





 operator for definite descriptions. Rules specific to free logic give rise to new kinds of maximal formulas additional to those familiar from standard intuitionist and classical logic. When
operator for definite descriptions. Rules specific to free logic give rise to new kinds of maximal formulas additional to those familiar from standard intuitionist and classical logic. When  is added it must be ensured that reduction procedures involving replacements of parameters by terms do not introduce new maximal formulas of higher degree than the ones removed. The problem is solved by a rule that permits restricting these terms in the rules for
is added it must be ensured that reduction procedures involving replacements of parameters by terms do not introduce new maximal formulas of higher degree than the ones removed. The problem is solved by a rule that permits restricting these terms in the rules for 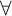

 to parameters or constants. A restricted subformula property for deductions in systems without
to parameters or constants. A restricted subformula property for deductions in systems without  is considered. It is improved upon by an alternative formalisation of free logic building on an idea of Jaśkowski’s. In the classical system the rules for
is considered. It is improved upon by an alternative formalisation of free logic building on an idea of Jaśkowski’s. In the classical system the rules for  require treatment known from normalisation for classical logic with
require treatment known from normalisation for classical logic with 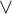

1. Introduction
It goes without saying that Russell’s theory of definite descriptions, expressions of the form ‘the F’, carries great philosophical significance, and its importance in the development of analytic philosophy is hard to overstate. As there may not be a unique F, Russell proposed that ‘The F is G’ means ‘There is exactly one F and it is G’: the definite description disappears upon analysis and is not a genuine singular term.Footnote 1
Despite its paradigmatic status, Russell’s theory has not met with universal acceptance. A motive in the development of free logic by Hintikka, Lambert and others was the formalisation of alternative theories.Footnote 2 Free logic does not require that singular terms refer nor that domains of quantification be non-empty. Definite descriptions are treated as genuine singular terms. Nonetheless, negative free logic retains some Russellian spirit: atomic formulas containing singular terms cannot be true unless the terms refer.
The present paper investigates systems of natural deduction for classical and intuitionist negative free logic with and without definite descriptions from a proof-theoretic perspective. Normalisation theorems for various systems formalised in Gentzen’s natural deduction are proved. They establish that maximal formulas—major premises of elimination rules that are concluded by an introduction rule—can be removed from deductions by applying reduction procedures that transform them so that these inferences are avoided. Normalisation theorems are analogous to Gentzen’s Hauptsatz for sequent calculus.Footnote 3
I shall begin with systems without definite descriptions familiar from the literature. To the best of my knowledge, no normalisation theorems have been proved for them. To fill this gap is the first contribution of this paper. The proofs largely follow Prawitz’s method [Reference Prawitz26]. For the classical system with ![]() a method of Andou’s is adapted [Reference Andou1]. Normalisation for free logic requires considering new cases of maximal formulas that do not occur in standard classical and intuitionist logic. Furthermore, I shall investigate the form of normal deductions and consider a suitable subformula property. Due to the rules for the quantifiers and those characteristic of negative free logic, this notion has to be rather restricted. Thus I shall propose an alternative way of formalising free logic inspired by Jaśkowski that improves on the situation.
a method of Andou’s is adapted [Reference Andou1]. Normalisation for free logic requires considering new cases of maximal formulas that do not occur in standard classical and intuitionist logic. Furthermore, I shall investigate the form of normal deductions and consider a suitable subformula property. Due to the rules for the quantifiers and those characteristic of negative free logic, this notion has to be rather restricted. Thus I shall propose an alternative way of formalising free logic inspired by Jaśkowski that improves on the situation.
The next contribution is to prove normalisation theorems for systems with the ![]() operator to formalise definite descriptions. Rules for
operator to formalise definite descriptions. Rules for ![]() suitable for negative free logic were given by Neil Tennant. Tennant also gives reduction procedures for maximal formulas of the form
suitable for negative free logic were given by Neil Tennant. Tennant also gives reduction procedures for maximal formulas of the form ![]() , but to the best of my knowledge, no one has explicitly proved normalisation for Tennant’s systems. In fact, for normalisation to be provable as is standardly done by an induction over the complexity of maximal formulas, the systems require modification. In a nutshell, the problem is that as they stand, once
, but to the best of my knowledge, no one has explicitly proved normalisation for Tennant’s systems. In fact, for normalisation to be provable as is standardly done by an induction over the complexity of maximal formulas, the systems require modification. In a nutshell, the problem is that as they stand, once ![]() terms are added, applying the reduction procedures for maximal formulas with quantifiers and
terms are added, applying the reduction procedures for maximal formulas with quantifiers and ![]() may produce maximal formulas of unbounded complexity because
may produce maximal formulas of unbounded complexity because ![]() terms are substituted for free variables. To solve this problem I transpose an observation of Andrzej Indrzejczak’s relating to sequent calculi for free logics without definite descriptions [Reference Indrzejczak10, sec. 4] to natural deduction.Footnote
4
The natural deduction version of a rule of Indrzejczak’s permits the restriction of the rules for the quantifiers and
terms are substituted for free variables. To solve this problem I transpose an observation of Andrzej Indrzejczak’s relating to sequent calculi for free logics without definite descriptions [Reference Indrzejczak10, sec. 4] to natural deduction.Footnote
4
The natural deduction version of a rule of Indrzejczak’s permits the restriction of the rules for the quantifiers and ![]() to free variables or constants in such a way that only these are replaced for free variables in the reduction procedures. This ensures that the complexity of any new maximal formulas is less than that of the maximal formula removed, and induction can proceed as usual.
to free variables or constants in such a way that only these are replaced for free variables in the reduction procedures. This ensures that the complexity of any new maximal formulas is less than that of the maximal formula removed, and induction can proceed as usual.
I shan’t consider a suitable subformula property for the systems with ![]() . As Tennant’s rules introduce and eliminate the
. As Tennant’s rules introduce and eliminate the ![]() operator in terms flanking
operator in terms flanking
 $=$
, this would require too many exceptions.
$=$
, this would require too many exceptions.
Although the present paper focuses on formal issues, there will be occasion to comment briefly on the philosophical upshot of the results. Normalisation theorems are of interest in themselves, but they also have a wider philosophical significance. In proof-theoretic semantics, the theory that the meanings of logical expressions are defined by the rules of inference governing them, it is regarded as a necessary condition for them to do so that they permit normalisation.Footnote 5
Given the significance of Russell’s theory of definite description, it is a little surprising that there is next to no discussion of the theory of definite descriptions in proof-theoretic semantics. Proof-theoretic semantics so far has rarely considered free logic and largely been restricted to sentence-forming operators and quantifiers. Term-forming operators hardly feature in the literature at all. A notable exception is Neil Tennant’s work.Footnote 6 The present paper is a contribution to the further development of a proof-theoretic semantics for definite descriptions and term-forming operators in general.
2. Systems of intuitionist and classical free logic
2.1. Preliminaries
The definition of the language is standard, except that there is a special one-place predicate
 $\exists !$
and in some systems the operator
$\exists !$
and in some systems the operator ![]() . As usual in proof-theoretic investigation, I assume that there is an unlimited stock of variables, called parameters, used as free variables, distinct in shape from those whose occurrences are bound by quantifiers:
. As usual in proof-theoretic investigation, I assume that there is an unlimited stock of variables, called parameters, used as free variables, distinct in shape from those whose occurrences are bound by quantifiers:
 $a, b \ldots $
for the former,
$a, b \ldots $
for the former,
 $x, y, z\ldots $
for the latter. Constants are designated by
$x, y, z\ldots $
for the latter. Constants are designated by
 $c, d\ldots $
, predicate letters by
$c, d\ldots $
, predicate letters by
 $P, Q, R\ldots $
, identity by
$P, Q, R\ldots $
, identity by
 $=$
, and the ‘existence predicate’, indicating that a term refers, by
$=$
, and the ‘existence predicate’, indicating that a term refers, by
 $\exists !$
.
$\exists !$
.
 $A, B\ldots F, G \ldots $
range over formulas. If necessary, subscripts are used. The connectives are
$A, B\ldots F, G \ldots $
range over formulas. If necessary, subscripts are used. The connectives are
 $\bot $
,
$\bot $
,
 $\land $
,
$\land $
,
 $\lor $
,
$\lor $
,
 $\rightarrow $
,
$\rightarrow $
,
 $\exists $
and
$\exists $
and
 $\forall $
.
$\forall $
.
 $\neg A$
is defined as
$\neg A$
is defined as
 $A\rightarrow \bot $
.
$A\rightarrow \bot $
. ![]() takes a variable and a formula F and forms a singular term out of them,
takes a variable and a formula F and forms a singular term out of them, ![]() , where x is bound by
, where x is bound by ![]() in F. The terms of the language are the constants, parameters and the
in F. The terms of the language are the constants, parameters and the ![]() terms, the former two atomic, the latter complex. t ranges over terms.
terms, the former two atomic, the latter complex. t ranges over terms.
 $A_t^x$
names the formula that results from replacing the term t for all free occurrences of x in A. The distinction between parameters and bound variables ensures that replacements of terms in formulas is always possible.
$A_t^x$
names the formula that results from replacing the term t for all free occurrences of x in A. The distinction between parameters and bound variables ensures that replacements of terms in formulas is always possible.
Definition 1.
Prime formulas are those formed from parameters and constants by predicate letters,
 $\exists !$
or =. Atomic formulas are those formed from terms by these expressions.
$\exists !$
or =. Atomic formulas are those formed from terms by these expressions.
Deductions are defined as usual as certain kinds of trees labeled with formulas. I follow Troelstra’s and Schwichtenberg’s conventions for the discharge or closing of assumptions [Reference Troestra and Schwichtenberg37, sec 2.1.1]: assumptions are assigned assumption classes, rules close or discharge all formulas in an assumption class, indicated by square brackets around the formulas in that class and a numeral to their right and to the right of the inference at which these assumptions are closed or discharged. Empty assumption classes, for vacuous discharge, are permitted. I’ll use
 $\Pi $
,
$\Pi $
,
 $\Xi $
,
$\Xi $
,
 $\Sigma $
to stand for deductions, often, as is customary, displaying their conclusions below and some assumptions on top.
$\Sigma $
to stand for deductions, often, as is customary, displaying their conclusions below and some assumptions on top.
Definition 2.
 $\Gamma \vdash _S A$
means that there is a deduction of A in formal system S from some of the formulas in
$\Gamma \vdash _S A$
means that there is a deduction of A in formal system S from some of the formulas in
 $\Gamma $
as open assumptions.
$\Gamma $
as open assumptions.
2.2. Intuitionist negative free logic
These are the rules of Tennant’s system of intuitionist negative free logic
 $\mathbf {INF}$
[Reference Tennant32, sec. 7.10]:
$\mathbf {INF}$
[Reference Tennant32, sec. 7.10]:



where in
 $(\forall I)$
, a does not occur in
$(\forall I)$
, a does not occur in
 $\forall xA$
nor in any undischarged assumptions of
$\forall xA$
nor in any undischarged assumptions of
 $\Pi $
except those in the assumption class of
$\Pi $
except those in the assumption class of
 $\exists !a$
.
$\exists !a$
.

where in
 $(\exists E)$
, a is not free in C, nor in
$(\exists E)$
, a is not free in C, nor in
 $\exists xA$
, nor in any undischarged assumptions of
$\exists xA$
, nor in any undischarged assumptions of
 $\Pi $
except those in the assumption classes of
$\Pi $
except those in the assumption classes of
 $A_a^x$
and
$A_a^x$
and
 $\exists ! a$
.
$\exists ! a$
.

where R is an n-place predicate letter (but not
 $\exists !$
) or identity and
$\exists !$
) or identity and
 $1\leq i\leq n$
.
$1\leq i\leq n$
.
The superscript n of
 $(=I^n)$
indicates that this is in the introduction rule for identity in negative free logic.
$(=I^n)$
indicates that this is in the introduction rule for identity in negative free logic.
 $(AD)$
, the rule of atomic denotation, is typical for negative free logic: an atomic sentence can only be assertible or true if all terms that occur in it refer.
$(AD)$
, the rule of atomic denotation, is typical for negative free logic: an atomic sentence can only be assertible or true if all terms that occur in it refer.
I will often omit labels of rules in deductions, especially when they are simple and the rules mentioned in the surrounding text, but I’ll add them where I think this helps understanding, especially when deductions are more complex and the rules involved less familiar.
 $\exists !$
is in one sense redundant, as what is often called Hintikka’s Law holds:Footnote
7
$\exists !$
is in one sense redundant, as what is often called Hintikka’s Law holds:Footnote
7
 $\vdash \exists ! t\leftrightarrow \exists x \ x=t.$
$\vdash \exists ! t\leftrightarrow \exists x \ x=t.$
In another sense it makes good sense to keep it primitive, if the meanings of the quantifiers are to be defined by the rules governing them, as they are by Tennant: without it, the definition of the meaning of the existential quantifier would be circular.
2.3. Intuitionist negative free logic with a definite description operator
The system ![]() results by adding the
results by adding the ![]() operator and Tennant’s introduction and elimination rules for it to
operator and Tennant’s introduction and elimination rules for it to
 $\mathbf {INF}$
[Reference Tennant32, sec. 7.10]:
$\mathbf {INF}$
[Reference Tennant32, sec. 7.10]:

where a does not occur in ![]() , nor in t, nor in any undischarged assumptions except those in the assumption classes of
, nor in t, nor in any undischarged assumptions except those in the assumption classes of
 $a=t$
in
$a=t$
in
 $\Xi $
or of
$\Xi $
or of
 $F_a^x$
and
$F_a^x$
and
 $\exists ! a$
in
$\exists ! a$
in
 $\Pi $
.
$\Pi $
.

![]() is a special case of the rule
is a special case of the rule
 $(AD)$
. But it is properly regarded as an elimination rule for
$(AD)$
. But it is properly regarded as an elimination rule for ![]() , for, as we’ll see, there is a reduction procedure for maximal formulas of the form
, for, as we’ll see, there is a reduction procedure for maximal formulas of the form ![]() that have been concluded by
that have been concluded by ![]() and are premises of
and are premises of ![]() . So whenever
. So whenever
 $(AD)$
could be applied to the conclusion of
$(AD)$
could be applied to the conclusion of ![]() , that is, when it is concluded that the right term refers, this is regarded as an application of
, that is, when it is concluded that the right term refers, this is regarded as an application of ![]() . If it is the left term, the rule is
. If it is the left term, the rule is
 $(AD)$
.
$(AD)$
.
The rules for ![]() are what is now often called Lambert’s Axiom in rule form:
are what is now often called Lambert’s Axiom in rule form:
![]() is thus an intuitionist version of the minimal theory of definite descriptions in negative free logic.Footnote
8
is thus an intuitionist version of the minimal theory of definite descriptions in negative free logic.Footnote
8
A second axiom of Lambert’s, sometimes called ‘cancellation’,
is provable conditionally on the existence of t by an application of ![]() in which F is
in which F is
 $x=t$
and
$x=t$
and
 $\exists !a$
in the rightmost subdeduction is discharged vacuously:
$\exists !a$
in the rightmost subdeduction is discharged vacuously:

2.4. Classical negative free logic with and without a definite description operator
 $\mathbf {CNF}$
has the introduction and elimination rules for
$\mathbf {CNF}$
has the introduction and elimination rules for
 $\rightarrow $
,
$\rightarrow $
,
 $\forall $
and
$\forall $
and
 $=$
,
$=$
,
 $(AD)$
and
$(AD)$
and
 $(\bot E_C)$
:
$(\bot E_C)$
:

Vacuous discharged being permitted,
 $(\bot E)$
is a special case of
$(\bot E)$
is a special case of
 $(\bot E_C)$
. I’ll refer to these applications of
$(\bot E_C)$
. I’ll refer to these applications of
 $(\bot E_C)$
by the former label.
$(\bot E_C)$
by the former label.
![]() results by adding
results by adding ![]() and its rules to
and its rules to
 $\mathbf {CNF}$
.
$\mathbf {CNF}$
.
2.5. Two simplifying lemmas
The two lemmas in this section absolve us from having to consider certain tiresome cases in the normalisation theorem.
Lemma 1.
 $(=E)$
may be restricted to atomic conclusions.
$(=E)$
may be restricted to atomic conclusions.
Proof. Well known and standard: break up a non-atomic formula by applying elimination rules until atomic formulas are reached, apply
 $(=E)$
, reconstitute it by applying introduction rules.
$(=E)$
, reconstitute it by applying introduction rules.
Lemma 1 holds for all the systems to be considered. More interesting and as far as I know new to the literature is the following:
Lemma 2.
 $(\bot E)$
may be restricted to prime conclusions.
$(\bot E)$
may be restricted to prime conclusions.
Proof. (i) Evidently it is unnecessary to conclude
 $\bot $
from
$\bot $
from
 $\bot $
by
$\bot $
by
 $(\bot E)$
. (ii) By a well known and standard result,
$(\bot E)$
. (ii) By a well known and standard result,
 $(\bot E)$
may be restricted to atomic conclusions. Thus it suffices to consider the case where the conclusion of
$(\bot E)$
may be restricted to atomic conclusions. Thus it suffices to consider the case where the conclusion of
 $(\bot E)$
is an atomic formula. We’ll first reduce these cases to identities flanked by only one
$(\bot E)$
is an atomic formula. We’ll first reduce these cases to identities flanked by only one ![]() term and then treat those.
term and then treat those.
(iii) Let G be either
 $\exists !$
or
$\exists !$
or
 $=$
flanked by two
$=$
flanked by two ![]() terms or an
terms or an
 $(n+m)$
-place predicate letter,
$(n+m)$
-place predicate letter,
 $1<n, 0\leq m$
, forming a formula with
$1<n, 0\leq m$
, forming a formula with ![]() terms and m atomic terms, the latter left implicit below:
terms and m atomic terms, the latter left implicit below:
These cases can all be reduced to applications of
 $(\bot E)$
to identities flanked by only one
$(\bot E)$
to identities flanked by only one ![]() term by the following method. Take n fresh parameters
term by the following method. Take n fresh parameters
 $a_1\ldots a_n$
and infer
$a_1\ldots a_n$
and infer ![]() and
and
 $G(a_1\ldots a_n)$
by
$G(a_1\ldots a_n)$
by
 $n+1$
applications of
$n+1$
applications of
 $(\bot E)$
, then apply
$(\bot E)$
, then apply
 $(=E)\ n$
times to deduce
$(=E)\ n$
times to deduce ![]() :
:

When G is an identity flanked by two ![]() terms,
terms, ![]() , there is a shorter method, as
, there is a shorter method, as ![]() , but the method above works, too.
, but the method above works, too.
(iv) This leaves the case of an identity flanked by one ![]() term. As
term. As
 $=$
is symmetric, it suffices to consider the case:
$=$
is symmetric, it suffices to consider the case:
where b is a an atomic term. Apply ![]() with vacuous discharge, where a is a fresh parameter:
with vacuous discharge, where a is a fresh parameter:

F may be a complex formula or
 $\bot $
and contain further
$\bot $
and contain further ![]() terms, so to establish the lemma, parts (i)–(iv) may need to be applied again. (i) is trivial: delete an application of
terms, so to establish the lemma, parts (i)–(iv) may need to be applied again. (i) is trivial: delete an application of
 $(\bot E)$
that concludes
$(\bot E)$
that concludes
 $\bot $
immediately whenever it arises as part of the procedure. The method for establishing (ii) reduces the number of connectives and quantifiers in conclusions of
$\bot $
immediately whenever it arises as part of the procedure. The method for establishing (ii) reduces the number of connectives and quantifiers in conclusions of
 $(\bot E)$
. The methods of (iii) and (iv) reduce in addition the number of
$(\bot E)$
. The methods of (iii) and (iv) reduce in addition the number of ![]() s in conclusions of
s in conclusions of
 $(\bot E)$
. The result, therefore, can be established by an induction over the complexity of conclusions of
$(\bot E)$
. The result, therefore, can be established by an induction over the complexity of conclusions of
 $(\bot E)$
. For the purposes of this lemma, let the degree for a formula be the sum of connectives, quantifiers and
$(\bot E)$
. For the purposes of this lemma, let the degree for a formula be the sum of connectives, quantifiers and ![]() s in it. The measure
s in it. The measure
 $\langle d, e\rangle $
, ordered lexicographically, will do, where d is the highest degree of any conclusion of
$\langle d, e\rangle $
, ordered lexicographically, will do, where d is the highest degree of any conclusion of
 $(\bot E)$
, and e is the number of conclusions of
$(\bot E)$
, and e is the number of conclusions of
 $(\bot E)$
of highest degree. Applying any of the procedures in (ii), (iii), or (iv) either reduces e or, if there is only one conclusion of
$(\bot E)$
of highest degree. Applying any of the procedures in (ii), (iii), or (iv) either reduces e or, if there is only one conclusion of
 $(\bot E)$
of highest degree, reduces d.
$(\bot E)$
of highest degree, reduces d.
Lemma 2 holds for
 $\mathbf {INF}$
,
$\mathbf {INF}$
, ![]() and carries over to
and carries over to
 $\mathbf {CNF}$
and
$\mathbf {CNF}$
and
 $(\bot E_C)$
: its conclusion, too, can be restricted to prime formulas (here the same as the atomic ones).
$(\bot E_C)$
: its conclusion, too, can be restricted to prime formulas (here the same as the atomic ones).
Lemma 2 does not carry over to
 $(\bot E_C)$
in
$(\bot E_C)$
in ![]() : when discharge is not vacuous, conclusions of
: when discharge is not vacuous, conclusions of
 $(\bot E_C)$
cannot be restricted to prime, but only to atomic conclusions: conclusions containing
$(\bot E_C)$
cannot be restricted to prime, but only to atomic conclusions: conclusions containing ![]() terms must be admitted, but only atomic ones. It would go too far to give a rigorous proof of this result here, and in any case, a further restriction is not needed for the normalisation proof to be given later. The following should suffice to elucidate the reason why the result fails. To show that
terms must be admitted, but only atomic ones. It would go too far to give a rigorous proof of this result here, and in any case, a further restriction is not needed for the normalisation proof to be given later. The following should suffice to elucidate the reason why the result fails. To show that
 $(\bot E_C)$
need not be applied to conclude a complex formula A, the usual procedure is to apply an elimination rule for the main operator of A, derive
$(\bot E_C)$
need not be applied to conclude a complex formula A, the usual procedure is to apply an elimination rule for the main operator of A, derive
 $\bot $
by assuming the negation of a subformula of A, conclude
$\bot $
by assuming the negation of a subformula of A, conclude
 $\neg A$
, apply
$\neg A$
, apply
 $(\bot E_C)$
to the subformula, and to do so as often as required to apply an introduction rule for the main operator of A to conclude A and discharge any auxiliary assumptions. This method does not work here. Suppose
$(\bot E_C)$
to the subformula, and to do so as often as required to apply an introduction rule for the main operator of A to conclude A and discharge any auxiliary assumptions. This method does not work here. Suppose ![]() . We could take a fresh parameter b and conclude
. We could take a fresh parameter b and conclude
 $F_b^x$
by
$F_b^x$
by ![]() from
from ![]() and
and
 $b=a$
, assume
$b=a$
, assume
 $\neg F_b^x$
to derive
$\neg F_b^x$
to derive
 $\bot $
, and so deduce
$\bot $
, and so deduce ![]() ; thus
; thus
 $\Gamma , b=a\vdash F_b^x$
. We could apply
$\Gamma , b=a\vdash F_b^x$
. We could apply ![]() to
to ![]() and
and
 $\exists !b$
to derive
$\exists !b$
to derive
 $b=a$
, assume
$b=a$
, assume
 $\neg \ b=a$
to derive
$\neg \ b=a$
to derive
 $\bot $
and so deduce
$\bot $
and so deduce ![]() ; thus
; thus
 $\Gamma , F_b^x, \exists !b\vdash b=a$
. Thus we have the two left deductions required for an application of
$\Gamma , F_b^x, \exists !b\vdash b=a$
. Thus we have the two left deductions required for an application of ![]() . But we do not have
. But we do not have
 $\exists !b$
, and there is no way to derive it from the material we are given. Besides, even with
$\exists !b$
, and there is no way to derive it from the material we are given. Besides, even with
 $\exists !b$
we’d only be able to derive
$\exists !b$
we’d only be able to derive ![]() , not
, not ![]() , as
, as ![]() requires a fresh parameter. The situation is no better for atomic formulas other than identities. To avoid concluding
requires a fresh parameter. The situation is no better for atomic formulas other than identities. To avoid concluding ![]() we’d need a formula
we’d need a formula ![]() to conclude
to conclude ![]() from
from
 $\neg P(a)$
, and there is no way to discharge it.
$\neg P(a)$
, and there is no way to discharge it.
Henceforth I shall assume all applications of
 $(=E)$
,
$(=E)$
,
 $(\bot E)$
and
$(\bot E)$
and
 $(\bot E_C)$
to be restricted according to Lemmas 1 and 2. That is, in
$(\bot E_C)$
to be restricted according to Lemmas 1 and 2. That is, in ![]() , applications of
, applications of
 $(\bot E_C)$
with vacuous discharge are assumed to have prime conclusions, just as for applications of
$(\bot E_C)$
with vacuous discharge are assumed to have prime conclusions, just as for applications of
 $(\bot E)$
in
$(\bot E)$
in ![]() .
.
3. Preliminaries to normalisation
3.1. General notions
As usual, I assume that in any application of rules with restrictions on parameters the parameter is introduced into the deduction solely for the purpose of that application of the rule, occurring nowhere else.Footnote
9
This ensures that in the transformations applied to deductions in the process of normalisation, no ‘clashes’ of variables can occur.
 $\Pi _t^a$
names the deduction that results from replacing the term t for all occurrences of the parameter a in
$\Pi _t^a$
names the deduction that results from replacing the term t for all occurrences of the parameter a in
 $\Pi $
.
$\Pi $
. ![]() indicates that
indicates that
 $\Pi $
is used to conclude all assumptions in the assumption class of A in
$\Pi $
is used to conclude all assumptions in the assumption class of A in
 $\Sigma $
. This notation is used to indicate that formulas discharged by a rule in one deduction are instead concluded by another rule in a transformed deduction.
$\Sigma $
. This notation is used to indicate that formulas discharged by a rule in one deduction are instead concluded by another rule in a transformed deduction.
Definition 3. The major premise of an elimination rule is the formula that displays the connective or ![]() in the general statement of the rule, here always the leftmost premise. All others are minor premises.
in the general statement of the rule, here always the leftmost premise. All others are minor premises.
Applications of
 $(\lor E)$
and
$(\lor E)$
and
 $(\exists E)$
give rise to sequences of formulas of the same shape, all minor premises and conclusions of
$(\exists E)$
give rise to sequences of formulas of the same shape, all minor premises and conclusions of
 $(\lor E)$
or
$(\lor E)$
or
 $(\exists E)$
, except the first and the last ones: the first is only a minor premise, the last only a conclusion. It is convenient to capture this situation in a way that covers every formula in a deduction (cf. [Reference Prawitz26, p. 49] and [Reference Troestra and Schwichtenberg37, p. 179]):
$(\exists E)$
, except the first and the last ones: the first is only a minor premise, the last only a conclusion. It is convenient to capture this situation in a way that covers every formula in a deduction (cf. [Reference Prawitz26, p. 49] and [Reference Troestra and Schwichtenberg37, p. 179]):
Definition 4. A segment is a sequence of formulas
 $C_1\ldots C_n$
such that
$C_1\ldots C_n$
such that
 $C_1$
is not the conclusion of
$C_1$
is not the conclusion of
 $(\lor E)$
or
$(\lor E)$
or
 $(\exists E)$
,
$(\exists E)$
,
 $C_n$
is not a minor premise of
$C_n$
is not a minor premise of
 $(\lor E)$
or
$(\lor E)$
or
 $(\exists E)$
, and if
$(\exists E)$
, and if
 $n>1$
then for all
$n>1$
then for all
 $i<n$
,
$i<n$
,
 $C_i$
is a minor premise of
$C_i$
is a minor premise of
 $(\lor E)$
or
$(\lor E)$
or
 $(\exists E)$
,
$(\exists E)$
,
 $C_{i+1}$
the conclusion. n is the length of the segment.
$C_{i+1}$
the conclusion. n is the length of the segment.
I’ll say that C is on a segment and speak of segments as being premises, conclusions, discharged assumptions of rules depending on whether their last or first formulas are.
A segment of length
 $1$
is a formula, and I shall often refer to them as such. Occasionally I shall use the pleonasm ‘formula or segment’.
$1$
is a formula, and I shall often refer to them as such. Occasionally I shall use the pleonasm ‘formula or segment’.
Definition 4 ignores a minor issue. Call an application of
 $(=E)$
vacuous if the major premise is
$(=E)$
vacuous if the major premise is
 $t=t$
. The definition ignores the possibility that the formulas on a segment are minor premises and conclusions of vacuous applications of
$t=t$
. The definition ignores the possibility that the formulas on a segment are minor premises and conclusions of vacuous applications of
 $(=E)$
. However, as then the minor premise and the conclusion of
$(=E)$
. However, as then the minor premise and the conclusion of
 $(=E)$
are identical, they can evidently be removed from deductions without loss and without trouble. Including this possibility is a needless complication. Vacuous applications of
$(=E)$
are identical, they can evidently be removed from deductions without loss and without trouble. Including this possibility is a needless complication. Vacuous applications of
 $(=E)$
can arise as a result of the transformations of deductions in normalisation procedures. I shall assume that they are always removed together with the procedure. I shall leave this largely implicit, but as a reminder that they may occur, I shall at various points mention vacuous applications of
$(=E)$
can arise as a result of the transformations of deductions in normalisation procedures. I shall assume that they are always removed together with the procedure. I shall leave this largely implicit, but as a reminder that they may occur, I shall at various points mention vacuous applications of
 $(=E)$
.
$(=E)$
.
Definition 5. A segment is maximal if its last formula is the major premise of an elimination rule, and if its length is
 $1$
, it is the conclusion of an introduction rule.
$1$
, it is the conclusion of an introduction rule.
Accordingly a maximal formula is a formula occurrence that is the conclusion of an introduction rule and the major premise of an elimination rule.
The degree of a formula is normally defined as the number of logical symbols occurring in it. For our purposes, however, quantifiers need to count for two because of the existence assumptions in their rules. This ensures that
 $\forall xA$
and
$\forall xA$
and
 $\exists xA$
always have a higher complexity than the premises and discharged assumptions of their introduction rules. This is not needed for
$\exists xA$
always have a higher complexity than the premises and discharged assumptions of their introduction rules. This is not needed for ![]() , as counting
, as counting ![]() and
and
 $=$
as one each,
$=$
as one each, ![]() always has a higher complexity than any premise or discharged assumption of
always has a higher complexity than any premise or discharged assumption of ![]() (at least 2). The degree
(at least 2). The degree
 $d(A)$
of a formula A and
$d(A)$
of a formula A and
 $d(t)$
of terms is defined by simultaneous induction as follows:
$d(t)$
of terms is defined by simultaneous induction as follows:
Definition 6. (a) If A is a prime formula
 $Rt_1\ldots t_n$
, then
$Rt_1\ldots t_n$
, then
 $d(A)=0$
if R is a predicate letter, and
$d(A)=0$
if R is a predicate letter, and
 $d(A)=1$
if R is
$d(A)=1$
if R is
 $\exists !$
or
$\exists !$
or
 $=$
. (b)
$=$
. (b)
 $d(t)=0$
, if t is an atomic term,
$d(t)=0$
, if t is an atomic term,
 $d(F)+1$
if t is
$d(F)+1$
if t is ![]() . (c) If A is an atomic formula
. (c) If A is an atomic formula
 $Rt_1\ldots t_n$
, then
$Rt_1\ldots t_n$
, then
 $d(A)=d(t_1)+\ldots d(t_n)$
if R is a predicate letter, and
$d(A)=d(t_1)+\ldots d(t_n)$
if R is a predicate letter, and
 $d(A)=d(t_1)+\ldots d(t_n)+1$
if R is
$d(A)=d(t_1)+\ldots d(t_n)+1$
if R is
 $\exists !$
or
$\exists !$
or
 $=$
. (d). If A is:
$=$
. (d). If A is:
(i)
 $\bot $
, then
$\bot $
, then
 $d(A)=1$
.
$d(A)=1$
.
(ii)
 $\neg B$
, then
$\neg B$
, then
 $d(A)=d(B)+1$
.
$d(A)=d(B)+1$
.
(iii)
 $B\land C$
,
$B\land C$
,
 $B\supset C$
or
$B\supset C$
or
 $B\lor C$
, then
$B\lor C$
, then
 $d(A)=d(B)+d(C)+1$
.
$d(A)=d(B)+d(C)+1$
.
(iv)
 $\forall xB$
or
$\forall xB$
or
 $\exists xB$
, then
$\exists xB$
, then
 $d(A)=d(B)+2.$
$d(A)=d(B)+2.$
The degree of a segment is the degree of the formula on it.
3.2. Failure of the subformula property
As I won’t consider the subformula property for systems with ![]() , the definition of subformula is standard:
, the definition of subformula is standard:
Definition 7.
A is a subformula of A; A is a subformula of
 $\neg A$
;
$\neg A$
;
 $A, B$
are subformulas of
$A, B$
are subformulas of
 $A\land B$
,
$A\land B$
,
 $A \lor B$
,
$A \lor B$
,
 $A \rightarrow B$
; and for any atomic term t,
$A \rightarrow B$
; and for any atomic term t,
 $A_t^x$
is a subformula of
$A_t^x$
is a subformula of
 $\exists xA$
,
$\exists xA$
,
 $\forall xA$
; and if A is a subformula of B and B is a subformula of C, then A is a subformula of C.
$\forall xA$
; and if A is a subformula of B and B is a subformula of C, then A is a subformula of C.
The subformula property is usually defined as follows:
Definition 8. A deduction has the subformula property if every formula occurring on it is a subformula of the conclusion or of some open assumption.
This fails already in standard first-order logic with identity. For instance:

 $Rt_2t_3$
is not a subformula of any other formula, and there is no way to rearrange the deduction to change this. It also fails due to rules specific to negative free logic. For instance, to deduce
$Rt_2t_3$
is not a subformula of any other formula, and there is no way to rearrange the deduction to change this. It also fails due to rules specific to negative free logic. For instance, to deduce
 $A_t^x$
from
$A_t^x$
from
 $\forall xA$
requires
$\forall xA$
requires
 $\exists !t$
, which we may be able to infer from an atomic formula
$\exists !t$
, which we may be able to infer from an atomic formula
 $Pt$
:
$Pt$
:

 $\exists !t$
need not be a subformula of another formula, and there may be no way to rearrange this deduction. Identity gives rise to further cases, e.g., to conclude
$\exists !t$
need not be a subformula of another formula, and there may be no way to rearrange this deduction. Identity gives rise to further cases, e.g., to conclude
 $t=t$
by
$t=t$
by
 $(=I^n)$
requires
$(=I^n)$
requires
 $\exists !t$
, which may be concluded from
$\exists !t$
, which may be concluded from
 $Pt$
.
$Pt$
.
This circumscribes where exceptions to the subformula property are found. I will later define a restricted version that holds for deductions in
 $\mathbf {INF}$
and
$\mathbf {INF}$
and
 $\mathbf {CNF}$
.
$\mathbf {CNF}$
.
Comment. I am not regarding
 $(AD)$
as an introduction rule for
$(AD)$
as an introduction rule for
 $\exists !$
, nor
$\exists !$
, nor
 $(\exists I)$
,
$(\exists I)$
,
 $(\forall E)$
and
$(\forall E)$
and
 $(=I^n)$
as elimination rules for it. There are philosophical questions that arise here, which I will discuss briefly on p. 19. and p. 22. An extended discussion must wait for another occasion.Footnote
10
$(=I^n)$
as elimination rules for it. There are philosophical questions that arise here, which I will discuss briefly on p. 19. and p. 22. An extended discussion must wait for another occasion.Footnote
10
3.3. Maximal segments specific to negative free logic
Maximal formulas arise because of detours in deductions, to use Gentzen’s phrase. Normalisation theorems show that these detours can be avoided. They are unnecessary to derive the conclusion. The process of normalisation may also remove unnecessary assumptions from the deduction. The thought is that a proof in normal form appeals only to what is essential to prove the conclusion.
The rules of negative free logic give rise to detours in addition to those of Definition 5. For instance,
 $(=I^n)$
followed by
$(=I^n)$
followed by
 $(AD)$
and sometimes conversely:
$(AD)$
and sometimes conversely:

This is clearly unnecessary. Similarly when
 $t=t$
and
$t=t$
and
 $\exists !t$
are stretched out by
$\exists !t$
are stretched out by
 $(\lor E)$
or
$(\lor E)$
or
 $(\exists E)$
. In the systems with
$(\exists E)$
. In the systems with ![]() ,
, ![]() could be applied instead of
could be applied instead of
 $(AD)$
, but this clearly makes no difference, as we can just rename the rule.
$(AD)$
, but this clearly makes no difference, as we can just rename the rule.
Definition 9. A maximal
 $=$
-segment is a segment (of formulas
$=$
-segment is a segment (of formulas
 $t=t$
) such that its first formula is concluded by
$t=t$
) such that its first formula is concluded by
 $(=I^n)$
and its last is the premise of
$(=I^n)$
and its last is the premise of
 $(AD)$
. A maximal
$(AD)$
. A maximal
 $\exists !$
-segment is a segment (of formulas
$\exists !$
-segment is a segment (of formulas
 $\exists !t$
) such that its first formula is concluded from
$\exists !t$
) such that its first formula is concluded from
 $t=t$
by
$t=t$
by
 $(AD)$
and its last is the premise of
$(AD)$
and its last is the premise of
 $(=I^n)$
.
$(=I^n)$
.
In
 $\mathbf {CNF}$
and
$\mathbf {CNF}$
and ![]() we may speak of maximal
we may speak of maximal
 $\exists !$
- and
$\exists !$
- and
 $=$
-formulas.
$=$
-formulas.
Recall that we are ignoring vacuous applications of
 $(=E)$
. This absolves us from considering the case that a maximal
$(=E)$
. This absolves us from considering the case that a maximal
 $=$
-segment contains what might be called totally vacuous applications of
$=$
-segment contains what might be called totally vacuous applications of
 $(=E)$
, those where all three formulas of the inference are
$(=E)$
, those where all three formulas of the inference are
 $t=t$
.
$t=t$
.
 $(=E)$
gives rise to sequences of formulas quite similar to segments, except that terms are replaced in the formulas constituting the segment:
$(=E)$
gives rise to sequences of formulas quite similar to segments, except that terms are replaced in the formulas constituting the segment:
Definition 10. An
 $(=E)$
-segment is a sequence of segments
$(=E)$
-segment is a sequence of segments
 $\sigma _1\ldots \sigma _n$
such that
$\sigma _1\ldots \sigma _n$
such that
 $\sigma _1$
is the minor premise but not the conclusion of
$\sigma _1$
is the minor premise but not the conclusion of
 $(=E)$
,
$(=E)$
,
 $\sigma _n$
is the conclusion but not the minor premise of
$\sigma _n$
is the conclusion but not the minor premise of
 $(=E)$
, and if
$(=E)$
, and if
 $1<i<n$
,
$1<i<n$
,
 $\sigma _i$
is the conclusion of
$\sigma _i$
is the conclusion of
 $(=E)$
and the minor premise of
$(=E)$
and the minor premise of
 $(=E)$
.
$(=E)$
.
I’ll refer to the major premises to the left of formulas on an
 $(=E)$
-segment as the major premises of the segment.
$(=E)$
-segment as the major premises of the segment.
 $(=E)$
-segments can give rise to unnecessary detours, if
$(=E)$
-segments can give rise to unnecessary detours, if
 $(AD)$
is applied to their last formulas or if their formulas have the form
$(AD)$
is applied to their last formulas or if their formulas have the form
 $\exists !t$
. For example:
$\exists !t$
. For example:

These constructions involve terms that may not be needed to derive the conclusion. In the systems without ![]() , these would be atomic terms that name objects the existence of which may be irrelevant to proving the conclusion (by
, these would be atomic terms that name objects the existence of which may be irrelevant to proving the conclusion (by
 $(AD)$
, for any
$(AD)$
, for any
 $t_j$
in (a) and (b),
$t_j$
in (a) and (b),
 $\exists !t_j$
). Free logic being concerned with the avoidance of existence assumptions, this is undesirable. In the systems with
$\exists !t_j$
). Free logic being concerned with the avoidance of existence assumptions, this is undesirable. In the systems with ![]() , there may in addition be complex terms that refer to objects by predicates that not are needed to prove the conclusion: this would be a case of introducing unnecessary concepts into the proof.
, there may in addition be complex terms that refer to objects by predicates that not are needed to prove the conclusion: this would be a case of introducing unnecessary concepts into the proof.
The
 $(=E)$
-segments can be omitted:
$(=E)$
-segments can be omitted:
(a) If
 $i=3$
,
$i=3$
,
 $\exists !t_3$
could have been concluded by
$\exists !t_3$
could have been concluded by
 $(AD)$
from the minor premise of the first application of
$(AD)$
from the minor premise of the first application of
 $(=E)$
; if
$(=E)$
; if
 $i=4$
,
$i=4$
,
 $\exists !t_4$
could have been concluded by
$\exists !t_4$
could have been concluded by
 $(AD)$
from the major premise of the last application of
$(AD)$
from the major premise of the last application of
 $(=E)$
.
$(=E)$
.
(b)
 $\exists !t_i$
could have been concluded by
$\exists !t_i$
could have been concluded by
 $(AD)$
from one of the major premises of
$(AD)$
from one of the major premises of
 $(=E)$
; if one or more of
$(=E)$
; if one or more of
 $t_4, t_5$
or
$t_4, t_5$
or
 $t_6$
happens to be the same as
$t_6$
happens to be the same as
 $t_1, t_2$
or
$t_1, t_2$
or
 $t_3$
,
$t_3$
,
 $\exists !t_i$
could also have been concluded from the first formula of the segment.
$\exists !t_i$
could also have been concluded from the first formula of the segment.
(c)
 $\exists !t_4$
could have been concluded by
$\exists !t_4$
could have been concluded by
 $(AD)$
from the major premise of the last application of
$(AD)$
from the major premise of the last application of
 $(=E)$
.
$(=E)$
.
Clearly this situation generalises, and also to cases with
 $(\lor E)$
or
$(\lor E)$
or
 $(\exists E)$
interspersed. As before, in the systems with
$(\exists E)$
interspersed. As before, in the systems with ![]() ,
, ![]() could be applied instead of
could be applied instead of
 $(AD)$
, but this again makes no difference, and we just rename the rule.
$(AD)$
, but this again makes no difference, and we just rename the rule.
Definition 11. An
 $(=E)$
-segment is maximal if its last segment is premise of
$(=E)$
-segment is maximal if its last segment is premise of
 $(AD)$
or if all formulas on it are formed from
$(AD)$
or if all formulas on it are formed from
 $\exists !$
and a term.
$\exists !$
and a term.
To distinguish the maximal segments defined in this section from those defined in the last section, I’ll refer to the latter by ‘maximal
 $I/E$
-segments’ (for introduction/elimination). By ‘maximal segment’ I usually mean both, but sometimes only
$I/E$
-segments’ (for introduction/elimination). By ‘maximal segment’ I usually mean both, but sometimes only
 $I/E$
-segments, if it is clear from context what is meant.
$I/E$
-segments, if it is clear from context what is meant.
The reduction procedures that remove the new maximal segments from deductions are as follows:
I. For maximal
 $\exists !$
- and
$\exists !$
- and
 $=$
-segments: remove the application of the rule that concludes the segment, the segment and the formula concluded from it (i.e., we proceed directly from the formula from which the segment is concluded to the rule applied to the formula concluded from the segment).
$=$
-segments: remove the application of the rule that concludes the segment, the segment and the formula concluded from it (i.e., we proceed directly from the formula from which the segment is concluded to the rule applied to the formula concluded from the segment).
II. For maximal
 $(=E)$
-segments: (i) If the formula on the segment is formed from
$(=E)$
-segments: (i) If the formula on the segment is formed from
 $\exists !$
and a term, conclude its last formula from the major premise of the last application of
$\exists !$
and a term, conclude its last formula from the major premise of the last application of
 $(=E)$
, removing all the rest. (ii) If not, conclude
$(=E)$
, removing all the rest. (ii) If not, conclude
 $\exists !t_i$
from either the first formula of the segment or from the lowest major premise of an application of
$\exists !t_i$
from either the first formula of the segment or from the lowest major premise of an application of
 $(=E)$
that contains
$(=E)$
that contains
 $t_i$
, removing all the rest.
$t_i$
, removing all the rest.
Lemma 3. Any deduction can be transformed into one without maximal
 $\exists !$
-,
$\exists !$
-,
 $=$
- and
$=$
- and
 $(=E)$
-segments.
$(=E)$
-segments.
Proof. Procedures I and II reduce the number of applications of rules in the deduction. None is added. Applying them will therefore come to an end. We can proceed in the following way. (1) Recall that vacuous applications of
 $(=E)$
are always removed. (2) Remove maximal
$(=E)$
are always removed. (2) Remove maximal
 $=$
- and
$=$
- and
 $\exists !$
-segments. Carrying out procedure I does not introduce new maximal
$\exists !$
-segments. Carrying out procedure I does not introduce new maximal
 $=$
-,
$=$
-,
 $\exists !$
- or
$\exists !$
- or
 $(=E)$
-segments. The latter is evident. Removing a maximal
$(=E)$
-segments. The latter is evident. Removing a maximal
 $=$
-segment could only introduce a maximal
$=$
-segment could only introduce a maximal
 $\exists !$
-segment if the segment from which it is concluded and the segment concluded from it are concluded by
$\exists !$
-segment if the segment from which it is concluded and the segment concluded from it are concluded by
 $(AD)$
and premise of
$(AD)$
and premise of
 $(=I^n),$
respectively, in which case they are both already maximal
$(=I^n),$
respectively, in which case they are both already maximal
 $\exists !$
-segments. Then two maximal
$\exists !$
-segments. Then two maximal
 $\exists !$
-segments are fused into one (with length one less than their sum). Similarly when removing maximal
$\exists !$
-segments are fused into one (with length one less than their sum). Similarly when removing maximal
 $\exists !$
-segments. The procedure shortens any such sequence of maximal
$\exists !$
-segments. The procedure shortens any such sequence of maximal
 $=$
- and
$=$
- and
 $\exists !$
-segments, but as they have the same formulas first and last, the entire sequence can also be removed at once. (3) Three cases are to be considered when removing maximal
$\exists !$
-segments, but as they have the same formulas first and last, the entire sequence can also be removed at once. (3) Three cases are to be considered when removing maximal
 $(=E)$
-segments. (a) Both parts of procedure II can introduce a new maximal
$(=E)$
-segments. (a) Both parts of procedure II can introduce a new maximal
 $=$
-segment if the last or lowest major premise of
$=$
-segment if the last or lowest major premise of
 $(=E)$
is
$(=E)$
is
 $t_i=t_i$
or if the first formula of the maximal
$t_i=t_i$
or if the first formula of the maximal
 $(=E)$
-segment has this form. If the former, the application of
$(=E)$
-segment has this form. If the former, the application of
 $(=E)$
is vacuous, and the problem is avoided by removing vacuous applications of
$(=E)$
is vacuous, and the problem is avoided by removing vacuous applications of
 $(=E)$
. If the latter, the first formula is the conclusion of
$(=E)$
. If the latter, the first formula is the conclusion of
 $(=I^n)$
and the last formula of the maximal
$(=I^n)$
and the last formula of the maximal
 $(=E)$
-segment is the premise of
$(=E)$
-segment is the premise of
 $(AD)$
, so the problem is solved by removing everything between the premise of
$(AD)$
, so the problem is solved by removing everything between the premise of
 $(=I^n)$
and the conclusion of
$(=I^n)$
and the conclusion of
 $(AD)$
(i.e., move straight from the premise of
$(AD)$
(i.e., move straight from the premise of
 $(=I^n)$
to the rule applied to the conclusion of
$(=I^n)$
to the rule applied to the conclusion of
 $(AD)$
). (b) Both parts of procedure II can introduce a new maximal
$(AD)$
). (b) Both parts of procedure II can introduce a new maximal
 $\exists !$
-segment if the last formula of the
$\exists !$
-segment if the last formula of the
 $(=E)$
-segment is the premise of
$(=E)$
-segment is the premise of
 $(=I^n)$
. In the case of part (i), the major premise of the last application of
$(=I^n)$
. In the case of part (i), the major premise of the last application of
 $(=E)$
would then have to have the form
$(=E)$
would then have to have the form
 $t=t$
, in which case the application is vacuous and the problem solved by removing it. In the case of part (ii), either the first formula of the maximal
$t=t$
, in which case the application is vacuous and the problem solved by removing it. In the case of part (ii), either the first formula of the maximal
 $(=E)$
-segment or the lowest major premise is
$(=E)$
-segment or the lowest major premise is
 $t_i=t_i$
. If the latter, the application of
$t_i=t_i$
. If the latter, the application of
 $(=E)$
is vacuous, so remove it. If the former,
$(=E)$
is vacuous, so remove it. If the former,
 $\exists ! t_i$
is concluded by
$\exists ! t_i$
is concluded by
 $(AD)$
from premise
$(AD)$
from premise
 $t_i=t_i$
, so the problem is solved by removing everything between the premise of
$t_i=t_i$
, so the problem is solved by removing everything between the premise of
 $(AD)$
and the conclusion of
$(AD)$
and the conclusion of
 $(=I^n)$
(i.e., move straight from the premise of
$(=I^n)$
(i.e., move straight from the premise of
 $(AD)$
to the rule applied to the conclusion of
$(AD)$
to the rule applied to the conclusion of
 $(=I^n)$
). (c) It can create a maximal
$(=I^n)$
). (c) It can create a maximal
 $(=E)$
-segment if one of the major premises is the last formula of an
$(=E)$
-segment if one of the major premises is the last formula of an
 $(=E)$
-segment. Then continue the process there. Consider the entire cluster of
$(=E)$
-segment. Then continue the process there. Consider the entire cluster of
 $(=E)$
-segments, that is, the maximal
$(=E)$
-segments, that is, the maximal
 $(=E)$
-segment, all
$(=E)$
-segment, all
 $(=E)$
-segments concluding any of its major premises, and all
$(=E)$
-segments concluding any of its major premises, and all
 $(=E)$
-segments concluding any of their major premises, etc. By removing the maximal
$(=E)$
-segments concluding any of their major premises, etc. By removing the maximal
 $(=E)$
-segment the number of applications of
$(=E)$
-segment the number of applications of
 $(=E)$
has been reduced in this cluster, hence the process comes to an end.
$(=E)$
has been reduced in this cluster, hence the process comes to an end.
3.4. Normal form and rank of deductions
The definition of normal form is standard:
Definition 12. A deduction is in normal form if it contains no maximal segments.
Normalisation is proved by induction over the complexity of deductions, where maximal
 $\exists !$
-,
$\exists !$
-,
 $=$
- and
$=$
- and
 $(=E)$
-segments are not counted, as they are taken care of by Lemma 3:
$(=E)$
-segments are not counted, as they are taken care of by Lemma 3:
Definition 13. The rank of a deduction is the pair
 $\langle d, l\rangle $
, where d is the highest degree of a maximal I/E-segment or
$\langle d, l\rangle $
, where d is the highest degree of a maximal I/E-segment or
 $0$
if there is none, and l is the sum of the lengths of I/E maximal segments of highest degree.
$0$
if there is none, and l is the sum of the lengths of I/E maximal segments of highest degree.
 $\langle d, l\rangle < \langle d', l'\rangle $
iff either (i)
$\langle d, l\rangle < \langle d', l'\rangle $
iff either (i)
 $d<d'$
or (ii)
$d<d'$
or (ii)
 $d=d'$
and
$d=d'$
and
 $l<l'$
.
$l<l'$
.
4. Normalisation and subformula property for
 $\mathbf {INF}$
$\mathbf {INF}$

4.1. Normalisation
The reduction procedures for removing maximal segments of length 1 (i.e., formulas) with the sentential connectives as main operators are standard and won’t be repeated: they are those given by Prawitz [Reference Prawitz26, 35ff]. The permutative reduction procedures for shortening maximal segments of length longer than 1 are standard, too: for
 $(\lor E)$
they are those given by Prawitz [Reference Prawitz26, p. 51], for
$(\lor E)$
they are those given by Prawitz [Reference Prawitz26, p. 51], for
 $(\exists E)$
a trivial variation of those given by him. The reduction procedures that remove applications of
$(\exists E)$
a trivial variation of those given by him. The reduction procedures that remove applications of
 $(\lor E)$
and
$(\lor E)$
and
 $(\exists E)$
in which vacuous discharge occurs are also as usual: applications of
$(\exists E)$
in which vacuous discharge occurs are also as usual: applications of
 $(\lor E)$
in which no or only one assumption is discharged are evidently superfluous, similarly if no assumption is discharged by
$(\lor E)$
in which no or only one assumption is discharged are evidently superfluous, similarly if no assumption is discharged by
 $(\exists E)$
. Applications of that rule that discharge only one assumption, however, are not superfluous and not removed, unless the major premise is derived by
$(\exists E)$
. Applications of that rule that discharge only one assumption, however, are not superfluous and not removed, unless the major premise is derived by
 $(\exists I)$
.
$(\exists I)$
.
The reduction procedures for maximal formulas with quantifiers as main operators do not pose much of a problem either, but Tennant omits them from [Reference Tennant32], and Troelstra and Schwichtenberg do not consider normalisation of a corresponding system [Reference Troestra and Schwichtenberg37, Sec. 6.5], so here they are. Replace the inferences on the left by those on the right:

Theorem 1. Deductions in
 $\mathbf {INF}$
can be brought into normal form.
$\mathbf {INF}$
can be brought into normal form.
Proof. By an induction over the rank of deductions by applying the reduction procedures for maximal segments. The methods of Prawitz [Reference Prawitz26, p. 50] and Troelstra and Schwichtenberg [Reference Wansing40, p. 182] work here, too. Prawitz chooses a maximal segment of highest degree such that no maximal segment of highest degree stands above it or above a minor premise to its right or has an element that is such a minor premise. Troelstra and Schwichtenberg choose the rightmost maximal segment of highest degree that has no maximal segment of highest degree standing above it. We check that the reduction procedures lower the rank of deductions. But first apply Lemma 3. Hence the reduction procedures cannot increase the lengths of maximal
 $(=E)$
-segments, as they were all removed. For the sentential connectives, the situation is as for intuitionist logic, except that maximal
$(=E)$
-segments, as they were all removed. For the sentential connectives, the situation is as for intuitionist logic, except that maximal
 $=$
-,
$=$
-,
 $\exists !$
- or
$\exists !$
- or
 $(=E)$
-segments may be created. So apply Lemma 3 afterwards. The following cases need to be considered regarding the reduction procedures for the quantifiers. (a) They could introduce a maximal formula
$(=E)$
-segments may be created. So apply Lemma 3 afterwards. The following cases need to be considered regarding the reduction procedures for the quantifiers. (a) They could introduce a maximal formula
 $A_t^x$
or, if it is already on a maximal segment, increase its length. In both cases the rank of the deduction is lowered because the degree of
$A_t^x$
or, if it is already on a maximal segment, increase its length. In both cases the rank of the deduction is lowered because the degree of
 $A_t^x$
is lower than that of the maximal formula removed. (b) (i) If
$A_t^x$
is lower than that of the maximal formula removed. (b) (i) If
 $\exists !t$
is the conclusion of
$\exists !t$
is the conclusion of
 $(AD)$
in
$(AD)$
in
 $\Sigma $
and
$\Sigma $
and
 $\exists !a$
is premise of
$\exists !a$
is premise of
 $(=I^n)$
in
$(=I^n)$
in
 $\Pi $
the procedure introduces a maximal
$\Pi $
the procedure introduces a maximal
 $\exists $
-segment. (ii) If
$\exists $
-segment. (ii) If
 $\exists !t$
is conclusion of
$\exists !t$
is conclusion of
 $(=E)$
in
$(=E)$
in
 $\Sigma $
and
$\Sigma $
and
 $\exists !a$
is premise of
$\exists !a$
is premise of
 $(AD)$
in
$(AD)$
in
 $\Pi $
the procedure introduces a maximal
$\Pi $
the procedure introduces a maximal
 $(=E)$
-segment. Both cases are dealt with by applying Lemma 3 immediately after the reduction step.
$(=E)$
-segment. Both cases are dealt with by applying Lemma 3 immediately after the reduction step.
4.2. Subformula property
The following modifies Prawitz’s notion of a path slightly to fit
 $\mathbf {INF}$
:
$\mathbf {INF}$
:
Definition 14. A path is a sequence of formulas
 $A_1\ldots A_n$
such that:
$A_1\ldots A_n$
such that:
(a)
 $A_1$
is an assumption not discharged by
$A_1$
is an assumption not discharged by
 $(\lor E)$
of
$(\lor E)$
of
 $(\exists E)$
.
$(\exists E)$
.
(b) If
 $A_i$
is any premise of an introduction rule other than
$A_i$
is any premise of an introduction rule other than
 $(\exists I)$
, the left premise of
$(\exists I)$
, the left premise of
 $(\exists I)$
, the premise of
$(\exists I)$
, the premise of
 $(AD)$
or
$(AD)$
or
 $(=I^n)$
, the minor premise of
$(=I^n)$
, the minor premise of
 $(=E)$
or the major premise of an elimination rule other than
$(=E)$
or the major premise of an elimination rule other than
 $(\lor E)$
,
$(\lor E)$
,
 $(\exists E)$
or
$(\exists E)$
or
 $(=E)$
, then
$(=E)$
, then
 $A_{i+1}$
is the conclusion of the rule.
$A_{i+1}$
is the conclusion of the rule.
(c) If
 $A_i$
is the major premise of
$A_i$
is the major premise of
 $(\lor E)$
or
$(\lor E)$
or
 $(\exists E)$
, then
$(\exists E)$
, then
 $A_{i+1}$
is an assumption discharged by the rule.
$A_{i+1}$
is an assumption discharged by the rule.
(d)
 $A_n$
is either the minor premise of
$A_n$
is either the minor premise of
 $(\rightarrow E)$
or
$(\rightarrow E)$
or
 $(\forall E)$
, the right premise of
$(\forall E)$
, the right premise of
 $(\exists I)$
, the major premise of
$(\exists I)$
, the major premise of
 $(=E)$
or the conclusion of the deduction.
$(=E)$
or the conclusion of the deduction.
Paths are naturally divided into segments. Indeed, in the definition above, ‘segment’ could replace ‘formula’. I will speak of paths being in deductions and of formulas and segments being on paths.
Definition 15. A path that ends in the conclusion of a deduction has order
 $0$
; a path has order
$0$
; a path has order
 $n+1$
if its last formula ends to the left or right of a formula on a path with order n.
$n+1$
if its last formula ends to the left or right of a formula on a path with order n.
Corollary 1. On a path in a deduction in
 $\mathbf {INF}$
in normal form major premises of elimination rules precede conclusions of introduction rules.
$\mathbf {INF}$
in normal form major premises of elimination rules precede conclusions of introduction rules.
Proof. Suppose there is a conclusion A of an introduction rule on a path. Let
 $\sigma _1$
be the segment beginning with A. If the path does not end with
$\sigma _1$
be the segment beginning with A. If the path does not end with
 $\sigma _1$
, then (1)
$\sigma _1$
, then (1)
 $\sigma _1$
cannot be the major premise of
$\sigma _1$
cannot be the major premise of
 $(=E)$
, nor the right premise of
$(=E)$
, nor the right premise of
 $(\forall E)$
or
$(\forall E)$
or
 $(\exists I)$
; (2) as A is the conclusion of an introduction rule,
$(\exists I)$
; (2) as A is the conclusion of an introduction rule,
 $\sigma _1$
cannot be the minor premise of
$\sigma _1$
cannot be the minor premise of
 $(=E)$
, nor the premise of
$(=E)$
, nor the premise of
 $(=I^n)$
,
$(=I^n)$
,
 $(AD)$
or
$(AD)$
or
 $(\bot E)$
; (3) as the deduction is normal, it cannot be the major premise of an elimination rule. Hence it can only be premise of an introduction rule for a sentential connective or the left premise of
$(\bot E)$
; (3) as the deduction is normal, it cannot be the major premise of an elimination rule. Hence it can only be premise of an introduction rule for a sentential connective or the left premise of
 $(\forall I)$
or
$(\forall I)$
or
 $(\exists I)$
. But the same applies to any other segment, if the path continues. Hence for any path on which there is a conclusion of an introduction rule, if there are also major premises of elimination rules on it, they must precede the conclusions of introduction rules.
$(\exists I)$
. But the same applies to any other segment, if the path continues. Hence for any path on which there is a conclusion of an introduction rule, if there are also major premises of elimination rules on it, they must precede the conclusions of introduction rules.
Corollary 2. A path in a deduction in
 $\mathbf {INF}$
in normal form begins with a (possibly empty) sequence of major premises of elimination rules (only formulas, not segments), which is followed either by the last segment of the path or by a sequence of premises of
$\mathbf {INF}$
in normal form begins with a (possibly empty) sequence of major premises of elimination rules (only formulas, not segments), which is followed either by the last segment of the path or by a sequence of premises of
 $(AD)$
or
$(AD)$
or
 $(=I^n)$
or minor premises of
$(=I^n)$
or minor premises of
 $(=E)$
or by a premise of an introduction rule, and ends in a (possibly empty) sequence of conclusions of introduction rules.
$(=E)$
or by a premise of an introduction rule, and ends in a (possibly empty) sequence of conclusions of introduction rules.
Proof. By Corollary 1, any major premises of elimination rules precede the introduction rules. The premises of
 $(=I^n)$
,
$(=I^n)$
,
 $(=E)$
and
$(=E)$
and
 $(AD)$
are atomic and so cannot come before major premises of elimination rules. For the same reason, they cannot come after any introduction rules. This leaves the place in between.
$(AD)$
are atomic and so cannot come before major premises of elimination rules. For the same reason, they cannot come after any introduction rules. This leaves the place in between.
The first part of a path may be called the E-part, the last the I-part, the one in the middle the M-part. Notice that the M-part is never empty. The following corollary establishes a result about the form of M-parts of paths in deductions in normal form. It is here that
 $(=E)$
and the rules specific to negative free logic,
$(=E)$
and the rules specific to negative free logic,
 $(=I^n)$
and
$(=I^n)$
and
 $(AD)$
, are applied, and because of normal form, these applications are only very limited and follow a certain order. For instance, if all three rules just mentioned are applied, they must be applied in the order
$(AD)$
, are applied, and because of normal form, these applications are only very limited and follow a certain order. For instance, if all three rules just mentioned are applied, they must be applied in the order
 $(AD)$
,
$(AD)$
,
 $(=I^n)$
,
$(=I^n)$
,
 $(=E)$
, where (
$(=E)$
, where (
 $=I^n)$
concludes the minor premise of
$=I^n)$
concludes the minor premise of
 $(=E)$
, and there follow no more applications of
$(=E)$
, and there follow no more applications of
 $(AD)$
or
$(AD)$
or
 $(=I^n)$
.
$(=I^n)$
.
Corollary 3.
 $\mathrm{(i)}$
On the M-part of a path in a deduction in normal form:
$\mathrm{(i)}$
On the M-part of a path in a deduction in normal form:
 $\mathrm{(a)}$
There is at most one application of
$\mathrm{(a)}$
There is at most one application of
 $(AD)$
.
$(AD)$
.
 $\mathrm{(b)}$
There is at most one application of
$\mathrm{(b)}$
There is at most one application of
 $(=I^n)$
.
$(=I^n)$
.
 $\mathrm{(c)}$
If there is an application of
$\mathrm{(c)}$
If there is an application of
 $(AD)$
and an application of
$(AD)$
and an application of
 $(=I^n)$
,
$(=I^n)$
,
 $(AD)$
precedes
$(AD)$
precedes
 $(=I^n)$
and there are no applications of
$(=I^n)$
and there are no applications of
 $(=E)$
between them.
$(=E)$
between them.
 $\mathrm{(ii)}$
The first segment of an M-part of a path in a deduction in normal form may be:
$\mathrm{(ii)}$
The first segment of an M-part of a path in a deduction in normal form may be:
 $\mathrm{(a)}$
The first segment of an
$\mathrm{(a)}$
The first segment of an
 $(=E)$
-segment: then its last segment is the last segment of the M-part.
$(=E)$
-segment: then its last segment is the last segment of the M-part.
 $\mathrm{(b)}$
The premise of
$\mathrm{(b)}$
The premise of
 $(AD)$
: then its conclusion is either the last segment of the M-part, or it is the premise of
$(AD)$
: then its conclusion is either the last segment of the M-part, or it is the premise of
 $(=I^n)$
, in which case the premise of
$(=I^n)$
, in which case the premise of
 $(AD)$
is different from the conclusion of
$(AD)$
is different from the conclusion of
 $(=I^n)$
, and the conclusion of
$(=I^n)$
, and the conclusion of
 $(=I^n)$
is either the last segment of the M-part or first premise of an
$(=I^n)$
is either the last segment of the M-part or first premise of an
 $(=E)$
-segment the last conclusion of which is the first segment of the M-part.
$(=E)$
-segment the last conclusion of which is the first segment of the M-part.
 $\mathrm{(c)}$
The premise of
$\mathrm{(c)}$
The premise of
 $(=I^n)$
: then its conclusion is either the last segment of the M-part or the first premise of an
$(=I^n)$
: then its conclusion is either the last segment of the M-part or the first premise of an
 $(=E)$
-segment the last conclusion of which is the last segment of the M-part.
$(=E)$
-segment the last conclusion of which is the last segment of the M-part.
 $\mathrm{(d)}$
The last segment of the M-part.
$\mathrm{(d)}$
The last segment of the M-part.
Proof. (i) (a) The conclusion of
 $(AD)$
has the form
$(AD)$
has the form
 $\exists !t$
. To apply it again we need a formula that is either an identity or formed from a predicate letter. The only rules that could be applied are
$\exists !t$
. To apply it again we need a formula that is either an identity or formed from a predicate letter. The only rules that could be applied are
 $(\lor E)$
,
$(\lor E)$
,
 $(\exists E)$
,
$(\exists E)$
,
 $(=E)$
and
$(=E)$
and
 $(=I^n)$
. The first two conclude
$(=I^n)$
. The first two conclude
 $\exists !t$
again and
$\exists !t$
again and
 $(=E)$
concludes a formula of the same form and there’d be a maximal
$(=E)$
concludes a formula of the same form and there’d be a maximal
 $(=E)$
-segment, which is excluded as the deduction is in normal form. Applying
$(=E)$
-segment, which is excluded as the deduction is in normal form. Applying
 $(=I^n)$
permits us to conclude a formula to which
$(=I^n)$
permits us to conclude a formula to which
 $(AD)$
may be applied, but doing so would create a maximal
$(AD)$
may be applied, but doing so would create a maximal
 $\exists !$
-segment, which is excluded on paths of deductions in normal form. (b) follows for similar reasons: to apply
$\exists !$
-segment, which is excluded on paths of deductions in normal form. (b) follows for similar reasons: to apply
 $(=I^n)$
twice, the second application requires a premise of the form
$(=I^n)$
twice, the second application requires a premise of the form
 $\exists !t$
, and this could only be brought along by an application of
$\exists !t$
, and this could only be brought along by an application of
 $(AD)$
, which would create a maximal
$(AD)$
, which would create a maximal
 $=$
-segment. (c) follows because if
$=$
-segment. (c) follows because if
 $(=I^n)$
preceded
$(=I^n)$
preceded
 $(AD)$
there would be a maximal
$(AD)$
there would be a maximal
 $=$
-segment, and if there were applications of
$=$
-segment, and if there were applications of
 $(=E)$
in between
$(=E)$
in between
 $(AD)$
and
$(AD)$
and
 $(=I^n)$
, there would be a maximal
$(=I^n)$
, there would be a maximal
 $(=E)$
-segment.
$(=E)$
-segment.
(ii) (a) If there was an application of
 $(AD)$
later, this would be a maximal
$(AD)$
later, this would be a maximal
 $(=E)$
-segment, contradicting normality. If there was an application of
$(=E)$
-segment, contradicting normality. If there was an application of
 $(=I^n)$
, the formulas on the
$(=I^n)$
, the formulas on the
 $(=E)$
-segment would have the form
$(=E)$
-segment would have the form
 $\exists ! t$
, also contradicting normality. (b) The conclusion of
$\exists ! t$
, also contradicting normality. (b) The conclusion of
 $(AD)$
is of form
$(AD)$
is of form
 $\exists !t$
and hence by normality no
$\exists !t$
and hence by normality no
 $(=E)$
can follow immediately. If the premise of
$(=E)$
can follow immediately. If the premise of
 $(AD)$
was the same as the conclusion of
$(AD)$
was the same as the conclusion of
 $(=I^n)$
, we’d have a maximal
$(=I^n)$
, we’d have a maximal
 $\exists !$
-segment. If a
$\exists !$
-segment. If a
 $(=E)$
-segment follows after
$(=E)$
-segment follows after
 $(=I^n$
), it follows from (a) that it ends the path. (c) follows from clause (i). (d) requires no argument.
$(=I^n$
), it follows from (a) that it ends the path. (c) follows from clause (i). (d) requires no argument.
Corollary 4.
 $\mathrm{(i)}$
Any formula in the E-part of a path in a deduction in normal form is a subformula of the immediately preceding formula.
$\mathrm{(i)}$
Any formula in the E-part of a path in a deduction in normal form is a subformula of the immediately preceding formula.
 $\mathrm{(ii)}$
Any formula in the I-part of such a path is a subformula of its immediate successor.
$\mathrm{(ii)}$
Any formula in the I-part of such a path is a subformula of its immediate successor.
 $\mathrm{(iii)}$
The first formula of the M-part is either the first formula of the path or a subformula of the last formula of the E-part
$\mathrm{(iii)}$
The first formula of the M-part is either the first formula of the path or a subformula of the last formula of the E-part
 $;$
the last formula of the M-part is either the last formula of the path or a subformula of the first formula of the I-part. Formulas in between may not be subformulas of any other formulas.
$;$
the last formula of the M-part is either the last formula of the path or a subformula of the first formula of the I-part. Formulas in between may not be subformulas of any other formulas.
Proof. (i)–(iii) are evident by inspection of the rules and Corollary 3.
Definition 16. A deduction has the free subformula property if all formulas are subformulas of the undischarged assumptions or of the conclusion of the deduction, except possibly formulas of the form
 $t_1=t_2$
or
$t_1=t_2$
or
 $Rt_1\ldots t_n$
on
$Rt_1\ldots t_n$
on
 $(=E)$
-segments; formulas of the form
$(=E)$
-segments; formulas of the form
 $\exists !t$
that are minor premises of
$\exists !t$
that are minor premises of
 $(\forall E)$
or right premises of
$(\forall E)$
or right premises of
 $(\exists I)$
; or formulas of the form
$(\exists I)$
; or formulas of the form
 $\exists !a$
that are discharged by
$\exists !a$
that are discharged by
 $(\forall I)$
or
$(\forall I)$
or
 $(\exists E)$
.
$(\exists E)$
.
Corollary 5. Deductions in
 $\mathbf {INF}$
in normal form have the free subformula property.
$\mathbf {INF}$
in normal form have the free subformula property.
Proof. By inspection of the rules and an induction over the order of paths. For paths of order
 $0$
this follows immediately from Corollary 4. Evidently the exempt formulas all and only occur on M-part of paths. Suppose the corollary holds for paths of order n and consider a path
$0$
this follows immediately from Corollary 4. Evidently the exempt formulas all and only occur on M-part of paths. Suppose the corollary holds for paths of order n and consider a path
 $\pi $
of order
$\pi $
of order
 $n+1$
. There are four ways in which a path can end.
$n+1$
. There are four ways in which a path can end.
(I)
 $\pi $
ends in a minor premise of
$\pi $
ends in a minor premise of
 $(\rightarrow E)$
. There are two options.
$(\rightarrow E)$
. There are two options.
(A)
 $\pi $
has an E-part. Then apart from any formulas between the first and the last of the M-part, which are exempt, the situation is as in intuitionist logic. The last formula of
$\pi $
has an E-part. Then apart from any formulas between the first and the last of the M-part, which are exempt, the situation is as in intuitionist logic. The last formula of
 $\pi $
is a subformula of a formula of a path of lower order, hence any formulas on
$\pi $
is a subformula of a formula of a path of lower order, hence any formulas on
 $\pi $
’s I-part and the last formula of the M-part are subformulas of a path of lower order. The first formula of the M-part is a subformula of the last formula of
$\pi $
’s I-part and the last formula of the M-part are subformulas of a path of lower order. The first formula of the M-part is a subformula of the last formula of
 $\pi $
’s E-part, and all formulas on the E-part are either subformulas of an undischarged assumption of the deduction or, if they are subformulas of a discharged assumption of the deduction, they are discharged by
$\pi $
’s E-part, and all formulas on the E-part are either subformulas of an undischarged assumption of the deduction or, if they are subformulas of a discharged assumption of the deduction, they are discharged by
 $(\rightarrow E)$
, and hence are subformulas of a formula on a path of lower order. (As there is an E-part, they cannot be discharged by
$(\rightarrow E)$
, and hence are subformulas of a formula on a path of lower order. (As there is an E-part, they cannot be discharged by
 $(\forall I)$
).
$(\forall I)$
).
(B)
 $\pi $
has no E-part. Then the first formula of the M-part is either an undischarged assumption of the deduction, or it is discharged by
$\pi $
has no E-part. Then the first formula of the M-part is either an undischarged assumption of the deduction, or it is discharged by
 $(\rightarrow E)$
, or it has the form
$(\rightarrow E)$
, or it has the form
 $\exists !a$
and is discharged by
$\exists !a$
and is discharged by
 $(\forall I)$
or
$(\forall I)$
or
 $(\exists E)$
(it can’t be
$(\exists E)$
(it can’t be
 $A_t^x$
, as then there’d be an E-part). In the first two cases, we’re done. In the other two cases,
$A_t^x$
, as then there’d be an E-part). In the first two cases, we’re done. In the other two cases,
 $\exists !a$
is exempt, but we need to consider any other formulas on the path.
$\exists !a$
is exempt, but we need to consider any other formulas on the path.
 $\exists !a$
can only be premise of
$\exists !a$
can only be premise of
 $(=I^n)$
or the last formula of the M-part, hence only options (ii) (c) and (d) of Corollary 3 can be the case. If (ii)(d), there are four options.
$(=I^n)$
or the last formula of the M-part, hence only options (ii) (c) and (d) of Corollary 3 can be the case. If (ii)(d), there are four options.
 $\exists !a$
is on a segment that is (1) minor premise of
$\exists !a$
is on a segment that is (1) minor premise of
 $(\forall I)$
, (2) right premise of
$(\forall I)$
, (2) right premise of
 $(\exists E)$
, (3) minor premise of
$(\exists E)$
, (3) minor premise of
 $(\rightarrow E)$
or (4) premise of an introduction rule. (1) and (2) are exempt. If (3), it is a subformula of a formula on a path of lower order. If (4),
$(\rightarrow E)$
or (4) premise of an introduction rule. (1) and (2) are exempt. If (3), it is a subformula of a formula on a path of lower order. If (4),
 $\pi $
ends in a minor premise of
$\pi $
ends in a minor premise of
 $(\rightarrow E)$
, and again it is a subformula of a formula on a path of lower order.
$(\rightarrow E)$
, and again it is a subformula of a formula on a path of lower order.
If (ii)(c), there are two options. (1) If there is no
 $(=E)$
-segment, the conclusion of
$(=E)$
-segment, the conclusion of
 $(=I^n)$
is on the last segment of the M-part, which can only be minor premise of
$(=I^n)$
is on the last segment of the M-part, which can only be minor premise of
 $(\rightarrow E)$
or premise of an introduction rule, and hence it is a subformula of a formula on a path of lower order. (2) If there is an
$(\rightarrow E)$
or premise of an introduction rule, and hence it is a subformula of a formula on a path of lower order. (2) If there is an
 $(=E)$
-segment, the formulas on it are exempt, and its last formula is either on a segment that is minor premise of
$(=E)$
-segment, the formulas on it are exempt, and its last formula is either on a segment that is minor premise of
 $(\rightarrow E)$
or premise of an introduction rule, and the situation is as before.
$(\rightarrow E)$
or premise of an introduction rule, and the situation is as before.
(II)
 $\pi $
ends in the major premise of
$\pi $
ends in the major premise of
 $(=E)$
. Then
$(=E)$
. Then
 $\pi $
has no I-part and the last formula of its M-part is
$\pi $
has no I-part and the last formula of its M-part is
 $t_1=t_2$
. There are two options. (1)
$t_1=t_2$
. There are two options. (1)
 $t_1=t_2$
is also the first formula of
$t_1=t_2$
is also the first formula of
 $\pi $
’s M-part. If it is an undischarged assumption of the deduction or discharged by
$\pi $
’s M-part. If it is an undischarged assumption of the deduction or discharged by
 $(\rightarrow E)$
, we’re done. If it is discharged by
$(\rightarrow E)$
, we’re done. If it is discharged by
 $(\lor E)$
or
$(\lor E)$
or
 $(\exists E)$
, it is a subformula of a formula on the E-part of
$(\exists E)$
, it is a subformula of a formula on the E-part of
 $\pi $
, and hence a subformula of the first formula on
$\pi $
, and hence a subformula of the first formula on
 $\pi $
, and thus either of an undischarged assumption or one discharged by
$\pi $
, and thus either of an undischarged assumption or one discharged by
 $(\rightarrow I)$
and again we’re done. (2)
$(\rightarrow I)$
and again we’re done. (2)
 $t_1=t_2$
is not the first formula of
$t_1=t_2$
is not the first formula of
 $\pi $
’s M-part. As the deduction is normal, it cannot have been concluded by
$\pi $
’s M-part. As the deduction is normal, it cannot have been concluded by
 $(=I^n)$
, and hence can only be the last formula of an
$(=I^n)$
, and hence can only be the last formula of an
 $(=E)$
-segment or concluded by an elimination rule. If the latter, we’re done as in previous cases. If the former, it and all formula on the
$(=E)$
-segment or concluded by an elimination rule. If the latter, we’re done as in previous cases. If the former, it and all formula on the
 $(=E)$
-segment are exempt, but the usual reasoning applies to the first formula of the
$(=E)$
-segment are exempt, but the usual reasoning applies to the first formula of the
 $(=E)$
-segment.
$(=E)$
-segment.
(III) Here we consider the two options that
 $\pi $
ends in a minor premise of
$\pi $
ends in a minor premise of
 $(\forall I)$
or the right premise of
$(\forall I)$
or the right premise of
 $(\exists E)$
. Then
$(\exists E)$
. Then
 $\pi $
has no I-part, and there are two options for its M-part. (1) It consists only of a segment
$\pi $
has no I-part, and there are two options for its M-part. (1) It consists only of a segment
 $\exists !t$
. (2)
$\exists !t$
. (2)
 $\exists !t$
is concluded by
$\exists !t$
is concluded by
 $(AD)$
. (The option that it is concluded by
$(AD)$
. (The option that it is concluded by
 $(=E)$
is excluded by normality.) (1) If
$(=E)$
is excluded by normality.) (1) If
 $\exists !t$
is an undischarged assumption, discharged by
$\exists !t$
is an undischarged assumption, discharged by
 $(\rightarrow I)$
, or if
$(\rightarrow I)$
, or if
 $\pi $
has an E-part, we’re done, for reasons as before; if it is discharged by (
$\pi $
has an E-part, we’re done, for reasons as before; if it is discharged by (
 $\forall I)$
or
$\forall I)$
or
 $(\exists E)$
(right discharged assumption), it is exempt. (2) Then it is exempt, and reasoning as before applies to the premise of
$(\exists E)$
(right discharged assumption), it is exempt. (2) Then it is exempt, and reasoning as before applies to the premise of
 $(AD)$
.
$(AD)$
.
In relation to the usual definition of subformula property we have the following:
Corollary 6. Any exceptions to the subformula property in deductions in normal form in
 $\mathbf {INF}$
occur between the first and the last formula of the M-part of paths.
$\mathbf {INF}$
occur between the first and the last formula of the M-part of paths.
5. A system inspired by Jaśkowski
It would be possible to loosen the restriction on the subformula property for deductions in normal form a little. The proof of Corollary 5 shows that formulas
 $(\exists !a)$
that are premises of
$(\exists !a)$
that are premises of
 $(\forall E)$
or
$(\forall E)$
or
 $(\exists I)$
are often subformulas of the undischarged premises or conclusions of deductions in normal form, namely if they are concluded by elimination rules or discharged by
$(\exists I)$
are often subformulas of the undischarged premises or conclusions of deductions in normal form, namely if they are concluded by elimination rules or discharged by
 $(\lor E)$
or
$(\lor E)$
or
 $(\rightarrow I)$
or if they take the place of the discharged assumption
$(\rightarrow I)$
or if they take the place of the discharged assumption
 $A_a^x$
of
$A_a^x$
of
 $(\exists E)$
. Similarly for those discharged by
$(\exists E)$
. Similarly for those discharged by
 $(\forall I)$
or
$(\forall I)$
or
 $(\exists E)$
, if they are premises of introduction rules. We could also count formulas of the form
$(\exists E)$
, if they are premises of introduction rules. We could also count formulas of the form
 $\exists !t$
that are the minor premise of
$\exists !t$
that are the minor premise of
 $(\forall E)$
as subformulas of its major premise and those that are the right premise of
$(\forall E)$
as subformulas of its major premise and those that are the right premise of
 $(\exists I)$
as subformulas of its conclusion, in analogy with
$(\exists I)$
as subformulas of its conclusion, in analogy with
 $(\rightarrow E)$
and
$(\rightarrow E)$
and
 $(\land I)$
; and analogously counting assumptions
$(\land I)$
; and analogously counting assumptions
 $\exists !a$
discharged by
$\exists !a$
discharged by
 $(\forall I)$
and
$(\forall I)$
and
 $(\exists E)$
as subformulas of the conclusion and the major premise, respectively. This makes some sense, as after all the quantifiers are supposed to carry existential import and range only over what exists. But this still leaves occurrences of formulas of the form
$(\exists E)$
as subformulas of the conclusion and the major premise, respectively. This makes some sense, as after all the quantifiers are supposed to carry existential import and range only over what exists. But this still leaves occurrences of formulas of the form
 $\exists !t$
that are not subformulas of any formulas on the deduction, namely those concluded by
$\exists !t$
that are not subformulas of any formulas on the deduction, namely those concluded by
 $(AD)$
and the premises of
$(AD)$
and the premises of
 $(=I^n)$
and variations thereof.
$(=I^n)$
and variations thereof.
A more elegant option with a better result goes back to Jaśkowski [Reference Jaśkowski13, sec. 5]. Eschew use of
 $\exists !$
altogether, permit terms to occur in rules, and reformulate the rules in which it occurred accordingly:
$\exists !$
altogether, permit terms to occur in rules, and reformulate the rules in which it occurred accordingly:

where in
 $(\forall I)$
, a does not occur in
$(\forall I)$
, a does not occur in
 $\forall xA$
nor in any undischarged assumptions of
$\forall xA$
nor in any undischarged assumptions of
 $\Pi $
except those in the assumption class of a.
$\Pi $
except those in the assumption class of a.

where in
 $(\exists E)$
, a is not free in C, nor in
$(\exists E)$
, a is not free in C, nor in
 $\exists xA$
, nor in any undischarged assumption of
$\exists xA$
, nor in any undischarged assumption of
 $\Pi $
except those in the assumption classes of
$\Pi $
except those in the assumption classes of
 $A_a^x$
and a.
$A_a^x$
and a.
where R is an n-place predicate letter or identity and
 $1\leq i\leq n$
.
$1\leq i\leq n$
.
Call the reformulated system
 $\mathbf {INF}^J$
.
$\mathbf {INF}^J$
.
 $\mathbf {INF}^J$
loses none of the expressiveness of
$\mathbf {INF}^J$
loses none of the expressiveness of
 $\mathbf {INF}$
: as observed,
$\mathbf {INF}$
: as observed,
 $\vdash \exists !t\leftrightarrow \exists x \ x=t$
, so
$\vdash \exists !t\leftrightarrow \exists x \ x=t$
, so
 $\exists !$
is in this sense redundant.
$\exists !$
is in this sense redundant.
 $(=E)$
-segments in which the minor premises and conclusions have the form
$(=E)$
-segments in which the minor premises and conclusions have the form
 $\exists !t$
are no longer possible, but the normalisation theorem showed them to be superfluous.
$\exists !t$
are no longer possible, but the normalisation theorem showed them to be superfluous.
Terms appearing as premises or conclusions of the J-rules also occur in their conclusions or other premises. This gives a notion of a subformula property:
Definition 17. A deduction has the free term subformula property if all formulas and terms on it are or occur in subformulas of its undischarged assumptions or its conclusion, except possibly formulas of the form
 $t_1=t_2$
or
$t_1=t_2$
or
 $Rt_1\ldots t_n$
on
$Rt_1\ldots t_n$
on
 $(=E)$
-segments.
$(=E)$
-segments.
The normalisation proof goes through exactly as before, except that it is a little simpler, as one kind of maximal
 $(=E)$
-segments need no longer be considered:
$(=E)$
-segments need no longer be considered:
Theorem 2. Deductions in
 $\mathbf {INF}^J$
can be brought into normal form.
$\mathbf {INF}^J$
can be brought into normal form.
The form of paths in deductions in normal form stays mutatis mutandis the same as established in Corollaries 1–4, and so:
Corollary 7. Deductions in normal form in
 $\mathbf {INF}^J$
have the free term subformula property.
$\mathbf {INF}^J$
have the free term subformula property.
For the classical version
 $\mathbf {CNF}^J$
similar results hold as to be established for
$\mathbf {CNF}^J$
similar results hold as to be established for
 $\mathbf {CNF}$
.
$\mathbf {CNF}$
.
It should be possible to go even further by adopting an approach to identity formalised by Indrzejczak, where the role of terms is assimilated entirely to that of formulas, and identity statements are proved on the basis of rules for terms. Then the subformula property holds even in the presence of identity (see [Reference Indrzejczak11]). Pursuing this further must be left for another occasion.
Comment. If the rules for the quantifiers are to define their meanings, a thesis of proof-theoretic semantics, an explanation of the use of terms as premises and conclusions in the J-rules is required. Adopting Jaśkowski’s account lends itself to a neat approach to addressing this issue, and it has an interesting historical antecedent as a philosophical foundation. Jaśkowski introduces a symbol analogous to the sign of supposition of propositions to be placed in front of variables (although he preferred to call them ‘arbitrary constants’). This marks that the referent of the variable, not otherwise defined, is kept constant throughout the reasoning to follow. It corresponds to the phrase ‘Consider an arbitrary x’ used in proofs. Like the domains of suppositions of propositions, the ‘domain of constancy’, as Jaśkowski calls it, of a variable can be closed by an application of a rule, in his case the introduction rule for the universal quantifier. Jaśkowski has no primitive rules for the existential quantifier, but evidently they are exactly analogous to those for the universal quantifier. A philosophical foundation for this approach can be found in Brentano. Textor develops an explanation of the meaning of the existence predicate on the basis of Brentano’s account of acknowledging or positing objects [Reference Textor36].Footnote
11
This is a non-propositional attitude: thinkers acknowledge or posit objects in thought. Acknowledging or positing that something exists is to be explained as a propositional attitude derivative thereof. Textor motivates the use of an existence predicate in natural deduction as part of his account, and this could be used to motivate the rules of
 $\mathbf {INF}$
. But the attitude of acknowledging or positing objects also lends itself to be incorporated directly into the rules to motivate those of
$\mathbf {INF}$
. But the attitude of acknowledging or positing objects also lends itself to be incorporated directly into the rules to motivate those of
 $\mathbf {INF}^J$
. Using t as a premise in
$\mathbf {INF}^J$
. Using t as a premise in
 $(\forall E^J)$
and
$(\forall E^J)$
and
 $(\exists I^J)$
indicates that t has been acknowledged: only terms referring to acknowledged objects are legitimate terms to use in these rules. An object can only be asserted to be self-identical if it has been acknowledged, which is
$(\exists I^J)$
indicates that t has been acknowledged: only terms referring to acknowledged objects are legitimate terms to use in these rules. An object can only be asserted to be self-identical if it has been acknowledged, which is
 $(=I^{nJ})$
. Some rules permit the discharge of such acknowledgments: their conclusions hold no matter which object has been acknowledged, as is the case in
$(=I^{nJ})$
. Some rules permit the discharge of such acknowledgments: their conclusions hold no matter which object has been acknowledged, as is the case in
 $(\forall I^J)$
and
$(\forall I^J)$
and
 $(\exists E^J)$
: they no longer commit to the acknowledgement. ‘Positing an object’ is a neat description of what happens if an assumption is made for the sake of discharge by
$(\exists E^J)$
: they no longer commit to the acknowledgement. ‘Positing an object’ is a neat description of what happens if an assumption is made for the sake of discharge by
 $(\forall I)$
and
$(\forall I)$
and
 $(\exists E)$
. Finally, some propositions commit one to acknowledging objects, e.g., atomic propositions, which motivates
$(\exists E)$
. Finally, some propositions commit one to acknowledging objects, e.g., atomic propositions, which motivates
 $(AD^J)$
.
$(AD^J)$
.
6. Adding definite descriptions
6.1. A problem solved by a new rule for identity
For a normalisation theorem to be provable by induction over the complexity of formulas, we must count ![]() terms in addition to connectives and quantifiers, as was already done in Definition 6. This creates a problem with the reduction procedures for maximal formulas of form
terms in addition to connectives and quantifiers, as was already done in Definition 6. This creates a problem with the reduction procedures for maximal formulas of form
 $\forall x A$
and
$\forall x A$
and
 $\exists xA$
: if t is a complex term, they may introduce maximal formulas of higher degree than those removed. There is no apparent systematic way of avoiding this, e.g., by applying the reduction procedures to a suitably chosen formula. Replacing a parameter by an
$\exists xA$
: if t is a complex term, they may introduce maximal formulas of higher degree than those removed. There is no apparent systematic way of avoiding this, e.g., by applying the reduction procedures to a suitably chosen formula. Replacing a parameter by an ![]() term increases the complexity of the formula. Looking only at a maximal formula of highest degree, we do not know whether the replacement of a parameter by an
term increases the complexity of the formula. Looking only at a maximal formula of highest degree, we do not know whether the replacement of a parameter by an ![]() term will not turn a maximal formula that had a lower than maximal degree before into one the degree of which is now higher.
term will not turn a maximal formula that had a lower than maximal degree before into one the degree of which is now higher.
The problem is most straightforwardly solved by an observation made by Indrzejczak [Reference Indrzejczak10, sec. 4] in relation to a number of free logics formulated in cut free sequent calculi:
 $(\forall E)$
and
$(\forall E)$
and
 $(\exists I)$
can be restricted to atomic instantiating terms, given the rule of the next lemma, which is derivable in
$(\exists I)$
can be restricted to atomic instantiating terms, given the rule of the next lemma, which is derivable in
 $\mathbf {INF}$
.
$\mathbf {INF}$
.
Lemma 4. This rule is derivable given
 $(=I^n)$
,
$(=I^n)$
,
 $(\exists I)$
and
$(\exists I)$
and
 $(\exists E)$
:
$(\exists E)$
:

where the parameter a does not occur in t, C nor any open assumptions of
 $\Pi $
other than those of the assumption class of
$\Pi $
other than those of the assumption class of
 $a=t$
.
$a=t$
.
Proof. As observed earlier,
 $\exists !t\vdash \exists x \ x=t$
, apply
$\exists !t\vdash \exists x \ x=t$
, apply
 $(\exists E)$
.
$(\exists E)$
.
 $(=I^{nG})$
is a new introduction rule for
$(=I^{nG})$
is a new introduction rule for
 $=$
. It has the form of what Negri and von Plato [Reference Negri and von Plato25, p. 217] and Milne [Reference Milne23, Reference Milne and Wansing24] call general introduction rules. In its presence
$=$
. It has the form of what Negri and von Plato [Reference Negri and von Plato25, p. 217] and Milne [Reference Milne23, Reference Milne and Wansing24] call general introduction rules. In its presence
 $(=I^n)$
is redundant:
$(=I^n)$
is redundant:
Lemma 5. Given
 $(=E)$
and
$(=E)$
and
 $(=I^{nG})$
,
$(=I^{nG})$
,
 $(=I^n)$
is derivable.
$(=I^n)$
is derivable.
Proof.

The symmetry of identity will play a prominent role in the following, so we prove it here, which also gives another example of a use of
 $(=I^{nG})$
:
$(=I^{nG})$
:
Lemma 6.
 $t_1=t_2\vdash t_2=t_1$
.
$t_1=t_2\vdash t_2=t_1$
.
Proof.

Notice once more how the subformula property cannot be upheld:
 $\exists !t_1$
,
$\exists !t_1$
,
 $a=t_1$
and
$a=t_1$
and
 $a=t_2$
are not subformulas of any undischarged premises or of the conclusion.
$a=t_2$
are not subformulas of any undischarged premises or of the conclusion.
Now for the point of introducing
 $(=I^{nG})$
:
$(=I^{nG})$
:
Lemma 7. Given
 $(=I^{nG})$
,
$(=I^{nG})$
,
 $(\forall E)$
and
$(\forall E)$
and
 $(\exists I)$
may be restricted to atomic terms.
$(\exists I)$
may be restricted to atomic terms.
Proof. Any application of
 $(\exists I)$
and
$(\exists I)$
and
 $(\forall E)$
where t is complex can be replaced by the following, where a is a fresh parameter:
$(\forall E)$
where t is complex can be replaced by the following, where a is a fresh parameter:


The proof in fact shows something stronger:
 $(\forall E)$
and
$(\forall E)$
and
 $(\exists I)$
can be restricted to parameters, as t might as well be a constant. But this is not needed in the following.
$(\exists I)$
can be restricted to parameters, as t might as well be a constant. But this is not needed in the following.
Comment. Kürbis [Reference Kürbis16, Reference Kürbis17] counts formulas discharged by general introduction rules that are the major premises of their elimination rules as maximal. There would, indeed, be a reduction procedure for such formulas, where all maximal formulas arising from an application of
 $(=I^{nG})$
are replaced together after the following pattern:
$(=I^{nG})$
are replaced together after the following pattern:

If there are non-maximal formulas in the assumption class of
 $a=t$
, then
$a=t$
, then
 $\Pi _t^a\ast $
and
$\Pi _t^a\ast $
and
 $\Sigma _t^a\ast $
are the results of removing the ensuing vacuous applications of
$\Sigma _t^a\ast $
are the results of removing the ensuing vacuous applications of
 $(=E)$
. But this won’t work if t is an
$(=E)$
. But this won’t work if t is an ![]() term. As before, the replacement of a by t in
term. As before, the replacement of a by t in
 $\Pi $
and
$\Pi $
and
 $\Sigma $
may then create maximal formulas of unknown degree. What is more, the use to which
$\Sigma $
may then create maximal formulas of unknown degree. What is more, the use to which
 $(=I^{nG})$
is put in handing normalisation in the presence of
$(=I^{nG})$
is put in handing normalisation in the presence of ![]() prevents us from removing Kürbis-style maximal formulas from deductions: this use will generate maximal formulas of exactly that kind.
prevents us from removing Kürbis-style maximal formulas from deductions: this use will generate maximal formulas of exactly that kind.
The following philosophical questions arise. Should we not demand that these formulas be removable from deductions? Furthermore, the deduction that derives
 $(=I^{nG})$
in the proof of Lemma 4 contains a maximal formula. So
$(=I^{nG})$
in the proof of Lemma 4 contains a maximal formula. So
 $(=I^{nG})$
comes at the cost of hiding a detour.Footnote
12
This is not the place to address these questions exhaustively, so a sketch of an answer must suffice. The answer to both questions lies, I think, in the connection between reference and existence. If a definite description
$(=I^{nG})$
comes at the cost of hiding a detour.Footnote
12
This is not the place to address these questions exhaustively, so a sketch of an answer must suffice. The answer to both questions lies, I think, in the connection between reference and existence. If a definite description ![]() refers, i.e., if
refers, i.e., if ![]() , then
, then
 $(=I^{nG})$
permits the introduction of an ad hoc name for its referent. We can, that is, baptise the object, to use Kripke’s expression. This allows us to refer to it without having to describe it as an F. The significance of this comes out in modal contexts. The name is rigid, the definite description need not be. The move ensures that we can talk about the same object in every possible world. By contrast, we cannot baptise what does not exist; here all we have is the definite description. These are issues orthogonal to those of how the meanings of logical expressions are defined by their rules. So even if
$(=I^{nG})$
permits the introduction of an ad hoc name for its referent. We can, that is, baptise the object, to use Kripke’s expression. This allows us to refer to it without having to describe it as an F. The significance of this comes out in modal contexts. The name is rigid, the definite description need not be. The move ensures that we can talk about the same object in every possible world. By contrast, we cannot baptise what does not exist; here all we have is the definite description. These are issues orthogonal to those of how the meanings of logical expressions are defined by their rules. So even if
 $(=I^{nG})$
hid or gave rise to unremovable maximal formulas, this would not upset the aims of proof-theoretic semantics. Further discussion of the wider issues touched upon here must wait for another occasion.
$(=I^{nG})$
hid or gave rise to unremovable maximal formulas, this would not upset the aims of proof-theoretic semantics. Further discussion of the wider issues touched upon here must wait for another occasion.
6.2. Reduction procedures for and restrictions of its rules
The reduction procedures for identities flanked by an ![]() term, the first two taken from [Reference Tennant32, p. 169], are the following:
term, the first two taken from [Reference Tennant32, p. 169], are the following:
1. ![]() followed by
followed by ![]() :
:

2. ![]() followed by
followed by ![]() :
:

3. ![]() followed by
followed by ![]() :
:

The same problem as for the quantifiers arises. If u is a complex term,
 $\Xi _u^a$
and
$\Xi _u^a$
and
 $\Sigma _u^a$
may contain maximal formulas of higher degree than the formula
$\Sigma _u^a$
may contain maximal formulas of higher degree than the formula ![]() that is removed by the first and second reduction procedures. A new problem is that if u is a complex term,
that is removed by the first and second reduction procedures. A new problem is that if u is a complex term,
 $F_u^x$
can turn into a maximal formula of unknown degree.
$F_u^x$
can turn into a maximal formula of unknown degree.
 $u=t$
,
$u=t$
,
 $\exists !u$
and
$\exists !u$
and
 $\exists !t$
pose no problem, as, if maximal, they are handled by Lemma 3.
$\exists !t$
pose no problem, as, if maximal, they are handled by Lemma 3.
This problem is solved by the following lemma, which also builds on an observation of Indrzejczak’s [Reference Indrzejczak12]. In the following deductions, double lines mark inferences by symmetry of identity (Lemma 6).
Lemma 8. Given
 $(=I^{nG})$
and
$(=I^{nG})$
and
 $(=E)$
, t and u in
$(=E)$
, t and u in ![]() ,
, ![]() and
and ![]() can be restricted to atomic terms.
can be restricted to atomic terms.
Proof. (1) Replace an application of ![]() where t is a complex term
where t is a complex term ![]() by
by

where a and b are fresh parameters.
(2) (a) Replace an application of ![]() where t is a term
where t is a term ![]() and u atomic by
and u atomic by

where a is a fresh parameter.
(b) Replace an application of ![]() where u is a term
where u is a term ![]() and t atomic by
and t atomic by

where b is a fresh parameter.
(c) If both t and u are complex, either carry out procedure (a) and replace the inference by ![]() by the construction in (b), or carry out procedure (b) and replace the inference by the construction in (a).
by the construction in (b), or carry out procedure (b) and replace the inference by the construction in (a).
If both t and u are complex, there are also two alternative methods that lead to less complex deductions. (i) Say u is ![]() . Then replace u in
. Then replace u in ![]() by a fresh parameter b, so that it concludes
by a fresh parameter b, so that it concludes
 $F_b^x$
, derive
$F_b^x$
, derive ![]() from
from ![]() by
by
 $(=E)$
, and discharge the former by an application of
$(=E)$
, and discharge the former by an application of
 $(=I^{nG})$
, with its premise derived from
$(=I^{nG})$
, with its premise derived from ![]() by
by
 $(AD)$
. Then apply construction (a). (ii) Say t is
$(AD)$
. Then apply construction (a). (ii) Say t is ![]() . Then replace t in
. Then replace t in ![]() by a fresh parameter a and discharge the ensuing formulas
by a fresh parameter a and discharge the ensuing formulas ![]() and
and
 $u=a$
by applications of
$u=a$
by applications of
 $(=I^{nG})$
with their premises derived by
$(=I^{nG})$
with their premises derived by
 $(AD)$
. Then apply construction (b).
$(AD)$
. Then apply construction (b).
(3) (a) Replace an application of ![]() where t is a term
where t is a term ![]() and u atomic by
and u atomic by

where a is a fresh parameter.
(b) Replace an application of ![]() where u is a term
where u is a term ![]() and t atomic by
and t atomic by

(c) If both t and u are complex, either carry out procedure (a) and replace the inference by ![]() by the construction in (b), or carry out procedure (b) and replace the inference by the construction in (a).
by the construction in (b), or carry out procedure (b) and replace the inference by the construction in (a).
Here, too, when both t and u are complex, there are methods that lead to less complex deductions, but this is left to the reader.
Comment. The restriction on the rules for ![]() may have philosophical significance. Došen requires of an analysis of the meaning of an expression that a sentence in which it occurs only once is paraphrased by an equivalent sentence in which it does not occur [Reference Došen3, p. 369, 371f]. The reason is that otherwise it is not clear that the expression or rather a sequence of occurrences of that expression has been analysed. This requirement is reminiscent of one often imposed on rules of sequent calculi, especially those intended to define the meanings of connectives by their inference rules. Wansing calls rules in which the connective they govern occurs only once and only in the conclusion explicit (see [Reference Wansing39, p. 127], [Reference Wansing40, p. 10]). Although
may have philosophical significance. Došen requires of an analysis of the meaning of an expression that a sentence in which it occurs only once is paraphrased by an equivalent sentence in which it does not occur [Reference Došen3, p. 369, 371f]. The reason is that otherwise it is not clear that the expression or rather a sequence of occurrences of that expression has been analysed. This requirement is reminiscent of one often imposed on rules of sequent calculi, especially those intended to define the meanings of connectives by their inference rules. Wansing calls rules in which the connective they govern occurs only once and only in the conclusion explicit (see [Reference Wansing39, p. 127], [Reference Wansing40, p. 10]). Although
 $(AD)$
cannot be so restricted, it may be motivated independently by a general requirement behind negative free logic: the truth or assertibility of an atomic proposition requires that all the terms occurring in it refer. Another criterion Wansing imposes is separation: no other connective than the one they govern is mentioned in the rules. The rules for
$(AD)$
cannot be so restricted, it may be motivated independently by a general requirement behind negative free logic: the truth or assertibility of an atomic proposition requires that all the terms occurring in it refer. Another criterion Wansing imposes is separation: no other connective than the one they govern is mentioned in the rules. The rules for ![]() do not satisfy separation, as identity occurs in them, but requiring separation is rather too stringent. It is a legitimate procedure to define one expression in terms of another. The meaning of the second expression then depends on the first. In set theory, e.g., operations on the numbers are defined after the numbers have been defined. What should be avoided is that such dependencies are circular.
do not satisfy separation, as identity occurs in them, but requiring separation is rather too stringent. It is a legitimate procedure to define one expression in terms of another. The meaning of the second expression then depends on the first. In set theory, e.g., operations on the numbers are defined after the numbers have been defined. What should be avoided is that such dependencies are circular.
6.3. Normalisation
Due to these problems and their solutions I will prove normalisation not for ![]() , but for the system
, but for the system ![]() that results from it by replacing
that results from it by replacing
 $(=I^n)$
by
$(=I^n)$
by
 $(=I^{nG})$
and restricting t in
$(=I^{nG})$
and restricting t in
 $(\forall E)$
,
$(\forall E)$
,
 $(\exists I)$
and
$(\exists I)$
and ![]() , and t and u in
, and t and u in ![]() and
and ![]() to atomic terms. These systems are equivalent:
to atomic terms. These systems are equivalent:
Theorem 3.
![]() iff
iff ![]()
We need to modify some definitions.
 $(=I^{nG})$
is often treated similarly to
$(=I^{nG})$
is often treated similarly to
 $(\exists E)$
. The parameter of an application of
$(\exists E)$
. The parameter of an application of
 $(=I^{nG})$
is assumed to be used solely for that application and to occur nowhere else in the deduction, and it also gives rise to segments:
$(=I^{nG})$
is assumed to be used solely for that application and to occur nowhere else in the deduction, and it also gives rise to segments:
Definition 18. In Definition 4, insert ‘or
 $(=I^{nG})$
’ after
$(=I^{nG})$
’ after
 $(\exists E)$
.
$(\exists E)$
.
Definition 5 stays the same. In Definition 14, paths continue with a discharged assumption from the premise of
 $(=I^{nG})$
, but we won’t have much occasion to consider this notion.
$(=I^{nG})$
, but we won’t have much occasion to consider this notion.
Definition 9 requires change and there is one more case to be considered:
Definition 19. A maximal
 $=$
-segment is (i) a segment of formulas
$=$
-segment is (i) a segment of formulas
 $t=t$
such that one of them is the minor premise of
$t=t$
such that one of them is the minor premise of
 $(=I^{nG})$
and the last is the premise of
$(=I^{nG})$
and the last is the premise of
 $(AD)$
or
$(AD)$
or ![]() , or (ii) a segment (of formulas
, or (ii) a segment (of formulas
 $a=t$
) such that the first is discharged by
$a=t$
) such that the first is discharged by
 $(=I^{nG})$
and the last is the premise of
$(=I^{nG})$
and the last is the premise of
 $(AD)$
or
$(AD)$
or ![]() with conclusion
with conclusion
 $\exists !t$
. A maximal
$\exists !t$
. A maximal
 $\exists !$
-segment is a segment that is concluded by
$\exists !$
-segment is a segment that is concluded by
 $(AD)$
or
$(AD)$
or ![]() and major premise of an application of
and major premise of an application of
 $(=I^{nG})$
with conclusion
$(=I^{nG})$
with conclusion
 $t=t$
.
$t=t$
.
If
 $\exists !a$
is concluded, this is not counted as maximal. Such segments are used in the proof that the rules for quantifiers and
$\exists !a$
is concluded, this is not counted as maximal. Such segments are used in the proof that the rules for quantifiers and ![]() can be restricted. These are not detours and a formula different from the premise is concluded.
can be restricted. These are not detours and a formula different from the premise is concluded.
The new reduction procedures are as follows:
I. Maximal
 $=$
-segments (i): proceed from the rule that concludes the major premise to the rule applied to the maximal segment, removing all the rest. To illustrate the case where the last formula of the segment is the premise of
$=$
-segments (i): proceed from the rule that concludes the major premise to the rule applied to the maximal segment, removing all the rest. To illustrate the case where the last formula of the segment is the premise of
 $(AD)$
or
$(AD)$
or ![]() :
:

II. Maximal
 $=$
-segments (ii): conclude the conclusion of
$=$
-segments (ii): conclude the conclusion of
 $(AD)$
or
$(AD)$
or ![]() from whatever concludes the major premise of
from whatever concludes the major premise of
 $(=I^{nG})$
, leave everything else. To illustrate with a simple example:
$(=I^{nG})$
, leave everything else. To illustrate with a simple example:

The final application of
 $(=I^{nG})$
is required only if there are formulas in the assumption class of
$(=I^{nG})$
is required only if there are formulas in the assumption class of
 $a=t$
that are not premises of
$a=t$
that are not premises of
 $(AD)$
or
$(AD)$
or ![]() .
.
III. Analogous to I: proceed from the rule that concludes the major premise to the rule applied to the maximal segment, removing all the rest. To illustrate the case where the first formula of the segment is the premise of
 $(AD)$
or
$(AD)$
or ![]() :
:

Should there be more than one application of
 $(=I^{nG})$
in the rules that give rise to the segment, pick the lowest one.
$(=I^{nG})$
in the rules that give rise to the segment, pick the lowest one.
Lemma 3 goes through with a slight modification. In case II, if more than one formula
 $a=t$
is discharged and
$a=t$
is discharged and
 $\Pi $
is not empty, the new reduction procedure increases the number of applications of rules in a deduction and multiplies any maximal
$\Pi $
is not empty, the new reduction procedure increases the number of applications of rules in a deduction and multiplies any maximal
 $\exists !$
-,
$\exists !$
-,
 $=$
- or
$=$
- or
 $(=E)$
-segments in
$(=E)$
-segments in
 $\Pi $
.
$\Pi $
.
Lemma 9. Any deduction can be transformed into one without maximal
 $\exists !$
-,
$\exists !$
-,
 $=$
- and
$=$
- and
 $(=E)$
-segments.
$(=E)$
-segments.
Proof. The procedures cannot introduce new maximal
 $(=E)$
-segments. As before, the procedures may introduce new maximal
$(=E)$
-segments. As before, the procedures may introduce new maximal
 $=$
- and
$=$
- and
 $\exists !$
-segments or increase the length of existing ones, but as before in this case we remove them all together at once. To avoid multiplying maximal segments by procedure II, apply it to a maximal
$\exists !$
-segments or increase the length of existing ones, but as before in this case we remove them all together at once. To avoid multiplying maximal segments by procedure II, apply it to a maximal
 $=$
-segment of this kind so that no other of that kind stands above it and remove all maximal
$=$
-segment of this kind so that no other of that kind stands above it and remove all maximal
 $=$
-segments of kind (i) and all maximal
$=$
-segments of kind (i) and all maximal
 $(=E)$
- and
$(=E)$
- and
 $\exists !$
-segments that stand above it before applying the procedure.
$\exists !$
-segments that stand above it before applying the procedure.
Theorem 4. Deductions in ![]() can be brought into normal form.
can be brought into normal form.
Proof. By induction over the rank of deductions.
The usual method for handling maximal segments works also when a formula concluded by
 $(=I^{nG})$
is major premise of an elimination rule: permute the application upwards.
$(=I^{nG})$
is major premise of an elimination rule: permute the application upwards.
Vacuous applications of
 $(=E)$
are removed as before and assumed to be removed whenever they arise.
$(=E)$
are removed as before and assumed to be removed whenever they arise.
With
 $(\forall E)$
and
$(\forall E)$
and
 $(\exists I)$
restricted to atomic terms, the degree of any maximal formula affected by the replacement of parameters by terms in the reduction procedures stays the same. Thus the rank of deductions is reduced when the reduction procedures are applied according to the methods of Prawitz or Troelstra and Schwichtenberg. They can introduce new maximal
$(\exists I)$
restricted to atomic terms, the degree of any maximal formula affected by the replacement of parameters by terms in the reduction procedures stays the same. Thus the rank of deductions is reduced when the reduction procedures are applied according to the methods of Prawitz or Troelstra and Schwichtenberg. They can introduce new maximal
 $\exists !t$
- or
$\exists !t$
- or
 $=$
-segments: these are removed by an appeal to Lemma 9 immediately after carrying out the reduction procedure.
$=$
-segments: these are removed by an appeal to Lemma 9 immediately after carrying out the reduction procedure.
With ![]() ,
, ![]() and
and ![]() restricted so that t and u are atomic, the reduction procedures for maximal formulas
restricted so that t and u are atomic, the reduction procedures for maximal formulas ![]() work as they should. Replacements of parameters by terms can no longer increase the degree of any maximal formulas. Any maximal formulas
work as they should. Replacements of parameters by terms can no longer increase the degree of any maximal formulas. Any maximal formulas
 $F_u^x$
that are introduced by the procedure now have lower degree than the one removed, as
$F_u^x$
that are introduced by the procedure now have lower degree than the one removed, as ![]() . They can introduce vacuous applications of
. They can introduce vacuous applications of
 $(=E)$
, which are removed as usual, and new maximal
$(=E)$
, which are removed as usual, and new maximal
 $\exists !$
- and
$\exists !$
- and
 $=$
–segments, which are removed by an appeal to Lemma 9 immediately after the reduction.
$=$
–segments, which are removed by an appeal to Lemma 9 immediately after the reduction.
6.4. Failure of the subformula property
I shan’t consider a modified subformula property for deductions in ![]() . There are too many exceptions. To give but one example, consider a derivation of ‘The F is G’, where G is not
. There are too many exceptions. To give but one example, consider a derivation of ‘The F is G’, where G is not
 $=$
, arguably the more typical use of definite descriptions:
$=$
, arguably the more typical use of definite descriptions:

![]() would need to be exempt from the subformula property.
would need to be exempt from the subformula property.
There may be something systematic to the exceptions: they all involve
 $\exists !$
or
$\exists !$
or
 $=$
. But further investigation of this question must await another occasion.
$=$
. But further investigation of this question must await another occasion.
7. Normalisation for
$\mathbf {CNF}$

Here I shall be brief. Normalisation is a little easier, as there are no segments longer than
 $1$
to be considered, and paths are little simpler, too. But the rest stays more or less the same, and we have the following:
$1$
to be considered, and paths are little simpler, too. But the rest stays more or less the same, and we have the following:
Theorem 5. Deductions in
 $\mathbf {CNF}$
can be brought into normal form.
$\mathbf {CNF}$
can be brought into normal form.
Deductions in normal form in
 $\mathbf {CNF}$
have a version of the subformula property similar to what Prawitz finds in classical logic [Reference Prawitz26, p. 42]:
$\mathbf {CNF}$
have a version of the subformula property similar to what Prawitz finds in classical logic [Reference Prawitz26, p. 42]:
Corollary 8. Any exceptions to the subformula property in normal deductions in
 $\mathbf {CNF}$
occur between the first and the last formula of the M-part of paths or are assumptions
$\mathbf {CNF}$
occur between the first and the last formula of the M-part of paths or are assumptions
 $\neg A$
discharged by
$\neg A$
discharged by
 $(\bot E_C)$
and formulas
$(\bot E_C)$
and formulas
 $\bot $
concluded from them.
$\bot $
concluded from them.
8. Normalisation for
![]() arises from
arises from ![]() by replacing
by replacing
 $(=I^n)$
by
$(=I^n)$
by
 $(=I^{nG})$
, and restricting
$(=I^{nG})$
, and restricting
 $(\forall E)$
to atomic instantiating terms and
$(\forall E)$
to atomic instantiating terms and ![]() ,
, ![]() and
and ![]() to atomic t and u.
to atomic t and u.
Theorem 6.
![]() iff
iff ![]()
Proof. As for Theorem 3.
Recall that
 $(\bot E_C)$
with vacuous charges is treated like
$(\bot E_C)$
with vacuous charges is treated like
 $(\bot E)$
, i.e., its conclusions are restricted to prime conclusions (Lemma 2). If discharge is not vacuous, its conclusions cannot be so restricted. Atomic formulas containing
$(\bot E)$
, i.e., its conclusions are restricted to prime conclusions (Lemma 2). If discharge is not vacuous, its conclusions cannot be so restricted. Atomic formulas containing ![]() terms must be admitted. We therefore need to consider further cases of maximal formulas, namely formulas concluded by
terms must be admitted. We therefore need to consider further cases of maximal formulas, namely formulas concluded by
 $(\bot E_C)$
that are major premise of
$(\bot E_C)$
that are major premise of ![]() ,
, ![]() ,
, ![]() or premise of
or premise of
 $(AD)$
. The last gives rise to an anomaly: the maximal formula may have degree
$(AD)$
. The last gives rise to an anomaly: the maximal formula may have degree
 $0$
if
$0$
if
 $t_i$
in the conclusion is atomic.
$t_i$
in the conclusion is atomic.
The new reduction procedures follow the pattern of those given by Stålmarck in his normalisation proof for classical logic [Reference Stålmarck31, 131ff]: they permute the applications of the elimination rules or
 $(AD)$
upwards and, assuming the negations of their conclusions, apply
$(AD)$
upwards and, assuming the negations of their conclusions, apply
 $(\bot E_C)$
to them instead. Here the latter only happens in two of the new cases, though. I shall adapt Andou’s simplification of Stålmarck’s method to the present case [Reference Andou1].Footnote
13
In fact, due to the absence of
$(\bot E_C)$
to them instead. Here the latter only happens in two of the new cases, though. I shall adapt Andou’s simplification of Stålmarck’s method to the present case [Reference Andou1].Footnote
13
In fact, due to the absence of
 $\exists $
and
$\exists $
and
 $\lor $
from
$\lor $
from ![]() and the ensuing possibility of restricting
and the ensuing possibility of restricting
 $(\bot E_C)$
to atomic formulas, the proof is simpler than Andou’s.
$(\bot E_C)$
to atomic formulas, the proof is simpler than Andou’s.
Following Andou, define a new kind of segment and when they are maximal:
Definition 20. A segment is a sequence of formulas arising from applications of
 $(=I^{nG})$
as in Definition 4 or a sequence of formulas
$(=I^{nG})$
as in Definition 4 or a sequence of formulas
 $A_1\ldots A_n$
such that
$A_1\ldots A_n$
such that
 $A_1$
is not the conclusion of
$A_1$
is not the conclusion of
 $(\bot E_C)$
, and for all i,
$(\bot E_C)$
, and for all i,
 $A_i$
is the minor premise of
$A_i$
is the minor premise of
 $(\rightarrow E)$
the major premise of which is discharged by
$(\rightarrow E)$
the major premise of which is discharged by
 $(\bot E_C)$
,
$(\bot E_C)$
,
 $A_{i+i}$
is the conclusion of that application of
$A_{i+i}$
is the conclusion of that application of
 $(\bot E_C)$
, and
$(\bot E_C)$
, and
 $A_n$
is not a minor premise of
$A_n$
is not a minor premise of
 $(\rightarrow E)$
the major premise of which is discharged by
$(\rightarrow E)$
the major premise of which is discharged by
 $(\bot E_C)$
.
$(\bot E_C)$
.
Where there is need to distinguish the two, call the latter ‘
 $(\bot E_C)$
-segments’. The length of segments is defined as always, their degree as in Definition 6.
$(\bot E_C)$
-segments’. The length of segments is defined as always, their degree as in Definition 6.
Definition 21. Add the following at the end of Definition 5 of maximal segment: ‘or a segment the last formula of which is the conclusion of
 $(\bot E_C)$
and the major premise of an elimination rule or the premise of
$(\bot E_C)$
and the major premise of an elimination rule or the premise of
 $(AD)$
’.
$(AD)$
’.
Crucial to Andou’s method is the following:
Definition 22. An assumption discharged by
 $(\bot E_C)$
is regular if it is the major premise of
$(\bot E_C)$
is regular if it is the major premise of
 $(\rightarrow E)$
. A proof is regular if all assumptions discharged by
$(\rightarrow E)$
. A proof is regular if all assumptions discharged by
 $(\bot E_C)$
in it are regular.
$(\bot E_C)$
in it are regular.
Lemma 10.
 $\mathrm{(a)}$
Any proof can be transformed into a regular proof.
$\mathrm{(a)}$
Any proof can be transformed into a regular proof.
 $\mathrm{(b)}$
In a regular proof, any assumption discharged by
$\mathrm{(b)}$
In a regular proof, any assumption discharged by
 $(\bot E_C)$
stands to the right of a formula on a
$(\bot E_C)$
stands to the right of a formula on a
 $(\bot E_C)$
-segment.
$(\bot E_C)$
-segment.
Proof. (a) If
 $\neg A$
is discharged by
$\neg A$
is discharged by
 $(\bot E_C)$
but not major premise of
$(\bot E_C)$
but not major premise of
 $(\rightarrow E)$
, deduce it by
$(\rightarrow E)$
, deduce it by
 $(\bot E_C)$
and discharge a regular assumption instead:
$(\bot E_C)$
and discharge a regular assumption instead:

where i is the label of the original application of
 $(\bot E_C)$
and j is fresh. (b) is immediate.
$(\bot E_C)$
and j is fresh. (b) is immediate.
The effect of this lemma is that the minor premise of
 $(\rightarrow E)$
is always available in the upwards permutations of the elimination rules or
$(\rightarrow E)$
is always available in the upwards permutations of the elimination rules or
 $(AD)$
. Remove all formulas in assumption class i by concluding the conclusion of
$(AD)$
. Remove all formulas in assumption class i by concluding the conclusion of
 $(\rightarrow E)$
according to the pattern below and replace
$(\rightarrow E)$
according to the pattern below and replace
 $(\bot E_C)$
accordingly or remove it altogether:
$(\bot E_C)$
accordingly or remove it altogether:
1.
 $(\bot E_C)$
followed by
$(\bot E_C)$
followed by ![]() :
:

2.
 $(\bot E_C)$
followed by
$(\bot E_C)$
followed by ![]() :
:

3.
 $(\bot E_C)$
followed by
$(\bot E_C)$
followed by
 $(AD)$
:
$(AD)$
:

![]() being a special case of
being a special case of
 $(AD)$
,
$(AD)$
,
 $(\bot E_C)$
followed by
$(\bot E_C)$
followed by ![]() is handled as in 3.
is handled as in 3.
Theorem 7. Deductions in ![]() can be brought into normal form.
can be brought into normal form.
Proof. First, transform the deduction into a regular deduction. Lemma 9 goes through as before, so apply it next. Then proceed by an induction over the rank of deductions, defined as in Definition 13 adjusted so as to count the new maximal segments of Definition 21. Note that the highest degree of a maximal segment can now be
 $0$
, namely if the formula on a maximal
$0$
, namely if the formula on a maximal
 $(\bot E_C)$
-segment is prime. Hence deductions may have rank
$(\bot E_C)$
-segment is prime. Hence deductions may have rank
 $\langle 0, l\rangle $
, where
$\langle 0, l\rangle $
, where
 $l>0$
, which cannot happen in standard classical logic.
$l>0$
, which cannot happen in standard classical logic.
Maximal segments arising from
 $(=I^{nG})$
and from introducing and eliminating formulas as major premises are treated as usual.
$(=I^{nG})$
and from introducing and eliminating formulas as major premises are treated as usual.
Maximal
 $(\bot E_C)$
-segments are handled as follows. Due to the restriction of
$(\bot E_C)$
-segments are handled as follows. Due to the restriction of
 $(\bot E_C)$
, their last formulas are atomic. All four procedures shorten or remove the maximal segment to which they are applied.
$(\bot E_C)$
, their last formulas are atomic. All four procedures shorten or remove the maximal segment to which they are applied.
In cases 1 and 2, any new maximal segments created by the reduction procedure have lower degree than the one shortened or removed, because due to the restriction on ![]() and u are atomic. Thus
and u are atomic. Thus ![]() and
and ![]() .
.
In case 3, the following possibilities arise:
(a) If
 $Rt_1\ldots t_n$
is prime (i.e., R is a predicate letter), the degree of the maximal
$Rt_1\ldots t_n$
is prime (i.e., R is a predicate letter), the degree of the maximal
 $(\bot E_C)$
-segment is
$(\bot E_C)$
-segment is
 $0$
, and cannot be lowered. But as the segment on which it is is shortened by
$0$
, and cannot be lowered. But as the segment on which it is is shortened by
 $1$
, this poses no problem.
$1$
, this poses no problem.
(b) If
 $Rt_1\ldots t_n$
is
$Rt_1\ldots t_n$
is ![]() and it is concluded by
and it is concluded by ![]() in
in
 $\Xi $
, the procedure creates a maximal formula of the same degree as the one removed, so we remove it immediately by the third reduction procedure for maximal formulas
$\Xi $
, the procedure creates a maximal formula of the same degree as the one removed, so we remove it immediately by the third reduction procedure for maximal formulas ![]() , leaving only the deduction of the premise
, leaving only the deduction of the premise
 $\exists !t$
of
$\exists !t$
of ![]() .
.
(c) The possibilities removed with Lemma 9 are: If
 $Rt_1\ldots t_n$
is concluded by
$Rt_1\ldots t_n$
is concluded by
 $(=E)$
in
$(=E)$
in
 $\Xi $
, then the procedure introduces a maximal
$\Xi $
, then the procedure introduces a maximal
 $(=E)$
-segment. If
$(=E)$
-segment. If
 $Rt_1\ldots t_n$
is
$Rt_1\ldots t_n$
is
 $t=t$
, then if it is concluded by
$t=t$
, then if it is concluded by
 $(=I^{nG})$
in
$(=I^{nG})$
in
 $\Xi $
the procedure introduces a new maximal
$\Xi $
the procedure introduces a new maximal
 $=$
-segment. It cannot introduce a new maximal
$=$
-segment. It cannot introduce a new maximal
 $\exists !$
-segment: this would require the conclusion
$\exists !$
-segment: this would require the conclusion
 $\exists !t$
of
$\exists !t$
of
 $(AD)$
to be major premise of
$(AD)$
to be major premise of
 $(=I^{nG})$
, so there would have been a maximal
$(=I^{nG})$
, so there would have been a maximal
 $\exists !$
-segment already, which were assumed to have been removed.
$\exists !$
-segment already, which were assumed to have been removed.
The method by which Prawitz or Troelstra and Schwichtenberg choose a maximal segment to which to apply a permutative reduction procedure works for maximal
 $(\bot E_C)$
-segments, too. It ensures that there are no longest maximal segments of highest degree in
$(\bot E_C)$
-segments, too. It ensures that there are no longest maximal segments of highest degree in
 $\Xi $
or the
$\Xi $
or the
 $\Sigma $
s, and so the rank of the deduction is lowered.
$\Sigma $
s, and so the rank of the deduction is lowered.
9. Conclusion
The normalisation theorems for systems of intuitionist and classical negative free logic without and with definite descriptions proved in this paper required considering new kinds of maximal formulas specific to negative free logic. The systems with definite descriptions required a formulation that avoids reduction procedures that involve arbitrarily complex terms being substituted for parameters. For the systems without definite descriptions, deductions in normal form have been shown to fulfil a restricted notion of subformula property. A system inspired by Jaśkowski with an improved result has been proposed. The question remains whether there is an interesting notion of subformula property for the systems with definite descriptions.
From the philosophical perspective, what is often considered to be a necessary condition for the meanings of expressions to be defined by rules of inference is thus fulfilled. A novelty of the present paper is that it opens up the prospects that the meanings of term-forming operators may also be so defined. Whether what has been established is also sufficient for proof-theoretic semantics is open to further discussion. Philosophical questions that arise have been touched upon. A satisfactory discussion of these issues must await another occasion.
Acknowledgements
Thank you, as always, to Andrzej Indrzejczak, who encouraged me to work on this topic. This paper was improved substantially in response to the reports for this journal. I thank the referees for the exceptional refereeing and the time and effort they put into their thoughtful, encouraging and constructive criticism.
Funding
The research in this paper was funded by the European Union (ERC, ExtenDD, project number: 101054714). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council. Neither the European Union nor the granting authority can be held responsible for them.

 Open access
Open access