



No CrossRef data available.
Published online by Cambridge University Press: 18 September 2024
The Vlasov–Maxwell equations provide an ab initio description of collisionless plasmas, but solving them is often impractical because of the wide range of spatial and temporal scales that must be resolved and the high dimensionality of the problem. In this work, we present a quantum-inspired semi-implicit Vlasov–Maxwell solver that uses the quantized tensor network (QTN) framework. With this QTN solver, the cost of grid-based numerical simulation of size $N$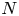 is reduced from $O(N)$
is reduced from $O(N)$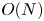 to $O(\text {poly}(D))$
to $O(\text {poly}(D))$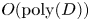 , where $D$
, where $D$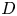 is the ‘rank’ or ‘bond dimension’ of the QTN and is typically set to be much smaller than $N$
is the ‘rank’ or ‘bond dimension’ of the QTN and is typically set to be much smaller than $N$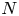 . We find that for the five-dimensional test problems considered here, a modest $D=64$
. We find that for the five-dimensional test problems considered here, a modest $D=64$ appears to be sufficient for capturing the expected physics despite the simulations using a total of $N=2^{36}$
appears to be sufficient for capturing the expected physics despite the simulations using a total of $N=2^{36}$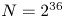 grid points, which would require $D=2^{18}$
grid points, which would require $D=2^{18}$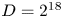 for full-rank calculations. Additionally, we observe that a QTN time evolution scheme based on the Dirac–Frenkel variational principle allows one to use somewhat larger time steps than prescribed by the Courant–Friedrichs–Lewy constraint. As such, this work demonstrates that the QTN format is a promising means of approximately solving the Vlasov–Maxwell equations with significantly reduced cost.
for full-rank calculations. Additionally, we observe that a QTN time evolution scheme based on the Dirac–Frenkel variational principle allows one to use somewhat larger time steps than prescribed by the Courant–Friedrichs–Lewy constraint. As such, this work demonstrates that the QTN format is a promising means of approximately solving the Vlasov–Maxwell equations with significantly reduced cost.
 -quantics approximation of $N$
-quantics approximation of $N$ -$d$
-$d$ tensors in high-dimensional numerical modeling. Constr. Approx. 34, 257–280.Google Scholar
tensors in high-dimensional numerical modeling. Constr. Approx. 34, 257–280.Google Scholar matrices using tensor decomposition. SIAM J. Sci. Comput. 31 (4), 2130–2145.Google Scholar
matrices using tensor decomposition. SIAM J. Sci. Comput. 31 (4), 2130–2145.Google Scholar

To send this article to your Kindle, first ensure no-reply@cambridge.org is added to your Approved Personal Document E-mail List under your Personal Document Settings on the Manage Your Content and Devices page of your Amazon account. Then enter the ‘name’ part of your Kindle email address below. Find out more about sending to your Kindle. Find out more about saving to your Kindle.
Note you can select to save to either the @free.kindle.com or @kindle.com variations. ‘@free.kindle.com’ emails are free but can only be saved to your device when it is connected to wi-fi. ‘@kindle.com’ emails can be delivered even when you are not connected to wi-fi, but note that service fees apply.
Find out more about the Kindle Personal Document Service.
To save this article to your Dropbox account, please select one or more formats and confirm that you agree to abide by our usage policies. If this is the first time you used this feature, you will be asked to authorise Cambridge Core to connect with your Dropbox account. Find out more about saving content to Dropbox.
To save this article to your Google Drive account, please select one or more formats and confirm that you agree to abide by our usage policies. If this is the first time you used this feature, you will be asked to authorise Cambridge Core to connect with your Google Drive account. Find out more about saving content to Google Drive.