

I. INTRODUCTION
Speech recognition systems, which convert speech into text, make it possible for computers to process the information contained in human speech. The current successes in speech recognition and related speech-processing applications are based on pattern recognition that uses statistical learning theory. Maximum likelihood (ML) methods have become the standard techniques for constructing acoustic and language models for speech recognition. They guarantee that ML estimates approach the stationary values of the parameters. ML methods are also applicable to latent variable models, such as hidden Markov models (HMMs) and Gaussian mixture models (GMMs), thanks to the expectation–maximization (EM) algorithm [Reference Dempster, Laird and Rubin1]. Acoustic modeling based on HMMs and GMMs is one of the most successful examples of the ML–EM approach, and it has been greatly developed in previously reported studies [Reference Jelinek2–Reference Gales and Young4].
However, the performance of current speech recognition systems is far from satisfactory. Specifically, the recognition performance is much poorer than the human capability of recognizing speech. This is because speech recognition suffers from a distinct lack of robustness to unknown conditions, which is crucial for practical use. In a real environment, there are many fluctuations originating in various factors such as the speaker, context, speaking style, and noise. For example, the performance of acoustic models trained using read speech degrades greatly when the models are used to recognize spontaneous speech due to the mismatch between the read and spontaneous speech characteristics [Reference Furui5]. More generally, most of the problems posed by current speech recognition techniques result from a lack of robustness. This lack of robustness is an obstacle to the deployment of commercial applications based on speech recognition. This paper addresses various attempts to improve the acoustic model training method beyond the conventional ML approach by employing Bayesian approaches.
In Bayesian approaches, all the variables that are introduced when models are parameterized, such as model parameters and latent variables, are regarded as probabilistic variables, and their posterior distributions are simply obtained by using the probabilistic sum and product rules. The difference between the Bayesian and ML approaches is that the estimation target is a probability distribution in the Bayesian approach, whereas it is a parameter value in the ML approach. Based on this posterior distribution estimation, the Bayesian approach can generally achieve more robust model construction and classification than an ML approach [Reference Berger6–Reference Bishop8]. However, the Bayesian approach requires complex integral and expectation computations to obtain posterior distributions when models have latent variables. For example, to infer the posterior distribution of HMM/GMM model parameters Θ given speech feature vectors O, we need to calculate the following equation:
 $$p\lpar {\bf \Theta}\vert {\bf O}\rpar ={\sum_{\bf Z}} {p\lpar {\bf O}\comma \; {\bf Z} \vert {\bf \Theta}\rpar p\lpar {\bf \Theta}\rpar \over {p\lpar {\bf O}\rpar }}\comma \; \eqno\lpar 1\rpar$$
$$p\lpar {\bf \Theta}\vert {\bf O}\rpar ={\sum_{\bf Z}} {p\lpar {\bf O}\comma \; {\bf Z} \vert {\bf \Theta}\rpar p\lpar {\bf \Theta}\rpar \over {p\lpar {\bf O}\rpar }}\comma \; \eqno\lpar 1\rpar$$where Z is a set of HMM state and GMM component sequences. Once we obtain the posterior distribution, we classify category c (phoneme or word) given new speech feature vectors x based on the following posterior distribution:
 $$p\lpar c \vert {\bf x}\comma \; {\bf O}\rpar =\vint p\lpar c\vert {\bf \Theta}\comma \; {\bf x}\rpar p\lpar {\bf \Theta}\vert {\bf O}\rpar d {\bf \Theta}. \eqno\lpar 2\rpar$$
$$p\lpar c \vert {\bf x}\comma \; {\bf O}\rpar =\vint p\lpar c\vert {\bf \Theta}\comma \; {\bf x}\rpar p\lpar {\bf \Theta}\vert {\bf O}\rpar d {\bf \Theta}. \eqno\lpar 2\rpar$$Since the integral and expectation often cannot be computed analytically, we need some approximations if we are to implement a Bayesian approach for a classification problem in speech processing.
There have already been many attempts to undertake Bayesian speech processing by approximating the above Bayesian inference [Reference Bishop8, Reference Ghahramani9]. The most famous application of Bayesian approaches employs maximum a posteriori (MAP) approximation, which uses the maximum value of the posterior distribution instead of integrating out the latent variable or model parameter [Reference Bernardo and Smith7]. Historically, MAP-based speech recognition approaches constitute the first successful applications of Bayesian approaches to speech processing. These approaches were introduced in the early 1990s to deal with speaker adaptation problems in speech recognition [Reference Lee, Lin and Juang10,Reference Gauvain and Lee11]. Around 1995, they started to be applied to more practical speech processing problems (e.g., continuous density HMM [Reference Gauvain and Lee12], which is a standard acoustic model in speech recognition, and speaker recognition based on a universal background model [Reference Reynolds, Quatieri and Dunn13]). Other successful methods are based on the Bayesian information criterion (BIC), which is obtained by using asymptotic approximations [Reference Schwarz14,Reference Akaike, Bernardo, DeGroot, Lindley and Smith15]. Starting around 2000, these methods have been applied to wide areas of speech processing, from phonetic decision tree clustering to speaker segmentation [Reference Shinoda and Watanabe16–Reference Shinoda and Iso19]. Recently, advanced Bayesian topics such as variational Bayes (VB) and Markov chain Monte Carlo (MCMC) have been actively studied in the machine learning field [Reference Bishop8], and these approaches are also starting to be applied to speech processing [Reference Watanabe, Minami, Nakamura and Ueda20–Reference Tawara, Watanabe, Ogawa and Kobayashi23], by following the successful Bayesian applications based on MAP and BIC.
Focusing on the four major trends as regards approximating Bayesian inferences, i.e., MAP approximation, asymptotic approximation for model complexity control, variational approximation, and MCMC, this paper aims to provide an overview of the various attempts described above in order to encourage researchers in the speech-processing field to investigate Bayesian approaches and guide them in this endeavor.
In addition to the above topics, there are other interesting Bayesian approaches that have been successfully applied to speech recognition, e.g., on-line Bayesian adaptation [Reference Huo and Lee24,Reference Watanabe and Nakamura25], structural Bayes [Reference Shinoda and Lee26,Reference Siohan, Myrvoll and Lee27], quasi-Bayes [Reference Makov and Smith28–Reference Chien30], graphical model representation [Reference Zweig and Russell31–Reference Rennie, Hershey and Olsen33], and Bayesian sensing HMM [Reference Saon and Chien34]. Although we do not focus on these approaches in detail, they have been summarized in other review and tutorial articles [Reference Lee and Huo35–Reference Watanabe and Chien37].
II. MAP
MAP approaches were introduced into speech recognition to utilize prior information [Reference Lee, Lin and Juang10–Reference Gauvain and Lee12]. The Bayesian approach is based on posterior distributions of the distribution parameters, while the ML approach only considers a particular value for these distribution parameters. Let O = {ot ∈ ℝD|t = 1, …,T} be a given training dataset of D-dimensional feature vectors and Z = {z t|t = 1,…,T} be a set of corresponding latent variables. The posterior distribution for a distribution parameter Θc of category c is obtained by using the well-known Bayes theorem as follows:
 $$p\lpar \Theta_{c}\vert {\bf O}\comma \; m\rpar ={\sum_{{\bf Z}}} {\vint} {p\lpar {\bf O}\comma \; {\bf Z} \vert \Theta\comma \; m\rpar p\lpar \Theta \vert m\rpar \over {p\lpar {\bf O} \vert m\rpar }} {d \Theta_{- c}}\comma \; \eqno\lpar 3\rpar$$
$$p\lpar \Theta_{c}\vert {\bf O}\comma \; m\rpar ={\sum_{{\bf Z}}} {\vint} {p\lpar {\bf O}\comma \; {\bf Z} \vert \Theta\comma \; m\rpar p\lpar \Theta \vert m\rpar \over {p\lpar {\bf O} \vert m\rpar }} {d \Theta_{- c}}\comma \; \eqno\lpar 3\rpar$$where p(Θ | m) is a prior distribution for all distribution parameters Θ, and m denotes the model structure index, for example, the number of Gaussian components or HMM states. Here, −c represents the set of all categories except c. In this paper, we regard the hyperparameter setting as the model structure, and include its variations in the index m. From equation (3), prior information can be utilized via estimations of the posterior distribution, which depends on prior distributions.
Equation (3) generally cannot be calculated analytically due to the summation over latent variables. To avoid the problem, MAP approaches approximate the distribution estimation as a point estimation. Namely, instead of obtaining the posterior distribution in equation (3), MAP approaches consider the following value
 $$\eqalign{\Theta_{c}^{MAP} & =\mathop{\rm argmax}\limits_{\Theta_{c}} p\lpar \Theta_{c}\vert {\bf O}\comma \; m\rpar \cr &=\mathop{\rm argmax}\limits_{\Theta_{c}} \sum_{{\bf Z}} p\lpar {\bf O}\comma \; {\bf Z} \vert \Theta_{c}\comma \; m\rpar p\lpar \Theta_{c}\vert m\rpar .} \eqno\lpar 4\rpar$$
$$\eqalign{\Theta_{c}^{MAP} & =\mathop{\rm argmax}\limits_{\Theta_{c}} p\lpar \Theta_{c}\vert {\bf O}\comma \; m\rpar \cr &=\mathop{\rm argmax}\limits_{\Theta_{c}} \sum_{{\bf Z}} p\lpar {\bf O}\comma \; {\bf Z} \vert \Theta_{c}\comma \; m\rpar p\lpar \Theta_{c}\vert m\rpar .} \eqno\lpar 4\rpar$$This estimation can be efficiently performed by using the EM algorithm. The MAP approximation was first applied to the estimation of single-Gaussian HMM parameters in [Reference Lee, Lin and Juang10] and later extended to GMM–HMMs in [Reference Gauvain and Lee11,Reference Gauvain and Lee12]. The effectiveness of MAP approaches can be illustrated in a speaker recognition task where prior distributions are set by speaker-independent HMMs. For example, Gauvain and Lee [Reference Gauvain and Lee12] compares speaker adaptation performance by employing ML and MAP estimations of acoustic model parameters using the DARPA Naval Resources Management (RM) task [Reference Price, Fisher, Bernstein and Pallett38]. With 2 minutes of adaptation data, the ML word error rate was 31.5% and was worse than the speaker independent word error rate (13.9%) due to the over-training effect. However, the MAP word error rate was 8.7%, clearly showing the effectiveness of the MAP approach. MAP estimation has also been used in speaker recognition based on universal background models [Reference Reynolds, Quatieri and Dunn13], and in the discriminative training of acoustic models in speech recognition as a parameter-smoothing technique [Reference Povey39].
III. BIC
BIC approaches were introduced into speech recognition to perform model selection [Reference Shinoda and Watanabe16,Reference Chou and Reichl17]. To deal with model structure in a Bayesian approach, we can consider the following posterior distribution:
 $$p\lpar m\vert {\bf O}\rpar ={\sum_{\bf Z}} \vint {{p\lpar {\bf O}\comma \; {\bf Z} \vert \Theta\comma \; m\rpar p \lpar \Theta \vert m\rpar p\lpar m\rpar } \over {p\lpar {\bf O}\rpar }} {d \Theta}\comma \; \eqno \lpar 5\rpar$$
$$p\lpar m\vert {\bf O}\rpar ={\sum_{\bf Z}} \vint {{p\lpar {\bf O}\comma \; {\bf Z} \vert \Theta\comma \; m\rpar p \lpar \Theta \vert m\rpar p\lpar m\rpar } \over {p\lpar {\bf O}\rpar }} {d \Theta}\comma \; \eqno \lpar 5\rpar$$where p(m) denotes a prior distribution for the model structure m. However, as with MAP approaches, equation (5) cannot be calculated analytically due to the summation over latent variables. The BIC only focuses on models that do not have latent variables. Under the asymptotic assumption (i.e., the assumption that there is a large amount of data), one can obtain the following equation:
 $$\log p\lpar m\vert {\bf O}\rpar \propto \log p\lpar {\bf O} \vert \Theta\comma \; m\rpar - {\# \lpar \Theta\rpar \over 2} {\log T}.\eqno\lpar 6\rpar$$
$$\log p\lpar m\vert {\bf O}\rpar \propto \log p\lpar {\bf O} \vert \Theta\comma \; m\rpar - {\# \lpar \Theta\rpar \over 2} {\log T}.\eqno\lpar 6\rpar$$The first term on the right-hand side is a log-likelihood term and the second term is a penalty term, which is proportional to the number of model parameters, denoted by # (Θ).
This criterion is widely used in speech processing. For example, it enables phonetic decision tree clustering to be performed in [Reference Shinoda and Watanabe16,Reference Chou and Reichl17] without having to set a heuristic stopping criterion as was done in [Reference Young, Odell and Woodland40]. Shinoda and Watanabe [Reference Shinoda and Watanabe16] show the effectiveness of the BIC/MDLFootnote 1 criterion for phonetic decision tree clustering in a 5000 Japanese word recognition task by comparing the performance of acoustic models based on BIC/MDL with models based on heuristic stopping criteria (namely, the state occupancy count and the likelihood threshold). BIC/MDL selected 2069 triphone HMM states automatically with an 80.4% recognition rate, while heuristic stopping criteria selected 1248 and 591 states with recognition rates of 77.9 and 66.6% in the best and worst cases, respectively. This result clearly shows the effectiveness of model selection using BIC/MDL. An extension of the BIC objective function by considering a tree structure is also discussed in [Reference Hu and Zhao41], and an extension based on VB is discussed in Section IV. In addition, BIC/MDL is used for Gaussian pruning in acoustic models [Reference Shinoda and Iso19], and speaker segmentation [Reference Chen and Gopinath18]. BIC-based speaker segmentation is a particularly important technique for speaker diarization, which has been widely studied recently [Reference Anguera Miro, Bozonnet, Evans, Fredouille, Friedland and Vinyals42].
MAP and BIC, together with Bayesian Predictive Classification (BPC) [Reference Jiang, Hirose and Huo43,Reference Huo and Lee44], which marginalizes model parameters so that the effect of over-training is mitigated and robust classification is obtained, can be practically realized in speech recognition. However, while Bayesian approaches can potentially have the three following advantages:
(1) Effective utilization of prior knowledge through prior distributions (prior utilization).
(2) Model selection that obtains a model structure with the highest probability of posterior distribution of model structures (model selection).
(3) Robust classification by marginalizing model parameters (robust classification).
MAP, BIC, and BPC each have only one. In general, these advantages make pattern recognition methods more robust than those based on ML approaches. For example, a MAP-based framework approximates the posterior distribution of the parameter by using a MAP approximation to utilize prior information. BIC/MDL- and BPC-based frameworks, respectively, perform some sort of model selection and robust classification. These approaches are simple and powerful frameworks with which to transfer some of the advantages expected from Bayesian approaches to speech recognition systems. However, they also lose some of these advantages due to the approximations they introduce, as shown in Table 1. In the next section, we introduce another method for approximating a Bayesian inference, variational approximation, which includes all three Bayesian advantages simultaneously unlike the MAP, BIC, and BPC approaches.
Table 1. Comparison of VBEC and other Bayesian frameworks in terms of Bayesian advantages.

IV. VB
This section presents an application of VB, a technique originally developed in the field of machine learning [Reference Jordan, Ghahramani, Jaakkola and Saul45–Reference Ueda and Ghahramani48], to speech recognition. With this VB approach, approximate posterior distributions (VB posterior distributions) can be obtained effectively by iterative calculations similar to the EM algorithm used in the ML approach, while the three advantages of the Bayesian approaches are retained. Therefore, the framework is formulated using VB to replace the ML approaches with Bayesian approaches in speech recognition. We briefly review a speech recognition framework based on a fully Bayesian approach to overcome the lack of robustness described above by utilizing the three Bayesian advantages [Reference Watanabe, Minami, Nakamura and Ueda20,Reference Watanabe, Minami, Nakamura and Ueda21]. A detailed discussion of the formulation and experiments can be found in [Reference Watanabe49].
A) Application of VB to speech recognition
As we saw earlier, Bayesian approaches aim at obtaining posterior distributions for the model parameters, but these posterior distributions cannot be generally obtained analytically. The goal of VB is to approximate these posterior distributions using some other distributions, referred to as variational distributions, which are optimized so that they are as close as possible, in some sense yet to be defined, to the true posterior distributions. The variational distributions are generally assumed to belong to a family of distributions of a simpler form than the original posterior distributions. Here, we consider an arbitrary posterior distribution q, and assume that it can be factorized as
 $$q\lpar \Theta\comma \; {\bf Z}\comma \; m\vert {\bf O}\rpar = {\prod_c} q\lpar \Theta_c\vert {\bf O}_c\comma \; m\rpar q\lpar {\bf Z}_c\vert {\bf O}_c\comma \; m\rpar q\lpar m\vert {\bf O}_c\rpar \comma \; \eqno\lpar 7\rpar$$
$$q\lpar \Theta\comma \; {\bf Z}\comma \; m\vert {\bf O}\rpar = {\prod_c} q\lpar \Theta_c\vert {\bf O}_c\comma \; m\rpar q\lpar {\bf Z}_c\vert {\bf O}_c\comma \; m\rpar q\lpar m\vert {\bf O}_c\rpar \comma \; \eqno\lpar 7\rpar$$where c is a category index (e.g., a phoneme if we deal with a phoneme-based acoustic model). VB then focuses on minimizing the Kullback–Leibler divergence from q(Θ, Z, m|O) to p(Θ, Z,m|O), which can be shown to be equivalent to maximizing the following objective functional:
 $$\eqalign{& {\cal F} ^m \lsqb q\lpar \Theta_c\vert {\bf O}_c\comma \; m\rpar \comma \; q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar \rsqb \cr & \quad = \left\langle{\log} {p\lpar {\bf O}_c\comma \; {\bf Z}_c \vert \Theta_c\comma \; m\rpar p\lpar \Theta_c \vert m\rpar \over {q\lpar \Theta_c \vert {\bf O}_c\comma \; m\rpar }q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar } \right\rangle_{q\lpar \Theta_c \vert {\bf O}_c\comma m\rpar \comma q\lpar {\bf Z}_c \vert {\bf O}_c\comma m\rpar }}\comma \; \eqno\lpar 8\rpar$$
$$\eqalign{& {\cal F} ^m \lsqb q\lpar \Theta_c\vert {\bf O}_c\comma \; m\rpar \comma \; q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar \rsqb \cr & \quad = \left\langle{\log} {p\lpar {\bf O}_c\comma \; {\bf Z}_c \vert \Theta_c\comma \; m\rpar p\lpar \Theta_c \vert m\rpar \over {q\lpar \Theta_c \vert {\bf O}_c\comma \; m\rpar }q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar } \right\rangle_{q\lpar \Theta_c \vert {\bf O}_c\comma m\rpar \comma q\lpar {\bf Z}_c \vert {\bf O}_c\comma m\rpar }}\comma \; \eqno\lpar 8\rpar$$where the brackets 〈 〉 denote the expectation, i.e., 〈g(y)〉p (y) ≡ ∫ g(y) p(y) d y for a continuous variable y and 〈g(n)〉p(n) ≡ ∑ng(n)p(n) for a discrete variable n. Equation (8) can be shown to be a lower bound of the marginalized log likelihood. The optimal posterior distribution can be obtained by a variational method, which due to the factorization assumption (7) leads to:
 $$\eqalign{\tilde{q}\lpar \Theta_c\vert {\bf O}_c\comma \; m\rpar & =\mathop{\rm argmax}\limits_{q\lpar \Theta_c\vert {\bf O}\comma m\rpar } {\cal F}^m\lsqb q\lpar \Theta_c \vert {\bf O}_c\comma \; m\rpar \comma \; q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar \rsqb \comma \; \cr \tilde{q}\lpar {\bf Z}_c\vert {\bf O}_c\comma \; m\rpar & =\mathop{\rm argmax}\limits_{q\lpar {\bf Z}_c\vert {\bf O}\comma m\rpar } {\cal F}^m\lsqb q\lpar \Theta_c \vert {\bf O}_c\comma \; m\rpar \comma \; q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar \rsqb \comma \; \cr \tilde{q}\lpar m\vert {\bf O}\rpar & =\mathop{\rm argmax}\limits_{q\lpar m\vert {\bf O}\rpar } {\sum_c}{\cal F}^m\lsqb q\lpar \Theta_c \vert {\bf O}_c\comma \; m\rpar \comma \; q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar \rsqb .}\eqno\lpar 9\rpar$$
$$\eqalign{\tilde{q}\lpar \Theta_c\vert {\bf O}_c\comma \; m\rpar & =\mathop{\rm argmax}\limits_{q\lpar \Theta_c\vert {\bf O}\comma m\rpar } {\cal F}^m\lsqb q\lpar \Theta_c \vert {\bf O}_c\comma \; m\rpar \comma \; q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar \rsqb \comma \; \cr \tilde{q}\lpar {\bf Z}_c\vert {\bf O}_c\comma \; m\rpar & =\mathop{\rm argmax}\limits_{q\lpar {\bf Z}_c\vert {\bf O}\comma m\rpar } {\cal F}^m\lsqb q\lpar \Theta_c \vert {\bf O}_c\comma \; m\rpar \comma \; q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar \rsqb \comma \; \cr \tilde{q}\lpar m\vert {\bf O}\rpar & =\mathop{\rm argmax}\limits_{q\lpar m\vert {\bf O}\rpar } {\sum_c}{\cal F}^m\lsqb q\lpar \Theta_c \vert {\bf O}_c\comma \; m\rpar \comma \; q\lpar {\bf Z}_c \vert {\bf O}_c\comma \; m\rpar \rsqb .}\eqno\lpar 9\rpar$$ By assuming that p(m) is a uniform distribution, we obtain the proportion relation between 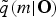 $\tilde{q}\lpar m\vert {\bf O}\rpar $ and
$\tilde{q}\lpar m\vert {\bf O}\rpar $ and 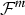 ${\cal F}^m $, and an optimal model structure where the MAP probability can be selected as follows:
${\cal F}^m $, and an optimal model structure where the MAP probability can be selected as follows:
 $$\tilde{m}= \mathop{\rm argmax}\limits_{\lcub m \rcub} \tilde{q}\lpar m\vert {\bf O}\rpar =\mathop{\rm argmax}\limits_{\lcub m \rcub} {\cal F}^m.\eqno\lpar 10\rpar$$
$$\tilde{m}= \mathop{\rm argmax}\limits_{\lcub m \rcub} \tilde{q}\lpar m\vert {\bf O}\rpar =\mathop{\rm argmax}\limits_{\lcub m \rcub} {\cal F}^m.\eqno\lpar 10\rpar$$
This indicates that by maximizing the total 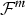 ${\cal F}^m $ with respect to not only q(Θc|Oc, m) and q(Z c|Oc, m) but also m, we can obtain the optimal parameter distributions and can select the optimal model structure simultaneously [Reference Attias47,Reference Ueda and Ghahramani48]. The VB approach is applied to a continuous density HMM (left-to-right HMM with a GMM for each state) in the variational Bayesian estimation and clustering (VBEC) for speech recognition framework [Reference Watanabe, Minami, Nakamura and Ueda20,Reference Watanabe, Minami, Nakamura and Ueda21]. The continuous density HMM is a standard acoustic model that represents a phoneme category for speech recognition. VBEC is a fully Bayesian framework, where all the following acoustic model procedures for speech recognition (acoustic model construction and speech classification) are re-formulated in a VB manner:
${\cal F}^m $ with respect to not only q(Θc|Oc, m) and q(Z c|Oc, m) but also m, we can obtain the optimal parameter distributions and can select the optimal model structure simultaneously [Reference Attias47,Reference Ueda and Ghahramani48]. The VB approach is applied to a continuous density HMM (left-to-right HMM with a GMM for each state) in the variational Bayesian estimation and clustering (VBEC) for speech recognition framework [Reference Watanabe, Minami, Nakamura and Ueda20,Reference Watanabe, Minami, Nakamura and Ueda21]. The continuous density HMM is a standard acoustic model that represents a phoneme category for speech recognition. VBEC is a fully Bayesian framework, where all the following acoustic model procedures for speech recognition (acoustic model construction and speech classification) are re-formulated in a VB manner:
• Output distribution setting
→ Output and prior distribution setting
• Parameter estimation by ML Baum–Welch
→ Posterior estimation by VB Baum–Welch
• Model selection by using heuristics
→ Model selection by using variational lower bound
• Classification using ML estimates
→ BPC using VB posteriors
Consequently, VBEC includes the three Bayesian advantages unlike the conventional Bayesian approaches, as illustrated in Table 1.
B) Experiments and related work
We briefly illustrate the effectiveness of the VBEC framework using the results of speech recognition experiments (see [Reference Watanabe49] for details). Figure 1 compares word accuracies on Japanese read speech data (JNAS) for various amounts of training data used in acoustic model construction. The difference between VBEC and conventional ML- and BIC/MDL-based acoustic modeling is whether or not the approach utilizes prior distributions. VBEC significantly improved the performance for a small amount of training data, which shows the effectiveness of (1) a prior utilization function in Bayesian approaches. Table 2 shows experimental results for the automatic determination of the acoustic model topology by using VBEC and the conventional heuristic approach that determines the model topology by evaluating ASR performance on development sets. In the various ASR tasks, VBEC obtained comparable performance to the conventional method by selecting appropriate model topologies without using a development set, which shows the effectiveness of (2) a model selection function in Bayesian approaches. Finally, Fig. 2 shows a comparison of word accuracies with Corpus of Spontaneous Japanese (CSJ) data [Reference Furui5] in speaker adaptation experiments. VBEC and MAP used the same prior distributions, and the difference between them is whether or not the model parameters are marginalized (integrated out). VBEC also significantly improved the performance for a small amount of training data, which shows the effectiveness of (3) a robust classification function in Bayesian approaches. Thus, these results confirm experimentally that VBEC includes the three Bayesian advantages unlike the conventional Bayesian approaches, as shown in Table 1.

Fig. 1. Superiority of VBEC-based acoustic model construction for a small amount of training data.

Fig. 2. Robust classification based on marginalization effect.
Table 2. Automatic determination of acoustic model topology.

VB is becoming a common technique in speech processing. Table 3 summarizes the technical trend in speech processing techniques involving VB. Note that VB has been widely applied to speech recognition and other forms of speech processing. Given such a trend, VBEC is playing an important role in pioneering the main formulation and implementation of VB-based speech recognition, which is a core technology in this field. In addition to the approximation of Bayesian inferences, the variational techniques are used as an effective approximation method in some speech processing problems, e.g., approximating the Kullback–Leibler divergence between GMMs [Reference Hershey and Olsen73], and the Bayesian treatment of a discriminative HMM by using minimum relative entropy discrimination [Reference Kubo, Watanabe, Nakamura and Kobayashi74].
Table 3. Technical trend of speech recognition using VB

V. MCMC
In previous sections, we described Bayesian approaches based on deterministic approximations (MAP, asymptotic approximation, and VB). Another powerful way to implement Bayesian approaches is to rely on a sampling method, which obtains expectations by using Monte Carlo techniques [Reference Bernardo and Smith7,Reference Bishop8]. The main advantage of the sampling approaches is that they can avoid local optimum problems in addition to providing other Bayesian advantages (mitigation of data sparseness problems and capacity for model structure optimization). While their heavy computational cost could be a problem in practice, recent improvements in computational power and the development of theoretical and practical aspects have allowed researchers to start applying them to practical problems (e.g., [Reference Goldwater and Griffiths75,Reference Mochihashi, Yamada and Ueda76] in natural language processing). This paper describes our recent attempts to apply a sampling approach to acoustic modeling based on MCMC, in particular Gibbs sampling [,23,7177]. Gibbs sampling is a simple and widely applicable sampling algorithm [Reference Geman and Geman78] that samples the latent variable z t by using the conditional distribution p(z t|Z\t) where Z\t is the set of all latent variables except z t. By iteratively sampling z \t for all t based on this conditional distribution, we can efficiently sample the latent variables, which are then used to compute the expectations (e.g., equation (1)) required in Bayesian approaches. Here, we focus on an example of a hierarchical GMM, called a multi-scale mixture model, used as an acoustic model in speaker clustering, and introduce a formulation based on Gibbs sampling.
A) Formulation
Multi-scale mixture model (M3)
M3 considers two types of observation vector sequences. One is an utterance- (or segment-) level sequence and the other is a frame-level sequence. A D-dimensional observation vector (e.g., MFCC) at frame t in utterance u is represented as ou, t (∈ ℝD). A set of observation vectors in utterance u is represented as ou≜{ou, t}t=1T u.
We assume that the frame-level sequence is modeled by a GMM as usual, and the utterance-level sequence is modeled by a mixture of these GMMs. Two kinds of latent variables are involved in MReference Huang, Ariki and Jack3 for each sequence: utterance-level latent variables z u and frame-level latent variables v u, t. Utterance-level latent variables may represent emotion, topic, and speaking style as well as speakers, depending on the speech variation. The likelihood function of U observation vectors (O≜{ou}u=1U) given the latent variable sequences (Z≜{z u}u and V≜{v u, t}u, t) can be expressed as follows:
 $$p\lpar {\bf O}\vert {\bf Z}\comma \; {\bf V}\comma \; {\bf \Theta}\rpar = \prod_{u = 1} ^{U} h_{{z}_{u}} \prod_{t = 1} ^{T_{u}} w_{z_{u}\comma v_{u\comma t}} {\cal N} \lpar {\bf o}_{u\comma t}\vert {\bf \mu}_{z_{u}\comma v_{u\comma t}}\comma \; {\bf \Sigma}_{z_{u}\comma v_{u\comma t}}\rpar \comma \; \eqno\lpar 11\rpar$$
$$p\lpar {\bf O}\vert {\bf Z}\comma \; {\bf V}\comma \; {\bf \Theta}\rpar = \prod_{u = 1} ^{U} h_{{z}_{u}} \prod_{t = 1} ^{T_{u}} w_{z_{u}\comma v_{u\comma t}} {\cal N} \lpar {\bf o}_{u\comma t}\vert {\bf \mu}_{z_{u}\comma v_{u\comma t}}\comma \; {\bf \Sigma}_{z_{u}\comma v_{u\comma t}}\rpar \comma \; \eqno\lpar 11\rpar$$
where {h s}s, {w s, k}s, k, {μs, k}s, k, {Σs, k}s, k (≜ Θ) are the utterance-level mixture weight, frame-level mixture weight, mean vector, and covariance matrix parameters, respectively. s and k denote utterance-level and frame-level mixture indexes, respectively. 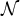 ${\cal N} $ denotes a normal distribution.
${\cal N} $ denotes a normal distribution.
Let us now consider the Bayesian treatment of this multi-scale mixture model. We assume a diagonal covariance matrix for the Gaussian distributions as usual, where the d–d diagonal element of the covariance matrix is expressed as σdd, and use the following conjugate distributions as the prior distributions of the model parameters:
 $$p\lpar {\bf \Theta}\vert {\bf \Psi} ^{0}\rpar =\left\{\matrix{{\bf h}\hfill & \sim {\cal D} \lpar {\bf h} ^{0}\rpar \hfill \cr {\bf w}_{s}\hfill & \sim {\cal D} \lpar {\bf w} ^{0}\rpar \hfill\cr {\bf \mu}_{s\comma k}\hfill & \sim {\cal N} \lpar {\bi \mu} ^{0}_{k}\comma \; \lpar \xi ^{0} \rpar ^{-1} {\bf \Sigma}_{s\comma k}\rpar \hfill\cr \lpar \sigma_{s\comma k\comma dd}\rpar ^{-1}\hfill & \sim {\cal G} \lpar \eta ^{0}\comma \; \sigma ^{0}_{k\comma dd}\rpar \hfill} \right\}\comma \; \eqno\lpar 12\rpar$$
$$p\lpar {\bf \Theta}\vert {\bf \Psi} ^{0}\rpar =\left\{\matrix{{\bf h}\hfill & \sim {\cal D} \lpar {\bf h} ^{0}\rpar \hfill \cr {\bf w}_{s}\hfill & \sim {\cal D} \lpar {\bf w} ^{0}\rpar \hfill\cr {\bf \mu}_{s\comma k}\hfill & \sim {\cal N} \lpar {\bi \mu} ^{0}_{k}\comma \; \lpar \xi ^{0} \rpar ^{-1} {\bf \Sigma}_{s\comma k}\rpar \hfill\cr \lpar \sigma_{s\comma k\comma dd}\rpar ^{-1}\hfill & \sim {\cal G} \lpar \eta ^{0}\comma \; \sigma ^{0}_{k\comma dd}\rpar \hfill} \right\}\comma \; \eqno\lpar 12\rpar$$
where h0, w0, μk0, ξ0, σk, dd0, η0 (≜ Ψ0) are the hyperparameters. 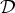 ${\cal D} $ and
${\cal D} $ and 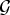 ${\cal G} $ denote Dirichlet and Gamma distributions, respectively. The generative process of MReference Huang, Ariki and Jack3 is shown in Fig. 3. Based on the generative model, we derive analytical solutions for Gibbs samplers of the multi-scale mixture model based on the marginalized likelihood for the complete data.
${\cal G} $ denote Dirichlet and Gamma distributions, respectively. The generative process of MReference Huang, Ariki and Jack3 is shown in Fig. 3. Based on the generative model, we derive analytical solutions for Gibbs samplers of the multi-scale mixture model based on the marginalized likelihood for the complete data.

Fig. 3. Graphical representation of multi-scale mixture model.
Gibbs sampler
Frame-level mixture component
The function form of the Gibbs sampler, which assigns frame-level mixture component k at frame t probabilistically, is analytically obtained as follows:
 $$\eqalign{& p\lpar v_{u\comma t} = k^{\prime} \vert {\bf O}\comma \; {\bf V}_{\backslash t}\comma \; {\bf Z}_{\backslash u}\comma \; z_{u} = s\rpar \cr & \quad = \displaystyle{{\exp \left(g_{s\comma k^{\prime}} \lpar \tilde{{\bf \Psi}}_{s\comma k^{\prime}}\rpar - g_{s\comma k^{\prime}} \lpar \tilde{\bf \Psi}_{s\comma k^{\prime} \backslash t}\rpar \right)} \over {\sum_{k} \exp \left(g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k}\rpar - g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k \backslash t}\rpar \right)}.}} \eqno\lpar 13\rpar$$
$$\eqalign{& p\lpar v_{u\comma t} = k^{\prime} \vert {\bf O}\comma \; {\bf V}_{\backslash t}\comma \; {\bf Z}_{\backslash u}\comma \; z_{u} = s\rpar \cr & \quad = \displaystyle{{\exp \left(g_{s\comma k^{\prime}} \lpar \tilde{{\bf \Psi}}_{s\comma k^{\prime}}\rpar - g_{s\comma k^{\prime}} \lpar \tilde{\bf \Psi}_{s\comma k^{\prime} \backslash t}\rpar \right)} \over {\sum_{k} \exp \left(g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k}\rpar - g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k \backslash t}\rpar \right)}.}} \eqno\lpar 13\rpar$$
Here, O\t and V\t indicate sets that do not include the tth frame elements. Z\u indicates a set that does not include the uth utterance element. 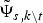 $\tilde{{\bf \Psi}}_{s\comma k \backslash t}$ is computed by the sufficient statistics using O\t and V\t· g s, k (·) is defined as follows:
$\tilde{{\bf \Psi}}_{s\comma k \backslash t}$ is computed by the sufficient statistics using O\t and V\t· g s, k (·) is defined as follows:
 $$\eqalign{g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k}\rpar & \triangleq \log \Gamma\lpar \tilde{w}_{s\comma k}\rpar - \displaystyle{{D}\over{2}} \log \tilde{\xi}_{s\comma k}\cr & \quad+ D \log \Gamma \left(\displaystyle{\tilde{\eta}_{s\comma k}}\over{2} \right)- \displaystyle{{\tilde{\eta}_{s\comma k}}\over {2}} \sum_{d} \log \tilde{\sigma}_{s\comma k\comma dd}\comma \; }$$
$$\eqalign{g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k}\rpar & \triangleq \log \Gamma\lpar \tilde{w}_{s\comma k}\rpar - \displaystyle{{D}\over{2}} \log \tilde{\xi}_{s\comma k}\cr & \quad+ D \log \Gamma \left(\displaystyle{\tilde{\eta}_{s\comma k}}\over{2} \right)- \displaystyle{{\tilde{\eta}_{s\comma k}}\over {2}} \sum_{d} \log \tilde{\sigma}_{s\comma k\comma dd}\comma \; }$$
where 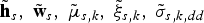 $\tilde{{\bf h}}_{s}\comma \; \tilde{{\bf w}}_{s}\comma \; \tilde{{\bf \mu}}_{s\comma k}\comma \; \tilde{\xi}_{s\comma k}\comma \; \tilde{\sigma}_{s\comma k\comma dd}$ and
$\tilde{{\bf h}}_{s}\comma \; \tilde{{\bf w}}_{s}\comma \; \tilde{{\bf \mu}}_{s\comma k}\comma \; \tilde{\xi}_{s\comma k}\comma \; \tilde{\sigma}_{s\comma k\comma dd}$ and 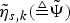 $\tilde{\eta}_{s\comma k} \lpar \triangleq \tilde{{\bf \Psi}}\rpar $ are the hyperparameters of the posterior distributions for Θ, which are obtained from the hyperparameters of the prior distributions (Ψ0) and the sufficient statistics as follows:
$\tilde{\eta}_{s\comma k} \lpar \triangleq \tilde{{\bf \Psi}}\rpar $ are the hyperparameters of the posterior distributions for Θ, which are obtained from the hyperparameters of the prior distributions (Ψ0) and the sufficient statistics as follows:
 $$\left\{\matrix{\tilde{h}_{s} \hfill & = h_{s} ^{0} + c_{s}\comma \; \hfill\cr \tilde{w}_{s\comma k} \hfill& = w ^{0}_{k} + n_{s\comma k}\comma \; \hfill\cr \tilde{\xi}_{s\comma k} \hfill& = \xi ^{0} + n_{s\comma k}\comma \; \hfill\cr \tilde{\mu}_{s\comma k} \hfill& = \displaystyle{{\xi ^{0} {\bf \mu} ^{0}_{k} + {\bf m}_{s\comma k}}\over{\tilde{\xi}_{s\comma k}}}\comma \; \hfill \cr \tilde{\eta}_{s\comma k} \hfill & = \eta ^{0} + n_{s\comma k}\comma \; \hfill \cr \tilde{\sigma}_{s\comma k\comma dd} \hfill & = \sigma ^{0}_{k\comma dd} + r_{s\comma k\comma dd} + \xi ^{0} \lpar \mu ^{0}_{k\comma d}\rpar ^{2} - \tilde{\xi}_{s\comma k} \lpar \tilde{\mu}_{s\comma k\comma d}\rpar ^{2}. }\right. \eqno\lpar 14\rpar$$
$$\left\{\matrix{\tilde{h}_{s} \hfill & = h_{s} ^{0} + c_{s}\comma \; \hfill\cr \tilde{w}_{s\comma k} \hfill& = w ^{0}_{k} + n_{s\comma k}\comma \; \hfill\cr \tilde{\xi}_{s\comma k} \hfill& = \xi ^{0} + n_{s\comma k}\comma \; \hfill\cr \tilde{\mu}_{s\comma k} \hfill& = \displaystyle{{\xi ^{0} {\bf \mu} ^{0}_{k} + {\bf m}_{s\comma k}}\over{\tilde{\xi}_{s\comma k}}}\comma \; \hfill \cr \tilde{\eta}_{s\comma k} \hfill & = \eta ^{0} + n_{s\comma k}\comma \; \hfill \cr \tilde{\sigma}_{s\comma k\comma dd} \hfill & = \sigma ^{0}_{k\comma dd} + r_{s\comma k\comma dd} + \xi ^{0} \lpar \mu ^{0}_{k\comma d}\rpar ^{2} - \tilde{\xi}_{s\comma k} \lpar \tilde{\mu}_{s\comma k\comma d}\rpar ^{2}. }\right. \eqno\lpar 14\rpar$$c s is the count of utterances assigned to s and n s, k is the count of frames assigned to k in s. ms, k and r s, k, dd are first-order and second-order sufficient statistics, respectively.
Utterance-level mixture component
As with the frame-level mixture component case, the Gibbs sampler assigns utterance-level mixture s at utterance u by using the following equation:
 $$\eqalign{& \log p\lpar z_{u} = s \vert {\bf O}\comma \; {\bf V}\comma \; {\bf Z}_{\backslash u}\rpar \cr & \quad \propto\log \displaystyle{{\Gamma\lpar \sum_{k} \tilde{w}_{s \backslash u\comma k}\rpar } \over {\Gamma\lpar \sum_{k} \tilde{w}_{s\comma k}\rpar }} + \sum_{k} g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k}\rpar - g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s \backslash u\comma k}\rpar .}$$
$$\eqalign{& \log p\lpar z_{u} = s \vert {\bf O}\comma \; {\bf V}\comma \; {\bf Z}_{\backslash u}\rpar \cr & \quad \propto\log \displaystyle{{\Gamma\lpar \sum_{k} \tilde{w}_{s \backslash u\comma k}\rpar } \over {\Gamma\lpar \sum_{k} \tilde{w}_{s\comma k}\rpar }} + \sum_{k} g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k}\rpar - g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s \backslash u\comma k}\rpar .}$$O\u and V\u indicate sets that do not include subsets of the frame elements in u. 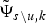 $\tilde{{\bf \Psi}}_{s \backslash u\comma k}$ is computed by the sufficient statistics using O\u and V\u. Therefore, the posterior probability can be obtained as follows:
$\tilde{{\bf \Psi}}_{s \backslash u\comma k}$ is computed by the sufficient statistics using O\u and V\u. Therefore, the posterior probability can be obtained as follows:
 $$\eqalign{& p\lpar z_{u} = s^{\prime}\vert {\bf O}\comma \; {\bf V}\comma \; {\bf Z}_{\backslash u}\rpar \cr &\quad = \displaystyle{{\exp \left(\log \displaystyle{{\Gamma\lpar \sum_{k} \tilde{w}_{s^{\prime} \backslash u\comma k}\rpar }\over{\Gamma\lpar \sum_{k} \tilde{w}_{s^{\prime}\comma k}\rpar }} + \sum_{k} g_{s^{\prime}\comma k} \lpar \tilde{{\bf \Psi}}_{s^{\prime}\comma k}\rpar - g_{s^{\prime}\comma k} \lpar \tilde{{\bf \Psi}}_{s^{\prime} \backslash u\comma k}\rpar \right)} \over {\sum_{s\comma k} \exp \left(\log \displaystyle{{\Gamma\lpar \sum_{k} \tilde{w}_{s \backslash u\comma k}\rpar } \over {\Gamma\lpar \sum_{k} \tilde{w}_{s\comma k}\rpar }} + g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k}\rpar - g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s \backslash u\comma k}\rpar \right)}}.} \eqno\lpar 15\rpar$$
$$\eqalign{& p\lpar z_{u} = s^{\prime}\vert {\bf O}\comma \; {\bf V}\comma \; {\bf Z}_{\backslash u}\rpar \cr &\quad = \displaystyle{{\exp \left(\log \displaystyle{{\Gamma\lpar \sum_{k} \tilde{w}_{s^{\prime} \backslash u\comma k}\rpar }\over{\Gamma\lpar \sum_{k} \tilde{w}_{s^{\prime}\comma k}\rpar }} + \sum_{k} g_{s^{\prime}\comma k} \lpar \tilde{{\bf \Psi}}_{s^{\prime}\comma k}\rpar - g_{s^{\prime}\comma k} \lpar \tilde{{\bf \Psi}}_{s^{\prime} \backslash u\comma k}\rpar \right)} \over {\sum_{s\comma k} \exp \left(\log \displaystyle{{\Gamma\lpar \sum_{k} \tilde{w}_{s \backslash u\comma k}\rpar } \over {\Gamma\lpar \sum_{k} \tilde{w}_{s\comma k}\rpar }} + g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s\comma k}\rpar - g_{s\comma k} \lpar \tilde{{\bf \Psi}}_{s \backslash u\comma k}\rpar \right)}}.} \eqno\lpar 15\rpar$$These solutions for the multi-scale mixture model based on Gibbs sampling jointly infer the latent variables by interleaving frame-level and utterance-level samples.
Algorithm 1 provides a sample code of the multi-scale mixture model.
Algorithm 1 Gibbs sampling based multi-scale mixture model.

B) Experiments
We describe experimental results obtained with the multi-scale mixture model for meeting data, recorded by NTT Communication Science Laboratories to analyze and recognize meetings [Reference Hori, Araki, Yoshioka, Fujimoto, Watanabe, Oba, Ogawa, Otsuka, Mikami and Kinoshita79]. We used four of the sessions (3402 utterances) to construct a prior GMM in advance, and the other two sessions as development (495 utterances spoken by four speakers), and evaluation sets (560 utterances spoken by four speakers), respectively. As an observation vector, we used MFCC features with log energy, Δ, and ΔΔ components. As a preliminary experiment, the numbers of clusters were set at the correct answer. First, a prior GMM (i.e., a universal background model) was estimated by using the four sessions consisting of 3402 utterances based on the conventional ML–EM algorithm, and the values of the GMM parameters were set as those of the hyperparameters in MReference Huang, Ariki and Jack3 (w0, μk0, Σk0). Figure 4 shows the speaker clustering performance of the multi-scale mixture (MReference Huang, Ariki and Jack3 Gibbs), the MAP-based approach (MReference Huang, Ariki and Jack3 MAP–EM) and the conventional BIC-based approach in terms of the frame-level error rate of each method based on the diarization error rate defined by NIST [Reference Fiscus, Ajot and Garofolo80]. Speaker clustering experiments showed that MReference Huang, Ariki and Jack3 Gibbs provided a significant improvement over the conventional BIC and MReference Huang, Ariki and Jack3 MAP–EM-based approaches. The main advantage of MReference Huang, Ariki and Jack3 Gibbs and MReference Huang, Ariki and Jack3 MAP–EM over BIC is that they can precisely model speaker clusters based on the GMM unlike the single Gaussian model used in BIC. In addition, MReference Huang, Ariki and Jack3 Gibbs further improved on the speaker clustering performance of MReference Huang, Ariki and Jack3 MAP–EM because the Gibbs sampling algorithm can avoid local optimum solutions unlike the MAP–EM algorithm. These superior characteristics are derived from the Gibbs-based Bayesian properties.

Fig. 4. Diarization error rate for NTT meeting data.
MCMC-based acoustic modeling for speaker clustering was further investigated with respect to the difference in the MCMC and VB estimation methods by [Reference Tawara, Ogawa, Watanabe and Kobayashi71]. Table 4 shows speaker clustering results in terms of the average cluster purity (ACP), average speaker purity (ASP), and geometric mean of those values (K value) to the evaluation criteria in the speaker clustering. We used the Corpus of Spontaneous Japanese (CSJ) dataset [Reference Furui5] and investigated the speaker clustering performance for MCMC and VB for various amounts of data. Table 4 showed that the MCMC-based method outperformed the VB method by avoiding local optimum solutions, especially when only few utterances could be used. These results also supported the importance derived from the Gibbs-based Bayesian properties.
Table 4. Comparison of MCMC and VB for speaker clustering

VI. SUMMARY AND FUTUREPERSPECTIVE
This paper introduced selected topics regarding Bayesian applications to acoustic modeling in speech processing. As standard techniques, we first explained MAP- and BIC-based approaches. We then focused on applications of VB and MCMC, following the recent trend of Bayesian applications to speech recognition emphasizing the advantages of fully Bayesian approaches that explicitly obtain posterior distributions of model parameters and structures based on these two methods. These approaches are associated with the progress of Bayesian approaches in the statistics and machine learning fields, and speech recognition based on Bayesian approaches is likely to advance further, thanks to the recent progress in these fields.
One promising example of further progress is structure learning by using Bayesian approaches. This paper introduced a powerful advantage of Bayesian model selection for the structure learning of standard acoustic models in Sections III and IV. Furthermore, the recent success of deep learning for acoustic modeling [Reference Hinton, Deng, Yu, Dahl, Mohamed, Jaitly, Senior, Vanhoucke, Nguyen, Sainath and Kingsbury81] places more importance on the structure learning of deep network topologies (e.g., number of layers and number of hidden states) in addition to the conventional HMM topologies. To deal with the problem, advanced structure learning techniques based on non-parametric Bayes [Reference Ferguson82] would be a powerful candidate. These approaches have recently been actively studied in the machine-learning field [Reference Griffiths and Ghahramani83–Reference Blei, Griffiths and Jordan85]. In conjunction with this trend, various applications of non-parametric Bayes have been proposed in speech processing [Reference Fox, Sudderth, Jordan and Willsky22,Reference Tawara, Watanabe, Ogawa and Kobayashi23,Reference Lee and Glass86], spoken language processing [Reference Goldwater and Griffiths75,Reference Mochihashi, Yamada and Ueda76,Reference Neubig, Mimura, Mori and Kawahara87], and music signal processing [Reference Hoffman, Blei and Cook88–Reference Nakano, Le Roux, Kameoka, Nakamura, Ono and Sagayama90].
Another important future work is how to involve Bayesian approaches with discriminative approaches theoretically and practically, since discriminative training [Reference Povey39,Reference McDermott, Hazen, Le Roux, Nakamura and Katagiri91], structured discriminative models [Reference Gales, Watanabe and Fossler-Lussier92], and deep discriminative learning [Reference Hinton, Deng, Yu, Dahl, Mohamed, Jaitly, Senior, Vanhoucke, Nguyen, Sainath and Kingsbury81] have become standard approaches in acoustic modeling. One promising approach for this direction is the marginalization of model parameters and margin variables to provide Bayesian interpretations with discriminative methods [Reference Jebara93]. However, applying [Reference Jebara93] to acoustic models requires some extensions to deal with large-scale structured data problems [Reference Kubo, Watanabe, Nakamura and Kobayashi74]. This extension enables the more robust regularization of discriminative approaches, and allows structure learning by combining Bayesian and discriminative criteria.
Finally, we believe that further progress based on Bayesian approaches for acoustic models would improve the success of speech processing applications including speech recognition. To this end, we encourage people in a wide range of research areas (e.g., speech processing, machine learning, and statistics) to explore this exciting and interdisciplinary topic.
ACKNOWLEDGMENTS
The authors thank Dr Jonathan Le Roux at Mitsubishi Electric Research Laboratories (MERL) for fruitful discussions. We also thank the anonymous reviewers for their valuable comments on our paper, which have improved its quality.










 Open access
Open access