



Introduction
Language acquisition is characterized by a cascading and overlapping series of changes across different domains. Acquisition begins before birth, as phonetic perception begins in the womb (Moon, Lagercrantz & Kuhl, Reference Moon, Lagercrantz and Kuhl2013). During the first year of life, phonetic perception begins to narrow (Kuhl, Conboy, Padden, Nelson & Pruitt, Reference Kuhl, Conboy, Padden, Nelson and Pruitt2005; Kuhl, Stevens, Hayashi, Deguchi, Kiritani & Iverson, Reference Kuhl, Stevens, Hayashi, Deguchi, Kiritani and Iverson2006), although this period is longer in learners of multiple languages (Kuhl, Tsao & Liu, Reference Kuhl, Tsao and Liu2003). By the end of their first year they are linking words to objects in their daily lives (Werker & Yeung, Reference Werker and Yeung2005). Next is a rapid explosion in lexical inventory, from approximately 10 words at 12 months to nearly 600 by 30 months (Dromi, Reference Dromi1987). At approximately 18 months, children begin combining these words into sentences that grow steadily more complex (Fenson, Marchman, Thal, Dale, Reznik & Bates, Reference Fenson, Marchman, Thal, Dale, Reznik and Bates2007), which requires the grammaticalization of the relation between referents. By about 5 years of age syntactic development is thought to be nearly adult-like (Gleason & Ratner, Reference Gleason and Ratner2017). Syntax promotes further lexical development, and points to higher-level regularities and concepts within a language such as the past, the future, and causal relations.
The notion of function words and content words is one of the oldest distinctions in (Indo-European) linguistics. Some ways of formalizing the classes are as follows: (1) content words have specific or detailed lexical content, where function words do not; (2) content words select top-down (e.g., a verb selects certain direct objects), but function words are determined by their lexical complement; and (3) content words enter theta marking, and function words do not. However, the distinction is not perfect: for example, some prepositions carry both semantics and play a necessary grammatical role in an utterance (Corver & van Riemsdijk, Reference Corver, van Riemsdijk, Corver and van Riemsdijk2013). In English, content words (nouns, adjectives, and most verbs) are mostly “open”-class, where new words can be derived and coined without restriction, whereas the function words (e.g., pronouns, interrogatives, and demonstratives) are “closed”-class, where new words are not easily added to each category. However, cross-linguistically, these classes are not perfectly synonymous, and there is wide variation in which syntactic categories are open or closed (e.g., Bhat, Reference Bhat, Vogel and Comrie2000), including adjectives (Dixon & Aikhenvald, Reference Dixon and Aikhenvald2004).
This distinction is recognized in early work involving the MacArthur-Bates Communicative Development Inventories (MB-CDI; Fenson et al., Reference Fenson, Marchman, Thal, Dale, Reznik and Bates2007). Early MB-CDI findings showed growth in closed-class words follows growth in open-class lexical terms, rather than happening simultaneously, with the use of function words – which we take to reflect use of these words in sentences and therefore representative of “syntax” – starting roughly at the 400-word mark (Bates, Marchman, Thal, Fenson, Dale, Reznick, Reilly & Hartung, Reference Bates, Marchman, Thal, Fenson, Dale, Reznick, Reilly and Hartung1994). Mean length of utterance (MLU; R. Brown, Reference Brown1973), the average number of words or morphemes out of a set of a child's utterances is a common estimate of syntactic ability. Cross-linguistic estimates of syntactic ability, as measured by MLU, are more strongly predicted by lexical inventory size than age (Bates & Goodman, Reference Bates, Goodman and MacWhinney1999).
Many later studies of language acquisition, including its relation to other areas of development, or that use language as a predictor, often estimate language ability by relying on percentiles, count, or percentage of words understood or produced on a standardized inventory, often the MB-CDI. However, such analyses seem to ignore the differing roles function and content words play in a sentence.
The distinction between content and function words is evident as early as a child's first birthday. Function words and morphemes are high-frequency, short, and often occur at the borders of prosodic units. By 16 to 24 months, infants can infer the role of function words based on their complements (i.e., pronouns signal verbs, and determiners nouns), see Christophe, Millotte, Bernal and Lidz (Reference Christophe, Millotte, Bernal and Lidz2008) for a review of early function word recognition. Other case-study evidence suggests that syntactic categories such as adjectives, nouns, noun phrases, prepositions, and prepositional phrase are understood by age 2:6 (Valian, Reference Valian1986)
Based on the theoretical and experimental findings of the distinction between function and content words in English, we hypothesize that the acquisition of these classes will be dissociable in inventories of children's speech, independently of metrics such as MLU. In this study, we use both forms of the MB-CDI: Words & Gestures (WG; 8–18 months) and Words & Sentences (WS; 16–30 months). Although some authors have suggested that “syntax” may start as early as the two-word stage, when children are approximately between 18 and 24 months of age (Hyams & Orfitelli, Reference Hyams, Orfitelli, Cairns and Fernandez2015), WG provides no measures of syntactic ability in the vein of the WS sections. The goal of the present study is to examine (1) whether estimates of skill with content and function words separately can be generated from the complete WS form, informed by the additional morphological and syntactic ratings; and (2) whether this analysis is extendable to WG, despite (appropriately) lacking categories akin to WS “Sentences and Grammar”. Thus, the primary objective of this paper is to use an exploratory/confirmatory factor analysis (EFA/CFA) approach (e.g., T. A. Brown, Reference Brown2015) to delineate latent categories on the MB-CDI and map them onto development of content and function vocabularies.
The repository of data we use for this study, the Stanford Wordbank (Frank, Braginsky, Yurovsky & Marchman, Reference Frank, Braginsky, Yurovsky and Marchman2017) provides some demographic information from its constituent studies, including age, sex, mother's education, birth order, and ethnicity. Long-standing findings hold that boys speak fewer words at a given age than girls (Bates et al., Reference Bates, Marchman, Thal, Fenson, Dale, Reznick, Reilly and Hartung1994; Bouchard, Trudeau, Sutton, Boudreault & Deneault, Reference Bouchard, Trudeau, Sutton, Boudreault and Deneault2009; Van Hulle, Goldsmith & Lemery, Reference Van Hulle, Goldsmith and Lemery2004), and children of more highly educated mothers (Bates et al., Reference Bates, Marchman, Thal, Fenson, Dale, Reznick, Reilly and Hartung1994) – with mixed findings with respect to fathers (Bates et al., Reference Bates, Marchman, Thal, Fenson, Dale, Reznick, Reilly and Hartung1994; Pancsofar & Vernon-Feagans, Reference Pancsofar and Vernon-Feagans2006) – speak more words. Furthermore, first-born children often perform better on simple measures of language production and comprehension compared to later-born children (Bates et al., Reference Bates, Marchman, Thal, Fenson, Dale, Reznick, Reilly and Hartung1994; Berglund, Eriksson & Westerlund, Reference Berglund, Eriksson and Westerlund2005; Hoff-Ginsberg, Reference Hoff-Ginsberg1998). We will perform exploratory analyses to see whether these demographic variables are differentially associated with lexical and syntactic ability, measured through content and function words, respectively.
Methods
Participants
The American English scores from 7,955 children between the ages of 10 and 30 months were obtained from Wordbank on November 5, 2019. All forms were included to capture the widest range of variability. Although the norming sample is the most strictly curated, the complete sample is not meant to include any children with developmental disorders. Data from 2,435 English WG forms and 5,520 WS forms were analyzed. Table 1 shows the summary data for demographic variables contained within Wordbank. For numeric analyses, mother's education was converted to a numeric approximation based on typical North American education schemes (primary: 5; some secondary: 8; secondary: 12; some college: 14; college: 16; some graduate: 18; graduate: 20), rather than as a categorical variable.
Table 1. Demographic variables given in Wordbank for WG and WS. Percentages given as percent of non-missing data.

Instruments
WG provides an inventory of 396 words over 19 categories where caregivers are asked to rate whether their child “understands” or “says and understands” each word. WS provides an inventory of 680 words over 22 categories where caregivers are asked to rate whether their child produces each word. All words listed in WG are present in WS. WG “Actions and Gestures” (II), Actions and Gestures, which asks the rater whether the child performs certain gestures or actions such as “waving goodbye”, is not included as this article focuses on the word categories for comparability between WS and WG.
WS also contains a second part, “Sentences and Grammar”, designed to assess morphological and syntactic ability. It contains the five sections listed below in which raters are asked about a child's language, where raters are asked:
1. Whether their child applies common English morphosyntactic rules. This section is excluded from this paper because it is short (five items), and the underlying forms also reflected in “Word Endings”.
2. Word Forms: To identify from a list which correct irregular noun (n = 5; e.g., children) and verb forms (n = 20; e.g., ate) their child produces.
3. Word Endings: Incorrect overgeneralization of morphological rules for nouns (n = 14; e.g., *childs) and verbs (n = 17; e.g., *ated) their child produces.
4. To report three of the longest sentences their child has said recently, which is used to compute MLU. This section was not included in the Wordbank data.
5. Complexity: To mark one sentence each out of 37 pairs of sentences, indicating what complexity level is most like their child's speech (e.g., “Doggie kiss me” vs. “Doggie kissed me”).
Analytic strategy
Factor analyses were performed using the psych package (version 2.0.9) (Revelle, Reference Revelle2018) in R (version 4.0.2, “Taking Off Again”) (R Core Team, 2020). WG lexical subsections were scored as 1 for “says and understands” and 0 for “understands” for consistency with WS. For lexical and morphological lists, each category was scored as proportion of words selected, and therefore given equal weight in analyses, as is necessary for factor analyses. WS sentence complexity was scored as proportion where the more complex option was chosen.
Before filling out WS “Complexity” (II.E), responders are asked if their child has begun combining words. If they choose “not yet”, they are not asked to fill out the sentence complexity section. These individuals (n = 1,426) were given a complexity score of 0%.
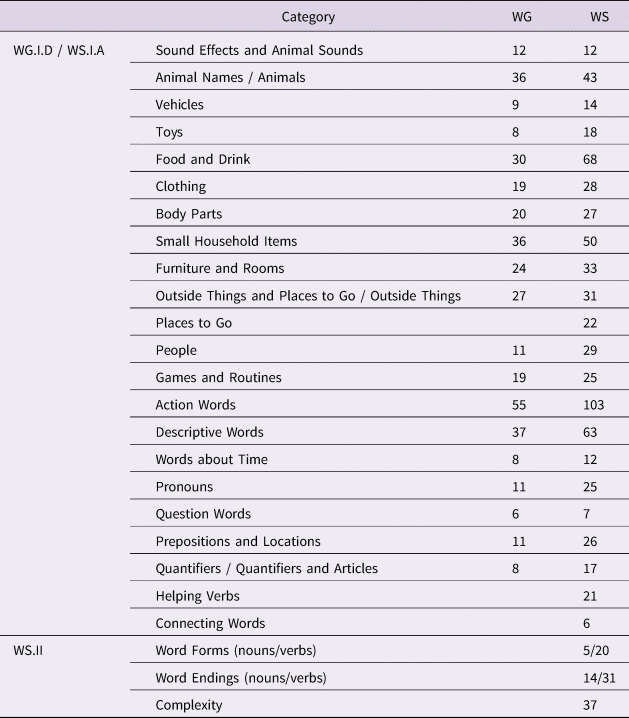
Factor analyses were performed by treating WG “Phrases” (I.B) categories as indicators; and WS “Vocabulary Checklist” I.A categories, as well as “Word Forms” (II.B), “Word Endings” (II.C), and “Complexity” (II.E), all equally weighted once scored as proportions endorsed. The categories and the number of items in each are given in Table 3.
Table 3. The number of items in the categories shared and distinct between WG and WS. Where the categories are not named identically, the names are given as WG / WS. “Word Forms” is use of correct irregulars and “Word Endings” is use of incorrect overgeneralizations.
Words & Sentences analysis
A principle axis factoring (PAF) analysis of the EFA data (n = 2250) is used to guide factor number (m) selection for the EFAs. PAF identifies commonalities in the correlations between measurements (here, MB-CDI subsections). We use PAF to identify the most parsimonious model that explains the most variance. Figure 1 shows the parallel analysis scree plot of the eigenvalues for this PAF. The dashed redline shows simulated data with population correlations of 0. Factors with values below this line do not offer useful improvements on the model. The first value following a large drop is typically considered the most parsimonious fit; as subsequent smaller decreases in eigenvalue show decreasing improvement and interpretability on the model (Woods & Edwards, Reference Woods, Edwards, Rao, Miller and Rao2011). However, absolutist decisions about m are disfavored, so we explore m between these two cutoffs, at m = {2, 3}, using the oblique rotation method “oblimin” (Carroll, Reference Carroll1957), as lexical/syntactic ability are theoretically highly related. Oblique rotation does not force factors to be as orthogonal as possible. Each factor analysis (FA) was repeated 1,000 times to bootstrap confidence intervals. It is these results that are used for interpretation.
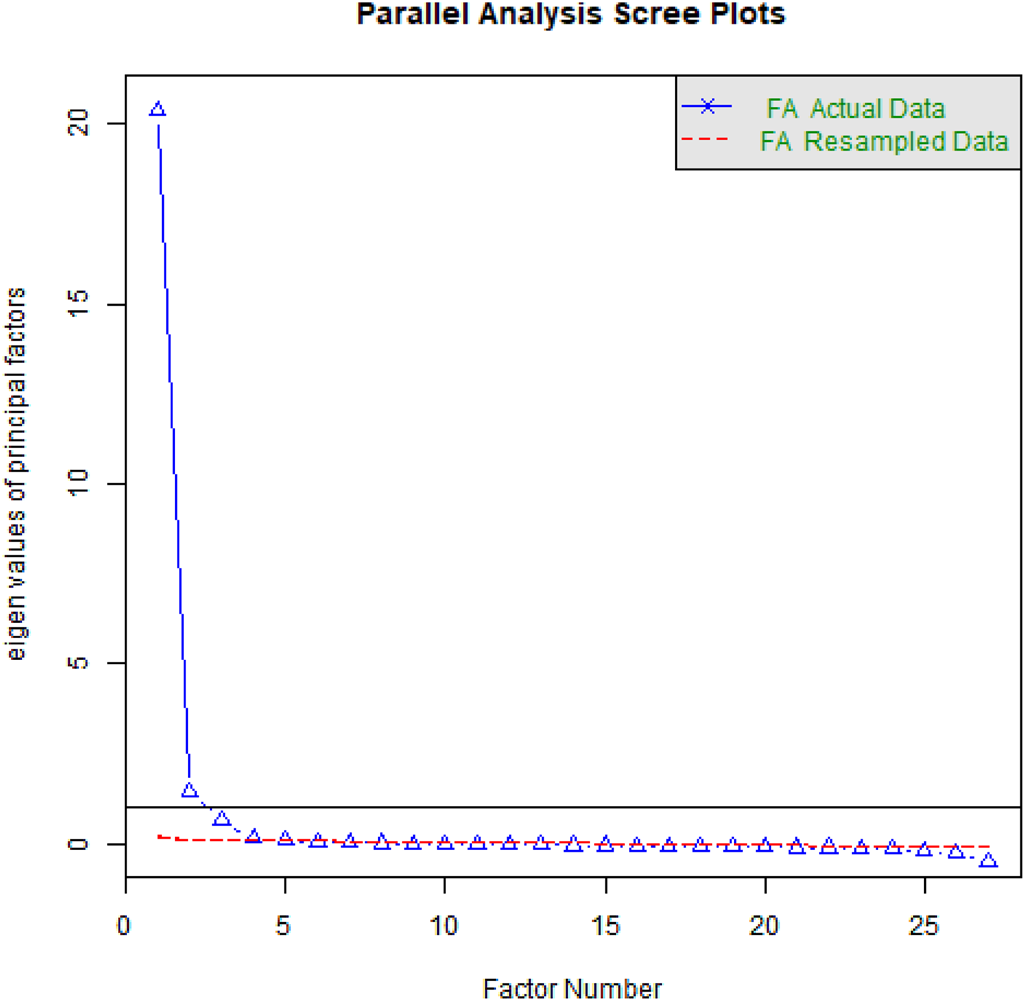
Figure 1. Scree plot for a principal axis factoring of the WS data, used to select the number of factors to extract from a subsequent FA. Two factors show the most improvement in variance explained. The dashed red line shows the eigenvalue for simulated random data; factor solutions below this line are considered to not be valid. The line at y = 1 is the Kaiser criterion for selecting factors; however, we also examine the third factor (just below).
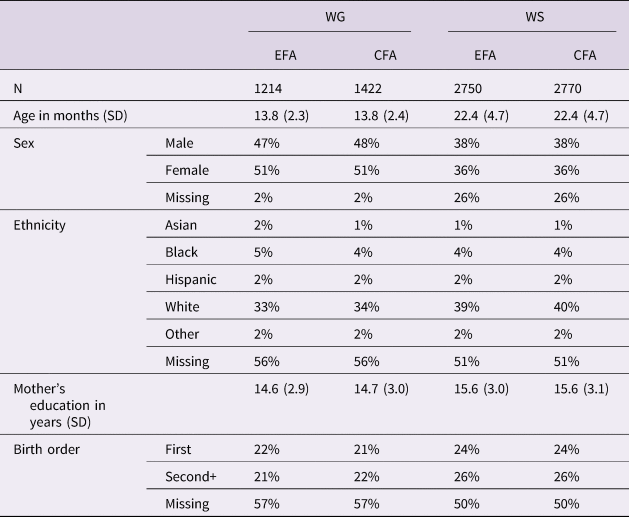
Data were split in half using stratified sampling with the slice_sample() function from the tidyverse package (ver. 1.3.0, Wickham et al., Reference Wickham, Averick, Bryan, Chang, McGowan, François, Grolemund, Hayes, Henry, Hester, Kuhn, Pedersen, Miller, Bache, Müller, Ooms, Robinson, Seidel, Spinu and Yutani2019), holding the most important potential predictors constant between halves: age, sex, mother's education (including missing). An EFA was conducted on one half (n = 2250), and a CFA (n = 2270) on the other. Descriptive statistics for each group are included in Table 2.
Table 2. Descriptive statistics for the EFA/CFA divisions of the WG and WS forms. Percentages may not add to 100% because of rounding. For this analysis, mother's education was converted to years and birth order simplified to first vs. later.
Words & Gestures analysis
The data from WG participants were similarly split into EFA (n = 1214) and CFA (n = 1221) halves. Descriptive statistics for each group are included in Table 2.
Following PAF guidance, EFAs were tested for WG at m = {2, 3}, using the same rotation method and iterations. Inventory scores were calculated as percent marked “says and understands” to maintain consistency with WS. Part II Actions and Gestures was not included.
Joint analyses
While all words in the WG inventory exist in the WS inventory, they are not consistently categorized between forms, e.g., “church” is listed under WG “Outside Things” but WS “Places”; and “wait” under WG “Games and Routines” but WS “Action Words”. Therefore, WG words were redistributed as necessary according to the WS organization. Following redistribution, only the WS category “Connecting Words” had no items represented on WG. Furthermore, “in” and “inside” are separate items on WG but given as “in/inside” on WS. As a resolution, “in” was dropped from WG and “inside” was treated as corresponding to WS “in/inside”. “Connecting Words”, as well as morphology and syntax sections for WG, were modeled having scores of 0%.
Using the best factor solution, we then calculate the lexical and structural scores for all (n = 7, 955) individuals across the 10 − 30 month age range, regressing them against the demographic variables available in Wordbank. All code is available on GitHub (https://github.com/TrevorKMDay/MCDI-analysis).
Results
Words & Sentences
Factor structure
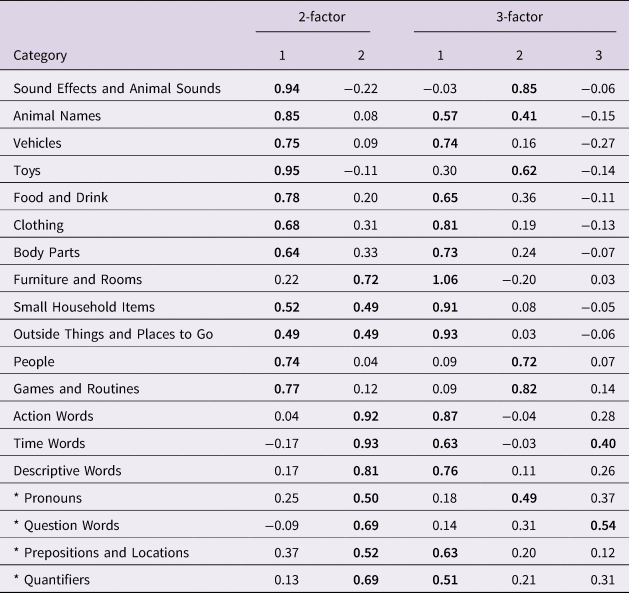
Postulating that words can be grouped into open-class lexical items and closed-class function words, a simple correlation of all lexical categories shows reasonable groupings (hclust) of (1) the final seven categories (Words about Time, Pronouns, Question Words, Prepositions and Locations, Quantifiers and Articles, Helping Verbs, and Connecting Words), hereafter “L7” (Figure 2), and (2) the remaining categories, hereafter “L15” (Sound Effects and Animal Sounds, Animals, Vehicles, Toys, Food and Drink, Clothing, Body Parts, Small Household Items, Furniture and Rooms, Outside Things, Places to Go, People, Games and Routines, Action Words, and Descriptive Words). All of L15 can be considered open-class. Of L7, all categories except Words about Time can easily be considered closed-class. That section (after, before, day, later, morning, night, now, time, today, tomorrow, tonight, yesterday) may share properties with both closed- and open-class words. See Table 4.

Figure 2. Correlations between lexical subcategories (WS). Note that all correlations are positive.
Table 4. Factor loadings for the 2- and 3-factor EFAs on the Wordbank WS data. Loadings greater than 0.4 bolded “Word Forms” is use of correct irregulars and “Word Endings” is use of incorrect overgeneralizations. Categories with asterisks are easily considered function categories.
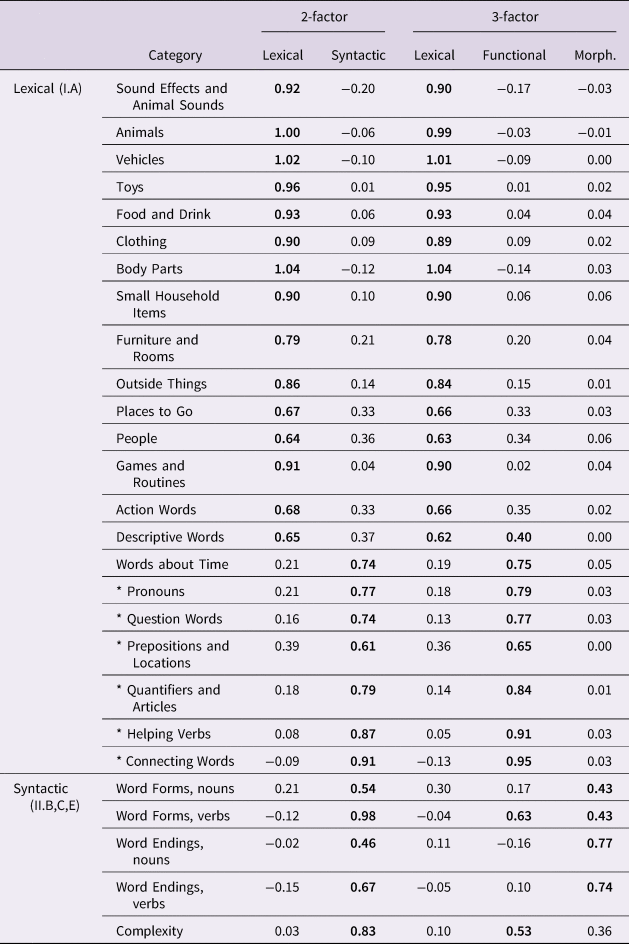
A priori, one might hypothesize successive factor solutions of the MB-CDI to represent (1) a general language factor; (2) lexical/structural ability; (3) lexical/syntactic/morphological ability. The utility of the four-factor division is not immediately obvious. Here, we discuss the two- and three-factor solutions as they are the most useful and interpretable. Although problematic in orthogonal FAs, loadings greater than 1 are permissible in oblique FAs.
The two-factor solution shows a clear division in factor assignments. There is no consensus at what loading value an indicator can be considered assigned. The cut-off we use, 0.4, is somewhat conservative (T. A. Brown, Reference Brown2015). At this cut-off no indicators are cross-loaded. We see a clear division between the L15 lexical categories, and the L7 lexical categories and the four morphological categories (word endings, word forms) and the Complexity section. It is thus reasonable to name the former factor “lexical”, and the latter “structural”. The factor loadings are given in Table 4, where loadings ⩾ 0.4 are bolded. The correlation between the factor scores was .79, 95% CI [.77, .80].
The L15, “lexical” category is maintained: however, the structural factor is divided in two, with the L7 category joined by Word Forms, Verbs and Complexity, and the remaining morphological categories on their own in the third factor. However, at the same cut-off at 0.4, Word Endings, Verbs is cross-loaded between the latter categories. All indicators are assigned to a factor. The factor loadings are given in Table 4, where loadings ⩾ 0.4 are bolded. The correlations between the factors was: lexical/syntactic: .77, 95% CI [.75, .78]; lexical/morphological: .47 [.39, .57]; syntactic/morphological: .52 [.44, .60].
CFA
We used the cfa function from the package lavaan (Rosseel, Reference Rosseel2012 ver. 0.6-6) to calculate model fit indices on the confirmatory half (n = 2270). Given the non-normality and non-independence of the indicators, using maximum likelihood parameter estimates (MLR), the CFA produced reasonable fit for the 2-factor solution. The model fit was evaluated using the following fit indices: model Chi-square, comparative fit index (CFI), the Tucker-Lewis index (TLI), root-mean-square error of approximation (RSMEA), and standardized root mean square residual (SRMR). However, we note Chi-square significance tests are almost always significant (indicating bad fit) in large sample sizes (Hooper, Coughlan & Mullen, Reference Hooper, Coughlan and Mullen2008). The fit statistics for the two- and three-factor solutions are given in Table 6.
Table 6. Model fit indices for WS CFAs. Typical criteria for “good fit” are given in the first row. CFI: comparative fit index; Tucker-Lewis index: TLI; RMSEA: root-mean-square error of approximation; SRMR: standardized root mean square residual. 95% confidence interval given for RMSEA. Chi-square tests are almost always significant (indicating bad fit) in large sample sizes.

Theoretical validation
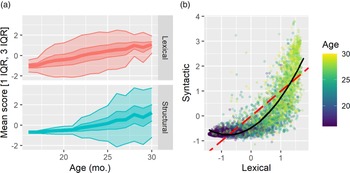
One test of the validity of our lexical/syntactic ability scores is whether syntactic ability lags lexical ability as measured in this framework. Figure 3 presents two arguments for this finding, using factor scores estimated over all 5,520 WS individuals (psych function factor.scores, estimation method tenBerge). Figure 3(a) shows that both lexical and syntactic ability scores increase over 16 to 30 months, with the variation in lexical ability narrowest (representing low variability) at younger age/low ability and higher age/higher ability (representing consolidation of ability across individuals). However, syntactic ability only begins to grow roughly in the 20- to 24-month age range. Variability is high and ability does not consolidate by 30 months.
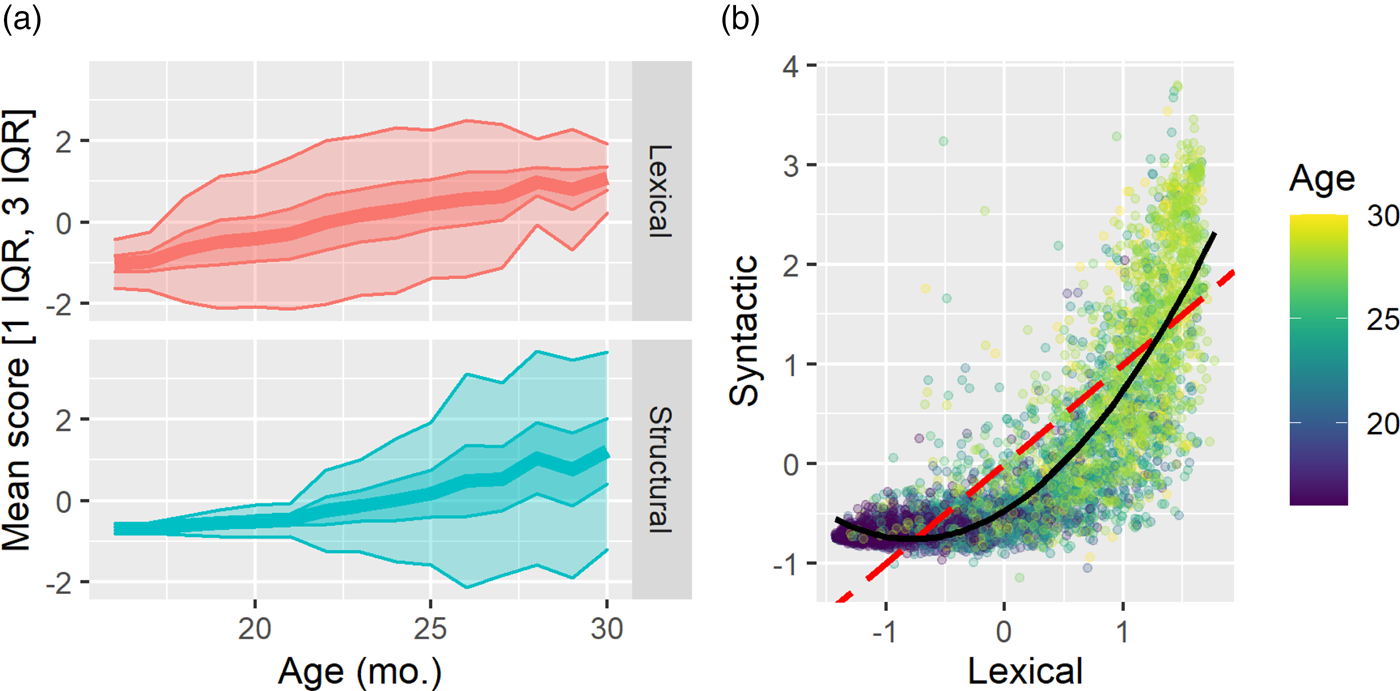
Figure 3. (a) Distribution of lexical/syntactic ability scores plotted by age band. The central line represents the mean score, and the bands 1 IQR (inner; 50%) and 3 IQR (outer; 99%). (b) Lexical and syntactic ability scores plotted against each other within-individual. The red dashed line indicates the hypothetical equal-development rate, and the solid black line indicates the second-degree polynomial line of best fit. Age is plotted youngest (purple) to oldest (yellow-green) using viridis (Garnier, Reference Garnier2018).
Figure 3(b) shows a distinct lag effect, where normalized syntactic ability is almost always lower than normalized lexical ability, and syntactic ability only develops when lexical ability is highest. Perfectly synchronous development would result in a distribution surrounding the line y = 1, plotted in red. A second-degree polynomial regression produces a good fit, R 2 = .760, F(2, 5517) = 8788, p < .001, 95% CI [0.749, 0.771].
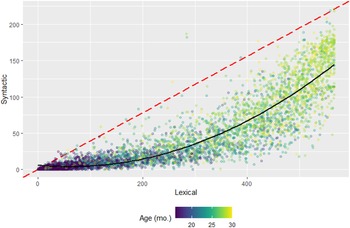
Factor estimates
Presuming comprehensive characterizations of measurement invariance across various potential moderators, the underlying latent factor structure should hold across samples. An alternative approach would derive sums of items, but as we demonstrate, this approach yields highly colinear factors. Summed lexical and structural scores are the sum of the number of items endorsed across L15 and L7 for each individual. As a simple sum, this is easily done for any MB-CDI form and is comparable between studies (see Figure 4). However, the R2 between the lexical and syntactic scores in this formulation was .894, 95% CI [.889, .899], higher than the FA score R2 of .76 95% CI [0.749, 0.771], showing greater collinearity among the factor scores in the simple sum formulation. While FA scores should be used as a predictor or outcome; the summed approach has the benefits of (1) being applicable in samples too small for a FA; (2) being applicable in samples with theoretically different factor structure, and (3) being more interpretable.
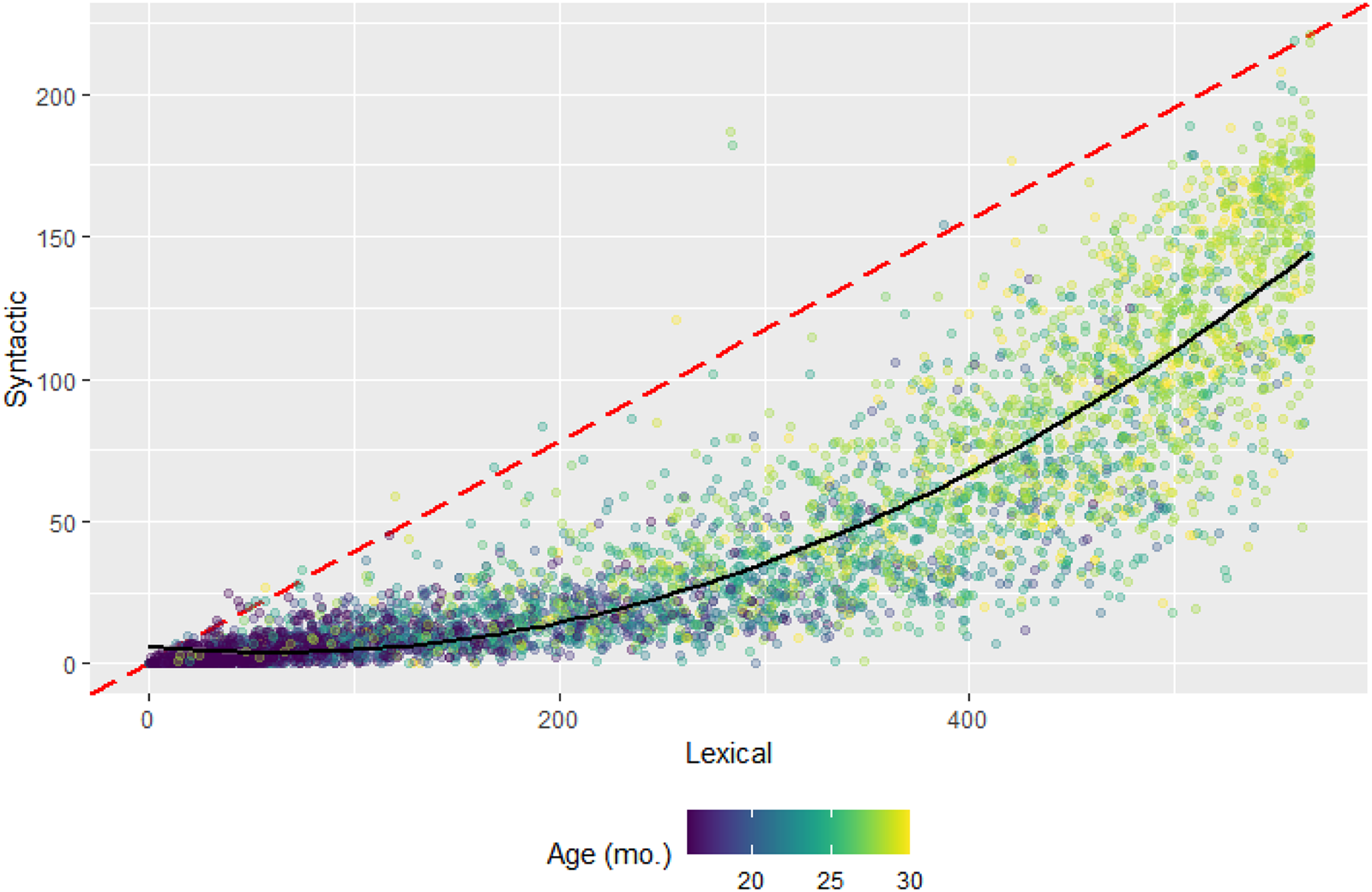
Figure 4. Estimates of lexical and syntactic ability scores plotted against each other. Each dot represents the scores from one individual. The red dashed line indicates the hypothetical equal-development rate, and the solid black line indicates the second-degree polynomial line of best fit. All 5520 WS individuals are included.
Words & Gestures
EFA
A similar EFA is significantly less clear for WG. At a cutoff of 0.4, the two-factor analysis groups Words about Time, Action Words, Descriptive Words, Question Words, Quantifiers and Articles, and Pronouns, but also Furniture/Rooms. Furthermore, Household and Outside are cross-loaded. A three-factor solution groups in one factor Question Words and Time Words, but Pronouns is grouped with Sound Effects and Animal Sounds, Animal Names, Toys, People, and Games and Routines. The rest of the lexical categories are joined by Prepositions and Locations and Quantifiers. All indicators were assigned to a factor. The interpretation of these factors is unclear (Table 5).
Table 5. Factor loadings for the 2- and 3-factor EFAs on the Wordbank WG data. Loadings greater than 0.4 bolded. Categories with asterisks are easily considered function categories.
The poor factor structure may be due to the relatively low subcategory scores. Across all subjects, only 8% of subcategory scores exceeded 30% endorsed. Even among the 18-month-olds, only 27% of subcategory scores exceeded 30% endorsed. This suggests that in typically developing toddlers between 8–18 months, a lexical/functional distinction is either not developed or not able to be estimated with WG.
CFA
WG CFAs were performed in the same manner on the confirmatory half (n = 1221). The two- and three-factor CFAs did not converge.
Joint analysis
Factor structure
We estimated factor scores (psych function factor.scores) using the WS-only structure as applied to all WS and WG participants jointly. Such an analysis creates a very similar distribution (Figure 5). While most WG individuals are grouped at the low end of both syntactic and lexical ability (lower left corner), notably, some individuals estimated to have greater syntactic and lexical ability than many WS individuals. A second-degree polynomial regression produces a good fit, R 2 = .73, F(2, 7952) = 10930, p < .001.
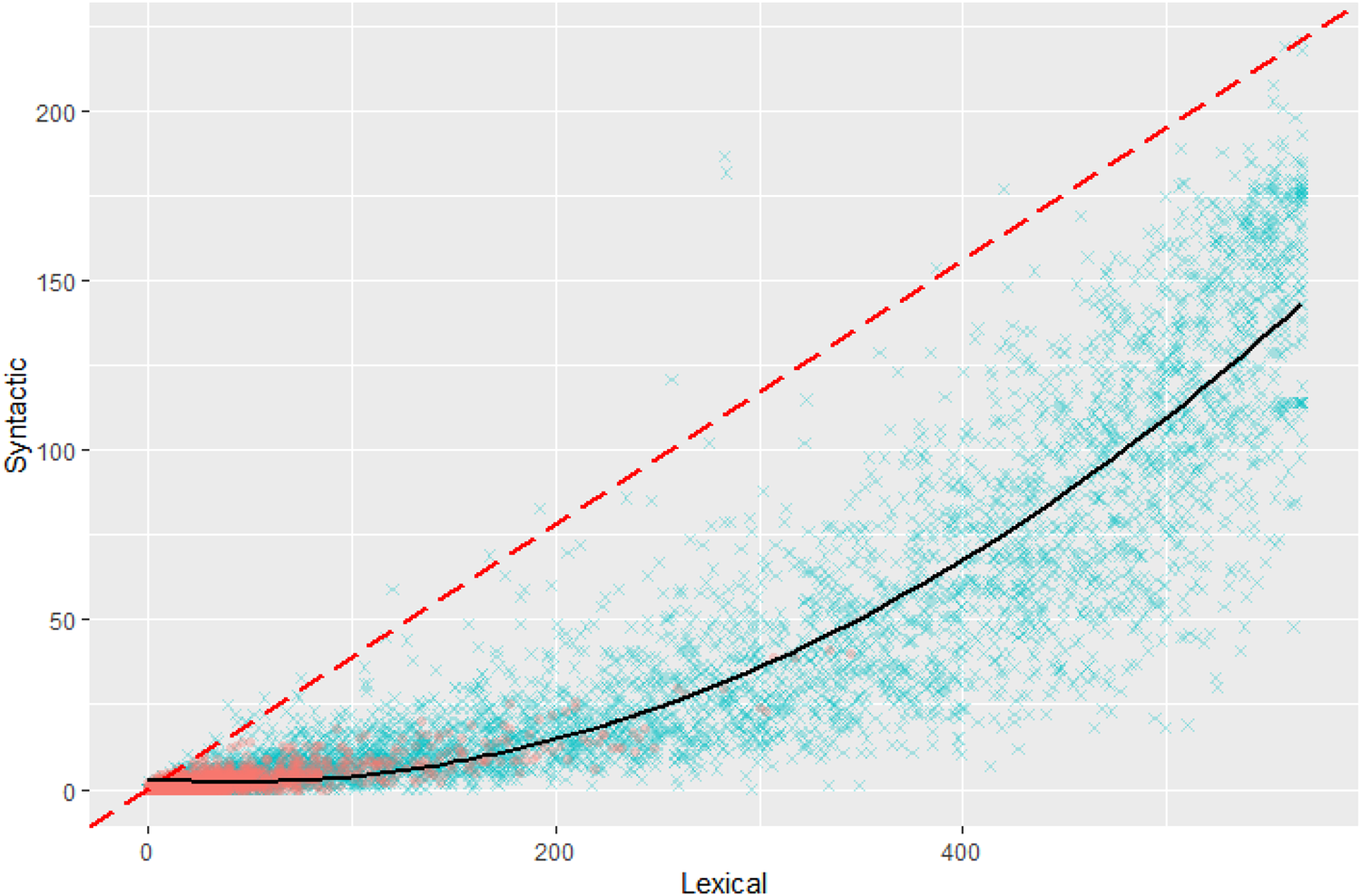
Figure 5. Distribution of lexical/syntactic ability scores plotted against one another within individual, in both WS (blue) and WG (red). Ages are obscured for clarity. The red dashed line represents y = 1, the hypothesized relationship if abilities developed at the same rate. All WG and WG individuals included.
Factor estimates
A similar linear combination of categories assigned to each group was performed; however, in this model, lexical ability explains more of the variance in syntactic ability compared to factor scores, R 2 = .86, F(2, 7952) = 25090, p < .001, reducing the independence of the two score estimates.
Demographics
In the linear-estimate joint dataset, both lexical and syntactic ability are associated with age (lexical: R 2 = .66, F(1, 7953) = 15500, p < .001; syntactic: R 2 = .50, F(1, 7953) = 7971, p < .001). These estimates are used for interpretability of betas in the following section. For context, the lexical category comprises 566 items and the syntactic, 221.
We analyzed the effect of sex and mother's education in a single model for each outcome, controlling for age, on lexical and syntactic scores (n = 3841, accounting for missing sex and mother's education). Males had fewer words in both categories (lexical: β = −31.6 (5.5%), p < .001; syntactic: β = −9.2 (4.2%), p < .001). Mother's education level affected lexical (β = 2.0 (0.35%), p < .001) and syntactic (n = 3842, β = .39 (0.18%), p = .0014) inventory size. Uncorrected p values are listed. However, these confounds are not regressed out in order to examine the full range of lexical/syntactic learning relationships.
Finally, in order to examine the possibility of a demographic-based differences in syntactic ability compared to lexical ability, we regressed syntactic score against lexical score squared (LEX:β = −0.073, p < .001; LEX2:β = 0.00054, p < .001) and age squared (age:β = −1.2, p < .001; age2:β = 0.059, p < .001), including sex and mother's education. There was a significant effect of sex (β = −2.6, p < .001), but not mother's education (p = .37). This effect was further tested by examining the interaction of sex with all four terms. In this analysis, sex (β = −12.7, p = .013) and the interactions with lexical score (sex*LEX:β = 0.0035, p = .73, sex*LEX2:β = −3.2 × 10−7, p = .99) were not significant.
Discussion
The evidence suggests separate learning streams for lexical and syntactic ability, measured through content and function word production. While these categories are largely open- and closed-class, respectively, this analysis doesn't distinguish whether the difference in acquisition timing is related to one categorization or the other. The two- and three-factor solutions had similar fit statistics, and based on their structure and parsimony, we propose that the two-factor solution is the most informative. The most important finding in this paper is that the categories nominally included in the lexical inventory on WS, together with the later morphological and syntactic items represent growth on an underlying factor, here termed “structural”, representing both developing knowledge of sentential structure and inflectional morphology. Follow-up research on English and similar languages should investigate the timing and relationship of derivational morphology to these factors, as correct derivation would indicate structural learning of syntactic categories and the adoption of language-specific derivational rules.
The morphological categories were left off the WG form entirely; due to the fact most children by 16 months are producing very few, if any, of the words indicated. However, some function words are included in the inventory section. While the FA was not successful, in part because of low endorsement rates, a longitudinal analysis might clarify the relationship between WG scores by involving more detailed WS scores through an analysis such as moderated nonlinear factor analysis (Bauer, Reference Bauer2017).
Another drawback is that both collect many more content items than function items: however, this is more a drawback to studying these features. However, the results of the FA mathematically support the theoretical grouping of categories. Although lexical and syntactic ability were highly correlated, syntactic ability was found to lag lexical ability throughout development, both between and within subjects.
Our findings of girls and children of more educated mothers knowing more words in both factors is consistent with long-standing and cross-linguistic findings (Bates et al., Reference Bates, Marchman, Thal, Fenson, Dale, Reznick, Reilly and Hartung1994; Bouchard et al., Reference Bouchard, Trudeau, Sutton, Boudreault and Deneault2009; Van Hulle et al., Reference Van Hulle, Goldsmith and Lemery2004). Sex-based differences, but not mother's education, were evident in examining differences in syntax, controlling for lexical inventory size.
These findings suggest this way of scoring the MB-CDI may be meaningful and useful in future analyses for distinguishing whether the effect of broadly specified “language” on behavior or in the brain is more closely tied to the learning of structure or predictors of sentence structure in a child's language, or to their raw lexical inventory. This would be useful in studying disorders or individuals who may be developing across categories asymmetrically.
An important limitation of the study is the different sizes of content vs. function inventories, which is natural in any language. However, this means that almost all function words can be interrogated, whereas only a small fraction of content words can be asked about on a form of reasonable length, although the MB-CDI was carefully prepared to provide an accurate representation of common early English words. Furthermore, the model fit was marginal, suggesting that an instrument geared toward distinguishing function and content words could perform better. However, given the proliferation of studies using the MB-CDI, we propose the division proposed herein is still valuable. Finally, the measures remain highly correlated (FA: .79, one-weighted analysis; .87), making their effects difficult to distinguish.
The MB-CDI was designed for estimates of morphological and syntactic ability to come from the relevant sections. However, this paper shows that acquisition of function words, as reported by caregivers, is more closely related to structural ability than to acquisition of content words. We propose these factors as a way for investigating these separate abilities in future studies, especially when complete utterances or an MLU value are not available.
Acknowledgements
This study was supported by a National Science Foundation Graduate Research Fellowship Program (NSF-GRF) award to T. Day (#2020295366) and NIMH (R01 MH104324 and R01 HD092430) to J. Elison. The funders had no role in study design, data collection, analysis, data interpretation, or the writing of the report.
Author Contributions
TKMD: Conceptualization, Methodology, Software, Formal analysis, Writing – Original Draft, Writing – Review & Editing, Visualization, Funding acquisition JTE: Methodology, Formal analysis, Writing – Review & Editing, Supervision, Funding acquisition










 Open access
Open access