



1. Introduction
Detecting negation in texts is one of the unavoidable prerequisites in many information retrieval and extraction tasks. In the biomedical field in particular, negation is very common and plays an important role. In the case of cohort selection for clinical trials, for instance, it can provide decisive criteria for recruiting a patient or not. Thus, it provides crucial information in many situations such as: detecting a patient’s pathologies and co-morbidities, determining a person’s smoking or non-smoking status, detecting whether or not a particular medication has been prescribed or taken, and defining whether a patient is pregnant or not at the time of recruitment. In order to efficiently identify negation instances, one must first identify the negation cues, that is, words (or morphological units) that express negation, and secondly identify their scopes, that is, tokens within the sentence which are affected by these negation cues.
Figure 1 provides a general overview of our contribution and of its presentation. We first present the specificity of expressing negation in French and Brazilian Portuguese: the issues that can arise with examples from our corpora are described in Section 2. Some of the existing work in this field is presented in Section 3. In Section 4, we describe our manually annotated corpora, which provide the training and evaluation material for the approach. The proposed approach for negation detection, with all its components (word vector representations, recurrent neural network, conditional random fields (CRF), and the evaluation rationale), is then detailed in Section 5. The results obtained are presented and discussed in Sections 6 and 7 for the cue and scope detection, respectively. Finally, Section 8 provides conclusive remarks and introduces some directions for future work.
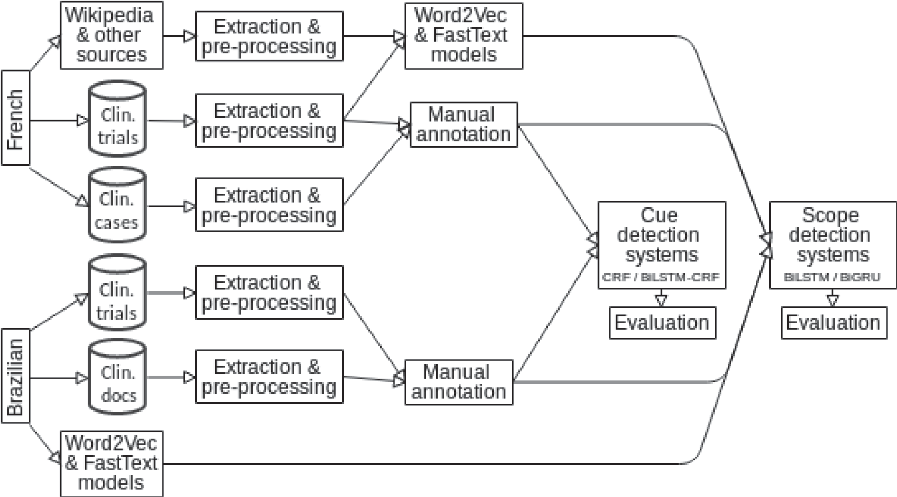
Figure 1. General overview of our work: from the development of annotated corpora in French and Brazilian Portuguese to the automatic detection of negation and its scope.
2. Expression of negation in French and Brazilian Portuguese
As pointed out in the literature (Chapman et al. Reference Chapman, Bridewell, Hanbury, Cooper and Buchanan2001; Elkin et al. Reference Elkin, Brown, Bauer, Husser, Carruth, Bergstrom and Wahner-Roedler2005; Denny and Peterson Reference Denny and Peterson2007; Gindl, Kaiser and Miksch Reference Gindl, Kaiser and Miksch2008), negation is frequently used and plays an important role in the biomedical field. However, its expression is very variable and thus it presents a first challenge for its automatic detection. As stated earlier, cue detection can be a rather complex task, due in part to the variety and ambiguity of negations marks. Moreover, extracting the scope of these negation is necessary to decide which part of the sentence is negated. Some specific linguistic realizations of negation in the two languages under consideration, French and Brazilian Portuguese, are introduced hereafter.
2.1 Negation in French
In French, the negation cues either consist of one word/prefix or of multiple words. Moreover, negation can be expressed via a large panel of cues which can be morphological, such as the following prefixes an, in, im, ir, dis; lexical, such as absence de (absence of), à l’exception de (except); and grammatical, such as non, ne…pas, ni…ni. In the following examples, we present and explain sentences with instances of negation which either correspond to specific situations in the detection of negation scope or are proper to the biomedical language (in the rest of the paper, the cues are underlined, scopes in bold, scope altering tokens in brackets).
1. En alternative des traitements locaux (chirurgie, radiothérapie, radiofréquence, cryoablation) peuvent être indiqués mais ils ne sont pas [toujours] faisables. (Alternatively, local treatments (surgery, radiotherapy, radiofrequency, cryoablation) may be indicated but are not [always] feasible.)
2. Il n’existe toujours pas aujourd’hui de consensus quant à une définition précise de ce phénomène hétérogène ou des modalités de sa prise en charge. (There is still no consensus today on a precise definition of this heterogeneous phenomenon or the modalities of its management.)
3. il n’y a pas de traitement curateur de la maladie [en dehors de] l’allogreffe de moelle. (there is no curative treatment for this disease [apart from] bone-marrow homograft)
4. Autre immunothérapie concomitante, excepté les corticostéroïdes à faible dose. (Other concomitant immunotherapy, except low dose corticosteroids.)
5. [Lymphome non hodgkinien] à cellules B matures récidivant/réfractaire. (Relapsed/ refractory mature B-cell [non-Hodgkin’s lymphoma].)
6. Cancers bronchiques [non à petites cellules]. ([Non-small cell] bronchial cancers.)
7. Le traitement par tazemetostat continuera jusqu’à progression de la maladie ou l’apparition d’un [effet in désirable] inacceptable. (The treatment with tazemetostat will be maintained until progression of the disease or appearance of an unacceptable [adverse effect].)
8. Elle n’est soulagée que par la marche et doit donc écouter la télévision en faisant les cent [pas] dans son salon. (She is only relieved by walking and must therefore listen to the TV [pacing] in her living room.)
Examples 1 and 2 show the possible effect of the frequency adverbs, here toujours (always), on negation. In Example 1, traitements locaux (chirurgie, radiothérapie, radiofréquence, cryoablation), the content would be negated without toujours (always). In Example 2, with or without toujours, the meaning of the sentence does not change, therefore, the scope of the negation remains the same.
Example 3 shows how the preposition, en dehors de (apart from), can stop the scope of negation. Many other prepositions such as à part, à l’exception de or excepté, with more or less the same meaning than en dehors de (apart from), would have the same effect on the negation scope. However, these prepositions can also play the role of negation by themselves, as shown in Example 4.
Examples 5–7 show that cues can also be included in medical concepts such as non hodgkinien (non-Hodgkin’s), non à petites cellules (non-small cell), or effet indésirable (adverse effect). In biomedical texts, such sequences correspond to single concepts such as identified by single UMLS CUIs. Hence, we do not consider the consider the sub-concept negation: Hodgkin’s and small cell are not negated.
Finally, Example 8 shows the context in which the ambiguous word pas (meaning both no/not and footstep) does not bear the meaning of a negation. Indeed, in this example, pas is part of the idiomatic expression faire les cent pas (pacing, walking around). This is the real issue for cue detection, yet, fortunately, the latter form only appears twice in our data. Another example of ambiguity of the kind is related to the adverb plus meaning either more or, in conjunction with ne, no more.
2.2 Brazilian Portuguese negation
In Brazilian Portuguese, the main negation cues are lexical units, such as sem (without), nega (denies), não (no), or ausência de (absence of). In some cases, the cues may also correspond to prefixes like in, im, des, dis, or a. Below, we provide some typical examples of negation found in clinical narratives and clinical protocols.
1. Crise de dor pontada em hipocôndrio direito. Não relacionada com a alimentação. (Crisis of puncture pain in the right hypochondrium. Not related to food.)
2. Ausência de irritação peritoneal. (Absence of peritoneal irritation.)
3. Nega outrascomorbidades. (Denies other comorbidities.)
4. Nega dispareunia, corrimento e cólica. (Denies dyspareunia, vaginal discharge and colic.)
5. Relata muito des conforto mesmo usando a cinta diariamente. (Reports a lot of discomfort even using the tape daily.)
6. Lesão no menisco indolor no momento. (Meniscus injury that is painless at the moment.)
7. Exame Físico: bom estado geral, hidratada e a febril. (Physical Examination: good general condition, hydrated and afebrile.)
8. Sem lesões ou fratura de ossos. (No injury or bone fracture.)
9. Declarar não estar gestante. (Declare not being pregnant.)
10. Teste de elevação da perna estendida negativo. (Negative extended leg lift test.)
Examples 1–7 are provided by the corpus of clinical narratives. The most traditional and frequent cue is the grammatical cue não (not) as presented in Example 1. In Example 2, the negation is based on the use of the lexical cue absence of. As one can also see, the scope of one negation cues may concern a single (Example 3) or multiple entities when they are coordinated (Example 4). In Examples 5–7, the negation is stated by the use of prefixes.
Examples 8–10 are provided by a corpus of clinical trials recruitment protocols. In these protocols, the third person verbs and pronouns are never used: hence, the writing style is different from the one used in narratives. Consequently, some of the ways of expressing the negation are specific: uses of negative non-verbal sentences (Example 8), the verb declare is often used to assess having or not certain conditions (Example 9), mentions of negative results for a given condition, examination or lab results (Example 10).
3. Related work
Negation detection is a very well researched problem. In this section, we present several corpora and methods that have been proposed in the literature.
3.1 Data
In the recent years, with the democratization of supervised machine learning techniques, several specialized corpora in English have been annotated with negation-related information, which has resulted in pre-trained models for automatic detection. These corpora can be divided into two categories: (1) corpora annotated with cues and scopes of negation, such as BioScope and *SEM-2012, and (2) corpora focusing on medical concepts/entities, such as i2b2 and MiPACQ. We briefly describe these corpora. The BioScope corpus (Vincze et al. Reference Vincze, Szarvas, Farkas, Móra and Csirik2008) contains reports of radiological examinations, scientific articles as well as abstracts from biomedical articles. Available in the XML format, each sentence and each negation and uncertainty cue/scope pair receives a unique identifier. Table 1 provides some statistics about each subcorpus in BioScope. We can see for instance that the prevalence of sentences with negation and uncertainty is high. The *SEM-2012 corpus (Morante, Schrauwen and Daelemans Reference Morante, Schrauwen and Daelemans2011) consists of a Sherlock Holmes novel and three other short stories written by Sir Arthur Conan Doyle. It contains 5520 sentences, among which 1227 sentences are negated. Each occurrence of the negation, the cue and its scope are annotated, as well as the focus of the negation if relevant. The peculiarity of this corpus is that cues and scopes can be discontinuous, as indicated in the annotation guidelines. In addition to lexical features, that is, lemmas, the corpus also offers syntactic features, that is, part-of-speech tagging and chunking. The i2b2/VA-2010 challenge (Uzuner et al. Reference Uzuner, South, Shen and DuVall2011) featured several information retrieval and extraction tasks using US clinical records. One of the tasks involved the detection of assertions, that is, each medical problem concept (diseases, symptoms, etc.) was associated with one of six assertion types: present, absent, possible, conditional, hypothetical, or not associated with the patient. MiPACQ (Albright et al. Reference Albright, Lanfranchi, Fredriksen, Styler, Warner, Hwang, Choi, Dligach, Nielsen, Martin, Ward, Palmer and Savova2013) is another corpus which consists of clinical data in English annotated with several layers of syntactic and semantic labels. Each detected UMLS entity has two attribute locations: negation, which can take two values (true or false), and status, which can take four values (none, possible, HistoryOf, or FamilyHistoryOf).
Table 1. Statistics of the BioScope corpora (Vincze et al. Reference Vincze, Szarvas, Farkas, Móra and Csirik2008)

3.2 Rule-based systems
Among the rule-based systems dedicated to negation detection, NegEx (Chapman et al. Reference Chapman, Bridewell, Hanbury, Cooper and Buchanan2001), which pioneered the area, is still popular. This system uses regular expressions to detect the cues and to identify medical terms in their scope. Later this system was adapted to other languages such as Swedish (Velupillai, Dalianis and Kvist Reference Velupillai, Dalianis and Kvist2011) and French (Deléger and Grouin Reference Deléger and Grouin2012). NegFinder (Mutalik, Deshpande and Nadkarni Reference Mutalik, Deshpande and Nadkarni2001) is another pioneering system which combines a lexical analyzer, which uses regular expressions to generate a finite state machine, and a parser, which relies on a restricted subset of the non-contextual Look-Ahead Left Recursive grammar. NegFinder makes it possible to identify the concepts impacted by negation in medical texts when they are close to the linguistic units marking the negation. Derived from NegEx, ConText (Harkema et al. Reference Harkema, Dowling, Thornblade and Chapman2009) covers additional objectives. This system detects negation, temporality, as well as the subject concerned by this information in the clinical texts. It has been adapted to French (Abdaoui et al. Reference Abdaoui, Tchechmedjiev, Digan, Bringay and Jonquet2017). NegBio (Peng et al. 2017) relies on rules defined from the universal dependency graph (UDG). The code for this system is available online.Footnote a
3.3 Supervised machine learning
The system of Velldal et al. (Reference Velldal, Øvrelid, Read and Oepen2012) considers the set of negation cues as a closed class. This system uses an SVM and simple n-grams features, calculated on the words and lemmas, to the right and left of the candidate cues. This system offers a hybrid detection of the scope of negation. It combines expert rules, operating on syntactic dependency trees, with a ranking SVM, which operates on syntagmatic constituents. It was further improved by Read et al. (Reference Read, Velldal, Øvrelid and Oepen2012) and is used as a fall-back by Packard et al. (Reference Packard, Bender, Read, Oepen and Dridan2014) when the main MRS (minimal recursion semantics) Crawler cannot parse the sentence. Fancellu, Lopez and Webber (Reference Fancellu, Lopez and Webber2016) use neural networks to solve the problem of negation scope detection. One approach uses feed-forward neural network, an artificial neural network where the connections between the units do not form loops. Another approach, which appears to be more efficient for the task, uses a bidirectional Long Short-Term Memory (biLSTM) neural network. Li and Lu (Reference Li and Lu2018) use CRF, semi-Markov CRF, as well as latent-variable CRF models to capture negation scopes.
4. Data: Creation of annotated corpora in French and Brazilian
There are very few, if any, corpora which are annotated with negation-related information in languages other than English. In order to train effective machine learning-based models for negation detection in the languages we work with, we developed our own annotated corpora. The corpora that we describe in this section were developed in cooperation by French and Brazilian researchers. Table 2 presents some statistics on these corpora: the number of words, the variety of the vocabulary, the number of sentences, the number of sentences with one or more negations, and the inter-annotator agreements (IAA). However, as explained in Section 4.5, we cannot provide any IAA for the Brazilian clinical protocols. The IAA provided for the Brazilian clinical narratives was computed on both cue and scope tokens.
Table 2. Statistics on the four corpora created and annotated


Figure 2. Example of the summary from a clinical trial protocol in French.
4.1 ESSAI: French corpus with clinical trial protocols
Our first corpus contains clinical trial protocols in French. The clinical trial protocols are mainly obtained from the National Cancer Institute registryFootnote b. As shown in Figures 2 and 3, the typical French protocol consists of two parts. First, the summary of the trial indicates the purpose of the trial and the applied methods. Then, another document, from a different page of the website, describes in detail the trial, and particularly, the inclusion and exclusion criteria. In both those parts, negation provides useful information regarding the specification of the target cohort and the recruitment of patients. As shown in Table 2, the ESSAI corpus is our second largest corpus in terms or sentences and tokens and contains more than a thousand sentences with at least one instance of negation (about 16% of all sentences).

Figure 3. Example of the detailed description from clinical trial protocol in French.
4.2 CAS: French Corpus with Clinical Cases
The CAS corpus (Grabar, Claveau and Dalloux Reference Grabar, Claveau and Dalloux2018) contains clinical cases in French. The collected clinical cases are issued from different journals and websites from French-speaking countries (e.g., France, Belgium, Switzerland, Canada, African countries…). These clinical cases are related to various medical specialties (e.g., cardiology, urology, oncology, obstetrics, pulmonology, gastroenterology). The purpose of clinical cases is to describe clinical situations for real (de-identified) or fake patients. Common clinical cases are typically part of education programs used for the training of medical students, while rare cases are usually shared through scientific publications for the illustration of less common clinical situations. As for the clinical cases found in legal sources, they usually report on situations which became complicated due to various reasons: medical doctor, healthcare team, institution, health system, and their interactions. Similarly to clinical documents, the content of clinical cases depends not only on the clinical situations illustrated and on the disorders but also on the purpose of the presented cases: description of diagnoses, treatments or procedures, evolution, family history, expected audience, etc. Figure 4 shows a typical example of a clinical case from the CAS corpus. The document starts with the introduction of the patient (44-year-old female), explaining why she was hospitalized (1). The following sentences (2) add some information about the patient’s history of Crohn’s disease. Then, the next section (3) describes the examination and lab results obtained for this patient. Finally, the last sentence (4) describes which treatment was chosen, its effect on the patient, and the outcome of the healthcare process. In clinical cases, the negation is frequently used for describing patient signs and symptoms and for the diagnosis of patients. It can also be used for the description of the patient evolution. As shown in Table 2, this negation annotated version of the CAS corpus currently contains fewer sentences than ESSAI. However, CAS has a larger vocabulary and percentage of sentences with at least one instance of negation (about 21% of all sentences).

Figure 4. Example of the clinical case in French.

Figure 5. Example of a clinical protocol in Brazilian Portuguese.
4.3 Brazilian clinical trial protocols
The Brazilian clinical trial protocols were provided by the dedicated Brazilian websiteFootnote c. Figure 5 shows an excerpt from Brazilian clinical trial protocol. Its structure is similar to the French example presented above. Each protocol indicates its public title, scientific title, a description of the trial, as well as the inclusion and exclusion criteria. In these documents, negation provides useful information regarding the specification of the target cohort and the recruitment of patients. As shown in Table 2, this corpus has fewer sentences, tokens, and negative sentences than the others (about 20% of all sentences).
4.4 Brazilian clinical narratives
The clinical narratives were provided by three Brazilian hospitals and are related to several medical specialties such as cardiology, nephrology, or endocrinology. Thousand documents of various nature (discharge summaries, medical nursing notes, ambulatory records, clinical evolution, etc.) were manually annotated with negation cues and their scope. An example of Brazilian Portuguese clinical narrative is presented in Figure 6. This example follows the SOAP (Subjective, Objective, Assessment and Plan) note structure, which corresponds to the typical organization of clinical notes created by the healthcare workers. As shown in Table 2, this is our largest corpus in terms of sentences, tokens, vocabulary, and negative sentences (about 18% of all sentences).

Figure 6. Example of a clinical narrative in Brazilian Portuguese.
4.5 Annotation process
In this section, we present the basic annotation guidelines that were used to develop all four corpora; we also present the annotation process and its results. Regarding negation cues, annotators were asked to annotated any token usually triggering negation (if several cues are present in a sentence, they are numbered) that is not part of a biomedical concept identified by a French or Portuguese UMLS CUI. Accordingly, Cancer bronchique non à petites cellules (C0007131) is not annotated; however, mésothéliome pleural malin non résécable is annotated (1). Regarding negation scopes, we only annotated the sequences of tokens which contained the focus of the negation (with the identifying number of the corresponding cue if needed). As our purpose is to create data and methods usable in a clinical environment, we only annotate a medical concept as part of a scope when it is the focus of the negation instance. For instance, in Example 1, mésothéliome pleural malin should not be marked as negated since the sentence cannot be rephrased as no malignant pleural mesothelioma. Conversely, in Example 2, une autopsie is part of the scope as we can summarize the sentence as no autopsy. Example 3 shows that if the effect of the negation cue is altered by another token, the annotated scope is affected. Indeed, without toujours, Le traitement de référence would be part of the scope.
1. Mésothéliome pleural malin non résécable. (Unresectable malignant pleural mesothelioma.)
2. Une autopsie n’était pas réalisée. (An autopsy was not performed.)
3. Le traitement de référence est chirurgical mais celui-ci n’est pas toujours possible. (The reference treatment is surgical, but is not always possible.)
The annotators were given a description of the task and examples as guidelines. The annotation of both French corpora involved three annotators. One annotated both corpora and the others each annotated either ESSAI or CAS. While the ESSAI corpus was annotated manually to mark up negation cues and scopes, the CAS corpus was first annotated automatically with models trained on the ESSAI corpus. Then, the two annotators manually verified every single sentence in order to correct annotations and annotate forgotten instances of negation. Regarding cue annotation, the resulting IAAs are strong, a Cohen’s kappa coefficient of 0.9001 on the ESSAI corpus and of 0.9933 on the CAS corpus. While disagreements on the CAS corpus were a few forgotten cues during the manual annotation process, most of the disagreements on the ESSAI corpus were related to biomedical concepts. Indeed, biomedical concepts such as anti-angiogéniques and anti-tumorale were annotated by one annotator. During the adjudication process, it was decided that those would not be annotated. From these annotations, we can compute the most frequent cues: ne. pas (53 % of all cues), non (18 %), sans (13 %), aucun (7 %). Regarding scope annotation, the resulting IAAs are strong as well. A Cohen’s kappa coefficient of 0.8089 on the ESSAI corpus and of 0.8461 on the CAS corpus. Apart from the scopes associated with cue disagreements, only a few tokens were annotated differently on the ESSAI corpus. For instance, this from the sequence this has not been demonstrated in immunocompromised patients was wrongly annotated as part of the scope. Disagreements on the CAS corpus were mostly related to punctuation and subjects annotated as part of the scope, for instance, the patient from the sequence the patient had no clinical recurrence.
The annotation of the Brazilian clinical protocols involved three students from the Pontifical Catholic University of Paraná. However, they all ended up annotating different parts of the corpus for lack of time; therefore, IAA are unavailable. Regarding Brazilian clinical narratives, seven students and a nurse took part in the annotation process. The resulting level of agreement between annotators is rather high, with a Cohen’s kappa coefficient of 0.7414. Ultimately, the nurse, along with a physician, took part in the adjudication process. The annotation process is described in detail in Oliveira et al. (2020). The most frequent cues are naõ (39 %), sem (11 %), in- (9 %), de- (6 %), and ausência (5 %).
Moreover, Table 3 presents one annotated sentence in each language in the CoNLL format: 40-year-old male without clinical history and without compromising functional capacity. All corpora offer several additional annotation layers. The French corpora were pre-processed with TreeTagger (Schmid Reference Schmid1994) for part-of-speech tagging and lemmatization. The Brazilian part-of-speech tags (Universal POS tags) were obtained using RDRPOSTagger (Nguyen et al. Reference Nguyen, Nguyen, Pham and Pham2014). The stems were obtained using the Portuguese Snowball Stemmer from NLTKFootnote d.
Table 3. Excerpts from the two French corpora. The columns contain linguistic information (lemmas, POS-tag), negation cues, and their scope

5. Methodology
The second purpose of our work is to design a cross-domain approach for the automatic and effective detection of negation (cues and their scope). In this section, we describe the methods that were designed and tested. They rely on specifically trained word vectors and supervised learning techniques. The objective is to predict whether each word is a part of the negation cue and/or scope or not.
5.1 Word vector representations
Various methods have been used to represent words as vectors. Let’s mention for instance, the bag-of-word models like simple token counts or TF-IDF, to which Latent Dirichlet allocation (Blei, Ng and Jordan Reference Blei, Ng and Jordan2003) or Latent semantic analysis (Deerwester et al. Reference Deerwester, Dumais, Furnas, Landauer and Harshman1990) can be applied. Even though these approaches are still used, several more recent models have been introduced for a better representation of semantic relations between words needed by machine learning approaches. We present the methods we use for training the word vectors prior to the negation detection task.
word2vec (Mikolov et al. Reference Mikolov, Sutskever, Chen, Corrado and Dean2013) is a particularly efficient predictive model to learn word embeddings from plain text. Word embeddings can be calculated using two model architectures: the continuous bag-of-words (CBOW) and Skip-Gram (SG) models. Algorithmically, these models are similar except that CBOW predicts the target words from the words of the source context, while the skip-gram model does the opposite and predicts the source context words from the target words.
fastText (Bojanowski et al. Reference Bojanowski, Grave, Joulin and Mikolov2017) addresses the word2vec’s main issue: the words which do not occur in the vocabulary cannot be represented. Indeed, word2vec ignores the morphological structure of words and only assigns the features based on their semantic context. Hence, the authors address this limitation by using subword information: each word is represented as a bag of all possible character n-grams it contains. The word is padded using a set of unique symbols which helps singling out prefixes and suffixes. With a large enough corpus, every possible character n-gram may be covered, and, since the representations across words are often shared, rare words can also get reliable representations.
In French, the two word embedding models are trained using the Skip-Gram algorithm, 100 dimensions, a window of five words left and right, a minimum count of five occurrences for each word, and negative sampling. The training data are composed of the French Wikipedia articles and biomedical data. The latter includes the ESSAI and CAS corpora, the French Medical Corpus from CRTT,Footnote e and the Corpus QUAERO Médical du françaisFootnote f (Névéol et al. Reference Névéol, Grouin, Leixa, Rosset and Zweigenbaum2014). These models are trained using the GensimFootnote g (Rehurek and Sojka Reference Rehurek and Sojka2010) python library. In Brazilian Portuguese, we use the pre-trained models available on the NILC (Núcleo Interinstitucional de Lingustica Computacional) websiteFootnote h (Hartmann et al. Reference Hartmann, Fonseca, Shulby, Treviso, Rodrigues and Aluisio2017). These models were obtained using the Skip-Gram algorithm and 100 dimensions. In English, we use two fastText models. The original fastText model: 1 million word vectors trained on Wikipedia 2017, UMBC webbase corpus and statmt.org news dataset (16B tokens); and our own model trained on Conan Doyle’s novels, the assumption being that this domain-specific model will outperform models trained on generic data. The latter was trained with Gensim using CBOW, hierarchical softmax, and 100 dimensions for 100 epochs. For all languages, we also use randomly initialized vectors as input to our neural networks. In this case, the weights are initialized very close to zero, but randomly. Lemma and part-of-speech embeddings are randomly initialized as well. Then, those embeddings’ weights are updated during training.
5.2 Recurrent neural network
A recurrent neural network is a class of network which is capable of adapting its decision by taking into account the previously seen data, in addition to the currently seen data. This operation is implemented thanks to the loops in the architecture of the network, which allows the information to persist in memory. Among the RNNs, long short-term memory networks (LSTM) (Hochreiter and Schmidhuber Reference Hochreiter and Schmidhuber1997) are the most efficient at learning long-term dependencies and are therefore more suitable to solve the problem of discontinuous scope, which is typical with negation. The gated recurrent unit (GRU) network (Cho et al. Reference Cho, van Merriënboer, Gulcehre, Bougares, Schwenk and Bengio2014) is a variant of the LSTM where the forget and input gates are merged into one single update gate. The cell state C and the hidden state h are also merged. The created model is therefore simpler than the model obtained with the standard LSTM.
In our experiments, we used a bidirectional recurrent neural network, which operates forward and backward, to detect both negation cues and scopes. The backward pass is particularly relevant for the scope detection because the negated words may occur before or after the cue. Implemented with Keras using TensorFlow (Abadi et al. Reference Abadi, Agarwal, Barham, Brevdo, Chen, Citro, Corrado, Davis, Dean, Devin, Ghemawat, Goodfellow, Harp, Irving, Isard, Jia, Jozefowicz, Kaiser, Kudlur, Levenberg, Mane, Monga, Moore, Murray, Olah, Schuster, Shlens, Steiner, Sutskever, Talwar, Tucker, Vanhoucke, Vasudevan, Viegas, Vinyals, Warden, Wattenberg, Wicke, Yu and Zheng2016) as backend, our systems include French-language and Brazilian Portuguese-language versions of the bidirectional LSTM inspired by Fancellu et al. (Reference Fancellu, Lopez and Webber2016), as well as a bidirectional GRU (BiGRU). Prediction is computed either by a softmax layer, which is the most common method, or by a CRF layer, which seems to be particularly suitable for sequence labeling. An overview of the BiRNN architecture is shown in Figure 7. We use embedding layers of dimension k = 100 with 0.5 dropout and a dimensionality of the output space of 400 units per layer (backward/forward) with 0.5 recurrent dropout. Fifty epochs seem more than enough to achieve the highest possible F 1 score on the validation sets.

Figure 7. Our BiRNN uses LSTM or GRU cells and a softmax or CRF output layer.
5.3 Conditional random fields
CRFs (Lafferty, McCallum and Pereira Reference Lafferty, McCallum and Pereira2001) are statistical methods used in natural language processing to label word sequences. CRFs generally obtain good results with much lower training time than neural networks. In our experiments, we performed gradient descent using the L-BFGS (Limited-memory BFGS) method. We only experiment with CRFs for the cue detection task, in comparison with the BiLSTM-CRF model.
5.4 Evaluating labeling systems
To evaluate our systems, we use the standard evaluation measures: precision P, which quantifies the relevance of the automatic categorization, recall R, which quantifies the sensitivity of the automatic categorization, as well as F 1-score (harmonic mean of the precision and recall noted F 1). To evaluate the detection of the negation scope, we compute those measures in two ways: (1) on individual scope tokens which is the standard evaluation and (2) on exact scopes in order to assess more strictly how efficient our models are for the labeling of all tokens correctly in each negation instance. For the latter, we use the error analysis script available online from previous workFootnote i.
6. The cue detection task
Cue detection is the first step of the negation detection task. To tackle this problem, we experiment with two supervised learning approaches. First, a CRF model is trained using several features: words, lemmas, and part of speech tags, with a window over features which is defined empirically for each corpus. Our second approach uses a bidirectional LSTM with a CRF output layer, which is trained on the same features. We use embedding layers of dimension k = 100 with randomly initialized vectors for all features.
Table 4 presents the results obtained with our approaches on all four corpora. In all cases, the BiLSTM-CRF performs better than the CRF alone, which indicates that even on the task that appears to be simple enough for (non neural) machine learning methods, deep-learning methods can further improve the results. Indeed, the F 1 score obtained increases by up to three points.
Overall, the cue detection results are very high. However, our systems’ results drop dramatically on Brazilian clinical trials. While cues such as Falta de were not found as no examples were available in the training set, the main reason for this drop lies in the lack of adjudication process. Indeed, as the discrepancies between annotators were not dealt with, they affect both precision and recall. For instance, a few occurrences of anti- were annotated as cues, but most were not, which caused recall errors. Moreover, precision errors were mostly forgotten cues such as não, nehum or sem.
Table 4. Results for the cue detection task on the four corpora. The results are given as Precision, Recall and F1-score. The best scores are in bold

7. The scope detection task
In all of the proposed scope detection experiments, the neural networks are trained only on sentences with negations. The base system takes an instance I(n, c, t) as its input, where each word is represented by: n vector with word-embedding, c vector with cue-embedding, t vector with postag-embedding. Cue and PoS-tag vectors are randomly initialized. We use embedding layers of 100 dimensions. For each system, we use the same empirically defined hyperparameters given before. During training, the embeddings weights are updated. Each of our corpora has been randomly segmented into the training set (80%, 20% for validation) and the test set (20%). We train and evaluate our systems on the *SEM-2012 datasets to get comparable results in English as well.
Table 5. Results for the scope detection task. The results are given in terms of Precision, Recall and F1-score. The best scores are in bold

aWord embedding: either random initialization (RI), word2vec (W2V) or fastText (FT) for French and Brazilian Portuguese; either random initialization (RI), a fastText model trained on Conan Doyle’s novels (FT-D) or the original fastText model (1 million word vectors, FT-O) for English.bTrain: the corpus the system was trained on; Test: the corpus the system was tested on.
7.1 Results
Our first experiment compares the efficiency of both output layers (softmax and CRF) and three vector representations of words (random initialization, word2vec and fastText). Table 5 shows that using pre-trained word embeddings improves F 1 scores in most cases. On three out of four corpora, F 1 scores on scope tokens are similar for all output layer/word embeddings combinations (two points gap maximum). However, on Brazilian clinical trial protocols, the softmax/fastText combination gets significantly better results (78.20 while second best score is 74.87). Regarding the exact scope detection, the CRF output layer gets the best results on three out of four corpora. We expected such results because the CRFs are particularly efficient for tagging sequences. This hypothesis is confirmed by the results shown in Table 5, which position our results by comparison with the results obtained by other researchers on the *SEM-2012 data in English. Indeed, when computed on the *SEM-2012 data, our BiLSTM-CRF trained with FT-D gets a much higher F 1 than Li and Lu (Reference Li and Lu2018) in terms of correctly labeled tokens (+1.27 points); however, we only get slightly higher results for the exact scope match (+0.41 points). Besides, in the medical domain, the returned scopes need to be as precise as possible and not to include medical concepts, which is more correctly managed by the CRF output layer. In both languages, we get better results on clinical data (clinical narratives and clinical cases) than on clinical trials. Overall, we get the best results on the CAS corpus with French clinical cases, with outstanding F 1 scores for the exact scope match. These results indicate that negative instances in clinical documents have simpler and more stable structures: typically, they contain less discontinuous cues and gaps in scopes. Moreover, we experiment with both recurrent neural network cells. As expected, the results in Table 5 indicate that the LSTM cells perform better than the GRU cells. Indeed, the review of the performances of RNNs on multiple tasks (Jozefowicz, Zaremba and Sutskever Reference Jozefowicz, Zaremba and Sutskever2015) indicates that GRUs always show better results than LSTMs, except for the language modeling task. Although all gates have positive impact on the results, the experiments proposed in our work show that the forget gate gives the advantage to the LSTM. Regarding the exact scope detection, the BiGRU model benefits from the CRF ouput layer as well.
In our second set of experiments, in order to assess the efficiency of models trained on different sources of documents in a given language, we train the BiLSTM-CRF on one corpus (for instance clinical trials) and use another corpus (for instance clinical cases) to test this model. The results, shown in Table 5, indicate that clinical trial protocols offer more diverse instances of negation than clinical narratives. Indeed, the models acquired on clinical narratives perform poorly when compared to clinical trials. However, when trained on clinical trials, the models provide decent results for scope token detection, both in French and in Brazilian Portuguese. Regarding exact scopes, the results suffer from huge drops in all cases except when training on Brazilian clinical trials. Indeed, the best F 1 score on exact scopes from our first experiment on Brazilian protocols was 54.24, while now, when tested on clinical narratives, we get up to 73.30. Therefore, the poor results previously obtained on Brazilian protocols may be related to the fact that the testing set contains several instances of negation missing in the training set.
Figure 8 shows that 300–350 examples on average are necessary to achieve relatively good results. Adding more examples only slightly improves the results. Indeed, on French clinical trial protocols and Brazilian clinical narratives, using 650 training instances only improves the results by approximately 1.5 points. This Figure also indicates that negation detection can be further improved on Brazilian clinical trial protocols when more reference data are available.

Figure 8. Learning curve for the BiLSTM-CRF, without pre-trained Word Embeddings.
7.2 Error analysis
Although our results on most corpora seem consistent, our results drop dramatically on Brazilian clinical trials. Once again, as conflicts between annotators were not resolved in this case, many tokens end up incorrectly annotated as being part of a scope. Indeed, in several cases, tokens surrounding anti- were annotated as scope tokens, even with cue embeddings signaling the absence of anti- as a cue.
In order to study the frequent types of errors, a large portion of sentences containing at least one prediction error was manually examined and the causes of error were annotated. In the examples below, the negation cues are underlined, the scopes are in bold, and the predictions are between brackets. In Example 1, the prediction fails at labeling rénale(renal). This problem of missed adjectival attachment is due to the fact that, in the majority of cases in the reference data, the scopes associated to the cue sans often only include one token, which may be causing this error that impacts recall:
1. Le patient sortira du service de réanimation guéri et sans [insuffisance] rénale après huit jours de prise en charge et cinq séances d’hémodialyse.
(The patient will be discharged from the intensive care unit without renal failure after eight days of management and five hemodialysis sessions.)
This type of error also occurs with prepositional attachment that are missed (impacting recall) or wrongly included in the scope (impacting precision). It occurs especially with the French preposition de and the Brazilian one da as in the following examples in which da última consulta was wrongly predicted as part of the scope:
2. NEGA [INTERCORRÊNCIAS DA ÚLTIMA CONSULTA] PRA CÁ
(Denies intercurrent disease from the last consultation to now)
Example 2 illustrates the error that impacts precision. Here, the model wrongly predicts that all tokens in the sentence are within the scope. In the reference data, the cue aucun (any, no) often occurs at the beginning of sentences and in sentences with many instances of negation. The model, mostly trained on this kind of examples, may try to reproduce these structures which cause bad prediction in some cases.
3. [Les colorations spéciales (PAS, coloration de Ziehl-Neelsen, coloration de Grocott]) ne [mettaient en évidence] aucun [agent pathogène].
(Special stains (PAS, Ziehl-Neelsen stain, Grocott stain) showed no pathogens.)
In Example 3, the error impacts both precision and recall. In this example, we have two instances of negation with the same cues: n…pas. Usually, its scope follows, however, in the first instance it precedes. As we do not have many examples of this kind to train on, the model fails to correctly label the sequence. In the second negation instance, the scope may be shorter than usual, which impacts precision.
4. Le retrait du matériel d’ostéosynthèse incriminé n’[est] pas [systématique], ce qui explique qu’il n’[ait] pas [été proposé à notre patient asymptomatique].
(The removal of the implicated osteosynthesis material is not systematic, which explains why it has not been proposed to our asymptomatic patient.)
The error illustrated by Example 4 indicates that the cues nul and a are underrepresented in our corpus. Indeed they only occur once. Therefore, this model was not trained on them and thus assigns a partially incorrect scope.
5. A. Tracé nul [et] a[réactif].
(Null and unresponsive route)
The errors illustrated by the next examples are due to errors in annotation. Indeed, performing an error analysis is useful to detect the annotation mistakes as well. Thus, in the following example, the model predicts every token correctly. However, the comma was wrongly annotated as part of the scope. Overall, this error affects both recall and exact scope match scores.
6. La patiente ne [fume] pas, ne prend que très rarement de l’alcool et n’[a] pas [d’allergie aux médicaments].
(The patient does not smoke, only rarely takes alcohol and has no drug allergy.)
The last example on French presents the annotation error as well. In this case, ce (this) and est (is) should not be within the scope since n’ is not a cue.
7. Ce n’est que 48 heures après la dernière dose que les troubles visuels et les hallucinations disparaissent complètement, sans [laisser de séquelles].
(It is only 48 hours after the last dose that the visual disturbances and hallucinations disappear completely, without leaving any sequelae.)
The types of errors found in Brazilian corpora prove to be even more complex. Indeed, we find that a large number of predictions combine precision and recall errors within a single sentence. The examples below illustrate this situation:
8. Ausencia de diagnóstico [de doenças neuromusculares], [trauma], tumores ou [abscessos raquimedulares], hemiplegia/ paresia, lesão de plexo ou [encefalopatia] cerebral.
(Absence of diagnosis of neuromuscular diseases, trauma, spinal tumors or abscesses, hemiplegia/paresis, plexus injury or cerebral encephalopathy.)
9. que não apresentem [outras doenças neurológicas] ou [ortopédicas] diagnosticadas.
(Does not have other diagnosed neurological or orthopedic diseases.)
The error in Example 8 corresponds to the inclusion or not of function words (de, outras) within the scope of the markers. Another error (Ex. 9) is related to the completeness of nominal groups (encefalopatia cerebral and ortopédicas diagnosticadas).
Last, for English, the errors are also due to similar problems (eg. prepositional attachment). Compared to other approaches, our system solves errors committed by Fancellu et al. (Reference Fancellu, Lopez and Webber2016), such as Example 10 in which the scope predicted by their system includes the main predicate with its subject in the scope.
10. You felt so strongly about it that [I knew you could] not [think of Beecher without thinking of that also].
Moreover, by running their code, we can find several errors committed by their system but correctly resolved by our system, such as in the following examples. However, the predictions we get from their system may not be identical to their best predictions since the word2vec model they use is unavailable.
11. [Just the word], nothing [more].
12. “Well, can [you give] me no [further indications] ?”
8. Conclusion and future work
The interest for automatic detection of negation in English with supervised machine learning has increased in the recent years. Yet, the lack of data for other languages and for specialized domains hampers the further development of such approaches. In this work, after presenting the difficulties related to this task and after a brief reminder of existing work, we presented new bodies of biomedical data in French and Brazilian Portuguese annotated with information on the negation (cues and their scope). Prior to the dissemination to the research community, the French and Brazilian clinical trial protocols corpora will be finalized through the integration of new data and the computation of the IAA. The French CAS corpus will be distributed as more automatically annotated sentences are corrected. The Brazilian corpus with clinical narratives may prove to be more difficult to share with the community, as it contains data on real patients.
Another contribution of our work is the exploitation of different types of word vector representations and recurrent neural networks for the automatic recognition of the cues and scope of negation. The experiments are conducted and evaluated in three languages: in English, which has independent reference data, and in French and Brazilian Portuguese, which have not experienced much work of this type, especially for the biomedical domain which contains specific negation phenomena. Our system yields state of the art results on *SEM-2012, which validates our approach. It also shows good performances on our corpora except for the Brazilian clinical protocols. From a more technical point of view, our work also indicates that the LSTM-based neural architectures are more efficient than GRUs in the scope detection task, although the latter are now preferred in many other NLP tasks. In addition, the CRF layer brings better performance than the softmax on exact scope match which is of importance to us given the need to correctly assess which medical concepts are present or absent. Finally, the models are applied to general-language and medical data.
In the future, we plan to extend the system to the detection of uncertainties and of their scope, whose setting is very similar to the negation task. Besides, we plan to improve our neural network performance by providing richer feature set. In particular, recent embedding techniques, such as BERT or ELMo (Devlin et al. 2018; Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018), may provide more accurate representation of the sentences. Syntactic parsing of sentences may also provide useful features for scope detection.
Financial support
This work was partly funded by the French government support granted to the CominLabs LabEx managed by the ANR in Investing for the Future program under reference ANR-10-LABX-07- 01.














 Open access
Open access