



Significant outcomes
-
Clinical notes in the electronic health records (EHRs) from a large psychiatric service in Denmark were found to be lexically stable over time, with no major changes observed on the aggregate level in the usage of terms describing psychopathology.
-
The discontinuation of a specific note type and an increase in the use of virtual communication during the COVID-19 pandemic were the main factors contributing to the identified changepoints in the EHR content.
-
While there were some changes in the usage of terms describing mood disorders during the COVID-19 pandemic, the overall novelty in the use of words related to psychopathology was relatively low, suggesting consistency in the content of the clinical notes over time. However, gradual changes in note length and other characteristics may have implications for the performance of prediction models over time, emphasising the need for continuous monitoring and evaluation.
Limitations
-
The calculation of novelty based on word frequency may not identify emerging terms or shifts in writing style, potentially missing important changes in the clinical notes.
-
The analysis is sensitive to relative changes in rare terms describing psychopathology, which might increase the risk of finding artefacts due to changes in the patient population.
-
The study’s changepoint detection models may not be sensitive to slow distribution shifts and drifts, requiring manual analysis and inspection to identify such changes in the clinical notes.
Introduction
In medical care, electronic health record (EHR) systems are used to document all patient-related information. The type of recorded information is highly heterogeneous and covers lab results, diagnoses, administered medication, as well as subjective (reported by the patient) and objective (findings made by the healthcare professionals) descriptions of behaviour and symptoms in the form of text in clinical notes (Häyrinen et al., Reference Häyrinen, Saranto and Nykänen2008). Notably, the clinical notes are not only a site for collection – but also of aggregation and synthesis – of clinical information (Rosenbloom et al., Reference Rosenbloom, Stead, Denny, Giuse, Lorenzi, Brown and Johnson2010). Especially in psychiatry, important clinical information is often documented as text (Abbe et al., Reference Abbe, Grouin, Zweigenbaum and Falissard2016).
As the volume of information increases in EHR systems, it may become increasingly harder for healthcare professionals to make meaningful decisions based on this information (Cimino, Reference Cimino2013). In these situations, decision support based on analysis of the EHR data can guide clinicians towards relevant information and suggest courses of action (Sutton et al., Reference Sutton, Pincock, Baumgart, Sadowski, Fedorak and Kroeker2020). Whereas structured numerical data can relatively easily be aggregated with conventional statistical descriptors (e.g. minimum and maximum values, means, medians etc.), extracting relevant information from free-form clinical text requires a different approach (Wang et al., Reference Wang, Wang, Rastegar-Mojarad, Moon, Shen, Afzal, Liu, Zeng, Mehrabi, Sohn and Liu2018). In recent years, however, the field of natural language processing (NLP) has made marked progress (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017; Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019; Otter et al., Reference Otter, Medina and Kalita2020), and textual information is no longer outside the purview of, for example, machine learning algorithms. Indeed, the utility of written text for prediction models in healthcare has been investigated in multiple studies and has been found to improve performance (Goldstein et al., Reference Goldstein, Navar, Pencina and Ioannidis2017; Boag et al., Reference Boag, Doss, Naumann and Szolovits2018; Rajkomar et al., Reference Rajkomar, Oren, Chen, Dai, Hajaj, Hardt, Liu, Liu, Marcus, Sun, Sundberg, Yee, Zhang, Zhang, Flores, Duggan, Irvine, Le, Litsch, Mossin, Tansuwan, Wang, Wexler, Wilson, Ludwig, Volchenboum, Chou, Pearson, Madabushi, Shah, Butte, Howell, Cui, Corrado and Dean2018; Danielsen et al., Reference Danielsen, Fenger, Østergaard, Nielbo and Mors2019; Huang et al., Reference Huang, Altosaar and Ranganath2019; Huang et al., Reference Huang, Altosaar and Ranganath2019). However, the stability of this predictive performance relies on the EHR source’s stability, including the text in the clinical notes. Specifically, the performance of prediction models tends to degrade markedly the more the data used for prediction differs from that used for training (Marcus, Reference Marcus2018). Formally, in the case of distribution shift or drift, the assumption of identically distributed data no longer holds. This can lead to spurious or highly time-dependent patterns in prediction, which are unlikely to generalise (Shen et al., Reference Shen, Liu, He, Zhang, Xu, Yu and Cui2021).
Hospital services using EHR are highly dynamic; for instance, clinical procedures, treatments, diagnostic criteria, the distribution of tasks between healthcare professions, healthcare staff composition and EHR systems tend to change substantially over time. The EHR information contained in written clinical notes may be particularly prone to changes over time, but – to our knowledge – the stability of the written clinical notes from EHR is never directly tested. Therefore, we aimed to assess the lexical stability over time of written clinical notes from a large psychiatric hospital system. More specifically, we aimed to answer the question of lexical stability using data from the Psychiatric Clinical Outcome Prediction (PSYCOP) cohort (Hansen et al., Reference Hansen, Enevoldsen, Bernstorff, Nielbo, Danielsen and Østergaard2021), which contains EHR clinical notes covering almost 130,000 patients and more than 14,000,000 clinical notes over the 10 years from 2011 to 2021. We employed changepoint detection models to examine whether (i) the use of words describing psychopathology (symptoms) in clinical notes in the EHR is stable over time and (ii) if sentence length, readability, syntactic complexity, and usage of different types of clinical notes are stable over time. The methods employed and the results obtained may serve as a benchmark for future studies testing the lexical stability of clinical notes from other hospital systems.
Material and methods
Data source
We used data from an updated version of the PSYCOP cohort (Hansen et al., Reference Hansen, Enevoldsen, Bernstorff, Nielbo, Danielsen and Østergaard2021). Specifically, we analysed all EHR clinical notes from all patients with at least one contact with the Psychiatric Services of the Central Denmark Region in the period from January 1, 2011, to November 22, 2021, covering 129,570 patients and 14,811,551 notes. In the EHR, the clinical notes are labelled according to their content, for example, ‘current mental state’, ‘current social state’ or ‘medication’ (all labels are listed in the Supplementary Information). For the present study, we selected 17 note types, which are among the most widely used and rich in text. See Supplementary Table 1 for a description of the note types.
Tables 1 and 2 (and Supplementary Table 2) show dataset characteristics related to the number of patients and note types. The dataset contains data from a total of 129,570 patients, of whom 66,575 (51%) are female, and is representative of all age groups. The dataset contains more than 1 billion tokens and 14.8 million notes across the 17 selected note types, with a mean note length of 71.5 tokens.
Table 1. Demographic characteristics of the cohort

The table shows the number of unique patients grouped by their last ICD-10 diagnosis, age group at the first visit and sex. * If less than 10 patients in a group, the cell count is set at <10 to avoid the identification of individuals. See Supplementary Table 2 for further age stratification.
Table 2. Number and length of notes by note type sorted in descending order based on total number of tokens

Data processing
For the analysis (i) of the stability of descriptions of psychopathological symptoms over time, a total of 365 terms deemed most important for describing psychopathology were chosen by authors EP and AAD (both registrars in psychiatry). The chosen terms were based on psychopathology described in the Present State Examination (Danish version) (Pedersen and Bertelsen, Reference Pedersen and Bertelsen2018) and the ICD-10 (World Health Organization, 1993). The 365 terms describing psychopathology were grouped by the International Statistical Classification of Diseases and Related Health Problems 10th Revision (ICD-10) diagnostic category which the symptom best described. Subsequently, we counted how many times (summed at the quarterly level) each of the terms describing psychopathology – grouped by ICD-10 diagnostic category as well as a category for terms used in a mental state examination – occurred in each of the 17 types of clinical notes. Terms that occurred less than 10 times in 5 or more quarters were removed to reduce the sparsity of the keyword matrix and thereby increase the robustness of the analysis. A total of 56 terms were removed due to this criterion (see Supplementary Table 3 for a full list of included and excluded keywords), resulting in 309 terms used for the analysis. For each diagnostic group (ICD-10: F0–F9 and mental status examination), as well as for all terms describing psychopathology together (aggregated words describing psychopathology), the counts of terms describing psychopathology were transformed to proportions to calculate the novelty of each quarter to the previous two quarters. Novelty is a measure of windowed relative entropy that expresses information novelty as a difference in content from the past and is further described (under ‘Metrics’) below.
For the analysis (ii) of the stability of sentence length, readability metrics, syntactic complexity and usage of the clinical notes over time, we extracted the mean note length, the mean automated readability index (ARI) (Kincaid et al., Reference Kincaid, Fishburne, Rogers and Chissom1975) and mean dependency distance from each note type using the spaCy v3.1.1 (Montani et al., Reference Montani, Honnibal, Honnibal, Landeghem, Boyd, Peters, Samsonov, McCann, Geovedi, Regan, Orosz, Altinok, Kristiansen, Roman, Fiedler, Bot, Howard, Phatthiyaphaibun, Tamura, Bozek, Amery, Böing, Tippa, Vogelsang, Balakrishnan, Mazaev, GregDubbin, jeannefukumaru and Henry2021) and textdescriptives v1.0.6 (Hansen et al., Reference Hansen, Olsen, Bernstorff, Enevoldsen and Hæstrup2022) Python libraries and the spaCy da_core_news_lg model. For these analyses, we randomly sampled 10% of the notes to reduce computational costs. The proportion of total notes was calculated by dividing the number of notes of each type by the total number of notes (out of the 17 note types). Each metric was aggregated as the quarterly mean, and the resulting time series of quarterly means were then analysed using changepoint detection algorithms. The aggregation was carried out to reduce noise and computational costs. The metrics, as well as the changepoint detection analysis, are described in more detail below.
Data from before 2013 were found to be highly noisy and therefore excluded from the main analyses (Bernstorff et al., Reference Bernstorff, Hansen, Perfalk, Danielsen and Østergaard2022). The noise was largely due to the gradual implementation of a new EHR system in the region starting in 2011 (Hansen et al., Reference Hansen, Enevoldsen, Bernstorff, Nielbo, Danielsen and Østergaard2021; Bernstorff et al., Reference Bernstorff, Hansen, Perfalk, Danielsen and Østergaard2022). See Supplementary Figure 1 for more details.
Metrics
Novelty
Novelty measures the average divergence between the present keyword distribution s (j) and past keyword distributions s (j−1), s (j−2), …, s (j−w) in window w:
 $${\rm{Novelt}}{{\rm{y}}_w}\left( j \right) = {1 \over w}\sum\limits_{d = 1}^w {{\rm{JSD}}} \left( {{s^{\left( j \right)}}|{s^{\left( {j - d} \right)}}} \right)$$
$${\rm{Novelt}}{{\rm{y}}_w}\left( j \right) = {1 \over w}\sum\limits_{d = 1}^w {{\rm{JSD}}} \left( {{s^{\left( j \right)}}|{s^{\left( {j - d} \right)}}} \right)$$
where JSD is the Jensen–Shannon divergence:
 $${\rm{JSD}}\left( {P\left\| Q \right.} \right) = {1 \over 2}D\left( {P\left\| M \right.} \right) + {1 \over 2}D\left( {Q\left\| M \right.} \right)$$
$${\rm{JSD}}\left( {P\left\| Q \right.} \right) = {1 \over 2}D\left( {P\left\| M \right.} \right) + {1 \over 2}D\left( {Q\left\| M \right.} \right)$$
where P and Q are probability distributions,
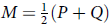 $M = {1 \over 2}(P + Q)$
and D is the Kullback–Leibler divergence.
$M = {1 \over 2}(P + Q)$
and D is the Kullback–Leibler divergence.
Novelty can be interpreted as the degree of relative entropy or ‘surprise’ in the distribution based on the recent past. The novelty will rise if word usage changes, but if the change becomes more permanent, the novelty will fall again as it becomes the new normal. Many continual changes, that is, low predictability, cause high novelty, and conversely, few changes cause novelty to be low. A visual representation of how changes affect novelty is shown in Fig. 1. Code for calculating novelty can be found on the following Github repository: https://github.com/Aarhus-Psychiatry-Research/lexical-stability

Figure 1. Example of novelty calculation with a window size of 2. The figure shows the distribution shift over time of four keywords from the F4 category. The distribution of the four keywords at each time point is represented with a histogram, with the height of the bars indicating word counts and the colour indicating novelty levels. Major shifts such as from time 4 to 5 lead to high novelty, which gradually decreases as the distribution becomes stable. The larger the shift in distribution, the greater the novelty. Novelty cannot be calculated for the first two points as we have defined the window size to be 2.
Mean note length
We calculated the mean note length as the mean number of tokens in each document. A token is a meaningful segment of text and includes whitespace-separated words, punctuation and more (Webster and Kit, Reference Webster and Kit1992). For the present study, the documents were tokenised using spaCy’s Danish tokenisation module (Honnibal et al., Reference Honnibal, Montani, Van Landeghem and Boyd2020).
Automated readability index
The ARI is a measure of the readability of a text, designed to estimate the grade level required to comprehend the text (Kincaid et al., Reference Kincaid, Fishburne, Rogers and Chissom1975). The equation below shows the formula for calculating the ARI:
 $${\rm{ARI}} = 4.71\left( {{{{\rm{characters}}} \over {{\rm{words}}}}} \right) + 0.5\left( {{{{\rm{words}}} \over {{\rm{sentences}}}}} \right) - 21.43$$
$${\rm{ARI}} = 4.71\left( {{{{\rm{characters}}} \over {{\rm{words}}}}} \right) + 0.5\left( {{{{\rm{words}}} \over {{\rm{sentences}}}}} \right) - 21.43$$
Dependency distance
We define dependency distance as the number of words between a word and its headword. The mean dependency distance is the average dependency distance of a document or sentence, as visualised in Fig. 2. The dependency tree is obtained by performing a dependency parse using spaCy, and dependency distance was calculated using textdescriptives (Hansen et al., Reference Hansen, Olsen and Enevoldsen2023).

Figure 2. Calculation of dependency distance. Numbers on arrows indicate the distance from the head to the word. Note that ‘experienced’ has no arrows pointing to it, as it is the root of the sentence. The dependency distance of ‘experienced’ is therefore zero. The mean dependency distance of the sentence is (1 + 2 + 1 + 0 + 2 + 1 + 3) / 7 = 1.43.
Changepoint detection
All time series (83) were analysed for multiple changepoints in both mean and variance using the Pruned Exact Linear Time (PELT) algorithm (Killick et al., Reference Killick, Fearnhead and Eckley2012). Specifically, the time series were (1) one for each of the 17 note types for each for the 4 descriptive statistics (mean number of tokens, mean dependency distance, ARI and proportion of notes (68 in total)), (2) three time series for the 17 note types combined (mean number of tokens, mean dependency distance and ARI) and (3) a time series for the novelty of each of the 10 ICD-10 diagnostic categories of words describing psychopathology, one for the novelty of words used in the mental state examination, and one for the novelty of all words (aggregate) describing psychopathology (12 in total). PELT automatically finds the appropriate number of changepoints by iteratively searching for new changepoints at each data split. This makes PELT particularly suitable for tasks without prior information on the location and number of changepoints. Variables were detrended by differencing with a lag of one time step and z-scored before input to PELT using the default parameters of the cpt.meanvar function (penalty = ’MBIC’, minseqlen = 2). Changepoint detection was conducted in R v3.6.1 (R Core Team, 2019) using the tidyverse v1.3.1 (Wickham et al., Reference Wickham, Averick, Bryan, Chang, McGowan, François, Grolemund, Hayes, Henry and Hester2019) and changepoint v2.2.2 (Killick and Eckley, Reference Killick and Eckley2014) packages. Given the 83 time series with a data point for each quarter for nine years (2013 Q1–2021 Q4), the number of data points (and hence the number of possible changepoints) was 4 × 9 × 83 = 2988.
Stability of the use of words describing psychopathology
The analyses of the stability in the use of the 309 words describing psychopathology (Fig. 5) were conducted by identifying the words that had the largest relative change from the mean of the two preceding time points to the time point of interest. The relative change in word usage was quantified as the ratio between the current novelty value and the mean of the two previous points. The divergence metric in the novelty equation is sensitive to relative changes in proportions as opposed to absolute changes, that is, a change in proportional usage of a keyword from 0.4 to 0.2 will have the same impact on novelty as a change from 0.1 to 0.05. Hence, words that are used rarely are more likely to have large fluctuations in relative proportions and are therefore stronger drivers of novelty than more commonly used words.
Sensitivity analyses
To assess the effect of different window sizes for calculating novelty, we reran the analysis on the stability of descriptions of psychopathological symptoms over time with window sizes of 2, 4, 6 and 8 quarters, respectively. To investigate the robustness of the analysis on the stability of sentence length, readability metrics, syntactic complexity and usage of the clinical notes over time, we reran the analysis on a different 10% random sample of the data. Finally, upon a suggestion from a reviewer, we also employed an alternative model for dependency parsing (DaCy large (Enevoldsen et al., Reference Enevoldsen, Hansen and Nielbo2021)).
Code availability
All code used for extracting and analysing the data can be found on the following Github repository: https://github.com/Aarhus-Psychiatry-Research/lexical-stability. While not all steps can be reproduced due to data privacy, we have provided the aggregated data files used for the changepoint analyses.
Results
Stability across all notes and words describing psychopathology
As seen in Fig. 3, the mean number of tokens, mean dependency distance, ARI and novelty on the aggregate level (across all clinical notes or all words describing psychopathology) were relatively stable over the course of the study. No changepoints were found in any of the groups. However, the mean number of tokens increased steadily over time.

Figure 3. Time series of text stability. The figure panels illustrate the automated readability index (ARI), mean dependency distance, the mean number of tokens for the aggregated clinical notes (top three rows) and novelty across all psychopathological keywords. The grey line indicates the estimated changepoint segments (none found for any groups). The left column shows the data with the y-axis going to 0, and the right column shows the data with the y-axes allowed to vary.
Analysis i: Stability in the use of terms describing psychopathology
As shown in Fig. 4, a total of three changes in novelty were found in 2 out of the 12 (diagnostic) categories of terms describing psychopathology (ICD-10 codes F0–F9, objective description and aggregated words), namely F1 (substance abuse) and F3 (mood disorders). The novelty was low across the categories, which indicates that the distributions are generally stable over time. Visual inspection of the identified changepoints in F1 – substance abuse (Supplementary Figure 2) suggests that these are artefacts rather than actual changepoints as they do not map onto any visually salient changes. The novelty for words describing psychopathology related to substance abuse was extremely low, which suggests that the distribution is particularly stable. For F3 – mood disorders, the changepoint reveals a slight rise in novelty in 2020 Q2, followed by a consistent drop (see Supplementary Figure 2). Figure 5 shows that this rise was mainly driven by decreased use of ‘nihilistic delusions’ and ‘grandiose delusions’ as well as increased use of ‘dysthymia’.

Figure 4. Location of changepoints on novelty for terms across diagnostic categories.

Figure 5. The 12 words describing psychopathology with the largest relative change at the 2020 Q2 changepoint for F3 – mood disorders. The x-axis shows the quotient difference between the mean of the two previous time points (novelty window) to the time point of interest (1 = no difference). The shape indicates whether there was an increase or decrease in word use. The text next to the label denotes the actual difference in means, that is, a change of 0.012 means that the use of a word rose to comprise an additional 0.012% of all words in the F3 – mood disorder category (the 68 words in the F3 – mood disorder category are available in Supplementary Table 3) in 2020 Q2 compared to the previous two quarters.
Analysis ii: Stability of sentence length, readability metrics and syntactic complexity of clinical notes
Figure 6 shows the changepoints for the mean number of tokens, mean dependency distance, ARI and proportion of total notes for each note type. Across the 17 note types and 4 categories of variables, a single changepoint was identified for the number of tokens, two for dependency distance, four for ARI and seven for note-type proportion (a total of 14 changepoints). The changepoints were concentrated mainly around the year 2020; however, most of the estimated changepoints were due to deviations from a linear trend or represented artefacts caused by reduced usage of the note type due to administrative changes (see the discussion for further explanation). No changepoints were found for eight of the note types, nor when analysing all notes together (aggregate).

Figure 6. Location of the 14 changepoints in the mean number of tokens, dependency distance, automated readability index (ARI) and proportion of total notes for each note type. The colours indicate which metric the changepoint occurred in.
Supplementary Figures 3–6 show the time series for the mean number of tokens, dependency distance, ARI and proportion of total notes for all note types with the output from the changepoint model overlaid. Half of the estimated changepoints (7 out of 14) were related to changes in how large a proportion of the total notes the note type made up. ‘Conclusion’ had the most significant change by practically falling out of use after 2020 Q3, going from comprising a mean of 2.7% of notes from 2013 to 2020 Q2 to only comprising a mean of 0.3% afterwards. Therefore, the changes in ARI and dependency distance in 2020 Q4 and 2021 Q1, respectively, are likely to be artefacts driven by a very low number of examples (see the discussion for further explanation). The proportion of notes stemming from ‘Phone consultations’ rose from comprising 2.5% of notes on average in 2014–2019 Q2 (pre-COVID-19 pandemic) to 3.9% afterwards (during the COVID-19 pandemic). The proportion of ‘Telephone notes’ also rose during the COVID-19 pandemic. ‘Conversation with treatment aim’ saw a drop in usage in 2019, from comprising approximately 6.5% of notes to 5%. The change in ‘Current mental state’ seems to reflect a minor deviation from a linearly decreasing trend after 2018. ‘Objective, somatic’ saw a halving in usage from comprising a mean of 1.2% of notes before 2014 Q4 to a mean of 0.5% afterwards.
The changepoints in the ARI (4 out of 14) include a slight increase in trend for ARI for ‘Appointments, Psychiatry’ in 2020, and a slight outlier in 2014 Q2 for ‘Patient note’, with a mean ARI of 9.5 compared to a mean of 8.5 in the previous year. The changepoint in ARI for ‘Conclusion’ in 2020 Q3 is due to reduced usage of the ‘Conclusion’ note type. All dependency distance-related changepoints (2 out of 14) seem to be related to reductions in the use of the note type. As with ARI, the 2020 Q4 ‘Conclusion’ changepoint is an artefact of reduced usage. The 2021 Q1 changepoint in ‘Medicine’ appears to reflect a degree of variability over time rather than a salient changepoint. Only a single changepoint (1 out of 14) was identified in the mean number of tokens per note in the ‘Conclusion’ note type in 2013 Q2. Visual inspection of Supplementary Figure 3 revealed the changepoint to be a minor deviation from a linearly increasing trend.
Sensitivity analyses
Overall, the sensitivity analyses yielded results highly similar to those from the main analyses reported above. Using larger window sizes for calculating novelty led to an estimated changepoint for aggregated notes in 2017 Q3, but values of novelty were highly similar (see Supplementray Figures 7 and 8). The sensitivity analysis of sentence length, readability metrics and syntactic complexity of clinical notes found the extracted metrics to be extremely similar to those from the main analysis (see Supplementary Figures 9–13). Additional changepoints for mean dependency distance in the semi-structured diagnostic interview note type in 2015 Q2 and Q4, and for Appointment, Psychiatry in 2020 Q4 were identified by using the DaCy large model for dependency parsing. The location of estimated changepoints were, however, highly similar to those identified by the main analyses, and deviations seem to mainly stem from the sensitivity of the PELT algorithm rather than major changes in the actual metrics. See the supplementary material for further discussion of the results from the sensitivity analyses.
Discussion
This study investigated the lexical stability of clinical notes in EHR from a large cohort of patients attending psychiatric services in Denmark. Analyses of changepoints in (i) the use of words describing psychopathology – as well as in (ii) note length, readability, syntactic complexity and usage of the clinical notes found the EHR content to generally be stable over time. Notably, no changepoints were found on the aggregate level, that is, when analysing all notes and all words describing psychopathology together. Out of 2988 data points, 17 (0.6%) possible changepoints were identified. We found most changepoints to be related to the discontinuation of a specific note type (’Conclusion’) or from increases in the use of virtual communication during the COVID-19 pandemic. Changepoints for words describing psychopathology were only found in the ICD-10 F3 – mood disorders category and were likely caused by a change in the patient presentation during COVID-19. A slow distribution shift was, however, observed in the note length of some specific note types (’Current mental state’, ‘Current social, Psychiatry’, ‘Current somatic, Psychiatry’, ‘Patient note’, ‘Medication’, ‘Plan’ and ’Semi-structured diagnostic interview’), which was also apparent on the aggregate level. These changes were not detected by changepoint analyses yet might gradually degrade the performance of prediction models over time. This underlines the importance of thoroughly evaluating the performance of clinical prediction models over time and continuously monitoring them after deployment to ensure model quality.
The most prominent change was found in the use of the ‘Conclusion’ note type, which dropped from comprising a mean of 2.7% of notes before 2020 Q3 to only comprise a mean of 0.3% afterwards. Conversations with officials from the Business Intelligence Office of the Central Denmark Region, which administers the EHR, revealed the large drop in usage of ‘Conclusion’ to be caused by the introduction of a new note type in December 2020, namely ‘Evaluation/conclusion’, which was intended to replace ‘Conclusion’. This change was not otherwise documented and implies that one should be cautious if using ‘Conclusion’ as a point of analysis and highlights the importance of evaluating the stability of EHR data records before use for research purposes.
Furthermore, the analysis revealed a rise in the proportion of ‘Phone consultations’ and ‘Telephone notes’ during the COVID-19 pandemic, which is compatible with the regional policy on replacing physical meetings with patients with telephone or video calls to avoid the spread of the coronavirus. In fact, the build-up of changepoints around the year 2020 is likely influenced by the COVID-19 pandemic. Previous research from the Central Denmark Region has identified changes to language use in the clinical notes during the pandemic (Enevoldsen et al., Reference Enevoldsen, Danielsen, Rohde, Jefsen, Nielbo and Østergaard2022), exacerbation of psychopathology amongst patients (Jefsen et al., Reference Jefsen, Rohde, Nørremark and Østergaard2020; Kølbæk et al., Reference Kølbæk, Jefsen, Speed and Østergaard2022) and large fluctuations in the number of referrals to the psychiatric services (Kølbæk et al., Reference Kølbæk, Nørremark and Østergaard2021), which has likely led to a different patient mix during the pandemic. These factors are likely contributors to the relative instability from 2020 to 2021.
The analysis of the use of words describing psychopathology suggests that there are changes in the use of terms related to mood disorders in 2020 Q2, after which novelty immediately dropped. Due to the timing of this changepoint, it may be caused by the COVID-19 pandemic – as a consequence of either the logistic changes described in the paragraph above (e.g. physical meetings replaced by phone or video consultation) or of changes in psychopathology due to the COVID-19 pandemic (Kølbæk et al., Reference Kølbæk, Nørremark and Østergaard2021, Reference Kølbæk, Jefsen, Speed and Østergaard2022). However, as described in the Methods section, the calculation of novelty is sensitive to relative changes in the use of words describing psychopathology rather than absolute changes. Therefore, due to the rarity of the words driving the change in novelty for F3 – mood disorders, a small increase in the number of patients with these symptoms can lead to relatively large changes in novelty. These changes in novelty are likely of minor importance, supported by the fact that the overall novelty in the present dataset is low compared to other sources, such as literature or Danish news (Jing et al., Reference Jing, DeDeo and Ahn2019; Baglini et al., Reference Baglini, Nielbo, Hæstrup, Enevoldsen, Vahlstrup and Roepstorff2021). For instance, for the group of words describing psychotic and mood disorders, the mean novelty was around 0.001, whereas the novelty of literature or Danish news rarely drops below 0.2. Although different representations were used to calculate novelty (topic model for news and word frequencies in the present case), we argue that the novelty in the use of words describing psychopathology is particularly low.
Limitations
There are several limitations to this study. First, using frequencies of words describing psychopathology as the basis for novelty calculation will not identify the emergence of new terms or find shifts in writing style. Novelty can be calculated on any distribution and is often based on topic modelling (e.g. Latent Dirichlet Allocation (LDA) (Blei et al., Reference Blei, Ng and Edu2003)), which might provide a higher-level representation of the data. Because LDA and other latent variable models are known to perform badly on short texts (Wu et al., Reference Wu, Li, Zhu and Miao2020), we chose to use the relative words usage describing psychopathology over time to calculate novelty, as this is invariant to the length of the clinical notes. Another option for short texts is to use contemporary neural embedding techniques such as transformer-based topic modelling (Grootendorst, Reference Grootendorst2022), but these are not feasible to use without GPU access, which was not available to us on the server of the Central Denmark Region at the time of the study. Second, novelty is based on relative changes, not absolute changes. This means that our analysis is sensitive to changes in rare psychopathological keywords as they are likely to fluctuate more than commonly used words. This might increase the risk of finding artefacts due to changes in the patient population. Third, to identify changes in writing style and writing conventions, one could use methods for out-of-distribution detection such as perplexity of the texts over time (Arora et al., Reference Arora, Huang and He2021). This, however, requires the use of a GPU as well as a generative language model, neither of which were available to us. Fourth, changepoint detection models are not sensitive to slow distribution shifts and drifts but rather to changes in means or variance that persist over some time. As a consequence, our method will identify major breaks, such as the discontinuation of the ‘Conclusion’ note type but will not find distribution shifts, such as the increase in note length, without manual analysis and inspection. Fifth, there are several different formulas for calculating readability. We chose to use ARI as it is simple to implement, coupled with the fact that it had the highest mean correlation (0.93) to the other readability metrics available in the textdescriptives python package (Hansen et al., Reference Hansen, Olsen and Enevoldsen2023). Given the high correlation, it is reasonable to expect other readability metrics to produce very similar results. Sixth, the sensitivity analysis revealed that the PELT model with default parameters might be too sensitive, that is, it has a false-positive rate that is too high. Future studies would be advised to adjust the penalty to avoid finding spurious changepoints. Lastly, the degree to which these changepoints will impact other tasks such as prediction modelling remains to be tested. Future studies on the PSYCOP cohort will investigate this matter.
In conclusion, in a large body of clinical notes from psychiatric services spanning almost a decade, the mean length of notes, readability, syntactic complexity, note type distribution and usage of words describing psychopathology were generally stable over time. The discontinuation of the ‘Conclusion’ note type was the cause of most of the changepoints detected. There were changes in novelty in some groups of words describing psychopathology, but the overall novelty was relatively low, suggesting consistency in the content of the clinical notes over time. Taken together, these findings suggest that prediction models can be trained on the content of clinical notes without fitting to idiosyncrasies of a specific time period. However, one should be cautious of gradual changes in the data distribution, such as an increase in the average note length. To ensure reliable results of future studies based on text from clinical notes, we encourage that checks of stability similar to those presented here are conducted ahead of analysis.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/neu.2023.46
Data availability statement
In accordance with Danish law for the protection of privacy, the data used for this study are only available for research projects conducted by employees in the Central Denmark Region upon approval from the Legal Office under the Central Denmark Region (in accordance with the Danish Health Care Act §46, Section 2).
Acknowledgements
The authors thank Bettina Nørremark from Aarhus University Hospital – Psychiatry for her assistance with data extraction.
Author contribution
Conception and design: all authors. Funding obtainment: S.D.Ø. Provision of study data: S.D.Ø. and A.A.D. Data analysis: L.H. and K.C.E. Interpretation: All authors. Manuscript writing: L.H., E.P, M.B. and S.D.Ø. Revision of manuscript for important intellectual content: K.C.E., A.A.D. and K.L.N. Final approval of the manuscript: all authors.
Financial support
The study is supported by grants from the Lundbeck Foundation (grant number: R344-2020-1073), the Danish Cancer Society (grant number: R283-A16461), the Central Denmark Region Fund for Strengthening of Health Science (grant number: 1-36-72-4-20) and the Danish Agency for Digitisation Investment Fund for New Technologies (grant number 2020-6720) to Østergaard, who reports further funding from the Lundbeck Foundation (grant number: R358-2020-2341), the Novo Nordisk Foundation (grant number: NNF20SA0062874) and Independent Research Fund Denmark (grant number: 7016-00048B). The funders played no role in the study design, collection, analysis or interpretation of data, the writing of the report or the decision to submit the paper for publication.
Competing interests
Danielsen has received a speaker honorarium from Otsuka Pharmaceutical. SDØ received the 2020 Lundbeck Foundation Young Investigator Prize. Furthermore, SDØ owns/has owned units of mutual funds with stock tickers DKIGI, IAIMWC and WEKAFKI and has owned units of exchange-traded funds with stock tickers BATE, TRET, QDV5, QDVH, QDVE, SADM, IQQH, USPY, EXH2, 2B76 and EUNL. The remaining authors declare no conflicts of interest.
Ethics
This study was carried out to ensure the validity/stability of the data used for studies based on the PSYCOP cohort (Hansen et al., Reference Hansen, Enevoldsen, Bernstorff, Nielbo, Danielsen and Østergaard2021). The use of EHRs from the Central Denmark Region was approved by the Central Denmark Region Legal Office per the Danish Health Care Act §46, Section 2. We submitted the study to the Central Denmark Region ethical review board, which waived informed consent (waiver for this project: 1-10-72-1-22). All data were processed and stored in accordance with the European Union General Data Protection Regulation, and the project is registered on the internal list of research projects having the Central Denmark Region as the data steward. All experiments were performed in accordance with regulations.











 Open access
Open access