
$\left[ {{x_k};{\chi _k}} \right] \in {H_i}$
. Since
 ${H_1},{H_2}$
and
${H_1},{H_2}$
and
 ${A_1},{A_2}$
provide a solution to Prob. 2, it follows that
${A_1},{A_2}$
provide a solution to Prob. 2, it follows that
 $$\begin{gathered}\parallel {y_k} - {B_i}{x_k} - {C_i}{\chi _k}{\parallel _\infty } \le \varepsilon ,\;\;\;\; \hfill \\
\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\parallel \left[ {{\varepsilon _e}} \right] - {C_i}{\chi _k}{\parallel _\infty } \le \varepsilon ,\;\;\;\;\parallel \left[ {{\varepsilon _e}} \right] + {C_i}{\chi _k}{\parallel _\infty } \le \varepsilon . \hfill \\ \end{gathered}$$
$$\begin{gathered}\parallel {y_k} - {B_i}{x_k} - {C_i}{\chi _k}{\parallel _\infty } \le \varepsilon ,\;\;\;\; \hfill \\
\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\parallel \left[ {{\varepsilon _e}} \right] - {C_i}{\chi _k}{\parallel _\infty } \le \varepsilon ,\;\;\;\;\parallel \left[ {{\varepsilon _e}} \right] + {C_i}{\chi _k}{\parallel _\infty } \le \varepsilon . \hfill \\ \end{gathered}$$
The last two conditions imply that
 ${C_i}{\chi _k} = 0$
, so that
${C_i}{\chi _k} = 0$
, so that
 $\parallel {y_k} - {B_i}{x_k}{\parallel _\infty } \le \varepsilon $
. Since
$\parallel {y_k} - {B_i}{x_k}{\parallel _\infty } \le \varepsilon $
. Since
 $k$
was arbitrary, this shows that
$k$
was arbitrary, this shows that
 ${B_1},{B_2}$
provide a solution to Prob. 3; thereby proving the ‘if direction’.
${B_1},{B_2}$
provide a solution to Prob. 3; thereby proving the ‘if direction’.
Proof of ‘only if direction’. Assume that Prob. 3 has a solution given by . Then, for each
 $k \in \left[ N \right]$
, define the intervals as follows:
$k \in \left[ N \right]$
, define the intervals as follows:
 ${I_{i,k}} = \left[ {0,1} \right]$
if
${I_{i,k}} = \left[ {0,1} \right]$
if
 $\parallel {y_k} - {A_i}{x_k}{\parallel _\infty } \le \varepsilon $
, and
$\parallel {y_k} - {A_i}{x_k}{\parallel _\infty } \le \varepsilon $
, and
 ${I_{i,k}} = \left\{ 0 \right\}$
otherwise. Now, define the rectangular regions as follows: . Also define the matrices as follows:
${I_{i,k}} = \left\{ 0 \right\}$
otherwise. Now, define the rectangular regions as follows: . Also define the matrices as follows:
 ${B_i} = \left[ {{A_i},} \right[0{]_{e,K}}]$
. We will show that
${B_i} = \left[ {{A_i},} \right[0{]_{e,K}}]$
. We will show that
 ${H_1},{H_2}$
and
${H_1},{H_2}$
and
 ${B_1},{B_2}$
provide a solution to Prob. 2.
${B_1},{B_2}$
provide a solution to Prob. 2.
Therefore, fix
 $k \in \left[ N \right]$
and
$k \in \left[ N \right]$
and
 $i \in \left\{ {1,2} \right\}$
. First, assume
$i \in \left\{ {1,2} \right\}$
. First, assume
 $\parallel {y_k} - {A_i}{x_k}{\parallel _\infty } \le \varepsilon $
. We show that (a)
$\parallel {y_k} - {A_i}{x_k}{\parallel _\infty } \le \varepsilon $
. We show that (a)
 $\left[ {{x_k};{\chi _k}} \right]$
,
$\left[ {{x_k};{\chi _k}} \right]$
,
 $\left[ { - {x_k};{\chi _k}} \right]$
and
$\left[ { - {x_k};{\chi _k}} \right]$
and
 $[\left[ {0{]_d};{\chi _k}} \right]$
belong to
$[\left[ {0{]_d};{\chi _k}} \right]$
belong to
 ${H_i}$
, and (b)
${H_i}$
, and (b)
 $$\begin{gathered} \parallel {y_k} - {B_i}\left[ {{x_k};{\chi _k}} \right]{\parallel _\infty } \le \varepsilon ,\;\;\;\;\parallel - {y_k} - {B_i}\left[ { - {x_k};{\chi _k}} \right]{\parallel _\infty } \le \varepsilon ,\;\;\;\; \hfill \\\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!
\parallel \left[ { \pm {\varepsilon _e}} \right] - {B_i}\left[ {\left[ {{0_d}} \right];{\chi _k}} \right]{\parallel _\infty } \le \varepsilon . \hfill \\ \end{gathered}$$
$$\begin{gathered} \parallel {y_k} - {B_i}\left[ {{x_k};{\chi _k}} \right]{\parallel _\infty } \le \varepsilon ,\;\;\;\;\parallel - {y_k} - {B_i}\left[ { - {x_k};{\chi _k}} \right]{\parallel _\infty } \le \varepsilon ,\;\;\;\; \hfill \\\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!
\parallel \left[ { \pm {\varepsilon _e}} \right] - {B_i}\left[ {\left[ {{0_d}} \right];{\chi _k}} \right]{\parallel _\infty } \le \varepsilon . \hfill \\ \end{gathered}$$
This is direct (a) by the definition of
 ${I_{i,k}}$
, and (b) by the definition of
${I_{i,k}}$
, and (b) by the definition of
 ${B_i}$
. Now, assume that
${B_i}$
. Now, assume that
 $\parallel {y_k} - {A_i}{x_k}{\parallel _\infty } \le \varepsilon $
does not hold. We show that
$\parallel {y_k} - {A_i}{x_k}{\parallel _\infty } \le \varepsilon $
does not hold. We show that
 $\left[ {{x_k};{\chi _k}} \right]$
,
$\left[ {{x_k};{\chi _k}} \right]$
,
 $\left[ { - {x_k};{\chi _k}} \right]$
do not belong to
$\left[ { - {x_k};{\chi _k}} \right]$
do not belong to
 ${H_i}$
. This is direct since
${H_i}$
. This is direct since
 $1\,\notin\,{I_{i,k}}$
. Thus, we have shown that
$1\,\notin\,{I_{i,k}}$
. Thus, we have shown that
 ${H_1},{H_2}$
and
${H_1},{H_2}$
and
 ${B_1},{B_2}$
provide a solution to Prob. 2; thereby proving the ‘only if direction’.
${B_1},{B_2}$
provide a solution to Prob. 2; thereby proving the ‘only if direction’.
Hence, we have built a polynomial-time reduction from Prob. 3 to Prob. 2. Since Prob. 3 is NP-hard (Lauer and Bloch Reference Lauer and Bloch2019, Sec. 5.2.4), this shows that Prob. 2 is NP-hard as well. □
Remark 1.
Note that the reduction from Prob. 3 to Prob. 2 in the above proof relies on the fact that
 $M = 2$
. Two comments are due here. First, the fact that Prob. 2 is NP-hard with
$M = 2$
. Two comments are due here. First, the fact that Prob. 2 is NP-hard with
 $M = 2$
implies that Prob. 2 is NP-hard with any
$M = 2$
implies that Prob. 2 is NP-hard with any
 $M2$
. Indeed, if Prob. 2 can be solved in polynomial time for some
$M2$
. Indeed, if Prob. 2 can be solved in polynomial time for some
 $M = \hat M \gt 2$
, then one can add spurious data points (e.g., at a far distance of the original data points) to enforce the value of
$M = \hat M \gt 2$
, then one can add spurious data points (e.g., at a far distance of the original data points) to enforce the value of
 $\hat M - 2$
affine pieces of the PWA function. The satisfiability of Prob. 2 with
$\hat M - 2$
affine pieces of the PWA function. The satisfiability of Prob. 2 with
 $M = \hat M$
and the augmented data set is then equivalent to the satisfiability of Prob. 2 with
$M = \hat M$
and the augmented data set is then equivalent to the satisfiability of Prob. 2 with
 $M = 2$
and the original data set. Second, given
$M = 2$
and the original data set. Second, given
 $\hat M2$
and any template
$\hat M2$
and any template
 $p$
, a construction similar to the one used in the above proof can be used to reduce Prob. 3 to Prob. 2 at the cost of introducing a small gap in the reduction. Indeed, fix
$p$
, a construction similar to the one used in the above proof can be used to reduce Prob. 3 to Prob. 2 at the cost of introducing a small gap in the reduction. Indeed, fix
 $\lambda \gt 0$
and consider the data set . Then, one can show that if Prob. 2 with
$\lambda \gt 0$
and consider the data set . Then, one can show that if Prob. 2 with
 ${\cal D}^{\rm{\prime}}$
,
${\cal D}^{\rm{\prime}}$
,
 $p$
,
$p$
,
 $\varepsilon = \hat \varepsilon \left( {1 - {{2}\over{\lambda }}} \right)$
and
$\varepsilon = \hat \varepsilon \left( {1 - {{2}\over{\lambda }}} \right)$
and
 $M = \hat M$
has a solution, then Prob. 3 with
$M = \hat M$
has a solution, then Prob. 3 with
 ${\cal D}$
,
${\cal D}$
,
 $\varepsilon = \hat \varepsilon $
and
$\varepsilon = \hat \varepsilon $
and
 $M = \hat M$
has a solution. The gap corresponds to the factor
$M = \hat M$
has a solution. The gap corresponds to the factor
 $1 - {{2}\over{\lambda }}$
, which can be made arbitrarily close to one.
$1 - {{2}\over{\lambda }}$
, which can be made arbitrarily close to one.
 $ \triangleleft $
$ \triangleleft $
So, we showed that Prob. 2 is NP-hard, thereby implying no known algorithm with complexity polynomial in the problem input size
 $N\left( {d + e} \right) + h$
. Nevertheless, one can show that for fixed dimension
$N\left( {d + e} \right) + h$
. Nevertheless, one can show that for fixed dimension
 $d$
, template size
$d$
, template size
 $h$
and number of pieces
$h$
and number of pieces
 $M$
, the complexity is polynomial in the data size
$M$
, the complexity is polynomial in the data size
 $N$
.
$N$
.
Theorem 2. (Polynomial complexity in N). For fixed dimension
 $d$
, template
$d$
, template
 $p:{\mathbb{R}}^d \to {{\mathbb{R}}^h}$
and number of pieces
$p:{\mathbb{R}}^d \to {{\mathbb{R}}^h}$
and number of pieces
 $M$
, the complexity of Prob. 2 is bounded by
$M$
, the complexity of Prob. 2 is bounded by
 $O\left( {{N^{Mh}}} \right)$
.
$O\left( {{N^{Mh}}} \right)$
.
The following notation will be useful in the proof of Theorem 2 below and also later in the paper. For every
 $c \in {\mathbb{R}}^h$
, let
$c \in {\mathbb{R}}^h$
, let
 $I\left( c \right) = \left\{ {k \in \left[ N \right]:{x_k} \in H\left( c \right)} \right\}$
be the set of all indices
$I\left( c \right) = \left\{ {k \in \left[ N \right]:{x_k} \in H\left( c \right)} \right\}$
be the set of all indices
 $k$
such that
$k$
such that
 ${x_k} \in H\left( c \right)$
. Also, let
${x_k} \in H\left( c \right)$
. Also, let
 ${\cal I} = \left\{ {I\left( c \right):c \in {\mathbb{R}}^h}\!\right\}$
be the set of all such index sets.
${\cal I} = \left\{ {I\left( c \right):c \in {\mathbb{R}}^h}\!\right\}$
be the set of all such index sets.
Proof. The crux of the proof is to realize that
 $\left| {\cal I} \right| \le {N^h} + 1$
.
$\left| {\cal I} \right| \le {N^h} + 1$
.
For every
 $c \in {\mathbb{R}}^h$
, define
$c \in {\mathbb{R}}^h$
, define
 $P\left( c \right) = \left\{ {p\left( {{x_k}} \right):k \in \left[ N \right],{\rm{\;}}p\left( {{x_k}} \right) \le c} \right\}$
and let
$P\left( c \right) = \left\{ {p\left( {{x_k}} \right):k \in \left[ N \right],{\rm{\;}}p\left( {{x_k}} \right) \le c} \right\}$
and let
 ${\cal P} = \left\{ {P\left( c \right):c \in {{\mathbb{R}}^h}} \right\}$
. First, we prove that
${\cal P} = \left\{ {P\left( c \right):c \in {{\mathbb{R}}^h}} \right\}$
. First, we prove that
 $\left| {\cal P} \right| \le {N^h} + 1$
. For convenience, we write
$\left| {\cal P} \right| \le {N^h} + 1$
. For convenience, we write
 $p\left( x \right) = \left[ {{p^1}\left( x \right), \ldots, {p^h}\left( x \right)} \right]$
. Note that for any
$p\left( x \right) = \left[ {{p^1}\left( x \right), \ldots, {p^h}\left( x \right)} \right]$
. Note that for any
 $c \in {\mathbb{R}}^h$
such that
$c \in {\mathbb{R}}^h$
such that
 $P\left( c \right) \ne \emptyset $
, it holds that
$P\left( c \right) \ne \emptyset $
, it holds that
 $P\left( c \right) = P\left( {\hat c} \right)$
where
$P\left( c \right) = P\left( {\hat c} \right)$
where
 $\hat c = {\rm{max}}\left( {\left\{ {p\left( {{x_k}} \right):k \in \left[ N \right],{\rm{\;}}p\left( {{x_k}} \right) \le c} \right\}} \right)$
and the ‘max’ is elementwise. Therefore, we can identify at most
$\hat c = {\rm{max}}\left( {\left\{ {p\left( {{x_k}} \right):k \in \left[ N \right],{\rm{\;}}p\left( {{x_k}} \right) \le c} \right\}} \right)$
and the ‘max’ is elementwise. Therefore, we can identify at most
 $h$
elements
$h$
elements
 ${x_{{k_1}}}, \ldots, {x_{{k_h}}}$
wherein
${x_{{k_1}}}, \ldots, {x_{{k_h}}}$
wherein
 ${k_1}, \ldots, {k_h} \in \left[ N \right]$
such that
${k_1}, \ldots, {k_h} \in \left[ N \right]$
such that
 $\hat c \in \left\{ {\left[ {{p^1}\left( {{x_{{k_1}}}} \right), \ldots, {p^h}\left( {{x_{{k_h}}}} \right)} \right]:{k_1},\ldots, {k_h} \in \left[ N \right]} \right\}$
. Each element can be seen as ‘fixing’ the maximum value along some dimension of
$\hat c \in \left\{ {\left[ {{p^1}\left( {{x_{{k_1}}}} \right), \ldots, {p^h}\left( {{x_{{k_h}}}} \right)} \right]:{k_1},\ldots, {k_h} \in \left[ N \right]} \right\}$
. Each element can be seen as ‘fixing’ the maximum value along some dimension of
 $p\left( x \right)$
. Hence, there are at most
$p\left( x \right)$
. Hence, there are at most
 ${N^h}$
distinct such
${N^h}$
distinct such
 $\hat c$
. This implies that there are at most
$\hat c$
. This implies that there are at most
 ${N^h}$
distinct nonempty sets
${N^h}$
distinct nonempty sets
 $P\left( c \right)$
, concluding the proof that
$P\left( c \right)$
, concluding the proof that
 $\left| {\cal P} \right| \le {N^h} + 1$
.
$\left| {\cal P} \right| \le {N^h} + 1$
.
Next, observe that there is a one-to-one correspondence between
 ${\cal P}$
and
${\cal P}$
and
 ${\cal I}$
given by:
${\cal I}$
given by:
 $P\left( c \right)\,\mapsto\,I\left( c \right)$
. Indeed, it is clear that if
$P\left( c \right)\,\mapsto\,I\left( c \right)$
. Indeed, it is clear that if
 $I\left( {{c_1}} \right) = I\left( {{c_2}} \right)$
, then
$I\left( {{c_1}} \right) = I\left( {{c_2}} \right)$
, then
 $P\left( {{c_1}} \right) = P\left( {{c_2}} \right)$
. On the other hand, if
$P\left( {{c_1}} \right) = P\left( {{c_2}} \right)$
. On the other hand, if
 $I\left( {{c_1}} \right)$
⊈
$I\left( {{c_1}} \right)$
⊈
 $I\left( {{c_2}} \right)$
, then there is at least one
$I\left( {{c_2}} \right)$
, then there is at least one
 $k$
such that
$k$
such that
 $p\left( {{x_k}} \right) \le {c_1}$
but . This implies that
$p\left( {{x_k}} \right) \le {c_1}$
but . This implies that
 $P\left( {{c_1}} \right)$
⊈
$P\left( {{c_1}} \right)$
⊈
 $P\left( {{c_2}} \right)$
. Therefore,
$P\left( {{c_2}} \right)$
. Therefore,
 $\left| {\cal P} \right| = \left| {\cal I} \right| \in O\left( {{N^h}} \right)$
.
$\left| {\cal P} \right| = \left| {\cal I} \right| \in O\left( {{N^h}} \right)$
.
Now, Prob. 2 can be solved by enumerating the
 $L = {N^h}$
nonempty index sets
$L = {N^h}$
nonempty index sets
 ${I_1}, \ldots, {I_L}$
in
${I_1}, \ldots, {I_L}$
in
 ${\cal I}$
, and keeping only those
${\cal I}$
, and keeping only those
 ${I_\ell }$
for which we can fit an affine function over the data
${I_\ell }$
for which we can fit an affine function over the data
 ${\{ \left( {{x_k},{y_k}} \right)\} _{k \in {I_\ell }}}$
with error bound
${\{ \left( {{x_k},{y_k}} \right)\} _{k \in {I_\ell }}}$
with error bound
 $\varepsilon $
. Next, we enumerate all combinations of
$\varepsilon $
. Next, we enumerate all combinations of
 $M$
such index sets that cover the indices
$M$
such index sets that cover the indices
 $\left[ N \right]$
. There are at most
$\left[ N \right]$
. There are at most
 ${L^M}$
such combinations. This concludes the proof of the theorem. □
${L^M}$
such combinations. This concludes the proof of the theorem. □
Remark 2. Note that a similar result holds for Prob. 3 (Lauer and Bloch Reference Lauer and Bloch2019, Theorem 5.4). The proof of Theorem 2 is however simpler than that in Lauer and Bloch Reference Lauer and Bloch2019 because in our case we can use the template to build the different regions.
 $ \triangleleft $
$ \triangleleft $
The algorithm presented in the proof of Theorem 2, although polynomial in the size of the dataset, can be quite expensive in practice. For instance, in dimension
 $d = 2$
, with rectangular regions (i.e.,
$d = 2$
, with rectangular regions (i.e.,
 $h = 4$
) and
$h = 4$
) and
 $N = 100$
data points, one would need to solve
$N = 100$
data points, one would need to solve
 ${N^h} = {10^8}$
regression problems,Footnote
3
each of which is a linear program.
${N^h} = {10^8}$
regression problems,Footnote
3
each of which is a linear program.
In the next section, we present an algorithm for TPWA regression that is generally several orders of magnitude faster by using a top-down approach that avoids having to systematically enumerate all the elements in
 ${\cal I}$
.
${\cal I}$
.
Top-down algorithm
We first define the concept of compatible and maximal compatible index sets. We will assume an instance of Prob. 2 with data
 $\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
, template
$\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
, template
 $p$
, and error bound
$p$
, and error bound
 $\varepsilon $
.
$\varepsilon $
.
Definition 1
(Maximal compatible index set.) An index set
 $I \subseteq \left[ N \right]$
is compatible if (a)
$I \subseteq \left[ N \right]$
is compatible if (a)
 $I \in {\cal I}$
and (b) there is an affine function
$I \in {\cal I}$
and (b) there is an affine function
 $f\left( x \right) = Ax + b$
such that
$f\left( x \right) = Ax + b$
such that
 $\forall \;k \in I$
,
$\forall \;k \in I$
,
 $\parallel {y_k} - f\left( {{x_k}} \right){\parallel _\infty } \le \varepsilon $
. A compatible index set
$\parallel {y_k} - f\left( {{x_k}} \right){\parallel _\infty } \le \varepsilon $
. A compatible index set
 $I$
is maximal if there is no compatible index set
$I$
is maximal if there is no compatible index set
 $I^\prime$
such that
$I^\prime$
such that
 $I$
⊊
$I$
⊊
 $I^\prime$
.
$I^\prime$
.
The key idea is that we can restrict ourselves to searching for maximal compatible index sets in order to find a solution to Prob. 2.
Lemma 1.
Let
 $M$
be given. Prob. 2 has a solution if and only if it has a solution wherein the regions correspond to maximal compatible index sets.
$M$
be given. Prob. 2 has a solution if and only if it has a solution wherein the regions correspond to maximal compatible index sets.
Proof. The ‘if direction’ is clear. We prove the ‘only if direction’. Consider a solution of Prob. 2 with regions
 ${H_1}, \ldots, {H_M}$
. For each
${H_1}, \ldots, {H_M}$
. For each
 $i \in \left[ M \right]$
, there is a maximal compatible index set
$i \in \left[ M \right]$
, there is a maximal compatible index set
 ${I_i} = I\left( {{c_i}} \right)$
such that
${I_i} = I\left( {{c_i}} \right)$
such that
 ${H_i} \cap \{ {x_k}\} _{k = 1}^N \subseteq H\left( {{c_i}} \right)$
. Since
${H_i} \cap \{ {x_k}\} _{k = 1}^N \subseteq H\left( {{c_i}} \right)$
. Since
 $\{ {x_k}\} _{(k = 1)}^N \subseteq \cup _{(i = 1)}^M{H_i}$
, it holds that
$\{ {x_k}\} _{(k = 1)}^N \subseteq \cup _{(i = 1)}^M{H_i}$
, it holds that
 $\{ {x_k}\} _{(k = 1)}^N \subseteq \cup _{(i = 1)}^MH({c_i})$
. Hence,
$\{ {x_k}\} _{(k = 1)}^N \subseteq \cup _{(i = 1)}^MH({c_i})$
. Hence,
 $H\left( {{c_1}} \right), \ldots, H\left( {{c_q}} \right)$
, along with affine functions
$H\left( {{c_1}} \right), \ldots, H\left( {{c_q}} \right)$
, along with affine functions
 ${f_i}\left( x \right) = {A_i}x + {b_i}$
satisfying (b) in Def. 1, provide a solution to Prob. 2, concluding the proof. □
${f_i}\left( x \right) = {A_i}x + {b_i}$
satisfying (b) in Def. 1, provide a solution to Prob. 2, concluding the proof. □
The main result of this section is that maximal compatible index sets can be computed by using a recursive top-down approach as follows (implemented in Algo. 1). Consider the lattice
 $\langle {\cal I}, \subseteq \rangle $
consisting of elements of
$\langle {\cal I}, \subseteq \rangle $
consisting of elements of
 ${\cal I}$
ordered by set inclusion. Our algorithm starts at the very top of follows (implementethis lattice with a set of points
${\cal I}$
ordered by set inclusion. Our algorithm starts at the very top of follows (implementethis lattice with a set of points
 $I = \left[ N \right]$
and descends until we find maximal compatible index sets. At each step, we consider a current set
$I = \left[ N \right]$
and descends until we find maximal compatible index sets. At each step, we consider a current set
 $I \in {\cal I}$
(initially,
$I \in {\cal I}$
(initially,
 $I = \left[ N \right]$
) that is a candidate for being compatible and check it for compatibility. If
$I = \left[ N \right]$
) that is a candidate for being compatible and check it for compatibility. If
 $I$
is not compatible, we find subsets
$I$
is not compatible, we find subsets
 ${I_1}, \ldots, {I_S}$
⊊
${I_1}, \ldots, {I_S}$
⊊
 $I$
using the FindSubsets procedure, which is required to be consistent, as defined below:
$I$
using the FindSubsets procedure, which is required to be consistent, as defined below:
Algorithm 1. Top-down algorithm to compute maximal compatible index sets

Definition 2.
(Consistency). Given a noncompatible index set
 $I \in {\cal I}$
, a collection of index sets
$I \in {\cal I}$
, a collection of index sets
 ${I_1}, \ldots, {I_S} \in {\cal I}$
is said to be consistent w.r.t.
${I_1}, \ldots, {I_S} \in {\cal I}$
is said to be consistent w.r.t.
 $I$
if (a) for each
$I$
if (a) for each
 $s$
,
$s$
,
 ${I_s}$
⊊
${I_s}$
⊊
 $I$
and (b) for every compatible index set
$I$
and (b) for every compatible index set
 $J \subseteq I$
, there is
$J \subseteq I$
, there is
 $s$
such that
$s$
such that
 $J \subseteq {I_s}$
.
$J \subseteq {I_s}$
.
We will assume that the procedure FindSubsets is implemented such that for any noncompatible index set
 $I$
, the collection of sets
$I$
, the collection of sets
 ${I_1}, \ldots, {I_S}$
output by FindSubsets(I) is consistent w.r.t
${I_1}, \ldots, {I_S}$
output by FindSubsets(I) is consistent w.r.t
 $I$
.
$I$
.
Theorem 3.
(Correctness of Algo.1). If FindSubsets satisfies that for every noncompatible index set
 $I \in {\cal I}$
, the output of FindSubsets
(I) is consistent w.r.t.
$I \in {\cal I}$
, the output of FindSubsets
(I) is consistent w.r.t.
 $I$
, then Algo. 1 always terminates and the output
$I$
, then Algo. 1 always terminates and the output
 ${\cal S}$
contains all the maximal compatible index sets.
${\cal S}$
contains all the maximal compatible index sets.
Proof. Termination follows from the fact that each index set
 $I \in {\cal I}$
is picked at most once, because when some
$I \in {\cal I}$
is picked at most once, because when some
 $I \in {\cal I}$
is picked, it is then added to the collection
$I \in {\cal I}$
is picked, it is then added to the collection
 ${\cal V}$
of visited index sets, so that it cannot be added a second time to
${\cal V}$
of visited index sets, so that it cannot be added a second time to
 ${\cal U}$
(line 12). Since
${\cal U}$
(line 12). Since
 ${\cal I}$
is finite, this implies that the algorithm terminates in a finite number of steps.
${\cal I}$
is finite, this implies that the algorithm terminates in a finite number of steps.
Now, we prove that, upon termination, any maximal compatible index set is in the output
 ${\cal S}$
of the algorithm. Therefore, let
${\cal S}$
of the algorithm. Therefore, let
 $J$
be a maximal compatible index set. Then, among all sets
$J$
be a maximal compatible index set. Then, among all sets
 $I$
picked during the execution of the algorithm and satisfying
$I$
picked during the execution of the algorithm and satisfying
 $J \subseteq I$
, let
$J \subseteq I$
, let
 ${I^{\rm{*}}}$
have minimal cardinality. Such an index set exists since
${I^{\rm{*}}}$
have minimal cardinality. Such an index set exists since
 $J \subseteq \left[ N \right]$
. We will show that:
$J \subseteq \left[ N \right]$
. We will show that:
Main result.
 ${I^{\rm{*}}} = J$
.
${I^{\rm{*}}} = J$
.
Proof of main result. For a proof by contradiction, assume that
 ${I^{\rm{*}}} =\hskip-6pt/ \,J$
. Since
${I^{\rm{*}}} =\hskip-6pt/ \,J$
. Since
 $J$
is maximal and
$J$
is maximal and
 $J$
⊊
$J$
⊊
 ${I^{\rm{*}}}$
,
${I^{\rm{*}}}$
,
 ${I^{\rm{*}}}$
is not compatible. Hence, the index sets
${I^{\rm{*}}}$
is not compatible. Hence, the index sets
 $\left( {{I_1}, \ldots, {I_S}} \right) = {\small{FindSubsets}}\left( {{I^{\rm{*}}}} \right)$
were added to
$\left( {{I_1}, \ldots, {I_S}} \right) = {\small{FindSubsets}}\left( {{I^{\rm{*}}}} \right)$
were added to
 ${\cal U}$
(line 11). Using the assumption on FindSubsets, let
${\cal U}$
(line 11). Using the assumption on FindSubsets, let
 $s$
be such that
$s$
be such that
 $J \subseteq {I_s}$
⊊
$J \subseteq {I_s}$
⊊
 ${I^{\rm{*}}}$
. Since
${I^{\rm{*}}}$
. Since
 ${I_s}$
must have been picked during the execution of the algorithm, this contradicts the minimality of the cardinality of
${I_s}$
must have been picked during the execution of the algorithm, this contradicts the minimality of the cardinality of
 ${I^{\rm{*}}}$
, concluding the proof of the main result.
${I^{\rm{*}}}$
, concluding the proof of the main result.
Thus,
 $J$
was picked during the execution of the algorithm. Since it is compatible, it was added to
$J$
was picked during the execution of the algorithm. Since it is compatible, it was added to
 ${\cal S}$
at the iteration at which it was picked (line 8), and since it is maximal, it is not removed at later iterations. Hence, upon termination,
${\cal S}$
at the iteration at which it was picked (line 8), and since it is maximal, it is not removed at later iterations. Hence, upon termination,
 $J \in {\cal S}$
. Since
$J \in {\cal S}$
. Since
 $J$
was arbitrary, we conclude that upon termination,
$J$
was arbitrary, we conclude that upon termination,
 ${\cal S}$
contains all maximal compatible index sets.
${\cal S}$
contains all maximal compatible index sets.
Finally, we show that upon termination,
 ${\cal S}$
contains only maximal compatible index sets. This follows from the fact that, at each iteration of the algorithm, for any distinct
${\cal S}$
contains only maximal compatible index sets. This follows from the fact that, at each iteration of the algorithm, for any distinct
 ${I_1},{I_2} \in {\cal S}$
, it holds that
${I_1},{I_2} \in {\cal S}$
, it holds that
 ${I_1}$
⊈
${I_1}$
⊈
 ${I_2}$
and
${I_2}$
and
 ${I_2} $
⊈
${I_2} $
⊈
 ${I_1}$
. Indeed, when
${I_1}$
. Indeed, when
 ${I_1}$
is added to
${I_1}$
is added to
 ${\cal S}$
, all subsets of
${\cal S}$
, all subsets of
 ${I_1}$
are removed from
${I_1}$
are removed from
 ${\cal S}$
(line 9) and are ignored at later iterations (line 6). The same holds for
${\cal S}$
(line 9) and are ignored at later iterations (line 6). The same holds for
 ${I_2}$
. This concludes the proof of the theorem. □
${I_2}$
. This concludes the proof of the theorem. □
Algorithm 2. An implementation of FindSubsets using infeasibility certificates

Implementation of FindSubsets using infeasibility certificates
We now explain how to implement FindSubsets so that it is consistent. For that, we use infeasibility certificates, which are index sets that are not compatible.
Definition 3.
(Infeasibility certificate). An index set
 $C \subseteq \left[ N \right]$
is an infeasibility certificate if there is no affine function
$C \subseteq \left[ N \right]$
is an infeasibility certificate if there is no affine function
 $f(x) = Ax + b$
such that
$f(x) = Ax + b$
such that
 $\forall \;k \in C, \parallel {y_k} - f\left( {{x_k}} \right){\parallel _\infty } \le \varepsilon $
.
$\forall \;k \in C, \parallel {y_k} - f\left( {{x_k}} \right){\parallel _\infty } \le \varepsilon $
.
Note that any incompatible index set
 $I$
contains an infeasibility certificate
$I$
contains an infeasibility certificate
 $C \subseteq I$
(e.g.,
$C \subseteq I$
(e.g.,
 $C = I$
). However, it is quite useful to extract an infeasibility certificate
$C = I$
). However, it is quite useful to extract an infeasibility certificate
 $C$
that is as small as possible. We explain below how to compute small infeasibility certificates. Thereafter, from an infeasibility certificate
$C$
that is as small as possible. We explain below how to compute small infeasibility certificates. Thereafter, from an infeasibility certificate
 $C \subseteq I$
, one can compute a consistent collection of index subsets of
$C \subseteq I$
, one can compute a consistent collection of index subsets of
 $I$
by tightening each component of the template independently, in order to exclude a minimal nonzero number of indices from the infeasibility certificate, while keeping the other components unchanged. This results in an implementation of FindSubsets that satisfies the consistency property, described in Algo. 2. Figure 3 below shows an illustration for rectangular regions.
$I$
by tightening each component of the template independently, in order to exclude a minimal nonzero number of indices from the infeasibility certificate, while keeping the other components unchanged. This results in an implementation of FindSubsets that satisfies the consistency property, described in Algo. 2. Figure 3 below shows an illustration for rectangular regions.

Figure 3.
FindSubsets implemented by Algo. 2 with rectangular regions. The red dots represent the infeasibility certificate
 $C$
. Each
$C$
. Each
 ${I_s}$
excludes at least one point from
${I_s}$
excludes at least one point from
 $C$
by moving one face of the box but keeping the others unchanged.
$C$
by moving one face of the box but keeping the others unchanged.
Theorem 4.
(Correctness of Algo. 2). For every noncompatible index set
 $I \in {\cal I}$
, the output
$I \in {\cal I}$
, the output
 ${I_1}, \ldots, {I_S}$
of Algo. 2 is consistent w.r.t.
${I_1}, \ldots, {I_S}$
of Algo. 2 is consistent w.r.t.
 $I$
.
$I$
.
Proof. Observe that if
 $C$
is an infeasibility certificate, then every
$C$
is an infeasibility certificate, then every
 $I \subseteq \left[ N \right]$
satisfying
$I \subseteq \left[ N \right]$
satisfying
 $C \subseteq I$
is not compatible. Now, let
$C \subseteq I$
is not compatible. Now, let
 $J \subseteq I$
be compatible. Using that
$J \subseteq I$
be compatible. Using that
 $C$
⊈
$C$
⊈
 $J$
, let
$J$
, let
 $s$
be a component such that
$s$
be a component such that
 ${\rm{ma}}{{\rm{x}}_{k \in J}}{\rm{\;}}{p^s}\left( {{x_k}} \right) \lt {\rm{ma}}{{\rm{x}}_{k \in C}}{\rm{\;}}{p^s}\left( {{x_k}} \right)$
. It holds that
${\rm{ma}}{{\rm{x}}_{k \in J}}{\rm{\;}}{p^s}\left( {{x_k}} \right) \lt {\rm{ma}}{{\rm{x}}_{k \in C}}{\rm{\;}}{p^s}\left( {{x_k}} \right)$
. It holds that
 $J \subseteq {I_s}$
. Since
$J \subseteq {I_s}$
. Since
 $J$
was arbitrary, this concludes the proof. □
$J$
was arbitrary, this concludes the proof. □
Finding infeasibility certificates
We outline the process of finding an infeasibility certificate
 $C \subseteq I$
for a given noncompatible index set
$C \subseteq I$
for a given noncompatible index set
 $I \subseteq \left[ N \right]$
. Recall that the data is of the form
$I \subseteq \left[ N \right]$
. Recall that the data is of the form
 $\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
, wherein for each
$\{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
, wherein for each
 $k \in \left[ N \right]$
,
$k \in \left[ N \right]$
,
 ${x_k} \in {\mathbb{R}}^d$
and
${x_k} \in {\mathbb{R}}^d$
and
 ${y_k} \in {\mathbb{R}}^e$
. For simplicity, assume that the output is scalar, i.e.,
${y_k} \in {\mathbb{R}}^e$
. For simplicity, assume that the output is scalar, i.e.,
 $e = 1$
, or equivalently,
$e = 1$
, or equivalently,
 ${y_k} \in \mathbb{R}$
for all
${y_k} \in \mathbb{R}$
for all
 $k \in \left[ N \right]$
. We will subsequently show how technique for the scalar case will extend to the case of
$k \in \left[ N \right]$
. We will subsequently show how technique for the scalar case will extend to the case of
 $e \gt 1$
.
$e \gt 1$
.
For the scalar case, the goal is to find an affine function
 $f\left( x \right) = {a^{\rm T}}x + b$
wherein
$f\left( x \right) = {a^{\rm T}}x + b$
wherein
 $a \in {\mathbb{R}}^d$
and
$a \in {\mathbb{R}}^d$
and
 $b \in \mathbb{R}$
so that for all
$b \in \mathbb{R}$
so that for all
 $k \in I$
,
$k \in I$
,
 $\left| {{y_k} - f\left( {{x_k}} \right)} \right| \le \varepsilon $
. However, since
$\left| {{y_k} - f\left( {{x_k}} \right)} \right| \le \varepsilon $
. However, since
 $I$
is noncompatible, no such function exists by definition. Therefore, the system of linear inequalities involving unknowns
$I$
is noncompatible, no such function exists by definition. Therefore, the system of linear inequalities involving unknowns
 $\left( {a,b} \right) \in {\mathbb{R}}^d \times \mathbb{R}$
is infeasible:
$\left( {a,b} \right) \in {\mathbb{R}}^d \times \mathbb{R}$
is infeasible:
 $$\matrix{ {{x_k^{\rm T}}a + b - {y_k}} & \le & \varepsilon & {{\rm{}}\forall \,{\rm{}}k \in I{\rm{}},} \cr { - {x_k^{\rm T}}a - b + {y_k}} & \le & \varepsilon & {{\rm{}}\forall \, {\rm{}}k \in I{\rm{}}.} \cr } $$
$$\matrix{ {{x_k^{\rm T}}a + b - {y_k}} & \le & \varepsilon & {{\rm{}}\forall \,{\rm{}}k \in I{\rm{}},} \cr { - {x_k^{\rm T}}a - b + {y_k}} & \le & \varepsilon & {{\rm{}}\forall \, {\rm{}}k \in I{\rm{}}.} \cr } $$
Note that each constraint of the form
 $\left| \alpha \right| \le \beta $
is expanded as two constraints
$\left| \alpha \right| \le \beta $
is expanded as two constraints
 $\alpha \le \beta $
and
$\alpha \le \beta $
and
 $ - \alpha \le \beta $
. By applying Farkas’ Lemma or a theorem of the alternative (Rockafellar Reference Rockafellar1970, Theorem 21.3), and simplifying the result, we conclude that the system of inequalities above is infeasible (i.e.,
$ - \alpha \le \beta $
. By applying Farkas’ Lemma or a theorem of the alternative (Rockafellar Reference Rockafellar1970, Theorem 21.3), and simplifying the result, we conclude that the system of inequalities above is infeasible (i.e.,
 $I$
is noncompatible) if and only if there exists a multiplier
$I$
is noncompatible) if and only if there exists a multiplier
 ${\lambda _k} \in \mathbb{R}$
for each
${\lambda _k} \in \mathbb{R}$
for each
 $k \in I$
such that the following system of linear constraints is feasible:
$k \in I$
such that the following system of linear constraints is feasible:
 $$\matrix{ {\mathop \sum \nolimits_{k \in I} {\lambda _k}{x_k} = {{[0]}_d},} \hfill & {} \hfill \cr {\mathop \sum \nolimits_{k \in I} {\lambda _k} = 0,} \hfill & {} \hfill \cr {\mathop \sum \nolimits_{k \in I} {\lambda _k}{y_k} + \mathop \sum \nolimits_{k \in I} \left| {{\lambda _k}} \right|\varepsilon \le - 1{\rm{\;}}.} \hfill & {} \hfill \cr } $$
$$\matrix{ {\mathop \sum \nolimits_{k \in I} {\lambda _k}{x_k} = {{[0]}_d},} \hfill & {} \hfill \cr {\mathop \sum \nolimits_{k \in I} {\lambda _k} = 0,} \hfill & {} \hfill \cr {\mathop \sum \nolimits_{k \in I} {\lambda _k}{y_k} + \mathop \sum \nolimits_{k \in I} \left| {{\lambda _k}} \right|\varepsilon \le - 1{\rm{\;}}.} \hfill & {} \hfill \cr } $$
Thus, in order to check whether a given index set
 $I$
is noncompatible, we simply formulate the system of inequalities (3) involving unknowns
$I$
is noncompatible, we simply formulate the system of inequalities (3) involving unknowns
 ${\lambda _k} \in \mathbb{R}$
for each
${\lambda _k} \in \mathbb{R}$
for each
 $k \in I$
and attempt to find a feasible solution using a Linear Programming (LP) solver. If feasible, we conclude that
$k \in I$
and attempt to find a feasible solution using a Linear Programming (LP) solver. If feasible, we conclude that
 $I$
is noncompatible. In fact, given any solution
$I$
is noncompatible. In fact, given any solution
 ${({\lambda _k})_{k \in I}}$
to the system of inequalities above, we can extract a corresponding infeasibility certificate as
${({\lambda _k})_{k \in I}}$
to the system of inequalities above, we can extract a corresponding infeasibility certificate as
 $C = \left\{ {k \in I:{\lambda _k} =\hskip-6pt/ \,0} \right\}$
. It is easy to see why: any
$C = \left\{ {k \in I:{\lambda _k} =\hskip-6pt/ \,0} \right\}$
. It is easy to see why: any
 $k \in I$
with
$k \in I$
with
 ${\lambda _k} = 0$
indicates that
${\lambda _k} = 0$
indicates that
 $I\backslash \left\{ k \right\}$
remains a noncompatible set since such a variable
$I\backslash \left\{ k \right\}$
remains a noncompatible set since such a variable
 ${\lambda _k}$
can be removed from the system of inequalities while retaining feasibility.
${\lambda _k}$
can be removed from the system of inequalities while retaining feasibility.
Lemma 2.
If
 $I$
is noncompatible, then there exists an infeasibility certificate
$I$
is noncompatible, then there exists an infeasibility certificate
 $C \subseteq I$
such that
$C \subseteq I$
such that
 $\left| C \right| \le d + 2$
.
$\left| C \right| \le d + 2$
.
Proof. The system of constraints (3) has
 $\left| I \right|$
unknowns and
$\left| I \right|$
unknowns and
 $d + 2$
constraints of which
$d + 2$
constraints of which
 $d + 1$
are equality constraints. We may write
$d + 1$
are equality constraints. We may write
 ${\lambda _k} = {\alpha _k} - {\beta _k}$
for variables
${\lambda _k} = {\alpha _k} - {\beta _k}$
for variables
 ${\alpha _k},{\beta _k} \ge 0$
and therefore
${\alpha _k},{\beta _k} \ge 0$
and therefore
 $\left| {{\lambda _k}} \right| = {\alpha _k} + {\beta _k}$
. Under this transformation, the system of constraints can be rewritten as
$\left| {{\lambda _k}} \right| = {\alpha _k} + {\beta _k}$
. Under this transformation, the system of constraints can be rewritten as
 $$\matrix{ {\mathop \sum \nolimits_{k \in I} ({\alpha _k}-{\beta_k}){x_k} = {{[0]}_d},} \hfill & {} \hfill \cr {\mathop \sum \nolimits_{k \in I} ({\alpha _k}-{\beta_k}) = 0,} \hfill {} \hfill \cr {\mathop \sum \nolimits_{k \in I} ({\alpha _k}-{\beta_k}){\gamma_k} + \mathop \sum \nolimits_{k \in I} ({\alpha _k}+{\beta_k})} \varepsilon \le - 1,}$$
$$\matrix{ {\mathop \sum \nolimits_{k \in I} ({\alpha _k}-{\beta_k}){x_k} = {{[0]}_d},} \hfill & {} \hfill \cr {\mathop \sum \nolimits_{k \in I} ({\alpha _k}-{\beta_k}) = 0,} \hfill {} \hfill \cr {\mathop \sum \nolimits_{k \in I} ({\alpha _k}-{\beta_k}){\gamma_k} + \mathop \sum \nolimits_{k \in I} ({\alpha _k}+{\beta_k})} \varepsilon \le - 1,}$$
 $$\hskip-99pt({\alpha _k},{\beta_k}) \ge 0, \forall {k \in I}$$
$$\hskip-99pt({\alpha _k},{\beta_k}) \ge 0, \forall {k \in I}$$
With this transformation, the system above is a standard-form Linear Program with
 $d + 2$
constraints and decision variables
$d + 2$
constraints and decision variables
 ${\alpha _k},{\beta _k} \geqslant 0$
for each
${\alpha _k},{\beta _k} \geqslant 0$
for each
 $k \in I$
. We treat the objective function for this LP as the constant
$k \in I$
. We treat the objective function for this LP as the constant
 $0$
. Any basic feasible solution will have at most
$0$
. Any basic feasible solution will have at most
 $d + 2$
nonzero variables. Furthermore, from the theory of linear programming, we know that if a system is feasible, then it has a basic feasible solution (Vanderbei Reference Vanderbei2020). Translating this back to the original system (3), we get that there is a solution involving at most
$d + 2$
nonzero variables. Furthermore, from the theory of linear programming, we know that if a system is feasible, then it has a basic feasible solution (Vanderbei Reference Vanderbei2020). Translating this back to the original system (3), we get that there is a solution involving at most
 $d + 2$
nonzero values for
$d + 2$
nonzero values for
 ${\lambda _k}$
. That is, there exists an infeasibility certificate
${\lambda _k}$
. That is, there exists an infeasibility certificate
 $C$
such that
$C$
such that
 $\left| C \right| \le d + 2$
. □
$\left| C \right| \le d + 2$
. □
So far, we have assumed that the outputs
 ${y_k}$
are scalar, i.e.,
${y_k}$
are scalar, i.e.,
 $e = 1$
. However, if
$e = 1$
. However, if
 $e \gt 1$
, we can simply use the previous analysis by focusing separately on each component of the output vectors
$e \gt 1$
, we can simply use the previous analysis by focusing separately on each component of the output vectors
 ${y_k}$
. This is possible because if a given index set
${y_k}$
. This is possible because if a given index set
 $I$
is noncompatible, then there must exist a component
$I$
is noncompatible, then there must exist a component
 $s \in \left[ e \right]$
such that
$s \in \left[ e \right]$
such that
 $I$
is noncompatible even if the data set is restricted to
$I$
is noncompatible even if the data set is restricted to
 $\{ \left( {{x_k},y_k^s} \right)\} _{k = 1}^N$
, wherein
$\{ \left( {{x_k},y_k^s} \right)\} _{k = 1}^N$
, wherein
 $y_k^s$
denotes the
$y_k^s$
denotes the
 $s$
th component of
$s$
th component of
 ${y_k}$
. Indeed, if it were not the case, then for each component
${y_k}$
. Indeed, if it were not the case, then for each component
 $s$
, we could find an affine function
$s$
, we could find an affine function
 ${f_s}\left( x \right) = a_s^{\rm T}x + {b_s}$
such that for all
${f_s}\left( x \right) = a_s^{\rm T}x + {b_s}$
such that for all
 $k \in I$
,
$k \in I$
,
 $\left| {{f_s}\left( {{x_k}} \right) - y_k^s} \right| \le \varepsilon $
. By letting
$\left| {{f_s}\left( {{x_k}} \right) - y_k^s} \right| \le \varepsilon $
. By letting
 $A = \left[ {a_1^{\rm T}} \ldots ;a_e^{\rm T} \right]$
and
$A = \left[ {a_1^{\rm T}} \ldots ;a_e^{\rm T} \right]$
and
 $b = {[{b_1}, \ldots, {b_e}]^{\rm T}}$
, we see that
$b = {[{b_1}, \ldots, {b_e}]^{\rm T}}$
, we see that
 $f\left( x \right) = Ax + b$
satisfies that for all
$f\left( x \right) = Ax + b$
satisfies that for all
 $k \in I$
,
$k \in I$
,
 $\parallel f\left( {{x_k}} \right) - {y_k}{\parallel _\infty } \le \varepsilon $
. This contradicts the assumption that
$\parallel f\left( {{x_k}} \right) - {y_k}{\parallel _\infty } \le \varepsilon $
. This contradicts the assumption that
 $I$
is noncompatible. Thus, the infeasibility certificate for
$I$
is noncompatible. Thus, the infeasibility certificate for
 $e \gt 1$
is extracted by simply considering each output component in turn, thus reducing the problem to the scalar case considered above.
$e \gt 1$
is extracted by simply considering each output component in turn, thus reducing the problem to the scalar case considered above.
We conclude that checking whether a set
 $I$
is noncompatible and if so, finding an infeasibility certificate
$I$
is noncompatible and if so, finding an infeasibility certificate
 $C \subseteq I$
, can be solved by posing the system of constraints (3) and solving it using an algorithm such as the simplex algorithm.
$C \subseteq I$
, can be solved by posing the system of constraints (3) and solving it using an algorithm such as the simplex algorithm.
Good infeasibility certificates for the top-down approach
The implementation of FindSubsets boils down to finding infeasibility certificates, which can be done as explained above. However, not all certificates will be as good in terms of overall complexity of the top-down approach. To exclude noncompatible index sets more rapidly, it is desirable that the points in the certificate are ‘spatially concentrated’ in the input domain. This means that the points
 ${\{ {x_k}\} _{k \in C}}$
are close to each other w.r.t. some distance metric.
${\{ {x_k}\} _{k \in C}}$
are close to each other w.r.t. some distance metric.
We illustrate the benefit of spatially concentrated certificates with the example used to illustrate the top-down approach in the introduction.
Example 1. Consider the TPWA regression problem in Figure 2, introduced in the section ‘Approach at a glance’. In Plot II, we obtained the infeasibility certificate
 ${C_0} = \left\{ {4,5,6} \right\}$
. Note that
${C_0} = \left\{ {4,5,6} \right\}$
. Note that
 ${\hat C_0} = \left\{ {1,5,11} \right\}$
is another infeasibilitty certificate that could have been obtained as a result of solving the system (3). However,
${\hat C_0} = \left\{ {1,5,11} \right\}$
is another infeasibilitty certificate that could have been obtained as a result of solving the system (3). However,
 ${C_0}$
is more ‘spatially concentrated’ in the sense that the points in
${C_0}$
is more ‘spatially concentrated’ in the sense that the points in
 ${C_0}$
are closer to each other than those in
${C_0}$
are closer to each other than those in
 ${\hat C_0}$
.
${\hat C_0}$
.
Recall that using
 ${C_0}$
as the infeasibility certificate allowed to find the compatible subset
${C_0}$
as the infeasibility certificate allowed to find the compatible subset
 ${I_1} = \left\{ {1, \ldots, 5} \right\}$
directly and the compatible subsets
${I_1} = \left\{ {1, \ldots, 5} \right\}$
directly and the compatible subsets
 ${I_3} = \left\{ {5,6,7} \right\}$
and
${I_3} = \left\{ {5,6,7} \right\}$
and
 ${I_4} = \left\{ {7, \ldots, 11} \right\}$
at the subsequent steps.
${I_4} = \left\{ {7, \ldots, 11} \right\}$
at the subsequent steps.
However, if the certificate
 ${\hat C_0} = \left\{ {1,5,11} \right\}$
were used, then we would have obtained
${\hat C_0} = \left\{ {1,5,11} \right\}$
were used, then we would have obtained
 ${\hat I_1} = \left\{ {2, \ldots, 11} \right\}$
and
${\hat I_1} = \left\{ {2, \ldots, 11} \right\}$
and
 ${\hat I_2} = \left\{ {1, \ldots, 10} \right\}$
. Note that both
${\hat I_2} = \left\{ {1, \ldots, 10} \right\}$
. Note that both
 ${\hat I_1},{\hat I_2}$
are noncompatible because they contain
${\hat I_1},{\hat I_2}$
are noncompatible because they contain
 ${C_0}$
and thus further steps of our procedure are needed until we find maximally compatible sets.
${C_0}$
and thus further steps of our procedure are needed until we find maximally compatible sets.
 $ \triangleleft $
$ \triangleleft $
We now refine the above argument with a volume-contraction argument to discuss what would be the complexity of the overall top-down algorithm if all certificates are spatially concentrated in the input domain.
Example 2. Consider a PWA function
 $f$
with
$f$
with
 $M$
pieces whose domains
$M$
pieces whose domains
 ${H_1}, \ldots, {H_M}$
are rectangles, as illustrated in Figure 4. Let
${H_1}, \ldots, {H_M}$
are rectangles, as illustrated in Figure 4. Let
 $N \in {\mathbb{N}}$
>0 and consider a data set
$N \in {\mathbb{N}}$
>0 and consider a data set
 ${\cal D} = \{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
. We aim to solve Prob. 2 with
${\cal D} = \{ \left( {{x_k},{y_k}} \right)\} _{k = 1}^N$
. We aim to solve Prob. 2 with
 ${\cal D}$
,
${\cal D}$
,
 $\varepsilon = 0$
and the rectangular template. We will discuss the complexity of the top-down approach presented in Algo. 1 if all certificates are spatially concentrated. This means that
$\varepsilon = 0$
and the rectangular template. We will discuss the complexity of the top-down approach presented in Algo. 1 if all certificates are spatially concentrated. This means that
 ${\{ {x_k}\} _{k \in C}}$
consists in
${\{ {x_k}\} _{k \in C}}$
consists in
 $d + 2$
points concentrated around the center
$d + 2$
points concentrated around the center
 $\bar x$
of
$\bar x$
of
 $H\left( c \right)$
, where
$H\left( c \right)$
, where
 $C$
is the certificate for
$C$
is the certificate for
 $I\left( c \right)$
(see Figure 4).
$I\left( c \right)$
(see Figure 4).

Figure 4. Illustration of FindSubsets with a spatially concentrated certificate. The green and orange hatched rectangles illustrate two possible cases for
 $H\left( {{c_s}} \right)$
output by FindSubsets.
$H\left( {{c_s}} \right)$
output by FindSubsets.
This will imply that the rectangles
 $H\left( {{c_1}} \right), \ldots, H\left( {{c_h}} \right)$
computed by FindSubsets satisfy that for all
$H\left( {{c_1}} \right), \ldots, H\left( {{c_h}} \right)$
computed by FindSubsets satisfy that for all
 $s \in \left[ h \right]$
, either the volume of
$s \in \left[ h \right]$
, either the volume of
 $H\left( {{c_s}} \right)$
is half of that of
$H\left( {{c_s}} \right)$
is half of that of
 $H\left( c \right)$
since one face is tight at
$H\left( c \right)$
since one face is tight at
 $\bar x$
(see the green rectangle in Figure 4) or
$\bar x$
(see the green rectangle in Figure 4) or
 $H\left( {{c_s}} \right)$
has one more face near the boundary of
$H\left( {{c_s}} \right)$
has one more face near the boundary of
 ${H_i}$
compared to
${H_i}$
compared to
 $H\left( c \right)$
(see the orange rectangle in Figure 4). By adding the natural assumption that all regions
$H\left( c \right)$
(see the orange rectangle in Figure 4). By adding the natural assumption that all regions
 ${H_j}$
have a volume of at least
${H_j}$
have a volume of at least
 $\nu \in \left( {0,1} \right]$
and discarding regions with volume smaller than
$\nu \in \left( {0,1} \right]$
and discarding regions with volume smaller than
 $\nu $
, we get that the algorithm cannot divide the volume of a region more than
$\nu $
, we get that the algorithm cannot divide the volume of a region more than
 $ -\!{\rm{lo}}{{\rm{g}}_2}\left( \nu \right)$
times. Hence, the depth of the tree underlying the algorithm is upper bounded by
$ -\!{\rm{lo}}{{\rm{g}}_2}\left( \nu \right)$
times. Hence, the depth of the tree underlying the algorithm is upper bounded by
 $h - {\rm{lo}}{{\rm{g}}_2}\left( \nu \right)$
. Since, each node of the tree has at most
$h - {\rm{lo}}{{\rm{g}}_2}\left( \nu \right)$
. Since, each node of the tree has at most
 $h$
children (the subsets given by FindSubsets), the number of rectangles encountered during the algorithm is upper bounded by
$h$
children (the subsets given by FindSubsets), the number of rectangles encountered during the algorithm is upper bounded by
 ${h^{h - {\rm{lo}}{{\rm{g}}_2}\left( \nu \right)}}$
. Note that this upper bound on the complexity of the algorithm is independent of the data size
${h^{h - {\rm{lo}}{{\rm{g}}_2}\left( \nu \right)}}$
. Note that this upper bound on the complexity of the algorithm is independent of the data size
 $N$
. This concludes the example.
$N$
. This concludes the example.
 $ \triangleleft $
$ \triangleleft $
To conclude this section on good certificates, we explain briefly how spatially concentrated certificates can be computed by adding a cost function to the Linear Program (3). For simplicity, we will assume that the output dimension
 $e = 1$
. For the case when
$e = 1$
. For the case when
 $e \gt 1$
, we can apply our approach to each component of the output in turn.
$e \gt 1$
, we can apply our approach to each component of the output in turn.
Given a center point
 $\overline x = {1 \over N}\sum\nolimits_{i \in I} {{x_i}} $
for a noncompatible index set
$\overline x = {1 \over N}\sum\nolimits_{i \in I} {{x_i}} $
for a noncompatible index set
 $I \subseteq \left[ N \right]$
, we consider the following Linear Program with variables
$I \subseteq \left[ N \right]$
, we consider the following Linear Program with variables
 ${\lambda _k} \in \mathbb{R}$
for each
${\lambda _k} \in \mathbb{R}$
for each
 $k \in I$
,
$k \in I$
,
 $$\matrix{ {{\rm{minimize}}} & {\mathop \sum \nolimits_{k \in I} \left| {{\lambda _k}} \right|\parallel {x_k} - \overline x {\parallel ^2}} \hfill \cr {{\rm{s}}.{\rm{t}}.} & {\mathop \sum \nolimits_{k \in I} {\lambda _k}{x_k} = {{[0]}_d},} \hfill\cr {} & {\mathop \sum \nolimits_{k \in I} {\lambda _k} = 0,} \hfill\cr {} & {\mathop \sum \nolimits_{k \in I} {\lambda _k}{y_k} + \mathop \sum \limits_{k \in I} \left| {{\lambda _k}} \right|\varepsilon \le - 1{\rm{\;}}.} \hfill\cr {} & {} \cr } $$
$$\matrix{ {{\rm{minimize}}} & {\mathop \sum \nolimits_{k \in I} \left| {{\lambda _k}} \right|\parallel {x_k} - \overline x {\parallel ^2}} \hfill \cr {{\rm{s}}.{\rm{t}}.} & {\mathop \sum \nolimits_{k \in I} {\lambda _k}{x_k} = {{[0]}_d},} \hfill\cr {} & {\mathop \sum \nolimits_{k \in I} {\lambda _k} = 0,} \hfill\cr {} & {\mathop \sum \nolimits_{k \in I} {\lambda _k}{y_k} + \mathop \sum \limits_{k \in I} \left| {{\lambda _k}} \right|\varepsilon \le - 1{\rm{\;}}.} \hfill\cr {} & {} \cr } $$
The objective function of (4) tends to put zero value to
 ${\lambda _k}$
whenever
${\lambda _k}$
whenever
 $\parallel {x_k} - \bar x\parallel $
is large. This promotes proximity of the point
$\parallel {x_k} - \bar x\parallel $
is large. This promotes proximity of the point
 ${x_k}$
to
${x_k}$
to
 $\bar x$
when
$\bar x$
when
 ${\lambda _k} =\hskip-6pt/ \,0$
.Footnote
4
${\lambda _k} =\hskip-6pt/ \,0$
.Footnote
4
Early stopping using set cover algorithms
Finally, Algo. 1 can be made more efficient by enabling early termination if
 $\left[ N \right]$
is optimally covered by the compatible index sets computed so far. For that, we add an extra step at the beginning of each iteration, that consists in (i) computing a lower bound
$\left[ N \right]$
is optimally covered by the compatible index sets computed so far. For that, we add an extra step at the beginning of each iteration, that consists in (i) computing a lower bound
 $\beta $
on the size of an optimal cover of
$\beta $
on the size of an optimal cover of
 $\left[ N \right]$
with compatible index sets and (ii) checking whether we can extract from
$\left[ N \right]$
with compatible index sets and (ii) checking whether we can extract from
 ${\cal S}$
a collection of
${\cal S}$
a collection of
 $\beta $
index sets that form a cover of
$\beta $
index sets that form a cover of
 $\left[ N \right]$
. The extra step returns
$\left[ N \right]$
. The extra step returns
 $break$
if (ii) is successful. An implementation of the extra step is provided in Algo. 3.
$break$
if (ii) is successful. An implementation of the extra step is provided in Algo. 3.
Algorithm 3. Extra step at the beginning of each iteration of Algo. 1

The soundness of Algo. 3 follows from the following lemma.
Lemma 3.
Let
 $\beta $
be as in Algo. 3. Then, any cover of
$\beta $
be as in Algo. 3. Then, any cover of
 $\left[ N \right]$
with compatible index sets has size at least
$\left[ N \right]$
with compatible index sets has size at least
 $\beta $
.
$\beta $
.
Proof. The crux of the proof relies on the observation from the proof of Theorem 3 that for any compatible index set
 $I \in {\cal I}$
, there is
$I \in {\cal I}$
, there is
 $J \in {\cal S} \cup {\cal U}$
such that
$J \in {\cal S} \cup {\cal U}$
such that
 $I \subseteq J$
. It follows that for any cover of
$I \subseteq J$
. It follows that for any cover of
 $\left[ N \right]$
with
$\left[ N \right]$
with
 $M$
compatible index sets, there is a cover of
$M$
compatible index sets, there is a cover of
 $\left[ N \right]$
with
$\left[ N \right]$
with
 $M$
index sets in
$M$
index sets in
 ${\cal S} \cup {\cal U}$
. Since
${\cal S} \cup {\cal U}$
. Since
 $\beta $
is the smallest size of such a cover, this concludes the proof. □
$\beta $
is the smallest size of such a cover, this concludes the proof. □
The implementation of the extra step in Algo. 1 is provided in Algo. 4. The correctness of the algorithm follows from that of Algo. 1 (Theorem 3) and Algo. 3 (Lemma 3). In conclusion, we provided an algorithm for optimal TPWA regression.
Algorithm 4. Top-down algorithm for Prob. 2.

Theorem 5
(Optimal TPWA regression). Algo. 4 solves Prob. 2 with minimal
 $M$
.
$M$
.
Proof. Let
 ${I_1}, \ldots, {I_M}$
be the output of Algo. 4. For each
${I_1}, \ldots, {I_M}$
be the output of Algo. 4. For each
 $i \in \left[ M \right]$
, let
$i \in \left[ M \right]$
, let
 ${H_i} = H\left( {{c_i}} \right)$
where
${H_i} = H\left( {{c_i}} \right)$
where
 ${I_i} = I\left( {{c_i}} \right)$
and let
${I_i} = I\left( {{c_i}} \right)$
and let
 ${f_i}\left( x \right) = {A_i}x + {b_i}$
be as in (b) of Def. 1. The fact that
${f_i}\left( x \right) = {A_i}x + {b_i}$
be as in (b) of Def. 1. The fact that
 ${H_1}, \ldots, {H_M}$
and
${H_1}, \ldots, {H_M}$
and
 ${f_1}, \ldots, {f_M}$
is a solution to Prob. 2 follows from the fact that
${f_1}, \ldots, {f_M}$
is a solution to Prob. 2 follows from the fact that
 ${I_1}, \ldots, {I_M}$
is a cover of
${I_1}, \ldots, {I_M}$
is a cover of
 $\left[ N \right]$
and the definition of
$\left[ N \right]$
and the definition of
 ${f_1}, \ldots, {f_M}$
. The fact that it is a solution with minimal
${f_1}, \ldots, {f_M}$
. The fact that it is a solution with minimal
 $M$
follows from the optimality of
$M$
follows from the optimality of
 ${I_1}, \ldots, {I_M}$
among all covers of
${I_1}, \ldots, {I_M}$
among all covers of
 $\left[ N \right]$
with compatible index sets. □
$\left[ N \right]$
with compatible index sets. □
Remark 3. To solve the optimal set cover problems (known to be NP-hard in general) in Algo. 3, we use MILP formulations. The complexity of solving these MILPs grows as
 ${2^{\left| {\cal S} \right|}}$
and
${2^{\left| {\cal S} \right|}}$
and
 ${2^{\left| {{\cal S}\; \cup \;{\cal U}} \right|}}$
, respectively. However, in our numerical experiments (see next section), we observed that the gain of stopping the algorithm early if an optimal cover is found systematically outbalanced the computational cost of solving the set cover problems. Furthermore, if one is satisfied with a suboptimal solution, they can use an approximation algorithm, such as the greedy algorithm, which outputs a cover whose size is within some factor
${2^{\left| {{\cal S}\; \cup \;{\cal U}} \right|}}$
, respectively. However, in our numerical experiments (see next section), we observed that the gain of stopping the algorithm early if an optimal cover is found systematically outbalanced the computational cost of solving the set cover problems. Furthermore, if one is satisfied with a suboptimal solution, they can use an approximation algorithm, such as the greedy algorithm, which outputs a cover whose size is within some factor
 $t\left( N \right) \geq 1$
of the optimal set cover size (Chvatal Reference Chvatal1979). In this case, Algo. 3 outputs
$t\left( N \right) \geq 1$
of the optimal set cover size (Chvatal Reference Chvatal1979). In this case, Algo. 3 outputs
 $break$
if
$break$
if
 $\alpha \le t\left( N \right)\beta $
.
$\alpha \le t\left( N \right)\beta $
.
 $ \triangleleft $
$ \triangleleft $
Numerical experiments
In this section, we demonstrate the applicability of our algorithm on three numerical examples.Footnote 5 We also compare it with the MILP and Piecewise Affine Regression and Classification (PARC) (Bemporad Reference Bemporad2023) approaches to solve SA and PWA regression, and we discuss the impact of different templates in terms of simplicity of the model and efficiency of the algorithm.
PWA approximation of insulin–glucose regulation model
Dalla Man, Rizza, and Cobelli (Reference Dalla Man, Rizza and Cobelli2007) present a nonlinear model of insulin–glucose regulation that has been widely used to test artificial pancreas devices for treatment of type-1 diabetes. The model is nonlinear and involves
 $10$
state variables. However, the nonlinearity arises mainly from the term
$10$
state variables. However, the nonlinearity arises mainly from the term
 ${U_{{\rm{id}}}}$
(insulin-dependent glucose utilization) involving two state variables, say
${U_{{\rm{id}}}}$
(insulin-dependent glucose utilization) involving two state variables, say
 ${x_1}$
and
${x_1}$
and
 ${x_2}$
(namely, the level of insulin in the interstitial fluid, and the glucose mass in rapidly equilibrating tissue):
${x_2}$
(namely, the level of insulin in the interstitial fluid, and the glucose mass in rapidly equilibrating tissue):
 $${U_{{\rm{id}}}}\left( {{x_1},{x_2}} \right) = {{{\left( {3.2667 + 0.0313{x_1}} \right){x_2}}}\over{{253.52 + {x_2}}}}.$$
$${U_{{\rm{id}}}}\left( {{x_1},{x_2}} \right) = {{{\left( {3.2667 + 0.0313{x_1}} \right){x_2}}}\over{{253.52 + {x_2}}}}.$$
We consider the problem of approximating
 ${U_{{\rm{id}}}}$
with a PWA model, thus converting the entire model into a PWA model. Therefore, we simulated trajectories and collected
${U_{{\rm{id}}}}$
with a PWA model, thus converting the entire model into a PWA model. Therefore, we simulated trajectories and collected
 $N = 100$
values of
$N = 100$
values of
 ${x_1}$
,
${x_1}$
,
 ${x_2}$
and
${x_2}$
and
 ${U_{{\rm{id}}}}\left( {{x_1},{x_2}} \right)$
; see Figure 5(a). For three different values of the error tolerance,
${U_{{\rm{id}}}}\left( {{x_1},{x_2}} \right)$
; see Figure 5(a). For three different values of the error tolerance,
 $\varepsilon \in \left\{ {0.2,0.1,0.05} \right\}$
, we used Algo. 4 to compute a PWA regression of the data with rectangular domains. The results of the computations are shown in Figure 5(b,c,d). The computation times are, respectively,
$\varepsilon \in \left\{ {0.2,0.1,0.05} \right\}$
, we used Algo. 4 to compute a PWA regression of the data with rectangular domains. The results of the computations are shown in Figure 5(b,c,d). The computation times are, respectively,
 $1$
,
$1$
,
 $22,$
and
$22,$
and
 $112$
s. Finally, we evaluate the accuracy of the PWA regression for the modeling of the glucose-insulin evolution by simulating the system with
$112$
s. Finally, we evaluate the accuracy of the PWA regression for the modeling of the glucose-insulin evolution by simulating the system with
 ${U_{{\rm{id}}}}$
replaced by the PWA models. The results are shown in Figure 5(e, f). We see that the PWA model with
${U_{{\rm{id}}}}$
replaced by the PWA models. The results are shown in Figure 5(e, f). We see that the PWA model with
 $\varepsilon = 0.05$
induces a prediction error less than
$\varepsilon = 0.05$
induces a prediction error less than
 $2{\rm{\;\% }}$
over the whole simulation interval, which is a significant improvement compared to the PWA models with only
$2{\rm{\;\% }}$
over the whole simulation interval, which is a significant improvement compared to the PWA models with only
 $1$
affine piece (
$1$
affine piece (
 $\varepsilon = 0.2$
) or
$\varepsilon = 0.2$
) or
 $2$
affine pieces (
$2$
affine pieces (
 $\varepsilon = 0.1$
).
$\varepsilon = 0.1$
).

Figure 5. Glucose–insulin system. (a)
 $100$
sampled points (black dots) on the graph of
$100$
sampled points (black dots) on the graph of
 ${U_{{\rm{id}}}}$
(surface). (b,c,d) Optimal TPWA regression for various error tolerances
${U_{{\rm{id}}}}$
(surface). (b,c,d) Optimal TPWA regression for various error tolerances
 $\varepsilon $
. (e) Simulations using the nonlinear model versus the PWA approximations. (f) Error between nonlinear and PWA models averaged over
$\varepsilon $
. (e) Simulations using the nonlinear model versus the PWA approximations. (f) Error between nonlinear and PWA models averaged over
 $50$
simulations with different initial conditions.
$50$
simulations with different initial conditions.
Finally, we compare with SA regression and classical PWA regression. To find a SA model, we solved Prob. 3 with
 $\varepsilon = 0.05$
and
$\varepsilon = 0.05$
and
 $M = 3$
using a MILP approach. The computation is very fast (
$M = 3$
using a MILP approach. The computation is very fast (
 $ \lt 0.5$
s); however, the computed clusters of data points (see Figure 6) do not allow to learn a (simple) PWA model, thereby hindering the derivation of a model for
$ \lt 0.5$
s); however, the computed clusters of data points (see Figure 6) do not allow to learn a (simple) PWA model, thereby hindering the derivation of a model for
 ${U_{{\rm{id}}}}$
that can be used for simulation and analysis.
${U_{{\rm{id}}}}$
that can be used for simulation and analysis.

Figure 6. Clusters of data points from SA regression.
Hybrid system identification: double pendulum with soft contacts
We consider a hybrid linear system consisting in an inverted double pendulum with soft contacts at the joints, as depicted in Figure 7(a). This system has nine linear modes, depending on whether the contact force of each joint is inactive, active on the left or active on the right (Aydinoglu, Preciado, and Posa Reference Aydinoglu, Preciado and Posa2020). Our goal is to learn these linear modes as well as their domain of validity, from data. For that, we simulated trajectories and collected
 $N = 250$
sampled values of
$N = 250$
sampled values of
 ${\theta _1}$
,
${\theta _1}$
,
 ${\theta _2}$
and the force applied on the lower joint. We used Algo. 4 to compute a PWA regression of the data with rectangular domains and with error tolerance
${\theta _2}$
and the force applied on the lower joint. We used Algo. 4 to compute a PWA regression of the data with rectangular domains and with error tolerance
 $\varepsilon = 0.01$
. The result is shown in Figure 7(b). The number of iterations of the algorithm was about
$\varepsilon = 0.01$
. The result is shown in Figure 7(b). The number of iterations of the algorithm was about
 $23,000$
for a total time of
$23,000$
for a total time of
 $800$
s.
$800$
s.

Figure 7. Inverted double pendulum with soft contacts. (a): Elastic contact forces apply when
 $\theta $
is outside gray region, (b): optimal TPWA regression of the data with rectangular domains.
$\theta $
is outside gray region, (b): optimal TPWA regression of the data with rectangular domains.
We see that the affine pieces roughly divide the state space into a grid of
 $3 \times 3$
regions. This is consistent with our ground-truth model, in which the contact force at each joint has three linear modes depending only on the angle made at the joint. The PWA regression provided by Algo. 4 allows us to learn this feature of the system from data, without assuming anything about the system except that the domains of the affine pieces are rectangular.
$3 \times 3$
regions. This is consistent with our ground-truth model, in which the contact force at each joint has three linear modes depending only on the angle made at the joint. The PWA regression provided by Algo. 4 allows us to learn this feature of the system from data, without assuming anything about the system except that the domains of the affine pieces are rectangular.
We compare with SA regression and classical PWA regression. The MILP approach to solve the SA regression (Prob. 3) with
 $\varepsilon = 0.01$
and
$\varepsilon = 0.01$
and
 $M = 9$
could not handle more than
$M = 9$
could not handle more than
 $51$
data points within reasonable time (
$51$
data points within reasonable time (
 $1000$
s); see Figure 8(a). Furthermore, the computed clusters of data points (see Figure 6) do not allow to learn a (simple) PWA model, thereby hindering to learn important features of the system. Last but not least, we compare with the recent tool PARC (Bemporad Reference Bemporad2023).Footnote
6
The fitting accuracy on training data is high (
$1000$
s); see Figure 8(a). Furthermore, the computed clusters of data points (see Figure 6) do not allow to learn a (simple) PWA model, thereby hindering to learn important features of the system. Last but not least, we compare with the recent tool PARC (Bemporad Reference Bemporad2023).Footnote
6
The fitting accuracy on training data is high (
 ${R^2} = 0.995$
). The resulting partition of the input space is depicted in Figure 8(b). As we can see, PARC finds a PWA function with
${R^2} = 0.995$
). The resulting partition of the input space is depicted in Figure 8(b). As we can see, PARC finds a PWA function with
 $8$
modes, although an upper bound (
$8$
modes, although an upper bound (
 $K$
) of
$K$
) of
 $10$
was given. However, the regions do not align with the axis (as this is not enforced by the algorithm). Consequently, regions with a small number of samples (e.g., lower-right) are missing, while regions with many samples (e.g., central) are overly divided.
$10$
was given. However, the regions do not align with the axis (as this is not enforced by the algorithm). Consequently, regions with a small number of samples (e.g., lower-right) are missing, while regions with many samples (e.g., central) are overly divided.

Figure 8. (a): Comparison with MILP approach for SA regression. Time limit is set to
 $1000$
secs. (b) Partition of the input space by the PWA function computed using the state-of-the-art tool PARC (Bemporad Reference Bemporad2023).
$1000$
secs. (b) Partition of the input space by the PWA function computed using the state-of-the-art tool PARC (Bemporad Reference Bemporad2023).
Hybrid system identification: carts with springs
We consider a hybrid linear system consisting in two carts with springs, as depicted in Figure 9(a). The force applied on the left cart has four linear modes, depending on the values of
 ${x_1}$
and
${x_1}$
and
 ${x_2}$
. Our goal is to learn these linear modes as well as their domain of validity, from data. For that, we used
${x_2}$
. Our goal is to learn these linear modes as well as their domain of validity, from data. For that, we used
 $N = 400$
data obtained by gridding the input domain
$N = 400$
data obtained by gridding the input domain
 ${[0,L]^2}$
uniformly. We used Algo. 4 to compute a PWA regression with error tolerance
${[0,L]^2}$
uniformly. We used Algo. 4 to compute a PWA regression with error tolerance
 $\varepsilon = 0.01$
. We considered two templates: first the ‘rectangular–octagonal’ template wherein each region can have up to eight faces consisting in horizontal, vertical and oblique lines (see Figure 9(b) for an example); then, we compared with the rectangular template.
$\varepsilon = 0.01$
. We considered two templates: first the ‘rectangular–octagonal’ template wherein each region can have up to eight faces consisting in horizontal, vertical and oblique lines (see Figure 9(b) for an example); then, we compared with the rectangular template.

Figure 9. Carts with springs. (a): Elastic contact forces apply when the springs are compressed. (b): Example of rectangular–octagonal region. (c): Optimal TPWA regression of the data with rectangular–octagonal domains. (d): Optimal TPWA regression of the data with rectangular domains.
The results are shown in Figure 9(c,d). The running time of the algorithm was about
 $950$
secs for the rectangular–octagonal template, and
$950$
secs for the rectangular–octagonal template, and
 $120$
s for the rectangular template. It is natural that the rectangular–octagonal template takes more time because we allow for degrees of freedom in the shape of the regions. However, we observe in Figure 9(c,d) that the most expressive template gives better result in terms of simplicity of the PWA function.
$120$
s for the rectangular template. It is natural that the rectangular–octagonal template takes more time because we allow for degrees of freedom in the shape of the regions. However, we observe in Figure 9(c,d) that the most expressive template gives better result in terms of simplicity of the PWA function.
Conclusion
To conclude, we have presented an algorithm for fitting PWA models wherein each piece ranges over a region whose shape is dictated by a user-provided template. The complexity of the problem has been analyzed in terms of the number of data points, the dimension of the input domain and the template, X the desired number of pieces of the model. We have presented a top-down algorithm that explores subsets of the data guided by the concept of infeasibility certificates. Finally, our implementation provides some interesting applications of this approach to cyber-physical systems. Despite these contributions, the problem of identifying hybrid systems from data remains a computationally hard problem and the computational challenges of providing precise solutions with mathematical guarantees remain formidable. Our future work will investigate the use of better data structures to help scale our algorithms to larger and higher dimensional data sets. We are also investigating other approaches to PWA identification involving regions that are separated by arbitrary hyperplanes rather than fixed templates. Finally, we are interested in connections between the approach presented here and ideas from computational geometry. In particular, the link between the VC dimension of the shapes used to specify the regions in our PWA model and the complexity of the regression procedure offers interesting venues for future work.
Data availability statement
The code and data used in this paper are available at https://github.com/guberger/L4DC2023_Tool_PWA_Regression_Top-Down.
Author contribution
GB and SS conceived the method and the experimental setup, produced the technical results and wrote the paper together. GB implemented the code and produced the experimental results.
Financial support
This research was supported by grants from the Federation Wallonie-–Bruxelles (WBI) and the US National Science Foundation (NSF) under award numbers 1836900 and 1932189.
Competing interests
None.
Ethics statements
No experiments involving humans or animals were conducted in the context of this research.































 Open access
Open access
Comments
No accompanying comment.