



Introduction
Recent technical developments have enabled the collection and analysis of vast quantities of data from cyber-physical systems (CPS) during their operational phase. Manufacturers can leverage product usage data to gain a deeper understanding of how products are used and how they perform. Insights can then be fed back into product planning, where, for example, new product requirements or new product ideas can be derived. Product planning, the initial stage of product development, identifies future potential, discovers product ideas, and plans business strategies (Gausemeier et al., Reference Gausemeier, Dumitrescu, Echterfeld, Pfänder, Steffen and Thielemann2019). Data analytics, drawing from various disciplines such as statistics and machine learning (ML), plays a crucial role in optimizing existing and future products by integrating analytical insights into decision-making processes.
The research area of data-driven product planning encompasses CPS, product planning, and data analytics (Meyer et al. Reference Meyer, Wiederkehr, Koldewey and Dumitrescu2021). Although the utilization of data analytics in product planning is not a novel concept, new and previously unidentified options are being introduced by the emergence of novel data sources generated by smart and connected products (Kusiak and Smith Reference Kusiak and Smith2007; Wilberg et al. Reference Wilberg, Triep, Hollauer and Omer2017). The availability of use phase data, including failure messages, system status data, and customer feedback, has led to the emergence of several new strategic options and use cases. In this context, the term ‘use phase data’ refers to all data generated and collected by the product itself (through sensors and actuators), an associated service, or its users during the use phase of the product. This use phase data is particularly valuable for strategic product planning, as it is characterized by good availability and enables the systematic assessment of product characteristics that were essentially defined much earlier in the planning phase (Bosch-Sijtsema and Bosch Reference Bosch-Sijtsema and Bosch2015; Ehrlenspiel and Meerkamm Reference Ehrlenspiel and Meerkamm2013).
The implementation of data analytics in product planning presents significant challenges for companies (Hou and Jiao Reference Hou and Jiao2020; Wilberg et al. Reference Wilberg, Triep, Hollauer and Omer2017), particularly in terms of organizational hurdles such as a lack of expertise, a shortage of qualified staff, a dominance of domain specialists, and a limited awareness of the benefits of data analytics and AI, especially among small and medium-sized enterprises (SMEs; Coleman et al. Reference Coleman, Goeb, Manco, Pievatolo, Tort-Martorell and Reis2016; Hopkins and Booth Reference Hopkins, Booth and Marion2021). The successful implementation of data analytics processes necessitates a comprehensive understanding of the entire process, including all stages. It is of the utmost importance to note that the design of the data analytics workflow or pipeline involves the assembly of appropriate components for tasks such as data cleaning, preprocessing, feature extraction, modeling, and post-processing (Reinhart et al. Reference Reinhart, Kühn and Dumitrescu2017; Shabestari et al. Reference Shabestari, Herzog and Bender2019). There is no universal method or algorithm that can be applied to all problems and domains (Hilario et al. Reference Hilario, Kalousis, Nguyen and Woznica2009; Shabestari et al. Reference Shabestari, Herzog and Bender2019); The selection of components is dependent on the target application and the available data (Brodley and Smyth Reference Brodley and Smyth1995; Nalchigar et al. Reference Nalchigar, Yu, Obeidi, Carbajales, Green, Chan, Paolo and Barbara2019). It is essential to consider the entirety of the process, from the definition of use cases to the holistic evaluation of models.
It is currently not possible for implementers to benefit from many best practices, as companies rarely implement data-driven product planning projects. This is due to the fact that products are still insufficiently equipped with sensors (Meyer et al. Reference Meyer, Fichtler, Koldewey and Dumitrescu2022). In particular, in the context of engineering, where innovation cycles are lengthy and costly, the reliability and trustworthiness of analytics pipelines must be established (Saremi and Bayrak Reference Saremi and Bayrak2021). This can be achieved, for instance, through the traceability of the analytics process. The aforementioned factors render the design of a comprehensive data analytics pipeline for data-driven product planning a challenging and largely automatable task that necessitates expert knowledge.
In the context of skills shortages (Bauer et al. Reference Bauer, Stankiewicz, Jastrow, Horn, Teubner and Kersting2018), the democratization of data science through automated ML, no-code tools, and training initiatives represents a promising approach to empowering both non-experts and domain experts to engage in analytics tasks. Training and learning are crucial to prevent failures, with the provision of guidelines, best practices, and templates aiding continuous learning for citizen data scientists (Blackman and Sipes Reference Blackman and Sipes2022). The structuring of analytics knowledge in a toolbox streamlines the design and implementation of pipelines for data-driven product planning, offering insights into components such as use cases, data types, preprocessing methods, models, and evaluation metrics. This systematic approach reduces the vast solution space of possible pipeline components. In order to address research questions about potential applications, preprocessing methods, models, and evaluation metrics for data-driven product planning, a systematic literature review (SLR) and a practitioner survey were conducted. Our contributions include the collation of results in a morphological box and an investigation of the potential of the toolbox based on this to generate pipelines for data-driven product planning.
The paper is structured as follows: Section Foundations provides an overview of the data analytics process, outlining the steps of a data analytics pipeline and the challenges associated with data-driven product planning. At the end of the section, a generic pipeline is derived, which is to be populated with concrete components. Section Related work presents a brief review of related work. Section Research methodology then describes the research method, while Section Results presents the results. Section Data analytics toolbox for data-driven product planning translates the results into a methodological tool and provides an outlook on a potential application. Finally, the last section summarises the limitations of the study and outlines future work.
Foundations
Foundations in product planning
The activities that precede product development are critical to the success of new products (Cooper Reference Cooper1986). These activities are referred to as strategic product planning (Gausemeier et al. Reference Gausemeier, Dumitrescu, Echterfeld, Pfänder, Steffen and Thielemann2019) or phase zero of product development (Ulrich and Eppinger Reference Ulrich and Eppinger2016). Strategic product planning covers the process from determining the potential for future success to the creation of development orders (Gausemeier et al. Reference Gausemeier, Dumitrescu, Echterfeld, Pfänder, Steffen and Thielemann2019). It addresses the following areas of responsibility: potential identification, product identification, and business planning. The aim of potential identification is to find future success potential and the corresponding business options. The aim of product identification is to find new product ideas that take advantage of the recognized potential for success. Business planning starts with the business strategy, that is the question of which market segments should be covered. Based on this, the product strategy and the business plan are developed. The use of data analytics offers great added value, particularly in the context of potential and product identification. For example, by uncovering weaknesses, patterns, and trends in use phase data or extracting information from it through analyses such as defect detection or clustering, potential improvements to existing products can be uncovered and new ideas for product features developed.
Foundations in data science
The data analytics process typically comprises six iterative phases outlined in the Cross Industry Standard Process for Data Mining (CRISP-DM; Shearer Reference Shearer2000): Business understanding, data understanding, data preparation, modeling, evaluation, and deployment. Other similar processes like the Knowledge Discovery in Databases (KDD) process (Fayyad et al. Reference Fayyad, Piatetsky-Shapiro and Smyth1996) or data mining methodology for engineering applications (DMME; Huber et al. Reference Huber, Wiemer, Schneider and Ihlenfeldt2019) share core tasks such as domain understanding, data understanding, preprocessing, model building, and evaluation (Kurgan and Musilek Reference Kurgan and Musilek2006).
One task in domain understanding is to transform the business goal into a data analytics goal (Chapman et al. Reference Chapman, Clinton, Kerber, Khabaza, Reinartz, Shearer and Wirth2000). While the business objective describes a business or economic perspective, the data analytics goal contains the tasks to be fulfilled from a data analytics view. For example, a data analytics goal of the business goal of product improvement can be fault diagnosis. Data analytics goals can further be described as data analytics problems (e.g., classification or clustering). These problem types can further specify the goal (e.g., fault diagnosis) by determining the analytics solution (e.g., dependency analysis).
The main goal of data understanding is to gain general insights about the data that will potentially be helpful for further steps in the data analysis process (Berthold et al. Reference Berthold, Borgelt, Höppner and Klawonn2010). Before the properties of the data can be analyzed, the relevant data must first be determined and collected. The data generated during the use phase of a product are very diverse and emerge at different locations throughout the company. Examples of use phase data or data in the middle of the product life cycle (MOL) are user manuals, product information, product status information, and usage environment information (Li et al. Reference Li, Tao, Cheng and Zhao2015). The multiplicity of different data sources is accompanied by the heterogeneity of their properties, such as structured and unstructured data or signal and text data.
Data preprocessing is the process of making real-world data more suitable for the data analytics process and quality input (Shobanadevi and Maragatham Reference Shobanadevi and Maragatham2017). Real-world data, and usage data in particular are very differently positioned in terms of their characteristics and data quality. There are different techniques to make the data suitable for analyzing purposes (Jane Reference Jane2021). It includes operations such as data cleaning (e.g., missing values handling, outlier detection), data transformation (numeralization, discretization, normalization, and numerical transformations), dimensionality reduction, and feature extraction (FE ; Li Reference Li2019).
Selecting the appropriate model during model building that provides the desired output is a well-known problem in ML. For use cases in data-driven product planning such as analysis of errors, many algorithms can be considered, since both unsupervised and supervised methods are useful, and the data basis can be so diverse.
After modeling, the topic of evaluation is central to any data analysis process. Evaluation serves the purposes of performance measurement, model selection, and comparison of models and algorithms (Raschka Reference Raschka2018). Since the space of possible models in data-driven product planning is currently very large, the potential metrics are also numerous, which also complicates the selection of evaluation metrics.
This process with an end-to-end sequence of steps to achieve the goal, is also referred to as a data analytics pipeline or workflow (Braschler Reference Braschler2019). Each data analytics task is unique and requires a tailored pipeline. Pipelines vary in granularity and need to be designed with specific components for specific projects or use cases. Selecting pipeline components to build the best-performing pipeline is an important task for data scientists, involving critical design choices and consideration of individual requirements and dependencies (Nalchigar and Yu Reference Nalchigar and Yu2018; Zschech Reference Zschech2022). Figure 1 summarizes the key steps in the data analytics pipeline. This pipeline forms the structuring basis for the toolbox to be developed.
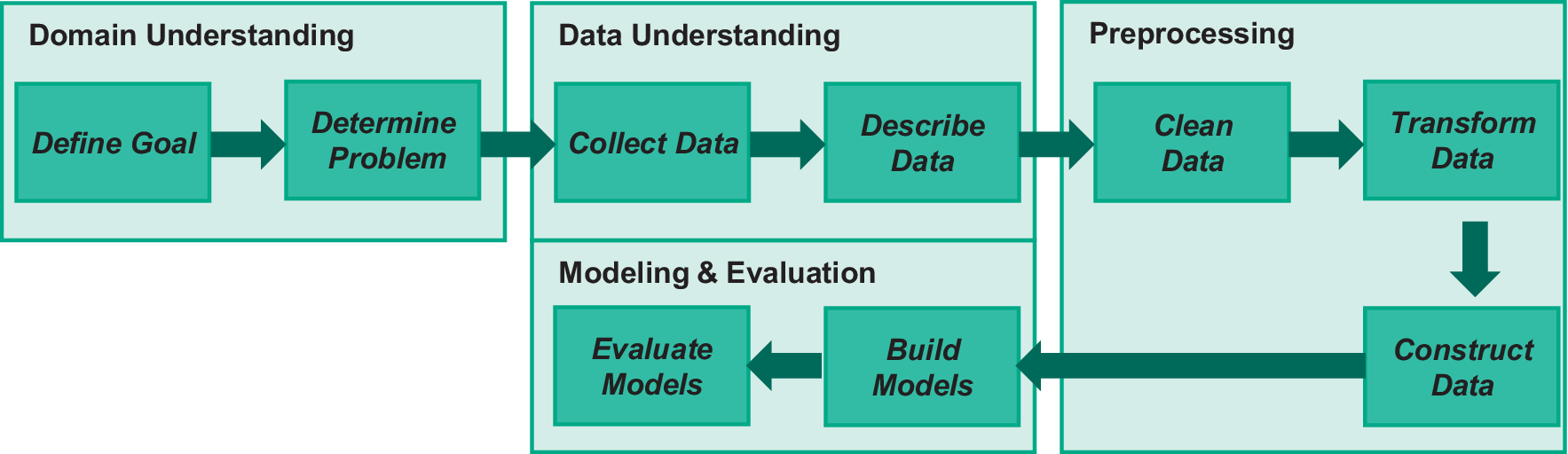
Figure 1. Generic data analytics pipeline for data-driven product planning.
Foundations of democratization and enablement for data science
The democratization of data science and ML is becoming increasingly important due to the shortage of skilled professionals mentioned above. One approach to democratization is the use of efficient tools that automate parts of the analytics pipeline. These tools are often based on automated ML (Masood and Sherif Reference Masood and Sherif2021; Prasad et al. Reference Prasad, Venkata, Senthil Kumar, Venkataramana, Prasannamedha, Harshana and Jahnavi Srividya2021). However, these approaches reach their limits in some scenarios, such as those where trust and transparency are critical, and in exploratory situations where the problem is not well defined. The lack of human control and interpretability can be problematic here (Lee et al. Reference Lee, Macke, X, Lee, Huang and Parameswaran2019). Furthermore, such automated tools carry the risk that data science novices or untrained citizen data scientists in particular will use them without any contextual understanding, increasing the likelihood of errors. This is because AutoML tools do not compensate for gaps in expertise, training, and experience (Blackman and Sipes Reference Blackman and Sipes2022). For this reason, more educational approaches may be used in some places to build the necessary background knowledge and thus reduce the risk of error. While offerings such as online courses, training, and meet-ups promise to provide the necessary in-depth understanding, such one-off measures are not usually able to provide the necessary ongoing practical experience; guidelines, best practices, and templates can also help here.
Specification of objectives
In summary, the challenge is that the process of determining suitable pipeline components for use cases in product planning is particularly difficult for domain experts and so-called citizen data scientists due to the huge possible solution space of methods and algorithms and the strong interdependence of the steps and components. However, this process should not be fully automated for didactic reasons and due to the frequent iterations required in the context of explorative potential identification. Therefore, an overview of relevant analytics components is required first, followed by selection support in the next step. The following objectives should therefore be considered:
-
- Provision of the relevant components for the possible data analytics pipelines of data-driven product planning: goals and problems, data characteristics, preprocessing methods, algorithms, and evaluation metrics
-
- An approach for the transparent and independent selection of individual components relevant to the use case
-
- A transparent, explanatory, and methodical tool that can be further developed into a digital assistant.
Related work
In this section, existing approaches that have similar overall objectives-providing an overview of relevant analytics components in product planning as well as guiding the analytics process and the design of analytics pipelines-are introduced.
With regard to the first objective, it should be noted that, to the best of our knowledge, no study compiles relevant components specifically for product planning and the early identification of product potentials. However, several SLRs have already been conducted in the context of product development (Fournier-Viger et al. Reference Fournier-Viger, Nawaz, Song, Gan, Michael, Irena, Adrien, Tassadit, Benoît and Luis2022; Quan et al. Reference Quan, Li, Zeng, Wei and Hu2023; Shabestari et al. Reference Shabestari, Herzog and Bender2019; Souza et al. Reference Souza, Jesus, Ferreira, Chiroli, Piekarski and Francisco2022).
In her dissertation, Eddahab presents demonstrative functional elements of a smart data analytics toolbox, which is intended to support product designers in product improvement based on product usage data (middle-of-life data [MoLD]). Using various proprietary and existing algorithms, she implemented three functions; (1) the merging of different MoL data streams from multiple sensor sources and recommendations for the designer in the form of an action plan on what to do with the product, (2) recommendation of task-relevant data analysis tools such as Support Vector Machines, and (3) intelligent user identification to create a secure analysis environment. This data analytics toolbox is a knowledge-based system that recommends relevant data analysis algorithms, among other things. However, it focuses on the recommendation of very specific actions based on anomalies in sensor data and not on the exploratory detection of trends and initial tendencies in any operating data. Furthermore, it does not claim to empower its users for the data analytics process and individual use cases by enabling a transparent and independent selection of components from application definition, data identification, preprocessing, and modeling.
Flath and Stein introduce a data science toolbox for industrial analytics applications and highlight key data preparation and analysis steps to address challenges such as the acquisition of relevant data, data preprocessing, model selection, and result interpretation (Flath and Stein Reference Flath and Stein2018). The toolbox comprises five steps: data collection phase, exploratory data analysis, selection of evaluation metric, algorithm selection, and derivation of features. The toolbox therefore provides more of a framework; no specific procedures for the respective steps are provided.
Ziegenbein et al. present a systematic algorithm selection method for production contexts, utilizing the CRISP-DM process. Their approach involves integrating pre-selected ML algorithms and relevant data sources using quality function deployment (QFD) during the data understanding phase. The evaluation considers criteria such as data source availability, implementation effort, and ML procedure suitability for objectives. The method comprises two steps: entering data sources with weights based on implementation effort and representability, and selecting ML methods based on strengths and weaknesses, considering factors like model accuracy and computing effort. The final step prioritizes ML methods based on how well they match the properties of selected data sources, identifying the most suitable method for the application. The fact that the method uses decision criteria to select suitable algorithms creates a transparent procedure for the user. However, the selection support is limited to the algorithm; the other steps of the pipeline are not taken into account. In addition, product planning is not focused.
Riesener et al. introduce an evaluation method designed to assist users lacking in-depth knowledge of ML algorithms in identifying strengths and weaknesses of selected algorithms for potential use in the product development process (Michael Riesener et al. Reference Michael, Christian, Michael and Niclas2020) Through an SLR, they identified 11 dominant ML algorithms in product development, such as k-nearest Neighbor Algorithm, Support Vector Machine, and Decision Tree. The authors established nine evaluation criteria crucial for pre-selecting ML algorithms, covering aspects like learning tasks, accuracy, training duration, and computational effort. The identified algorithms were then evaluated using these criteria through literature findings and an expert survey. The authors propose selecting an algorithm based on a problem description, which outlines the task (e.g., clustering and classification) and solution requirements. The best-fitting algorithms are determined by assessing the minimal distance between the problem description and the algorithm evaluations. The approach provides relevant algorithms for product development and offers a fairly transparent tool thanks to criteria-based selection. However, the approach is limited to algorithms for modeling.
Nalchigar and Yu developed a modeling framework for analyzing requirements and designing data analysis systems. The framework combines three views: business, analytics design and data preparation to support the design and implementation of holistic analytics solutions (Nalchigar and Yu Reference Nalchigar and Yu2018). Their solution patterns for ML are built on this (Nalchigar et al. Reference Nalchigar, Yu, Obeidi, Carbajales, Green, Chan, Paolo and Barbara2019). These represent generic ML designs for commonly known and recurring business analytics problems such as fraud detection. Their meta-model describes the different elements of a solution pattern and shows their semantics relationships. The solution patterns offer a solution approach for the conception of data analytics pipelines for generally known business analytics problems. However, they only provide for the use of the patterns with defined components rather than the independent and learning-promoting selection of the relevant components for an individual use case.
Tianxing et al. propose a domain-oriented multi-level ontology (DoMO) by merging and improving existing data mining ontologies (Tianxing and Zhukova Reference Tianxing and Zhukova2021). It includes four layers: (1) restrictions described by data characteristics, (2) definition of domain data characteristics, (3) core ontology for a specific domain, and (4) user queries and the generation of a data mining process. As an intelligent assistant, the purpose of DoMO is to help especially non-experts in describing data in the form of ontology entities, choosing suitable solutions based on the data characteristics and task requirements, and obtaining the data processing processes of the selected solutions. Non-experts can benefit from the ontology in the form of assistants by querying suitable solutions based on specific task requirements and data characteristics. However, defined knowledge is not made accessible.
All in all, none of these approaches provides the necessary overview of possible pipeline components along the entire data analytics process for product planning. Furthermore, not all these approaches function as transparent learning tools for non-experts.
Research methodology
The objective of the presented research is to support the design of data analytics pipelines in data-driven product planning. To this end, we aim to identify typical data analytics pipeline components within this domain that can be arranged in a toolbox. To achieve this goal, a SLR was carried out. To obtain the whole picture and not only the academic view afterward a survey with data scientists was conducted.
SLR
The review follows the guidelines by Kitchenham et al. and Kuhrmann et al. In accordance with these guidelines, the review passes through three main phases (Kitchenham et al. Reference Kitchenham, Brereton, Budgen, Turner, Bailey and Linkman2009; Kuhrmann et al. Reference Kuhrmann, Fernández and Daneva2017): (1) planning and preparation of the review, (2) conducting the review including data collection and study selection, and (3) analysis. In the following subsections, we will describe each of these phases in more detail.
Planning the review
In this phase, the research objectives and the way the review will be executed were defined. We formulated the following research questions structured according to the general pipeline steps and the identified challenges (section 2):
RQ1: For which applications in product planning is data analytics used?
The use of data analytics in product planning offers a lot of potential, but one major challenge is the definition of suitable use cases that can be realized with data analytics. Even if the business goals are clear, the data perspective and cases that can be implemented through analytics may be missing or unclear. Therefore, we investigate in the literature which specific goals and problems in product planning are solved using data analytics techniques.
RQ2: Which preprocessing methods (cleaning, transformation, and FE) are typically used?
Since the data generated in the operational phase of products and used for product planning is very heterogeneous, and sometimes of poor quality, pre-processing is essential. Which techniques are important for the relevant use cases and associated algorithms will be investigated based on this research question.
RQ3: What algorithms/models are typically used for modeling?
At the center of the pipeline is the algorithm, which takes the pre-processed data as input and generates, for example, cluster assignments, classes, etc., depending on the problem type—depending on the type of problem. As mentioned before, the choice of the appropriate algorithm is not trivial. There are a large number of different possibilities, plus the factors that need to be considered, such as the objective and the data. To narrow down the solution space and simplify the selection, we analyze which models are increasingly used in the literature to solve product planning problems.
RQ4: What evaluation metrics are used?
The evaluation of the models is important to assess the results. Since both supervised and unsupervised methods are used in product planning, the number of possible evaluation metrics is large. Which ones are relevant to product planning models and problems will be answered by this question.
To gain a comprehensive picture of the research area, we created a concept map to identify key concepts and their synonyms (Rowley and Slack Reference Rowley and Slack2004). We used the concept map to iteratively develop and evaluate search strings by combining the concepts represented in the map. After several rounds of refinement, we finalized the two-part search string that addressed (1) the applications and (2) the analytics components (Figure 2). To identify the use cases and applications of data analytics in product planning, and to narrow the search results, we focused on review articles and case studies. Our search string was applied only to titles, abstracts, and keywords. To further reduce the number of hits, we defined inclusion and exclusion criteria (Table 1).

Figure 2. Procedure of the systematic literature review.
Table 1. Inclusion and exclusion criteria

Conducting the review
In the execution phase, the search string was used to search the databases: We performed an automated search in the online libraries IEEE Xplore, Scopus, SpringerLink, and ScienceDirect in October 2023. These are often mentioned among the best standard libraries (e.g., Kuhrmann et al. Reference Kuhrmann, Fernández and Daneva2017). The detailed procedure is shown in Figure 2.
Our queries returned a total of 1,603 papers. The dataset was reviewed and analyzed for publications relevant to our research questions. This step in the selection of studies was carried out using the principle of double-checking within the team of authors. Our first step was to check the title, abstract, and keywords of each paper. If these sections did not provide relevant information, we looked at the conclusion for possible relevance. Using the criteria outlined in Table 1, we then filtered out publications that did not meet our inclusion criteria and retained those that did for further analysis. After this review, 78 publications were included in this step. In addition, we used a snowballing search. This involved two main steps: backward snowballing and forward snowballing. Backward snowballing involved searching for additional studies cited in the papers we had selected. Similarly, forward snowballing aimed to find articles that cited the selected papers. Using these snowballing search methods and our study selection criteria, we identified 15 additional papers through backward snowballing and 12 through forward snowballing. After careful assessment of these papers against our inclusion and exclusion criteria, we determined that 22 of them were relevant to our study. After further quality control to ensure the quality of the selected set and duplicate removal, we obtained a final dataset of 82 relevant papers.
Analysis
The publications that passed the check were carefully studied and the applications, pre-processing techniques, models, and evaluation metrics were extracted. In the second step, unambiguous labels were derived from the extracted content. Two researchers independently assigned the extracted applications, techniques, and metrics to the defined categories. If the assignments did not match, this was discussed and, if necessary, a different assignment was made or a more appropriate category was defined. A quantitative evaluation was then performed to determine how often the different categories of applications and algorithms could be assigned to the papers. It is assumed that the importance of algorithms is higher when the frequency of references and details in the literature is high. Categories with very few matches were reviewed to see if they could be integrated into another category. Such an evaluation was not done for preprocessing methods, as only a part of the papers dealt with them and therefore rarely more than one mention could be found. However, all mentioned methods and metrics were clustered to define larger categories, such as scaling and normalization. These were then used to structure the preprocessing methods. Evaluation metrics were also not counted at this point due to the low number of mentions but were used as input for the survey.
Survey
To evaluate the results from the literature research from a practical perspective and to enrich them with practically relevant procedures, a survey was then set up and carried out following the guidelines by Linåker et al. (Reference Linåker, Sulaman, Host and Mello2015). These guidelines show how the conducting of a survey can be divided into a number of sequential steps, tailored for software engineering research:
Defining the objective: The objective of the survey was (1) to evaluate if the identified preprocessing and modeling techniques and metrics from the scientific literature are also applied in practice and (2) to identify other relevant techniques used in practice.
Defining the target audience/population: The Target audience are data science professionals in Germany who recently worked on industry projects with use-phase data or operational data such as sensor and log data. This is to ensure that procedures relevant to this data are mentioned. The implementation of product planning use cases was not assumed, as these have only rarely or occasionally been implemented in practice to date.
Formulating a sampling design: We chose accidental sampling and we recruited participants through our network, as the willingness to participate is increased by the personal connection. This resulted in the recruitment of 35 subjects. The survey was executed in November 2022. From the 35 subjects recruited, 20 participants answered all questions, resulting in a participation rate of 57.14%.
Designing a questionnaire: The survey consisted of 19 questions in total, of which two introductory questions about the company and experience with the analysis of operational data. This was followed by several questions about models in the form: “Which of the following do you use regularly?”—about (1) models, (2) preprocessing procedures, and (3) metrics, respectively, structured by (1) analysis problem, (2) data quality issues and data type, and (3) learning mode (unsupervised vs supervised).
The questionnaire was designed as a self-administered web-based variant in order to facilitate ease of administration and to prevent any potential influence on the part of the researcher. In order to minimize the issue of lower response rates, appropriate introductions were provided and a test run was conducted with external colleagues.
Analyzing of survey data: Since the responses are nominal data, we performed a frequency analysis of the mentions.
Results
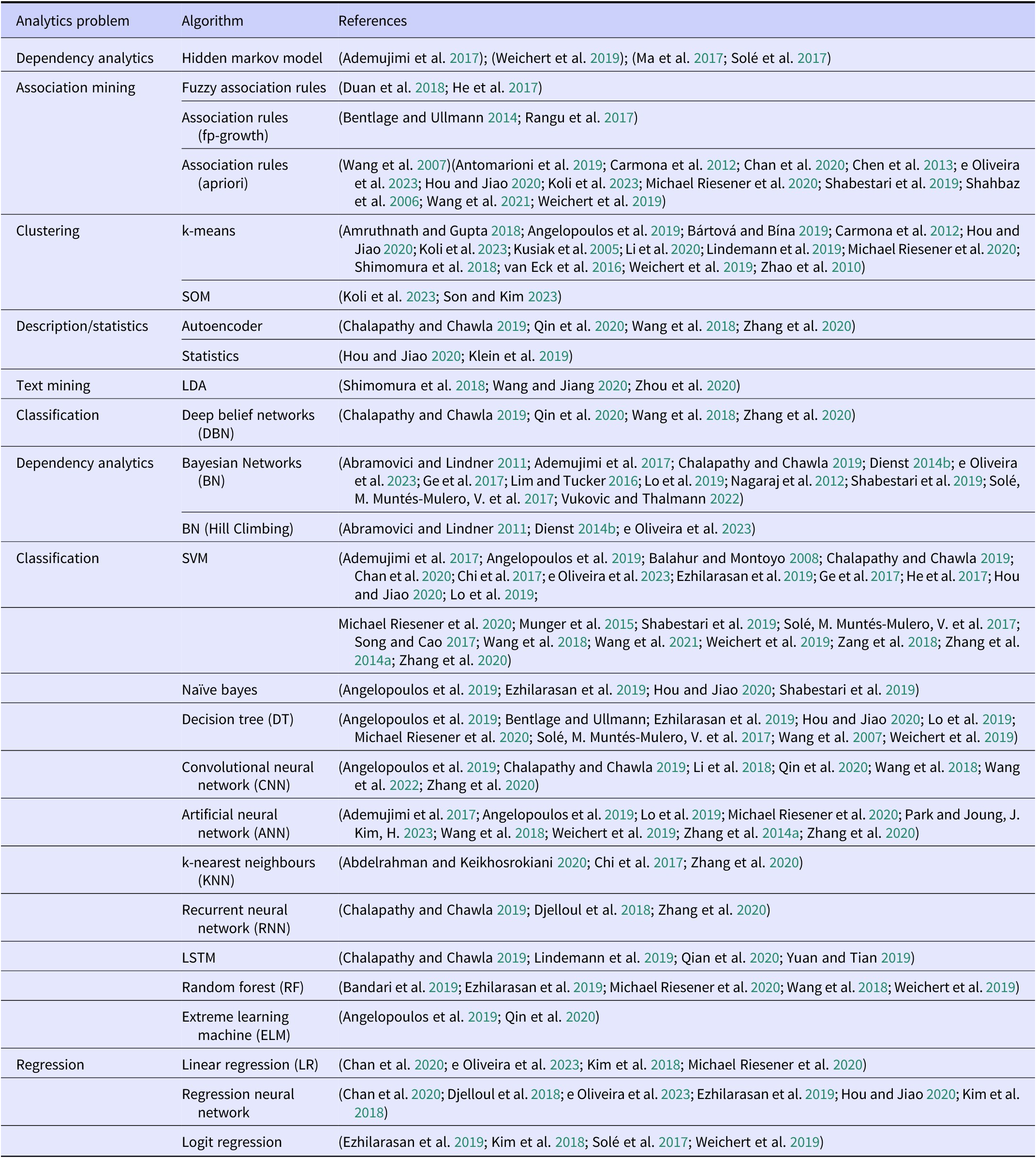
In this section, we present the results of the SLR for the research questions RQ1 and RQ3 and those of the survey, which take the practical view on RQ2, RQ3, and RQ4. The literature references for the applications and algorithms are listed in a table (see Table 2 and Table 3).
Table 2. Data analytics applications for data-driven product planning-literature overview
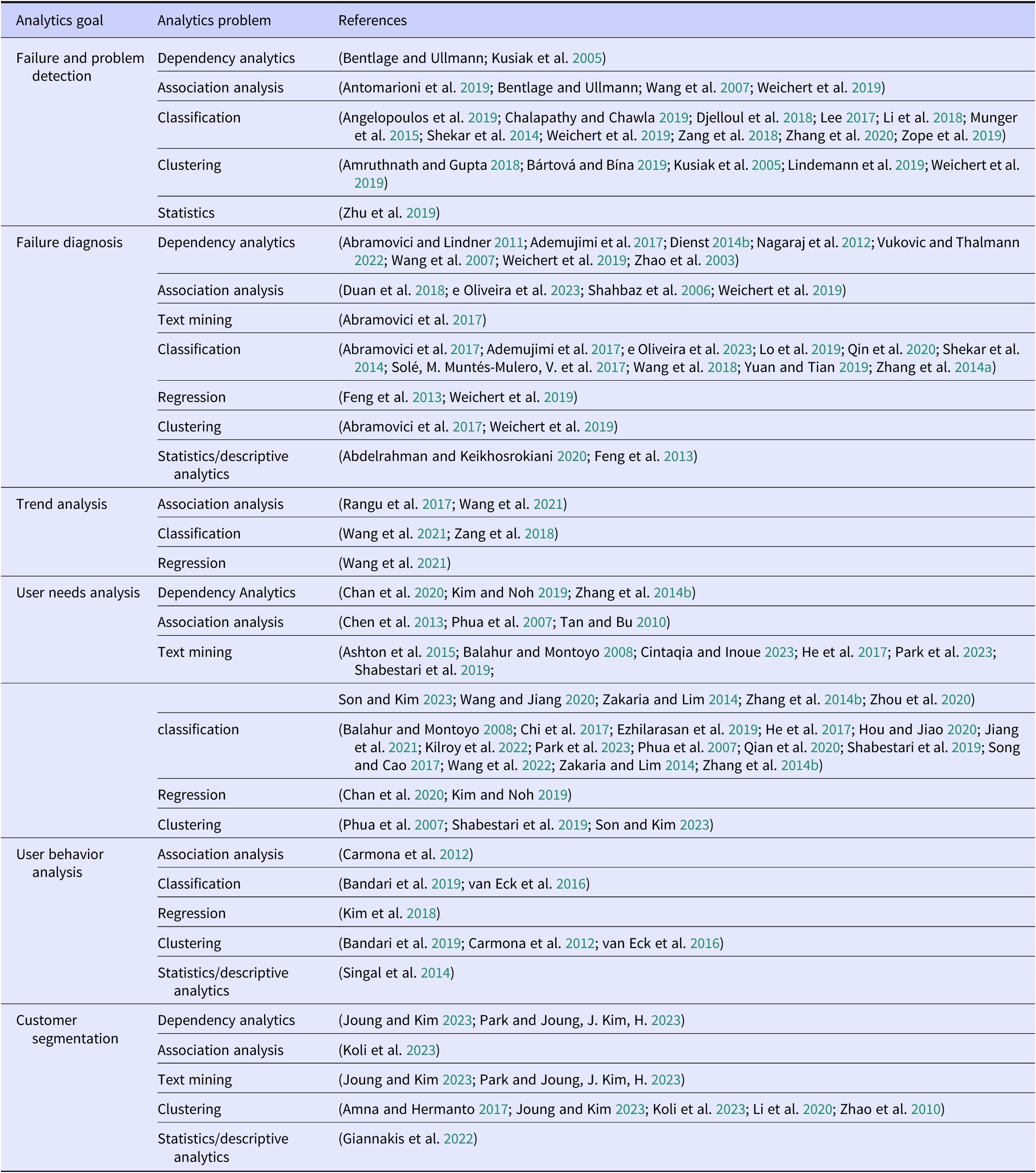
Table 3. Algorithms in literature used in data-driven product planning-literature overview
SLR results
RQ1: For which applications (analytics goals and problems) in product planning is data analytics used?
Figure 3 illustrates the distribution of the applications addressed in the dataset. The most prevalent theme was that of user needs. The focus was on three key areas: (1) extracting satisfaction/sentiment about the product and concrete product attributes to identify needs for action on the development side, (2) clarifying customer needs in order to obtain clues for product adaptations and new requirements, and (3) directly determining customer requirements that can be passed on to product development. The most common approach to achieving these goals was classification, although text mining was also a popular choice in this context, particularly for processing review data. Failure diagnosis was also used to obtain information about the product, with factors influencing defects uncovered to identify potential weaknesses and their causes. Here, too, classification approaches were the most frequently used, with 10 mentions. Dependency analysis was used eight times for diagnosis. The third most frequently employed approach was association mining, which was used to derive dependencies in the form of association rules. This was followed by the detection of errors, which preceded diagnosis and detected errors and problems. Classification approaches were predominantly employed in this context. Clustering was also identified as a potential solution for error detection, particularly in the absence of labels.

Figure 3. Data analytics applications for data-driven product planning in literature.
Other applications in product planning that are relevant to research include user behavior analysis, trend analysis, and user segmentation analysis. User behavior analysis and user segmentation analysis examine users in order to identify their behavior and group them in meaningful ways. This can be accompanied by further indications for product adjustments. Clustering appears to be a popular approach in this context. Trend analysis focuses on new market trends and changes, which can result in new requirements for a product.
RQ3: What algorithms/models are typically used for modeling?
The majority of the papers present supervised classification approaches. The support vector machine (SVM) model is particularly prevalent, with 26 mentions. In addition, it is necessary to consider the contributions of other techniques, such as neural networks, convolutional neural networks, and decision trees, which are situated at a greater distance from the present study. Overall, regression methods are employed to a lesser extent than other techniques.
However, unsupervised methods are also frequently employed as they facilitate the discovery of previously unknown patterns and relationships. The majority of models presented in this area focus on dependency and association analysis. Bayesian networks and association rules (Apriori) are two popular research tools. K-Means is the most frequently employed clustering algorithm. All frequencies are shown in Figure 4. Additionally, a number of individual mentions were excluded from the diagram for reasons of clarity:
-
• Dependency analytics: bayesian networks (K2; Dienst Reference Dienst2014a), Bayesian Networks (PC; Vuković and Thalmann 2022), and (partial) correlation coefficient (Kim and Noh Reference Kim and Noh2019).
-
• Clustering: DBSCAN (Koli et al. Reference Koli, Singh, Mishra, Badhani and Yadav2023), hierarchical clustering (Son and Kim Reference Son and Kim2023), and biclustering (BCBimax; Amna and Hermanto Reference Amna, Hermanto and Amien2017).
-
• Description/statistics: parallel coordinates (Zhao et al. Reference Zhao, Liu, Tirpak, Schaller and Wu2003), frequency analysis (Son and Kim Reference Son and Kim2023).
-
• Text mining: LLM (Han et al. Reference Han, Nanda and Moghaddam2023), Word2Vec (Cintaqia and Inoue Reference Cintaqia and Inoue2023), BERT (Cintaqia and Inoue Reference Cintaqia and Inoue2023), NER (Kilroy et al. Reference Kilroy, Healy and Caton2022), and LSA (Ashton et al. Reference Ashton, Evangelopoulos and Prybutok2015).
-
• Unsupervised classification: one class SVM (Zope et al. Reference Zope, Singh, Nistala, Basak, Rathore and Runkana2019).
-
• Supervised classification: conditional random fields (Shabestari et al. Reference Shabestari, Herzog and Bender2019).

Figure 4. Algorithms in literature used in data-driven product planning.
Survey results
In order to address RQ3 regarding the algorithms, an examination of the practice reveals that SVM is a highly popular choice for classification. However, its usage is almost equal to that of random forests and decision trees. Additionally, data scientists also employ statistical and regression methods with similar frequency. The k-means algorithm is the most frequently used algorithm overall, with 17 mentions. In contrast, dependency analysis and its models are employed by only a minority of data scientists on a regular basis. Figure 5 illustrates the distribution of all the algorithms mentioned in the survey.
RQ2: Which pre-processing methods (cleaning, transformation, FE) are typically used?

Figure 5. Algorithms mentioned in the survey.
Figure 6 summarizes how popular various pre-processing methods are in practice: Outliers are typically addressed through the use of statistical techniques, including means and standard deviations, as well as limits (boxplots). Scaling and normalization are also common practices in the context of preprocessing, particularly when dealing with operational data. The min-max scaler appears to be a popular choice in this regard. Systematic errors, however, appear to be addressed with less frequency. To transform the data into the desired format, one-hot encoders play a crucial role. In order to extract features from time series, the most commonly employed techniques are fast Fourier transformation and time windows.
RQ4: What evaluation metrics are used?

Figure 6. Preprocessing techniques mentioned in the survey.
The majority of evaluation metrics can be assigned to supervised learning (Figure 7). The most commonly used metrics in this context are precision and recall. In unsupervised learning, external validation is the dominant approach, whereby the output is compared with that of other experts. In this context, classification metrics can be employed once more.

Figure 7. Evaluation metrics mentioned in the survey.
For detailed descriptions of all the methods, we recommend standard literature and papers (e.g., Alloghani et al. Reference Alloghani, Al-Jumeily, Mustafina, Hussain, Aljaaf, Berry, Mohamed and Yap2020; Kubat Reference Kubat2017; Nalini Durga and Usha Rani Reference Nalini Durga and Usha Rani2020).
Data analytics toolbox for data-driven product planning
To prepare the results of the SLR and survey for further application as a transparent and methodical tool, we have summarized the most important components, namely the applications and techniques that appeared at least three times during the SLR and the survey. This has been done together with the results of a previous research study defining typical data sources and combinations of data characteristics (Panzner et al. Reference Panzner, Enzberg, Meyer and Dumitrescu2022). This information has been presented in a morphological box. The toolbox comprises five dimensions, which correspond to the five stages of the generic data analytics pipeline (cf. Figure 1). These are domain understanding, data understanding, pre-processing, modeling, and evaluation (Figure 8).

Figure 8. Toolbox of data analytics components for pipelines in data-driven product planning.
At the top, the application level is shown with the two categories analysis goal and analysis problem, which form the intersection with the business use case. This is followed by the data understanding dimension, which includes data sources for data collection and data characteristics for description. The preprocessing dimension is followed by the tasks of data cleaning, data transformation, and feature engineering. Subsequently, models for the key analysis (e.g., clustering, classification, or regression) are represented in a layer before the evaluation components are depicted. The dimensions of preprocessing and modeling were further subdivided according to individual data characteristics, such as quality and data type (Panzner et al. Reference Panzner, Enzberg, Meyer and Dumitrescu2022), and the problem types resulting from the SLR. The respective methods and procedures are listed below.
The toolbox can be employed for the design of the data analytics pipeline by mapping out the solution space of potential and relevant applications and processes, thereby facilitating an initial pre-selection. The selection of individual components and the determination of a highly specific pipeline can be further supported by illustrating the dependencies and contexts of the respective models. To this end, we propose profiles, as illustrated in Figure 9, which summarize the most crucial knowledge for the application of each component. In addition to a brief description, the profiles provide a reference to the other pipeline steps of application, data, and evaluation. Furthermore, possible user requirements are also considered in the context of the human factor. A compilation of relevant criteria in this context is presented, for example, by Nalchigar et al. and Ziegenbein et al. (Nalchigar and Yu Reference Nalchigar and Yu2018; Ziegenbein et al. Reference Ziegenbein, Stanula, Metternich, Abele, Schmitt and Schuh2019).

Figure 9. Example algorithm profile (based on details by e.g., Kotsiantis Reference Kotsiantis2013 ).
The requisite information can be extracted from standard literature, with the assistance of experts and/or automatically. By utilizing tags, which are components from the toolbox, a concrete connection to the other levels and the dependencies there can be established. This simplifies the selection of suitable pipeline elements based on a model. All of these elements provide the user with transparent explanations and demonstrate the relationships between the various pipeline components, thus enabling even users with limited prior knowledge of analytics to design a pipeline for the focused problem. Other tools, such as AutoML tools, can provide support during implementation.
A potential application of the data analytics toolbox may be as follows: A citizen data scientist is interested in analyzing usage data for the first time with the objective of generating ideas for product improvements. To this end, the individual in question decides to first perform a fault diagnosis of the product in question, with the objective of identifying any potential weaknesses. In the field of research, classification or dependency analysis is the most commonly employed methodology for achieving this objective. The data scientist, basing their decision on personal preferences, opts for a classification approach and sets out the requirements for this, including the greatest possible transparency. A consultation with domain experts revealed that status and product behavior data were of particular interest for the use case.
Subsequently, the data that has already been acquired is subjected to further analysis and its characteristics are recorded. The data scientist notes that the data are time series with continuous values that have some missing values and are high dimensional. With this information about the analytics problem and the data characteristics, the selection of modeling methods can begin. The data scientist can then proceed to examine the relevant models from the toolbox in more detail, using the profiles to identify those that are most suitable for their needs. They can then combine these models with preprocessing methods and evaluation metrics that match the model and the data.
The data scientist’s objective is to develop an easily understandable and interpretable model that can be monitored to identify the factors associated with the error messages that occur intermittently. The input variables are various machine parameters, while the target variable is the error category. The decision tree is a suitable approach for this task. In the fact sheet, the data scientist is able to identify the dependencies that still require consideration. Given the minimal preprocessing requirements of the model, the data scientist opts for a basic approach to addressing the missing data, namely linear interpolation. As a feature engineering approach, the data scientist tests a range of techniques from the toolbox. One resulting pipeline is depicted in Figure 10.

Figure 10. Example of specific data analytics pipeline.
The degree of support can be freely dosed, for example, by considering the procedures of the construction kit only as a preliminary indication of the possible solution space and freely composing them according to one’s own discretion.
Conclusion, limitations, and outlook
This paper proposes a methodological toolbox for enabling data-driven product planning in the form of a morphological box based on the results of a comprehensive SLR. The box illustrates the different components that are suitable for designing pipelines in product planning to explore new product potentials, across the different dimensions of the data analytics pipeline application, namely pre-processing, modeling, and evaluation. A toolbox based on this is intended to support data scientists and citizen data scientists in the design of tailored pipelines that take into account dependencies and different contexts. The resulting pipelines can be used as a good starting point for implementation. In addition to serving as a structuring guide and knowledge base, the toolbox is also a basis for further automation of the implementation of data analytics pipelines for data-driven product planning. In further user-centered studies with experts from product innovation, product engineering, and data analytics, repetitive steps can be identified in the usage of the toolbox. Further methods as well as tools can be identified and developed, or the usability or plug-and-play capabilities of existing tools can be improved.
One limitation of the work presented is that only applications from industry, particularly product development, were considered. Another limitation is that the relevance of analytics techniques is determined based on the number of literature found in relation to these methods. Therefore, relatively new algorithms may be disadvantaged and might not be considered within the evaluated algorithms. However, an integration of new algorithms into the general framework of the toolbox is simple. In addition, since data-driven product planning is a relatively new research field, interesting new use cases might be missing in the literature and might be unknown in practice so far. Moreover, the survey was only able to fully consider the responses of 18 participants, which precludes any representative numbers. However, the toolbox is intended as an initial knowledge base that will be expanded.
In the future, the toolbox will be transformed into a software-based expert system that enables non-experts to understand the conception of data analytics pipelines and the resulting results. Depending on the user’s level of knowledge, such a system can also provide additional explanations of terms and important background knowledge in order to train users as comprehensively as possible. In addition, further extensions are conceivable, such as the recommendation of suitable tools for the respective pipelines.
In the future, we intend to assess the usability and benefits of the data analytics toolbox via a user study.
Funding support
This work is funded by the German Federal Ministry of Education and Research (BMBF). There are no relevant financial or non-financial competing interests to report.
Competing interest
None declared.














 Open access
Open access