



1. Introduction
Hate speech spreading on the web and social media is an important research problem, and its regulation is still ineffective due to the high difficulty in identifying, quantifying, and classifying hateful communication. While hateful content is found in different platforms and languages, the majority of data resources are proposed for the English language. As a result, there is a lack of research and resources for low-resource hate speech detection.
The hate speech detection literature has focused on different tasks, such as (i) automatically detecting hate speech targets such as racism (Hasanuzzaman, Dias, and Way Reference Hasanuzzaman, Dias and Way2017), antisemitism (Ozalp et al. Reference Ozalp, Williams, Burnap, Liu and Mostafa2020; Zannettou et al. Reference Zannettou, Finkelstein, Bradlyn and Blackburn2020), religious intolerance (Ghosh Chowdhury et al. Reference Ghosh Chowdhury, Didolkar, Sawhney and Shah2019), misogyny and sexism (Jha and Mamidi Reference Jha and Mamidi2017; Guest et al. Reference Guest, Vidgen, Mittos, Sastry, Tyson and Margetts2021), and cyberbullying (Van Hee et al. Reference Van Hee, Lefever, Verhoeven, Mennes, Desmet, De Pauw, Daelemans and Hoste2015a), (ii) filtering pages with hateful content and violence (Liu and Forss Reference Liu and Forss2015), (iii) offensive language detection (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019; Steimel et al. Reference Steimel, Dakota, Chen and Kübler2019; Vargas et al. Reference Vargas, Goes, Carvalho, Benevenuto and Pardo2021); (iv) toxic comment detection (Guimarães et al. Reference Guimarães, Reis, Ribeiro and Benevenuto2020), (v) multimodal hateful content (Cao et al. Reference Cao, Lee, Chong and Jiang2022), and (vi) countering hate speech in dialogue systems (Bonaldi et al. Reference Bonaldi, Dellantonio, Tekiroğlu and Guerini2022). Finally, comprehensive surveys on automatic detection of hate speech were also proposed (Schmidt and Wiegand Reference Schmidt and Wiegand2017; Fortuna and Nunes Reference Fortuna and Nunes2018; Poletto et al. Reference Poletto, Basile, Sanguinetti, Bosco and Patti2021; Vidgen and Derczynski Reference Vidgen and Derczynski2021).
Corroborating the particular relevance to fill the gap of data resources for low-resource languages, the possibility of proposing reliable data is essential to build better automatic applications, besides boosting the linguist diversity for hate speech research. Nevertheless, the annotation process of hate speech is intrinsically challenging, considering that what is considered offensive is strongly influenced by pragmatic (cultural) factors, and people may have different opinions on an offense. In addition, there is the presence of implicit content and sarcasm, which hides the real intention of the comment and makes the decision of the annotators confusing.
Indeed, subjective tasks (e.g., hate speech detection, sentiment and emotion analysis, sarcasms and irony detection, etc.) in natural language processing (NLP) present high complexity and a wide variety of technical challenges. Recent proposals have discussed the implications of the annotation process its impact to model hate speech phenomena (Poletto et al. Reference Poletto, Basile, Sanguinetti, Bosco and Patti2021), the proposing of multilayer annotation scheme (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019), target-aware hate speech annotation (as known as hate speech targets) (Basile et al. Reference Basile, Bosco, Fersini, Nozza, Patti, Rangel Pardo, Rosso and Sanguinetti2019), and the implicit-explicit distinction in the hate speech annotation process (Caselli et al. Reference Caselli, Basile, Mitrović, Kartoziya and Granitzer2020). In fact, a well-defined annotation schema has a considerable impact on the consistency and quality of the data, as well as the performance of the derived machine-learning classifiers.
In addition, there are also different research gaps in order to address hate speech in terms of methods and data resources. For instance, most existing offensive lexicons are built by means of large crowd-sourced lexical resources, which is limited due to a wide range of irrelevant terms, resulting in high rates of false positives (Davidson, Bhattacharya, and Weber Reference Davidson, Bhattacharya and Weber2019). Moreover, hate speech detection methods based on large language models (LLMs) are trained on real-world data, which are known to embed a wide range of social biases (Nadeem, Bethke, and Reddy Reference Nadeem, Bethke and Reddy2021; Davani et al. Reference Davani, Atari, Kennedy and Dehghani2023). Finally, the relevant issue in the area is related to scarce data resources and methods for low-resource languages.
Toward addressing the lack of data resources for low-resource languages, this paper provides different data resources for low-resource hate speech detection. More specifically, we introduce two data resources: the HateBR 2.0 and MOL – multilingual offensive lexicon, which are both expert data resources for hate speech detection. The HateBR 2.0 consists of a large corpus of 7,000 comments extracted from Brazilian politicians’ accounts on Instagram and manually annotated by experts for Brazilian Portuguese hate speech detection. It is an updated version of HateBR corpus (Vargas et al. Reference Vargas, Carvalho, Rodrigues de Góes, Pardo and Benevenuto2022), in which highly similar and one-word comments were replaced. We aim to release the HateBR 2.0 version that is still more consistent and reliable. In the same settings, the MOL comprises explicit and implicit pejorative terms and expressions annotated with context information. The lexicon was also translated by native speakers taking into account cultural adaptations for low-resource languages (Turkish, German, French) and for the English and Spanish languages.
Finally, in order to support the high interhuman agreement score obtained for both data resources (HateBR 2.0 and MOL), besides assessing the reliability of annotated data, we also provide baseline experiments on the HateBR 2.0 corpus and baseline experiments using machine learning (ML) models, which embed terms and expressions extracted from the MOL in English, Spanish, and Portuguese. Results show the reliability of proposed data resources, outperforming baseline dataset results in Portuguese, besides presetting promising results for hate speech detection in different languages.
In what follows, in Section 2, we present related works. Sections 3 and 4 describe the definitions for hate speech and offensive language used in this paper. In Sections 5 and 6, we describe the HateBR 2.0 corpus and the MOL, which are expert and context-aware data resources for low-resource languages, respectively. Section 7 provides data statistics, and Section 8 baseline experiments, evaluation, and results are presented. Finally, in Section 9, the final remarks and future works are presented.
2. Related work
The hate speech detection corpora lie to user-generated public content, mostly microblog posts, and are often retrieved with a keyword-based approach and using words with a negative polarity (Poletto et al. Reference Poletto, Basile, Sanguinetti, Bosco and Patti2021). In addition, hate speech detection methods, according to the literature, have focused mainly on the following approaches (Schmidt and Wiegand Reference Schmidt and Wiegand2017):
-
(1) Simple surface features: Simple surface-based features such as a bag-of-words (BoW) using unigram and larger n-grams have been proposed by a wide range of authors (Chen et al. Reference Chen, Zhou, Zhu and Xu2012; Xu et al. Reference Xu, Jun, Zhu and Bellmore2012; Waseem and Hovy Reference Waseem and Hovy2016; Nobata et al. Reference Nobata, Tetreault, Thomas, Mehdad and Chang2016). Besides that, n-gram features are also applied along with several other features (Nobata et al. Reference Nobata, Tetreault, Thomas, Mehdad and Chang2016).
-
(2) Word generalization: Considering the data sparsity phenomenon, a wide variety of authors have applied such an approach for word generalization, which consists of carrying out word clustering and then using induced cluster IDs representing sets of words as additional (generalized) features (Schmidt and Wiegand Reference Schmidt and Wiegand2017). A set of approaches have been most considered such as clustering (Brown et al. Reference Brown, Della Pietra, deSouza, Lai and Mercer1992), latent Dirichlet allocation (Blei, Ng, and Jordan Reference Blei, Ng and Jordan2003), word embeddings (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013), and paragraph embeddings (Le and Mikolov Reference Le and Mikolov2014). Word generalization strategies have been explored by Xiang et al. (Reference Xiang, Fan, Wang, Hong and Rose2012), Nobata et al. (Reference Nobata, Tetreault, Thomas, Mehdad and Chang2016), and Warner and Hirschberg (Reference Warner and Hirschberg2012).
-
(3) Sentiment analysis: This approach assumes that semantic polarity may predict hateful and offensive messages. For example, a method proposed by Van Hee et al. (Reference Van Hee, Lefever, Verhoeven, Mennes, Desmet, De Pauw, Daelemans and Hoste2015b) used a sentiment lexicon to compute the number of positive, negative, and neutral words that occur in a given comment. Examples of this approach were also proposed by Njagi et al. (Reference Njagi, Zuping, Hanyurwimfura and Long2015), Burnap and Williams (Reference Burnap and Williams2014), and Burnap et al. (Reference Burnap, Williams, Sloan, Rana, Housley, Edwards, Knight, Procter and Voss2014).
-
(4) Lexical resources: In this approach, a controlled vocabulary of hateful and offensive terms and expressions is used as features to build a model of classification for hate speech and offensive language (Xiang et al. Reference Xiang, Fan, Wang, Hong and Rose2012; Burnap and Williams Reference Burnap and Williams2016; Vargas et al. Reference Vargas, Goes, Carvalho, Benevenuto and Pardo2021).
-
(5) Linguistic features: Linguistic information is surely relevant for text classification and has been explored for hate speech detection such as part-of-speech (POS), syntactical tree and dependency tuple, semantic relations, etc (Chen et al. Reference Chen, Zhou, Zhu and Xu2012; Burnap and Williams Reference Burnap and Williams2014; Burnap et al. Reference Burnap, Williams, Sloan, Rana, Housley, Edwards, Knight, Procter and Voss2014; Zhong et al. Reference Zhong, Li, Squicciarini, Rajtmajer, Griffin, Miller and Caragea2016; Nobata et al. Reference Nobata, Tetreault, Thomas, Mehdad and Chang2016).
-
(6) Knowledge-based features: Corroborating the fact that the hate speech detection tasks are highly context-dependent; in this approach, cultural and world knowledge-based information are used as features (Dinakar et al. Reference Dinakar, Jones, Havasi, Lieberman and Picard2012; Dadvar et al. Reference Dadvar, Trieschnigg, Ordelman and de Jong2013; Vargas et al. Reference Vargas, Goes, Carvalho, Benevenuto and Pardo2021).
-
(7) Meta-information: In this approach, meta-information (i.e., information about an utterance) is also used as a feature for the hate speech classification tasks (Xiang et al. Reference Xiang, Fan, Wang, Hong and Rose2012; Dadvar et al. Reference Dadvar, Trieschnigg, Ordelman and de Jong2013; Waseem and Hovy Reference Waseem and Hovy2016).
-
(8) Multimodal information: Since different modalities of content also may present hateful content, in this approach, different features are explored to classify hate speech in images, video, and audio content (Boishakhi, Shill, and Alam Reference Boishakhi, Shill and Alam2021; Zhu, Lee, and Chong Reference Zhu, Lee and Chong2022; Thapa et al. Reference Thapa, Jafri, Hürriyetoğlu, Vargas, Lee and Naseem2023).
2.1 Hate speech detection for low-resource languages
While most hate speech corpora are proposed for the English language (Davidson et al. Reference Davidson, Warmsley, Macy and Weber2017; Gao and Huang Reference Gao and Huang2017; Jha and Mamidi Reference Jha and Mamidi2017; Golbeck et al. Reference Golbeck, Ashktorab, Banjo, Berlinger, Bhagwan, Buntain, Cheakalos, Geller, Gergory, Gnanasekaran, Gunasekaran, Hoffman, Hottle, Jienjitlert, Khare, Lau, Martindale, Naik, Nixon, Ramachandran, Rogers, Rogers, Sarin, Shahane, Thanki, Vengataraman, Wan and Wu2017; Fersini, Rosso, and Anzovino Reference Fersini, Rosso and Anzovino2018; Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019; AlKhamissi et al. Reference AlKhamissi, Ladhak, Iyer, Stoyanov, Kozareva, Li, Fung, Mathias, Celikyilmaz and Diab2022), there are a set of proposals toward boosting low-resource hate speech technologies. For example, in French, a corpus of Facebook and Twitter annotated data for Islamophobia, sexism, homophobia, religious intolerance, and disability detection was also proposed (Chung et al. Reference Chung, Kuzmenko, Tekiroglu and Guerini2019; Ousidhoum et al. Reference Ousidhoum, Lin, Zhang, Song and Yeung2019). In Germany, a new anti-foreigner prejudice corpus was proposed (Bretschneider and Peters Reference Bretschneider and Peters2017). This corpus is composed of 5,836 Facebook posts and hierarchically annotated with slightly and explicitly/substantially offensive language according to six targets: foreigners, government, press, community, other, and unknown. In Greek, an annotated corpus of Twitter and Gazeta posts for offensive content detection is also available (Pavlopoulos, Malakasiotis, and Androutsopoulos Reference Pavlopoulos, Malakasiotis and Androutsopoulos2017; Pitenis, Zampieri, and Ranasinghe Reference Pitenis, Zampieri and Ranasinghe2020). In Slovene and Croatian, a large-scale corpus composed of 17,000,000 posts, with 2 percent of hate speech on a leading media company website was built (Ljubešić et al. Reference Ljubešić, Erjavec and Fišer2018). In the Arabic language, there is a corpus of 6,136 Twitter posts, which are annotated according to religion intolerance subcategories (Albadi, Kurdi, and Mishra Reference Albadi, Kurdi and Mishra2018). In the Indonesian language, a hate speech annotated corpus from Twitter data was also proposed in Alfina et al. (Reference Alfina, Mulia, Fanany and Ekanata2017).
2.2 Hate speech detection for the Portuguese language
For the Portuguese languages, an annotated corpus of 5,668 European and Brazilian Portuguese tweets was proposed in Fortuna et al. (2019). The corpus comprises two annotation levels: binary classification (hate speech versus non-hate speech) and hierarchical labels of nine direct social groups targeted by discrimination. In addition, automated methods using a hierarchy of hate were proposed. They used pretrained Glove word embedding with 300 dimensions for feature extraction and an Long Short-Term Memory (LSTM) architecture proposed in Badjatiya et al. (Reference Badjatiya, Gupta, Gupta and Varma2017). The authors obtained an F1-score of 78 percent using cross-validation. Furthermore, a new specialized lexicon was also proposed specifically for European Portuguese, which may be useful to detect a broader spectrum of content referring to minorities (Fortuna et al. Reference Fortuna, Cortez, Sozinho Ramalho and Pérez-Mayos2021).
More specifically for Brazilian Portuguese, a corpus of 1,250 comments collected from Brazilian online newspaper G1,Footnote a annotated with a binary class (offensive and non-offensive), and six hate speech targets (racism, sexism, homophobia, xenophobia, religious intolerance, or cursing) was provided by de Pelle and Moreira (Reference de Pelle and Moreira2017). The authors provide a baseline using a support vector machine (SVM) with linear kernel and multinomial Naive Bayes (NB). The best model obtained an F1-score of 80 percent. Specifically for toxicity classification in Twitter posts for the Brazilian Portuguese language, a corpus composed of 21,000 tweets manually annotated according to seven hate speech targets—nontoxic, LGBTQ + phobia, obscene, insult, racism, misogyny, and xenophobia—was proposed in Leite et al. (Reference Leite, Silva, Bontcheva and Scarton2020), in which the BERT fine-tuning baseline was presented reaching an F1-score of 76 percent. Furthermore, the Offensive Language Identification Dataset for Brazilian Portuguese (OLID-BR) (Trajano, Bordini, and Vieira Reference Trajano, Bordini and Vieira2023) was also provided for Brazilian Portuguese, which was inspired by the original OLID in English. This corpus consists of 7,943 comments extracted from YouTube and Twitter and annotated according to different categories: health, ideology, insult, LGBTQphobia, other lifestyle, physical aspects, profanity/obscene, racism, religious intolerance, sexism, and xenophobia. The authors provide a BERT fine-tuning baseline reaching an F1-score of 77 percent. Finally, the HateBR corpus (Vargas et al. Reference Vargas, Carvalho, Rodrigues de Góes, Pardo and Benevenuto2022) comprises 7,000 Instagram comments manually annotated by experts according to a binary class (offensive and non-offensive) and hate speech targets.In addiation, baseline experiments on HateBR corpus outperfromed the current state-of-the-art for Portuguese. In Table 1, we summarize the literature data resources for the Portuguese language.
Table 1. Portuguese data resources
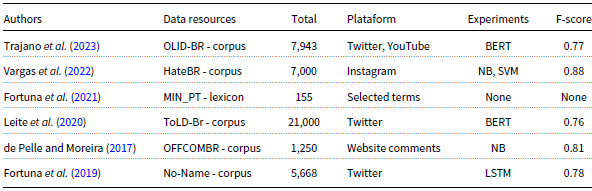
Note: BERT, Bidirectional Encoder Representations from Transformers; NB, Naive Bayes.
3. Offensive language definition
Offensive posts include insults, threats, and messages containing any form of untargeted profanity (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019). In the same settings, offensive language consists of any profanity, strongly impolite, rude, or vulgar language expressed with fighting or hateful words in order to insult a targeted individual or group (Fortuna and Nunes Reference Fortuna and Nunes2018). Accordingly, in this paper, we assume that offensive language consists of a type of language containing terms or expressions used with any pejorative connotation against people, institutions, or groups regardless of their social identity, which may be expressed explicitly or implicitly.
Table 2 shows examples of offensive and non-offensive comments extracted from the HateBR 2.0 corpus. Note that bold indicates terms or expressions with explicit pejorative connotation and underline indicates “clues” of terms or expressions with an implicit pejorative connotation.
Table 2. Offensive and non-offensive comments extracted from the HateBR 2.0 corpus
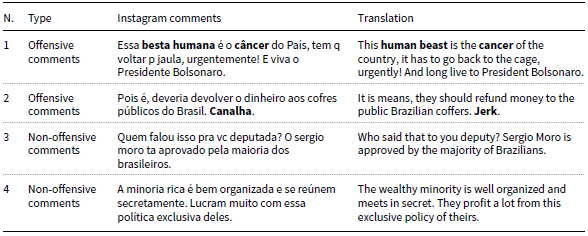
As shown in Table 2, offensive comments comprise terms or expressions with pejorative connotations, which were expressed explicitly and implicitly. For example, in comments 1 and 2, while the term “cancer” may be used in non-pejorative contexts (e.g., he has cancer), in this comment context, it was used with a pejorative connotation. Differently, the expression “human beast” and the term “jerk” both present pejorative connotations and are mostly found in the pejorative context of use. Furthermore, in offensive comments, there are offensive terms or expressions expressed implicitly. For example, the expressions “go back to the cage” and “refund money” are clue elements that indicate terms used with pejorative connotations such as “criminal” and “thief,” respectively. Finally, non-offensive comments do not present any terms or expressions used with pejorative connotations, as observed in comments 3 and 4.
4. Hate speech definition
Here, we defined hate speech as a type of offensive language that attacks or diminishes inciting violence and hate against groups, based on specific characteristics (e.g., physical appearance, religion, descent, national or ethnic origin, sexual orientation, gender identity, etc.), and it may occur with different linguistic styles, even in subtle forms or when humor is used. Hence, hate speech is a type of offensive language used against hate targets (Fortuna and Nunes Reference Fortuna and Nunes2018). Accordingly, in order to precisely elucidate them, nine different hate speech targets are defined in this paper, which we described in detail as follows:
-
(1) Antisemitism: The definition of antisemitism adopted by the International Holocaust Remembrance Alliance (IHRA)Footnote b in 2016 states that “Antisemitism is a certain perception of Jews, which may be expressed as hatred towards Jews. Rhetorical and physical manifestations of antisemitism might include the targeting of the state of Israel, conceived as a Jewish collectivity,” as in the following example: Que escroto caquético! É a velha hipocrisia judaica no mundo dos pilantras monetários. Judeu dos infernos!
-
Translation: What a cachectic asshole! It’s the old Jewish hypocrisy in the world of monetary hustlers. Jew from hell!..
-
(2) Apologist for dictatorship: According to the Brazilian Penal Code,Footnote c apologist for dictatorship consists of comments that incite the subversion of the political or social order, the animosity among the Armed Forces, or among these and the social classes or civil institutions, as in the following example: Intervenção militar já !!! Acaba Supremo Tribunal Federal, não serve pra nada mesmo &
-
Translation: Military intervention now !!! Close the Supreme Court,Footnote d it is of no use at all &.
-
(3) Fatphobia: Fatphobia is defined as negative attitudes based on stereotypes against people socially considered fat (Robinson, Bacon, and O’Reilly Reference Robinson, Bacon and O’reilly1993), as in the following example: Velha barriguda e bem folgada, heim? Porca rosa, Peppa!.
-
Translation: Old potbellied and very lazy, huh? Pink Nut, Peppa Footnote e!.
-
(4) Homophobia: HomophobiaFootnote f is considered an irrational fear or aversion to homosexuality, or, in other words, to lesbian, gay, and bisexual people based on prejudice, as in the following example: Quem falou isso deve ser um global que não sai do armário :) :( e tem esse desejo :( :( nessa hora que tinha que intervir aqui e botar um merda desse no pau. & Dá muito o cú.
-
Translation: Whoever said that must be an artist who does not come out of the closet :) :( and has that desire :( :( at this point they should intervene here and apply the law against them. & They give the ass a lot.
-
(5) Partyism: Partyism is a form of extreme hostility and prejudice against people or group based on their political orientation, which influences non-political behaviors and judgment (Westwood et al. Reference Westwood, Iyengar, Walgrave, Leonisio, Miller and Strijbis2018). In our corpus, the most relevant occurrence of hate speech consists of partyism, as in the following example: Os petralhas colocaram sua corja em todos os lugares, não salva ninguém, que tristeza & Esquerda parasita lixo.
-
Translation: The petralhasFootnote g have puted their crowds everywhere, no one can be saved, how sad. They are parasite and wreckage.
-
(6) Racism/racial segregation: Racism consists of an ideology of racial domination (Wilson Reference Wilson1999). It presumes biological or cultural superiority of one or more racial groups, used to justify or prescribe the inferior treatment or social position(s) of other racial groups (Clair and Denis Reference Clair and Denis2015). In our corpus, we found a wide range of offenses related to racial discrimination, such as “monkey” and “cheetah,” as an example of racist comment: E uma chita ela né! Opssss, uma chata.
-
Translation: So,she is a cheetah right! Opssss, a boring girl.
-
(7) Religious intolerance: Theoretical constructs loom large in the literature on religiosity and intolerance, namely, religious fundamentalism, which is consistently associated with high levels of intolerance and prejudice against religion groups (Altemeyer Reference Altemeyer1996). For instance, observe the following comments: Pastor dos Infernos and O chamado crente do demônio, né?
-
Translation: Pastor of the Church from Hell and The so-called Christian of the devil, right?
-
(8) Sexism: Sexist behavior is mostly related to patriarchy that consists of a system of social structures that allow men to exploit women (Walby Reference Walby1990). Therefore, sexism consists of hostility against self-identified people as female gender, treated them as objects of sexual satisfaction of men, reproducers labor force, and new breeders (Delphy Reference Delphy2000). The following example was extracted from the corpus: Cala esse bueiro de falar merda sua vagabunda safada.
-
Translation: Shut that speaking manhole up you nasty slut.
-
(9) Xenophobia: Xenophobia is a form of racial prejudice (Silva et al. Reference Silva, Modal, Correa, Benevenuto and Weber2016; Davidson et al. Reference Davidson, Bhattacharya and Weber2019), which is manifested through discriminating actions and hate against people based on their origin, as in the following example: Ele está certo. Vai ter um monte de argentino faminto invadindo o Brazil.
-
Translation: He is right. There will be a lot of hungry Argentine people invading Brazil.
5. HateBR 2.0 corpus
Brazil occupies the third position in the worldwide ranking of Instagram’s audience with 110 million active Brazilian users, ahead of Indonesia with an audience of 93 million users.Footnote h On the Instagram platform, each person has an account with shared photos, and it is possible for others to like, comment, save, and share this information. Taking advantage of the fact that Instagram is an online platform with high engagement in Brazil, HateBR (Vargas et al. Reference Vargas, Carvalho, Rodrigues de Góes, Pardo and Benevenuto2022) and HateBR 2.0 data collection relied on this platform.
The proposed approach for the construction of the HateBR corpus is divided into two macro-steps: (A) data collection and (B) data annotation. Data collection relied on four tasks: (first) domain definition, (second) criteria for selecting platform accounts, (third) data extraction, and (fourth) data cleaning. Data annotation relied on three tasks: (first) selection of annotators, (second) annotation schema, and (third) annotation evaluation. In this paper, we introduce an updated version of HateBR corpus (Vargas et al. Reference Vargas, Carvalho, Rodrigues de Góes, Pardo and Benevenuto2022) entitled HateBR 2.0, and we followed the same methodology for data collection and data annotation, except the fact that in this version the comments were manually collected from Instagram in order to replace one-word and highly similar comments.
5.1 Data collection
We provide an updated version of HateBR corpus (Vargas et al. Reference Vargas, Carvalho, Rodrigues de Góes, Pardo and Benevenuto2022) entitled HateBR 2.0. In this version, we used the original data from the HateBR and replaced a set of comments taking into account two criteria: (A) highly similar comments and (B) one-word comments, as shown in Table 3. We aim to release a corpus version that is still more consistent and reliable. For example, we aim to replace highly similar and one-word comments to improve the ability of classifiers to consistently recognize and generalize each class. In total, 17.4 percent of the corpus was replaced totaling 1,216 comments through which 911 were non-offensive and 305 were offensive, as shown in Section 7.
Table 3. Criteria for updating the HateBR corpus

Observe that, as shown in Table 3, comments with only one word as “criminal” or “bitch” or “pig” were replaced by newly collected data. In addition, we also replaced highly similar comments. For instance, example 1 shows both comments “the best president” and “the best president hahahah.” In this case, the difference between both is the laugh (hahahah). In the same settings, in examples 2 and 3, the difference between comments is the account (@veronica_michelle_bachelett) and the emotions (:) =) :) =)).
Toward collecting new Instagram data, we followed the same settings used for data collection previously in HateBR corpus (Vargas et al. Reference Vargas, Carvalho, Rodrigues de Góes, Pardo and Benevenuto2022). For example, in the first step—domain definition—we have chosen the political domain. In the second step—criteria for selecting accounts—the following criteria were defined to improve the representatives of the corpus in terms of localization, gender, and political orientation. Hence, 6 (six) different Brazilian politicians’ accounts were selected, of which 3 (three) accounts are from left-wing politicians and 3 (three) accounts are from right-wing politicians. In addition, we selected 4 (four) accounts from women Brazilian politicians and 2 (two) men Brazilian politicians. In the third step—data extraction—differently from the data collection for the HateBR (initial version), for the HateBR 2.0, we manually collected comments from the selected Brazilian politicians’ accounts. In the fourth step—data cleaning, we proposed an approach for data cleaning, which consists of removing noise, such as links, characters without semantic value, and also comments that presented only emoticons, laughs (kkk, hahah, hshshs), mentions (e.g., @namesomeone), or hashtags (#lulalive) without any textual content. Comments that comprise text along with hashtags or emotions were kept.
5.2 Annotation process
5.2.1 Selection of annotators
The first step of our annotation process consists of the selection of annotators. We argue that for hate speech tasks, only specialists with relevant levels of education should be selected due to the high complexity of tasks that tackle highly politicized domains. In addition, it is necessary to provide a strategy toward the mitigation of annotator bias such as a diverse profile of annotators. Hence, we selected annotators from different Brazilian regions (North and Southeast), and they had at least a PhD study. Furthermore, they were white and black women and were aligned with different political parties (liberal or conservative).
5.2.2 Annotation schema
Since the offensiveness definition is a challenge and most existing definitions struggle with ambiguity, we propose an accurate definition for offensive language and hate speech through a new annotation schema, which is divided into two layers: (1) offensive language classification and (2) hate speech classification. The definitions for offensive language and hate speech used in this paper are described in detail in Sections 3 and 4, which were used to propose our annotation schema described as follows.
-
(1) Offensive language classification: We assume that comments that present at least one term or expression used with any pejorative connotation against people, institutions, or groups regardless of their social identity, which may be expressed explicitly or implicitly, should be classified as offensive. Otherwise, comments that have no terms or expressions with any pejorative connotation should be classified as non-offensive. Examples of offensive and non-offensive annotations are shown in Figure 1.

Figure 1. Offensive language classification: Each Instagram comment was classified according to a binary class: offensive or non-offensive. We manually balanced the classes and obtained 3,500 offensive comments labeled as (1) and 3,500 non-offensive comments labeled as (0).
Figure 2. Hate speech classification: We identified nine hate speech targets, and we labeled them as follows: antisemitism was annotated as (1), apologist for dictatorship as (2), fatphobia as (3), homophobia as (4), partyism as (5), racism as (6), religious intolerance as (7), sexism as (8), and xenophobia as (9). It should be pointed out that a couple of comments belong to more than a target. For example, the comment comunista, vagabunda e safada (“shameless, communist and slut”) was classified as partyism and sexism; hence it was labeled as (5,8). Offensive comments without hate speech were annotated as (−1).
-
(2) Hate speech classification: We assume that offensive comments targeted against groups based on their social identity (e.g., gender, religion, etc.) should be classified as hate speech into nine hate speech targets (xenophobia, racism, homophobia, sexism, religious intolerance, partyism, apologist for dictatorship, antisemitism, and fatphobia). On the other hand, offensive comments not targeted against groups should be classified as non-hate speech. Examples are shown in Figure 2.


Finally, we selected the final label for the HateBR 2.0 corpus considering the majority of votes for offensive language classification. For hate speech classification, we also considered the majority of votes and a linguist judged tie cases.
5.2.3 Annotation evaluation
The third step of our annotation process consists of applying metrics to evaluate the annotated data. Accordingly, we used two different evaluation metrics: Cohen’s kappa (Sim and Wright Reference Sim and Wright2005; McHugh Reference McHugh2012) and Fleiss’ kappa (Fleiss Reference Fleiss1971), as shown in Tables 4 and 5. Specifically, for the HateBR 2.0 corpus, we recalculated both Kappa and Fleiss for the updated data taking into consideration the replaced comments.
Cohen’s kappa results are shown in Table 4. Notice that a high inter-annotator agreement of 75 percent was achieved for the binary class (offensive and non-offensive comments). In the same settings, as shown in Table 5, a high Fleiss kappa score was obtained of 74 percent. Therefore, the annotation evaluation results corroborate the quality of the HateBR 2.0 annotated corpus proposed in this paper.
Table 4. Cohen’s kappa

Table 5. Fleiss’ kappa

Table 6. Explicit and implicit information

Table 7. Terms annotated with hate speech targets

6. MOL – multilingual offensive lexicon
We argue that hate speech should be addressed as a cultural-aware research problem since it is a complex issue that deals with commonsense knowledge and normative social stereotypes. Consequently, hate speech technologies should be able to distinguish terms and expressions used with pejorative connotations according to the context of use. For instance, while the terms “cancer,” “garbage,” and “worms” may be used with pejorative connotations, they could be also used without any pejorative connotation (e.g., “he was cured of cancer” “the garden is full of parasites and worms” “disposal of garbage on streets”).
According to linguistic studies, the pejorative connotation is used to express emotions, especially hate, anger, and frustration. In addition, it is heavily influenced by pragmatic (cultural) factors (Allan Reference Allan2007; Rae Reference Rae2012; Anderson and Lepore Reference Anderson and Lepore2013; Bousfield Reference Bousfield2013). In the same settings, swear words express the speaker’s emotional state and provide a link to impoliteness and rudeness research. They are considered a type of opinion-based information that is highly confrontational, rude, or aggressive (Jay and Janschewitz Reference Jay and Janschewitz2008).
Furthermore, recent studies have shown that large crowd-sourced lexical resources tend to include a wide range of irrelevant terms, resulting in high rates of false positives (Davidson et al. Reference Davidson, Bhattacharya and Weber2019), besides the fact that pretrained language models are trained on large real-world data, consequently, they are known to embody social biases (Nadeem et al. Reference Nadeem, Bethke and Reddy2021). In this paper, toward addressing some of these limitations, we introduce a new data resource that follows a different proposal for context recognition. The proposed resource entitled MOL – multilingual offensive lexicon comprises 1,000 explicit and implicit terms and expressions used with pejorative connotations, which was manually extracted by a linguist from the HateBR corpus and annotated by 3 different experts with contextual information, reaching a high human agreement score (73 percent Kappa).
The methodology used for building the MOL comprises five steps: (i) terms extraction, (ii) hate speech targets, (iii) context annotation, (iv) annotation evaluation, and (v) translation and cultural adaptation. We describe in more detail each of these steps as follows.
6.1 Terms extraction
In the first step, the explicit and implicit terms and expressions used with any pejorative connotation were manually identified by a linguist from the HateBR corpus (Vargas et al. Reference Vargas, Carvalho, Rodrigues de Góes, Pardo and Benevenuto2022). In other words, the linguist manually identified explicit and implicit terms and expressions that presented any pejorative context of use. For instance, the terms “trash,” “pig,” and “bitch” are examples of explicit terms that can be used with a pejorative connotation. On the other hand, implicit terms and expressions were identified using clues. For example, “go back to the cage” is clue to identify the implicit offensive term “criminal,” and “the easy woman” is a clue to identify the implicit offensive term “bitch.” In total, 1,000 explicit and implicit pejorative terms and expressions were identified, as shown in Table 6 (see Section 7.2). Lastly, a set of terms and expressions were classified by the linguist according to a category called deeply culture-rooted.Footnote i Indeed, deeply culture-rooted terms and expressions do not make sense in other cultures; hence there are no “ideal translations.” For example, the term “bolsonazi” is used in Brazil as a neologism by agglutination of the words “Bolsonaro” (former Brazilian president) with the word “Nazism.” Approximately 10 percent of terms were classified as deeply culture-rooted.
6.2 Hate speech targets
In the second step, the linguist accurately identified terms and expressions used to express hate against groups based on their social identity. For example, the term “bitch” and the expression “Jews from hell” potentially are able to indicate hate speech comments against gender and Jews. For terms and expressions without any potential to indicate hate speech, the label “no-hate speech” was provided. It should be pointed out that a set of terms and expressions received more than one label. For example, the term “feminazi” received both partisan and sexist labels. There were some ambiguous cases, in which the linguist made a decision on the most suitable label. In total, 150 terms were labeled as hate speech targets, as shown in Table 7 (see Section 7.2).
6.3 Context annotation
In the third step, three different annotators classified each 1 of 1,000 identified pejorative terms and expressions according to a binary class: context-dependent or context-independent. The annotators first checked whether the term or expression was mostly found in the pejorative context of use. If yes, it was annotated as context-independent. Second, the annotators checked if the term or expression may be found in both the pejorative context of use and non-pejorative context of use. If yes, it was annotated as context-dependent. For example, the terms “wretched” and “hypocritical” are examples of terms annotated as context-independent due to the fact that both terms are mostly found in pejorative contexts of use. On the other hand, the terms “worm” and “useless” are examples of terms annotated as context-dependent given that these terms may be found in both non-pejorative and pejorative contexts of use. Lastly, in order to support the contextual annotation process, the annotators also checked the dictionary meaning for each term and expression and evaluated whether it presented or not a pejorative connotation. Then, the annotators made the decision on the best label for each term or expression also considering their world vision and expertise.
6.4 Annotation evaluation
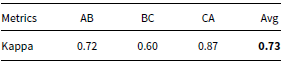
In this fourth step, we evaluated the consistency and reliability of the contextual information annotation process using Cohen’s kappa (Sim and Wright Reference Sim and Wright2005; McHugh Reference McHugh2012). The obtained results are shown in Table 8, in which A, B, and C letters stand for the annotators, and agreement is measured by pair combination. Note that a high inter-annotator agreement of 73 percent was obtained. It is worth emphasizing that values around 70 percent are considered a substantial agreement (Landis and Koch Reference Landis and Koch1977).
Table 8. Kappa score obtained for the contextual-aware offensive lexicon annotation
6.5 Translation and cultural adaptation
The MOL terms and expressions were originally written in Brazilian Portuguese and manually translated by native speakers for five different languages: English, Spanish, French, German, and Turkish. The native speakers proposed literal translations, as well as adaptations in terms of culture. For example, the native speakers proposed translations and cultural adaptations for the 1,000 explicit and implicit terms and expressions corroborating regional and cultural aspects of the target language. Furthermore, a set of terms and expressions were categorized as “deeply culture-rooted,” in which there were no suitable translations, which comprised 10 percent of the data. Finally, the contextual labels were reevaluated by native speakers, and there were no significant modifications.
7. Data statistics
7.1 HateBR 2.0 corpus
As a result, we present the HateBR 2.0 corpus statistics in Tables 9, 10, and 11. Observe that the HateBR 2.0 corpus maintained the same number of comments: 3,500 offensive and 3,500 non-offensive. Moreover, in total 17 percent of the corpus was replaced through which 305 were offensive and 911 were non-offensive. Lastly, as shown in Table 11, most offensive comments were published in posts of right-wing politicians’ accounts totaling 2,099 offensive comments in contrast to 1,401 offensive comments published in posts of left-wing politicians’ accounts.
Table 9. Binary class

Table 10. Replaced comments

Table 11. Political orientation

7.2 MOL – multilingual offensive lexicon
We also present the MOL statistics in Tables 6, 7, 12, and 13. Observe that the specialized lexicon comprises 951 offensive terms or expressions used to explicitly express offensiveness and 49 “clues,” which are used to implicitly express offensiveness, totaling 1,000 terms and expressions. In addition, 612 terms are annotated as context-independent and 388 as context-dependent. Lastly, the MOL comprises 724 terms (unigram) and 276 expressions (n-grams), and 150 terms were also annotated according to their hate speech target.
Table 12. Contextual information labels

Table 13. Terms and expressions

8. Baseline experiments
In order to support the high interhuman agreement score obtained for both data resources (HateBR 2.0 and MOL), besides assessing the reliability of data, we implemented baseline experiments on the HateBR 2.0 corpus. We further implemented two ML-based models, which embed the terms and expressions from the MOL using corpora in English, Spanish, and Portuguese. We describe our experiments in Sections 8.1 and 8.2
8.1 Experiments on the HateBR 2.0 corpus
In our experiments, we used Python 3.6, scikit-learn,Footnote j pandas,Footnote k spaCy,Footnote l and KerasFootnote m and sliced our data in 90 percent train and 10 percent validation. We used a wide range of feature representation models and learning methods, described as follows:
The features set
We implemented text feature representation models, such as BoW (Manning and Schutze Reference Manning and Schutze1999) using TF-IDF (Term Frequency–Inverse Dense Frequency), Facebook word embeddings (Joulin et al. Reference Joulin, Grave, Bojanowski and Mikolov2017), and mBERT (Bidirectional Encoder Representations from Transformers (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). For fastText, we proposed three models (unigram, bigram, and trigram). We implemented mBERT with a maximum feature size of 500, batch size of 64, and at a 1cycle learning rate of 0.00002,1, using Keras and Ktrain. As preprocessing, we only carried out the lemmatization of corpora for BoW models. We used the scikit-learn library and CountVectorizer and TfidfVectorizer.
Learning methods
We implemented different ML methods: NB (Eyheramendy, Lewis, and Madigan Reference Eyheramendy, Lewis and Madigan2003), SVM with linear kernel (Scholkopf and Smola Reference Scholkopf and Smola2001), fastText (Joulin et al. Reference Joulin, Grave, Bojanowski and Mikolov2017), and mBERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019).
8.2 Experiments using the MOL – multilingual offensive lexicon
We also performed experiments using the MOL. We implemented models that embed the lexicon and evaluated it on different corpora including the HateBR 2.0. Specifically, the following corpora were used in our experiments: the HateBR 2.0, which is a corpus of Instagram comments in Brazilian Portuguese; the OLID (Zampieri et al., Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019), which is a corpus of tweets in English; and the HatEval (Basile et al., Reference Basile, Bosco, Fersini, Nozza, Patti, Rangel Pardo, Rosso and Sanguinetti2019), which is a corpus of tweets in Spanish. As learning methods, we used SVM with linear kernel (Scholkopf and Smola Reference Scholkopf and Smola2001) and used two different feature text representations (models), called MOL and B + M (Vargas et al. Reference Vargas, Goes, Carvalho, Benevenuto and Pardo2021), which we describe in more detail as follows:
MOL
(Vargas et al. Reference Vargas, Goes, Carvalho, Benevenuto and Pardo2021): This model consists of a BoW generated using only the terms or expressions extracted from the MOL, which were used as features. For instance, for each comment, the occurrence of the MOL terms was counted. Additionally, context labels (context-independent and context-dependent) were considered to compute different weights to features. For example, terms annotated with context-independent labels were assigned a strong weight. Differently, terms annotated with context-dependent labels were assigned weak weight.
B+M
(Vargas et al. Reference Vargas, Goes, Carvalho, Benevenuto and Pardo2021): This model consists of a BoW, which embed the labels from the MOL. In this model, a BoW was generated using the vocabulary from all comments in the corpus. Then, we performed the match with terms in the MOL, and then we assigned a weight for terms or expressions annotated as context-dependent (weak weight) and context-independent (strong weight).
8.3 Evaluation and results
We evaluated the ML models using precision, recall, and F1-score measures. We presented the results for each class involved and the arithmetic average. The results are shown in Tables 14 and 15.
HateBR 2.0 corpus
The results of experiments on the HateBR 2.0 corpus are shown in Table 14. Observe that we implemented six different models (TF-IDF (SVM), TF-IDF (NB), fastText-unigram, fastText-bigram, fastText-trigram, and mBERT) and three different learning methods (BoW, word embeddings, and transformers). The best performance was obtained using mBert (85 percent of F1-score). Surprisingly, the models TF-IDF (SVM) obtained relevant performance (84 percent of F1-score) similar to results obtained in fastText-unigram (84 percent of F1-score). The worst performance was obtained using TF-IDF (NB) (77 percent of F1-score). Finally, despite the fact that corpus comparison is a generally challenging task in NLP, we propose a comparison analysis between Portuguese corpora. We compared the HateBR 2.0 corpus and our baselines with current corpora and literature baselines for European and Brazilian Portuguese. First, the interhuman agreement obtained in the HateBR 2.0 corpus overcame the other Portuguese data resources (see Table 1). In addition, our corpus presents a balanced class (3.500 offensive and 3.500 non-offensive), in contrast to the other Portuguese corpora, in which the classes are unbalanced. Analyzing the current baseline on Portuguese datasets, the results obtained on HateBR 2.0 corroborate the initial premise that an expert annotated corpus and accurate definitions may provide better performance for automatic ML classifiers. Our baseline experiments on the HateBR 2.0 overcame the current baseline datasets for the Portuguese language, as shown in Tables 1 and 14, reaching 85 percent of F1-score by fine-tuned mBert.
Table 14. Baseline experiments on the HateBR 2.0 corpus

Note: TF-IDF, Term Frequency–Inverse Dense Frequency; SVM, support vector machine; NB, Naive Bayes; mBert, Bidirectional Encoder Representations from Transformers.
Multilingual Offensive Lexicon
The results of experiments using the MOL are shown in Table 15 and in Figures 3, 4, and 5. Notice that the experiments relied on corpora in three different languages (English, Spanish, and Portuguese) using models that embed the specialized lexicon. In general, the obtained results are highly satisfactory for both models that embed the lexicon entitled MOL and B + M on the corpus in English, Spanish, and Portuguese. For instance, the MOL model presented better performance for Spanish (82 percent) and Portuguese (88 percent), and the B + M model presented better performance for English (73 percent). The best performance was obtained using MOL on the corpus in Portuguese, and the worst performance was obtained using the same model on the corpus in English (72 percent). It should be pointed out that we are not proposing a corpora comparison here, we aim to present baseline experiments on hate speech data in different languages, in which the implemented models embed the MOL lexicon. Therefore, the experiments demonstrate that models that embed the proposed MOL lexicon are promising for hate speech detection in different languages.
Table 15. Baseline experiments using the MOL – multilingual offensive lexicon

In addition, we evaluated the prediction errors of models that embed the MOL, as shown in Figure 3. Based on the receiver operating characteristic (ROC) curves analysis, the MOL model presented more unsuccessful predictions compared to the B + M model on the tree corpus in English, Spanish, and Portuguese. Therefore, even though the MOL model presents the best performance in terms of F-score, it also presents wrong predictions. Hence, the B + M is the best model in terms of successful predictions. We also observed that the extraction of pejorative terms and their context of use are factors relevant toward maximizing successful prediction and better performance for the B + M model. Hence, in future work, an automatic extractor of pejorative terms taking into account their context of use should be developed in order to maximize successful prediction and performance for the B + M model. Finally, as shown in Figures 4 and 5, the overall results of the confusion matrix present an expected low rate of false positives and false negatives. For Spanish, the rate of false positives and false negatives was lower compared to English and Portuguese. We show examples of misclassification cases in Table 16.
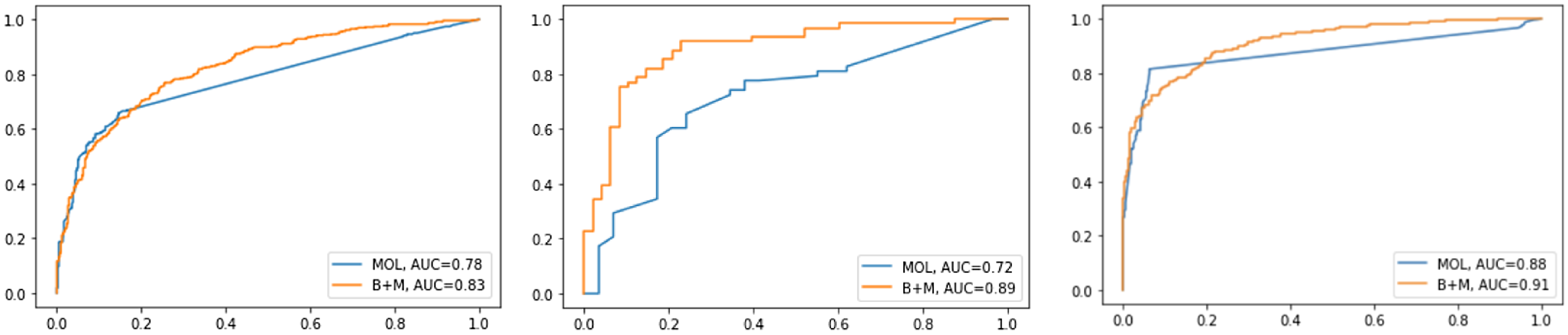
Figure 3. ROC curves for the MOL and B + M models. We evaluated these models on the OLID corpus of English tweets (left), the HatEval corpus of Spanish tweets (center), and the HateBR 2.0 of Brazilian Portuguese Instagram comments (right).

Figure 4. Confusion matrix for the MOL model. Specifically, we implemented the MOL on the OLID corpus of English tweets (left), the HatEval corpus of Spanish tweets (center), and the HateBR 2.0 corpus of Brazilian Portuguese Instagram comments (right).

Figure 5. Confusion matrix for the B + M model. Specifically, We implemented the B + M on the OLID corpus of English tweets (left), the HatEval corpus of Spanish tweets (center), and the HateBR 2.0 corpus of Brazilian Portuguese Instagram comments (right).
Table 16. Examples of misclassification cases

Note: MOL, multilingual offensive lexicon.
Note that, as shown in Table 16, the results of false negative and false positive cases are mostly composed of verbs and terms highly ambiguous. For example, “coxinha” in Brazilian Portuguese is very often pejoratively referred to people or groups with social privilege. While we propose the MOL lexicon as a solution toward tackling these challenges, which also showed relevant performance in terms of precision, it is still necessary to address some limitations of our approach including the limitation related to vocabulary coverage.
9. Final remarks and future works
This paper provides context-aware and expert data resources for low-resource hate speech detection. Specifically, we introduced the HateBR 2.0, a large-scale expert annotated corpus for Brazilian Portuguese hate speech detection, and a new specialized lexicon manually extracted from this corpus, which was annotated with contextual information. It was also translated and culturally adapted by native speakers for English, Spanish, French, German, and Turkish. The HateBR 2.0 corpus consists of an updated version of HateBR, in which highly similar and one-word comments were replaced in order to improve its consistency and reliability. The proposed specialized lexicon consists of a context-aware offensive lexicon called MOL – multilingual offensive lexicon. It was extracted manually by a linguist and annotated by three different expert annotators according to a binary class: context-dependent and context-independent. A high human annotation agreement was obtained for both corpus and lexicon (75 percent and 73 percent Kappa, respectively). Baseline experiments were implemented on the proposed data resources, and results outperformed the current baseline hate speech dataset results for the Portuguese language reaching 85 percent at F1-score. Lastly, the obtained results demonstrate that models that embed our specialized lexicon are promising for hate speech detection in different languages. As future works, we aim to investigate methods to predict the pejorative connotation of terms and expressions according to their context of use.
Acknowledgments
The authors are grateful to Zohar Rabinovich (USA), Laura Quispe (Peru), Diallo Mohamed (Burkina Faso/Africa), Rebeka Mengel (German), and Ali Hürriyetoğlu (Turkey) for providing native-speakers translations and its cultural adaptations for the MOL and Fabiana Góes for helping us with annotation.
Competing interests
The author(s) declare none.






















 Open access
Open access